1. Introduction and Background
Recurrent neural networks (RNNs) are an important class of algorithms for computing matrix (generalized) inverses. These algorithms are used to find the solutions of matrix equations or to minimize certain nonlinear matrix functions. RNNs are divided into two subgroups: Gradient Neural Networks (GNNs) and Zhang Neural Networks (ZNNs). The GNN design is explicit and mostly applicable to time-invariant problems, which means that the coefficients of the equations that are addressed are constant matrices. ZNN models can be implicit and are able to solve time-varying problems, where the coefficients of the equations depend on the variable
representing time [
1,
2,
3].
The Moore–Penrose inverse of
is the unique matrix
which is the solution to the well-known Penrose equations [
4,
5]:
where
denotes the transpose matrix. The rank of a matrix
A, i.e., the maximum number of linearly independent columns in
A, is denoted by
.
Applications of linear algebra tools and generalized inverses can be found in important areas such as the modeling of electrical circuits [
6], the estimation of DNA sequences [
7] and the balancing of chemical equations [
8,
9], as well as in other important research domains related to robotics [
10] and statistics [
11]. A number of iterative methods for solving matrix equations based on gradient values have been proposed [
12,
13,
14,
15].
In the following sections, we will focus on GNN and ZNN dynamical systems based on the gradient of the objective function and their implementation. The main goal of this research is the analysis of convergence and the study of analytic solutions.
Models with GNN neural designs for computing the inverse or the Moore–Penrose inverse and linear matrix equations were proposed in [
16,
17,
18,
19]. Further, various dynamical systems aimed at approximating the pseudo-inverse of rank-deficient matrices were developed in [
16]. Wei, in [
20], proposed three RNN models for the approximation of the weighted Moore–Penrose inverse. Online matrix inversion in a complex matrix case was considered in [
21]. A novel GNN design based on nonlinear activation functions (AFs) was proposed and analyzed in [
22,
23] for solving the constant Lyapunov matrix equation online. A fast convergent GNN aimed at solving a system of linear equations was proposed and numerically analyzed in [
24]. Xiao, in [
25], investigated the finite-time convergence of an appropriately accelerated ZNN for the online solution of the time-varying complex matrix equation
. A comparison with the corresponding GNN design was considered. Two improved nonlinear GNN dynamical systems for approximating the Moore–Penrose inverse of full-row or full-column rank matrices were proposed and considered in [
26]. GNN-type models for solving matrix equations and computing related generalized inverses were developed in [
1,
3,
13,
16,
18,
20,
27,
28,
29]. The acceleration of GNN dynamics to a finite-time convergence has been investigated recently. A finite-time convergent GNN for approximating online solutions of the general linear matrix equation
was proposed in [
30]. This goal was achieved using two activation functions (AFs) in the construction of the GNN. The influence of AFs on the convergence performance of a GNN design for solving the matrix equation
was investigated in [
31]. A fixed-time convergent GNN for solving the Sylvester equation was investigated in [
32]. Moreover, noise-tolerant GNN models equipped with a suitable activation function (AF) able to solve convex optimization problems were developed in [
33].
Our goal is to solve the equation
and apply its particular cases in computing generalized inverses in real time by improving the GNN model developed in [
34]. The developed dynamical system is denoted by GNN
. Or motivation is to improve the GNN model denoted by GNN
and develop a novel gradient-based GGNN model, termed GGNN
, utilizing a novel type of dynamical system. The proposed GGNN model is based on the standard GNN dynamics along the gradient of the standard error matrix. The convergence analysis reveals the global asymptotic convergence of GGNN
without restrictions, while the output belongs to the set of general solutions to the matrix equation
.
In addition, we propose gradient-based modifications of the hybrid models developed in [
35] as proper combinations of GNN and ZNN models for solving the matrix equations
and
with constant coefficients. Analogous hybridizations for approximating the matrix inverse were developed in [
36], while two modifications of the ZNN design for computing the Moore–Penrose inverse were proposed in [
37]. Hybrid continuous-gradient–Zhang neural dynamics for solving linear time-variant equations were investigated in [
38,
39]. The developed hybrid GNN-ZNN models in this paper are aimed at solving the matrix equations
and
, denoted by
and
, respectively.
The implementation was performed in MATLAB Simulink, and numerical experiments were performed with simulations of the GNN, GGNN and HGZNN models.
