
Optimizing a Bayesian Method for Estimating the Hurst Exponent in Behavioral Sciences


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Methods
2.1. The HK Method for Estimating the Hurst Exponent
- is the observed time series of length n;
- is the autocorrelation matrix with entries determined by the lag-k autocorrelation function for fractional Gaussian noise (fGn), parameterized by H (see Equation (1));
- is an column vector of ones;
- denotes the determinant of ;
- is the inverse of the autocorrelation matrix.
2.2. Generating Synthetic Time Series with A Priori Known Values of the Hurst Exponent
2.3. Empirical Stride Interval Time Series Across Various Locomotion Modes and Support Surface
3. Results
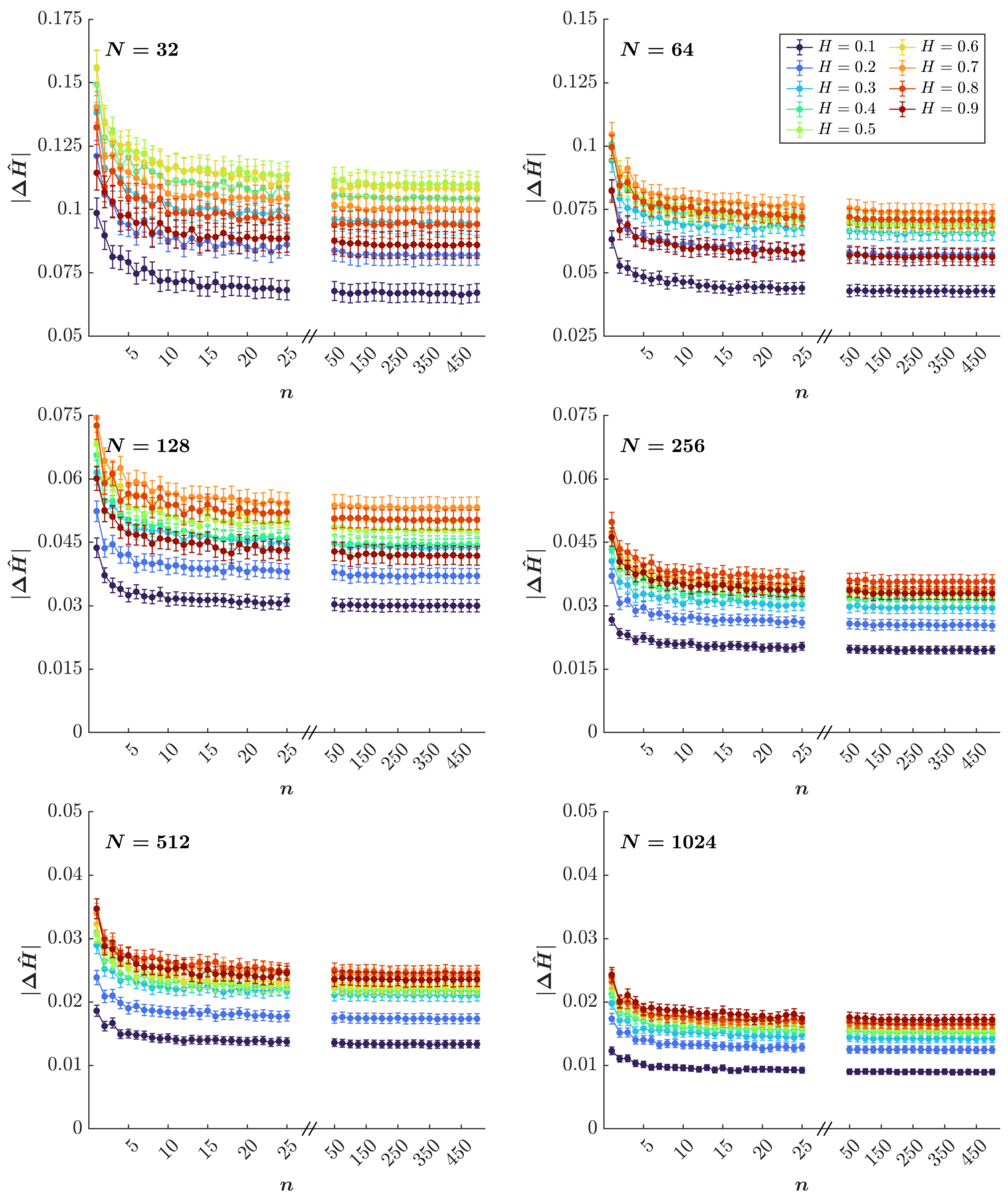
3.1. Simulation Results
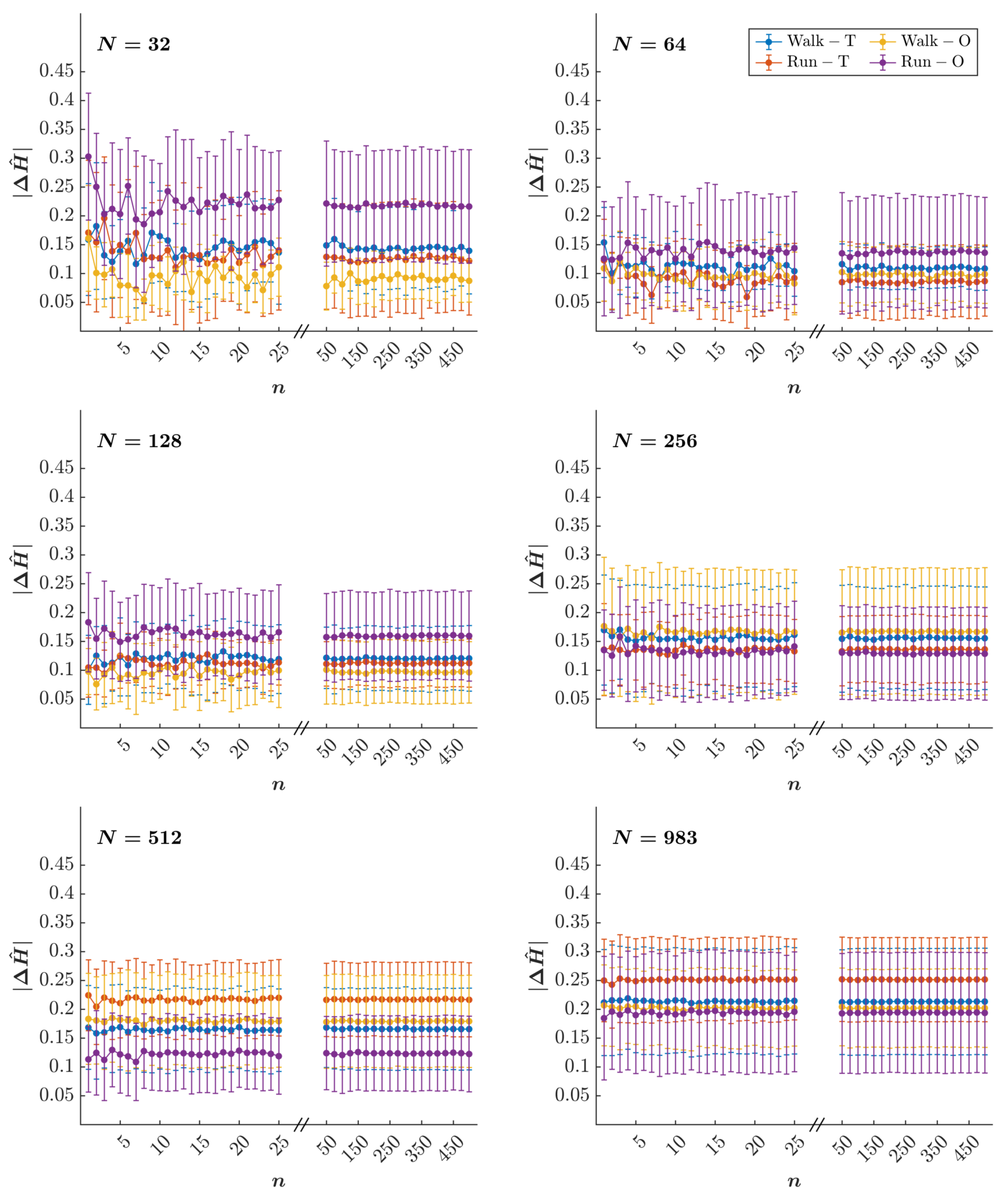
3.2. Empirical Results
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mandelbrot, B.B.; Wallis, J.R. Computer experiments with fractional Gaussian noises: Part 1, Averages and variances. Water Resour. Res. 1969, 5, 228–241. [Google Scholar] [CrossRef]
- Hurst, H.E. Long-term storage capacity of reservoirs. Trans. Am. Soc. Civ. Eng. 1951, 116, 770–799. [Google Scholar] [CrossRef]
- Efstathiou, M.; Varotsos, C. On the altitude dependence of the temperature scaling behaviour at the global troposphere. Int. J. Remote Sens. 2010, 31, 343–349. [Google Scholar] [CrossRef]
- Ivanova, K.; Ausloos, M. Application of the detrended fluctuation analysis (DFA) method for describing cloud breaking. Phys. A Stat. Mech. Its Appl. 1999, 274, 349–354. [Google Scholar] [CrossRef]
- Tatli, H.; Dalfes, H.N. Long-time memory in drought via detrended fluctuation analysis. Water Resour. Manag. 2020, 34, 1199–1212. [Google Scholar] [CrossRef]
- Alvarez-Ramirez, J.; Alvarez, J.; Rodriguez, E. Short-term predictability of crude oil markets: A detrended fluctuation analysis approach. Energy Econ. 2008, 30, 2645–2656. [Google Scholar] [CrossRef]
- Grau-Carles, P. Empirical evidence of long-range correlations in stock returns. Phys. A Stat. Mech. Its Appl. 2000, 287, 396–404. [Google Scholar] [CrossRef]
- Ivanov, P.C.; Yuen, A.; Podobnik, B.; Lee, Y. Common scaling patterns in intertrade times of US stocks. Phys. Rev. E 2004, 69, 056107. [Google Scholar] [CrossRef]
- Liu, Y.; Cizeau, P.; Meyer, M.; Peng, C.K.; Stanley, H.E. Correlations in economic time series. Phys. A Stat. Mech. Its Appl. 1997, 245, 437–440. [Google Scholar] [CrossRef]
- Liu, Y.; Gopikrishnan, P.; Cizeau, P.; Meyer, M.; Peng, C.-K.; Stanley, H.E. Statistical properties of the volatility of price fluctuations. Phys. Rev. E 1999, 60, 1390. [Google Scholar] [CrossRef]
- Alados, C.L.; Huffman, M.A. Fractal long-range correlations in behavioural sequences of wild chimpanzees: A non-invasive analytical tool for the evaluation of health. Ethology 2000, 106, 105–116. [Google Scholar] [CrossRef]
- Bee, M.A.; Kozich, C.E.; Blackwell, K.J.; Gerhardt, H.C. Individual variation in advertisement calls of territorial male green frogs, Rana clamitans: Implications for individual discrimination. Ethology 2001, 107, 65–84. [Google Scholar] [CrossRef]
