Support Vector Machine-Based Fault Diagnosis under Data Imbalance with Application to High-Speed Train Electric Traction Systems


Abstract
1. Introduction
2. The Electric Traction System of CRH2 High-Speed Train
3. Problem Description
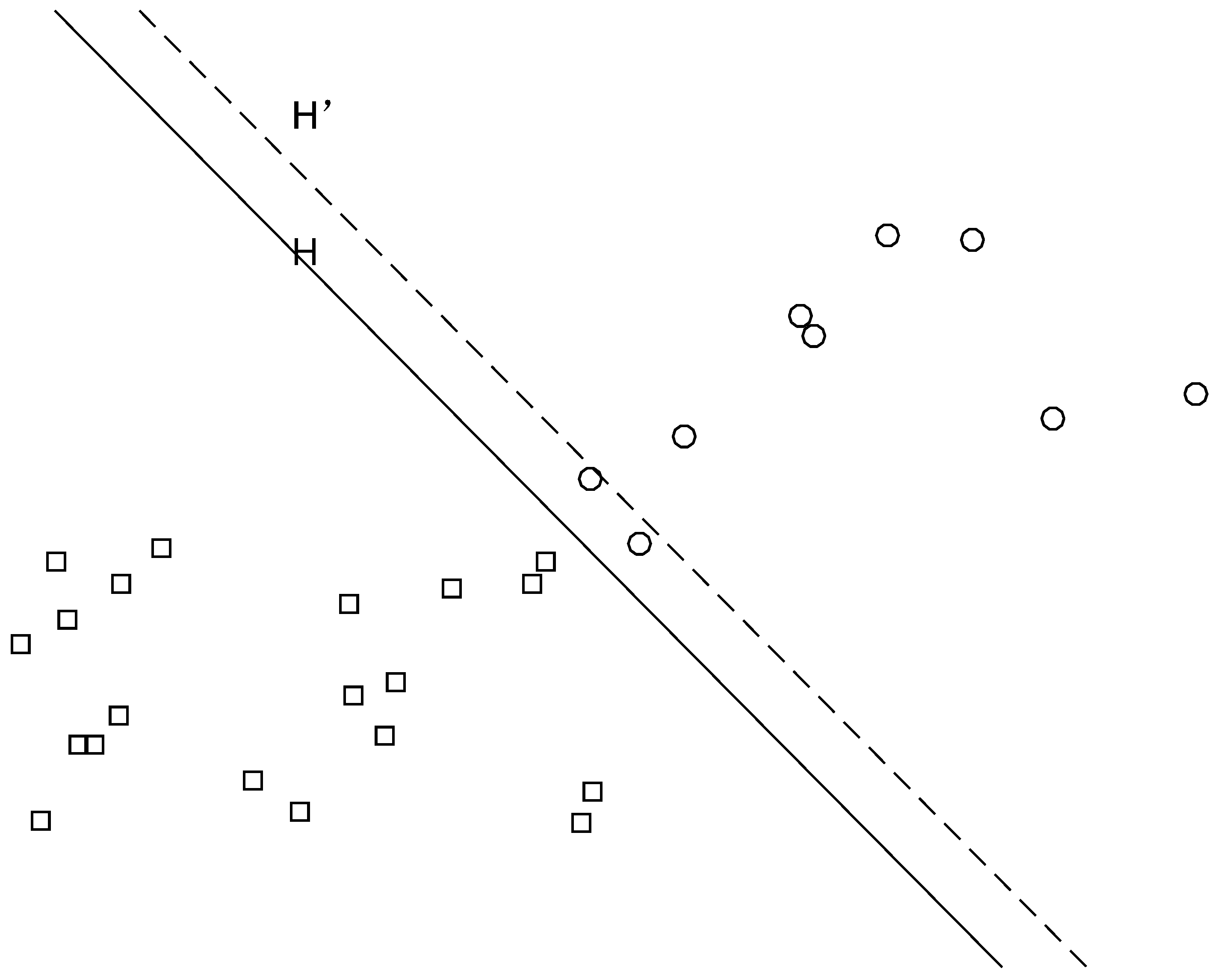
4. Self-Tuning Support Vector Machine
4.1. Self-Tuning Penalty Factor
4.2. Classification Performance
5. Experiment and Analysis
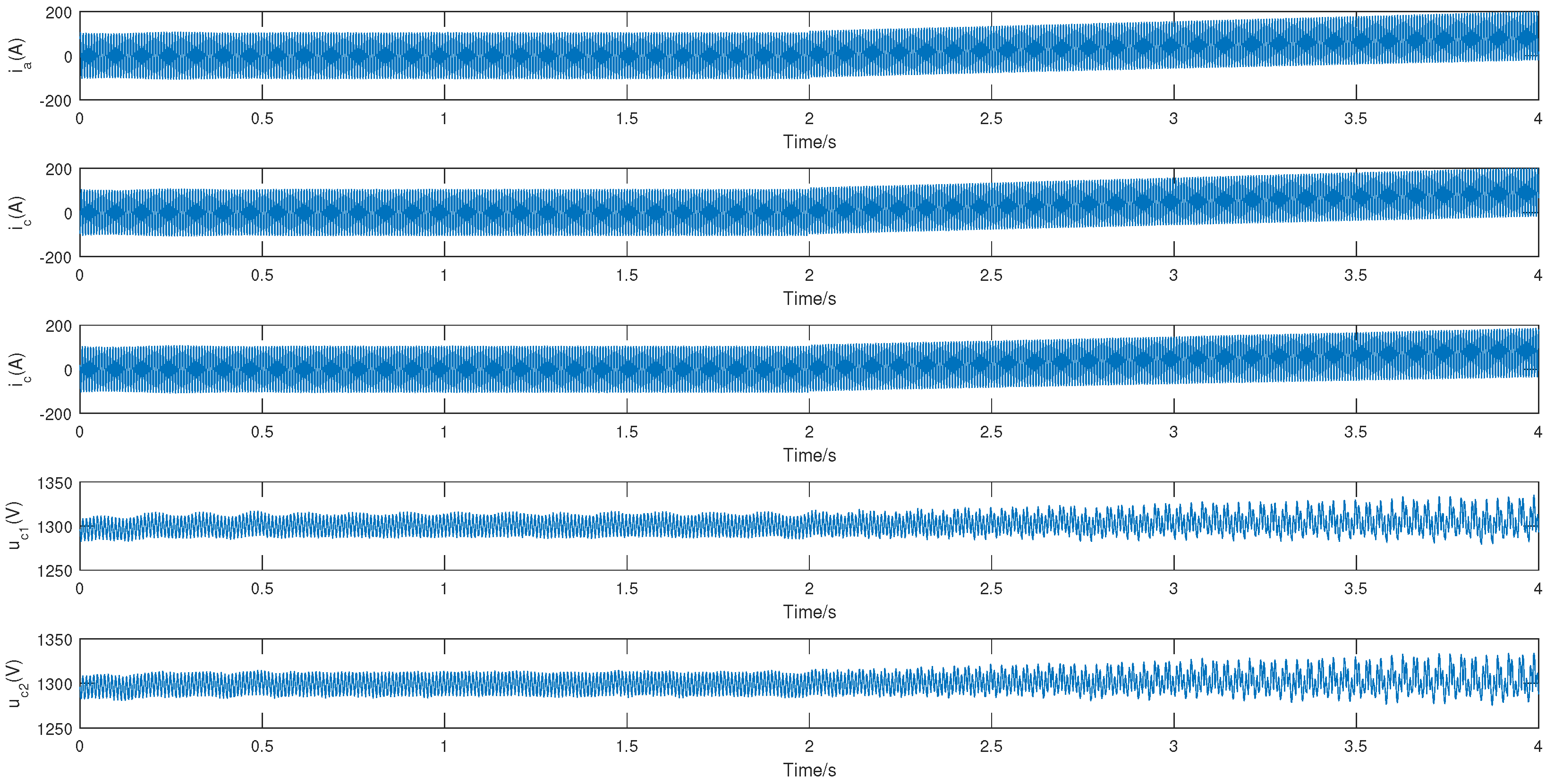
5.1. Fault Injection in the TDCS-FIB Platform
5.2. Parameter Settings and Evaluation Metrics
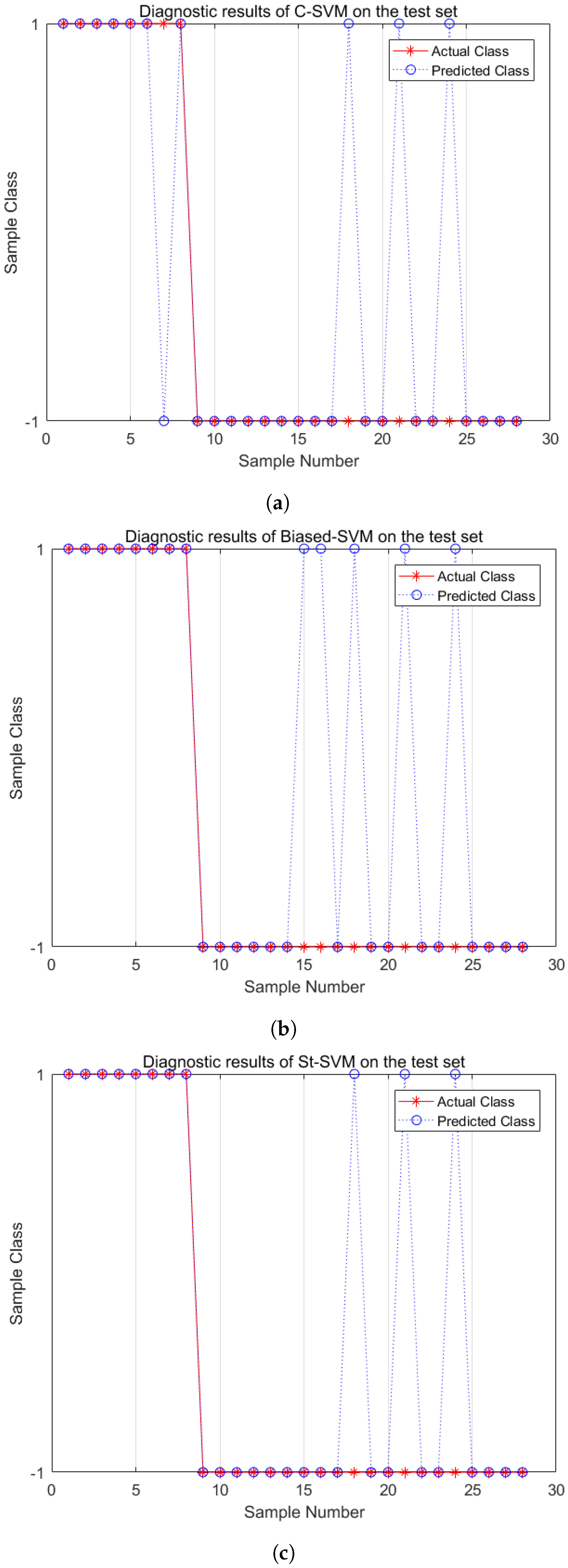
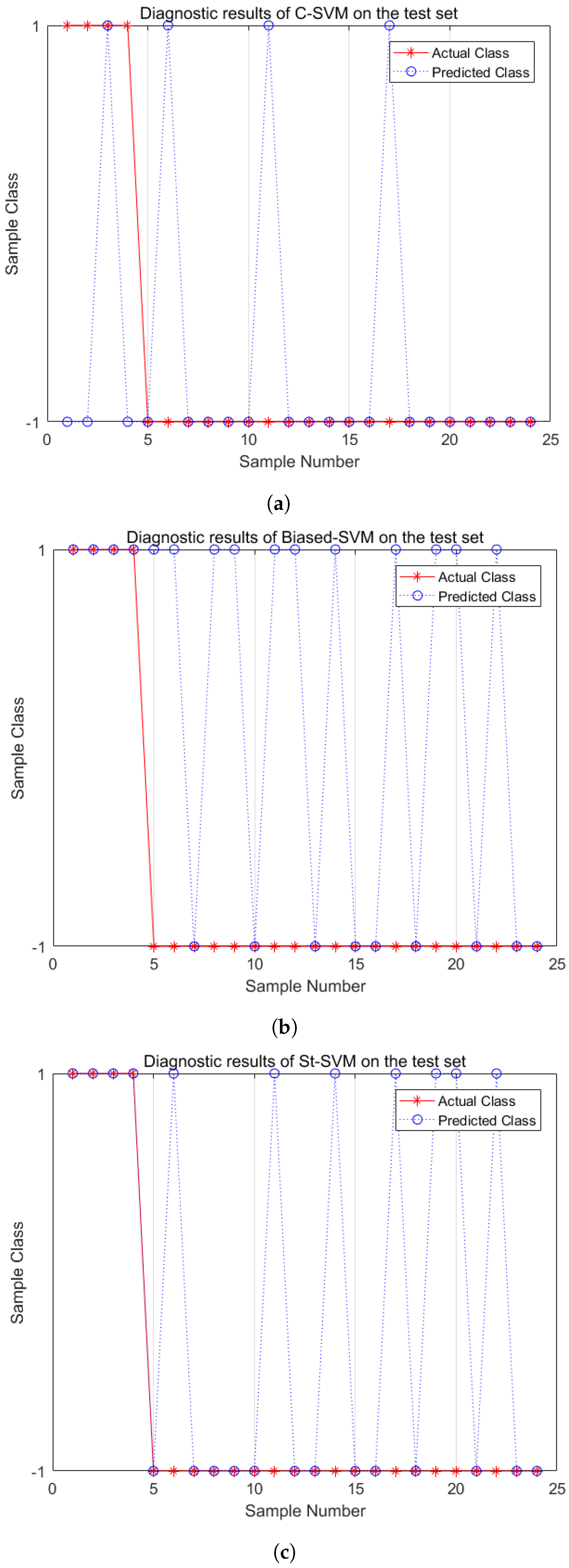
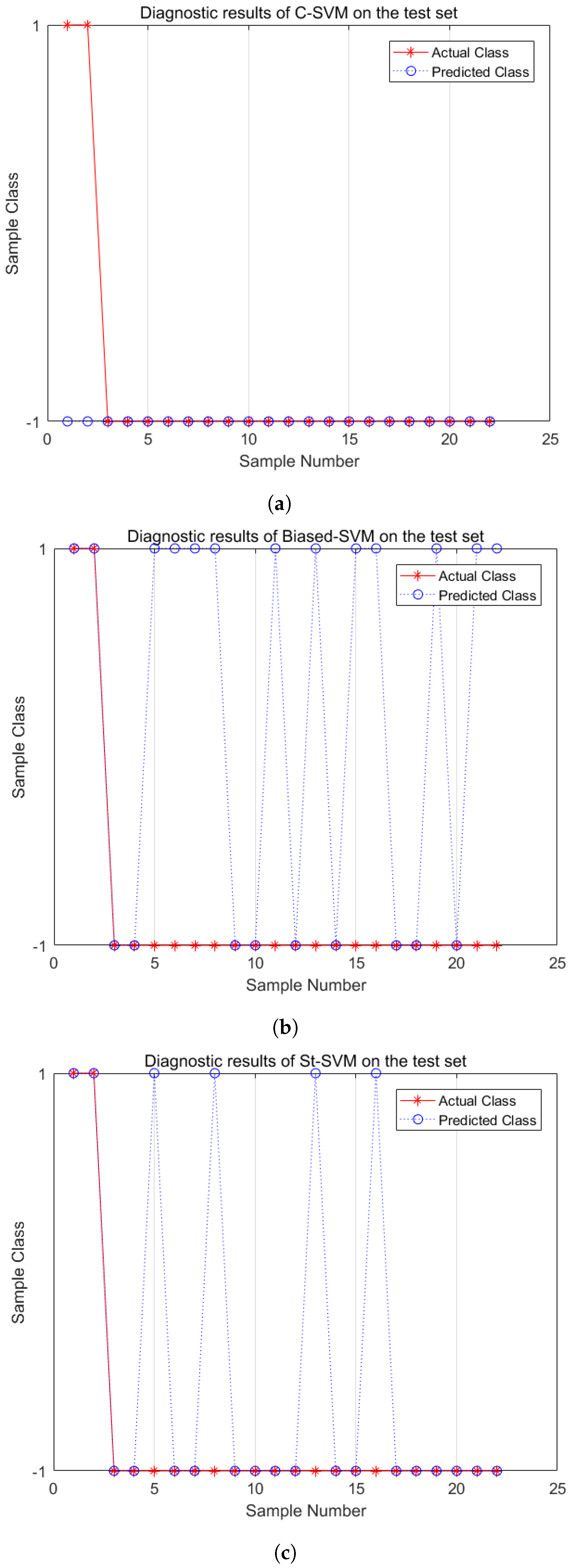
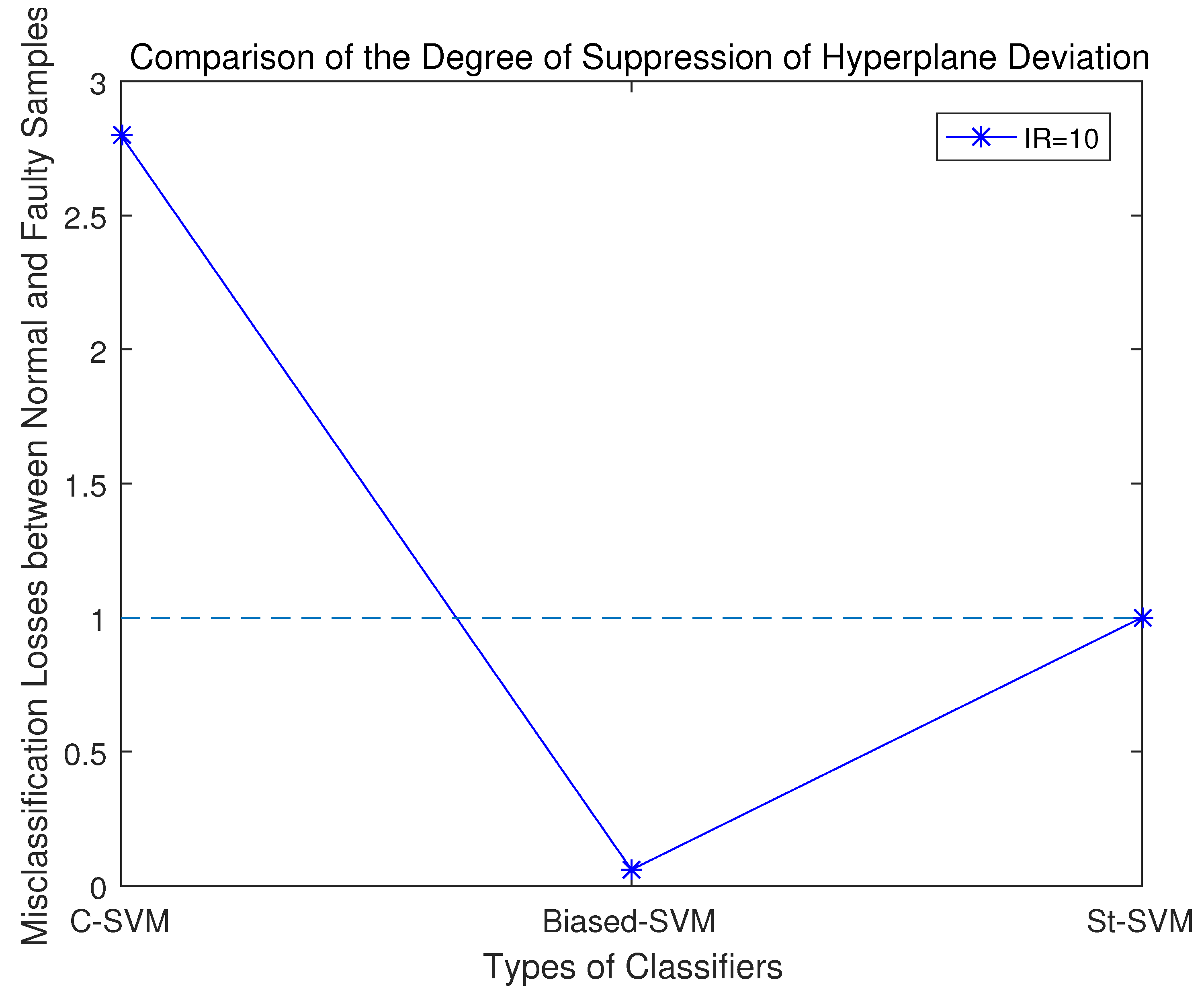
5.3. Diagnostic Performance Analysis
5.4. Application on Real-World Imbalanced Fault Datasets of Electric Traction Systems
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SVM | Support Vector Machine |
| St-SVM | Self-tuning Support Vector Machine |
| IR | Imbalance Ratio |
| CRH | China Railway High-speed |
