1. Introduction
The American Welding Society (AWS) defines Quality Assurance (QA) as all the actions that provide adequate confidence that a weld will perform according to its design requirements or intended use. Quality Control (QC) is the partial or complete implementation of a QA program, in which the examination of the physical characteristics of the weld and their comparison with predetermined requirements from applicable codes, specifications, standards, and drawings is made [
1]. QC includes among many practices, process control and inspection, which are having a great impact on the final product’s quality. Inspection in particular, was and in the majority of industries still is performed according to well-established procedures (standards) offline, before or after the process according to specific sampling plans (e.g., MIL STD 105D), which are ensuring the statistical significance of the measured results and the minimum interference between inspection and production [
2].
Inspection methods/techniques can be either destructive, aiming at defining the chemical, mechanical, and metallurgical features of a joint by directly measuring them, or non-destructive, as defined in ISO 9712, whereby they are aiming to correlate changes in the signal generated by the interaction of a physical quantity with an imperfection or a weld feature. While for many applications offline inspections can be considered adequate especially if the designed product includes a single or a few welds, for products where the number of welds is high, the effects of process variability [
3] are amplified (e.g., body in white, battery assembly for electric vehicles [
4]). This raises the aspect of security for both the use phase [
5] and manufacturing [
6].
At the same time, with the digital twins and cloud manufacturing emerging, security is becoming of high importance. For instance, ransomware alone has been quite important in 2021 [
7], while other types are related to IPR, theft, social engineering, and employee misuse of IT systems [
8]. Constituents of these attacks can even be communication-related [
9], blockchain issues [
10], or could pertain to machine learning, such as attacks toward efficiency [
11] and transfer learning [
12].
Herein, the robustness of machine learning addressing quality monitoring with respect to specific attacks is considered. Different attacks in two different cases are considered, studying the effectiveness and the mechanism of a potential threat interfering with the decision making procedure. Regarding the taxonomy of the attacks considered, the focus of the current work will be indiscriminate exploratory attacks on the integrity of the ML system [
13,
14]. The goal is to test the corresponding aspect of the robustness of a quality monitoring system for welding, with the attacks being independent of the implementation of the cyber-physical system, since attacks can occur either on local quality monitoring systems [
15] or on cloud-based ones [
16].
An ML threat in general can be characterized through the attack surface, i.e., the combination of the domain it takes place in and the system it refers to [
17]. There are different types of attacks depending on the type of input. Since the current applications concern images and videos, this is what the focus will be on. To begin with, it seems that regarding images, one-pixel attacks can be used to adversely affect the output of deep neural networks [
18]. In addition, patch-wise attacks can also be used; in this case, patterns are located at the specific [
19]. More sophisticated attacks would include ML-based attacks [
20], while at the same time, attacks have even been studied under the context of steganographic universality [
21].
Regarding videos, it seems that an initial classification of attacks can be conducted into spatial and temporal [
22]. It is possible, also, to have different partitions and perturbations of the frames [
23]. It is worth noting that even the transferability of the attacks for both images and video has been investigated [
24]. An additional study utilizes geometric transformation, achieving image to video attacks [
25]. However, the simplest attack, regardless of its spatiotemporal distribution and how it was generated, appears to be the so-called “false data injection” [
26].
Due to spatiotemporal relations among pixels in videos, besides single-pixels, patterns, and spatial or temporal attacks, it seems that wavelets can be used to the same end as well [
27,
28], offering some extra degrees of freedom. On the other hand, the robustness of machine learning systems has been studied, and defense systems against such attacks have been considered [
29].