- Buldyrev, S.; Dokholyan, N.; Goldberger, A.; Havlin, S.; Peng, C.K.; Stanley, H.; Viswanathan, G. Analysis of DNA sequences using methods of statistical physics. Phys. A Stat. Mech. Its Appl. 1998, 249, 430–438. [Google Scholar] [CrossRef]
- Mantegna, R.N.; Buldyrev, S.V.; Goldberger, A.L.; Havlin, S.; Peng, C.K.; Simons, M.; Stanley, H.E. Linguistic features of noncoding DNA sequences. Phys. Rev. Lett. 1994, 73, 3169. [Google Scholar] [CrossRef]
- Peng, C.K.; Buldyrev, S.; Goldberger, A.; Havlin, S.; Simons, M.; Stanley, H. Finite-size effects on long-range correlations: Implications for analyzing DNA sequences. Phys. Rev. E 1993, 47, 3730. [Google Scholar] [CrossRef]
- Castiglioni, P.; Faini, A. A fast DFA algorithm for multifractal multiscale analysis of physiological time series. Front. Physiol. 2019, 10, 115. [Google Scholar] [CrossRef]
- Goldberger, A.L.; Amaral, L.A.; Hausdorff, J.M.; Ivanov, P.C.; Peng, C.K.; Stanley, H.E. Fractal dynamics in physiology: Alterations with disease and aging. Proc. Natl. Acad. Sci. USA 2002, 99, 2466–2472. [Google Scholar] [CrossRef] [PubMed]
- Hardstone, R.; Poil, S.S.; Schiavone, G.; Jansen, R.; Nikulin, V.V.; Mansvelder, H.D.; Linkenkaer-Hansen, K. Detrended fluctuation analysis: A scale-free view on neuronal oscillations. Front. Physiol. 2012, 3, 450. [Google Scholar] [CrossRef] [PubMed]
- Peng, C.K.; Mietus, J.; Hausdorff, J.; Havlin, S.; Stanley, H.E.; Goldberger, A.L. Long-range anticorrelations and non-Gaussian behavior of the heartbeat. Phys. Rev. Lett. 1993, 70, 1343. [Google Scholar] [CrossRef]
- Delignières, D.; Torre, K.; Bernard, P.L. Transition from persistent to anti-persistent correlations in postural sway indicates velocity-based control. PLoS Comput. Biol. 2011, 7, e1001089. [Google Scholar] [CrossRef]
- Duarte, M.; Sternad, D. Complexity of human postural control in young and older adults during prolonged standing. Exp. Brain Res. 2008, 191, 265–276. [Google Scholar] [CrossRef] [PubMed]
- Lin, D.; Seol, H.; Nussbaum, M.A.; Madigan, M.L. Reliability of COP-based postural sway measures and age-related differences. Gait Posture 2008, 28, 337–342. [Google Scholar] [CrossRef]
- Chen, Y.; Ding, M.; Kelso, J.S. Long memory processes (1/fα type) in human coordination. Phys. Rev. Lett. 1997, 79, 4501. [Google Scholar] [CrossRef]
- Diniz, A.; Wijnants, M.L.; Torre, K.; Barreiros, J.; Crato, N.; Bosman, A.M.; Hasselman, F.; Cox, R.F.; Van Orden, G.C.; Delignières, D. Contemporary theories of 1/f noise in motor control. Hum. Mov. Sci. 2011, 30, 889–905. [Google Scholar] [CrossRef]
- Allegrini, P.; Menicucci, D.; Bedini, R.; Fronzoni, L.; Gemignani, A.; Grigolini, P.; West, B.J.; Paradisi, P. Spontaneous brain activity as a source of ideal 1/f noise. Phys. Rev. E 2009, 80, 061914. [Google Scholar] [CrossRef]
- Gilden, D.L.; Thornton, T.; Mallon, M.W. 1/f noise in human cognition. Science 1995, 267, 1837–1839. [Google Scholar] [CrossRef]
- Kello, C.T.; Brown, G.D.; Ferrer-i Cancho, R.; Holden, J.G.; Linkenkaer-Hansen, K.; Rhodes, T.; Van Orden, G.C. Scaling laws in cognitive sciences. Trends Cogn. Sci. 2010, 14, 223–232. [Google Scholar] [CrossRef] [PubMed]
- Stephen, D.G.; Stepp, N.; Dixon, J.A.; Turvey, M. Strong anticipation: Sensitivity to long-range correlations in synchronization behavior. Phys. A Stat. Mech. Its Appl. 2008, 387, 5271–5278. [Google Scholar] [CrossRef]
