
A Novel Electronic Chip Detection Method Using Deep Neural Networks





Abstract
:1. Introduction
- (1)
- there are multiple chips in one picture;
- (2)
- the background of PCB image is complex, including pins, pads, flame retardant layer, and silk screen;
- (3)
- the size, color, and other characteristics of chips vary greatly.
2. Related Work
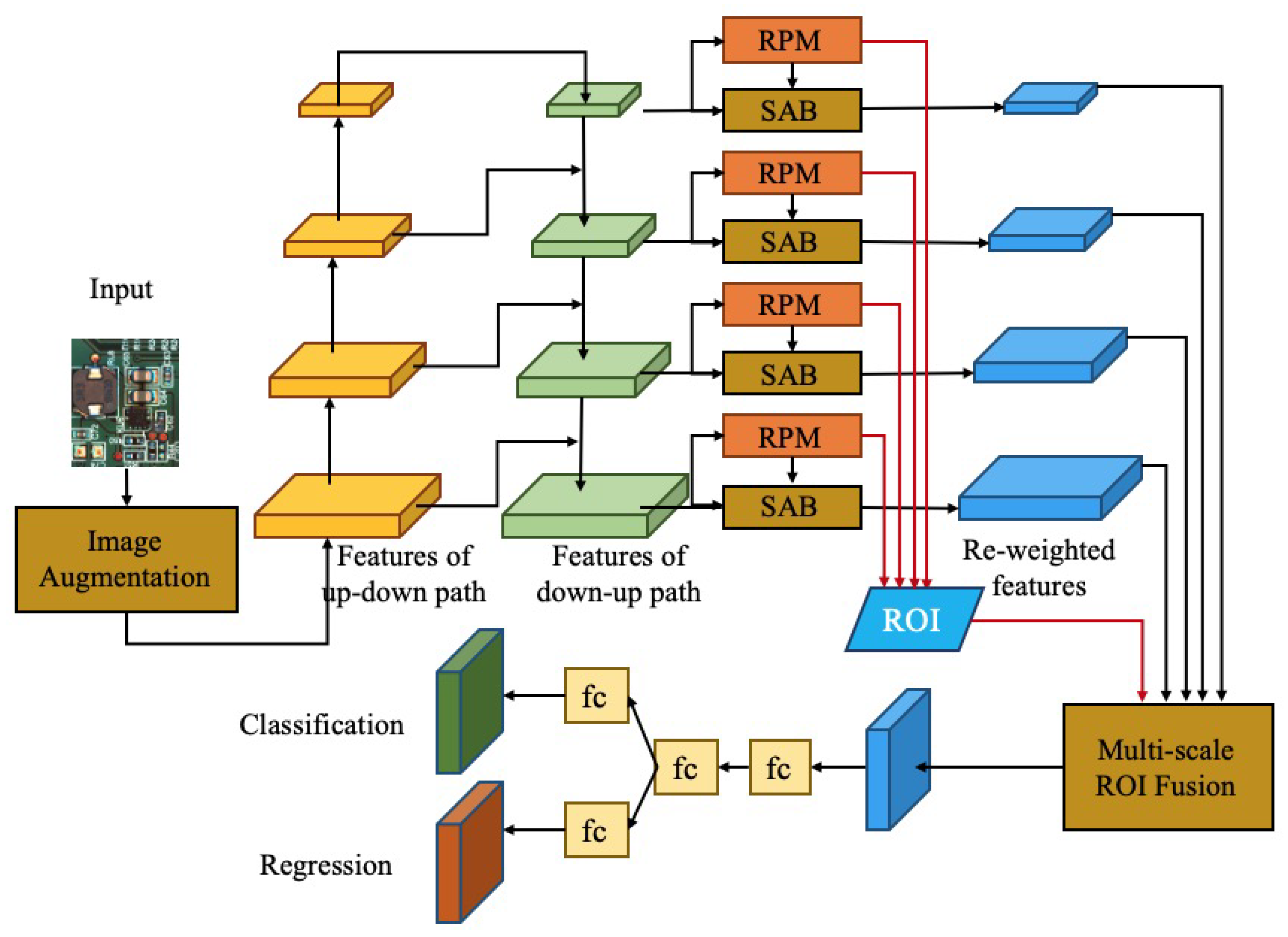
3. Proposed Methodology
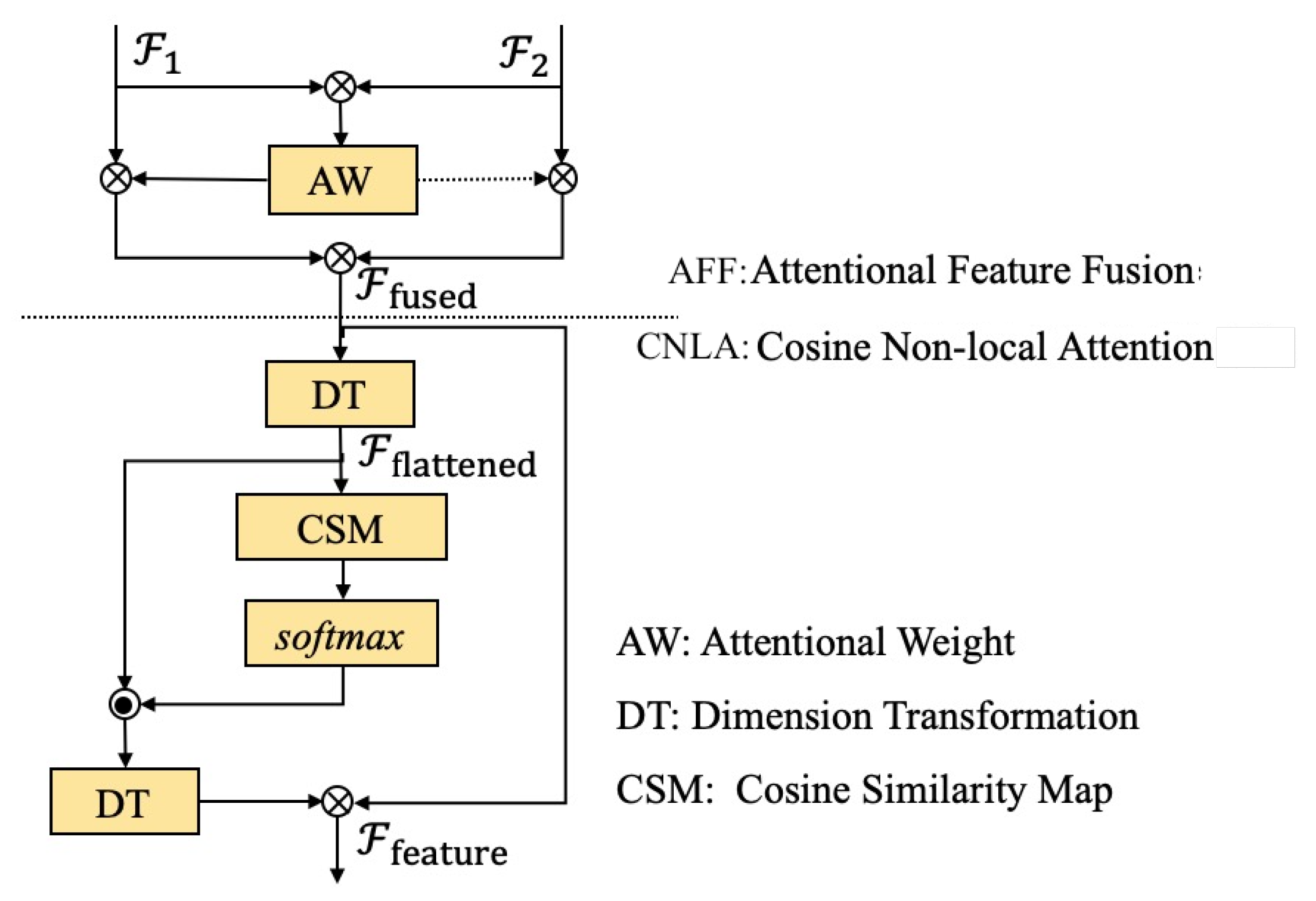
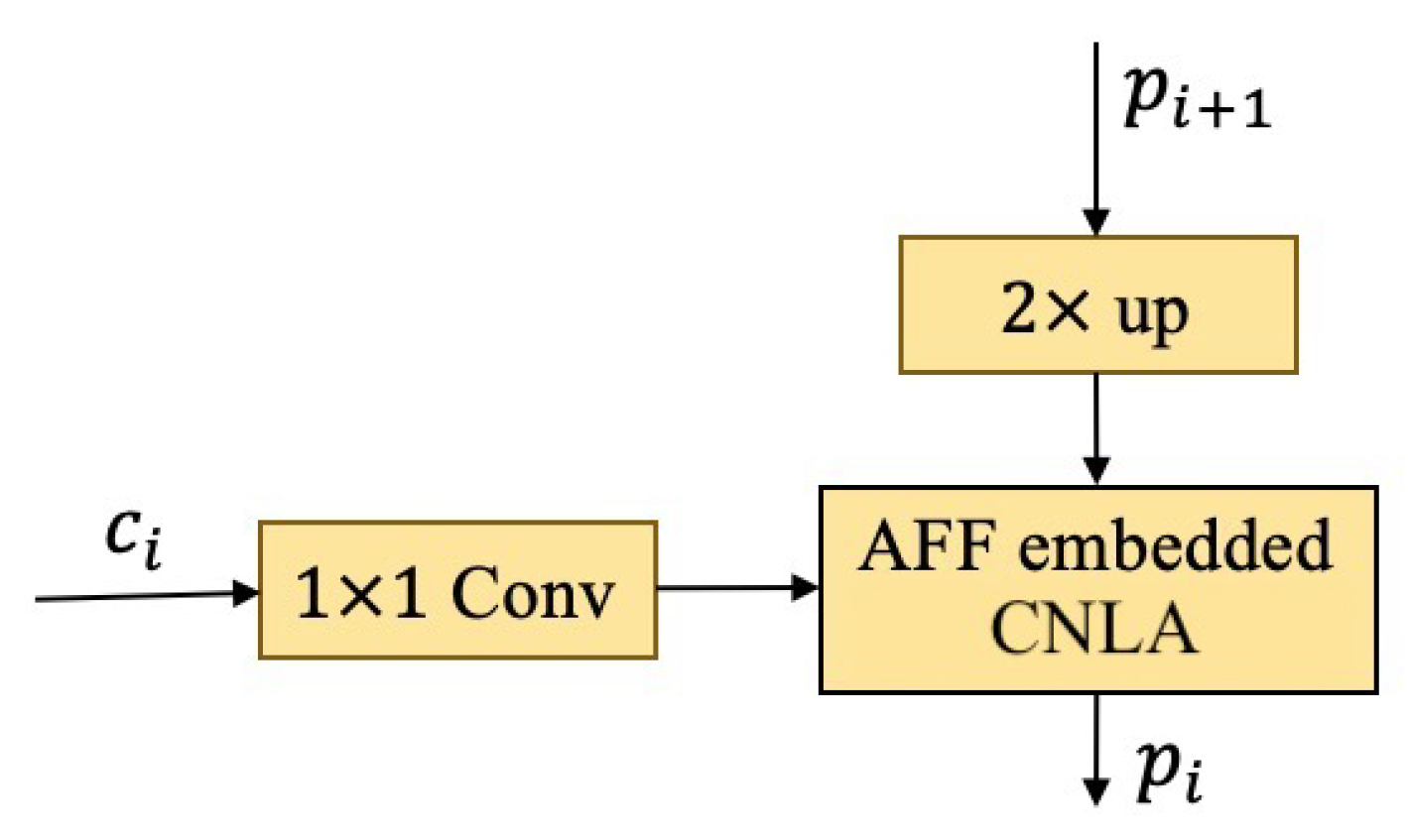
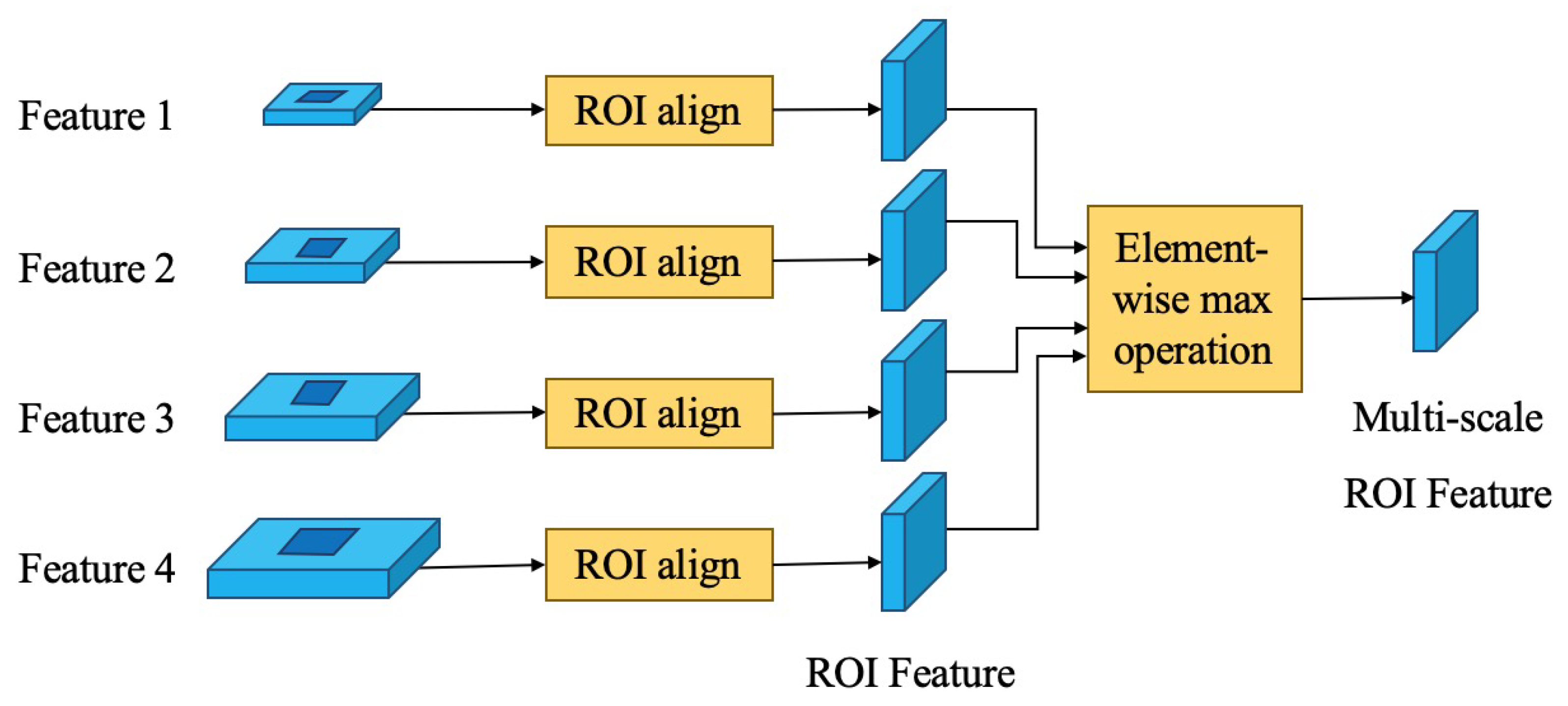
3.1. Feature Extraction Module
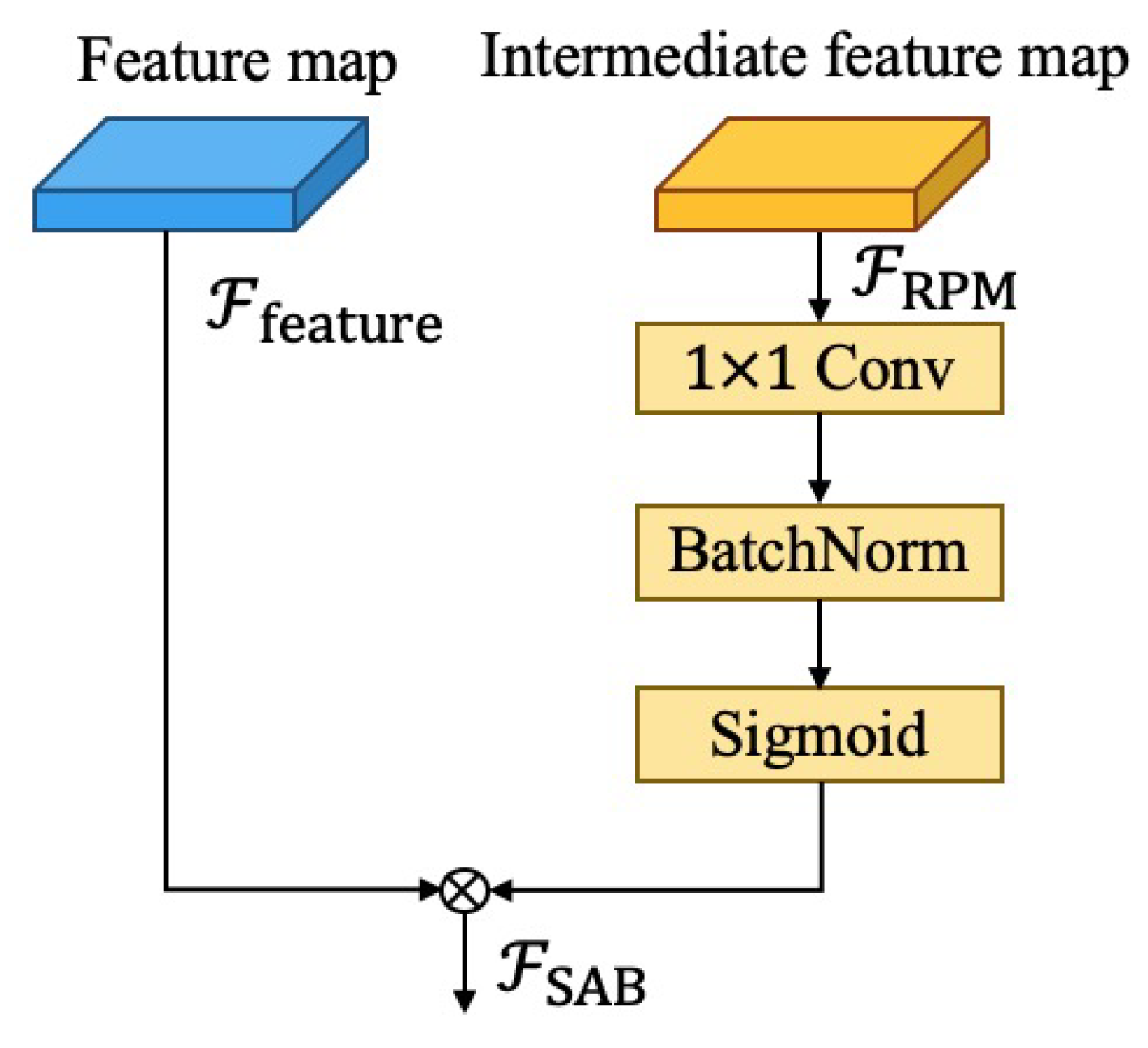
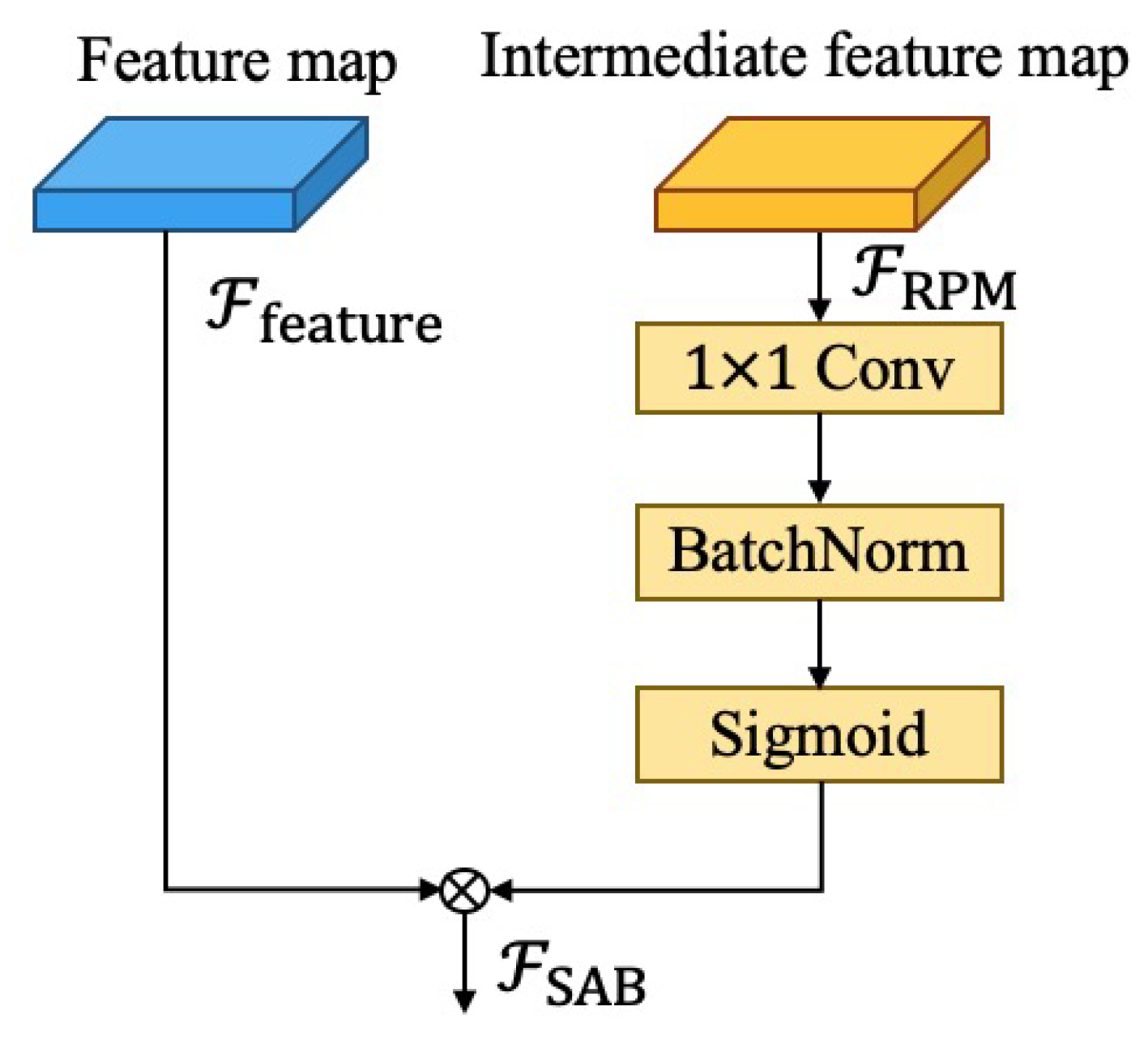
3.2. Region Proposal Module
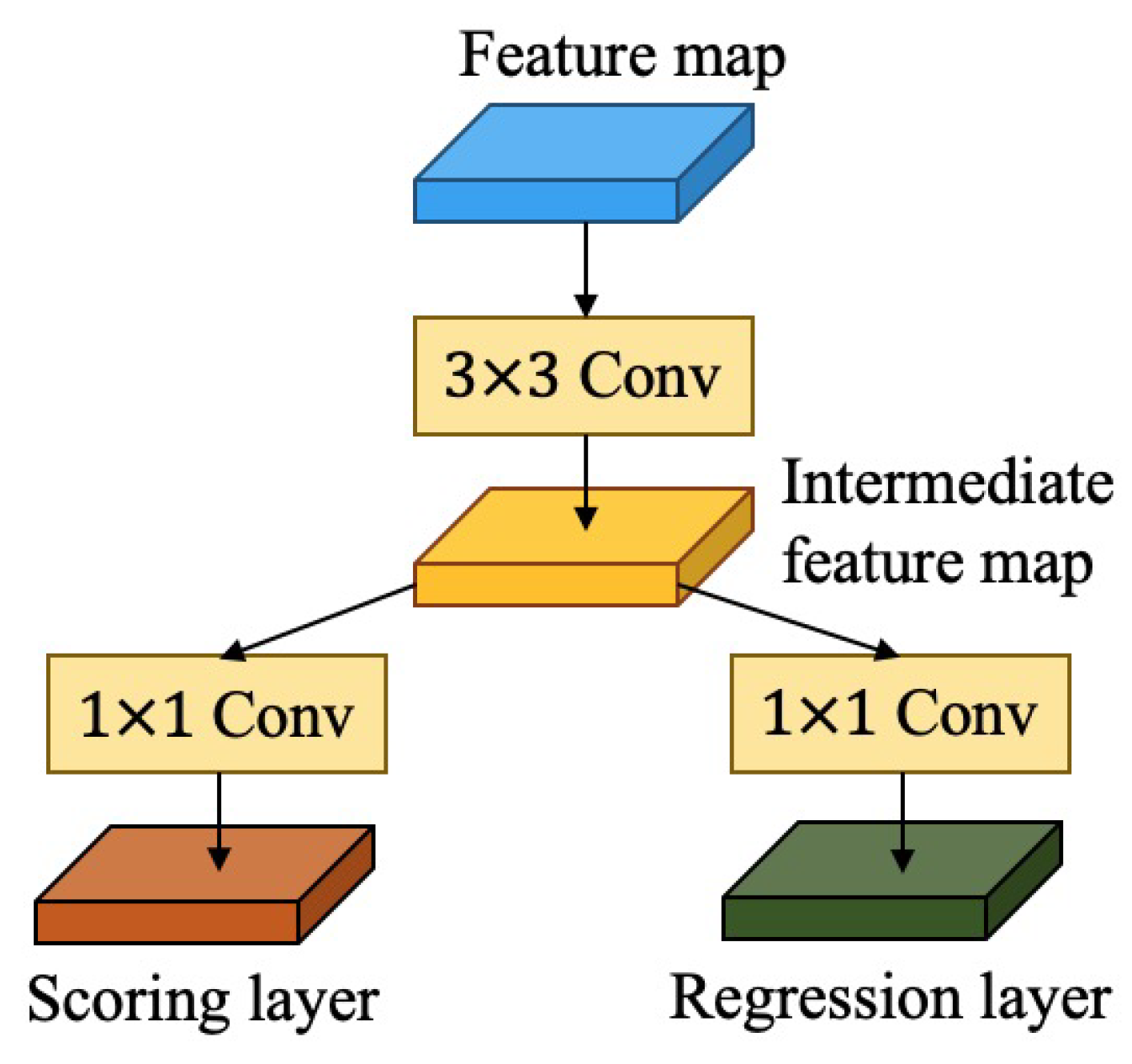
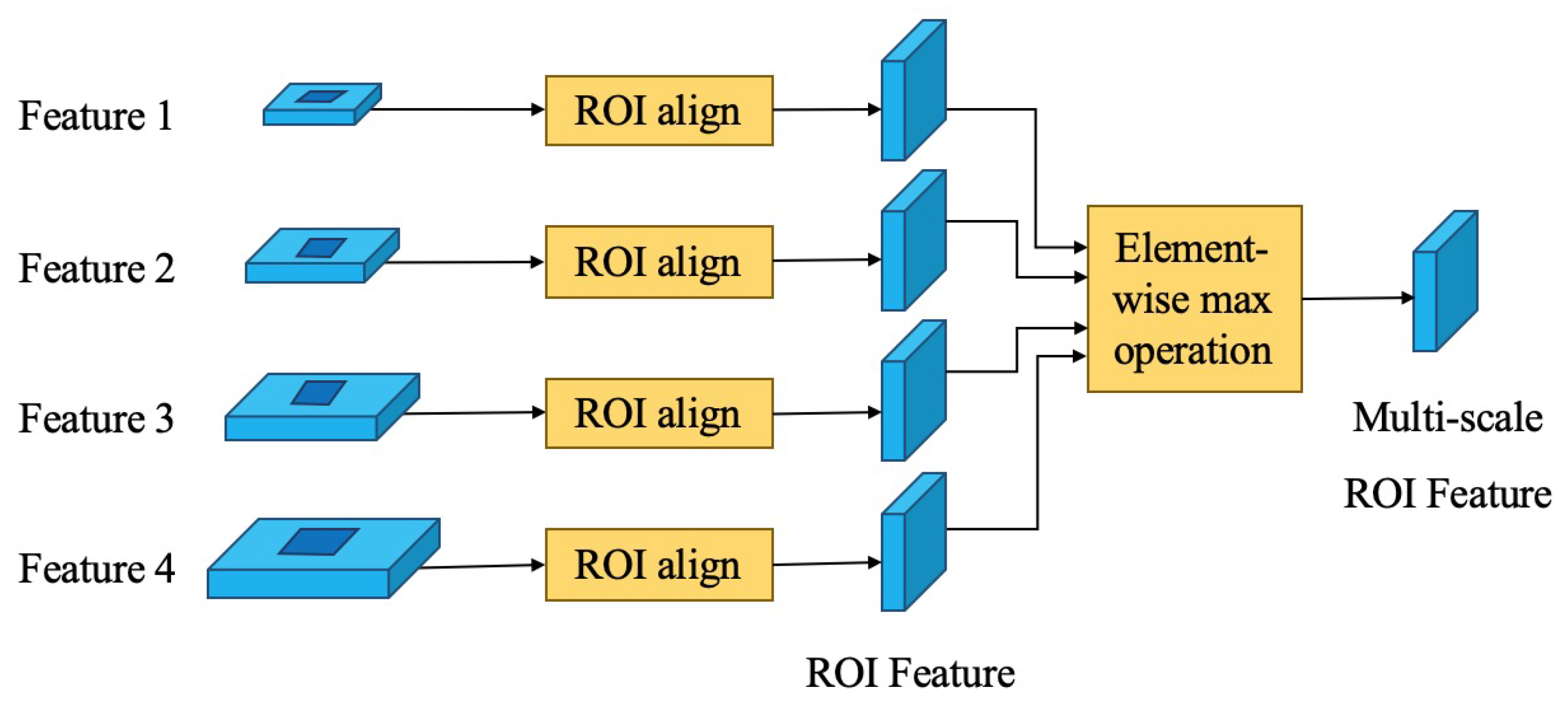
3.3. Detection Module
3.4. Multitask Loss
4. Experimental Results
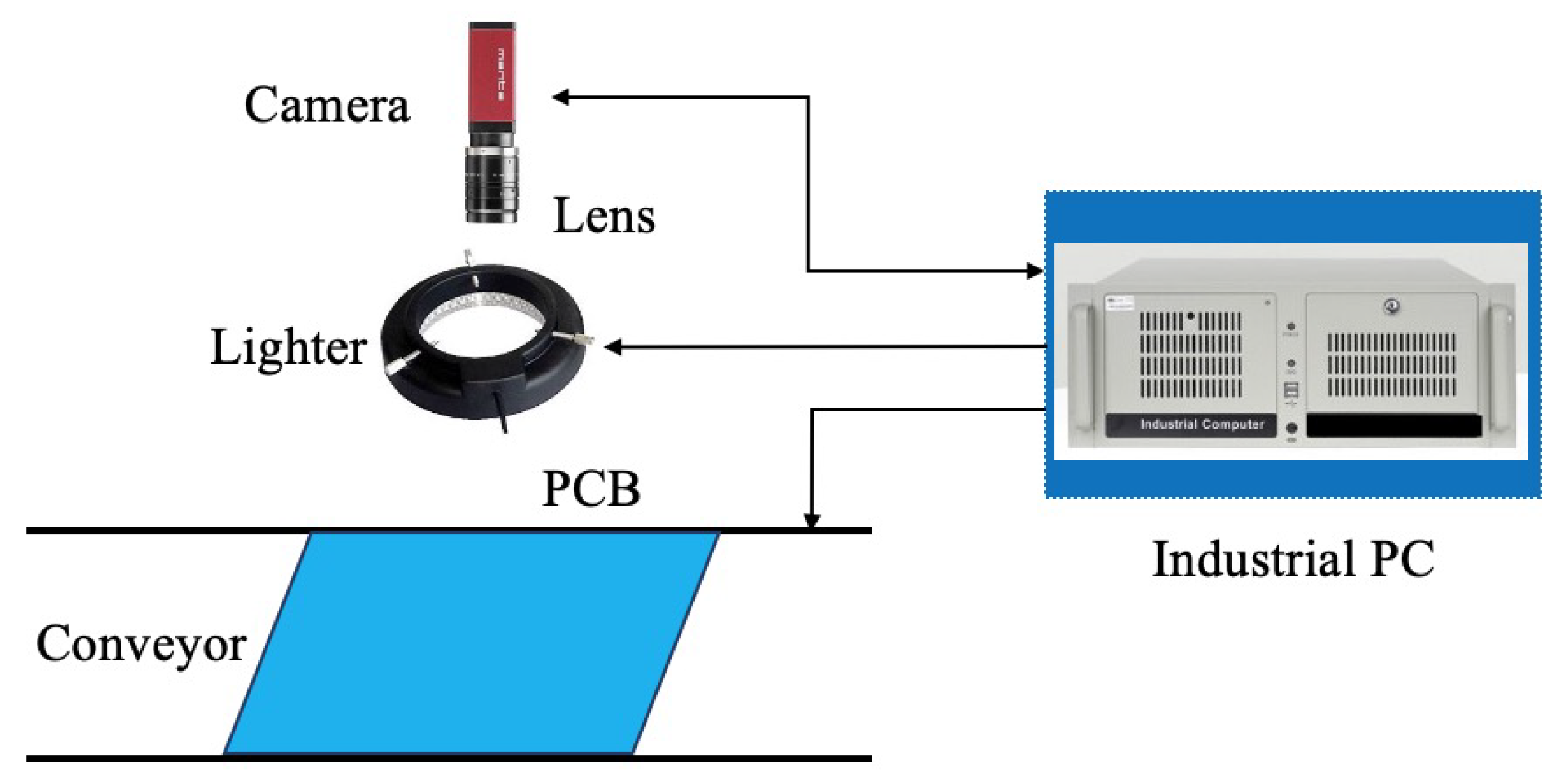
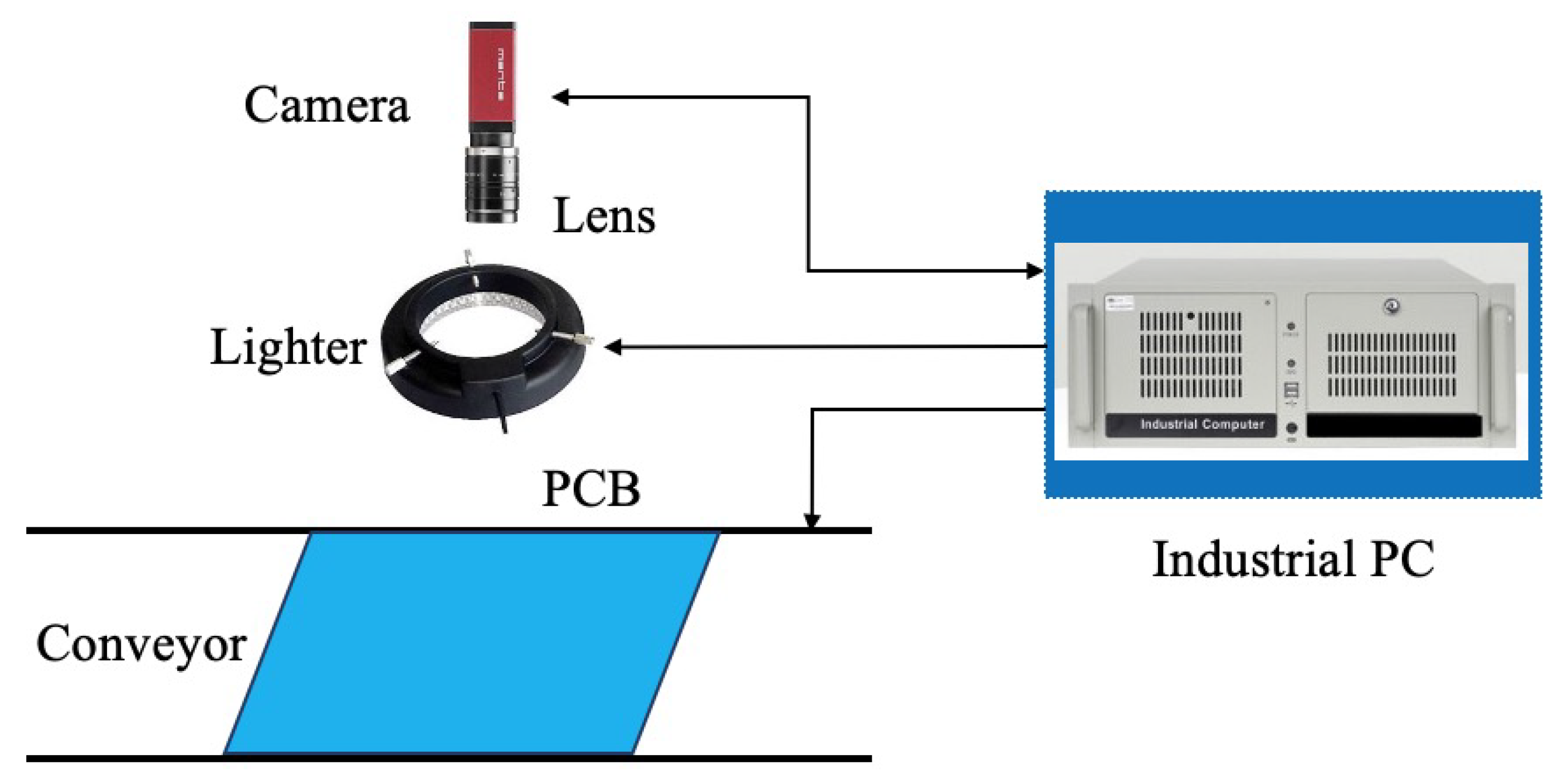
4.1. Dataset
4.2. Implement Details
- (1)
- random crop augmentation: cropping a region with random size from raw images;
- (2)
