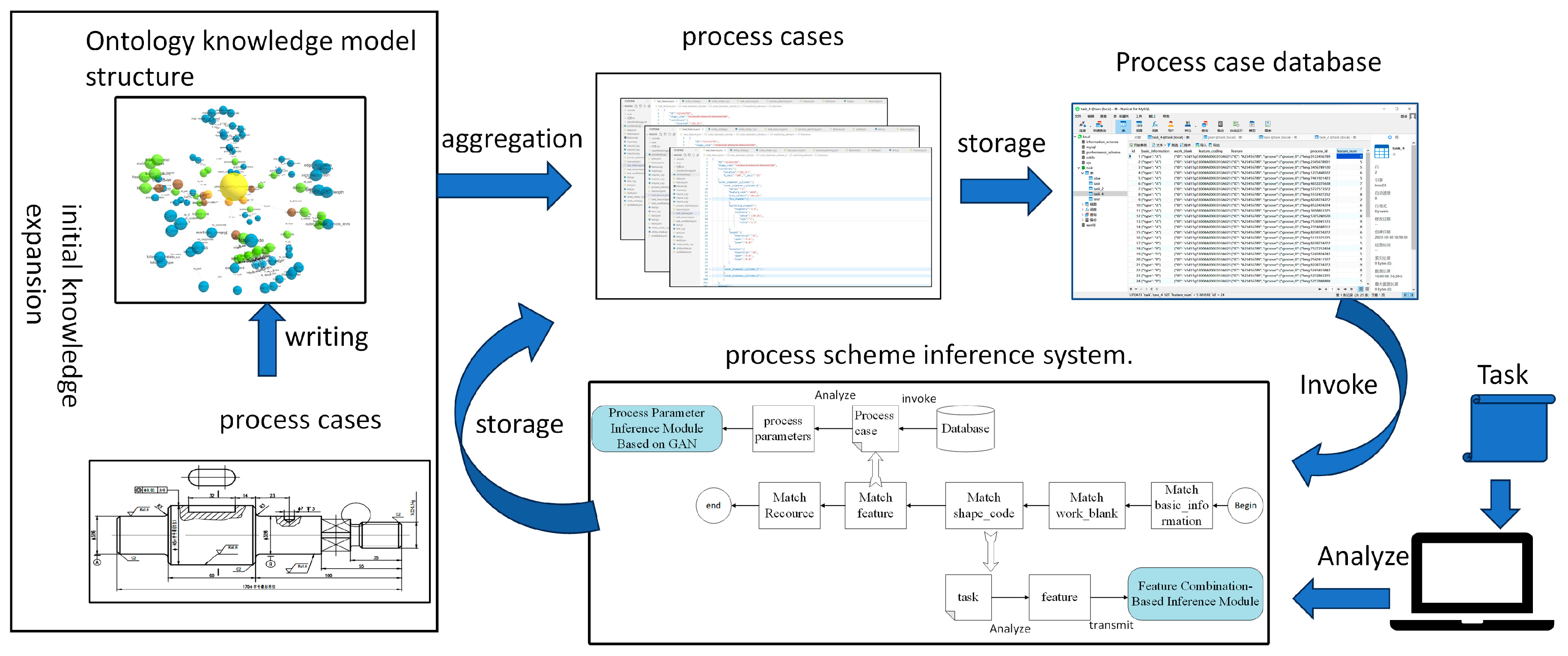
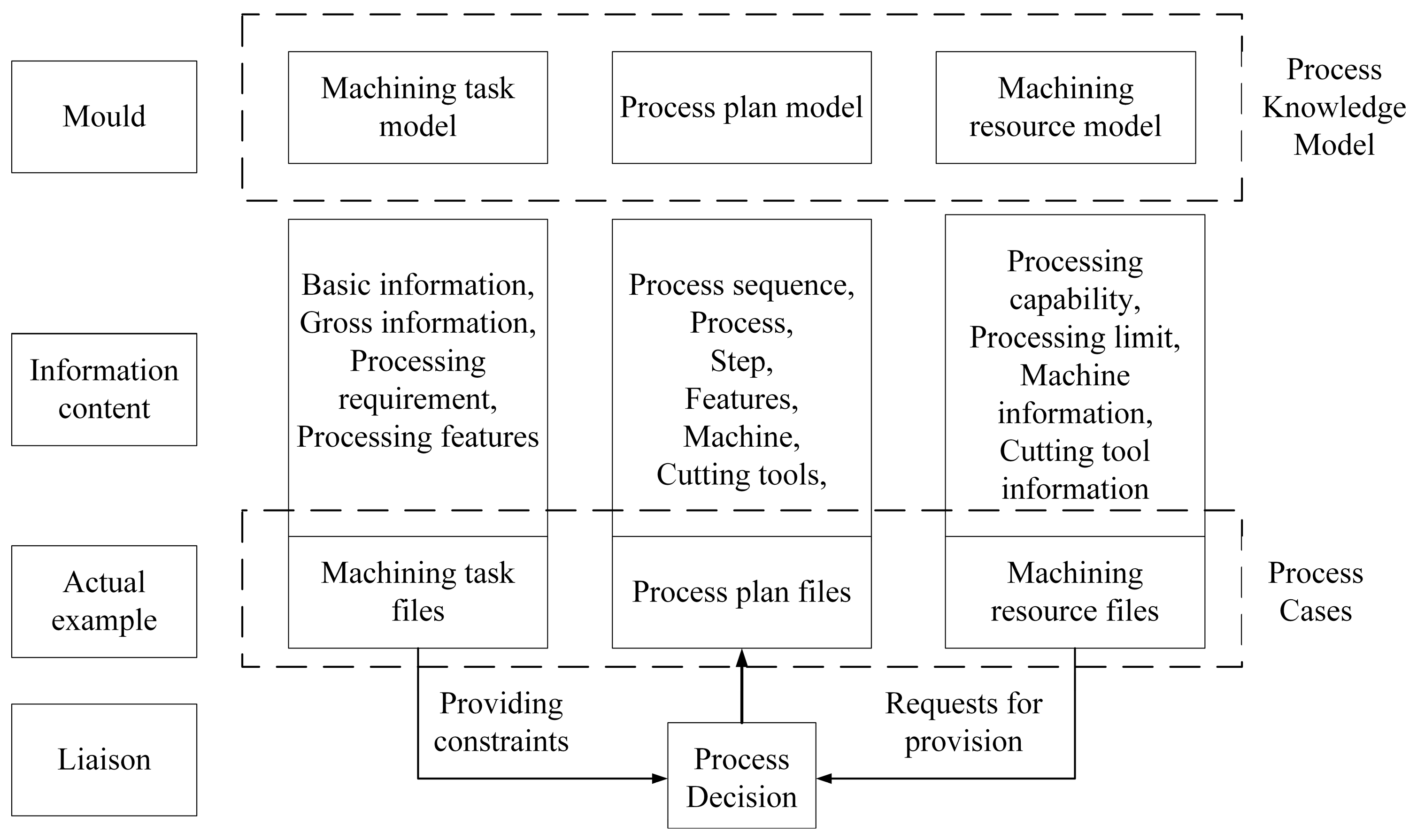
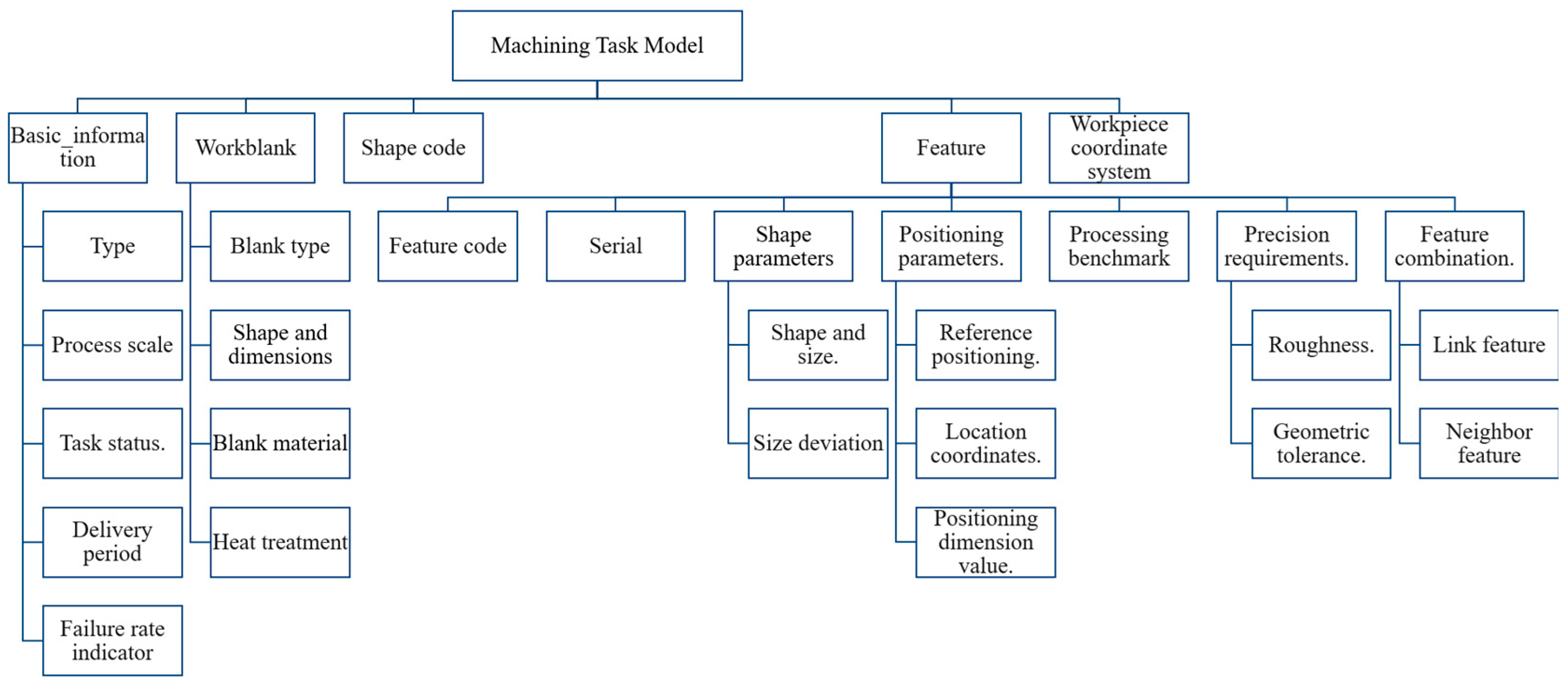
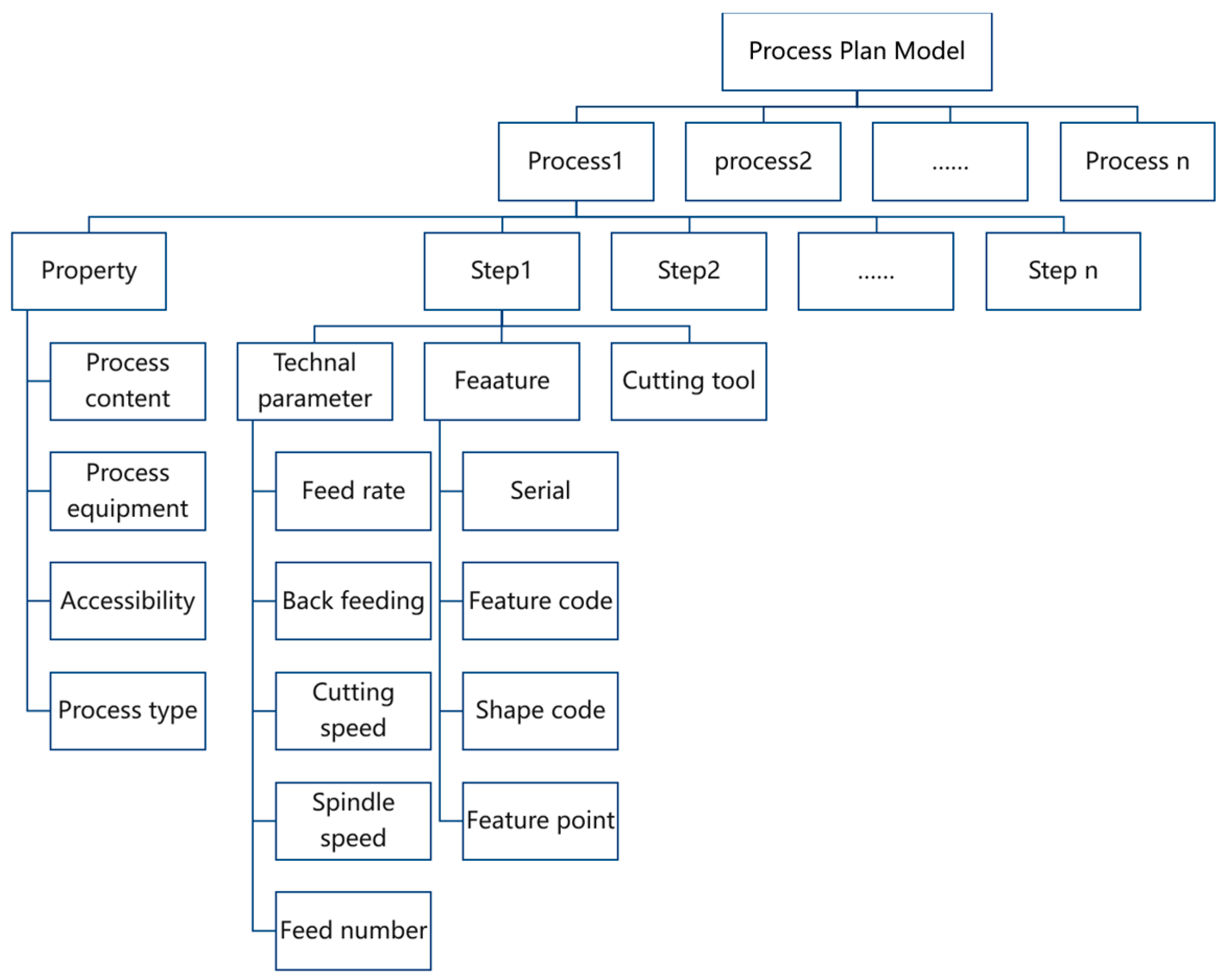
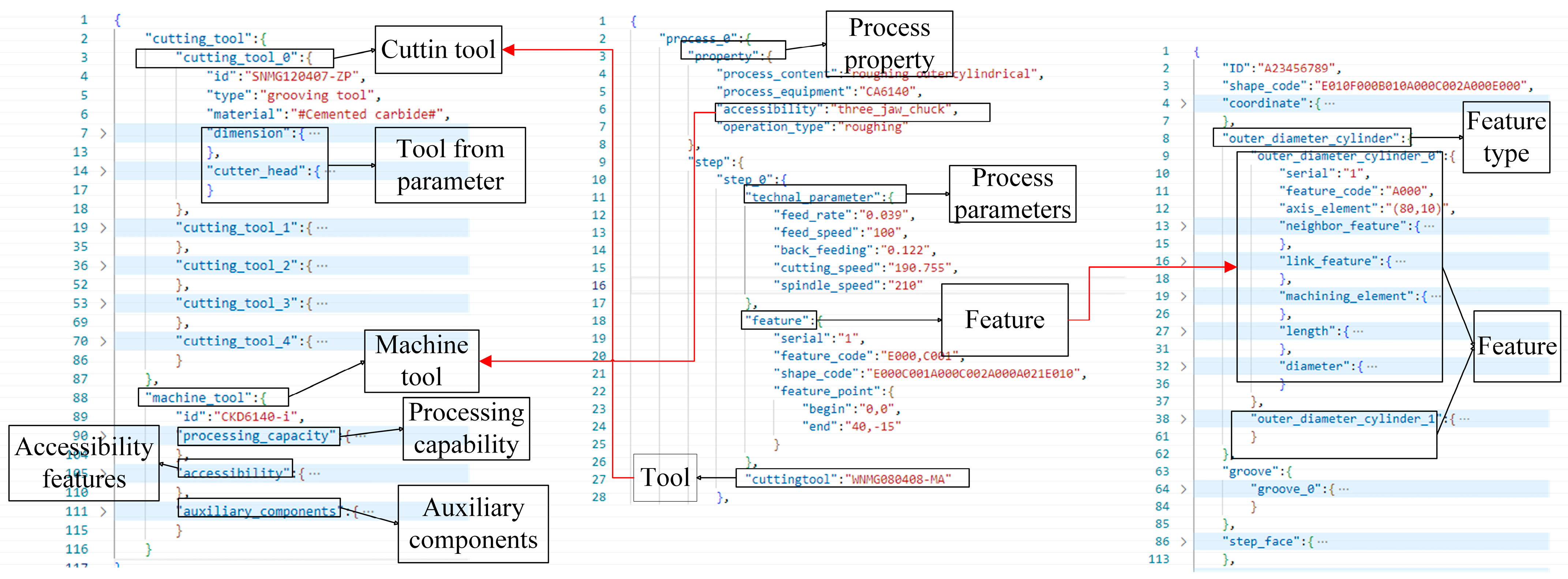
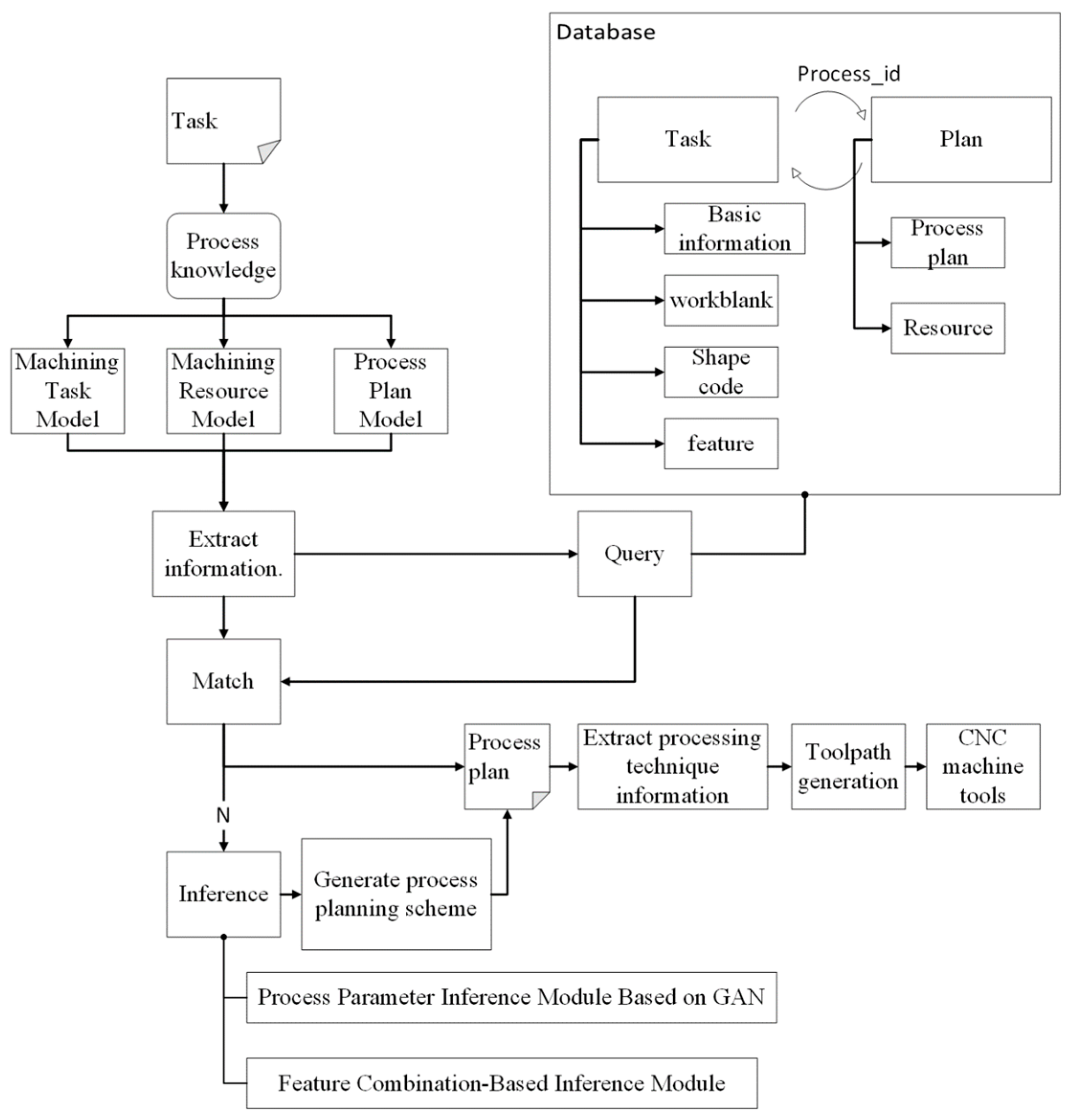
The design of the process knowledge database accomplishes more than just large-scale storage and management of manufacturing process knowledge; it establishes a dynamically updatable knowledge ecosystem that forms the foundation for subsequent process planning. In typical application scenarios, after users input machining task requirements and available resource information, the system employs intelligent retrieval mechanisms to match similar cases from the knowledge base and outputs process planning solution files (as demonstrated by the database matching module in
Figure 8). However, real-world production environments present greater complexity, requiring the system to handle diverse operating conditions. To address this challenge, our solution adopts a modular design philosophy, implementing specialized reasoning modules (shown as the four branches in
Figure 8) for different operational scenarios.
