Abstract
In recent decades, the study of discrete distributions has received increasing attention in the field of statistics, mainly because discrete distributions can model a wide range of count data. One common distribution used for modeling count data, for instance, is the negative binomial distribution (NBD), which performs well with over-dispersed data. In this paper, a new count distribution is introduced, called the conflation of negative binomial and logarithmic distributions, which is formed by conflating the negative binomial and logarithmic distributions, resulting in a distribution that possesses some of the properties of negative binomial and logarithmic distributions. The distribution has two parameters and is verified by a positive integer. Two modifications are proposed to the distribution, which includes zero as a support point. The new distribution is valuable from a theoretical perspective since it is a member of the weighted negative binomial distribution family. In addition, the distribution differs from the NBD in the sense that the probability of lower counts is inflated. This study discusses the characteristics of the proposed distribution and its modified versions, such as moments, probability generating functions, likelihood stochastic ordering, log-concavity, and unimodality properties. Real-world data are used to evaluate the performance of the proposed models against other models. All computations shown in this paper were produced using the R programming language.
Keywords:
conflation distributions; weighted distribution; shifted distribution; negative binomial distribution; logarithmic distribution; discrete distributions; dispersion index; likelihood ratio stochastic order; log-concavity; unimodality MSC:
60E05; 62F10; 65C20
1. Introduction
The analysis and modeling of count data have received significant attention in recent decades, with a particular emphasis being placed on the development of discrete distributions. A widely used model for the analysis and modeling of count data is the Poisson distribution (PD). The important condition for the PD is an equal dispersion of count data. The equal dispersion can be evaluated using a statistical measure known as an index of dispersion (ID). The ID defines the quantity of variability in a distribution. The definition of the ID is given below:
Definition 1.
The index of dispersion of a distribution, denoted as ID, can be defined as follows:
where Var(Y) and μ are the variance and the mean of Y, respectively. The ID implies the following:
- If , then it is over-dispersion.
- If , then it is under-dispersion.
- If , then it is equal dispersion.
For more details, see [1].
However, this condition is rarely observed in practical scenarios. Count data often show over-dispersion, thereby requiring an investigation of modeling alternatives, which provide greater flexibility than the PD. The negative binomial distribution (NBD) is a frequently employed alternative distribution for modeling count data, particularly for data that show over-dispersion. The NBD is extensively employed in the modeling of diverse datasets, including biological, medical sciences, accident statistics, social sciences, economics, quality control, ecology, and so forth. The study [2] outlines the NBD as a mixture of PDs, and the mean of the PD is a random variable following a gamma distribution. The probability mass function (pmf) of the NBD is denoted as follows:
For more details about the NBD and its properties, see [1].
Furthermore, count data frequently display an excess of zeros and heterogeneity in variance, making traditional statistical distributions insufficient for modeling purposes. Nevertheless, the NBD is frequently favored over the PD because of its ability to provide increased flexibility in modeling data that appear over-dispersed, as previously indicated. Many studies have developed alternative models to deal with the presence of excess zeros and variability in the dataset. For example, zero-inflated models, hurdle models, or finite mixture models have been proposed in order to more efficiently deal with this issue. In addition, the mixing of PD or NBD with a lifetime distribution is frequently employed for the same issue. For example, numerous research studies have demonstrated that the mixed negative binomial distribution offers a superior fit for count data in comparison to the PD and NBD. Moreover, weighted distributions are used to solve the problem by multiplying count distributions with weight functions, as developed in [3,4]. Since then, the concept of weighted distributions has established itself in the literature as a powerful tool for modeling. By allowing us to adjust probabilities based on specific weights assigned to each outcome, weighted distributions provide a flexible framework that enhances our ability to accurately represent and analyze complex real-world phenomena. This adaptability has made weighted distributions invaluable in various fields such as statistics, biostatistics, biomedicine, ecology, survival data analysis, meta-analysis, and intervention data analysis. For discrete distributions, the weighted distribution is defined as follows:
Definition 2.
Let X be a random variable with pmf and let be a non-negative weighting function such that exists and is finite. Then, the pmf is defined as follows:
is a weighted distribution of .
For more information on weighted distributions for discrete random variables, refer to the work [1] on the subject. For example, the modified negative binomial distribution in [5] can be viewed as a weighted geometric distribution.
