
Multilevel Ordinal Logit Models: A Proportional Odds Application Using Data from Brazilian Higher Education Institutions



Abstract
1. Introduction
2. Ordinal Logit Regression—A Traditional Proportional Odds Approach
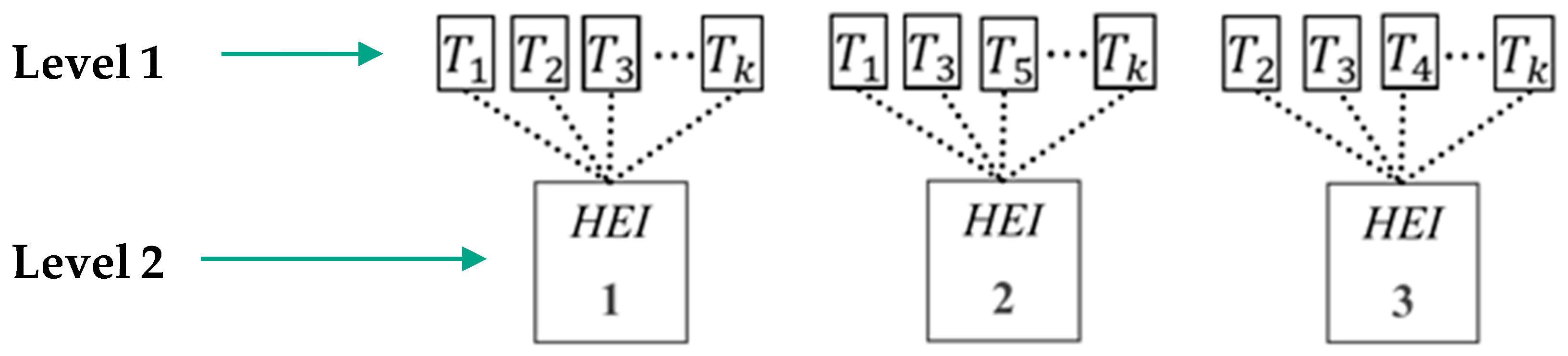
3. Multilevel Perspective
4. A Multilevel Proportional Odds Approach
- Level 1:where refers to the logits of an event of interest for the observations belonging to the group ; and refers to the level 1 parameters of the estimation.
- Level 2:where and correspond to the level 2 parameters; corresponds to the intercept random effects of the second level, and indicates the slope random effects of level 2.
- General Model:
5. Data
6. Empirical Application
- Linear GLM estimation:
- Binary GLM estimation:
- Ordinal GLM estimation:
- GLLAMM estimation:
7. Comparison of Research Models and Discussion
7.1. The GLM Linear Estimation
7.2. The GLM Binary Estimation
- ▪
- If the intention is to try to study, based on the variables present in the database, which factors lead an HEI to be in the top positions of the WEBOMETRICS ranking (Group , in this case), why should the stratum be mixed with the stratum ?
- ▪
- On the other hand, if the intention is to understand what leads an HEI to fall into the very bottom positions of the ranking studied, why mix group with stratum ?
- ▪
- However, if the intention is to study the composition of the Group or the Group , what should be performed with the HEIs in the groups , , and ?
- ▪
- If we assume the conjunction of groups and , forming a new category, and the mixture of and generating another category, what should we do with the individuals in the Group ?
7.3. The GLM and GLLAMM Ordinal Estimations
7.3.1. OR Analysis
- For Ordinal GLM estimation:
- For Ordinal GLLAMM estimation:
- For Ordinal GLM estimation:
- For Ordinal GLLAMM estimation:
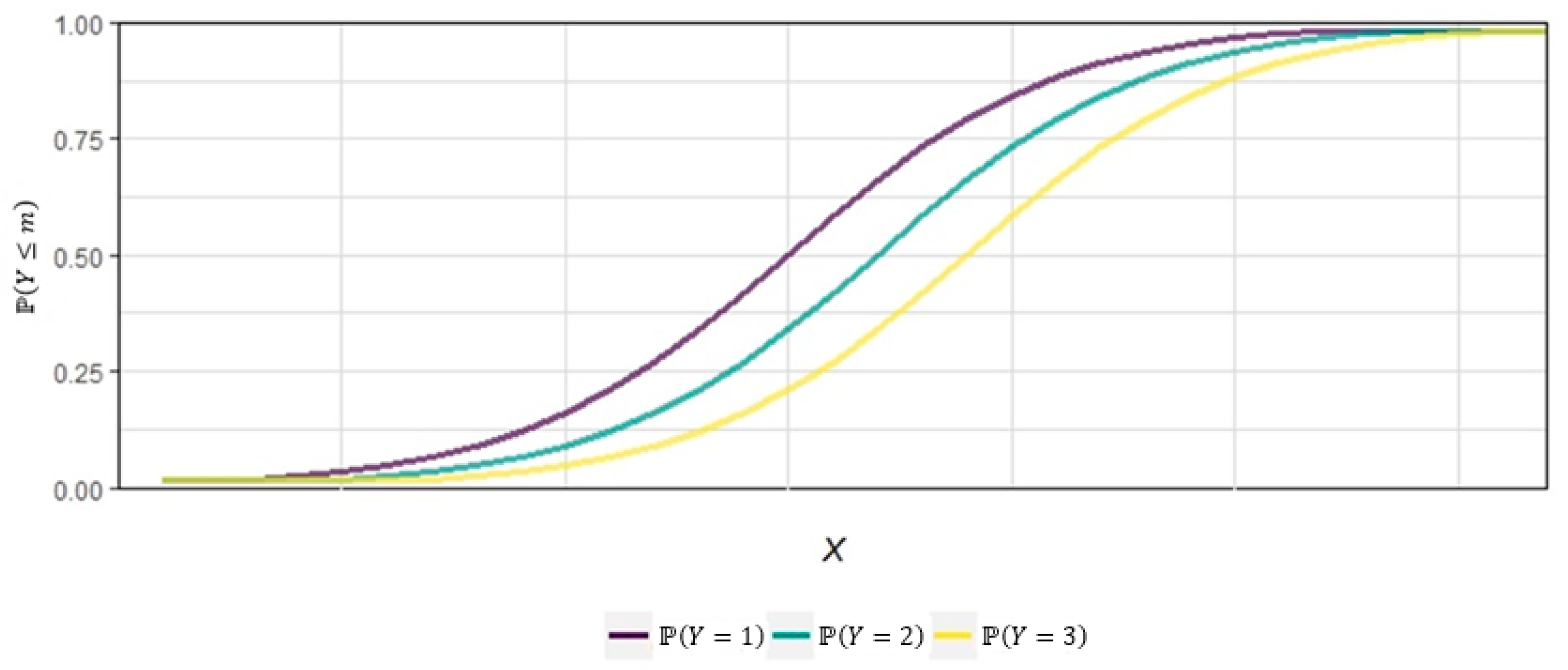
7.3.2. Intercept (Threshold) Analysis
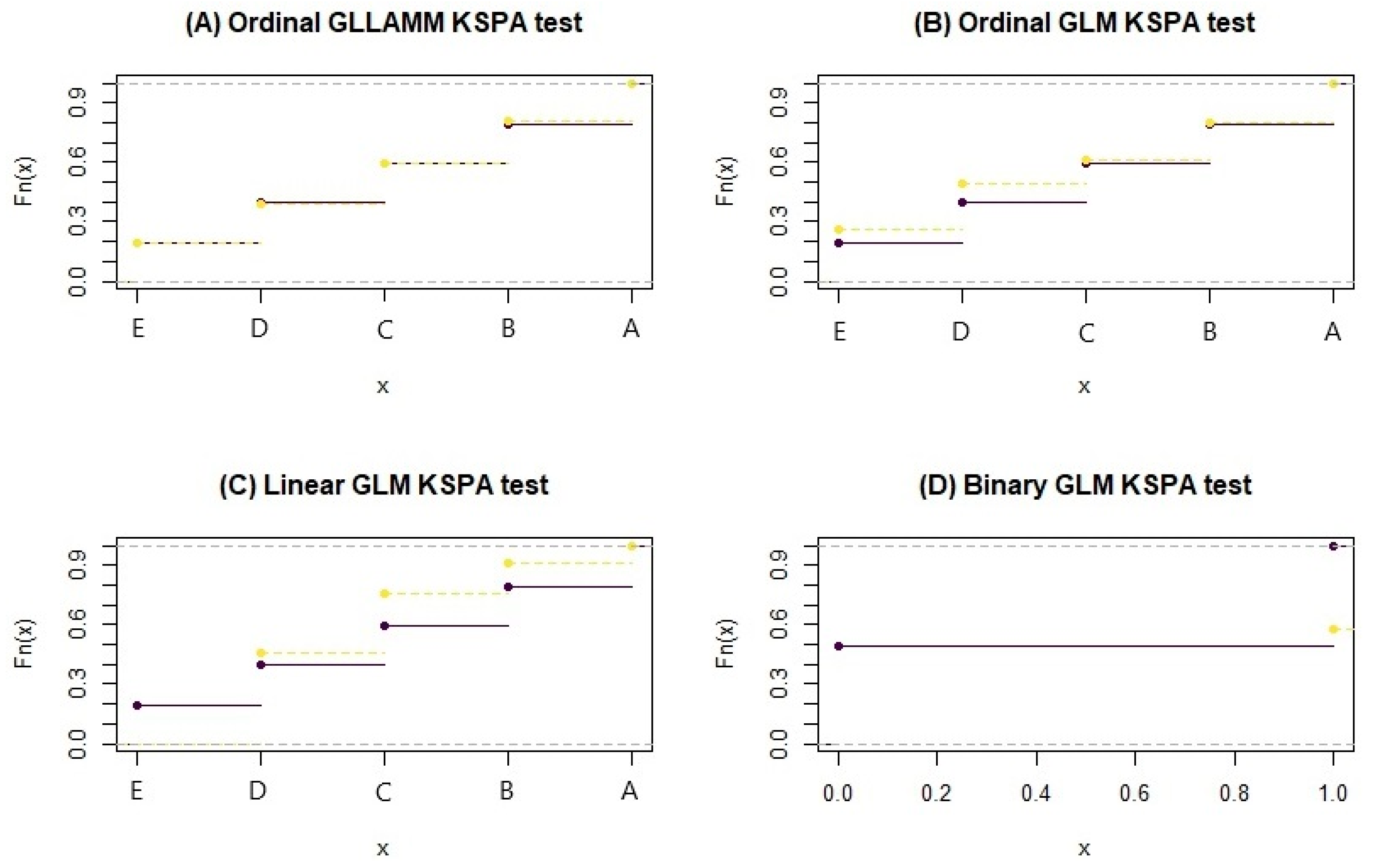
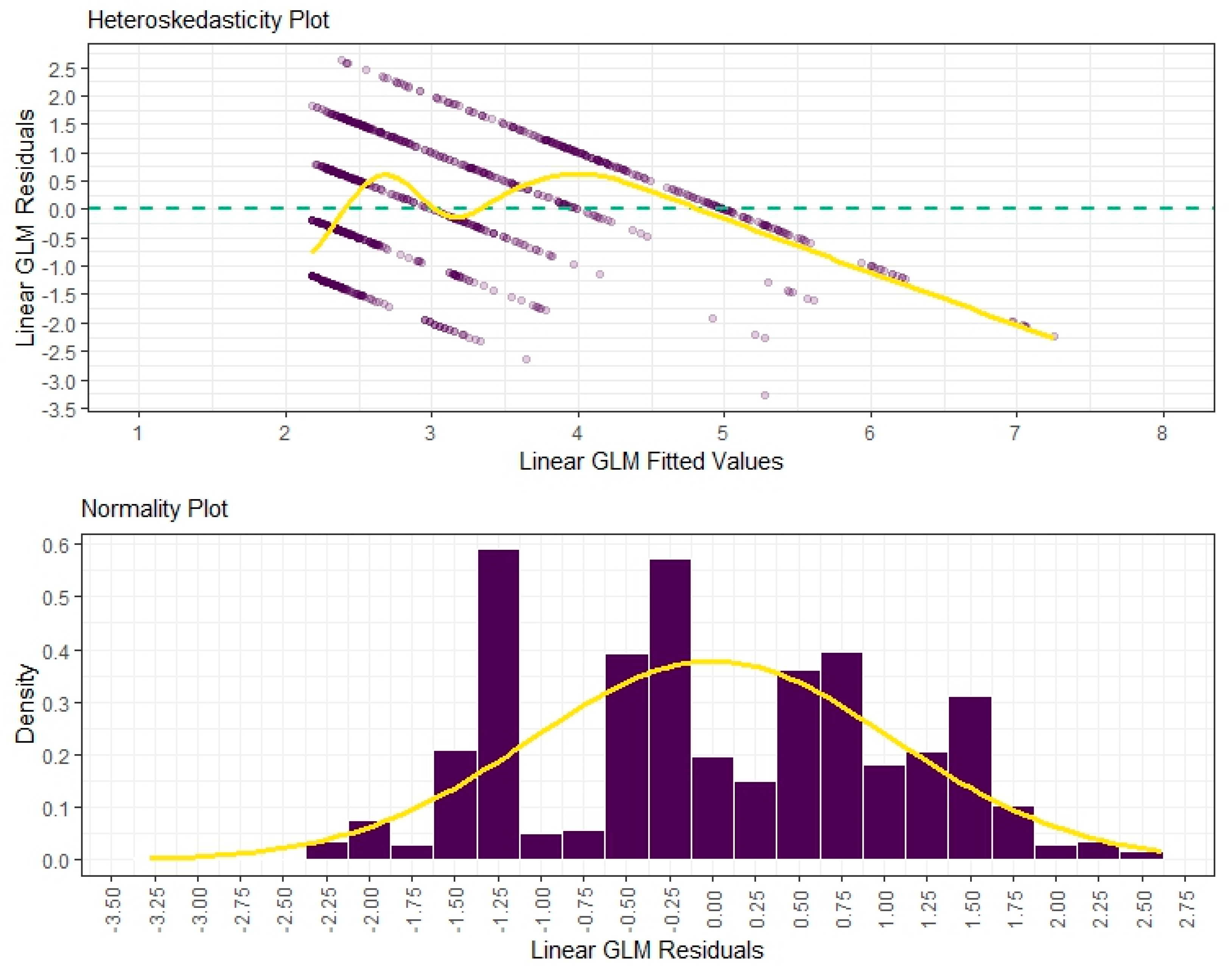
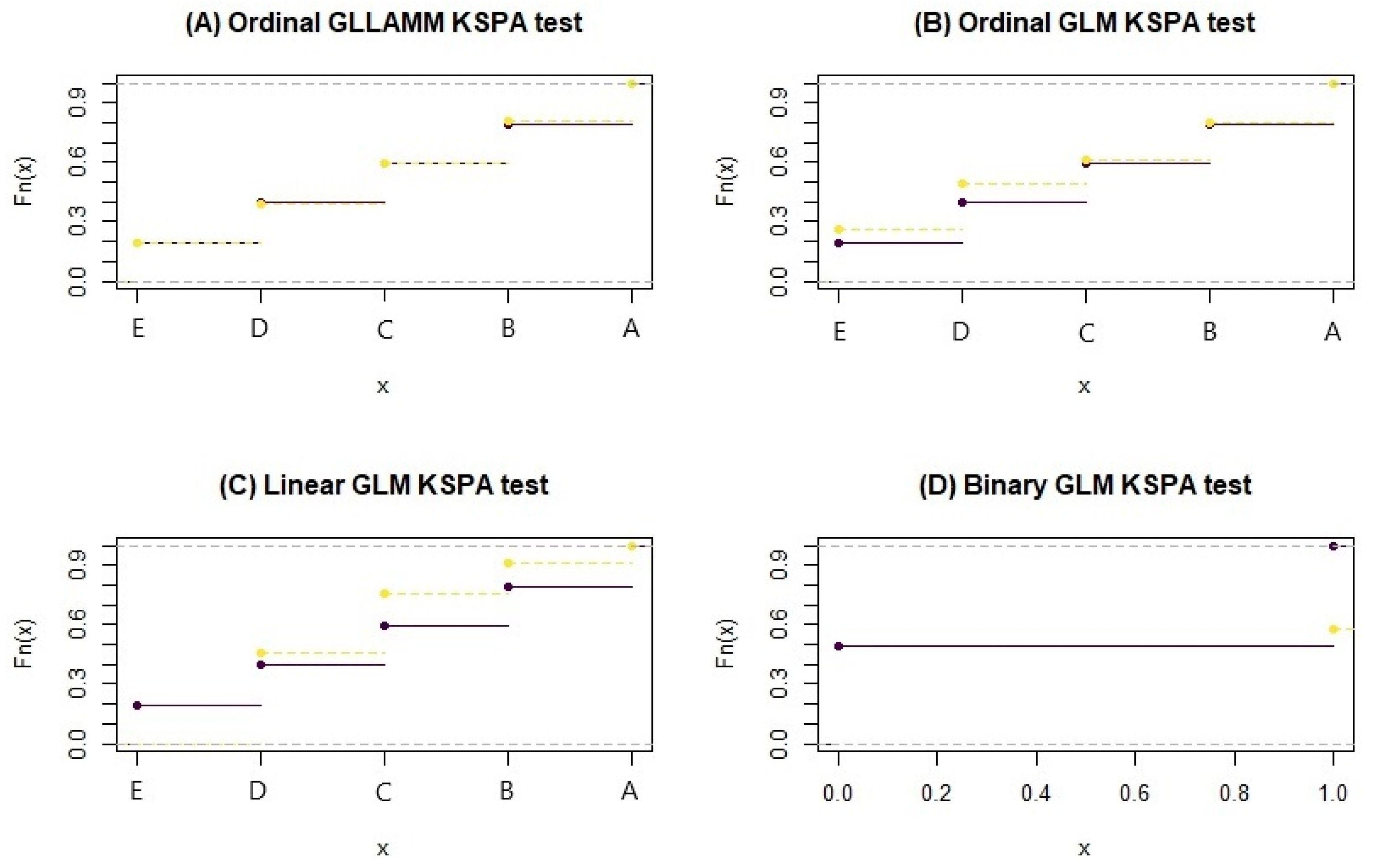
7.4. Accuracy and Suitability of Estimates
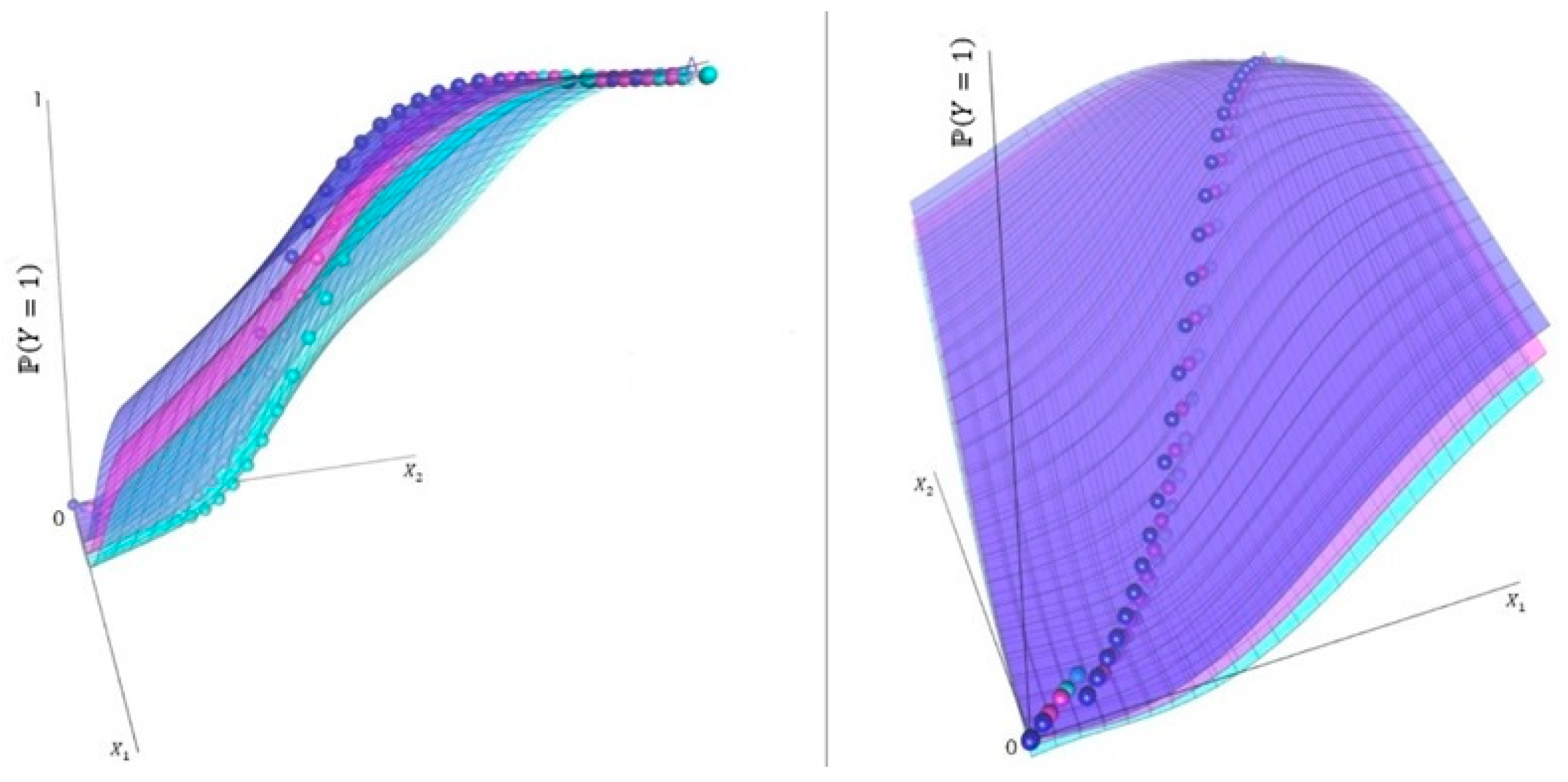
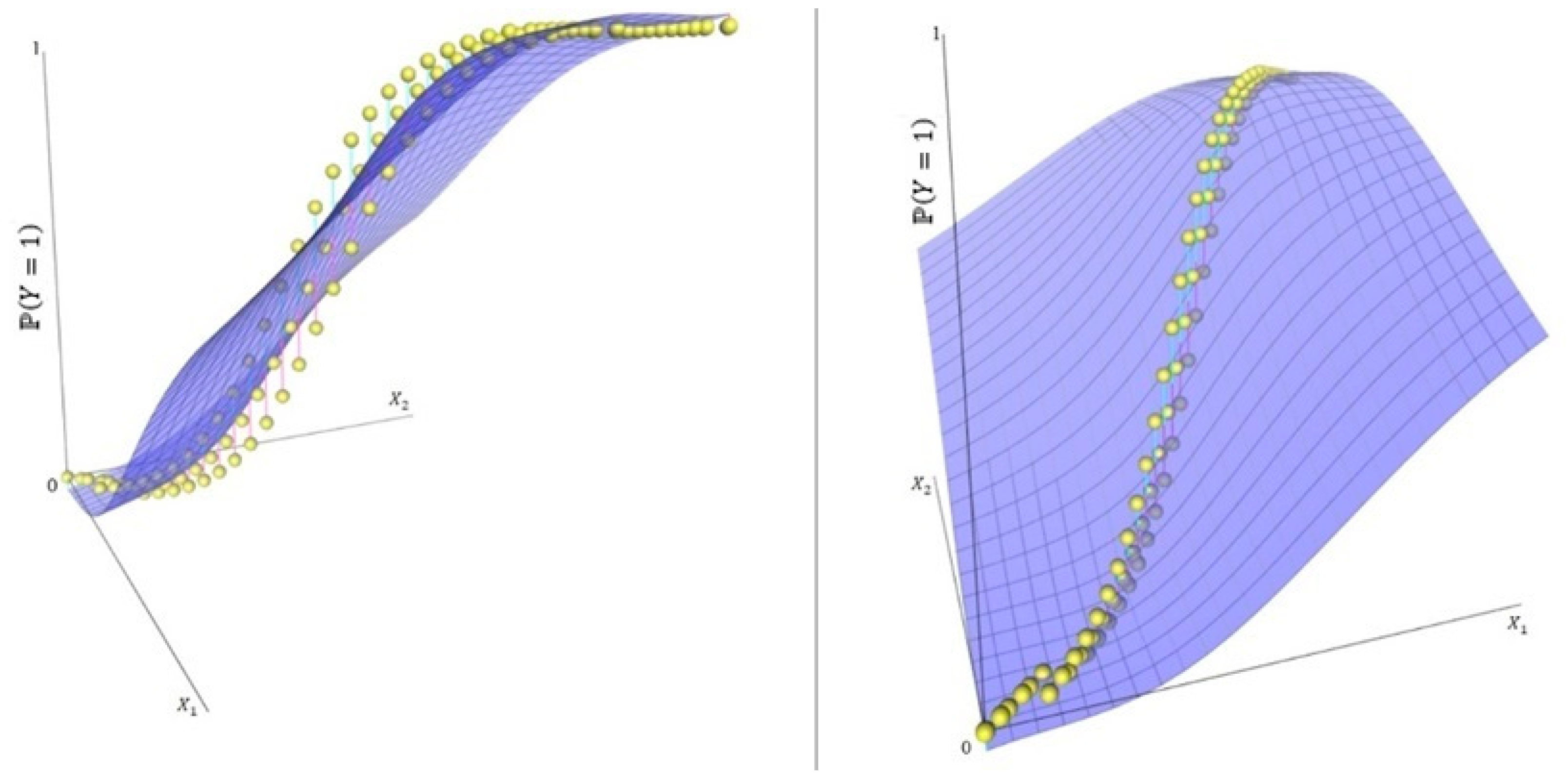
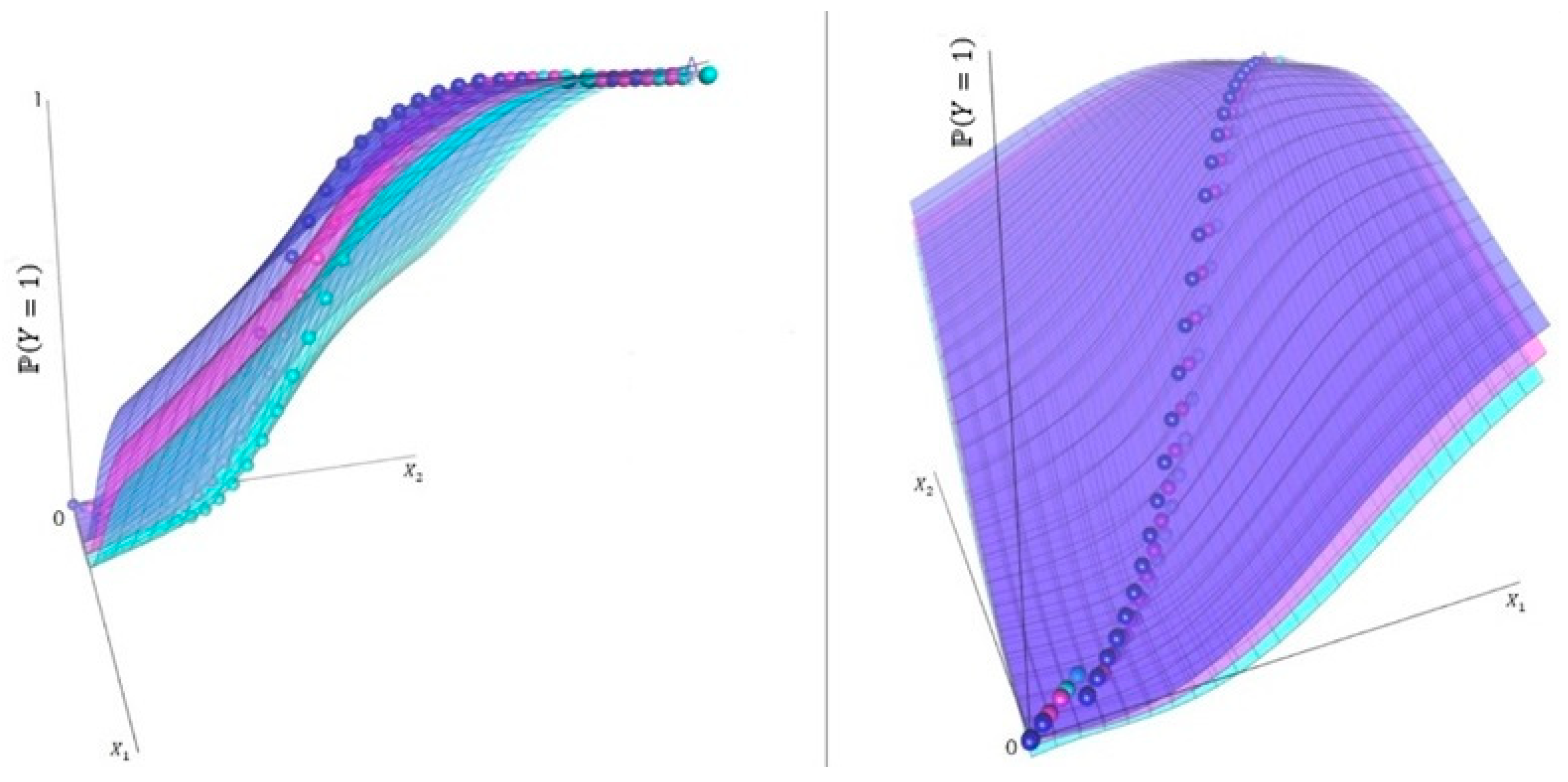
7.5. The Expected Values as a Function of the Study’s Predictor Variables
8. Final Considerations
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| HEI Names | Is It a Federal University? | |
|---|---|---|
| Federal University of Western Para | yes | −14.99009635 |
| Federal University of The Southern Border | yes | −13.73180070 |
| Darcy Ribeiro North Fluminense State University | no | −13.67610299 |
| Federal University of Latin American Integration | yes | −13.51506685 |
| University of the International Integration of Afro-Brazilian Lusophony | yes | −13.27160473 |
| Federal University of Health Sciences of Porto Alegre | yes | −10.37416534 |
| Sao Francisco University | no | −9.752614271 |
| Catholic University of Petropolis | no | −9.506667313 |
| Municipal University of Sao Caetano Do Sul | no | −9.215742952 |
| University of the Sapucai Valley | no | −9.123246743 |
| Federal University Of Lavras | yes | −8.436202000 |
| Vila Velha University | no | −8.411085314 |
| Nilton Lins University | no | −8.354072711 |
| Candido Mendes University | no | −8.347125089 |
| Marilia University | no | −8.234944757 |
| Cuiaba University | no | −8.232441189 |
| Metropolitan University of Santos | no | −8.188602961 |
| Amapa State University | no | −8.079419237 |
| State University of Health Sciences of Alagoas | no | −8.064994723 |
| Severino Sombra University | no | −8.064994723 |
| Santa Ursula University | no | −8.064994723 |
| Presidente Antonio Carlos University | no | −8.064994723 |
| Camilo Castelo Branco University | no | −8.064994723 |
