1. Introduction
Point cloud is a set of points in 3D space that can be viewed as a representation of object surface. Due to greatly compensating for the lack of spatial structure information of 2D images, point cloud has been extensively used in various fields such as automatic drive [
1], virtual reality [
2], and intelligent robot technology [
3,
4]. These contemporary applications usually call for advanced processing methods of point cloud. As is well known, point cloud is unordered and irregular [
5], which is distinct from 2D images. All algorithms for point cloud feature extraction, therefore, must be independent of the order of input points and point cloud is a collection of uneven sampling points. On one hand, it makes the relationship between points difficult to be used for extracting features. On the other hand, convolutional neural networks, which have already been applied in image and video processing, are not applicable to be used in point cloud processing directly. This research focuses on shape classification and part segmentation of point cloud, which are two basic and challenging tasks that have received a lot of attention from researchers in point cloud processing.
In the early stages of point cloud research, most researchers usually convert point cloud data into regular 3D voxel grids [
6] or a collection of images before feeding them into a convolutional neural network. Voxelization is a simple method of transforming a sparse and uneven point cloud to a conventional grid structure, which can be fed to standard CNNs to extract features. Voxnet [
7] vowelizes the point cloud into a volumetric grid that denotes spatial occupancy for each voxel, then uses a standard 3D CNN (Convolutional Neural Network) to predict the categories of objects based on the occupied voxels. For high spatial resolution, it is obvious that sparsely-occupied volumetric grid consumes a lot of memory and incurs vast computational costs. Therefore, several improvements are mentioned to work out the scarcity issue. Kd-net [
8] constructs an efficient 3D space division structure using kd-tree [
9], along with a deep neural architecture to learn point cloud representations. Analogously, in OctNet [
10], 3D CNN is applied to a hybrid grid-octree structure produced from a collection of shallow octrees, which makes it capable of achieving high resolution. The octree structure is effectively encoded using a bit string format, and each voxel’s feature vector is indexed by plain mathematics. OctNet [
10] requires substantially less memory and expense for high-resolution point clouds than a baseline network based on dense input grids. Nevertheless, this data conversion not only makes the generated data unnecessarily large, but also introduces quantization artifacts that may overshadow the natural inflexibility of the data.
In recent years, as a groundbreaking work, PointNet [
11] directly applied convolutional neural network on the raw point cloud. To extract global features, an MLP (Multi-Layer Perceptron) module and a symmetric function are applied to each point. This method comes up with a useful way for the representation of unstructured point cloud; however, the architecture only deals with independent points without cogitating connections between points in local regions so that local feature is not captured effectively. On the foundation of PointNet, PointNet++ [
12] is a hierarchical neural network that exploits local representations by repeatedly applying PointNet with a sampling layer and a grouping layer. In order to better aggregate each point and the matching edges connected to adjacent pairs, DGCNN [
13] tries to extend PointNet according to the edge convolutional neural network practical operation (EdgeConv) designed to be applied to edge features. Capitalizing on the advantages of typical CNN practice, PointCNN [
14] transforms the given chaotic point set to a latent canonical order by learning a
-convolutional operator, and then selects a standard CNN architecture to capture local features.
Transformer has been proved to be effectual in various practical application including machine translation tasks [
15,
16], computer vision tasks [
17,
18,
19], and graph-based tasks [
20]. Nowadays, transformer has been introduced in many specific yields such as remote sensing, cultural heritage, urban environments, and so on. For the purpose of learning the fine-grained local features of point cloud, a variety of attempts for point cloud segmentation have been made to extract spatial relationships between points through applying attention mechanism. The recently successful approaches [
21,
22,
23] further improve semantic segmentation accuracy by ignoring immaterial information and focusing on crucial information. For example in [
22], combining transformer with the random sampling algorithm, it is suitable for lightweight point cloud semantic segmentation of large-scale 3D point cloud. However, such approaches have not made it possible to learn more about the structural links between neighboring points.
Inspired by PCT [
24] and GRNet [
25], we propose a novel architecture TR-Net based on transformer for point cloud processing. In natural language processing, positional encoding module is usually used to express the word order in a sentence. It can show the positional relationship between words at the same time as discriminating the same word in different positions. However, there is no constant order in point cloud data. The raw positional encoding and the input embedding are combined into a coordinate-based input embedding module, which is considered as a viable solution. Because each point has distinct coordinates that describe their spatial placements, it may create distinguishable features. By capitalizing on the idea of PCT [
24], we introduce the neighbor embedding strategy to ameliorate the point embedding to enhance the capability of local feature extraction. Furthermore, we employ the encoder-decoder architecture to convert fundamental tasks of point cloud processing as a set-to-set translation issue. The encoder of TR-Net initially embeds the input three-dimensional coordinates into a high dimensional feature space. Then the embedded features are used as input of an attention-based sub-network to learn a semantically abundant representation for each point. It lowers the effect of noise and sharpens attention weights, which is advantageous for downstream tasks. To learn context-aware and spatially-aware features of point cloud, we design a residual neural network which generates global features used for the decoder input. For different specific tasks, the respective decoders have been designed to adaptively respond to task demands. More details about decoder are shown in
Section 3.
The major contributions of this work are are summarized as follows:
We propose a novel network architecture named TR-Net, which directly works on raw point cloud, reducing the memory usage.
We design a residual backbone with skip connections to learn context-aware and spatial-aware features.
Extensive experiments demonstrate that the TR-Net achieves state-of-the-art performance on shape classification and part segmentation.
