1. Introduction
Weighted distributions frequently occur in research related to survival analysis, analysis of intervention data, ecology and biomedicine, and other areas. Fisher [
1] and Rao [
2] introduced the concept of weighted distributions to improve the fit of appropriate statistical models; this idea has been used to select an appropriate model for the data observed (see Rao [
3]). A random variable
Y follows the weighted distribution if its probability density function (pdf) is given by
where
f is a density function, and
w is a positive function. Analysis and applications using this methodology can be found in Patil and Ord [
4], Patil and Rao [
5], Gupta and Kirmani [
6], Gupta and Tripathi [
7], Gupta and Akman [
8], Gupta and Kundu [
9], Reyes et al. [
10], Hassan and Hijazi [
11], Gómez-Déniz et al. [
12], Chesneau et al. [
13], Alzaghal et al. [
14], Cortés et al. [
15], and others.
Reyes et al. [
10] considered the exponential model,
, and the weight function
; using (
1) they constructed and study the bimodal exponential (BE) distribution, the pdf of which is given by
with
and
. It is denoted by
. The BE distribution is bimodal and is an extension of the exponential distribution. Furthermore, it can be used to fit datasets containing zeroes and/or very small values. The motivation for studying these families of bimodal distributions stems from the lack of alternative models that can effectively replace mixture distributions, which—as is well known—present estimation problems when using classical approaches like Bayesian methods (see McLachan and Peel [
16]; Marin et al. [
17]).
The object of the present work is to modify the BE distribution considering a new function which increases the flexibility of the second mode. We thus obtain a modified bimodal exponential (MBE) distribution, which we denote by . We study its properties, estimating the parameters, and compare it with the BE distribution using a real dataset.
The work is organized as follows. In
Section 2, we present the pdf of the MBE distribution and study some of its properties. In
