1. Introductory Notes
Solving nonlinear scalar equations is fundamental in numerous scientific and engineering disciplines, as many real-world problems involve nonlinear behavior that cannot be accurately captured by linear models [
1,
2,
3]. These equations frequently arise in physics, engineering, economics, and biology, where exact analytical solutions are often unavailable [
4,
5]. In physics and engineering, nonlinear equations govern the behavior of complex systems such as fluid dynamics, structural mechanics, and electrodynamics [
6]. A notable example is the motion of a projectile under air resistance, modeled by the following equation:
where
represents velocity,
is the mass,
g is gravitational acceleration, and
is the drag coefficient. Similarly, in financial mathematics [
7], the valuation of options under transactions is determined by the nonlinear Black–Scholes equation, which is inherently nonlinear due to the presence of transactions. To enlighten the issue, when solving the nonlinear partial differential equation using the finite difference discretization, this process leads to a collection of nonlinear algebraic equations, mainly of a large sparse size, that needs to be tackled by iterative Newton-type methods. Biological and medical sciences also rely heavily on nonlinear models to describe population dynamics, such as the logistic growth model, as follows:
wherein
is the intrinsic growth rate,
P is the population size, and
K shows the carrying capacity of the environment.
Let us now introduce the fundamental concepts of solving nonlinear equations using iterative methods [
1], with a particular focus on multipoint methods. These methods are known for their higher computational efficiency compared to classical one-point methods. We provide a classification of iteration solvers via the information needed from current and previous iterates, and we discuss key features such as the convergence order, computational efficiency, initial approximations, and stopping criteria.
1.1. Classification of Iterative Solvers
Iterative schemes for resolving
can be classified based on the information they use [
8,
9]:
One-point methods: These methods use only the current approximation
to calculate the subsequent approximation
. A classic example is Newton’s scheme (NIM, second-order speed), expressed as follows:
One-point methods with memory [
8]: These methods reuse previous approximations
to compute
. The secant solver is a well-known instance expressed as follows:
Multipoint methods without memory: These methods use the current approximation
and additional expressions
to compute
; see [
10,
11] for more details.
Multipoint methods with memory: These methods use information from multiple previous iterates, including both approximations and additional expressions [
12,
13].
Despite the widespread use of Newton-type iterative methods, traditional solvers face several well-known limitations. One-point methods, like Newton’s method, exhibit quadratic convergence but require the computation of derivatives, which can be computationally expensive or analytically intractable for complex functions. Additionally, these methods are highly sensitive to the choice of the initial approximation; poor initial guesses can lead to divergence or slow convergence. To address these issues, multipoint methods have been developed, improving convergence rates by incorporating additional function evaluations. However, these approaches often come at the cost of increased computational effort, as each iteration requires multiple function evaluations, reducing overall efficiency.
Multipoint methods without memory aim to balance accuracy and computational cost by evaluating the function at strategically chosen auxiliary points [
14]. Nevertheless, their performance is still limited by the quantity of function evaluations required per cycle, which restricts their efficacy for large-scale problems. On the other hand, schemes with memory offer a promising alternative by utilizing past iterates to boost convergence without additional functional evaluations. This advantage allows them to achieve higher-order convergence while maintaining computational efficiency. However, existing memory-based approaches often lack a systematic framework for integrating historical information optimally, leading to suboptimal performance in certain cases. The present work aims to address these limitations by constructing a Newton-type iterative solver with memory that maximizes convergence efficiency while preserving the quantity of function evaluations per cycle.
1.2. One-Point Iteration Solvers
Several one-point iterative schemes for finding simple zeros are reviewed, including that in [
15]; Halley’s method (cubic convergence), expressed as follows [
16]:
And the Chebyshev’s method (cubic convergence), expressed as follows [
17]:
1.3. Methods for Multiple Zeros
For functions with multiple zeros, modified versions of one-point methods are introduced. For example, Schröder’s method for multiple zeros of multiplicity
m is given by the following [
18,
19]:
1.4. Motivation and Organization
The development of methods with memory has been a research direction in recent years [
20,
21], as such methods offer the potential for higher convergence rates while preserving computational efficiency. By integrating memory into a Newton-type solver, it is possible to construct a more effective iterative scheme that reduces the number of required iterations and improves accuracy. Motivated by these considerations, this study aims to construct a higher-order iterative scheme with memory that outperforms traditional solvers in terms of convergence speed and computational cost. Our approach is designed to achieve a superior
R-order of convergence while maintaining the identical quantity of function evaluations as existing two-point methods. Through rigorous analysis and extensive numerical tests, we show that the proposed scheme provides a practical and efficient alternative in resolving nonlinear equations.
