
Autonomous Vehicle Decision-Making and Control in Complex and Unconventional Scenarios—A Review




Abstract
1. Introduction
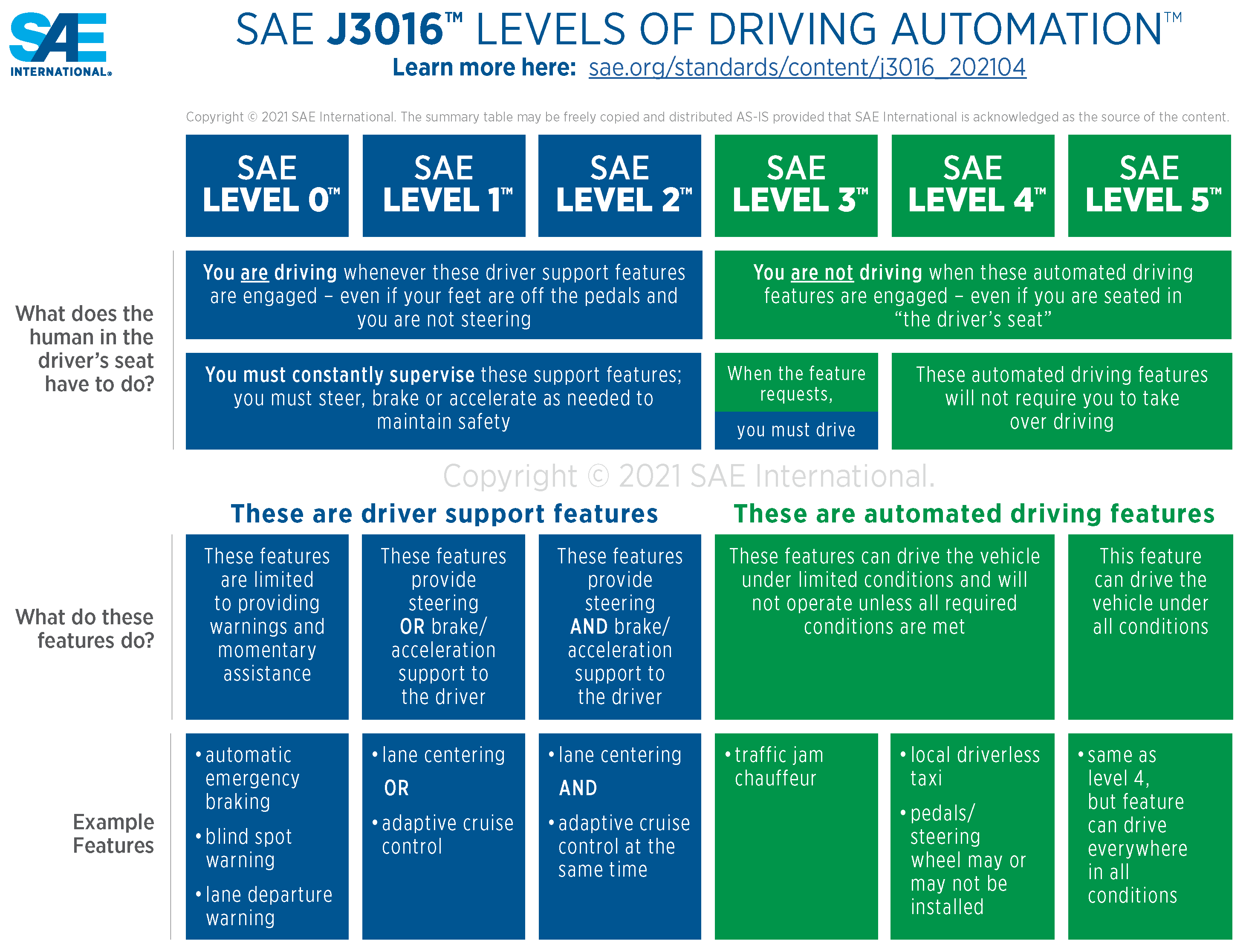
1.1. Levels of Automation
- Level 0: No driving automation. The vehicle relies entirely on the human driver, with no automated assistance available.
- Level 1: Driver assistance. The vehicle offers limited assistance, such as steering or brake/acceleration support, to the driver.
- Level 2: Partial automation. The vehicle provides both steering and brake/acceleration support simultaneously, but the driver remains responsible for monitoring the driving environment.
- Level 3: Conditional automation. The vehicle can manage most aspects of driving under specific conditions, but the driver must be ready to intervene when necessary.
