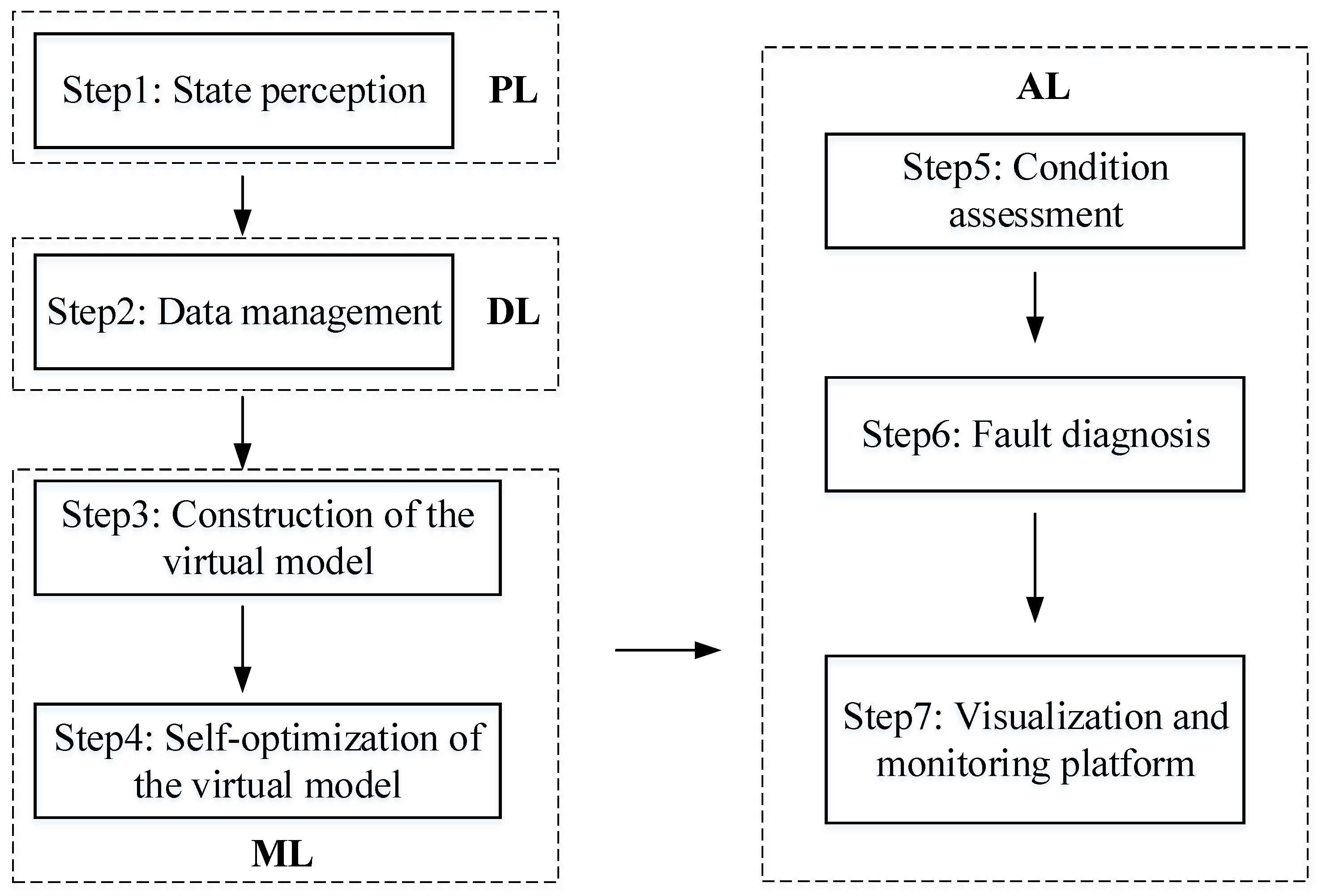
This Section provides a practical validation of the theories and methods mentioned above using the coal mill of a coal-fired power plant as an example.
4.3. The Methodology for Data Management
Coal-fired power companies have strict data management regulations that do not allow other systems to send operational commands to the control system in the segregated area of production, and all interactions with the information systems in the office area must also be strictly regulated.