- Van Orden, G.C.; Holden, J.G.; Turvey, M.T. Self-organization of cognitive performance. J. Exp. Psychol. Gen. 2003, 132, 331–350. [Google Scholar] [CrossRef]
- Mangalam, M.; Conners, J.D.; Kelty-Stephen, D.G.; Singh, T. Fractal fluctuations in muscular activity contribute to judgments of length but not heaviness via dynamic touch. Exp. Brain Res. 2019, 237, 1213–1226. [Google Scholar] [CrossRef]
- Mangalam, M.; Chen, R.; McHugh, T.R.; Singh, T.; Kelty-Stephen, D.G. Bodywide fluctuations support manual exploration: Fractal fluctuations in posture predict perception of heaviness and length via effortful touch by the hand. Hum. Mov. Sci. 2020, 69, 102543. [Google Scholar] [CrossRef] [PubMed]
- Mangalam, M.; Carver, N.S.; Kelty-Stephen, D.G. Global broadcasting of local fractal fluctuations in a bodywide distributed system supports perception via effortful touch. Chaos Solitons Fractals 2020, 135, 109740. [Google Scholar] [CrossRef]
- Ashkenazy, Y.; Lewkowicz, M.; Levitan, J.; Havlin, S.; Saermark, K.; Moelgaard, H.; Thomsen, P.B. Discrimination between healthy and sick cardiac autonomic nervous system by detrended heart rate variability analysis. Fractals 1999, 7, 85–91. [Google Scholar] [CrossRef]
- Ho, K.K.; Moody, G.B.; Peng, C.K.; Mietus, J.E.; Larson, M.G.; Levy, D.; Goldberger, A.L. Predicting survival in heart failure case and control subjects by use of fully automated methods for deriving nonlinear and conventional indices of heart rate dynamics. Circulation 1997, 96, 842–848. [Google Scholar] [CrossRef] [PubMed]
- Peng, C.K.; Havlin, S.; Hausdorff, J.; Mietus, J.; Stanley, H.; Goldberger, A. Fractal mechanisms and heart rate dynamics: Long-range correlations and their breakdown with disease. J. Electrocardiol. 1995, 28, 59–65. [Google Scholar] [CrossRef]
- Bartsch, R.; Plotnik, M.; Kantelhardt, J.W.; Havlin, S.; Giladi, N.; Hausdorff, J.M. Fluctuation and synchronization of gait intervals and gait force profiles distinguish stages of Parkinson’s disease. Phys. A Stat. Mech. Its Appl. 2007, 383, 455–465. [Google Scholar] [CrossRef]
- Hausdorff, J.M.; Mitchell, S.L.; Firtion, R.; Peng, C.K.; Cudkowicz, M.E.; Wei, J.Y.; Goldberger, A.L. Altered fractal dynamics of gait: Reduced stride-interval correlations with aging and Huntington’s disease. J. Appl. Physiol. 1997, 82, 262–269. [Google Scholar] [CrossRef]
- Hausdorff, J.M.; Ashkenazy, Y.; Peng, C.K.; Ivanov, P.C.; Stanley, H.E.; Goldberger, A.L. When human walking becomes random walking: Fractal analysis and modeling of gait rhythm fluctuations. Phys. A Stat. Mech. Its Appl. 2001, 302, 138–147. [Google Scholar] [CrossRef]
- Hausdorff, J.M. Gait dynamics, fractals and falls: Finding meaning in the stride-to-stride fluctuations of human walking. Hum. Mov. Sci. 2007, 26, 555–589. [Google Scholar] [CrossRef]
- Herman, T.; Giladi, N.; Gurevich, T.; Hausdorff, J. Gait instability and fractal dynamics of older adults with a “cautious” gait: Why do certain older adults walk fearfully? Gait Posture 2005, 21, 178–185. [Google Scholar] [CrossRef]
