1. Introduction
In modern healthcare, the accurate diagnosis of diseases holds paramount significance. Timely and precise identification of medical conditions is pivotal for effective treatment and essential for mitigating their potentially dire consequences. In recent years, the incorporation of artificial intelligence (AI) into medical diagnostics has emerged as a transformative force, offering innovative approaches to disease classification and detection, allowing health experts more tools to provide a correct diagnosis. Artificial intelligence represents a powerful ally in pursuing more accurate and efficient disease diagnosis with its capacity to analyze extensive datasets, discern patterns, and adapt to evolving scenarios. Machine learning algorithms have demonstrated remarkable proficiency in the early detection of diseases, often preceding the manifestation of clinical symptoms [
1,
2,
3,
4]. But another area within AI is fuzzy logic (FL), which, since its creation, has had many areas of application where it has demonstrated its effectiveness in solving highly complex problems. Its applications range from the classification of foods based on their characteristics [
5], fuzzy control problems where the inputs of the FIS play an important role in obtaining important output values that allow the stability of the models [
6], to responses combination for pattern recognition applied to time series prediction [
7] or human recognition [
8], and classification problems [
9] to mention a few applications. A significant contribution that FL has had is in medical applications, where, either alone or in combination with other techniques, it has allowed it to be an excellent support tool in medical diagnosis [
10,
11]. In Ref. [
12], a fuzzy rule-based model is presented for Diabetes classification, where the results achieved demonstrated its effectiveness to be proven in the healthcare sector to help in the diagnosis. In Ref. [
13], a system based on FL to predict postoperative complications is proposed using characteristics about current voltage for acupuncture points; the proposed method was successfully applied to the surgical treatment of benign prostatic hyperplasia, demonstrating it to be a tool to help in the diagnosis. In Ref. [
