1. Introduction
Monoblock centrifugal pumps (MCP) are widely applied in various sectors such as agriculture, industry and civil engineering due to their reliable performance and robustness. In addition, these centrifugal pumps are extensively utilized for domestic purposes including, gardens, apartments, bungalows, small farms, hospitals, hotels and farmhouses [
1]. A monoblock pump is a mechanical apparatus where the motor and the pump are assembled within a single enclosure. The pump system consists of rotating components on its shaft. Functioning on the principles of centrifugal force, an MCP harnesses the energy supplied by the motor and converts it into kinetic energy in the pumped liquid. It is advisable to employ fresh water and non-corrosive fluids to ensure the longevity of the pump components. The operational mechanism of MCPs is uncomplicated as they convert the rotational energy generated by a motor into kinetic energy in a flowing fluid. However, it is important to note that MCPs can encounter various faults including bearing, sealing, cavitation and impeller faults. Neglecting these faults can have detrimental consequences, potentially leading to the failure of the entire system. The significance of addressing MCPs’ fault diagnosis arises from their substantial energy consumption, representing a notable portion of global energy production [
2]. While these pumps have extended operational lifespans, the risk of sudden failures leading to disruptions and costly breakdowns necessitates continuous monitoring. Current practices involving human intervention for monitoring MCPs suffer from limitations such as scalability issues, subjectivity, lack of real-time analysis, and high false positive rates. Moreover, dependence on human expertise can be hindered by turnover and skilled operator shortages [
3].
A shift toward scalable and automated solutions is crucial to overcome these limitations and enhance MCP fault diagnosis reliability. Signal processing and AI technologies offer transformative possibilities. By adopting automation, monitoring systems can efficiently handle data from multiple MCPs concurrently, reducing the need for an increasingly extensive workforce. Algorithms provide objective analysis, eliminating human subjectivity and fatigue, thus ensuring consistent assessments and faster responses. Real-time insights enabled by AI enable quick anomaly detection, curbing potential problems before they escalate. AI’s data-driven predictive maintenance and continuous learning capabilities enable the anticipation of faults based on patterns, minimizing downtime and repair costs. Human–machine collaboration emerges as a synergy between human expertise and machine capabilities, allowing human operators to focus on intricate decision-making while AI handles routine monitoring tasks [
4].
Therefore, it is crucial to promptly address and rectify any issues that arise to ensure the smooth and reliable operation of the pump. The main focus of this study is on the detection and diagnosis of cavitation (CAV), bearing and impeller faults (BFIF), bearing faults (BF) and seal defects and impeller faults (IF) in MCPs. Unusual noise, leakage, excessive vibration, decreased hydraulic performance (resulting in a reduced head capacity and efficiency) and potential damage to the pump through pitting, erosion and structural vibration are the significant problems that can arise due to malfunction in MCP components [
1]. Neglecting fault detection and diagnosis can lead to system failures, suboptimal performance, compromised safety, shortened equipment lifespan and escalated costs.
In the realm of fault detection and diagnosis (FDD), many techniques can be found in the literature. These techniques encompass model-based approaches such as structural graphs and data-driven approaches including pattern recognition and neural networks [
5]. While encompassing various approaches, data-driven methods have gained considerable popularity due to their ability to swiftly identify faulty situations, ease of implementation and reduced dependency on prior knowledge [
6]. In conventional fault diagnosis, several steps are involved, starting with collecting data from sensors connected to the component and then significant feature extraction, selection and classification. Data types such as current, temperature, vibration, acoustic and speed are collected during the data acquisition phase. Among these signals, vibration signals are often prioritized due to their significant capability to offer valuable insights into the state of mechanical systems. Following this, relevant information is extracted from the acquired signals and these extracted features are carefully chosen. Depending on the specific application, the fault detection technique may vary, allowing for selecting the most suitable approach. Various options such as vibration analysis [
7], sound and acoustic emission analysis [
8], current and voltage analysis [
9], infrared analysis [
10], oil analysis [
11], pressure analysis [
12] and noise analysis [
13] are widely considered. This study employs a data-driven approach with a specific emphasis on vibration analysis, whereby the vibration signals are transformed into spectrogram images.
