
High-Precision Detection Algorithm for Metal Workpiece Defects Based on Deep Learning


Abstract
:1. Introduction
- (1)
- Introducing an advanced and effective deep learning neural network that builds upon the Yolov7 algorithm, utilizing the CotNet Transformer as the backbone, incorporating the parameter-free attention mechanism SinAM, and using WIoUv3 as the loss function.
- (2)
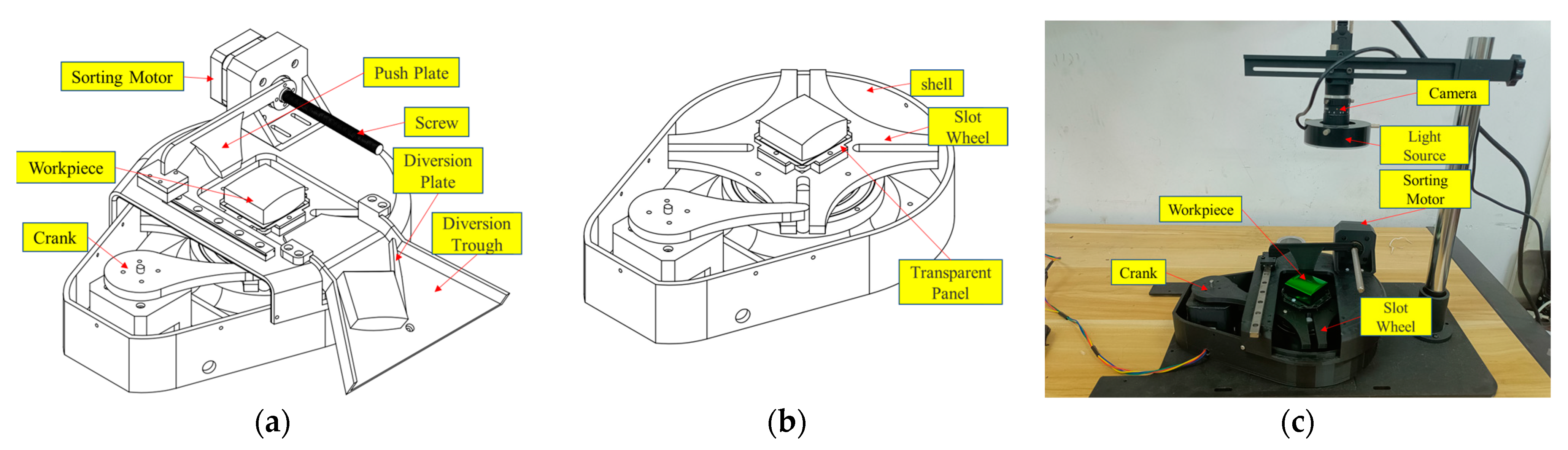
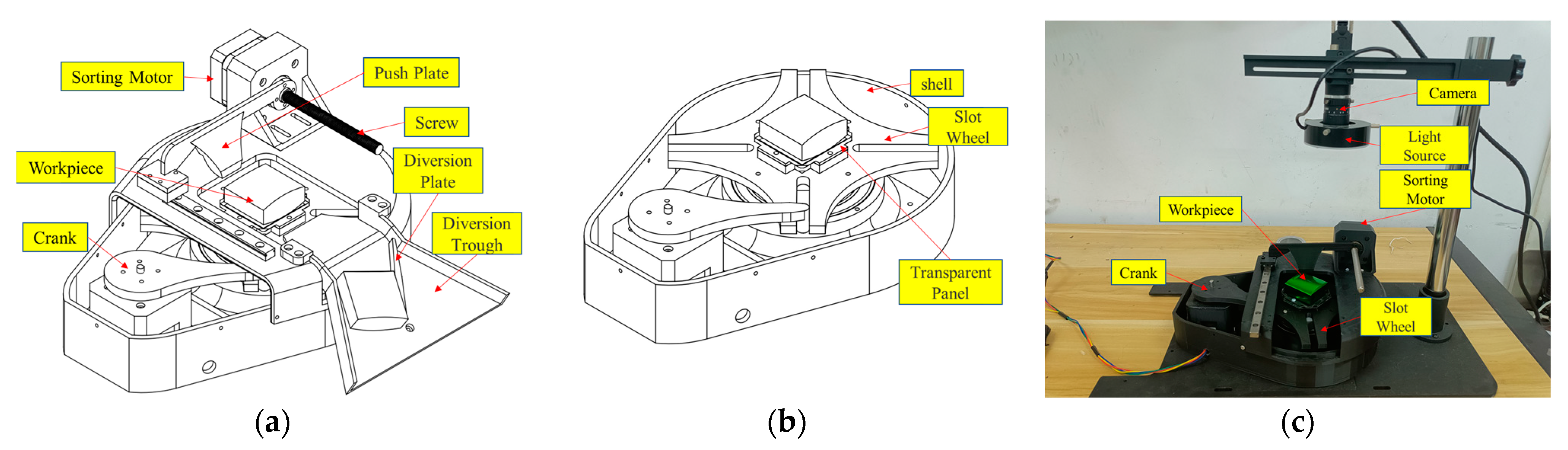
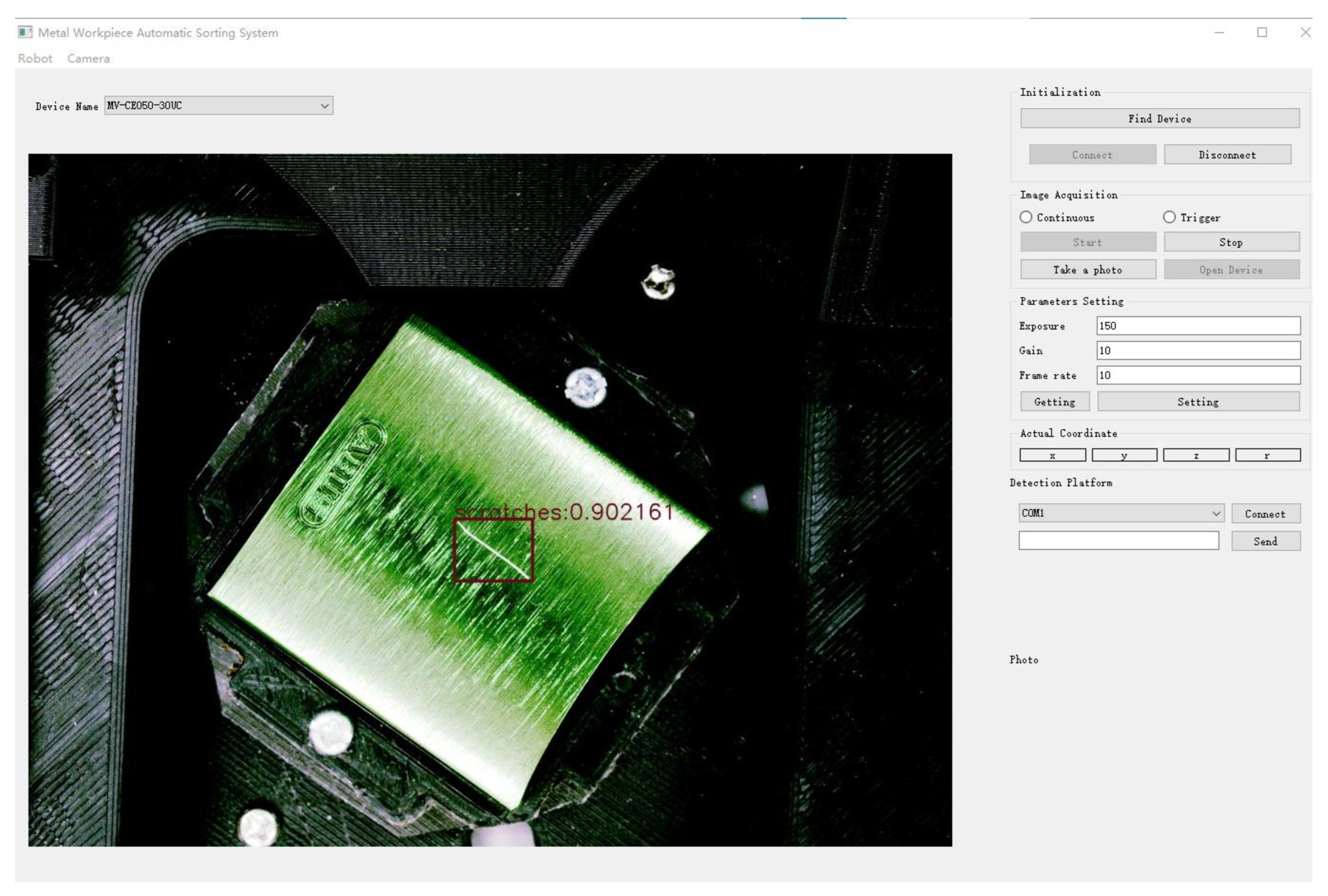
- To validate the efficiency and accuracy of the proposed algorithm, a polyhedral metal workpiece detection system was designed, including a detection platform and its operating software v1.0.
- (3)
- Providing an automated control solution for automated detection and sorting.
2. Related Work
3. Proposed Method
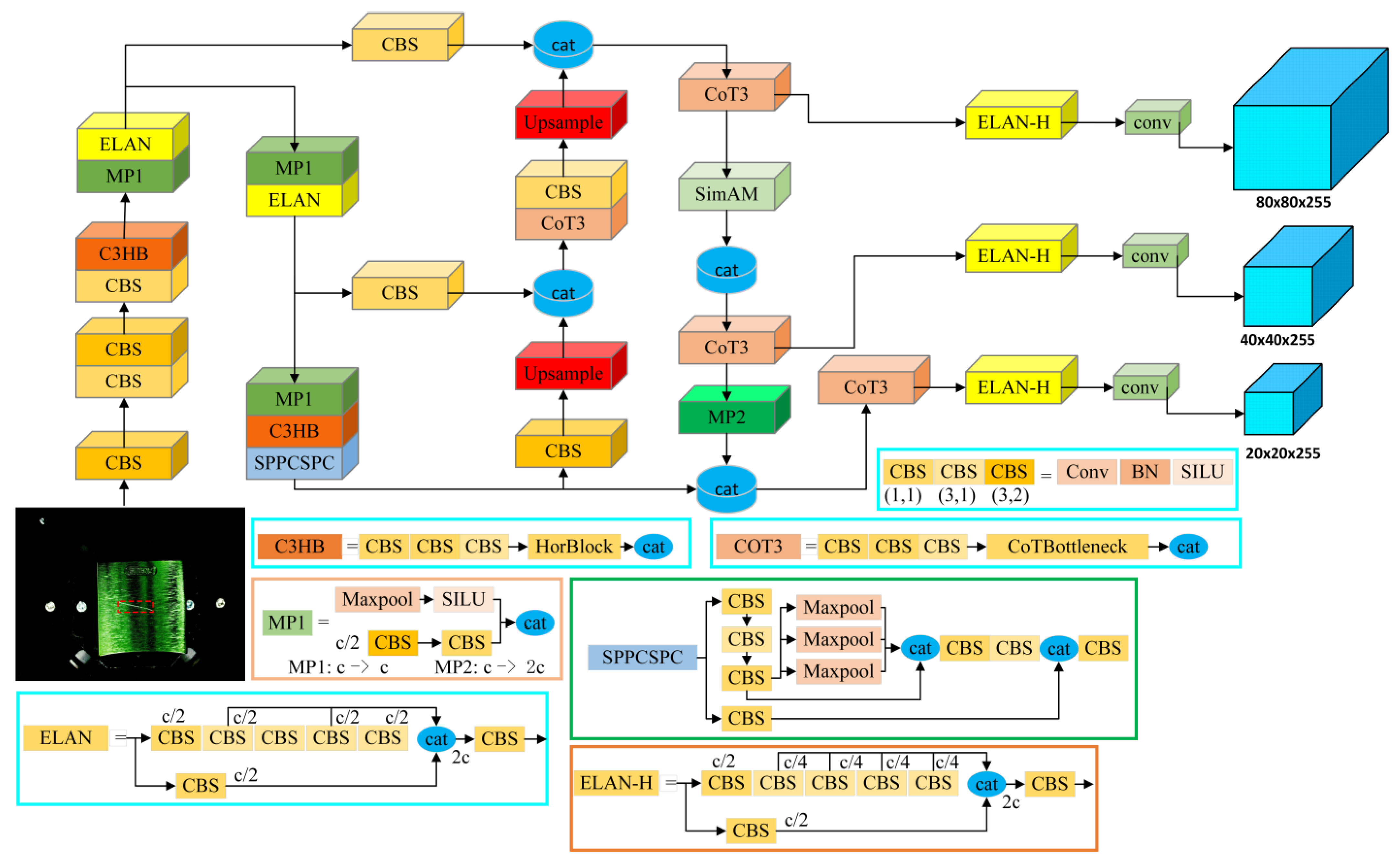
3.1. Yolov7 Algorithm Model
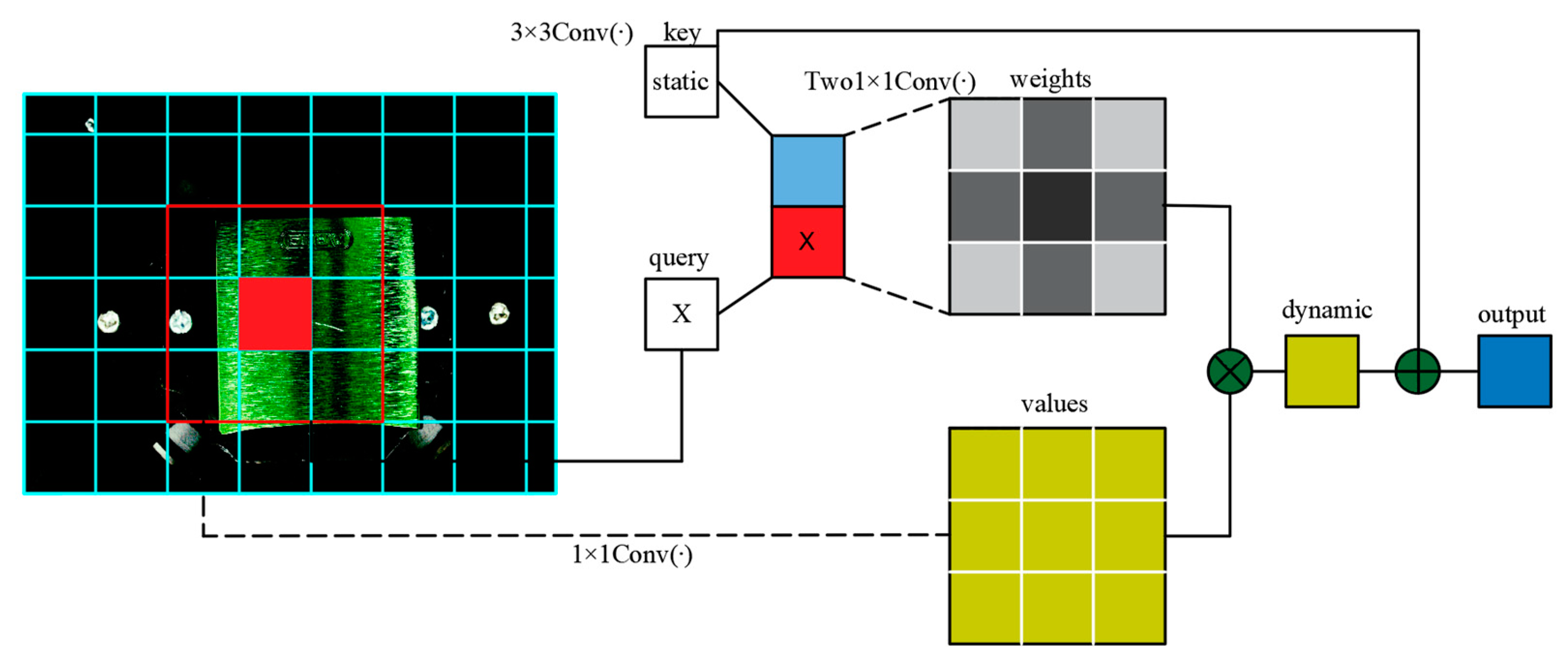
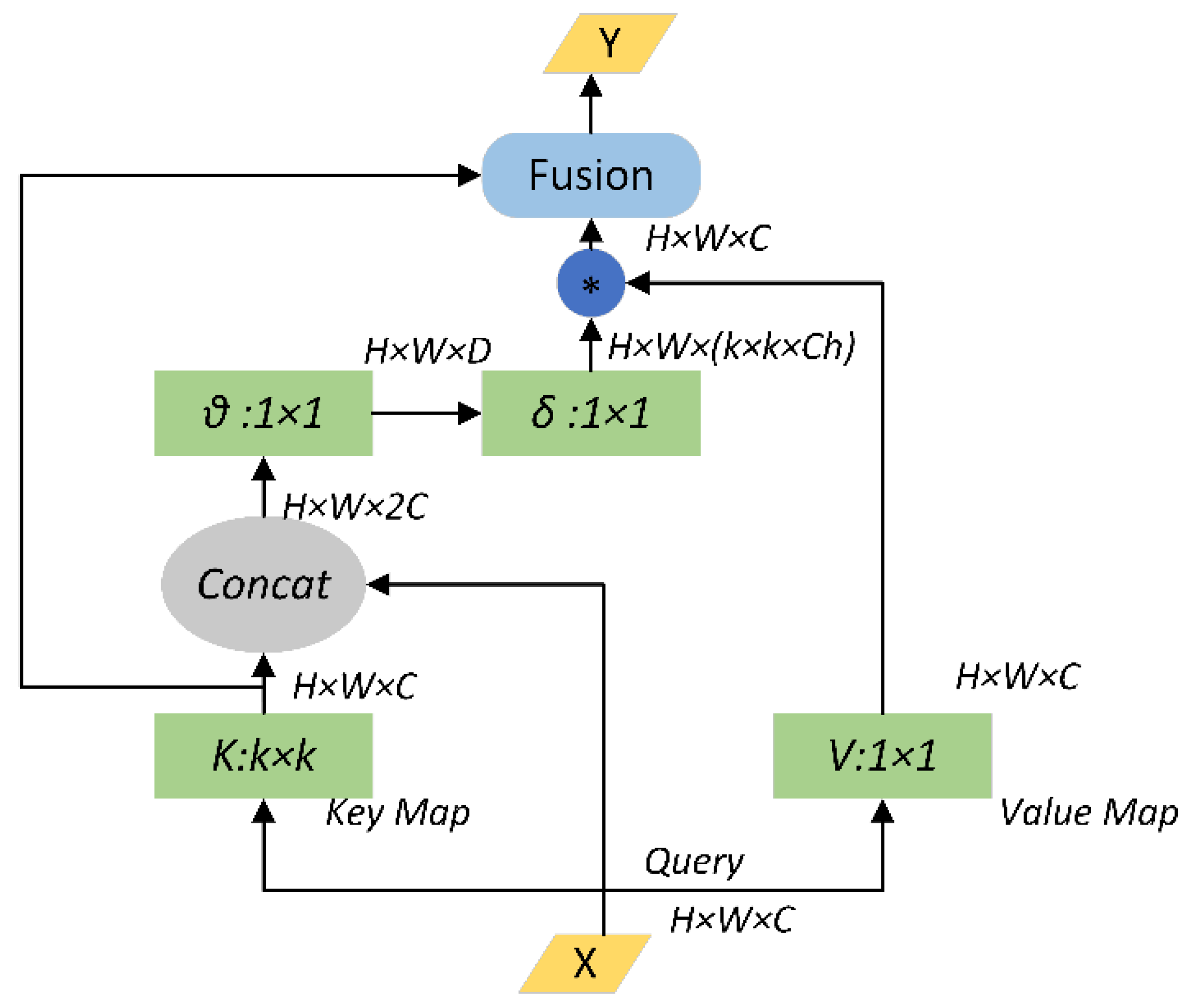
3.2. Using CotNet Transformer as the Backbone
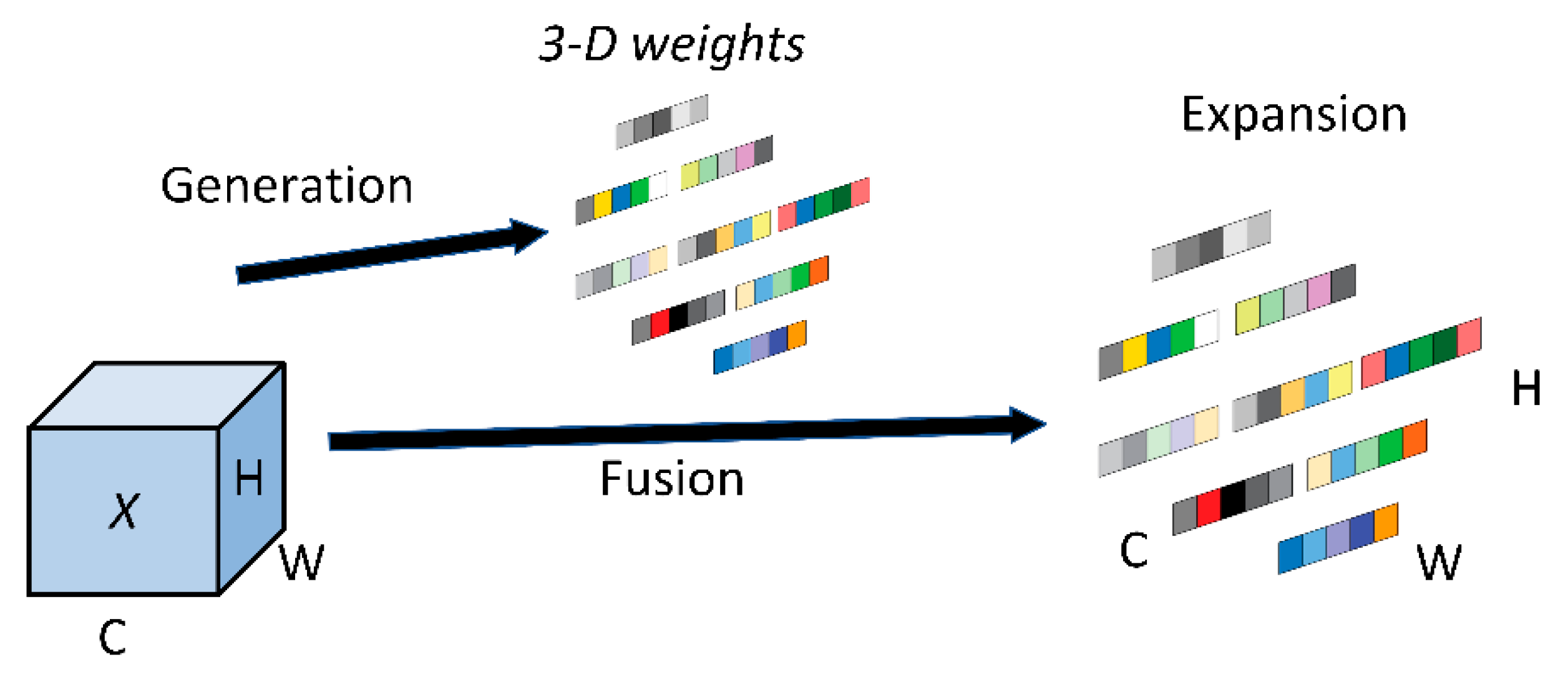
3.3. Introducing Parameter-Free Attention Mechanism
3.4. Using WIoUv3 as the Loss Function
4. Experiments and Results
4.1. Dataset and Experimental Setup
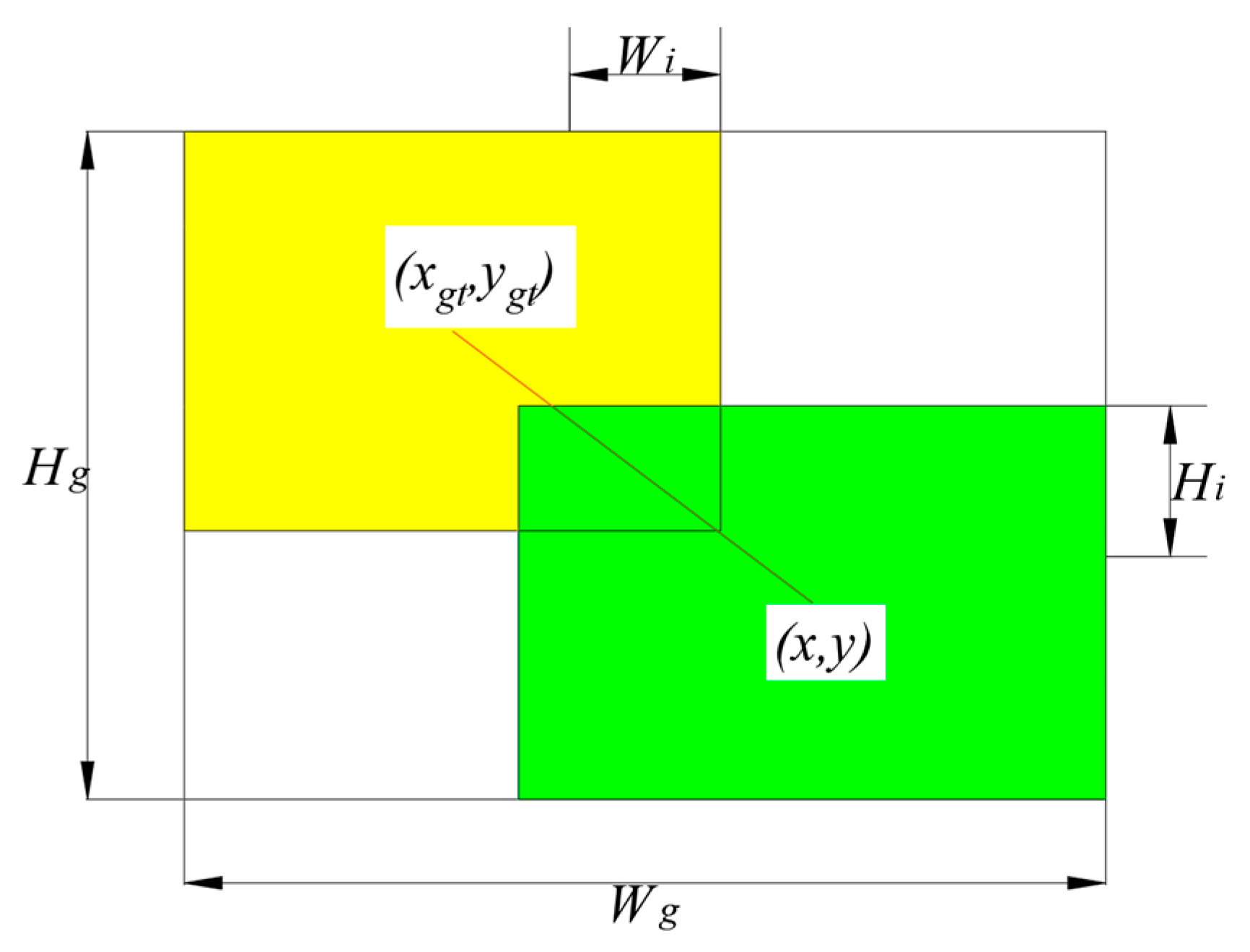
4.2. Evaluation Index
4.3. Analysis of Experimental Results
4.3.1. Ablation Experiment
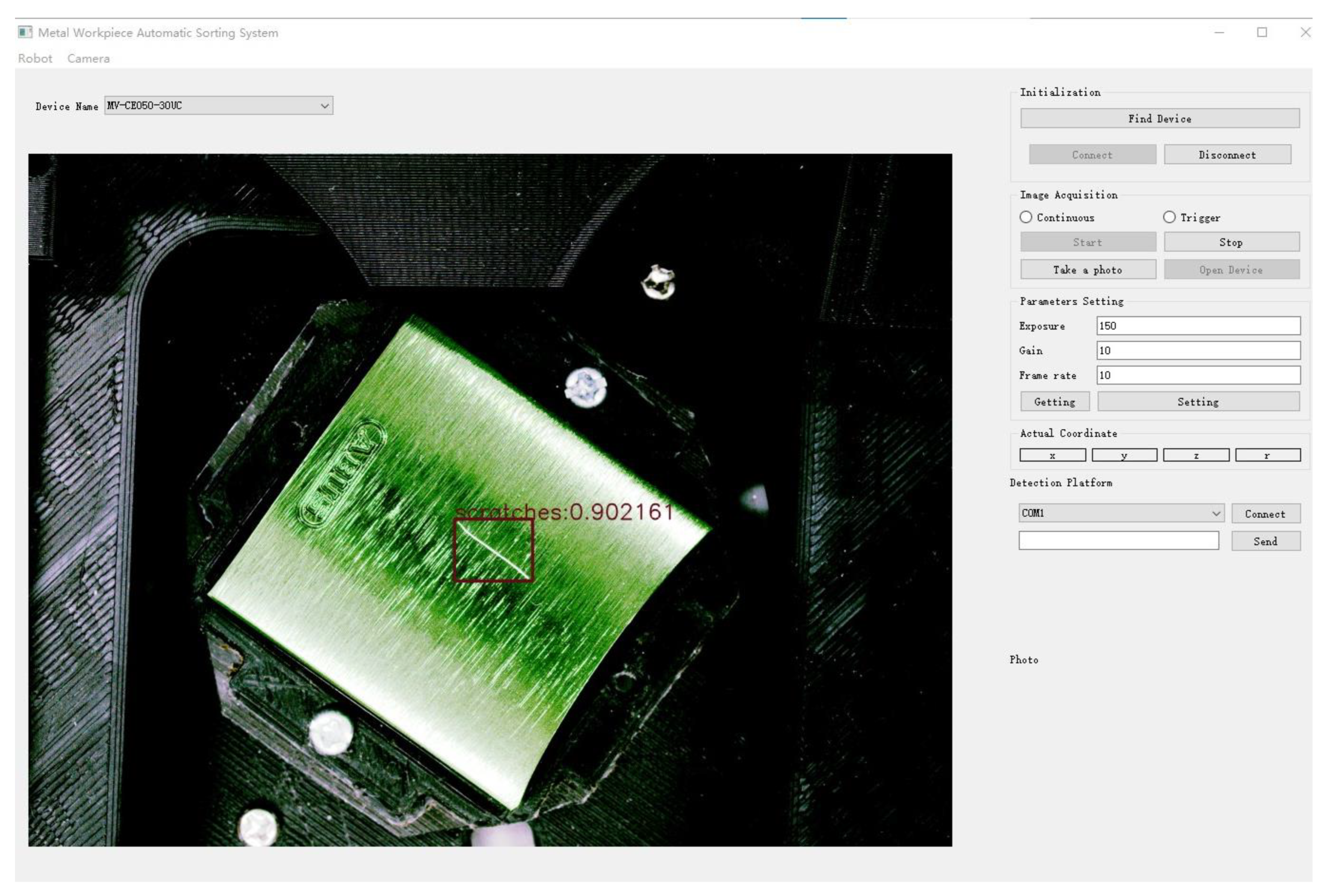
4.3.2. Practical Application of the Algorithm
5. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rasheed, A.; Zafar, B.; Rasheed, A.; Ali, N.; Sajid, M.; Dar, S.H.; Habib, U.; Shehryar, T.; Mahmood, M.T. Fabric Defect Detection Using Computer Vision Techniques: A Comprehensive Review. Math. Probl. Eng. 2020, 2020, 8189403. [Google Scholar] [CrossRef]