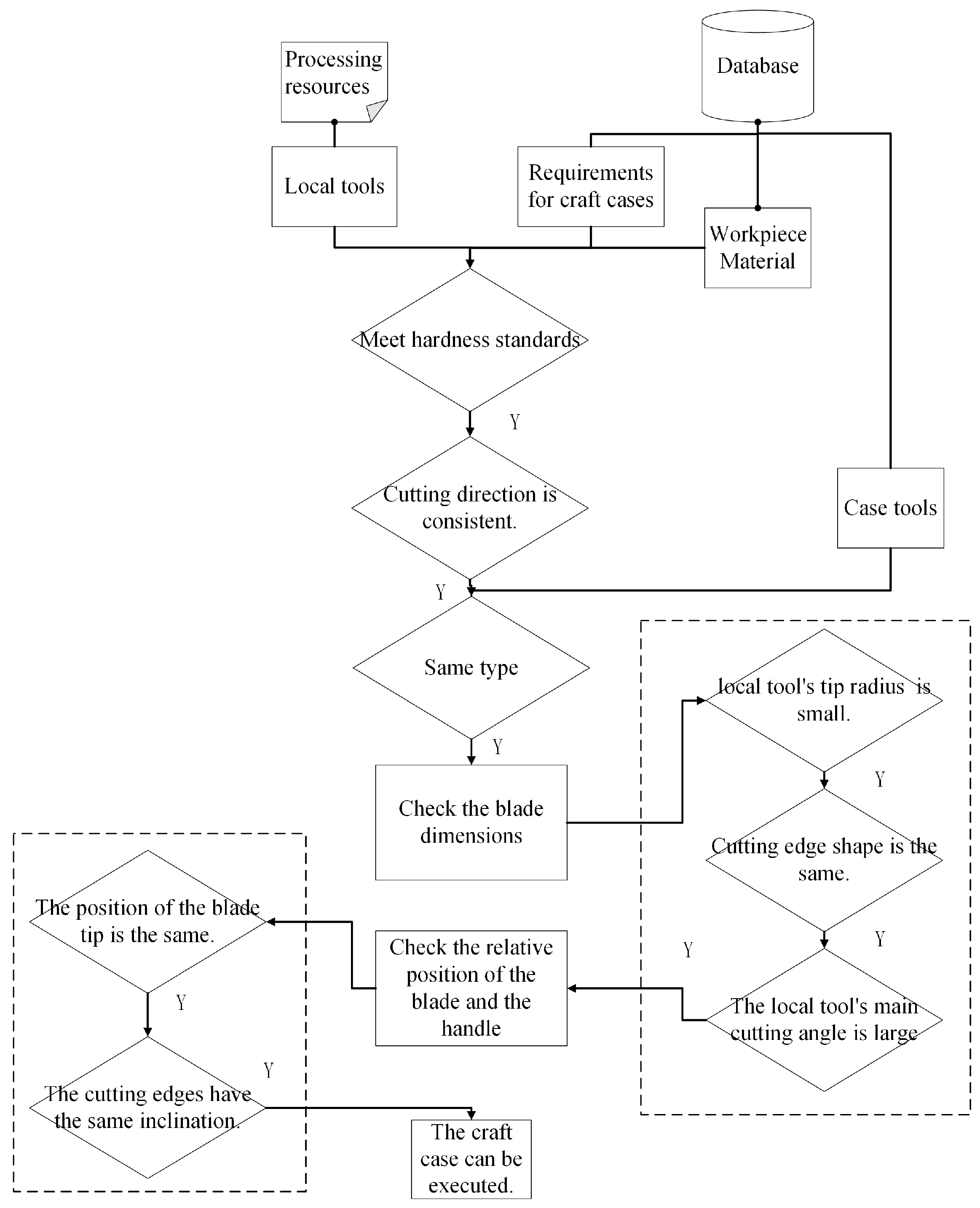
The matching module based on the database performs case screening from the process knowledge base following a hierarchical sequence: (1) blank information, (2) workpiece geometry, (3) feature attributes, and (4) machining resources, identifying cases that fully match the machining task requirements. When exact matching fails, the system retrieves the most similar case from the process database and adapts it through targeted modifications to generate a new process plan that complies with task specifications.
A failed shape code match indicates the absence of geometrically identical cases in the process knowledge database. The system consequently transitions to the ‘feature-combination-based reasoning module’, bypassing the ‘feature similarity assessment’ matching phase entirely.
This study utilizes the nearest-neighbor indexing method for case matching, based on the similarity calculations between instances, which include local similarity and global similarity. Global similarity refers to the similarity of individual features, while local similarity characterizes the degree of similarity of a specific attribute within a feature, serving as the foundation for calculating global similarity. Global similarity quantifies the level of similarity between feature instances, derived from the weighted sum of the local similarities.
3.1.1. Weighted Similarity Calculation Method Based on Euclidean Distance
Matching feature attribute information involves checking all machining requirements within the machining task, including the dimensions, dimensional tolerances, geometric tolerances, and roughness of each feature, to ensure that the machining plan fully complies with the requirements of the machining task.