Recent times have seen an excessive incorporation of advanced signal processing techniques and machine learning algorithms such as neural networks [
14], Bayesian networks [
15], principal component analysis [
16], k-nearest neighbors [
17], fuzzy C-means [
17], support vector machines [
18], hierarchical clustering [
19], etc., to enhance the accuracy and effectiveness of fault diagnosis methods. Utilizing these classifiers holds immense significance in assessing and categorizing the equipment’s condition, facilitating efficient fault diagnosis. Extensive research has been undertaken to explore various facets of fault diagnosis in numerous realms; numerous studies have delved into different aspects of the subject matter, aiming to enhance understanding and knowledge in this field. By utilizing gene expression programming (GEP), a study by Sakthivel et al. compares the classification accuracy of fault detection and isolation in rotating machinery with a support vector machine (SVM), Wavelet-GEP and proximal support vector machine (PSVM) [
20]. The study revealed that GEP and SVM outperform other classifiers and demonstrate their effectiveness in achieving industrial maintenance and cost savings. By considering flow instabilities and fault interactions in centrifugal pumps (CPs), Rapur and Tiwari utilized vibration and current data, applying an SVM classifier with novel features. The approach achieved a robust fault identification and severity assessment across various operating conditions [
21]. Dutta et al. proposed a machine learning (ML)-based computational technique with a three-axis accelerometer to automatically detect faults in a cascade pumping system. The multiclass support vector machine (MSVM) algorithm outperformed other algorithms in terms of accuracy, prediction speed and training time, highlighting the effectiveness of ML for automated fault detection in the pumping system [
22]. Cao et al. proposed a fault diagnosis method for centrifugal pump blades using principal component analysis (PCA) and the Gaussian mixed model (GMM). The authors combined signal processing and knowledge, producing a highly effective classifier for crack faults under various working conditions [
23]. Manikandan and Duraivelu performed a vibration-based fault diagnosis method for industrial mono-block centrifugal pumps using a deep convolution neural network (DCNN). The model achieved a high accuracy of 99.07% in detecting broken impeller and seal failure conditions [
24]. This underscores the importance of applying machine learning techniques in fault diagnosis to achieve more reliable and efficient systems.
Table 1 presents the various ML approaches for mechanical systems.
With the advent of industry 4.0, current industrial processes are undergoing a metamorphosis into intelligent systems. Specifically, numerous modernized industrial processes are equipped with a plethora of well-developed sensors to gather process-related data to enable fault diagnosis for existing or emerging issues. As a result of this evolution in industrial environments, complete equipment and process automation is essential with higher levels of careful supervision. This includes comprehensive process control and suitable corrective actions to ensure accurate fault diagnosis, maximizing process efficiency [
29]. Intelligent fault diagnosis involves detecting and identifying system faults through a compelling synergy with Deep Learning. Deep Learning has emerged as a promising tool in fault diagnosis with the ability to extract intricate patterns and features from raw data using deep architectures [
30]. Implementing a deep learning (DL) model typically consists of three consecutive phases: initial data comprehension and preprocessing, construction and training of the DL model followed by validation and interpretation of the results.
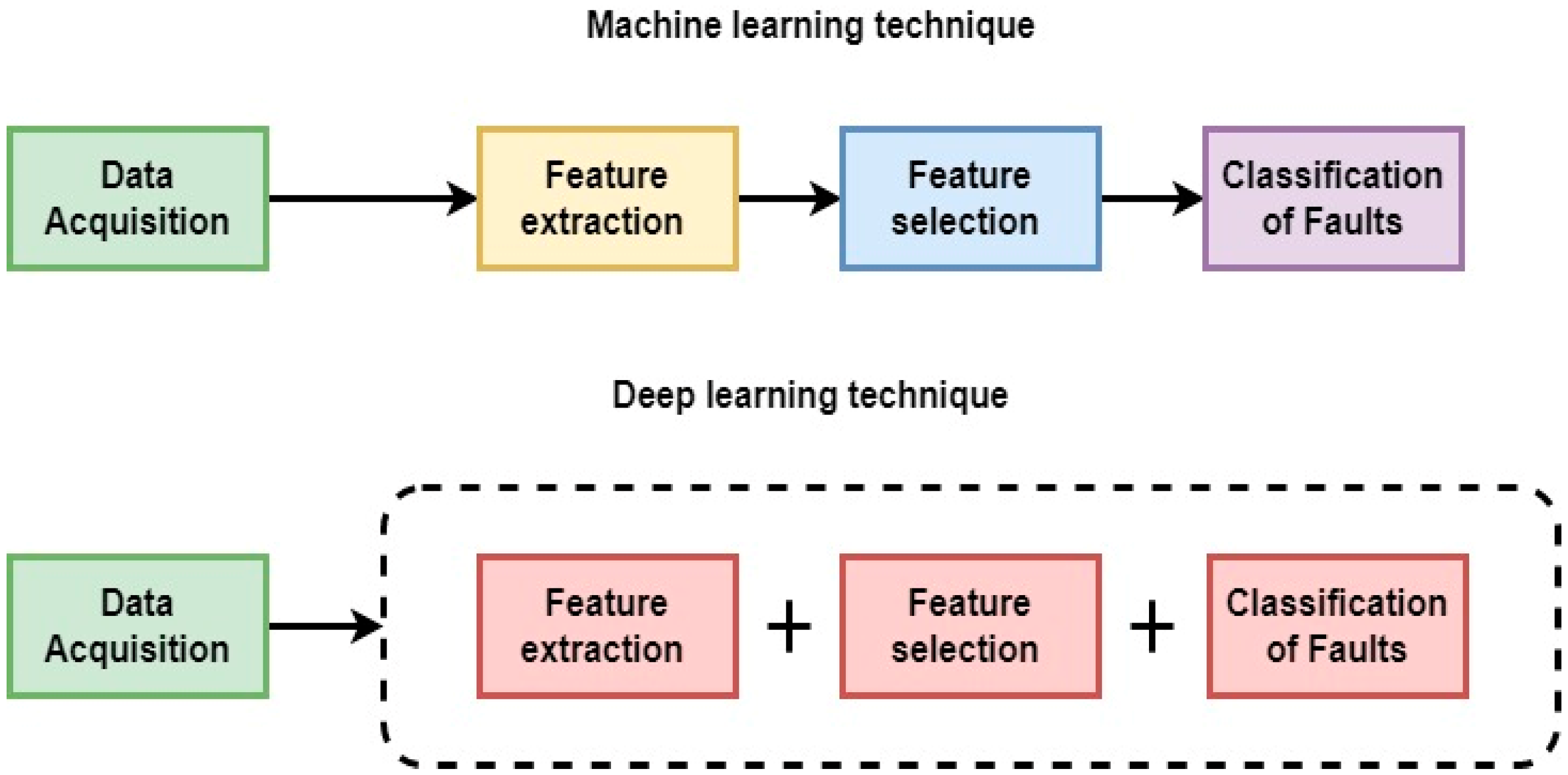
Figure 1 presents the various stages in ML and DL.