Although the standard distributions possess attractive characteristics, they do not provide the best fit for real-world data that have deviations. The source of deviations can be either inflation in low counts or high dispersion. Hence, there is a need to develop new distributions that demonstrate superior performance. In this study, we employ the idea of conflation as a tool to cope with the presence of excess zeros or generally low counts and over-dispersed data. The concept of the conflation of probability distributions is presented by [6] and defined as follows:
Definition 3.
If are pmfs, then the corresponding conflated distribution is
where A is the intersection of the supports of all the distributions. In terms of random variables, if are independent with pmfs , respectively, then
Ref. [6] presented conflation as a method for consolidating data from several independent experiments, all of which were designed to measure the same unknown quantity. In other words, distribution conflation is a distribution that inherits some properties from its components. For , Equation (1) can be viewed as a weighted distribution, where one mass function is the parent distribution and the other one is a weight function. In this sense, the conflation distributions are weighted distributions. Hence, one may use conflation methods to model data with a high excess of low counts and over-dispersion by conflating a distribution with a decreasing mass function with an over-dispersed distribution.
As a result, we introduce a new distribution by combining the NBD and the logarithmic distribution (LD) into a single distribution that reflects the common information between them with minimal loss of information. The pmf of the LD is given by:
For more details about the logarithmic distribution and its properties, see [1].
The new distribution is called the conflation of negative binomial and logarithmic distributions (CNBLD). The LD has a decreasing pmf, hence it is capable of modeling data with a high frequency for low counts while the NBD is over-dispersed; therefore, their conflation is expected to handle data expressing high excesses of low counts and over-dispersion. The LD does not support zero, hence the CNBLD inherits this property, which limits the applications of the CNBLD to positive count data. To overcome this problem, the study also presents two modifications of the CNBLD. The first modification shifts the CNBLD one position to the left, resulting in the shifted CNBLD that is denoted as SCNBLD. The SCNBLD retains the flexibility of the CNBLD but extends its support to zero values. The second modification conflates a shifted logarithmic distribution with the NBD, resulting in the conflation of a negative binomial shift logarithmic distribution (CNBSLD). The CNBSLD also aims to combine the features of both distributions to provide flexibility and the ability to model a wider range of data.
The structure of this paper is organized as follows: Section 2 presents the definitions and discusses the graphical representations of the proposed models; Section 3 describes some of the statistical properties of the proposed models, such as moments, log-concavity, index of dispersion, and likelihood ratio stochastic order; Section 4 discusses the estimation of the parameters using the method of moments and the maximum likelihood method and evaluates the accuracy of these estimates by a simulation study; Section 5 outlines the usefulness of the new distribution across several fields, showing its superior performance compared to the existing modified negative binomial distributions employed to fit similar data; finally, Section 6 presents a conclusion.
2. Conflation of Negative Binomial and Logarithmic Distributions
In this section, the conflation of negative binomial logarithmic distributions (CNBLD), and the developed versions of the CNBLD are introduced. The developed versions of the CNBLD are named as follows: shifted conflation of negative binomial logarithmic distributions (SCNBLD) and conflation of negative binomial weighted by shift logarithmic distribution (CNBSLD). This section outlines the , the cumulative distribution functions (), which are denoted as , the survival functions (), which are denoted as (, and the hazard rate functions (h) of the CNBLD, SCNBLD, and CNBSLD.
Definition 4.
The random variable Y is said to follow the CNBLD with parameters and if its is given as follows:
Here, is the normalizing constant that can be expressed as follows:
where is the Pochhammer symbol, and is a generalized hypergeometric function; for more details, see [1,7].
The generalized hypergeometric function is available in popular programming packages such as R, Mathematica, MATLAB, Python, and others. In this paper, we used the genhypergeo(.) function from the hypergeo package in R.
In comparison with (1), in terms of random variables, if X and Z are independent random variables with X following an NBD and Z following an LD, then . In the special case when , the CNBLD reduces to the LD.
Remark 1.
It should be noted that according to Definition 4, the CNBLD is a weighted negative binomial distribution with an LD as the weight function. In addition, the CNBLD can be considered as a weighted logarithmic distribution with an NBD as the weighting function.
Next, the of the CNBLD are visualized for different values of parameters , 0.5, and and , and 8 in Figure 1. The parameter has an impact on the dispersion of the distribution, while the parameter r is mainly responsible for the shape of the CNBLD. In general, the shape of the s of the CNBLD is skewed to the right; however, with an increase in the value of r and , the distribution becomes less skewed and displays more symmetry. On the other hand, for smaller values of and r, the pmf of the CNBLD is a decreasing function with a high probability for low y values. However, as and r increase, the function’s behavior shifts, initially rising to a peak before decreasing. This change illustrates how larger parameters introduce greater variability into the distribution.

