
Solving Location Assignment and Order Picker-Routing Problems in Warehouse Management

 , and
, and
Abstract
1. Introduction
2. Related Work

{kind=link}
{kind=link}
{kind=link}
| Works | Picking System | Warehouse Layout | Integrated Solution | Stored in Multiple Locations | Considered Factors | Method |
|---|---|---|---|---|---|---|
| Daniels et al. [5] | Low-level | - | ✓ | ✓ | Demand | Mathematical model. Metaheuristic (Tabu search) |
| Dekker et al. [14] | Low-level | Multiple blocks | X | X | Demand. Type of product | Heuristics |
| Dijkstra and Roodbergen [21] | Low-level | Single block | X | X | Demand | Dynamic programming |
| Žulj et al. [15] | Low-level | Single block | X | X | Weight of product | Exact algorithm |
| Bolaños-Zuñiga et al. [18] | Low-level | General | ✓ | X | Demand. Weight of product | Mathematical model |
| Kordos et al. [7] | - | - | ✓ | X | Demand | Genetic algorithms |
| Silva et al. [11] | - | Single block | ✓ | X | Demand | Mathematical model. Metaheuristic (GVNS) |
| Cai et al. [27] | Robot | RMFS | ✓ | X | Demand | Mathematical model |
| Keung et al. [28] | Robot | RMFS | X | X | Demand | Deterministic and stochastic models. Shortest path heuristics |
| Xu and Ren [35] | Low-level | Single block | ✓ | ✓ | Demand correlations. Congestion of pickers | Mathematical model. Heuristic |
