1. Introduction
Scheduling is an important decision-making process in manufacturing and service industries and has been widely studied since 1954. As a typical scheduling problem, ASP is an effective way to balance batch production and production flexibility and has attracted much attention. After the pioneering works of Lee et al. [
1] and Potts et al. [
2], a number of related works have been obtained. In recent years, Framinan et al. [
3] gave a unified notation for ASP and provided a full review of the previous works and future topics. Komaki et al. [
4] implemented a consolidated survey of ASP and proposed salient research opportunities.
Two-stage ASP has been widely studied, which consists of a fabrication stage and an assembly stage, and various methods such as exact algorithm, heuristic and meta-heuristics are used to solve the problem. Since meta-heuristic performs better than the exact algorithm ([
5,
6]) on large-scale scheduling problems and often can produce better results than heuristics, meta-heuristics have become the main approach for solving two-stage ASP, which includes genetic algorithm (GA [
7,
8]), tabu search (TS [
9]), particle swarm optimization (PSO [
9]), grey wolf optimizer [
10], differential evolution (DE [
11]), and imperialist competitive algorithm (ICA [
12]) etc.
However, real-life assembly production is typically composed of three sequential stages: fabrication, transportation and assembly. It is unreasonable to ignore the collection and transfer of parts or components, so it is necessary to deal with a three-stage ASP with the transportation stage between the fabrication stage and the assembly stage.
The related results on the three-stage ASP are limited. Christos and George [
13] firstly handled the problem and showed that the problem is NP-hard. Hatami et al. [
14] presented a mathematical model, a TS and a simulated annealing (SA) for the problem with sequence-dependent setup times (SDST). Maleki-Darounkolaei et al. [
15] proposed a meta-heuristic based on SA for the problem with SDST and blocking times. Maleki-Darounkolaei and Seyedi [
16] developed a variable neighborhood search (VNS) algorithm and a well-known SA for the same problem. Shoaardebili and Fattahi [
17] provided two multi-objective meta-heuristics based on SA and GA to solve the problem with SDST and machine availability. For three-stage ASP with
layout, in which
m dedicated parallel machines exist at the fabrication stage and one assembly machine is at the assembly stage, Komaki et al. [
18] and Campos et al. [
19] presented an improved discrete cuckoo optimization algorithm and a general VNS heuristic, respectively.
With the further development of economic globalization, production is shifted from a single factory to multiple factories, and distributed scheduling in multiple factories has attracted much attention [
20,
21,
22,
23,
24,
25]. DASP is the extended version of ASP in multi-factory environments and a number of works have been obtained on DASP with various processing constraints. Some constructive heuristics and meta-heuristics have been developed for DASP with no-idle [
26,
27,
28,
29,
30]. Gonzalez-Neira et al. [
31] studied a biased-randomized simheuristic for the distributed assembly permutation flowshop problem considering stochastic processing times. Li et al. [
32] developed a fuzzy distributed assembly flow shop scheduling problem and presented a novel ICA with empire cooperation. Shao and Shao [
33] investigated a distributed assembly blocking flowshop scheduling problem and proposed a constructive heuristic algorithm and a product-based insertion process. They also designed a constructive heuristic and a water wave optimization algorithm with problem-specific knowledge to solve the same problem [
34]. Yang and Xu [
35] dealt with DASP with flexible assembly and batch delivery and presented seven algorithms using four heuristics, a VNS and two iterated greed (IG). Yang et al. [
36] proposed a scatter search-based memetic algorithm to solve the distributed assembly permutation flowshop scheduling problem with no-wait, no-idle and due date constraints. Zhang et al. [
37] studied a matrix-cube-based estimation of the distribution algorithm to address the energy-efficient distributed assembly permutation flow-shop scheduling problem.
DASP with setup times is also often considered. Song and Lin [
38] presented a genetic programming hyper-heuristic algorithm, and Hatami et al. [
39] proposed two constructive heuristics, VNS and IG, for the problem with SDST and makespan. Regarding DASP with a
layout and setup times, Xiong et al. [
40] developed a hybrid GA with reduced VNS and a hybrid discrete DE with reduced VNS. Deng et al. [
41] presented a mixed integer linear programming model and a competitive memetic algorithm. Zhang and Xing [
42] proposed a memetic social spider optimization algorithm by adopting two improvement techniques, the problem-special local search and self-adaptive restart strategy. Lei et al. [
43] designed a cooperated teaching-learning-based optimization algorithm with class cooperation.
As stated above, DASP with various processing constraints, such as the no-idle and setup, is considered; however, some constraints, such as factory eligibility, are seldom investigated. Take factory eligibility as an example; this constraint means that not all factories are eligible for each product, that is, at least one product cannot be produced by all factories. This is the extended version of machine eligibility [
44,
45,
46] and often exists in many real-life multi-factory production environments. For example, a large Chinese electronic display company consists of several factories located in different cities in China, and some products cannot be manufactured in all factories. Qin et al. [
46] studied a novel integrated production and distribution scheduling problem with factory eligibility and third-party logistics in hybrid flowshops and proposed three heuristics and an adaptive human-learning-based GA; however, DASP with factory eligibility has hardly been investigated; moreover, DASP with factory eligibility and other constraints such as setup times has also hardly been considered. In the real world, multiple factories, factory eligibility and setup times often exist simultaneously, and their considerations can result in a high application value of the obtained schedule; thus, it is necessary to deal with DASP with factory eligibility and setup times.
In recent years, the integration of reinforcement learning (RL) with meta-heuristics has become a new topic, and some results have been produced for production scheduling. Chen et al. [
47] solved flexible job shop scheduling by a self-learning GA with a Q-learning algorithm, which is used to adaptively adjust key parameters of GA. Cao et al. [
48] presented a cuckoo search (CS) with RL and surrogate modeling for a semiconductor final testing scheduling problem with multi-resource constraints. Cao et al. [
49] developed a knowledge-based CS with a knowledge base based on an RL algorithm for flexible job shop scheduling with sequencing flexibility. In these two papers, the parameters of CS are also adjusted by RL. Oztop et al. [
50] dealt with a no-idle flowshop scheduling problem by using a novel general VNS with Q-learning algorithm used to determine the parameters of VNS. Ma and Zhang [
51] provided an improved ABC algorithm based on a Q-learning algorithm. Lin et al. [
52] applied a Q-learning-based hyper-heuristic (QHH) algorithm to solve a semiconductor final testing scheduling problem. In QHH, a Q-learning algorithm is used to autonomously select a heuristic from a heuristic set. Karimi-Mamaghan et al. [
53] proposed a novel efficient IG algorithm for the permutation flowshop scheduling problem, which can adaptively select the perturbation operators using the Q-learning algorithm. The above integrations of RL and meta-heuristics are mainly used to adaptively adjust parameter settings or select a search operator [
54,
55]. As a result, the performance of the meta-heuristic can be improved, and thus, it is an effective way to add RL into a meta-heuristic for scheduling problems such as DASP with factory eligibility.
As shown above, meta-heuristics, including GA, PSO and VNS, are frequently applied to solve ASP and DASP. As the main method for production scheduling, ABC has been successfully applied to cope with various production scheduling problems in a single factory [
56,
57,
58,
59,
60] and multiple factories [
61,
62,
63,
64,
65]; however, ABC is seldom used to solve DASP. Compared with some meta-heuristics such as GA, ABC has some features such as simplicity and ease of implementation; on the other hand, ABC has successful applications in single factory scheduling and distributed scheduling [
64,
65,
66,
67] with permutation-based representation, and the solution of DASP is also represented as a permutation of products. ABC is suitable for solving DASP; moreover, the RL algorithm can be integrated easily with ABC because of its above features. As a result, the performance of ABC can be improved effectively, and thus, it can be concluded from the above analyses that it is beneficial to apply ABC to solve DASP by its integration with RL [
68].
