3.1. Dual-Tree Complex Wavelet Transform
Wavelet transform has shown its incomparable capabilities in non-stationary signal analysis and complex compound signal decomposing. Dual-tree complex wavelet transform (DTWCT) [
28], as one of the theoretical implementations of complex wavelet transform (CWT), has some promising advantages over real wavelet transforms.
Inheriting the idea of Fourier transform, DTCWT exploits imaginary unit
to encode phase information of signals. The forward and backward passages of dual-tree CWT employ two groups of filter banks (FBs), which are shown in
Figure 5. DTWCT consists of a two-channel discrete wavelet transform (DWT) with two different real wavelet functions
and
; thus, the composed complex wavelet function can be represented as follows:
To reach a better analyzing capability, DTCWT desires
to be in the region of analytical functions so that
and
should be a pair of Hilbert transform [
29]:
where
denotes Hilbert transform. However, an analytical function is not a valid wavelet function as it lacks the properties of finite support and fast decay. To bridge the gap between a valid wavelet function and a better analyzing capability,
should be as close as possible to the Hilbert transform of
and it must be certain that
is a valid wavelet function.
The technique to design two parallel FBs requires that the low-pass filters of both real and imaginary trees are approximately a half-sample shift to each other [
29]:
Based on the above conditions, the decomposition and reconstruction algorithms can be concluded as follows:
where
is the decomposed level and
is the maximum level.
are the high-frequency coefficients in level
, and
are the low-frequency coefficients in the final level
of the real tree. Similarly, the imaginary tree is decomposed under
. Combining both real and imaginary parts, the complex coefficients of DTCWT in each level can be derived as follows:
Im denotes the corresponding imaginary part of the decomposed signal. The reconstructed real signals of each level can be attained using the following equations:
DTCWT often proves to be a great innovation and improvement of DWT in the complex domain. Different from real wavelet transform, complex wavelet features have the properties of smoothness and regularity, making them more easily simulated.
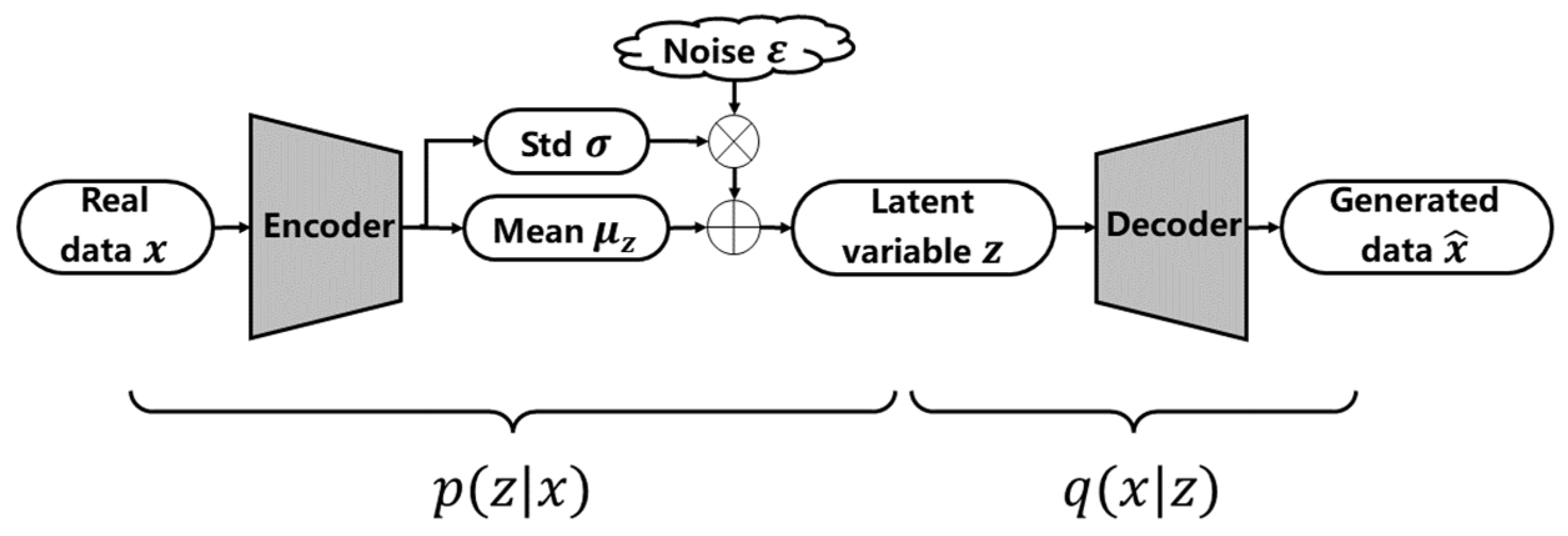
3.2. Bidirectional Autoregressive VAE
Traditional VAEs apply simple Gaussian priors on latent variables for ease of training. However, these oversimplified distributions limit the ability to generate complex industrial patterns. To address this limitation, we propose a Bidirectional Autoregressive VAE that enhances latent expressiveness through autoregressive modeling. As depicted in
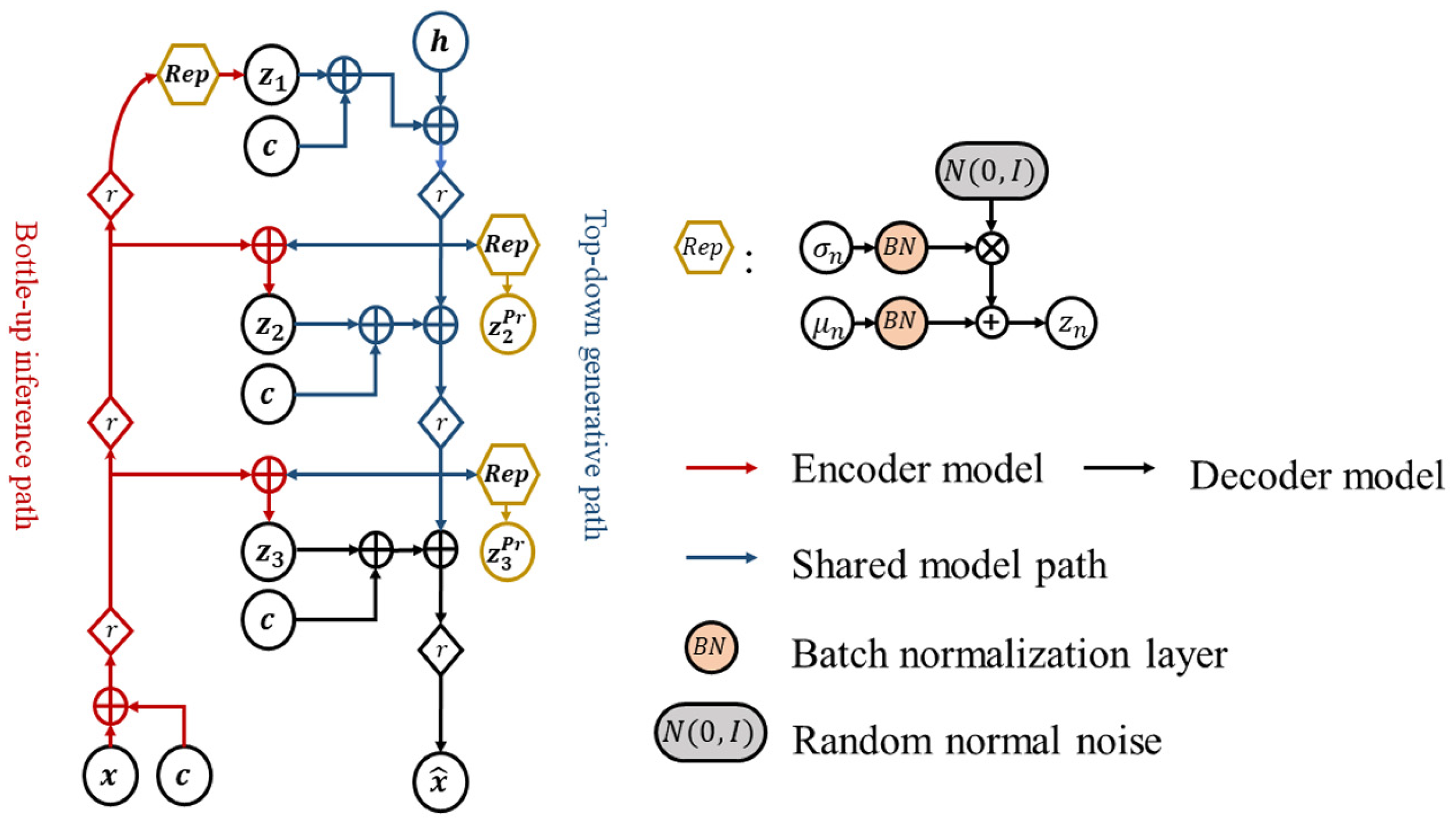
Figure 6, BAVAE integrates residual networks into its feature extraction module, structurally improving the decoder’s ability to synthesize high-fidelity industrial signals.
In the Bidirectional Autoregressive VAE, latent variables are partitioned into multiple mutually independent groups:
where
denotes the number of groups. The first-layer latent variable
is hierarchically conditioned by preceding groups through autoregressive modeling. Higher-layer latent distributions are learned via neural networks. The prior and approximate posterior distributions in BAVAE are formulated as follows:
where the first-layer prior is defined as a standard Gaussian, while subsequent priors follow factorized Gaussian distributions with learnable mean and variance parameters. These parameters are adaptively derived from preceding layers via neural networks, regularized by KL divergence to constrain deviations from the prior. The highest-layer latent distribution is conditioned on all preceding variables and decoded into generated signals, governed by KL divergence and reconstruction loss. The total KL divergence for BAVAE decomposes as follows:
As shown in
Figure 6, the architecture of the bidirectional network integrates the encoder and decoder through latent variables. The network on the left, from bottom to top, represents the encoding process. After obtaining the latent variables at each layer, the higher-level latent variables are derived from the encoded information in the preceding layers, moving from top to bottom. Simultaneously, the prior distributions of different latent variables are learned, ultimately decoding into the generated signal.