| Zhou et al. [24] | Low-level | Fishbone | X | X | Demand | Stochastic model |
| Lee [39] | Low-level | Single and two blocks | ✓ | X | Frequency and relation of SKUs | Analytical models |
| Alqahtani [40] | High-level | - | X | X | Picking frequency | Analytical formulas |
| This work | Low-level | General | ✓ | X | Demand. Frequency and weight of product | Mathematical model. Heuristic |
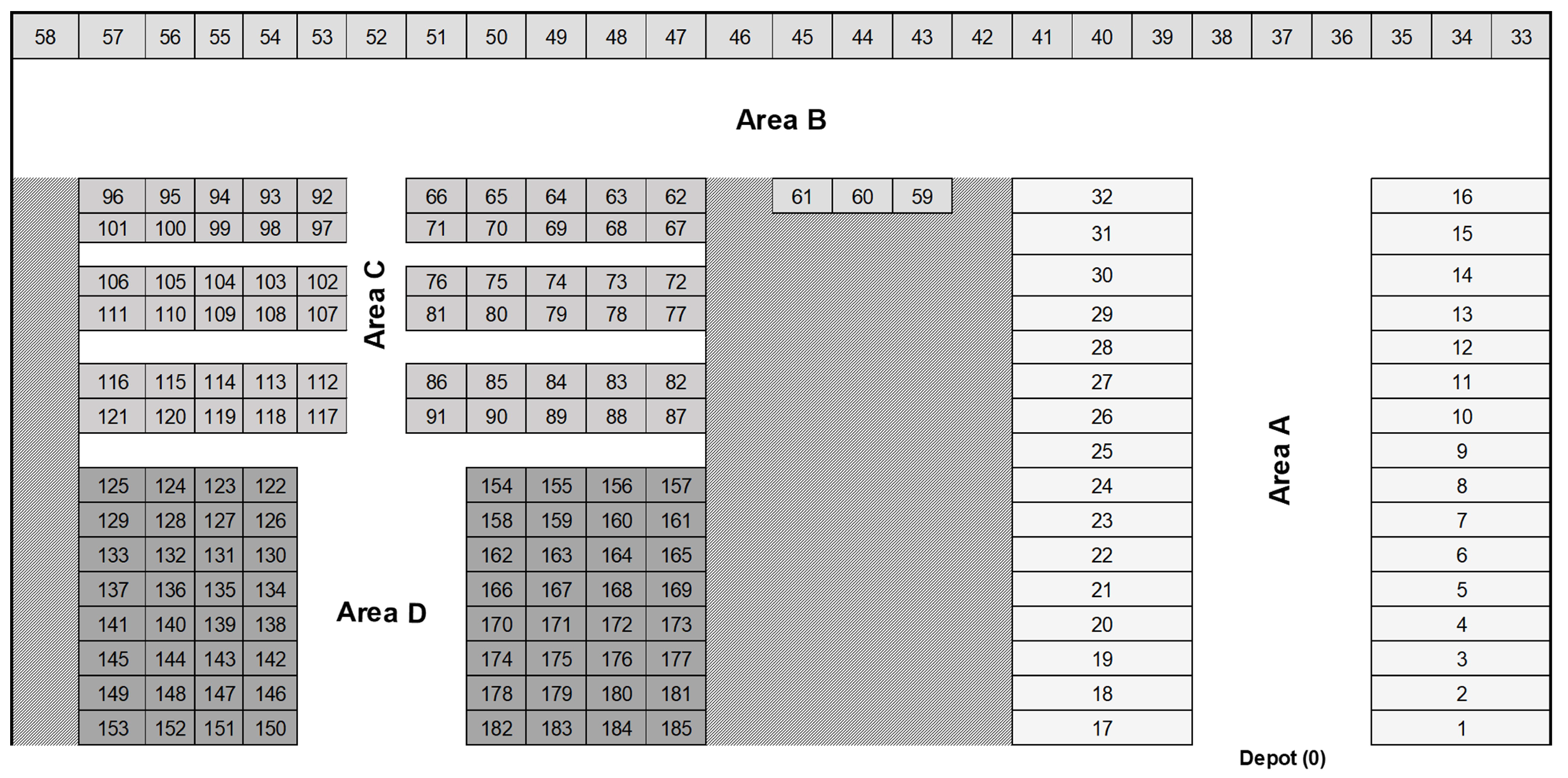
3. Case Study Description
4. Materials and Methods
4.1. Proposed Reformulations
- Constraints (3) and (8) were merged since it is possible to guarantee with a single constraint that the product is retrieved without exceeding the capacity (inventory) of the corresponding storage location:
- Redundant constraints (10) were removed.
- Constraints (11) were replaced bywhere corresponds to the number of different products in order . is a new parameter that is created to bound without losing feasibility in Constraints (11).
- In Constraint (14), parameter M is set as M = to bound the value in this parameter.
4.2. Proposed Heuristic
| Algorithm 1 Adaptive multi-start heuristic (AMH). |
|
4.2.1. Constructive Phase
| Algorithm 2 First step of the RCH: storage location assignment. |
|
4.2.2. Improvement Phase
4.2.3. Adaptive Process
5. Results and Discussion
5.1. Proposed Reformulations
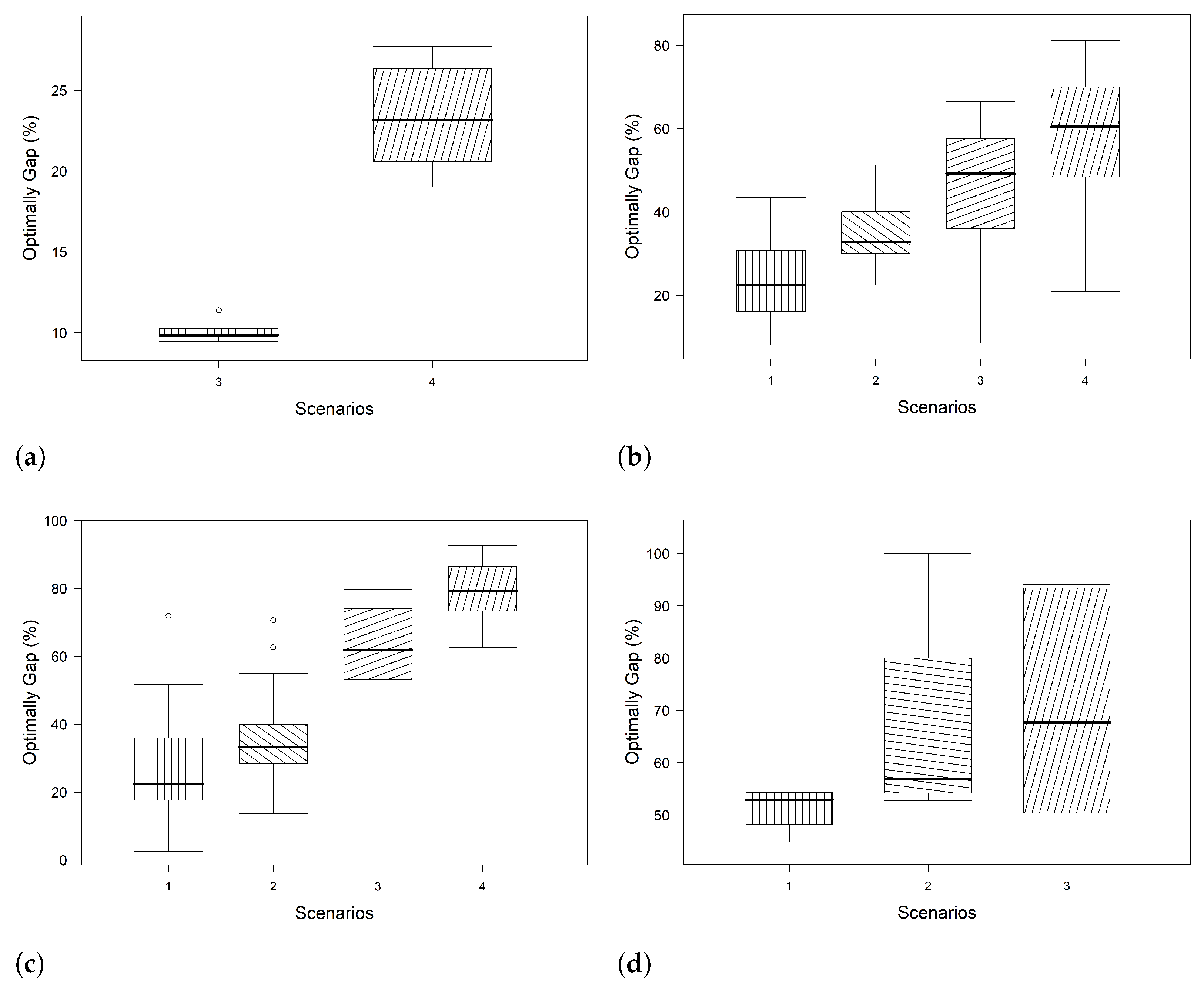