| Iguacu University | no | −8.064994723 |
| Ibirapuera University | no | −8.064994723 |
| Vale do Rio Doce University | no | −8.064994723 |
| Planalto Catarinense University | no | −8.064994723 |
| State University of Rio Grande Do Sul | no | −8.064994723 |
| Rio Verde University | no | −8.064994723 |
| State University of Roraima | no | −8.064994723 |
| State University of Alagoas | no | −8.064994723 |
| University of the Campanha Region | no | −7.974555746 |
| Braz Cubas University | no | −7.974555746 |
| Itauna University | no | −7.860477850 |
| Federal University of Amapa | yes | −7.677428376 |
| Grande ABC University | no | −7.174835087 |
| Jose do Rosario Vellano University | no | −6.468046656 |
| Joinville Region University | no | −6.242757024 |
| Federal University of Roraima | yes | −6.143240450 |
| State University of Northern Parana | no | −6.006872575 |
| Cruz Alta University | no | −5.891714847 |
| Federal Rural University of the Amazon | yes | −5.795563090 |
| Cruzeiro do Sul University | no | −5.657494653 |
| Foundation Federal University of Grande Dourados | yes | −5.334567978 |
| Catholic University of Salvador | no | −5.089159010 |
| Federal University of Triangulo Mineiro | yes | −5.007426154 |
| Federal Rural University of The Semi-Arid Region | yes | −4.281043460 |
| Federal University of the Jequitinhonha and Mucuri Valleys | yes | −4.252152738 |
| Federal University of Alfenas | yes | −3.731053337 |
| Sorocaba University | no | −3.492989706 |
| Federal University of Itajuba | yes | −3.298113673 |
| Anhanguera University | no | −3.133556781 |
| Federal University of Acre | yes | −2.978102075 |
| Dom Bosco Catholic University | no | −2.976272160 |
| Franca University | no | −2.805512911 |
| Federal Rural University of Pernambuco | yes | −2.636823118 |
| Salgado de Oliveira University | no | −2.629415418 |
| Ribeirao Preto University | no | −2.601152707 |
| Potiguar University | no | −2.475139817 |
| Federal Rural University of Rio De Janeiro | yes | −2.434885013 |
| Sagrado Coracao University | no | −2.421717770 |
| Acarau Valley State University | no | −2.386904761 |
| Tocantins University | no | −2.386904761 |
| Rondonia Federal University | yes | −2.321180703 |
| Federal University of The Sao Francisco Valley | yes | −2.268085483 |
| Pontifical Catholic University of Sao Paulo | no | −2.203539879 |
| Santos Catholic University | no | −2.185315550 |
| Federal University of Alagoas | yes | −2.143302503 |
| Bandeirante University of Sao Paulo | no | −2.123308368 |
| Federal University of the State of Rio De Janeiro | yes | −2.080315766 |
| Federal University of Tocantins Foundation | yes | −1.859696753 |
| Pampa Federal University Foundation | yes | −1.700680157 |
| Tuiuti University Of Parana | no | −1.658723722 |
| Professor “Jose De Souza Herdy” University of Grande Rio | no | −1.652905607 |
| Mogi Das Cruzes University | no | −1.619034111 |
| Fumec University | no | −1.516993675 |
| State University of Mato Grosso Do Sul | no | −1.436778710 |
| City of Sao Paulo University | no | −1.424392798 |
| Sao Judas Tadeu University | no | −1.415667314 |
| Minas Gerais State University | no | −1.007623742 |
| Regional University of Cariri | no | −0.936288606 |
| Reconcavo da Bahia Federal University | yes | −0.889593824 |
| Rio Verde Valley University | no | −0.866415961 |
| State University of Piaui | no | −0.866415961 |
| Santa Cecilia University | no | −0.866415961 |
| Amazonia University | no | −0.383843188 |
| State University of Campinas | no | 0.000001716 |
| Federal University of Rio Grande Do Sul | yes | 0.000441941 |
| University of Sao Paulo | no | 0.001643641 |
| Federal University of Rio De Janeiro | yes | 0.026150447 |
| Federal University of Minas Gerais | yes | 0.085981454 |