14], a fuzzy decision tree is proposed as a classification method for medical data, where authors show that the proposed method achieved better accuracy over conventional classifiers. Comparisons among Support Vector Machine (SVM), Naive Bayes (NB), Decision Tree (DT), Artificial Neural Networks (ANN), Type 1, Interval, and General Type-2 FIS have been performed, where the FIS are optimized using particle swarm optimization, the General Type-2 FIS proved to have better results over the other techniques applied to medical diagnosis even using different level of uncertainty and cross-validation [
15,
16].
Many works have compared the results obtained between different types of fuzzy systems. In these works, it has been observed that depending on the complexity of the problem and the data used, the type of FL to be used will depend. In Ref. [
6], The advantages of Interval Type-2 FIS are shown over Type-1 FIS, applied to a modification of Flower Pollination Optimization for Rotary Inverted Pendulum System. The application of noise effects and load disturbance mainly demonstrates the robustness and effectiveness of the method. In Ref. [
17], a General Type-2 fuzzy PID (proportional integral derivative) controller is presented and compared versus PID, Type-1 fuzzy PID, and Interval Type-2 fuzzy PID using uncertainties such as controller disturbance or output noise, and the proposed PID achieved better results than the other methods shown. It is also important to mention the combination that has been made of Type-2 fuzzy logic with the Internet of Things (IoT). In Ref. [
18], a control model using Type-2 fuzzy logic is presented to determine the intensity of water absorption applied to IoT infrastructure with sensors to measure humidity conditions. In Ref. [
19], Type-2 fuzzy logic is applied to analyze accelerometer signals for an IoT system for driving support, showing its ability to adjust to driving expectations by collecting information about driving conditions. In Ref. [
8], a comparison of T1FIS, IT2FIS, and GT2FIS optimized by a hierarchical genetic algorithm is shown for the combination of responses of modular granular neural networks applied to human recognition, where the achieved results prove the effectiveness of the GT2FIS when the biometric measures information has noise or have poor quality. Comparisons applied FL to time series prediction are also performed and applied to COVID-19-confirmed cases, where a fuzzy weighted average is proposed to obtain a final prediction of ensemble neural networks. The achieved results prove the advantages of the Interval Type-3 fuzzy weighted average in predicting information of complex time series. The parameters of the FIS are optimized using a Firefly Algorithm [