Firstly, the similarity calculation in task matching is based on numerical distance comparisons rather than statistical data or vector distance comparisons. Therefore, this study chooses to use Euclidean distance (straight-line distance) for the similarity calculation. The formula for Euclidean distance is shown in Equation (1), where
and
represent the numerical values for the machining task and the process case when calculating the same dimension.
In addition, attention must also be paid to whether the positioning references, types of errors, and dimensions are the same during the actual matching process. The following formula is used for this judgment:
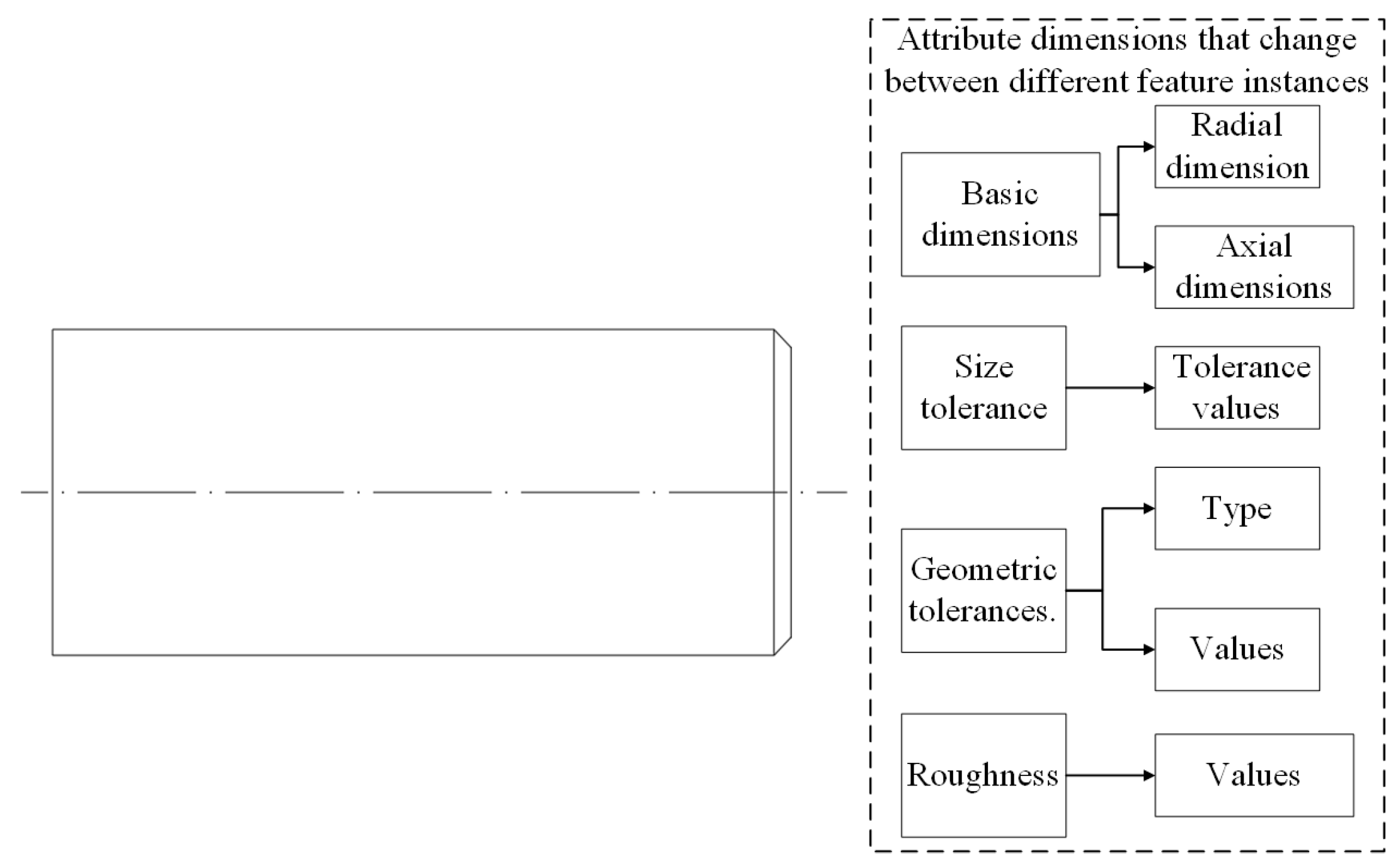
From the definitions provided earlier, it can be seen that the attributes of a feature consist of size information, precision requirements, surface quality, positional information, and so on. The formula for calculating the local similarity of each component attribute can be expressed as follows:
where
,
,
represent the similarity of surface quality, geometric tolerance, and dimensional tolerance, respectively. In Equation (7),
R denotes roughness. The subscript
t indicates information within the machining task, while the subscript
p pertains to information within the process case, and the same applies below. In Equation (8),
signifies the assessment of the datum,
indicates the judgment of whether the type of geometric tolerance is the same, and
v represents the tolerance value. In Equation (9),
T indicates the tolerance grade of dimensions. For the basic dimensions of features, due to the varying types of features and differing compositions of dimensions, the similarity calculation formulas for basic dimensions differ, as detailed in
Table 5 below.
Based on the analysis above, we can derive the formula for calculating the overall similarity of features as follows:
where
,
represent the feature serial numbers in the machining task and process case, respectively, used to distinguish different individuals within the same category of features;
~
are the weight coefficients.