- Level 4: High driving automation. The vehicle is capable of operating without driver input or intervention but is limited to predefined conditions and environments.
- Level 5: Full automation. The vehicle operates autonomously without requiring any driver input, functioning in all conditions and environments.
1.2. Selecting Edge Cases
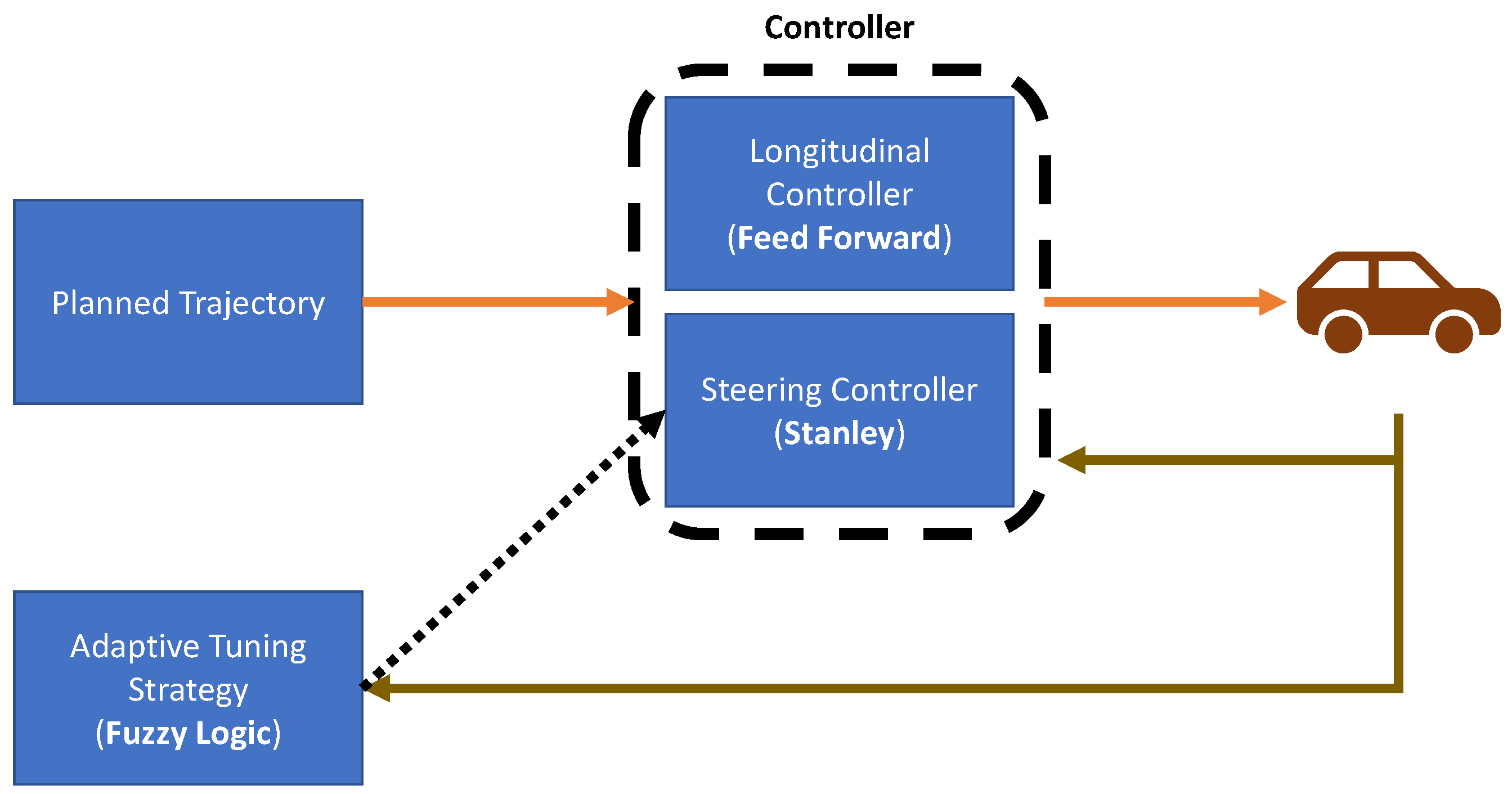
2. Adverse Weather Conditions
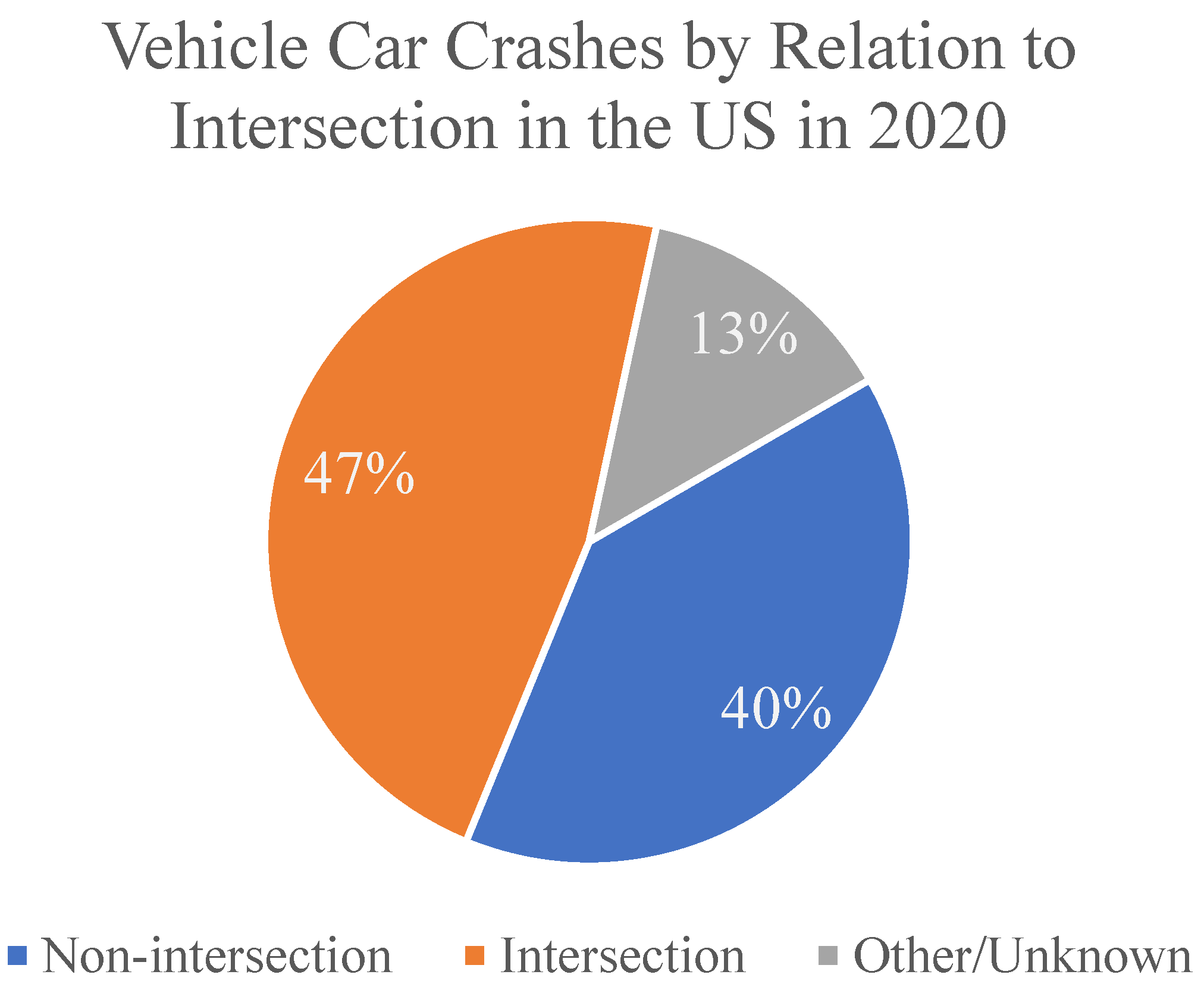
3. Unsignalized Intersections
3.1. Graph-Based Approach
3.2. Optimization-Based Approaches
3.3. Machine-Learning-Based Approaches
3.4. Fusion of Various Methods
4. Crosswalks
5. Roundabouts
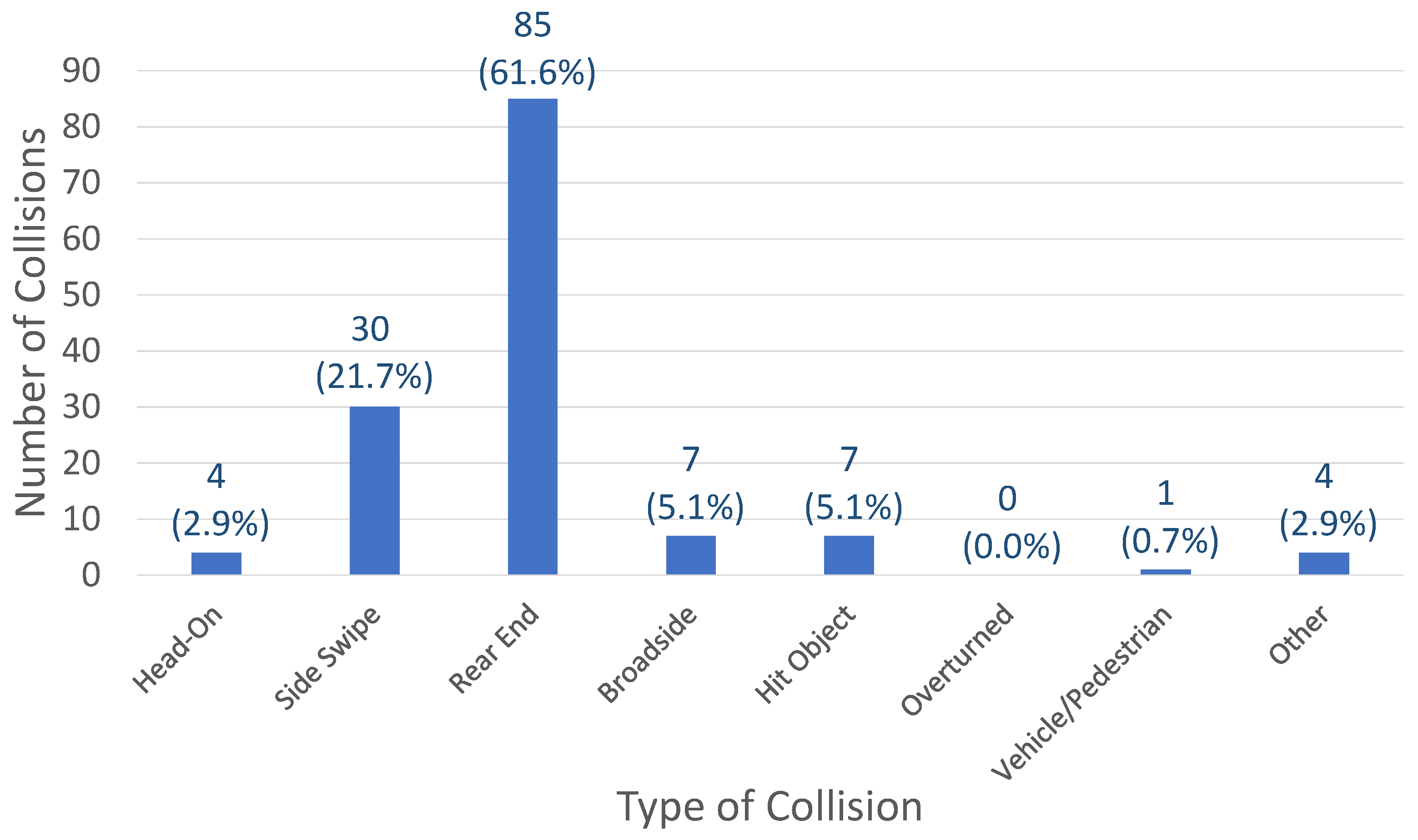
6. Near-Accident Scenarios
7. Challenges and Potential Future Research Directions
7.1. Benchmarking
7.2. Interpretability
7.3. Safety
7.4. Road User Interactions
- 1.