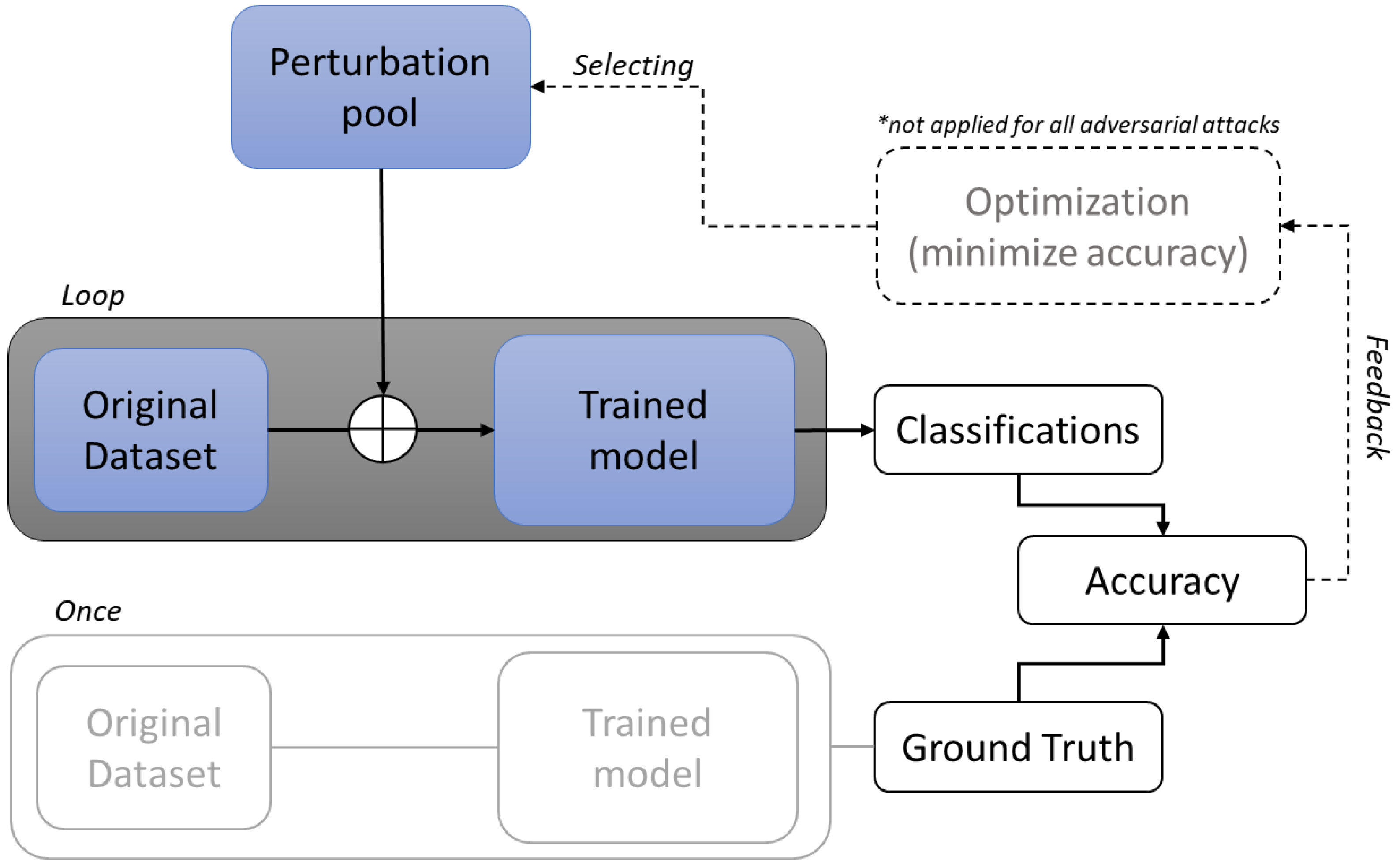
The current work attempts to address this in a multifold way. Firstly, it introduces a quality monitoring schema for welding applications, describing the architecture of the corresponding system at a software and hardware level. Following that, through introducing a framework of black-box, untargeted adversarial attacks, the study exploits the vulnerabilities of an infrared-based monitoring system that utilizes AI. Finally, the mechanisms through which these adversarial attacks cause harm are analyzed to determine which process features or defects are replicated. This enables the creation of a roadmap for evaluating the vulnerability and robustness of an AI-based quality monitoring system.
The current work is a study of these attacks; to this end, in the next section, the platform is described, followed by the presentation of the attacks. In the following section, the results of the attacks are presented, while some discussion follows.