- Yang, J.; Li, S.; Wang, Z.; Dong, H.; Wang, J.; Tang, S. Using Deep Learning to Detect Defects in Manufacturing: A Comprehensive Survey and Current Challenges. Materials 2020, 13, 5755. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Ding, Y.; Zhao, F.; Zhang, E.; Wu, Z.; Shao, L. Surface Defect Detection Methods for Industrial Products: A Review. Appl. Sci. 2021, 11, 7657. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Khan, F.; Salahuddin, S.; Javidnia, H. Deep Learning-Based Monocular Depth Estimation Methods—A State-of-the-Art Review. Sensors 2020, 20, 2272. [Google Scholar] [CrossRef]
- Yang, G.; Yang, J.; Sheng, W.; Junior, F.E.F.; Li, S. Convolutional Neural Network-Based Embarrassing Situation Detection under Camera for Social Robot in Smart Homes. Sensors 2018, 18, 1530. [Google Scholar] [CrossRef]
- Borji, A.; Cheng, M.; Jiang, H.; Li, J. Salient Object Detection: A Benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef]
- Ciaburro, G. Sound Event Detection in Underground Parking Garage Using Convolutional Neural Network. Big Data Cogn. Comput. 2020, 4, 20. [Google Scholar] [CrossRef]
- Ciaburro, G.; Iannace, G. Improving Smart Cities Safety Using Sound Events Detection Based on Deep Neural Network Algorithms. Informatics 2020, 7, 23. [Google Scholar] [CrossRef]
- Costa, D.G.; Vasques, F.; Portugal, P.; Aguiar, A. A Distributed Multi-Tier Emergency Alerting System Exploiting Sensors-Based Event Detection to Support Smart City Applications. Sensors 2020, 20, 170. [Google Scholar] [CrossRef] [PubMed]