- The development of proper road user interaction models including pedestrian–vehicle, pedestrian–pedestrian, as well as vehicle–vehicle interactions. This could be achieved using methodologies such as game theory, which take into account interactions of various agents at each time step update of an environment.
- 2.
- Incorporating the devised models in a high-fidelity simulation tool such as CARLA to allow for the development of both modular and end-to-end decision-making and control pipelines.
7.5. Incorporating Uncertainties in Perception
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| %SPET | Percentage short post encroachment time |
| A3C | Asynchronous advantage actor–critic |
| ACG | Automatic curriculum generation |
| AEB | Autonomous emergency brake |
| AES | Autonomous emergency steering |
| APF | Artificial potential function |
| Att-LSTM | Attention mechanism LSTM |
| AV | Autonomous vehicles |
| BC | Behavior cloning |
| B-MPC | Behavior-aware MPC |
| CAV | Connected autonomous vehicle |
| CDC | US Center for Disease Control |
| CL-RRT | Closed-loop-RRT |
| CTE | Cross-tracking error |
| CTR | Collision-to-timeout ratio |
| D-A3C | Delayed A3C |
| DARPA | Defense Advanced Research Projects Agency |
| DDPG | Deep deterministic policy gradient |
| DDQN | Double deep Q-network |
| DMV | Department of Motor Vehicles |
| DQN | Deep Q-learning |
| DRL | Deep RL |
| FC | Fully connected |
| FSM | Finite state machines |
| GAIL | Generative adversarial imitation learning |
| GNSS | Global navigation satellite system |
| GPR | Gaussian process regression |
| HD | High-definition |
| HJ | Hamilton–Jacobi |
| H-REIL | Hierarchical reinforcement and imitation learning |
| IDM | Intelligent driver model |
| IL | Imitation learning |
| IP-SAC | Interval prediction and self-attention mechanism |
| IRL | Inverse reinforcement learning |
| LiDAR | Light detection and ranging |
| LKS | Lane-keeping system |
| LSTM | Long short-term memory |
| MPC | Model predictive control |
| MSE | Mean squared error |
| MSFM | Modified social force model |
| NHTSA | National Highway Traffic Safety Administration |
| NMPC | Nonlinear MPC |
| POMDP | Partially observable Markov decision process |
| PPO | Proximal policy optimization |
| QP | Quadratic programming |
| RGB | Red, green, blue |
| RL | Reinforcement learning |
| ROS | Robot Operating System |
| RRT | Rapidly exploring random tree |
| SAC | Soft actor–critic |
| SAE | Society of Automotive Engineers |
| SHAIL | Safety-aware hierarchical adversarial imitation learning |
| SM | Sliding mode |
| SQIL | Soft-Q imitation learning |
| SUMO | Simulation of urban mobility |
| TD3 | Twin-delayed deep deterministic policy gradient |
| TTC | Time to collision |
| UAV | Unmanned aerial vehicle |
| V2V | Vehicle-to-vehicle |
| VAE | Variable autoencoder |
| WHO | World Health Organization |
References
- World Health Organization. Global Status Report on Road Safety 2018; Technical Report; World Health Organization: Geneva, Switzerland, 2018. [Google Scholar]
- Fagnant, D.J.; Kockelman, K. Preparing a nation for autonomous vehicles: Opportunities, barriers and policy recommendations. Transp. Res. Part A Policy Pract. 2015, 77, 167–181. [Google Scholar] [CrossRef]
- Singh, S. Critical Reasons for Crashes Investigated in the National Motor Vehicle Crash Causation Survey; Technical Report; National Highway Traffic Safety Administration: Washington, DC, USA, 2018.
- Montgomery, W.D.; Mudge, R.; Groshen, E.L.; Helper, S.; MacDuffie, J.P.; Carson, C. America’s Workforce and the Self-Driving Future: Realizing Productivity Gains and Spurring Economic Growth. 2018. Available online: https://trid.trb.org/view/1516782 (accessed on 8 November 2022).
- Thrun, S.; Burgard, W.; Fox, D. Probabilistic Robotics (Intelligent Robotics and Autonomous Agents); The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Koopman, P.; Wagner, M. Autonomous Vehicle Safety: An Interdisciplinary Challenge. IEEE Intell. Transp. Syst. Mag. 2017, 9, 90–96. [Google Scholar] [CrossRef]
- California Department of Motor Vehicles. Autonomous Vehicles Testing with a Driver; California Department of Motor Vehicles: Sacramento, CA, USA, 2022. [Google Scholar]
- California Department of Motor Vehicles. Autonomous Vehicle Collision Reports; California Department of Motor Vehicles: Sacramento, CA, USA, 2022. [Google Scholar]
- Leilabadi, S.H.; Schmidt, S. In-depth Analysis of Autonomous Vehicle Collisions in California. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 889–893. [Google Scholar]
- McCarthy, R.L. Autonomous Vehicle Accident Data Analysis: California OL 316 Reports: 2015–2020. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part B Mech. Eng. 2022, 8, 034502. [Google Scholar] [CrossRef]
- Society of Automotive Engineers. Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles. Soc. Automot. Eng. 2021, 4970, 1–5. [Google Scholar]
- Kalra, N.; Paddock, S.M. Driving to safety: How many miles of driving would it take to demonstrate autonomous vehicle reliability? Transp. Res. Part A Policy Pract. 2016, 94, 182–193. [Google Scholar] [CrossRef]
- National Center for Statistics and Analysis. Traffic Safety Facts 2020: A Compilation of Motor Vehicle Crash Data; Technical Report; National Highway Traffic Safety Administration: Washington, DC, USA, 2022.