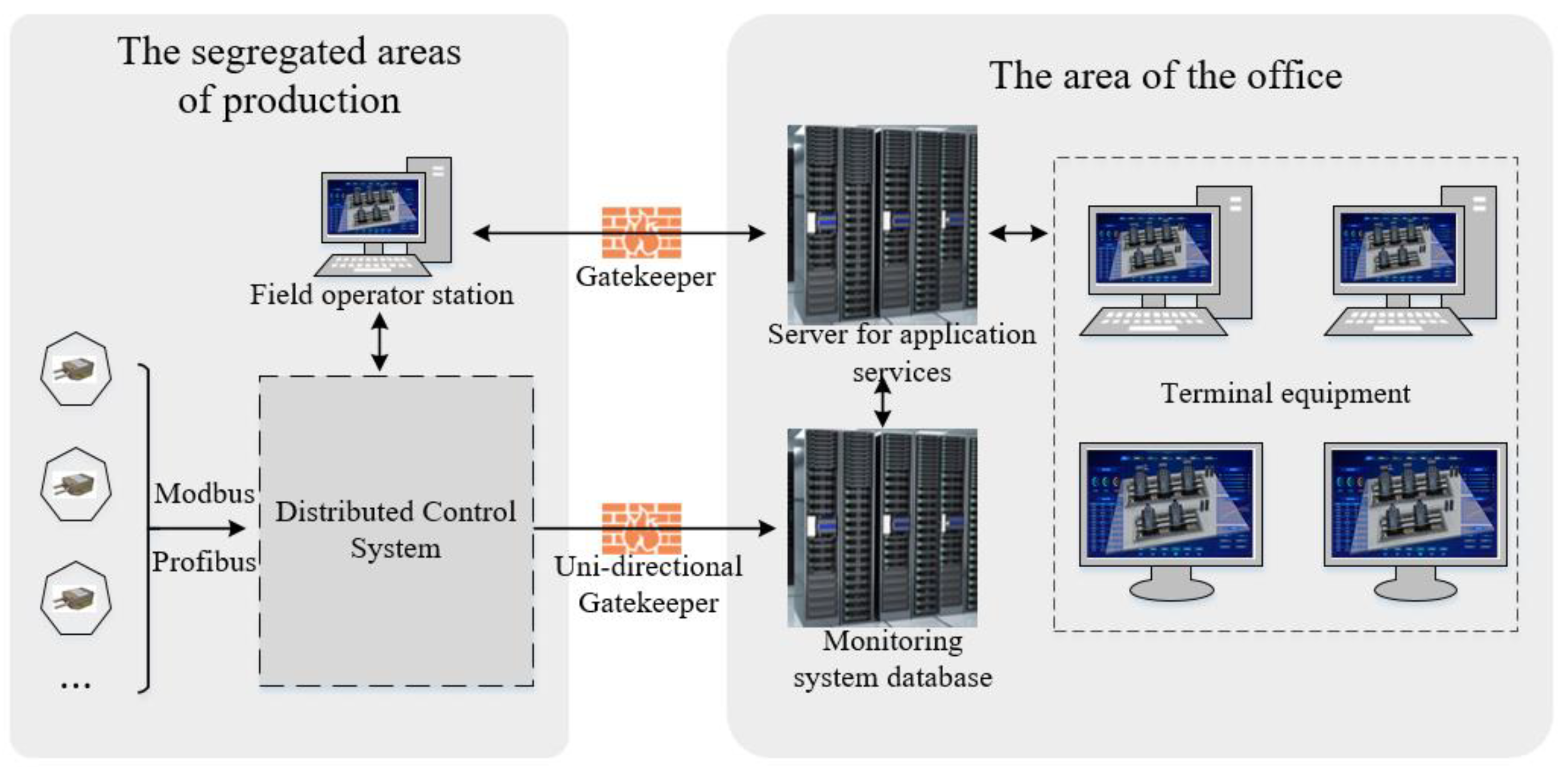
Based on this, this paper proposed to build a data service system connecting the production isolation area and the office area in the internal network environment of the enterprise, to realize the safe and efficient management of all the data in the intelligent monitoring system of the coal mill based on DT.
Figure 7 shows the schematic diagram of the data transmission process of the data service system built in this paper. The DCS in the segregated area of production transmits the real-time operation data of the equipment, environmental parameters, personnel situation, and other information to the data server in the office area through the communication protocol. The programs deployed in the application server will request the required data from the data server, and upload the important process data and calculation results of the programs to the data server for processing and storage. The condition monitoring platform deployed in the application servers will be made available to the office and segregated production areas through the local area network, and users will be able to realize real-time access to and operation of the monitoring platform using terminals within the network.
The data used in this article come from various sources and data types, and the read-and-write requirements of the applications deployed on the application server vary greatly. Therefore, to improve the comprehensive performance of the database, reduce data redundancy, and improve the flexibility of processing, this paper divides all the data involved into three categories and chooses relational database, document database, and Key-Value database for storage, respectively.
The first type of data includes the basic attributes of the coal mill, the parameter information of the virtual model, the basic data of the monitoring platform, etc. These kinds of data are an important basis for supporting the digital twin system. Although the amount of data is not large, there is a strong correlation between the data, so this paper uses the MySQL database to store them.
The second type of data is the monitoring data of the physical entity and the simulation analysis data of the virtual model, which contains the state information of equipment and is the basis for carrying out the research of equipment condition monitoring. These kinds of data are large in scale and diverse in type and require high real-time performance. Therefore, the MongoDB database is used to store these kinds of data in this paper.