7]. Although there are currently many techniques for performing optimizations, GA is one of the first methods used to search for parameters and architectures, which continues to be an excellent tool for obtaining optimized parameters related to FL [
20,
21,
22,
23]. In Ref. [
24], a method combining GA and FL is applied to improve the performance of a pump as a turbine is proposed. In Ref. [
25], a real-coded genetic algorithm with fuzzy control is proposed, where the fuzzy inference system establishes its parameters, such as the probability of mutation, type of crossover, and population size applied to system dynamics models. In Ref. [
26], a binary-coded genetic algorithm is proposed and applied to Magnetotelluric modeling, where each gene is used to optimize the resistivity and thickness of homogenously horizontal layers. In Ref. [
27], a real-coded genetic algorithm is proposed and applied to software mutation testing; the proposed method integrates the path coverage-based testing method with the novel idea of tracing a fault detection matrix. In Ref. [
28], a real-coded genetic algorithm is proposed and applied to optimize the Stewart platform with rotary actuators for the flight simulator mechanism. In Ref. [
29], implementing FL in a 3D printer is proposed. The authors work on modifying its base using the direct current motor, the acquisition card, and the power stage. The results show that the optimization of values of the MF of the FIS obtained better times than other techniques.
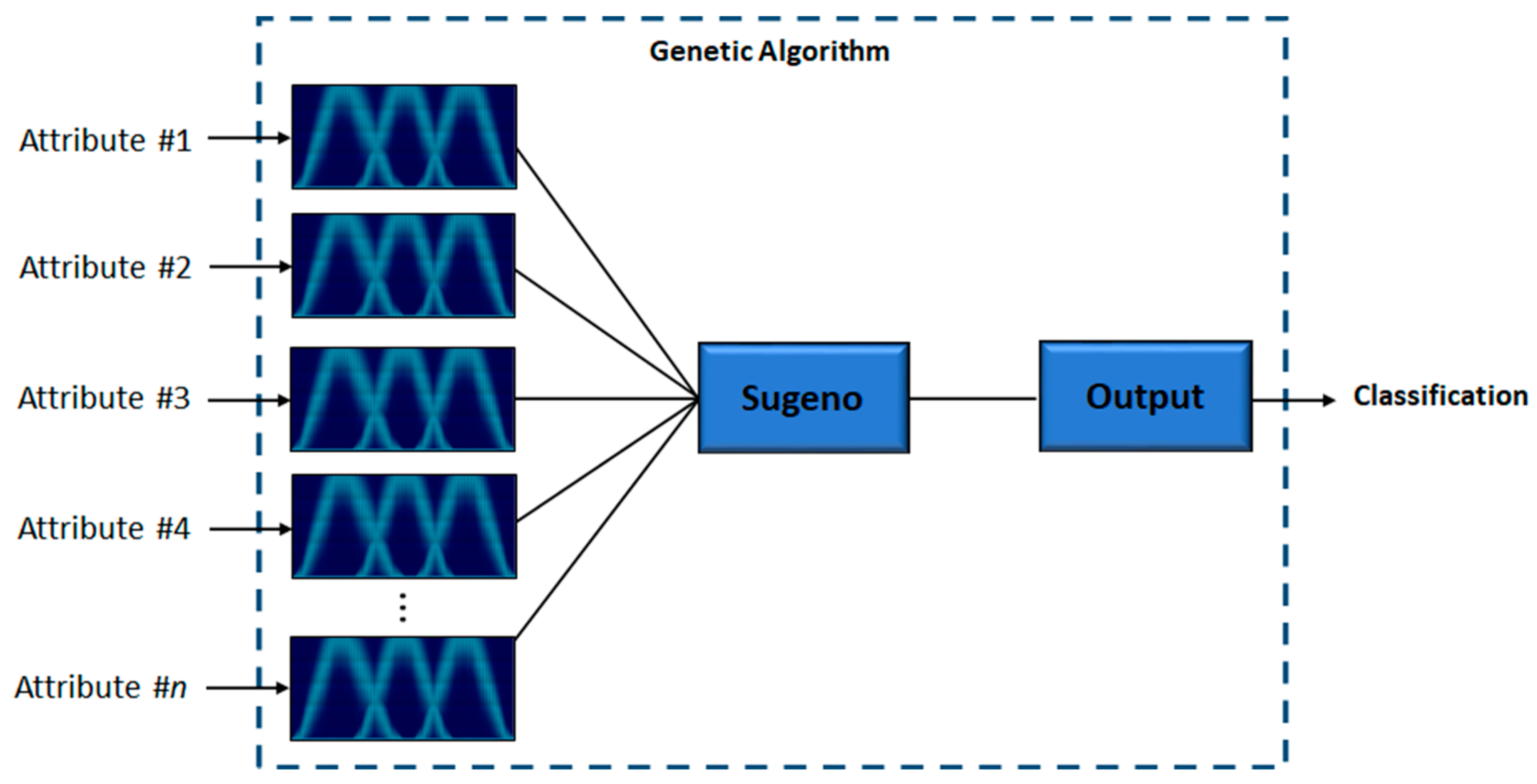
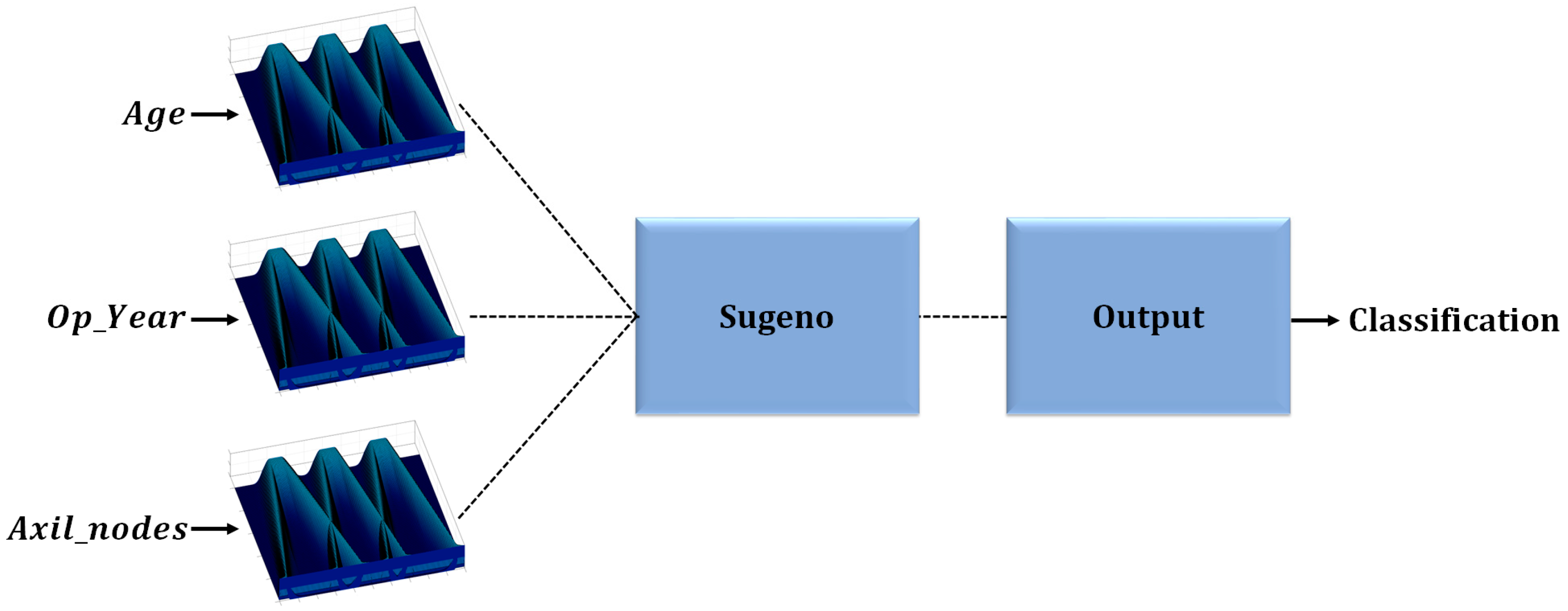
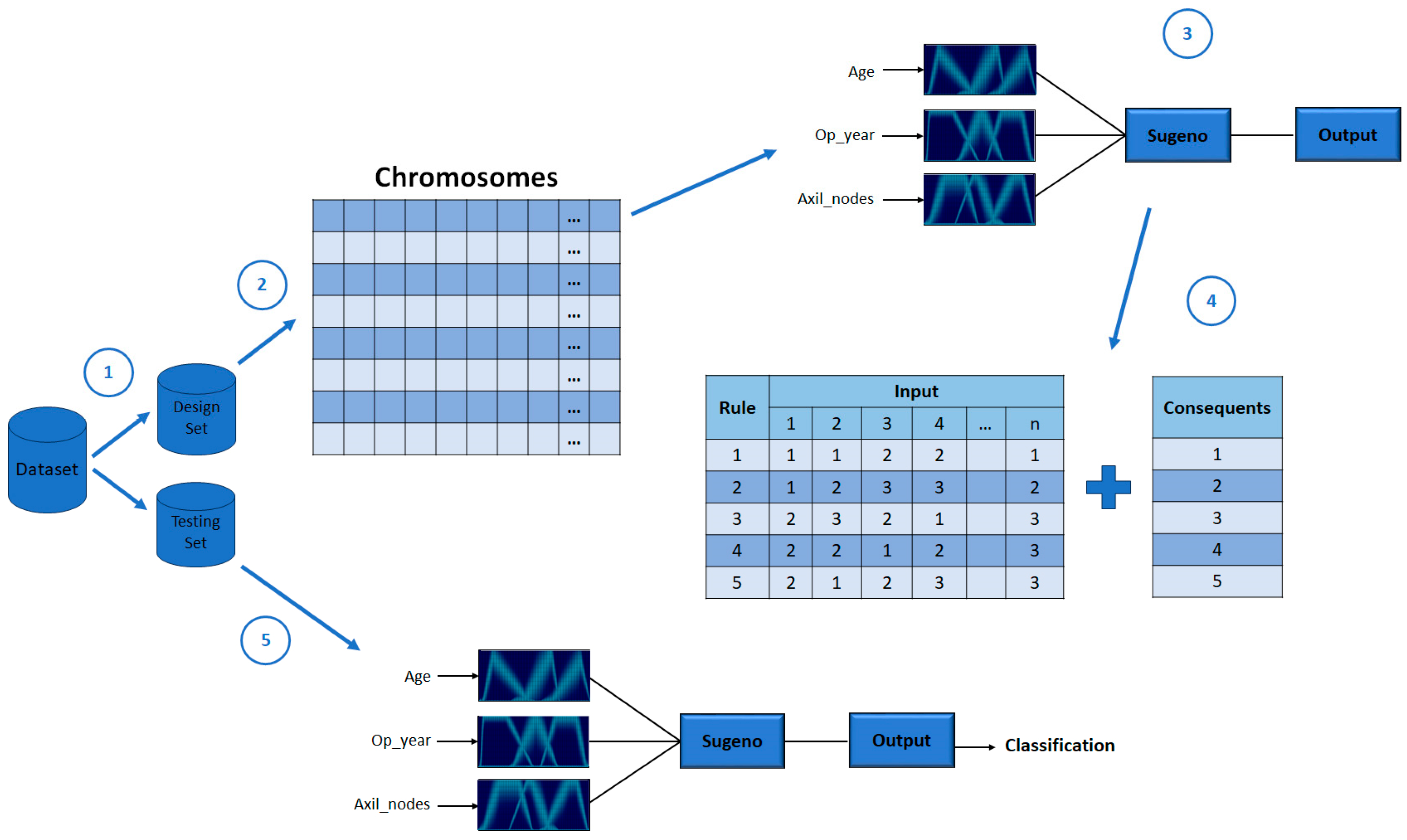
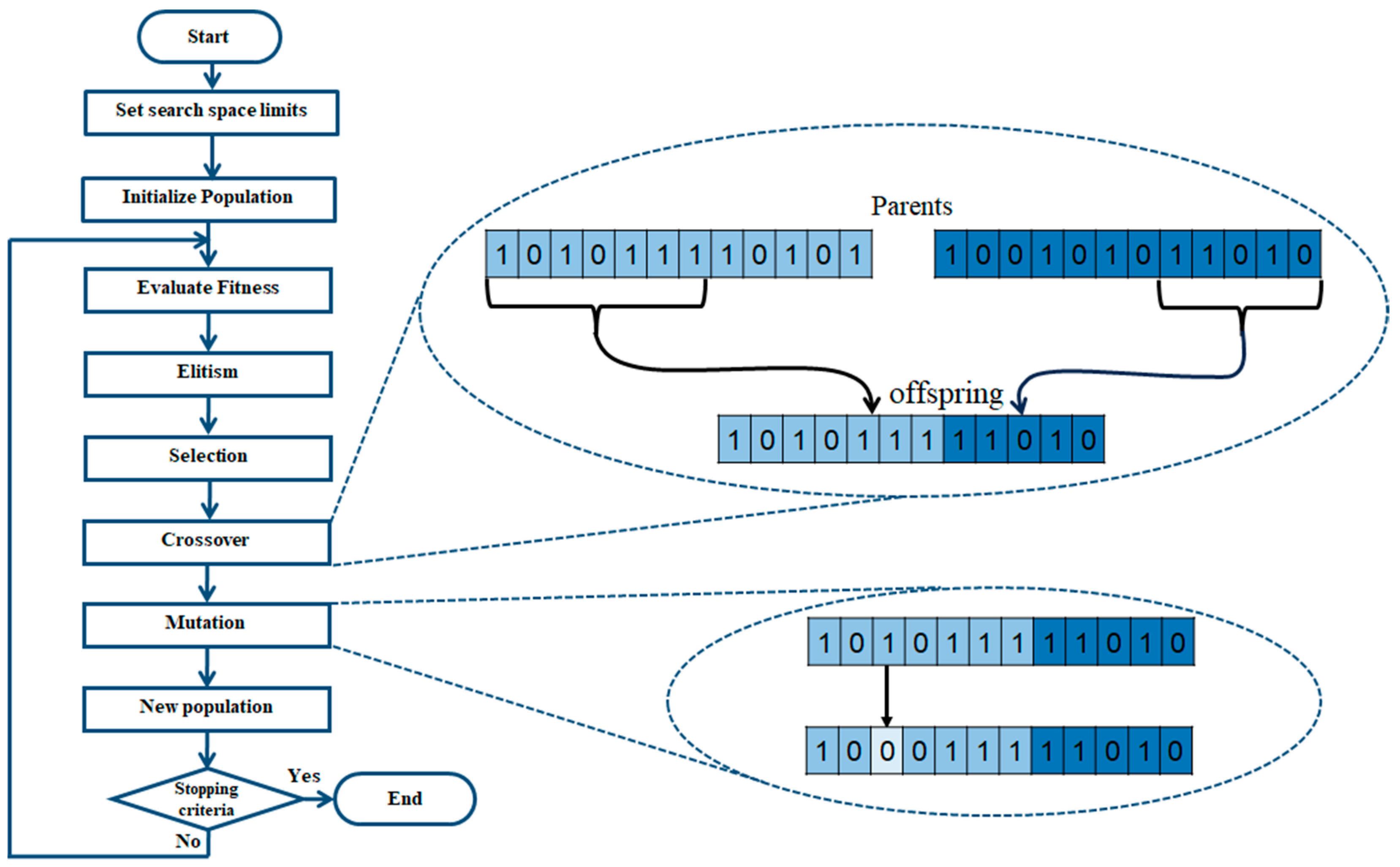
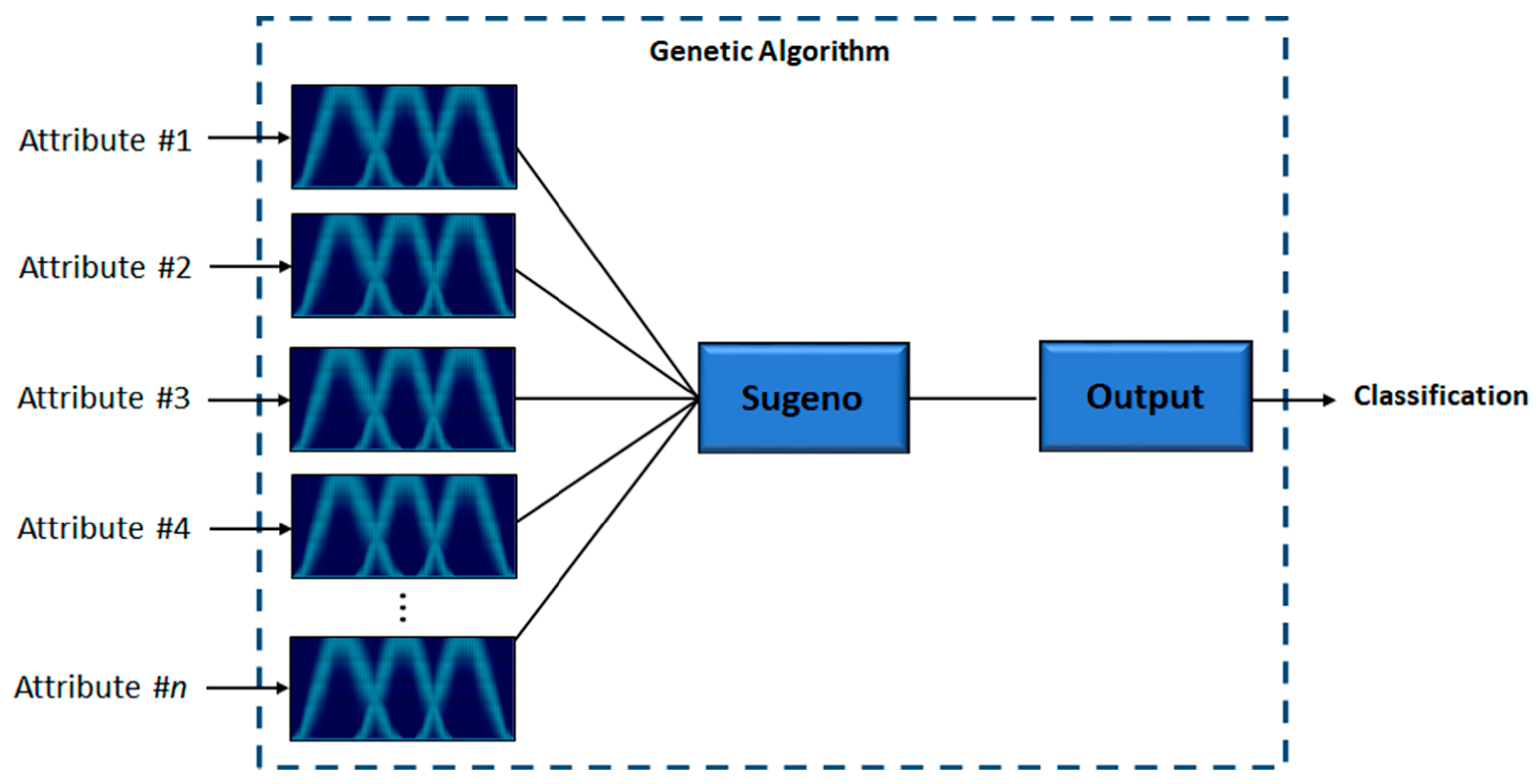
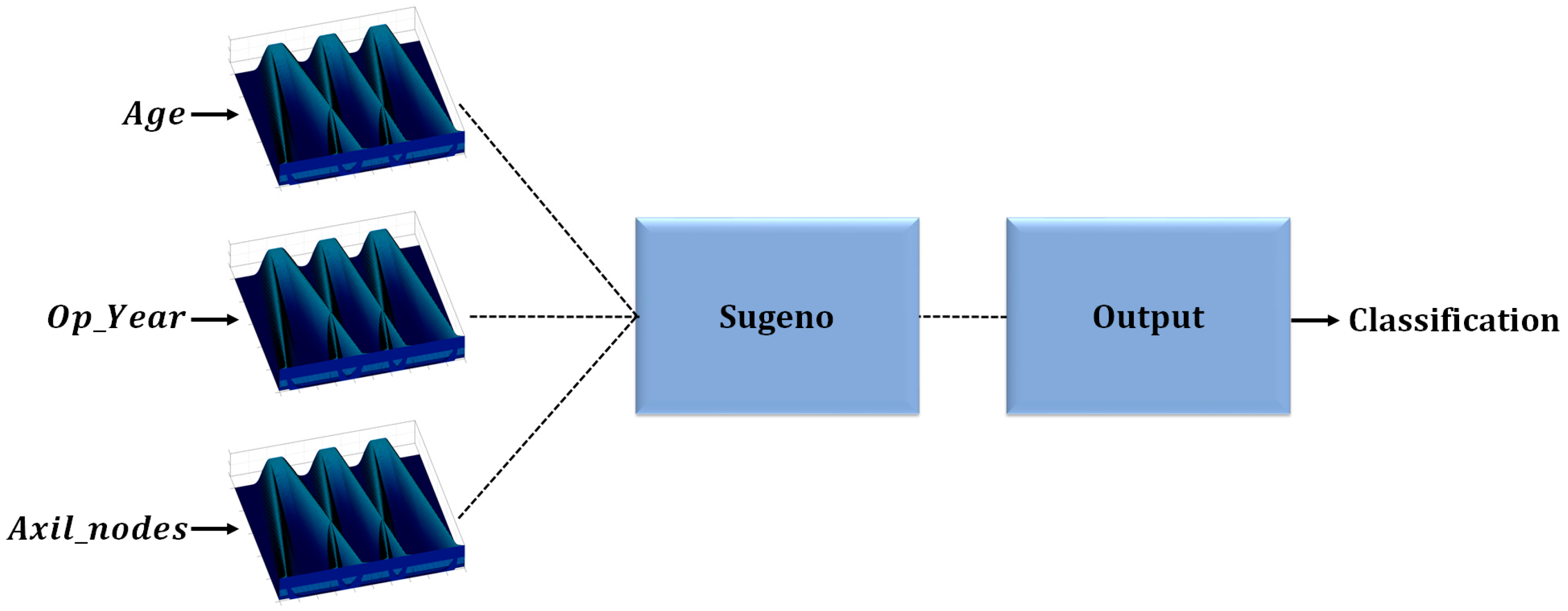
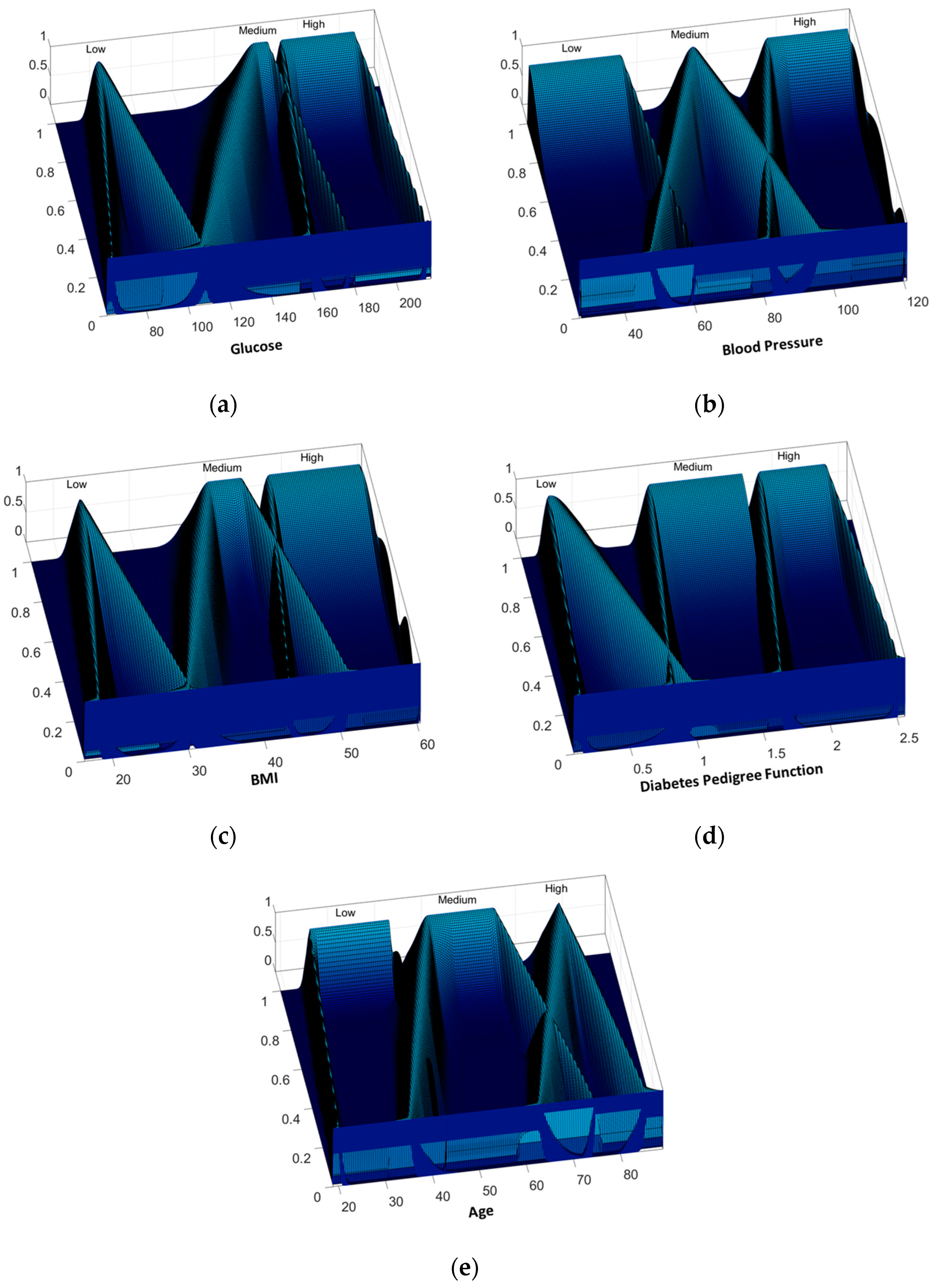
One of the main motivations of this work is to improve results obtained in previous works, where fuzzy systems were designed to classify diabetes using the PIMA Indian Diabetes dataset. The results showed the effectiveness of IT2FIS for classifying this disease. In Ref. [
30], a real-coded GA is developed to design Type-1 FIS using five attributes of the dataset, where a comparison designing different fuzzy if-then rules was presented, demonstrating the importance of designing them. In Ref. [