| Federal University of Santa Catarina | yes | 0.091604285 |
| University of Western Paulista | no | 0.126200469 |
| Federal University of Ceara | yes | 0.294389265 |
| Federal University of Sao Carlos | yes | 0.310381033 |
| Federal University of Rio Grande | yes | 0.343443136 |
| State University of Maranhao | no | 0.485721407 |
| Federal University of Pernambuco | yes | 0.547950963 |
| University of Western Santa Catarina | no | 0.576139939 |
| Castelo Branco University | no | 0.630102533 |
| Santo Amaro University | no | 0.630102533 |
| Contestado University | no | 0.630102533 |
| Federal University of Vicosa | yes | 0.822644994 |
| Federal University of Sao Paulo | yes | 0.919583062 |
| Brasilia University | yes | 1.214990312 |
| ABC Federal University | yes | 1.272662705 |
| Methodist University of Piracicaba | no | 1.299548471 |
| Positivo University | no | 1.455745927 |
| Paraiba Valley University | no | 1.553119688 |
| Federal University of Parana | yes | 1.624846845 |
| Federal University of Pelotas | yes | 1.638422371 |
| Federal University of Mato Grosso | yes | 1.884384028 |
| Mato Grosso State University | no | 1.939326056 |
| Catholic University of Pernambuco | no | 2.036981661 |
| Federal University of Piaui | yes | 2.120003238 |
| Federal University of Maranhao | yes | 2.139401048 |
| Amazonas State University | no | 2.336524924 |
| Federal University of Ouro Preto | yes | 2.394441009 |
| Regional University of Northwestern Rio Grande do Sul State | no | 2.616960817 |
| Technological Federal University of Parana | yes | 2.619387447 |
| Tiradentes University | no | 2.622135482 |
| Federal University of Mato Grosso Do Sul | yes | 2.632919886 |
| Federal University of Bahia | yes | 2.876477055 |
| Julio de Mesquita Filho Paulista State University | no | 3.132439958 |
| Federal University of Campina Grande | yes | 3.140551802 |
| North Parana University | no | 3.439539019 |
| Guarulhos University | no | 3.574697821 |
| Para State University | no | 3.587890006 |
| Uberaba University | no | 3.729799680 |
| Federal University of Rio Grande Do Norte | yes | 3.999376018 |
| Federal University of Amazonas | yes | 4.036775310 |
| Federal University of Sergipe | yes | 4.067316504 |
| Feevale University | no | 4.121768718 |
| Federal University of Santa Maria | yes | 4.145951484 |
| Federal University of Sao Joao Del Rei | yes | 4.185864581 |
| Veiga de Almeida University | no | 4.203584165 |
| Anhembi Morumbi University | no | 4.301687824 |
| Rio Grande do Norte State University | no | 4.318800807 |
| Paranaense University | no | 4.318800807 |
| Community University of the Chapeco Region | no | 4.318800807 |
| Alto Uruguai e das Missões Integrated Regional University | no | 4.345878060 |
| Federal University of Para | yes | 4.491504554 |
| Taubate University | no | 4.634044812 |
| Federal University of Uberlandia | yes | 4.804616760 |
| Fluminense Federal University | yes | 4.852823692 |
| Federal University of Paraiba | yes | 4.985137105 |
| Santa Cruz State University | no | 5.038850317 |
| State University of Southwest Bahia | no | 5.041621224 |
| Salvador University | no | 5.164845860 |
| State University of Midwest | no | 5.309082320 |
| Pontifical Catholic University Of Goias | no | 5.457353354 |
| State University of Ceara | no | 5.626526798 |
| Paulista University | no | 5.709381079 |
| Federal University of Goias | yes | 5.752312579 |
| State University of Goias | no | 5.802286719 |
| University of Extreme South Catarinense | no | 5.833866187 |
| Federal University of Juiz De Fora | yes | 5.948009565 |
| Santa Cruz do Sul University | no | 6.024406003 |
| Regional University of Blumenau | no | 6.220647133 |
| Federal University of Espírito Santo | yes | 6.229696268 |
| Catholic University of Pelotas | no | 6.237231979 |