3. Results
In this section, the results of applying the different types of attacks as described in the previous section are presented. The methods have been applied to data that has not been used for the training of the models. In the RSW case, a single data entry implies a video with 5283 grayscale frames of 32 × 32 pixels, while for the SAW, a single data entry refers to a single 32 × 32 pixel grayscale image. The pixel value for both cases ranges between zero and one having a 10-bit depth. The accuracy of the RSW and SAW models were 95% and 98%, respectively, on the test datasets, and their predictions were considered the ground truth for calculating the accuracy of the models on the modified data for each attack.
To this end, and in line with the previous section, the models subject to the adversarial attacks for the RSW and SAW have been developed in previous studies and were selected herein as they are representing two different quality assessment cases in welding. For the case of RSW, the assessment of the joint is made based on the captured video, or equivalently, on the spatiotemporal evolution of the surface of the heat-affected zone surrounding the workpiece–electrode interface area. On the other hand, for the case of SAW, the assessment of the joint is made across its length based on the captured images, which depict a unique part of the seam at a specific point in time after welding. These facts, along with the different amount of available data for training (which is significantly less in the case of RSW), the different types and number of defects of the two processes, as well as the requirements for automating the training process, were the main considerations for selecting the different machine learning methods (models) for the RSW and SAW cases.
Moreover, regarding the different methods for adversarial attacks, their selection was made to investigate three main factors. The preparation time and the computational resources required for crafting the attacks given a black-box model, the domain knowledge for crafting or tuning these attacks, and finally, the impact that they have on the different types of ML methods. Additionally, the different types of attacks were selected to identify common data features, which are strongly linked to the decision-making mechanism of both models.
3.1. Blind-Attacks—HEAVI
Starting with the Blind-Attacks for the RSW case, they included steps for identifying the location, duration and value of the perturbations within the 3D space defined by the video dimensions. These steps were performed in the context of optimization strategies which were more efficient than a simple Grid- Search.
The first step is all about finding which frame from the 5283 in total has to be changed to a frame with all its pixels equal to 0 s or 1 s for the accuracy of the model to be compromised the most. The number of total iterations is quite large, as for each one the accuracy is calculated over the entire test set (133 instances). This, along with the fact that there is no hardware acceleration for the given software model, meaning the feature extraction and feed-forward run the model, resulted in the overall execution time being prolonged. This non-linear integer programming problem was solved by incorporating an implementation of the genetic algorithm (GA), as described in previous works [
35]. The selection of the GA was also made to reduce the total number of iterations needed for finding a minimum and to also indicate other potential candidates that could inflict performance loss on the targeted model. The GA was implemented herein by setting a population of 20 frame–color individuals and was “converged” after 90 generations, reducing significantly the total number of iterations that would be needed in a simple grid search by an order of magnitude. The “color” herein refers to the pixel value. The final population and the optimization progress are depicted in the following figure (
Figure 7). Herein, a single frame of 1 s at position 25 can cause a 4% reduction in the accuracy compared to the original inputs.