3. Materials and Methods
In this section, we expound how our TR-Net can be used in some basic tasks of point cloud processing involving shape classification and part segmentation. The design details of TR-Net are also presented systematically.
Let be a sequence of unordered points, with F-dimension, where N represents the number of input points, and is treated as a feature vector containing coordinates in 3D space. In this work, we define and use 3D coordinates as input.
3.1. TR-Net Architecture
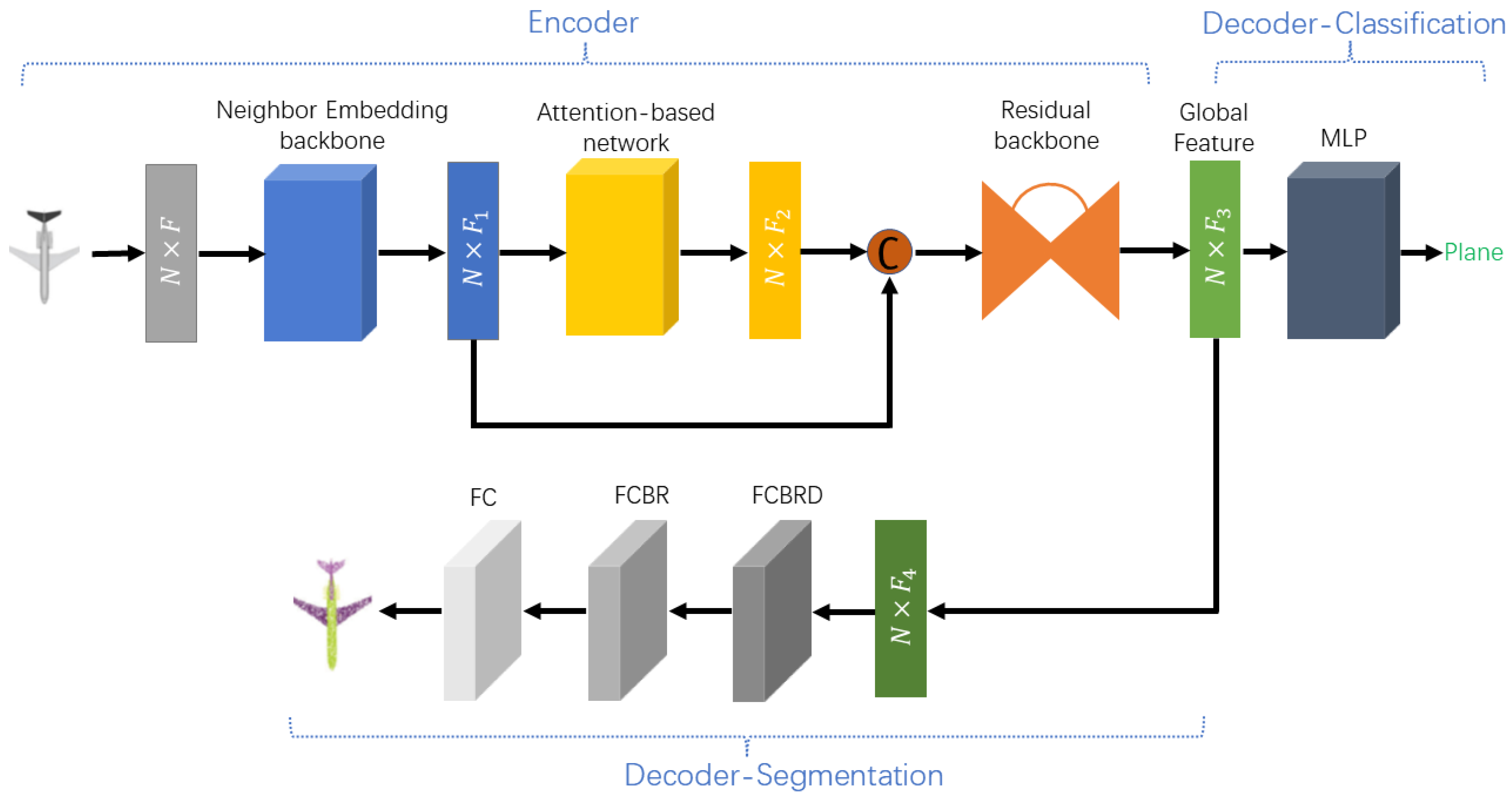
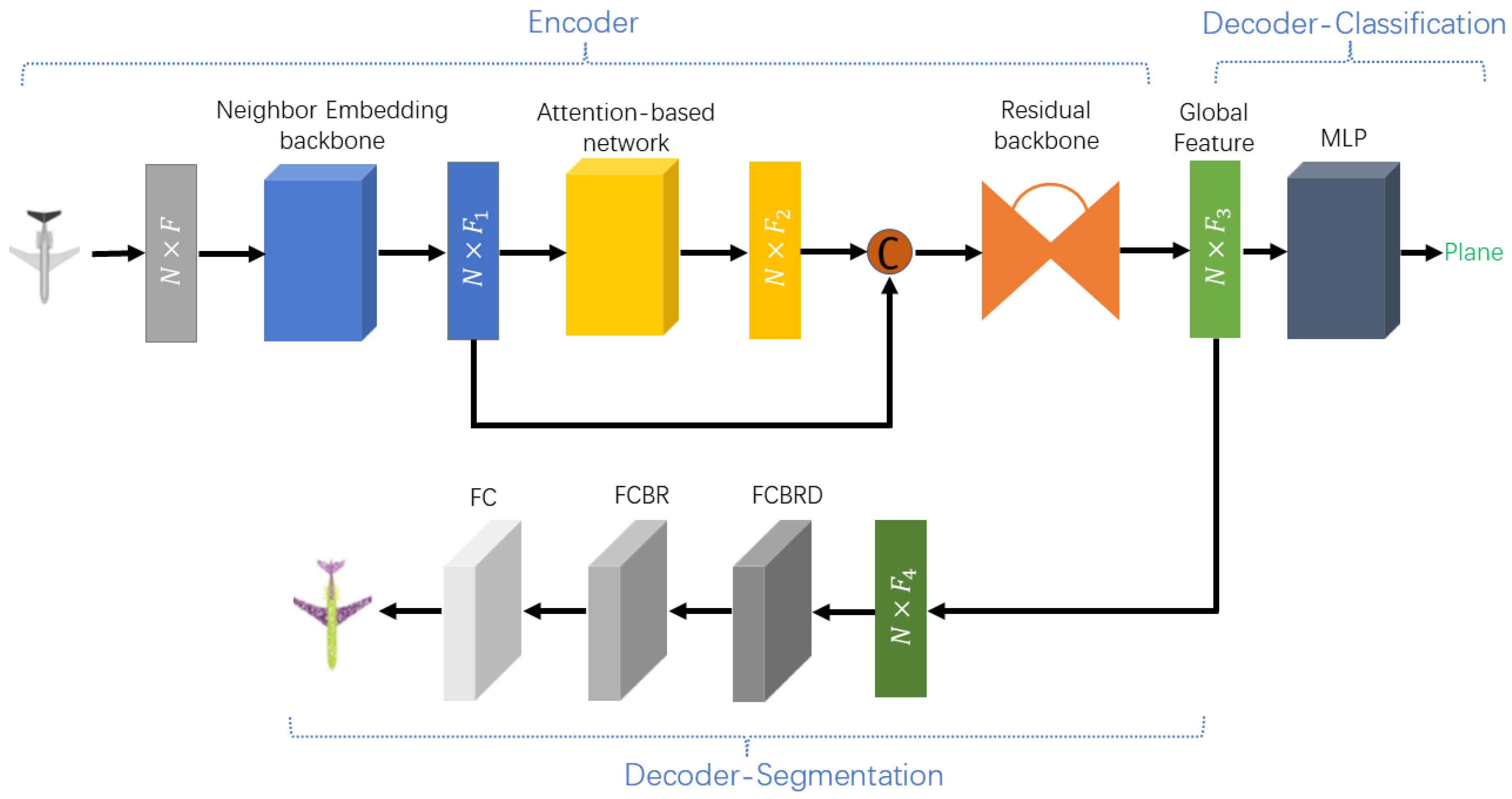
The overall architecture of TR-Net is presented in
Figure 1, including a neighborhood embedding backbone, an attention-based sub-network, a residual backbone, and decoders for different tasks. TR-Net shares similar principles to Transformer, which initially encodes the input features into a new high dimensional feature space. By this means, the semantic affinities between points are represented for various point cloud processing tasks. It firstly embeds the input coordinates of point cloud into a new space to learn the local neighboring information. The attention-based sub-network is comprised of four stacked offset-attention layers, which makes it better learn semantically abundant and discriminatory representation for each point. Then, we take the output feature of attention-based sub-network into residual backbone to exploit context information of point cloud, followed by a max pooling layer to yield global feature used for downstream tasks.
In the classification task. To recognize object categories in point cloud P, the global feature is fed into the classification decoder, which contains MLP layers (1024, 512, 256, ) and dropout operation with a invariable probability of 0.5 to convert global feature to object categories. In addition, we use the activation function LeakyReLU with batch normalization in each layer. Other hyperparameters are chosen in a similar way. The top-scoring category is determined as the category label of this point cloud.