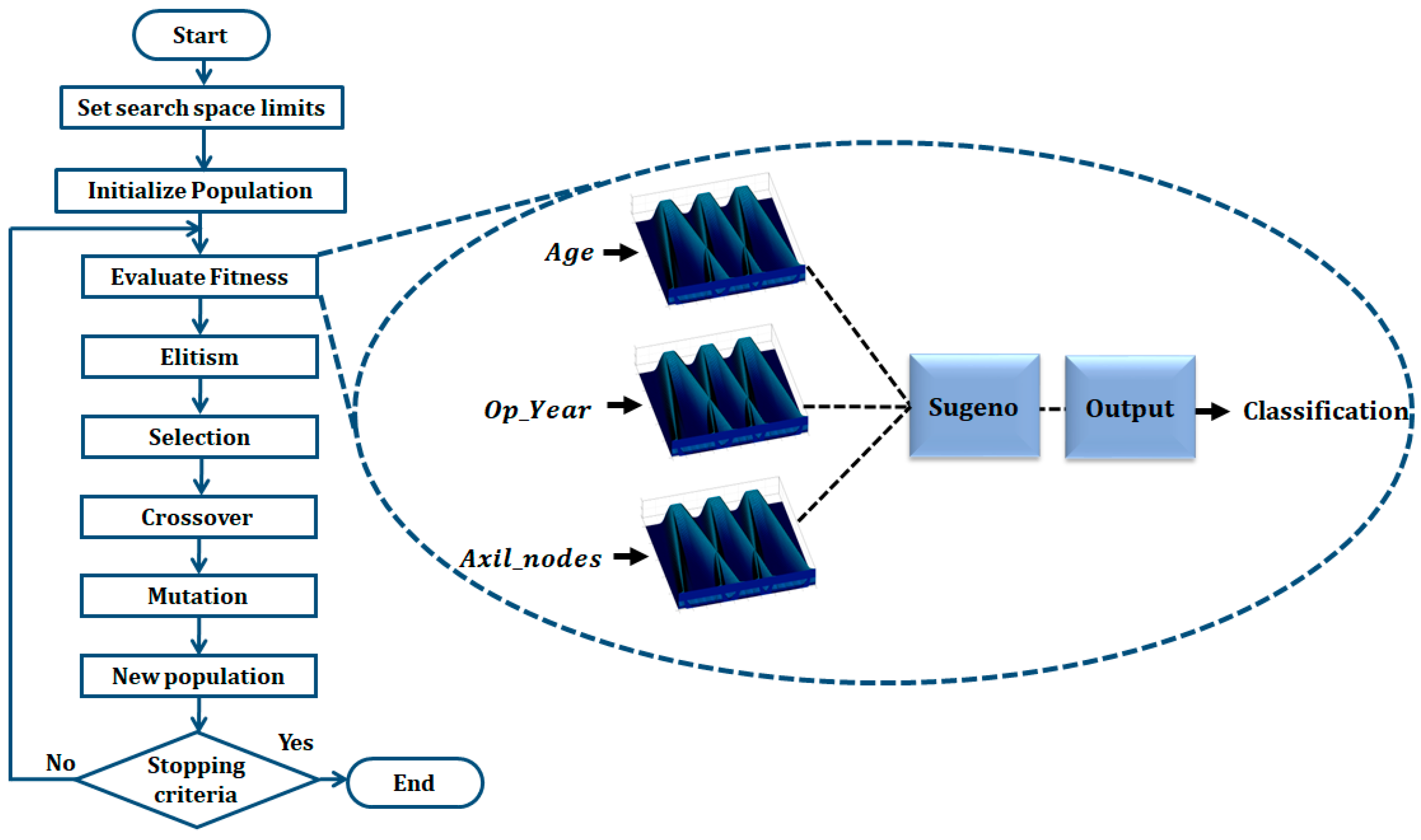
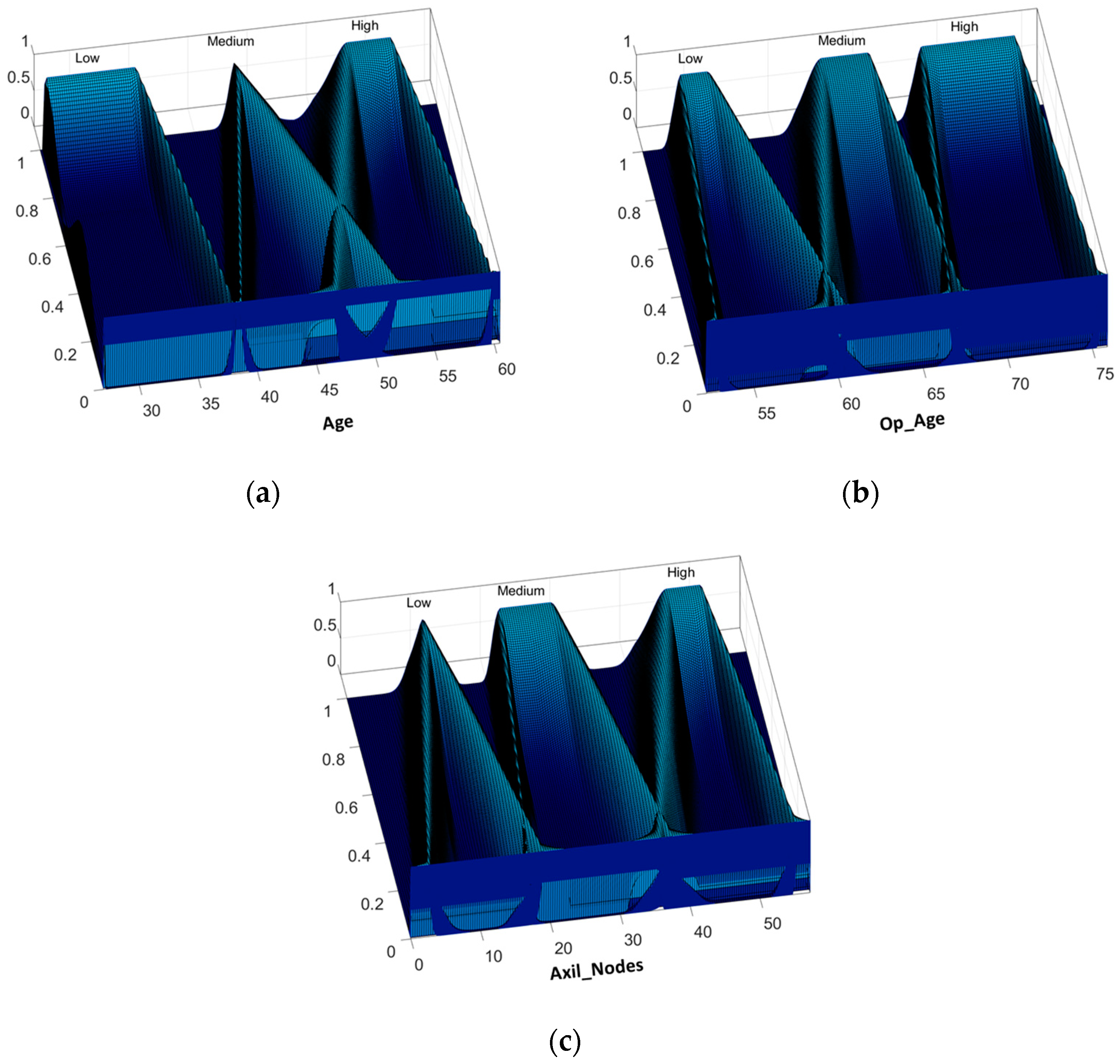
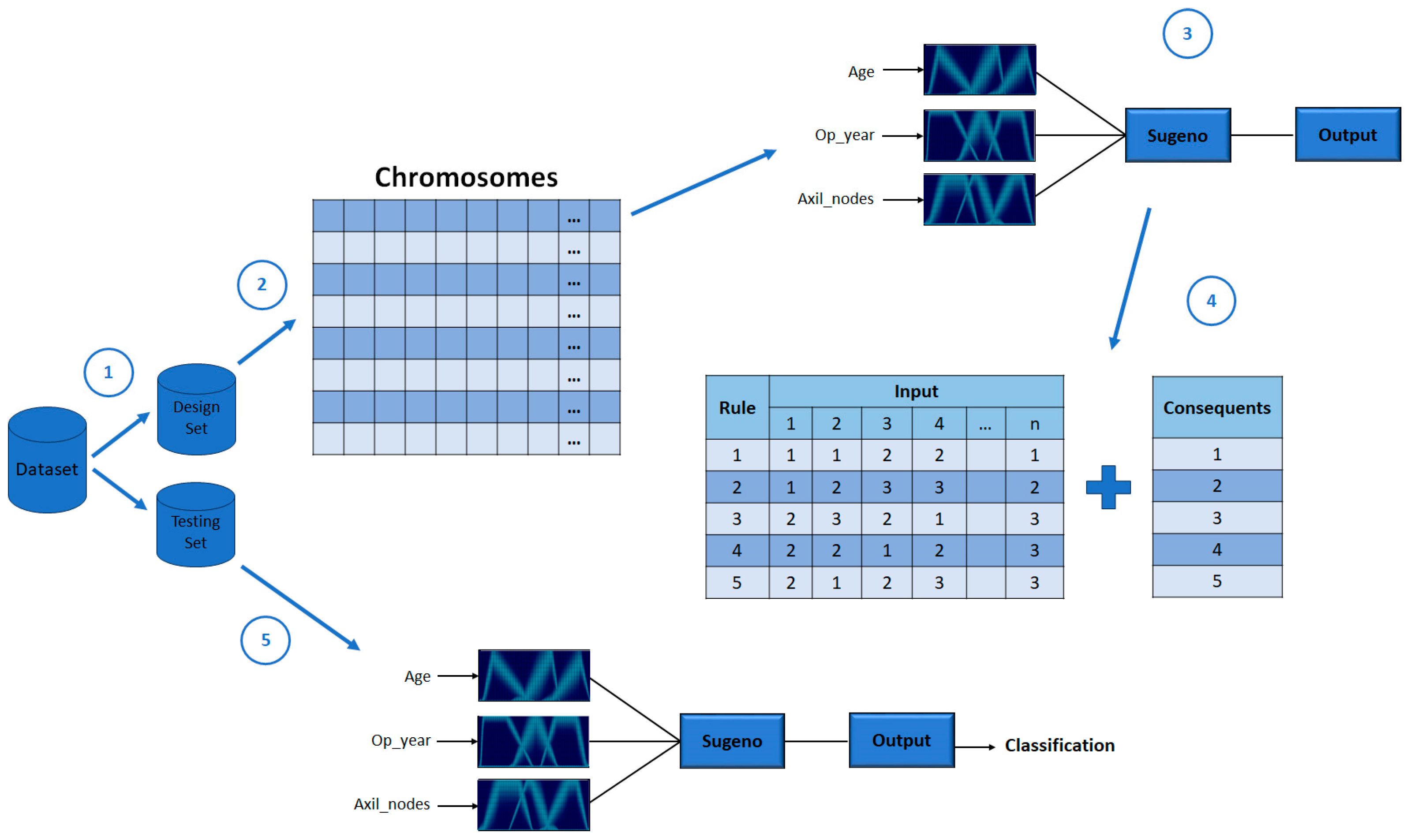
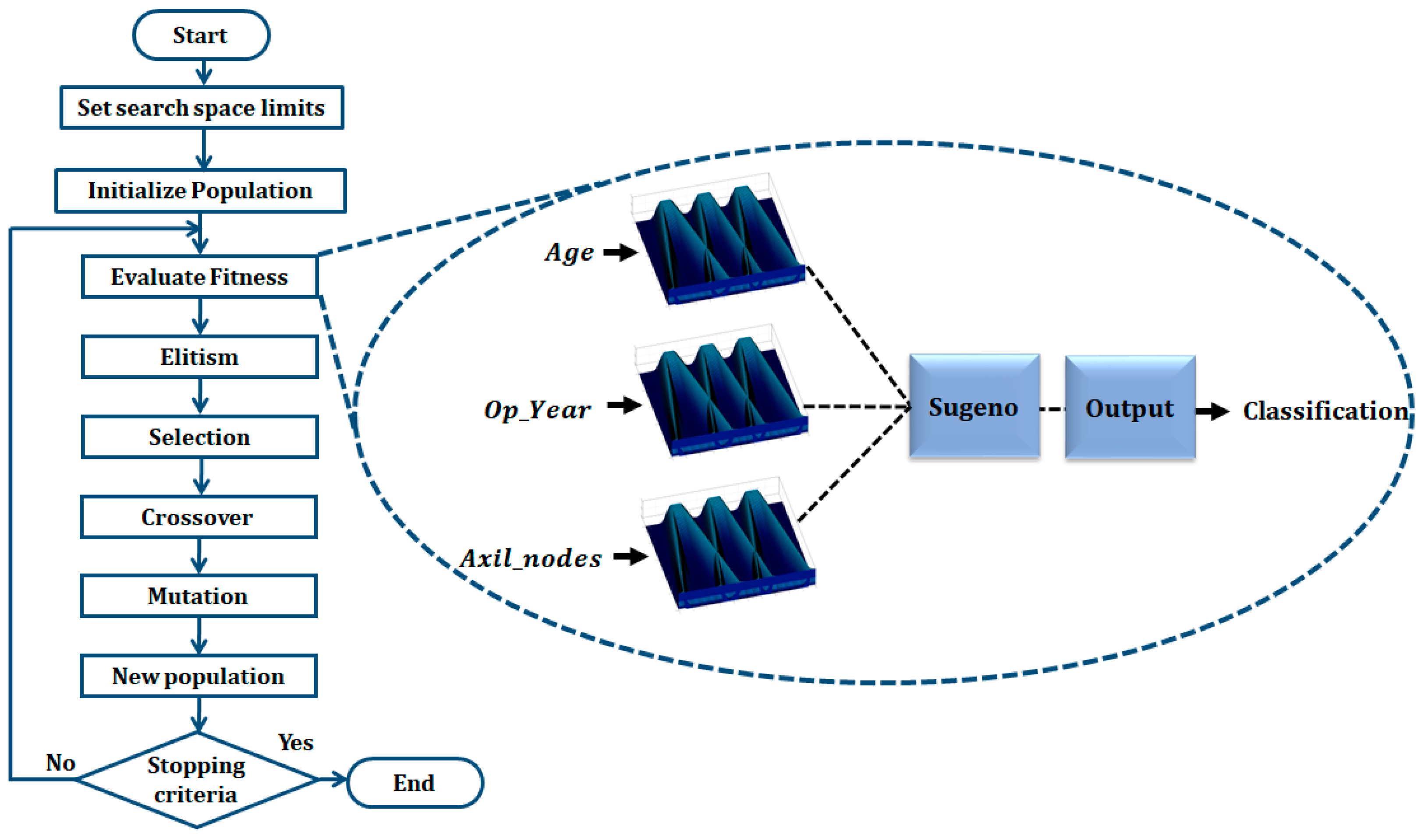
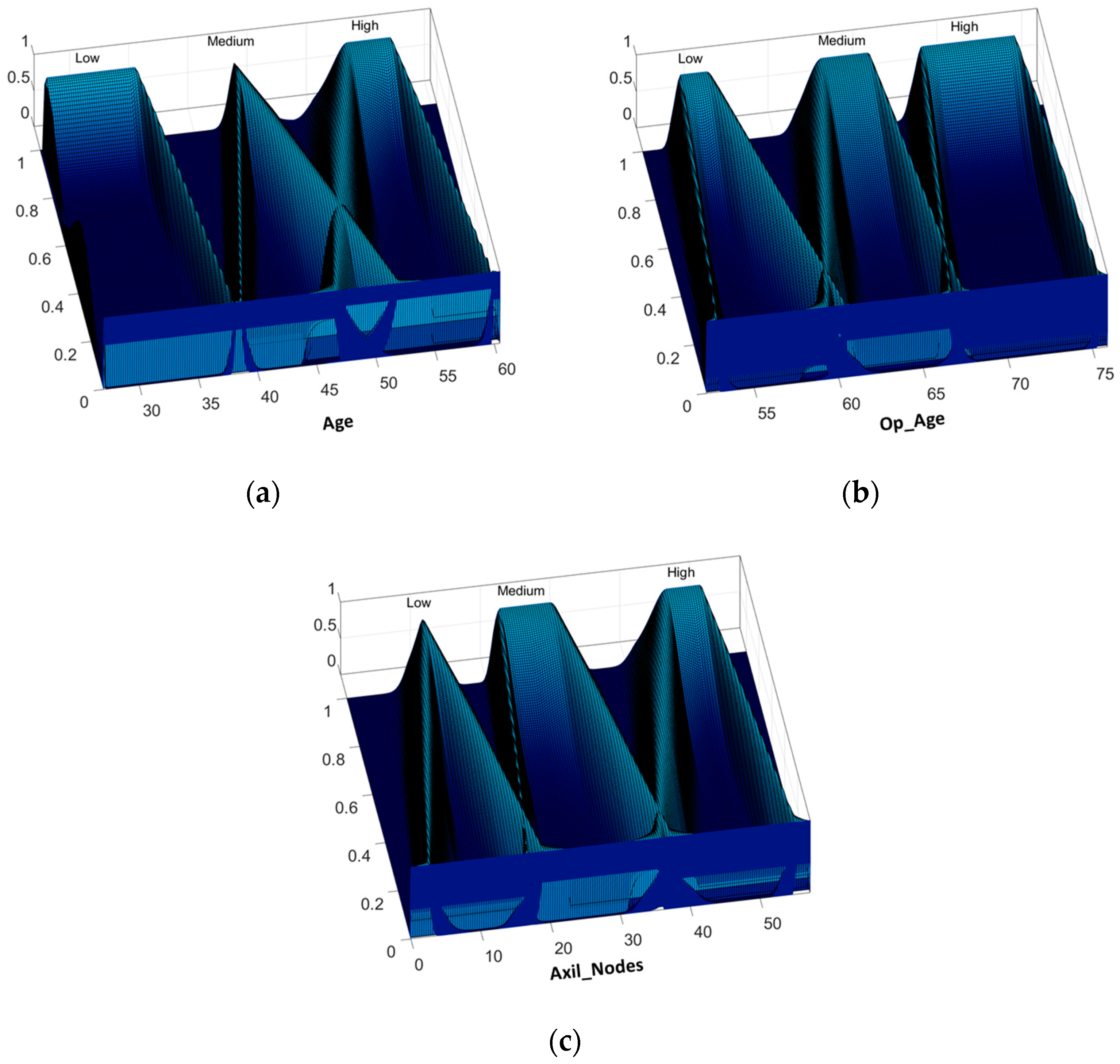
31], the design of Interval Type-2 FIS and its optimization using a GA is proposed, and the results achieved prove the effectiveness of these kinds of fuzzy systems over the Type-1 FIS applied to the PIMA Indian Diabetes dataset using the same five attributes. For both work the instances were divided into two sets: design and testing. In this work, we proposed the IT3FIS design. The novelty of the proposed method lies in the design of a general method capable of classifying by designing the IT3FIS using a percentage of instances. The design consists of establishing the ranges of the input fuzzy variables and the design of the fuzzy rules, allowing the reduction of the number of fuzzy rules, proving to be an excellent tool for classification and reducing time execution.
This paper has the following structure. A description of Type-3 fuzzy logic can be found in
Section 2. In
Section 3, a brief description of genetic algorithms is presented. The proposed method is described in
Section 4. In
Section 5, the results obtained by the proposed method are presented. In
Section 6, discussion and statistical tests are shown. In
Section 7, our conclusions are shown.
2. Type-3 Fuzzy Logic
Type-1 FL is a helpful intelligence technique that can be used to be applied to model elaborate problems. L.A. Zadeh proposed this technique in 1965 [
32,
33], where an element in part belongs with a particular membership grade with a crisp number between 0 and 1 to a set. An improvement of the FL was proposed in 1975: Type-2 FL [
34]. In Type-2 FL, unlike Type-1 FL, the elements do not have a crisp number [0, 1]. A fuzzy set (FS) in [0, 1] allows the definition of the MF [
35]. The description of a Type-2 fuzzy system is given by Equation (1):
where
X represents the domain of the fuzzy variable, a primary membership is represented by
, and
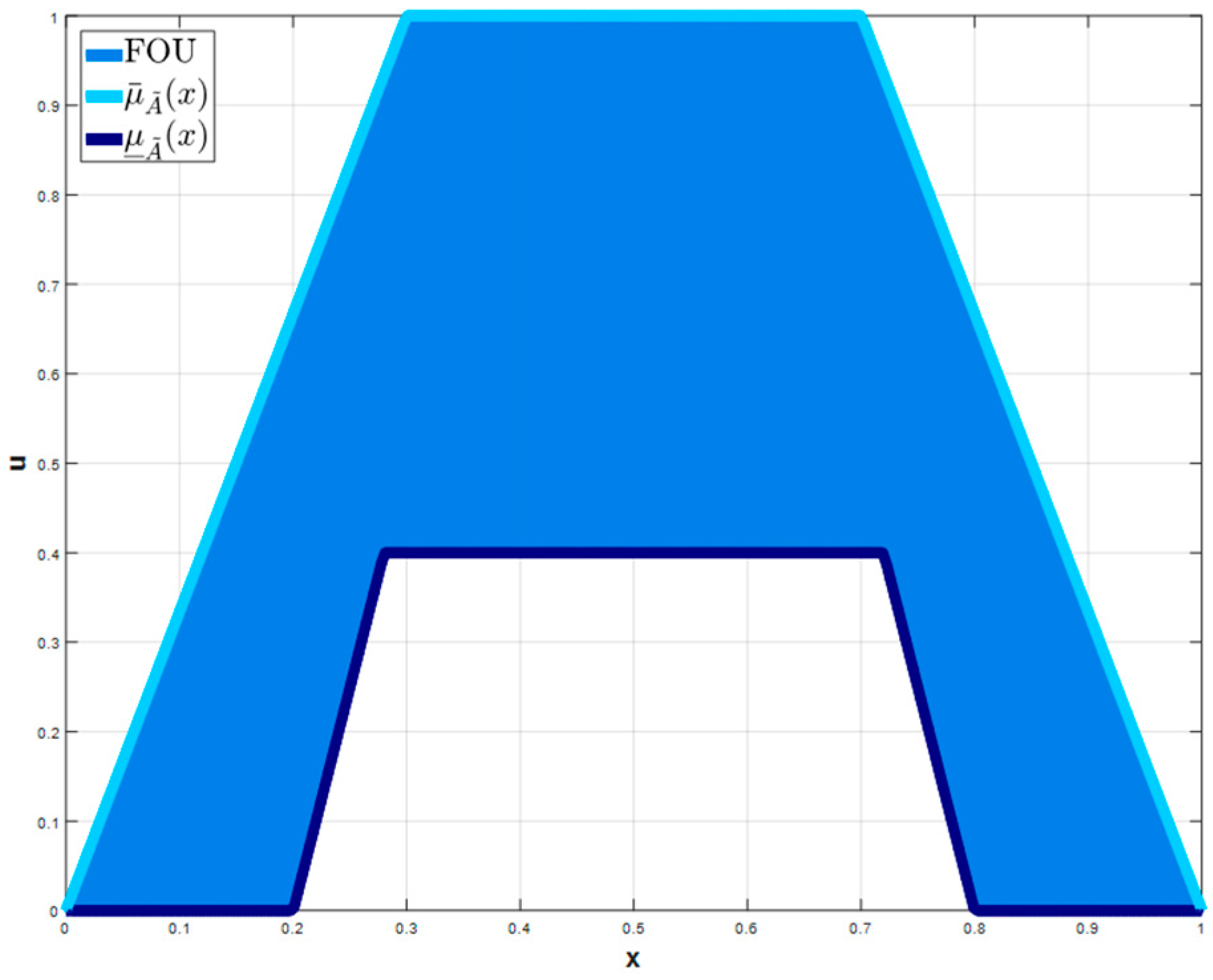
defines a secondary membership (Type-1 FS). The footprint of uncertainty (FOU) represents the uncertainty region. A Type-2 MF interval occurs when
= 1,
. In
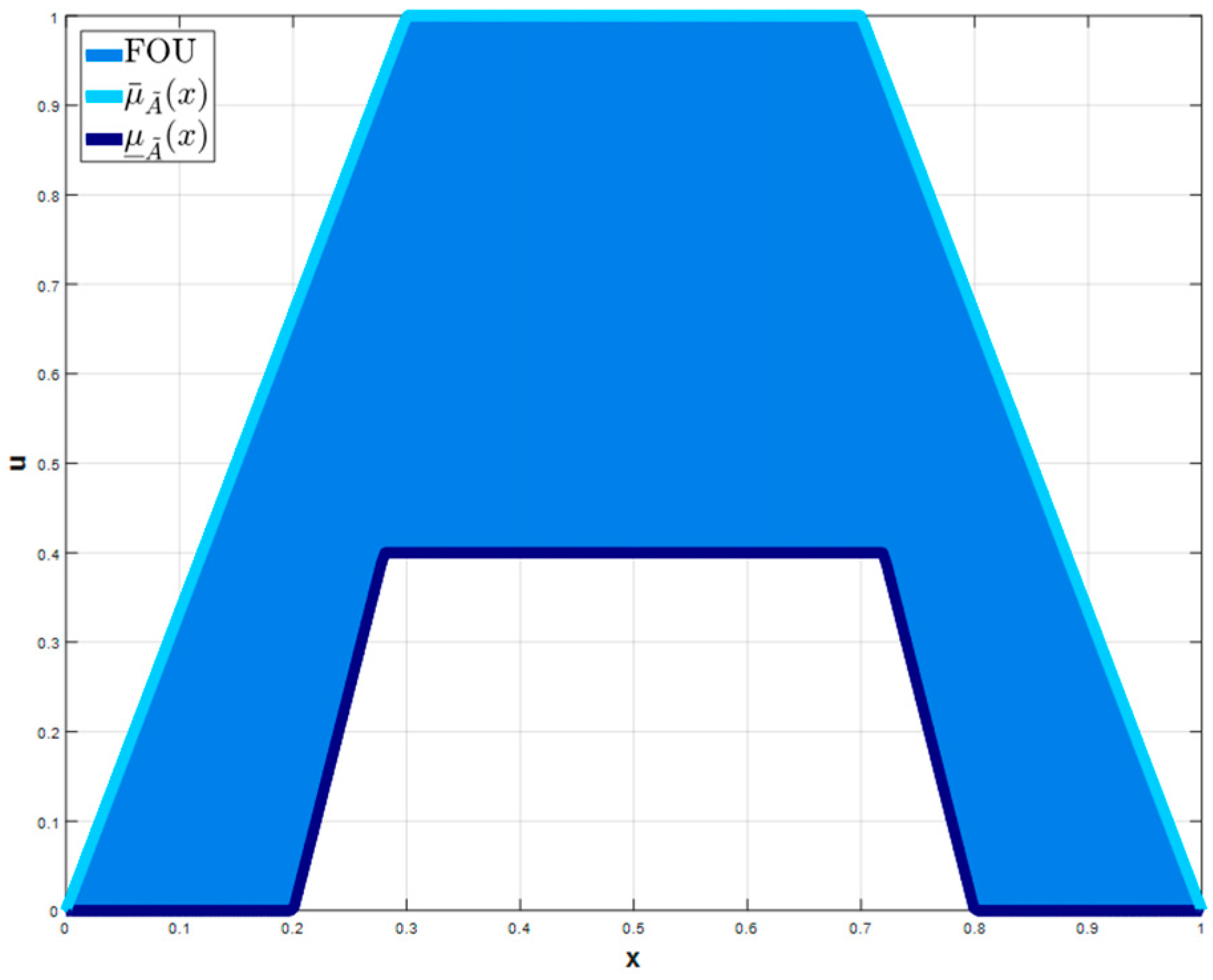
Figure 1, the upper
and lower
MF of a Trapezoidal Type-2 MF [
36] is shown. An Interval Type-2 fuzzy set is determined as Equation (2).
