In this section, we present the comprehensive methodology for our proposed framework to FJSP. This section details the design of HGNNR and its integration with deep reinforcement learning techniques. The aim is to develop an efficient and effective end-to-end scheduling framework that leverages advanced machine learning techniques to optimize scheduling decisions.
4.1. Markov Decision Process
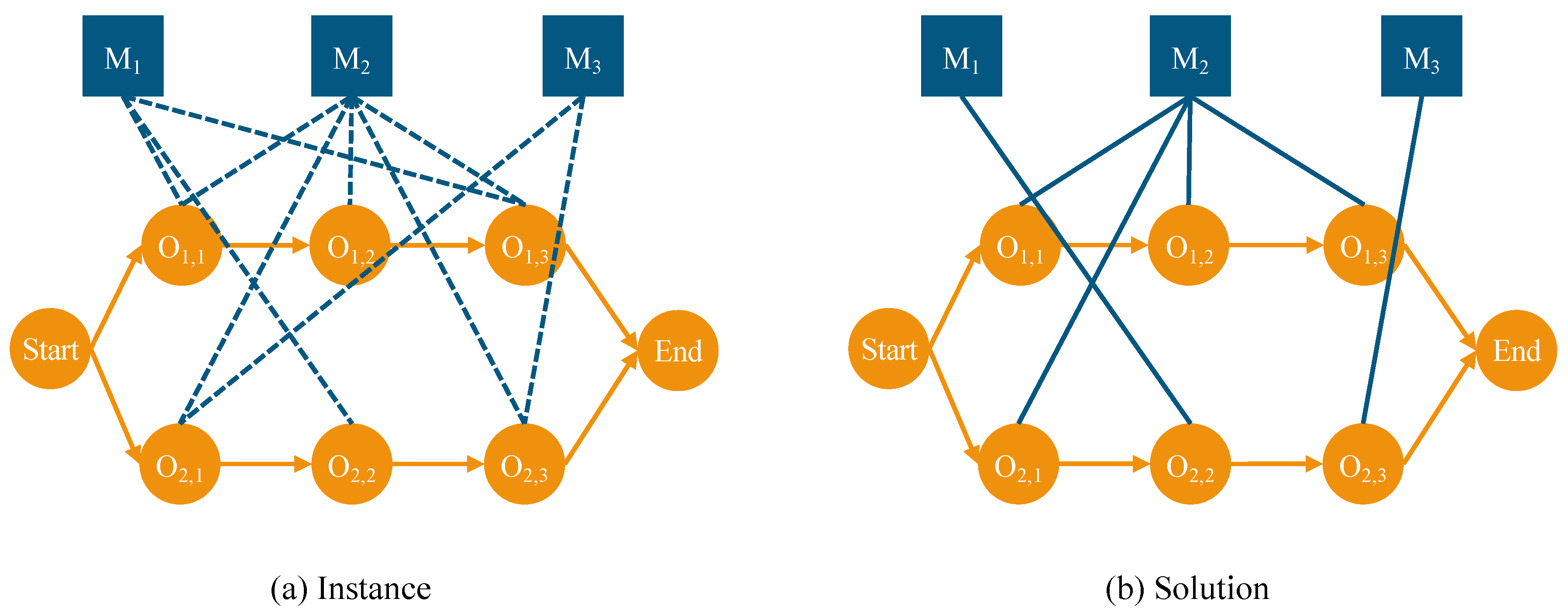
To explore the solution path for the FJSP, this study adopts a reinforcement learning framework and designs an MDP to intelligently schedule operations and allocate machines. With this method, at each decision point t (i.e., at start-up or after every operation is finished), the agent can decide based on the current environment state . In particular, the agent starts the starting time from timestep t and chooses a machine that is available to allocate to the anticipated operation. After that, the environment moves on to the following decision point, , and so on, iterating until all operations are scheduled.