In the part segmentation task. Aiming to segment the point cloud into
parts (e.g., cub handle, plane wings; a part hardly request to be contiguous), we need to obtain the specific semantic label for each point. As presented in
Figure 1, the global feature created by residual backbone is fed to the part segmentation decoder, which includes three shared full-connected layers
to classify each point. In more detail, the first full-connected layer is followed by the activation function ReLU and a dropout layer with probability 0.5. Only the activation function ReLU is applied on the second full-connected layer. Furthermore, all layers are batch normalized.
3.2. Point Cloud Sampling
The raw point cloud data could not represent the relations between neighboring points. So we design a neighborhood embedding backbone that is mainly used for point cloud sampling. However, point embedding is not the same as word embedding in NLP. For word embedding, similar words are placed closer to each other in the embedding space. This approach disregards interactions between points, which is quite important for point cloud learning. To enhance the ability of local feature extraction, we adopt a neighborhood embedding strategy [
24] in the locally adjacent points. This module first uses two cascaded 1D convolutional layers, each of which is followed by a universal batch normalization layer and the activation function ReLU to embed point cloud coordinates into a high-dimensional space. To develop the ability of local feature expression, the KNN (K-nearest neighbors) algorithm is utilized to search for the k nearest points on each point during point cloud sampling. Using Euclidean distance, KNN finds an inflexible quantity of neighboring points, then these points will be formed as a k-neighborhood structure. In contrast to coordinate-based point embedding in transform [
16], our sampling strategy considers the local neighbor information on each point, thus we can capture point-to-point relations in the local region.