- random flip augmentation: randomly flipping the image;
- (3)
- small object augmentation [33]: copying small objects from the original position and pasting them to different positions.
4.3. Evaluation Metrics
4.4. Evaluation Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BGA | Ball Grid Array |
| ROI | Region of Interest |
| PCB | Printed Circuit Board |
| NCC | Normalized Cross Correlation |
| LED | Light-Emitting Diode |
| CEM | Context Enhancement Module |
| SAM | Spatial Attention Module |
| RPM | Region Proposal Module |
| FPN | Feature Pyramid Network |
| FEM | Feature Extraction Module |
| AFF | Attentional Feature Fusion |
| CNLA | Cosine Non-Local Attention |
| ReLU | Rectified Linear Unit |
| SAB | Spatial Attention Block |
| IoU | Intersection over Union |
References
- Crispin, A.; Rankov, V. Automated inspection of PCB components using a genetic algorithm template-matching approach. Int. J. Adv. Manuf. Technol. 2007, 35, 293–300. [Google Scholar] [CrossRef] [Green Version]
- Zhong, F.; He, S.; Yi, J. A fast template matching method for LED chip Localization. MATEC Web Conf. 2015, 34, 04002. [Google Scholar] [CrossRef] [Green Version]
- Gao, H.; Jin, W.; Yang, X.; Kaynak, O. A line-based-clustering approach for ball grid array component inspection in surface-mount technology. IEEE Trans. Ind. Electron. 2016, 64, 3030–3038. [Google Scholar] [CrossRef]
- Wang, Z.; Gong, S.; Li, D.; Lu, H. Error analysis and improved calibration algorithm for LED chip localization system based on visual feedback. Int. J. Adv. Manuf. Technol. 2017, 92, 3197–3206. [Google Scholar] [CrossRef]
- Zhong, F.; He, S.; Li, B. Blob analyzation-based template matching algorithm for LED chip localization. Int. J. Adv. Manuf. Technol. 2017, 93, 55–63. [Google Scholar] [CrossRef]
- Bai, L.; Yang, X.; Gao, H. Corner point-based coarse–fine method for surface-mount component positioning. IEEE Trans. Ind. Inform. 2017, 14, 877–886. [Google Scholar] [CrossRef]