State: At each step t of the MDP, system state comprehensively presents the real-time status of each job and machine. The initial state is determined by sampling from the distribution of FJSP instances, establishing the benchmark for the scheduling process. For each state , the system tracks part of schedule , including the actual processing time of scheduled jobs and the estimated processing time of unscheduled jobs. If operation is scheduled, represents the actual start time ; if not scheduled, predictions are made based on the status of preceding operations and available machines. For example, if the preceding operation is started on machine , then ; otherwise, the average processing time in the optional machine set for operation is used for prediction. The state provides a global view, facilitating wise scheduling decisions under complete information.
Action: This work combines machine allocation and job selection into a single decision approach to solve the FJSP efficiently. The definition of action at timestep t is an appropriate operation-machine pair , where is available and is to be executed. The action set varies at each timestep and comprises all feasible operation–machine pairs available at that moment.
State Transition: State transitions are determined by the current state and action , replicating the dynamics of scheduling. Various states are distinguished by the heterogeneous graph’s structure and characteristics, offering a flexible and robust representation for scheduling. This deterministic transition allows for a clear and predictable evolution of the scheduling environment as decisions are made.
Reward: The reward is determined by the completion time difference between consecutive states and . Specifically, , where represents the maximum completion time. This reward mechanism encourages the agent to complete jobs as quickly as possible, aiming to improve scheduling efficiency and maximize cumulative rewards.
Policy: Policy defines a probability distribution for actions in each state. Through DRL algorithms, policy is parameterized in the form of a neural network to optimize the expected cumulative reward and solve the complex FJSP. The continuous iteration and optimization of the policy allow the agent to make efficient decisions in a versatile production environment, thereby contributing to improved production efficiency.
4.2. Heterogeneous Graph Neural Networks Based on Relation
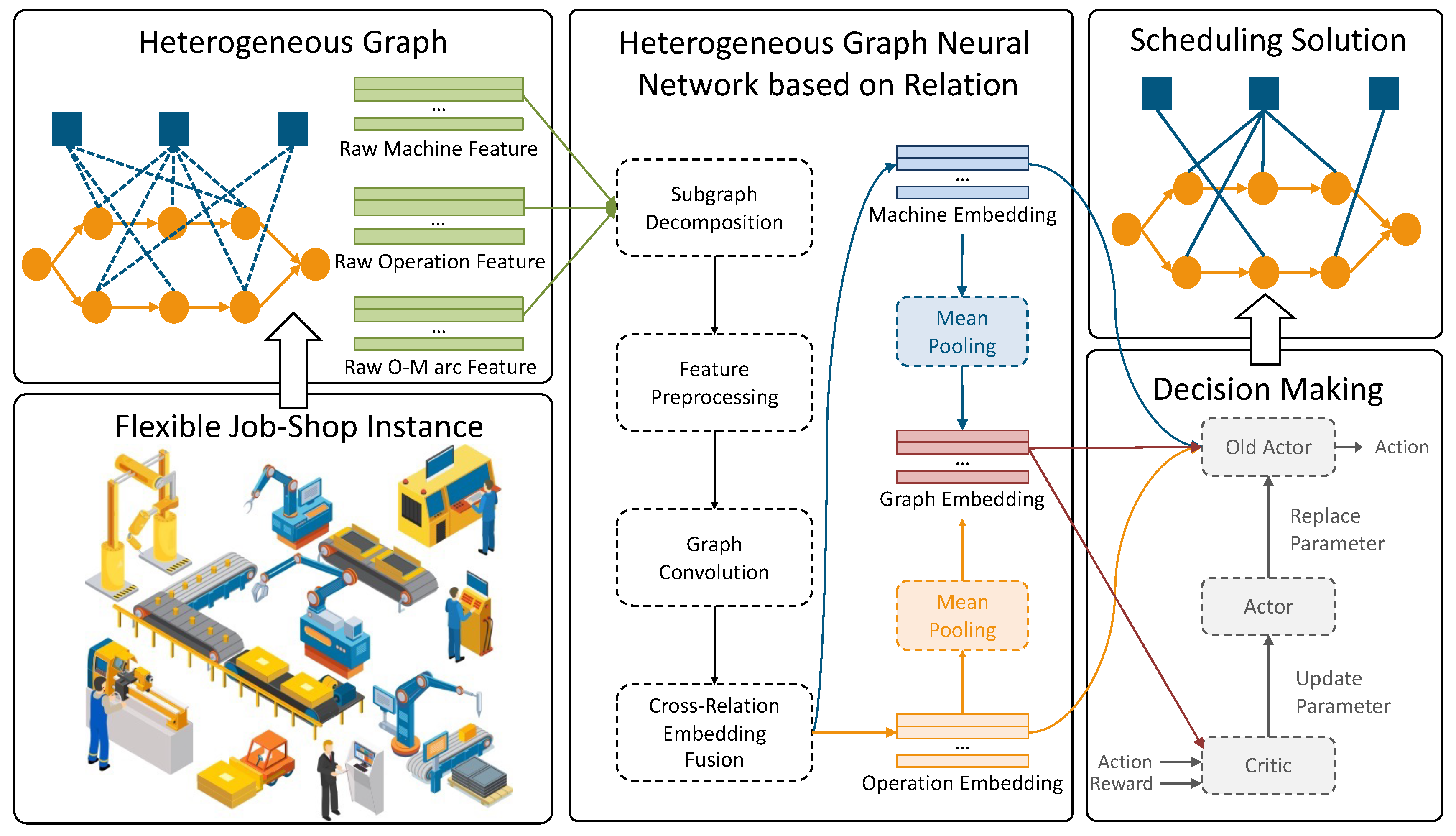
