
Research on Repetition Counting Method Based on Complex Action Label String


Abstract
:1. Introduction
1.1. Repetition Counting
1.2. Online Action Recognition
- The motion information contained in the skeletons sequence is converted into a one-dimensional signal [23], and the fragments of the skeleton sequence are segmented with several thresholds. Finally, the segmented fragments are sent into a classifier to obtain the action labels. Such methods rely on the depth camera or the 2D pose estimation algorithm [24,25,26] to collect the skeleton of people in the scene, which increases the consumption of computing resources.
- Methods based on sliding window process video frames in batches [27], with the next batch having some of the same frames as the last. Those methods may not accommodate the situation where the execution speed of the same action changes dramatically.
- The input video is classified frame by frame, and then historical results over some time are fused to obtain the result of the current moment. The input modes of such methods include RGB frames [28] and optical flow [29], but they cannot effectively take into account both spatial and temporal information at the same time.
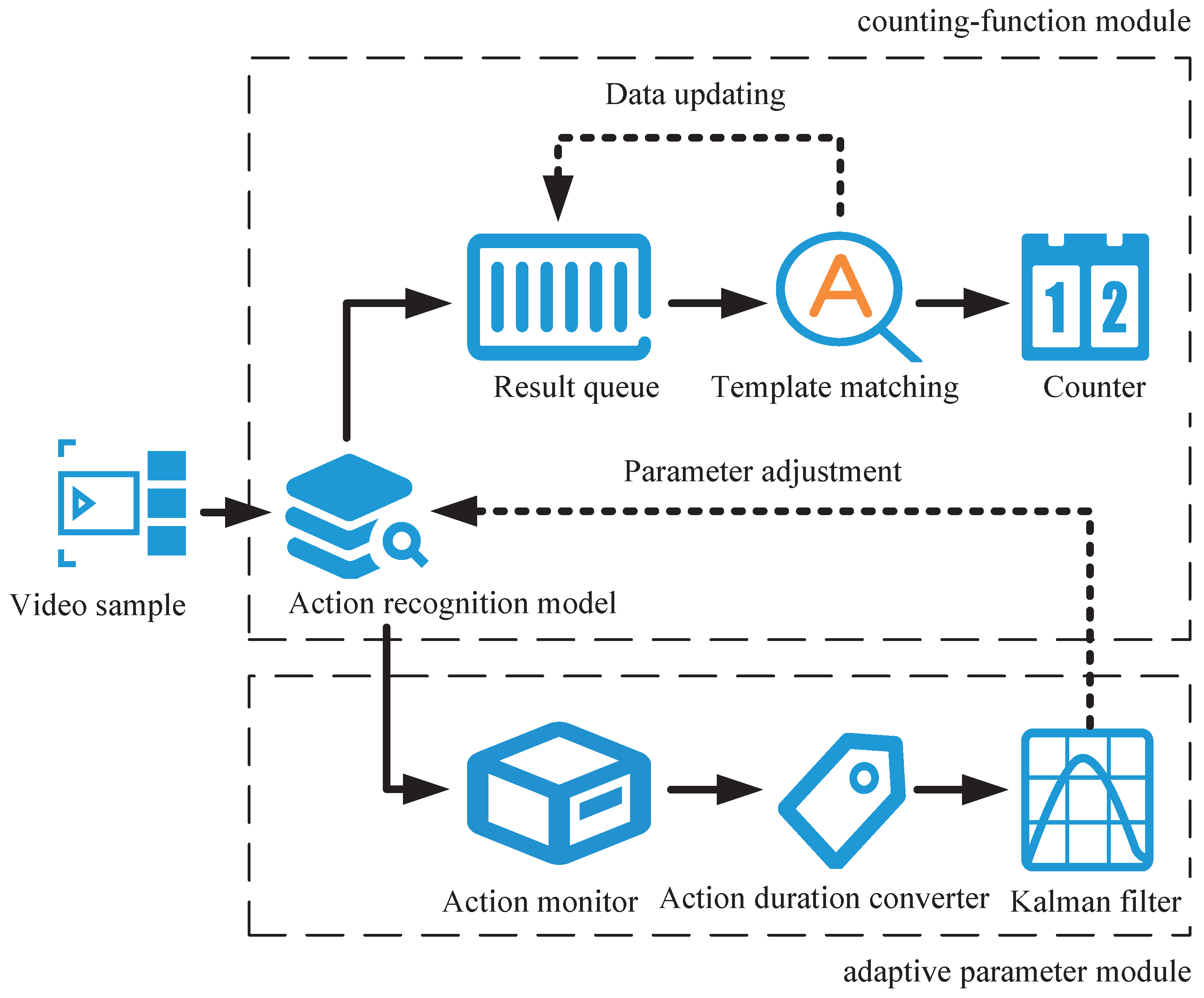
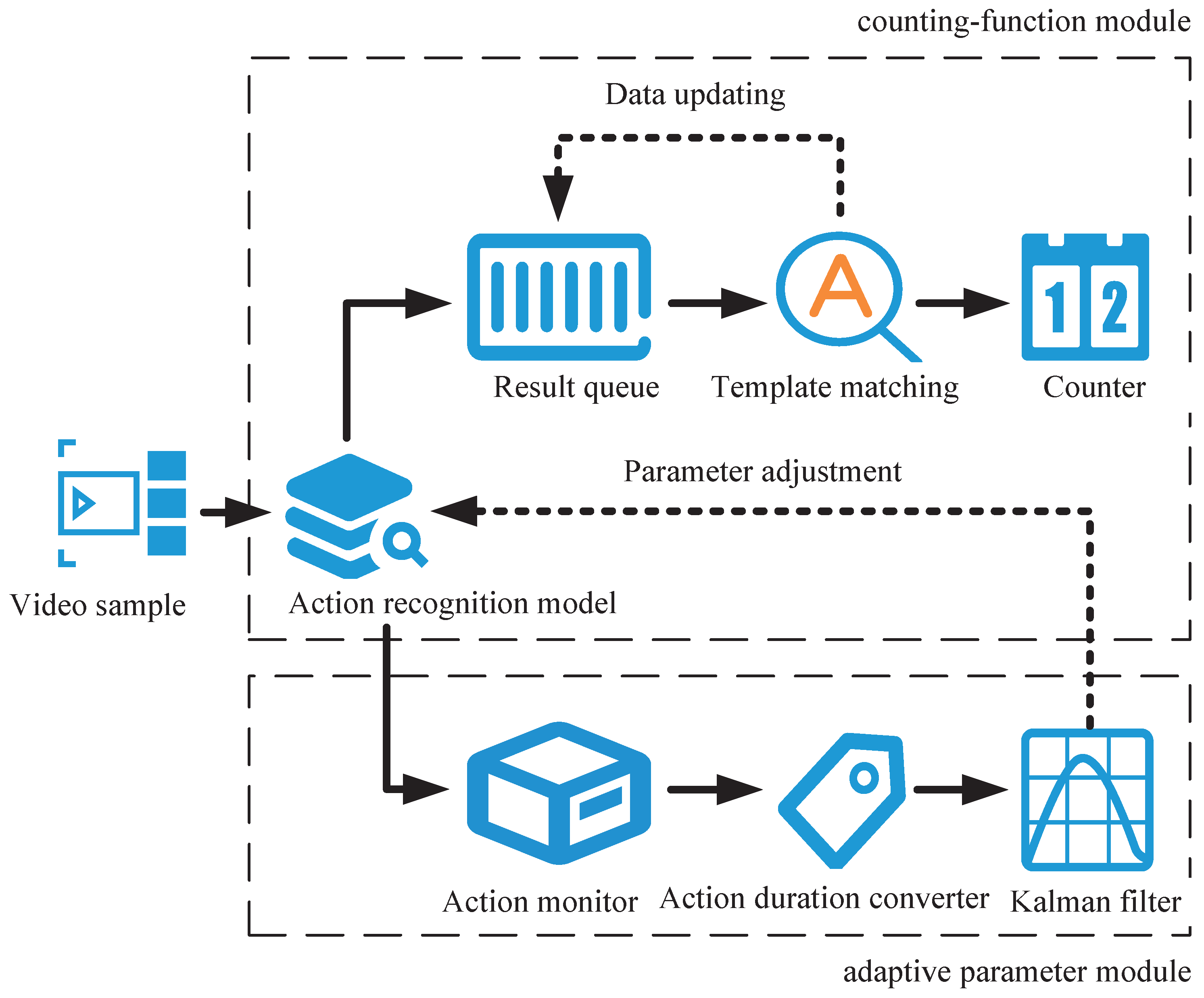
2. Method for Repeating Complex Action Counting
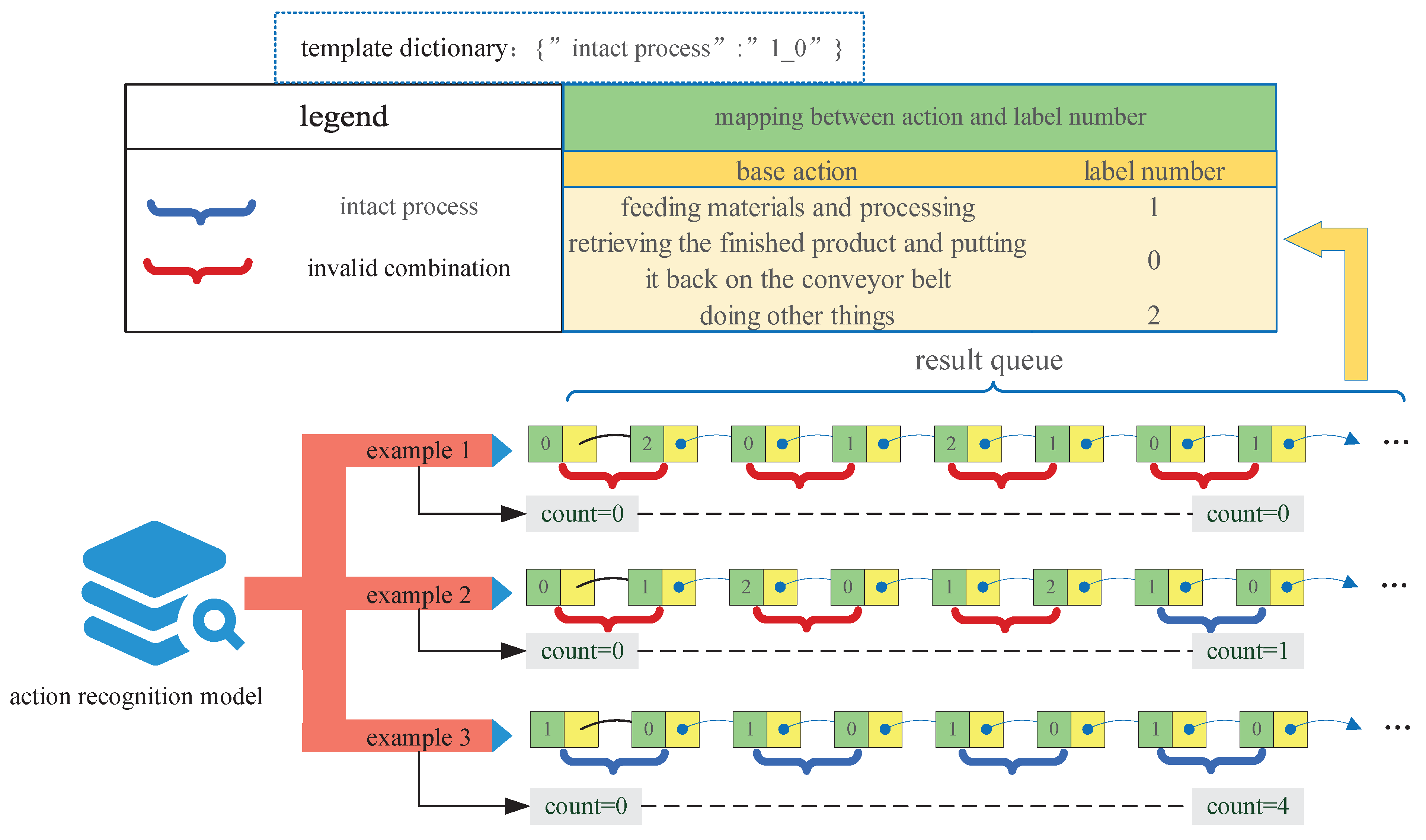
2.1. Decomposition Strategies for Complex Actions
- In order to make it easier for the online action recognition system to distinguish basic actions, the keypoints [34] of the human limbs involved in each basic action of a complex action should possess motion tracks that are markedly different.