Section 3, we study the inferential statistics of the MBE distribution, in particular the moments estimators and maximum likelihood (ML) estimators, and present a simulation study. In
Section 4, we present two applications to real-world datasets. Finally,
Section 5 provides concluding remarks.
2. Density and Properties
In this section, we present the pdf of the MBE distribution and some of its properties.
Proposition 1. Let . Then, the density function of Y is given bywith defining the rate parameter and defining the shape parameter. Proof. Considering
,
, and using (
1), we obtain the result.
□
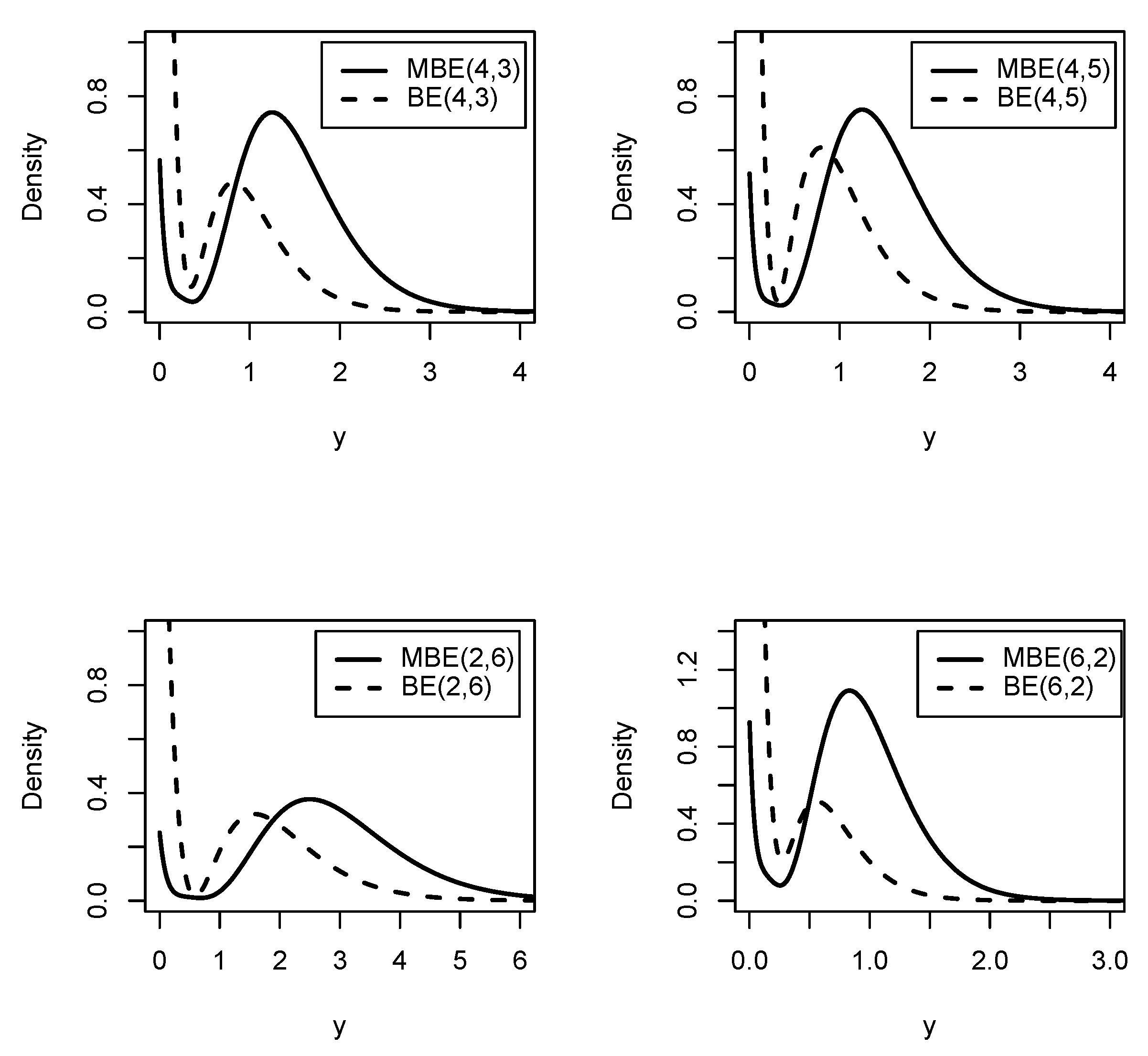
Below, we illustrate graphically the behavior of the density function of the MBE distribution, comparing it with the BE distribution.
Remark 1. We observe that the MBE can be used to model datasets with an excess of zeroes or very small values, as its support includes zero, and it possesses a mode at zero. We likewise observe that when the parameter , the exponential distribution is obtained as a particular case.
Proposition 2. Let . The solutions ofcorrespond to the anti-mode and the non-zero mode of the distribution of Y. Proof. This follows directly from analyzing the first derivative of (1) with respect to y. □
The quartic equation in (
4) can be solved analytically using the Cardano–Ferrari formulas (for details, see Abramowitz and Stegun [
18]). For numerical solutions, the WolframAlpha computational platform (
https://www.wolframalpha.com/) provides an efficient alternative; for more details we refer the reader to Weisstein [
19].
Let
, and let
.
Table 1 shows the values of the modes for the BE and MBE distributions with the same parameter values as in
Figure 1.
Proposition 3. Let and . Then, the height of the second mode of Y is greater than the height of the second mode of Z for , where the second mode of Y is between and , and Z becomes .
Proof. For
, the second mode of
Z is given by
(see Reyes et al. [
10]). The first derivative of
is given by
Evaluating this at
and
yields
Thus,
, which implies that the height of the second mode of
Y is greater than
. Furthermore, we calculate
The inequality
holds for
, as established by solving
Since , the proof is complete. □