In this study, transportation stage, factory eligibility and setup times are adopted in a distributed three-stage ASP, and an effective path is given to integrate the Q-learning algorithm and ABC. The main contributions can be summarized as follows. (1) A distributed three-stage ASP with
layout, factory eligibility and setup times is considered. (2) A Q-learning-based artificial bee colony (QABC) is proposed to minimize total tardiness. A Q-learning algorithm is implemented by using eight states based on population quality evaluation, eight actions defined by global search and neighborhood search, a new reward and an adaptive
greedy selection. Unlike the previous works [
47,
48,
49,
50], the Q-learning algorithm is applied to dynamically select a search operator. Population division, the employed bee phase with adaptive migration and a new scout phase based on a modified restart strategy are also added. (3) Extensive experiments are conducted to test the performances of QABC by comparing it with other methods from the literature. Computational results demonstrate that the usage of new strategies, including Q-learning, is effective and efficient, and QABC can provide promising results for the considered problem.
The remainder of the paper is organized as follows. The problem description is given in
Section 2 followed by an introduction to ABC and Q-learning in
Section 3.
Section 4 shows the proposed QABC for the problem. Numerical experiments on QABC are reported in
Section 5, the conclusions are summarized in the final section and some topics of future research are provided.
2. Problem Description
Distributed three-stage ASP with
layout, factory eligibility, and setup times is described as follows. Notations used for this problem are shown in
Table 1.
There are n products and F factories in a factory set . Factory eligibility means that there exists an available factory set for product i, . Each factory f has m dedicated parallel machines for fabrication, a transportation machine and an assembly machine . With respect to , it just works in a factory f, suppose that has sufficient capacity so that all components of any products can be transferred at one time. In a transportation, moves components of just one product i from the fabrication machine of the last finished component to . All components of each product are transported by once.
Each product has m components. When product i is allocated into factory , its m components are first processed on at the fabrication stage, and then they are collected by and transferred to at the assembly stage; finally, the product is obtained by assembling its all components.
Setup time is anticipatory and can start when a machine is available, which is required for three stages. For production i transferred by , its setup time is used to load and unload product i.
Factory eligibility indicates that not all factories are eligible for each product, that is, at least one product i has a set .
All products can be produced at time 0; each machine can fabricate, transport or assemble at most one product at a time; each product can be fabricated, transported or assembled at most one machine at a time; no interruption and breakdowns are considered; once a product is assigned to a factory, it cannot be transferred to another factory.
The problem can be divided into factory assignment sub-problem and scheduling sub-problem. There are strong coupled relations between the two sub-problems. Factory assignment notably affects the results of the scheduling sub-problem, and optimal solutions can be obtained after the solutions to the two sub-problems are effectively combined.
The goal of the problem is to minimize total tardiness when all constraints are met.
An illustrative example with six products (
), three factories (
) and three machines (
) at the fabrication stage of each factory is shown in
Table 2. For factory set
, product
i can be produced by the factory in
,
,
,
,
,
,
. “—” For example, in
, product 1 cannot be assigned to factories 1 and 3, then
,
, and so on. A Gantt chart of a schedule of the example is shown in
Figure 1,
,
,
,
,
,
, total tardiness of factory 1, 2, and 3 is 37, 6, 34, respectively, and the corresponding
is 77.
3. Introduction to ABC and Q-Learning
In this study, ABC and an RL algorithm named Q-learning are integrated together; thus, we introduce ABC and the Q-learning algorithm.
3.1. ABC
In ABC, a feasible solution to the problem is represented by a food source, and a search agent is represented by a bee. All bees are categorized into three groups: employed bees, onlooker bees and scouts. In general, the employed bee tries to exploit a food source, the onlooker bee waits in the hive to make a decision of choosing a food source, and the scout carries out a random search for a new food source.
ABC begins with a randomly generated initial population P with N solutions, and then three phases called employed bee phase, onlooker bee phase, and scout phase are executed sequentially.
In the employed bee phase, each employed bee produces a candidate source
from
.
where
D is the number of dimensions,
is a real random number in the range
, and
is a randomly selected solution,
,
,
.
A greedy selection is applied: if , then substitutes for , where denotes fitness of .
In the onlooker bee phase, the onlooker bee chooses a food source by roulette selection based on the probability
.
Once an onlooker bee selects a food solution , a new solution is obtained, and then the above greedy selection is applied to decide if can be replaced with .
In the above two phases, a is computed for each . Initially, . If the newly obtained cannot update , ; otherwise, .
In the scout phase, if of a food source exceeds a threshold , the corresponding employed bee will turn into a scout, which randomly produces a solution to substitute for the food source.
3.2. Introduction to Q-Learning Algorithm
RL is a learning approach that can be applied to a wide variety of complex problems. RL has been extensively considered and has been successfully applied to solve many problems [
47,
48,
49,
50,
51,
69,
70].
The Q-learning algorithm [
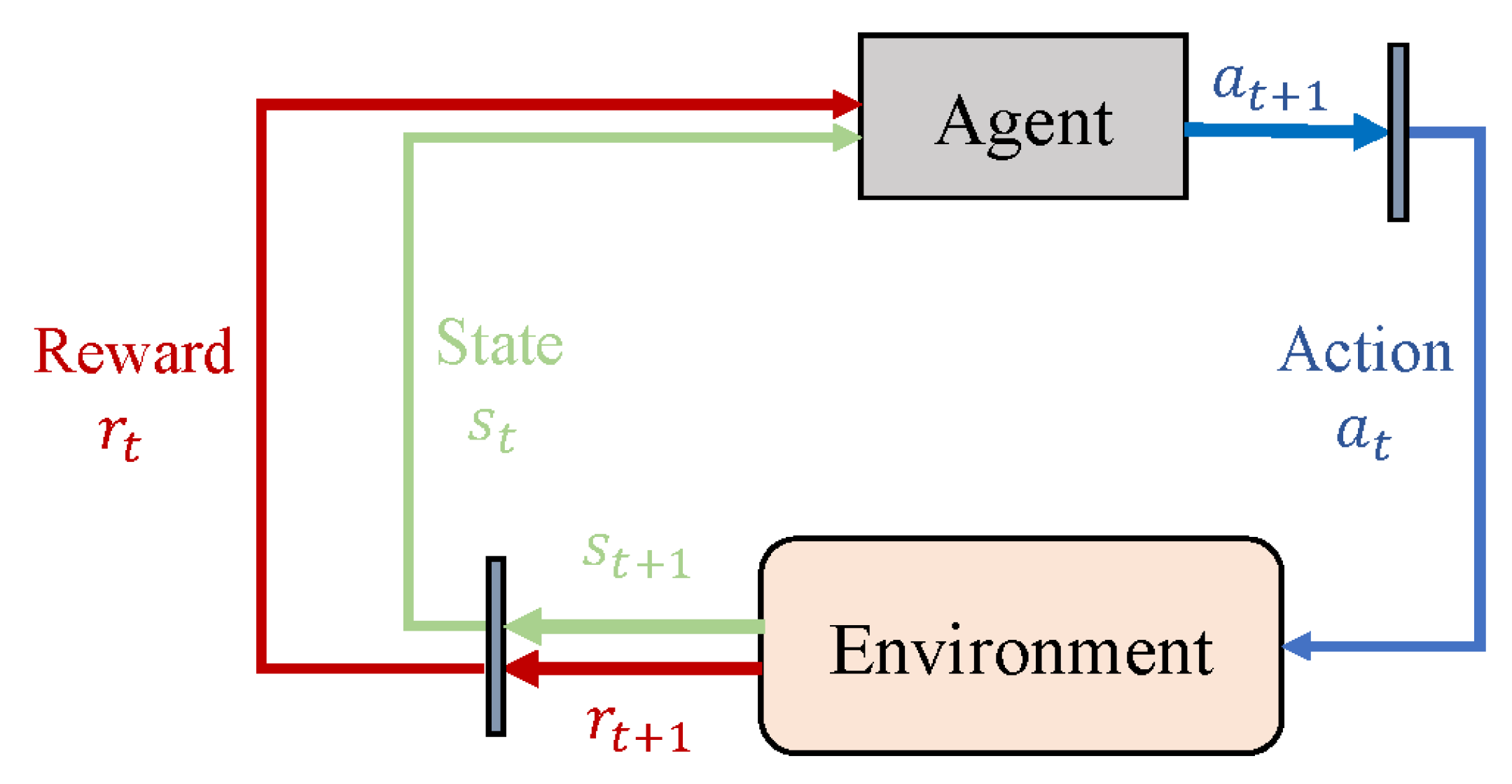
71] is the most commonly used model-free RL algorithm. It provides a learning capability for the intelligence system in the Markov environment to select the optimal action using the experienced action. The main components of Q-learning include a learning agent, an environment, states, actions, and rewards. The illustration plot is shown in
Figure 2. The Q-learning algorithm has a simple structure and is implemented easily. It has been successfully integrated with meta-heuristics such as GA, CS and QHH for production scheduling [
47,
48,
52]. Its simplest form is defined by
where
is the learning rate,
indicates the discount factor,
is the reward received from the environment by taking the
of
, and
represents the biggest Q value in the Q-table at state
.
