
A Multi-Information Fusion ViT Model and Its Application to the Fault Diagnosis of Bearing with Small Data Samples


Abstract
:1. Introduction
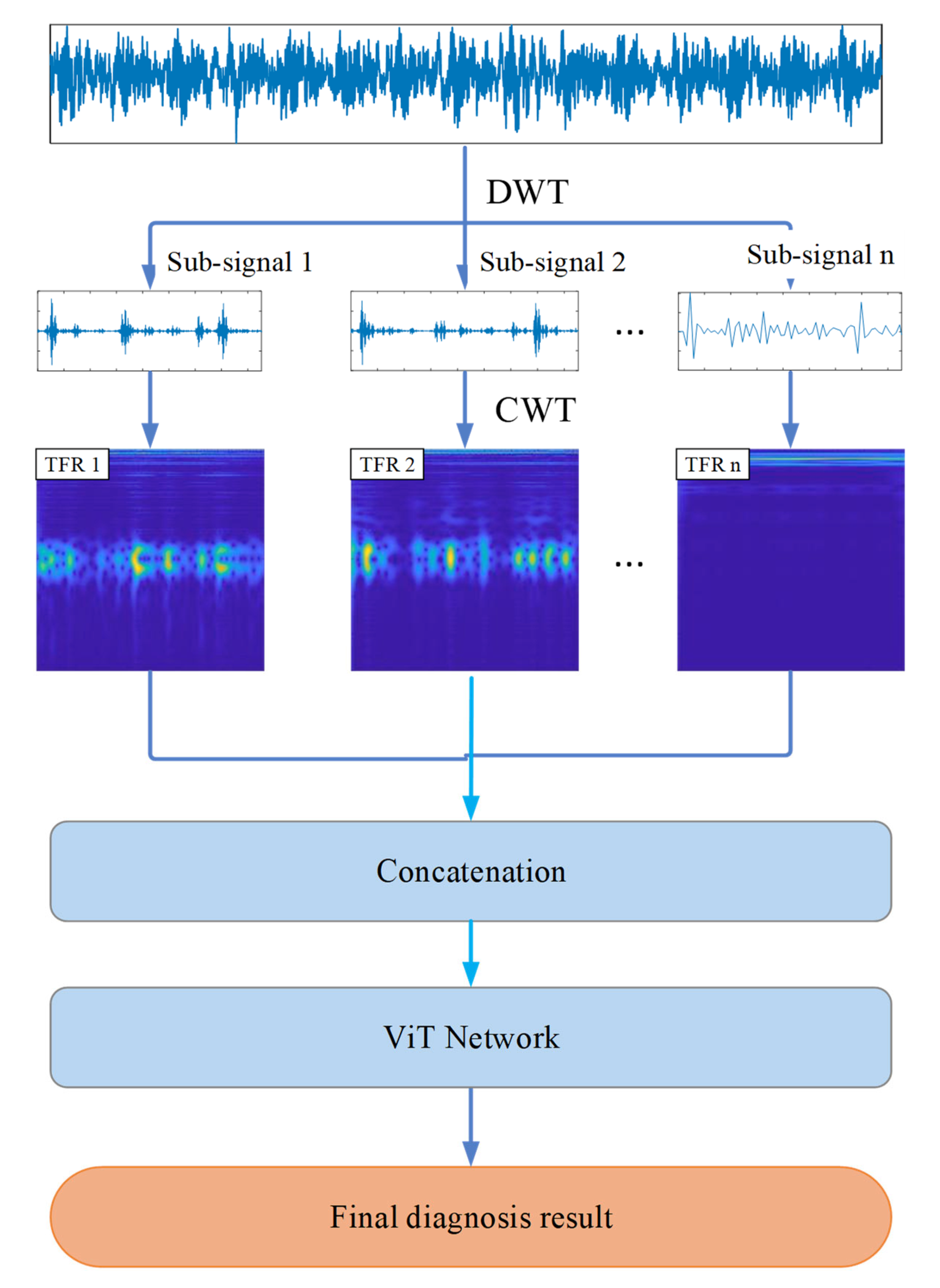
2. The Multi-Information Fusion ViT-Based Diagnosis Model
2.1. DWT-Based Signal Decomposition
2.2. CWT-Based Time–Frequency Representation Maps
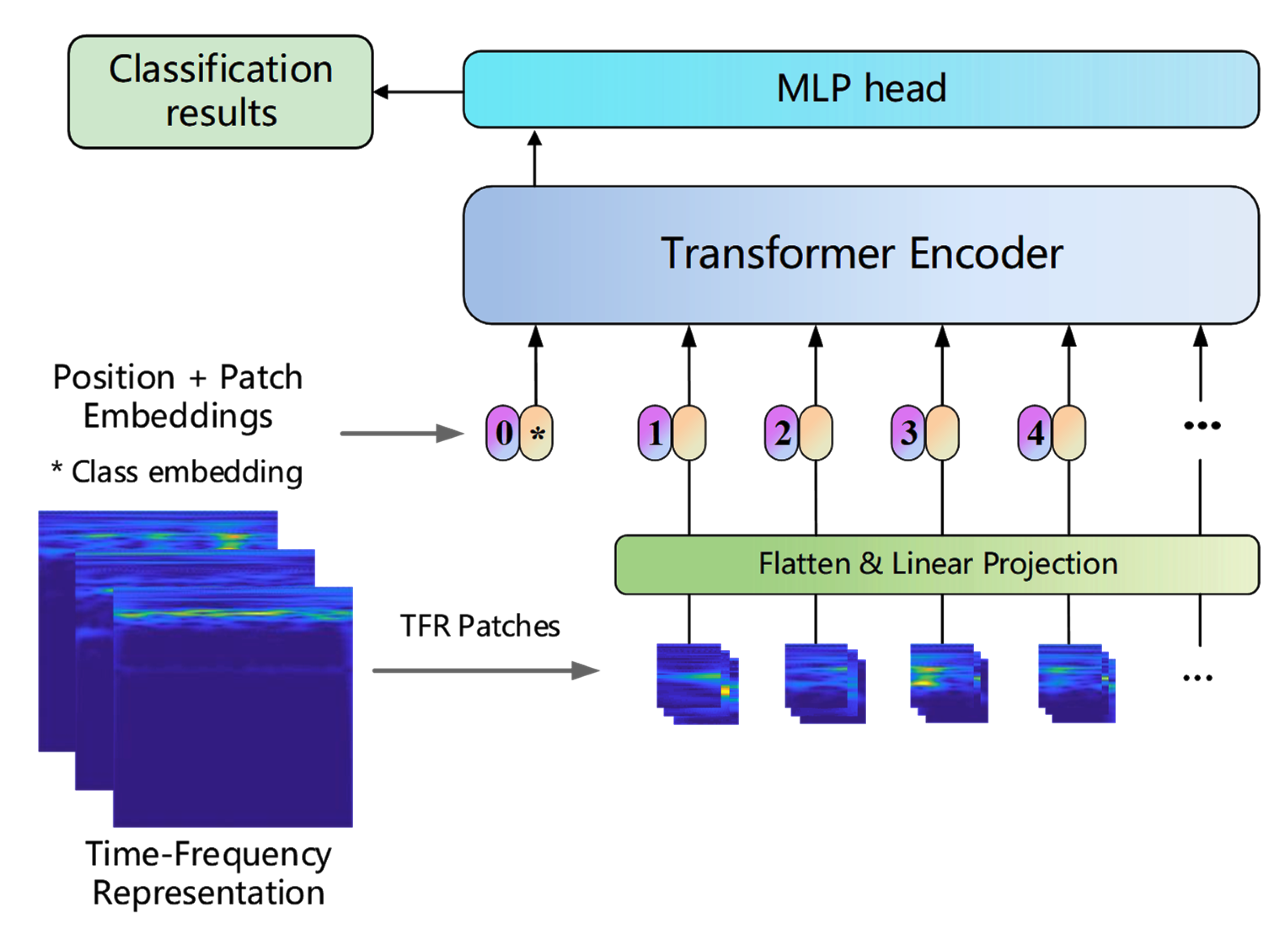
2.3. ViT Model
2.3.1. Embedding Layer
2.3.2. Position Encoding Module
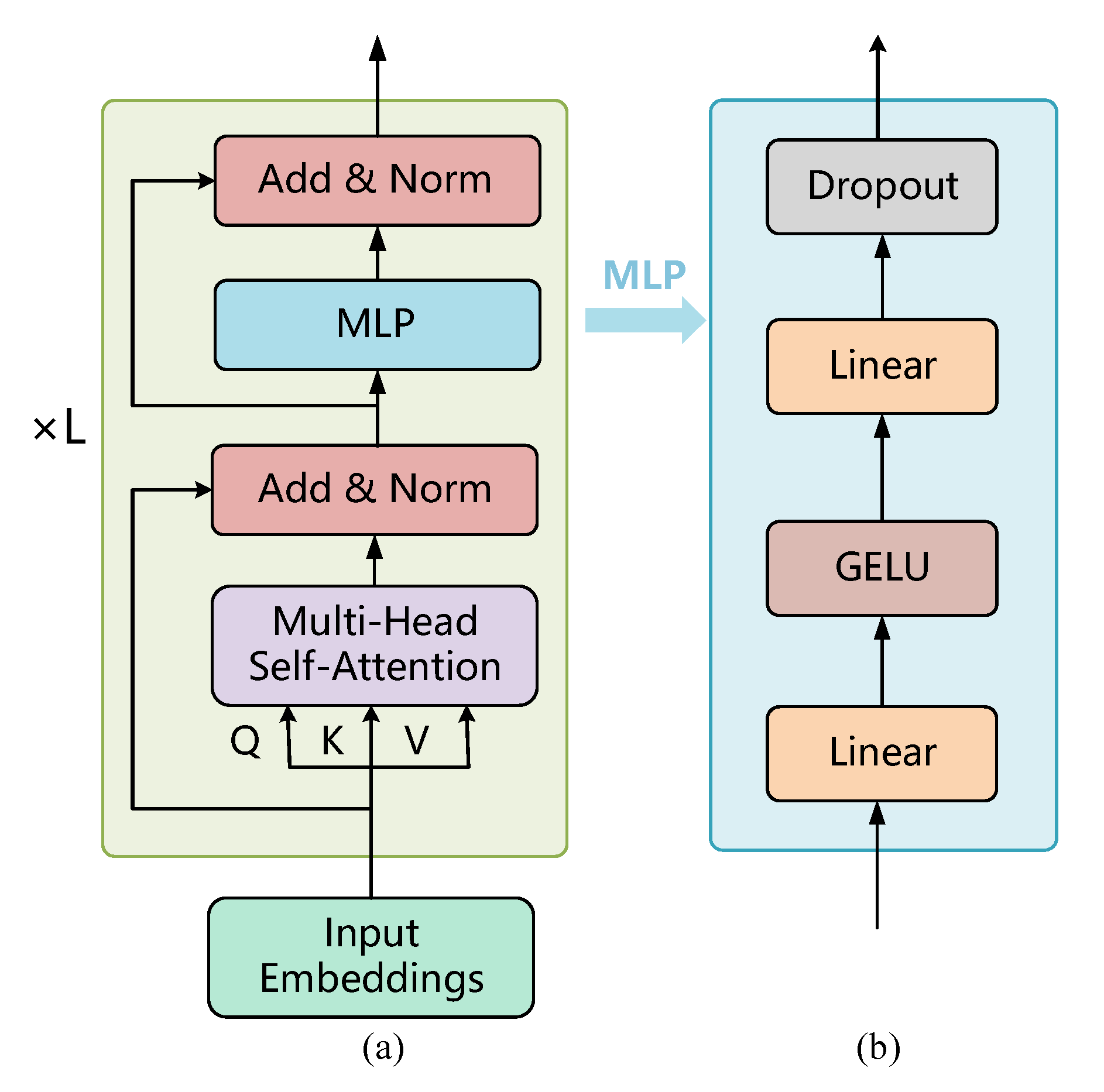
2.3.3. Encoder
- Multihead self-attention layer
- MLP layer
2.3.4. Classifier
2.3.5. Loss Function
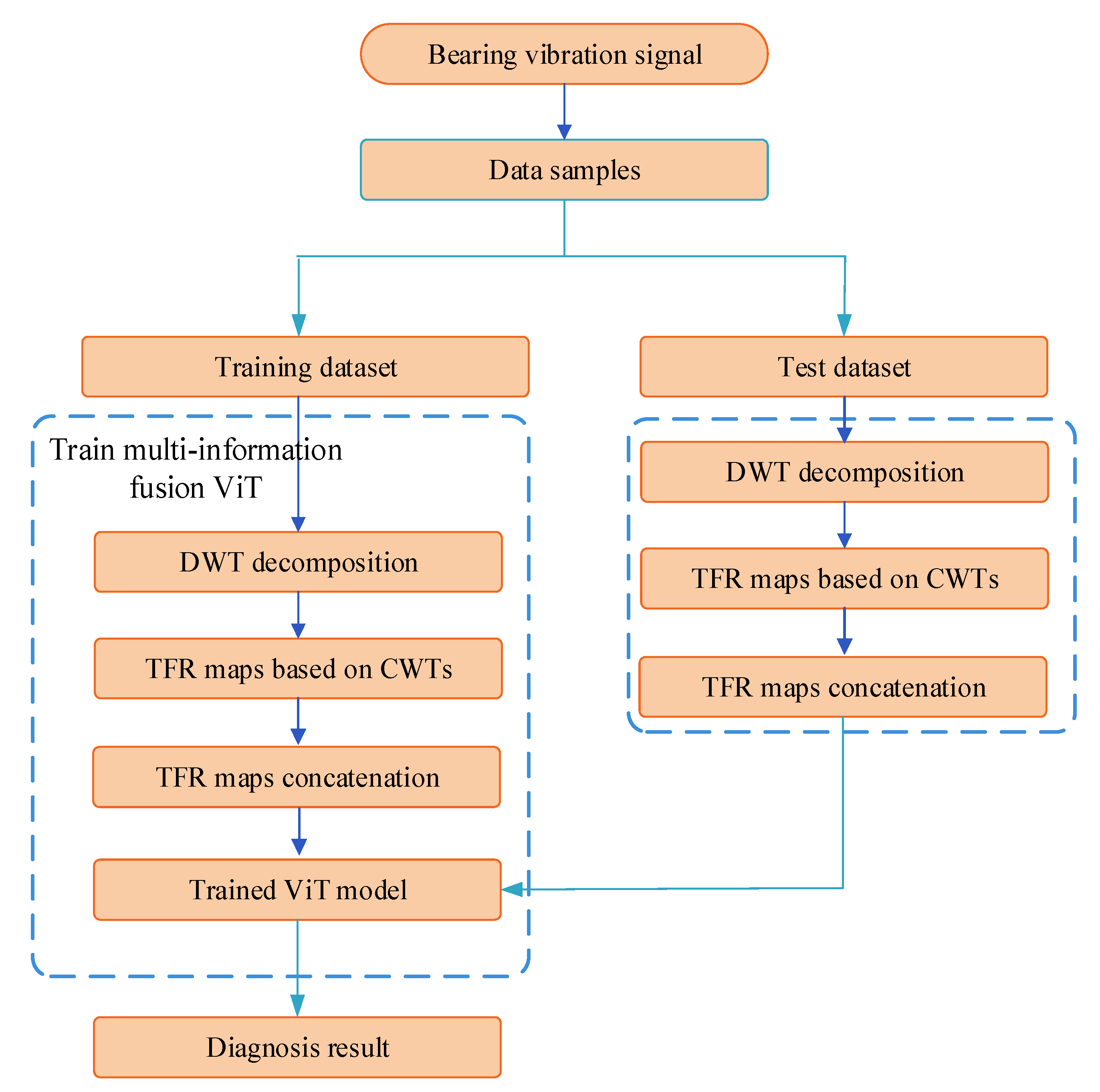
3. Diagnosis Algorithm of the Multi-Information Fusion ViT Model
4. Fault Diagnosis Analysis of Rolling Bearing
4.1. Dataset Description
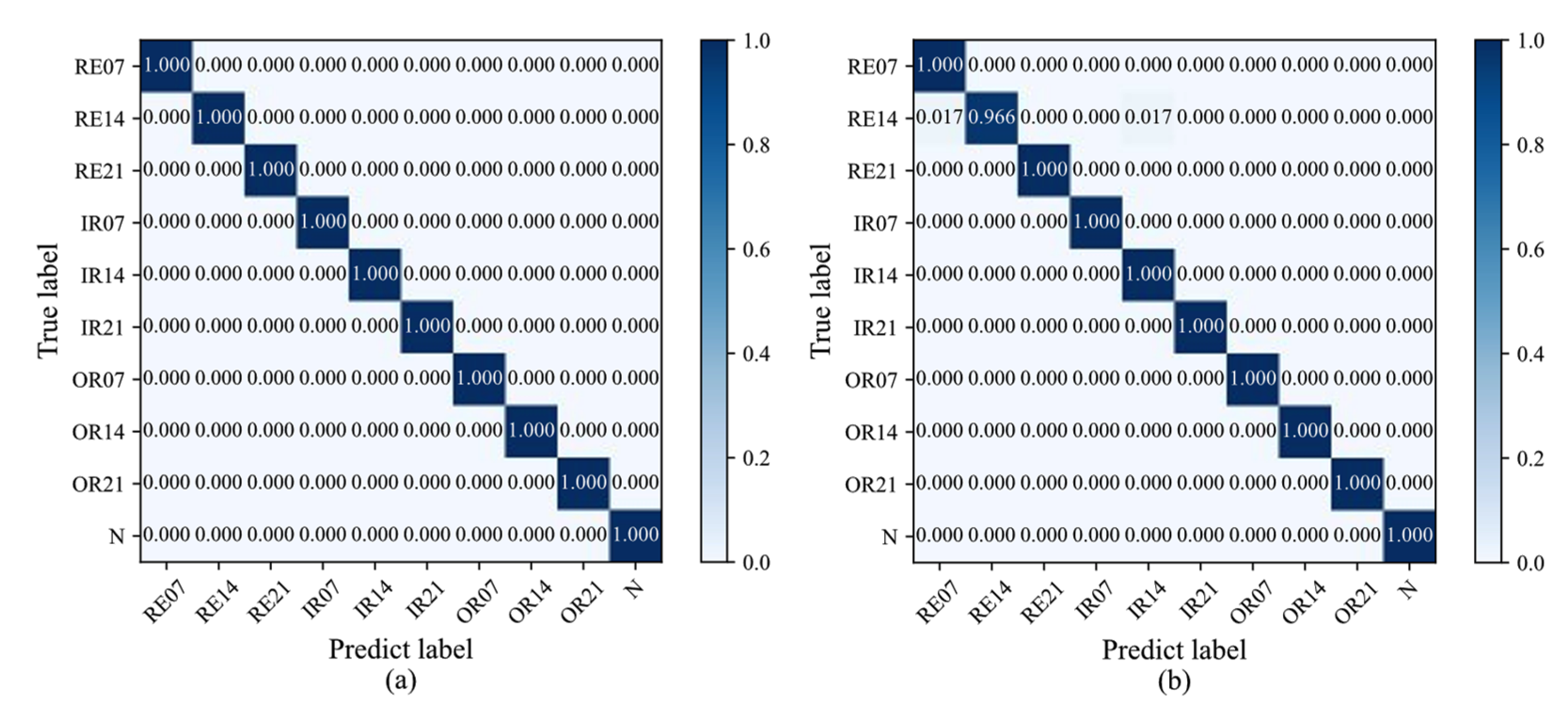
4.2. Diagnosis Analysis
4.3. Diagnosis Generalization Analysis on Different Small Data Samples
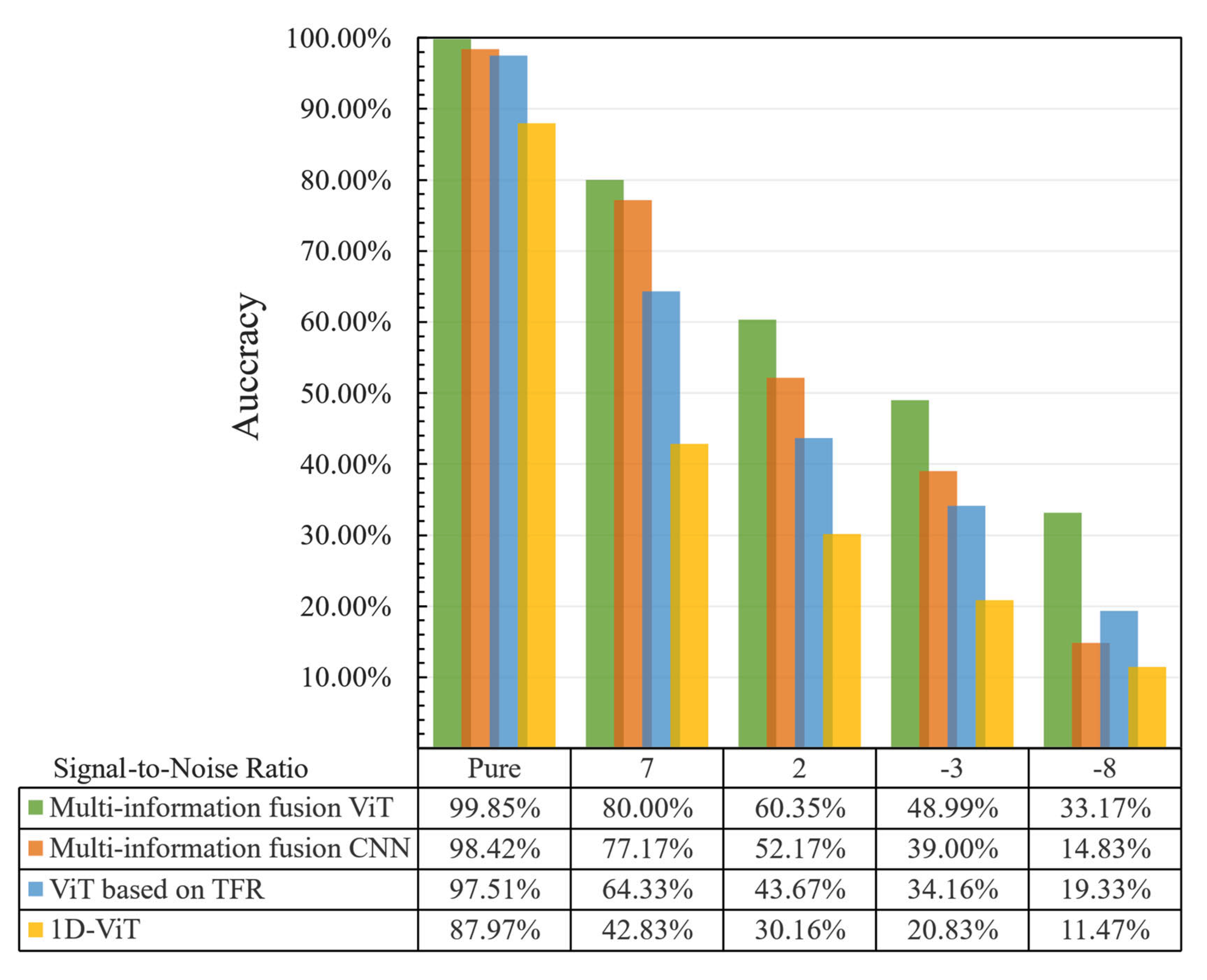
4.4. Anti-Noise Diagnosis Ability Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Upadhyay, R.K.; Kumaraswamidhas, L.A.; Azam, M.S. Rolling element bearing failure analysis: A case study. Case Stud. Eng. Fail. Anal. 2013, 1, 15–17. [Google Scholar] [CrossRef]