References
- Cheng, C.; Wang, W.; Chen, H.; Zhang, B.; Shao, J.; Teng, W. Enhanced fault diagnosis using broad learning for traction systems in high-speed trains. IEEE Trans. Power Electron. 2020, 36, 7461–7469. [Google Scholar] [CrossRef]
- Liu, Z.X.; Wang, Z.Y.; Wang, Y.; Ji, Z.C. Optimal zonotopic Kalman filter-based state estimation and fault-diagnosis algorithm for linear discrete-time system with time delay. Int. J. Control Autom. Syst. 2022, 20, 1757–1771. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, B.; Ding, S.X.; Huang, B. Data-driven fault diagnosis for traction systems in high-speed trains: A survey, challenges, and perspectives. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1700–1716. [Google Scholar] [CrossRef]
- Yang, X.; Yang, C.; Yang, C.; Peng, T.; Chen, Z.; Wu, Z.; Gui, W. Transient fault diagnosis for traction control system based on optimal fractional-order method. ISA Trans. 2020, 102, 365–375. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, X.; Wang, Y.L.; Li, Q.; Guo, Z.; Jiang, Y. Improved deep PCA and Kullback–Leibler divergence based incipient fault detection and isolation of high-speed railway traction devices. Sustain. Energy Technol. Assess. 2023, 57, 103208. [Google Scholar] [CrossRef]
- Li, Y.; Li, F.; Lu, C.; Fei, J.; Chang, B. Composite fault diagnosis of traction motor of high-speed train based on support vector machine and sensor. Soft Comput. 2023, 27, 8425–8435. [Google Scholar] [CrossRef]
- Liao, J.; Shi, X.J.; Zhou, S.L.; Xiao, Z.C. Analog circuit fault diagnosis based on local graph embedding weighted-penalty SVM. Trans. China Electrotech. Soc. 2016, 31, 28–35. [Google Scholar]
- Zhang, Y.; Jiang, Y.; Chen, Y.; Zhang, Y. Fault diagnosis of high voltage circuit breaker based on multi-classification relevance vector machine. J. Electr. Eng. Technol. 2020, 15, 413–420. [Google Scholar] [CrossRef]
- Li, Y. Exploring real-time fault detection of high-speed train traction motor based on machine learning and wavelet analysis. Neural Comput. Appl. 2022, 34, 9301–9314. [Google Scholar] [CrossRef]