| Pontifical Catholic University of Rio de Janeiro | no | 6.599206352 |
| Rio dos Sinos Valley University | no | 6.699586880 |
| Mackenzie Presbyterian University | no | 6.703518715 |
| Fortaleza University | no | 7.200753664 |
| Itajai Valley University | no | 7.296747253 |
| Lutheran University Of Brazil | no | 7.47832689 |
| Pernambuco University | no | 7.481812386 |
| Bahia State University | no | 7.512211886 |
| Brazilian Catholic University | no | 7.566038025 |
| State University of Western Parana | no | 7.654403455 |
| Pontifical Catholic University Of Rio Grande Do Sul | no | 7.961440315 |
| Nove de Julho University | no | 7.996981951 |
| Pontifical Catholic University of Campinas | no | 8.087346315 |
| State University of Feira de Santana | no | 8.281796599 |
| Rio de Janeiro State University | no | 8.606858437 |
| Santa Catarina State University | no | 8.611956177 |
| Ponta Grossa State University | no | 8.637562072 |
| Caxias do Sul University | no | 8.711704534 |
| Methodist University of Sao Paulo | no | 8.908381972 |
| Paraiba State University | no | 9.227040499 |
| Pontifical Catholic University of Minas Gerais | no | 9.310656616 |
| University of Southern Santa Catarina | no | 9.448175941 |
| State University Of Maringa | no | 9.515227693 |
| Estacio de Sa University | no | 9.615633159 |
| Passo Fundo University | no | 10.12255267 |
| State University of Montes Claros | no | 11.46164999 |
| State University of Londrina | no | 11.51611222 |
| Pontifical Catholic University of Parana | no | 12.82779457 |
References
- Lalla, M. Fundamental characteristics and statistical analysis of ordinal variables: A review. Qual. Quant. 2017, 51, 435–458. [Google Scholar] [CrossRef]
- Vogt, W.P.; Johnson, R.B. The SAGE Dictionary of Statistics & Methodology: A Nontechnical Guide for the Social Sciences, 5th ed.; SAGE Publications: London, UK, 2015. [Google Scholar]
- Kampen, J.; Swyngedouw, M. The Ordinal Controversy Revisited. Qual. Quant. 2000, 34, 87–102. [Google Scholar] [CrossRef]
- Fullerton, A.S.; Anderson, K.F. Ordered Regression Models: A Tutorial. Prev. Sci. 2023, 24, 431–443. [Google Scholar] [CrossRef]
- Liddell, T.M.; Kruschke, J.K. Analyzing ordinal data with metric models: What could possibly go wrong? Exp. Soc. Psychol. 2018, 79, 328–348. [Google Scholar] [CrossRef]
- Nadler, J.T.; Weston, R.; Voyles, E.C. Stuck in the Middle: The Use and Interpretation of Mid-Points in Items on Questionnaires. J. Gen. Psychol. 2015, 142, 71–89. [Google Scholar] [CrossRef] [PubMed]
- Bauer, D.J.; Sterba, S.K. Fitting multilevel models with ordinal outcomes: Performance of alternative specifications and methods of estimation. Psychol. Methods 2011, 16, 373–390. [Google Scholar] [CrossRef] [PubMed]
- Hedeker, D.; Gibbons, R.D. A Random-Effects Ordinal Regression Model for Multilevel Analysis. Biometrics 1994, 50, 933. [Google Scholar] [CrossRef]
- Fielding, A.; Yang, M.; Goldstein, H. Multilevel ordinal models for examination grades. Stat. Model. 2003, 3, 127–153. [Google Scholar] [CrossRef]
- Li, B.; Lingsma, H.F.; Steyerberg, E.W.; Lesaffre, E. Logistic random effects regression models: A comparison of statistical packages for binary and ordinal outcomes. BMC Med. Res. Methodol. 2011, 11, 77. [Google Scholar] [CrossRef]
- Hedeker, D. Methods for Multilevel Ordinal Data in Prevention Research. Prev. Sci. 2015, 16, 997–1006. [Google Scholar] [CrossRef]
- Hilbe, J.M. Logistic Regression Models; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Fernandes, A.J.; Shukla, B.; Fardoun, H. Indian Higher Education in World University Rankings—The Importance of Reputation and Branding. J. Stat. Appl. Probab. 2022, 11, 673–681. [Google Scholar] [CrossRef]
- Liu, A.; He, H.; Tu, X.M.; Tang, W. On testing proportional odds assumptions for proportional odds models. Gen. Psychiatr. 2023, 36, e101048. [Google Scholar] [CrossRef] [PubMed]