Figure 1.
The s of the CNBLD for different values of and r.
The , , and h of the CNBLD, respectively, are as follows:
We have
where
Thus, according to , the can be given as follows:
Using the definition of the , the can be defined as follows:
Further, the h of the CNBLD can be calculated as follows:
Most real-life count data have zero as a possible value. Therefore, the current study developed the CNBLD using two methods for this purpose. The first method was the obvious one which shifted the CNBLD by one to the left. The second method shifted the LD conflated with the NBD. Therefore, we obtained the following two definitions:
Definition 5.
The random variable Y is said to follow the SCNBLD with parameters and , if its is given by the following:
Consequently, we obtain the , the , and the h functions of the SCNBLD, respectively, as follows:
Definition 6.
The random variable Y is said to follow the CNBSLD with parameters and if its is given as follows:
Remark 2.
Note that the CNBSLD is a shifted LD for and a geometric distribution for , and hence the CNBSLD can be considered as an extension of the two distributions.
The following theorem can be used to derive the CNBSLD.
Theorem 1.
If X and Z are independent random variables following an NBD with parameters and and a shifted logarithmic distribution with parameter , then
where
Proof.
The proof can be obtained directly by calculating the conditional probability. □
The , , and the h of the CNBSLD are, respectively:
Here, is the Gaussian hypergeometric function (see [1,7] for more information). It is possible to calculate the of the CNBSLD as follows:
where
Thus, according to , the can be given as follows:
Using the definition of the , the can be defined as follows:
Further, the h of the CNBSLD can be calculated as follows:
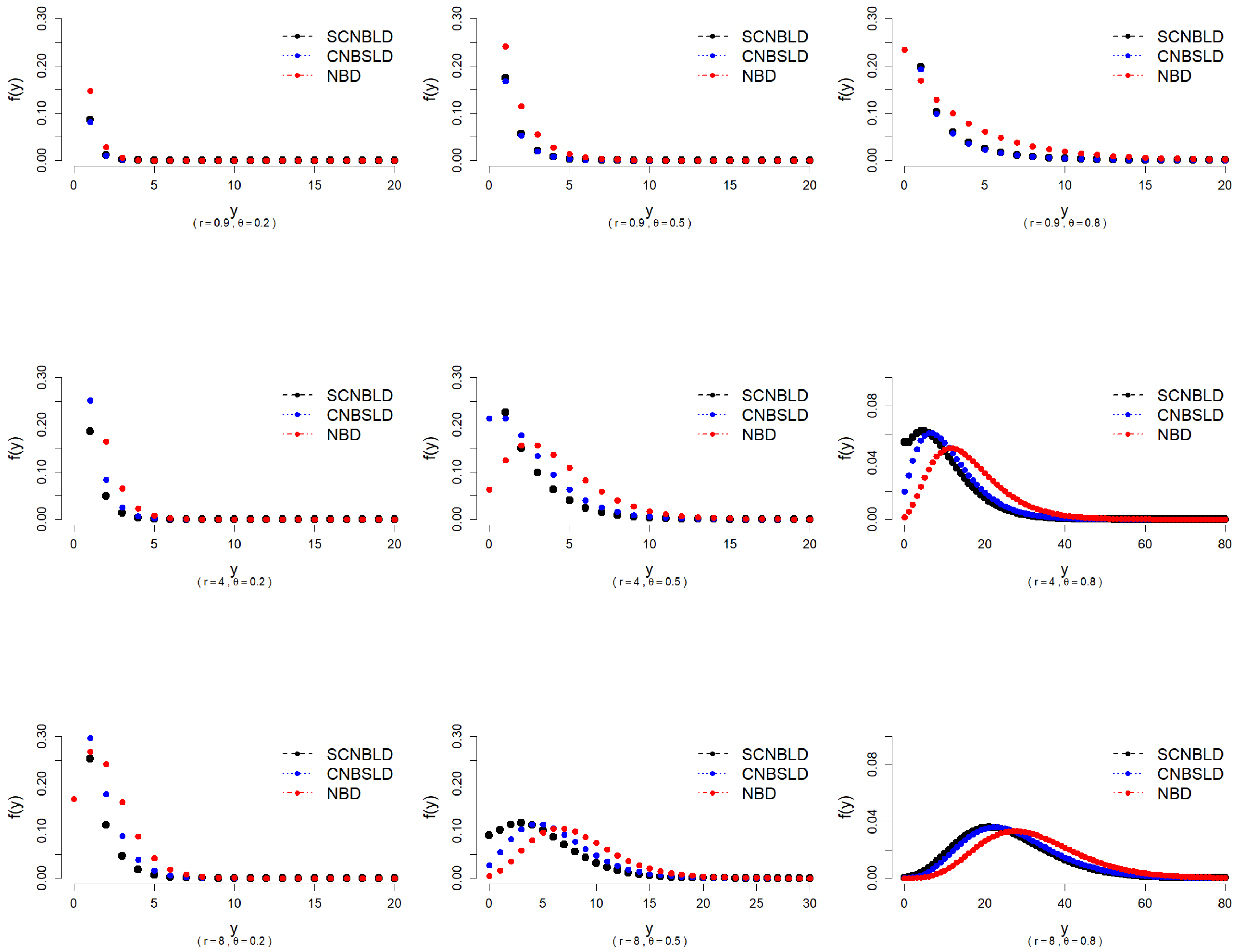
A comparison between the SCNBLD, the CNBSLD, and the NBD can be made by looking at the s for different values of and r. Figure 2 shows the for , and 8 with , and . The shape of all distributions is skewed to the right but tends to be symmetric for large and r. The difference between the distributions decreases significantly as and r increase, and the distributions behave more similarly. The appears identical for relatively large y, depending on the value of r in all plots with small probabilities of all distributions. For example, the s of all distributions are the same after when and . In general, as the value of r increases, the value of y at which the is constant increases. The plots show that both r and have a clear influence on the behavior of the different distributions.
Figure 2.
The s of the SCNBLD, the CNBSLD, and the NBD for different values of and r.
3. Some Statistical Properties
