
Component Criticality Analysis for Improved Ship Machinery Reliability



Abstract
1. Introduction
2. Critical Literature Review on Component Criticality Analysis
2.1. Dynamic Fault Tree Analysis (DFTA)
2.2. Reliability Importance Measures (IMs)
2.3. Artificial Neural Networks (ANNs)
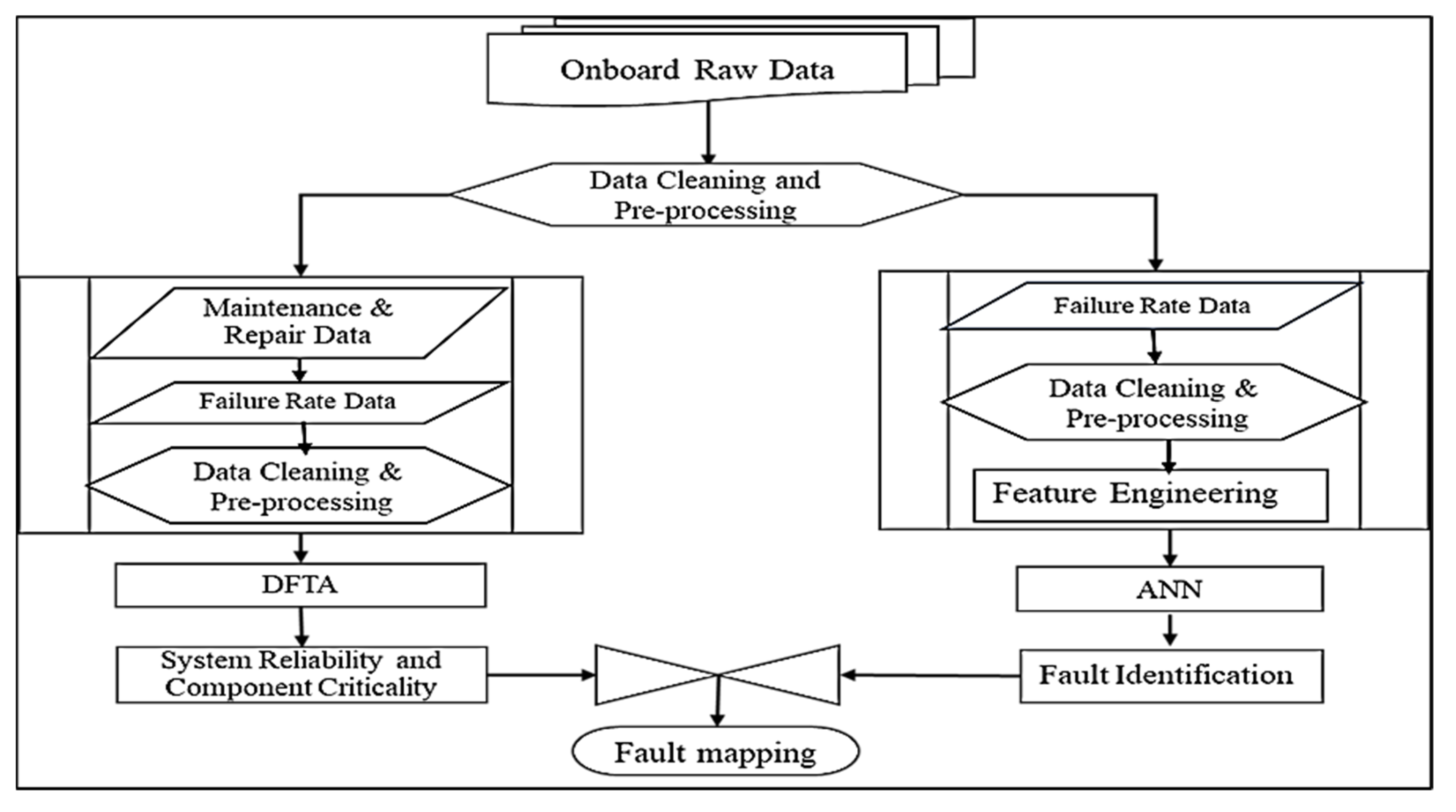
3. Methodology
3.1. DFTA Analysis
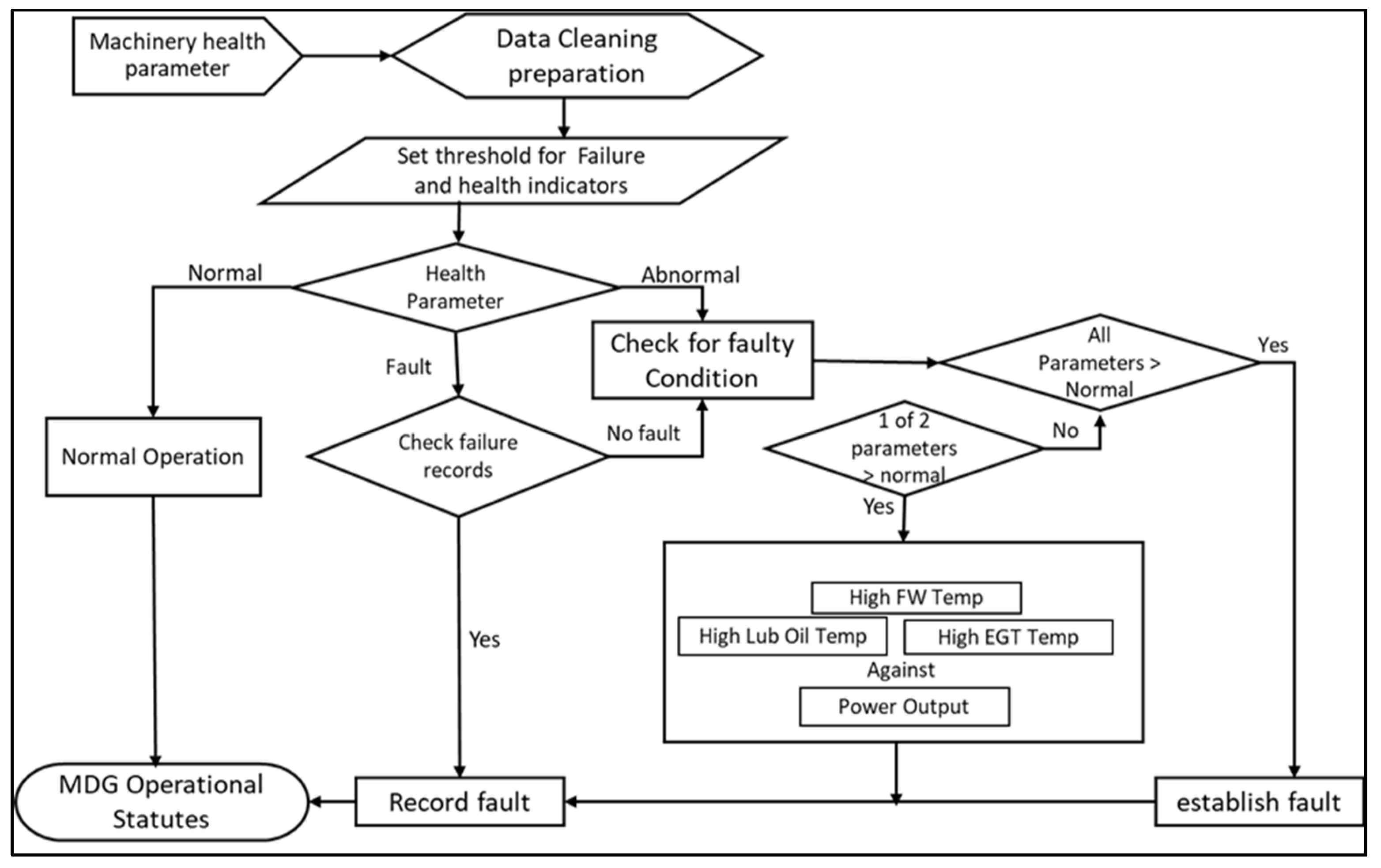
3.2. ANN Fault Identification
3.3. Data Labelling
4. Case Study
5. Results and Discussion
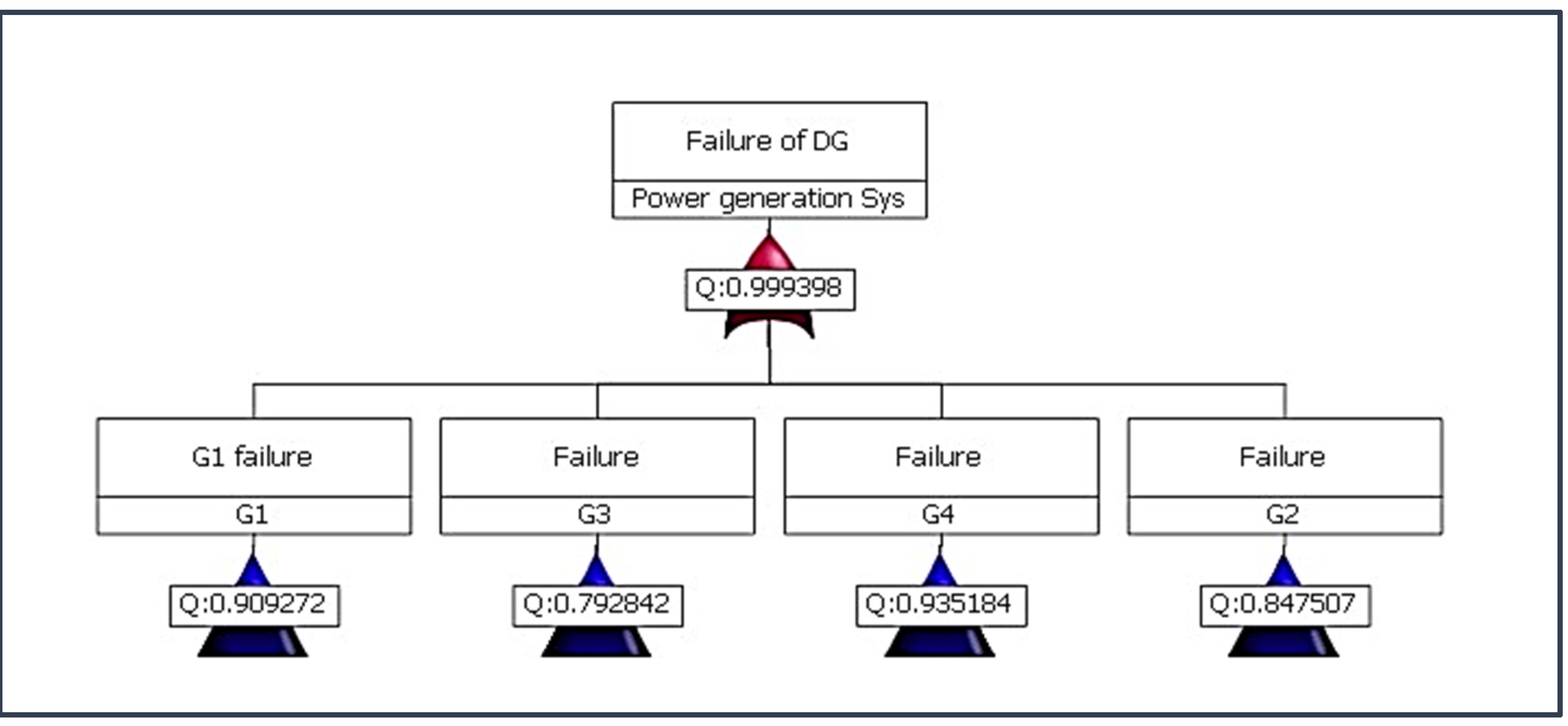
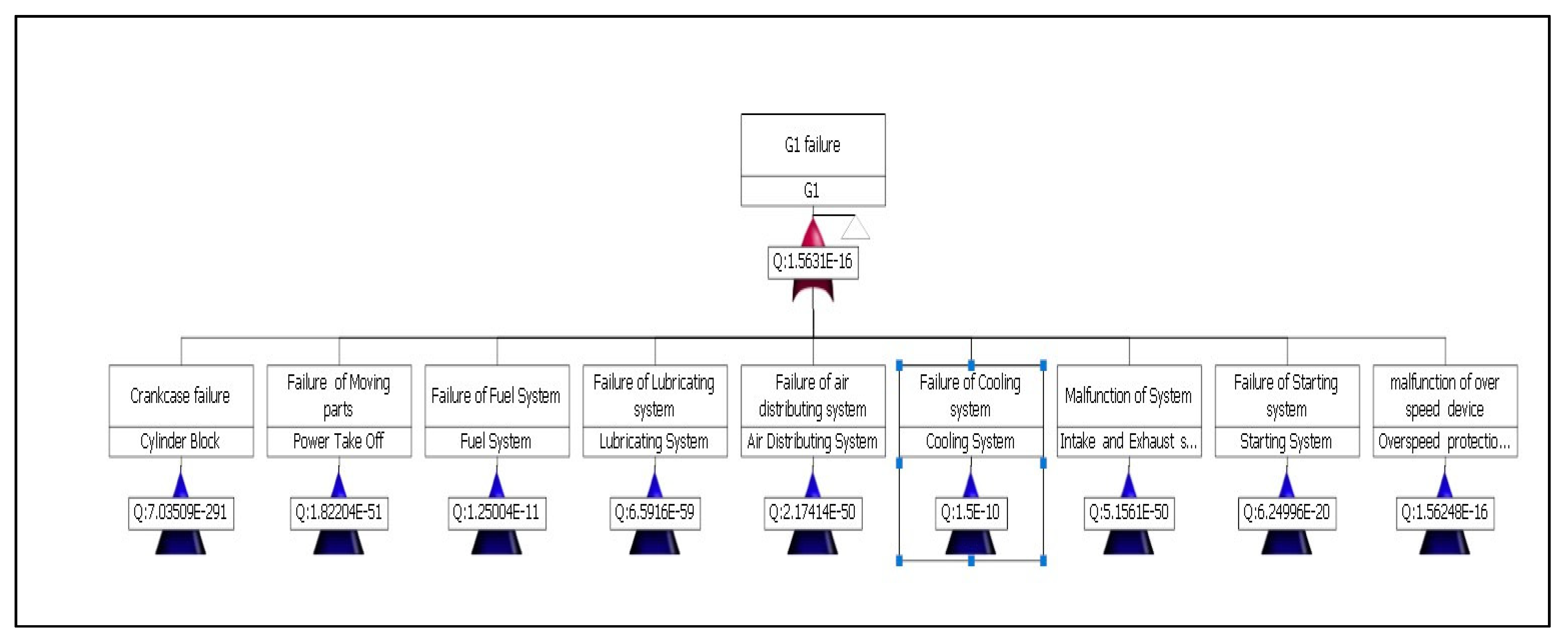
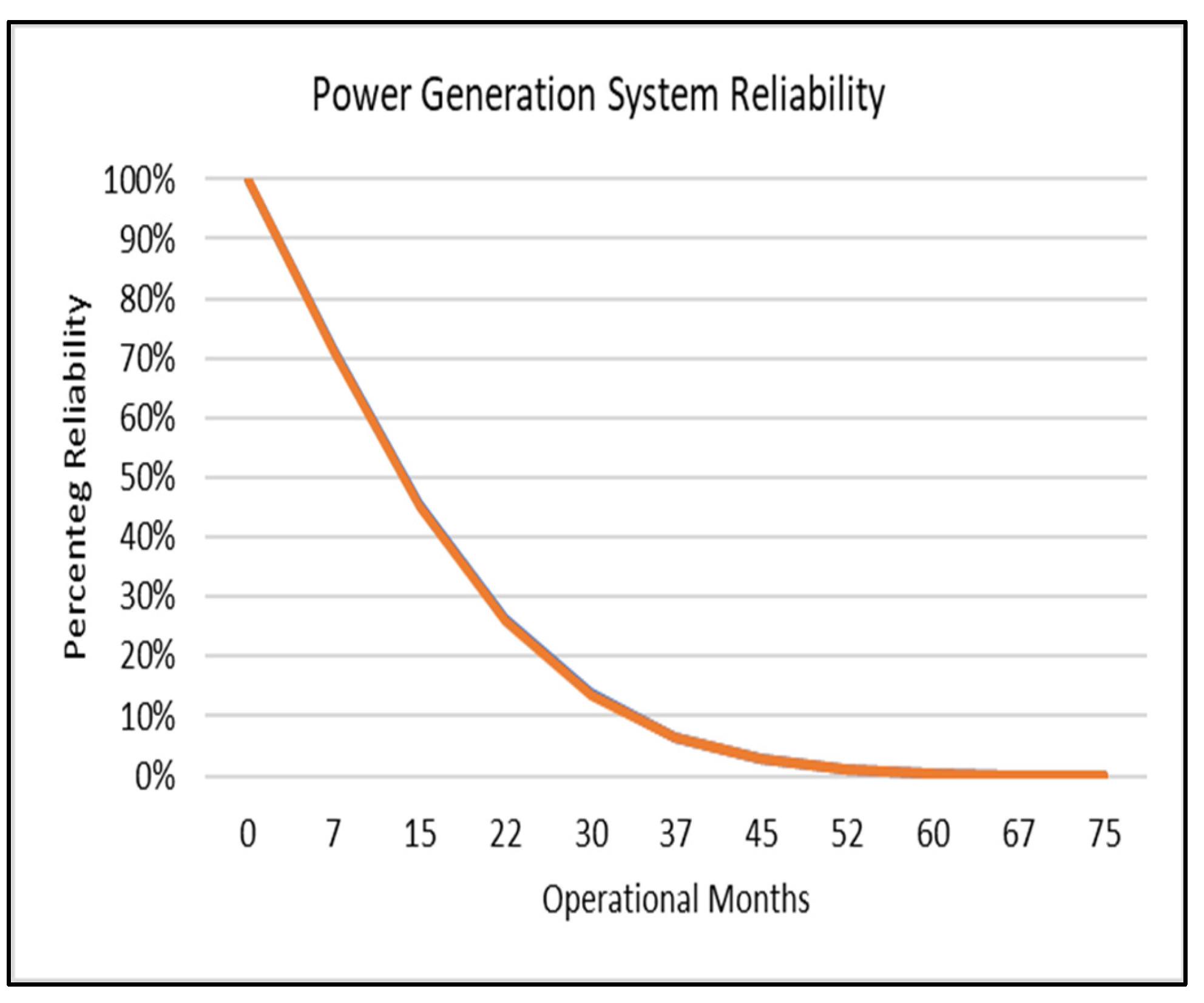
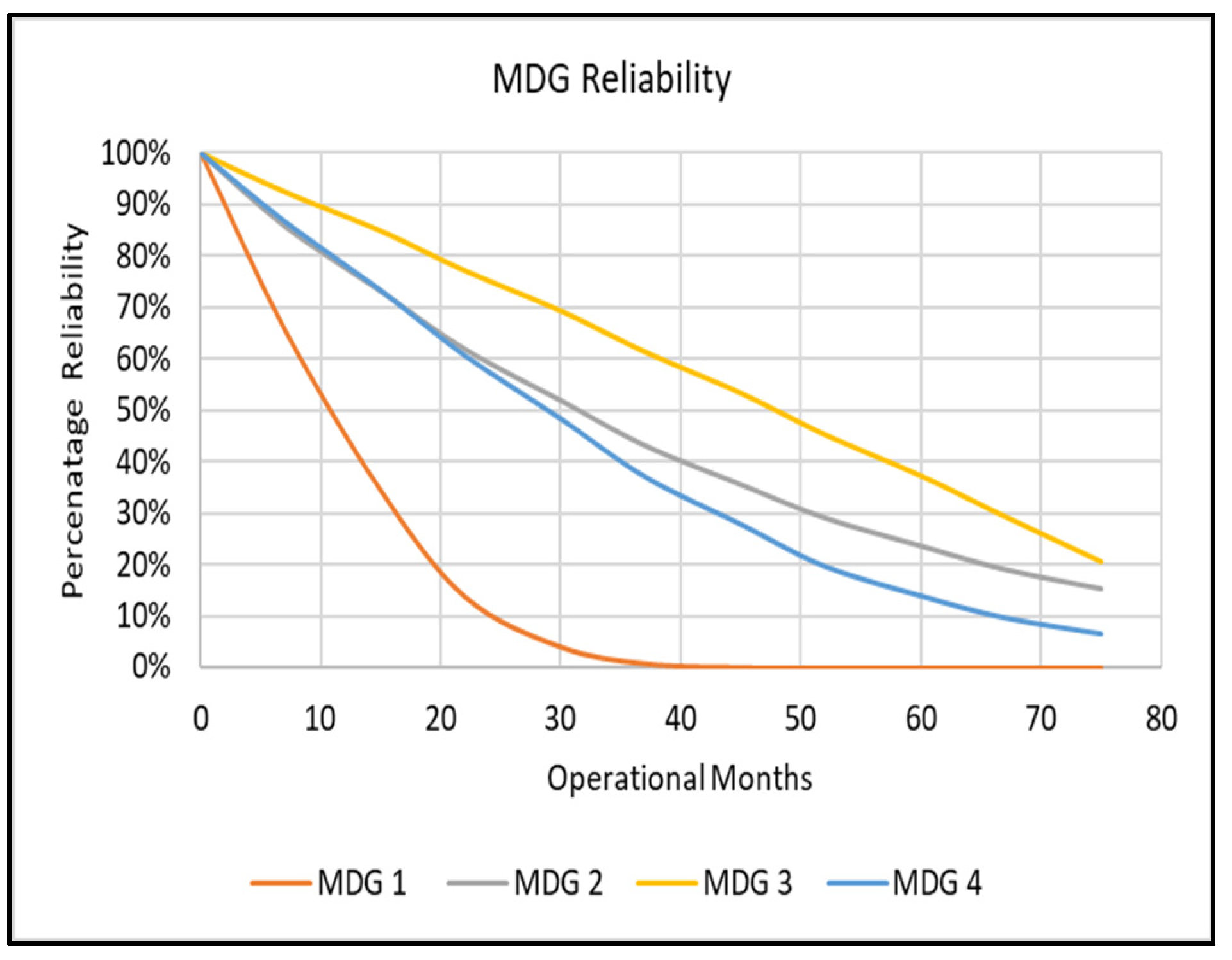
5.1. Subsystem Analysis
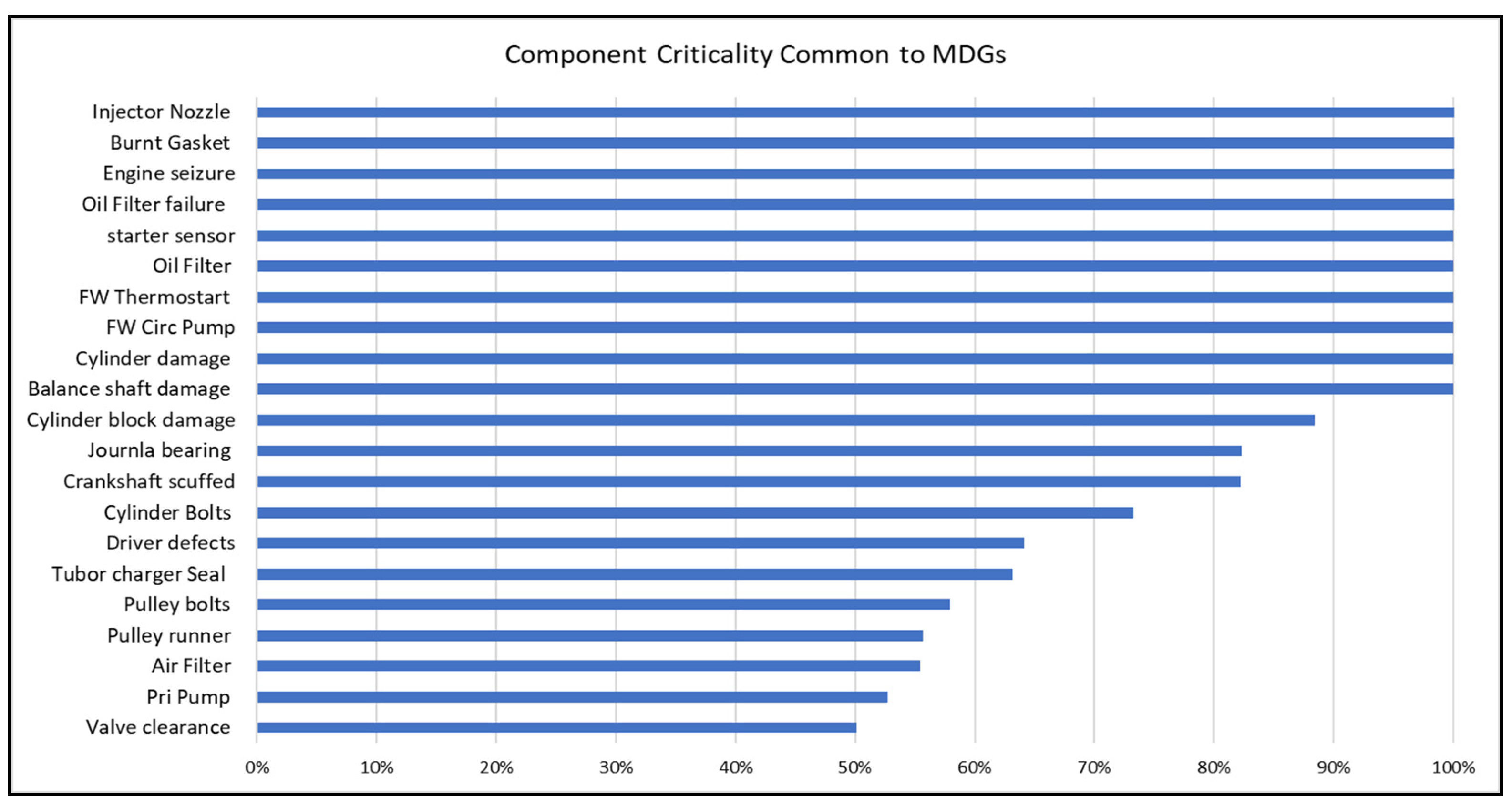
5.2. Component Criticality Analysis
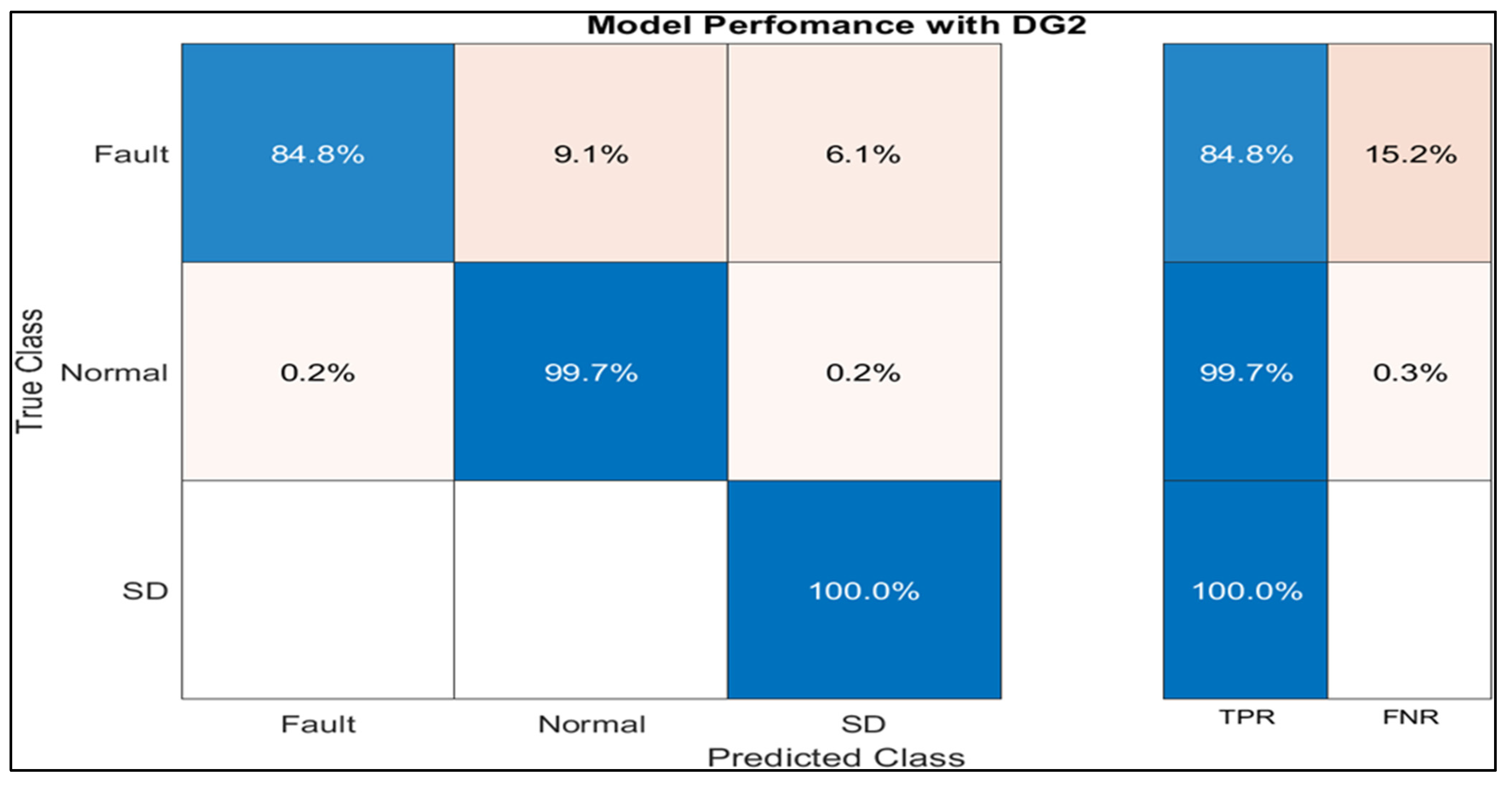
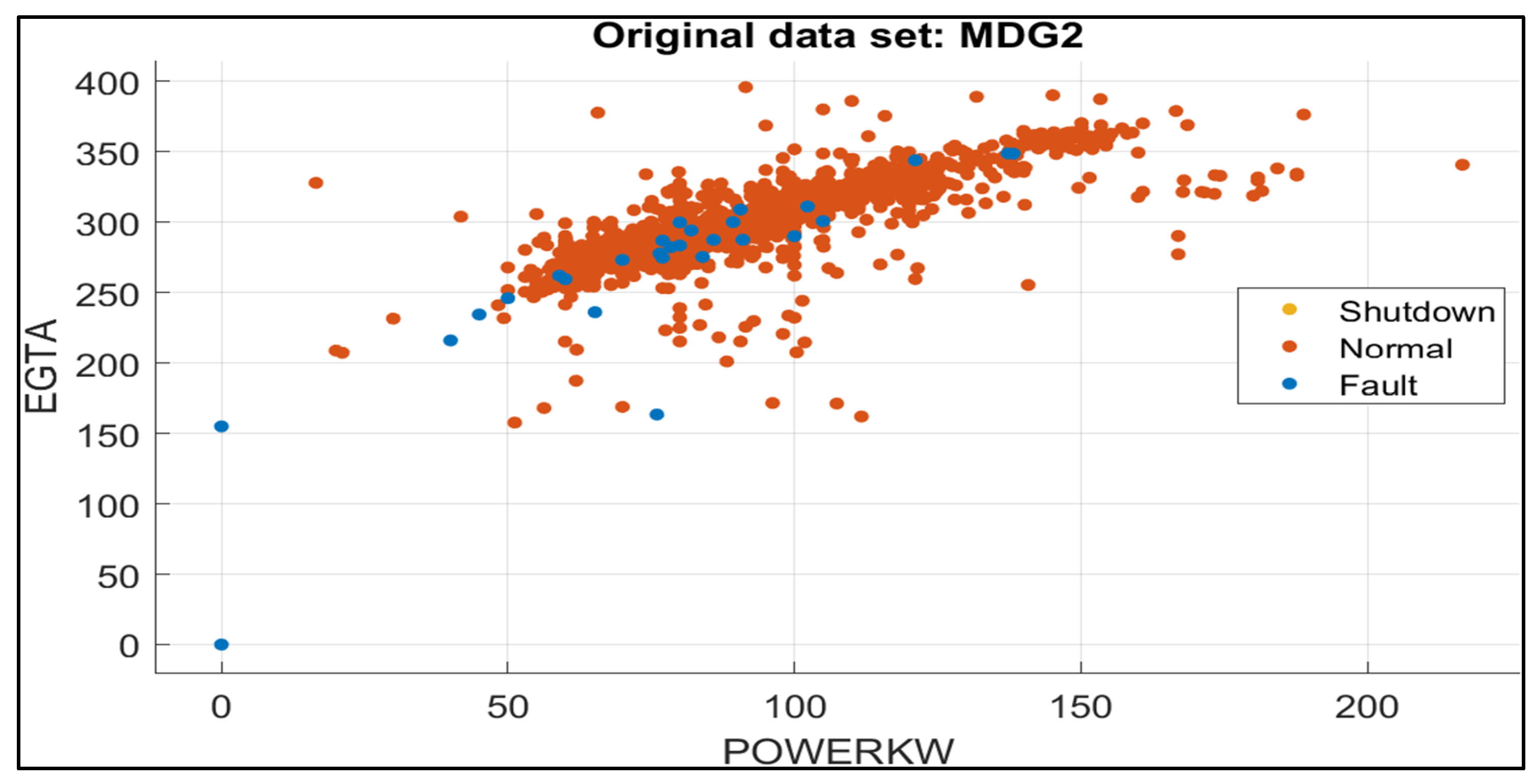
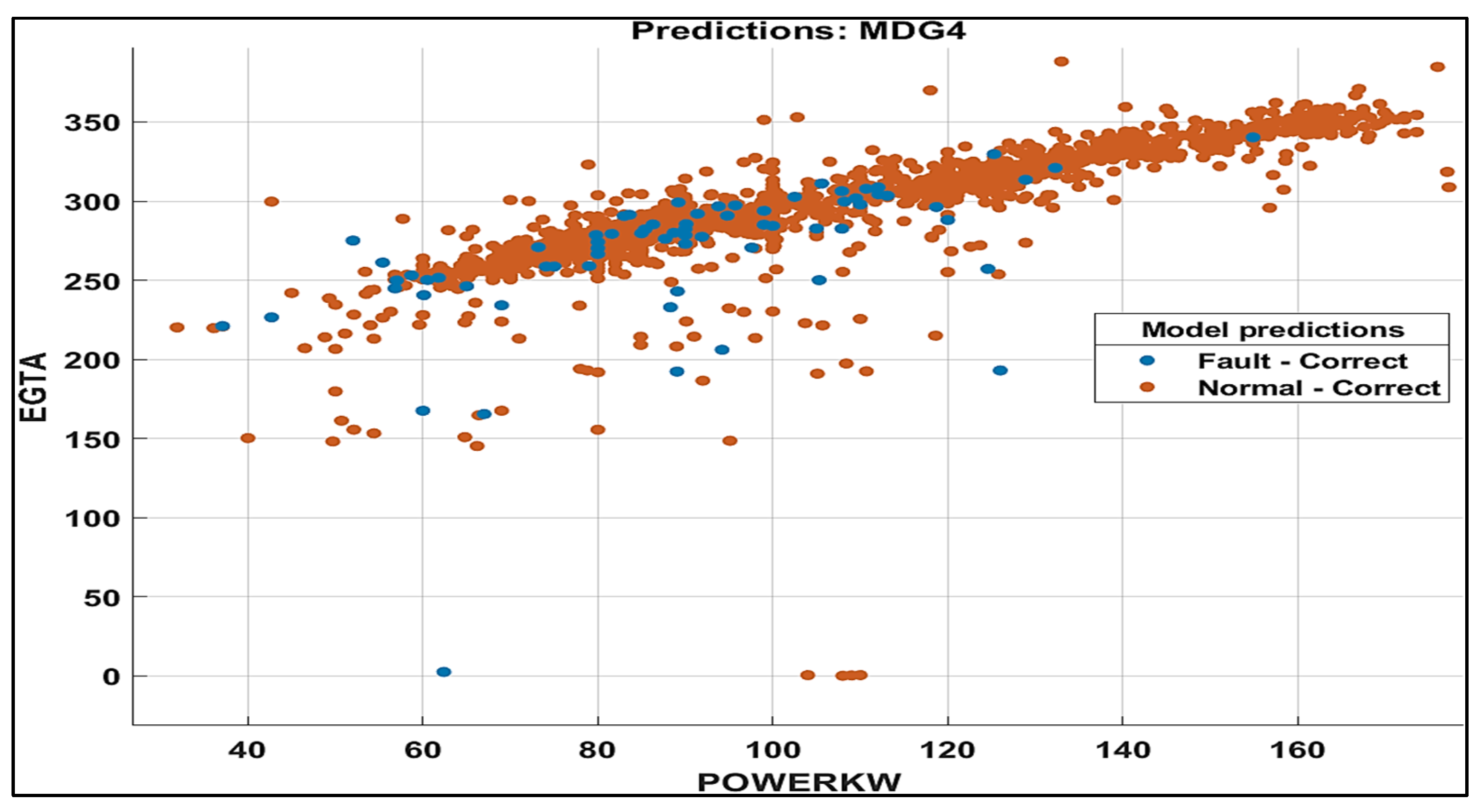
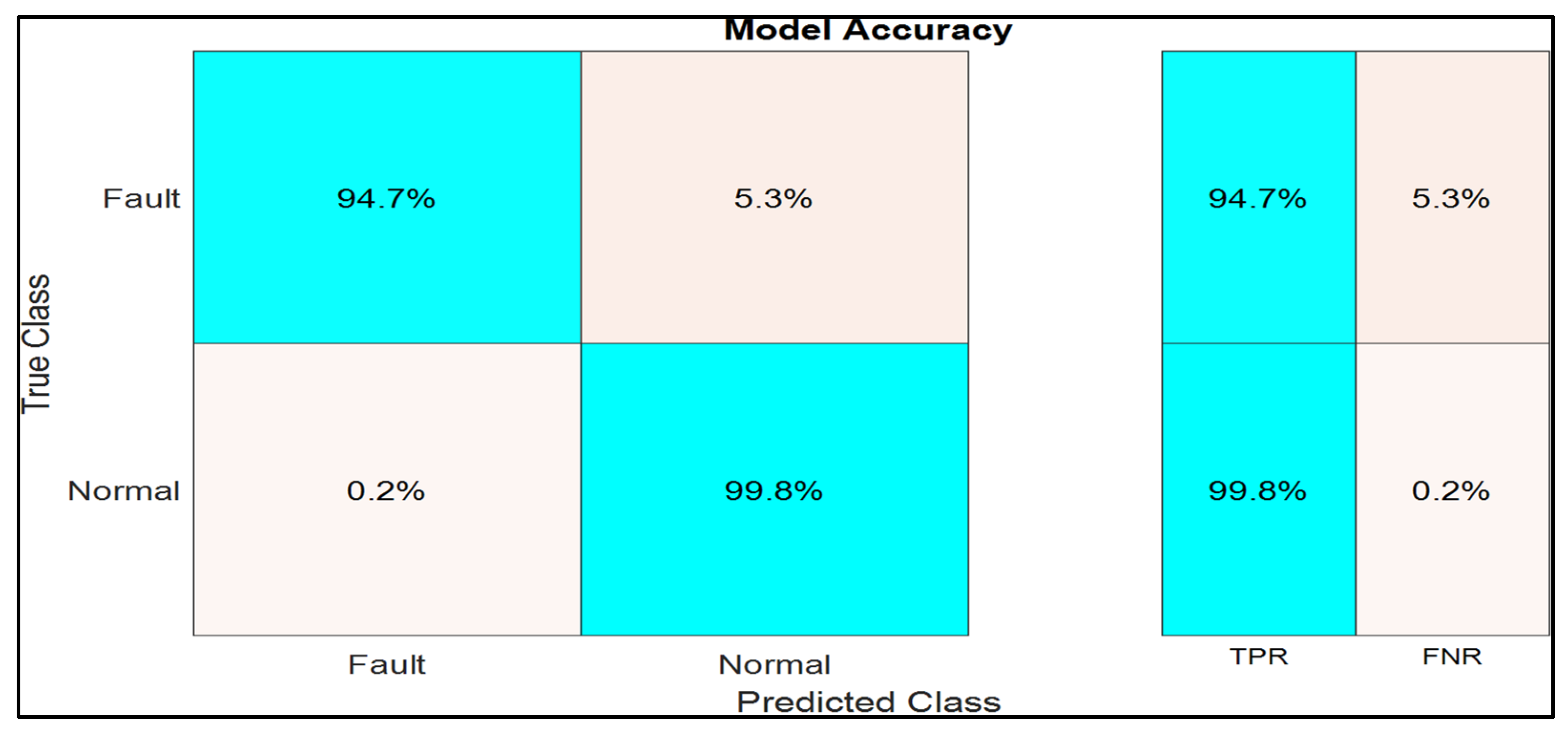
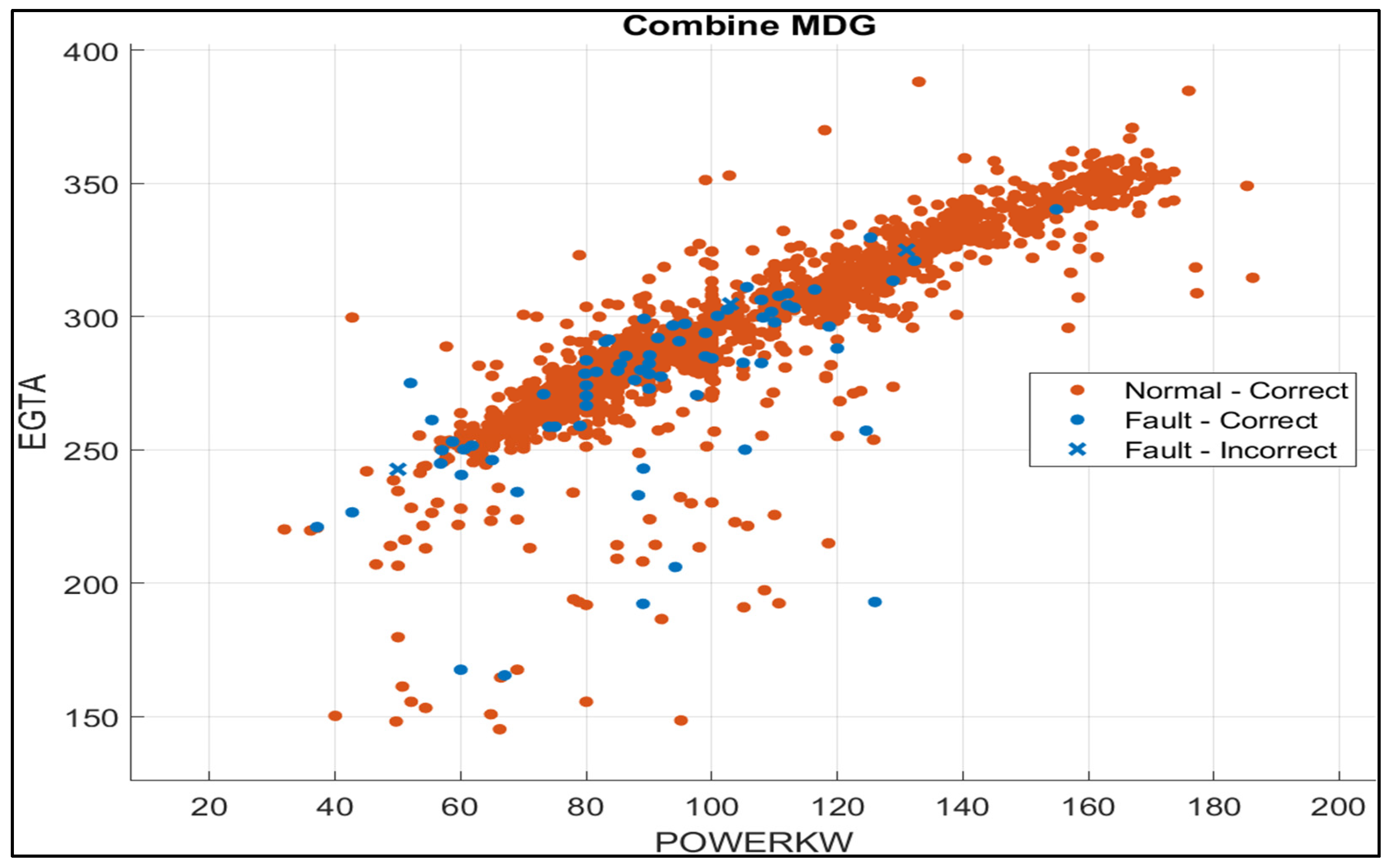
5.3. Fault Identification
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ABS (NS) | American Bureau of Shipping (Nautical System) | ISM code | International Safety Management |
| ANN | Artificial Neural Network | MCS | Minimal Cut Set |
| BBN | Bayesian Belief Network | MTTF | Mean Time to Failure |
| BE | Basic Event | MTBF | Mean Time Between Failure |
| BSI | British Standards Institution | MDT | Mean Down Time |
| CBM | Condition-Based Maintenance | MRO | Maintenance, Repair, and Overhaul |
| CMMS | Computerised Maintenance Management System | NASA | National Aeronautics and Space Administration |
| CPT | Conditional Probability Table | NPRD | Non-Electronic Reliability Data |
| RPN | Risk Priority Number | OEM | Original Equipment Manufacturer |
| OREDA | Offshore and Onshore Reliability Data | OPV | Offshore Patrol Vessel |
| MDG | Marine Diesel Generator | PAND | Priority- AND |
| ETA | Event Tree Analysis | DFTA | Dynamic Fault Tree |
| DSS | Decision Support System | PMS | Planned Maintenance System |
| GHG | Green House Gas | RCM | Reliability-Centred Maintenance |
| CII | Carbon Intensity Index | UN | United nations |
| EEXI | Energy Efficiency Existing Ship Index | RPM | Revolution Per Minute |
| SEEMP | Ship Energy Efficiency Management plan | LoP | Lubricating Oil Pressure |
| EEDI | Energy Efficiency Ship Design Index | FWT(A/B) | Fresh Water Temperature (Bank A/B) |
| FDEP | Functional Dependency | LoT | Lubricating Oil Temperature |
| FMEA | Failure Mode and Effect Analysis | FWP | Fresh Water Pressure |
| FMECA | Failure Mode Effect and Criticality Analysis | EGTA(A/B) | Exhaust Gas Temperature (Bank A/B) |
| FTA | Fault Tree Analysis | RH | Running Hours |
| IM | Importance Measure | KW | Kilo Watt |
| IMO | International Maritime Organisation | HRS | Hours |
References
- OREDA. OREDA Offshore Reliability Data Handbook, 4th ed.; OREDA: Ontario, OR, USA, 2002. [Google Scholar]
- BahooToroody, A.; Abaei, M.M.; Banda, O.V.; Kujala, P.; De Carlo, F.; Abbassi, R. Prognostic health management of repairable ship systems through different autonomy degree; From current condition to fully autonomous ship. Reliab. Eng. Syst. Saf. 2022, 221, 108355. [Google Scholar] [CrossRef]