- Iannace, G.; Ciaburro, G.; Trematerra, A. Fault Diagnosis for UAV Blades Using Artificial Neural Network. Robotics 2019, 8, 59. [Google Scholar] [CrossRef]
- Peng, L.; Liu, J. Detection and analysis of large-scale WT blade surface cracks based on UAV-taken images. IET Image Process. 2018, 12, 2059–2064. [Google Scholar] [CrossRef]
- Saied, M.; Lussier, B.; Fantoni, I.; Shraim, H.; Francis, C. Fault Diagnosis and Fault-Tolerant Control of an Octorotor UAV using motors speeds measurements. IFAC-PapersOnLine 2017, 50, 5263–5268. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Tao, X.; Wang, Z.; Zhang, Z.; Zhang, D.; Xu, D.; Gong, X.; Zhang, L. Wire Defect Recognition of Spring-Wire Socket Using Multitask Convolutional Neural Networks. IEEE Trans. Compon. Packag. Manuf. Technol. 2018, 8, 689–698. [Google Scholar] [CrossRef]
- Jiang, J.; Chen, Z.; He, K. A feature-based method of rapidly detecting global exact symmetries in CAD models. Comput. Aided Des. 2013, 45, 1081–1094. [Google Scholar] [CrossRef]
- Cheng, J.C.P.; Wang, M. Automated detection of sewer pipe defects in closed-circuit television images using deep learning techniques. Autom. Constr. 2018, 95, 155–171. [Google Scholar] [CrossRef]
- Bergmann, P.; Löwe, S.; Fauser, M.; Sattlegger, D.; Steger, C. Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders. arXiv 2019, arXiv:1807.02011. [Google Scholar]
- Fang, X.; Luo, Q.; Zhou, B.; Li, C.; Tian, L. Research Progress of Automated Visual Surface Defect Detection for Industrial Metal Planar Materials. Sensors 2020, 20, 5136. [Google Scholar] [CrossRef]