A pre-trained neural network has undergone training on a substantial dataset for a specific task, acquiring valuable features and patterns from the data. In the current study, we utilized this concept by selecting 15 pre-trained networks, originally designed for related tasks, and integrated additional layers to their architectures. These added layers were tailored to extract intricate patterns from pump vibration data. Subsequently, the modified networks were trained on our dataset through fine-tuning, enabling them to learn task-specific representations. This approach combined the advantages of pre-trained features with customized adaptations, enhancing the network’s capacity to derive meaningful insights from the complex pump vibration data.
Many research studies have recently embraced deep learning techniques for fault diagnosis in mechanical systems. For instance, Xie et al. proposed a fusion of deep learning (FFP-DL) framework, integrating fault frequency into deep learning to enhance interpretability. The authors applied an FFP-CNN model to offshore wind turbines data with experimental results demonstrating improved fault diagnosis accuracy and interpretability even with reduced training data. The pre-trained algorithm accelerates the rate of convergence and training speed [
31]. Zhang et al. introduced an approach for fault diagnosis in wind turbine gearboxes employing empirical mode decomposition and a 1D CNN, demonstrating the enhanced representation capacity and efficacy of deep learning models under variable working conditions [
32]. Wang et al. introduced an innovative algorithm for diagnosing faults in industrial motor bearings utilizing a multi-local model approach to resolve decision conflicts. The model effectively integrates diverse information sources, thereby enhancing fault diagnosis accuracy in the motor bearings [
33]. These findings emphasize the notable performance of deep learning methods in fault detection and diagnosis for mechanical systems.
- 1.
Analysis of six conditions of the centrifugal pump, namely cavitation (CAV), bearing and impeller fault (BFIF), bearing fault (BF), good, seal fault (SF) and impeller fault (IF).
- 2.
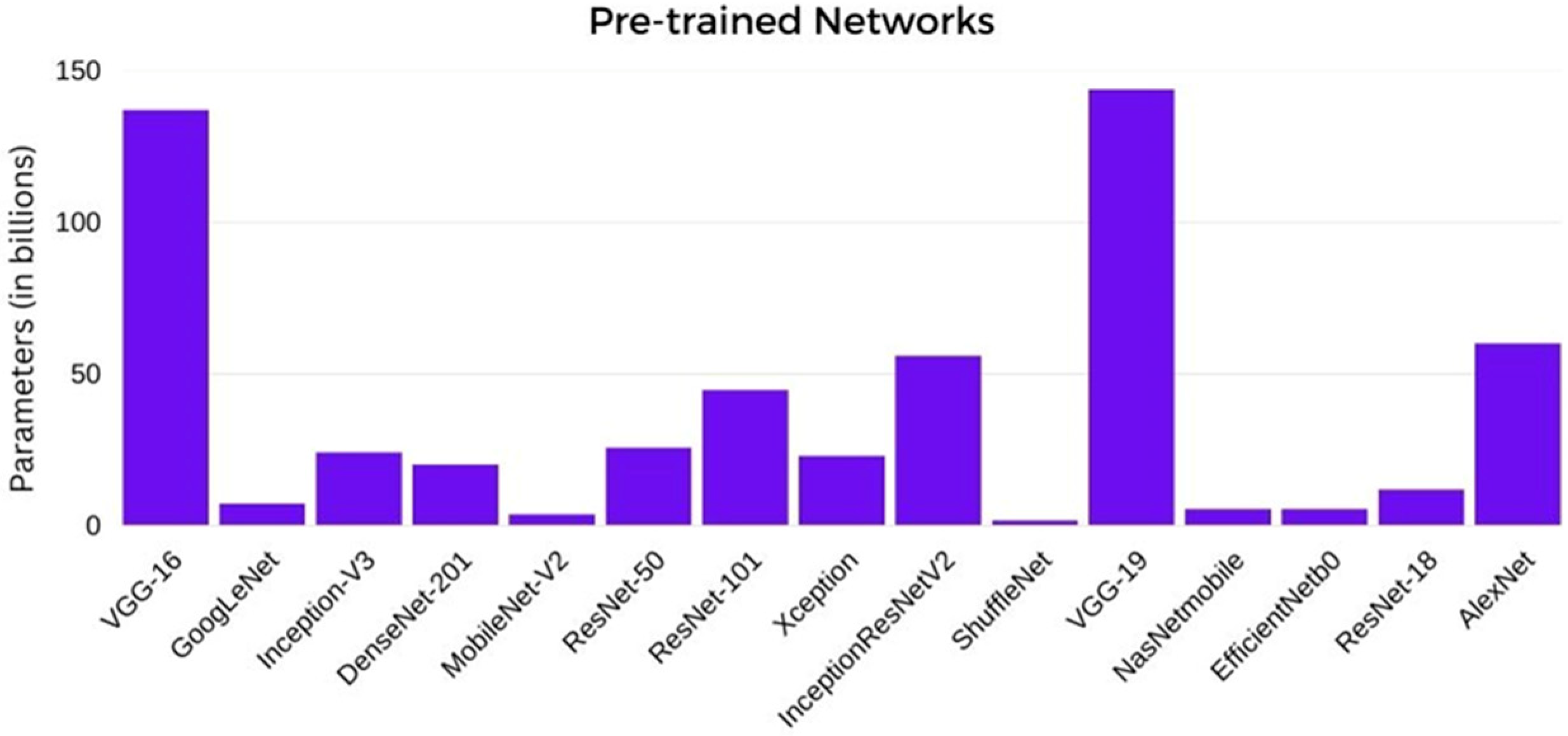