The third kind of data is mainly the temporary data in the system, such as the process data of user session calculation, cache data, etc. These data types are diverse, and the speed of reading and writing is fast, which is an important link to ensure the normal operation of the system. In this paper, the Redis database is used to store these kinds of data.
Data preprocessing is also required for the input data collected by the sensors because of the presence of information such as missing values, noise values, and redundancy values in the raw collected operating data. In this paper, data preprocessing steps such as missing value supplementation, trend term elimination, and noise signal rejection are carried out according to the differences in data types at the time of implementation.
4.4. The Construction of the Virtual Model
The virtual model is the core component to realize various functions such as simulation, fault diagnosis, etc. The virtual model can turn the application functions from theory to reality under the data drive, and the virtual model is the “heart” of the digital twin application. Therefore, the establishment of a digital twin virtual model that can accurately map and simulate the operating state of the coal mill is the basis and guarantee for subsequent research.
The research on coal mill modeling emerged in the 1970s and 1980s, with the rapid development of technology, some scholars have established models that can simulate the pulverizing process based on the rich historical data of the equipment in recent years [
49]. Our research group has constructed an improved coal mill model in previous studies and tried to apply the model to condition assessment, fault diagnosis, and trend prediction of the equipment [
50,
51]. However, these models failed to fully consider the substances and variables involved in the pulverizing process, and more importantly, they lacked the dynamic self-optimization mechanism, which made it difficult to adapt to the fluctuations of the equipment during the service process.
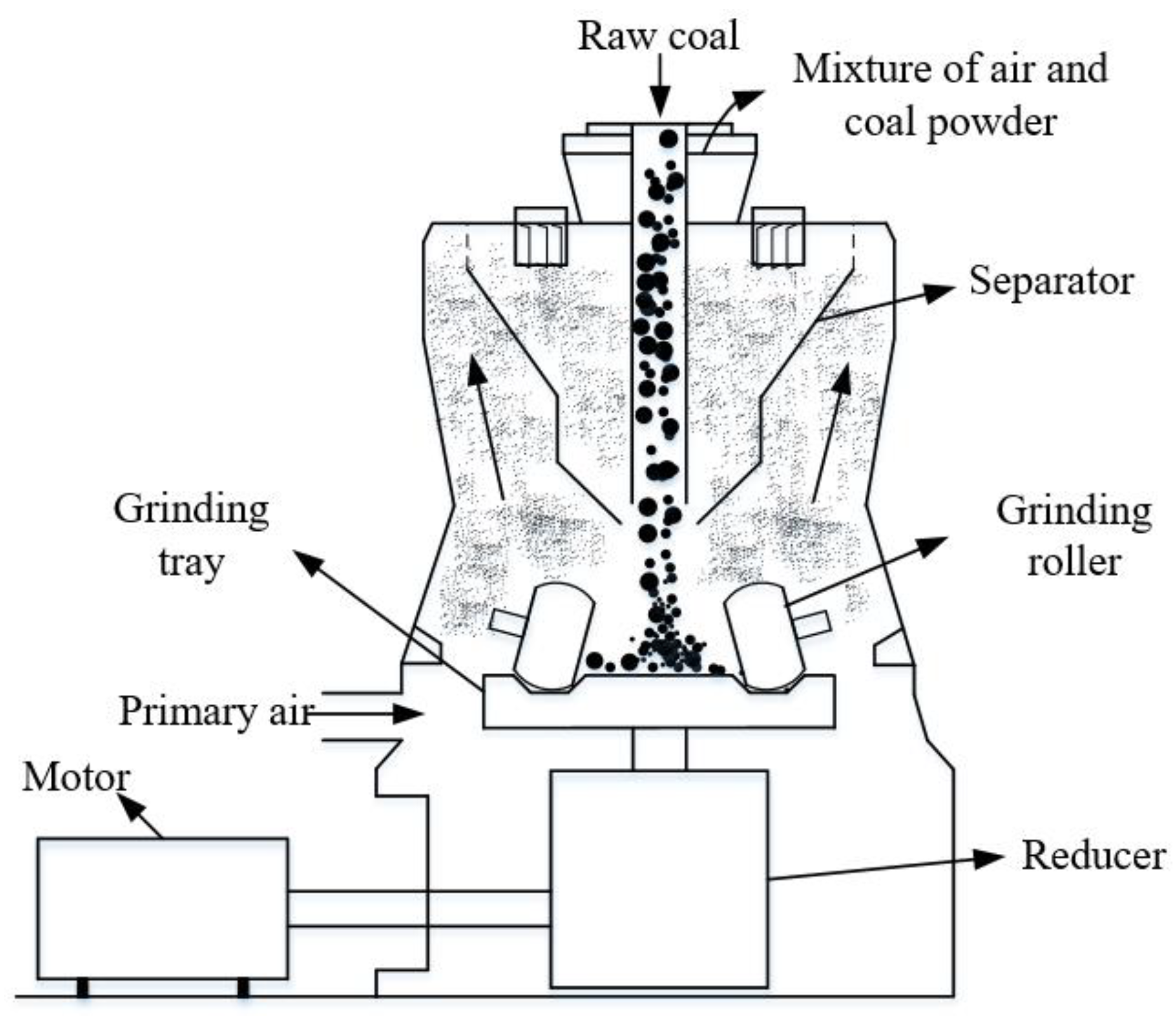
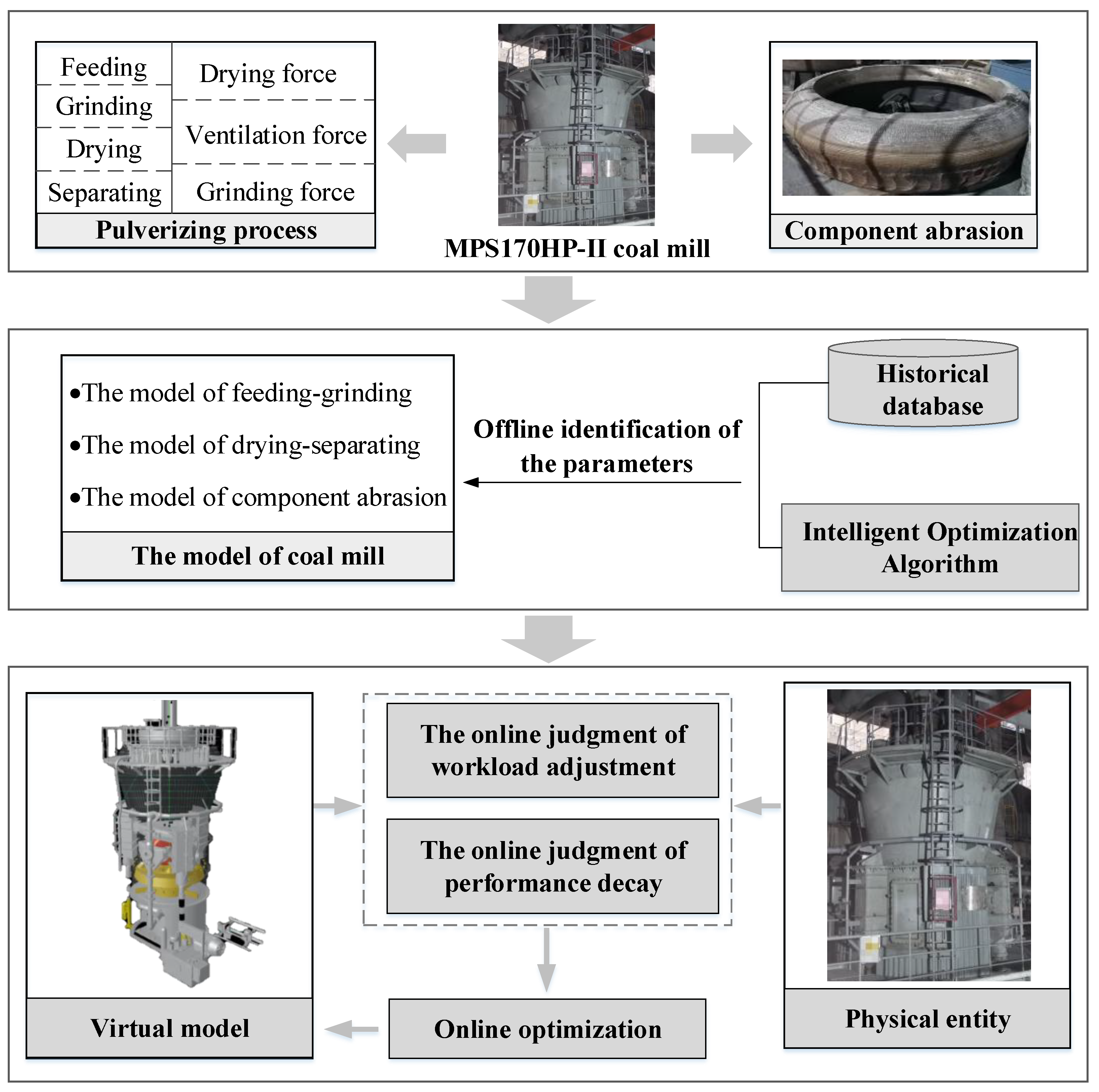
Through systematic analysis of material flow, energy delivery, and force characteristics of the pulverizing process, this research proposed to divide the virtual model of the coal mill into three processes, including feeding–grinding, drying–separating, and component abrasion. The feeding–grinding process includes raw coal dropping into the tray and grinding raw coal into powder, the drying–separating process includes evaporating the water in the coal and exporting qualified pulverized coal, and the component abrasion process considers the influence of abrasion on the output of the device. Then the model of each process is established according to the material flow situation, energy balance relationship, and parameter interactions, and is coupled based on the correlation relationship of inputs and outputs between the models of different processes. The model developed is expressed by Equations (1)–(21), and the meaning of the symbols in the model is given in the Nomenclature.