- Wang, C.; Bochkovskiy, A.; Liao, H.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual Transformer Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 1489–1500. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, A.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Long Beach, CA, USA, 2017; pp. 6000–6010. [Google Scholar]
- Yang, L.; Zhang, R.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Chetverikov, D.; Hanbury, A. Finding defects in texture using regularity and local orientation. Pattern Recogn. 2002, 35, 2165–2180. [Google Scholar] [CrossRef]
- Hou, Z.; Parker, J.M. Texture Defect Detection Using Support Vector Machines with Adaptive Gabor Wavelet Features. In Proceedings of the 2005 Seventh IEEE Workshops on Applications of Computer Vision (WACV/MOTION’05)-Volume 1, Breckenridge, CO, USA, 5–7 January 2005; pp. 275–280. [Google Scholar]
- Zheng, S.; Zhong, Q.; Chen, X.; Peng, L.; Cui, G. The Rail Surface Defects Recognition via Operating Service Rail Vehicle Vibrations. Machines 2022, 10, 796. [Google Scholar] [CrossRef]
- Cha, Y.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Zhang, Y.; Cai, W.; Fan, S.; Song, R.; Jin, J. Object Detection Based on YOLOv5 and GhostNet for Orchard Pests. Information 2022, 13, 548. [Google Scholar] [CrossRef]
- Ye, W.; Ren, J.; Zhang, A.A.; Lu, C. Automatic pixel-level crack detection with multi-scale feature fusion for slab tracks. Comput.-Aided Civ. Infrastruct. Eng. 2023, 1–18. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, W.; Li, L.; Jiao, H.; Li, Y.; Guo, L.; Xu, J. A framework for the efficient enhancement of non-uniform illumination underwater image using convolution neural network. Comput. Graph. 2023, 112, 60–71. [Google Scholar] [CrossRef]