- Kuutti, S.; Bowden, R.; Jin, Y.; Barber, P.; Fallah, S. A survey of deep learning applications to autonomous vehicle control. IEEE Trans. Intell. Transp. Syst. 2020, 22, 712–733. [Google Scholar] [CrossRef]
- Aradi, S. Survey of deep reinforcement learning for motion planning of autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 23, 740–759. [Google Scholar] [CrossRef]
- Ye, F.; Zhang, S.; Wang, P.; Chan, C.Y. A survey of deep reinforcement learning algorithms for motion planning and control of autonomous vehicles. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 1073–1080. [Google Scholar]
- Liu, W.; Hua, M.; Deng, Z.; Huang, Y.; Hu, C.; Song, S.; Gao, L.; Liu, C.; Xiong, L.; Xia, X. A Systematic Survey of Control Techniques and Applications: From Autonomous Vehicles to Connected and Automated Vehicles. arXiv 2023, arXiv:2303.05665. [Google Scholar]
- Trenberth, K.E.; Zhang, Y. How often does it really rain? Bull. Am. Meteorol. Soc. 2018, 99, 289–298. [Google Scholar] [CrossRef]
- Stevens, S.E.; Schreck, C.J.; Saha, S.; Bell, J.E.; Kunkel, K.E. Precipitation and fatal motor vehicle crashes: Continental analysis with high-resolution radar data. Bull. Am. Meteorol. Soc. 2019, 100, 1453–1461. [Google Scholar] [CrossRef]
- Arthi, V.; Murugeswari, R.; Nagaraj, P. Object Detection of Autonomous Vehicles under Adverse Weather Conditions. In Proceedings of the 2022 International Conference on Data Science, Agents & Artificial Intelligence (ICDSAAI), Chennai, India, 8–10 December 2022; Volume 1, pp. 1–8. [Google Scholar]
- Azam, S.; Munir, F.; Jeon, M. Channel boosting feature ensemble for radar-based object detection. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 762–769. [Google Scholar]
- Li, Y.J.; Park, J.; O’Toole, M.; Kitani, K. Modality-agnostic learning for radar-lidar fusion in vehicle detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 918–927. [Google Scholar]
- Zhang, Y.; Carballo, A.; Yang, H.; Takeda, K. Perception and sensing for autonomous vehicles under adverse weather conditions: A survey. ISPRS J. Photogramm. Remote Sens. 2023, 196, 146–177. [Google Scholar] [CrossRef]
- Zang, S.; Ding, M.; Smith, D.; Tyler, P.; Rakotoarivelo, T.; Kaafar, M.A. The impact of adverse weather conditions on autonomous vehicles: How rain, snow, fog, and hail affect the performance of a self-driving car. IEEE Veh. Technol. Mag. 2019, 14, 103–111. [Google Scholar] [CrossRef]
- Vargas, J.; Alsweiss, S.; Toker, O.; Razdan, R.; Santos, J. An overview of autonomous vehicles sensors and their vulnerability to weather conditions. Sensors 2021, 21, 5397. [Google Scholar] [CrossRef] [PubMed]
- Yoneda, K.; Suganuma, N.; Yanase, R.; Aldibaja, M. Automated driving recognition technologies for adverse weather conditions. IATSS Res. 2019, 43, 253–262. [Google Scholar] [CrossRef]
- Kordani, A.A.; Rahmani, O.; Nasiri, A.S.A.; Boroomandrad, S.M. Effect of adverse weather conditions on vehicle braking distance of highways. Civ. Eng. J. 2018, 4, 46–57. [Google Scholar] [CrossRef]
- Shibata, Y.; Arai, Y.; Saito, Y.; Hakura, J. Development and evaluation of road state information platform based on various environmental sensors in snow countries. In Proceedings of the Advances in Internet, Data and Web Technologies: The 8th International Conference on Emerging Internet, Data and Web Technologies (EIDWT-2020), Kitakyushu, Japan, 24–26 February 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 268–276. [Google Scholar]
- Šabanovič, E.; Žuraulis, V.; Prentkovskis, O.; Skrickij, V. Identification of road-surface type using deep neural networks for friction coefficient estimation. Sensors 2020, 20, 612. [Google Scholar] [CrossRef]
- Panhuber, C.; Liu, B.; Scheickl, O.; Wies, R.; Isert, C. Recognition of road surface condition through an on-vehicle camera using multiple classifiers. In Proceedings of the SAE-China Congress 2015: Selected Papers; Springer: Berlin/Heidelberg, Germany, 2016; pp. 267–279. [Google Scholar]
- Abdić, I.; Fridman, L.; Brown, D.E.; Angell, W.; Reimer, B.; Marchi, E.; Schuller, B. Detecting road surface wetness from audio: A deep learning approach. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 3458–3463. [Google Scholar]
- Taş, Ö.Ş.; Stiller, C. Limited visibility and uncertainty aware motion planning for automated driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1171–1178. [Google Scholar]
- Taş, Ö.Ş.; Salscheider, N.O.; Poggenhans, F.; Wirges, S.; Bandera, C.; Zofka, M.R.; Strauss, T.; Zöllner, J.M.; Stiller, C. Making bertha cooperate–team annieway’s entry to the 2016 grand cooperative driving challenge. IEEE Trans. Intell. Transp. Syst. 2017, 19, 1262–1276. [Google Scholar] [CrossRef]
- Peng, T.; Su, L.l.; Guan, Z.w.; Hou, H.j.; Li, J.k.; Liu, X.l.; Tong, Y.k. Lane-change model and tracking control for autonomous vehicles on curved highway sections in rainy weather. J. Adv. Transp. 2020, 2020, 8838878. [Google Scholar] [CrossRef]
- Joa, E.; Hyun, Y.; Park, K.; Kim, J.; Yi, K. Model Predictive Control based Stability Control of Autonomous Vehicles on Low Friction Road. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 419–424. [Google Scholar]
- He, S.; Xu, X.; Xie, J.; Wang, F.; Liu, Z. Adaptive control of dual-motor autonomous steering system for intelligent vehicles via Bi-LSTM and fuzzy methods. Control Eng. Pract. 2023, 130, 105362. [Google Scholar] [CrossRef]
- Hamid, U.Z.A.; Kyyhkynen, A.; Peralta-Cabezas, J.L.; Saarinen, J.; Santamala, H. All-Weather Autonomous Vehicle: Performance Analysis of an Automated Heavy Quadricycle in Non-Snow and Snowstorm Conditions using Single Map In The IAVSD International Symposium on Dynamics of Vehicles on Roads and Tracks; Springer: Cham, Switzerland, 2019; pp. 1100–1106. [Google Scholar]
- Samokhin, S.; Mehndiratta, M.; Hamid, U.Z.A.; Saarinen, J. Adaptive Fuzzy Tuning Framework for Autonomous Vehicles: An Experimental Case Study. In Proceedings of the 2021 IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Helsinki, Finland, 25–28 April 2021; pp. 1–5. [Google Scholar]
- Hoffmann, G.M.; Tomlin, C.J.; Montemerlo, M.; Thrun, S. Autonomous automobile trajectory tracking for off-road driving: Controller design, experimental validation and racing. In Proceedings of the 2007 American Control Conference, New York, NY, USA, 9–13 July 2007; pp. 2296–2301. [Google Scholar]
- Tominaga, K.; Takeuchi, Y.; Tomoki, U.; Kameoka, S.; Kitano, H.; Quirynen, R.; Berntorp, K.; Cairano, S. GNSS Based Lane Keeping Assist System via Model Predictive Control; Technical Report; SAE Technical Paper; SAE: Warrendale, PA, USA, 2019. [Google Scholar]
- Takeuchi, Y.; Hideyuki, T.; Kazuo, H.; Tomoki, U. Development of Autonomous Driving System Using GNSS and High Definition Map; Technical Report; SAE Technical Paper; SAE: Warrendale, PA, USA, 2018. [Google Scholar]
- National Highway Traffic Safety Administration. Traffic Safety Facts 2019: A Compilation of Motor Vehicle Crash Data; Technical Report; NHTS Administration: Washington, DC, USA, 2019.