The GNN used to solve the general linear matrix equation
is defined over the error matrix
, where
is time, and
is an unknown state-variable matrix that approximates the unknown matrix
X in
. The goal function is
, where
denotes the Frobenius norm of a matrix. The gradient of
is equal to
The GNN evolutionary design is defined by the dynamic system
where
is a real parameter used to speed up the convergence, and
denotes the time derivative of
. Thus, the linear GNN aimed at solving
is given by the following dynamics:
The dynamical flow (
2) is denoted as GNN
. The nonlinear GNN
for solving
is defined by
The function array
is based on the appropriate odd and monotonically increasing activation function, which is applicable to the elements of a real matrix
, i.e.,
.
Proposition 1 restates restrictions on the solvability of and its general solution.
Proposition 1 ([
4,
5])
. If and , then the fulfillment of the conditionis necessary and sufficient for the solvability of the linear matrix equation . In this case, the set of all solutions is given by The following results from [
34] describe the conditions of convergence and the limit of the unknown matrix
from (
3) as
.
Proposition 2 ([
34])
. Suppose the matrices and satisfy (4). Then, the unknown matrix from (3) converges as with the equilibrium statefor any initial state-variable matrix The research in [
40] investigated various ZNN models based on optimization methods. The goal of the current research is to develop a GNN model based on the gradient
of
instead of the original goal function
.
The obtained results are summarized as follows:
A novel error function is proposed for the development of the GNN dynamical evolution.
The GNN design based on the error function is developed and analyzed theoretically and numerically.
A hybridization of GNN and ZNN dynamical systems based on the error matrix is proposed and investigated.
The overall organization of this paper is as follows. The motivation and derivation of the GGNN and GZNN models are presented in
Section 2.
Section 3 is dedicated to the convergence analysis of GGNN dynamics. A numerical comparison of GNN and GGNN dynamics is given in
Section 4. Neural dynamics based on the hybridization of GGNN and GZNN models for solving matrix equations are considered in
Section 6. Numerical examples of hybrid models are analyzed in
Section 6. Finally, the last section presents some concluding remarks and a vision of further research.
2. Motivation and Derivation of GGNN and GZNN Models
The standard GNN design (
2) solves the GLME
under constraint (
4). Our goal is to resolve this restriction and propose dynamic evolutions based on error functions that tend to zero without restrictions.
Our goal is to define the GNN design for solving the GLME
based on the error function
According to known results from nonlinear unconstrained optimization [
41], the equilibrium points of (
7) satisfy
We continue the investigation from [
40]. More precisely, we develop the GNN model based on the error function
instead of the error function
. In this way, new neural dynamics are aimed at forcing the gradient
to zero instead of the standard goal function
. It is reasonable to call such an RNN model a gradient-based GNN (abbreviated GGNN).
Proposition 3 gives the conditions for the solvability of the matrix equations and and the general solutions to these systems.
Proposition 3 ([
40])
. Consider the arbitrary matrices , and . The following statements are true:- (a)
The equation is solvable if and only if (4) is satisfied, and the general solution to is given by (5). - (b)
The equation is always solvable, and its general solution coincides with (5).
Proof. (a) This part of the proof follows from known results on the solvability and general solution of the matrix equation
of generalized inverses [
4] (p. 52, Theorem 1) and its application to the matrix equation
.
(b) According to [
4] (p. 52, Theorem 1), the matrix equation
is consistent if and only if
is satisfied. Indeed, applying the properties
,
and
,
of the Moore–Penrose inverse [
5] results in
In addition, based on [
4] (p. 52, Theorem 1), the general solution
to
is
which coincides with (
5). □
In this way, the matrix equation
is solvable under condition (
4), while the equation
is always consistent. In addition, the general solutions to equations
and
are identical [
40].
The next step is to define the GGNN dynamics using the error matrix
. Let us define the objective function
, whose gradient is equal to
The dynamical system for the GGNN formula is obtained by applying the GNN evolution along the gradient of
based on
, as follows:
The nonlinear GGNN dynamics are defined as
in which
denotes the elementwise application of an odd and monotonically increasing function
, as mentioned in the previous section for the GNN model (
3). Model (
10) is termed GGNN
. Three activation functions
are used in numerical experiments:
- 1.
- 2.
Power-sigmoid activation function
where
, and
is an odd integer;
- 3.