Action selection is performed based on the Q-table. Initially, all elements of the Q-table are zero, which means that the agent does not have any learning experience. greedy is often used and expressed as follows. If a random number , then randomly select an action a; otherwise, select an action a that maximizes the Q values, that is, .
4. QABC for Distributed Three-Stage ASP with Factory Eligibility and Setup Times
This study contributes an effective integration of the Q-learning algorithm and ABC to implement the dynamical selection of the search operator. Moreover, two employed bee swarms are used for population division, and a new scout phase based on a modified restart strategy is also applied. The details of QABC are shown below.
4.1. Representation and Search Operators
4.1.1. Solution Representation
Because the problem has two sub-problems, a two-string representation is used, in which a solution is denoted by a factory assignment string , , ⋯, and a scheduling string , , ⋯, , where factory is allocated for product i, and is a real number in and corresponds to product i.
The scheduling string is a random key one, so suppose that products i, , ⋯, j are manufactured in the same factory, that is, = = ⋯ = , product permutation is determined after all are sorted in ascending order, , . If , then product i will be placed before product j because j is greater than i.
The decoding procedure is shown in Algorithm 1. For the example in
Table 2, a possible solution is composed of factory assignment string
, 3, 1, 2, 3,
and scheduling string
,
,
,
,
,
. For factory 1, products 3 and 6 are assigned to it in terms of factory assignment string, their permutation [3, 6] is obtained because
, that is, product 3 starts followed by product 6. Take product 3 as an example; three components of it are first processed on
, and then they are collected by
and transferred to
to assemble them. The corresponding schedule is illustrated in
Figure 1.
| Algorithm 1: Decoding procedure |
| Input: factory assignment string , , ⋯, ; scheduling string , , ⋯, |
| Output: Permutations of all factories |
| 1: for to F do |
| 2: Find all products allocated to factory f according to factory assignment string |
| 3: Determine permutation of all products in factory f by sorting in ascending order |
| 4: Start with the first product on the permutation, handle the fabrication of all of its components, transfer all of its components to and assemble them. |
| 5: end for |
4.1.2. Search Operators
In this study, a search operator is made up of a global search between two solutions, reassignment, inversion and neighborhood search.
A global search between solutions
is shown below. Solution
z is produced by a uniform crossover of both the factory assignment string and scheduling string of
, and greedy selection is applied: if
z is better than
x, then
x is replaced with
z.
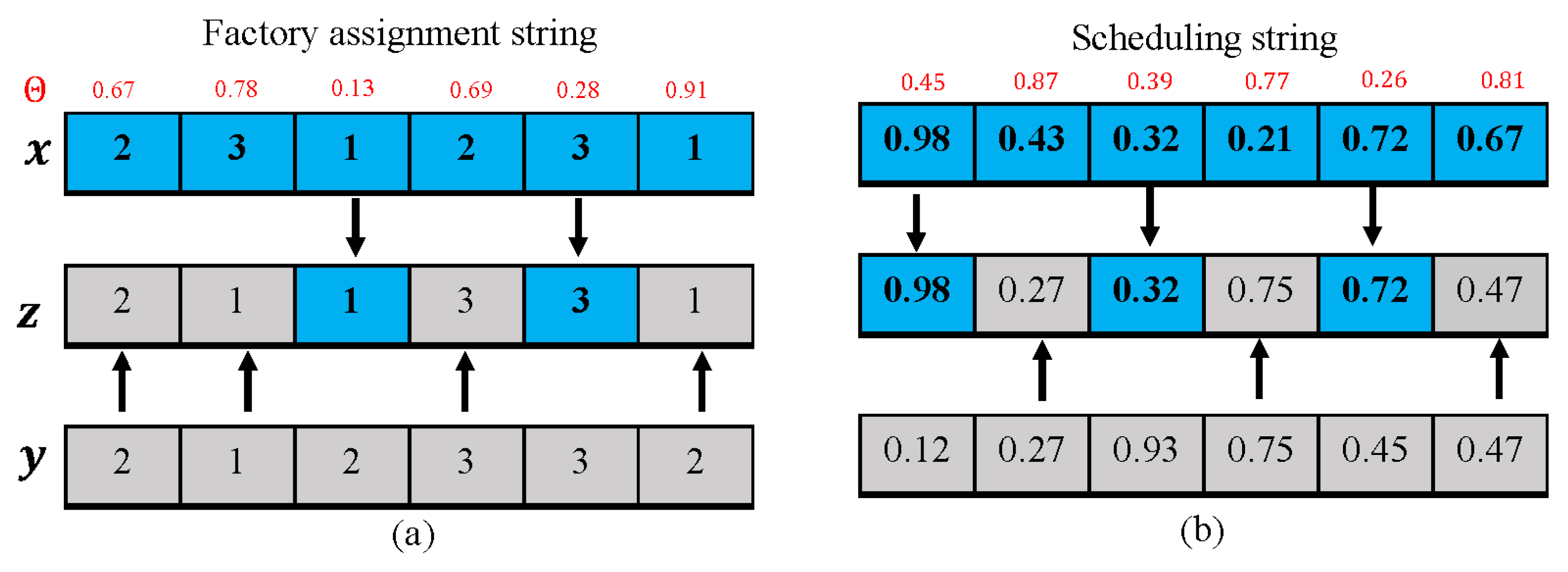
Figure 3 describes the process of a uniform crossover of the above two strings. In
Figure 3a, a string
of random numbers [0.67, 0.78, 0.13, 0.69, 0.28, 0.91] is obtained, and then, a new factory assignment string
is produced by elements in string
. For example, the first element is
, and the first gene of
z is selected from
y; the third element is
, and the third gene of
z is from
x.
Total tardiness is related to each factory, so uniform crossover is used and simultaneously acts on two strings of x, y.