- Kobsar, D.; Olson, C.; Paranjape, R.; Hadjistavropoulos, T.; Barden, J.M. Evaluation of age-related differences in the stride-to-stride fluctuations, regularity and symmetry of gait using a waist-mounted tri-axial accelerometer. Gait Posture 2014, 39, 553–557. [Google Scholar] [CrossRef] [PubMed]
- Mangalam, M.; Skiadopoulos, A.; Siu, K.C.; Mukherjee, M.; Likens, A.; Stergiou, N. Leveraging a virtual alley with continuously varying width modulates step width variability during self-paced treadmill walking. Neurosci. Lett. 2022, 793, 136966. [Google Scholar] [CrossRef] [PubMed]
- Raffalt, P.C.; Stergiou, N.; Sommerfeld, J.H.; Likens, A.D. The temporal pattern and the probability distribution of visual cueing can alter the structure of stride-to-stride variability. Neurosci. Lett. 2021, 763, 136193. [Google Scholar] [CrossRef] [PubMed]
- Raffalt, P.C.; Sommerfeld, J.H.; Stergiou, N.; Likens, A.D. Stride-to-stride time intervals are independently affected by the temporal pattern and probability distribution of visual cues. Neurosci. Lett. 2023, 792, 136909. [Google Scholar] [CrossRef]
- Kaipust, J.P.; McGrath, D.; Mukherjee, M.; Stergiou, N. Gait variability is altered in older adults when listening to auditory stimuli with differing temporal structures. Ann. Biomed. Eng. 2013, 41, 1595–1603. [Google Scholar] [CrossRef]
- Marmelat, V.; Duncan, A.; Meltz, S.; Meidinger, R.L.; Hellman, A.M. Fractal auditory stimulation has greater benefit for people with Parkinson’s disease showing more random gait pattern. Gait Posture 2020, 80, 234–239. [Google Scholar] [CrossRef]
- Vaz, J.R.; Knarr, B.A.; Stergiou, N. Gait complexity is acutely restored in older adults when walking to a fractal-like visual stimulus. Hum. Mov. Sci. 2020, 74, 102677. [Google Scholar] [CrossRef]
- Peng, C.K.; Buldyrev, S.V.; Havlin, S.; Simons, M.; Stanley, H.E.; Goldberger, A.L. Mosaic organization of DNA nucleotides. Phys. Rev. E 1994, 49, 1685. [Google Scholar] [CrossRef]
- Peng, C.K.; Havlin, S.; Stanley, H.E.; Goldberger, A.L. Quantification of scaling exponents and crossover phenomena in nonstationary heartbeat time series. Chaos 1995, 5, 82–87. [Google Scholar] [CrossRef]
- Bashan, A.; Bartsch, R.; Kantelhardt, J.W.; Havlin, S. Comparison of detrending methods for fluctuation analysis. Phys. A Stat. Mech. Its Appl. 2008, 387, 5080–5090. [Google Scholar] [CrossRef]
- Grech, D.; Mazur, Z. Statistical properties of old and new techniques in detrended analysis of time series. Acta Phys. Pol. Ser. B 2005, 36, 2403. [Google Scholar]
- Almurad, Z.M.; Delignières, D. Evenly spacing in detrended fluctuation analysis. Phys. A Stat. Mech. Its Appl. 2016, 451, 63–69. [Google Scholar] [CrossRef]
- Delignieres, D.; Ramdani, S.; Lemoine, L.; Torre, K.; Fortes, M.; Ninot, G. Fractal analyses for ‘short’ time series: A re-assessment of classical methods. J. Math. Psychol. 2006, 50, 525–544. [Google Scholar] [CrossRef]
- Dlask, M.; Kukal, J. Hurst exponent estimation from short time series. Signal Image Video Process. 2019, 13, 263–269. [Google Scholar] [CrossRef]
- Katsev, S.; L’Heureux, I. Are Hurst exponents estimated from short or irregular time series meaningful? Comput. Geosci. 2003, 29, 1085–1089. [Google Scholar] [CrossRef]
- Marmelat, V.; Meidinger, R.L. Fractal analysis of gait in people with Parkinson’s disease: Three minutes is not enough. Gait Posture 2019, 70, 229–234. [Google Scholar] [CrossRef]