This autoregressive hierarchy enhances latent expressiveness for complex industrial data generation. The bidirectional design streamlines training by eliminating redundant connections and reducing computational overhead.
Although the proposed BAVAE draws inspiration from hierarchical latent variable models such as Ladder VAE [
30] and PixelVAE [
31], it differs significantly in both structure and application. In contrast to Ladder VAE’s skip-connections and auxiliary variables, BAVAE adopts autoregressive modeling between latent variable groups in a bidirectional manner. Compared with PixelVAE’s spatial pixel-level dependency for images, BAVAE is tailored to vibration feature sequences and incorporates residual networks for industrial signal generation. Moreover, a feature discrimination loss is introduced to guide the latent representation to be class-sensitive, which is crucial for handling class imbalance in industrial fault diagnosis.
3.3. Enhanced Loss Function
The conventional VAE loss, as shown in Equation (8), jointly optimizes reconstruction fidelity and latent regularization:
To enhance the discriminability of data generated on imbalanced datasets, this paper introduces a feature discrimination loss function based on the existing two loss functions. Specifically, an additional mapping network is constructed on the basis of the last latent variable layer, comprising global pooling and fully connected layers, with the output being the predicted labels of the latent variables. By widening the gap between samples of different classes during the training process of the Variational Autoencoder, the loss function can be formulated as follows:
where
denotes the latent mapping function. The composite loss is calculated as follows:
Here, and are tunable weights, and represents the KL divergence in Equation (17). By incorporating , latent representations become class-sensitive during training, enlarging inter-class margins. This facilitates fault classification by generating label-aware synthetic samples, ultimately boosting diagnostic accuracy.