The adjustable parameters are the key to determining the performance of the model. Compared with the parameter identification method in the previous studies, this research presents a combination of offline identification and online self-optimization of the parameters. In the offline identification phase, it is required to manually select the representative data as the training set, and identify the values of all adjustable parameters through iterative optimization by the genetic algorithm [
49,
50]; after this phase, the model is able to accurately map the current state of the coal mill.
During the service of the equipment, this research designed an online optimization mechanism based on workload adjustment and performance decay. A significant adjustment of the workload will modify the quantity of feed coal, which will trigger the automatic control logic of the equipment to adjust other inputs and affect the balance between the parameters inside the machine, so the optimization of the parameters of the model is necessary. Performance decay is unavoidable in the life cycle of the equipment, such as fatigue or wear of the components, at which time the virtual model must be optimized adaptively to keep pace with the entity.
Figure 8 illustrates the process of constructing the virtual model of the coal mill.
It is to be noted that the model should be validated for accuracy after the optimization, both in the offline and online phases. This study evaluates the model based on the deviation between the computed output of the model and the actual values. If the accuracy fails to meet the requirements, then the model needs to be optimized again.
Table 3 displays the performance comparison between the model in this study and the model in the previous study, where
I denotes the current of the coal mill, Δ
Ppa denotes the differential pressure of primary air, and
Tout denotes the outlet temperature. The
MSE denotes the mean square error between the actual value and the output calculated by the model, while the
RE denotes the relative error. The results show that the model constructed in this study is closer to the actual coal mill when the equipment is in healthy operation.
4.5. The Development of Condition Monitoring Applications
To address the condition monitoring demands of coal mills, this research designs algorithms for parameter monitoring, condition assessment, and fault diagnosis based on the foregoing, and they are practically deployed in coal-fired power plants.