The remainder of this investigation is structured as follows.
Section 2 lays out the mathematical formulations for two-point solvers, providing the necessary theoretical background.
Section 3 presents our main contribution–a two-step method with memory and a derivative-free approach–derived from a Newton-type solver. We provide a detailed derivation of the proposed method along with a mathematical analysis of its convergence order.
Section 4 validates the efficacy of the proposed scheme through various numerical tests and test scenarios. Finally,
Section 5 concludes the study with a discussion of the findings and several directions for forthcoming research.
3. An Enhanced Iterative Scheme with Memory
Let us initially consider the following structure:
Now we propose a Newton-type iteration method by modifying Newton’s scheme in the first substep and introducing a free parameter
a. This modification preserves the convergence order while incorporating
a into the error equation, allowing for enhanced solver speed. So first we consider
and then, we replace the first derivative of this Newton-type method (
15) as follows:
where
On the one hand, this iteration scheme is based on the Newton-type solver (
15), while on the other hand, it can lead to a Steffensen-type method (
16) and could also be called a Steffensen-type method. Writing Taylor series up to appropriate orders and making several simplification, it is possible to derive the theorem below.
Theorem 1. Suppose that is a simple zero of the sufficiently differentiable smooth function . As long as the initial guess is selected close enough to α, then (16) converges to α with fourth-order accuracy. Proof. The proof is straightforward (and is similar to [
27,
29]). Let
be the simple root of the function
f. Assuming that
f is adequately smooth, we expand
and its derivative
in a Taylor series over
, leading to the following expressions:
and
In this context, the error term is represented as
, while the coefficients
are defined as
Inserting Equations (
18) and (
19) into (
16), we arrive at the following:
Utilizing Equations (
18)–(
20), the corresponding error equation associated with (
16) is given by the following:
This concludes the proof by illustrating the fourth convergence order. □
Our objective is to eliminate the asymptotic error constant, expressed as
. To achieve this, the R-order can be enhanced by implementing the following transformation:
Since the exact location of the root is unknown, the direct application of relation (
22) is not feasible in its precise form. Therefore, an iterative approximation must be employed. This gives the improvement of a memory-enhanced variant of Newton’s scheme, constructed using the following:
where
. Consider the case where
represents the Newton interpolatory polynomial of degree three, constructed from the four available approximates of the root
,
,
,
at the conclusion of every cycle. In this context, we introduce a novel method with memory, as follows (PM1):
It is important to note that the interpolating polynomial can be expressed in the following form in the Wolfram Mathematica environment [
30]:
data = {{x, fx}, {W, fW}, {Y, fY}, {X, fX}};
L[t_] := InterpolatingPolynomial[data, t] // Simplify;
a1[k] = (1/6) (L’’’[X]/L’[X]);
The speed enhancement for (
24) relies on the introduction of a free nonzero parameter, which is varied at each iteration. This parameter is computed via information from both the current and previous iterations. Therefore, the method can be classified as one with memory, as per Traub’s classification [
8].
We now proceed to discuss the analytical aspects underlying our presented scheme, defined in (
24).