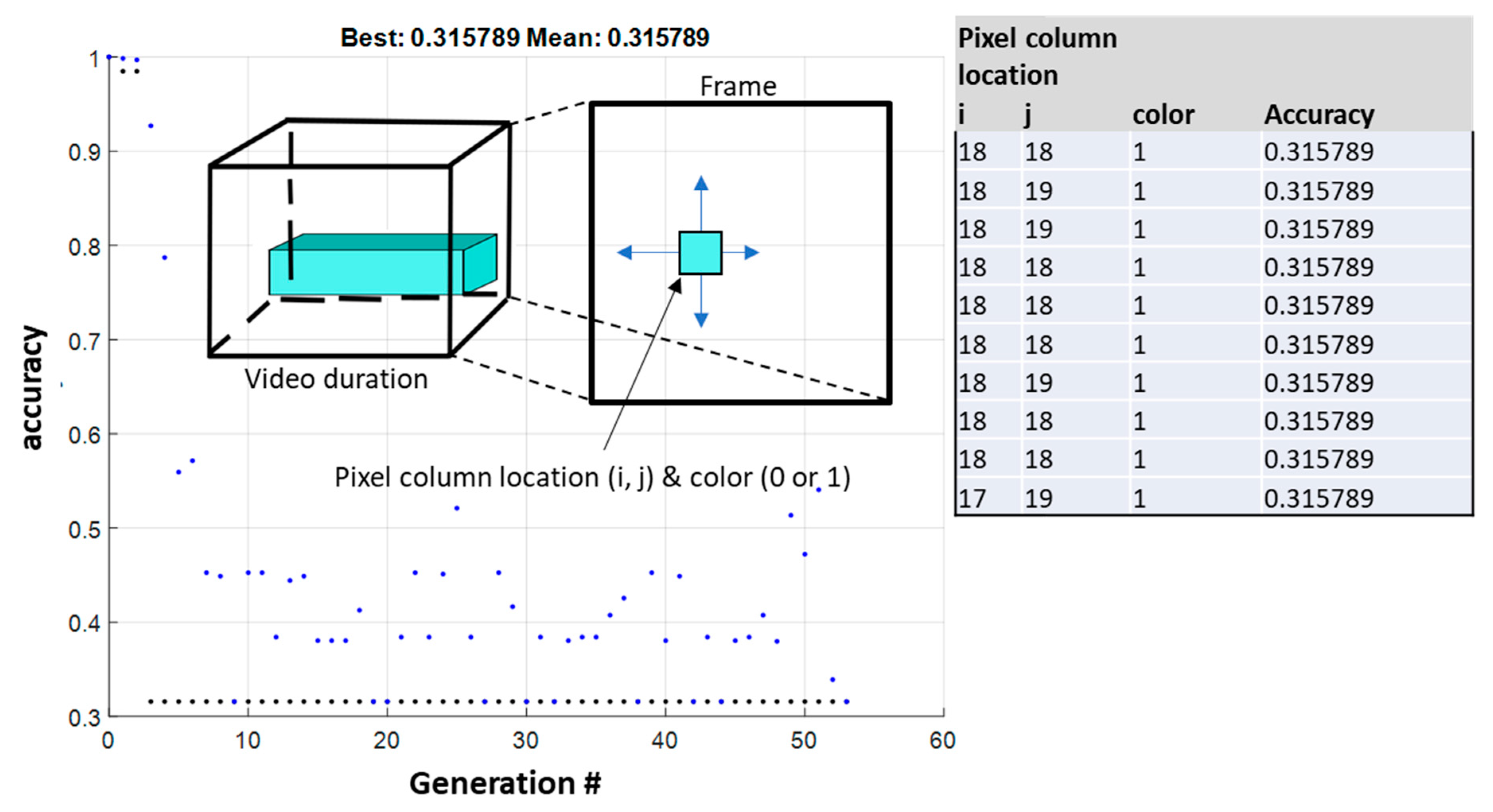
The second step included a similar procedure for locating, which are the coordinates of the “pixel column” on the frame plane and its color (zero or one), in order the achieve the maximum accuracy drop. The implementation included minor changes to the GAs parameters, such as its population size, which was reduced to 10 coordinate–color pairs. After 50 generations, the algorithm stopped, as no significant changes in the value of the objective function were observed. The results indicated a “pixel column” with coordinates (18,18) and a value of one, causing a significant drop in the model’s accuracy, which was 32% compared to the model prediction on the unmodified inputs (
Figure 8), again using an order of magnitude of fewer iterations compared to a simple grid search.
With the above-mentioned steps completed, the logical continuation for constraining the perturbation into a single pixel was to combine the previous approach and change the pixel (18,18) at the frame position 25 to the value one. This did not, however, result in any changes in the accuracy. Thus, a third step was added in order to find the smallest pixel column possible, which can cause the same accuracy to drop as achieved in the previous step. The optimization problem in this case was to identify the length and location of this pixel column, which will cause the biggest accuracy drop. The position and length of the column were constrained between 1 and 200 pixels as during a preliminary hand-crafted search, these were indicated as the most promising candidates. Once again, a GA was implemented with a population of 10 individuals of position–length individuals. The results indicate that a column with a length of 194 pixels with a value of one staring at frame position 11 can have the same accuracy drop as step 2. In the following figure, the progress of the GA is depicted along with the final population (
Figure 9). Note that the score does not correspond to the accuracy as another term was added to the objective function, ensuring that the length will be kept as small as possible.