- Verwaeren, J.; Waegeman, W.; de Baets, B. Learning partial ordinal class memberships with kernel-based proportional odds models. Comput. Stat. Data Anal. 2012, 56, 928–942. [Google Scholar] [CrossRef]
- Abrudan, I.-N.; Pop, C.-M.; Lazăr, P.-S. Using a General Ordered Logit Model to Explain the Influence of Hotel Facilities, General and Sustainability-Related, on Customer Ratings. Sustainability 2020, 12, 9302. [Google Scholar] [CrossRef]
- Bender, R.; Grouven, U. Ordinal logistic regression in medical research. J. R. Coll. Physicians Lond. 1997, 31, 546–551. [Google Scholar] [PubMed]
- Ma, C.; Zhou, J.; Yang, D. Causation Analysis of Hazardous Material Road Transportation Accidents Based on the Ordered Logit Regression Model. Int. J. Environ. Res. Public Health 2020, 17, 1259. [Google Scholar] [CrossRef] [PubMed]
- Jayawardena, S.; Epps, J.; Ambikairajah, E. Ordinal Logistic Regression with Partial Proportional Odds for Depression Prediction. IEEE Trans. Affect. 2023, 14, 563–577. [Google Scholar] [CrossRef]
- Humphrey, S.E.; LeBreton, J.M. The Handbook of Multilevel Theory, Measurement, and Analysis; American Psychological Association: Worcester, MA, USA, 2018. [Google Scholar]
- Wu, L. Mixed Effects Models for Complex Data; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Singmann, H.; Kellen, D. An Introduction to Mixed Models for Experimental Psychology. In New Methods in Cognitive Psychology; Spieler, D., Schumacher, E., Eds.; Routledge: London, UK, 2019; pp. 4–27. [Google Scholar]
- Agresti, A. Categorical Data Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Hosmer, D.W.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Brant, R. Assessing Proportionality in the Proportional Odds Model for Ordinal Logistic Regression. Biometrics 1990, 46, 1171–1178. [Google Scholar] [CrossRef]
- Courgeau, D. Methodology and Epistemology of Multilevel Analysis: Approaches from Different Social Sciences; Springer: London, UK, 2003. [Google Scholar]
- Headley, M.G.; Plano Clark, V.L. Multilevel Mixed Methods Research Designs: Advancing a Refined Definition. J. Mix. Methods Res. 2020, 14, 145–163. [Google Scholar] [CrossRef]
- Mathieu, J.E.; Chen, G. The Etiology of the Multilevel Paradigm in Management Research. J. Manag. 2011, 37, 610–641. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, F.; Wang, D.; Ang, S. Efficiency evaluation for higher education institutions in China considering unbalanced regional development: A meta-frontier super-SBM model. Socio-Economic. Plan. Sci. 2023, 88, 101648. [Google Scholar] [CrossRef]
- Benito, M.; Gil, P.; Romera, R. Funding, is it key for standing out in the university rankings? Scientometrics 2019, 121, 771–792. [Google Scholar] [CrossRef]
- Salmi, J.; D’Addio, A. Policies for achieving inclusion in higher education. Policy Rev. High. Educ. 2021, 5, 47–72. [Google Scholar] [CrossRef]
- Yang, J.; Wang, C.; Liu, L.; Croucher, G.; Moore, K.; Coates, H. The Productivity of Leading Global Universities. In Responsibility of Higher Education Systems; Broucker, B., Borden, V.M.H., Kallenberg, T., Milsom, C., Eds.; BRILL: Leiden, The Netherlands, 2020; pp. 224–249. [Google Scholar] [CrossRef]
- Núnez Chicharro, M.; Mangena, M.; Alonso Carrillo, M.I.; Priego De La Cruz, A.M. The effects of stakeholder power, strategic posture and slack financial resources on sustainability performance in UK higher education institutions. Sustain. Account. Manag. 2024, 15, 171–206. [Google Scholar] [CrossRef]
- Lepori, B.; Borden, V.M.H.; Coates, H. Opportunities and challenges for international institutional data comparisons. Eur. J. High. Educ. 2022, 12 (Suppl. S1), 373–390. [Google Scholar] [CrossRef]