Theorem 2. Consider a function that is adequately smooth in the vicinity of its simple zero, denoted by α. If an initial estimate is chosen such that it lies adequately close to α, then the iterative scheme (24) incorporating memory exhibits an R-order of convergence of no less than 4.23607. Proof. Suppose
denotes the sequence of approximated roots obtained via (
24). The error equations for (
24), with the self-accelerator
, are given by the following:
A key distinction between our approach and previous methodologies, such as the one presented in [
28], lies in the treatment of the acceleration parameter. In prior works, the acceleration was primarily implemented through modifications to the parameter
. In contrast, our approach retains
as a fixed nonzero parameter while incorporating a novel memorization mechanism applied to the new parameter
a at the conclusion of the first substep. This modification introduces an alternative acceleration strategy that differs fundamentally from the conventional adjustments made solely to
. We derive the following result:
By substituting the expression for
from (
28) into (
27), the following formulation can be obtained:
It is possible to notice that, in general, the error equation takes the form
, where the parameters
A and
r must be determined. Consequently, it follows that
, leading to the subsequent derivation:
From this, it is straightforward to obtain
where
C is a constant. This formulation ultimately leads to the equation
which admits the following two possible solutions:
. Evidently, the value
is the appropriate choice, establishing the R-order of convergence for the memory-based method (
24). This concludes the proof. □
The enhancement of the R-order is attained without introducing any additional functional evaluations, ensuring that the newly developed memory-based method maintains a high TEI. This approach extends the existing scheme (
16), effectively increasing the R-order from 4 to
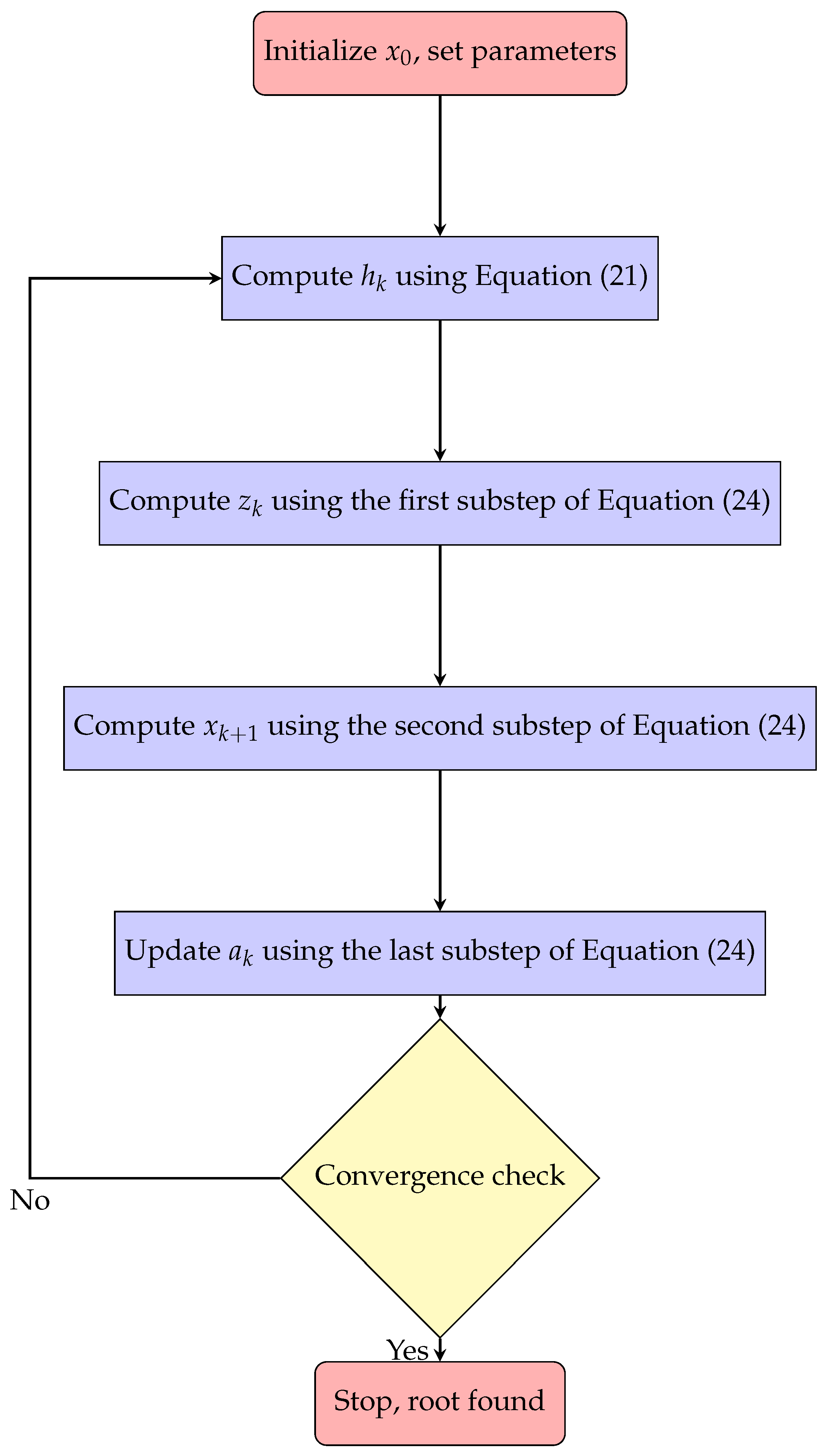
. The procedure of the proposed solver is provided in the Flowchart
Figure 1.