In Type-3, we can potentially handle higher degrees of uncertainty with respect to Type-2 due to the nature of the membership functions. A Type-3 fuzzy set (T3 FS) [
37,
38] is represented by the notation
, is the graph of a trivariate function named MF of
, in the cartesian product defined by Equation (3), where the primary variable of
has a universe
,
. The membership function of
is defined by
, and is a Type-3 membership function of the T3 fuzzy set defined by Equation (4):
where
u is the secondary variable and has the universe
U, and
V for the tertiary variable
v. A Trapezoidal Interval Type-3 MF
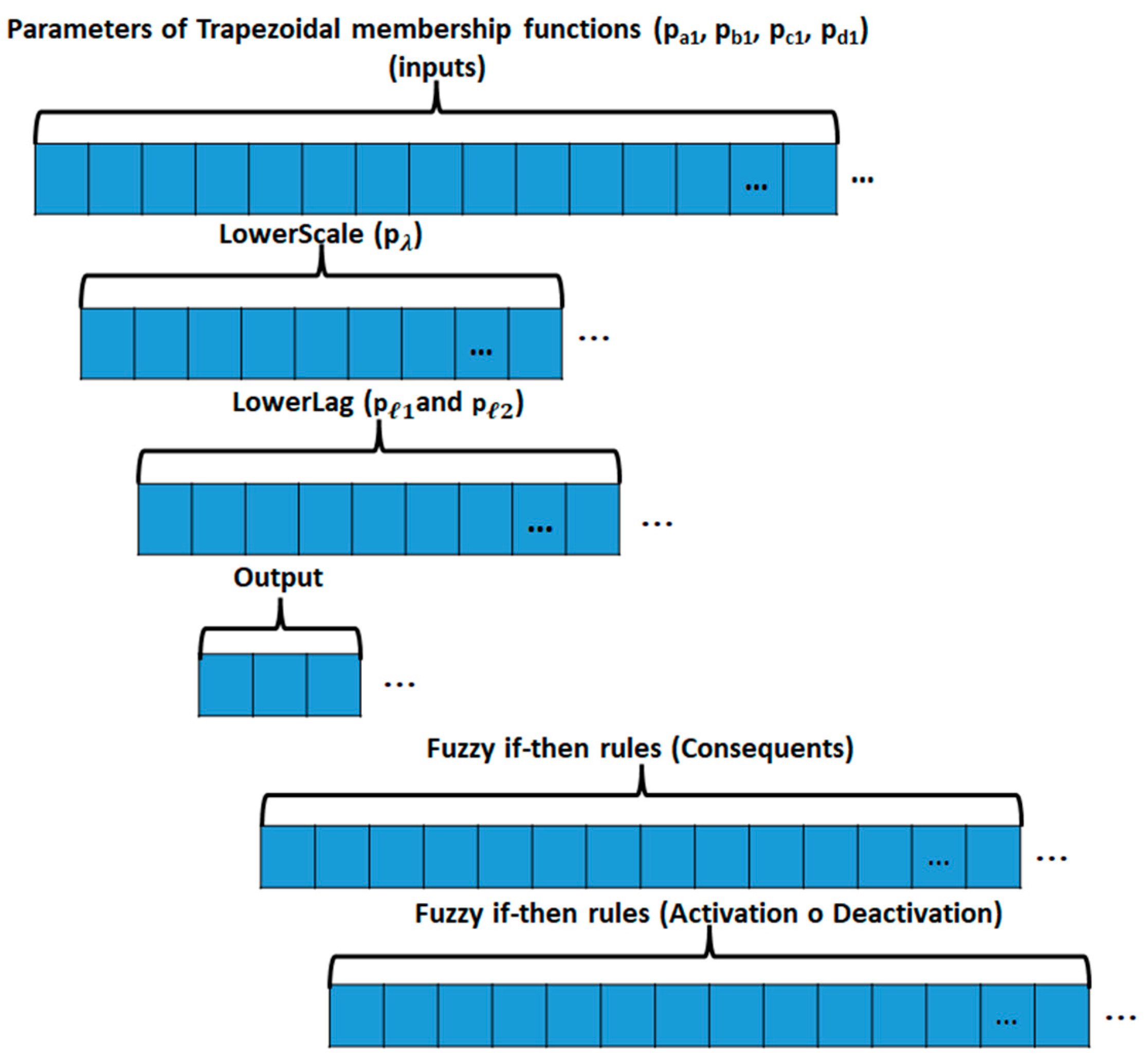
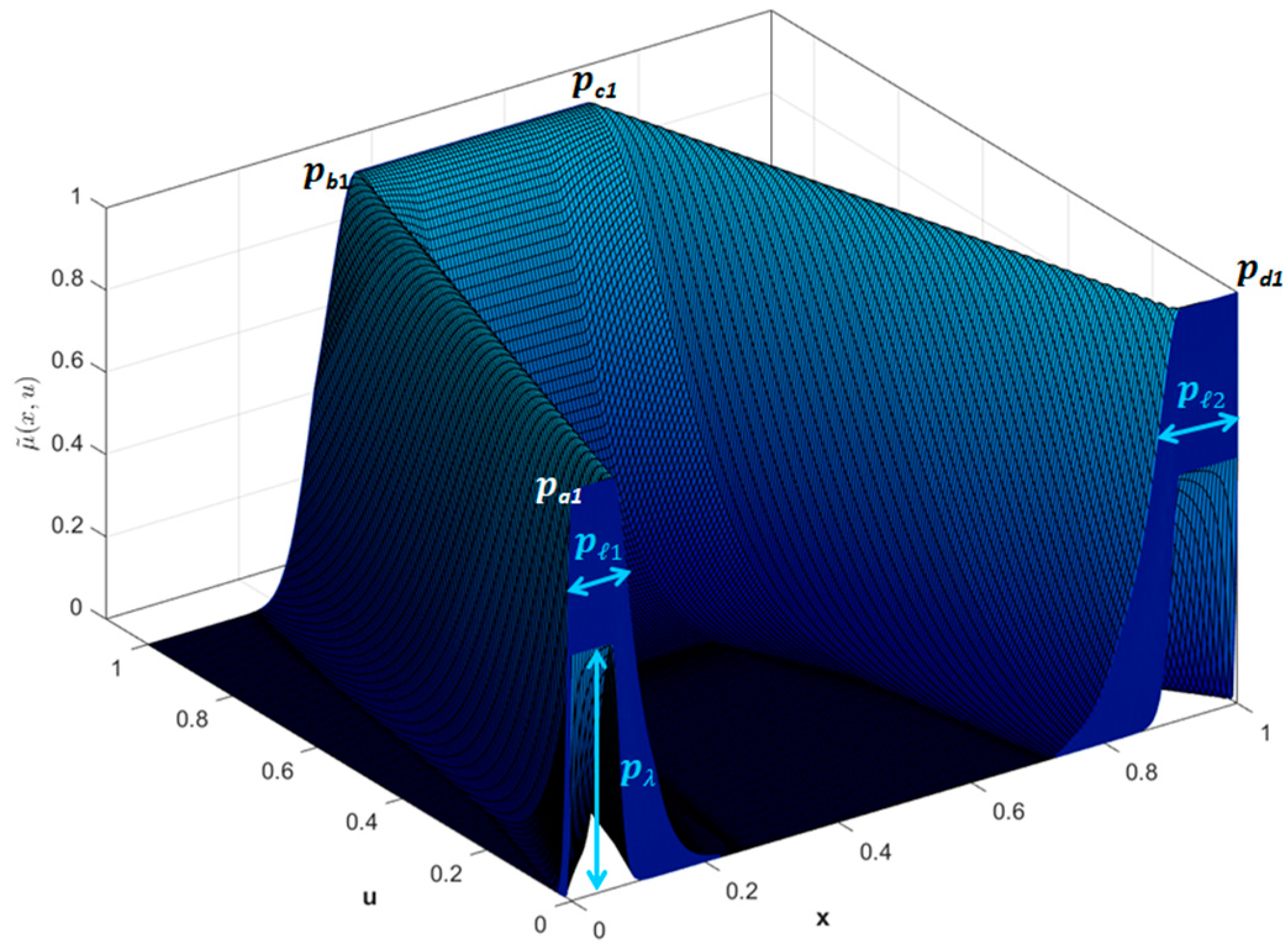
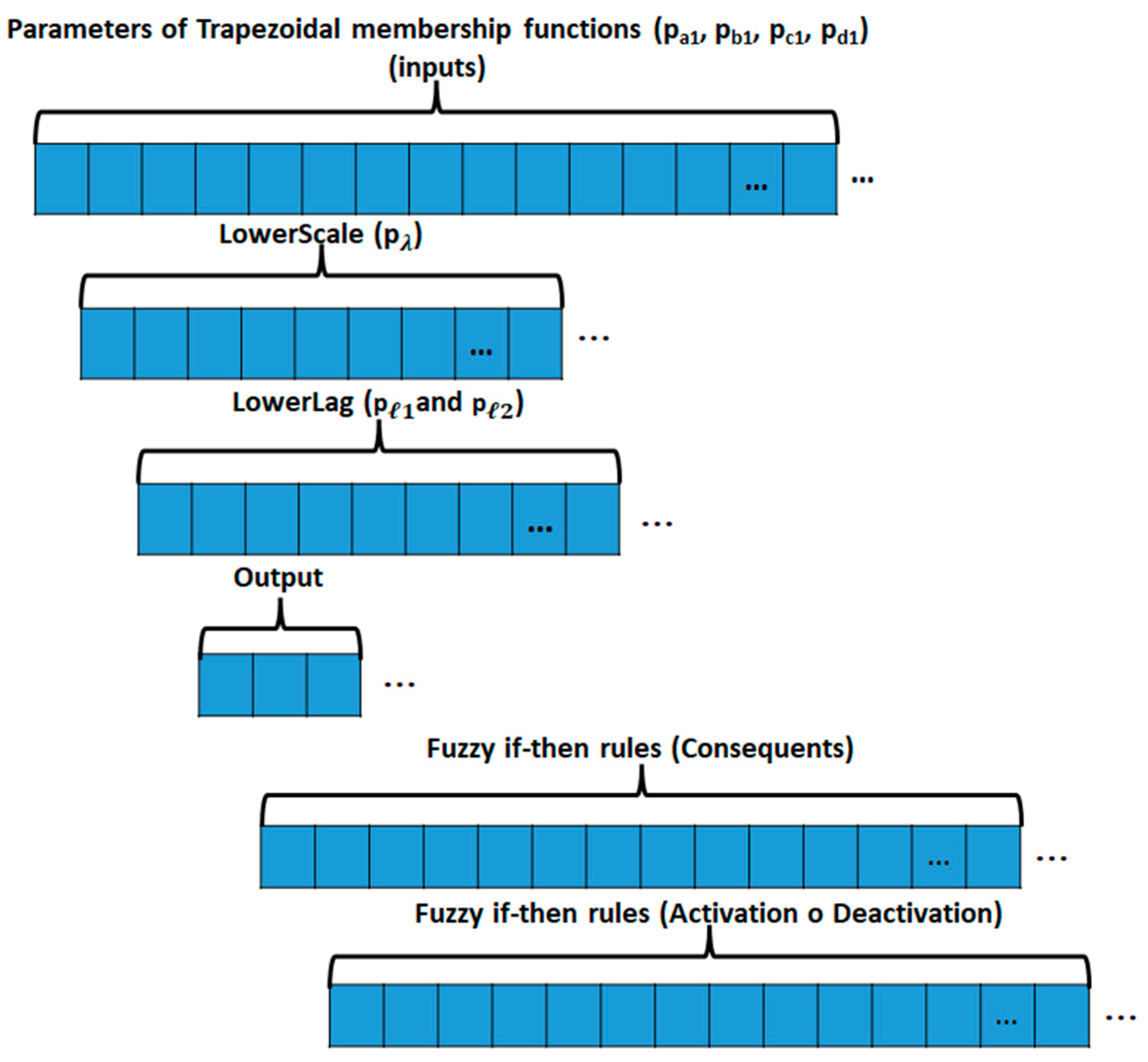
= ScaleTrapScaleGaussIT3MF with Trapezoidal
has for the upper membership function (UMF) as parameters
, and the lower membership function (LMF):
(LowerScale) and
(LowerLag) to form
]. The representation of this MF is given by Equation (5).