- Ravi, D.K.; Marmelat, V.; Taylor, W.R.; Newell, K.M.; Stergiou, N.; Singh, N.B. Assessing the temporal organization of walking variability: A systematic review and consensus guidelines on detrended fluctuation analysis. Front. Physiol. 2020, 11, 562. [Google Scholar] [CrossRef]
- Roume, C.; Ezzina, S.; Blain, H.; Delignières, D. Biases in the simulation and analysis of fractal processes. Comput. Math. Methods Med. 2019, 2019, 4025305. [Google Scholar] [CrossRef]
- Schaefer, A.; Brach, J.S.; Perera, S.; Sejdić, E. A comparative analysis of spectral exponent estimation techniques for 1/fβ processes with applications to the analysis of stride interval time series. J. Neurosci. Methods 2014, 222, 118–130. [Google Scholar] [CrossRef]
- Yuan, Q.; Gu, C.; Weng, T.; Yang, H. Unbiased detrended fluctuation analysis: Long-range correlations in very short time series. Phys. A Stat. Mech. Its Appl. 2018, 505, 179–189. [Google Scholar] [CrossRef]
- Höll, M.; Kantz, H. The relationship between the detrendend fluctuation analysis and the autocorrelation function of a signal. Eur. Phys. J. B 2015, 88, 1–7. [Google Scholar] [CrossRef]
- Kiyono, K. Establishing a direct connection between detrended fluctuation analysis and Fourier analysis. Phys. Rev. E 2015, 92, 042925. [Google Scholar] [CrossRef]
- Stroe-Kunold, E.; Stadnytska, T.; Werner, J.; Braun, S. Estimating long-range dependence in time series: An evaluation of estimators implemented in R. Behav. Res. Methods 2009, 41, 909–923. [Google Scholar] [CrossRef]
- Tyralis, H.; Koutsoyiannis, D. A Bayesian statistical model for deriving the predictive distribution of hydroclimatic variables. Clim. Dyn. 2014, 42, 2867–2883. [Google Scholar] [CrossRef]
- Likens, A.D.; Mangalam, M.; Wong, A.Y.; Charles, A.C.; Mills, C. Better than DFA? A Bayesian method for estimating the Hurst exponent in behavioral sciences. arXiv 2023, arXiv:2301.11262. [Google Scholar]
- Koutsoyiannis, D. Climate change, the Hurst phenomenon, and hydrological statistics. Hydrol. Sci. J. 2003, 48, 3–24. [Google Scholar] [CrossRef]
- Golub, G.H.; Van Loan, C.F. Matrix Computations; John Hopkins University Press: Baltimore, MD, USA, 2013. [Google Scholar]
- Robert, C.P.; Casella, G.; Casella, G. Monte Carlo Statistical Methods; Springer: New York, NY, USA, 1999; Volume 2. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 1995. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing. R Version 4.0.4 2024. Available online: https://www.R-project.org/ (accessed on 31 March 2023).
- Tyralis, H. Package ‘HKprocess’. R Package Version 0.1-1 2022. Available online: https://cran.r-project.org/package=HKprocess (accessed on 31 March 2023).
- Davies, R.B.; Harte, D. Tests for Hurst effect. Biometrika 1987, 74, 95–101. [Google Scholar] [CrossRef]
- Likens, A.; Wiltshire, T. fractalRegression: An R Package for Fractal Analyses and Regression 2021. Available online: https://github.com/aaronlikens/fractalRegression (accessed on 31 March 2023).
- Wilson, T.; Mangalam, M.; Stergiou, N.; Likens, A. Multifractality in stride-to-stride variations reveals that walking entails tuning and adjusting movements more than running. Hum. Mov. Sci. 2023, 3, 1294545. [Google Scholar]