The nodes in include various types of neighbors for operation node , such as direct predecessor , direct successor , and multiple machine nodes belonging to the set . Specifically, with directed arcs pointing in opposing directions, and are connected to , revealing the sequential dependencies between operations, while machine nodes are associated with it through undirected arcs, demonstrating the pairing relationship between operations and machines. Traditional attention mechanisms struggle to efficiently handle heterogeneous graphs with rich relationship types, and existing methods for heterogeneous graph learning often focus on the propagation of node representations without fully exploring the intrinsic properties of different relationships. To fully exploit the multiple relations in heterogeneous graphs and achieve deep fusion of node features, we design a framework specifically for heterogeneous graphs, i.e., HGNNR, aiming to enhance the identification and utilization of different relationship types, thereby optimizing the quality and granularity of node representations, improving the accuracy and efficiency of scheduling strategy formulation, and providing a more powerful and flexible tool for solving the FJSP.
This component aims to process the heterogeneous graph
and the corresponding node feature matrix extracted for any operation node
as the target node, ultimately obtaining the updated feature representation
for the operation node and
for the machine node. It ensures that for any operation node
and any machine node
, the updated node features have rich information density and relevance, providing precise and detailed feature support for Reinforcement Learning decisions, further enriching the functionality and application scope of the model. As shown in
Figure 3, the proposed HGNNR is composed of four stages: (1) Subgraph Decomposition based on Relation, which divides the heterogeneous graph into subgraphs based on different types of relationships, simplifying the complexity of the problem; (2) Preprocessing of Node Features, where original features are transformed into high-dimensional vectors suitable for graph neural network processing; (3) Relation-Specific Graph Convolution, which applies graph convolution to extract and aggregate features specific to each relationship type; and (4) Cross-Relation Feature Fusion, which integrates the features from various subgraphs using a multi-head attention mechanism to generate a comprehensive node representation. The implementation details of these four stages are explained as follows.
Subgraph Decomposition based on Relation. Throughout the full manufacturing process, the FJSP consists in complex relationships among several machines and operations. We first divide the many graph representations of FJSP into several subgraphs depending on different kinds of relationships, such as operation–operation (O-O) subgraphs and operation–machine (O-M) subgraphs, so enabling us to fully understand and control these links. Simplifying the heterogeneous graph of the problem is the key component of this decomposition approach since it enables a more targeted and precise investigation and control of many kinds of interactions.