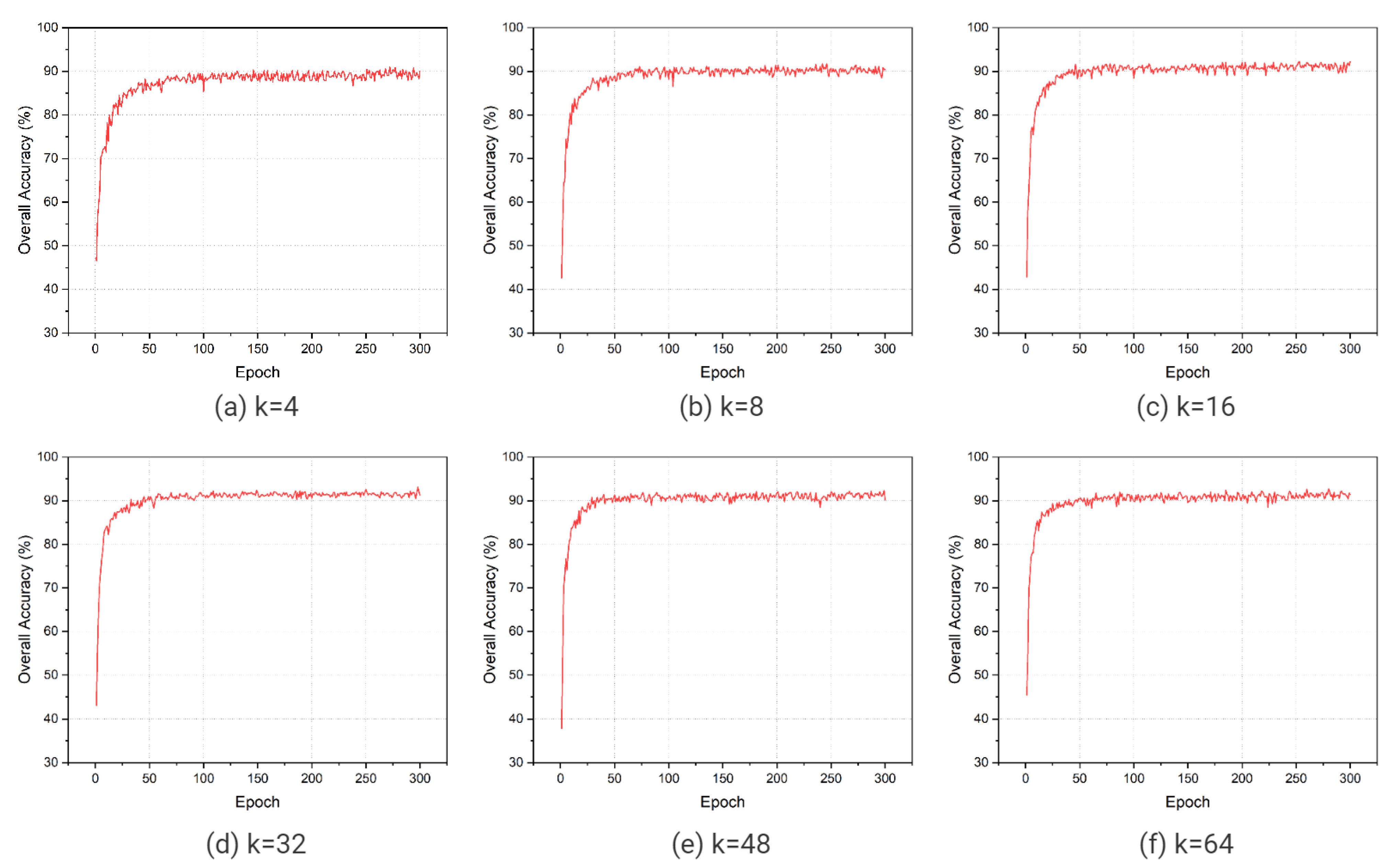
In more detail, we assume the input point cloud P contains N points, which are fed into two convolutional layers to generate corresponding features F. Then, point cloud P is down sampled to by adopting the farthest point sampling (FPS) algorithm. For each sampled point , we assign KNN to its k-nearest neighbors in P, which aggregates the local neighboring features. Finally, we obtain the output features from sampled point cloud P.