- Mahmoud, N.; Abdel-Aty, M.; Cai, Q.; Abuzwidah, M. Analyzing the Difference Between Operating Speed and Target Speed Using Mixed-Effect Ordered Logit Model. Transp. Res. Rec. J. Transp. Res. Board 2022, 2676, 596–607. [Google Scholar] [CrossRef]
- Palardy, G.J. Review of HLM 7. Soc. Sci. Comput. Rev. 2011, 29, 515–520. [Google Scholar] [CrossRef]
- Austin, P.C. A Tutorial on Multilevel Survival Analysis: Methods, Models and Applications. Int. Stat. Rev. 2017, 85, 185–203. [Google Scholar] [CrossRef]
- Molina-Azorín, J.F.; Pereira-Moliner, J.; López-Gamero, M.D.; Pertusa-Ortega, E.M.; José Tarí, J. Multilevel research: Foundations and opportunities in management. BRQ Bus. Res. Q. 2020, 23, 319–333. [Google Scholar] [CrossRef]
- Volpert-Esmond, H.I.; Page-Gould, E.; Bartholow, B.D. Using multilevel models for the analysis of event-related potentials. Int. J. Psychophysiol. 2021, 162, 145–156. [Google Scholar] [CrossRef]
- Kim, M.; van Horn, M.L.; Jaki, T.; Vermunt, J.; Feaster, D.; Lichstein, K.L.; Taylor, D.J.; Riedel, B.W.; Bush, A.J. Repeated measures regression mixture models. Behav. Res. Methods 2020, 52, 591–606. [Google Scholar] [CrossRef] [PubMed]
- Nezlek, J.B.; Mroziński, B. Applications of multilevel modeling in psychological science: Intensive repeated measures designs. L’Année Psychol. 2020, 120, 39–72. [Google Scholar] [CrossRef]
- Rabe-Hesketh, S.; Skrondal, A. Multilevel and Longitudinal Modeling Using Stata; Stata Press: College Station, TX, USA, 2022. [Google Scholar]
- Demidenko, E. Mixed Models: Theory and Application; Wiley: Hoboken, NJ, USA, 2004. [Google Scholar]
- Bliese, P. Within-group agreement, non-independence, and reliability: Implications for data aggregation and analysis. In Multilevel Theory, Research, and Methods in Organizations: Foundations, Extensions, and New Directions; Klein, K., Kozlowski, S., Eds.; Jossey-Bass: San Francisco, CA, USA; pp. 349–381.
- WEBOMETRICS. Ranking Web of Universities 2019; WEBOMETRICS: Madrid, Spain, 2019. [Google Scholar]
- Aguillo, I.F.; Granadino, B.; Ortega, J.L.; Prieto, J.A. Scientific research activity and communication measured with cybermetrics indicators. J. Am. Soc. Inf. Sci. 2006, 57, 1296–1302. [Google Scholar] [CrossRef]
- Aguillo, I.F.; Ortega, J.L.; Fernández, M. Webometric Ranking of World Universities: Introduction, Methodology, and Future Developments. High. Educ. Eur. 2008, 33, 233–244. [Google Scholar] [CrossRef]
- McManus, C.; Neves, A.A.B.; Diniz Filho, J.A.; Maranhão, A.Q.; Souza Filho, A.G. Profiles not metrics: The case of Brazilian universities. An. Da Acad. Bras. De Ciências 2021, 93, 1–23. [Google Scholar] [CrossRef]
- McCowan, T.; Bertolin, J. Inequalities in Higher Education Access and Completion in Brazil (No. 3). Working Paper 2020. Available online: https://www.econstor.eu/handle/10419/246235 (accessed on 12 November 2023).
- Doi, S.A.R.; Kostoulas, P.; Glasziou, P. Likelihood ratio interpretation of the relative risk. BMJ Evid.-Based Med. 2023, 28, 241–243. [Google Scholar] [CrossRef]
- Dörnemann, N. Likelihood ratio tests under model misspecification in high dimensions. J. Multivar. Anal. 2023, 193, 105122. [Google Scholar] [CrossRef]
- Hassani, H.; Silva, E. A Kolmogorov-Smirnov Based Test for Comparing the Predictive Accuracy of Two Sets of Forecasts. Econometrics 2015, 3, 590–609. [Google Scholar] [CrossRef]
- Long, J.S.; Freese, J. Regression Models for Categorical Dependent Variables Using Stata; Stata Press: College Station, TX, USA, 2014. [Google Scholar]
- Onifade, O.C.; Olanrewaju, S.O. Investigating Performances of Some Statistical Tests for Heteroscedasticity Assumption in Generalized Linear Model: A Monte Carlo Simulations Study. Open J. Stat. 2020, 10, 453–493. [Google Scholar] [CrossRef]