In this section, we examine several useful statistical properties of the CNBLD, SCNBLD, and CNBSLD. These include deriving the mean, variance, and probability generating functions for each distribution. In addition, we calculate the index of dispersion (ID) for the CNBLD, SCNBLD, and CNBSLD, which provides information about the variability relative to their means. Furthermore, we discuss the likelihood ratio stochastic order and log-concavity property for the new distributions. The likelihood ratio stochastic order study is extended to the NBD to provide a more comprehensive understanding of the relative behaviors and properties of these distributions.
3.1. Moments and Probability Generating Functions
The statistical results for the moment and probability generating functions associated with the CNBLD are reviewed below.
The mean, the variance, and the probability generating function for the CNBLD are given as follows:
The formulas above can be given as follows:
For the variance, the second moment can be expressed as follows:
Hence, the variance can be shown to be as follows:
The form of the probability generating function becomes obvious from the of the CNBLD.
The following introduces the moments and probability generating function related to the SCNBLD.
The results can be obtained from the fact that , where Y follows a CNBLD.
Finally, the moments and probability generating function of the CNBSLD are as follows:
The mean, the variance, and the probability generating function for the CNBSLD can be given as follows:
They can be obtained as follows:
Hence,
For the variance, we obtain the following:
Hence, the variance is
The form of the probability generating function becomes obvious from the shape of the of the CNBSLD.
3.2. Index of Dispersion
In this subsection, we introduce the ID of the NBD, SCNBLD, and CNBSLD that are denoted as , , and , respectively, for different values of r and . The , , and for different values of and r are calculated in Table 1. Since and have complicated mathematical formulas, the IDs are calculated for selected values of r and .

Table 1.
The index of dispersion for the NBD, SCNBLD, and CNBSLD for different values of r and .
- is given by . This implies that as increases, increases, indicating higher dispersion with higher .
- For SCNBLD and CNBSLD, as increases, and increase. This means that for a fixed r, the dispersion increases as increases.
- For SCNBLD and CNBSLD, as r increases, and also increase. This suggests that for a fixed , the dispersion increases as r increases.
- If , then ; as a result, the SCNBLD is more suitable for data with greater dispersion. This suggests that the value of r determines the interchangeability of the two distributions.
3.3. Log-Concavity Property
Log-concave probability distributions are essential in various areas, including reliability theory, labor economics, monopoly theory, mechanism design theory, political science, and law. Refer to [8] for additional information.
Definition 7.
A discrete random variable X is log-concave if for all x.
Theorem 2.
The pmf of the CNBLD is log-concave for and log-convex for .