- The time span of different basic actions should be equal to the greatest extent for the sake of setting the parameters of the online action recognition system, named historical result length.
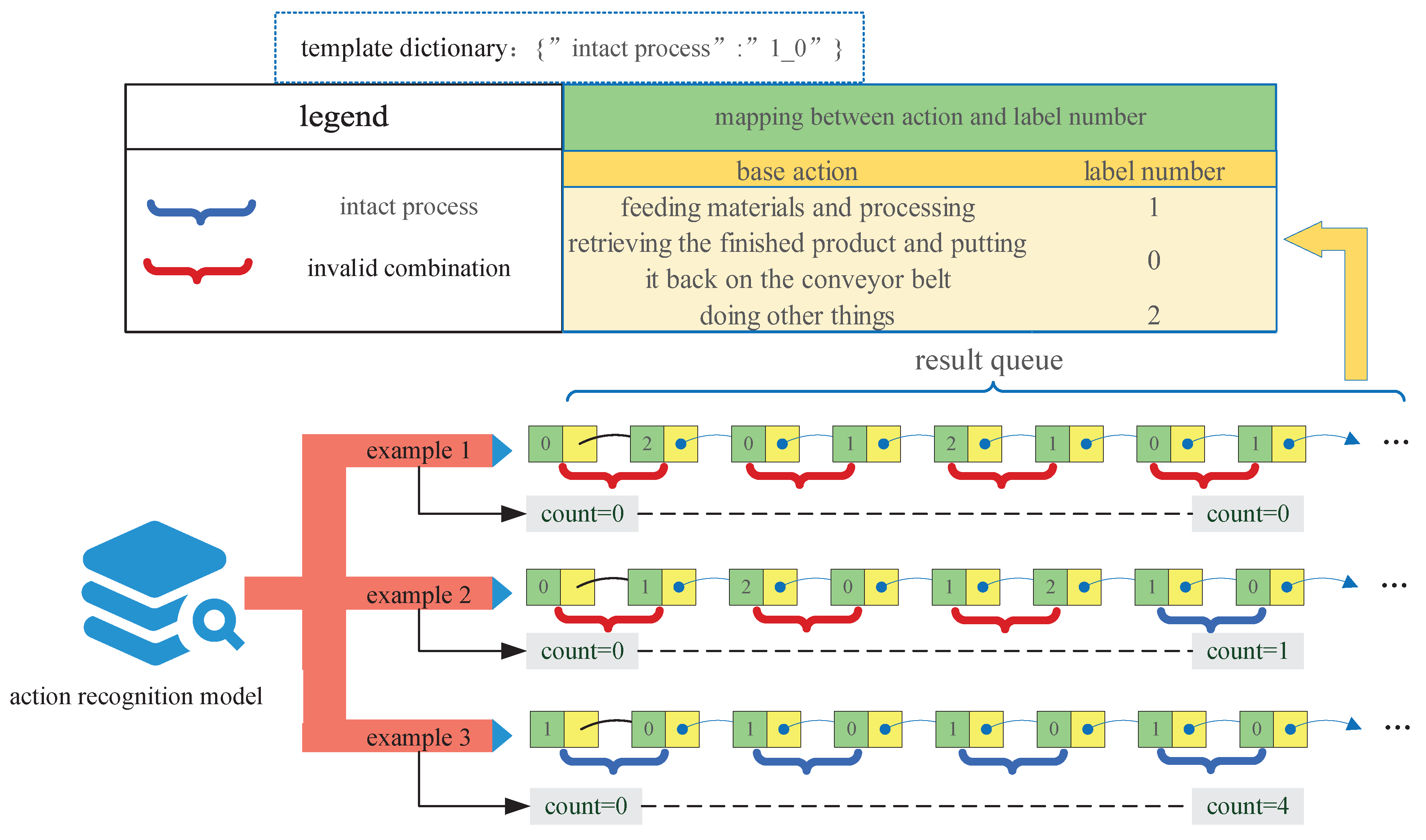
- Of all the complex actions that need to be counted, any two complex actions cannot have semantic–subsumption relations.
- For a complicated movement, each basic motion, due to explicit semantic and basic actions with the same semantic cannot appear continuously, because the latter basic action will lead to the online action recognition model’s output without changing. As a result, the counting module may not be able to perceive it, and eventually bring about an error-counting result.
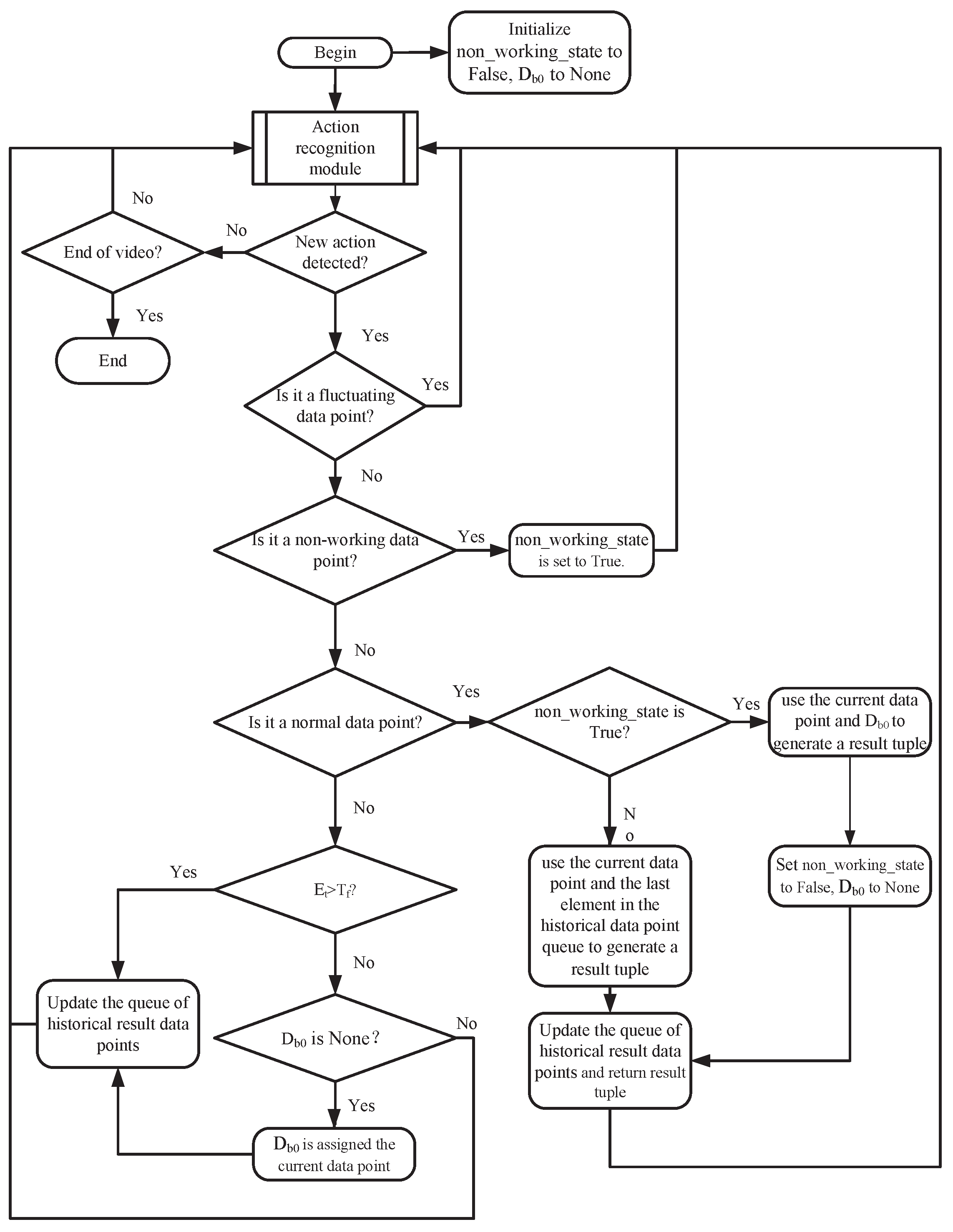
2.2. Counting Principle
3. Optimization of Online Action Recognition Algorithm
3.1. Primary Optimization Strategy
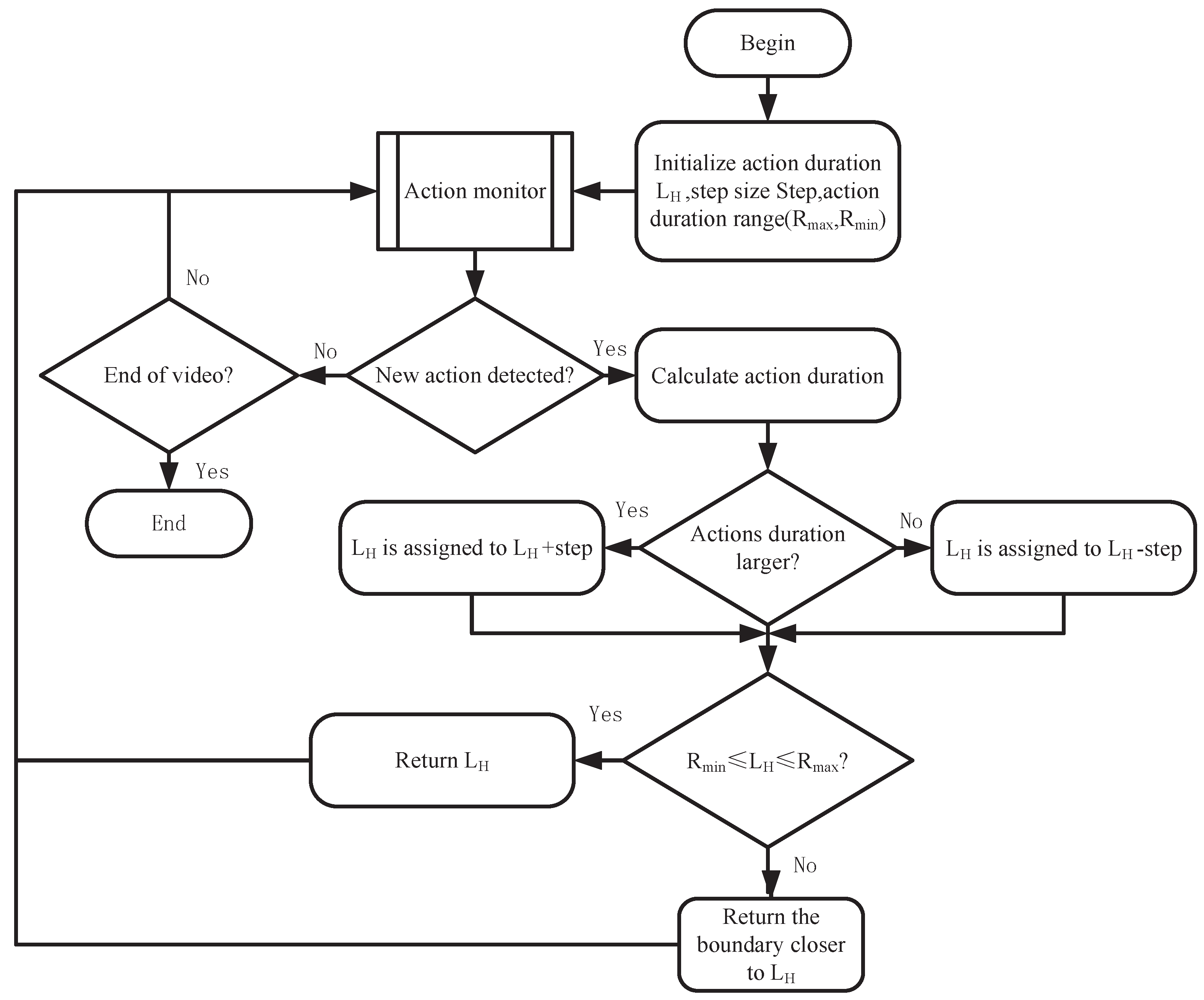
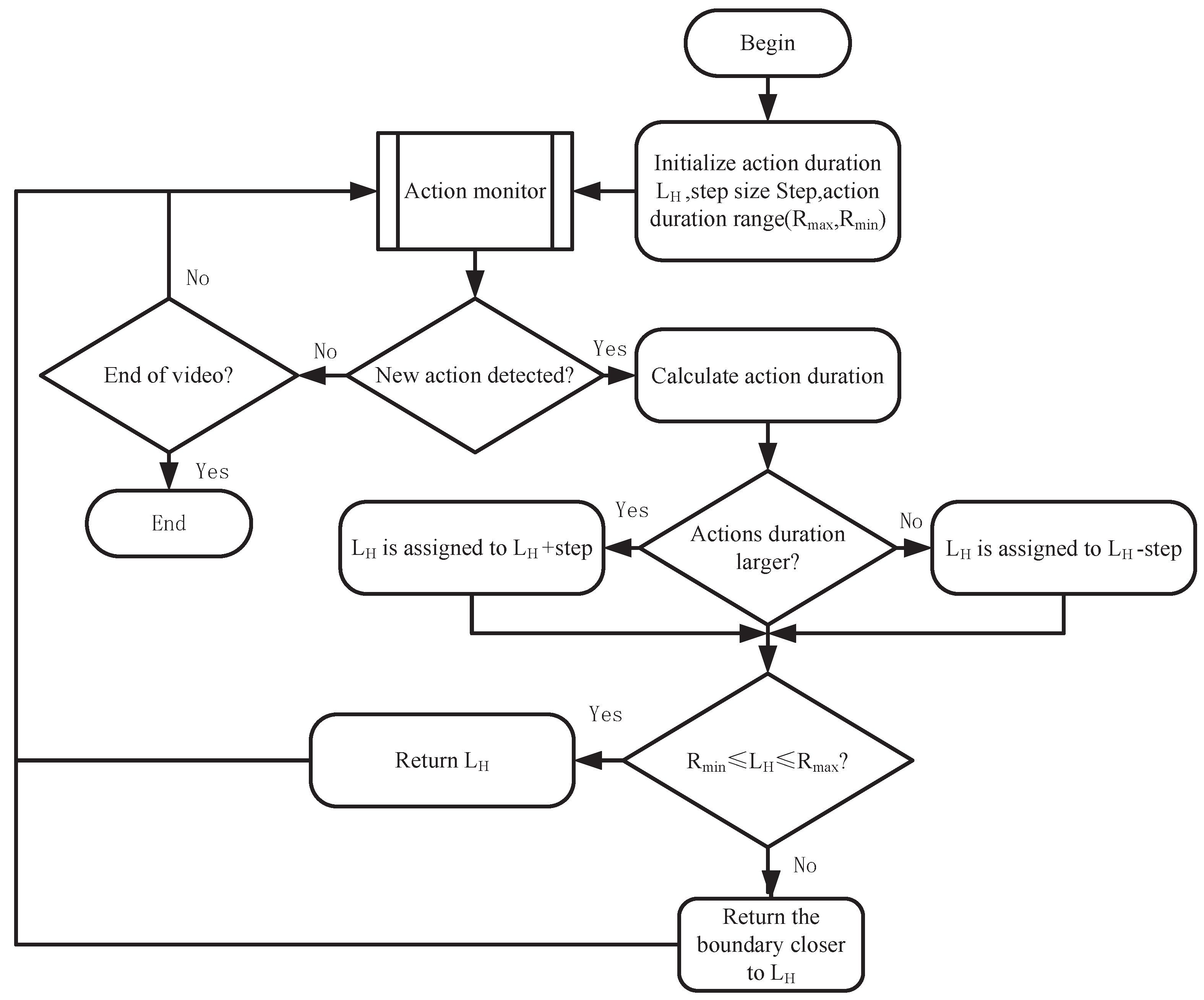
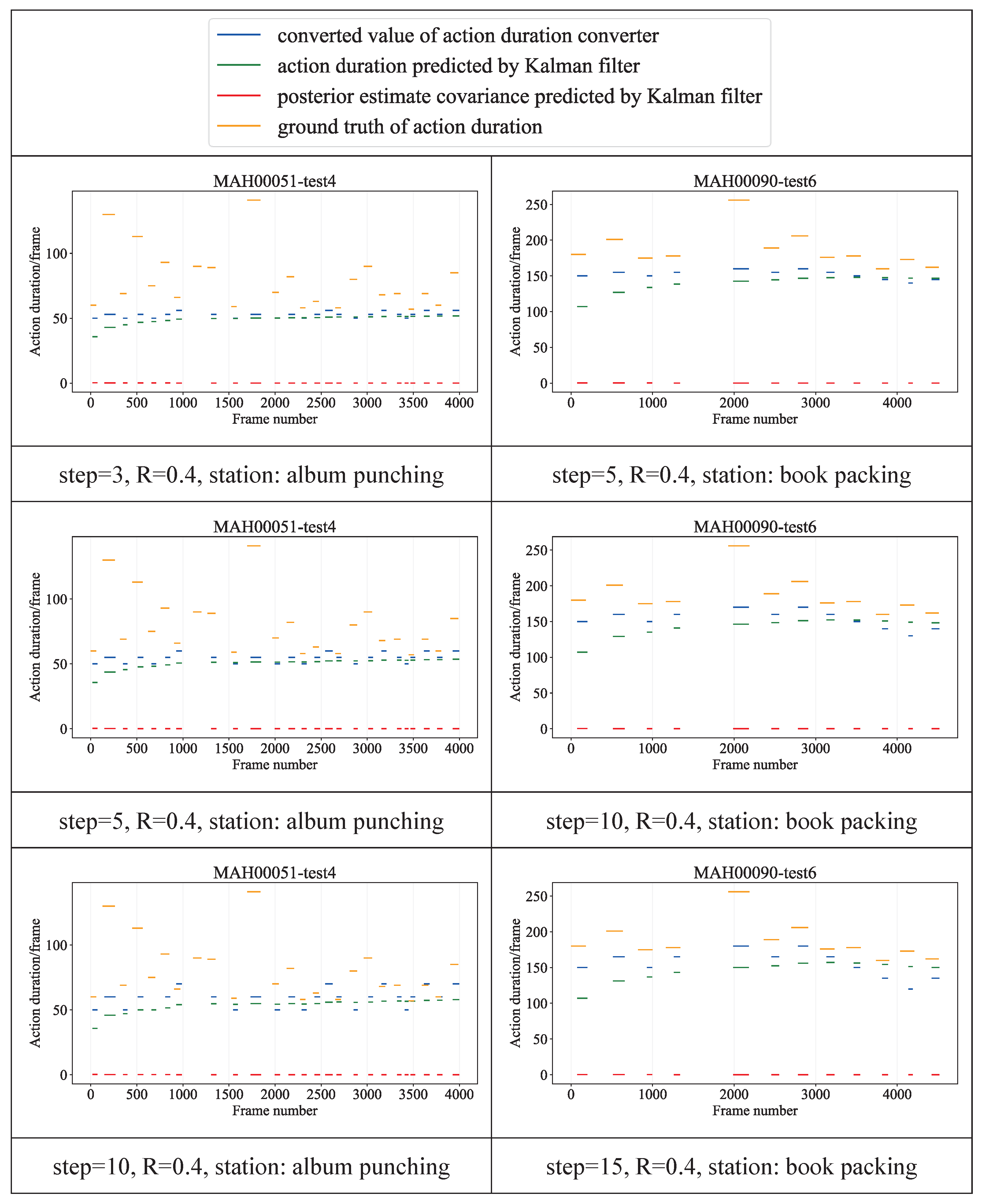