Every node in the O-O subgraph represents a different operation; the edges show the sequential links between these processes. This provides important contextual information for extracting characteristics from operation nodes and helps us to understand and describe the sequence of events in the manufacturing process. We investigate the potential allocation linkages between operations and the currently accessible machines within the O-M subgraph. While edges show the possibility of operations to be carried out on specific machines, nodes are operations and machines. This clarifies for the model the possibilities and constraints of resource allocation and machine choice for every operation.
For further feature extraction and graph structure research, this decomposition technique presents a unique and focused viewpoint. It not only helps to simplify the complexity of the problem but also facilitates the feature extraction and analysis for several kinds of relationships. This prepares the ground strongly for the next phases of the algorithm. Furthermore, this decomposition approach helps us to independently observe and clarify the particular effects of various relationships on scheduling decisions, so enabling a more effective comprehension and improvement of scheduling strategies.
Preprocessing of Node Features. After completing the subgraph decomposition, this stage focuses on transforming the original features of each node into high-dimensional feature vectors suitable for processing by Graph Neural Networks through normalization and feature enhancement mappings. This process not only optimizes the scale and distribution of features but also enhances their expressive power, preparing for capturing deeper graph structural information.
In this stage, the features of all machine nodes and operation nodes are first normalized to ensure a unified numerical range among different features, improving the stability of model training and reducing learning biases due to feature scale differences [
27]. Subsequently, we enhance the node features through MLP, which not only learns the nonlinear relationships between features but also maps these features to a higher-dimensional space [
46]. For machine nodes, the MLP explores the intrinsic connections and complexity of machine features, providing a comprehensive and representative high-dimensional feature vector. Meanwhile, for operation nodes, the MLP takes into account the intrinsic properties of operation nodes and their potential connections with other nodes, achieving deep enhancement and high-dimensional mapping of operation features.
This preprocessing of features not only enriches and makes the node features more representative but also provides a solid foundation for the subsequent learning and analysis by graph neural networks. Through this process, the model can more effectively understand the roles and interactions of each node in the FJSP, thereby achieving higher accuracy and efficiency in solving scheduling problems.
Relation-Specific Graph Convolution. After preprocessing the node features, the next key step is to perform graph convolution on subgraphs of different relationship types, namely Relation-Specific Graph Convolution. Graph Convolution Network is a powerful neural network architecture that operates directly on graph-structured data and can effectively extract and aggregate features of nodes in the graph [
47]. We adopt a generic graph convolution computation method that can adapt to different types of relationships and subgraph structures. For every given relationship type
r, the formula below shows the method of updating node characteristics using graph convolution on the corresponding subgraph:
where the node features produced following graph convolution are shown by matrix
. By adding adjacency matrix
of the subgraph to identity matrix
I, we generate matrix
. Self-loops in this addition help to maintain the node self-features. Every vertex in graph
has a degree shown by matrix
. Graph convolution uses weight matrix
to retain the parameters. Nonlinearity is introduced and the expressive capacity of the model is increased by means of the Rectified Linear Unit (ReLU) activation function.
Any node can effectively examine input from all connected nodes throughout this process, therefore gathering comprehensive contextual information while preserving its own properties and providing strong support for further optimization and decision-making.
Cross-Relation Feature Fusion. This stage aims to merge node properties from several subgraphs thereby generating a complete node representation. Capturing the complex links among the several diverse network nodes depends on this. Cross-relation feature fusion uses a multi-head attention method to integrate elements from several subgraphs, hence improving the adaptability of the model. This method helps the model to independently learn the significance weights of various subgraph features, hence generating optimal feature representations for every node in several environments [
48]. More exactly, for every operation node and subject, we combine the features from the O-O and O-M subgraphs and apply a multi-head attention layer for additional processing. Every head in the model adds a different feature perspective; the weights learnt by each head are aggregated to provide a complete node feature. One may characterize the process of aggregating the outputs from several sources by means of the following equation:
where each head
is calculated as follows:
where
correspond to query, key, and value derived from linear transformations and splitting into multiple heads. Query (
Q) represents the current node’s feature, Key (
K) represents the features of nodes connected to it, and Value (
V) contains relevant information about nodes used to update the query node’s feature.
are parameter matrices corresponding to each head, and
is the weight matrix for linear transformation of the outputs of all heads.