- Zhao, X.; Jia, M.; Bin, J.; Wang, T.; Liu, Z. Multiple-Order Graphical Deep Extreme Learning Machine for Unsupervised Fault Diagnosis of Rolling Bearing. IEEE Trans. Instrum. Meas. 2020, 70, 3506012. [Google Scholar] [CrossRef]
- Yan, X.; Jia, M. A novel optimized SVM classification algorithm with multi-domain feature and its application to fault diagnosis of rolling bearing. Neurocomputing 2018, 313, 47–64. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Zhao, H.; Wang, F. A novel deep autoencoder feature learning method for rotating machinery fault diagnosis. Mech. Syst. Signal Process. 2017, 95, 187–204. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, R.; Pan, R.; Pan, H. Imbalanced Fault Diagnosis of Rolling Bearing Using Enhanced Generative Adversarial Networks. IEEE Access 2020, 8, 185950–185963. [Google Scholar] [CrossRef]
- Hoang, D.-T.; Kang, H.-J. A survey on Deep Learning based bearing fault diagnosis. Neurocomputing 2019, 335, 327–335. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Wang, B.; Habetler, T.G. Deep learning algorithms for bearing fault diagnostics—A comprehensive review. IEEE Access 2020, 8, 29857–29881. [Google Scholar] [CrossRef]