3.2. Optimization Strategy Base on Adaptive Parameter Strategy
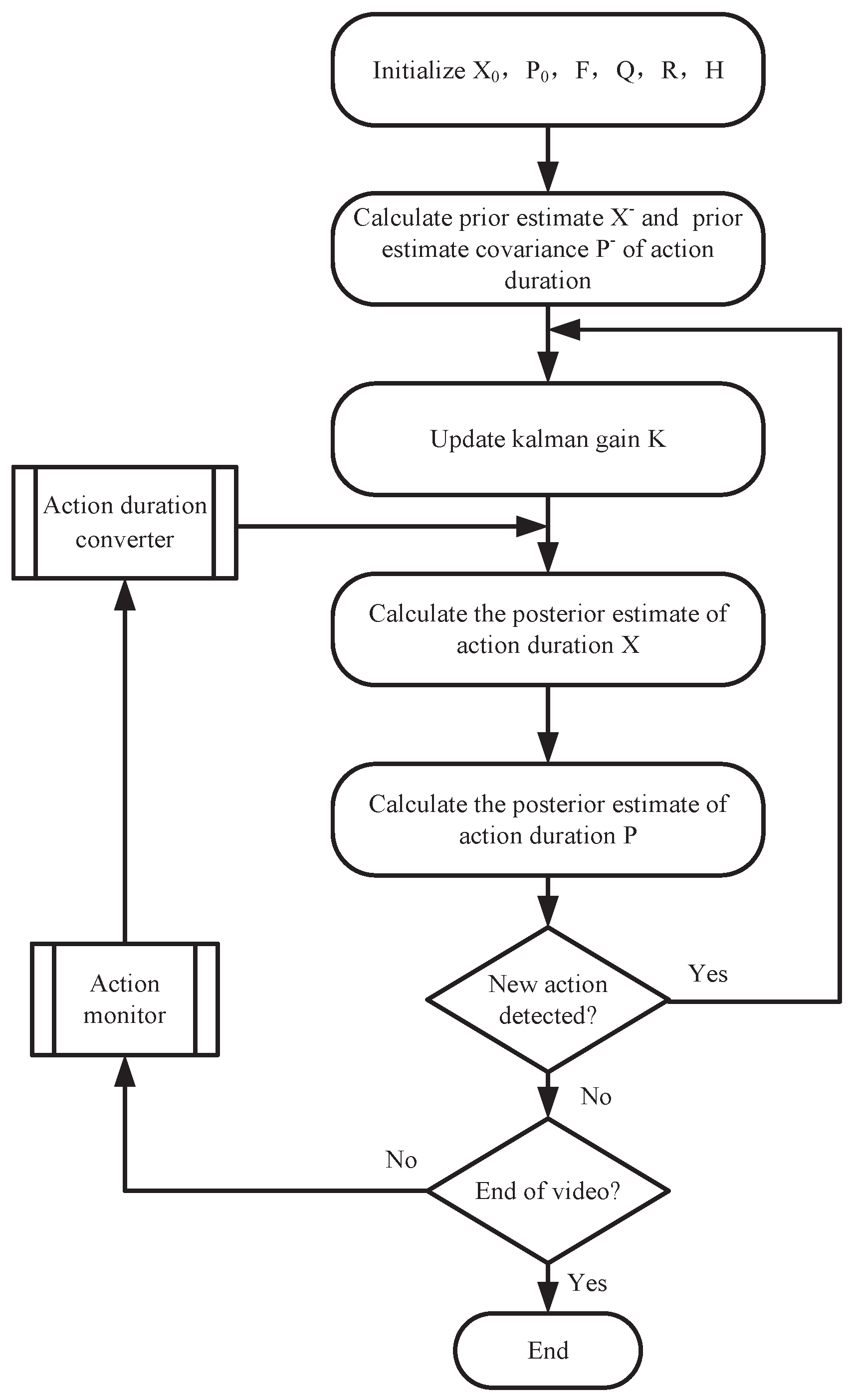
3.2.1. Kalman Filter Design
- Calculate the a priori estimate: we take the action duration into account in our research. The unit of action duration is the frame (that is, the number of frames that the action lasts). Since our system has no external input, the state transition equation of the system can be given by the following:where and denote the prior estimate at time t and the optimal estimation at time , respectively. Moreover, F denotes the state transition matrix. Since it is assumed that the action maintains a uniform speed during the execution process, we obtain . Therefore, the state transition equation of the system can be given by the following.
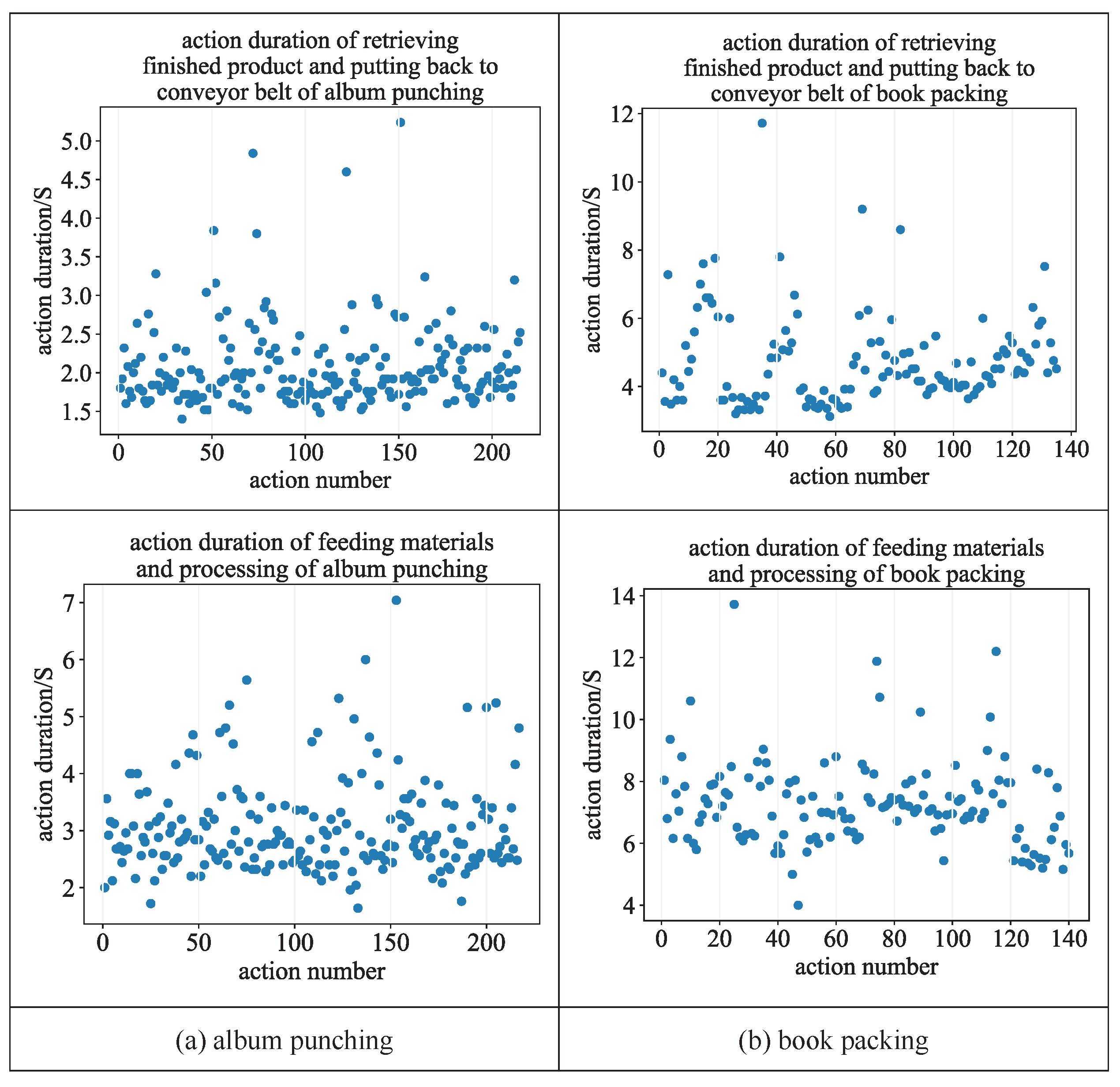
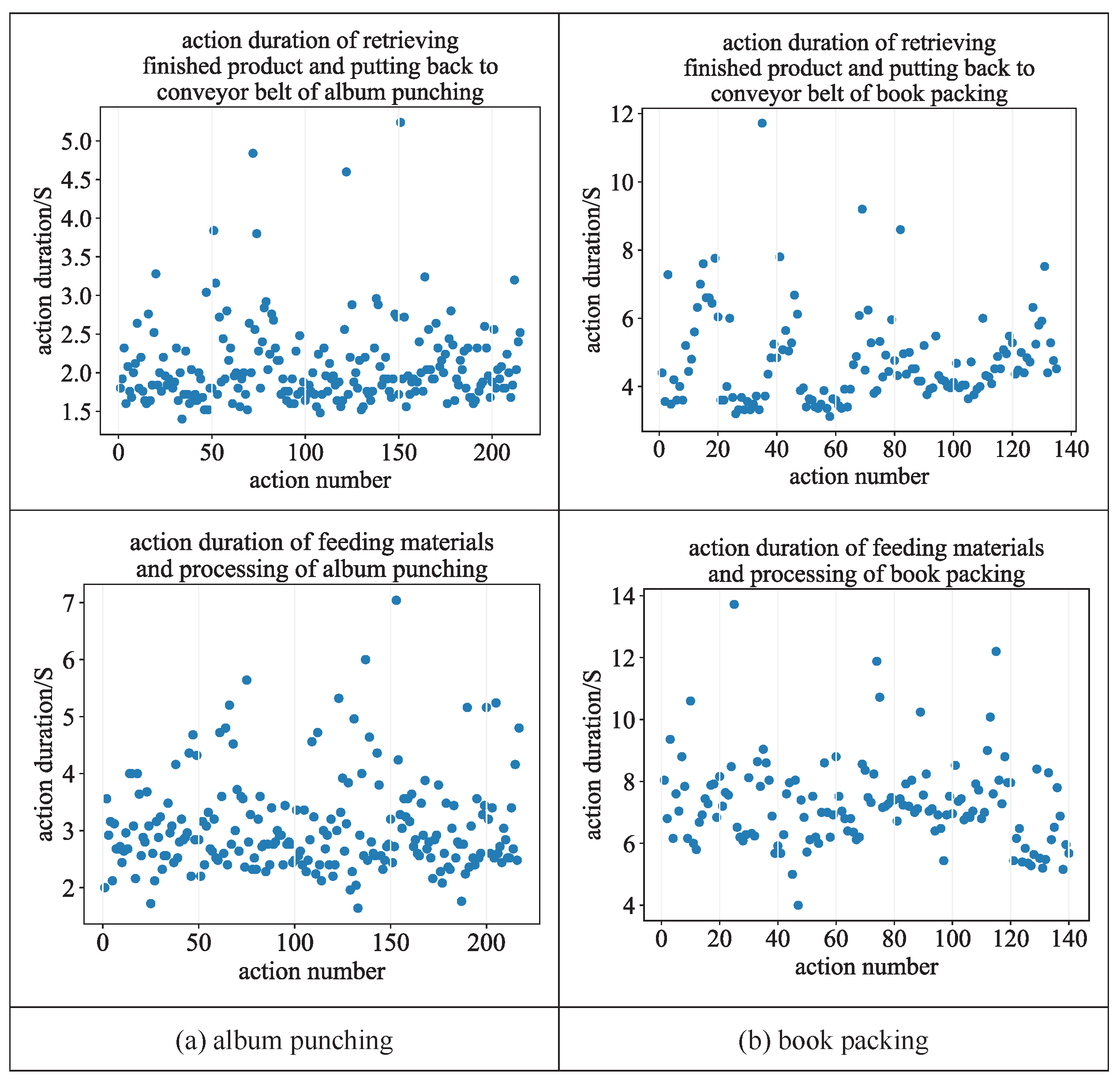
