1. Introduction
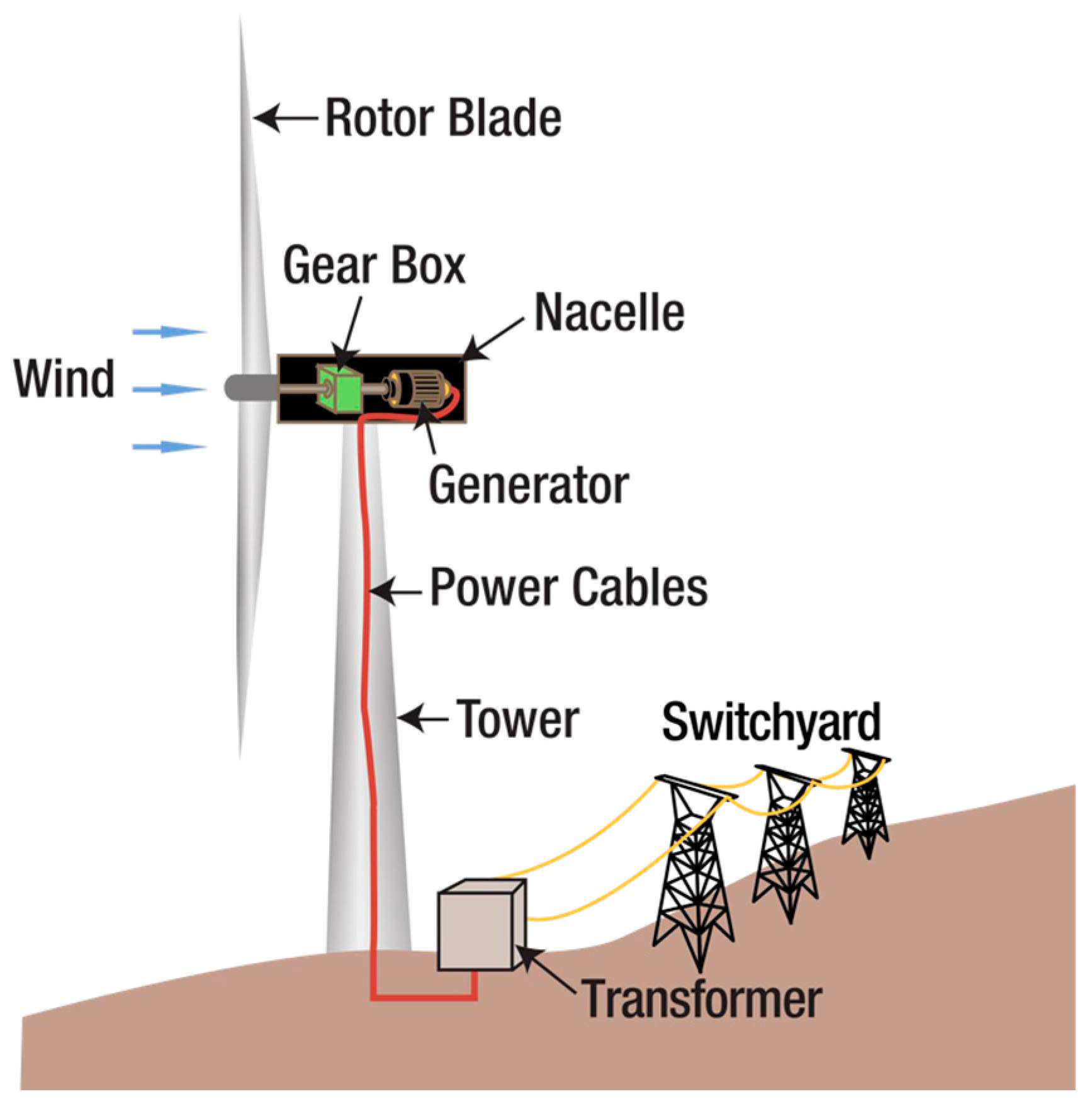
Since the beginning of the 21st century, issues such as global energy security, ecological environmental protection, and climate change have become increasingly severe. Wind energy, as a rapidly developing renewable energy technology in recent decades, is gradually demonstrating its immense potential and value. However, with the annual increase in wind turbine installations and their long-term operation, the number of faulty units has risen significantly, leading to a growing number of accidents and associated losses. The structure of a wind turbine is shown in
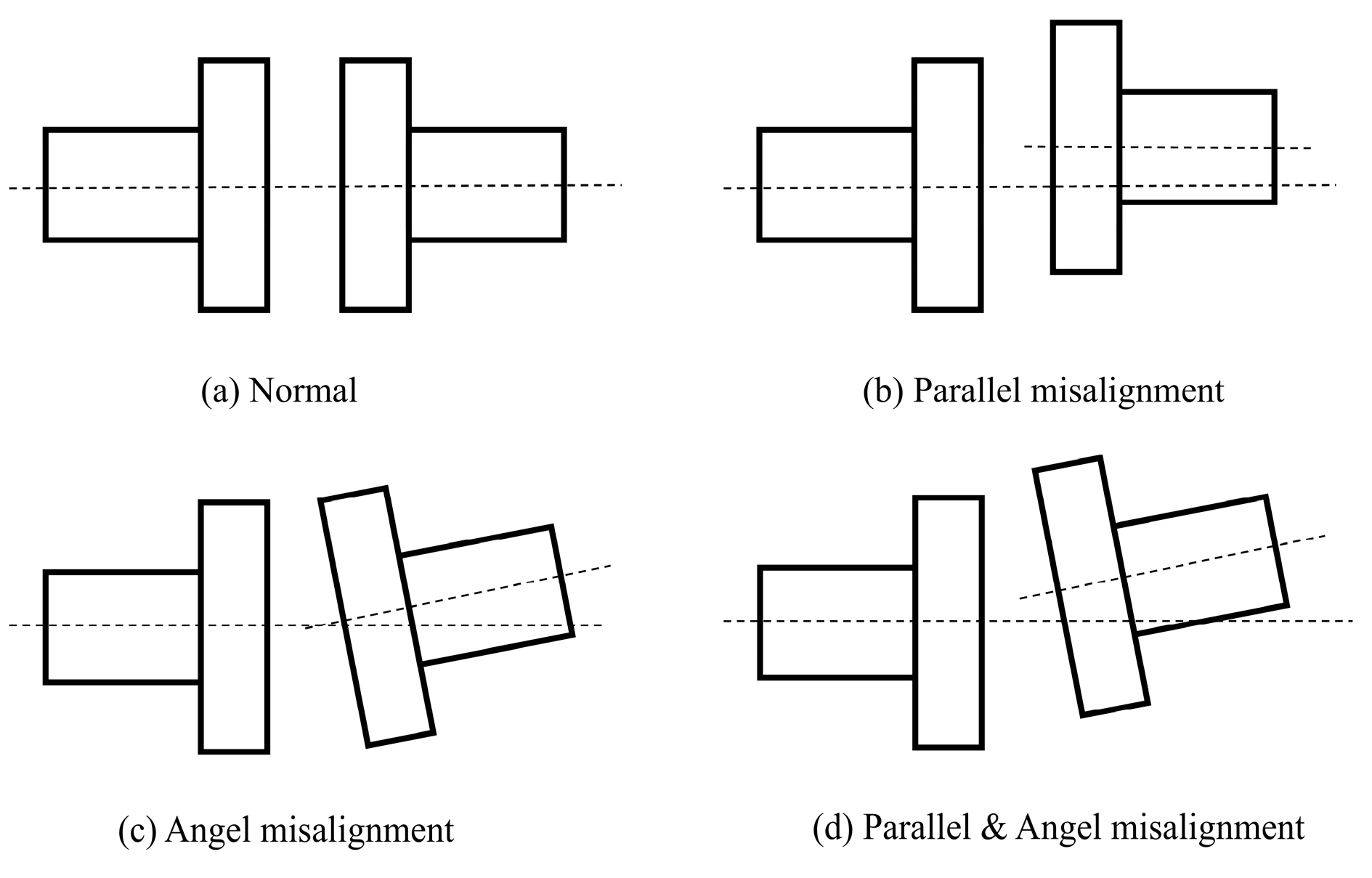
Figure 1, including blades, gearboxes, couplings, generators, and so on. Common failures of wind turbines mainly include blade damage, gearbox wear, drive train misalignment failure, and generator failure. Among these, drivetrain misalignment refers to the misalignment of the rotor shaft system composed of the gearbox and generator, which are connected by a coupling. During the actual operation of wind turbines, factors such as installation errors, load-induced deformation, and uneven settling of the turbine’s foundation can lead to misalignment. Misalignment faults inevitably lead to turbine vibrations, compromising the reliability of the transmission and power generation systems. As a result, monitoring and diagnosing misalignment faults in transmission systems have become critical areas of research in the development of wind power technology.
Fault diagnosis methods can be mainly divided into signal analysis methods, machine learning methods, and deep learning methods.
Signal analysis methods mainly include time-domain analysis methods, frequency-domain analysis methods, and time-frequency analysis methods. For example, Bajric et al. proposed a method for diagnosing wind turbine high-speed shaft gear faults based on discrete wavelet transform and time-synchronous averaging [
1]. Yi et al. proposed an adaptive fault diagnosis method for rotating machinery based on the incomplete S-transform with maximum kurtosis [
2]. Zhao et al. developed a scaled chirp transform method based on frequency-chirp synchronous compression for health monitoring and fault diagnosis of planetary gearboxes and bearings [
3]. However, signal analysis methods predominantly depend on manual prior knowledge to extract frequencies and interpret spectra from the collected signals on-site, which imposes stringent requirements on the expertise of the personnel.
With the development of computer technology, machine learning-based fault diagnosis methods have become increasingly popular. For instance, Long et al. proposed a fault diagnosis method for wind turbines based on a cloud bat algorithm-kernel extreme learning machine [
4]. Pu et al. developed a feature enhancement mapping method to minimize the intra-class distance of deep features in triaxial vibration signals and fed the fused triaxial features into an echo state network for fault classification [