- Nguyen, V.H. Optimal Ship Maintenance Scheduling under Restricted Conditions and Constrained Resoures. Ph.D. Thesis, Old Dominion University, Norfolk, VA, USA, 2017. [Google Scholar]
- Wan, Z.; El Makhloufi, A.; Chen, Y.; Tang, J. Decarbonizing the international shipping industry: Solutions and policy recommendations. Mar. Pollut. Bull. 2018, 126, 428–435. [Google Scholar] [CrossRef] [PubMed]
- IMO. 2021 Revised MARPOL Annex VI. In MEPC.328(76); IMO: Imo, Nigeria, 2021. [Google Scholar]
- IMO. Prohibition on the Carriege of Non-Compliant Oil for Combustion Onboard A Ship. In MEPC.305(73); IMO: Imo, Nigeria, 2018. [Google Scholar]
- Balcombe, P.; Brierley, J.; Lewis, C.; Skatvedt, L.; Speirs, J.; Hawkes, A.; Staffell, I. How to decarbonise international shipping: Options for fuels, technologies and policies. Energy Convers. Manag. 2019, 182, 72–88. [Google Scholar] [CrossRef]
- Ren, J.; Liang, H. Measuring the sustainability of marine fuels: A fuzzy group multi-criteria decision making approach. Transp. Res. Part D Transp. Environ. 2017, 54, 12–29. [Google Scholar] [CrossRef]
- Specialty, A.G.C.a. Shipping Loss and Accident Locations and Common Causes; Allianz Global Corporate & Specialty: Hong Kong, China, 2019. [Google Scholar]
- Gkerekos, C.; Lazakis, I.; Theotokatos, G. Machine learning models for predicting ship main engine Fuel Oil Consumption: A comparative study. Ocean Eng. 2019, 188, 106282. [Google Scholar] [CrossRef]
- Iheukwumere-Esotu, L.O.; Yunusa-Kaltungo, A. Knowledge Criticality Assessment and Codification Framework for Major Maintenance Activities: A Case Study of Cement Rotary Kiln Plant. Sustainability 2021, 13, 4619. [Google Scholar] [CrossRef]
- Daya, A.A.; Lazakis, I. Investigating ship system performance degradation and failure criticality using FMECA and Artificial Neural Networks. Trends Marit. Technol. Eng. 2022, 2, 185–195. [Google Scholar]
- Daya, A.A.; Lazakis, I. Application of Artifical Neural Network and Dynamic Fault Tree Analysis to Enhance Reliability in Predicitive Ship Machinery Health Condintion Monitoring. In Proceedings of the 2nd International Conference on Ship and Marine Technology, Istanbul, Turkey, 16–17 September 2021. [Google Scholar]
- Kim, G.S.; Lee, Y.H. Transformation towards a Smart Maintenance Factory: The Case of a Vessel Maintenance Depot. Machines 2021, 9, 267. [Google Scholar] [CrossRef]
- Cheliotis, M.; Lazakis, I.; Theotokatos, G. Machine learning and data-driven fault detection for ship systems operations. Ocean Eng. 2020, 216, 107968. [Google Scholar] [CrossRef]
- Karatuğ, Ç.; Arslanoğlu, Y. Development of condition-based maintenance strategy for fault diagnosis for ship engine systems. Ocean Eng. 2022, 256, 111515. [Google Scholar] [CrossRef]
- Zhang, P.; Gao, Z.; Cao, L.; Dong, F.; Zou, Y.; Wang, K.; Zhang, Y.; Sun, P. Marine Systems and Equipment Prognostics and Health Management: A Systematic Review from Health Condition Monitoring to Maintenance Strategy. Machines 2022, 10, 72. [Google Scholar] [CrossRef]
- Rausand, M.; Barros, A.; Hoyland, A. System Reliability Theory Models, Statistical Methods and Application; Wiley: Hoboken, NJ, USA, 2021. [Google Scholar]