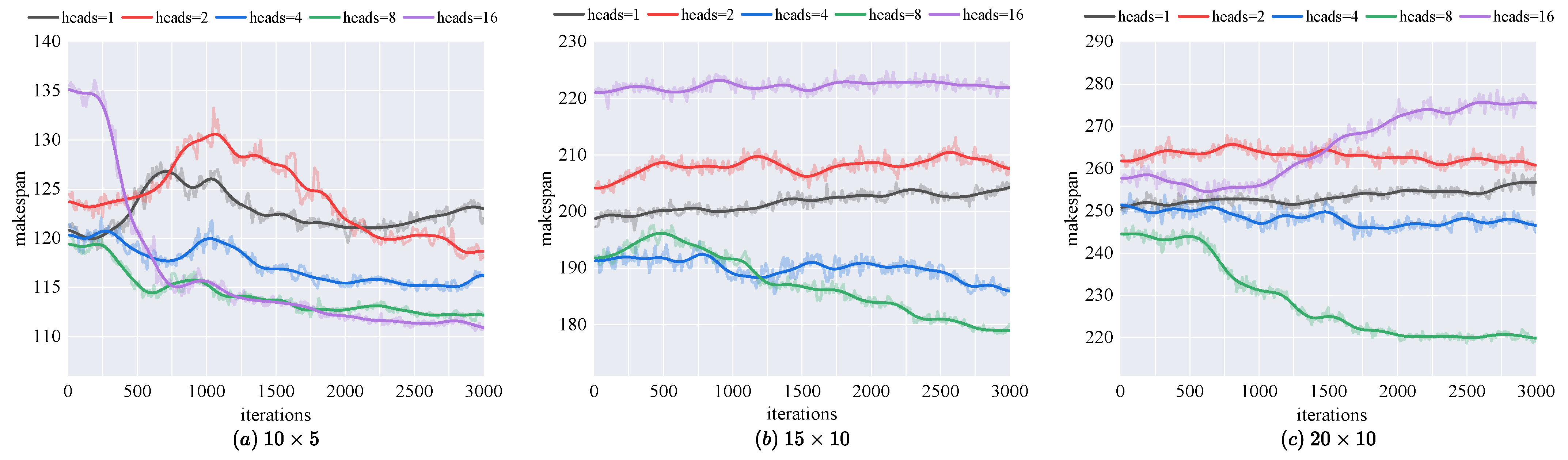
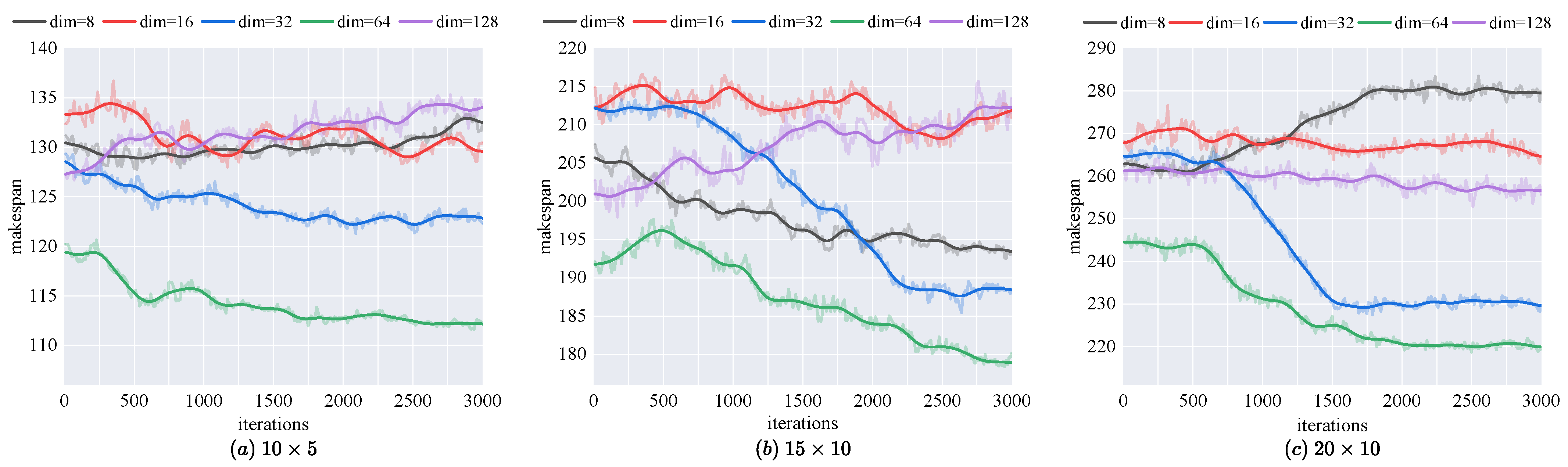
d is the output dimension of each head, usually determined by the total model dimension
L and the number of heads
z, i.e.,
.
In this step, the attention weights calculated for each head provide information about the importance of each head, and by concatenating the outputs of each head and performing the linear transformation, a comprehensive feature representation that incorporates information from all heads is obtained, serving as the updated embedding representation for operation .
This comprehensive node feature representation captures the roles and information of each node under different relationships, providing a comprehensive perspective for the next decision-making step. In this way, the model can consider the execution sequence of operations, the status of machines, and the resource allocation requirements when making decisions, thereby achieving more effective and accurate scheduling in FJSP.
4.4. Proximal Policy Optimization
In our study, to address the job-shop scheduling problem, we developed a deep learning framework incorporating a policy network that can effectively select operation–machine pairs. The key to this framework lies in utilizing HGNN to extract high-quality embedding representations, which can simplify the state space and facilitate rapid learning of the policy network. To train this network, we employed the PPO algorithm, which utilizes an actor–critic architecture for reinforcement learning.
The policy network accepts the updated features of operation nodes, the updated features of machine nodes, and the global features obtained from mean pooling as inputs, and outputs the probability of selecting the operation–machine pair. Formally, we let
be the feature vector for an operation node,
be the feature vector for a machine node, and
be the global feature vector. The input to the policy network is