- Fuan, W.; Hongkai, J.; Haidong, S.; Wenjing, D.; Shuaipeng, W. An adaptive deep convolutional neural network for rolling bearing fault diagnosis. Meas. Sci. Technol. 2017, 28, 095005. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention//International Conference on Machine Learning. PMLR 2021, 139, 10347–10357. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual Conference, 26 April–1 May 2020. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.; Tay, F.E.H.; Feng, J.; Yan, S. Tokens-to-Token Vit: Training Vision Transformers from Scratch on Imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 558–567. [Google Scholar]
- Ding, Y.; Jia, M.; Miao, Q.; Cao, Y. A novel time–frequency Transformer based on self–attention mechanism and its application in fault diagnosis of rolling bearings. Mech. Syst. Signal Process. 2022, 168, 108616. [Google Scholar] [CrossRef]
- Zhou, K.; Diehl, E.; Tang, J. Deep convolutional generative adversarial network with semi-supervised learning enabled physics elucidation for extended gear fault diagnosis under data limitations. Mech. Syst. Signal Process. 2023, 185, 109772. [Google Scholar] [CrossRef]
- Luo, J.; Huang, J.; Ma, J.; Li, H. An evaluation method of conditional deep convolutional generative adversarial networks for mechanical fault diagnosis. J. Vib. Control. 2021, 28, 1379–1389. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks//International conference on machine learning. PMLR 2017, 70, 214–223. [Google Scholar]
- Yang, J.; Liu, J.; Xie, J.; Wang, C.; Ding, T. Conditional GAN and 2-D CNN for Bearing Fault Diagnosis with Small Samples. IEEE Trans. Instrum. Meas. 2021, 70, 3525712. [Google Scholar] [CrossRef]
- Yan, R.; Shen, F.; Sun, C.; Chen, X. Knowledge Transfer for Rotary Machine Fault Diagnosis. IEEE Sensors J. 2019, 20, 8374–8393. [Google Scholar] [CrossRef]
- He, Z.Y.; Shao, H.D.; Wang, P.; Janet, L.; Cheng, J.S.; Yang, Y. Deep transfer multi-wavelet auto-encoder for intelligent fault diagnosis of gearbox with few target training samples. Knowl. Based Syst. 2020, 191, 105313. [Google Scholar] [CrossRef]