- BSI. Information and Documentation Management Systems for Records-Reqirements; BSI: London, UK, 2011. [Google Scholar]
- Lazakis, I.; Ölçer, A. Selection of the best maintenance approach in the maritime industry under fuzzy multiple attributive group decision-making environment. Proc. Inst. Mech. Eng. Part M J. Eng. Marit. Environ. 2015, 230, 297–309. [Google Scholar] [CrossRef]
- Kiran, S.; Prajeeth Kumar, K.P.; Sreejith, B.; Muralidharan, M. Reliability Evaluation and Risk Based Maintenance in a Process Plant. Procedia Technol. 2016, 24, 576–583. [Google Scholar] [CrossRef]
- Lazakis, I.; Raptodimos, Y.; Varelas, T. Predicting ship machinery system condition through analytical reliability tools and artificial neural networks. Ocean Eng. 2018, 152, 404–415. [Google Scholar] [CrossRef]
- Ben-Daya, M.; Duffuaa, S.O.; Raouf, A.; Knezevic, J.; Ait-Kadi, D. (Eds.) Handbook of Maintenance Management and Engineering; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar] [CrossRef]
- Lazakis, I.; Dikis, K.; Michala, A.L.; Theotokatos, G. Advanced Ship Systems Condition Monitoring for Enhanced Inspection, Maintenance and Decision Making in Ship Operations. Transp. Res. Procedia 2016, 14, 1679–1688. [Google Scholar] [CrossRef]
- Dao, P.B.; Staszewski, W.J.; Barszcz, T.; Uhl, T. Condition monitoring and fault detection in wind turbines based on cointegration analysis of SCADA data. Renew. Energy 2018, 116, 107–122. [Google Scholar] [CrossRef]
- Soliman, M.H. Machine Reliability and Condition Monitoring A Comprehensive Guide to Predictive Maintenance Planing; KDP and Lulu: Cairo, Egypt, 2020. [Google Scholar]
- Bousdekis, A.; Papageorgiou, N.; Magoutas, B.; Apostolou, D.; Mentzas, G. Enabling condition-based maintenance decisions with proactive event-driven computing. Comput. Ind. 2018, 100, 173–183. [Google Scholar] [CrossRef]
- Martin-del-Campo, S.; Sandin, F. Online feature learning for condition monitoring of rotating machinery. Eng. Appl. Artif. Intell. 2017, 64, 187–196. [Google Scholar] [CrossRef]
- NASA. Fault Tree Handbook with Aerospace Applications; NASA: Washington, DC, USA, 2002. [Google Scholar]
- Chojnacki, E.; Plumecocq, W.; Audouin, L. An expert system based on a Bayesian network for fire safety analysis in nuclear area. Fire Saf. J. 2019, 105, 28–40. [Google Scholar] [CrossRef]
- de Jonge, B.; Teunter, R.; Tinga, T. The influence of practical factors on the benefits of condition-based maintenance over time-based maintenance. Reliab. Eng. Syst. Saf. 2017, 158, 21–30. [Google Scholar] [CrossRef]
- Melani, A.H.A.; Murad, C.A.; Caminada Netto, A.; Souza, G.F.M.D.; Nabeta, S.I. Criticality-based maintenance of a coal-fired power plant. Energy 2018, 147, 767–781. [Google Scholar] [CrossRef]
- Volkanovski, A.; Čepin, M.; Mavko, B. Application of the fault tree analysis for assessment of power system reliability. Reliab. Eng. Syst. Saf. 2009, 94, 1116–1127. [Google Scholar] [CrossRef]
- Leimeister, M.; Kolios, A. A review of reliability-based methods for risk analysis and their application in the offshore wind industry. Renew. Sustain. Energy Rev. 2018, 91, 1065–1076. [Google Scholar] [CrossRef]