5]. Tang et al. proposed a novel fault diagnosis method for wind turbine transmission systems based on manifold learning and Shannon wavelet support vector machines [
6]. Although these methods have achieved notable success, they are constrained by their inability to perform automatic feature extraction, and their classification algorithms exhibit limited learning capabilities, rendering them inadequate for addressing the demands of fault diagnosis in large-scale data scenarios.
In recent years, deep learning has been extensively applied in fault diagnosis owing to its robust capabilities in feature learning, multi-modal data fusion, and large-scale data processing. Numerous neural network architectures have been developed to effectively handle complex monitoring data; for example, Zhao et al. proposed a Multi-scale Dynamic Graph Mutual Information Network (MDGMIN) for health monitoring of planetary bearings under unbalanced data [
7]. Gao et al. introduced an interpretable wavelet basis unit convolutional network for mechanical fault diagnosis [
8]. Zhao et al. developed a hierarchical health monitoring model called the Adaptive Threshold and Coordinate Attention Tree Heuristic Network (ATCATN) for monitoring the health of aero-engine bearings under strong background noise [
9]. Zhao et al. developed a Multi-Perceptual Graph Convolutional Tree Embedded Network (MPGCTN) [
10]. Xu et al. proposed a cross-modal fusion convolutional neural network for mechanical fault diagnosis [
11]. Li et al. introduced a method for searching globally optimal hyperparameters for LSTMs using an addictive attention serpentine optimization algorithm [
12]. Mohammad-Alikhani et al. proposed a long short-term memory-regulated deep residual network for data-driven fault diagnosis in motors [
13]. Tao et al. developed a deep neural network algorithm framework based on stacked autoencoders and Softmax regression for bearing fault diagnosis [
14]. Zhao et al. proposed a hybrid deep autoencoder network for bearing fault detection and diagnosis [
15]. Wang et al. introduced a fault diagnosis method based on a rolling bearing residual shrinkage network [
16]. Wang et al. developed a method integrating an improved deep residual network and wavelet transform to address gearbox health detection problems [
17]. Shi et al. proposed an intelligent fault diagnosis algorithm for rolling bearings based on a residual dilated pyramid network and a fully convolutional denoising autoencoder [
18]. These research methods are able to automatically learn deep discriminative features from raw data but often exhibit slow convergence and low accuracy when faced with signals containing non-smooth and transient abrupt changes.
Since the vibration signals reflecting wind turbine misalignment faults are non-stationary due to the fluctuation of wind speed, in order to increase the convergence speed and further improve the diagnostic accuracy, this paper proposes a wind turbine misalignment fault diagnosis method based on U-Net and ResNet50 feature extractions.