3.3. Attention-Based Sub-Network
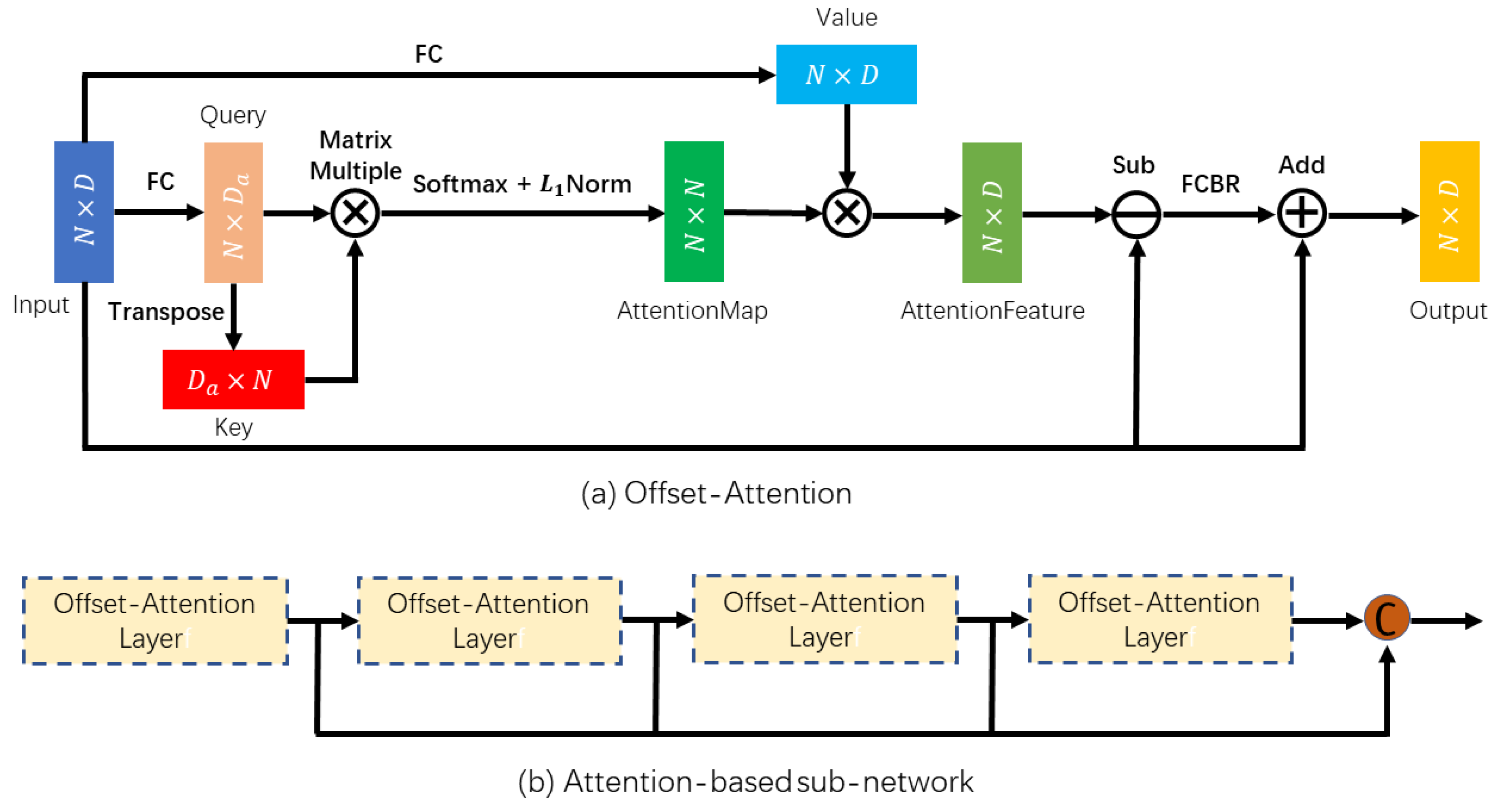
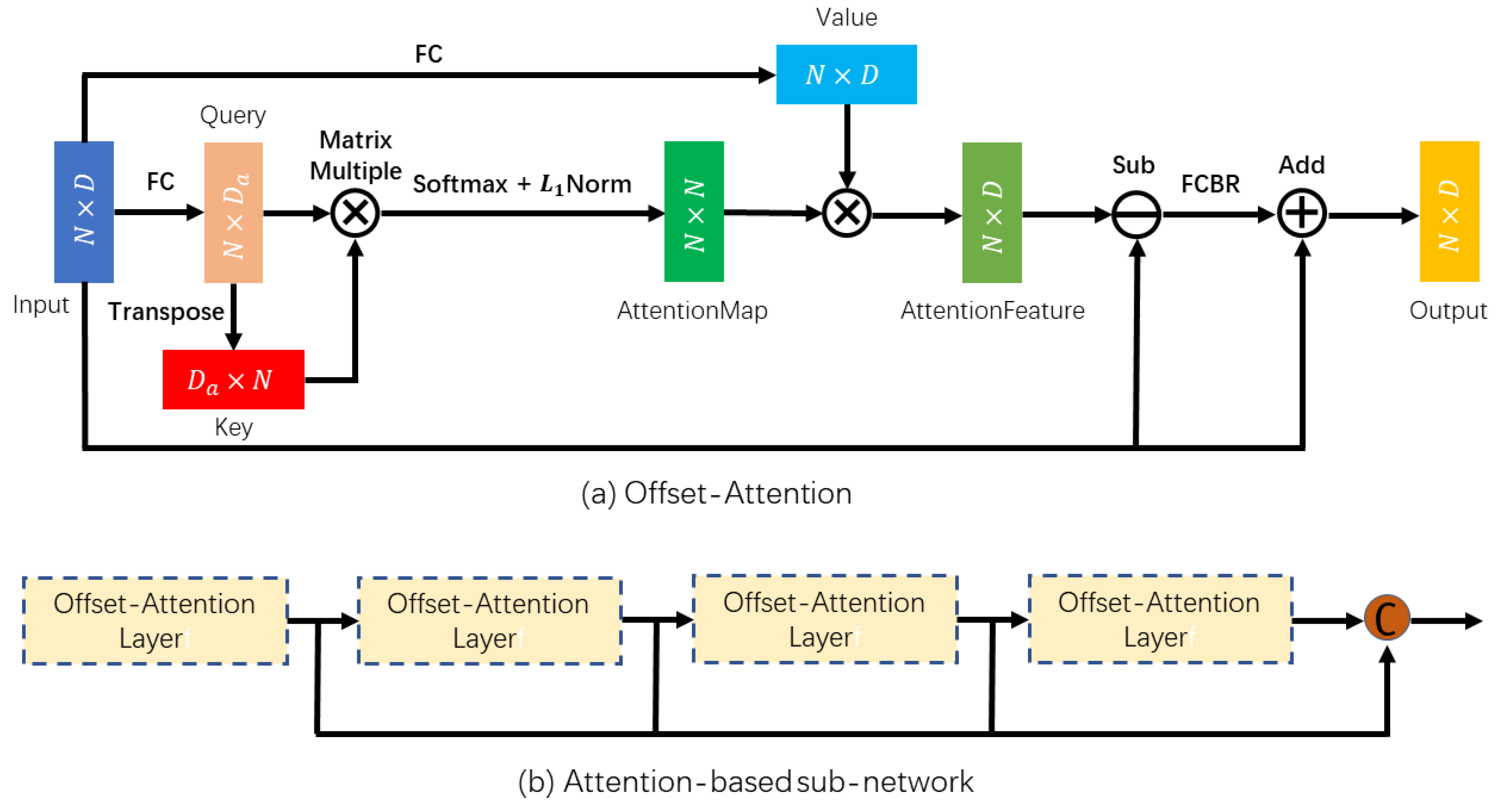
In
Figure 2, the attention-based sub-network is comprised of four stacked offset-attention layers to better learn a semantically abundant and discriminatory representation for each point. The attention mechanism could powerfully capture valuable information by paying different attention to different features, which has performed advantages in various tasks. Self-attention [
16], also called intra-attention, is a mechanism for connecting different positions in a sequence together to receive a representation of the sequence. It considers self-geometric information for each individual point to learn self-coefficients. Furthermore, the study in PCT indicates that self-attention ignores the relationship between points which makes it inadequate to learn a semantically abundant and discriminatory representation from the embedded features effectively. Our work draws upon the idea of offset-attention [
24] which is advantageous to downstream tasks by diminishing the influence of noise and sharpening the attention weights.
Generally, an attention function may be described as a vector that maps a query and a pair of key values to an output, in which the query, key, value, and output are vectors. The output is calculated as a weighted sum of the values, in which the weight assigned to each value is calculated by querying a compatible function with the corresponding key. Specifically, the offset-attention following the terminology in transformer [
16] uses
Q,
K,
V to represent the query, key and value metrices, respectively, produced by linear transformations of the input features
in Equation (
1).
where
means 1D-convolution, and they are different with each other.
Then, using the query matrix and the key matrix, the weight of attention is calculated by matrix point product as follows:
There are two widely employed attention functions, which are additive attention and dot-product attention. Dot-product attention is very analogous to algorithm. Additive attention is paid to compute compatibility functions using feed-forward networks with a single hidden layer. Although the theoretical complexity of them is similar, dot-product attention is significantly faster and less space-using by using highly optimized matrix multiplication code in practice. The input involves queries and keys of dimension
, and values of dimension
. If
is too large, dot products may grow rapidly in magnitude and force the softmax function into areas with extremely tiny gradients. To minimize such impact, these weights are normalized to obtain
refer to Equations (3) and (4).
It is evident that the normalization in offset-attention is different from traditional self-attention that scales the first dimension by and normalizes the second dimension with softmax. For the sake of normalizing the attention map in the offset-attention mechanism, the softmax operator is used on the first dimension, while a -norm is applied on the second dimension.
Because the input feature
and shared matching linear transformation matrices determine the query, key, and value matrices, all of them are independent of order. In addition, both softmax and weighted sum are independent of permutations. As a result, the entire offset-attention process is permutation-invariant which makes it very suitable for the unordered, irregular domain shown by point cloud. Inspired by Laplacian matrix in Graph convolution networks [
36], the offset-attention output features
are shown in Equation (
5). In this stage, we obtain the augmented feature that will be fed to the residual backbone.
where
denotes a full-connected layer linear layer with the activation function ReLU.