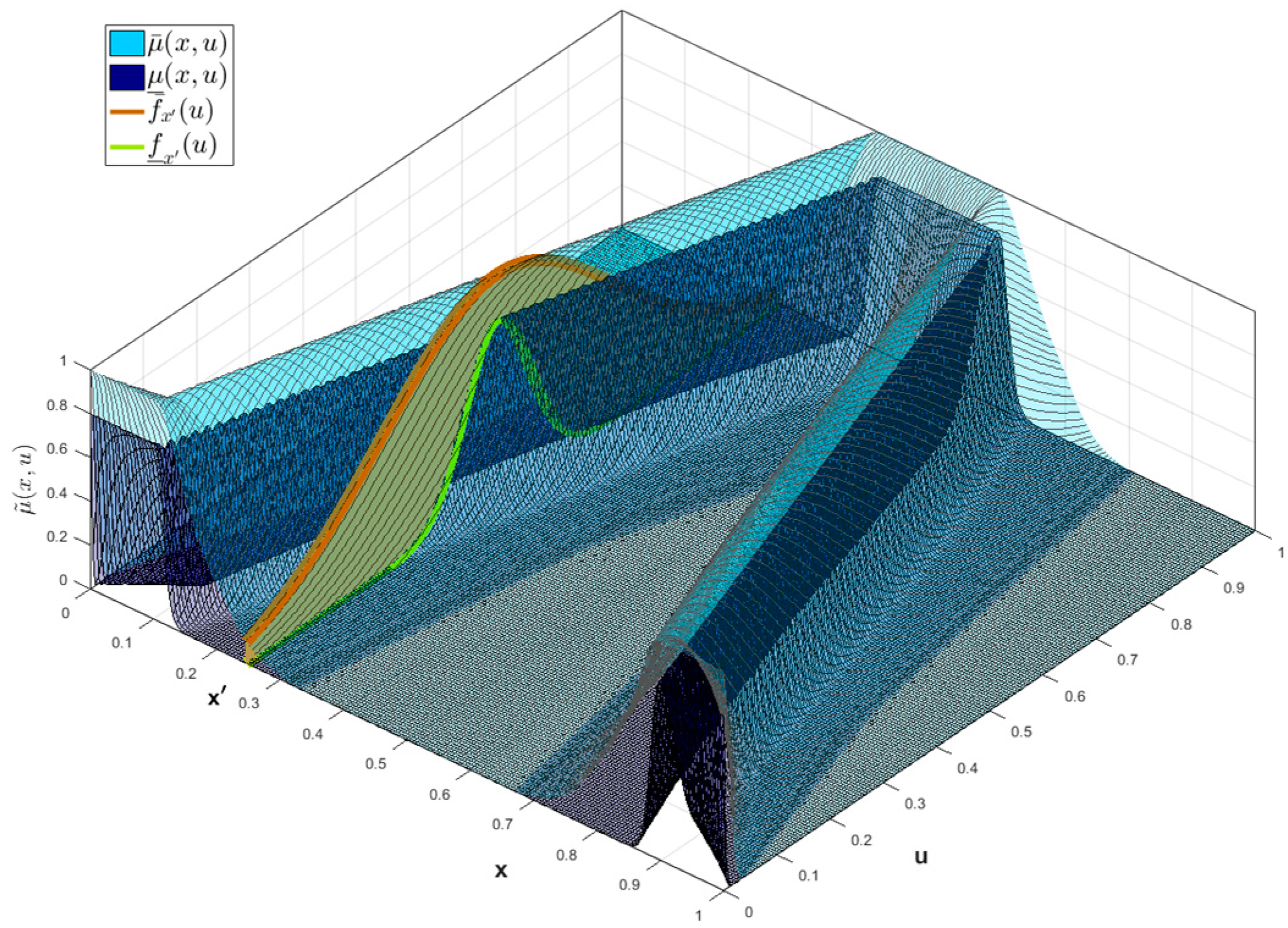
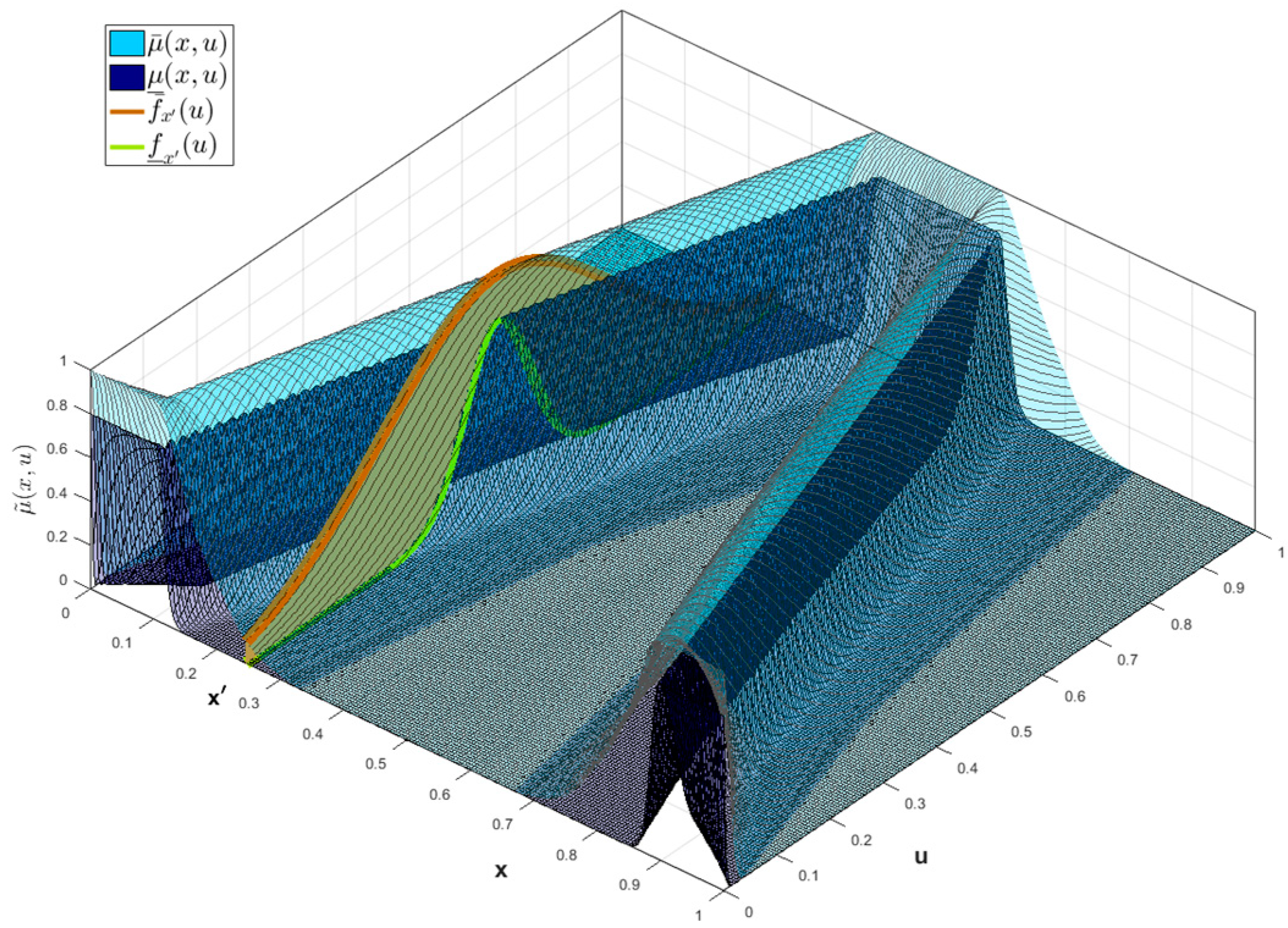
The vertical cuts
identify the
, these are Interval Type-2 FS with Gaussian Interval Type-2 MF,
with parameters
for the UMF, and for LMF:
(LowerScale) and
(LowerLag). An illustration of a Type-3 Trapezoidal MF with a vertical cut is shown in
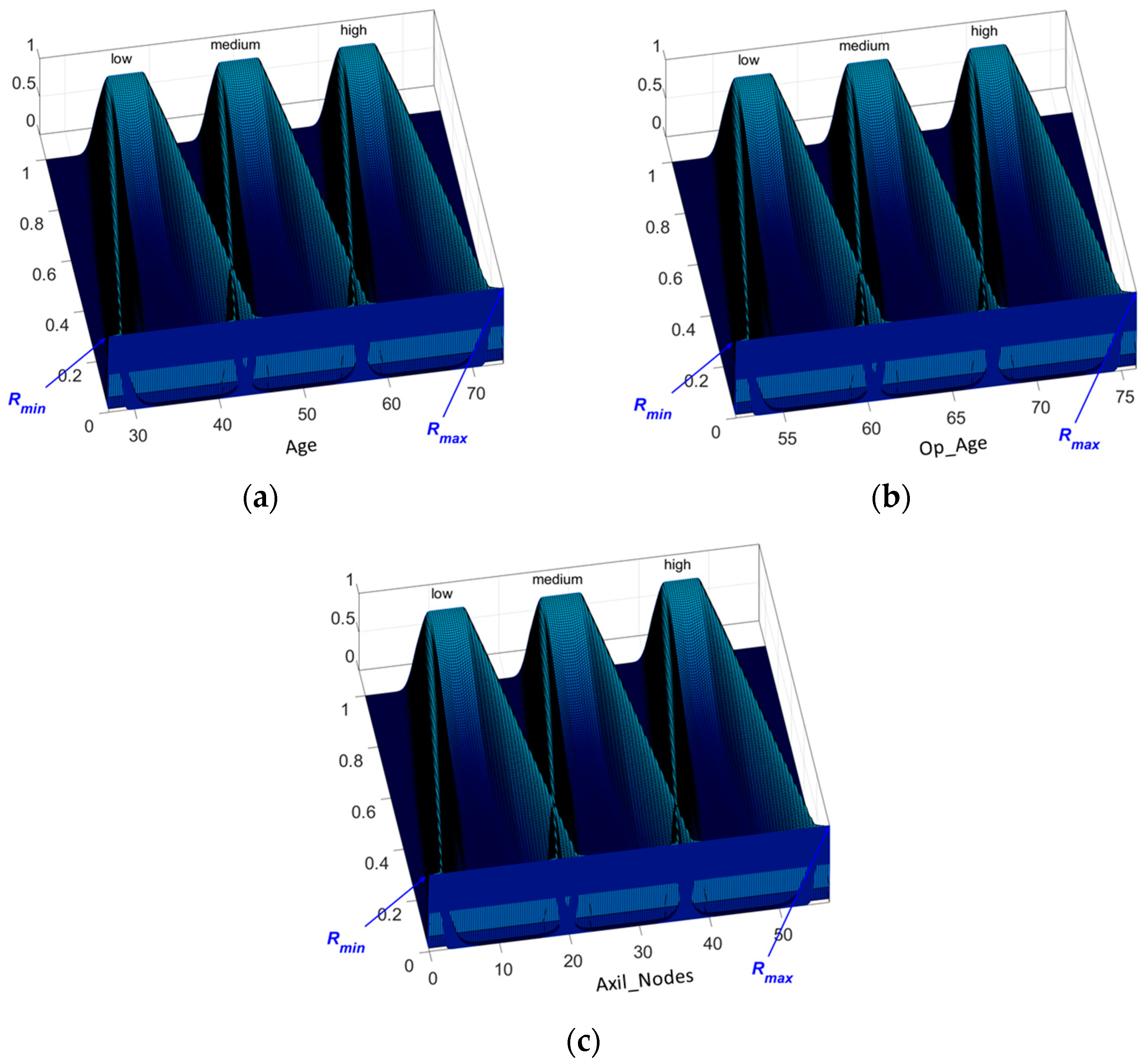
Figure 2. This Interval Type-3 membership function is defined with the Equation (6).
The values (
) determine the lower membership function of the domain of uncertainty (DOU),
is determined by the values where these are functions of the parameters (
) of the UMF for the domain of uncertainty,
, and the elements of the LowerLag (
) vector. i.e.,
The function
and the parameter
are multiplicated to create the LMF of the domain of uncertainty,
, is described as the following:
. Then, the upper and lower limits of the domain of uncertainty are represented respectively by
and
. The range,
, and radio,
, of the footprint of uncertainty are calculated by Equations (14) and (15).
where machine epsilon is represented by
. Equation (16) defines the apex,
, of the IT3 MF
.
where
,
, and
y
. Then, the vertical cuts with Interval Type-2 MF,
, are presented with the Equations (17) and (18).
where
,
. If
, then
. Then,
and
are the UMF and LMF of the vertical cuts IT2 FS of the secondary IT2 MF of the IT3 FS [
39].
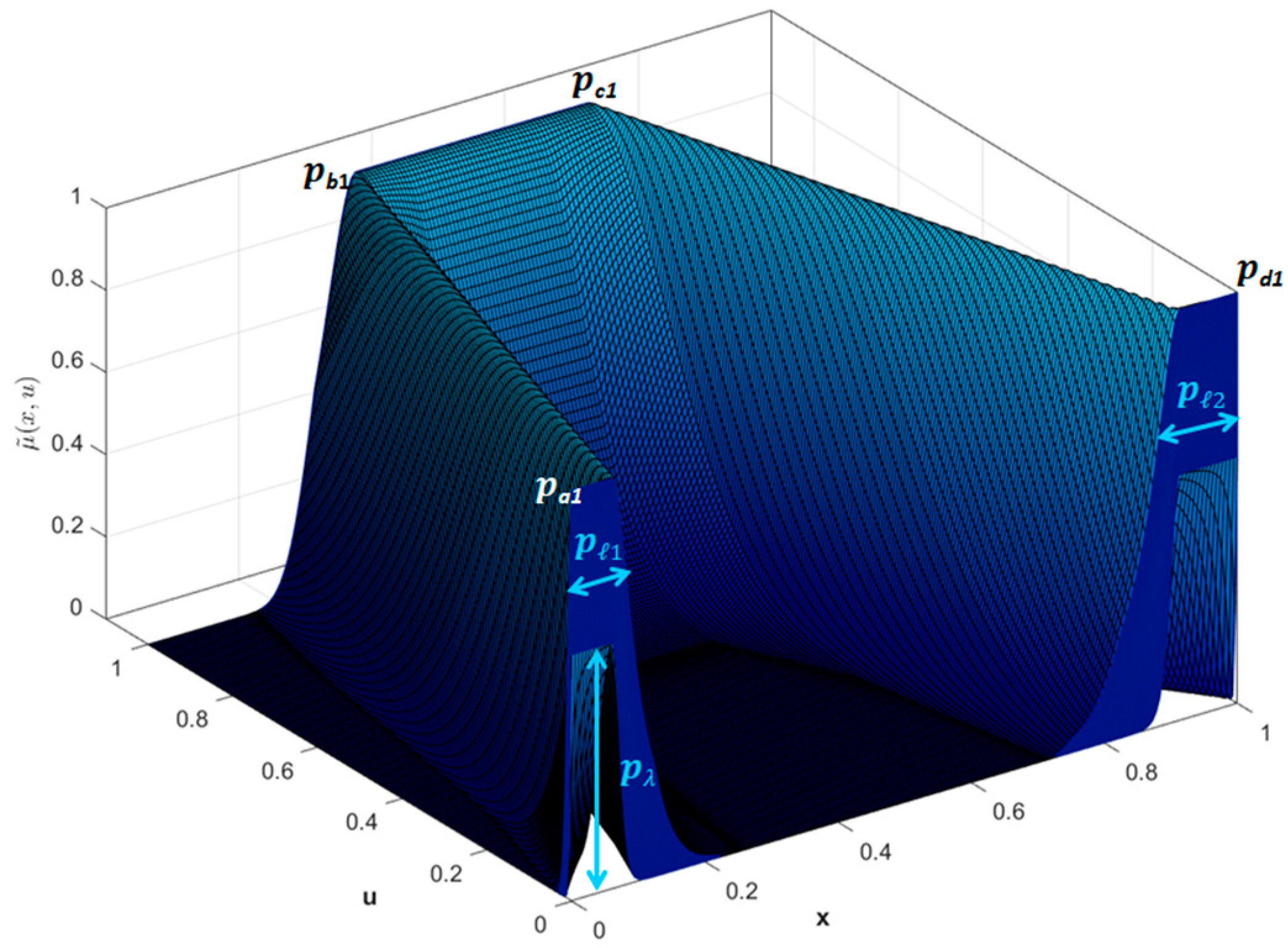
Figure 3 shows a representation of this IT3 MF.
6. Discussion
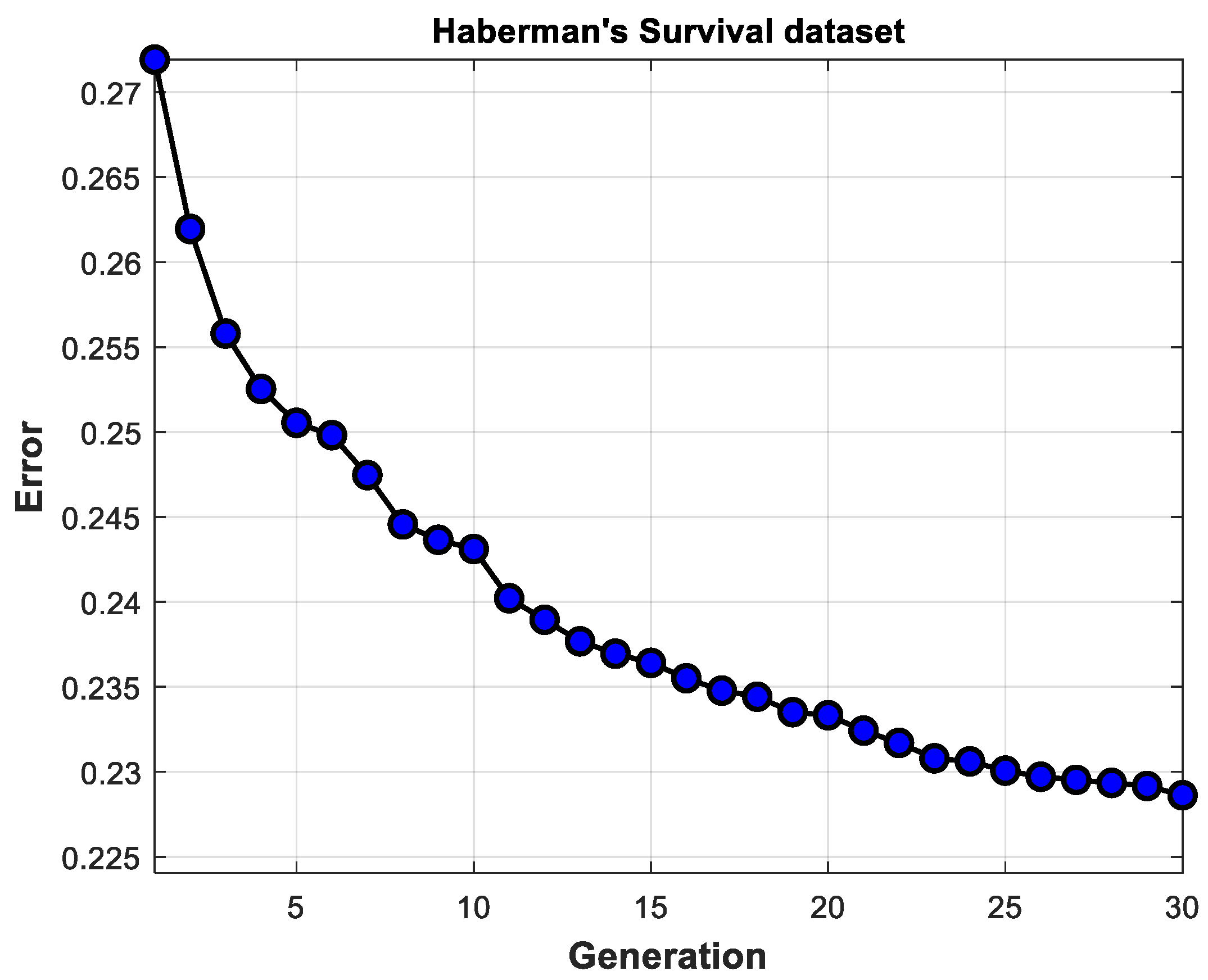
Experiments with and without cross-validation were carried out to evaluate the performance of the proposed method.