- Calculate prior estimate covariance: The calculation method of prior estimate covariance is as follows:where is the optimally estimated covariance at time , and Q is the process noise covariance. We sort the action durations of feeding materials and processing, removed 5% of the data at the beginning and end, and obtained the mean and variance of the action durations by Gaussian distribution fitting. The mean of Q is set to zero, and the variance is the same as the variance of the action durations of feeding materials and processing.
- Update the Kalman gain as follows:where is the Kalman gain at time t, and is the a priori estimated covariance at time t. H is the measurement matrix, and R is the measurement noise covariance. Since the action duration can be obtained from action monitor, we obtain .
- Revise the following estimate:where is the observed value of the action duration.
- Update posterior estimate covariance:where is the posterior estimate covariance at time t.
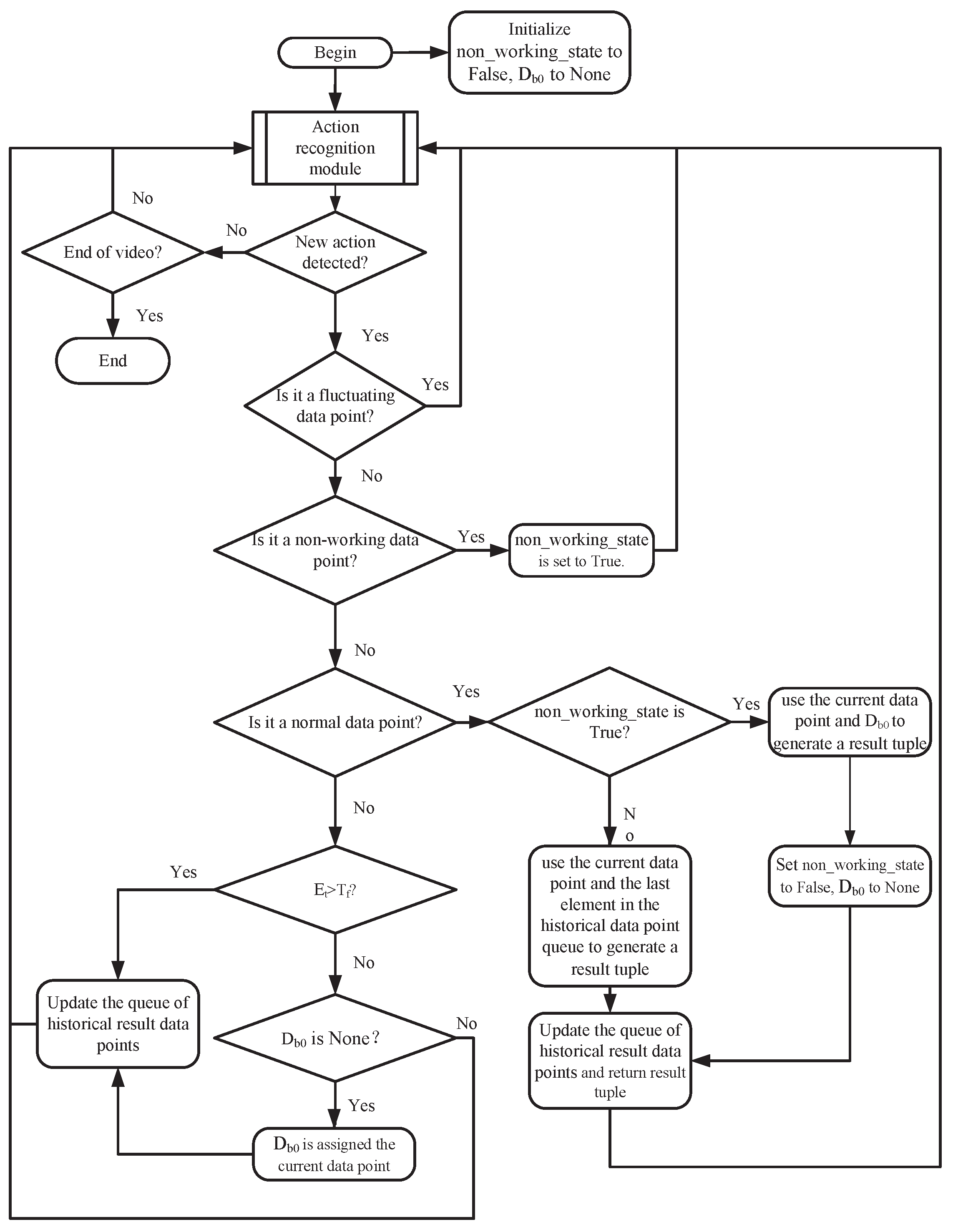
3.2.2. Action Monitor Design
- Fluctuating data point: Fluctuating data point refers to a data point for which its difference between the frame number of the current data point and the last data point in the historical data point queue is less than the fluctuation threshold;
- Non-working data point: Non-working data point refers to a data point for which its category corresponds to non-processing action (do other things). Note that the non-working data points and fluctuating data points have an intersection, but they do not conflict in the working process.
- Normal data point: A normal data point is a data point for which its action duration is greater than the fluctuation threshold and for which its label number is different from the label number of the last element in the historical data point queue;
- Disturbed data point: A disturbed data point is a data point for which its action duration is greater than the fluctuation threshold and for which its label number is the same as its counterpart of the last element in the historical data point queue.