- Stopford, M. Maritime Economics; Routledge: London, UK, 2009. [Google Scholar]
- IMO. International Safety Management Code with Guidance for Its Implementation; Organistaion, I.M., Ed.; IMO: Imo, Nigeria, 2018. [Google Scholar]
- IACS. A Guide to Managing Maintenance in Accordance with the Requirements of the ISM Code; IACS: Hamburg, Germany, 2018. [Google Scholar]
- ISO. Condition Monitoring and Diagnostics of Machines—General Guidelines; ISO: London, UK, 2018. [Google Scholar]
- ClassNK. Good Maintenance Onboard Ships; ClassNK, Ed.; ClassNK: Tokyo, Japan, 2017. [Google Scholar]
- ABS. Equipment Condition Monitoring; ABS: Houston, TX, USA, 2016. [Google Scholar]
- Raptodimos, Y.; Lazakis, I.; Theotokatos, G.; Varelas, T.; Drikos, L. Ship Sensors Data Collection & Analysis for Condition Monitoring of Ship Structures & Machinery Systems. Smart Ships Technol. 2016, 2016, 77–86. [Google Scholar]
- Emovon, I.; Norman, R.A.; Murphy, A.J. Hybrid MCDM based methodology for selecting the optimum maintenance strategy for ship machinery systems. J. Intell. Manuf. 2015, 29, 519–531. [Google Scholar] [CrossRef]
- Lazakis, I.; Turan, O.; Aksu, S. Increasing ship operational reliability through the implementation of a holistic maintenance management strategy. Ships Offshore Struct. 2010, 5, 337–357. [Google Scholar] [CrossRef]
- Raptodimos, Y.; Lazakis, I. Using artificial neural network-self-organising map for data clustering of marine engine condition monitoring applications. Ships Offshore Struct. 2018, 13, 649–656. [Google Scholar] [CrossRef]
- Cicek, K.; Celik, M. Application of failure modes and effects analysis to main engine crankcase explosion failure on-board ship. Saf. Sci. 2013, 51, 6–10. [Google Scholar] [CrossRef]
- Hirzinger, B.; Nackenhorst, U. Efficient model-correction-based reliability analysis of uncertain dynamical systems. Acta Mech. 2023. [Google Scholar] [CrossRef]
- Byun, S.; Papaelias, M.; Márquez, F.P.G.; Lee, D. Fault-Tree-Analysis-Based Health Monitoring for Autonomous Underwater Vehicle. J. Mar. Sci. Eng. 2022, 10, 1855. [Google Scholar] [CrossRef]
- Relex. Reliability: Practitioner’s Guide; Bangalore, B., Paul, D., Geoff, P., Ron, S., Robert, W., Eds.; Relex Software Corporation: Greensburg, PA, USA, 2003; p. 350. [Google Scholar]
- Kabir, S. An overview of fault tree analysis and its application in model based dependability analysis. Expert Syst. Appl. 2017, 77, 114–135. [Google Scholar] [CrossRef]
- Turan, O.; Lazakis, I.; Judah, S. Establishing the Optimum Vessel Maintenance Approach Based on System Reliability and Criticality Analysis. In Managing Reliability & Maintainability in the Maritime Industry; Royal Institution of Naval Architects: London, UK, 2012; pp. 59–70. [Google Scholar]
- Ruijters, E.; Stoelinga, M. Fault tree analysis: A survey of the state-of-the-art in modeling, analysis and tools. Comput. Sci. Rev. 2015, 15–16, 29–62. [Google Scholar] [CrossRef]
- Raptodimos, Y. Combination of Reliability Tools and Artificial Intelligence for Ship Machinery Systems. Ph.D. Thesis, University of Strathclyde, Glasgow, UK, 2018. [Google Scholar]