Leveraging ResNet-50, InceptionV3, GoogLeNet, DenseNet-201, ShuffleNet, VGG-19, MobileNet-v2, InceptionResNetV2, VGG-16, NasNetmobile, EfficientNetb0, AlexNet, ResNet-18, Xception, ResNet101 and ResNet-18 for MCP fault diagnostic.
- 3.
Evaluating pre-trained networks performance and their effectiveness with varied hyperparameters.
- 4.
Identifying the optimal network for MCP fault diagnosis based on the results.
This research study presents a groundbreaking approach to fault diagnosis, incorporating components such as 1D vibration signals, sensor technology, spectrogram image conversion and transfer learning. The study expands the available information by transforming the 1D signals into spectrogram images. It facilitates the visualization and extraction of intricate fault patterns that might be challenging to discern in the original signal domain. Leveraging the power of transfer learning, a pre-trained network is employed to train the system for fault classification, allowing the model to leverage the knowledge and patterns learned from a large dataset. This novel and integrated approach revolutionizes traditional fault diagnosis methodologies, providing an efficient and accurate solution with great promise for real-world industrial applications. By combining advanced signal processing techniques, cutting-edge sensor technology and transfer learning capabilities, this research study presents an innovative framework that enhances fault diagnosis capabilities that pave the way for improved fault detection, diagnosis and maintenance strategies in various industrial settings.
Overall, integrating fault detection and diagnosis (FDD) techniques with deep learning (DL) approaches proves crucial in enhancing the accuracy and effectiveness of fault diagnosis in mechanical systems, particularly in the case of MCP. This integration is vital for maintaining the overall smooth operation of these systems, ensuring safety, prolonging equipment lifespan and reducing maintenance costs. This study significantly contributes to the ongoing efforts to enhance MCP’s fault detection and diagnosis capabilities by employing advanced techniques and leveraging the power of data-driven approaches.