In terms of operation parameter monitoring, this study filters and presents the data of all monitoring points of the coal mill. Several points have been set with alarm thresholds or shutdown thresholds during the design stage, so these parameters are required to set different grades of alarm conditions in strict accordance with the design criteria. For critical monitoring points without alarm thresholds, different priority alarms are designed by integrating expert operational experience and statistical analysis of historical data.
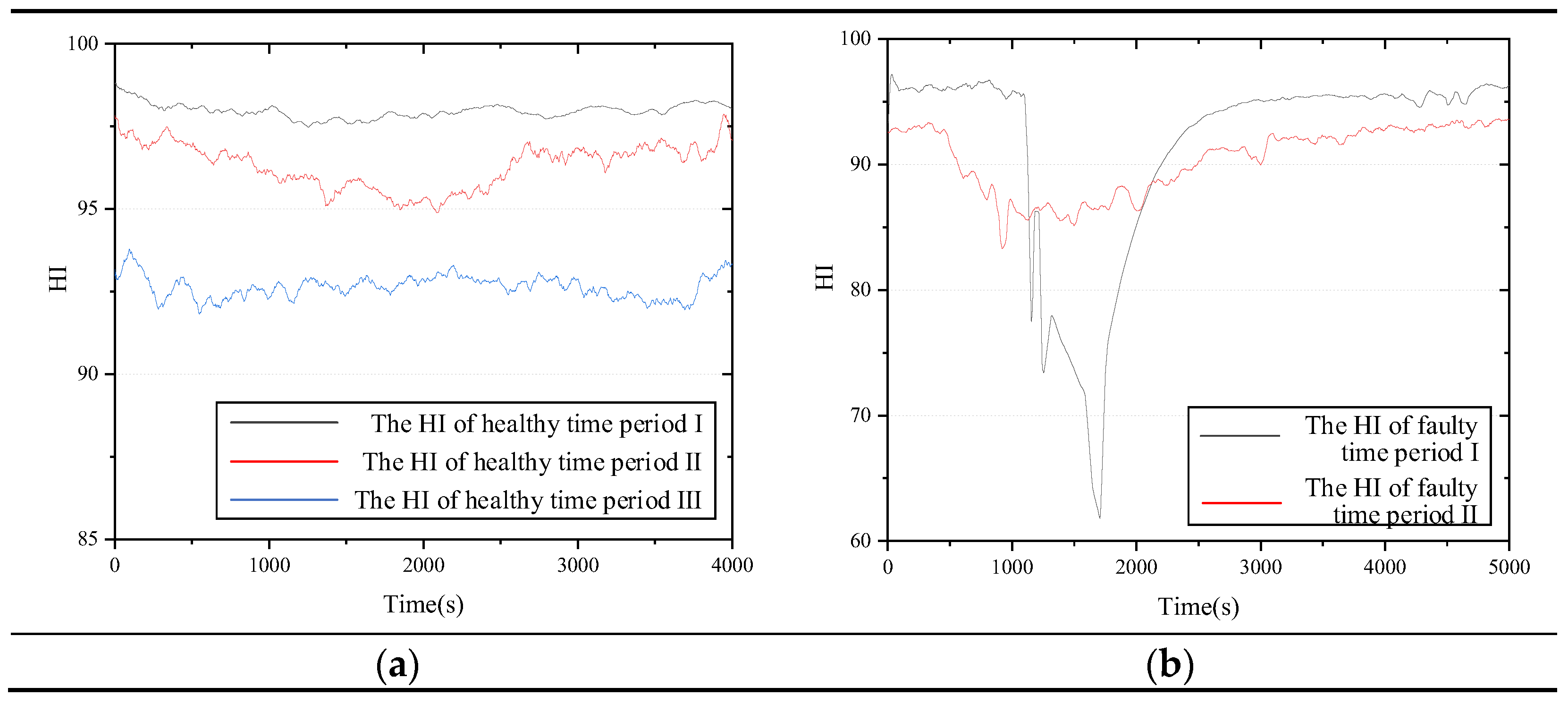
For condition assessment, this study constructed the health indicator (HI) for coal mills to characterize the current health state of the equipment. We introduced a method for constructing the HI in a published article [
50], and although the model developed in that study is significantly different from the model constructed in this paper, the method for constructing the HI is consistent, so we followed this technique.
First, the deviation between the computed value of the virtual model and the actual value of the physical entity is calculated; this study designs a deviation measure formula based on the Euclidean distance and verifies the accuracy with the equipment operation data in different states. Then, a typical fault characterization factor is designed for the special situation in which the input parameters of the model are affected by the fault. Lastly, the HI is obtained by performing a joint calculation of the deviation and the fault characterization factor. HI is a positive number less than 100, and the larger its value indicates the healthier state of the equipment.
Figure 9 shows the computed HIs of the coal mill in different states.
For fault diagnosis, this research established a coal mill fault diagnosis model based on fusion data and the deep belief network (DBN). DBN is a kind of deep learning network proposed by Professor Hinton in 2006, which is characterized by using a layer-by-layer greedy learning algorithm to optimize the connection weights in the network [
51].
Firstly, the different operating states of the equipment are simulated using the model, and massive simulated data are obtained. The simulated data are mixed with the practical operating data to generate the original dataset.
This paper has analyzed the fault record table of the coal mill of this unit in the past two years, and according to the frequency and influence degree of each fault, the four faults of coal breakage, coal blockage, low oil pressure of grinding, and low primary air volume were selected to carry out the research. The four faults were simulated separately by changing the parameters or structure of the model, as well as the case where two faults could occur simultaneously.