Proof.
For , we have
Using the property that , we can obtain:
As a result, we observe that shows an increase in r for . Therefore, implies for any y, but if and only if . Equivalently, this is true if and only if . Thus, indicates that is log-concave when .
For , , resulting in
This completes the proof. □
The CNBLD offers a flexible alternative to the NBD, with properties that depend on the parameter r. While the NBD is log-concave and unimodal for and log-convex for , the CNBLD has similar properties, but with different transition points: it is log-concave and unimodal when and log-convex when . Moreover, the transition from log-convex to log-concave in the CNBLD is gradual as r increases from 2 to 7, which improves its ability to model more diverse and precise datasets. This flexibility makes the CNBLD particularly well suited for developing precise statistical models that better fit the unique characteristics of the data and allow for a more effective analysis and interpretation compared to the NBD.
Remark 3.
Using a similar argument, we can conclude that if and only if . Thus, for , the pmf of the CNBLD is log-concave on the set . The transition from log-convexity to log-concavity occurs gradually as r rises from 2 to 7.
Remark 4.
The SCNBLD is log-convex for and log-concave for , in contrast to the NBD, which is log-convex for and log-concave for . This is because log-concavity does not change with shifting.
Theorem 3.
The CNBSLD is log-convex for and log-concave for .
Proof.
The conclusion is derived from the log-concavity of the NBD, which remains unchanged by truncation and shifting. □
3.4. Likelihood Ratio Stochastic Order
The likelihood ratio stochastic ordering provides a powerful method for comparing distributions, regardless of whether they belong to the same family with different parameters or are of completely different types. We can determine the ordering relationship between random variables by analyzing the likelihood ratio, which gives us insights into their probabilistic behavior and trends. In this section, we discuss the likelihood ratio stochastic ordering for our new distributions. We also extend this discussion to compare the likelihood ratio stochastic ordering for our new distributions with the NBD.
First, we introduce the definition of the likelihood ratio stochastic order used in this subsection.
Definition 8.
Let and be two discrete random variables with pmfs and , respectively. We say that is smaller than in the likelihood ratio stochastic order (denoted by if the ratio is non-decreasing in y over the union of the supports of and .
The likelihood ratio stochastic order is very strong; it implies the hazard stochastic order and other stochastic orders. For more details on the implications and applications of stochastic ordering, see [9]. In this subsection, we refer to the CNBLD with parameters and r as CNBLD(r,).
Theorem 4.
Let and be two random variables following CNBLD (,r) and CNBLD(,r), respectively. If , then .
Proof.
Let be the of the CNBLD (, r). Then, we obtain the following:
Here, . Since the ratio increases in y if and only if , this implies . □
Remark 5.
For the SCNBLD and the CNBSLD, the following implications hold:
- If and are two random variables following SCNBLD(, r) and SCNBLD(, r), respectively, such that , then .
- If and are two random variables following CNBSLD(, r) and CNBSLD(, r), respectively, such that , then .
Proof.
The proof is similar to the proof of Theorem 4. □
Theorem 5.
Let and be two random variables following CNBLD(θ,) and CNBLD(θ,), respectively. If , then .
Proof.
Let be the of CNBLD(, r). Then, we obtain the following:
Here . Since, the ratio increases in y if and only if , this implies . □
Remark 6.
For the SCNBLD and the CNBSLD, the following implications hold:
- If and are two random variables following SCNBLD(θ, ) and SCNBLD(θ, ), respectively, such that , then .
- If and are two random variables following CNBSLD(θ, ) and CNBSLD(θ, ), respectively, such that , then .
Proof.
The proof is similar to the proof of Theorem 5. □
Corollary 1.
Let be a random variable from CNBLD. If , and , then we conclude from Theorems 4 and 5 the following:
Hence, the following is given:
Theorem 6.
Let , and be three random variables following SCNBLD, CSNBLD and NBD, respectively. Then, .
Proof.
To prove that , we examine the following ratio:
where . We observe that the term is an increasing function of y when . Therefore, .
Similarly, we need to examine the following ratio:
Here, . We observe that the term is an increasing function of y. Hence, .
Since we have showed that and , we conclude that . This means that in the likelihood ratio stochastic order, is stochastically larger than , and is stochastically larger than .