- Noe, S.M.; Zin, T.T.; Tin, P.; Kobayashi, I. Automatic detection and tracking of mounting behavior in cattle using a deep learning-based instance segmentation model. Int. J. Innov. Comput. Inf. Control 2022, 18, 211–220. [Google Scholar]
- Naufal, G.R.; Kumala, R.; Martin, R.; Amani, I.T.A.; Budiharto, W. Deep learning-based face recognition system for attendance system. ICIC Express Lett. Part B Appl. 2021, 12, 193–199. [Google Scholar]
- Putra, E.P.; Michael, S.; Wingardi, T.O.; Tatulus, R.L.; Budiharto, W. Smart traffic light model using deep learning and computer vision. ICIC Express Lett. 2021, 15, 297–305. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qin, Z.; Li, Z.; Zhang, Z.; Bao, Y.; Yu, G.; Peng, Y.; Sun, J. ThunderNet: Towards real-time generic object detection on mobile devices. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6717–6726. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, T.; Zhao, Y.; Wei, Y.; Zhao, Y.; Wei, S. Concealed object detection for activate millimeter wave image. IEEE Trans. Ind. Electron. 2019, 66, 9909–9917. [Google Scholar] [CrossRef]
- Fang, Y.; Ding, G.; Wen, W.; Yuan, F.; Yang, Y.; Fang, Z.; Lin, W. Salient object detection by spatiotemporal and semantic features in real-time video processing systems. IEEE Trans. Ind. Electron. 2020, 67, 9893–9903. [Google Scholar] [CrossRef]
- Wang, K.; Bi, H.; Zhang, Y.; Zhang, C.; Liu, Z.; Zheng, S. D2C-Net: A dual-branch, dual-guidance and cross-refine network for camouflaged object detection. IEEE Trans. Ind. Electron. 2022, 69, 5364–5374. [Google Scholar] [CrossRef]
- Gu, B.; Ge, R.; Chen, Y.; Luo, L.; Coatrieux, G. Automatic and robust object detection in X-Ray baggage inspection using deep convolutional neural networks. IEEE Trans. Ind. Electron. 2021, 68, 10248–10257. [Google Scholar] [CrossRef]
- Su, B.; Chen, H.; Zhou, Z. BAF-detector: An dfficient CNN-based detector for photovoltaic cell defect detection. IEEE Trans. Ind. Electron. 2022, 69, 3161–3171. [Google Scholar] [CrossRef]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional feature fusion. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2021; pp. 3559–3568. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning (ICLM), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 11 October 2019).
