
A Survey on Data-Driven Scenario Generation for Automated Vehicle Testing

Abstract
1. Introduction
- State-of-the-art methodologies used for DDSG, such as Reinforcing Learning (RL), Accelerated Evaluation (AE), and so on, are generally introduced. The generation of customized scenarios for the VUT is also covered by this survey, which cannot be found in existing reviews.
- Solutions to sub-problems involved in these methodologies are described in detail. These sub-problems include source data collection, scenario identification, and criticality metrics used for scenario evaluation.
- Some remaining problems are pointed out, and responding potential solutions are provided.
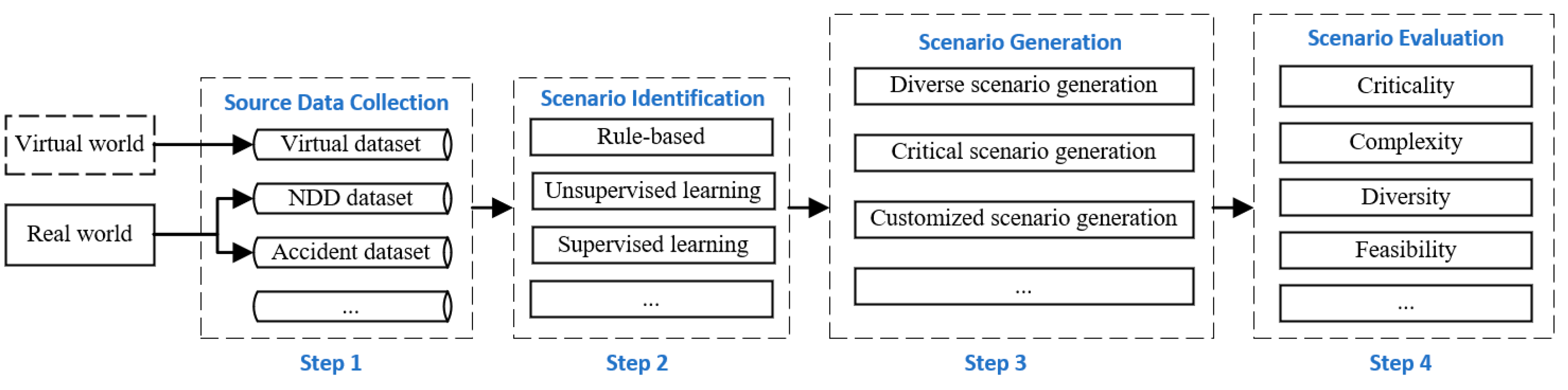
2. Framework
3. Definitions
3.1. Scene, Scenario, and ODD
3.2. Critical, Challenging Scenarios
4. Source Data Collection
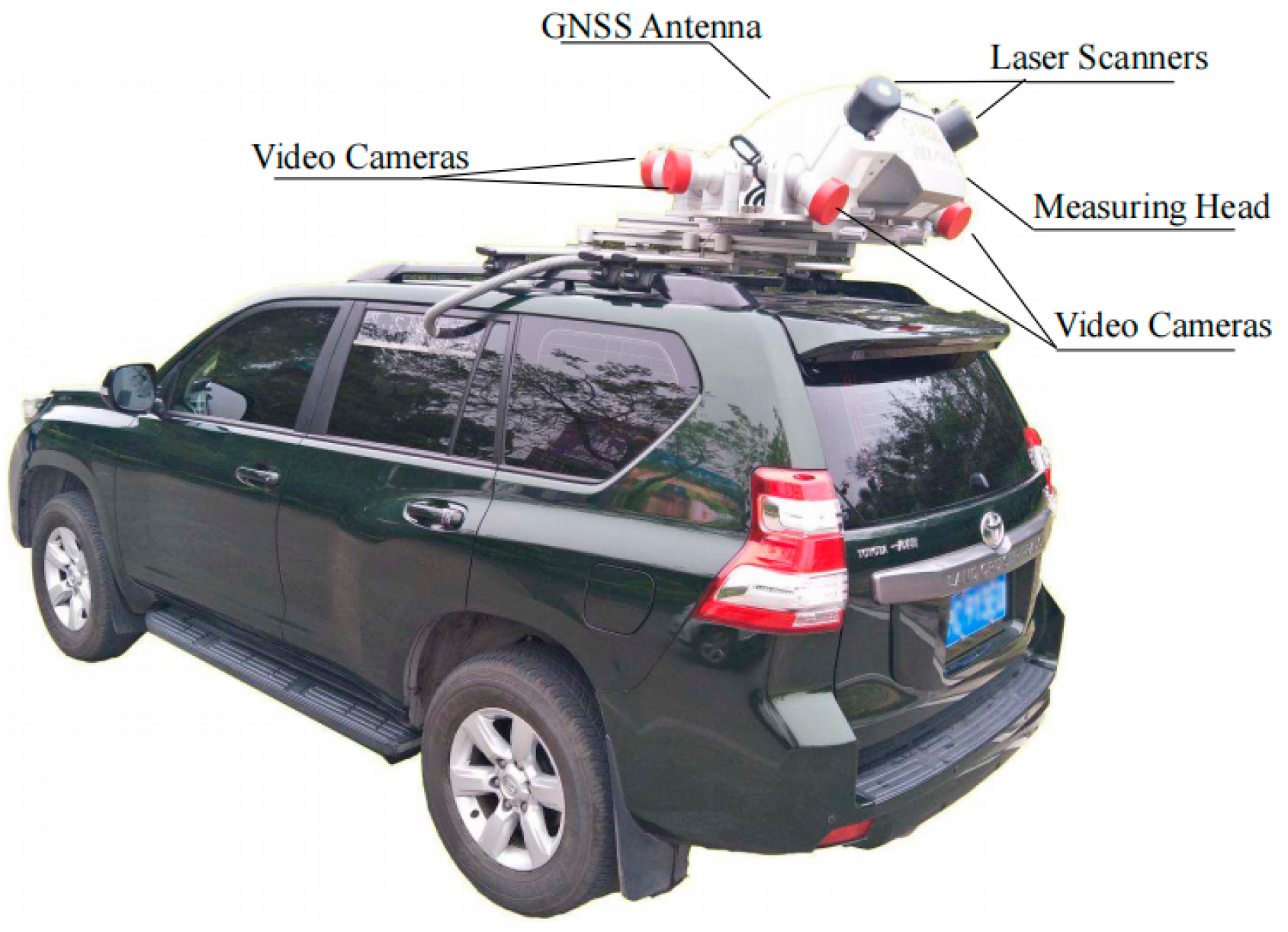
4.1. Natural Driving Data
4.2. Accident Data
4.3. Virtual Data
4.4. Conclusions of Source Data Collection
5. Scenario Identification
5.1. Region of Interest
5.2. Feature Dimension Reduction
5.3. Rule-Based Methods
5.4. Unsupervised Machine Learning
5.5. Supervised Machine Learning
5.6. Conclusions of Scenario Identification
6. Scenario Generation
6.1. Diverse Scenario Generation
6.1.1. Random Sampling
6.1.2. Combinatorial Testing