- Ye, M.; Yan, X.; Jia, M. Rolling bearing fault diagnosis based on VMD-MPE and PSO-SVM. Entropy 2021, 23, 762. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.X.; Chai, Y.; Hu, Y.; Yin, H.P. Review of imbalanced data classification methods. Control. Decis. 2019, 34, 673–688. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, J.; Li, F.; Zhang, K.; Lv, H.; He, S.; Xu, E. Intelligent fault diagnosis of machines with small & imbalanced data: A state-of-the-art review and possible extensions. ISA Trans. 2022, 119, 152–171. [Google Scholar] [PubMed]
- Shi, Q.; Zhang, H. Fault diagnosis of an autonomous vehicle with an improved SVM algorithm subject to unbalanced datasets. IEEE Trans. Ind. Electron. 2020, 68, 6248–6256. [Google Scholar] [CrossRef]
- Viegas, F.; Rocha, L.; Gonçalves, M.; Mourão, F.; Sá, G.; Salles, T.; Andrade, G.; Sandin, I. A genetic programming approach for feature selection in highly dimensional skewed data. Neurocomputing 2018, 273, 554–569. [Google Scholar] [CrossRef]
- Sitompul, O.S.; Nababan, E.B. Biased support vector machine and weighted-SMOTE in handling class imbalance problem. Int. J. Adv. Intell. Inform. 2018, 4, 21–27. [Google Scholar]
- Xu, S.; Chai, H.; Hu, Y.; Huang, D.; Zhang, K.; Chai, Y. Simultaneous Fault Diagnosis of Broken Rotor Bar and Speed Sensor for Traction Motor in High-speed Train. Zidonghua Xuebao 2023, 49, 1214–1227. [Google Scholar]
- Akbani, R.; Kwek, S.; Japkowicz, N. Applying support vector machines to imbalanced datasets. In Machine Learning: ECML 2004: 15th European Conference on Machine Learning, Pisa, Italy, 20–24 September 2004. Proceedings; Springer: Berlin/Heidelberg, Germany, 2004; pp. 39–50. [Google Scholar]
- Sadollah, A.; Sinha, T. Recent Trends in Computational Intelligence; BoD—Books on Demand: Norderstedt, Germany, 2020. [Google Scholar]