During training, the reconstruction loss ensures the generated samples closely resemble the real samples in the feature space, promoting fidelity. Meanwhile, the feature discrimination loss introduces an additional constraint on the latent space to make the representations more class-discriminative. These two loss components are complementary: while the reconstruction loss focuses on input–output consistency, the discrimination loss pulls latent features apart across classes. The joint optimization drives the BAVAE to generate not only realistic but also class-aware samples, which is crucial for learning under data imbalance.
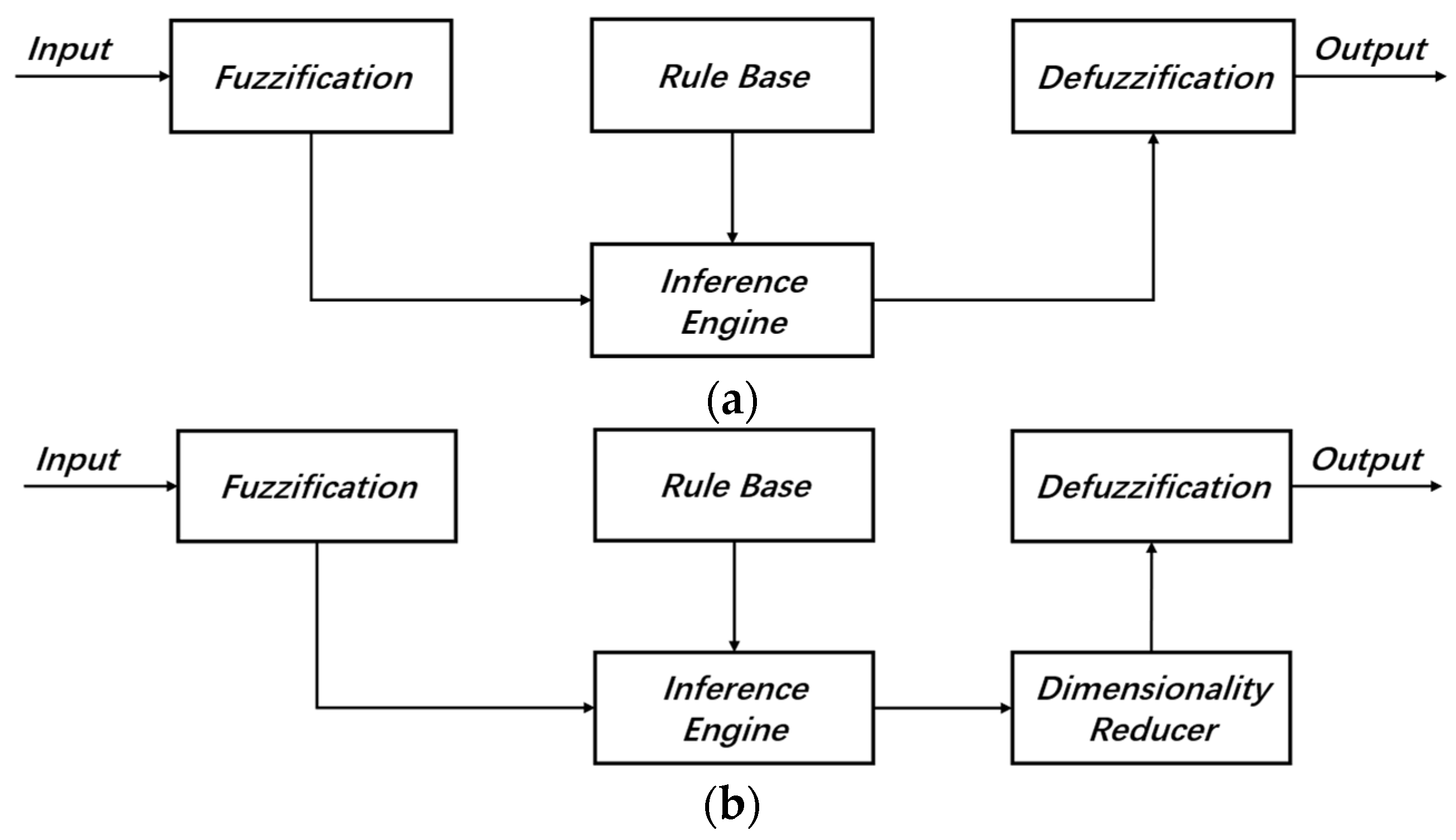
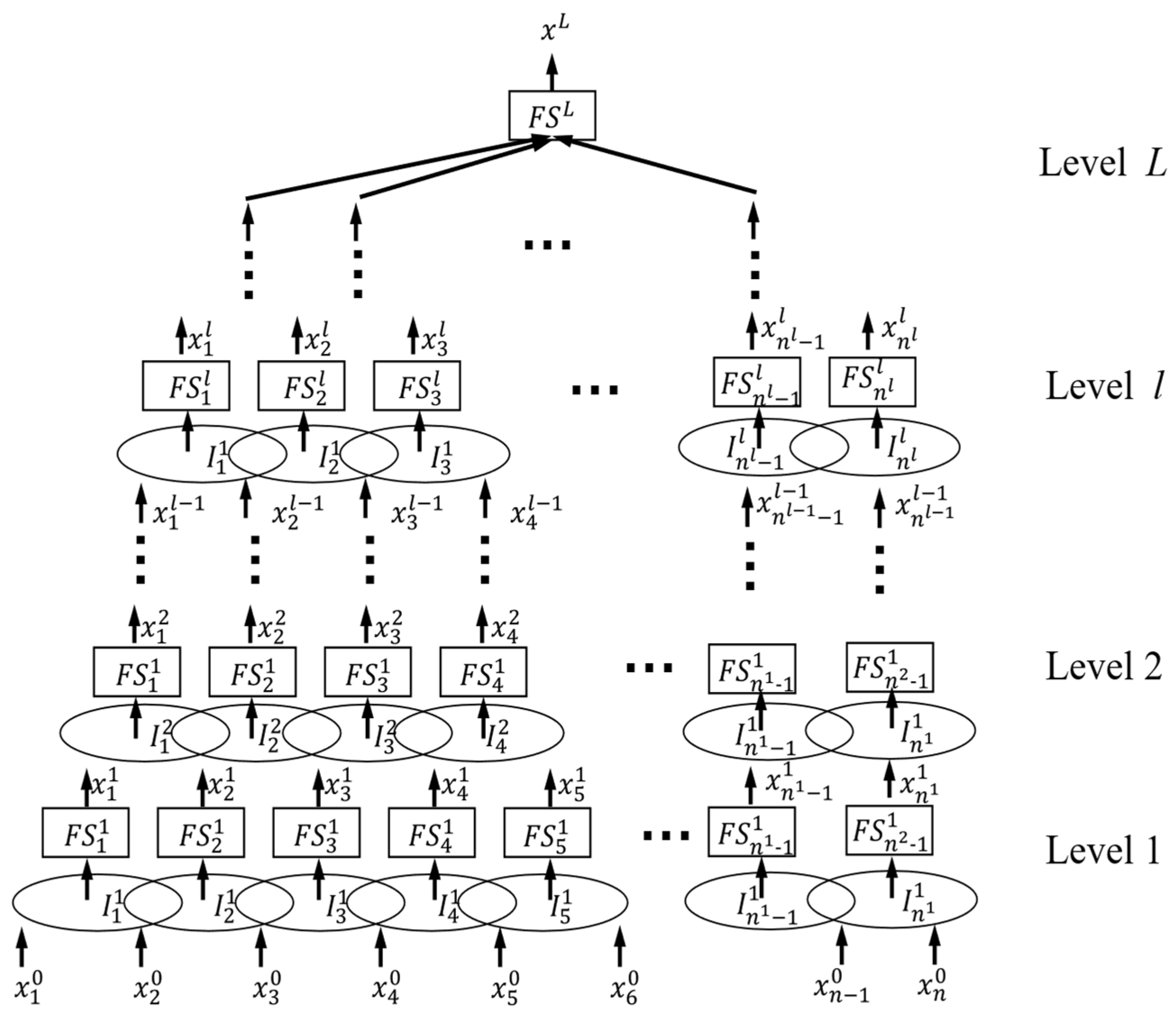
3.4. Deep Convolutional Interval Type-2 Fuzzy System