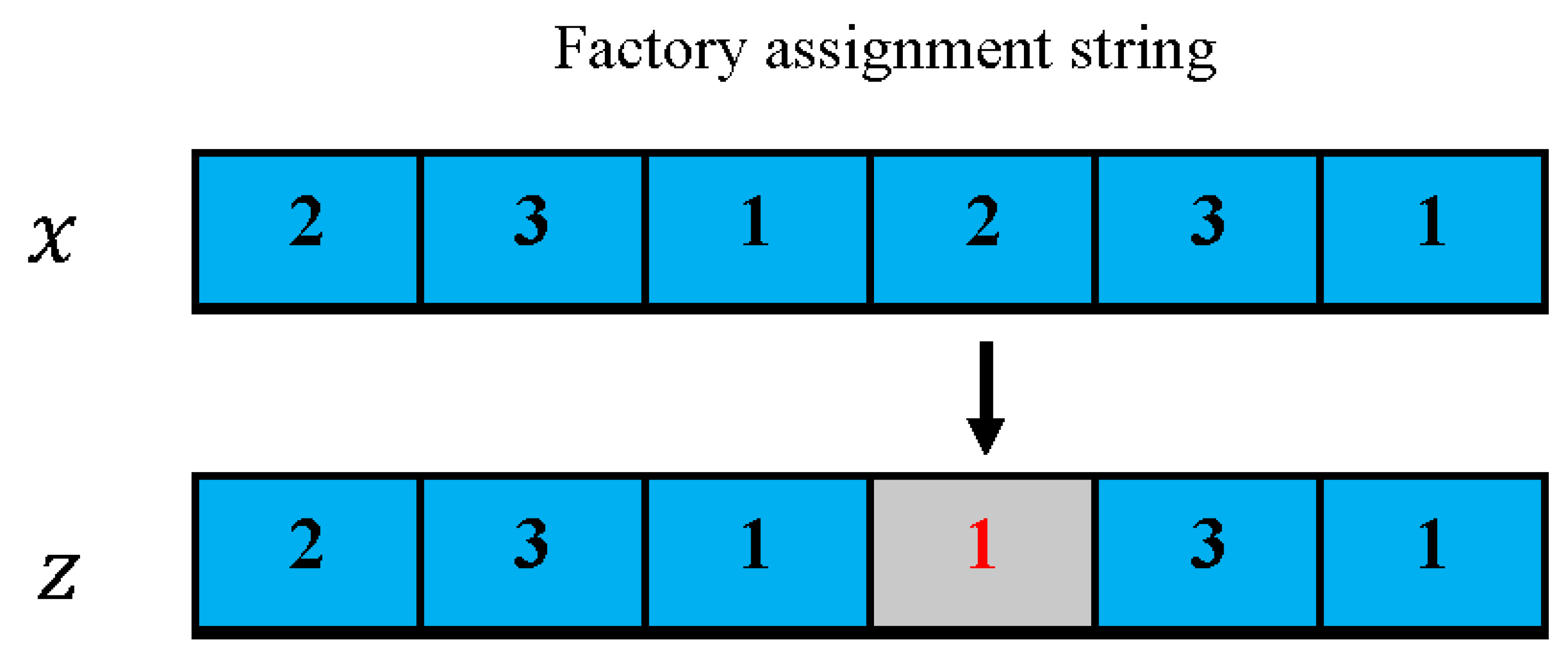
The reassignment operator acts on a factory assignment string of a solution
x in the following way: randomly select
genes, and then each chosen gene
is displaced by a randomly decided factory in
, a new solution
z is obtained, and a greedy selection is executed, where
is a random decimal in the range (0, 1], and
(
) indicates the closest integer to
u. An example of a reassignment operator is shown in
Figure 4. If
= 0.45,
, three products 2, 4, and 6 are randomly selected.
= 1 can be obtained, which is randomly chosen from
.
and
are generated similarly.
Inversion is described as follows. For scheduling string of a solution x, randomly decide , and invert genes between positions and . A new solution z is produced, and greedy selection is complete.
Eight neighborhood structures are used to construct a neighborhood search. The factory with maximum total tardiness is defined as the critical factory . The position is decided based on the product permutation of the factory.
Neighborhood structure is described below. Stochastically select a product i from the factory , insert i into a randomly decided position of the factory , and reassign of each product according to the product permutation of the factory . For the above solution of the example, the critical factory is 1, product 3 is inserted into the position of product 6, and a new permutation is , so and .
When a randomly chosen factory substitutes for the factory in , is obtained. is shown as follows. Swap two randomly selected products from the factory . differs from in that a stochastically chosen factory is used.
acts on the factory in the following way: a product i with is randomly selected from the factory , suppose that i is on the position of product permutation of the factory , insert i into a randomly decided position . When a randomly selected factory is substituted for factory in , is produced.
is shown below. Randomly find a product
i with
from the factory
and stochastically choose a factory
, remove
i from the critical factory and insert it into a randomly decided position of factory
f. An example of
is shown in
Figure 5, in which
,
with
is selected stochastically, and
is replaced by another factory 1 that is randomly chosen from
.
The above neighborhood structures of the critical factory are proposed because of the following feature of the problem: a new position of product i in critical factory or a movement of product i from factory to another factory is very likely to diminish total tardiness.
Seven neighborhood searches are constructed by different combinations of neighborhood structures. contains four neighborhood structures , , , related to the critical factory . consists of , , , . In , six insertion-related neighborhood structures , , , , , are applied. is composed of two swap-based neighborhood structures , .
is established by , , and . , , , and are used in . has all eight structures for a comprehensive effect.
The procedure of each
is given in Algorithm 2. Seven search operators are defined, each of which is composed of a global search, reassignment, inversion and
,
.
is the number of neighborhood structure in
,
,
,
,
,
,
,
.
| Algorithm 2: |
| Input:x, |
| Output: updated solution x |
| 1: let |
| 2: while do |
| 3: randomly decide a usage sequence of all neighborhood
|
| 4: structures of |
| 5: suppose that the obtained sequence is |
| 6: let |
| 7: while do |
| 8: produce a new solution |
| 9: if then |
| 10: |
| 11: else |
| 12: |
| 13: end if |
| 14: |
| 15: end while |
| 16: end while |
| 17: return updated solution x |
4.2. Q-Learning Algorithm
In this study, the Q-learning algorithm is integrated with ABC to dynamically select the search operator. To realize the above purpose, population evaluation results are used to describe state , the search operator described above is applied to depict action , and, as a result, action selection can result in a dynamical selection of the search operator.
4.2.1. State and Action
Three indices are used to evaluate population quality, which are
of elite solution
, evolution quality
of population
P and diversity index
. Initially,
, if elite solution
is updated, then
; otherwise,
, where
is defined similarly to
in
Section 3.1.
where
if
on generation
t and 0 otherwise;
on generation
t.
Eight states are depicted by using three indices, as shown in
Table 3.
means that the elite solution
is updated on generation
t. Elite solution
does not deteriorate because of greedy selection, so
may be 0 or positive,
,
are integers,
.
and
are obtained by experiments. For
and
, two cases exist, which are
and
.