- Mbah, A.K.; Paothong, A. Shapiro–Francia test compared to other normality test using expected p-value. J. Stat. Comput. Simul. 2015, 85, 3002–3016. [Google Scholar] [CrossRef]
- Turner, P. Critical values for the Durbin-Watson test in large samples. Appl. Econ. Lett. 2020, 27, 1495–1499. [Google Scholar] [CrossRef]
- Wooldridge, J.M. Introductory Econometrics: A Modern Approach; Cengage Learning: Boston, MA, USA, 2018. [Google Scholar]
- Shmueli, G.; Bruce, P.C.; Stephens, M.L.; Anandamurthy, M.; Nitin, R. Machine Learning for Business Analytics: Concepts, Techniques and Applications with JMP Pro; Wiley: Hoboken, NJ, USA, 2023. [Google Scholar]


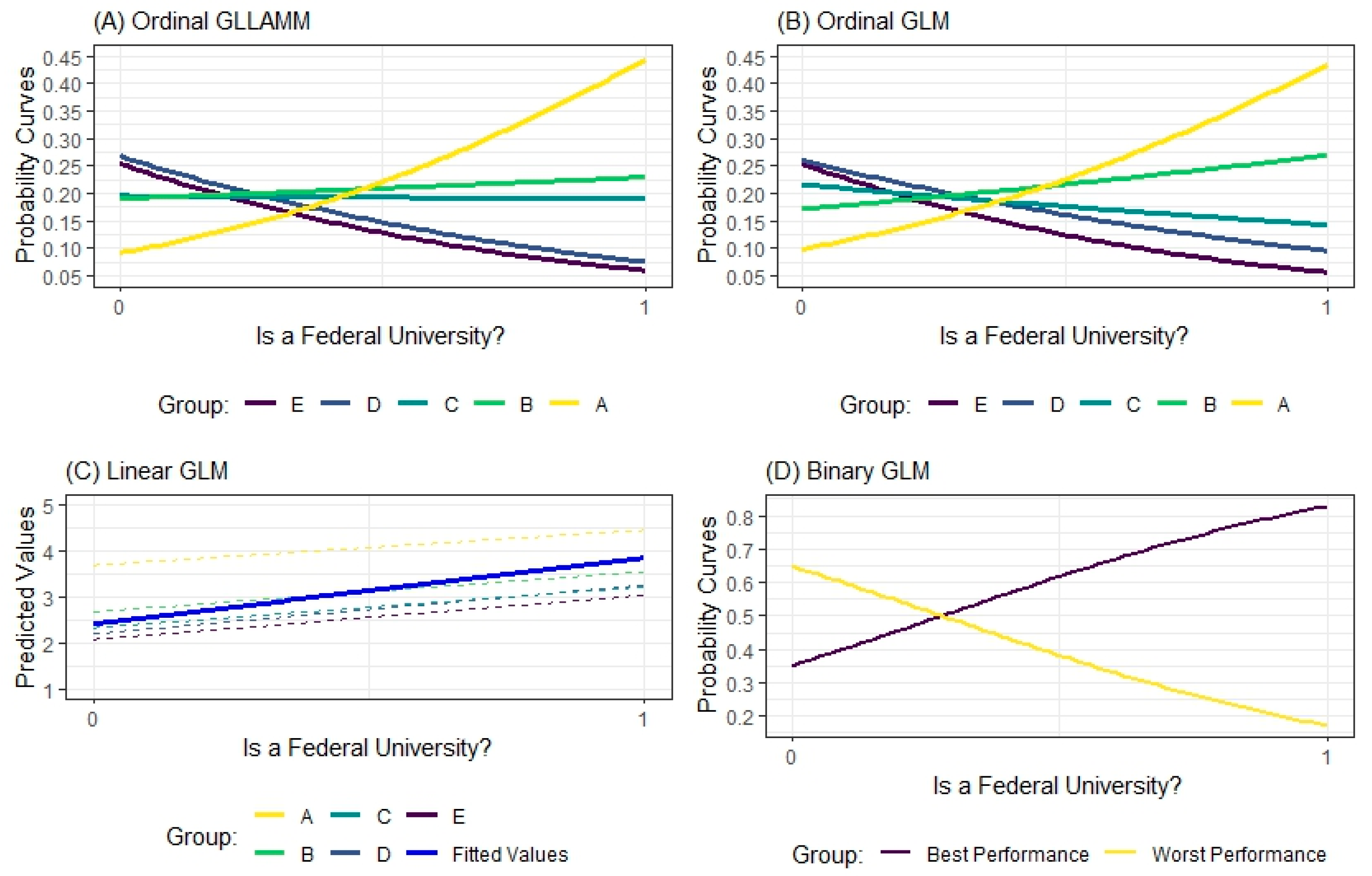
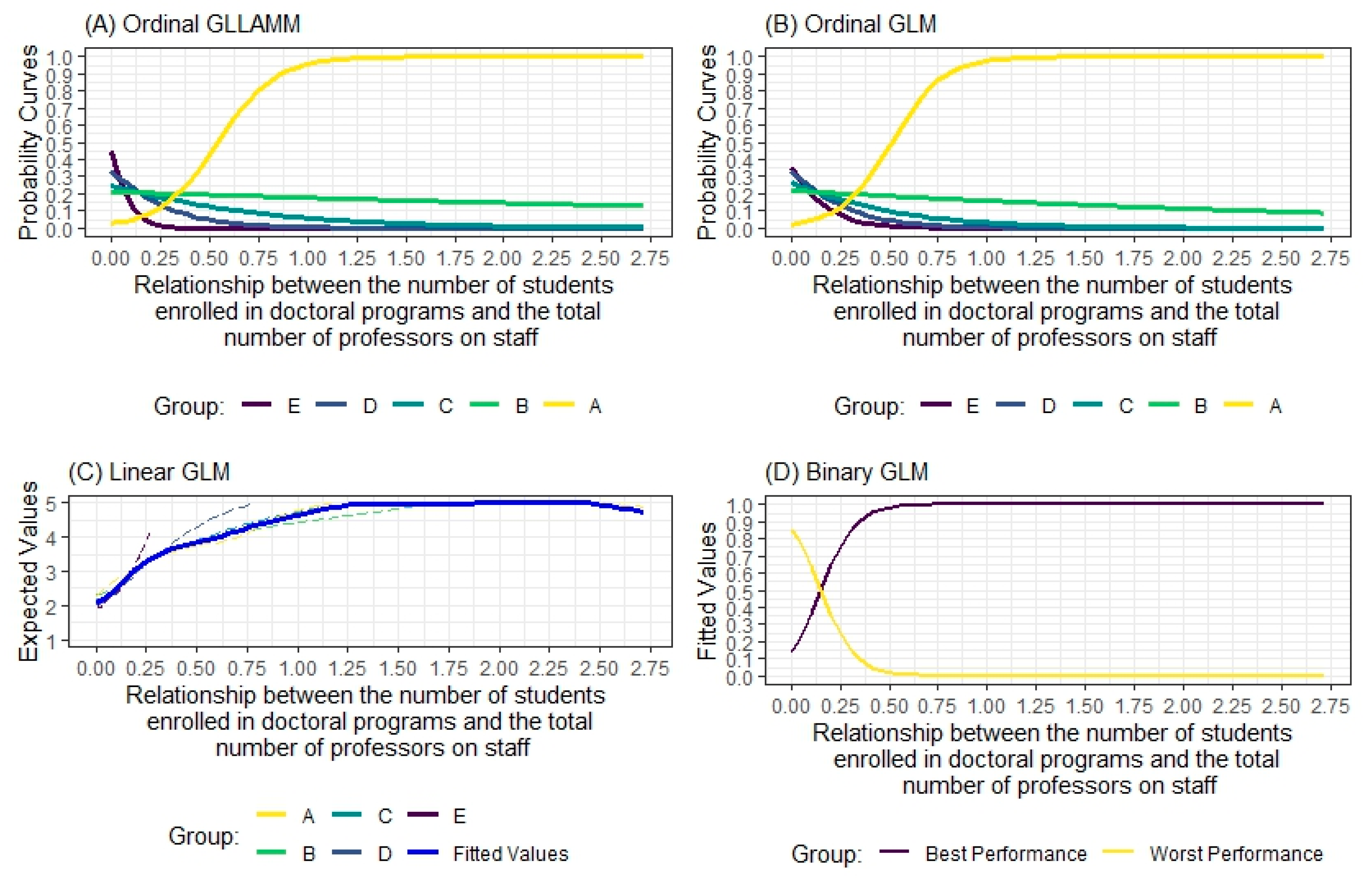
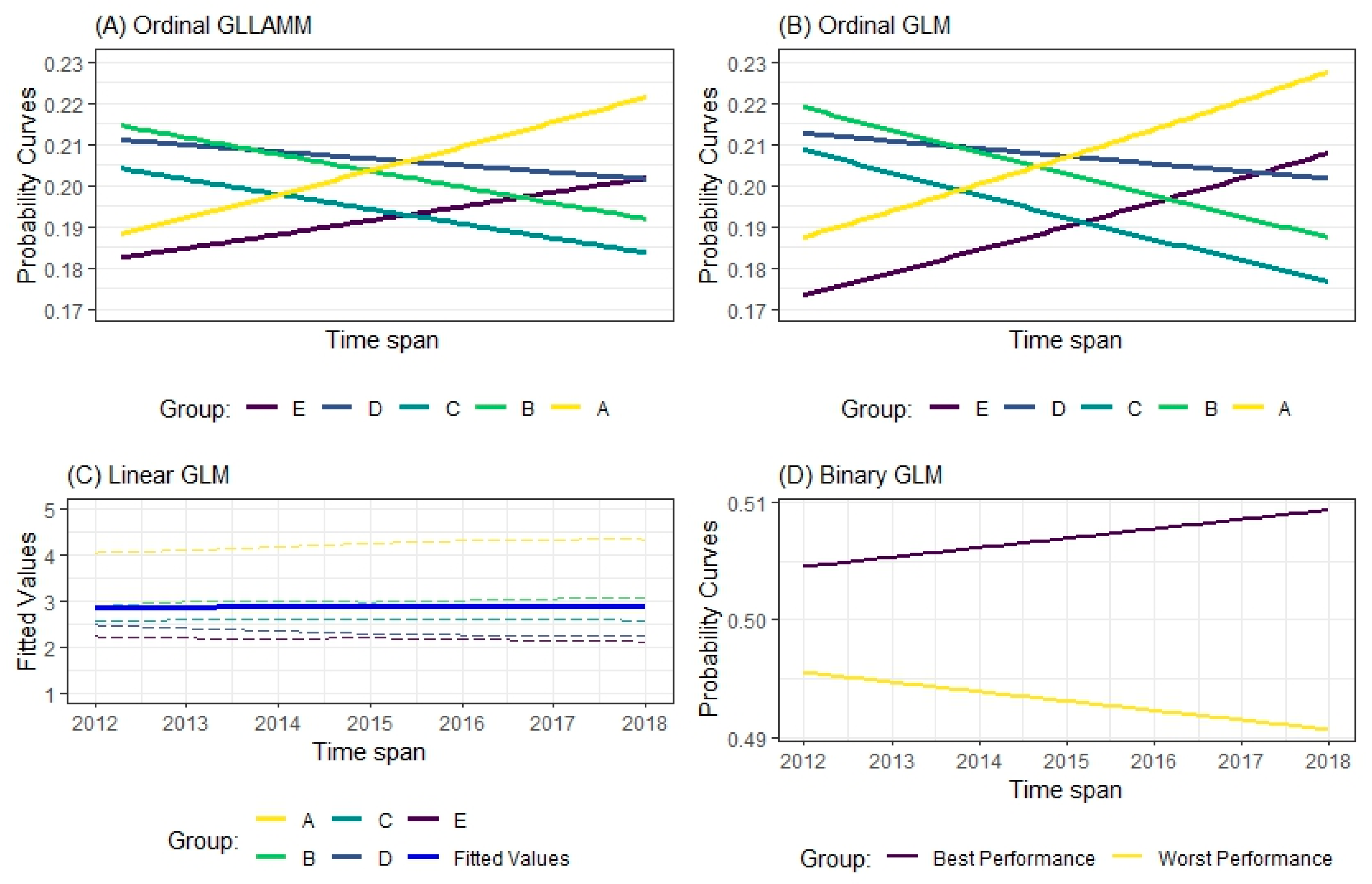
| Year | Number of Universities | Total | ||||
|---|---|---|---|---|---|---|
| Group | Group | Group | Group | Group | ||
| 2012 | 38 (20.7%) (14.6%) | 37 (20.1%) (14.4%) | 35 (19.1%) (14.3%) | 37 (20.1%) (14.3%) | 37 (20.1%) (15.0%) | 184 (100.0%) (14.5%) |
| 2013 | 38 (20.4%) (14.6%) | 38 (20.4%) (14.4%) | 36 (19.4%) (14.8%) | 38 (20.4%) (14.7%) | 36 (19.4%) (14.6%) | 186 (100.0%) (14.7%) |
| 2014 | 37 (20.4%) (14.2%) | 37 (20.4%) (14.4%) | 35 (19.3%) (14.3%) | 37 (20.4%) (14.3%) | 35 (19.3%) (14.2%) | 181 (100.0%) (14.3%) |
| 2015 | 37 (20.3%) (14.2%) | 37 (20.3%) (14.4%) | 36 (19.8%) (14.8%) | 37 (20.3%) (14.3%) | 35 (19.2%) (14.2%) | 182 (100.0%) (14.4%) |
| 2016 | 37 (20.3%) (14.2%) | 37 (20.3%) (14.4%) | 36 (19.8%) (14.8%) | 37 (20.3%) (14.3%) | 35 (19.2%) (14.2%) | 182 (100.0%) (14.4%) |
| 2017 | 37 (20.4%) (14.2%) | 37 (20.4%) (14.4%) | 35 (19.3%) (14.3%) | 37 (20.4%) (14.3%) | 35 (19.3%) (14.2%) | 181 (100.0%) (14.3%) |
| 2018 | 37 (21.8%) (14.2%) | 34 (20.0%) (13.2%) | 31 (18.2%) (12.7%) | 35 (20.6%) (13.6%) | 33 (19.4%) (13.4%) | 170 (100.0%) (13.4%) |
| Total | 261 (20.6%) (100.0%) | 257 (20.3%) (100.0%) | 244 (19.3%) (100.0%) | 258 (20.4%) (100.0%) | 246 (19.4%) (100.0%) | 1266 (100.0%) (100.0%) |
| Variable | Description |
|---|---|
| Year of monitoring of a given Brazilian university, considering the period from 2012 to 2018. | |
| Unique identifier of a given Brazilian university. | |
| Name of university. | |
| Nominal dichotomous variable that identifies the stratum if a given Brazilian university is, or is not, a university mostly maintained with Federal funds (Legally, Brazil comprises three types of universities: public universities (Federal, State, and Municipal), private non-profit universities (typically affiliated with religious entities), and private for-profit universities [48]. Broadly, Federal universities in Brazil are esteemed as the most prestigious; however, notable exceptions exist in international rankings, notably USP and the University of Campinas (UNICAMP), which are State universities [49]). | |
| Metric variable that relates the number of students enrolled in the institution’s doctoral programs (doctoral students and Ph.D. candidates) to the total number of professors at a given Brazilian university. |
| Metric Variables | |||||||
|---|---|---|---|---|---|---|---|
| Variable | Min | 1stQ | Median | 3rdQ | Max | Mean | SD |
| 0.000 | 0.006 | 0.099 | 0.326 | 2.719 | 0.265 | 0.410 | |
| Categorical Variables | |||||||
| yes: 405; no: 861. | |||||||
| Estimation | Transformation Applied to the Dependent Variable |
|---|---|
| Ordinal GLM | None. The dependent variable is the same as described in Section 5, i.e., groups ordered in ascending order from E to A. |
| Ordinal GLLAMM | Same as above. |
| Linear GLM | The consideration of groups ordered in ascending order from E to A in metric form, taking values from 1 to 5. |
| Binary GLM | Combining groups A and B to form the best_performance category; combining strata D and E to create the worst_performance category; disregarding the observations belonging to Group C. |