Smooth power-sigmoid function
where
, and
is an odd integer.
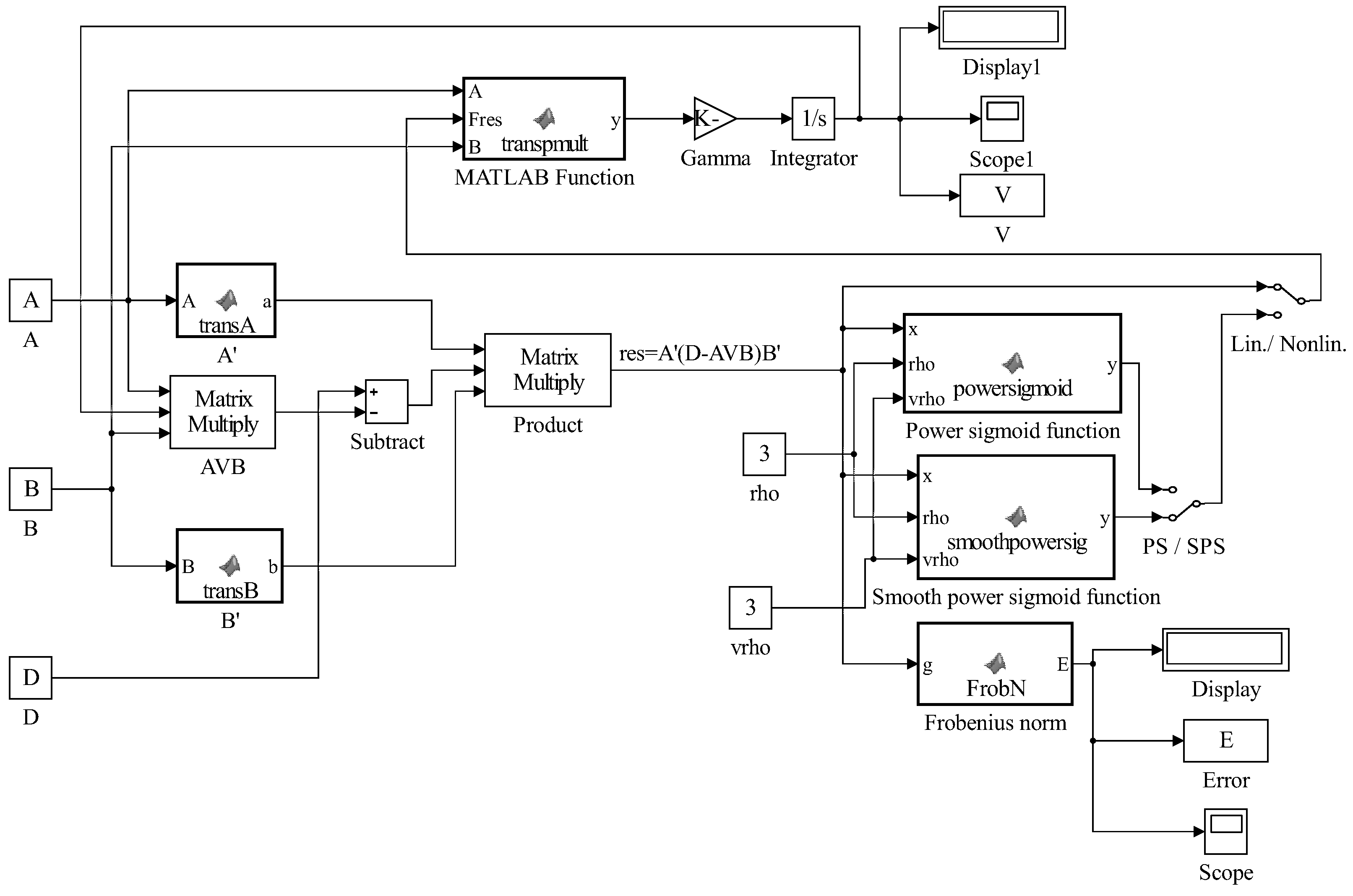
Figure 1 represents the Simulink implementation of GGNN
dynamics (
10).
On the other hand, the GZNN model, defined using the ZNN dynamics on the Zhangian matrix
, is defined in [
40] by the general evolutionary design
4. Numerical Experiments on GNN and GGNN Dynamics
The numerical examples in this section are based on the Simulink implementation of the GGNN formula in
Figure 1.