3.1.2. Determine the Weight Coefficients
This study employs subjective assignment and determines the specific weight values through objective statistical analysis. First, based on domain-specific research and empirical knowledge, we conduct preliminary subjective assignments of parameters by considering the priority levels and interrelationships of various local attributes. Subsequently, statistical analysis methods are employed to screen and validate the optimal weight combination, ensuring both objectivity and scientific rigor in weight determination. The specific method is as follows:
(1) Taking the external circular feature as an example, based on the knowledge modeling of external circular features discussed above, 51 groups of external circular feature instances with differing attribute information were randomly generated and stored in the database. As shown in
Figure 9, these instances vary randomly across six dimensions, resulting in different external circular feature instances.
(2) The setting of weights satisfies the following two conditions:
,
. By reviewing the relevant literature [
23,
24,
25], it was found that the basic dimensions of features have the greatest impact on the determination of similar cases, while the other three attributes have a smaller influence. Based on this observation, five sets of weight parameters have been established, as shown in
Table 6.
(3) Randomly select an external circular instance from the database as the target feature. Based on the weight groups set in
Table 6 calculate and determine the top 10 similar feature instances for each weight group. A threshold
ε is established to assess attribute reusability; when the local similarity is greater than or equal to
ε, the attribute can be reused. If there are reusable parts in the feature attributes of a single feature instance, mark the attribute as 1; otherwise, mark it as 0. Use
,
to record the counts of marked 1 s and 0 s, respectively. Finally, compile the results
S for each weight combination and select the weight group with the highest
S value.
where
is the number of attributes marked as 1 among the top 10 feature instances, and
is the number of attributes marked as 0 among the top 10 feature instances. The weight combination that yields the maximum value of the evaluation criterion
S is designated as the weight setting for Equation (11).
In process case similarity assessment, there is a theoretical positive correlation between the similarity value (Sim_f) and the reusable part of the case (S_1), i.e., a higher similarity value usually corresponds to a larger reusable content. However, due to the variability in feature weight assignment, there may be a mismatch between the two: when the similarity contribution of some high-weighted features is large, the overall similarity value may still be high, even though the actual reusable portion is small. This anomaly provides an important basis for the reasonableness test of the weight setting, specifically. Firstly, the S value should have a positive relationship with the Sim_f value. Secondly, the cases with a larger similarity value should also have a larger corresponding S value.
(4) Firstly, the threshold
ε is determined, and a random set of weight coefficients is selected to calculate the similarity and evaluation criterion
S, with the results shown in
Figure 10. It can be observed that when the threshold
ε is set below 0.95, the majority
,
,
,
represent reusable components, and the distinction between cases is relatively small. However, when the threshold
ε is set above 0.95, there are instances of high similarity values, but the reusable component (
) becomes 0. Therefore, the threshold is set at
ε = 0.95.
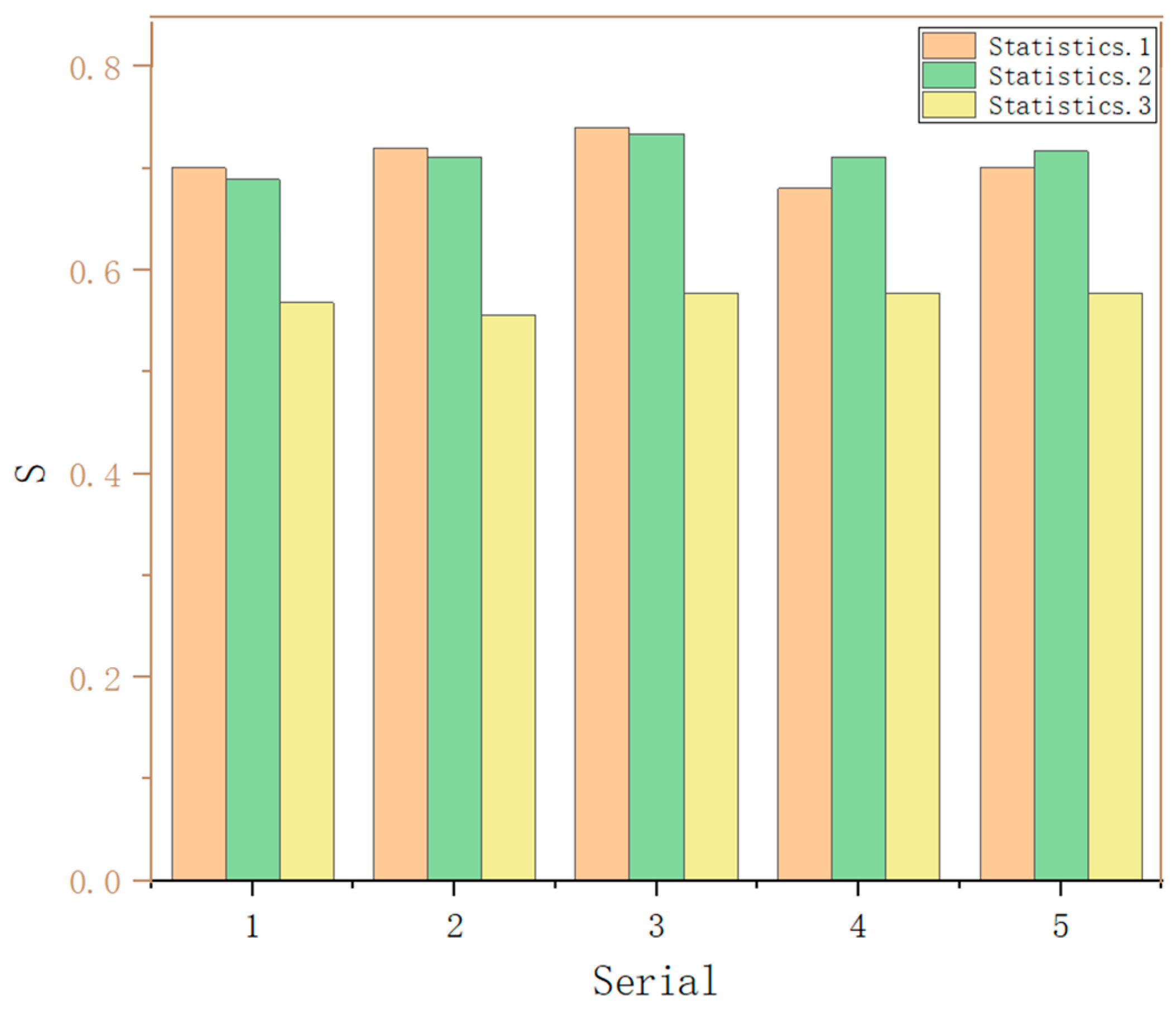
In order to ensure the reliability of the statistics, steps (1), (2), and (3) are repeated three times, with the target instance and target features randomly selected each time. The final summarized results are shown in
Figure 11. It can be observed that the S value of the third weight group is significantly higher than that of the other weight groups, with evaluation criterion
S values of 0.74, 0.825, and 0.65, respectively. Therefore, the third set of weight coefficients is chosen,
.