3.4. Residual Backbone
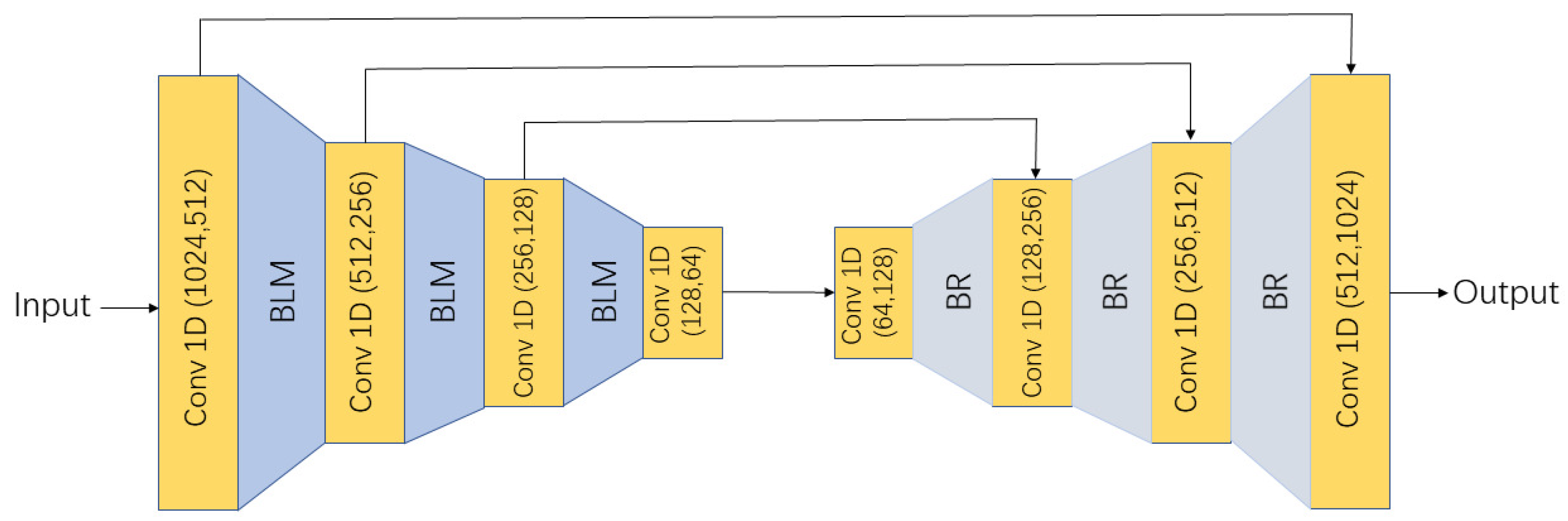
Traditional deep neural networks may cause a vanishing gradient problem. To address this, we thus design a residual backbone with skip connection following the attention-based sub-network to capture context information in the global space. As shown in
Figure 3, the whole convolutional layers are 1D convolution layer. The left convolutional layers are followed by BLM, but the right is BR. It has been proven by Szegedy [
37] that the batch normalization could accelerate network convergence and lower the complexity in training stage, thus, a batch normalization layer is used after each 1D convolution. The leakyReLU activation function is chosen to avoid jaggedness problem in gradient direction. A rectified linear unit layer (ReLU) is added after the left BachNorm layer to avoid gradient disappearance. The maximum pooling is to fuse the information of each point in point cloud. Finally, we obtain the output global features with context information as the input of decoder.
6. Conclusions
In this paper, we propose a new architecture named TR-Net, which is based on transformer for learning on point cloud. By adopting the neighborhood embedding strategy and residual backbone, TR-Net could exploit context-aware and spatially-aware features. Experiments show that our approach outperforms voxel-based, MLP-based, and