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Hosang, J.; Benenson, R.; Dollár, P.; Schiele, B. What makes for effective detection proposals? IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 814–830. [Google Scholar] [CrossRef] [PubMed] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Reference | Advantages |
|---|---|---|
| Computer-vision-based methods | FTM [2] | Fast template-matching method applied to LED chip localization. |
| LBC [3] | Line-based clustering approach applied to BGA component localization. | |
| VF [4] | Main cause of errors in chip detection was analyzed. | |
| BATM [5] | Blob-analysis-based template matching method introduced into LED chip detection. | |
| CPCF [6] | Corner-point-based coarse fine method introduced into chip localization. | |
| Deep-learning-based method | FPN | Feature-pyramid-based feature extraction introduced into object detection. |
| Thunder Net [18] | Context-enhancement and spatial-attention modules introduced into object detection. | |
| COB [20] | Context-embedding module introduced into concealed object detection form millimeter wave image. | |
| SOD [21] | Semantic object feature extraction module (Conv2dNet), spatiotemporal feature extraction module (Conv3DNet), and saliency feature-sharing module fused for real-time video object detection. | |
| D2C-Net [22] | Dual-branch feature extraction and gradually refined cross-fusion module fused for camouflaged object detection. | |
| XRBI [23] | X-ray proposal and X-ray discriminative networks assembled for baggage inspection. | |
| PCDD [24] | Bidirectional attention feature pyramid network introduced for photovoltaic-cell defect detection. |
| Dataset | Resistor | Capacitors | Transistor | IC | Inductor | Total |
|---|---|---|---|---|---|---|
| Training | 665 | 670 | 307 | 183 | 54 | 1879 |
| Evaluation | 70 | 62 | 32 | 16 | 8 | 188 |
| Faster R-CNN | 0.96570 | 0.91685 | 0.76109 |
| Our method | 0.98745 | 0.95142 | 0.81130 |