The main innovations of this paper are as follows:
The dual-branch feature fusion of U-Net and ResNet50 realizes the synergy and complementarity between local detail features and deep global features. The design of this structure enables the model to capture both local key features and global semantic information of wind turbine misalignment faults, which significantly improves the characterization ability and diagnosis accuracy of fault patterns.
- 2.
Introducing the multi-head attention (MHA) mechanism to optimize the U-Net jump connection.
In the U-Net branch, multi-scale feature extraction and the gradual recovery of detail information are realized through the encoding–decoding structure, and the multi-head attention (MHA) mechanism is an attention mechanism that captures the relationship between different subspace features in an input sequence by computing multiple attention heads in parallel, which is innovatively introduced in the jump connection part to enhance the cross-layer feature interaction capability. Meanwhile, the dynamically learnable weight coefficients further optimize the feature fusion effect of the jump connection, which is called hybrid U-Net in this paper, so that the model can focus more on the key fault feature region, thus significantly improving the ability to capture local details and important features.
- 3.
Proposing a shared hybrid expert attention (SHEA) module for efficient integration of global and local features.
In order to further optimize the feature expression ability of the two feature extraction paths, this paper proposes a SHEA module, which dynamically selects and weights the multi-scale local features output from the hybrid U-Net decoder and the deep global features extracted from the ResNet50 backbone network to achieve efficient fusion of multi-scale and multi-dimensional feature maps, which significantly improves the diagnostic accuracy and generalization ability of the model.