Moving on, the corresponding HEAVI attacks for the case of SAW were straightforward to implement. In this case, as the hardware acceleration was available for the given CNN, a simple grid search was implemented for finding how much each pixel location and value (one or zero) could compromise the accuracy of the model. The accuracy results are depicted in the following figure (
Figure 10) for a class-balanced set of 800 images sampled from a bigger one of 150,000 frames, which is not balanced (EP-13%, GW-58%, NW-6%, and PP-23%). For both color values, the accuracy was increasing radially, away from ground zero (pixel location for which the lowest accuracy value was observed). The calculation of the accuracy is made herein considering the predictions of the model on the unmodified samples as the ground truth. With the following pixel coordinates identified, the best candidates were used on the actual test set of 150,000 images. The accuracy result on this set for the pixel coordinates 19 and 20 and pixel value equal to 0, was 97%, while for the pixel coordinates 20 and 18 and pixel value equal to 1, the accuracy result was 44%.
3.2. Blind-Attacks—AWGN
AWGN attacks were performed frame-wise for both the RSW and SAW case, using the corresponding build-in function of MATLAB. The “intensity” of the noise is controlled by adjusting the SNR value, which ranges between 10 and 60 dB. For the case of RSW, the noise is applied on the flattened video vectors as depicted in the following figure (
Figure 11). The result was a sharp decrease in accuracy, which as with the previous HEAVI attacks on the RSW, bottomed out at 32% for an SNR value of 27 dB.