Table 4 lists the amount of data obtained from the simulations for each fault condition.
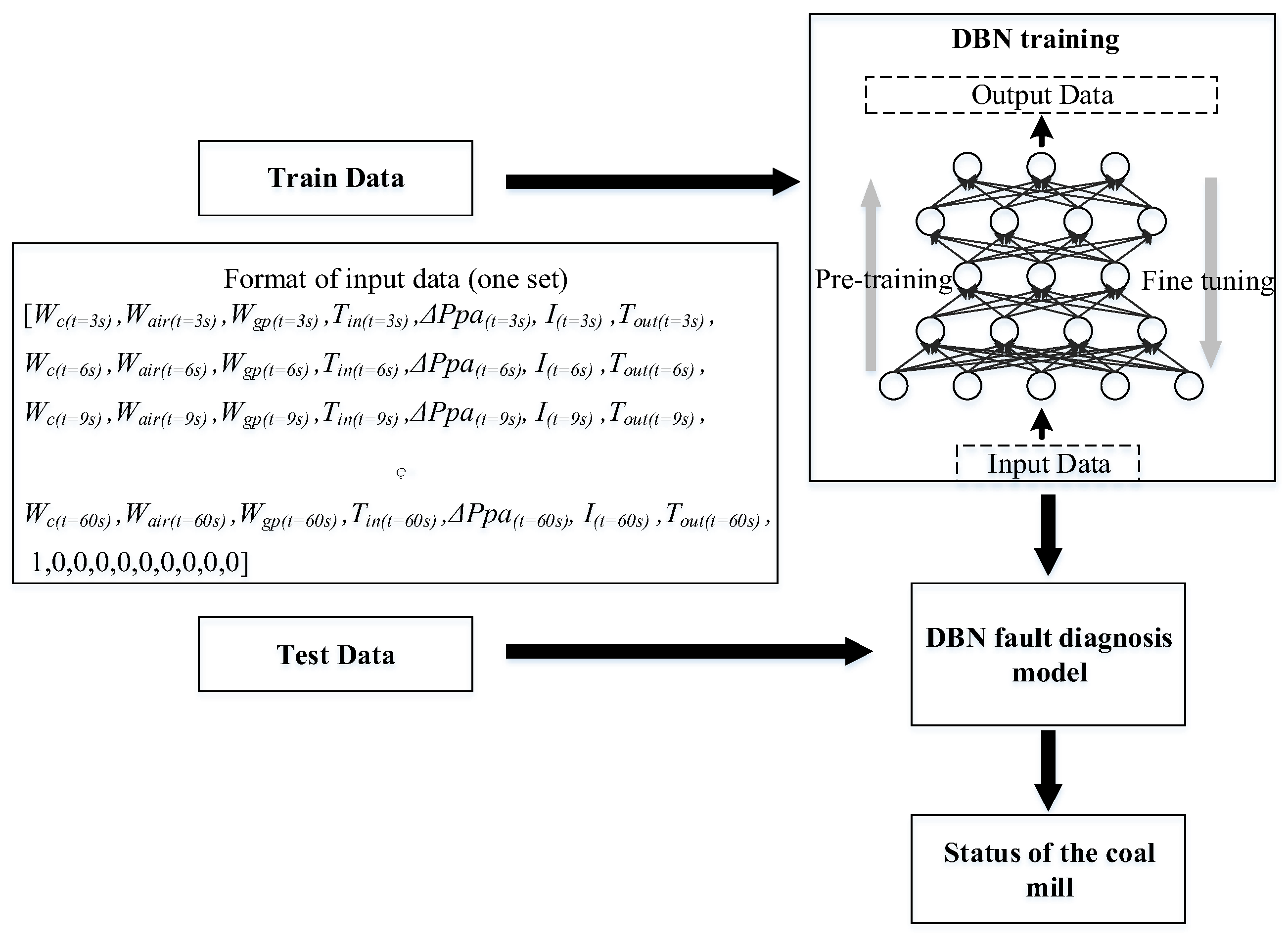
Then, this paper designed the DBN-based coal mill fault diagnosis process as shown in
Figure 10. The data utilized are from the actual operation data of the unit and the simulation data of the simulation model. In this study, 80% of the data is used as the training set, and the remaining 20% is used as the test set, and all the data need to be processed by normalization.
Table 5 shows the status labels corresponding to the various statuses.
To address the issue of the values of parameters in the DBN model, an orthogonal experiment with six factors and three levels is designed for further analysis.
Table 6 shows the setting of factors and levels in the orthogonal experiment.
Table 7 shows the results of the orthogonal experiment, where I, II, and III indicate the average accuracy of the factors at each level. Based on the actual performance of the factors, the parameter combination chosen in this paper is 2-1-2-1-2-3.
For the accuracy verification test of the diagnostic results, its diagnostic accuracy is 98.8% for the training set and 97.4% for the test set.
Figure 11 shows the analysis of the diagnostic results of the test set.
In order to further verify the effectiveness of the above method for coal mill fault identification, this paper selects 100 sets of actual operation data of the coal mill of this unit as the realistic dataset, including 41 sets of data when no fault occurs and 59 sets of data when a fault occurs. The diagnostic validation using this method yields a final diagnostic accuracy of 96%, which further proves the effectiveness of the proposed fault diagnosis method.
In addition, this paper also utilizes support vector machine (SVM), convolutional neural networks (CNN), and stacked autoencoder (SAE), which have been used in existing coal mill fault diagnosis studies, to train and compare the accuracy of the results. The diagnostic accuracy of each algorithm is calculated as shown in
Table 8.
As shown in the table, the diagnostic accuracy of the method used in this paper is better than the other three methods for both the test set and the actual test set, which further proves the effectiveness and superiority of the method.