| Estimation | Algorithm | Package | Version |
|---|---|---|---|
| Linear GLM | lm() | stats | 4.3.0 |
| Binary GLM | glm() | stats | 4.3.0 |
| Ordinal GLM | clm() | ordinal | 2023.12-4 |
| Ordinal GLLAMM | clmm() | ordinal | 2023.12-4 |
| Parameters | Linear GLM Coefficients | Binary GLM Coefficients | Ordinal GLM Coefficients | Ordinal GLLAMM Coefficients |
|---|---|---|---|---|
| - | - | −0.95857 (0.13414) | −4.72308 (0.53377) | |
| - | - | 0.34030 (0.13000) | 1.87845 (0.32800) | |
| - | - | 1.56304 (0.13852) | 6.93229 (0.00204) | |
| - | - | 3.73099 (0.18940) | 12.81046 (0.00314) | |
| 2.41243 (0.06940) | −1.35809 (0.20318) | - | - | |
| −0.03336 b (0.01498) | −0.14496 a (0.04641) | −0.11248 a (0.02767) | −0.12914 a (0.00163) | |
| 1.86460 a (0.07720) | 11.18187 a (0.91810) | 7.10328 a (0.38711) | 12.78852 a (0.00313) | |
| 0.77469 a (0.06760) | 0.88002 a (0.22474) | 0.83859 a (0.13499) | 6.19182 a (1.02605) | |
| - | - | - | 54.3560 | |
| −747.7575 * (d.f. = 3) | −651.1707 (d.f. = 3) | −982.7719 (d.f. = 3) | −106.3296 (d.f. = 3) | |
| −1863.838 (d.f. = 5) | −382.7152 (d.f. = 4) | −1.545.69700 (d.f. = 7) | −770.28320 (d.f. = 8) | |
| - | - | - | 0.94293 | |
| 1266 | 1022 | 1266 | 1266 |
| Comparing Estimates | d.f. | p-Value | |
|---|---|---|---|
| Linear GLM versus a null linear GLM estimation | 747.7315 | 2 | 0.000 |
| Binary GLM versus a null binary logistic GLM estimation | 651.1707 | 3 | 0.000 |
| Ordinal GLM versus a null ordinal logistic GLM estimation | 982.7719 | 3 | 0.000 |
| Ordinal GLLAMM versus a multilevel null ordinal logistic estimation | 106.3296 | 3 | 0.000 |
| Comparative Estimates | d.f. | p-Value | ||
|---|---|---|---|---|
| Linear GLM versus Binary GLM | - | - | - | - |
| Linear GLM versus Ordinal GLM | −1863.838 −1545.697 | 636.2818 | 2 | 0.000 |
| Linear GLM versus Ordinal GLLAMM | −1863.838 −770.2827 | 2187.111 | 3 | 0.000 |
| Binary GLM versus Ordinal GLM | - | - | - | - |
| Binary GLM versus Ordinal GLLAM | - | - | - | - |
| Ordinal GLM versus Ordinal GLLAMM | −1545.697 −770.2827 | 1550.829 | 1 | 0.000 |
| Model | Federal University | Group E Probability | Group D Probability | Group C Probability | Group B Probability | Group A Probability |
|---|---|---|---|---|---|---|
| GLM | No | 0.2771637 | 0.3070985 | 0.2425269 | 0.1498028 | 0.02340802 |
| Yes | 0.1421969 | 0.2357452 | 0.2956447 | 0.2738828 | 0.05253039 | |
| GLLAMM | No | 0.00880949216 | 0.85862298 | 0.1315927 | 0.0009720858 | 0.000002732045 |
| Yes | 0.00001818504 | 0.01319328 | 0.6638869 | 0.3215682073 | 0.001333463391 |
| Estimation | KSPA Test | p-Value |
|---|---|---|
| Ordinal GLLAMM | 0.0134 | 0.6335 |
| Ordinal GLM | 0.0901 | 0.000 |
| Linear GLM | 0.1651 | 0.000 |
| Binary GLM | 0.0802 | 0.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Freitas Souza, R.d.; Lima, F.G.; Corrêa, H.L. Multilevel Ordinal Logit Models: A Proportional Odds Application Using Data from Brazilian Higher Education Institutions. Axioms 2024, 13, 47. https://doi.org/10.3390/axioms13010047
Freitas Souza Rd, Lima FG, Corrêa HL. Multilevel Ordinal Logit Models: A Proportional Odds Application Using Data from Brazilian Higher Education Institutions. Axioms. 2024; 13(1):47. https://doi.org/10.3390/axioms13010047
Chicago/Turabian StyleFreitas Souza, Rafael de, Fabiano Guasti Lima, and Hamilton Luiz Corrêa. 2024. "Multilevel Ordinal Logit Models: A Proportional Odds Application Using Data from Brazilian Higher Education Institutions" Axioms 13, no. 1: 47. https://doi.org/10.3390/axioms13010047
APA StyleFreitas Souza, R. d., Lima, F. G., & Corrêa, H. L. (2024). Multilevel Ordinal Logit Models: A Proportional Odds Application Using Data from Brazilian Higher Education Institutions. Axioms, 13(1), 47. https://doi.org/10.3390/axioms13010047