, and the output is probability
for selecting the operation–machine pair
.
Next, the actor network applies the softmax function to the probabilities of all operation–machine pairs. During training mode, it uses a sampling strategy to select actions, while in validation and testing modes, the action with the highest probability is chosen directly by using a greedy strategy.
In training mode, actions are sampled from the probability distribution:
In validation and testing modes, the action with the highest probability is selected:
The value function accepts the global feature
as input and outputs the value estimate
:
The critic network constructs the optimization objective and loss function based on the actions, rewards, and value estimates to perform gradient updates. The goal is to maximize the expected cumulative reward, and the loss function takes into account both the policy loss and the value function loss. The policy loss is defined using the clipped surrogate objective to stabilize training:
where
is the probability ratio,
is the advantage estimate, and
is a hyperparameter controlling the clipping range.
The value function loss is defined as
where
is the discounted reward at time
t.
The total loss function for PPO is a combination of the policy loss and the value function loss, often with an entropy bonus to encourage exploration:
where the entropy bonus and the loss of the value function are balanced using coefficients
and
. The entropy of the policy is denoted by expression
, which discourages certainty in the choice of behavior hence fostering experimentation.
The system runs constantly throughout the training phase to validate and maximize the policy throughout numerous runs. This approach helps the model to efficiently control the trade-off between exploration and exploitation, thereby optimizing the efficiency in practical workshop scheduling conditions.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}