3.2.3. Action Duration Converter Design
4. Framework of Counting Algorithm
| Algorithm 1: Counting the repetitive movements of videos. |
 |
5. Experiments
5.1. Dataset
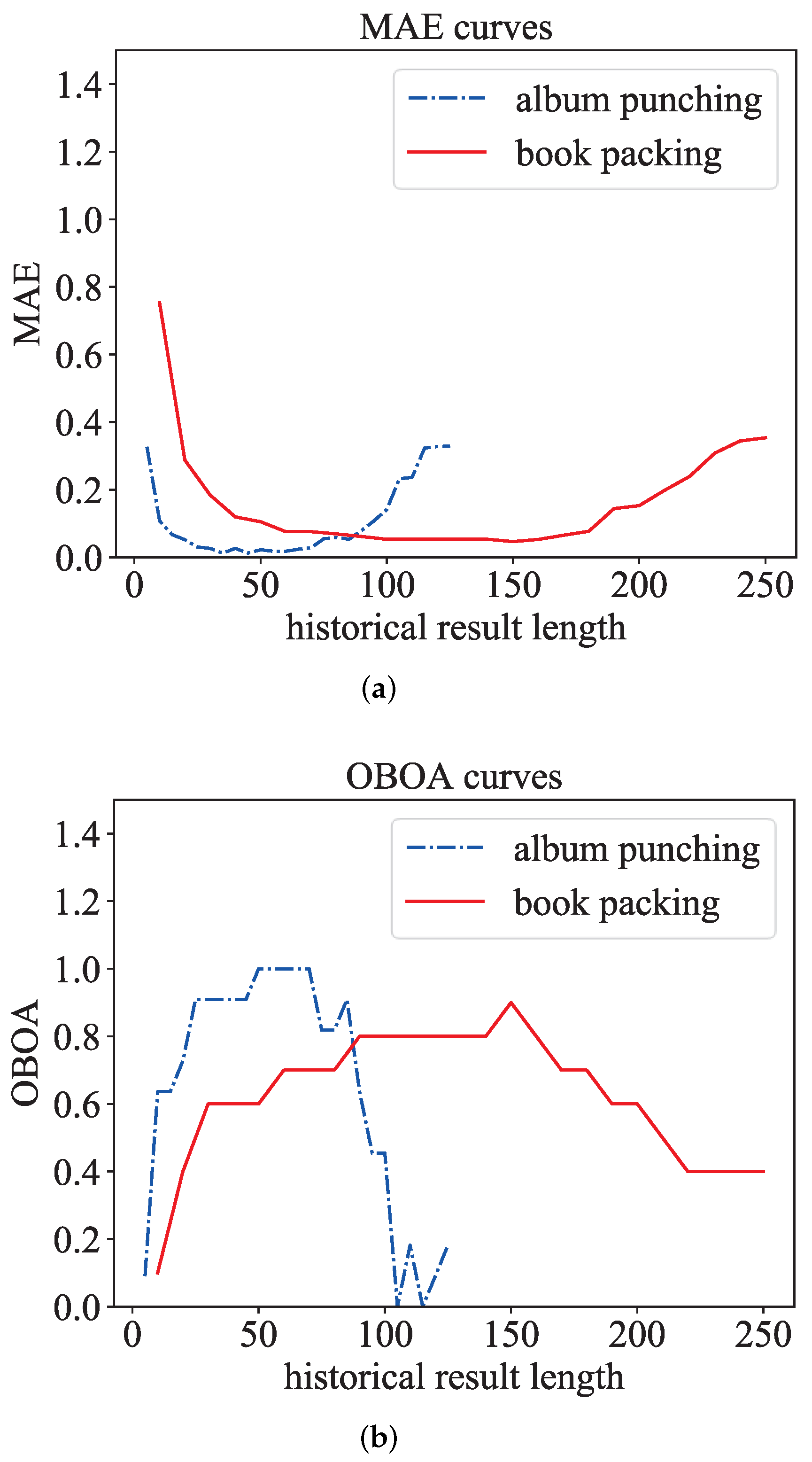
5.2. Evaluation Metrics
5.2.1. Evaluation Metrics of Action Counting
5.2.2. Evaluation Metrics of Action Monitor
5.3. Details and Results of Modules
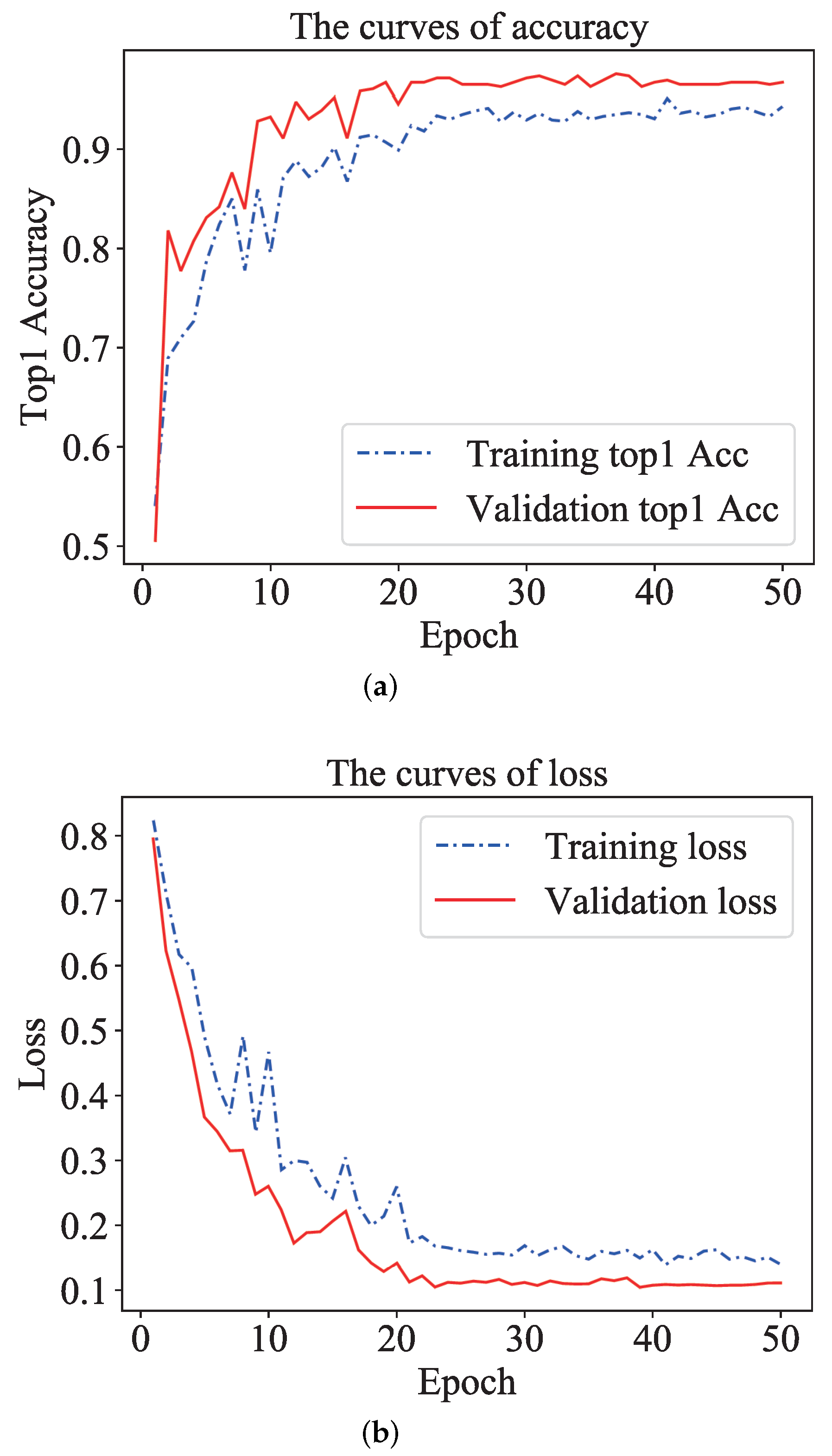
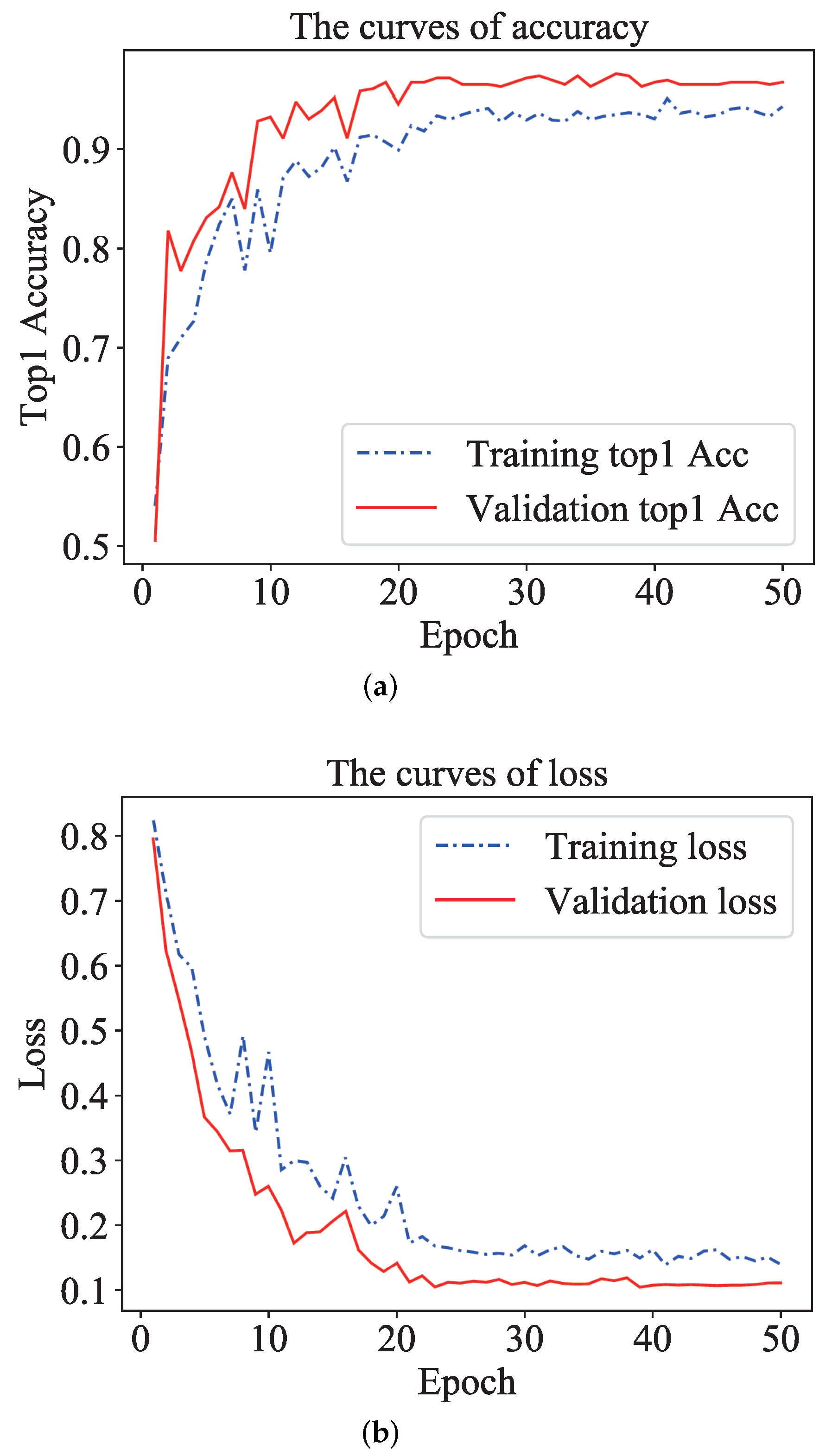
5.3.1. Details of TSM Model Training