The proposed acceleration scheme (
24) is novel and effective, offering an improvement in the speed, while requiring no further functional evaluations. This advantage sets it apart from optimal two-step methods that lack memory.
Furthermore, it is worth mentioning that another formulation of the presented memory-based scheme can be derived by employing a backward finite difference approximation at the initial stage of the first substep, coupled with a slight modification in the acceleration parameters. In other words, we introduce an alternative memory-based approach (PM2) that preserves the R-order of
, which is formulated as follows (only
differs and Appr will not be changed compared to PM1):
Theorem 3. Consider a function that is adequately smooth in the vicinity of its simple zero, denoted by α. If a starting estimate is chosen such that it lies close enough to α, then the solver (33) incorporating memory exhibits an R-order of convergence of no less than 4.23607. Proof Since the proof follows the same reasoning as Theorem 2, it is omitted for brevity. □
From one perspective, since
is a parameter that can assume either a positive or negative sign, the order of convergence and the conditions required to achieve it remain identical, as established in Theorems 2 and 3. However, in practical computations, the choice of sign influences the magnitude of posterior error as well as round-off errors, which, in turn, may lead to variations in the final numerical results. These differences will be analyzed in
Section 4.
The extension of the proposed techniques to the broader context of solving nonlinear systems of equations
may be systematically achieved by incorporating the formal definition of divided difference operators (DDOs), thereby enabling the effective treatment of these operators in the following manner. Specifically, the first-order DDO of the vector-valued function
F, evaluated at the pair of points
x and
y, can be formulated in a component-wise fashion, described as follows:
The expression under consideration represents a bounded linear operator that fulfills the identity
. According to the result established by Potra [
31], a necessary and sufficient criterion exists for characterizing the divided difference operator through the framework of the Riemann integral; more specifically, if function
F adheres to the Lipschitz-type continuity condition
It is worth mentioning that the work in [
32] proposed a symmetric operator for the second-order DDO, albeit at a higher computational expense compared to the first-order DDO. Accordingly, it must be stated that the extension of the proposed solvers for a nonlinear system is inefficient due to the load of computing DDO matrices. Because of this, we restrict our investigation to the scalar case in which the proposed methods are efficient.
4. Computational Aspects
The computational efficacy of various iteration solvers, both with and without memory, could be systematically assessed by employing the definition of the TEI given in
Section 1. Based on this criterion, we obtain
We perform an evaluation and comparative analysis of different iterative schemes for determining the simple roots of several nonlinear test functions. These experiments are implemented in the Mathematica programming environment [
33], utilizing multiple-precision arithmetic with 5000-digit precision to accurately illustrate the high R-order exhibited by both PM1 and PM2. The comparison is conducted among methods that require the same number of functional evaluations per iterate.
In this section, the computational order of convergence is determined utilizing the following relation [
29,
34,
35]:
The obtained value provides a reliable estimation of the theoretical order of convergence, provided that the iterative method does not exhibit pathological behavior, such as slow convergence in the initial iterations or oscillatory behavior of approximations.
Finally, the pieces of evidence of numerical comparisons for the selected experiments are presented. These experiments were conducted using the stopping criterion set as . Additionally, a parameter was used when necessary to fine-tune the iterative process, especially in cases where small initial approximations were employed.
The selection of starting approximations is crucial for the convergence of iteration solvers. A non-iterative method via numerical integration, known as the numerical integration method, was introduced for finding initial approximations [
36]. This method uses sigmoid-like functions such as tanh and arctan to approximate the root without requiring derivative information.