Proposition 4. Let . Then, the cumulative distribution function (cdf) of Y is given by Proof. Calculating directly from the definition of the cdf, we have
and the result is obtained by developing the integral. □
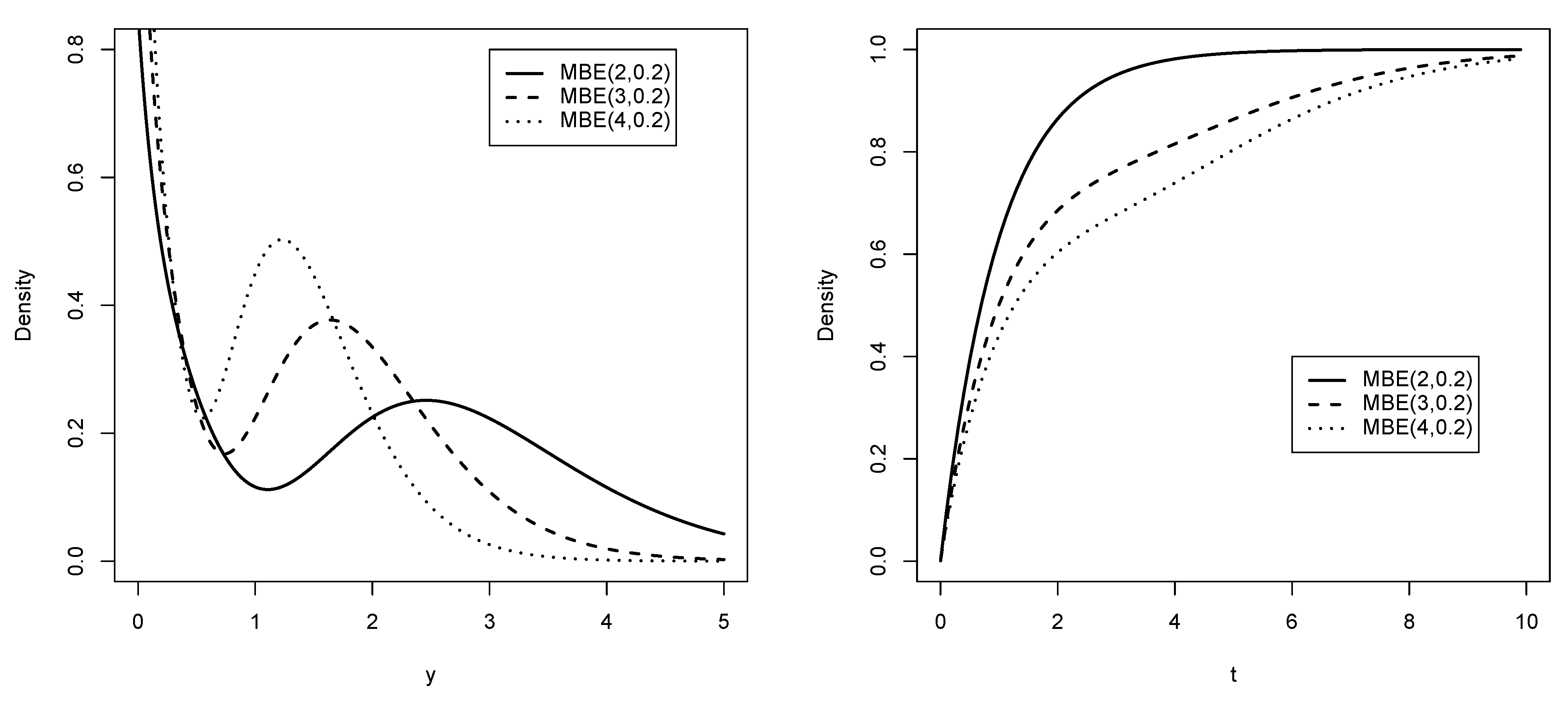
Remark 2. The BE distribution has a unique mode at zero when (see Reyes et al. [10]); otherwise, like the MBE distribution, it has two modes, as shown in Figure 2. The MBE distribution always has two modes: one at zero and another at a point , with the latter having a greater height. Below, we illustrate graphically the behavior of the pdf and cdf of the MBE distribution.
Figure 2.
Pdf and cdf for the MBE distribution for values of and q.
Figure 2.
Pdf and cdf for the MBE distribution for values of and q.
2.1. Order Statistics
Let be a random sample of the random variable ; let us denote by the order statistics .
Proposition 5. The pdf of isIn particular, the pdf of the minimum, , isand the pdf of the maximum, , is Proof. Since we are dealing with an absolutely continuous model, the pdf of the
order statistics is obtained by applying
where
F and
f denote the cdf and pdf of the parent distribution,
, in this case. More precisely, substituting Equations (
3) and (
5) yields the result. □
2.2. The Reliability and Hazard Rate Functions
Two important reliability measures are the reliability function and the hazard (failure) rate function. The reliability function of a random variable Y is defined by , where denotes the cdf of Y. The hazard rate function is defined by . For the BE distribution, as a direct consequence of Proposition 1 and Proposition 2, both reliability measures can be expressed in closed form. The corresponding expressions are obtained in a straightforward manner.
Proposition 6. Let . Then, the hazard function of Y is given by Proof. By definition of the hazard function, we have
and then by replacing
and
, the result is obtained. □
To prove the following proposition, we will use the theorem in Glaser [
20], together with the idea that to study the behavior of the harzard function
, we can examine the function
defined by
, where
is the pdf given in (1).