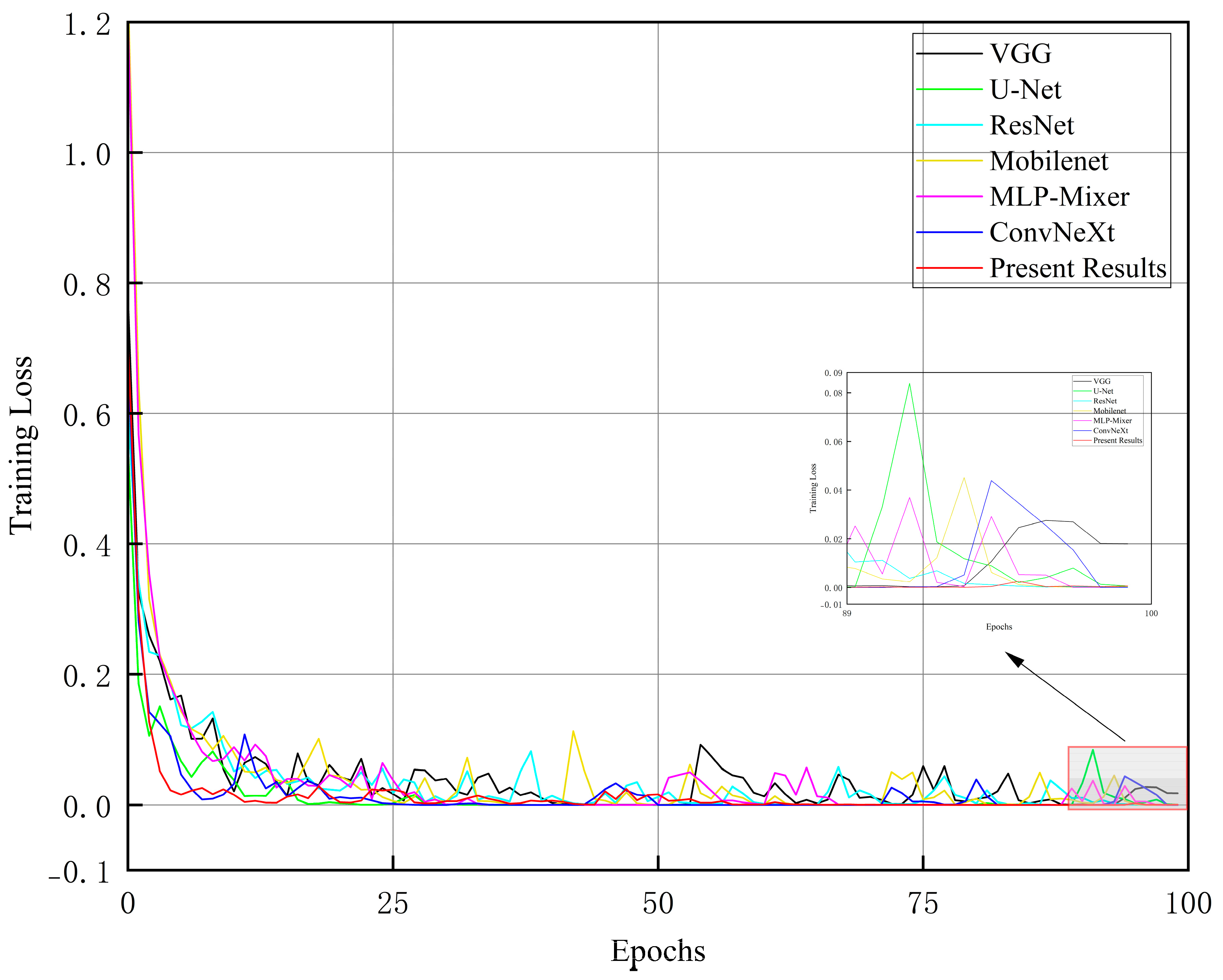
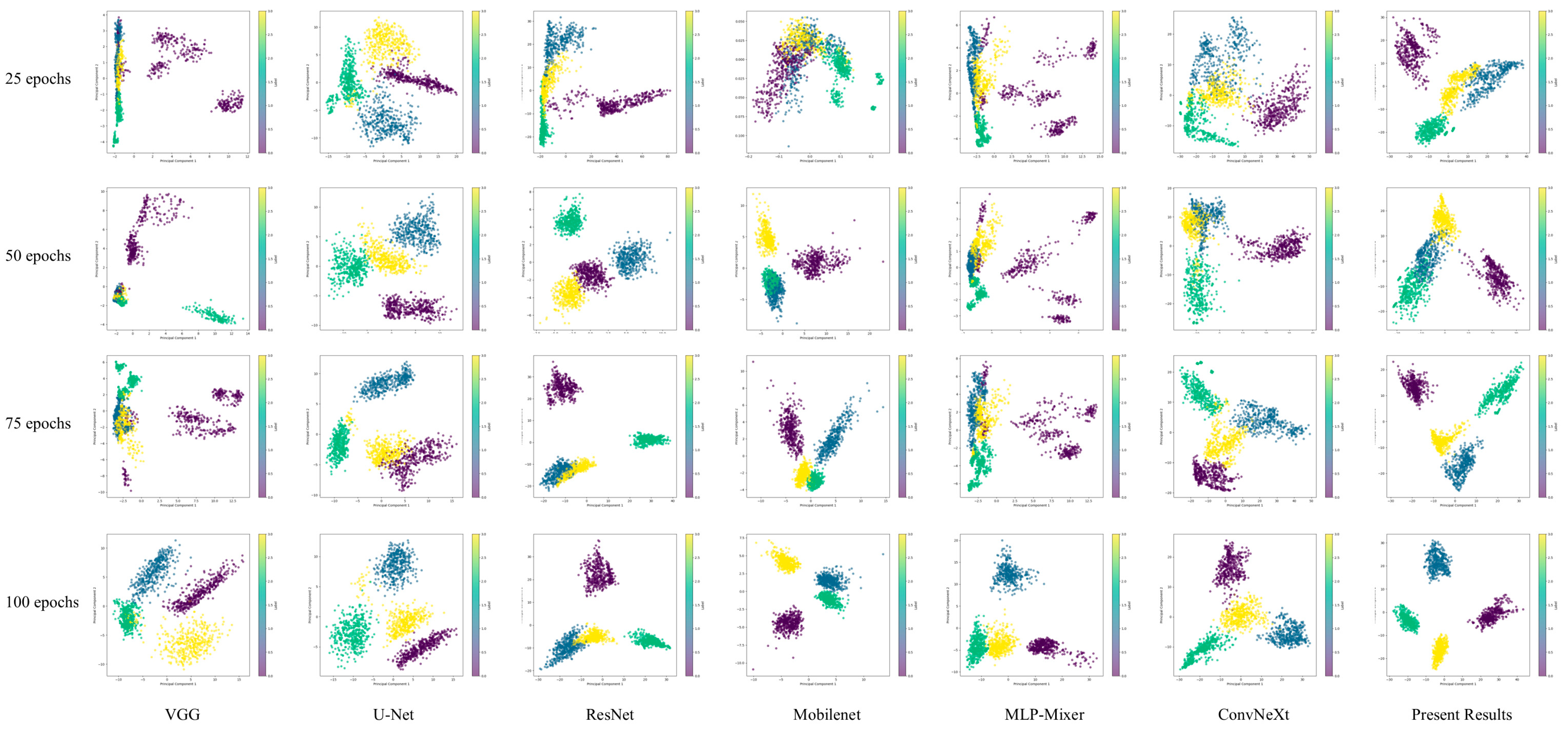
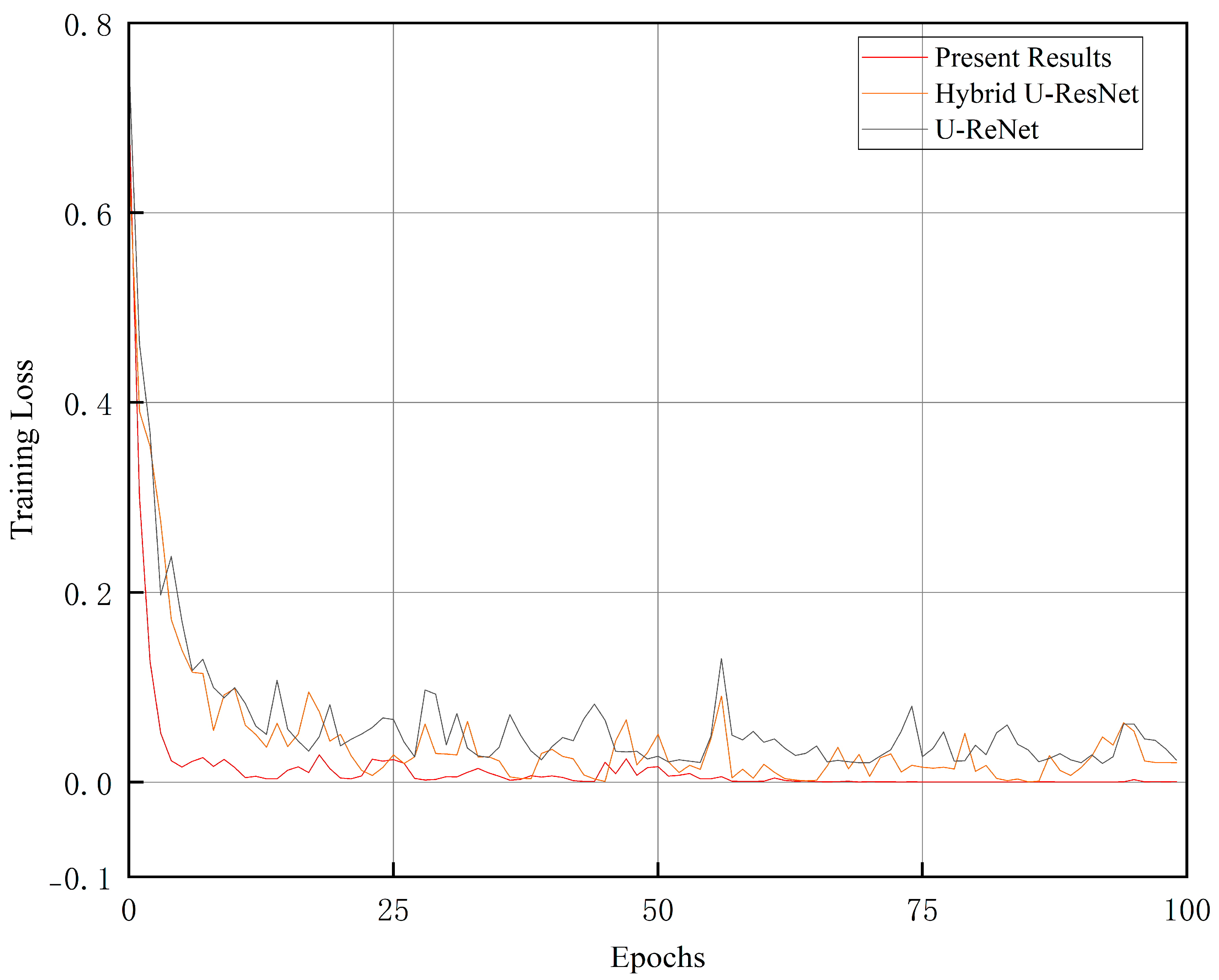
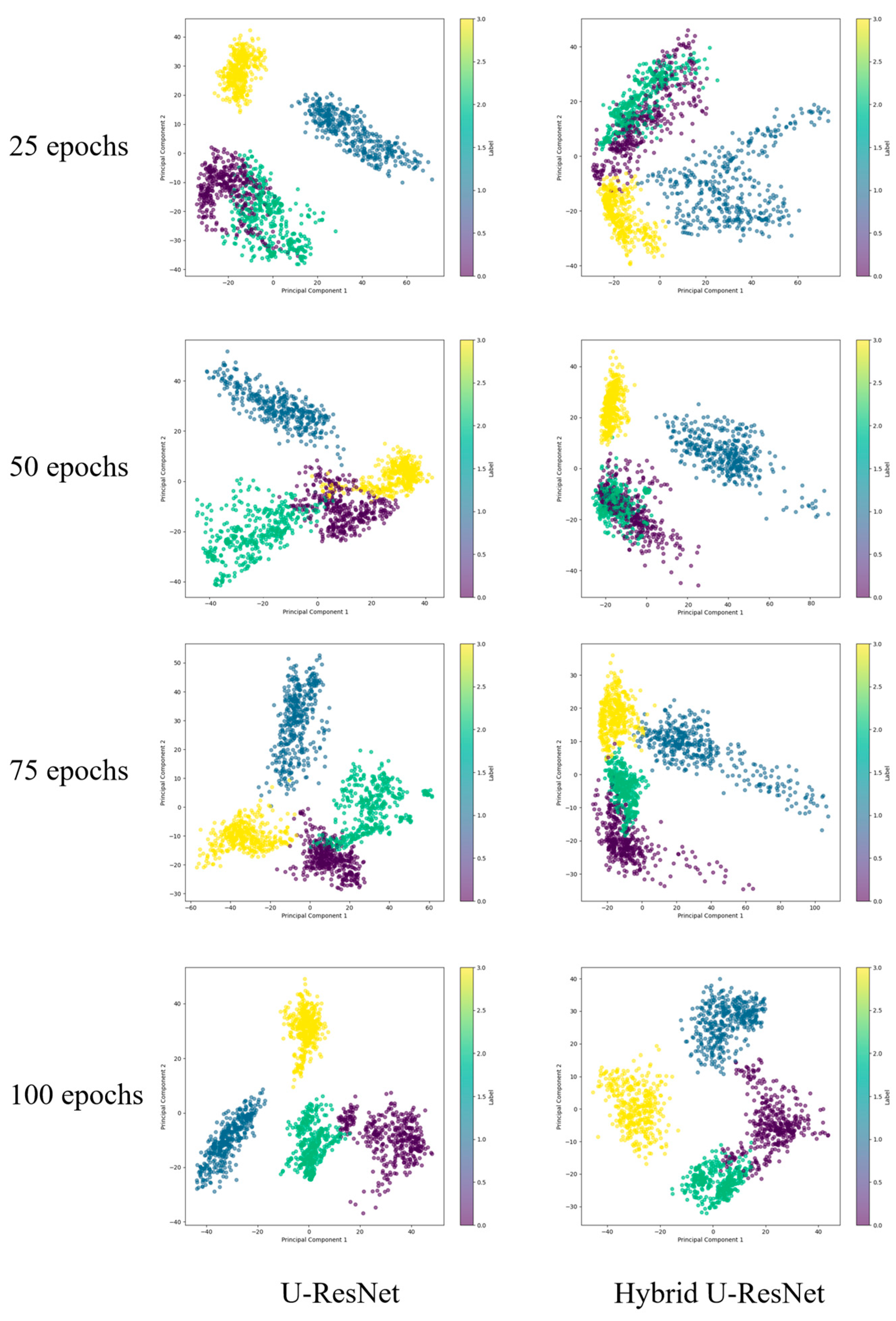
The experimental results show that the method in this paper exhibits an excellent fault recognition rate and a fast convergence speed under the complex working conditions of wind turbines.
The rest of the paper is organized as follows.
Section 2 describes the proposed diagnostic method in detail.
Section 3 presents the experimental design and results analysis.
Section 4 summarizes the main conclusions of this study.
2. Methodology
2.1. Architecture Design
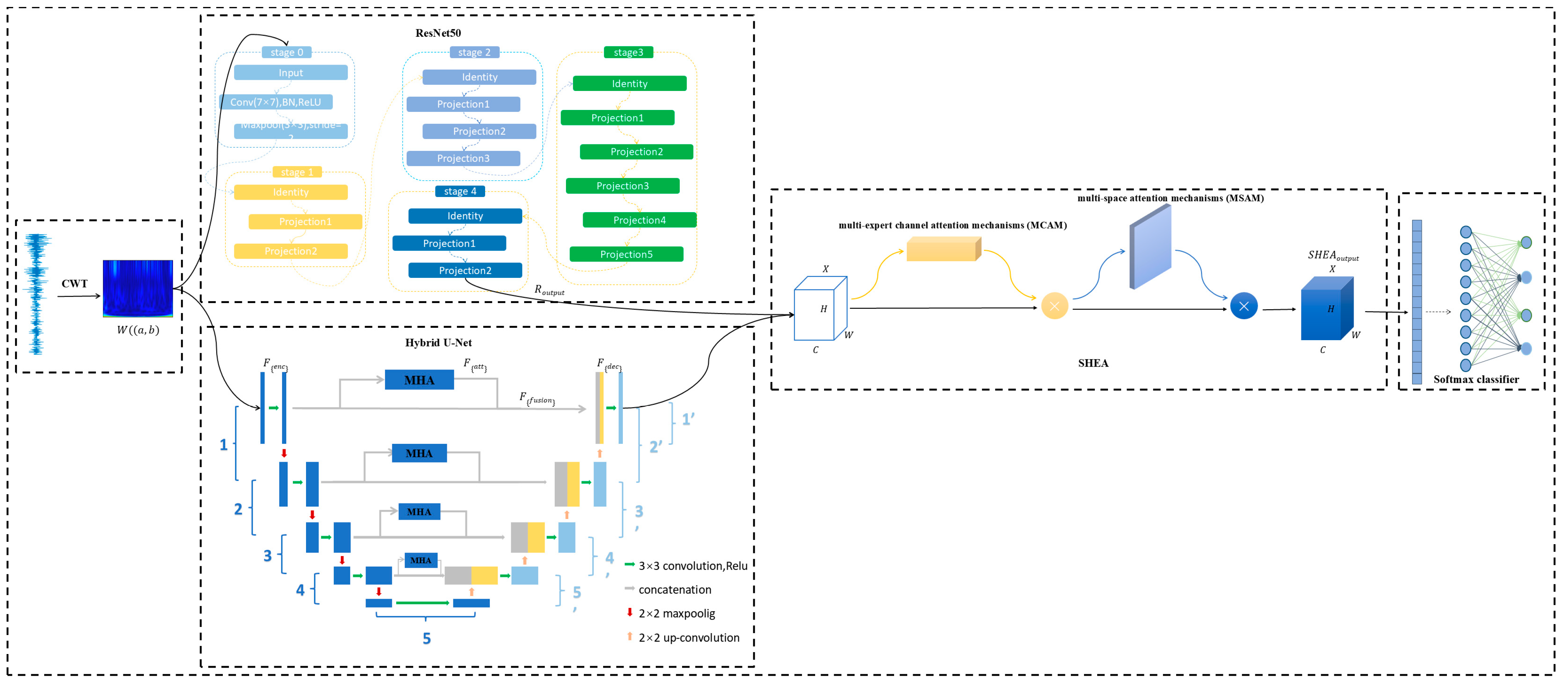
This paper proposes a fault diagnosis method for wind turbine misalignment based on dual-channel hybrid attention of U-Net and ResNet50, and its structure is shown in
Figure 2.