Table 8 shows the best and average results achieved in both phases (design and testing) with corresponding standard deviations.
Table 8 summarizes the results achieved with all the datasets used in this work. As
Table 8 shows, for Cryotherapy, Immunotherapy, and Breast Cancer Coimbra databases, the cross-validation allowed for improving the percentage of accuracy in both phases (design and testing).
In
Table 9, the comparison of the results obtained with the proposed method and the results obtained in a previous work [
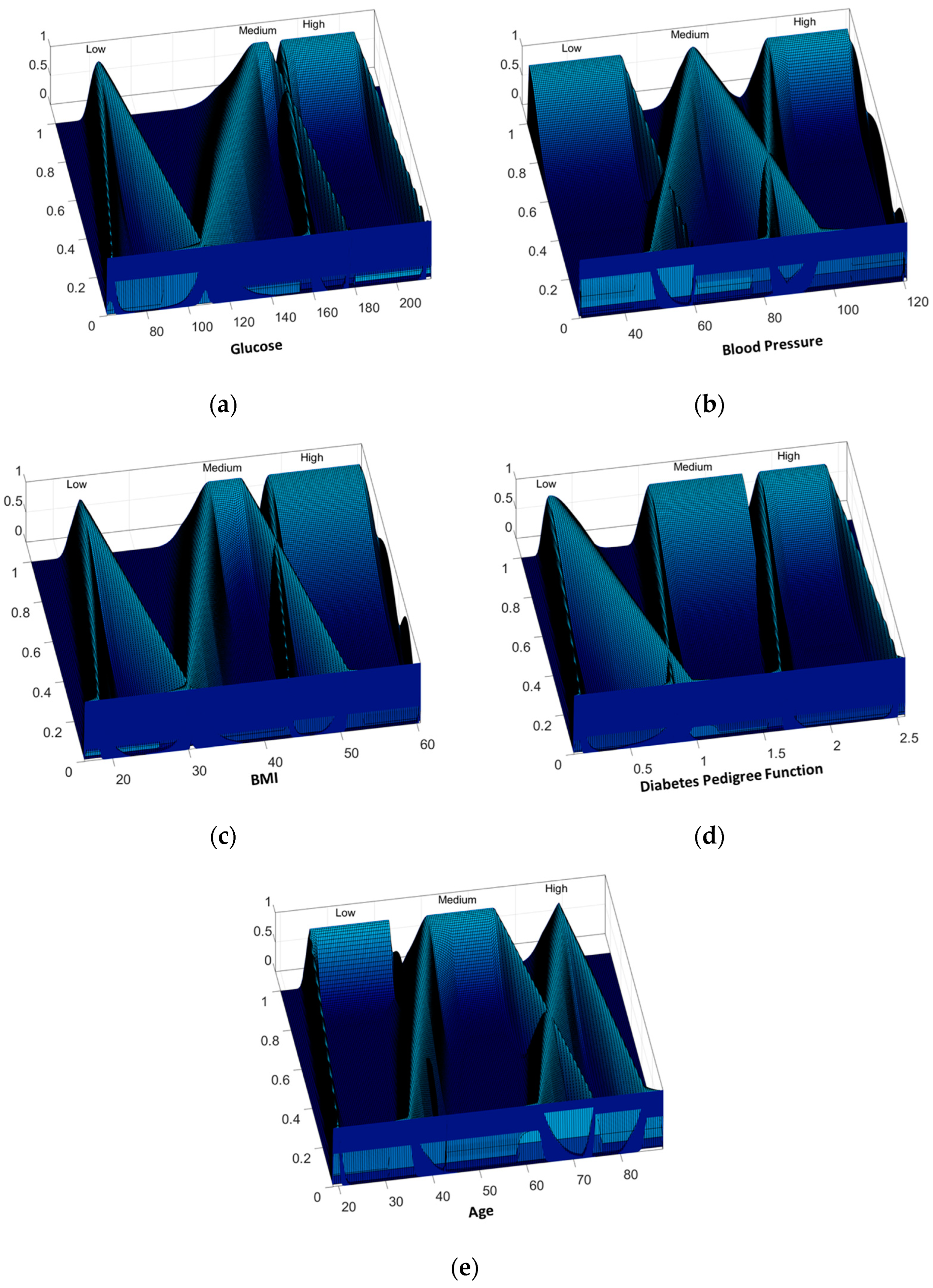
31] using five attributes of the PIMA Indian Diabetes is shown. These results were achieved using T1FIS and IT2FIS and its comparison with the proposed method (IT3FIS).
It can be observed that the best result obtained by the proposed method does not overcome the best results previously obtained by IT2FIS, but the average was surpassed by a large difference for both phases.
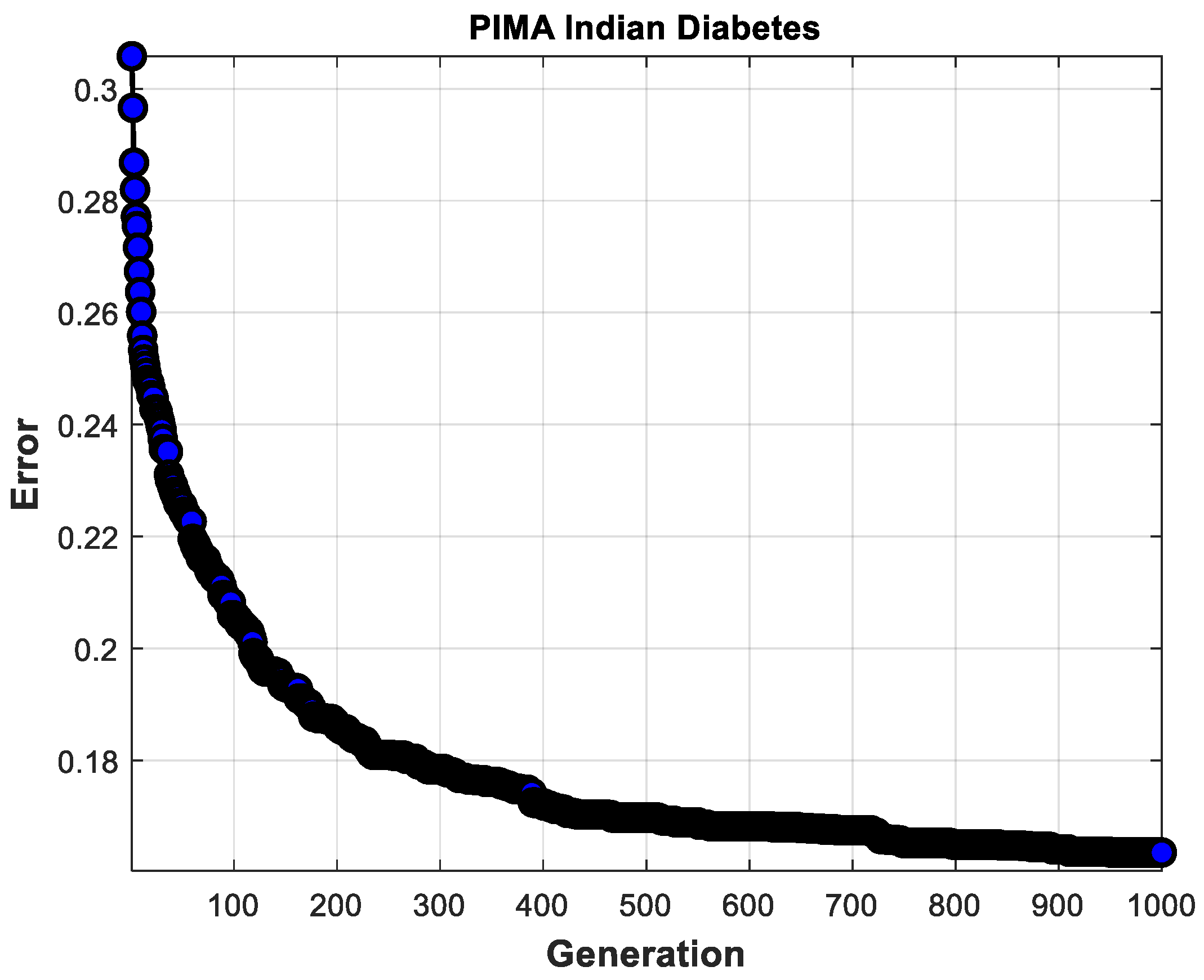
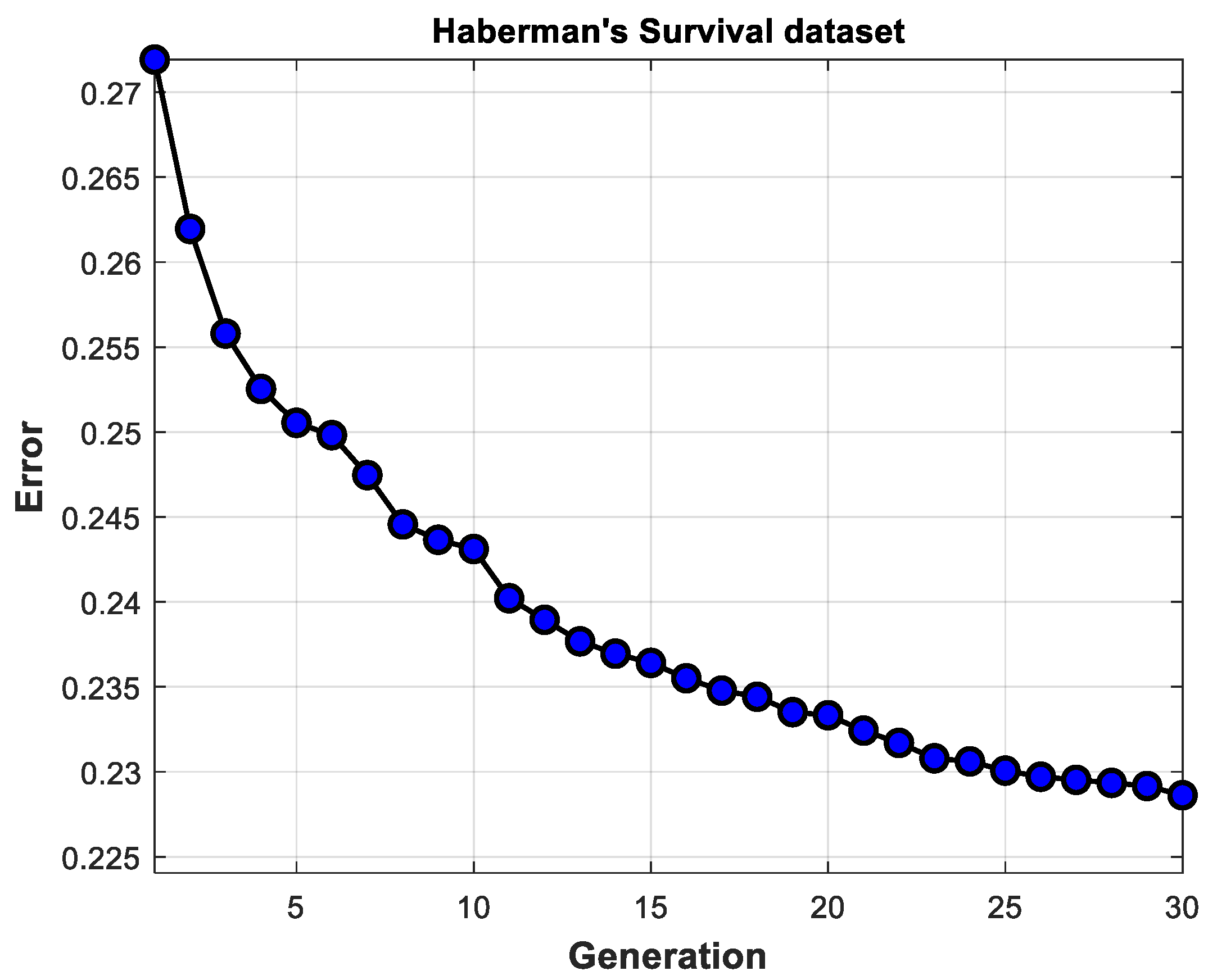
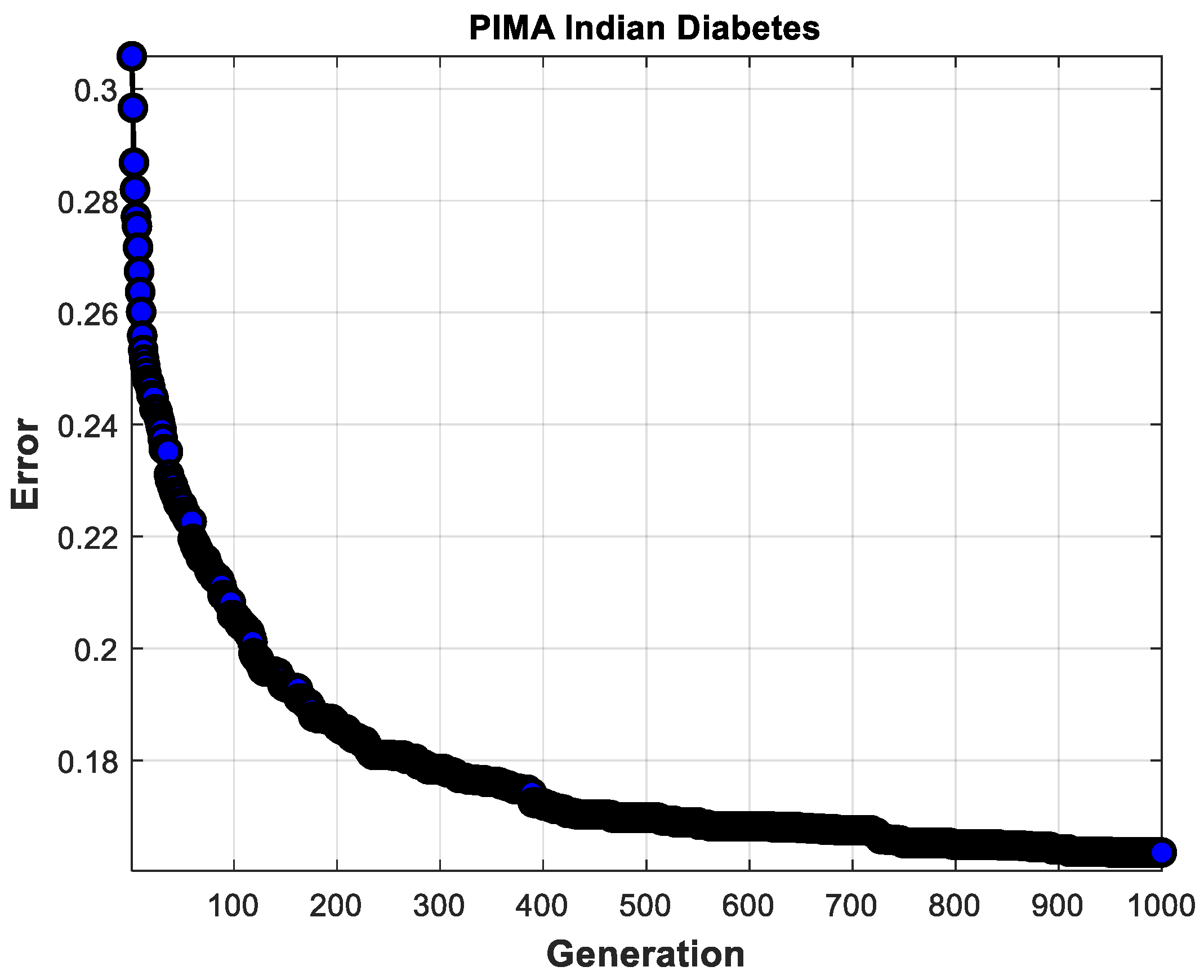
Table 10 shows the average times of the experiments performed with the genetic algorithm for each dataset with the different validations. It can be observed how the use of cross-validation increases the time. It is also important to mention that the number of generations is significant and impacts the amount of time, as in the case of the PIMA Indian dataset with five attributes, where 1000 generations were used for its execution.