For the instance of
depicted in
Section 5,
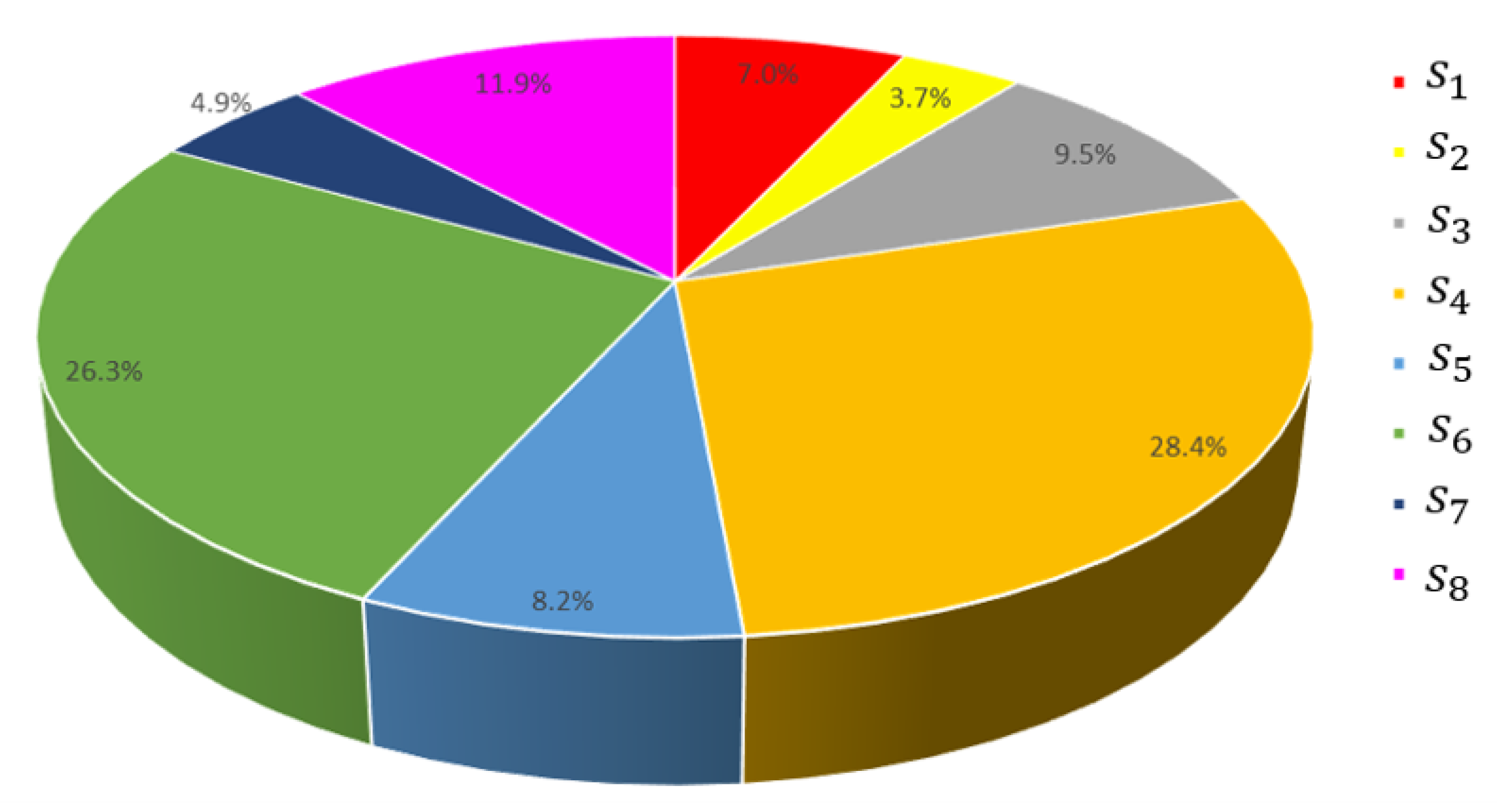
Figure 6 shows the percentage of occurrence in four cases of
and two cases of
and
in the whole search process of QABC, and
Figure 7 presents a pie chart of the percentage of the eight states. It can be found that all states exist in the search process of QABC, so it is reasonable to set eight states.
In QABC, population P is divided into two employed bee swarms , and an onlooker bee swarm . Population division is shown below. Initially, , , are empty. The dividing steps are shown below. Randomly select solutions from population P and add them into , then stochastically choose solutions from the remaining part of P and include them in ; finally, consists of the remaining solutions in P. , based on experiments.
Seven search operators are directly defined as actions , , ⋯, . is composed of global search, reassignment, inversion and . Once action , is chosen, it acts on , and . Action is defined by randomly selecting a search operator for , and , respectively, so when is selected, , and may apply different search operators.
4.2.2. Reward and Adaptive Action Selection
Elite solution
is the output of QABC, and its improvement is very important for QABC. When
, that is,
is updated, a positive reward should be given; moreover, the bigger the
is, the bigger the reward is. When
, the elite solution is kept invariant; in this case, a negative reward should be added. Based on the above analyses, reward
is defined by
Let
indicate
on generations
t and
, respectively,
For
-greedy action selection, the learner will explore with the probability
and exploit the historical experience with the probability of
by choosing the action with the highest Q value, where
plays a key role in the trade-off between exploration and exploitation, and some adaptive methods are used [
72,
73].
In this study, a new adaptive
-greedy action selection is proposed, where
is adaptively changed with
and the current selected action
,
where
. Obviously,
.
If and , that is, action with the biggest leads to new , in this case, should be reduced to enlarge the probability of exploitation; if and , that is, a randomly chosen results in a new , then should increase for a larger probability of exploration. Two other cases can be explained in the same way.
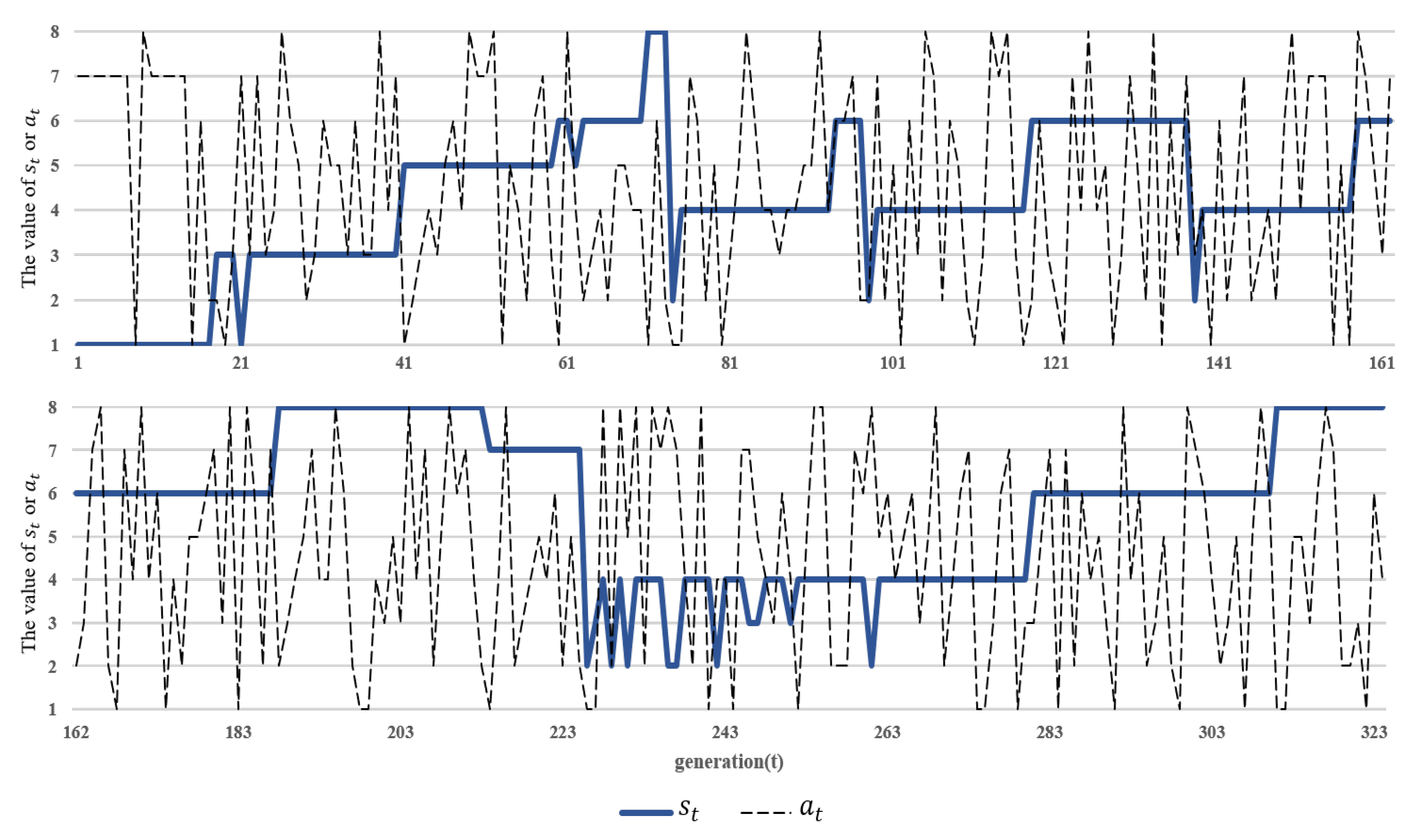
For instance
,
Figure 8 shows the updating processes of state and action. When the stopping condition reaches
,
Figure 8 describes the changes of state and action in the whole process of the Q-learning algorithm. It can be found that population
P can keep a state for many generations; for example, the population is in state 6 between generations 162 and 183. Moreover, the action often changes from
to
. An example of the update process of the Q-table is given in
Table 4. If
= 8,
= 2,
= 6,
= 0.1,
= 0.8,
= 1.38 according to Equation (
7). As shown in
Table 4(a), Q(8, 2) =
before updating, and after the Q-table is updated,
for Q(8, 2) is obtained by Equation (
4), which is shown in
Table 4(b). The selection of a search operator also exists in a hyper-heuristic, in which a low-level heuristic (LLH) is often selected by using a random method, choice function and tabu search; however, the selection of a hyper-heuristic is often time-consuming. Lin et al. [
52] applied a Q-learning algorithm to select an LLH from a set of LLH. Our Q-learning algorithm differs from the work of Lin et al. (1) Fitness proportion is used to depict the state [
52], while population evaluation is applied to describe the state in this study. (2) Lin et al. [
52] employed a Q-learning algorithm as high-level strategy, which is a part of the hyper-heuristic. The Q-learning algorithm is only adopted to select the search operator and does not substitute any phases of ABC, so in QABC, three phases still exist and are not replaced with Q-learning.