In various fields such as economics, insurance, and risk management, the stochastic order of the likelihood ratio is concerned with risk analysis and decision-making by identifying which distributions are more or less likely to produce large values. □
4. Estimation and Simulation Study
This section examines the estimation of CNBLD and CNBSLD parameters using the method of moment (MM) and the maximum likelihood (ML) method. Two scenarios were investigated: one where r was known, and another where r was unknown. In all scenarios, it was assumed that represented a random sample drawn from the distribution under study. Furthermore, simulation studies were employed to assess the efficiency of the estimates delivered by the proposed methods.
4.1. Parameter Estimation of the CNBLD
4.1.1. Case 1: r Is Known
Here, we had only one parameter to estimate using the MM as follows:
Or equivalently, this can be achieved as follows:
Using the ML method, the likelihood function can be given as follows:
Further, the log-likelihood function from Equation (3) above is given as follows:
The ML estimate of is the solution of the equation . Now, since , we have:
which is the same as Equation (2). Thus, if r is known, the ML estimate of is the same as that of the MM estimate.
4.1.2. Case 2: r Is Unknown
To obtain the MM estimates of and r, the following equations were used:
and
Or equivalently, the following could be used:
and
Numerical solutions for Equations (5) and (6) are not achievable using algebraic methods. Therefore, the equations were solved using the “nleqslv” function from the “nleqslv” package in the R programming language, which gave the MM estimate of r and .
Using the ML method, the likelihood function as defined in Equation (3) were used to determine the ML estimates for the unknown parameters r and as the solutions of the likelihood equations as the following:
These two equations must be solved numerically to determine the MLEs of the parameters and r. Since the generalized hypergeometric function makes the system of equations complex, numerical methods are generally used to obtain the solutions.
4.2. Simulation Study for the CNBLD
To evaluate the methods of estimation, we performed the following simulations as outlined below:
4.2.1. Case 1: r Is Known
In this simulation study, we considered the values and 10 and and . The simulation algorithm consisted of the following steps:
| Algorithm 1: Simulation algorithm wher r is known |
|
- Simulation and concluding results:
Table 2.
The ML results of the CNBLD for different values of when .
Table 3.
The ML results of the CNBLD for different values of when .
Table 4.
The ML results of the CNBLD for different values of when .
- The MSE of decreases along with an increase in n, and thus the estimator of is consistent.
- The |SBias| decreases as increases.
4.2.2. Case 2: r Is Unknown
Numerical solutions were used to obtain the parameter estimates of and r, when r was unknown. In that scenario, we considered and 8 and , and . The simulation algorithm involved the following steps:
| Algorithm 2: Simulation algorithm wher r is unknown |
|
- Simulation and concluding results:
Table 5.
The MM and ML results for the CNBLD for different values of and r.
- For MM and ML estimates, the MSE of r and decrease as n increases.
- For a large n, both the ML and MM estimates are good, but for a small n, the ML estimate is better than the MM estimate according to small values of the SBias for ML estimates.
4.3. Parameter Estimation of the CNBSLD
In this subsection, estimation methods and simulation study were conducted to assess the performance of the CNBSLD as follows:
4.3.1. Case 1: r Is Known
Here, we had only one parameter to estimate using the MM. It was obtained by the following equation:
Or equivalently, this could be achieved with the following:
Using the ML method, the likelihood function can be given as follows:
Simplified, the likelihood function becomes:
Further, the log-likelihood function from Equation (7) above is given as follows:
The ML estimate of is the solution of the equation . Then,
4.3.2. Case 2: r Is Unknown
To obtain the MM estimates of and r, the following equations were used:
and
Or equivalently, the following could be used:
and
Numerical solutions for Equations (8) and (9) are not achievable using algebraic methods. Therefore, the equations were solved numerically, which gave the MM estimate of r and .
Using the ML method, the likelihood function as defined in Equation (7) were used to determine the ML estimates for the unknown parameters r and as the solutions of the likelihood equations as the following:
These two equations must be solved simultaneously to determine the MLEs of the parameters and r.
4.4. Simulation Study for the CNBSLD
To evaluate the methods of estimation, we performed the following simulations as outlined below:
4.4.1. Case 1: r Is Known
In this simulation study, Algorithm 1 of the simulation outlined in Section 4.2.1 was implemented with the exception of the following:
- In step 3, was the of the CNBSLD.
- In step 2, the likelihood function employed was represented by Equation (7).
- Simulation and concluding results:
Table 6.
The ML estimates of the CNBSLD for different values of when .
Table 7.
The ML estimates of the CNBSLD for different values of when .
Table 8.
The ML estimates of the CNBSLD for different values of when .