graph-based frameworks and achieves state-of-the-art performance on classification and part segmentation benchmarks. This is due to the fact that the coordinates of point cloud contain spatial location information, and the offset-attention operator sharpens the attention weights to critical information when extracting global features.
Our experiments also suggest that the embedded features can be equally valuable if not more valuable than point coordinates. Developing a practical and theoretically-justified architecture for balancing global and local information in a learning pipeline will require insight from theory and practice in the attention mechanism. Given this, we will think about taking inspiration from image processing and natural language processing. Compared to natural language and 2D image, the available point cloud datasets are very limited nowadays. In the future, we will train it on larger datasets and compare it to other representative frameworks to observe what benefits and limitations it has. Another viable extension is to design a lightweight transformer network that reduces the amount of operations in the reasoning process, making it possible to apply in edge devices.




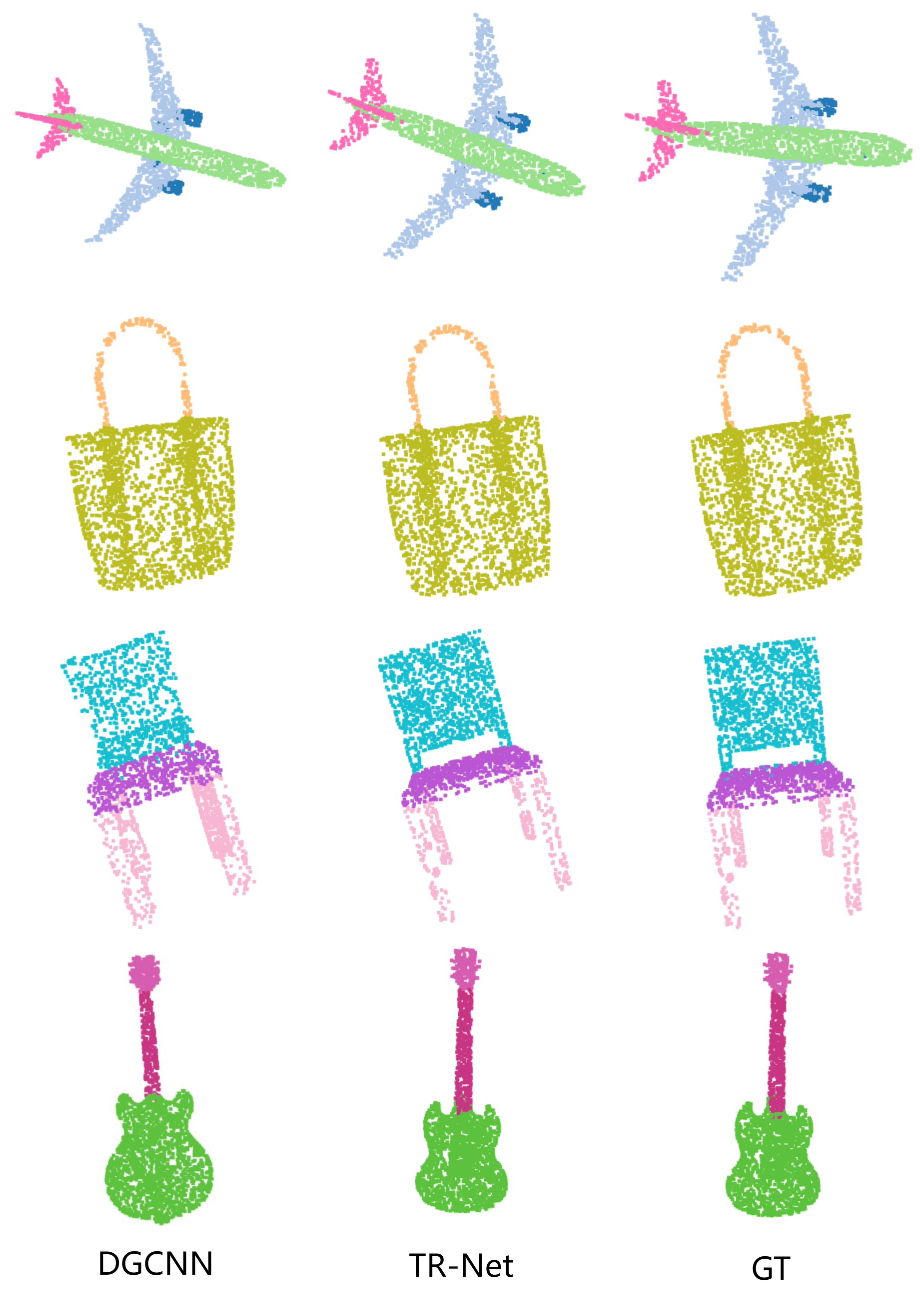


{kind=link}
{kind=link}
{kind=link}
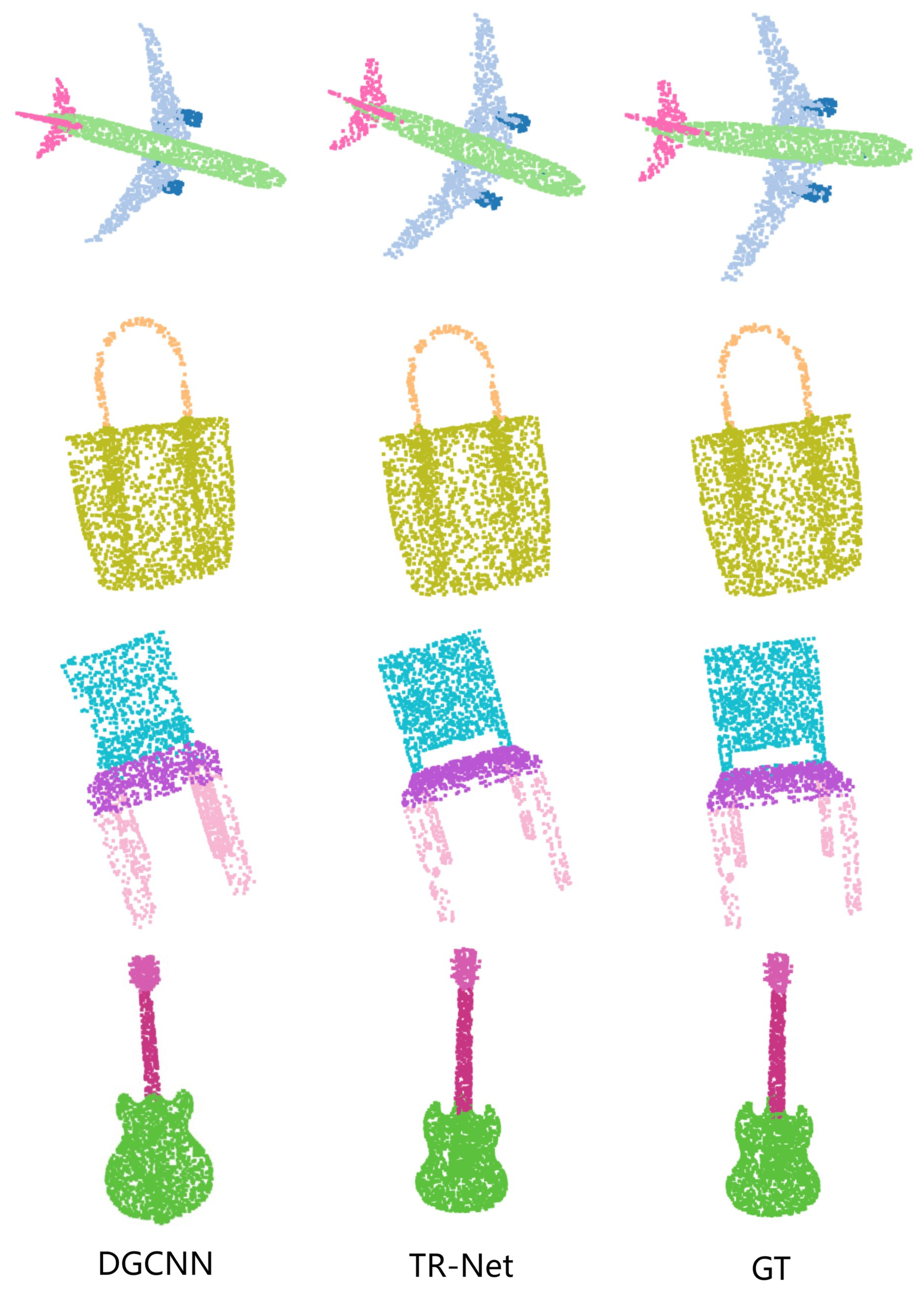{kind=link}
{kind=link}
{kind=link}