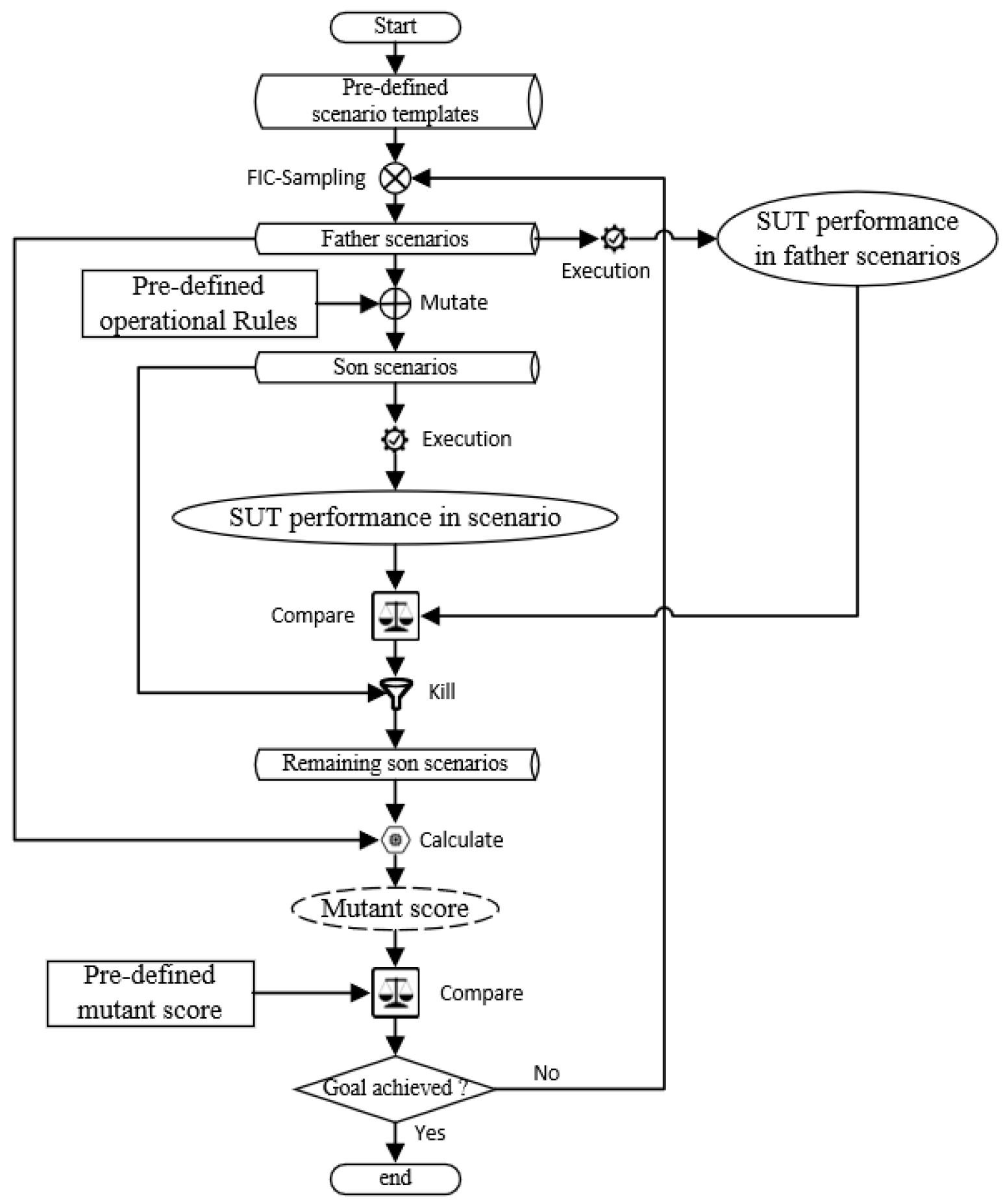
6.1.3. Mutation Testing
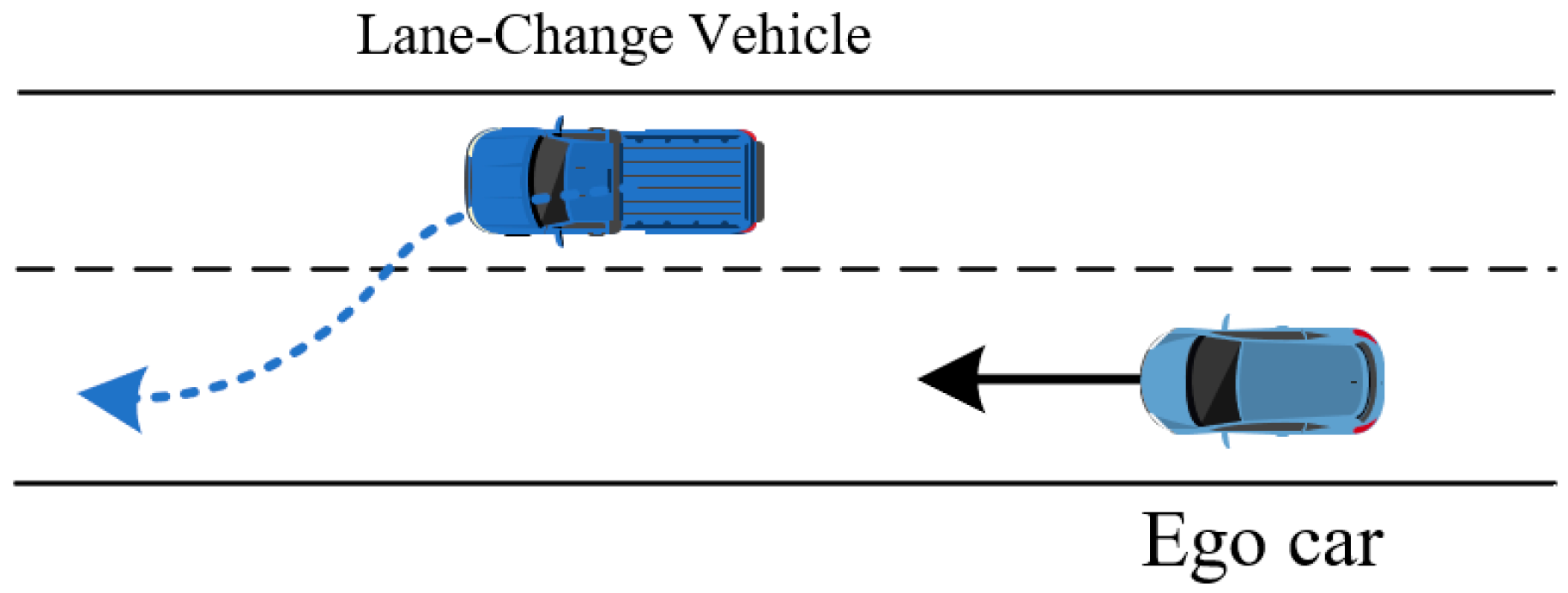
6.2. Critical Scenario Generation
6.2.1. Accelerated Evaluation
- Collect a large amount of NDD.
- Identify target scenarios.
- Fit the original Probability Density Function (PDF) of each scenario parameter.
- Skew the original PDF, deriving a modified PDF , which will lead to more radical behaviors of traffic agents or rare scenarios.
- Random sampling is conducted based on the modified PDF to generate accelerated scenarios, and then applied to test the VUT.
- The accelerated scenarios are statistically skewed back to obtain the performance of the VUT in natural traffic.
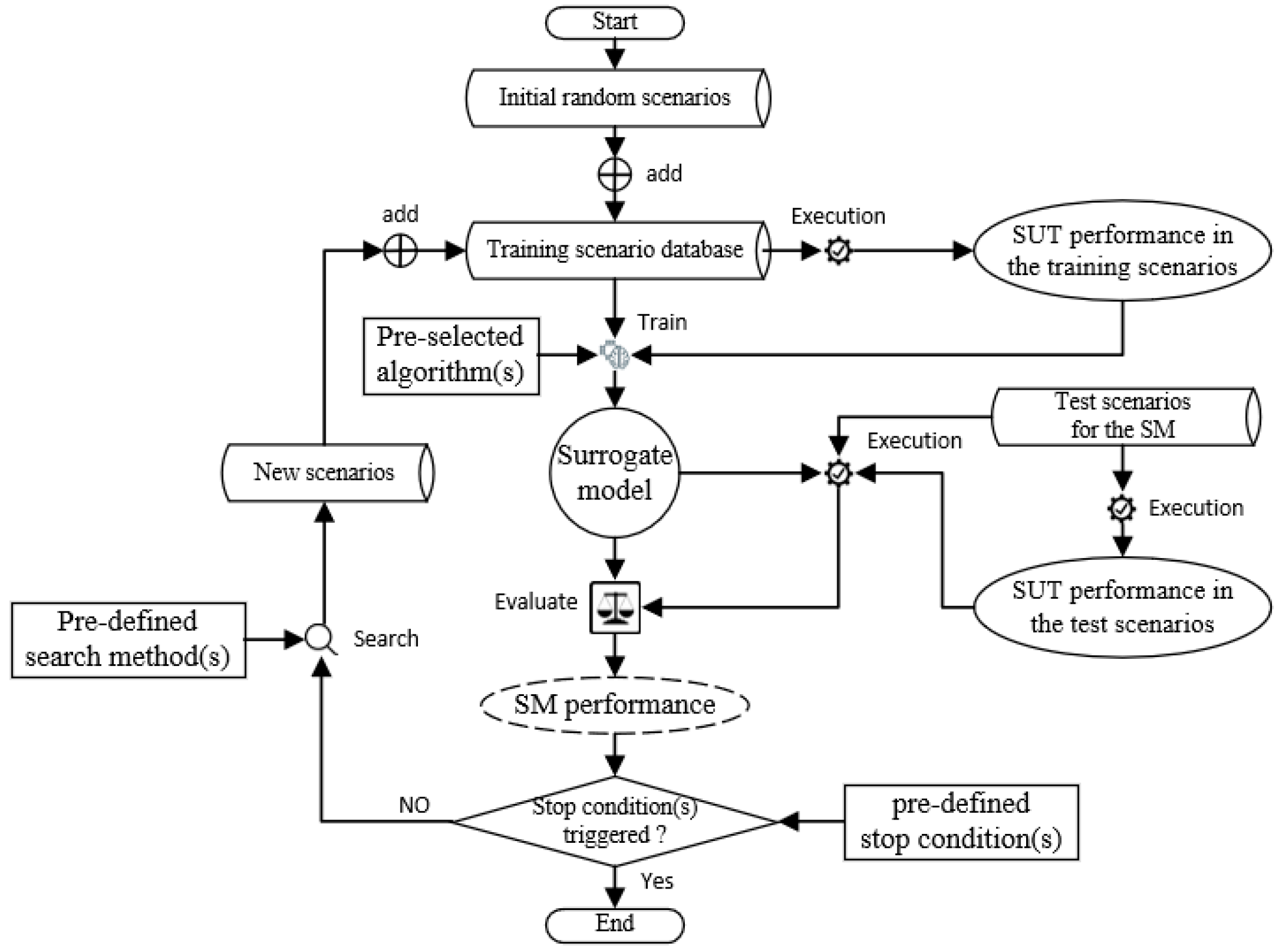
6.2.2. Search Algorithms
6.2.3. Reinforcement Learning
6.2.4. Others
6.3. Customized Scenario Generation
6.4. Conclusions of Scenario Generation
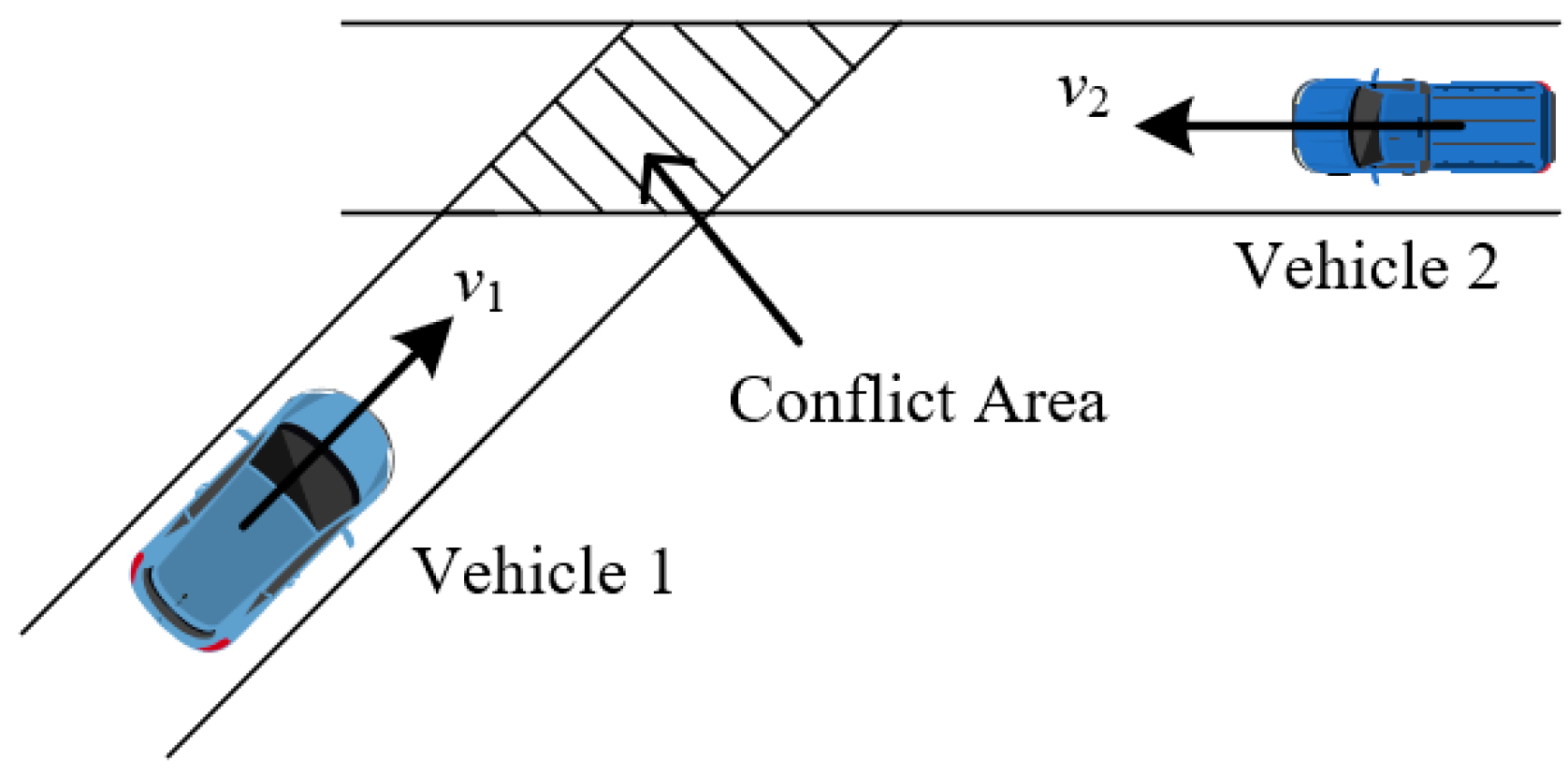
7. Criticality Metrics of Scenarios
7.1. Trajectory-Based
7.2. Maneuver-Based
7.3. Energy-Based
7.4. Uncertainty-Based
7.5. Combination-Based
7.6. Conclusions of Criticality Metrics of Scenarios
8. Discussions and Conclusions
- Develop a toolchain that can generate good-quality traffic-scenario data on simulation platforms to reduce the efforts and investments for gathering source data in the real world.