The feature similarity in the above equation is used to calculate the similarity of individual features. Considering the differences in feature types and the potential issue of non-uniqueness among similar features, the feature matching module is divided into multiple sub-modules, and each sub-module inspects a specific type of feature. The sub-module differentiates between different individual features within the same category based on keyword feature encoding and feature indices, like part in Equation (10).
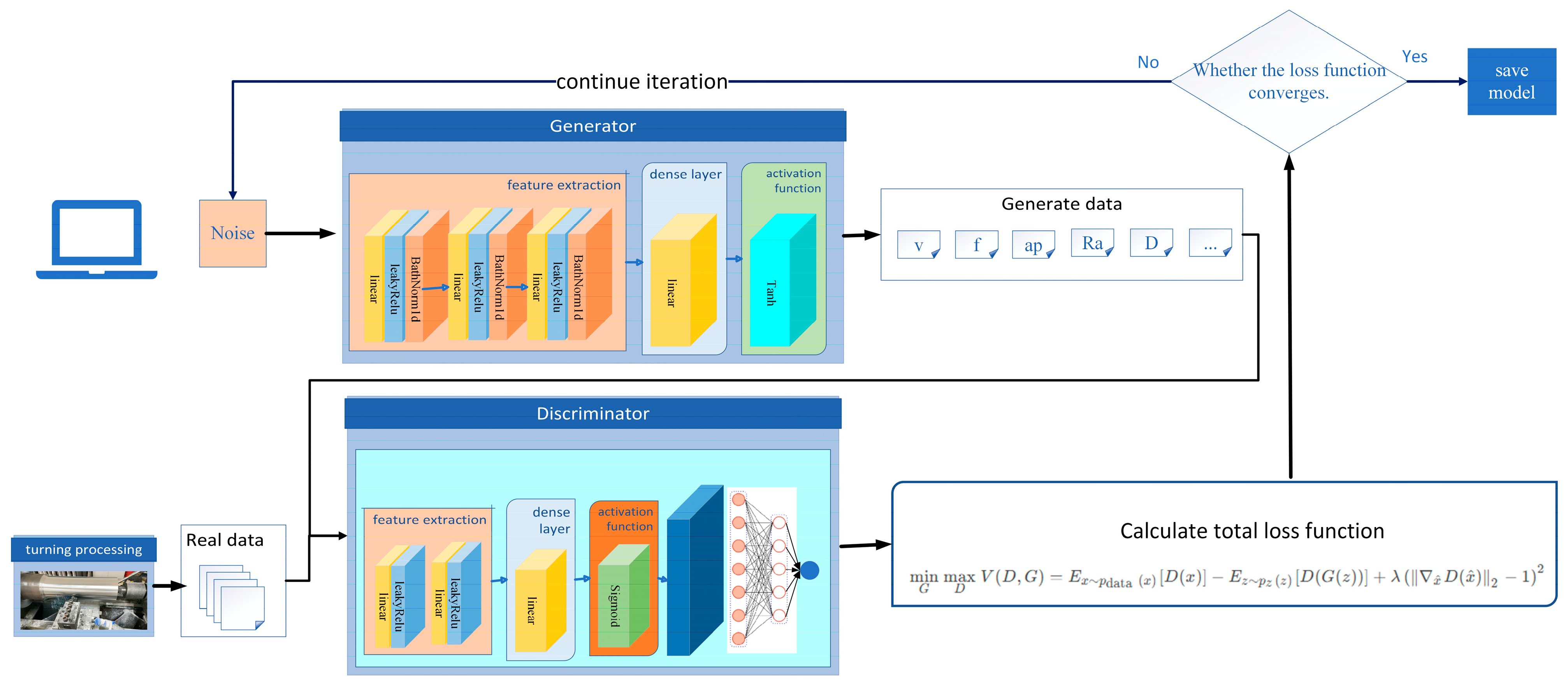
When no process cases can be found that meet the similarity requirements, the matching module does not produce an output, and the system transitions to Process Parameter Inference Module Based on GAN.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}