- Al-Dabbagh, M.S.M.; Al-Sherbaz, A.; Turner, S. The impact of road intersection topology on traffic congestion in urban cities. In Proceedings of the SAI Intelligent Systems Conference, London, UK, 6–7 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1196–1207. [Google Scholar]
- Lian, F.; Chen, B.; Zhang, K.; Miao, L.; Wu, J.; Luan, S. Adaptive traffic signal control algorithms based on probe vehicle data. J. Intell. Transp. Syst. 2021, 25, 41–57. [Google Scholar] [CrossRef]
- Wu, T.; Zhou, P.; Liu, K.; Yuan, Y.; Wang, X.; Huang, H.; Wu, D.O. Multi-Agent Deep Reinforcement Learning for Urban Traffic Light Control in Vehicular Networks. IEEE Trans. Veh. Technol. 2020, 69, 8243–8256. [Google Scholar] [CrossRef]
- Sahu, S.P.; Dewangan, D.K.; Agrawal, A.; Sai Priyanka, T. Traffic Light Cycle Control using Deep Reinforcement Technique. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; pp. 697–702. [Google Scholar] [CrossRef]
- Kamal, M.A.S.; Imura, J.i.; Hayakawa, T.; Ohata, A.; Aihara, K. A Vehicle-Intersection Coordination Scheme for Smooth Flows of Traffic Without Using Traffic Lights. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1136–1147. [Google Scholar] [CrossRef]
- Li, S.; Shu, K.; Chen, C.; Cao, D. Planning and decision-making for connected autonomous vehicles at road intersections: A review. Chin. J. Mech. Eng. 2021, 34, 1–18. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- LaValle, S.M. Rapidly-Exploring Random Trees: A New Tool for Path Planning; Computer Science Department, Iowa State University: Ames, IA, USA, October 1998. [Google Scholar]
- Karaman, S.; Frazzoli, E. Sampling-based algorithms for optimal motion planning. Int. J. Robot. Res. 2011, 30, 846–894. [Google Scholar] [CrossRef]
- Kuwata, Y.; Teo, J.; Karaman, S.; Fiore, G.; Frazzoli, E.; How, J. Motion planning in complex environments using closed-loop prediction. In Proceedings of the AIAA Guidance, Navigation and Control Conference and Exhibit, Honolulu, HI, USA, 18–21 August 2008; p. 7166. [Google Scholar]
- Ma, L.; Xue, J.; Kawabata, K.; Zhu, J.; Ma, C.; Zheng, N. Efficient sampling-based motion planning for on-road autonomous driving. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1961–1976. [Google Scholar] [CrossRef]
- Yoon, S.; Lee, D.; Jung, J.; Shim, D.H. Spline-based RRT* using piecewise continuous collision-checking algorithm for Car-like vehicles. J. Intell. Robot. Syst. 2018, 90, 537–549. [Google Scholar] [CrossRef]
- Yang, K.; Sukkarieh, S. An analytical continuous-curvature path-smoothing algorithm. IEEE Trans. Robot. 2010, 26, 561–568. [Google Scholar] [CrossRef]
- Wu, X.; Nayak, A.; Eskandarian, A. Motion planning of autonomous vehicles under dynamic traffic environment in intersections using probabilistic rapidly exploring random tree. SAE Int. J. Connect. Autom. Veh. 2021, 4, 383–399. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Z.; Zuo, Z.; Li, Z.; Wang, L.; Luo, X. Trajectory Planning and Safety Assessment of Autonomous Vehicles Based on Motion Prediction and Model Predictive Control. IEEE Trans. Veh. Technol. 2019, 68, 8546–8556. [Google Scholar] [CrossRef]
- Hult, R.; Zanon, M.; Gros, S.; Falcone, P. Optimal Coordination of Automated Vehicles at Intersections: Theory and Experiments. IEEE Trans. Control. Syst. Technol. 2019, 27, 2510–2525. [Google Scholar] [CrossRef]
- Liu, C.; Lee, S.; Varnhagen, S.; Tseng, H.E. Path planning for autonomous vehicles using model predictive control. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 174–179. [Google Scholar] [CrossRef]
- Moreau, J.; Melchior, P.; Victor, S.; Moze, M.; Aioun, F.; Guillemard, F. Reactive Path Planning for Autonomous Vehicle Using Bézier Curve Optimization. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1048–1053. [Google Scholar] [CrossRef]
- Kamran, D.; Lopez, C.F.; Lauer, M.; Stiller, C. Risk-aware high-level decisions for automated driving at occluded intersections with reinforcement learning. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1205–1212. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Qiao, Z.; Muelling, K.; Dolan, J.M.; Palanisamy, P.; Mudalige, P. Automatically generated curriculum based reinforcement learning for autonomous vehicles in urban environment. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1233–1238. [Google Scholar]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar]
- Sadigh, D.; Sastry, S.; Seshia, S.A.; Dragan, A.D. Planning for autonomous cars that leverage effects on human actions. In Proceedings of the Robotics: Science and Systems, Ann Arbor, MI, USA, 18–22 June 2016; Volume 2, pp. 1–9. [Google Scholar]
- Tram, T.; Batkovic, I.; Ali, M.; Sjöberg, J. Learning when to drive in intersections by combining reinforcement learning and model predictive control. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3263–3268. [Google Scholar]
- Tram, T.; Jansson, A.; Grönberg, R.; Ali, M.; Sjöberg, J. Learning negotiating behavior between cars in intersections using deep q-learning. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3169–3174. [Google Scholar]
- Koschi, M.; Pek, C.; Beikirch, M.; Althoff, M. Set-based prediction of pedestrians in urban environments considering formalized traffic rules. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2704–2711. [Google Scholar]
- Camara, F.; Bellotto, N.; Cosar, S.; Nathanael, D.; Althoff, M.; Wu, J.; Ruenz, J.; Dietrich, A.; Fox, C.W. Pedestrian Models for Autonomous Driving Part I: Low-Level Models, From Sensing to Tracking. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6131–6151. [Google Scholar] [CrossRef]
- Camara, F.; Bellotto, N.; Cosar, S.; Weber, F.; Nathanael, D.; Althoff, M.; Wu, J.; Ruenz, J.; Dietrich, A.; Markkula, G.; et al. Pedestrian Models for Autonomous Driving Part II: High-Level Models of Human Behavior. IEEE Trans. Intell. Transp. Syst. 2021, 22, 5453–5472. [Google Scholar] [CrossRef]
- Centers for Disease Control and Prevention. WISQARS: Web-Based Injury Statistics Query and Reporting System. 2021. Available online: https://www.cdc.gov/injury/wisqars/index.html (accessed on 21 June 2022).
- Stewart, T. Overview of Motor Vehicle Crashes in 2020; Technical Report; National Highway Traffic Safety Administration: Washington, DC, USA, 2022.
- Chao, E. Autonomous Driving: Mapping and Behavior Planning for Crosswalks. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2019. [Google Scholar]
- Kapania, N.R.; Govindarajan, V.; Borrelli, F.; Gerdes, J.C. A hybrid control design for autonomous vehicles at uncontrolled crosswalks. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1604–1611. [Google Scholar]
- Thornton, S.M. Autonomous Vehicle Motion Planning with Ethical Considerations. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2018. [Google Scholar]
- Kochenderfer, M.J. Decision Making under Uncertainty: Theory and Application; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Zhu, H.; Iryo-Asano, M.; Alhajyaseen, W.K.; Nakamura, H.; Dias, C. Interactions between autonomous vehicles and pedestrians at unsignalized mid-block crosswalks considering occlusions by opposing vehicles. Accid. Anal. Prev. 2021, 163, 106468. [Google Scholar] [CrossRef]
- Zhou, B.; Zhang, C.; Peng, H.; Lv, C.; Qiu, T.Z. Research on Pedestrian Crossing Behaviors at Unsignalized Multi-Lane Mid-Block Crosswalk: A Case Study in China; Technical Report; Transportation Research Board: Washington, DC, USA, 2016. [Google Scholar]
- Zhang, C.; Zhou, B.; Qiu, T.Z.; Liu, S. Pedestrian crossing behaviors at uncontrolled multi-lane mid-block crosswalks in developing world. J. Saf. Res. 2018, 64, 145–154. [Google Scholar] [CrossRef]
- Lopez, P.A.; Behrisch, M.; Bieker-Walz, L.; Erdmann, J.; Flötteröd, Y.P.; Hilbrich, R.; Lücken, L.; Rummel, J.; Wagner, P.; Wießner, E. Microscopic traffic simulation using sumo. In Proceedings of the 2018 21st international conference on intelligent transportation systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2575–2582. [Google Scholar]
- Chen, H.; Zhang, X. Path Planning for Intelligent Vehicle Collision Avoidance of Dynamic Pedestrian Using Att-LSTM, MSFM, and MPC at Unsignalized Crosswalk. IEEE Trans. Ind. Electron. 2021, 69, 4285–4295. [Google Scholar] [CrossRef]
- Li, Y.; Lu, X.Y.; Wang, J.; Li, K. Pedestrian trajectory prediction combining probabilistic reasoning and sequence learning. IEEE Trans. Intell. Veh. 2020, 5, 461–474. [Google Scholar] [CrossRef]
- Brunoud, A.; Lombard, A.; Zhang, M.; Abbas-Turki, A.; Gaud, N.; Koukam, A. Comparison of Deep Reinforcement Learning Methods for Safe and Efficient Autonomous Vehicles at Pedestrian Crossings. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 2556–2562. [Google Scholar]
- Jayaraman, S.K.; Robert, L.P.; Yang, X.J.; Pradhan, A.K.; Tilbury, D.M. Efficient behavior-aware control of automated vehicles at crosswalks using minimal information pedestrian prediction model. In Proceedings of the 2020 American Control Conference (ACC), Denver, CO, USA, 1–3 July 2020; pp. 4362–4368. [Google Scholar]
- Jayaraman, S.K.; Tilbury, D.M.; Yang, X.J.; Pradhan, A.K.; Robert, L.P. Analysis and prediction of pedestrian crosswalk behavior during automated vehicle interactions. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 6426–6432. [Google Scholar]
- Chen, Y.; Li, S.; Tang, X.; Yang, K.; Cao, D.; Lin, X. Interaction-Aware Decision Making for Autonomous Vehicles. IEEE Trans. Transp. Electrif. 2023. [Google Scholar] [CrossRef]
- Steyn, H.J.; Ashleigh, G.; Lee A., R. A Review of Fatal and Severe Injury Crashes at Roundabouts; Technical Report; United States Department of Transportation: Washington, DC, USA, 2020.