Common criteria include checking the difference between successive approximations as follows:
or evaluating the function value at the following approximation:
These criteria ensure that the iterative process terminates when the desired accuracy is achieved or when further iterations are unlikely to improve the result.
Example 1. ([
37]).
We examine the nonlinear test within the domain belowutilizing an initial estimate of and . The associated observations are provided in Table 1. It is crucial to emphasize that when applying any root-finding algorithm exhibiting local convergence, the careful selection of starting approximations is of paramount significance. If the starting values lie sufficiently near to the desired zeros, the anticipated (analytical) convergence order is observed in practice. Conversely, when the starting approximations are distant from the actual roots, iterative methods tend to exhibit slower convergence, particularly in the early stages of the iterative process.
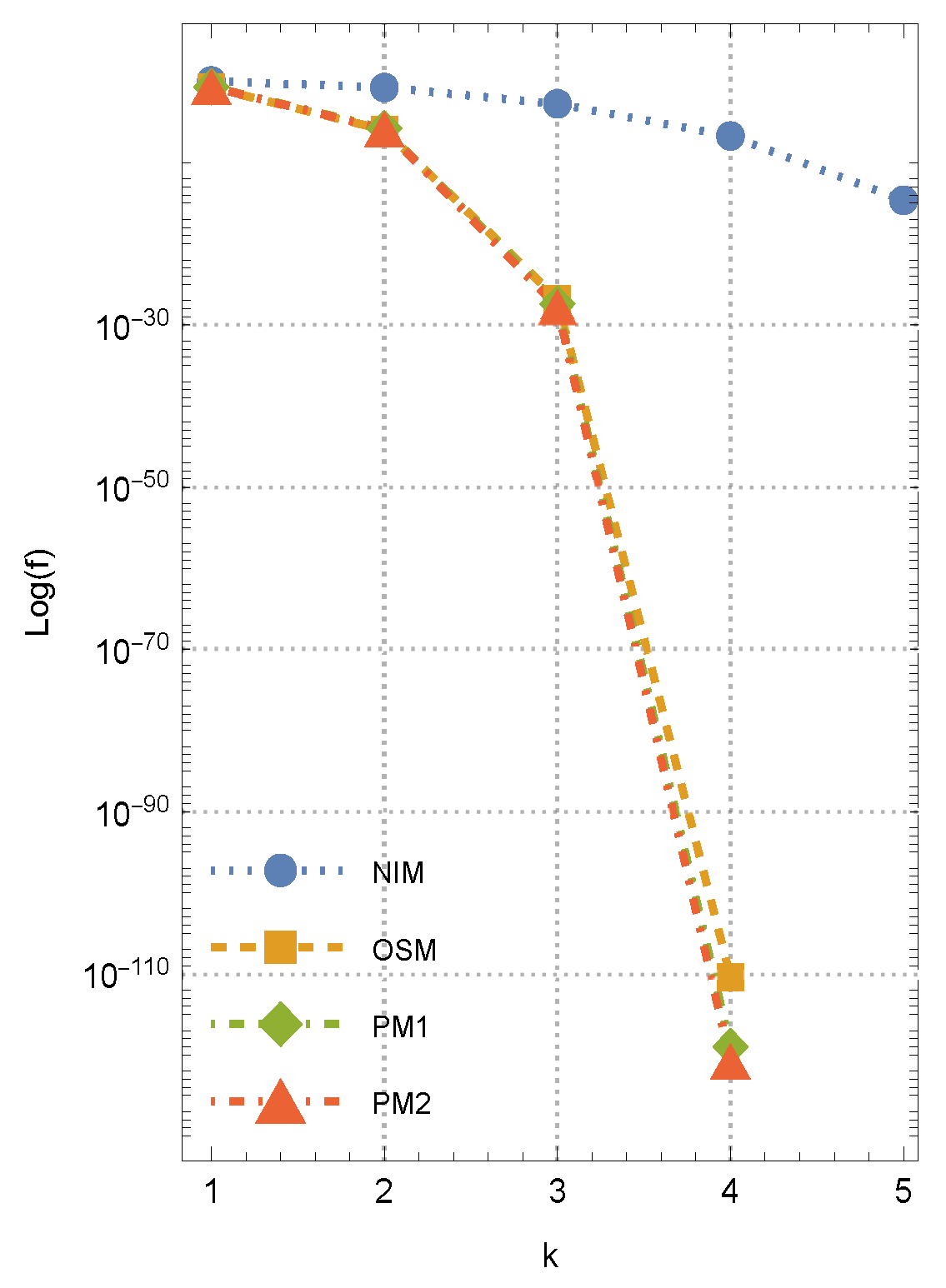
Example 2. Next, we analyze the performance of different iterative methods in determining the complex root of the nonlinear problemby initializing the procedure with , where the exact root is given by . The results for this scenario are presented in Table 2. A close inspection of
Table 1 and
Table 2 clearly demonstrates that the root approximations exhibit remarkable accuracy when the proposed memory-based method is employed. Furthermore, the values from the fourth and fifth iterations, as reported in
Table 1 and
Table 2, are included solely to illustrate the convergence speed of the evaluated solvers. In most practical applications, such additional iterations are generally unnecessary.