The parameter
, initial state
and parameters
and
of the nonlinear activation functions (
12) and (
13) are entered directly into the model, while matrices
A,
B and
D are defined from the workspace. It is assumed that
in all examples. The
ode15s differential equation solver is used in the configuration parameters. In all examples,
denotes the theoretical solution.
The blocks
powersig, smoothpowersig and
transpmult include the codes described in [
34,
42].
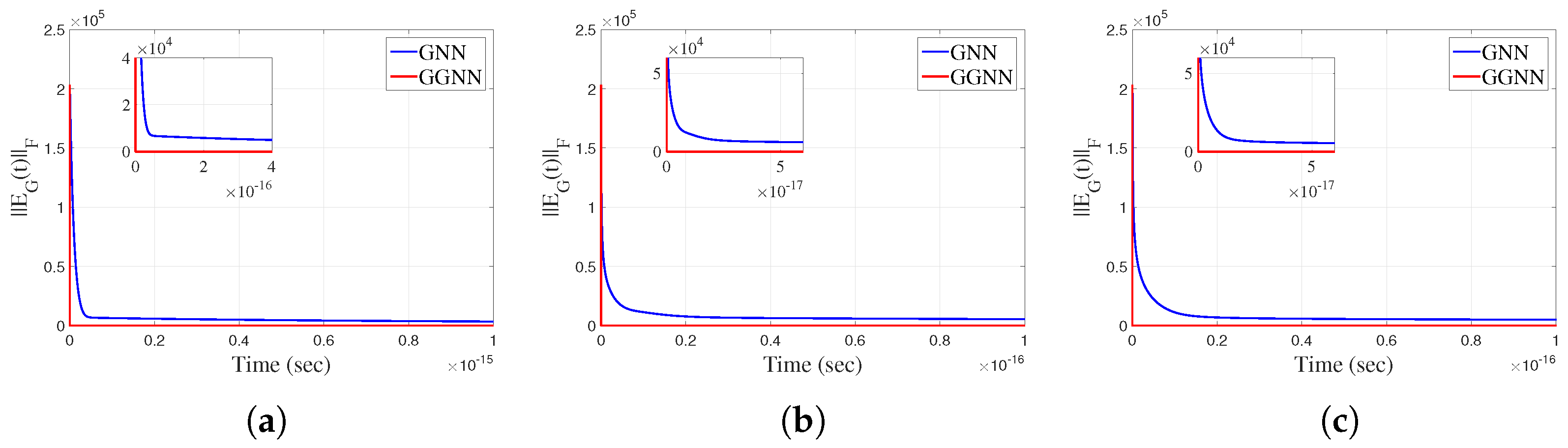
Example 1. Let us consider the idempotent matrix A from [43,44],of , and the theoretical Moore–Penrose inverse The matrix equation corresponding to the Moore–Penrose inverse is [16], which implies the error function . The corresponding GNN model is defined by GNN, where denotes the identity and zero matrix. Constraint (4) reduces to the condition , which is not satisfied. The input parameters of GNN are , , where denotes the zero matrix. The corresponding GGNN design is based on the error matrix The Simulink implementation of GGNN from Figure 1 and the Simulink implementation of GNN from [34] export, in this case, the graphical results presented in Figure 2 and Figure 3, which display the behaviors of the norms and , respectively. It is observable that the norms generated by the application of the GGNN formula vanish faster to zero than the corresponding norms in the GNN model. The graphs in the presented figures strengthen the fast convergence of the GGNN dynamical system and its important role, which can include the application of this specific model (10) to problems that require the computation of the Moore–Penrose inverse. Example 2. Let us consider the matrices The exact minimum-norm least-squares solution is The ranks of the input matrices are equal to , and . Constraint (4) is satisfied in this case. The linear GGNN formula (10) is applied to solve the matrix equation . The gain parameter of the model is , , and the stopping time is , which gives The elementwise trajectories of the state variables of the state matrix are shown in Figure 4a–c with solid red lines for linear, power-sigmoid and smooth power-sigmoid activation functions, respectively. The fast convergence of elementwise trajectories to the corresponding black dashed trajectories of the theoretical solution is notable. In addition, faster convergence caused by the nonlinear AFs and is noticeable in Figure 4b,c. The trajectories in the figures indicate the usual convergence behavior, so the system is globally asymptotically stable. The norms of the error matrix of both models GNN and GGNN under linear and nonlinear AFs are shown in Figure 5a–c. The power-sigmoid and smooth power-sigmoid activation functions show superiority in their convergence speed compared with linear activation. On each graph in Figure 5a–c, the Frobenius norm of the error matrix in the GGNN formula vanishes faster to zero than that in the GNN model. Moreover, in each graph in Figure 6a–c, the Frobenius norm in the GGNN formula vanishes faster to zero than that in the GNN model, which strengthens the fact that the proposed dynamical system (10) initiates accelerated convergence compared to (3). All graphs shown in
Figure 5 and
Figure 6 confirm the applicability of the proposed GGNN design compared to the traditional GNN design, even if constraint (
4) holds.