While data augmentation increases sample quantity, it may fail to address inherent class imbalance in original datasets. Augmented samples often deviate from the true feature distribution of real-world data, leading to biased learning of class distributions. To establish a robust bearing fault diagnosis model, we integrate Interval Type-2 fuzzy systems with deep convolutional networks via a bottom-up hierarchical architecture, as illustrated in
Figure 7.
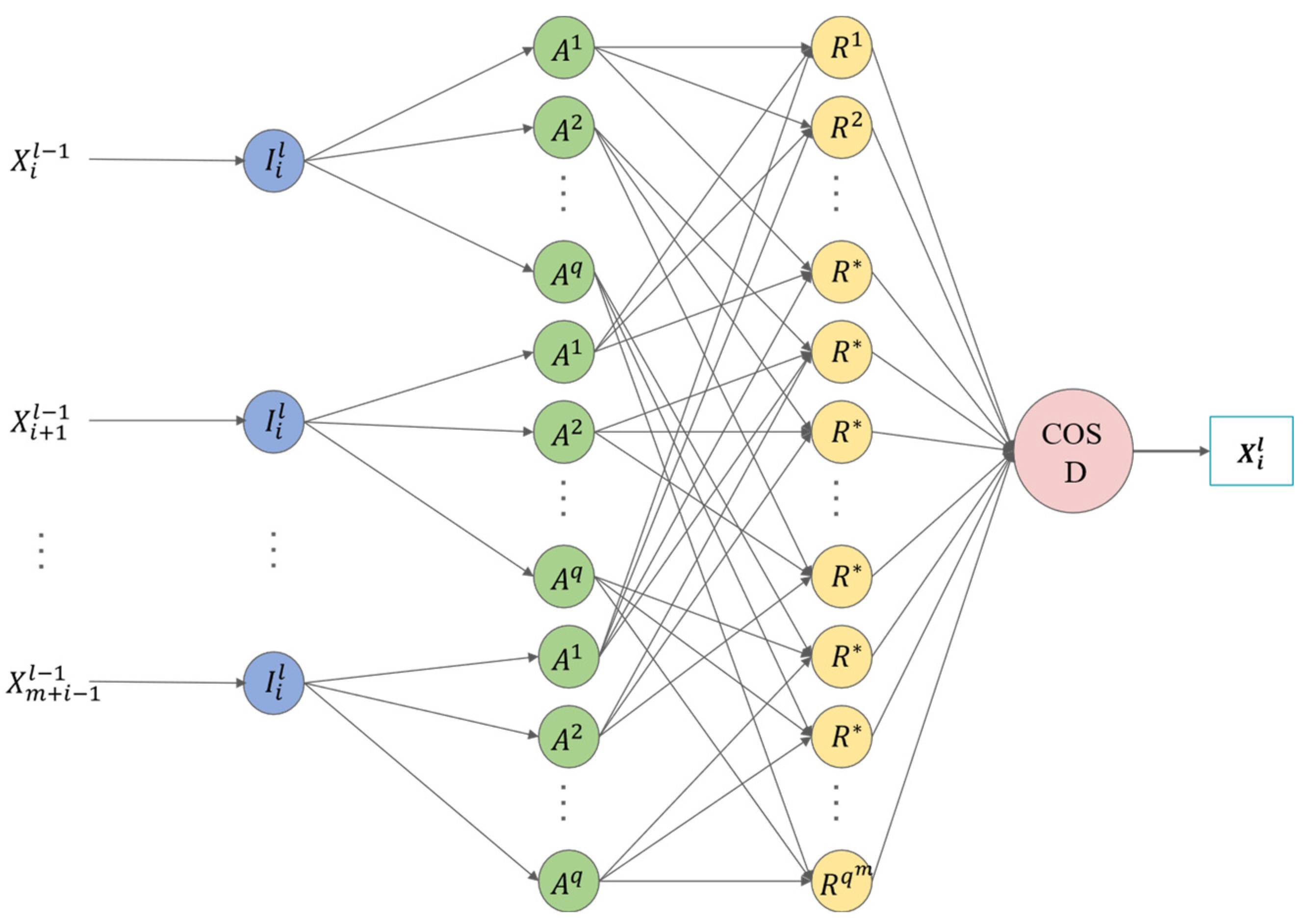
The internal structure of the
l-th layer
fuzzy subsystem
in the Deep Convolutional Fuzzy System is illustrated in
Figure 8. Its input vector is
, where
m is a small positive integer. Each input variable is associated with
fuzzy sets defined by trapezoidal membership functions:
where
(
denoting any input variable) is the center of the membership function, and
represents the distance from the center to its endpoints. The global minima
and maxima
are determined from training data. The
subsystem is governed by
fuzzy rules:
where