First, for the time-varying and non-stationary characteristics of wind turbine vibration signals, continuous wavelet transform (CWT) is used to perform multi-scale time-frequency analysis to generate a two-dimensional time-frequency image , which provides rich time-frequency information for the feature learning of the subsequent deep learning model.
Then, is fed in parallel to hybrid U-Net and ResNet50 for feature extraction. In the hybrid U-Net branch, multi-scale feature extraction with the gradual recovery of detailed information is realized through the encoding–decoding structure, and the MHA mechanism is introduced in the jump-joining part. In the ResNet50 branch, the residual module is used to realize deep feature mining, which can effectively alleviate the problem of gradient disappearance and improve the model’s ability to learn complex failure modes.
In order to further optimize the feature expression ability of the two feature extraction paths, this paper proposes the SHEA module to weigh the hybrid U-Net decoder output and ResNet50 output to obtain SHEA output.
Finally, the multi-scale and multi-dimensional feature maps optimized by the SHEA module are fused, and the intelligent identification of wind turbine misalignment faults is completed by the classifier.
2.2. Continuous Wavelet Transform
Traditional signal processing methods mainly focus on the spectral characteristics of the signal but often ignore the pattern of change in the signal over time. Time-frequency imaging, as an image representation method that integrates time and frequency information, can capture the dynamic features in the vibration signal more intuitively and improve the accuracy and efficiency of fault diagnosis. Common methods for converting vibration signals into time-frequency images include short-time Fourier transform, discrete wavelet transform, CWT, and Hilbert–Huang transform. Among them, CWT can automatically adjust the time resolution according to the frequency characteristics of the signal, provide fine detail features and extensive generalized information, make the time-frequency changes of the signal more intuitive, and make it easy to find abnormal or fault characteristics. The significant advantages shown in signal processing and analysis make CWT widely used. In this study, CWT is used to convert the original vibration signals of wind turbines into time-frequency images. For a given signal, the definition of CWT is expressed as shown in Equation (1) as follows:
where
represents the original signal,
is the complex conjugate of the wavelet function, and
and
are the scale parameter and translation parameter, respectively. The scale parameter
adjusts the oscillation frequency of the wavelet function by stretching or compressing it, while the translation parameter
shifts the position of the time window [
19].
2.3. Hybrid U-Net
The U-Net network is a classical encoder–decoder architecture widely used in image segmentation and feature extraction tasks [
20]. Its core idea is to realize multilevel feature extraction and reconstruction of images through the combination of contraction path (encoder) and expansion path (decoder). In order to further enhance the feature extraction capability of U-Net for time-frequency images, in this paper, the feature maps of the corresponding layers in the encoder are spliced with the feature maps of the decoder through jump connections after the up-sampling operation at each layer.
In the jump connection, the feature map of the encoder is divided into two parts. One part is directly passed to the decoder, and the other part undergoes multi-level multi-space feature extraction through the MHA to obtain . The encoder feature map and decoder feature map are merged to obtain through a weighted fusion strategy.