- Dikis, K.; Lazakis, I.; Taheri, A.; Theotokatos, G. Risk and Reliability Analysis Tool Development for Ship Machinery. In Proceedings of the 5th International Symposium on Ship Operations, Management and Economics (SOME), Athens, Greece, 28–29 May 2015. [Google Scholar]
- Ayo-Imoru, R.M.; Cilliers, A.C. A survey of the state of condition-based maintenance (CBM) in the nuclear power industry. Ann. Nucl. Energy 2018, 112, 177–188. [Google Scholar] [CrossRef]
- Fu, S.; Yu, Y.; Chen, J.; Han, B.; Wu, Z. Towards a probabilistic approach for risk analysis of nuclear-powered icebreakers using FMEA and FRAM. Ocean Eng. 2022, 260, 112041. [Google Scholar] [CrossRef]
- Liang, X.; Yi, H.; Zhang, Y.; Li, D. Reliability and safety analysis of an Underwater Dry Maintenance Cabin. Ocean Eng. 2010, 37, 268–276. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, C.; Wang, S.; Chen, R.; Tomovic, M.M. Performance Degradation Based on Importance Change and Application in Dissimilar Redundancy Actuation System. Mathematics 2022, 10, 843. [Google Scholar] [CrossRef]
- Chen, R.; Zhang, C.; Wang, S.; Zio, E.; Dui, H.; Zhang, Y. Importance measures for critical components in complex system based on Copula Hierarchical Bayesian Network. Reliab. Eng. Syst. Saf. 2023, 230, 108883. [Google Scholar] [CrossRef]
- Zhou, S.; Ye, L.; Xiong, S.; Xiang, J. Reliability analysis of dynamic fault trees with Priority-AND gates based on irrelevance coverage model. Reliab. Eng. Syst. Saf. 2022, 224, 108553. [Google Scholar] [CrossRef]
- Codetta-Raiteri, D.; Portinale, L. Generalized Continuous Time Bayesian Networks as a modelling and analysis formalism for dependable systems. Reliab. Eng. Syst. Saf. 2017, 167, 639–651. [Google Scholar] [CrossRef]
- Eriksen, S.; Utne, I.B.; Lützen, M. An RCM approach for assessing reliability challenges and maintenance needs of unmanned cargo ships. Reliab. Eng. Syst. Saf. 2021, 210, 107550. [Google Scholar] [CrossRef]
- Nadakatti, M.; Onori, M.; Ramachandra, A.; Santosh Kumar, A.N. Artificial intelligence-based condition monitoring for plant maintenance. Assem. Autom. 2008, 28, 143–150. [Google Scholar] [CrossRef]
- Cipollini, F.; Oneto, L.; Coraddu, A.; Murphy, A.J.; Anguita, D. Condition-Based Maintenance of Naval Propulsion Systems with supervised Data Analysis. Ocean Eng. 2018, 149, 268–278. [Google Scholar] [CrossRef]
- Coraddu, A.; Oneto, L.; Ghio, A.; Savio, S.; Anguita, D.; Figari, M. Machine learning approaches for improving condition-based maintenance of naval propulsion plants. Proc. Inst. Mech. Eng. Part M J. Eng. Marit. Environ. 2014, 230, 136–153. [Google Scholar] [CrossRef]
- Aizpurua, J.I.; Knutsen, K.E.; Heimdal, M.; Vanem, E. Integrated machine learning and probabilistic degradation approach for vessel electric motor prognostics. Ocean Eng. 2023, 275, 114153. [Google Scholar] [CrossRef]
- Cipollini, F.; Oneto, L.; Coraddu, A.; Murphy, A.J.; Anguita, D. Condition-based maintenance of naval propulsion systems: Data analysis with minimal feedback. Reliab. Eng. Syst. Saf. 2018, 177, 12–23. [Google Scholar] [CrossRef]