4.3. Three Phases of QABC
On each generation of t, two employed bee swarms , are used by population division, and the employed bee phase with adaptive migration between them is shown in Algorithm 3, where is an integer and is a parameter of migration.
If the condition of migration is met, the worst solution of is replaced with the best solution of ; as a result, the worst solutions are deleted, and the best solution of is reproduced.
A simple tournament selection is applied in the onlooker bee phase, and a detailed description is shown in Algorithm 4.
As shown above, when an action is selected, according to the Q-learning algorithm, the corresponding search operator, which is composed of a global search, reassignment, inversion and , is used for , and ; when action is chosen by the Q-learning algorithm, the search operator from is randomly selected for , , , respectively.
In general, when
, the corresponding employee bee of
will become a scout. In this study, when the condition of the elite solution
is met, a new scout phase is proposed based on a modified restart strategy [
74], which has been proven to be capable of being used to avoid premature convergence. The new scout phase is described in Algorithm 5, where
is an integer.
In Algorithm 5, when global search, reassignment and inversion are performed on
, the obtained new solution directly substitutes for
; that is, greedy selection is not used in the scout phase.
| Algorithm 3: Employed bee phase |
| Input: |
| 1: for to 2 do |
| 2: for each solution do |
| 3: execute the chosen search operator of on x |
| 4: end for |
| 5: update best solution and worst solution of |
| 6: end for |
| 7: if then |
| 8: for to 2 do |
| 9: replace the worst solution of with best
|
| 10: solution of |
| 11: end for |
| 12: |
| 13: else |
| 14: |
| 15: end if |
| Algorithm 4: Onlooker bee phase |
| 1: for each solution do |
| 2: Randomly select and |
| 3: if then |
| 4: |
| 5: else |
| 6: |
| 7: end if |
| 8: if then |
| 9: |
| 10: end if |
| 11: Execute the chosen search operator of on x |
| 12: end for |
| Algorithm 5: Scout phase |
| Input:, |
| 1: if then |
| 2: sort all solutions of P in ascending order of |
| 3: construct five sets , |
| 4: |
| 5: for each solution do |
| 6: randomly select a solution |
| 7: execute global search between and |
| 8: end for |
| 9: for each solution do |
| 10: apply reassignment operator on |
| 11: end for |
| 12: for each solution do |
| 13: perform inversion operator on |
| 14: end for |
| 15: for each solution do |
| 16: randomly generate a solution
|
| 17: end for |
| 18: |
| 19: else |
| 20: |
| 21: end if |
| 22: for each solution do |
| 23: update if is better than |
| 24: end for |
4.4. Algorithm Description
Algorithm 6 gives the detailed steps of QABC, and
Figure 9 describes its flow chart, in which
t indicates the number of generations, and it also denotes the number of iterations of the Q-learning algorithm.
| Algorithm 6: QABC |
| 1: let be 0, |
| 2: Randomly produce an initial population P |
| 3: Initialize Q-table
|
| 4: while termination condition is not met do |
| 5: divide P into , , and |
| 6: select action by Q-learning algorithm
|
| 7: execute employed bee phase by Algorithm 3
|
| 8: perform onlooker bee phase by Algorithm 4
|
| 9: apply scout phase by Algorithm 5
|
| 10: execute reinforcement search on |
| 11: update state and Q-table
|
| 12: |
| 13: end while |
The reinforcement search of elite solution is depicted below. Repeat the following steps times: execute the global search between and y ( and ) and apply reassignment and inversion on sequentially, for each operator, when a new solution z is obtained, and is updated if z is better than .
QABC has the following features: (1) The Q-learning algorithm is adopted by using eight states based on the population evaluation, eight actions and a new adaptive action selection strategy. (2) Population P is divided into three swarms , , , and the Q-learning algorithm is used to dynamically select a search operator for these swarms. (3) The employed bee phase with adaptive migration and a new scout phase is implemented based on the modified restart method that is used.
In the Q-learning algorithm, eight actions mean that there are eight different search operators, and one of them is dynamically chosen; that is, the evolution of three swarms can be evolved with different operators, and as a result, the exploration ability can be intensified, and the possibility of falling local optima also diminishes greatly. Moreover, a migration and restart can maintain the high diversity of a population; thus, these features may lead to a good performance.
5. Computational Experiments
Extensive experiments were conducted to test the performance of QABC for a distributed three-stage ASP with layout, factory eligibility and setup times. All experiments were coded in C by using CodeBlocks 16.01 and run on a desktop computer with an Intel i5-10210 CPU (2.10GHz) and 8-GB RAM.
5.1. Test Instances and Comparative Algorithms
A total of 92 instances are applied and depicted by , and . For each instance denoted as , , , , where + . The elements of are randomly selected from , and contains at least one factory. The above times and due date are integers and follow a uniform distribution on the above intervals.
As stated above, distributed ASP with factory eligibility is not considered, and there are no existing comparative algorithms.
For the distributed heterogeneous flowshop scheduling problem, Chen et al. [
75] presented a probability model-based memetic algorithm (PMMA) with search operators and a local intensification operator, Li et al. [
64] proposed a discrete artificial bee colony (DABC) with neighborhood search operators, a new acceleration method and a population update method, and Meng and Pan [
65] designed an enhanced artificial bee colony (NEABC) by using a collaboration mechanism and restart strategy.
PMMA [
75], DABC [
64] and NEABC [
65] have been successfully applied to solve the above distributed flowshop scheduling; moreover, these algorithms can be directly used to solve distributed three-stage ASP with factory eligibility after transportation and assembly are added into decoding process, and thus they are chosen as comparative algorithms.
Two variants named ABC1 and ABC2 are constructed. When the Q-learning algorithm is removed from QABC, ABC1 is obtained. When population division, migration, restart, and reinforcement search are removed from ABC1, and a scout phase is implemented as in
Section 3.1, ABC2 is produced. When the Q-learning algorithm is removed, the search operator of
P is fixed. We tested seven search operators, and two variants with
is better than these algorithms with other operators.
5.2. Parameter Settings
In this study, a stopping condition is defined by CPU time. We found through experiments that QABC converges fully on all instances when seconds is reached; moreover, all comparative algorithms, ABC1 and ABC2, also converge fully when this CPU time is reached, and so we set seconds as the stopping condition of all algorithms.
With respect to the parameters of the Q-learning algorithm, we directly use the initial
of 0.9 and learning rate
, according to Wang et al. [
76]. The following parameters of QABC, which are
N,
,
,
,
and discount rate
are tested according to the Taguchi method [
77] on instance
. The levels of each parameter are shown in
Table 5. The results of
and the S/N ratio are given in
Figure 10, where
is the average value of 10 elite solutions in 10 runs,
,
represents the elite solution for the
gth run, and the S/N ratio is defined as
.