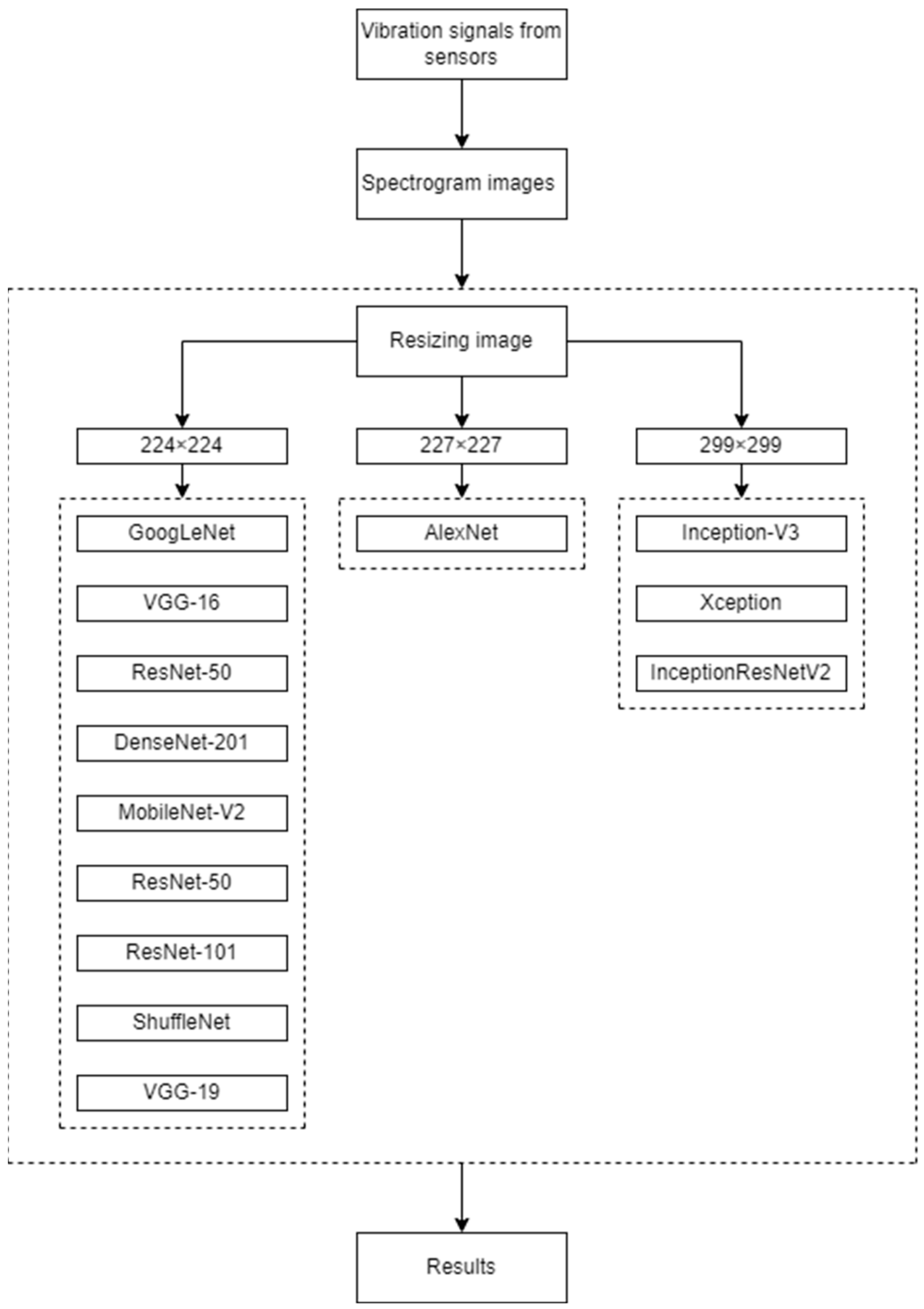
Figure 2 explains the procedure involved in the fault diagnosis of MCP using DL.
4. Results and Discussions
In the present study, a comprehensive investigation was conducted to determine the most effective pre-trained network among the 16 networks considered (ResNet-50, InceptionV3, GoogLeNet, DenseNet-201, ShuffleNet, VGG-19, MobileNet-v2, InceptionResNetV2, VGG-16, NasNetmobile, EfficientNetb0, AlexNet, ResNet-18, Xception, ResNet101 and ResNet-18). The selection process involved experimenting with parameters such as the solver type, learning rate, train-test split ratio and batch size. The experiments were performed using MATLAB R2023a, a widely recognized and extensively used tool for scientific computing. By systematically varying these key parameters, the optimal pre-trained network was identified, ensuring the highest performance and accuracy for the intended task.
4.1. Train-Test Split Ratio Influence on Pre-trained Network Performance
The train-test split ratio refers to the proportion of a dataset divided into training and testing subsets for deep learning. This allocation allows for evaluating the model performance on unseen data and detect overfitting. By increasing the split ratio, more training data are made available that have the potential to enhance performance. However, this comes at the expense of reduced reliability in the test set. On the other hand, decreasing the split ratio expands the size of the test set, facilitating a more robust evaluation. However, if the training set becomes excessively small, it may result in a diminished performance. Striking a balance is crucial, considering dataset size, model complexity and evaluation requirements. Common ratios depend upon the specific needs.
This experiment divided the dataset into two sets: a training set and a testing set. To evaluate the performance of the pre-trained networks, five different split ratios were conducted for each network. During these iterations, the other hyperparameters such as batch size (10), solver (sgdm), epochs (30) and learning rate (0.0001) were kept constant. This experimental setup allowed for a comprehensive exploration of the impact of different train-test split ratios (0.6, 0.7, 0.75, 0.8, 0.85) on the performance of the pre-trained networks.
Table 3 illustrates the performance variations of each network concerning the TR (train-test split ratio).
Table 3 shows that AlexNet consistently achieves 100% accuracy across all train-test split ratios. Additionally, the table reveals that AlexNet attains optimal performance, achieving 100% accuracy with a train-test split ratio of 0.6 while exhibiting the lowest computational time of 28 s compared to other ratios. The optimal TR ratios were found to be 0.60 for all the pre-trained networks.