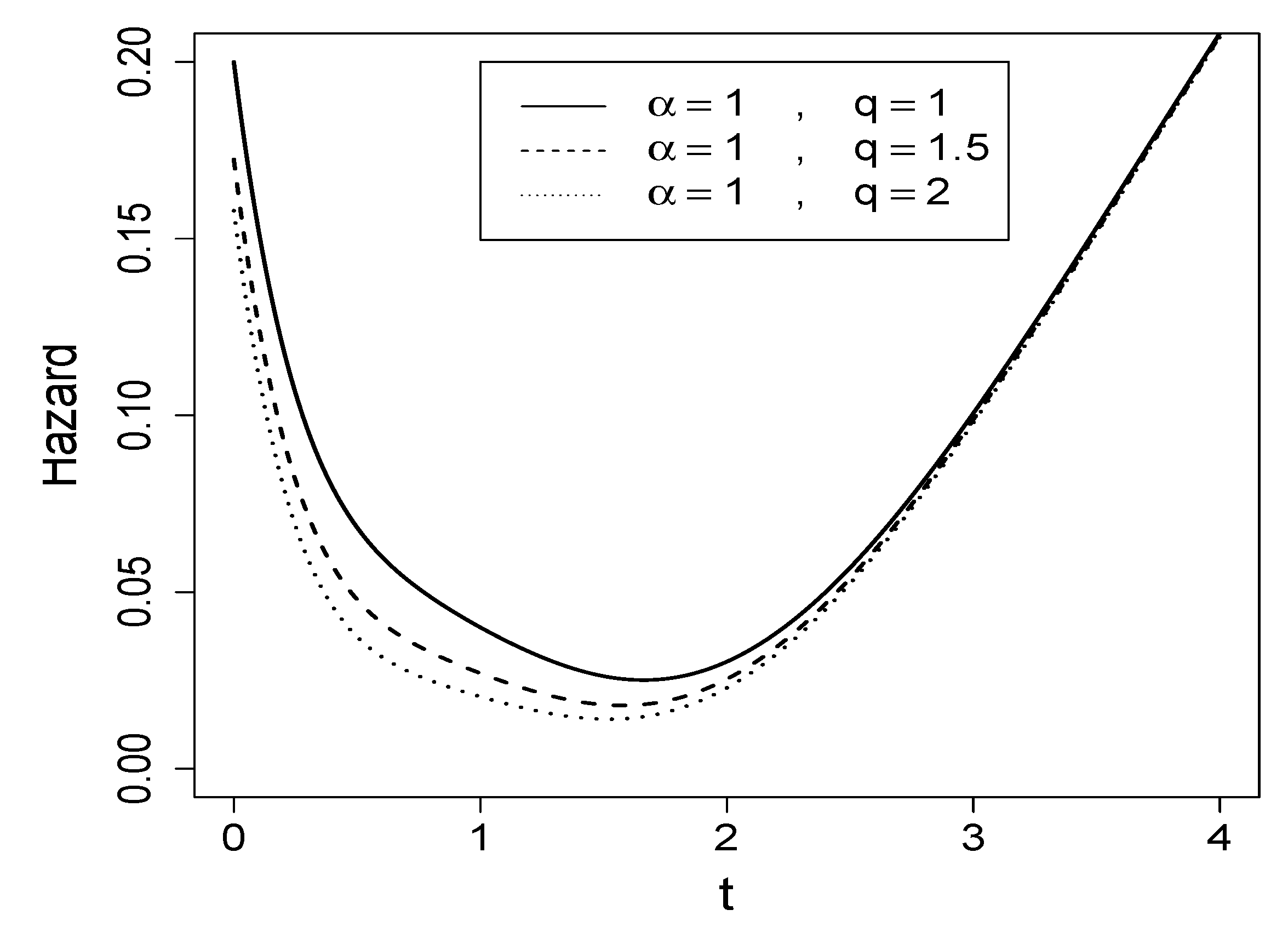
Proposition 7. Let . Then, the hazard function of T has a bathtub shape.
Proof. Using item
of Glaser’s Theorem [
20], we define the functions
and the function
. Their first derivatives are, respectively,
If
, we obtain the following:
in
,
, and
for all
when
.
On the other hand, we observe that as
,
, and
, which implies that
as
. Additionally, evaluating these functions at
, we have
yielding
. Since
is a continuous function for all
t, there exists
such that
. Consequently,
; by applying item
of Glaser’s Theorem [
20], the result follows.