For the SAW case as with the HEAVI attack, the noise was added to a sample of 800 images for calculating the effect on the accuracy. The noise levels varied as previously between 10 and 60 dBs and the accuracy had a sudden drop between 30 and 35 dB and finally reached its smallest value of 27% percent after a small flat spot, which is very close to the actual distribution of a single class (25%). The figure below (
Figure 12) depicts the previously mentioned results. With the accuracy being calculated on the 800-image sample, it was also calculated on the test set of images for 40, 30, 20, and 10 dB, to validate that it follows more or less the same trend. Thus, the resulting accuracy scores were 98, 85, 62, and 17%, respectively, qualitatively validating the same behaviors.
3.3. Domain-Informed Attacks
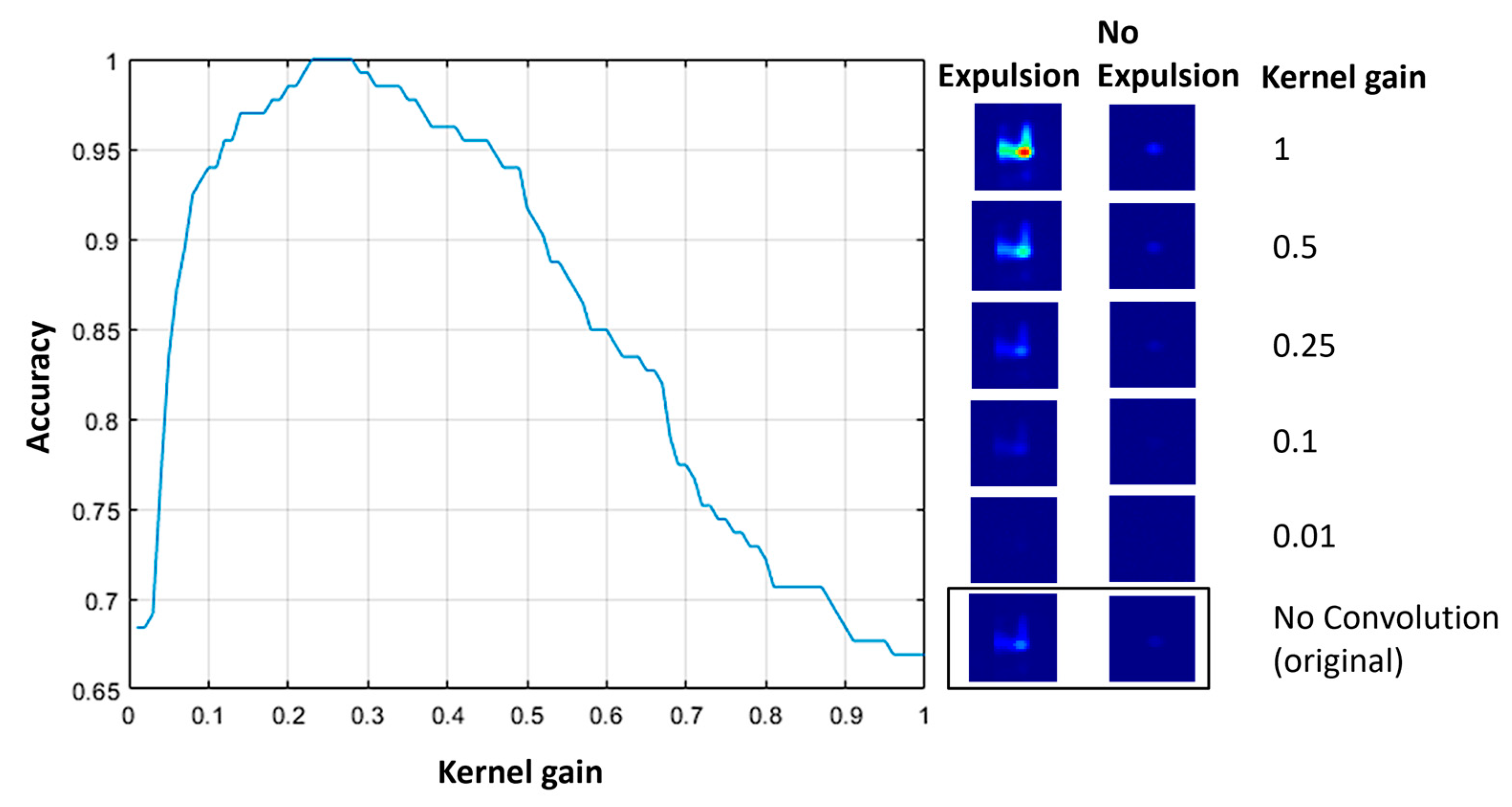
For the domain-informed attacks, as already mentioned, an identical approach followed for both the RSW and SAW cases. The 2 × 2 kernel was multiplied element-wise with a gain factor ranging from 0.01 to 1 and the accuracy was calculated for the two cases using the datasets that have been used in the previous attacks. The operation of convolution keeps only the central part, which means that the resulting matrix has the same size as the original image. Furthermore, white Gaussian noise (SNR: 50 dB) was added to each convoluted frame as calculated on the original to compensate for the blur effect that this kind of box-like filter causes. The following figure (
Figure 13) depicts the accuracy changes vs. the kernel gain for the RSW case.
For the SAW case, the accuracy was calculated the same as previously on a small sample (800 images), as depicted in the following figure (
Figure 14). The accuracy on the test set, as defined in previous paragraphs (150,000 frames), was calculated for the gain values of 0.01, 0.1, 0.25, 0.3, and 0.4, and resulted in 58%, 9%, 96%, 54%, and 16%. In addition, the accuracy is changing linearly and it is quantized for different values of the gain.