4.2. Solver Influence on Pre-trained Network Performance
Optimizer algorithms are instrumental in improving the performance of deep learning models. These optimization techniques significantly impact the accuracy and speed of training these models. The solvers ultimately minimize the loss function by modifying the neural network weights during each epoch. An optimizer is a function or algorithm that adjusts parameters such as weights and learning rates within a neural network. This adjustment process aids in reducing the overall loss and enhances the model’s precision. To assess the performance of pre-trained networks, the solvers, including sgdm, adam and rmsprop, were varied. However, other hyperparameters such as batch size (10), learning rate (0.0001) and epochs (30) remained constant. Additionally, the optimal TR split ratio from the previous section was utilized for every network.
Table 4 depicts the performance differences among various networks based on the optimizers used. Upon analyzing, it becomes apparent that AlexNet achieves 100% accuracy exclusively when the optimizer employed is sgdm, taking a computational time of 25 s. In contrast, it attains an accuracy of 99.70% when using other optimizers.
4.3. Batch Size Influence on Pre-trained Network Performance
The batch size refers to the number of samples used in each training iteration of a neural network and plays a critical role in determining the model performance and training time. A smaller batch size allows for faster training iterations that can be advantageous when time is crucial or when dealing with large datasets. On the other hand, a larger batch size provides more accurate gradient estimates, leading to potentially better generalizations and higher accuracy on unseen data. However, larger batch sizes can result in longer training times due to increased memory requirements and computational overhead. The optimal batch size depends on dataset size, model complexity, available resources and desired training time. Finding the right balance is essential for efficient training and model performance.
In order to determine the optimal batch size that yields the best performance, the learning rate and epochs were maintained at a constant value of 0.0001 and 30, respectively. The optimal combination of training data and optimizers obtained in the previous sections was utilized, while the batch size was systematically varied across the values of 8, 10, 16, 24 and 32. By exploring this range of batch sizes, the goal was to identify the batch size that maximizes the model performance in terms of accuracy and convergence. Based on these considerations, the following hyperparameters were found to yield the best performance: VGG-19, AlexNet (0.60 TR and sgdm optimizer), Xception (0.60 TR and sgdm optimizer), InceptionV3 (0.60 TR and sgdm optimizer), DenseNet-201 (0.60 TR and sgdm optimizer), GoogLeNet, ResNet-18, ResNet-50, ResNet101, ShuffleNet, VGG-16, EfficientNetb0, MobileNet-v2, NasNetmobile and InceptionResNetV2 (0.60 TR and sgdm optimizer).
Table 5 displays the performance of pre-trained networks across different batch sizes. AlexNet achieves 100% accuracy for all batch sizes except for batch size 24, as shown in
Table 5. The table illustrates that AlexNet attains the shortest computational time of 17 s specifically for a batch size of 32.
4.4. Learning Rate Influence on Pre-trained Network Performance
The learning rate is a vital hyperparameter in neural network training. It is assigned a small positive value, usually between 0.0 and 1.0, to greatly influence the learning process. It determines the speed at which a model learns and finds the right balance. Raising the learning rate decreases computational time, but also carries the risk of improper training for the model. On the other hand, a smaller learning rate increases the computational time needed for training. Achieving an optimal learning rate balances computational efficiency and effective model training. Finding the optimal learning rate often involves experimentation and fine-tuning. It requires balancing fast convergence and avoiding convergence issues such as overshooting or getting stuck in local minima. Understanding the data, model complexity and the problem at hand can guide the selection of an appropriate learning rate for effective neural network training.
The optimizers, train-test ratio and batch size were all fixed and the learning rate (0.0001,0.0003,0.001) was varied to evaluate the model performance. The fixed parameters are as follows: GoogLeNet (0.60 TR, sgdm, 24 BS), ResNet-18 (0.60 TR, sgdm, 32 BS), ResNet-50 (0.60 TR, sgdm, 32 BS), ResNet101 (0.60 TR, sgdm, 32 BS), ShuffleNet (0.60 TR, sgdm, 32 BS), VGG-19 (0.60 TR, sgdm, 16 BS), VGG-16 (0.60 TR, sgdm, 10 BS), EfficientNetb0 (0.60 TR, sgdm, 10 BS), MobileNet-v2 (0.60 TR, sgdm, 32 BS), DenseNet-201 (0.60 TR, sgdm, 32 BS), NasNetmobile (0.60 TR, sgdm, 24 BS), AlexNet (0.60 TR, sgdm, 32 BS), Xception (0.60 TR, sgdm, 10 BS), InceptionResNetV2 (0.60 TR, sgdm, 16 BS) and InceptionV3 (0.60 TR, sgdm, 24 BS).
Table 6 displays the performance analysis of different learning rates. It is evident that AlexNet achieves 100% accuracy across all the learning rates. Furthermore, it can be observed that AlexNet consistently maintains a computational time of 17 s, irrespective of the learning rate employed in
Table 6. These findings emphasize the robustness and effectiveness of these models across different learning rate configurations, solidifying their reliability as top choices for image classification tasks.