- Martin, P.E.; Rothstein, D.E.; Larish, D.D. Effects of age and physical activity status on the speed-aerobic demand relationship of walking. J. Appl. Physiol. 1992, 73, 200–206. [Google Scholar] [CrossRef]
- Mangalam, M.; Likens, A.D. Precision in brief: The Bayesian Hurst-Kolmogorov method for assessing long-range temporal correlations in short behavioral time series. Entropy 2025, 27, 500. [Google Scholar] [CrossRef]
- Agresta, C.E.; Goulet, G.C.; Peacock, J.; Housner, J.; Zernicke, R.F.; Zendler, J.D. Years of running experience influences stride-to-stride fluctuations and adaptive response during step frequency perturbations in healthy distance runners. Gait Posture 2019, 70, 376–382. [Google Scholar] [CrossRef] [PubMed]
- Bellenger, C.R.; Arnold, J.B.; Buckley, J.D.; Thewlis, D.; Fuller, J.T. Detrended fluctuation analysis detects altered coordination of running gait in athletes following a heavy period of training. J. Sci. Med. Sport 2019, 22, 294–299. [Google Scholar] [CrossRef] [PubMed]
- Brahms, C.M.; Zhao, Y.; Gerhard, D.; Barden, J.M. Long-range correlations and stride pattern variability in recreational and elite distance runners during a prolonged run. Gait Posture 2020, 92, 487–492. [Google Scholar] [CrossRef]
- Bollens, B.; Crevecoeur, F.; Nguyen, V.; Detrembleur, C.; Lejeune, T. Does human gait exhibit comparable and reproducible long-range autocorrelations on level ground and on treadmill? Gait Posture 2010, 32, 369–373. [Google Scholar] [CrossRef]
- Ducharme, S.W.; Liddy, J.J.; Haddad, J.M.; Busa, M.A.; Claxton, L.J.; van Emmerik, R.E. Association between stride time fractality and gait adaptability during unperturbed and asymmetric walking. Hum. Mov. Sci. 2018, 58, 248–259. [Google Scholar] [CrossRef]
- Fairley, J.A.; Sejdić, E.; Chau, T. The effect of treadmill walking on the stride interval dynamics of children. Hum. Mov. Sci. 2010, 29, 987–998. [Google Scholar] [CrossRef] [PubMed]
- Fuller, J.T.; Amado, A.; van Emmerik, R.E.; Hamill, J.; Buckley, J.D.; Tsiros, M.D.; Thewlis, D. The effect of footwear and footfall pattern on running stride interval long-range correlations and distributional variability. Gait Posture 2016, 44, 137–142. [Google Scholar] [CrossRef]
- Fuller, J.T.; Bellenger, C.R.; Thewlis, D.; Arnold, J.; Thomson, R.L.; Tsiros, M.D.; Robertson, E.Y.; Buckley, J.D. Tracking performance changes with running-stride variability when athletes are functionally overreached. Int. J. Sport. Physiol. Perform. 2017, 12, 357–363. [Google Scholar] [CrossRef]
- Hausdorff, J.M.; Peng, C.K.; Ladin, Z.; Wei, J.Y.; Goldberger, A.L. Is walking a random walk? Evidence for long-range correlations in stride interval of human gait. J. Appl. Physiol. 1995, 78, 349–358. [Google Scholar] [CrossRef]
- Hausdorff, J.M.; Purdon, P.L.; Peng, C.K.; Ladin, Z.; Wei, J.Y.; Goldberger, A.L. Fractal dynamics of human gait: Stability of long-range correlations in stride interval fluctuations. J. Appl. Physiol. 1996, 80, 1448–1457. [Google Scholar] [CrossRef]
- Jordan, K.; Challis, J.H.; Newell, K.M. Long range correlations in the stride interval of running. Gait Posture 2006, 24, 120–125. [Google Scholar] [CrossRef] [PubMed]