- Chen, W.; Qiu, Y.; Feng, Y.; Li, Y.; Kusiak, A. Diagnosis of wind turbine faults with transfer learning algorithms. Renew. Energy 2020, 163, 2053–2067. [Google Scholar] [CrossRef]
- Cao, P.; Zhang, S.; Tang, J. Preprocessing-free gear fault diagnosis using small datasets with deep convolutional neural network-based transfer learning. IEEE Access 2018, 6, 26241–26253. [Google Scholar] [CrossRef]
- Li, X.; Jiang, H.; Niu, M.; Wang, R. An enhanced selective ensemble deep learning method for rolling bearing fault diagnosis with beetle antennae search algorithm. Mech. Syst. Signal Process. 2020, 142, 106752. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Zhang, F.; Lv, S.; Zhang, L.; Jiang, M.; Sui, Q. Intelligent fault diagnosis of rolling bearing using the ensemble self-taught learning convolutional auto-encoders. IET Sci. Meas. Technol. 2022, 16, 130–147. [Google Scholar] [CrossRef]
- Hoang, D.T.; Tran, X.T.; Van, M.; Kang, H.J. A Deep Neural Network-Based Feature Fusion for Bearing Fault Diagnosis. Sensors 2021, 21, 244. [Google Scholar] [CrossRef] [PubMed]