| Resistor | Capacitors | Transistor | IC | Inductor | ||
|---|---|---|---|---|---|---|
| Faster R-CNN | 0.76109 | 0.73493 | 0.77381 | 0.75677 | 0.81387 | 0.72608 |
| Our method | 0.81130 | 0.72234 | 0.80324 | 0.77550 | 0.88759 | 0.86782 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Sun, H.; Shi, P.; Minchala, L.I. A Novel Electronic Chip Detection Method Using Deep Neural Networks. Machines 2022, 10, 361. https://doi.org/10.3390/machines10050361
Zhang H, Sun H, Shi P, Minchala LI. A Novel Electronic Chip Detection Method Using Deep Neural Networks. Machines. 2022; 10(5):361. https://doi.org/10.3390/machines10050361
Chicago/Turabian StyleZhang, Huiyan, Hao Sun, Peng Shi, and Luis Ismael Minchala. 2022. "A Novel Electronic Chip Detection Method Using Deep Neural Networks" Machines 10, no. 5: 361. https://doi.org/10.3390/machines10050361
APA StyleZhang, H., Sun, H., Shi, P., & Minchala, L. I. (2022). A Novel Electronic Chip Detection Method Using Deep Neural Networks. Machines, 10(5), 361. https://doi.org/10.3390/machines10050361