- Qiao, Y.; Shao, M.; Liu, H.; Shang, K. Mutual channel prior guided dual-domain interaction network for single image raindrop removal. Comput. Graph. 2023, 112, 132–142. [Google Scholar] [CrossRef]
- Koulali, I.; Eskil, M.T. Unsupervised textile defect detection using convolutional neural networks. Appl. Soft Comput. 2021, 113, 107913. [Google Scholar] [CrossRef]
- Wang, J.; Yu, L.; Yang, J.; Dong, H. DBA_SSD: A Novel End-to-End Object Detection Algorithm Applied to Plant Disease Detection. Information 2021, 12, 474. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Thongbai, S.; Wongweeranimit, W.; Santitamnont, P.; Suphan, K.; Charoenphon, C. Object Detection of Road Assets Using Transformer-Based YOLOX with Feature Pyramid Decoder on Thai Highway Panorama. Information 2022, 13, 5. [Google Scholar] [CrossRef]
- Tao, X.; Zhang, D.; Ma, W.; Liu, X.; Xu, D. Automatic Metallic Surface Defect Detection and Recognition with Convolutional Neural Networks. Appl. Sci. 2018, 8, 1575. [Google Scholar] [CrossRef]
- Gao, Y.; Gao, L.; Li, X. A hierarchical training-convolutional neural network with feature alignment for steel surface defect recognition. Robot. Comput.-Integr. Manuf. 2023, 81, 102507. [Google Scholar] [CrossRef]
- Yoon, S.; Song-Kyoo Kim, A.; Cantwell, W.J.; Yeun, C.Y.; Cho, C.; Byon, Y.; Kim, T. Defect detection in composites by deep learning using solitary waves. Int. J. Mech. Sci. 2023, 239, 107882. [Google Scholar] [CrossRef]
- Wang, J.; Xu, G.; Li, C.; Wang, Z.; Yan, F. Surface Defects Detection Using Non-convex Total Variation Regularized RPCA With Kernelization. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Yang, J.; Shi, Y.; Qi, Z. DFR: Deep Feature Reconstruction for Unsupervised Anomaly Segmentation. arXiv 2020, arXiv:2012.07122. [Google Scholar]