- Build a methodology that can effectively and efficiently identify known and unknown scenarios in source data without sacrificing feasibility to use all source data fully.
- Use different methodologies to generate diverse, critical, and natural scenarios to meet different requirements in different development stages.
- Find a strategy to obtain high-performance Surrogate Models (SM) based on limited resources.
- Design a general criticality metric that can objectively quantify the criticality of all scenarios.
- Simulation fidelity and computing power need improvement. Simulation with high fidelity is crucial to executing scenarios and can contribute to source data generation. Simulation technology has been widely utilized in SBT. However, on the one hand, many studies utilize simulation techniques to execute scenarios. On the other hand, no software companies claim that their software can replace experiments in the real world. If it is impossible to replace the real world with a virtual one, it will be helpful to quantify the gap between them, which can let us know how much we can trust the simulation results. Moreover, it is of great significance to use low-fidelity simulations to reduce high-fidelity simulations, which are more expensive and consume more time.
- There are no conclusions on how many of what scenarios are enough for AV testing. There is an infinite number of scenarios in the physical world. It is impossible to test AVs in all of them. An embarrassing dilemma is that many studies propose many scenario-based methods to test AVs, and no one concludes how many of what scenarios are enough for AV testing. It is significantly vital to draw a terminal line for this endless Marathon.
- Data sharing is crucial for AV testing. Safety-critical events hidden in NDD are crucial for DDSG. However, because of the Curse of Rarity (CoR) [206], a large amount of NDD would significantly contribute to DDSG. While some open datasets are available for researchers, giant companies like Tesla, Baidu, Didi, et al. hold a large amount of NDD privately. Furthermore, because many functions are complete black boxes, it is hard for a researcher or an engineer to generate customized scenarios for the VUT. It is reasonable to believe that more comprehensive cooperation between industry and academia can tremendously enhance the development of SBT of AVs.
- The unignorable gap between ideology and reality deserves more attention: While one of the aims of developing AVs is to reduce traffic accidents to zero, achieving zero accidents in practice is severely challenging. It might be good to mitigate the public expectation to an appropriate level to let more un-perfect but good AVs be tested in natural traffic. This way, AVs will evolve and collect more valuable data for researchers.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ju, Z.; Zhang, H.; Li, X.; Chen, X.; Han, J.; Yang, M. A Survey on Attack Detection and Resilience for Connected and Automated Vehicles: From Vehicle Dynamics and Control Perspective. IEEE Trans. Intell. Veh. 2022, 1–24. [Google Scholar] [CrossRef]
- Paradina, R.M.; Noroña, M.I. Applications and Challenges of Adopting Internet of Things (IoT) in Reducing Road Traffic Accidents. In Proceedings of the Second Asia Pacific International Conference on Industrial Engineering and Operations Management, Surakarta, Indonesia, 14–16 September 2021. [Google Scholar]
- Ghorpade, P.; Nema, A. A Review on Accident Detection System Using Iot. Int. Res. J. Mod. Eng. Technol. Sci. 2022, 4, 4278–4283. [Google Scholar]
- Sohrabi, S.; Khodadadi, A.; Mousavi, S.M.; Dadashova, B.; Lord, D. Quantifying the Automated Vehicle Safety Performance: A Scoping Review of the Literature, Evaluation of Methods, and Directions for Future Research. Accid. Anal. Prev. 2021, 152, 106003. [Google Scholar] [CrossRef] [PubMed]
- Shadrin, S.S.; Ivanova, A.A. Analytical Review of Standard Sae J3016 taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles with Latest Updates. Avtomob. Doroga Infrastrukt. 2019, 3, 10. [Google Scholar]
- Thorn, E.; Kimmel, S.C.; Chaka, M.; Hamilton, B.A. A Framework for Automated Driving System Testable Cases and Scenarios; Department of Transportation, National Highway Traffic Safety: Washington, DC, USA, 2018. [Google Scholar]
- Roesener, C.; Fahrenkrog, F.; Uhlig, A.; Eckstein, L. A Scenario-Based Assessment Approach for Automated Driving by Using Time Series Classification of Human-Driving Behaviour. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 1360–1365. [Google Scholar]
- Jesenski, S.; Rothert, J.; Tiemann, N.; Zöllner, J.M. Using Sum-Product Networks for the Generation of Vehicle Populations On Highway Sections. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–7. [Google Scholar]
- Fremont, D.J.; Sangiovanni-Vincentelli, A.L.; Seshia, S.A. Safety in Autonomous Driving: Can Tools Offer Guarantees? In Proceedings of the 2021 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 5–9 December 2021; pp. 1311–1314. [Google Scholar]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Karunakaran, D.; Worrall, S.; Nebot, E. Efficient Statistical Validation with Edge Cases to Evaluate Highly Automated Vehicles. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–8. [Google Scholar]
- Ding, W.; Xu, C.; Lin, H.; Li, B.; Zhao, D. A Survey on Safety-Critical Scenario Generation from Methodological Perspective. arXiv 2022, arXiv:2202.02215. [Google Scholar]
- Kalra, N.; Paddock, S.M. Driving to Safety: How Many Miles of Driving Would It Take to Demonstrate Autonomous Vehicle Reliability? Transp. Res. A Policy Pract. 2016, 94, 182–193. [Google Scholar] [CrossRef]
- Winner, H.; Lemmer, K.; Form, T.; Mazzega, J. PEGASUS—First Steps for the Safe Introduction of Automated Driving. In Road Vehicle Automation 5; Springer: Berlin/Heidelberg, Germany, 2019; pp. 185–195. [Google Scholar]
- Roesener, C.; Sauerbier, J.; Zlocki, A.; Fahrenkrog, F.; Wang, L.; Várhelyi, A.; de Gelder, E.; Dufils, J.; Breunig, S.; Mejuto, P. A Comprehensive Evaluation Approach for Highly Automated Driving. In Proceedings of the 25th International Technical Conference on the Enhanced Safety of Vehicles (ESV) National Highway Traffic Safety Administration, Detroit, MI, USA, 5–8 June 2017. [Google Scholar]
- Fahrenkrog, F.; Rösener, C.; Zlocki, A.; Eckstein, L. Technical Evaluation and Impact Assessment of Automated Driving. In Road Vehicle Automation 3; Springer: Berlin/Heidelberg, Germany, 2016; pp. 237–246. [Google Scholar]
- Makano, H. C-ITS and Connected Automated Driving in Japan. Routes/Roads 2017. Available online: https://trid.trb.org/view/1487881 (accessed on 1 October 2022).
- Elrofai, H.; Paardekooper, J.-P.; de Gelder, E.; Kalisvaart, S.; den Camp, O.O. Scenario-Based Safety Validation of Connected and Automated Driving. In Technical Report; Netherlands Organization for Applied Scientifific Research: Hague, The Newtherlands, 2018; Available online: http://resolver.tudelft.nl/uuid:2b155e03-5c51-4c9f-8908-3fa4c34b3897 (accessed on 1 October 2022).