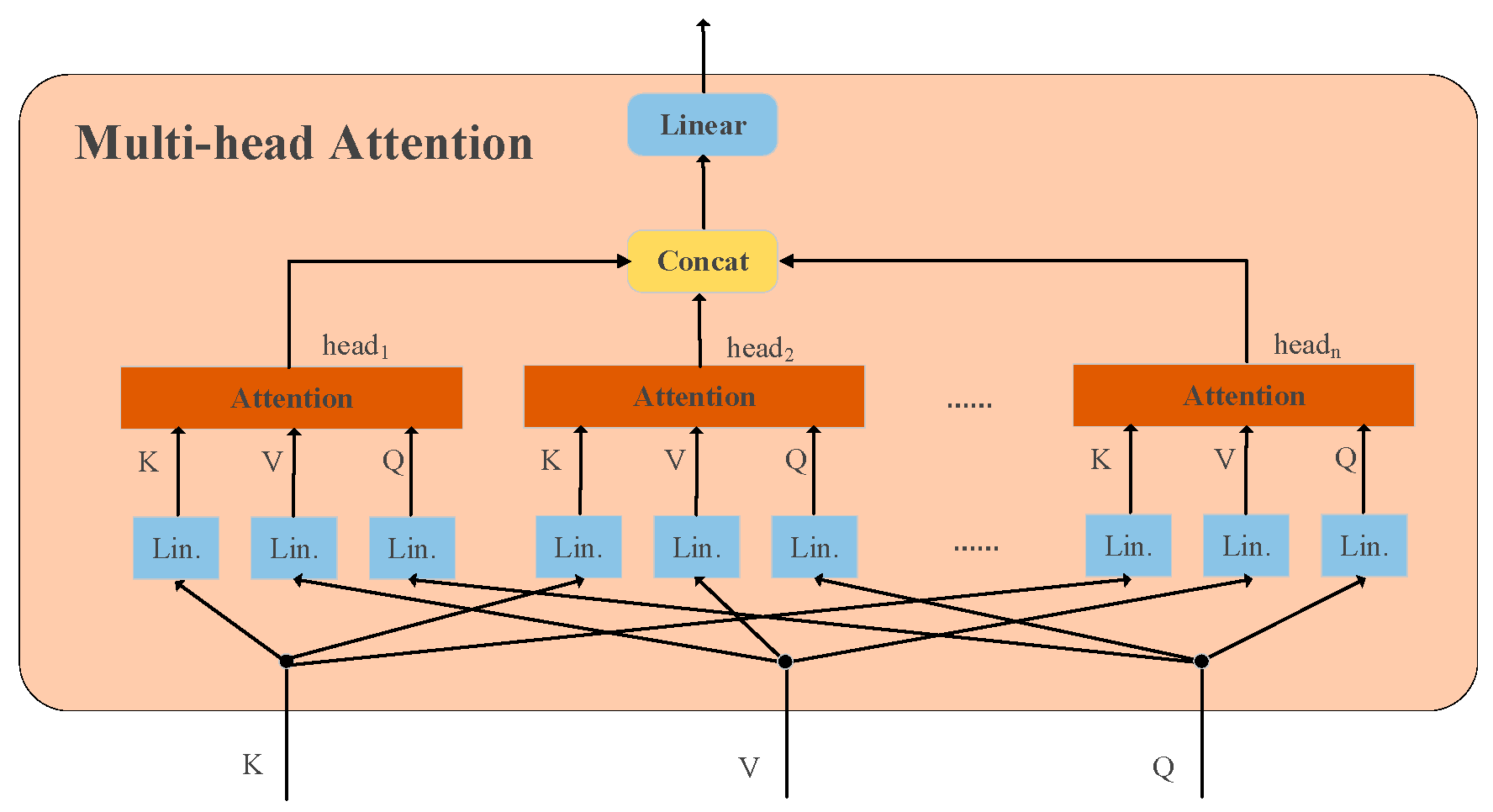
The MHA maps the input features into multiple subspaces and performs independent attention calculations so that the model can effectively capture the feature dependencies in multiple time scales and frequency scales and realize the global modeling and accurate discrimination of fault features, and its structure is shown in
Figure 3. Each head calculates its attentional output through Equation (2) as follows:
where
denotes the dimension size of each head,
,
, and
represent the query matrix, key matrix, and value matrix in the multi-head attention mechanism, respectively, and T stands for the transpose of the matrix. The outputs of multiple heads are then projected through the linear transformation layer after the splicing operation to form the final multi-head attention output, as shown in Equation (3) as follows:
where
is the output weight matrix.
The MHA weighted hopping connection enhances the model’s ability of long-distance-dependent modeling, multi-scale feature fusion, and dynamic feature weighting to improve the feature selection ability and reduce the information loss to enhance the feature reconstruction ability.
This enables the decoding part
to utilize the global and local information more comprehensively, thus improving the accuracy of feature reconstruction, as shown in Equations (4)–(6).
where
is a learnable parameter that adaptively adjusts the contribution of different features to enhance the feature reconstruction in the decoding stage.
Figure 3.
The structure of the multi-attention mechanism.
Figure 3.
The structure of the multi-attention mechanism.
Where , , and represent the query matrix, key matrix, and value matrix in the multi-head attention mechanism, respectively.
2.4. ResNet50
To extract deeper and more abstract features that are beneficial for classification, it is essential to increase the depth of the network. However, as the number of network layers increases, the number of parameters grows significantly, and issues such as vanishing or exploding gradients may arise, making the network challenging to train. To address the gradient vanishing problem associated with increasing network depth, He et al. proposed ResNet, a residual learning framework based on convolutional neural networks [
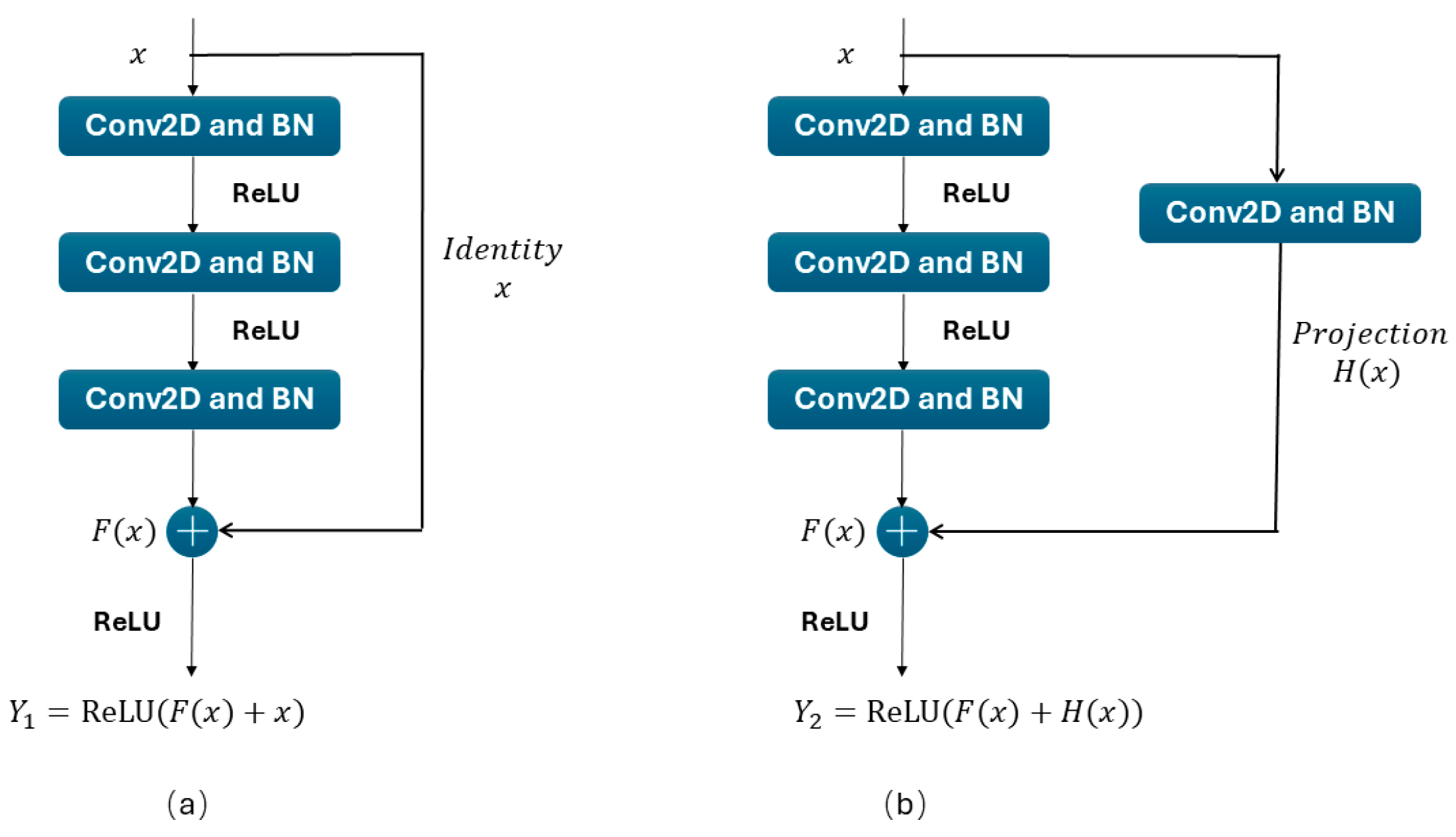
21]. In the residual learning framework, network layers do not simply learn a direct nonlinear mapping from input to output. Instead, they decompose this complex mapping into two components: a shortcut path and a residual path. The shortcut path directly transmits the input data to the output of the residual block, while the residual path consists of multiple convolutional and activation layers. At the output of the residual block, the original input information is combined with the information processed by the convolutional layers through an addition operation, producing the final output. The residual block, the core component of ResNet, typically comprises multiple convolutional layers, batch normalization, ReLU activation functions, and a shortcut connection. Residual blocks can be categorized into two types: identity mapping and projection mapping, as illustrated in
Figure 4.
Figure 4a illustrates the structure of identity mapping, where the input is
,
represents the residual path in the identity mapping, and the output of the identity mapping is expressed by Equation (7).
Figure 4b shows the structure of projection mapping, where the input is
,
represents the residual path in the projection mapping, and
represents the shortcut path in the projection mapping. The output of the projection mapping is expressed by Equation (8).
Multiple identity mapping blocks and projection mapping blocks are stacked following the initial convolutional layer to construct ResNet50 [
22].
goes through ResNet50 to obtain
, as shown in Equation (9).
2.5. The Shared Hybrid Expert Attention
In order to emphasize the importance of features and to improve the model’s expressiveness by enhancing key feature regions while suppressing irrelevant features, we propose a SHEA module for the feature maps generated by hybrid U-Net and ResNet50, which is derived from the improved convolutional block attention mechanism [
23]. SHEA utilizes two mutually independent attention mechanisms: multi-expert channel attention mechanisms (MCAMs) and multi-space attention mechanisms (MSAMs). MCAMs and MSAMs generate the corresponding weight maps to be fused with the input feature maps in an element-by-element multiplication manner. This process is an adaptive refinement of features and is shown in