- Xia, M.; Li, T.; Xu, L.; Liu, L.; De Silva, C.W. Fault diagnosis for rotating machinery using multiple sensors and convolutional neural networks. IEEE/ASME Trans. Mechatron. 2017, 99, 101–110. [Google Scholar] [CrossRef]
- Silik, A.; Noori, M.; Altabey, W.A.; Ghiasi, R.; Wu, Z. Comparative Analysis of Wavelet Transform for Time-Frequency Analysis and Transient Localization in Structural Health Monitoring. Struct. Durab. Heal. Monit. 2021, 15, 1–22. [Google Scholar] [CrossRef]
- Zhang, J.; Feng, F.; Marti-Puig, P.; Caiafa, C.F.; Sun, Z.; Duan, F.; Solé-Casals, J. Serial-EMD: Fast empirical mode decomposition method for multi-dimensional signals based on serialization. Inf. Sci. 2021, 581, 215–232. [Google Scholar] [CrossRef]
- Chaovalit, P.; Gangopadhyay, A.; Karabatis, G.; Chen, Z. Discrete wavelet transform-based time series analysis and mining. ACM Comput. Surv. 2011, 43, 1–37. [Google Scholar] [CrossRef]
- Morlet, J. Seismic tomorrow: Interferometry and quantum mechanics//Geophysics. SOC Explor. Geophys. 1976, 41, 366. [Google Scholar]
- Mallat, S.G. A theory for multi-resolution signal decomposition: The wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Kankar, P.K.; Sharma, S.C.; Harsha, S.P. Fault diagnosis of ball bearings using continuous wavelet transform. Appl. Soft Comput. 2011, 11, 2300–2312. [Google Scholar] [CrossRef]
- Chen, Z.; Cen, J.; Xiong, J. Rolling Bearing Fault Diagnosis Using Time-Frequency Analysis and Deep Transfer Convolutional Neural Network. IEEE Access 2020, 8, 150248–150261. [Google Scholar] [CrossRef]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning//International conference on machine learning. PMLR 2017, 70, 1243–1252. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasglow, Scotland, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Taud, H.; Mas, J.F. Multilayer Perceptron (MLP). In Geomatic Approaches for Modeling Land Change Scenarios; Springer: Cham, Switzerland, 2018; pp. 451–455. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- The Case Western Reserve University Bearing Data Center. Bearing Data Center Fault Test Data. 1998. Available online: http://csegroups.case.edu/bearingdatacenter/pages/download-data-file (accessed on 23 January 2021).