4.5. Comparison of the Pre-Trained Models
The effectiveness of pre-trained neural networks in fault diagnosis for MCPs was assessed and their performance was evaluated using various metrics. Among the pre-trained models, AlexNet stood out as the most accurate model with an accuracy of 100% and a relatively low execution time of 17 s, as shown in
Table 7. Therefore, it is highly recommended for fault diagnosis in MCPs. Further analysis using
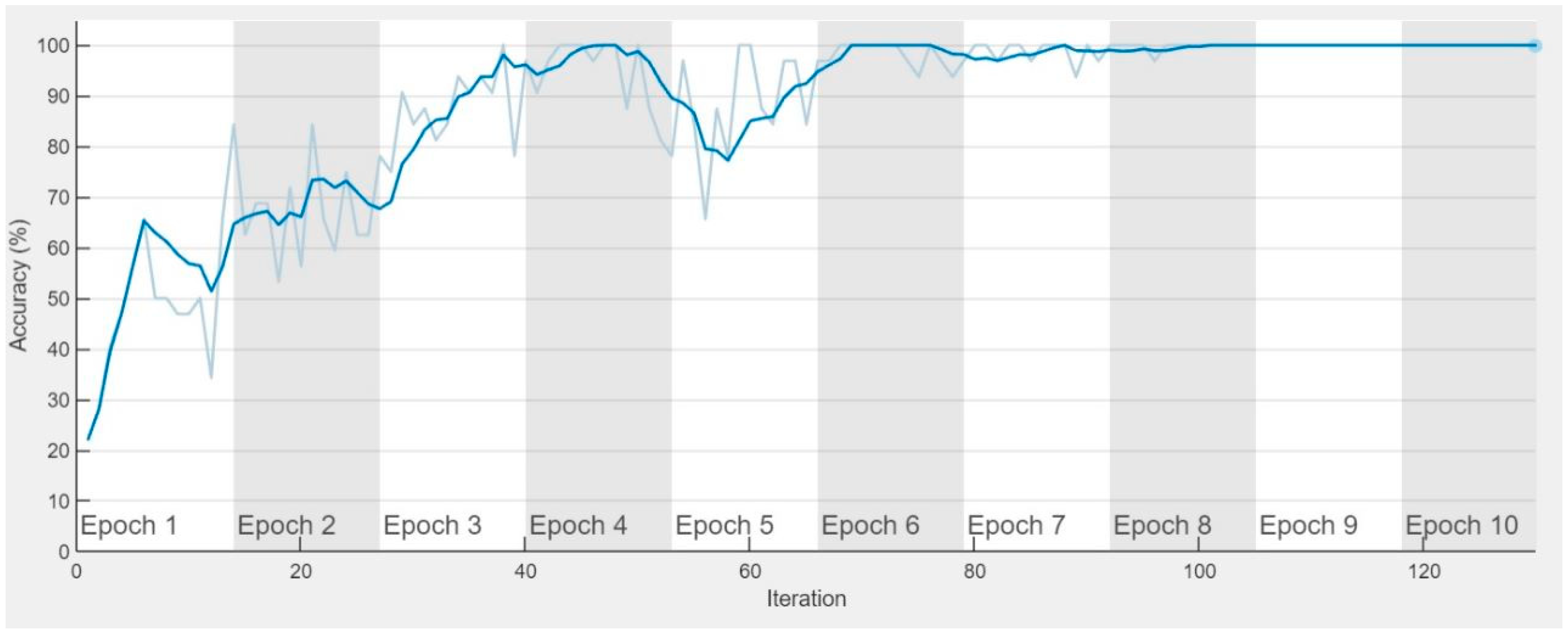
Figure 6 and
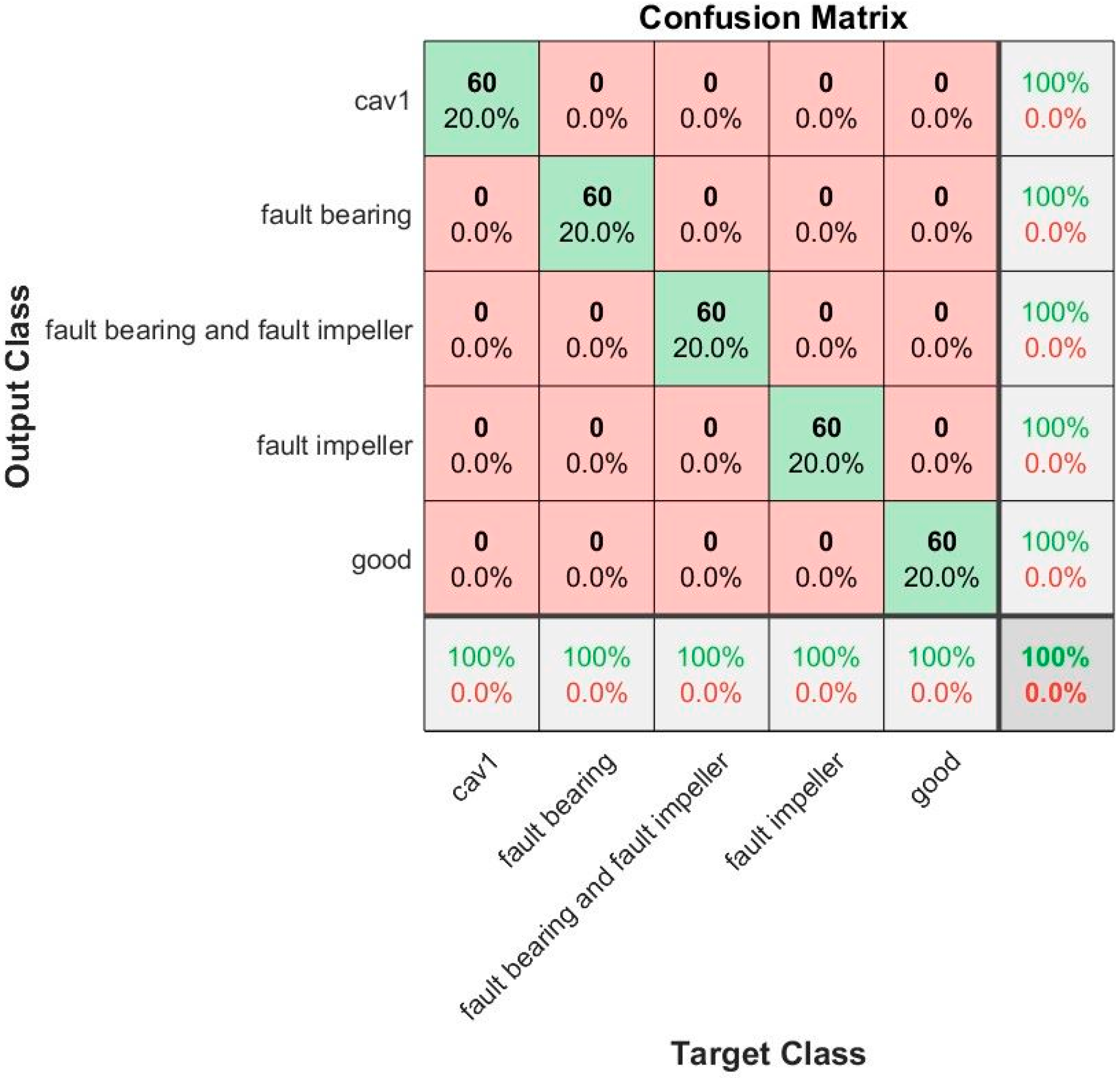
Figure 7 demonstrated the successful training progression of AlexNet and its confusion matrix. This matrix provides a comprehensive overview of the model classification capabilities by representing correct identifications on the diagonal and misclassifications on the non-diagonal elements. Throughout the training period, the total loss was dramatically decreased, illustrating the efficiency of the selected hyperparameters.
Table 7 presents the overall classification accuracy of the pre-trained networks and the best performing network has been highlighted.
Figure 6 illustrates the confusion matrix for the AlexNet network, further validating its effectiveness in fault identification and classification for MCP.
4.6. A Comparative Study: Pre-Trained Networks and Cutting-Edge Works
A comparison analysis is undertaken in this part to illustrate how the proposed approach outperforms other cutting-edge studies accessible in the literature.
Table 8 compares the efficacy of several techniques with that of the suggested methodology.
Table 8 demonstrates that the proposed approach exceeds all prior works by achieving a classification accuracy of 100%.
5. Conclusions