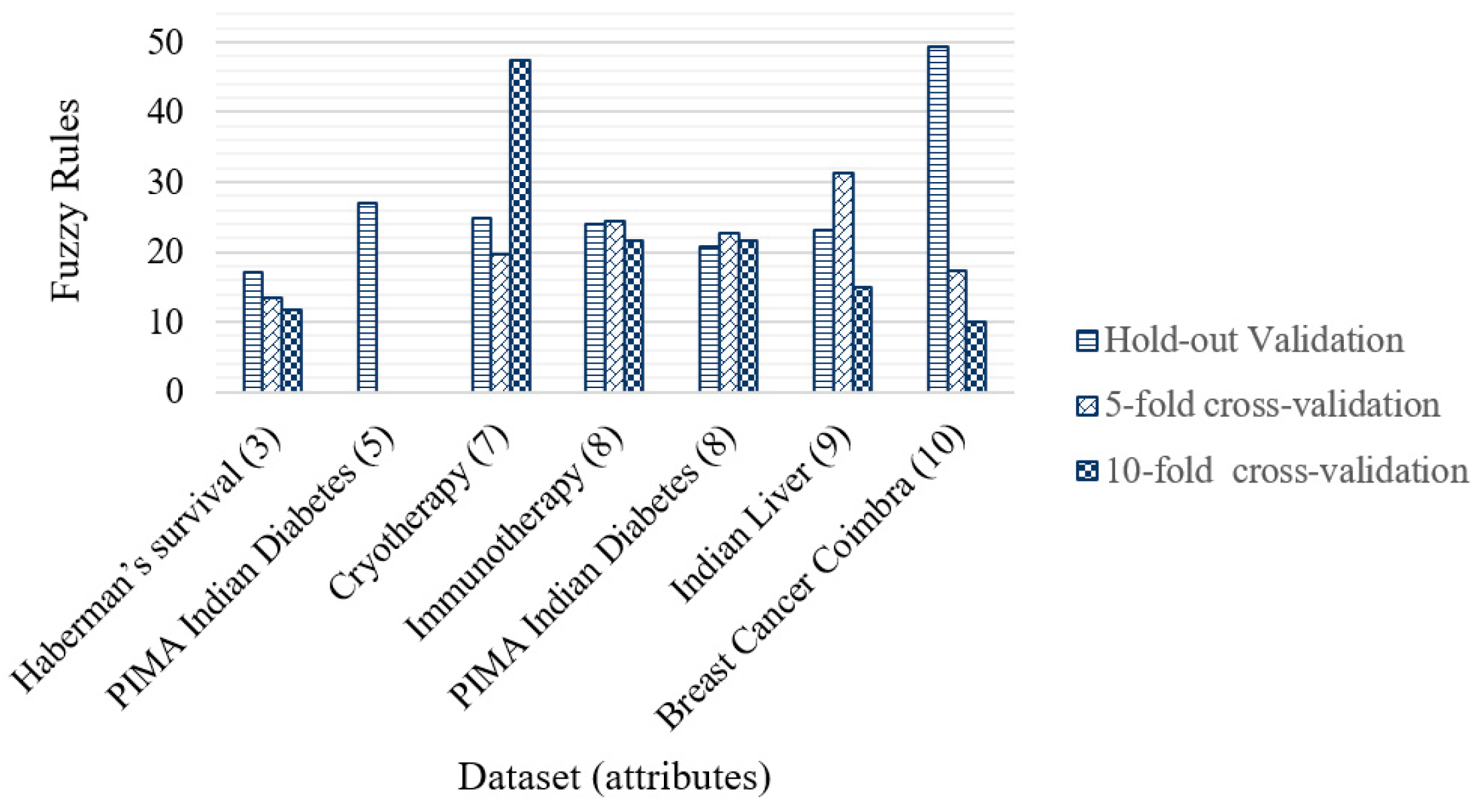
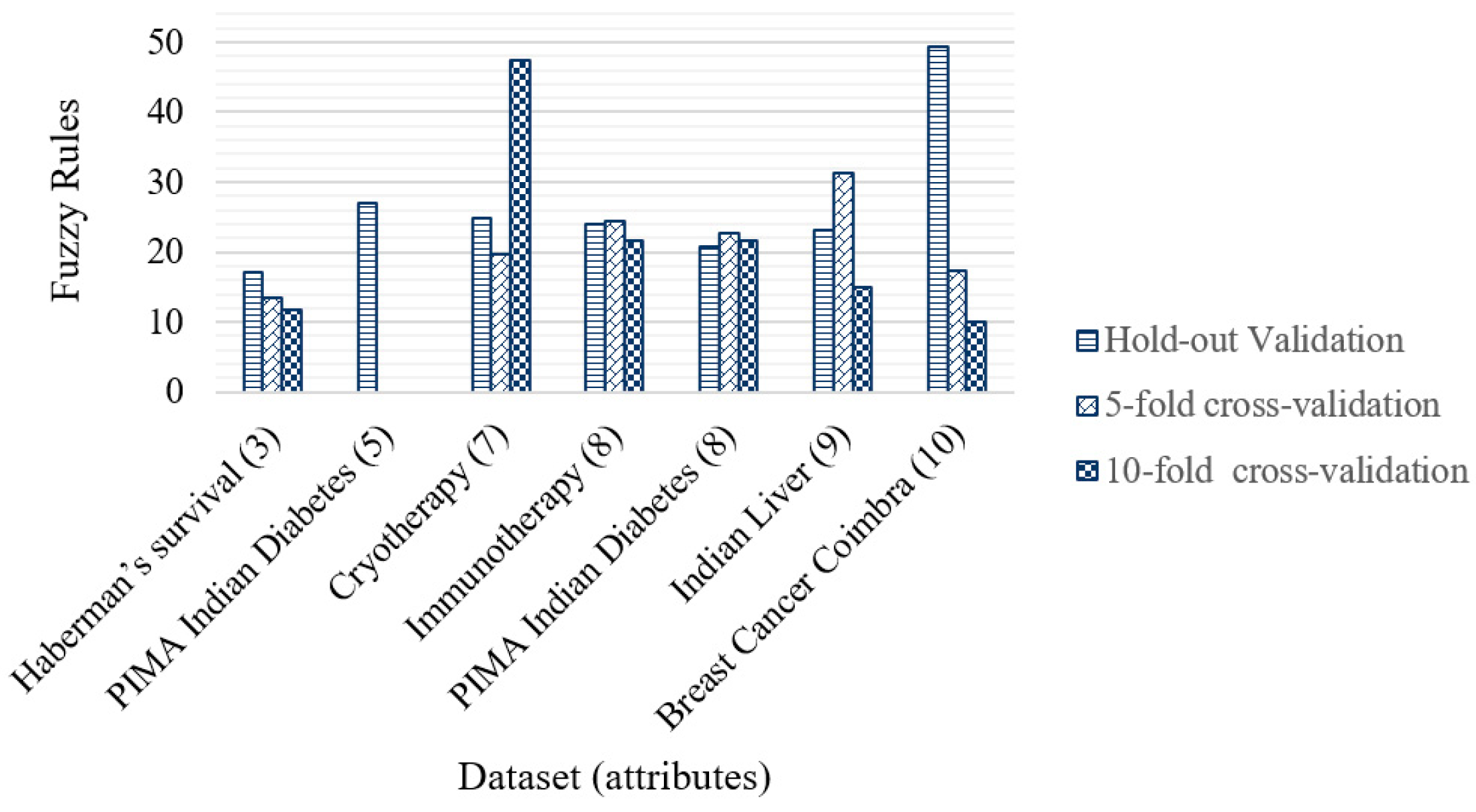
Figure 15 shows the average number of fuzzy rules generated by the genetic algorithm for each dataset with their number of attributes. It can be seen how the 5- and 10-fold cross-validation helped reduce the number of rules for Haberman’s Survival and Breast Cancer Coimbra datasets. In some other cases, only one of the cross-validations allowed a reduction in the number of fuzzy rules, as in the case of the Cryotherapy, Immunotherapy, and Indian Liver datasets. The number of fuzzy rules increased with cross-validations only for the PIMA Indian Diabetes dataset. The proposed method allows the maintenance of an appropriate number of fuzzy rules independently of the number of attributes. In general, the contribution of the optimization of fuzzy rules is essential because their design collaborates with the increase in the percentage of accuracy.
The complexity of a genetic algorithm can be established based on the number of iterations and the number of individuals. For the proposed method, the complexity of the evaluation of each individual lies in the use of Type-3 fuzzy inference systems. The complexity of a Type-3 fuzzy model was described in [
47], where it was determined that complexity based on the vertical-slices theory for centroid type reduction is approximately O(
NKL). Where it is assumed that a primary variable
x is sampled into
N points,
K is the number of iterations to approximate a switch point, and
L means samples for a vertical slice. The complexity is reduced from exponential to linear.
6.1. Statistical Comparison
The results previously shown are used to carry out statistical tests determining if the proposed method allows obtaining a significant advantage over other methods.
Table 11 shows the parameters used to perform the statistical Z-tests and
t-tests presented in this section.
In
Table 12, the comparison between the proposed method (IT3FIS) and T1FIS and IT2FIS developed in a previous work [
31] is shown. Where the Z-values are more than the critical value, then it is concluded that the H
0 is rejected. There is enough evidence to affirm that the proposed method is better than T1FIS and IT2FIS applied to the PIMA Indian Diabetes dataset using only five attributes and 30% of the instances for the evaluation of the FIS designed.
In the results presented in Refs. [
15,
16], the results achieved show the effectiveness of the GT2FIS over T1FIS and IT2FIS. For this reason, the statistical comparison is performed directly between GT2FIS and IT3FIS. In
Table 13, the results achieved using 40% of the instances for evaluating the FIS designed are presented, where the z-values achieved show the improvement provided by the IT3FIS in all the datasets except for Indian Liver and the Breast Cancer Coimbra, where the obtained results by the proposed method are better than GT2FIS but with not enough statistical evidence.
In
Table 14, the results achieved using 20% of the instances for evaluating the FIS designed are presented with five cross-validations, where the
t-values achieved show the improvement allowed by the Interval Type-3 FIS in all the datasets, proving that the proposed method is better than General Type-2 FIS with enough statistical evidence.
The results achieved using 10% of the instances for evaluating the FIS designed are presented in
Table 15 with 10 cross-validations, where the
t-values achieved show the improvement allowed by the Interval Type-3 FIS in all the datasets except for the Breast Cancer Coimbra, where the obtained results by the proposed method are better than General Type-2 FIS but with not enough statistical evidence.
7. Conclusions
This paper proposes the design of Interval Type-3 fuzzy inference systems using a GA applied to medical classification. The GA seeks to find the main fuzzy inference systems parameters, such as MF parameters and the fuzzy if-then rules. Type-3 Trapezoidal MFs are utilized in this work in each input of the FIS; the design of these MFs is based on their LowerScale and LowerLag. An important contribution of our method is the automatic establishment of ranges of the fuzzy variables, where the set of instances used for the design is used to establish them, which allows the proposed method to be applied to different databases with different numbers of attributes (inputs of the FIS). The results achieved in this work allowed us to improve results achieved by other methods based on fuzzy logic. The medical datasets Haberman’s Survival, Cryotherapy, Immunotherapy, PIMA Indian Diabetes, Indian Liver, and Breast Cancer Coimbra dataset achieved 75.30, 87.13, 82.04, 77.76, 71.86, and 71.06, respectively. Cross-validation tests were also carried out using 5- and 10-fold, where for Cryotherapy, Immunotherapy, and Breast Cancer Coimbra databases, the cross-validation improved the accuracy percentage on both phases (design and testing). Statistical tests were performed, and the Z-test demonstrates the effectiveness of the proposed method over General Type-2 FIS in almost all the datasets except for Indian Liver and the Breast Cancer Coimbra. T-tests were applied to validate the behavior of the proposed method with the cross-validation tests. For five cross-validation, the proposed method achieved better results; for the 10 cross-validation tests only for the Breast Cancer Coimbra, there is no statistical difference. In future works, the design of Type-3 FIS proposed in this work will be applied to other areas, such as the integration method applied to pattern recognition, images for edge detection, or control problems, to prove the ability of adaptation of the proposed method.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}