- Zhang, X.; Zhao, B.; Lin, Y. Machine learning based bearing fault diagnosis using the case western reserve university data: A review. IEEE Access 2021, 9, 155598–155608. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actual Class | ||
|---|---|---|
| Predicted Class | Positive (P) | Negative (N) |
| Positive (P) | True Positive (TP) | False Positive (FP) |
| Negative (N) | False Negative (FN) | True Negative (TN) |
| Classifier Type | Specificity | Sensitivity | G-Mean |
|---|---|---|---|
| C-SVM | 0.8 | 0.875 | 0.837 |
| Biased-SVM | 0.75 | 1 | 0.866 |
| St-SVM | 0.85 | 1 | 0.922 |
| Classifier Type | Specificity | Sensitivity | G-Mean |
|---|---|---|---|
| C-SVM | 0.85 | 0.25 | 0.461 |
| Biased-SVM | 0.45 | 1 | 0.671 |
| St-SVM | 0.65 | 1 | 0.806 |
| Classifier Type | Specificity | Sensitivity | G-Mean |
|---|---|---|---|
| C-SVM | 1 | 0 | 0 |
| Biased-SVM | 0.45 | 1 | 0.671 |
| St-SVM | 0.8 | 1 | 0.894 |
| Classifier Type | Specificity | Sensitivity | G-Mean |
|---|---|---|---|
| C-SVM | 0.988 | 0.62 | 0.781 |
| Biased-SVM | 0.652 | 1 | 0.801 |
| St-SVM | 0.848 | 1 | 0.921 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Ji, T.; Zhou, Y.; Zhou, Y. Support Vector Machine-Based Fault Diagnosis under Data Imbalance with Application to High-Speed Train Electric Traction Systems. Machines 2024, 12, 582. https://doi.org/10.3390/machines12080582
Wu Y, Ji T, Zhou Y, Zhou Y. Support Vector Machine-Based Fault Diagnosis under Data Imbalance with Application to High-Speed Train Electric Traction Systems. Machines. 2024; 12(8):582. https://doi.org/10.3390/machines12080582
Chicago/Turabian StyleWu, Yunkai, Tianxiang Ji, Yang Zhou, and Yijin Zhou. 2024. "Support Vector Machine-Based Fault Diagnosis under Data Imbalance with Application to High-Speed Train Electric Traction Systems" Machines 12, no. 8: 582. https://doi.org/10.3390/machines12080582
APA StyleWu, Y., Ji, T., Zhou, Y., & Zhou, Y. (2024). Support Vector Machine-Based Fault Diagnosis under Data Imbalance with Application to High-Speed Train Electric Traction Systems. Machines, 12(8), 582. https://doi.org/10.3390/machines12080582