Example 3. Let us explore the behavior of GNN and GGNN dynamics for computing the Moore–Penrose inverse of the matrix The Moore–Penrose inverse of A is equal to The rank of the input matrix is equal to . Consequently, the matrix A is left invertible and satisfies . The error matrix initiates the GNN dynamics for computing . The gradient-based error matrixinitiates the GGNN design. The gain parameter of the model is , and the initial state is with a stop time .
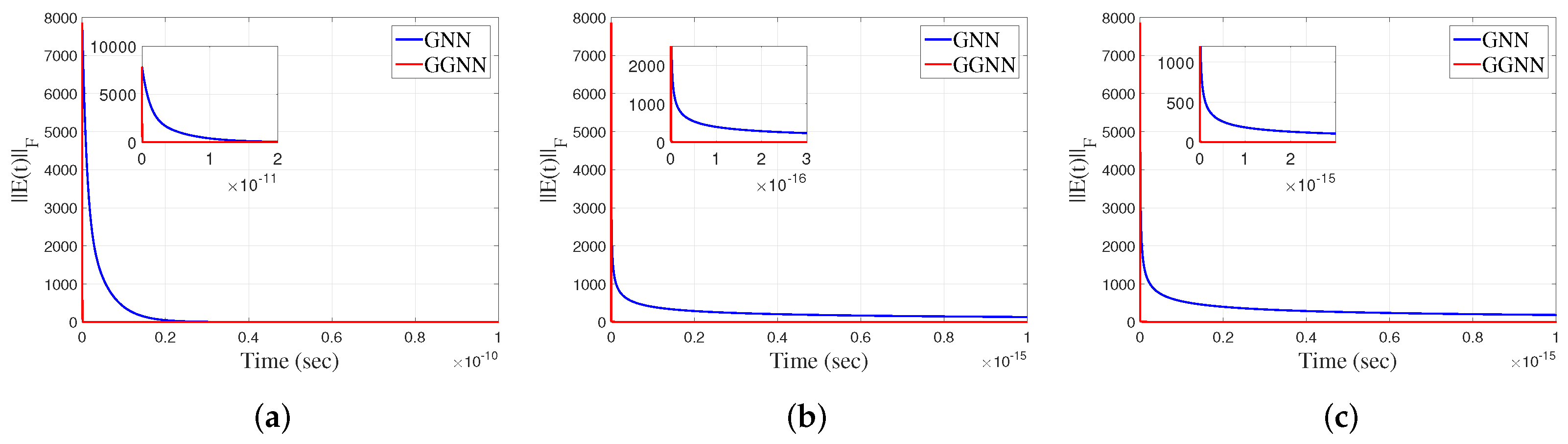
The Frobenius norms of the error matrix generated by the linear GNN and GGNN models for different values of γ () are shown in Figure 7a–c. The graphs in these figures confirm an increase in the convergence speed, which is caused by the increase in the gain parameter γ. Because of that, the considered time intervals are , and , respectively. In all three scenarios, a faster convergence of the GGNN model is observable compared to the GNN design. The values of the norm generated by both the GNN and GGNN models with linear and two nonlinear activation functions are shown in Figure 8a–c. Like the conclusion in the previous example, the perception is that the GGNN converges faster compared to the GNN model. In addition, the graphs in Figure 8b,c, corresponding to the power-sigmoid and smooth power-sigmoid AFs, respectively, show a certain level of instability in convergence, as well as an increase in the value of . Example 4. Consider the matriceswhich dissatisfy . Now, we apply the GNN and GGNN formulae to solve the matrix equation . The standard error function is defined as . So, we consider GNN. The error matrix for the corresponding GGNN model is which initiates the GGNN flow. The gain parameter of the model is , and the final time is . The zero initial state generates the best approximate solution of the matrix equation , given by The Frobenius norms of the error matrix in the GNN and GGNN models for both linear and nonlinear activation functions are shown in Figure 9a–c, and the error matrix in both models for linear and nonlinear activation functions are shown in Figure 10a–c. It is observable that the GGNN converges faster than GNN. Example 5. Table 1 and Table 2 show the results obtained during experiments we conducted with nonsquared matrices, where is the dimension of the matrix. Table 1 lists the input data that were used to perform experiments with the Simulink model and generated the results in Table 2. The best cases in Table 2 are marked in bold text. The numerical results arranged in
Table 2 are divided into two parts by a horizontal line. The upper part corresponds to the test matrices of dimensions
, while the lower part corresponds to the dimensions
. Considering the first two columns, it is observable from the upper part that the GGNN generates smaller values
compared to the GGNN. The values of
in the lower part generated by the GNN and GGNN are equal. Considering the third and fourth columns, it is observable from the upper part that the GGNN generates smaller values
compared to the GGNN. On the other hand, the values of
in the lower part, generated by the GGNN, are smaller than the corresponding values generated by the GNN. The last two columns show that the GGNN requires less CPU time compared to the GNN. The general conclusion is that the GGNN model is more efficient in rank-deficient test matrices of larger order