- Daniels, S.; Brijs, T.; Nuyts, E.; Wets, G. Extended prediction models for crashes at roundabouts. Saf. Sci. 2011, 49, 198–207. [Google Scholar] [CrossRef]
- Insurance Institute for Highway Safety. Roundabouts; Insurance Institute for Highway Safety: Ruckersville, VA, USA, 2022. [Google Scholar]
- Hang, P.; Huang, C.; Hu, Z.; Xing, Y.; Lv, C. Decision Making of Connected Automated Vehicles at an Unsignalized Roundabout Considering Personalized Driving Behaviours. IEEE Trans. Veh. Technol. 2021, 70, 4051–4064. [Google Scholar] [CrossRef]
- Lodinger, N.R.; DeLucia, P.R. Does automated driving affect time-to-collision judgments? Transp. Res. Part F Traffic Psychol. Behav. 2019, 64, 25–37. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, B.; Tomizuka, M. Model-free Deep Reinforcement Learning for Urban Autonomous Driving. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2765–2771. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Huang, Z.; Wu, J.; Lv, C. Efficient Deep Reinforcement Learning With Imitative Expert Priors for Autonomous Driving. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Zhou, M.; Luo, J.; Villella, J.; Yang, Y.; Rusu, D.; Miao, J.; Zhang, W.; Alban, M.; Fadakar, I.; Chen, Z.; et al. Smarts: Scalable multi-agent reinforcement learning training school for autonomous driving. arXiv 2020, arXiv:2010.09776. [Google Scholar]
- Jamgochian, A.; Buehrle, E.; Fischer, J.; Kochenderfer, M.J. SHAIL: Safety-Aware Hierarchical Adversarial Imitation Learning for Autonomous Driving in Urban Environments. arXiv 2022, arXiv:2204.01922. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Zhan, W.; Sun, L.; Wang, D.; Shi, H.; Clausse, A.; Naumann, M.; Kummerle, J.; Konigshof, H.; Stiller, C.; de La Fortelle, A.; et al. Interaction dataset: An international, adversarial and cooperative motion dataset in interactive driving scenarios with semantic maps. arXiv 2019, arXiv:1910.03088. [Google Scholar]
- Capasso, A.P.; Bacchiani, G.; Molinari, D. Intelligent roundabout insertion using deep reinforcement learning. arXiv 2020, arXiv:2001.00786. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, Singapore, 20–23 February 2016; pp. 1928–1937. [Google Scholar]
- Bacchiani, G.; Molinari, D.; Patander, M. Microscopic traffic simulation by cooperative multi-agent deep reinforcement learning. arXiv 2019, arXiv:1903.01365. [Google Scholar]
- Liu, H.; Huang, Z.; Wu, J.; Lv, C. Improved deep reinforcement learning with expert demonstrations for urban autonomous driving. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 4–9 June 2022; pp. 921–928. [Google Scholar]
- Reddy, S.; Dragan, A.D.; Levine, S. Sqil: Imitation learning via reinforcement learning with sparse rewards. arXiv 2019, arXiv:1905.11108. [Google Scholar]
- Masi, S.; Xu, P.; Bonnifait, P. Roundabout Crossing With Interval Occupancy and Virtual Instances of Road Users. IEEE Trans. Intell. Transp. Syst. 2022, 23, 4212–4224. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, X.; Wu, Z. Design of Unsignalized Roundabouts Driving Policy of Autonomous Vehicles Using Deep Reinforcement Learning. World Electr. Veh. J. 2023, 14, 52. [Google Scholar] [CrossRef]
- Leurent, E. An Environment for Autonomous Driving Decision-Making. 2018. Available online: https://github.com/eleurent/highway-env (accessed on 21 January 2023).
- Seong, H.; Jung, C.; Lee, S.; Shim, D.H. Learning to drive at unsignalized intersections using attention-based deep reinforcement learning. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 559–566. [Google Scholar]
- Riccardi, M.R.; Augeri, M.G.; Galante, F.; Mauriello, F.; Nicolosi, V.; Montella, A. Safety Index for evaluation of urban roundabouts. Accid. Anal. Prev. 2022, 178, 106858. [Google Scholar] [CrossRef] [PubMed]
- Alighanbari, S.; Azad, N.L. Deep Reinforcement Learning With NMPC Assistance Nash Switching for Urban Autonomous Driving. IEEE Trans. Intell. Veh. 2023, 8, 2604–2615. [Google Scholar] [CrossRef]
- Alighanbari, S.; Azad, N.L. Safe Adaptive Deep Reinforcement Learning for Autonomous Driving in Urban Environments. Additional Filter? How and Where? IEEE Access 2021, 9, 141347–141359. [Google Scholar] [CrossRef]
- Cao, Z.; Biyik, E.; Wang, W.Z.; Raventos, A.; Gaidon, A.; Rosman, G.; Sadigh, D. Reinforcement Learning based Control of Imitative Policies for Near-Accident Driving. In Proceedings of the Robotics: Science and Systems (RSS), Virtual, 12–16 July 2020. [Google Scholar]
- Lee, K.; Kum, D. Longitudinal and Lateral Integrated Safe Trajectory Planning of Autonomous Vehicle via Friction Limit. In Proceedings of the 2020 20th International Conference on Control, Automation and Systems (ICCAS), Busan, Republic of Korea, 13–16 October 2020; pp. 1177–1180. [Google Scholar] [CrossRef]
- Milliken, W.F.; Milliken, D.L.; Metz, L.D. Race Car Vehicle Dynamics; SAE International: Warrendale, PA, USA, 1995; Volume 400. [Google Scholar]
- Shang, X.; Eskandarian, A. Emergency Collision Avoidance and Mitigation Using Model Predictive Control and Artificial Potential Function. IEEE Trans. Intell. Veh. 2023, 8, 3458–3472. [Google Scholar] [CrossRef]
- Bansal, S.; Chen, M.; Herbert, S.; Tomlin, C.J. Hamilton-jacobi reachability: A brief overview and recent advances. In Proceedings of the 2017 IEEE 56th Annual Conference on Decision and Control (CDC), Melbourne, VIC, Australia, 12–15 December 2017; pp. 2242–2253. [Google Scholar]
- Caesar, H.; Kabzan, J.; Tan, K.S.; Fong, W.K.; Wolff, E.; Lang, A.; Fletcher, L.; Beijbom, O.; Omari, S. nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles. arXiv 2021, arXiv:2106.11810. [Google Scholar]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Xu, H.; Gao, Y.; Yu, F.; Darrell, T. End-to-end learning of driving models from large-scale video datasets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2174–2182. [Google Scholar]