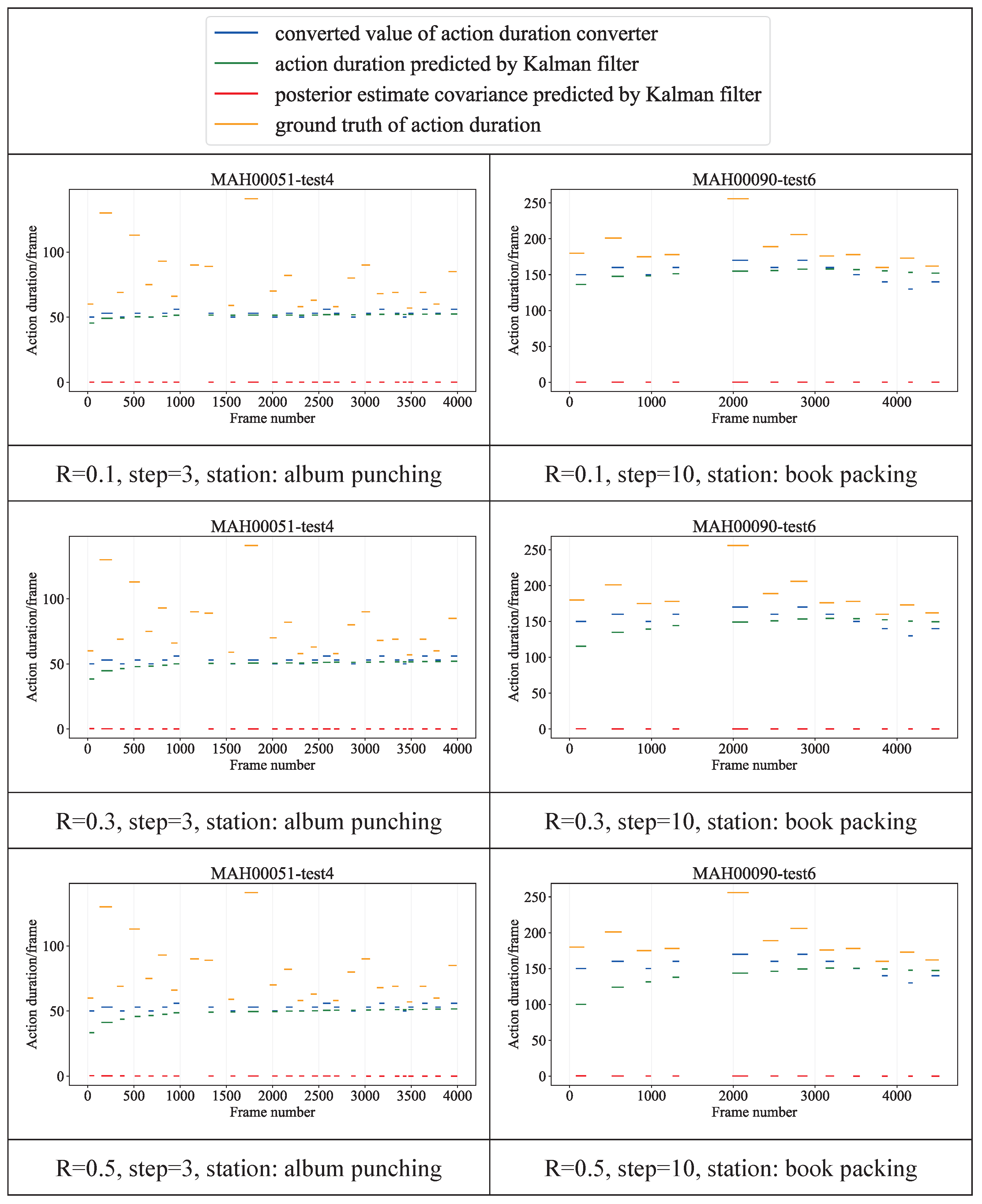
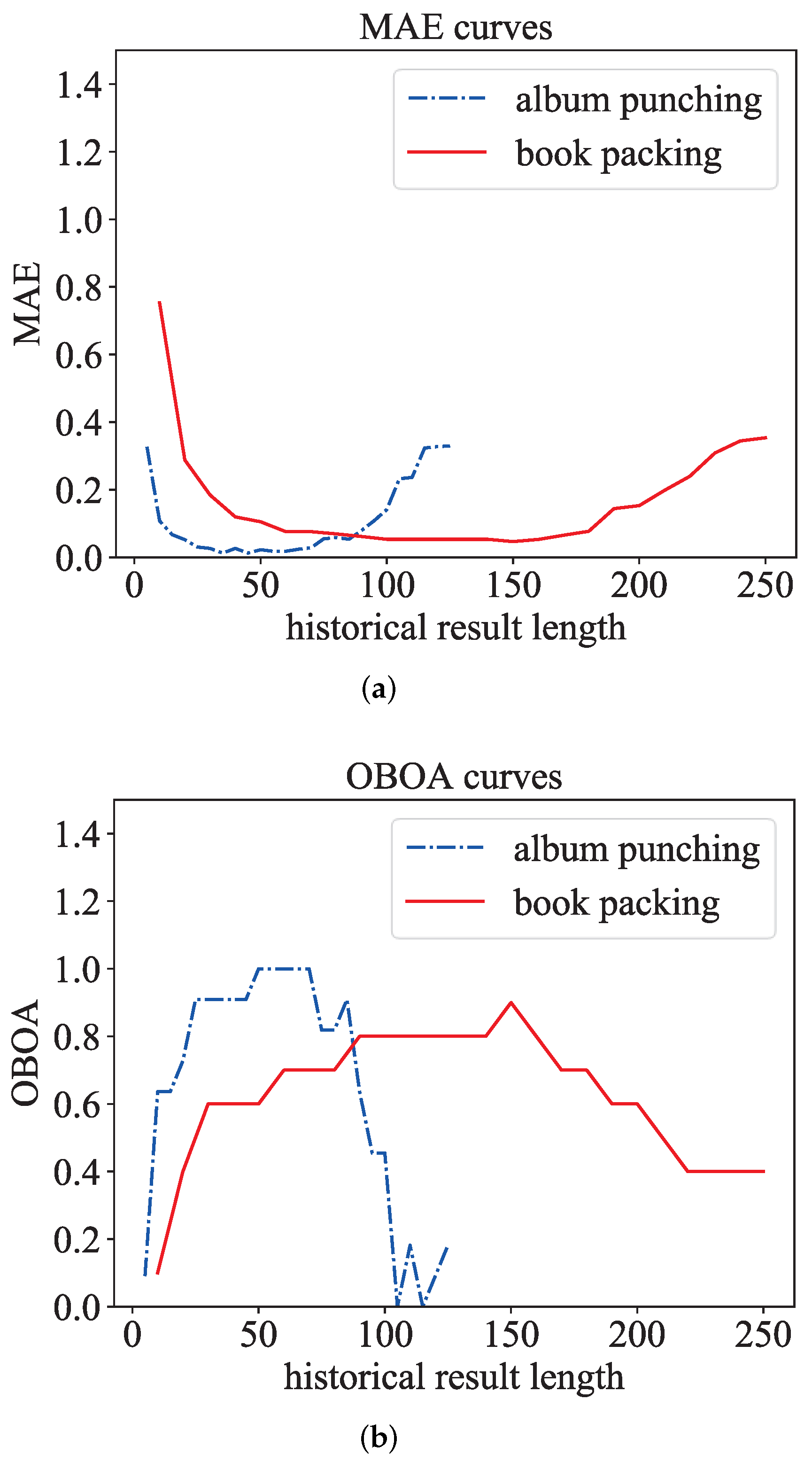
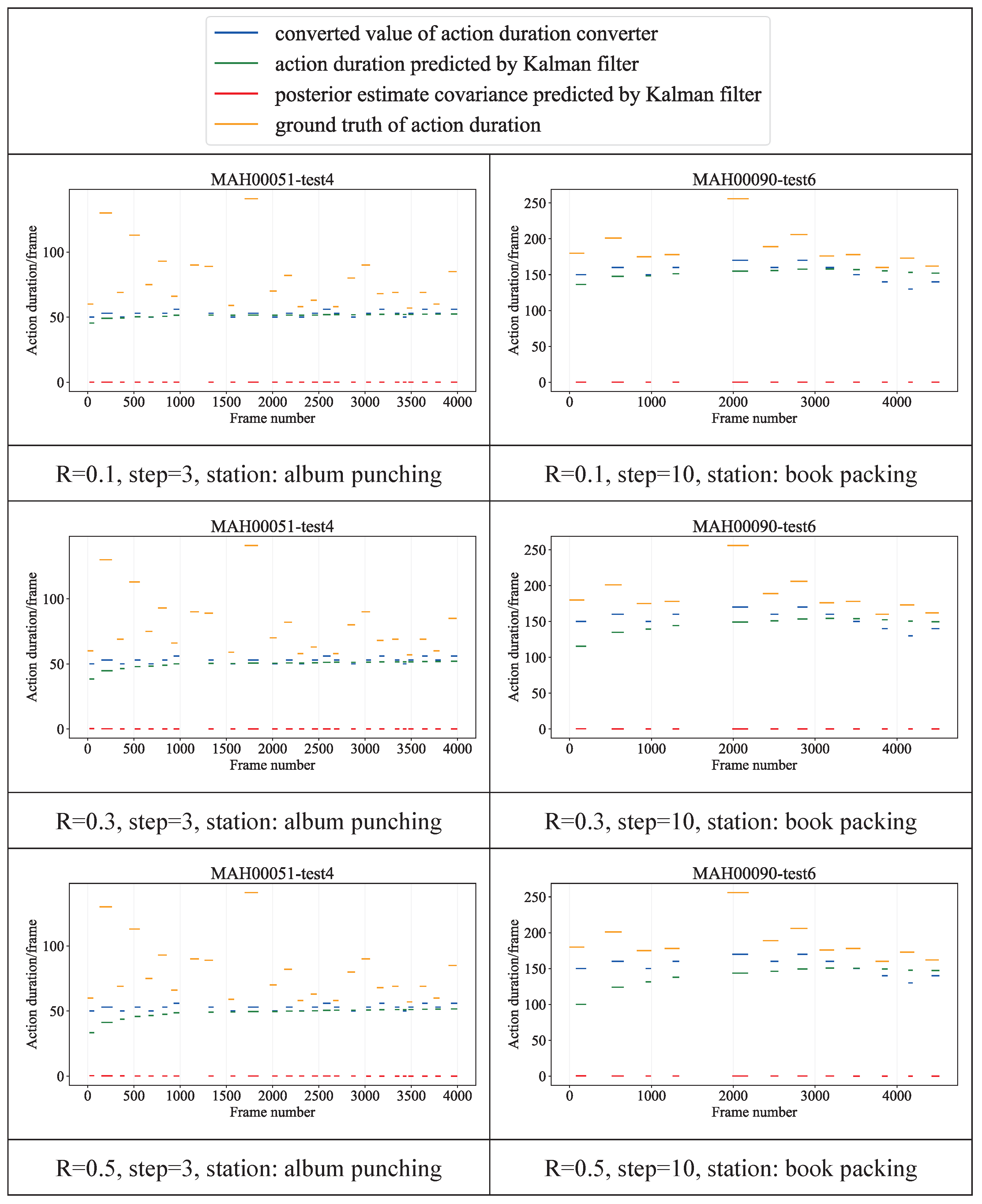
5.3.2. Details and Results of Adaptive Parameter Module
- Action monitor: : False, : None; L and needed to be set to different values at different stations, album punching: L: 25, : 10; book packing: L: 150, : 50;
- Action duration converter: album punching: : 70, : 50, Step: 3; book packing: : 200, : 100, Step: 10;
- Kalman filter: F: 1, H: 1, , : 0, : 1, R: 0.4.