- The MSE decreases along with an increase in n.
- The |SBias| decrease as n increases.
- Both|SBias| and MSE show that or more is required to accurately estimate .
4.4.2. Case 2: r Is Unknown
In this case, a similar strategy and the steps of Algorithm 2 of the simulation outlined in Section 4.2.2 were followed, with the exception of the following:
- In step 1, random samples were generated from the CNBSLD.
- In step 3, Equation (7) was solved numerically to obtain the ML estimates of and r.
- Simulation and concluding results:
The simulation results are shown in Table 9 below.
Table 9.
The MM and ML for the CNBSLD for different values of and r.
From Table 9, one can conclude the following:
- For the MM estimate, the MSE of r and decreases as n increases.
- For the ML estimate, the MSE of r and decreases as n increases.
- For a large n, both the ML and MM estimates are good, but for a small n, the ML estimate is better than the MM estimate according to the |SBias|.
5. Applications
In this section, the effectiveness of the CNBLD, SCNBLD, and CNBSLD is evaluated using real datasets and compared with other existing distributions. The parameter estimates for these distributions were obtained using the ML method. The tools of comparison used were the Akaike information criterion (AIC) and the Bayesian information criterion (BIC). In general, the smaller the values of these statistics, the better the fit to the data. The calculations were performed using the R programming language.
5.1. The Number of Eggs per Flower Head
According to [10], the zero-truncated Poisson–Lindley distribution (ZTPLD) provides a better fit for data relating to the number of eggs per flower head, shown in Table 10, compared to the zero-truncated PD (ZTPD). The study [11] proposes the application of the ZTPD to the dataset.
Table 10.
Number of counts of flower heads as per the number of fly eggs.
Application and Concluding Results
The calculated values for the mean, variance, and dispersion index were , , and , respectively. These values indicated the presence of over-dispersion. In Table 10, when comparing the observed frequencies of the ZTPLD and CNBLD, we noticed that the LD had an impact on the CNBLD by gradually raising the probability of small values of Y. On the other hand, the truncated zero effect on the ZTPLD just increased its probability at zero. Table 10 clearly shows that the CNBLD model provided a superior fit to the data with lower AIC and BIC values.
5.2. The Number of Hospital Stays by United States Residents Aged 66 and Over
These data cover the number of hospitalizations of United States residents aged 66 and up, as reported by [12]. This dataset had 80.37% zeros with a sample ID of . These characteristics showed over-dispersion and a high number of zero counts. The zero-inflated negative binomial-generalized exponential (ZINB-GE) distribution was used on the same dataset as in the analysis of [13]. The ZINB-GE distribution outperformed the zero-inflated Poisson distribution (ZIPD) and the zero-inflated negative binomial distribution (ZINBD) in terms of data fit.
Application and Concluding Results
Table 11 shows that the SCNBLD and CNBSLD models suited the data well. These models outperformed the ZINB-GE model based on the lower AIC and BIC values, indicating they could handle over-dispersion and significant numbers of zero counts in the dataset. As a result, the SCNBLD and CNBSLD models are most suited for modeling hospitalizations of United States residents aged 66 and older.
Table 11.
Number of hospital stays by United States residents aged 66 and over.
5.3. Accident Frequency Data among Machinists
In this subsection, the data concerning the frequency of accidents among 414 machinists originated from a study conducted towards the end of World War I. This study was performed by the Industrial Fatigue Research Board and was documented in a report published in [14]. The data covered a three-month period and were designed to assess the frequency of industrial accidents, particularly in environments with heavy machinery; they were used in [2].
Application and Concluding Results
The values for the mean, variance, and dispersion index were , , and , respectively. Based on Table 12, the SCNBLD and CNBSLD models were considered the best fit for these data as they had the lowest AIC and BIC values.
Table 12.
Accident frequency among 414 machinists: a statistical count over an undefined period.