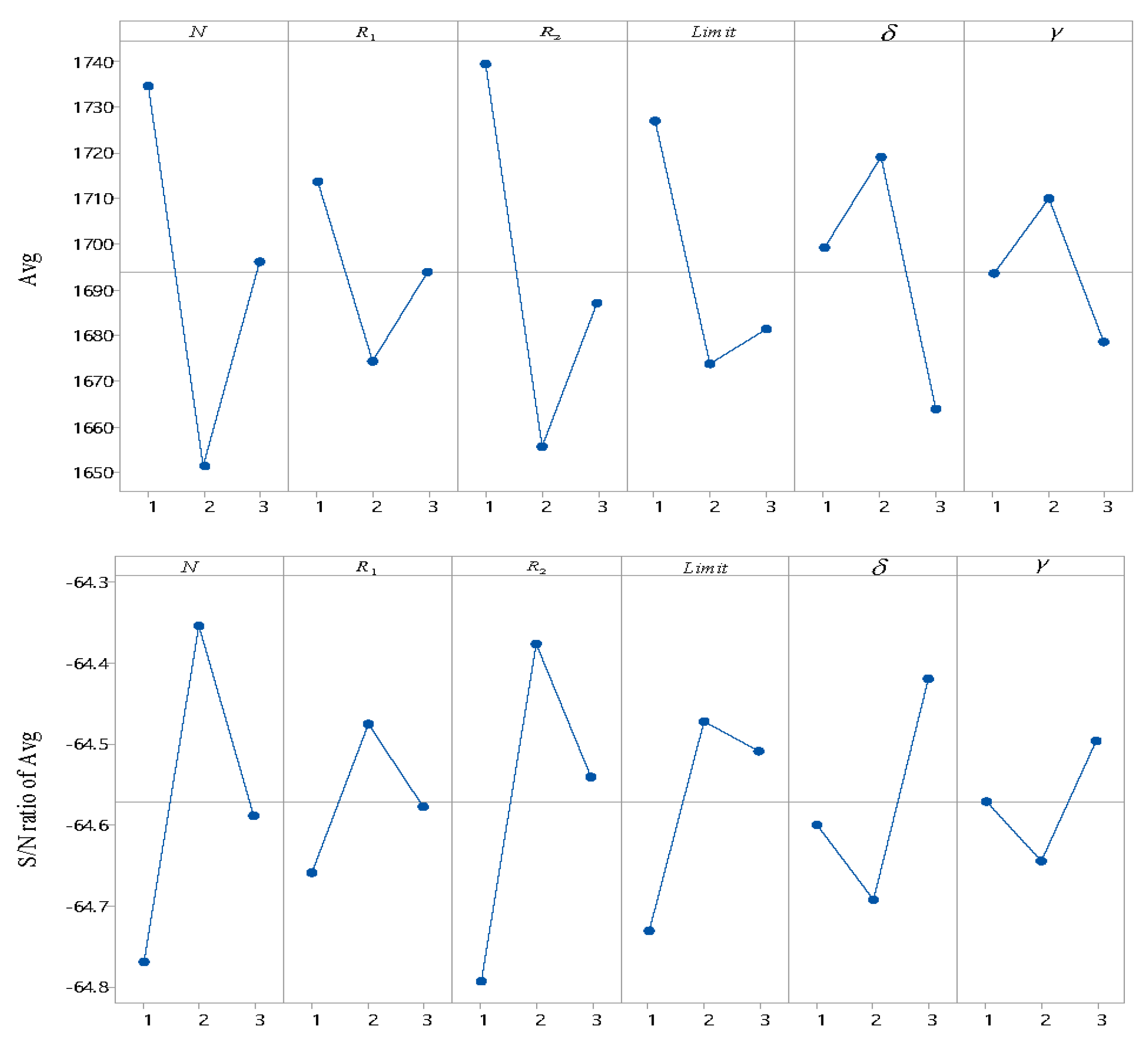
As shown in
Figure 10, when the levels of
N,
,
,
,
, and
are 2, 2, 2, 2, 3, 3, QABC produces a smaller average
and a bigger S/N ratio than QABC with other combinations of levels, and so the suggested settings are
,
,
,
,
and
.
Parameters of ABC1 and ABC2 are directly selected from QABC. Except for the stopping condition, the other parameters of PMMA, DABC, and NEABC are chosen from [
64,
65,
75]. We also found that these settings of comparative algorithms can result in a better performance than other settings.
5.3. Results and Analyses
QABC is compared with ABC1, ABC2, PMMA, DABC and NEABC. Each algorithm randomly runs 10 times on each instance.
Table 6,
Table 7 and
Table 8 show the computational results of QABC and its comparative algorithms, where
indicates the smallest total tardiness in 10 runs,
, and
is the standard deviation for 10 elite solutions in 10 runs,
. QA, A1, A2, PM, DA and NE denote QABC, ABC1, ABC2, PMMA, DABC and NEABC for simplicity, respectively.
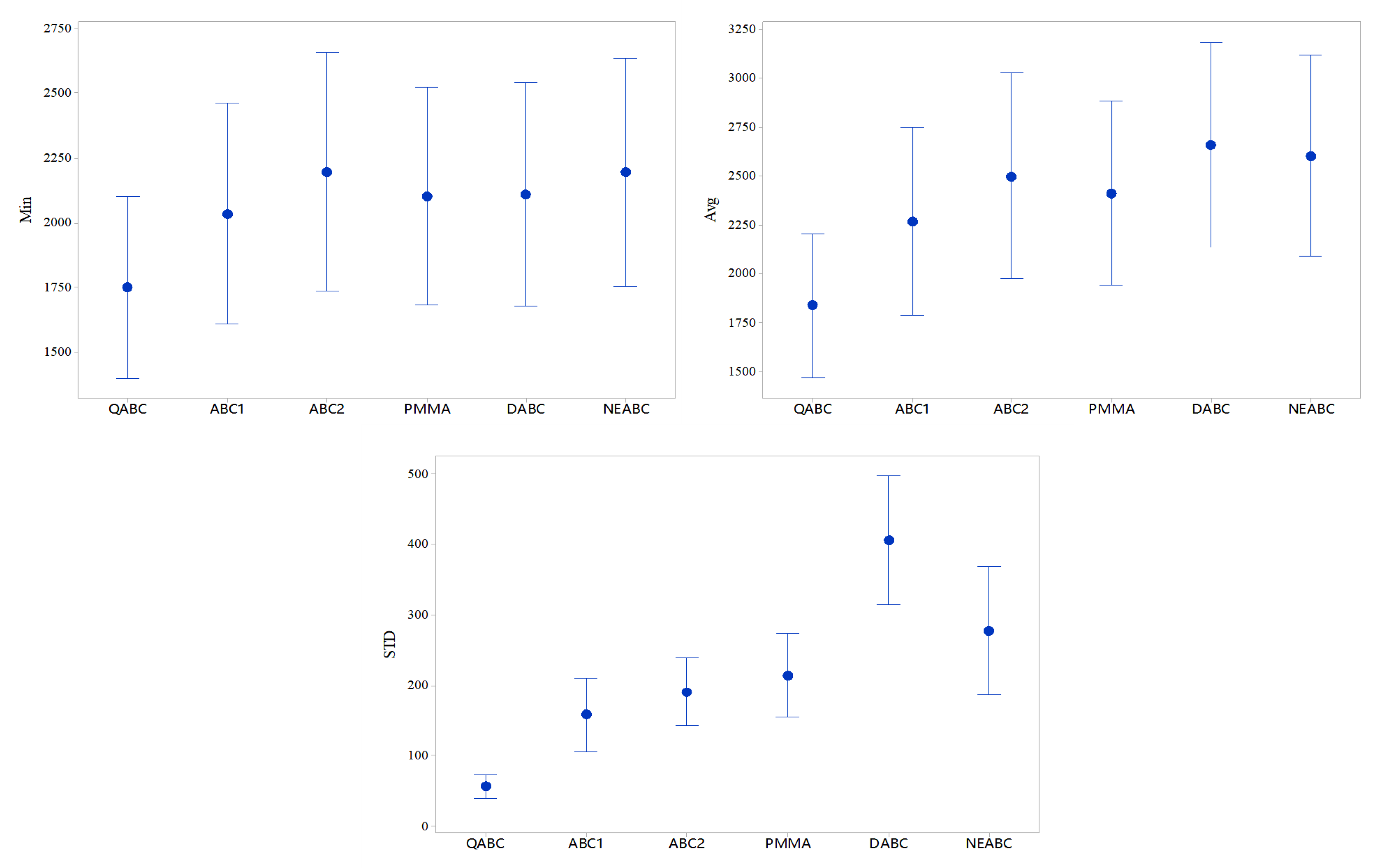
Figure 11 displays the mean plot with a 95% confidence interval of all algorithms, and
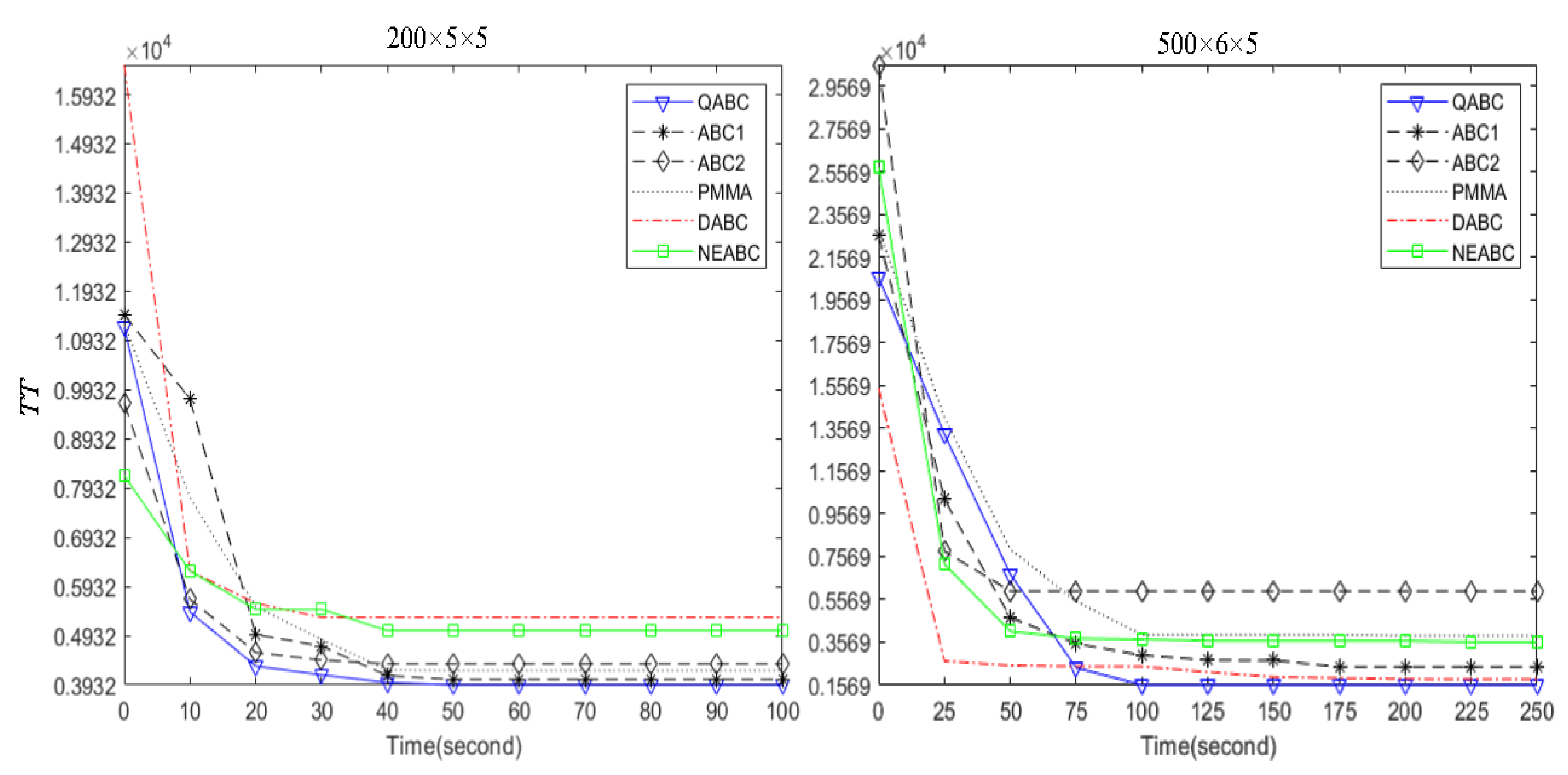
Figure 12 describes convergence curves for instances
and
.
Table 9 shows the results of pair-sample
t-test, in which
t-test (A, B) means that a paired
t-test is conducted to judge whether algorithm A gives a better sample mean than B. If a significance level is 0.05, there is a significant difference between A and B in the statistical sense if the
p-value is less than 0.05.
As shown in
Table 6,
Table 7 and
Table 8, QABC significantly performs better than ABC1 in most of the instances. The
of QABC is smaller than that of ABC1 by at least 10% in 31 instances,
of QABC is less than that of ABC1 by at least 200 in more than 35 instances and
of QABC is smaller than that of ABC1 in nearly all instances.
Table 9 shows that there are notable performance differences between QABC and ABC1 in a statistical sense.
Figure 11 depicts the notable differences between the
of the two algorithms, and
Figure 12 reveals that QABC significantly converges better than ABC1.
It can be found from
Table 6 that ABC1 produces better
than ABC2 in 54 of 92 instances. As shown in
Table 7,
of ABC1 is less than or equal to that of ABC2 in 84 of 92 instances.
Table 8 shows that ABC2 performs better than ABC1 on
in 64 instances.
Figure 12 and
Table 9 also reveal that ABC1 performed better than ABC2.
Although some new parameters such as and are added because of the inclusion of new strategies such as Q-learning and migration, the above analyses on ABC, ABC1 and ABC2 demonstrate that the Q-learning algorithm, migration and new scout phase, etc., have really positive impacts on the performance of QABC, and thus, these new strategies are effective and reasonable.