4. Discussion
4.1. Result Analysis
Regarding the attacks described in the previous section, the HEAVI attack on the RSW model was capable of compromising its performance completely. This is due to the fact that a 32% accuracy means that the attack entirely shifted the predictions of the majority class, which was the “No Expulsion” class. Beyond the raw metrics concerning the performance of the attack, its structure is important to be analyzed as it reveals insights into the feature extraction mechanisms and the decision-making of the corresponding model. Thus, in this case, the value, position, and length of the injected pixel column indicate that the dimensions that the PCA algorithm identifies as the ones having the highest variance are located temporary-wise at the start of the video and spatial-wise, approximately, at the middle of the frame. This is typically where the process thermal signature appears in each frame and when its maximum temperature is achieved during welding, as already analyzed in [
3]. Regarding decision-making, as hypothesized in the corresponding “Domain-Informed Attacks”, it is indeed dependent on the pixel value for the previously mentioned dimensions (pixel coordinates where the thermal signature appears), meaning that the higher the pixel value, the more probable it is in the corresponding video to be placed in the “Expulsion” class.
Looking at SAWs HEAVI attack results, the first thing that is obvious is that both for the zero and one pixel-value injections, the area for which these are having the most significant effect on the model’s accuracy is pretty much the same, with the area corresponding to the zero pixel-value injections, to be slightly smaller and having a milder effect (
Figure 10). Furthermore, the area that is affected by the injections seems to be located within the spatial margins of the process thermal signature and more specifically, toward the welding electrode or otherwise the upper right corner of the image. This could mean that the CNNs filters are configured for extracting features concerning this area in particular, which is good on one hand, as the model indeed considers the area of the image where the seam’s cooldown is more profound, but bad at the same time, as the model can be easily modified by utilizing a small perturbation. Same as with the RSW case, the pixel intensity, which depends on the temperature, seems to be strongly correlated with defects, as already implicitly hypothesized in [
32]. Finally, another artifact is that the severity of the accuracy drop for both pixel values fades away with moving further away from the point with the greatest impact.
Moving on with the AWGN attacks, it cannot be left undiscussed the fact that both models are quite robust to SNR levels as low as 40 dBs. While for the case of SAW, making assumptions on how this is achieved is not trivial, and for the RSW case, this can be justified to some extent by looking at the flattened video vectors and the temporal profile of the pixels that are located within the area where the thermal signature of the process typically appears (
Figure 14). So, as already hypothesized in the case of the HEAVI attacks, the classification is based on the values of certain pixels that are compared to a threshold. That is, the actual noise is added on the video ‘vector’ and not specifically on these video vector dimensions where the thermal signature of the process is registered. Thus, it requires quite low SNR values to increase the chances of inflicting “damage”, as most of the dimensions are corresponding to background pixels, which represent random noises by default. Thus, the addition of noise everywhere just amplifies the background noise for high SNR values. Another finding in the context of this AWGN attack for the RSW case, is that the spatio-temporal dimensions that the feature extraction algorithm weights the most, and the pixel threshold values upon which the model base its decisions, could be defined with relative ease using simple handcrafted rules. Thus, it could be stated with caution that adding noise specifically to an area of an imaginary box located at the middle of the frame and stretching it in the temporal dimension for a duration similar to the length of the HEAVI’s attack “pixel-column” could inflict the same “damage” to the RSW model. With that in mind, an exploratory attempt of adding a 5 × 5 × 197 pixel “noise” rectangular box of 20 dB around the pixel (18,18) resulted in an accuracy of 90%, while for a 15 dBs SNR, the accuracy eventually dropped to 32%. Increasing this box’s cross-section also resulted in an accuracy drop, but the same did not happen when increasing its length. Finally, in the same vein, creating a “noise-pixel-column” with the same specification as the one in the corresponding HEAVI attack did not have any effect, even for quite low SNR values.
Coming back to the SAW case, the AGWN attack had a similar effect. Increasing the amount of noise resulted in general in a decrease in the accuracy; however, this occurred in a non-linear fashion. Similarly to the RSW case, the capture frames are including pixels in the background that are following a white noise pattern. Thus, again a lot of noise is required to be added in order to inflict significant damage to the model’s accuracy as specific areas/pixels, as already identified in the HEAVI attack, are weighted more than others for the decision-making. To justify this hypothesis to a certain extent, as with the RSW case above, a similar experimentation of adding a 5 × 5 noise pad around the pixel (20,18), as identified in the HEAVI attack, was implemented. The resulting accuracy for an SNR level of 20 dBs was slightly higher (73%) compared to the corresponding one on the full-frame AWGN attack on the test set, which further justifies the claims made in the context of the HEAVI attack.