6. Conclusions
This study presented a novel distribution by employing the concept of conflating probability distributions, specifically combining the NBD and the LD into a single distribution that captured their shared information with minimal loss. The newly introduced distribution was referred to as the conflation of negative binomial and logarithmic distributions (CNBLD). The CNBLD is capable of modeling positive count data from the LD, but it does not take into consideration zero values, unlike the NBD. In order to overcome this constraint, two novel modified models were introduced. The first model was the SCNBLD, which was obtained by shifting the CNBLD one position to the left. The second model was the combination of the negative binomial and shifted logarithmic distributions (CNBSLD), which merged a shifted logarithmic distribution with the NBD to incorporate the characteristics of both distributions. These two distributions provided increased flexibility and the capacity to model a wider range of data. An investigation was conducted to examine the valuable statistical characteristics of the CNBLD, SCNBLD, and CNBSLD. In addition, we studied the estimation of the CNBLD and CNBSLD parameters using the methods of MM and ML. The efficiency of the estimations given by these methods was assessed by simulation studies. The simulation results demonstrated that both the ML and MM estimates exhibited consistency. The efficacy of these models was assessed by testing them against diverse distributions using real data. The new distributions exhibited superior performance in accurately fitting the data when compared to other models. Finally, despite the fact that we used these new models on particular datasets, we were able to expand their suitability and employ them in various study domains, demonstrating their potential as a proficient substitute for modeling count data.
Author Contributions
Conceptualization, A.A.A. (Abdulhamid A. Alzaid) and A.A.A. (Anfal A. Alqefari); methodology, A.A.A. (Abdulhamid A. Alzaid), A.A.A. (Anfal A. Alqefari) and N.Q.; validation, A.A.A. (Abdulhamid A. Alzaid), A.A.A. (Anfal A. Alqefari), and N.Q.; writing—original draft preparation, A.A.A. (Anfal A. Alqefari); writing—review and editing, A.A.A. (Abdulhamid A. Alzaid), A.A.A. (Anfal A. Alqefari), and N.Q.; visualization, A.A.A. (Anfal A. Alqefari) and N.Q.; funding acquisition, N.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R376), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Data Availability Statement
We used of publicly available data.
Acknowledgments
The authors gratefully acknowledge Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R376), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia for the financial support for this project.
Conflicts of Interest
The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Johnson, N.L.; Kemp, A.W.; Kotz, S. Univariate Discrete Distributions; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Greenwood, M.; Yule, G.U. An inquiry into the nature of frequency distributions representative of multiple happenings with particular reference to the occurrence of multiple attacks of disease or of repeated accidents. J. R. Stat. Soc. 1920, 83, 255–279. [Google Scholar] [CrossRef]
- Fisher, R.A. The effect of methods of ascertainment upon the estimation of frequencies. Ann. Eugen. 1934, 6, 13–25. [Google Scholar] [CrossRef]
- Rao, C.R. On discrete distributions arising out of methods of ascertainment. Sankhyā Indian J. Stat. Ser. A 1965, 27, 311–324. [Google Scholar]
- Barmalzan, G.; Saboori, H.; Kosari, S. A Modified Negative Binomial Distribution: Properties, Overdispersion and Underdispersion. J. Stat. Theory Appl. 2019, 18, 343–350. [Google Scholar] [CrossRef]
- Hill, T. Conflations of probability distributions. Trans. Am. Math. Soc. 2011, 363, 3351–3372. [Google Scholar] [CrossRef]
- Abramowitz, M.; A., S.I. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables; US Government Printing Office: Washington, DC, USA, 1968.
- Bagnoli, M.; Bergstrom, T. Log-concave probability and its applications. In Rationality and Equilibrium: A Symposium in Honor of Marcel K. Richter; Springer: New York, NY, USA, 2006; pp. 217–241. [Google Scholar]
- Shaked, M.; Shanthikumar, J.G. Stochastic Orders; Series in Statistics; Springer: New York, NY, USA, 2007. [Google Scholar]
- Shanker, R.; Hagos, F.; Sujatha, S.; Abrehe, Y. On zero-truncation of Poisson and Poisson-Lindley distributions and their applications. Biom. Biostat. Int. J. 2015, 2, 168–181. [Google Scholar] [CrossRef]
- Finney, D.; Varley, G. An example of the truncated Poisson distribution. Biometrics 1955, 11, 387–394. [Google Scholar] [CrossRef]
- Flynn, M.; Francis, L.A. More flexible GLMs zero-inflated models and hybrid models. Casualty Actuar. Soc. 2009, 2009, 148–224. [Google Scholar]
- Aryuyuen, S.; Bodhisuwan, W.; Supapakorn, T. Zero inflated negative binomial-generalized exponential distribution and its applications. Songklanakarin J. Sci. Technol. 2014, 36, 483–491. [Google Scholar]
- Greenwood, M.; Woods, H.M. The Incidence of Industrial Accidents upon Individuals: With Special Reference to Multiple Accidents; HM Stationery Office: London, UK, 1919. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).