As shown in
Table 6,
Table 7 and
Table 8, QABC and PMMA converge to the same best solution for most of the instances with
, QABC does not generate worse
than PMMA in any instances with
; moreover, QABC produces
and
smaller than or the same as PMMA in almost all instances. QABC performs better than PMMA. The statistical results in
Table 9 also reveal the above conclusion can be obtained.
Figure 11 and
Figure 12 show the performance difference between the two algorithms regarding
and
, respectively.
When QABC is compared with DABC, it can be seen from
Table 6,
Table 7 and
Table 8 that QABC has smaller
than DABC in 80 instances, generates smaller
than DABC in 85 instances and obtains smaller
than DABC in 85 instances; moreover, performance differences between QABC and DABC increase with an increase in
. The convergent curves in
Figure 12 and results in
Table 9 can also demonstrate the performance difference in
between QABC and DABC, the performance differences in
also can be validated by the statistical results in
Table 9, and
Figure 11 and
Table 9 show that QABC significantly outperforms DABC in
.
It can be concluded from
Table 6,
Table 7 and
Table 8 that QABC performs significantly better than NEABC. QABC produces smaller
than NEABC by at least 20% in about 39 instances, also generates better
than NEABC by at least 20% in more than 58 instances and obtains better
than or the same
as NEABC on nearly all instances. QABC performs notably better than NEABC, and the same conclusion can be found in
Table 9.
Figure 11 shows the significant difference in
, and
Figure 12 demonstrates the notable convergence advantage of QABC.
As stated above, the inclusion of the Q-learning algorithm, the migration between two employed bee swarms and modified restart strategy in the scout phase really improve the performance of QABC. The Q-learning algorithm results in the dynamical adjustment of search operators in the employed bee phase and onlooker bee phase. As a result, the search operator is not fixed and varied dynamically, and the exploration ability can be improved. Migration leads to the full use of the best solutions of and , and the restart strategy makes the population evolve with higher diversity. These features can lead to better search efficiency. Based on the above analyses, it can be concluded that QABC can effectively solve the distributed three-stage ASP with factory eligibility and setup times.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}