- McMinn, P. Search-Based Software Testing: Past, Present and Future. In Proceedings of the 2011 IEEE Fourth International Conference on Software Testing, Verification and Validation Workshops, Berlin, Germany, 21–25 March 2011; pp. 153–163. [Google Scholar]
- Menzel, T.; Bagschik, G.; Maurer, M. Scenarios for Development, Test and Validation of Automated Vehicles. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1821–1827. [Google Scholar]
- Li, Y.; Tao, J.; Wotawa, F. Ontology-Based Test Generation for Automated and Autonomous Driving Functions. Inf. Softw. Technol. 2020, 117, 106200. [Google Scholar] [CrossRef]
- Bagschik, G.; Menzel, T.; Maurer, M. Ontology Based Scene Creation for the Development of Automated Vehicles. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1813–1820. [Google Scholar]
- Tenbrock, A.; König, A.; Keutgens, T.; Weber, H. The ConScenD Dataset: Concrete Scenarios from the HighD Dataset According to ALKS Regulation UNECE R157 in OpenX. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium Workshops (IV Workshops), Nagoya, Japan, 11–17 July 2021; pp. 174–181. [Google Scholar]
- Kramer, B.; Neurohr, C.; Büker, M.; Böde, E.; Fränzle, M.; Damm, W. Identification and Quantification of Hazardous Scenarios for Automated Driving. In Proceedings of the International Symposium on Model-Based Safety and Assessment, Lisbon, Portugal, 14–16 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 163–178. [Google Scholar]
- Elspas, P.; Langner, J.; Aydinbas, M.; Bach, J.; Sax, E. Leveraging Regular Expressions for Flexible Scenario Detection in Recorded Driving Data. In Proceedings of the 2020 IEEE International Symposium on Systems Engineering (ISSE), Vienna, Austria, 12 October–12 November 2020; pp. 1–8. [Google Scholar]
- Riedmaier, S.; Ponn, T.; Ludwig, D.; Schick, B.; Diermeyer, F. Survey on Scenario-Based Safety Assessment of Automated Vehicles. IEEE Access 2020, 8, 87456–87477. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, H.; Zhou, H.; Yu, R.; Tian, Y. Scenario-Based Test Automation for Highly Automated Vehicles: A Review and Paving the Way for Systematic Safety Assurance. IEEE Trans. Intell. Transp. Syst. 2021, 23, 14088–14103. [Google Scholar] [CrossRef]
- Batsch, F.; Kanarachos, S.; Cheah, M.; Ponticelli, R.; Blundell, M. A Taxonomy of Validation Strategies to Ensure the Safe Operation of Highly Automated Vehicles. J. Intell. Transp. Syst. 2021, 26, 14–33. [Google Scholar] [CrossRef]
- Zhao, D. Accelerated Evaluation of Automated Vehicles. Ph.D. Thesis, The University of Michigan, Ann Arbor, MI, USA, 2016. [Google Scholar]
- Brown, B.; Park, D.; Sheehan, B.; Shikoff, S.; Solomon, J.; Yang, J.; Kim, I. Assessment of Human Driver Safety at Dilemma Zones with Automated Vehicles through a Virtual Reality Environment. In Proceedings of the 2018 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 27 April 2018; pp. 185–190. [Google Scholar]
- Yue, B.; Shi, S.; Wang, S.; Lin, N. Low-Cost Urban Test Scenario Generation Using Microscopic Traffic Simulation. IEEE Access 2020, 8, 123398–123407. [Google Scholar] [CrossRef]
- Scanlon, J.M.; Kusano, K.D.; Daniel, T.; Alderson, C.; Ogle, A.; Victor, T. Waymo Simulated Driving Behavior in Reconstructed Fatal Crashes within an Autonomous Vehicle Operating Domain. Accid. Anal. Prev. 2021, 163, 106454. [Google Scholar] [CrossRef]
- Damm, W.; Möhlmann, E.; Rakow, A. Traffic Sequence Charts for the Enable-s 3 Test Architecture. In Validation and Verification of Automated Systems; Springer: Berlin/Heidelberg, Germany, 2020; pp. 45–60. [Google Scholar]
- De Gelder, E.; Paardekooper, J.-P.; Saberi, A.K.; Elrofai, H.; op den Camp, O.; Kraines, S.; Ploeg, J.; de Schutter, B. Towards an Ontology for Scenario Definition for the Assessment of Automated Vehicles: An Object-Oriented Framework. IEEE Trans. Intell. Veh. 2022, 7, 300–314. [Google Scholar] [CrossRef]
- Ulbrich, S.; Menzel, T.; Reschka, A.; Schuldt, F.; Maurer, M. Defining and Substantiating the Terms Scene, Situation, and Scenario for Automated Driving. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015; pp. 982–988. [Google Scholar]
- Steimle, M.; Menzel, T.; Maurer, M. A Method for Classifying Test Bench Configurations in a Scenario-Based Test Approach for Automated Vehicles. arXiv 2019, arXiv:1905.09018. [Google Scholar]
- Sauerbier, J.; Bock, J.; Weber, H.; Eckstein, L. Definition of Scenarios for Safety Validation of Automated Driving Functions. ATZ Worldwide 2019, 121, 42–45. [Google Scholar] [CrossRef]
- Scholtes, M.; Westhofen, L.; Turner, L.R.; Lotto, K.; Schuldes, M.; Weber, H.; Wagener, N.; Neurohr, C.; Bollmann, M.H.; Körtke, F. 6-Layer Model for a Structured Description and Categorization of Urban Traffic and Environment. IEEE Access 2021, 9, 59131–59147. [Google Scholar] [CrossRef]
- Damm, W.; Möhlmann, E.; Rakow, A. A Scenario Discovery Process Based on Traffic Sequence Charts. In Validation and Verification of Automated Systems; Springer: Berlin/Heidelberg, Germany, 2020; pp. 61–73. [Google Scholar]
- Stepien, L.; Thal, S.; Henze, R.; Nakamura, H.; Antona-Makoshi, J.; Uchida, N.; Raksincharoensak, P. Applying Heuristics to Generate Test Cases for Automated Driving Safety Evaluation. Appl. Sci. 2021, 11, 10166. [Google Scholar] [CrossRef]
- Zhong, Z.; Tang, Y.; Zhou, Y.; Neves, V.d.O.; Liu, Y.; Ray, B. A Survey on Scenario-Based Testing for Automated Driving Systems in High-Fidelity Simulation. arXiv 2021, arXiv:2112.00964. [Google Scholar]
- Gettman, D.; Head, L. Surrogate Safety Measures from Traffic Simulation Models. Transp. Res. Rec. 2003, 1840, 104–115. [Google Scholar] [CrossRef]
- Junietz, P.M. Microscopic and Macroscopic Risk Metrics for the Safety Validation of Automated Driving. Ph.D. Theis, Technischen Universität Darmstadt, Darmstadt, Germany, 2019. [Google Scholar]
- Song, Q.; Tan, K.; Runeson, P.; Persson, S. Critical Scenario Identification for Realistic Testing of Autonomous Driving Systems. 2022. Available online: https://assets.researchsquare.com/files/rs-1280095/v1_covered.pdf?c=1642707391 (accessed on 1 October 2022).
- Ponn, T.; Breitfuß, M.; Yu, X.; Diermeyer, F. Identification of Challenging Highway-Scenarios for the Safety Validation of Automated Vehicles Based on Real Driving Data. In Proceedings of the 2020 Fifteenth International Conference on Ecological Vehicles and Renewable Energies (EVER), Monte-Carlo, Monaco, 10–12 September 2020; pp. 1–10. [Google Scholar]
- Ponn, T.; Gnandt, C.; Diermeyer, F. An Optimization-Based Method to Identify Relevant Scenarios for Type Approval of Automated Vehicles. In Proceedings of the ESV—International Technical Conference on the Enhanced Safety of Vehicles, Eindhoven, The Netherlands, 10–13 June 2019; pp. 10–13. [Google Scholar]
- Ponn, T.; Lanz, T.; Diermeyer, F. Automatic Generation of Road Geometries to Create Challenging Scenarios for Automated Vehicles Based on the Sensor Setup. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 694–700. [Google Scholar]
- Wang, X.; Zhang, S.; Peng, H. Comprehensive Safety Evaluation of Highly Automated Vehicles at the Roundabout Scenario. IEEE Trans. Intell. Transp. Syst. 2022, 1–16. [Google Scholar] [CrossRef]
- Zhang, X.; Tao, J.; Tan, K.; Törngren, M.; Sánchez, J.M.G.; Ramli, M.R.; Tao, X.; Gyllenhammar, M.; Wotawa, F.; Mohan, N. Finding Critical Scenarios for Automated Driving Systems: A Systematic Literature Review. arXiv 2021, arXiv:2110.08664. [Google Scholar]
- Steimle, M.; Menzel, T.; Maurer, M. Toward a Consistent Taxonomy for Scenario-Based Development and Test Approaches for Automated Vehicles: A Proposal for a Structuring Framework, a Basic Vocabulary, and Its Application. IEEE Access 2021, 9, 147828–147854. [Google Scholar] [CrossRef]
- Badue, C.; Guidolini, R.; Carneiro, R.V.; Azevedo, P.; Cardoso, V.B.; Forechi, A.; Jesus, L.; Berriel, R.; Paixao, T.M.; Mutz, F. Self-Driving Cars: A Survey. Expert Syst. Appl. 2021, 165, 113816. [Google Scholar] [CrossRef]
- Wu, Z.; Zhang, D.; Wang, Y.; Zhou, H.; Qi, H. Lane-Changing Behavior Recognition in the Connected Vehicle Environment. In Proceedings of the International Conference on Intelligent Transportation Engineering, Beijing, China, 12–13 November 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 50–61. [Google Scholar]
- Montanari, F.; German, R.; Djanatliev, A. Pattern Recognition for Driving Scenario Detection in Real Driving Data. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 590–597. [Google Scholar]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The Apolloscape Dataset for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 954–960. [Google Scholar]
- Krajewski, R.; Bock, J.; Kloeker, L.; Eckstein, L. The Highd Dataset: A Drone Dataset of Naturalistic Vehicle Trajectories on German Highways for Validation of Highly Automated Driving Systems. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2118–2125. [Google Scholar]
- Bock, J.; Krajewski, R.; Moers, T.; Runde, S.; Vater, L.; Eckstein, L. The Ind Dataset: A Drone Dataset of Naturalistic Road User Trajectories at German Intersections. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1929–1934. [Google Scholar]
- Krajewski, R.; Moers, T.; Bock, J.; Vater, L.; Eckstein, L. The Round Dataset: A Drone Dataset of Road User Trajectories at Roundabouts in Germany. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Punzo, V.; Borzacchiello, M.T.; Ciuffo, B. On the Assessment of Vehicle Trajectory Data Accuracy and Application to the Next Generation SIMulation (NGSIM) Program Data. Transp. Res. C Emerg. Technol. 2011, 19, 1243–1262. [Google Scholar] [CrossRef]
- Strigel, E.; Meissner, D.; Seeliger, F.; Wilking, B.; Dietmayer, K. The Ko-per Intersection Laserscanner and Video Dataset. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 1900–1901. [Google Scholar]
- Kang, Y.; Yin, H.; Berger, C. Test Your Self-Driving Algorithm: An Overview of Publicly Available Driving Datasets and Virtual Testing Environments. IEEE Trans. Intell. Veh. 2019, 4, 171–185. [Google Scholar] [CrossRef]
- Dingus, T.A.; Klauer, S.G.; Neale, V.L.; Petersen, A.; Lee, S.E.; Sudweeks, J.; Perez, M.A.; Hankey, J.; Ramsey, D.; Gupta, S. The 100-Car Naturalistic Driving Study, Phase II-Results of the 100-Car Field Experiment; Department of Transportation, National Highway Traffic Safety: Washington, DC, USA, 2006. [Google Scholar]
- Pham, Q.-H.; Sevestre, P.; Pahwa, R.S.; Zhan, H.; Pang, C.H.; Chen, Y.; Mustafa, A.; Chandrasekhar, V.; Lin, J. A* 3D Dataset: Towards Autonomous Driving in Challenging Environments. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2267–2273. [Google Scholar]
- Chang, M.-F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D. Argoverse: 3d Tracking and Forecasting with Rich Maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8748–8757. [Google Scholar]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. Bdd100k: A Diverse Driving Video Database with Scalable Annotation Tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic Object Classes in Video: A High-Definition Ground Truth Database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Cityscapes Dataset–Semantic Understanding of Urban Street Scenes. Available online: https://www.cityscapes-dataset.com/ (accessed on 1 November 2022).