.
5. Mixed GGNN-GZNN Model for Solving Matrix Equations
The gradient-based error matrix for solving the matrix equation
is defined by
The GZNN design (
14) corresponding to the error matrix
, designated GZNN
, is of the form:
Now, the scalar-valued norm-based error function corresponding to
is given by
The following dynamic state equation can be derived using the GGNN
design formula based on (
10):
Further, using a combination of
and the GNN dynamics (
23), it follows that
The next step is to define the new hybrid model based on the summation of the right-hand sides in (
22) and (
24), as follows:
The model (
25) is derived from the combination of the model GGNN
and the model GZNN
. Hence, it is equally justified to use the term Hybrid GGNN (abbreviated HGGNN) and Hybrid GZNN (abbreviated HGZNN) model. But model (
25) is implicit, so it is not a type of GGNN dynamics. On the other hand, it is designed for time-invariant matrices, which is not in accordance with the common nature of GZNN models, because usually, the GZNN is used in the time-varying case. A formal comparison of (
25) and GZNN
reveals that both these methods possess identical left-hand sides, and the right-hand side of (
25) can be derived by multiplying the right-hand side of GZNN
by the term
.
Formally, (
25) is closer to GZNN dynamics, so we will denote the model (
25) by HGZNN
, considering that this model is not the exact GZNN neural dynamics and is applicable to time-invariant case. This is the case of the constant coefficient matrices
A,
I and
B.
Figure 11 represents the Simulink implementation of HGZNN
dynamics (
25).
Now, we will take into account the process of solving the matrix equation
. The error matrix for this equation is defined by
The GZNN design (
14) corresponding to the error matrix
, denoted by GZNN
, is of the form:
On the other hand, the GGNN design formula (
10) produces the following dynamic state equation:
The GGNN model (
27) is denoted by GGNN
. It implies
A new hybrid model based on the summation of the right-hand sides in (
26) and (
28) can be proposed as follows:
The Model (
29) will be denoted by HGZNN
. This is the case with the constant coefficient matrices
I,
C and
D.
For the purposes of the proof of the following results, we will use to denote the exponential convergence rate of the model . With and , we denote the smallest and largest eigenvalues of the matrix K, respectively. Continuing the previous work, we use three types of activation functions : linear, power-sigmoid and smooth power-sigmoid.
The following theorem determines the equilibrium state of HGZNN and defines its global exponential convergence.
Theorem 3. Let be given and satisfy , and let be the state matrix of (25), where is defined by , or . - (a)
Then, achieves global convergence and satisfies when , starting from any initial state . The state matrix of HGZNN is stable in the sense of Lyapunov.
- (b)
The exponential convergence rate of the HGZNN
model (25) in the linear case is equal towhere is the minimum singular value of A. - (c)
The activation state variable matrix of the model HGZNN
is convergent when with the equilibrium state matrix
Proof. (a) The assumption provides the solvability of the matrix equation .