In conclusion, this research paper focused on the fault diagnosis of monoblock centrifugal pumps (MCP) using pre-trained neural networks. Six defects including CAV, BFIF, BF, Good, SF and IF were analyzed to develop an effective diagnostic system. The vibration signals acquired from MCP were processed using a spectrogram image conversion technique. This technique transformed the signals into spectrogram images which were then utilized as inputs for the pre-trained networks. Several state-of-the-art networks, namely ResNet-50, InceptionV3, GoogLeNet, DenseNet-201, ShuffleNet, VGG-19, MobileNet-v2, InceptionResNetV2, VGG-16, NasNetmobile, EfficientNetb0, AlexNet, ResNet-18, Xception, ResNet101 and ResNet-18, were leveraged for the fault diagnosis task. By evaluating the effectiveness of the pre-trained networks with varied hyperparameters, it is observed that AlexNet exhibited the highest level of accuracy among the tested models. Its exceptional classification precision makes it a strong candidate for MCP fault diagnosis. Furthermore, the execution time of the classification process was thoroughly analyzed. AlexNet achieved an impressive execution time of 17 s, indicating its applicability for real-time fault diagnosis. Based on the comprehensive evaluation of the pre-trained networks and their performance in MCP fault diagnosis, it can be concluded that AlexNet with optimized hyperparameters is the optimal choice. Its high accuracy and efficient execution time make it a reliable tool for identifying and classifying faults in MCPs. The findings of this research provide valuable insights for maintenance and troubleshooting purposes, enabling the timely and accurate detection of MCP faults to ensure operational efficiency and reliability.



 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}