- Zheng, O.; Abdel-Aty, M.; Yue, L.; Abdelraouf, A.; Wang, Z.; Mahmoud, N. CitySim: A Drone-Based Vehicle Trajectory Dataset for Safety Oriented Research and Digital Twins. arXiv 2022, arXiv:2208.11036. [Google Scholar]
- Zyner, A.; Worrall, S.; Nebot, E. Naturalistic Driver Intention and Path Prediction Using Recurrent Neural Networks. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1584–1594. [Google Scholar] [CrossRef]
- Patil, A.; Malla, S.; Gang, H.; Chen, Y.-T. The H3d Dataset for Full-Surround 3d Multi-Object Detection and Tracking in Crowded Urban Scenes. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9552–9557. [Google Scholar]
- Zhan, W.; Sun, L.; Wang, D.; Shi, H.; Clausse, A.; Naumann, M.; Kummerle, J.; Konigshof, H.; Stiller, C.; de La Fortelle, A. Interaction Dataset: An International, Adversarial and Cooperative Motion Dataset in Interactive Driving Scenarios with Semantic Maps. arXiv 2019, arXiv:1910.03088. [Google Scholar]
- Choi, Y.; Kim, N.; Hwang, S.; Park, K.; Yoon, J.S.; An, K.; Kweon, I.S. KAIST Multi-Spectral Day/Night Data Set for Autonomous and Assisted Driving. IEEE Trans. Intell. Transp. Syst. 2018, 19, 934–948. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision Meets Robotics: The Kitti Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Houston, J.; Zuidhof, G.; Bergamini, L.; Ye, Y.; Chen, L.; Jain, A.; Omari, S.; Iglovikov, V.; Ondruska, P. One Thousand and One Hours: Self-Driving Motion Prediction Dataset. In Proceedings of the Conference on Robot Learning, PMLR, London, UK, 8–11 November 2021; pp. 409–418. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 Year, 1000 Km: The Oxford RobotCar Dataset. Int. J. Robot. Res. 2017, 36, 3–15. [Google Scholar] [CrossRef]
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning Social Etiquette: Human Trajectory Prediction in Crowded Scenes. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Volume 2. [Google Scholar]
- Wu, F.; Wang, D.; Hwang, M.; Hao, C.; Lu, J.; Zhang, J.; Chou, C.; Darrell, T.; Bayen, A. Decentralized Vehicle Coordination: The Berkeley DeepDrive Drone Dataset. arXiv 2022, arXiv:2209.08763. [Google Scholar]
- Chandra, R.; Bhattacharya, U.; Bera, A.; Manocha, D. Traphic: Trajectory Prediction in Dense and Heterogeneous Traffic Using Weighted Interactions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8483–8492. [Google Scholar]
- Li, X.; Flohr, F.; Yang, Y.; Xiong, H.; Braun, M.; Pan, S.; Li, K.; Gavrila, D.M. A New Benchmark for Vision-Based Cyclist Detection. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 1028–1033. [Google Scholar]
- Zipfl, M.; Fleck, T.; Zofka, M.R.; Zöllner, J.M. From Traffic Sensor Data to Semantic Traffic Descriptions: The Test Area Autonomous Driving Baden-Württemberg Dataset (TAF-BW Dataset). In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–7. [Google Scholar]
- Yang, Z.; Zhang, Y.; Yu, J.; Cai, J.; Luo, J. End-to-End Multi-Modal Multi-Task Vehicle Control for Self-Driving Cars with Visual Perceptions. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2289–2294. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Goss, Q.; AlRashidi, Y.; Akbaş, M.İ. Generation of Modular and Measurable Validation Scenarios for Autonomous Vehicles Using Accident Data. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 251–257. [Google Scholar]
- Rabbani, M.B.A.; Musarat, M.A.; Alaloul, W.S.; Ayub, S.; Bukhari, H.; Altaf, M. Road Accident Data Collection Systems in Developing and Developed Countries: A Review. Int. J. Integr. Eng. 2022, 14, 336–352. [Google Scholar] [CrossRef]
- So, J.J.; Park, I.; Wee, J.; Park, S.; Yun, I. Generating Traffic Safety Test Scenarios for Automated Vehicles Using a Big Data Technique. KSCE J. Civ. Eng. 2019, 23, 2702–2712. [Google Scholar] [CrossRef]
- Xinxin, Z.; Fei, L.; Xiangbin, W. CSG: Critical Scenario Generation from Real Traffic Accidents. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1330–1336. [Google Scholar]
- Ahmed, A.; Sadullah, A.F.M.; Yahya, A.S. Errors in Accident Data, Its Types, Causes and Methods of Rectification-Analysis of the Literature. Accid. Anal. Prev. 2019, 130, 3–21. [Google Scholar] [CrossRef]
- Hu, L.; Bao, X.; Lin, M.; Yu, C.; Wang, F. Research on Risky Driving Behavior Evaluation Model Based on CIDAS Real Data. Proc. Inst. Mech. Eng. D J. Automob. Eng. 2021, 235, 2176–2187. [Google Scholar] [CrossRef]
- Tan, Z.; Che, Y.; Xiao, L.; Hu, W.; Li, P.; Xu, J. Research of Fatal Car-to-Pedestrian Precrash Scenarios for the Testing of the Active Safety System in China. Accid. Anal. Prev. 2021, 150, 105857. [Google Scholar] [CrossRef] [PubMed]
- Otte, D.; Jänsch, M.; Haasper, C. Injury Protection and Accident Causation Parameters for Vulnerable Road Users Based on German In-Depth Accident Study GIDAS. Accid. Anal. Prev. 2012, 44, 149–153. [Google Scholar] [CrossRef] [PubMed]
- Kaplan, S.; Prato, C.G. Risk Factors Associated with Bus Accident Severity in the United States: A Generalized Ordered Logit Model. J. Saf. Res. 2012, 43, 171–180. [Google Scholar] [CrossRef] [PubMed]
- Lemmen, P.; Fagerlind, H.; Unselt, T.; Rodarius, C.; Infantes, E.; van der Zweep, C. Assessment of Integrated Vehicle Safety Systems for Improved Vehicle Safety. Procedia-Soc. Behav. Sci. 2012, 48, 1632–1641. [Google Scholar] [CrossRef][Green Version]
- Richards, D.C.; Cookson, R.E.; Cuerden, R.W. Linking Accidents in National Statistics to In-Depth Accident Data; IHS: Bracknell, UK, 2010; ISBN 1846088909. [Google Scholar]
- Bauder, M.; Lecheler, K.; Wech, L.; Böhm, K.; Paula, D.; Schweiger, H.-G. Determination of Accident Scenarios via Freely Available Accident Databases. Open Eng. 2022, 12, 453–467. [Google Scholar] [CrossRef]
- Hu, L.; Hu, X.; Wang, J.; Kuang, A.; Hao, W.; Lin, M. Casualty Risk of E-Bike Rider Struck by Passenger Vehicle Using China in-Depth Accident Data. Traffic Inj. Prev. 2020, 21, 283–287. [Google Scholar] [CrossRef]
- Johannsen, H. Unfallmechanik und Unfallrekonstruktion; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Moosavi, S.; Samavatian, M.H.; Parthasarathy, S.; Ramnath, R. A Countrywide Traffic Accident Dataset. arXiv 2019, arXiv:1906.05409. [Google Scholar]
- Chen, Q.; Chen, Y.; Bostrom, O.; Ma, Y.; Liu, E. A Comparison Study of Car-to-Pedestrian and Car-to-E-Bike Accidents: Data Source: The China in-Depth Accident Study (CIDAS); SAE Technical Paper; SAE International: Warrendale, PA, USA, 2014. [Google Scholar]
- El Tayeb, A.A.; Pareek, V.; Araar, A. Applying Association Rules Mining Algorithms for Traffic Accidents in Dubai. Int. J. Soft Comput. Eng. 2015, 5, 1–12. [Google Scholar]
- Home|GIDAS. Available online: https://www.gidas.org/start-en.html (accessed on 1 November 2022).