- Jordan, K.; Challis, J.H.; Cusumano, J.P.; Newell, K.M. Stability and the time-dependent structure of gait variability in walking and running. Hum. Mov. Sci. 2009, 28, 113–128. [Google Scholar] [CrossRef] [PubMed]
- Lindsay, T.R.; Noakes, T.D.; McGregor, S.J. Effect of treadmill versus overground running on the structure of variability of stride timing. Percept. Mot. Skills 2014, 118, 331–346. [Google Scholar] [CrossRef] [PubMed]
- Mangalam, M.; Kelty-Stephen, D.G.; Sommerfeld, J.H.; Stergiou, N.; Likens, A.D. Temporal organization of stride-to-stride variations contradicts predictive models for sensorimotor control of footfalls during walking. PLoS ONE 2023, 18, e0290324. [Google Scholar] [CrossRef]
- Nakayama, Y.; Kudo, K.; Ohtsuki, T. Variability and fluctuation in running gait cycle of trained runners and non-runners. Gait Posture 2010, 31, 331–335. [Google Scholar] [CrossRef]
- Terrier, P.; Dériaz, O. Kinematic variability, fractal dynamics and local dynamic stability of treadmill walking. J. Neuroeng. Rehabil. 2011, 8, 12. [Google Scholar] [CrossRef]
- Hausdorff, J.M.; Rios, D.A.; Edelberg, H.K. Gait variability and fall risk in community-living older adults: A 1-year prospective study. Arch. Phys. Med. Rehabil. 2001, 82, 1050–1056. [Google Scholar] [CrossRef]
- Johansson, J.; Nordström, A.; Nordström, P. Greater fall risk in elderly women than in men is associated with increased gait variability during multitasking. J. Am. Med Dir. Assoc. 2016, 17, 535–540. [Google Scholar] [CrossRef]
- Paterson, K.; Hill, K.; Lythgo, N. Stride dynamics, gait variability and prospective falls risk in active community dwelling older women. Gait Posture 2011, 33, 251–255. [Google Scholar] [CrossRef]
- Toebes, M.J.; Hoozemans, M.J.; Furrer, R.; Dekker, J.; van Dieën, J.H. Local dynamic stability and variability of gait are associated with fall history in elderly subjects. Gait Posture 2012, 36, 527–531. [Google Scholar] [CrossRef]
- Bryce, R.; Sprague, K. Revisiting detrended fluctuation analysis. Sci. Rep. 2012, 2, 315. [Google Scholar] [CrossRef] [PubMed]
- Hu, K.; Ivanov, P.C.; Chen, Z.; Carpena, P.; Stanley, H.E. Effect of trends on detrended fluctuation analysis. Phys. Rev. E 2001, 64, 011114. [Google Scholar] [CrossRef] [PubMed]
- Horvatic, D.; Stanley, H.E.; Podobnik, B. Detrended cross-correlation analysis for non-stationary time series with periodic trends. Europhys. Lett. 2011, 94, 18007. [Google Scholar] [CrossRef]
- Chen, Z.; Ivanov, P.C.; Hu, K.; Stanley, H.E. Effect of nonstationarities on detrended fluctuation analysis. Phys. Rev. E 2002, 65, 041107. [Google Scholar] [CrossRef] [PubMed]
- Kantelhardt, J.W.; Koscielny-Bunde, E.; Rego, H.H.; Havlin, S.; Bunde, A. Detecting long-range correlations with detrended fluctuation analysis. Phys. A Stat. Mech. Its Appl. 2001, 295, 441–454. [Google Scholar] [CrossRef]
- Kelty-Stephen, D.G.; Palatinus, K.; Saltzman, E.; Dixon, J.A. A tutorial on multifractality, cascades, and interactivity for empirical time series in ecological science. Ecol. Psychol. 2013, 25, 1–62. [Google Scholar] [CrossRef]
- Cheng, S.; Quilodrán-Casas, C.; Ouala, S.; Farchi, A.; Liu, C.; Tandeo, P.; Fablet, R.; Lucor, D.; Iooss, B.; Brajard, J.; et al. Machine learning with data assimilation and uncertainty quantification for dynamical systems: A review. IEEE/CAA J. Autom. Sin. 2023, 10, 1361–1387. [Google Scholar] [CrossRef]