5.4. Experiments and Result Analysis
5.4.1. Optimization Strategy Experiment
5.4.2. Comparison Experiment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mortazavi, B.J.; Pourhomayoun, M.; Alsheikh, G.; Alshurafa, N.; Lee, S.I.; Sarrafzadeh, M. Determining the single best axis for exercise repetition recognition and counting on smartwatches. In Proceedings of the 2014 11th International Conference on Wearable and Implantable Body Sensor Networks, Zurich, Switzerland, 16–19 June 2014; pp. 33–38. [Google Scholar]
- Soro, A.; Brunner, G.; Tanner, S.; Wattenhofer, R. Recognition and repetition counting for complex physical exercises with deep learning. Sensors 2019, 19, 714. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prabhu, G.; O’Connor, N.E.; Moran, K. Recognition and repetition counting for local muscular endurance exercises in exercise-based rehabilitation: A comparative study using artificial intelligence models. Sensors 2020, 20, 4791. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Chen, H. Wi-ACR: A human action counting and recognition method based on CSI. J. Beijing Univ. Posts Telecommun. 2020, 43, 105–111. [Google Scholar]
- Wu, Y.; Sun, H.; Yin, J. Repetitive action counting based on linear regression analysis. J. Univ. Jinan Sci. Technol. 2019, 33, 496–499. [Google Scholar]
- Albu, A.B.; Bergevin, R.; Quirion, S. Generic temporal segmentation of cyclic human motion. Pattern Recognit. 2008, 41, 6–21. [Google Scholar] [CrossRef]
- Laptev, I.; Belongie, S.J.; Pérez, P.; Wills, J. Periodic motion detection and segmentation via approximate sequence alignment. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2021; pp. 816–823. [Google Scholar]
- Tralie, C.J.; Perea, J.A. (Quasi) Periodicity quantification in video data, using topology. SIAM J. Imaging Sci. 2018, 11, 1049–1077. [Google Scholar] [CrossRef] [Green Version]
- Pogalin, E.; Smeulders, A.W.; Thean, A.H. Visual quasi-periodicity. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Runia, T.F.; Snoek, C.G.; Smeulders, A.W. Real-world repetition estimation by div, grad and curl. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9009–9017. [Google Scholar]
- Yin, J.; Wu, Y.; Zhu, C.; Yina, Z.; Liu, H.; Dang, Y.; Liub, Z.; Liuc, J. Energy-based periodicity mining with deep features for action repetition counting in unconstrained videos. IEEE Trans. Circuits Syst. Video Technol. 2021, 14, 1–14. [Google Scholar] [CrossRef]
- Panagiotakis, C.; Karvounas, G.; Argyros, A. Unsupervised detection of periodic segments in videos. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 923–927. [Google Scholar]
- Dwibedi, D.; Aytar, Y.; Tompson, J.; Sermanet, P.; Zisserman, A. Counting out time: Class agnostic video repetition counting in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10387–10396. [Google Scholar]
- Levy, O.; Wolf, L. Live repetition counting. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3020–3028. [Google Scholar]
- Zhang, H.; Xu, X.; Han, G.; He, S. Context-aware and scale-insensitive temporal repetition counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 670–678. [Google Scholar]
- Panagiotakis, C.; Papoutsakis, K.; Argyros, A. A graph-based approach for detecting common actions in motion capture data and videos. Pattern Recognit. 2018, 79, 1–11. [Google Scholar] [CrossRef]
- Yuan, Z.; Stroud, J.C.; Lu, T.; Deng, J. Temporal action localization by structured maximal sums. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3684–3692. [Google Scholar]
- Chao, Y.W.; Vijayanarasimhan, S.; Seybold, B.; Ross, D.A.; Deng, J.; Sukthankar, R. Rethinking the faster r-cnn architecture for temporal action localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 18–23 June 2018; pp. 1130–1139. [Google Scholar]
- Qiu, H.; Zheng, Y.; Ye, H.; Lu, Y.; Wang, F.; He, L. Precise temporal action localization by evolving temporal proposals. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, Yokohama, Japan, 11–14 June 2018; pp. 388–396. [Google Scholar]
- Zeng, R.; Huang, W.; Tan, M.; Rong, Y.; Zhao, P.; Huang, J.; Gan, C. Graph convolutional networks for temporal action localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7094–7103. [Google Scholar]
- Ma, F.; Zhu, L.; Yang, Y.; Zha, S.; Kundu, G.; Feiszli, M.; Shou, Z. Sf-net: Single-frame supervision for temporal action localization. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 420–437. [Google Scholar]
- Zhao, P.; Xie, L.; Ju, C.; Zhang, Y.; Wang, Y.; Tian, Q. Bottom-up temporal action localization with mutual regularization. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 539–555. [Google Scholar]
- Liu, B.; Ju, Z.; Kubota, N.; Liu, H. Online action recognition based on skeleton motion distribution. In Proceedings of the 29th British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; pp. 312–323. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Osokin, D. Real-time 2d multi-person pose estimation on CPU: Lightweight OpenPose. In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods, Prague, Czech Republic, 22–24 February 2018; pp. 744–748. [Google Scholar]
- Hou, T.; Ahmadyan, A.; Zhang, L.; Wei, J.; Grundmann, M. Mobilepose: Real-time pose estimation for unseen objects with weak shape supervision. arXiv 2020, arXiv:2003.03522. [Google Scholar]
- Zolfaghari, M.; Singh, K.; Brox, T. Eco: Efficient convolutional network for online video understanding. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 695–712. [Google Scholar]
- Shinde, S.; Kothari, A.; Gupta, V. YOLO based human action recognition and localization. Proc. Comput. Sci. 2018, 133, 831–838. [Google Scholar] [CrossRef]
- Fan, Z.; Lin, T.; Zhao, X.; Jiang, W.; Xu, T.; Yang, M. An online approach for gesture recognition toward real-world applications. In Proceedings of the International Conference on Image and Graphics, Shanghai, China, 13–15 September 2017; pp. 262–272. [Google Scholar]
- Liu, F.; Xu, X.; Qiu, S.; Qing, C.; Tao, D. Simple to complex transfer learning for action recognition. IEEE Trans. Image Process. 2015, 25, 949–960. [Google Scholar] [CrossRef] [PubMed]
- Hussein, N.; Gavves, E.; Smeulders, A.W. Timeception for complex action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 15–20 June 2019; pp. 254–263. [Google Scholar]
- Ren, H.; Xu, G. Human action recognition with primitive-based coupled-HMM. In Object Recognition Supported by User Interaction for Service Robots; IEEE: Quebec City, QC, Canada, 2002; pp. 494–498. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7083–7093. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action | Station | Mean tIOU |
|---|---|---|
| Feeding materials and processing | Album punching | 0.57 |
| Book packaging | 0.57 | |
| Retrieving the finished product and putting it back on the conveyor belt | Album punching | 0.48 |
| Book packaging | 0.49 |
| Setting | Station | MAE | OBOA |
|---|---|---|---|
| TSM Default Setting | Album Punching | 0.052 | 0.727 |
| Book Packaging | 0.589 | 0.200 | |
| LNJS | Album Punching | 0.105 | 0.364 |
| Book Packaging | 0.047 | 0.900 | |
| LNJS&IAE | Album Punching | 0.026 | 1.0 |
| Book Packaging | 0.047 | 0.900 |
| Algorithm | Station | MAE | OBOA |
|---|---|---|---|
| Algorithm without adaptive parameter module | Album Punching | 0.026 | 1.0 |
| Book Packaging | 0.047 | 0.900 | |
| Algorithm with adaptive parameter module | Album Punching | 0.022 | 1.0 |
| Book Packaging | 0.047 | 0.900 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, F.; Wang, G.; Li, D.; Liu, N.; Min, F. Research on Repetition Counting Method Based on Complex Action Label String. Machines 2022, 10, 419. https://doi.org/10.3390/machines10060419
Yang F, Wang G, Li D, Liu N, Min F. Research on Repetition Counting Method Based on Complex Action Label String. Machines. 2022; 10(6):419. https://doi.org/10.3390/machines10060419
Chicago/Turabian StyleYang, Fanghong, Gao Wang, Deping Li, Ning Liu, and Feiyan Min. 2022. "Research on Repetition Counting Method Based on Complex Action Label String" Machines 10, no. 6: 419. https://doi.org/10.3390/machines10060419
APA StyleYang, F., Wang, G., Li, D., Liu, N., & Min, F. (2022). Research on Repetition Counting Method Based on Complex Action Label String. Machines, 10(6), 419. https://doi.org/10.3390/machines10060419