The appropriate Lyapunov function is defined as
Hence, from (
25) and
, it holds that
According to similar results from [
45], one can verify the following inequality:
We also consider the following inequality from [
46], which is valid for a real symmetric matrix
K and a real symmetric positive-semidefinite matrix
L of the same size:
Now, the following can be chosen:
and
. Consider
, where
is the minimum eigenvalue of
A, and
is the minimum singular value of
A. Then,
is the minimum nonzero eigenvalue of
, which implies
From (
33), it can be concluded
According to (
34), the Lyapunov stability theory confirms that
is a globally asymptotically stable equilibrium point of the HGZNN
model (
25). So,
converges to the zero matrix, i.e.,
, from any initial state
.
- (b)
From (a), it follows that
This implies
which confirms the convergence rate (
30) of HGZNN
.
- (c)
This part of the proof can be verified with the particular case of Theorem 2.
□
Theorem 4. Let be given and satisfy , and let be the state matrix of (29), where is defined by , or . - (a)
Then, achieves global convergence when , starting from any initial state . The state matrix of HGZNN is stable in the sense of Lyapunov.
- (b)
The exponential convergence rate of the HGZNN
model (29) in the linear case is equal to - (c)
The activation state variable matrix of the model HGZNN
is convergent when with the equilibrium state matrix
Proof. (a) The assumption ensures the solvability of the matrix equation .
Let us define the Lyapunov function by
Hence, from (
29) and
, it holds that
Following the principles from [
45], one can verify the following inequality:
Consider the inequality (
32) with the particular settings
,
. Let
be the minimum eigenvalue of
. Then,
is the minimal nonzero eigenvalue of
, which implies
From (
37), it can be concluded
According to (
38), the Lyapunov stability theory confirms that
is a globally asymptotically stable equilibrium point of the HGZNN
model (
29). So,
converges to the zero matrix, i.e.,
, from any initial state
.
This implies
which confirms the convergence rate (
35) of HGZNN
.
- (c)
This part of the proof can be verified with the particular case of Theorem 2.
□
Corollary 1. (a)
Let the matrices be given and satisfy , and let be the state matrix of (25), with an arbitrary nonlinear activation . Then, and .(b)
Let the matrices be given and satisfy , and let be the state matrix of (29) with an arbitrary nonlinear activation . Then, and .
From Theorem 3 and Corollary 1(a), it follows that
Similarly, according to Theorem 4 and Corollary 1(b), it can be concluded that
Remark 1. (a)
According to (40), it follows that . According to (39), it is obtained According to (41), it follows As a result, the following conclusions follow:
- -
HGZNN is always faster than GGNN;
- -
HGZNN is faster than GZNN in the case where ;
- -
GZNN is faster than GGNN in the case where .
(b)
According to (43), it follows that . According to (42), it follows thatAccording to (41) and (44), it can be verified As a result, the following conclusions follow:
- -
HGZNN is always faster than GGNN;
- -
HGZNN is faster than GZNN in the case where ;
- -
GZNN is faster than GGNN in the case where .
Remark 2. The particular HGZNN and GGNN designs define the corresponding modifications of the improved GNN design proposed in [26] if is invertible. In the dual case, HGZNN and GGNN define the corresponding modifications of the improved GNN design proposed in [26] if is invertible. Regularized HGZNN Model for Solving Matrix Equations
The convergence of HGZNN (resp. HGZNN), as well as GGNN (resp. GGNN), can be improved in the case where (resp. ). There exist two possible situations when the acceleration terms and improve the convergence. The first case assumes the invertibility of A (resp. C), and the second case assumes the left invertibility of A (resp. right invertibility of C). Still, in some situations, the matrices A and C could be rank-deficient. Hence, in the case where A and C are square and singular, it is useful to use the invertible matrices and , instead of A and C and to consider the models HGZNN and HGZNN. The following presents the convergence results considering the nonsingularity of and .
Corollary 2. Let , be given and be the state matrix of (25), where is defined by , or . Let be a selected real number. Then, the following statements are valid: - (a)
The state matrix of the model HGZNN
converges globally towhen , starting from any initial state , and the solution is stable in the sense of Lyapunov. - (b)
The exponential convergence rate of HGZNN
in the case where is equal to - (c)
Let be the limiting value of when . Then,
Proof. Since is invertible, it follows that .