The numerical observations presented in
Table 1 and
Table 2 illustrate the convergence behavior of various iterative methods applied to solve nonlinear scalar equations. In Example 1, the methods were tested on the function
within the domain
, with a starting guess
. The obtained results demonstrate that the OSM, the PM1, and the PM2 exhibit significantly faster convergence rates compared to the NIM. Specifically, OSM, PM1, and PM2 attain highly accurate solutions within just five iterations, with residual function values decreasing to approximately
,
, and
, respectively. Additionally, the convergence factor
confirms the expected order of convergence, where NIM converges quadratically (
), while OSM, PM1, and PM2 attain higher convergence rates. The higher accuracy of PM1 and PM2 compared to OSM suggests the effectiveness of approximations in accelerating convergence.
For the complex-valued nonlinear Equation
analyzed in Example 2, a similar pattern emerges. The iterative methods were initialized at
, targeting the exact complex root
. The numerical findings in
Table 2 further confirm the superiority of higher-order methods over NIM. OSM, PM1, and PM2 exhibit remarkably small residual function values in just five iterations, dropping to approximately
,
, and
, respectively. Again, the order of convergence values,
for OSM and
for PM1 and PM2, validate the high efficiency of these methods. Notably, while NIM requires more iterations to reach a reasonable accuracy, the new approaches maintain their superior convergence behavior, reinforcing their practical utility in solving nonlinear problems with complex roots. For Example 2, we provide
Figure 2, which shows the history of convergence for another initial approximation through the comparison of different methods.
A value for parameter beta has been selected for numerical testing and it is better to choose a small value in order to lead to larger attraction basins. However, based on the structure of either PM1 or PM2, memorization has been done only on , which means that there is no adaptation or acceleration based on . This is because in , there is a power of three for .
Moreover, the developed memory-based approaches (
24) and (
33) have been applied to a range of test problems, consistently yielding results that align with the aforementioned observations. Consequently, we can assert that the theoretical findings are well supported by numerical tests, thereby affirming the robustness and high computational efficiency of the proposed method.
5. Conclusions
Classical iteration solvers, such as Newton’s scheme, are widely employed due to their quadratic convergence properties; however, their efficiency can be further enhanced by incorporating memory, which exploits previously computed information to accelerate convergence without increasing the number of function evaluations. In this article, we have introduced a scheme with memory. The construction of this method leverages the existing framework of Newton’s method while incorporating memory to improve the convergence properties. Theoretical analysis confirms that the presented scheme achieves a higher R-order of convergence compared to the original two-point solver, without increasing the computational cost in terms of functional evaluations. Numerical experiments further validate the efficiency and robustness of the method, demonstrating its superiority in terms of convergence speed and accuracy.
The success of the proposed solver with memory provides some avenues for future works. Firstly, the extension of this approach to other families of iteration solvers, such as Halley’s or Chebyshev’s schemes, could be explored to further enhance their convergence properties. Secondly, the application of the method with memory to systems of nonlinear equations is a promising direction. Additionally, the development of hybrid methods that combine memory-based techniques with other acceleration strategies, such as weight functions or parameter optimization, could lead to even more efficient algorithms.





{kind=link}
{kind=link}