- Yang, H.; Chen, Y.; Song, K.; Yin, Z. Multiscale Feature-Clustering-Based Fully Convolutional Autoencoder for Fast Accurate Visual Inspection of Texture Surface Defects. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1450–1467. [Google Scholar] [CrossRef]
- Li, W.; Zhang, H.; Wang, G.; Xiong, G.; Zhao, M.; Li, G.; Li, R. Deep learning based online metallic surface defect detection method for wire and arc additive manufacturing. Robot. Comput.-Integr. Manuf. 2023, 80, 102470. [Google Scholar] [CrossRef]
- Wang, J.; Dai, H.; Chen, T.; Liu, H.; Zhang, X.; Zhong, Q.; Lu, R. Toward surface defect detection in electronics manufacturing by an accurate and lightweight YOLO-style object detector. Sci. Rep. 2023, 13, 7062. [Google Scholar] [CrossRef]
- Zhang, Y.; Ni, Q. A Novel Weld-Seam Defect Detection Algorithm Based on the S-YOLO Model. Axioms 2023, 12, 697. [Google Scholar] [CrossRef]
- Zhou, M.; Lu, W.; Xia, J.; Wang, Y. Defect Detection in Steel Using a Hybrid Attention Network. Sensors 2023, 23, 6982. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Zheng, Z.; Xu, T.; Guo, S.; Feng, S.; Yao, W.; Lan, Y. YOLO-Based UAV Technology: A Review of the Research and Its Applications. Drones 2023, 7, 190. [Google Scholar] [CrossRef]
- Li, X.; Wang, Q.; Yang, X.; Wang, K.; Zhang, H. Track Fastener Defect Detection Model Based on Improved YOLOv5s. Sensors 2023, 23, 6457. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Liu, H.; Chen, J.; Hu, J.; Zheng, E. Insu-YOLO: An Insulator Defect Detection Algorithm Based on Multiscale Feature Fusion. Electronics 2023, 12, 3210. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Configuration |