- Hecker, S.; Dai, D.; Van Gool, L. End-to-end learning of driving models with surround-view cameras and route planners. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 435–453. [Google Scholar]
- Tampuu, A.; Matiisen, T.; Semikin, M.; Fishman, D.; Muhammad, N. A survey of end-to-end driving: Architectures and training methods. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 1364–1384. [Google Scholar] [CrossRef]
- Zhang, Y.; Tiňo, P.; Leonardis, A.; Tang, K. A survey on neural network interpretability. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 726–742. [Google Scholar] [CrossRef]
- Chen, J.; Li, S.E.; Tomizuka, M. Interpretable End-to-End Urban Autonomous Driving With Latent Deep Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2022, 23, 5068–5078. [Google Scholar] [CrossRef]
- Wang, H.; Gao, H.; Yuan, S.; Zhao, H.; Wang, K.; Wang, X.; Li, K.; Li, D. Interpretable Decision-Making for Autonomous Vehicles at Highway On-Ramps With Latent Space Reinforcement Learning. IEEE Trans. Veh. Technol. 2021, 70, 8707–8719. [Google Scholar] [CrossRef]
- Schmidt, L.M.; Kontes, G.; Plinge, A.; Mutschler, C. Can You Trust Your Autonomous Car? Interpretable and Verifiably Safe Reinforcement Learning. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 171–178. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
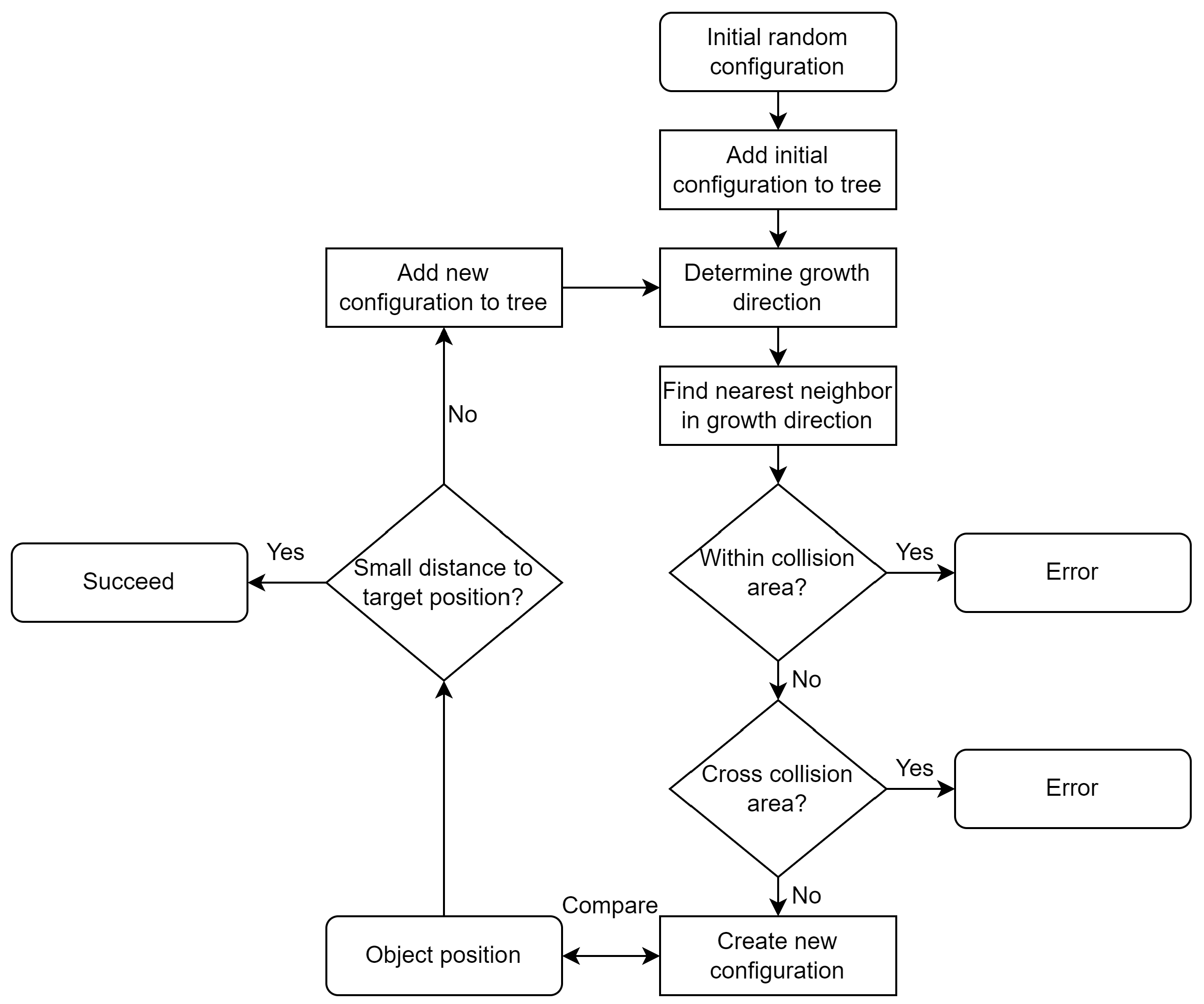{kind=link}
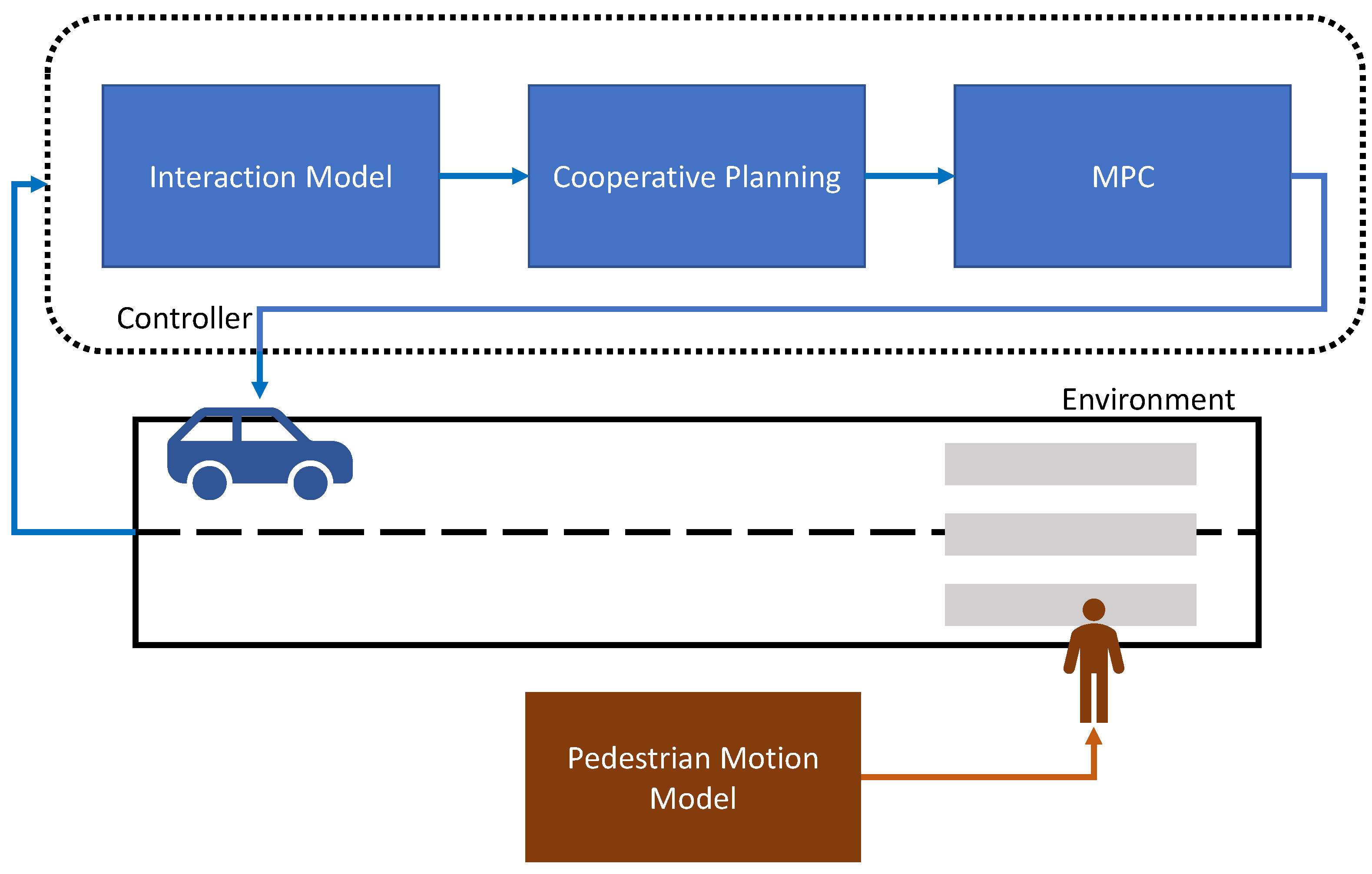{kind=link}
| Paper | Pros | Cons |
|---|---|---|
| [32] | Used stochastic model to predict the presence of obstacles in unobservable areas. Tested in the real world on the BERTHAONE vehicle [33]. | Complex maneuvers such as lane changes were not allowed due to FSM usage. Several simplistic assumptions such as a zero false negative detection rate for a specific range. |
| [34] | Incorporated the effect of rain and road friction coefficient into the optimization. | Only outputted the lateral control of the vehicle. Tested only on curved sections of highways. |
| [35] | Developed controller for adapting changes in road friction even without knowing the value. Able to detect the instability of the vehicle. | Possibly computationally expensive, due to separate MPCs for lateral and longitudinal control. Tests limited to a simple simulation environment. |
| [36] | Used hierarchical control: upper-level MPC and low-level pinion gear target position tracking. Hardware-in-the-loop testing. | Only outputted lateral control. |
| [37] | Controller was still able to track with error in positioning. | Tests were limited to smaller-size vehicles, particularly a heavy quadricycle. Maximum speed set to 35 km/h, which is not realistic. |
| [38] | Developed an online tuning strategy. Included both vehicle kinematics and dynamics in the controller. | Only outputted lateral control. Vehicle speed was set at 15 km/h, which does not truly represent urban driving. |
| [40] | Tested algorithm in the real world using a Mitsubishi Outlander. Reduced oscillation as compared to a PID controller. | Did not test in various weather conditions. Time delay of GNSS severely deteriorated the performance of the controller. |
| Controller | Success Rate | CTR | ||
|---|---|---|---|---|
| Single | Double | Single | Double | |
| SM | 96.1% | 90.9% | 72% | 93% |
| MPC | 97.3% | 95.2% | 45% | 76% |
| Paper | Pros | Cons |
|---|---|---|
| [53] | Allowed for obstacle avoidance due to the high-frequency regeneration of a tree. | Computationally expensive. Required much offline computation. |
| [54] | Ensured that paths generated were continuous and satisfied vehicle constraints. Tested in the real world. | Assumed that vehicles followed the path exactly with minimal error. |
| [56] | Fused stochastic maps with a sampling-based RRT algorithm. Tested at a 4-way unsignalized intersection. | The model was created for predicting other vehicle’s future locations and could not account for varying vehicle speeds. |
| [57] | Incorporated a safety process within the decision-making stage. The whole process of planning and safety assessment took less than 100 ms. | Assumed other vehicles kept a constant velocity along the road section. They did not account for unusual events such as jaywalking, sudden reversing, etc. |
| [58] | Improved stability and performance at intersections by using a bilevel controller. Demonstrated that the controller had a high performance even in cases of high positioning error. | Used V2V communication which does not always exist in current systems. Controller needs to be tested in the situation of continuously oncoming vehicles. |
| [59] | Allowed maneuvers such as ramp merging, lane change, etc., to be determined by the MPC generated path. Infused both safety as well as comfort within the MPC constraints. | Assumed fully observable environment. |
| [60] | Low computational cost of replanning. | Assumed no noise in perception. |
| [61] | Accounted for occlusions that occur at intersections. Defined a risk-based reward function instead of a sparse rewarding scheme. | Discretized action space (3 actions). Assumed all other vehicles were of the same length. |
| [63] | Used curriculum learning [64] to speed up training. High success rate for both intersection-traversing and -approaching scenarios. | Considered traffic users to only consist of vehicles. Required further testing in more complex scenarios. |