From (
31) and the invertibility of
, we conclude the validity of (a). In this case, it follows that
The part (b) is proved analogously to the proof of Theorem 3. The last part (c) follows from (a). □
Corollary 3. Let , be given and be the state matrix of (29), where or . Let be a selected real number. Then, the following statements are valid: - (a)
The state matrix of HGZNN
converges globally towhen , starting from any initial state , and the solution is stable in the sense of Lyapunov. - (b)
The exponential convergence rate of HGZNN
in the case where is equal to - (c)
Let be the limiting value of when . Then,
Proof. It can be proved analogously to Corollary 2. □
Remark 3. (a)
According to (40), it can be concluded thatBased on (39) it can be concludedAccording to (41), one concludes(b)
According to (43), it can be concludedAccording to (42), it followsBased on (41) and (44), it can be concluded 6. Numerical Examples on Hybrid Models
In this section, numerical examples are presented based on the Simulink implementation of the HGZNN formula. The previously mentioned three types of activation functions
in (
11), (
12) and (
13) will be used in the following examples. The parameters
, the initial state
and the parameters
and
of the nonlinear activation functions (
12) and (
13) are entered directly into the model, while the matrices
A,
B,
C and
D are defined from the workspace. We assume that
in all examples. The ordinary differential equation solver in the configuration parameters is ode15s.
We present numerical examples in which we compare Frobenius norms and , which are generated by HGZNN, GZNN and GGNN.
Example 6. In this example, we compare the HGZNN model with GZNN and GGNN, considering all three types of activation functions. The gain parameter of the model is , the initial state , and the final time is .
The Frobenius norm of the error matrix in the HGZNN, GZNN and GGNN models for both linear and nonlinear activation functions are shown in Figure 12a–c, and the error matrices of both models for linear and nonlinear activation functions are shown in Figure 13a–c. On each graph, the Frobenius norm of the error from the HGZNN formula vanishes faster to zero than those from the GZNN and GGNN models. Example 7. In this example, we compare the HGZNN model with GZNN and GGNN, considering all three types of activation functions. The gain parameter of the model is , the initial state , and the final time is .
The elementwise trajectories of the state variable are shown with red lines in
Figure 14a–c, for linear, power-sigmoid and smooth power-sigmoid activation functions, respectively. The solid red lines corresponding to HGZNN
converge to the black dashed lines of the theoretical solution
X. It is observable that the trajectories indicate the usual convergence behavior, so the system is globally asymptotically stable. The error matrices
of the HGZNN, GZNN and GGNN models for both linear and nonlinear activation functions are shown in
Figure 15a–c, and the residual matrices
of both models for linear and nonlinear activation functions are shown in
Figure 16a–c. In each graph, for both error cases, the Frobenius norm of the error of the HGZNN formula is similar to the Frobenius norm of the error of the GZNN model, and they both converges faster to zero than the GGNN model.
Remark 4. In this remark, we analyze the answer to the question, “how are the system parameters selected to obtain better performance?” The answer is complex and consists of several parts.
- 1.
The gain parameter γ is the parameter with the most influence on the behavior of the observed dynamic systems. The general rule is “the parameter γ should be selected as large as possible”. The numerical confirmation of this fact is investigated in Figure 7. - 2.
The influence of γ and AFs is indisputable. The larger the value of γ, the faster the convergence. And, clearly, AFs increase convergence compared to the linear models. In the presented numerical examples, we investigate the influence of three AFs: linear, power-sigmoid and smooth power-sigmoid.
- 3.
The right question is as follows: what makes the GGNN
better than the GNN
under fair conditions that assume an identical environment during testing? Numerical experiments show better performance of the GGNN
design compared to the GNN
with respect to all three tested criteria: , and . Moreover, Table 2 in Example 5 is aimed at convergence analysis. The general conclusion from the numerical data arranged in Table 2 is that the GGNN model is more efficient compared to the GNN in rank-deficient test matrices of larger order . - 4.
The convergence rate of the linear hybrid model depends on γ and the singular value , while the convergence rate of the hybrid model depends on γ and .
- 5.
The convergence of the linear regularized hybrid model depends on γ, and the regularization parameter , while the convergence of the linear regularized hybrid model depends on γ, and λ.
In conclusion, it is reasonable to analyze the system parameter selections to obtain better performance. But the best performance is not defined.


 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}