Figure 5, respectively.
The MCAM enhances the adaptive capability by introducing the dynamic selection mechanism of mixing of experts (MoE) in the channel attention module (CAM), which is a model that can dynamically select and enhance the key channels according to the diversity of the input features, thus improving the diversity of the feature expression and generalization capability. MoE consists of an expert network and a gated network. The gated network calculates the importance of the coefficients of different experts under the current task based on the specific features of the input samples and decides the contribution of each expert in the final output. The expert network, on the other hand, consists of a number of relatively structurally independent submodels, each of which is designed to deal with a particular subspace of the input data or to model specific types of features. In the whole MoE architecture, the computational process can be formalized as Equation (10) as follows:
where
denotes the input sample,
denotes the total number of expert networks, and
denotes the result of the
expert network for input
.
denotes the weight score computed by the gating network for the
expert, which satisfies that the sum of the weights of all experts is 1.
The gating network is controlled according to the input . The weights are dynamically adjusted according to the feature distribution of , thus providing flexible control over the combination of experts. Through the above-weighted fusion mechanism, MoE realizes sparse computation in the inference stage while maintaining a large model capacity, which effectively improves computational efficiency. In addition, the functional specificity among different experts enhances the model’s expressiveness and generalization performance for diverse inputs.
Specifically, the MCAM first performs spatial aggregation on the feature map using average and max pooling. Then, the two generated vectors are passed through shared fully connected layers to obtain two sets of channel weights,
and
, which are fused into
. Finally,
is used to weight the input feature map, selectively enhancing or suppressing the features, as shown in Equations (11)–(14).
In addition, the MSAM first averages and maximally pools
to generate two single-channel feature maps,
and
. They are then fused along the channel dimensions to generate the spatial attention weight map,
, by the MHA. Finally,
is used in
to refine important feature regions and suppress redundant information [
24], as shown in Equations (15)–(18).
and
are SHAE-processed to obtain
, as shown in Equation (19).
4. Conclusions
The dual-channel hybrid attention model proposed in this paper significantly improves the performance of wind turbine misalignment fault diagnosis by innovatively introducing the MHA in the jump connection of U-Net and combining the SHEA module to enhance the two feature extraction paths. The model realizes multi-scale feature extraction and detail recovery through the encoding–decoding structure in the hybrid U-Net branch using the MHA to enhance cross-layer feature interactions and the ability to focus on critical regions. In the ResNet50 branch, deep global features are mined, and the SHEA module dynamically weights and selects experts between multi-scale local features and global features to realize efficient fusion of global and local information. Therefore, facing the challenges of signal non-stationarity and transient mutation characteristics in the fault diagnosis of wind turbine drive train misalignment under complex working conditions, this method is able to realize efficient, accurate, and stable fault diagnosis, which provides reliable technical support for the intelligent monitoring of industrial equipment.
In the future, research can focus on optimizing the model’s computational efficiency and lightweight design, enhancing its generalization ability across different wind turbine types and noisy environments, and integrating multi-modal data for more comprehensive fault diagnosis. Additionally, exploring unsupervised or semi-supervised learning methods to reduce reliance on labeled data, improving model interpretability, and extending the framework to fault prognosis and predictive maintenance will further advance its applicability in real-world industrial scenarios.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}