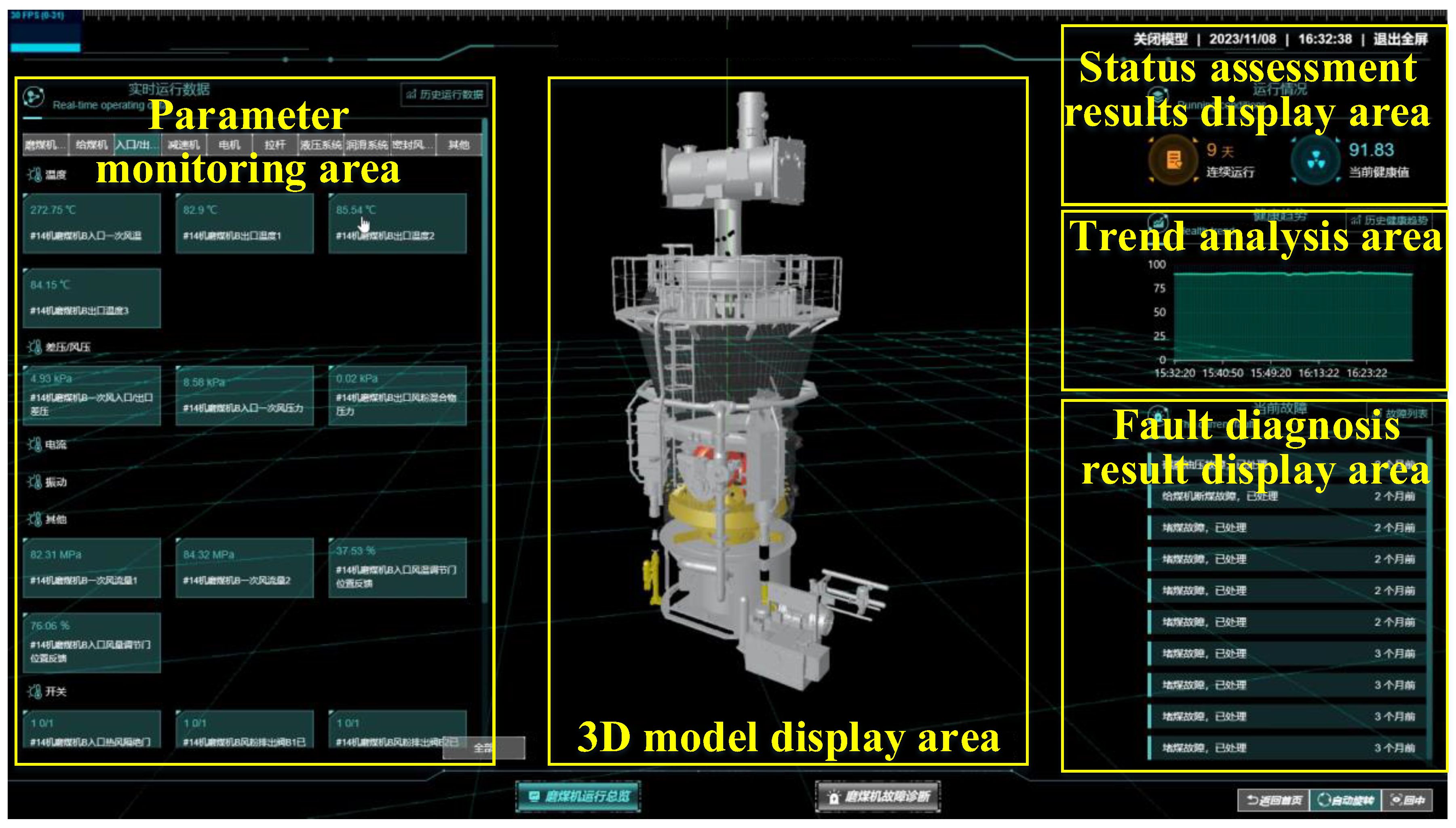
The monitoring platform is an implement tool for monitoring the operation status of the equipment, by accessing the platform, the users can quickly and intuitively obtain real-time operation data, condition assessment results, fault alarm information, and so on, and can also rapidly query and analyze the past status, which provides technical support for the maintenance plan of the equipment. In this study, a visualization platform is developed, and the main interface of the developed platform is shown in
Figure 12, which has five main display areas, respectively, the 3D model display area, the parameter monitoring area, the status assessment result display area, the fault diagnosis result display area, and the trend analysis area.
In the 3D model display area, the model depicts the MPS170HP-II coal mill, and it can be manually zoomed in and out and automatically locate the damaged parts. When the equipment is in operating condition, the motion parts in the model will also operate. When the status of the equipment changes, the model will indicate the current switching status by changing the overall color and displaying text.
In the parameter monitoring area, the monitoring points are divided into 10 groups according to the location of each sensor, and in each group, the points are arranged by type. This area displays the real-time data of each monitoring point on the device, and when the value of the point reaches the preset threshold, this area will provide a timely alarm.
In the status assessment result display area, the left side of this area displays the continuous operating time of the device, while the right side shows the computed values of the HI for the current moment.
The fault diagnosis result display area shows the moments and types of faults that occurred recently, and it can jump to the fault details screen by clicking on each fault.
The trend analysis area shows the trend of the HI values of the device in the last hour, and when a potential fault is detected, this area will send out a timely warning message.
Besides the above functions, the platform is also equipped with historical data query, statistical analysis of fault records, analysis of the equipment state, and many other functions. This platform has been running in the coal-fired power plant for approximately half a year, and the employees in the enterprise can promptly and quickly grasp the operation status of the equipment through the platform.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}