- Kim, S.; Lee, J.; Youn, Y. A Study on the Construction of the Database Structure for the Korea In-Depth Accident Study. Trans. Korean Soc. Automot. Eng. 2014, 22, 29–36. [Google Scholar] [CrossRef]
- Chung, Y. Development of an Accident Duration Prediction Model on the Korean Freeway Systems. Accid. Anal. Prev. 2010, 42, 282–289. [Google Scholar] [CrossRef]
- Mooney, P.; Corcoran, P. Characteristics of Heavily Edited Objects in OpenStreetMap. Future Internet 2011, 4, 285. [Google Scholar] [CrossRef]
- Deng, B.; Wang, H.; Chen, J.; Wang, X.; Chen, X. Traffic Accidents in Shanghai—General Statistics and in-Depth Analysis. In Proceedings of the 23rd International Technical Conference on the Enhanced Safety of Vehicles, Seoul, Republic of Korea, 27–30 May 2013. [Google Scholar]
- Tay, R.; Rifaat, S.M. Factors Contributing to the Severity of Intersection Crashes. J. Adv. Transp. 2007, 41, 245–265. [Google Scholar] [CrossRef]
- Clarke, D.D.; Ward, P.; Truman, W. In-Depth Accident Causation Study of Young Drivers; TRL Report 542; TRL Limited: Crowthorne, Berkshire, UK, 2002. [Google Scholar]
- Shah, A.P.; Lamare, J.-B.; Nguyen-Anh, T.; Hauptmann, A. CADP: A Novel Dataset for CCTV Traffic Camera Based Accident Analysis. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–9. [Google Scholar]
- Krajzewicz, D. Traffic Simulation with SUMO–Simulation of Urban Mobility. In Fundamentals of Traffic Simulation; Springer: Berlin/Heidelberg, Germany, 2010; pp. 269–293. [Google Scholar]
- Li, X.; Wang, Y.; Yan, L.; Wang, K.; Deng, F.; Wang, F.-Y. ParallelEye-CS: A New Dataset of Synthetic Images for Testing the Visual Intelligence of Intelligent Vehicles. IEEE Trans. Veh. Technol. 2019, 68, 9619–9631. [Google Scholar] [CrossRef]
- Liu, C.; Liu, Z.; Chai, Y.; Liu, T. Review of Virtual Traffic Simulation and Its Applications. J. Adv. Transp. 2020, 2020, 8237649. [Google Scholar] [CrossRef]
- Vrbanić, F.; Čakija, D.; Kušić, K.; Ivanjko, E. Traffic Flow Simulators with Connected and Autonomous Vehicles: A Short Review. Transform. Transp. 2021, 15–30. [Google Scholar] [CrossRef]
- Li, A.; Chen, S.; Sun, L.; Zheng, N.; Tomizuka, M.; Zhan, W. SceGene: Bio-Inspired Traffic Scenario Generation for Autonomous Driving Testing. IEEE Trans. Intell. Transp. Syst. 2022, 23, 14859–14874. [Google Scholar] [CrossRef]
- Zofka, M.R.; Ulbrich, S.; Karl, D.; Fleck, T.; Kohlhaas, R.; Rönnau, A.; Dillmann, R.; Zöllner, J.M. Traffic Participants in the Loop: A Mixed Reality-Based Interaction Testbed for the Verification and Validation of Autonomous Vehicles. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3583–3590. [Google Scholar]
- Feng, S.; Feng, Y.; Yan, X.; Shen, S.; Xu, S.; Liu, H.X. Safety Assessment of Highly Automated Driving Systems in Test Tracks: A New Framework. Accid. Anal. Prev. 2020, 144, 105664. [Google Scholar] [CrossRef]
- Di-Castro, S.; di Castro, D.; Mannor, S. Sim and Real: Better Together. Adv. Neural Inf. Process. Syst. 2021, 34, 6868–6880. [Google Scholar]
- Hauer, F.; Gerostathopoulos, I.; Schmidt, T.; Pretschner, A. Clustering Traffic Scenarios Using Mental Models as Little as Possible. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1007–1012. [Google Scholar]
- Jacobo, A.-M.; Nobuyuki, U.; Kunio, Y.; Koichiro, O.; Eiichi, K.; Satoshi, T. Development of a Safety Assurance Process for Autonomous Vehicles in Japan. In Proceedings of the ESV Conference 2019, Eindhoven, The Netherlands, 10–13 June 2019. [Google Scholar]
- Yu, X. Improvement and Validation of a Highway Traffic Complexity Metric for Test Scenarios of Automated Vehicles. Master’s Thesis, University of Munich, Munich, Germany, 2020. [Google Scholar]
- Wang, C.; Winner, H. Overcoming Challenges of Validation Automated Driving and Identification of Critical Scenarios. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2639–2644. [Google Scholar]
- Hasan, B.M.S.; Abdulazeez, A.M. A Review of Principal Component Analysis Algorithm for Dimensionality Reduction. J. Soft Comput. Data Min. 2021, 2, 20–30. [Google Scholar]
- Jia, W.; Sun, M.; Lian, J.; Hou, S. Feature Dimensionality Reduction: A Review. Complex Intell. Syst. 2022, 8, 2663–2693. [Google Scholar] [CrossRef]
- Oskolkov, N. Dimensionality Reduction. Appl. Data Sci. Tour. 2022, 151–167. [Google Scholar] [CrossRef]
- Paleyes, A.; Urma, R.-G.; Lawrence, N.D. Challenges in Deploying Machine Learning: A Survey of Case Studies. ACM Comput. Surv. (CSUR) 2021. [Google Scholar] [CrossRef]
- Lu, Y.; Cohen, I.; Zhou, X.S.; Tian, Q. Feature Selection Using Principal Feature Analysis. In Proceedings of the 15th ACM International Conference on Multimedia, Augsburg, Germany, 25–29 September 2007; pp. 301–304. [Google Scholar]
- Wagner, S.; Knoll, A.; Groh, K.; Kühbeck, T.; Watzenig, D.; Eckstein, L. Virtual Assessment of Automated Driving: Methodology, Challenges, and Lessons Learned. SAE Int. J. Connect. Autom. Veh. 2019, 2. [Google Scholar] [CrossRef]
- de Gelder, E.; Hof, J.; Cator, E.; Paardekooper, J.-P.; den Camp, O.O.; Ploeg, J.; de Schutter, B. Scenario Parameter Generation Method and Scenario Representativeness Metric for Scenario-Based Assessment of Automated Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Anowar, F.; Sadaoui, S.; Selim, B. Conceptual and Empirical Comparison of Dimensionality Reduction Algorithms (Pca, Kpca, Lda, Mds, Svd, Lle, Isomap, Le, Ica, t-Sne). Comput. Sci. Rev. 2021, 40, 100378. [Google Scholar] [CrossRef]
- Hoseini, F.S.; Rahrovani, S.; Chehreghani, M.H. A Generic Framework for Clustering Vehicle Motion Trajectories. arXiv 2020, arXiv:2009.12443. [Google Scholar]
- Demetriou, A.; Alfsvåg, H.; Rahrovani, S.; Chehreghani, M.H. A Deep Learning Framework for Generation and Analysis of Driving Scenario Trajectories. arXiv 2020, arXiv:2007.14524. [Google Scholar]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN Revisited, Revisited: Why and How You Should (Still) Use DBSCAN. ACM Trans. Database Syst. (TODS) 2017, 42, 19. [Google Scholar] [CrossRef]
- Carreira-Perpinán, M.A. A Review of Dimension Reduction Techniques. Dep. Comput. Sci. Univ. Sheffield Tech. Rep. 1997, 9, 1–69. [Google Scholar]
- Karunakaran, D.; Berrio, J.S.; Worrall, S.; Nebot, E. Automatic Lane Change Scenario Extraction and Generation of Scenarios in OpenX Format from Real-World Data. arXiv 2022, arXiv:2203.07521. [Google Scholar]
- Elrofai, H.; Worm, D.; Op den Camp, O. Scenario Identification for Validation of Automated Driving Functions. In Advanced Microsystems for Automotive Applications 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 153–163. [Google Scholar]
- De Gelder, E.; Manders, J.; Grappiolo, C.; Paardekooper, J.-P.; den Camp, O.O.; de Schutter, B. Real-World Scenario Mining for the Assessment of Automated Vehicles. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–8. [Google Scholar]
- Riedmaier, S.; Schneider, D.; Watzenig, D.; Diermeyer, F.; Schick, B. Model Validation and Scenario Selection for Virtual-Based Homologation of Automated Vehicles. Appl. Sci. 2020, 11, 35. [Google Scholar] [CrossRef]
- Montanari, F.; Stadler, C.; Sichermann, J.; German, R.; Djanatliev, A. Maneuver-Based Resimulation of Driving Scenarios Based on Real Driving Data. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 1124–1131. [Google Scholar]
- Paardekooper, J.-P.; Montfort, S.; Manders, J.; Goos, J.; de Gelder, E.; den Camp, O.O.; Bracquemond, A.; Thiolon, G. Automatic Identification of Critical Scenarios in a Public Dataset of 6000 Km of Public-Road Driving. In Proceedings of the 26th International Technical Conference on the Enhanced Safety of Vehicles (ESV), Eindhoven, The Netherlands, 10–13 June 2019; Mira Smart. pp. 1–8. [Google Scholar]
- Hartjen, L.; Philipp, R.; Schuldt, F.; Friedrich, B.; Howar, F. Classification of Driving Maneuvers in Urban Traffic for Parametrization of Test Scenarios. In Proceedings of the 9 Tagung Automatisiertes Fahren, Munich, Germany, 21–22 November 2019. [Google Scholar]
- Saini, P.; Kaur, J.; Lamba, S. A Review on Pattern Recognition Using Machine Learning. Adv. Mech. Eng. 2021, 619–627. [Google Scholar] [CrossRef]
- Kruber, F.; Wurst, J.; Botsch, M. An Unsupervised Random Forest Clustering Technique for Automatic Traffic Scenario Categorization. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2811–2818. [Google Scholar]
- Langner, J.; Grolig, H.; Otten, S.; Holzäpfel, M.; Sax, E. Logical Scenario Derivation by Clustering Dynamic-Length-Segments Extracted from Real-World-Driving-Data. In Proceedings of the VEHITS 2019, Crete, Greece, 3–5 May 2019; pp. 458–467. [Google Scholar]
- Deng, N.; Jiang, K.; Cao, Z.; Zhou, W.; Yang, D. Decision-Oriented Driving Scenario Recognition Based on Unsupervised Learning. In Proceedings of the 21st COTA International Conference of Transportation Professionals 2021, Xi’an, China, 16–19 December 2021; pp. 564–573. [Google Scholar]
- Li, S.; Wang, W.; Mo, Z.; Zhao, D. Clustering of Naturalistic Driving Encounters Using Unsupervised Learning. arXiv 2018, arXiv:1802.10214. [Google Scholar]
- Weber, N.; Thiem, C.; Konigorski, U. UnScenE: Toward Unsupervised Scenario Extraction for Automated Driving Systems from Urban Naturalistic Road Traffic Data. arXiv 2022, arXiv:2202.06608. [Google Scholar]