|---|---|
| Operating system | Windows 10 |
| Deep learning framework | 1.10.1+cu102 |
| Programming language | Python 3.8 |
| CUDA | CUDA10.2 |
| GPU | NVIDIA GeForce RTX 2060 |
| CPU | Intel(R) Core(TM) i7-10700 CPU@2.90 GHz |
| Equipment | Parameter | Data |
|---|---|---|
| LED ring light | Item code | JHZM-A40-W |
| Light source color | white | |
| Number of LEDs | 48 shell LEDs | |
| Industrial camera | Active pixels | 5 million |
| Type | multicolor | |
| Pixel size | 2.2 µm × 2.2 µm | |
| Frame rate/Resolution | 31 @ 2592 × 1944 | |
| Camera lens | Focal distance | 12 mm |
| Maximum image surface area | 1/1.8″ (φ9 mm) | |
| Aperture spectrum | F2.8–F16 |
| Total | Bad Stuff | Freckles | Scratches | Poor Contraction | Bad Cover | Bump Damage | Abrade |
|---|---|---|---|---|---|---|---|
| 4840 | 880 | 320 | 1040 | 640 | 640 | 680 | 640 |
| Parameter | Learning Rate | Batch Size | Epoch | Img. Size | Workers |
|---|---|---|---|---|---|
| Value | 0.01 | 4 | 300 | 640 | 8 |
| Model | mAP@0.5 | AP | ||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
| Yolov7 (original) | 0.854 | 0.596 | 0.85 | 0.995 | 0.945 | 0.946 | 0.689 | 0.954 |
| C-Yolov7 (CotNet) | 0.873 | 0.587 | 0.775 | 0.976 | 0.996 | 0.967 | 0.826 | 0.985 |
| S-Yolov7 (SimAM) | 0.897 | 0.687 | 0.823 | 0.982 | 0.995 | 0.969 | 0.837 | 0.985 |
| W-Yolov7 (WIoUv3) | 0.905 | 0.721 | 0.797 | 0.986 | 0.996 | 0.996 | 0.851 | 0.985 |
| CS-Yolov7 (CotNet + SimAM) | 0.908 | 0.752 | 0.819 | 0.985 | 0.995 | 0.996 | 0.822 | 0.985 |