denotes a rule index,
are fuzzy set indices for each of the
m input variables, ranging from 1 to
q, and
is the output fuzzy set. Defuzzification follows the center-of-sets (COSD) method. The input–output mapping of
is as follows:
Here, represents the center value of the corresponding fuzzy set , which is also the trainable parameter of . denotes the firing strength of the fuzzy rule shown in Equation (22), denoted as .
In the formula, the DCIT2FS model for
and
is a fuzzy system in the Interval Type-2 fuzzy system, where the fuzzy membership function is represented as follows:
In the equation,
and
are two variables of the asymmetric sigmoid function, and
(
is a user-defined constant). Equation (1) illustrates the Interval Type-2 fuzzy rule. This structure forms the foundation for constructing the predictive model DCIT2FS.
In the equation, the variable
is a type-2 fuzzy set. The type-1 fuzzy set describes the polynomial coefficients that follow, denoted as
. The conclusion parameter intervals also include predefined upper and lower bounds. The output interval of each rule is calculated as follows (
):
The reduction set of the model is an Interval Type-1 fuzzy model,
The precise output of the model is obtained using the centroid method:
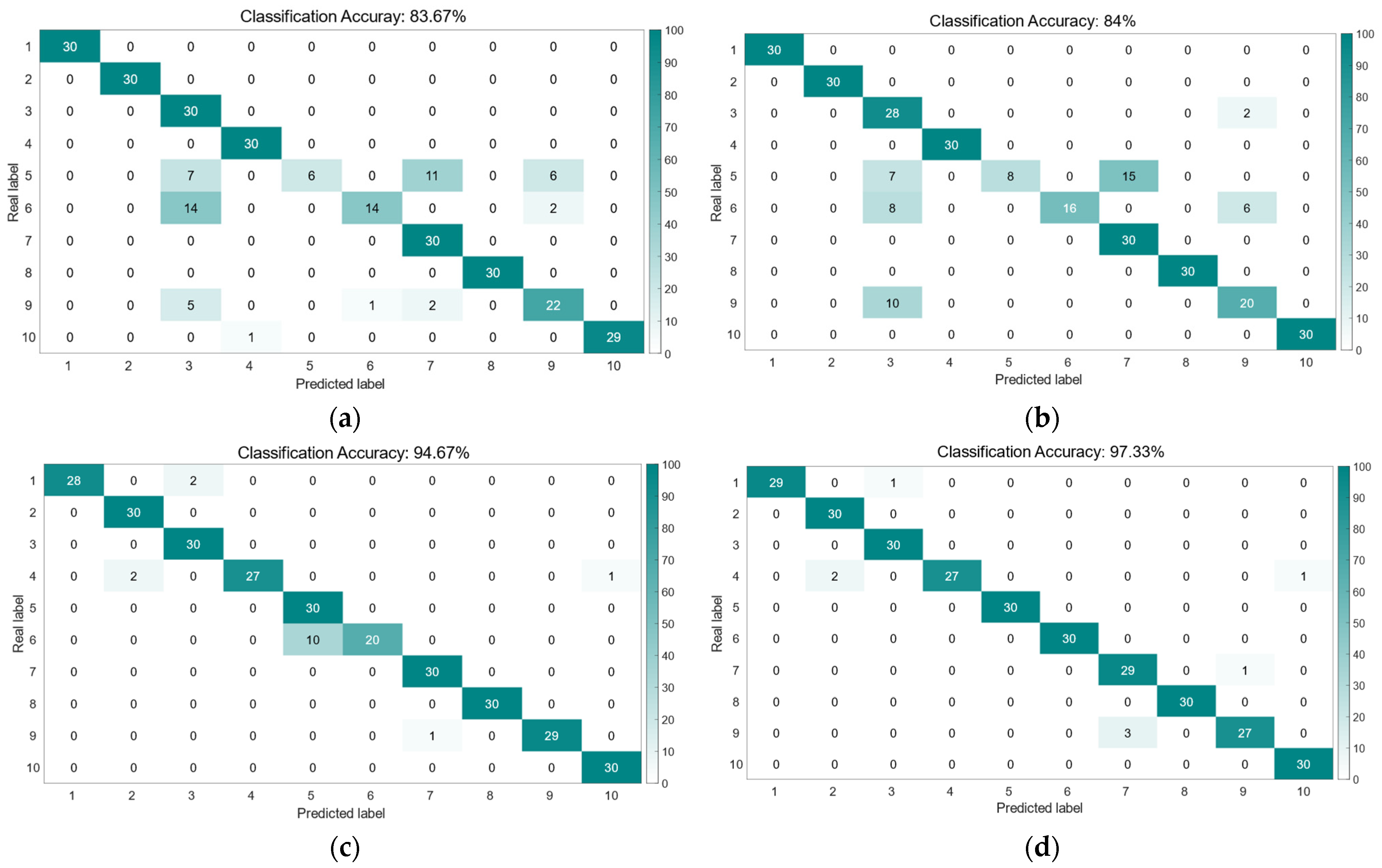
Each first-layer fuzzy system is regarded as a weak evaluator that outputs based on only a small subset of input variables. The fuzzy system adopts an IT2 fuzzy model based on an uncertain Gaussian function. The antecedent parameters of this model are optimized using the PSO algorithm.
As the number of features or fuzzy rules increases, scalability becomes an important consideration. To address this issue and maintain computational efficiency, we have implemented several techniques in the proposed DCIT2FS model. When the number of fuzzy rules increases, rule reduction methods, such as K-means or fuzzy C-means clustering, can be used to reduce the number of rules, thus decreasing the computational cost. Additionally, to handle the increase in feature dimensions, we employ feature selection techniques like Principal Component Analysis (PCA) and Mutual Information (MI), which help identify the most relevant features and reduce the dimensionality, thereby alleviating the computational burden. Furthermore, we leverage GPU acceleration during the fuzzy inference process to significantly enhance processing speed, making the model feasible for real-time applications. These strategies ensure that the DCIT2FS model remains scalable and efficient, even as the number of features or fuzzy rules increases, and maintain its applicability in real-time scenarios.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}