- Wu, S.-j.; Gebraeel, N.; Lawley, M.A.; Yih, Y. A Neural Network Integrated Decision Support System for Condition-Based Optimal Predictive Maintenance Policy. IEEE Trans. Syst. Man Cybern.—Part A Syst. Hum. 2007, 37, 226–236. [Google Scholar] [CrossRef]
- Gurney, K. An Introduction to Neural Networks; Taylor and Francis Group: London, UK, 1997. [Google Scholar]
- Farag, Y.B.A.; Ölçer, A.I. The development of a ship performance model in varying operating conditions based on ANN and regression techniques. Ocean Eng. 2020, 198, 106972. [Google Scholar] [CrossRef]
- Kang, Y.-J.; Noh, Y.; Jang, M.-S.; Park, S.; Kim, J.-T. Hierarchical level fault detection and diagnosis of ship engine systems. Expert Syst. Appl. 2023, 213, 118814. [Google Scholar] [CrossRef]
- Karatuğ, Ç.; Arslanoğlu, Y.; Guedes Soares, C. Design of a decision support system to achieve condition-based maintenance in ship machinery systems. Ocean Eng. 2023, 281, 114611. [Google Scholar] [CrossRef]
- Stetco, A.; Dinmohammadi, F.; Zhao, X.; Robu, V.; Flynn, D.; Barnes, M.; Keane, J.; Nenadic, G. Machine learning methods for wind turbine condition monitoring: A review. Renew. Energy 2019, 133, 620–635. [Google Scholar] [CrossRef]
- Velasco-Gallego, C.; Lazakis, I. Real-time data-driven missing data imputation for short-term sensor data of marine systems. A comparative study. Ocean Eng. 2020, 218, 108261. [Google Scholar] [CrossRef]
- Wang, R.; Chen, H.; Guan, C. A self-supervised contrastive learning framework with the nearest neighbors matching for the fault diagnosis of marine machinery. Ocean Eng. 2023, 270, 113437. [Google Scholar] [CrossRef]
- Velasco-Gallego, C.; Lazakis, I. RADIS: A real-time anomaly detection intelligent system for fault diagnosis of marine machinery. Expert Syst. Appl. 2022, 204, 117634. [Google Scholar] [CrossRef]
- Sazli, M.H. A brief review of feed-forward neural networks. Commun. Fac. Sci. Univ. Ank. 2006, 50, 11–17. [Google Scholar] [CrossRef]
- Sarwar, U.; Muhammad, M.B.; Karim, A.A.A. Time Series Method for Machine Performance Prediction Using Condition Monitoring Data. In Proceedings of the 2014 International Conference on Computer, Communications, and Control Technology (I4CT), Langkawi, Malaysia, 2–4 September 2014. [Google Scholar]
- Daya, A.A.; Lazakis, I. A Semi Automated Model for Improving Vessel System Reliability and Maintenance Management. In RINA Autonomos Ships; RINA: London, UK, 2022. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tool | Strength | Weakness |
|---|---|---|
| BBN |
|
|
| DFTA |
|
|
| ETA |
|
|
| FTA |
|
|
| RBD |
|
|
| ANN |
|
|
| Components | Frequency | |||||
|---|---|---|---|---|---|---|
| Failure type | Action taken | MDG1 | MDG2 | MDG3 | MDG4 | |
| Turbo charger | Black smoke | Replaced and repaired | 8 | 10 | 12 | 12 |
| Lube oil cooler | Oil leakage | 1. Replaced 2. Cleaned and the zinc anode replaced | 16 | 18 | 15 | 16 |
| External leakage | 10 | 8 | 8 | 12 | ||
| Oil cooler valve | Failed | remove/repaired | 1 | 1 | 2 | 1 |
| Cylinder head | 1. Oil leakage 2. Fresh water leakage from A2 exhaust 3. Unable to start | 1. Liner, O-ring replaced (G1, G3) 2. Cylinder replaced (G3, G2) Replaced gasket (G3) | 20 | 19 | 1× (A1, A2); 3× (A2, liner); 2× (A2 head); 1× (A3,B2 gskt) | 21 |