| [65] | Used IRL and incorporated a policy into the reward function while training the RL agent. | Assumed a fully observable environment with a bird’s-eye view of the environment. Only considered interaction with a single other human driver. |
| [66] | Used a hierarchical controller to separate high-level decision-making from lower-level control. Faster model convergence. | No safety layers. Only outputted longitudinal control, assuming lateral control existed. |
| Paper | Pros | Cons |
|---|---|---|
| [73] | Had parameters to adjust the conservativeness of the policy. | Assumed pedestrians walk at constant speed. Did not consider other road users such as cyclists. |
| [74] | Tested in the real world. Continuous state space of pedestrian distance and velocity | Assumed pedestrians walk at constant speed. All test cases were hand-generated. Even in the real world, pedestrians were simulated. |
| [75] | Represented as POMDP, which represents the real world closely. | Discretized the state space using a binary variable for the pedestrian. |
| [77] | Handled occlusions that normally occur. Considered different types of crosswalks. | Did not account for pedestrians walking in groups. Simulation environment only consisted of one type of vehicle and similar height pedestrians. |
| [81] | Incorporated the effect of pedestrian–vehicle interaction. | Used gender and age information of pedestrians, which is not readily available. Set constant speed of 30 km/h. |
| [83] | Continuous action space. Well-defined reward function incorporating safety, speed as well as end-road behavior. | Did not account for the case where a pedestrian stops at the crosswalk. Only tested with a single pedestrian. |
| [84] | Tested for varying pedestrian gaps and AV speeds. Higher overall minimum distance to a pedestrian as compared to the FSM approach. | Tested in a simple scenario with simple motion models. Assumed each discrete state had constant velocity and all pedestrians had the intent to cross. |
| [86] | Modeled aggression of external pedestrians to generate random behaviors. | Tested with a single pedestrian. |
| Paper | Pros | Cons |
|---|---|---|
| [92] | Used low-dimensional latent states rather than RGB images. Performance compared against 3 DRL algorithms alongside baseline | Computationally expensive. Low success rate of 58%. |
| [94] | Combined expert knowledge with agent learning. Outputted smooth motion. Tested on roundabouts as well as unprotected left turns. | Used high-level human decisions such as lane change as input. Increased the use of hyperparameters so tuning was time consuming |
| [96] | Hierarchical model with a safety layer to avoid collisions. Used real-world data to test in simulation. | Low success rate. Training and testing environments were similar. |
| [99] | Incorporated an aggressiveness parameter to control conservativeness. Tested system with perception system noise. | Needs further testing in unknown environments. |
| [102] | Incorporated expert knowledge with agent self-exploration. Similar to [94]. Compared against 5 DRL and 3 IL methods. Incorporated safety controller to take over vehicle control in near-collision situations. | Assumed perfect perception information was available. Only manipulated longitudinal control. |
| [104] | Accounted for inaccuracies in localization. Tested the algorithm on a vehicle in the real world. | Only manipulated longitudinal control. Assumed that vehicles within a roundabout drove at constant speed. |
| [105] | Combined interval prediction with DRL to allow the model to avoid these locations. | Assumed perfect perception information was available. Only trained and tested in 2-lane roundabouts. |
| [109] | Improved training speed by combining NMPC controller with DDPG agent. Considered the comfort of users as part of the reward function. | Simple simulation environment. No safety controller which led to collisions. |
| [110] | Incorporated NMPC-based safety controller during both training and testing. Demonstrated algorithm robustness to perception noise. | Vehicle dynamics ignored. |
| Paper | Pros | Cons |
|---|---|---|
| [111] | Hierarchical policy using both RL and IL to simplify reward function design. Combined both human expert demonstration and agent self-exploration. | Hand-designed all the simulation scenarios. Only tested the algorithm with 2 modes, timid and aggressive. |
| [112] | Produced a relative trajectory as compared to a global coordinate-based path. Avoided risky trajectories where even AES and AEB systems failed. | Only tested within a single lane and single-obstacle environment. |
| [114] | Considered the case where collision is unavoidable (collision mitigation). Developed a general method, not limited to specific scenarios. | Tests only limited to simulation. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sana, F.; Azad, N.L.; Raahemifar, K. Autonomous Vehicle Decision-Making and Control in Complex and Unconventional Scenarios—A Review. Machines 2023, 11, 676. https://doi.org/10.3390/machines11070676
Sana F, Azad NL, Raahemifar K. Autonomous Vehicle Decision-Making and Control in Complex and Unconventional Scenarios—A Review. Machines. 2023; 11(7):676. https://doi.org/10.3390/machines11070676
Chicago/Turabian StyleSana, Faizan, Nasser L. Azad, and Kaamran Raahemifar. 2023. "Autonomous Vehicle Decision-Making and Control in Complex and Unconventional Scenarios—A Review" Machines 11, no. 7: 676. https://doi.org/10.3390/machines11070676
APA StyleSana, F., Azad, N. L., & Raahemifar, K. (2023). Autonomous Vehicle Decision-Making and Control in Complex and Unconventional Scenarios—A Review. Machines, 11(7), 676. https://doi.org/10.3390/machines11070676