- Zhong, C.; Cheng, S.; Kasoar, M.; Arcucci, R. Reduced-order digital twin and latent data assimilation for global wildfire prediction. Nat. Hazards Earth Syst. Sci. 2023, 23, 1755–1768. [Google Scholar] [CrossRef]
- Mandelbrot, B.B.; Hudson, R.L. The (mis) Behaviour of Markets: A Fractal View of Risk, Ruin and Reward; Basic Books: New York, NY, USA, 2004. [Google Scholar]
- Cont, R. Long range dependence in financial markets. In Fractals in Engineering: New Trends in Theory and Applications; Lévy-Véhel, J., Lutton, E., Eds.; Springer: London, UK, 2005; pp. 159–179. [Google Scholar] [CrossRef]
- Fraedrich, K.; Blender, R. Scaling of atmosphere and ocean temperature correlations in observations and climate models. Phys. Rev. Lett. 2003, 90, 108501. [Google Scholar] [CrossRef]
- Kiyono, K.; Hayano, J.; Kwak, S.; Watanabe, E.; Yamamoto, Y. Non-Gaussianity of low frequency heart rate variability and sympathetic activation: Lack of increases in multiple system atrophy and Parkinson disease. Front. Physiol. 2012, 3, 34. [Google Scholar] [CrossRef]
- Hausdorff, J.M. Gait dynamics in Parkinson’s disease: Common and distinct behavior among stride length, gait variability, and fractal-like scaling. Chaos Interdiscip. J. Nonlinear Sci. 2009, 19, 026113. [Google Scholar] [CrossRef] [PubMed]
- Kirchner, M.; Schubert, P.; Liebherr, M.; Haas, C.T. Detrended fluctuation analysis and adaptive fractal analysis of stride time data in Parkinson’s disease: Stitching together short gait trials. PLoS ONE 2014, 9, e85787. [Google Scholar] [CrossRef] [PubMed]
- Del Din, S.; Godfrey, A.; Mazzà, C.; Lord, S.; Rochester, L. Free-living monitoring of Parkinson’s disease: Lessons from the field. Mov. Disord. 2016, 31, 1293–1313. [Google Scholar] [CrossRef] [PubMed]
- Espay, A.J.; Bonato, P.; Nahab, F.B.; Maetzler, W.; Dean, J.M.; Klucken, J.; Eskofier, B.M.; Merola, A.; Horak, F.; Lang, A.E.; et al. Technology in Parkinson’s disease: Challenges and opportunities. Mov. Disord. 2016, 31, 1272–1282. [Google Scholar] [CrossRef]
- Perkiömäki, J.S. Heart rate variability and non-linear dynamics in risk stratification. Front. Physiol. 2011, 2, 81. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mangalam, M.; Wilson, T.J.; Sommerfeld, J.H.; Likens, A.D. Optimizing a Bayesian Method for Estimating the Hurst Exponent in Behavioral Sciences. Axioms 2025, 14, 421. https://doi.org/10.3390/axioms14060421
Mangalam M, Wilson TJ, Sommerfeld JH, Likens AD. Optimizing a Bayesian Method for Estimating the Hurst Exponent in Behavioral Sciences. Axioms. 2025; 14(6):421. https://doi.org/10.3390/axioms14060421
Chicago/Turabian StyleMangalam, Madhur, Taylor J. Wilson, Joel H. Sommerfeld, and Aaron D. Likens. 2025. "Optimizing a Bayesian Method for Estimating the Hurst Exponent in Behavioral Sciences" Axioms 14, no. 6: 421. https://doi.org/10.3390/axioms14060421
APA StyleMangalam, M., Wilson, T. J., Sommerfeld, J. H., & Likens, A. D. (2025). Optimizing a Bayesian Method for Estimating the Hurst Exponent in Behavioral Sciences. Axioms, 14(6), 421. https://doi.org/10.3390/axioms14060421