With the results of the “Blind-Attacks” analyzed, it cannot be ignored the fact that for both the RSW and SAW cases, either by adding noise or simply by forcing a pixel or a number of pixels to have the maximum value possible for specific spatiotemporal dimensions is what “fools” the model of thinking that high temperatures above certain thresholds are depicted in the image. This is the essence of the “Domain-Informed Attacks”, which in simple words are amplifying the image features and simultaneously adding a blur, which aids in smoothening the transitions between image features with low and high values. Analyzing the “Domain-Informed Attacks” for the RSW case, in
Figure 13 the accuracy starts from 68% and reaches 100% for a gain value of 0.25. Both numbers are not random, with 68% accuracy to represent a complete shift of the minority class (expulsion) as the kernel heavily reduces the intensity of the thermal signatures, and 100% accuracy to validate that the blurring made by the box kernel does not cause any changes. For high gain values even greater compared to the ones investigated, the accuracy did not drop as much as to indicate a complete shift of the majority class (no-expulsion).
For the SAW case, having in mind that the data sample was balanced class-wise, it was easy to identify which gain value caused one or more classes to be misclassified. A total misclassification was achieved for a low gain value (0.1), so low in fact that it decreased the image intensity significantly compared to the original (
Figure 14). Based on the previous hypothesis, that the pixel intensity mainly determines the classification output, each of images belonging to the GW, PP, and EP classes were kind of demoted into the class with the next lower intensity “threshold” for a kernel gain of 0.1. However, if that is the case, it cannot be explained for how the NW was classified.
Table 4 summarizes all the macroscopic results.
5. Conclusions
In this study, two machine learning models purposed for two quality monitoring tasks in the context of two welding applications (RSW and SAW) and under the same software and hardware framework were used for crafting three different adversarial attack methods. Most of the attacks were able to compromise the accuracy of the corresponding models down to the point where the prediction ability of the models was no better than a random guess, even for the case of a deep learning model, which has been trained upon hundreds of thousands of examples.
More specifically, the temperature value and its temporal profile during welding, or otherwise the pixel intensity for these quality-monitoring cases, has been identified as a major factor upon which the decision-making is performed from both models.
In the context of the adversarial attacks for RSW, this means that the model’s accuracy is affected if the intensity of the pixels, at the image area where the thermal signature of the process appears, is changed for as long as the welding system provides energy to the spot and not during the cooldown. To this end, localized attacks, such as single-pixel/maximum pixel-value attacks, are causing significant drops in the targeted model’s accuracy and can be easily detected with threshold-based rules. On the other hand, mild perturbations in the form of localized noise or the selective amplification of image features are able to inflict moderate damage, which not only could be hardly detectable, but also, could be hardly correctable.
Similar conclusions can be drawn for the SAW case. Herein, amplifying and not just changing the pixels’ intensity around a specific area in a frame could cause the model to misclassify the input.
Regarding the attacks from an implementation perspective, single-pixel attacks and in general localized ones are the most difficult to tune and would require as much data as possible. On the contrary, domain knowledge attacks that are targeting on amplifying in general the intensity of specific image features can be applied with nearly no tunning at all, and they would most probably achieve a measurable drop in the performance of the targeted model.
The results of this study do not define a general rule that could limit the accuracy of a quality monitoring system based on infrared images for welding, but they can help toward creating a framework through which adversarial attacks’ tuning can be avoided.
However, the span of the manufacturing processes themselves is currently limited to SAW (seams) and RSW (spots). Additionally, despite the fact that this is a study on how the attacks affecting each model have been conducted, the means for detecting and defending them were only mentioned. Thus, future work is expected, aiming at developing a framework that is able to quantitatively distinguish potential adversarial inputs without utilizing user-defined thresholds and providing solutions during the training of a model for making it invulnerable to the majority of perturbations. The actual injection of the attacks having access to the model will have to be discussed as well.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}