| Guide bushing | 20 | 14 | 20 | 20 | ||
| O-ring | 28 | 32 | 23 | 23 | ||
| Holding bolts | 18 | 17 | 17 | 16 | ||
| Cylinder jacket/sleeve | 1. Scuffed × 4 2. Cracked × 2 | Replaced | 11 | 12 | 11 | 12 |
| Piston | Rings | Replaced | 12 | 13 | 13 | 14 |
| Cooling/crown | 8 | 13 | 15 | 14 | ||
| ConRod | Bent | 7 | 9 | 8 | 9 | |
| Gudgeon pin | 8 | 6 | 8 | 6 | ||
| Drive belt | Failed | Replaced | 8 | 8 | 9 | 11 |
| Torn(wear) | Replaced | 11 | 5 | 9 | 3 | |
| Mech Injector pump | 1. Cracked bolts 2. Broken bolts 3. Broken shims | 1. Replace bolt and drive (G1, G3) 2. Replace bolt and pulley and set injector timing (G1, G2) 3. Replaced shims | 16 | 12 | 12 | 13 |
| Drive | defects | 22 | 20 | 21 | 24 | |
| Parameter | Operating Ranges | ||
|---|---|---|---|
| Min | Max | Alarm Level | |
| Engine Speed (RPM) | 1789 | 1850 | 2052 |
| Lubricating Oil Pressure (Mpa) | 0.4 | 0.55 | >0.6 |
| Cooling Fresh Water Temperature banks, A/B (°C) | 75 | 80 | >85 °C |
| Fresh water pressure (Mpa) | 0.02 | 0.25 | >0.3 |
| Lubricating Oil Temperature (°C) | 30 | 110 | >120 °C |
| Exhaust Gas temperature banks A/B (°C) | 220 | 400 | >520 |
| Generator running hours | ≥2000 h | N/A | N/A |
| Power Output (Kw) | 0 | 350 Kw | 350 Kw |
| Date/time | January 2019 | December 2019 | N/A |
| Event | Birnbaum | Criticality | Fussell-Vesely |
|---|---|---|---|
| Sea Chest | 0.497018 | 0.497018 | 0.013959 |
| Intercooler | 0.497018 | 0.013959 | 0.013959 |
| Heat exchanger | 0.527822 | 0.024646 | 0.024646 |
| Fuel Supply pump | 0.604233 | 0.023861 | 0.023861 |
| Journal bearing | 0.632121 | 0.022580 | 0.022580 |
| Main bearing | 0.632121 | 0.022580 | 0.022580 |
| Cylinder head O-ring | 0.634048 | 0.062717 | 0.062717 |
| Tappets/Valves | 0.795919 | 0.027337 | 0.027337 |
| Heat Exchanger tubes | 0.826296 | 0.024646 | 0.024646 |
| Guide Bushing | 0.887586 | 0.062717 | 0.062717 |
| Crankshaft | 1.000000 | 0.046463 | 0.046463 |
| Governor | 1.00000 | 0.043901 | 0.043901 |
| Cylinder head Bolts | 1.0000 | 0.062942 | 0.062942 |
| Injection nozzles | 1.0000 | 0.073272 | 0.073272 |
| MDG1 | Percentage | MDG3 | Percentage |
|---|---|---|---|
| Sea Chest | 50 | Fuel return line | 61 |
| Intercooler | 50 | Gasket | 67 |
| Heat exchanger | 53 | Cylinder head bolt | 71 |
| Fuel Supply pump | 60 | Injector Camshaft | 84 |
| Journal bearing | 63 | Injector drive | 84 |
| Main bearing | 63 | Injector Plunger | 84 |
| Cylinder head O-ring | 63 | FW Circulation Pump | 90 |
| Tappets/Valves | 80 | Air Filter | 91 |
| Heat Exchanger tubes | 83 | Heat Ex SW Thermostat | 94 |
| Guide Bushing | 89 | Primary fuel lift pump | 95 |
| Crankshaft | 100 | Turbo Charger | 96 |
| Governor | 100 | FW Thermostat | 97 |
| Cylinder head Bolts | 100 | Sea Chest | 98 |
| Injection nozzles | 100 | Fuel Filter | 100 |
| MDG2 | MDG4 | ||
| Fuel Supply pump | 44 | Oil inlet hose | 53 |
| Fuel injection pump drive | 64 | Air Filter | 55 |
| Cylinder block damage | 89 | Pulley | 56 |
| Cylinder damage | 100 | Valve seats | 74 |
| FW HE Tubes | 100 | Water HE tubes | 79 |