- Vrbanić, F.; Miletić, M.; Ivanjko, E.; Majstorović, Ž. Creating Representative Urban Motorway Traffic Scenarios: Initial Observations. In Proceedings of the 2021 International Symposium ELMAR, Zadar, Croatia, 13–15 September 2021; pp. 183–188. [Google Scholar]
- Montanari, F.; Ren, H.; Djanatliev, A. Scenario Detection in Unlabeled Real Driving Data with a Rule-Based State Machine Supported by a Recurrent Neural Network. In Proceedings of the 2021 IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Helsinki, Finland, 25–28 April 2021; pp. 1–5. [Google Scholar]
- De Gelder, E.; Paardekooper, J.-P. Assessment of Automated Driving Systems Using Real-Life Scenarios. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 589–594. [Google Scholar]
- Huang, Z.; Guo, Y.; Arief, M.; Lam, H.; Zhao, D. A Versatile Approach to Evaluating and Testing Automated Vehicles Based on Kernel Methods. In Proceedings of the 2018 Annual American Control Conference (ACC), Milwaukee, WI, USA, 27–29 June 2018; pp. 4796–4802. [Google Scholar]
- Kuhn, D.R.; Bryce, R.; Duan, F.; Ghandehari, L.S.; Lei, Y.; Kacker, R.N. Combinatorial Testing: Theory and Practice. Adv. Comput. 2015, 99, 1–66. [Google Scholar]
- Gao, F.; Duan, J.; He, Y.; Wang, Z. A Test Scenario Automatic Generation Strategy for Intelligent Driving Systems. Math. Probl. Eng. 2019, 2019, 3737486. [Google Scholar] [CrossRef]
- Kuhn, D.R.; Reilly, M.J. An Investigation of the Applicability of Design of Experiments to Software Testing. In Proceedings of the 27th Annual NASA Goddard/IEEE Software Engineering Workshop, Greenbelt, MD, USA, 5–6 December 2002; pp. 91–95. [Google Scholar]
- Hartjen, L.; Schuldt, F.; Friedrich, B. Semantic Classification of Pedestrian Traffic Scenarios for the Validation of Automated Driving. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3696–3701. [Google Scholar]
- Xia, Q.; Duan, J.; Gao, F.; Chen, T.; Yang, C. Automatic Generation Method of Test Scenario for Adas Based on Complexity; SAE Technical Paper; SAE International: Warrendale, PA, USA, 2017. [Google Scholar]
- Tao, J.; Li, Y.; Wotawa, F.; Felbinger, H.; Nica, M. On the Industrial Application of Combinatorial Testing for Autonomous Driving Functions. In Proceedings of the 2019 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Xi’an, China, 22–23 April 2019; pp. 234–240. [Google Scholar]
- Birkemeyer, L.; Pett, T.; Vogelsang, A.; Seidl, C.; Schaefer, I. Feature-Interaction Sampling for Scenario-Based Testing of Advanced Driver Assistance Systems. In Proceedings of the 16th International Working Conference on Variability Modelling of Software-Intensive Systems, Florence, Italy, 23–25 February 2022; pp. 1–10. [Google Scholar]
- Laurent, T.; Arcaini, P.; Ishikawa, F.; Ventresque, A. A Mutation-Based Approach for Assessing Weight Coverage of a Path Planner. In Proceedings of the 2019 26th Asia-Pacific Software Engineering Conference (APSEC), Putrajaya, Malaysia, 2–5 December 2019; pp. 94–101. [Google Scholar]
- Huang, Z.; Lam, H.; LeBlanc, D.J.; Zhao, D. Accelerated Evaluation of Automated Vehicles Using Piecewise Mixture Models. IEEE Trans. Intell. Transp. Syst. 2017, 19, 2845–2855. [Google Scholar] [CrossRef]
- De Gelder, E.; Elrofai, H.; Saberi, A.K.; Paardekooper, J.-P.; den Camp, O.O.; de Schutter, B. Risk Quantification for Automated Driving Systems in Real-World Driving Scenarios. IEEE Access 2021, 9, 168953–168970. [Google Scholar] [CrossRef]
- Zhao, D.; Lam, H.; Peng, H.; Bao, S.; LeBlanc, D.J.; Nobukawa, K.; Pan, C.S. Accelerated Evaluation of Automated Vehicles Safety in Lane-Change Scenarios Based on Importance Sampling Techniques. IEEE Trans. Intell. Transp. Syst. 2016, 18, 595–607. [Google Scholar] [CrossRef]
- Xu, Y.; Zou, Y.; Sun, J. Accelerated Testing for Automated Vehicles Safety Evaluation in Cut-in Scenarios Based on Importance Sampling, Genetic Algorithm and Simulation Applications. J. Intell. Connect. Veh. 2018, 1, 28–38. [Google Scholar] [CrossRef]
- Zhang, S.; Peng, H.; Zhao, D.; Tseng, H.E. Accelerated Evaluation of Autonomous Vehicles in the Lane Change Scenario Based on Subset Simulation Technique. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3935–3940. [Google Scholar]
- Akagi, Y.; Kato, R.; Kitajima, S.; Antona-Makoshi, J.; Uchida, N. A Risk-Index Based Sampling Method to Generate Scenarios for the Evaluation of Automated Driving Vehicle Safety. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 667–672. [Google Scholar]
- Li, G.; Li, Y.; Jha, S.; Tsai, T.; Sullivan, M.; Hari, S.K.S.; Kalbarczyk, Z.; Iyer, R. AV-FUZZER: Finding Safety Violations in Autonomous Driving Systems. In Proceedings of the 2020 IEEE 31st International Symposium on Software Reliability Engineering (ISSRE), Coimbra, Portugal, 12–15 October 2020; pp. 25–36. [Google Scholar]
- Klischat, M.; Liu, E.I.; Holtke, F.; Althoff, M. Scenario Factory: Creating Safety-Critical Traffic Scenarios for Automated Vehicles. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–7. [Google Scholar]
- Zhu, B.; Zhang, P.; Zhao, J.; Deng, W. Hazardous Scenario Enhanced Generation for Automated Vehicle Testing Based on Optimization Searching Method. IEEE Trans. Intell. Transp. Syst. 2021, 23, 7321–7331. [Google Scholar] [CrossRef]
- Feng, S.; Feng, Y.; Sun, H.; Zhang, Y.; Liu, H.X. Testing Scenario Library Generation for Connected and Automated Vehicles: An Adaptive Framework. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1213–1222. [Google Scholar] [CrossRef]
- Tuncali, C.E.; Fainekos, G. Rapidly-Exploring Random Trees-Based Test Generation for Autonomous Vehicles. arXiv 2019, arXiv:1903.10629. [Google Scholar]
- Bussler, A.; Hartjen, L.; Philipp, R.; Schuldt, F. Application of Evolutionary Algorithms and Criticality Metrics for the Verification and Validation of Automated Driving Systems at Urban Intersections. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 128–135. [Google Scholar]
- Klischat, M.; Althoff, M. Generating Critical Test Scenarios for Automated Vehicles with Evolutionary Algorithms. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2352–2358. [Google Scholar]
- Almanee, S.; Wu, X.; Huai, Y.; Chen, Q.A.; Garcia, J. ScenoRITA: Generating Less-Redundant, Safety-Critical and Motion Sickness-Inducing Scenarios for Autonomous Vehicles. arXiv 2021, arXiv:2112.09725. [Google Scholar]
- Hauer, F.; Pretschner, A.; Holzmüller, B. Fitness Functions for Testing Automated and Autonomous Driving Systems. In Proceedings of the International Conference on Computer Safety, Reliability, and Security, Turku, Finland, 10–13 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 69–84. [Google Scholar]
- Hejase, M.; Ozguner, U.; Barbier, M.; Ibanez-Guzman, J. A Methodology for Model-Based Validation of Autonomous Vehicle Systems. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 2097–2103. [Google Scholar]
- Calò, A.; Arcaini, P.; Ali, S.; Hauer, F.; Ishikawa, F. Simultaneously Searching and Solving Multiple Avoidable Collisions for Testing Autonomous Driving Systems. In Proceedings of the 2020 Genetic and Evolutionary Computation Conference, Cancún, Mexico, 8–12 July 2020; pp. 1055–1063. [Google Scholar]
- Ben Abdessalem, R.; Nejati, S.; Briand, L.C.; Stifter, T. Testing Vision-Based Control Systems Using Learnable Evolutionary Algorithms. In Proceedings of the 2018 IEEE/ACM 40th International Conference on Software Engineering (ICSE), Gothenburg, Sweden, 27 May–3 June 2018; pp. 1016–1026. [Google Scholar]
- Koschi, M.; Pek, C.; Maierhofer, S.; Althoff, M. Computationally Efficient Safety Falsification of Adaptive Cruise Control Systems. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2879–2886. [Google Scholar]
- Song, Y.; Chitturi, M.V.; Noyce, D.A. Automated Vehicle Crash Sequences: Patterns and Potential Uses in Safety Testing. Accid. Anal. Prev. 2021, 153, 106017. [Google Scholar] [CrossRef]
- Karunakaran, D.; Worrall, S.; Nebot, E. Efficient Falsification Approach for Autonomous Vehicle Validation Using a Parameter Optimisation Technique Based on Reinforcement Learning. arXiv 2020, arXiv:2011.07699. [Google Scholar]
- Baumann, D.; Pfeffer, R.; Sax, E. Automatic Generation of Critical Test Cases for the Development of Highly Automated Driving Functions. In Proceedings of the 2021 IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Helsinki, Finland, 25–28 April 2021; pp. 1–5. [Google Scholar]
- Xu, L.; Zhang, C.; Liu, Y.; Wang, L.; Li, L. Worst Perception Scenario Search for Autonomous Driving. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1702–1707. [Google Scholar]
- Koren, M.; Alsaif, S.; Lee, R.; Kochenderfer, M.J. Adaptive Stress Testing for Autonomous Vehicles. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1–7. [Google Scholar]
- Koren, M.; Nassar, A.; Kochenderfer, M.J. Finding Failures in High-Fidelity Simulation Using Adaptive Stress Testing and the Backward Algorithm. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 5944–5949. [Google Scholar]
- Capito, L.; Weng, B.; Ozguner, U.; Redmill, K. A Modeled Approach for Online Adversarial Test of Operational Vehicle Safety. In Proceedings of the 2021 American Control Conference (ACC), New Orleans, LA, USA, 25–28 May 2021; pp. 398–404. [Google Scholar]
- Zhang, H.; Zhou, H.; Sun, J.; Tian, Y. Risk Assessment of Highly Automated Vehicles with Naturalistic Driving Data: A Surrogate-Based Optimization Method. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 5–9 June 2022; pp. 580–585. [Google Scholar]