- Keys, R. Cubic convolution interpolation for digital image processing. IEEE Trans. Acoust. Speech Signal Process. 1981, 29, 1153–1160. [Google Scholar] [CrossRef]
- Hebda-Sobkowicz, J.; Zimroz, R.; Wyłomańska, A. Selection of the Informative Frequency Band in a Bearing Fault Diagnosis in the Presence of Non-Gaussian Noise—Comparison of Recently Developed Methods. Appl. Sci. 2020, 10, 2657. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Class Conditions | Fault Size (mm) | Class Label | Number of Training Samples | Number of Test Samples |
|---|---|---|---|---|
| Slight rolling element | 0.18 | RE07 | 100 | 60 |
| Medium rolling element | 0.36 | RE14 | 100 | 60 |
| Severe rolling element | 0.53 | RE21 | 100 | 60 |
| Slight inner ring | 0.18 | IR07 | 100 | 60 |
| Medium inner ring | 0.36 | IR14 | 100 | 60 |
| Severe inner ring | 0.53 | IR21 | 100 | 60 |
| Slight outer ring | 0.18 | OR07 | 100 | 60 |
| Medium outer ring | 0.36 | OR14 | 100 | 60 |
| Severe outer ring | 0.53 | OR21 | 100 | 60 |
| Normal | 0 | N | 100 | 60 |
| Hyperparameter | 1D-ViT | ViT Based on TFR | Multifeature Fusion ViT |
|---|---|---|---|
| Input size | [32, 32, 1] | [224, 224, 3] | [224, 224, 15] |
| Batch size | 32 | 32 | 16 |
| Maximum epochs | 100 | 100 | 100 |
| Optimiser | SGDM | SGDM | SGDM |
| Momentum | 0.9 | 0.9 | 0.9 |
| Learning rate | 5 × 10−5 | 1 × 10−4 | 1 × 10−4 |
| Number of encoder layers | 8 | 6 | 4 |
| Hidden dimension | 1024 | 768 | 768 |
| Number of attention heads | 8 | 8 | 4 |
| Dropout rate | 0.1 | 0.1 | 0.1 |
| Structure (Units and Activation) | Hyperparameter |
|---|---|
| Conv2D ([224, 224, 128], activation = “ReLU”) | Dropout rate = 0.3 Maximum epochs = 100 Batch size = 16 Optimiser = Adam Learning rate = 5 × 10−5 |
| Conv2D ([224, 224, 128], activation = “ReLU”) | |
| MaxPooling2D ([112, 112, 128]) | |
| Flatten (112 × 112 × 128) | |
| Dense (128, activation = “ReLU”) | |
| Dense (num_class, activation = “softmax”) |
| Model | Mean Accuracy | Lowest Accuracy | Highest Accuracy |
|---|---|---|---|
| Multi-information fusion ViT | 99.85% | 99.67% | 100.00% |
| Multi-information fusion CNN | 98.42% | 97.83% | 99.00% |
| ViT based on TFR | 97.51% | 96.16% | 98.33% |
| 1D-ViT | 87.97% | 86.17% | 89.33% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Tang, X.; Wang, Z. A Multi-Information Fusion ViT Model and Its Application to the Fault Diagnosis of Bearing with Small Data Samples. Machines 2023, 11, 277. https://doi.org/10.3390/machines11020277
Xu Z, Tang X, Wang Z. A Multi-Information Fusion ViT Model and Its Application to the Fault Diagnosis of Bearing with Small Data Samples. Machines. 2023; 11(2):277. https://doi.org/10.3390/machines11020277
Chicago/Turabian StyleXu, Zengbing, Xinyu Tang, and Zhigang Wang. 2023. "A Multi-Information Fusion ViT Model and Its Application to the Fault Diagnosis of Bearing with Small Data Samples" Machines 11, no. 2: 277. https://doi.org/10.3390/machines11020277
APA StyleXu, Z., Tang, X., & Wang, Z. (2023). A Multi-Information Fusion ViT Model and Its Application to the Fault Diagnosis of Bearing with Small Data Samples. Machines, 11(2), 277. https://doi.org/10.3390/machines11020277