If
,
is null at three points:
This is because
Since
has a local minimum at
, the hazard function also attains a local minimum at
, resulting in a bathtub-shaped hazard function. □
Figure 3 presents the hazard rate function of the MBE distribution for various parameter configurations. Notably, the hazard function exhibits the characteristic bathtub shape, a feature frequently encountered in reliability and survival analysis.
2.3. Moments
The moments of a random variable with modified bimodal exponential distribution are given in the following proposition.
Proposition 8. If , the r-th moment of Y is given by Proof. Calculating directly from the definition, we have
The result is obtained by developing the integral. □
Corollary 1. Let ; then, Proof. This is an immediate consequence of the previous proposition. □
Corollary 2. Let ; then, the expectation and the variance of Y are given by Corollary 3. Let ; then, the asymmetry coefficient () and the kurtosis coefficient () of Y are given byrespectively. Proof. Using the expressions obtained in the previous corollary and the following equations, the result is obtained as
and
respectively. □
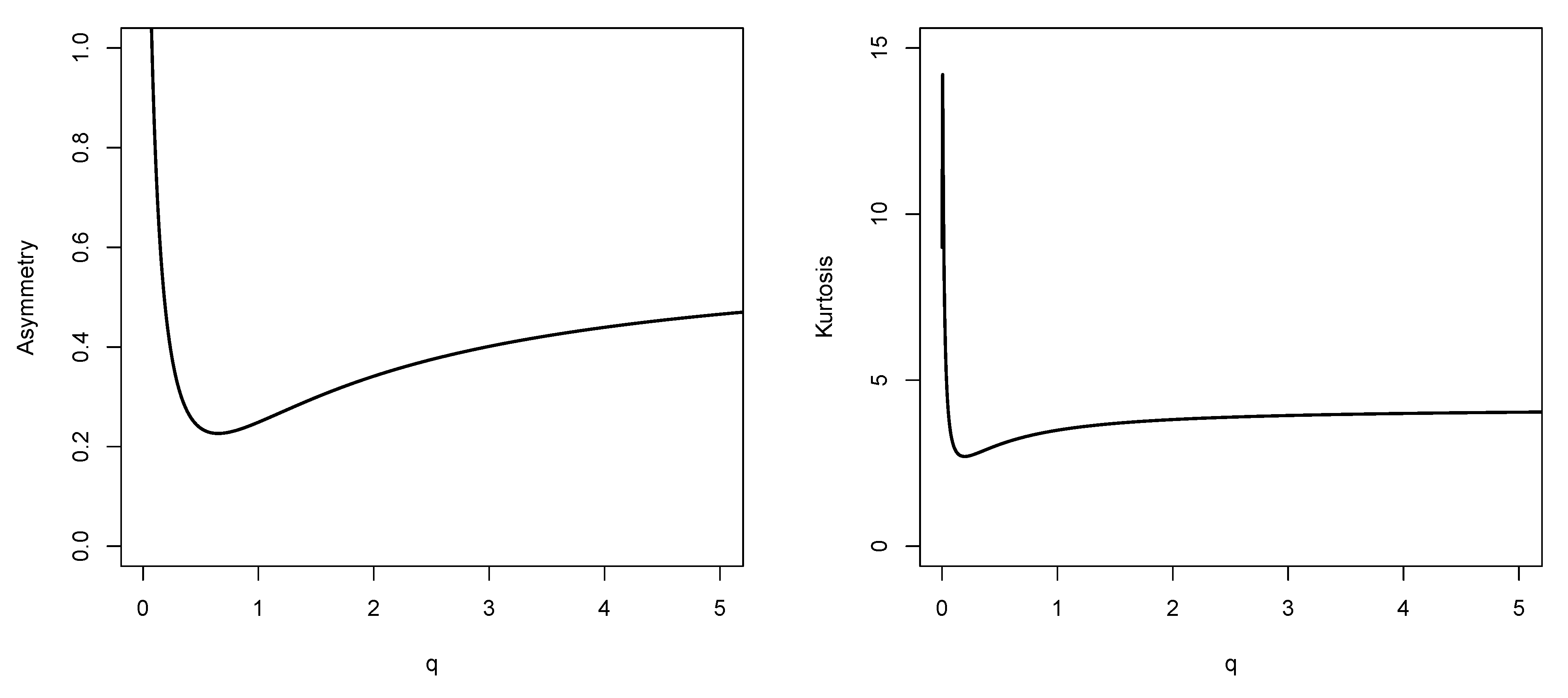
Figure 4 shows the skewness and kurtosis coefficients as a function of the parameter
q for the MBE model.