| FW Thermostat | 100 | Piston Crown | 100 |
| Fuel pump Pulley bolts | 100 | FW Circulation Pump | 100 |
| Sea Chest | 70 | Oil Filter | 100 |
| RPM | LoP | FWTA | FWTB | LoT | FWP | EGTA | EGTB | HRS | KW | |
|---|---|---|---|---|---|---|---|---|---|---|
| Count | 150 | 150 | 150 | 150 | 150 | 150 | 150 | 150 | 150 | 150 |
| Mean | 1800 | 0.5 | 66.1 | 68.8 | 84.4 | 0.08 | 334.7 | 317.6 | 2527 | 128 |
| std | 2.9 | 0.1 | 3.4 | 3.8 | 4.7 | 0.01 | 39.3 | 38.9 | 2703 | 34.7 |
| Min. | 1783 | 0.33 | 40.7 | 42.7 | 41.6 | 0.05 | 161.2 | 146.9 | 523 | 65 |
| 25% | 1799 | 0.38 | 65.2 | 67.7 | 82.4 | 0.07 | 310.2 | 287.5 | 603.3 | 100 |
| 50% | 1800 | 0.56 | 66.2 | 68.8 | 84.6 | 0.07 | 339.5 | 325.8 | 636.5 | 130 |
| 75% | 1801 | 0.57 | 67.4 | 70.3 | 86.4 | 0.08 | 352 | 337.5 | 6341 | 140 |
| Max. | 1812 | 0.86 | 74.1 | 77.1 | 94 | 0.12 | 426.8 | 408.1 | 6379 | 240 |
| RPM | LoP | FWTA | FWTB | LoT | FWP | EGTA | EGTB | RH | KW | Fault | Temp |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1800 | 0.458 | 72.9 | 75.4 | 90 | 0.067 | 332.1 | 319.5 | 5234 | 115 | Normal | NML |
| 1800 | 0.465 | 72.8 | 75.3 | 89.9 | 0.068 | 335.3 | 323.9 | 5235 | 120 | Normal | NML |
| 1800 | 0.59 | 72.01 | 74.06 | 89.3 | 0.068 | 329.5 | 316.7 | 5236 | 115 | Fault | HTM |
| 1800 | 0.53 | 70.7 | 73.2 | 87.6 | 0.068 | 310.2 | 29.4 | 5262 | 100 | Normal | NML |
| 1800 | 0.58 | 78 | 80.68 | 96.2 | 0.066 | 366.1 | 355.9 | 5294 | 150 | Abnormal | OVH |
| 1801 | 0.58 | 75.8 | 78.6 | 94.6 | 0.067 | 360.4 | 351.7 | 5298 | 140 | Abnormal | HTM |
| 1800 | 0.504 | 76.2 | 79.1 | 95 | 0.067 | 361.2 | 353.1 | 5299 | 140 | Normal | HTM |
| 1800 | 0.58 | 78.6 | 78.7 | 94.5 | 0.067 | 359.1 | 350.1 | 5300 | 140 | Abnormal | HTM |
| 1800 | 0.502 | 76.2 | 79.1 | 94.8 | 0.067 | 358.3 | 351 | 5201 | 140 | Normal | HTM |
| 1800 | 0.499 | 75.8 | 78.8 | 95.6 | 0.067 | 360.1 | 353.7 | 5302 | 150 | Normal | NML |
| 1800 | 0.488 | 77.8 | 80.5 | 96.1 | 0.066 | 374.2 | 363.3 | 5203 | 140 | Normal | OVH |
| 1800 | 0.498 | 77.3 | 80 | 95.8 | 0.066 | 364.3 | 354.3 | 5204 | 150 | Normal | HTM |
| Features | ANOVA Ranking |
|---|---|
| EGTA | 8.9 |
| EGTB | 8.5 |
| Lube Oil Pressure | 1.3 |
| FWTEMPA | 0.6 |
| FWTEMPB | 1.0 |
| Location | 4.2 |
| Power Output | 6.7 |
| Location | Period | Count | |
|---|---|---|---|
| January–December 2019 | Normal | Fault | |
| Harbour | 1043 | 17 | |
| Sea | 822 | 14 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daya, A.A.; Lazakis, I. Component Criticality Analysis for Improved Ship Machinery Reliability. Machines 2023, 11, 737. https://doi.org/10.3390/machines11070737
Daya AA, Lazakis I. Component Criticality Analysis for Improved Ship Machinery Reliability. Machines. 2023; 11(7):737. https://doi.org/10.3390/machines11070737
Chicago/Turabian StyleDaya, Abdullahi Abdulkarim, and Iraklis Lazakis. 2023. "Component Criticality Analysis for Improved Ship Machinery Reliability" Machines 11, no. 7: 737. https://doi.org/10.3390/machines11070737
APA StyleDaya, A. A., & Lazakis, I. (2023). Component Criticality Analysis for Improved Ship Machinery Reliability. Machines, 11(7), 737. https://doi.org/10.3390/machines11070737