- Feng, S.; Feng, Y.; Yu, C.; Zhang, Y.; Liu, H.X. Testing Scenario Library Generation for Connected and Automated Vehicles, Part I: Methodology. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1573–1582. [Google Scholar] [CrossRef]
- Feng, S.; Feng, Y.; Sun, H.; Bao, S.; Zhang, Y.; Liu, H.X. Testing Scenario Library Generation for Connected and Automated Vehicles, Part II: Case Studies. IEEE Trans. Intell. Transp. Syst. 2020, 22, 5635–5647. [Google Scholar] [CrossRef]
- Batsch, F.; Daneshkhah, A.; Cheah, M.; Kanarachos, S.; Baxendale, A. Performance Boundary Identification for the Evaluation of Automated Vehicles Using Gaussian Process Classification. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 419–424. [Google Scholar]
- Batsch, F.; Daneshkhah, A.; Palade, V.; Cheah, M. Scenario Optimisation and Sensitivity Analysis for Safe Automated Driving Using Gaussian Processes. Appl. Sci. 2021, 11, 775. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, R.; Qiu, S.; Sun, J.; Farah, H. Safety Performance Boundary Identification of Highly Automated Vehicles: A Surrogate Model-Based Gradient Descent Searching Approach. IEEE Trans. Intell. Transp. Syst. 2022, 1–12. [Google Scholar] [CrossRef]
- Westhofen, L.; Neurohr, C.; Koopmann, T.; Butz, M.; Schütt, B.; Utesch, F.; Neurohr, B.; Gutenkunst, C.; Böde, E. Criticality Metrics for Automated Driving: A Review and Suitability Analysis of the State of the Art. Arch. Comput. Methods Eng. 2022, 1–35. [Google Scholar] [CrossRef]
- Jansson, J. Collision Avoidance Theory: With Application to Automotive Collision Mitigation; Linköping University Electronic Press: Linköping, Sweden, 2005. [Google Scholar]
- Wachenfeld, W.; Junietz, P.; Wenzel, R.; Winner, H. The Worst-Time-to-Collision Metric for Situation Identification. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 729–734. [Google Scholar]
- Eggert, J. Predictive Risk Estimation for Intelligent ADAS Functions. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 711–718. [Google Scholar]
- Minderhoud, M.M.; Bovy, P.H.L. Extended Time-to-Collision Measures for Road Traffic Safety Assessment. Accid. Anal. Prev. 2001, 33, 89–97. [Google Scholar] [CrossRef]
- Varhelyi, A. Drivers’ Speed Behaviour at a Zebra Crossing: A Case Study. Accid. Anal. Prev. 1998, 30, 731–743. [Google Scholar] [CrossRef]
- Allen, B.L.; Shin, B.T.; Cooper, P.J. Analysis of Traffic Conflicts and Collisions; Transportation Research Record Department of Civil Engineering, McMaster University: Hamilton, ON, Canada, 1978. [Google Scholar]
- Hupfer, C. Deceleration to Safety Time (DST)-a Useful Figure to Evaluate Traffic Safety. In Proceedings of the ICTCT Conference Proceedings of Seminar, Lund, Sweden, 5–7 November 1997; Volume 3, pp. 5–7. [Google Scholar]
- Ghodsi, Z.; Hari, S.K.S.; Frosio, I.; Tsai, T.; Troccoli, A.; Keckler, S.W.; Garg, S.; Anandkumar, A. Generating and Characterizing Scenarios for Safety Testing of Autonomous Vehicles. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 157–164. [Google Scholar]
- Jeong, H.; Kim, I.; Han, K.; Kim, J. Comprehensive Analysis of Traffic Accidents in Seoul: Major Factors and Types Affecting Injury Severity. Appl. Sci. 2022, 12, 1790. [Google Scholar] [CrossRef]
- Cafiso, S.; Garcia, A.G.; Cavarra, R.; Rojas, M.A.R. Crosswalk Safety Evaluation Using a Pedestrian Risk Index as Traffic Conflict Measure. In Proceedings of the 3rd International Conference on Road safety and Simulation 2011, Indianapolis, IN, USA, 14–16 September 2011; pp. 1–15. [Google Scholar]
- Cunto, F.; Saccomanno, F.F. Calibration and Validation of Simulated Vehicle Safety Performance at Signalized Intersections. Accid. Anal. Prev. 2008, 40, 1171–1179. [Google Scholar] [CrossRef]
- Kolekar, S.; Gite, S.; Pradhan, B.; Kotecha, K. Behavior Prediction of Traffic Actors for Intelligent Vehicle Using Artificial Intelligence Techniques: A Review. IEEE Access 2021, 9, 135034–135058. [Google Scholar] [CrossRef]
- Bolte, J.-A.; Bar, A.; Lipinski, D.; Fingscheidt, T. Towards Corner Case Detection for Autonomous Driving. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 438–445. [Google Scholar]
- Schreier, M.; Willert, V.; Adamy, J. An Integrated Approach to Maneuver-Based Trajectory Prediction and Criticality Assessment in Arbitrary Road Environments. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2751–2766. [Google Scholar] [CrossRef]
- Huber, B.; Herzog, S.; Sippl, C.; German, R.; Djanatliev, A. Evaluation of Virtual Traffic Situations for Testing Automated Driving Functions Based on Multidimensional Criticality Analysis. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–7. [Google Scholar]
- de Gelder, E.; Saberi, A.K.; Elrofai, H. A Method for Scenario Risk Quantification for Automated Driving Systems. In Proceedings of the 26th International Technical Conference on the Enhanced Safety of Vehicles (ESV), Eindhoven, The Netherlands, 10–13 June 2019. Mira Smart. [Google Scholar]
- Liu, H.X.; Feng, S. “Curse of Rarity” for Autonomous Vehicles. arXiv 2022, arXiv:2207.02749. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Dataset | OpenSource | Method | Sensor | Trajectory |
|---|---|---|---|---|---|
| 1 | 100-car [61] | Yes | FV-based | Camera, GPS, radar | No |
| 2 | A*3D [62] | Yes | FV-based | Lidar, Camera | No |
| 3 | ApolloScape [54] | Yes | FV-based | Camera, Lidar, GPS/IMU | No |
| 4 | Argoverse [63] | Yes | FV-based | Lidar, Camera | Yes |
| 5 | Bdd100k [64] | Yes | FV-based | Camera, Lidar, GPS/IMU | No |
| 6 | CamVid [65] | Yes | FV-based | Lidar, Camera | No |
| 7 | Cityscapes [66] | Yes | FV-based | Camera | No |
| 8 | CitySim [67] | Yes | Fixed sensor-based | Camera | Yes |
| 9 | Five Roundabouts [68] | Yes | Fixed sensor-based | Lidar, Camera | Yes |
| 10 | H3D [69] | Yes | FV-based | Cameras, LiDAR and GPS/IMU | No |
| 11 | InD [56] | Yes | Fixed sensor-based | Camera | Yes |
| 12 | INTERACTION [70] | Yes | Fixed sensor-based | Camera | Yes |
| 13 | KAIST [71] | Yes | FV-based | Camera, Lidar, GPS/IMU | No |
| 14 | KITTI [72] | Yes | FV-based | Camera, Lidar, GPS/IMU | No |
| 15 | Ko-PER [73] | Yes | Fixed sensor-based | Lidar, Camera | Yes |
| 16 | Lyft Level 5 [59] | Yes | FV-based | Lidar, Camera | No |
| NGSIM [58] | Yes | Fixed sensor-based | Camera | Yes | |
| 17 | nuScenes [59] | Yes | FV-based | Radar, Lidar, Camera, GPS/IMU | No |
| 18 | Oxford RobotCar [74] | Yes | FV-based | Camera, Lidar, GPS/IMU | No |
| 19 | RondD [57] | Yes | Fixed sensor-based | Camera | Yes |
| 20 | SPMD [52] | Yes | FV-based | VAD, ASD, RSD, et.al. | No |
| 21 | Stanford Drone [75] | Yes | Fixed sensor-based | Camera | Yes |
| 22 | BDDDD [76] | Yes | Fixed sensor-based | Camera | Yes |
| 23 | TRAF [77] | Yes | FV-based | Camera | Yes |
| 24 | TDCDBD [78] | Yes | FV-based | Camera | No |
| 25 | TAF-BW [79] | Yes | FV-based | Camera | Yes |
| 26 | Udacity [80] | Yes | FV-based | Camera | No |
| 27 | Waymo Open [81] | Yes | FV-based | Cameras, LiDAR and GPS/IMU | No |
| Number | Dataset | Open Source | In-Depth | Region | Source of Raw Data |
|---|---|---|---|---|---|
| 1 | US-Accidents [96] | Yes | No | USA | MapQuest Traffic and Microsoft Bing Map Traffic |
| 3 | CIDAS [97] | No | Yes | China | accident report |
| 4 | Dubai [98] | No | No | Dubai | accident report |
| 5 | GIDAS [99] | No | Yes | German | accident report |
| 6 | KIDAS [100] | No | Yes | Korea | accident report |
| 7 | Korean Freeway [101] | No | No | Korea | accident report |
| 8 | NAIS [88] | No | Yes | China | accident report |
| 9 | GES [67] | Yes | Yes | USA | accident report |
| 10 | OSM [102] | Yes | No | Global | accident report |
| 11 | SHUFO [103] | No | Yes | Shanghai | accident report |
| 12 | Singapore [104] | No | No | Singapore | accident report |
| 13 | UKIDAS [105] | No | Yes | UK | accident report |
| 14 | CADP [106] | Yes | No | Global | Video |
| Type | Method | Diversity | Criticality | Knowledge | Iteration | Naturality | Scalability |
|---|---|---|---|---|---|---|---|
| Diversity-Oriented | Random Sampling | Y | N | N | N | Y/N | Y |
| CT | Y | Y | N | N | N | Y | |
| MT | Y | N | Y | Y | N | N | |
| Criticality-Oriented | AE | N | Y | Y/N | Y/N | Y | Y |
| Search Algorithms | N | Y | Y/N | Y | N | N | |
| RL | N | Y | Y/N | Y | N | N |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, J.; Deng, W.; Guang, H.; Wang, Y.; Li, J.; Ding, J. A Survey on Data-Driven Scenario Generation for Automated Vehicle Testing. Machines 2022, 10, 1101. https://doi.org/10.3390/machines10111101
Cai J, Deng W, Guang H, Wang Y, Li J, Ding J. A Survey on Data-Driven Scenario Generation for Automated Vehicle Testing. Machines. 2022; 10(11):1101. https://doi.org/10.3390/machines10111101
Chicago/Turabian StyleCai, Jinkang, Weiwen Deng, Haoran Guang, Ying Wang, Jiangkun Li, and Juan Ding. 2022. "A Survey on Data-Driven Scenario Generation for Automated Vehicle Testing" Machines 10, no. 11: 1101. https://doi.org/10.3390/machines10111101
APA StyleCai, J., Deng, W., Guang, H., Wang, Y., Li, J., & Ding, J. (2022). A Survey on Data-Driven Scenario Generation for Automated Vehicle Testing. Machines, 10(11), 1101. https://doi.org/10.3390/machines10111101