Proposition 9. Let . Then, the moment generating function for is given by Proof. Calculating directly from the definition, we have
and then, the result is obtained by calculating the integral for
. □










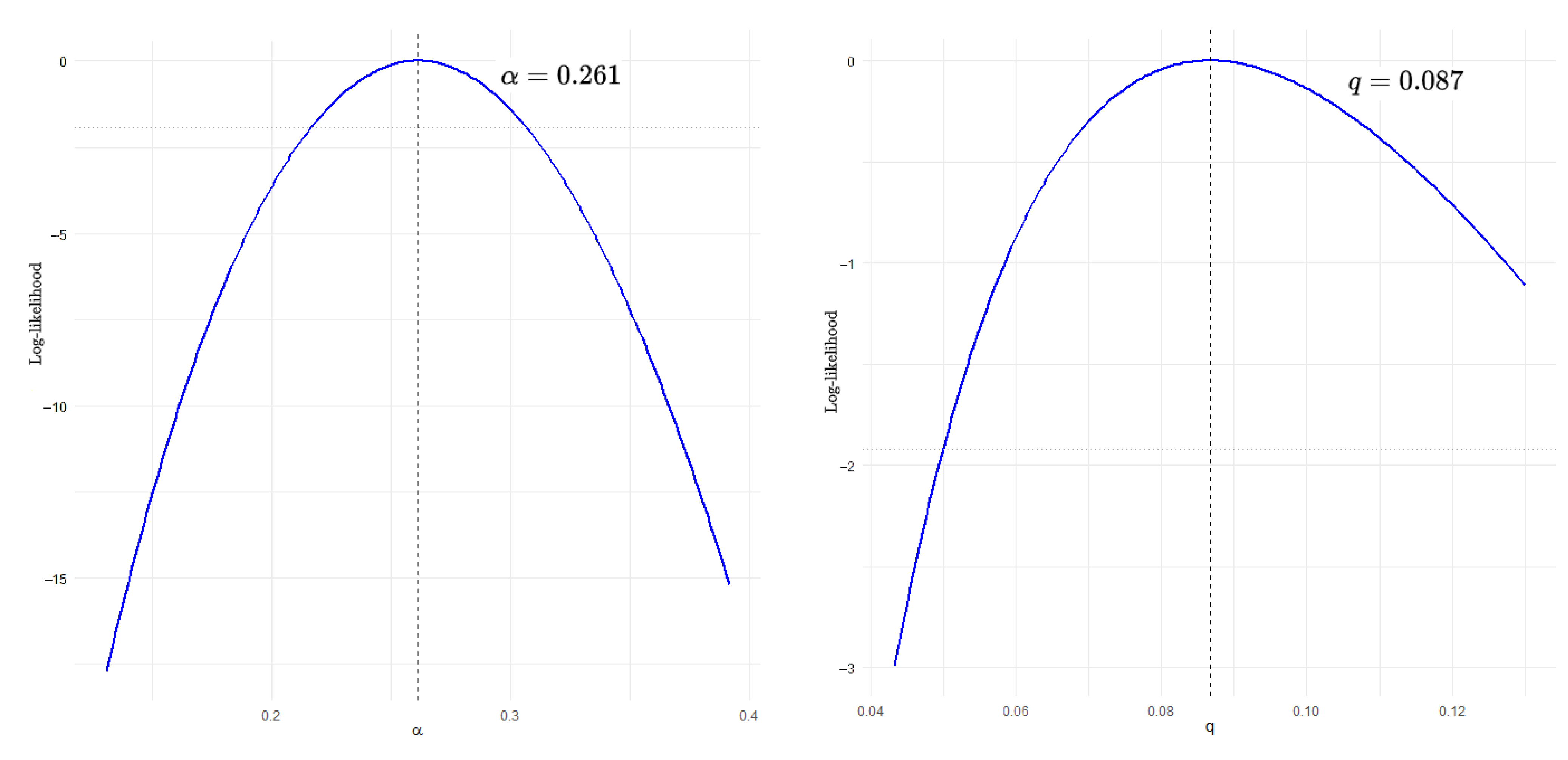

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}