| CW-Yolov7 (CotNet + WIoUv3) | 0.923 | 0.748 | 0.842 | 0.994 | 0.996 | 0.996 | 0.898 | 0.985 |
| WS-Yolov7 (SimAM + WIoUv3) | 0.916 | 0.732 | 0.870 | 0.982 | 0.978 | 0.987 | 0.872 | 0.990 |
| CSW-Yolov7 (CotNet + SimAM + WIoUv3) | 0.933 | 0.772 | 0.869 | 0.994 | 0.995 | 0.995 | 0.91 | 0.993 |
| Version | mAP@0.5 | Parameters | GFLOPS | Speed (Time: ms) | ||
|---|---|---|---|---|---|---|
| Inference | NMS | Preprocess | ||||
| YOLOv5s | 0.884 | 7.23 M | 16.6 | 5.1 | 1.0 | 0.20 |
| YOLOv6 | 0.916 | 17.19 M | 44.08 | 7.10 | 1.19 | 0.20 |
| YOLOv7 | 0.854 | 37.23 M | 105.2 | 10 | 1.1 | 11.2 |
| Yolov8 | 0.928 | 11.13 M | 28.5 | 5.6 | 0.5 | 0.3 |
| CSW-Yolov7 | 0.933 | 33.57 M | 40.3 | 8.4 | 1.1 | 9.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Zhang, G.; Zheng, W.; Zhao, A.; Zhong, Y.; Wang, H. High-Precision Detection Algorithm for Metal Workpiece Defects Based on Deep Learning. Machines 2023, 11, 834. https://doi.org/10.3390/machines11080834
Xu X, Zhang G, Zheng W, Zhao A, Zhong Y, Wang H. High-Precision Detection Algorithm for Metal Workpiece Defects Based on Deep Learning. Machines. 2023; 11(8):834. https://doi.org/10.3390/machines11080834
Chicago/Turabian StyleXu, Xiujin, Gengming Zhang, Wenhe Zheng, Anbang Zhao, Yi Zhong, and Hongjun Wang. 2023. "High-Precision Detection Algorithm for Metal Workpiece Defects Based on Deep Learning" Machines 11, no. 8: 834. https://doi.org/10.3390/machines11080834
APA StyleXu, X., Zhang, G., Zheng, W., Zhao, A., Zhong, Y., & Wang, H. (2023). High-Precision Detection Algorithm for Metal Workpiece Defects Based on Deep Learning. Machines, 11(8), 834. https://doi.org/10.3390/machines11080834