5.2. AMH Performance
5.3. MIPStart Analysis
5.4. Comparison of the Real Situation and AMH Solution
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bartholdi, J.; Hankman, S. Warehouse and Distribution Science Release 0.96. 2014. Available online: https://www.warehouse-science.com/book/index.html (accessed on 2 November 2021).
- Davarzani, H.; Norrman, A. Toward a relevant agenda for warehousing research: Literature review and practitioners’ input. Logist. Res. 2015, 8, 1. [Google Scholar] [CrossRef]
- Henn, S.; Schmid, V. Metaheuristics for order batching and sequencing in manual order picking systems. Comput. Ind. Eng. 2013, 66, 338–351. [Google Scholar] [CrossRef]
- Casella, G.; Volpi, A.; Montanari, R.; Tebaldi, L.; Bottani, E. Trends in order picking: A 2007–2022 review of the literature. Prod. Manuf. Res. 2023, 11, 2191115. [Google Scholar] [CrossRef]
- Daniels, R.L.; Rummel, J.L.; Schantz, R. A model for warehouse order picking. Eur. J. Oper. Res. 1998, 105, 1–17. [Google Scholar] [CrossRef]
- Petersen, C. The impact of routing and storage policies on warehouse efficiency. Int. J. Oper. Prod. Manag. 1999, 19, 1053–1064. [Google Scholar] [CrossRef]
- Kordos, M.; Boryczko, J.; Blachnik, M.; Golak, S. Optimization of Warehouse Operations with Genetic Algorithms. Appl. Sci. 2020, 10, 4817. [Google Scholar] [CrossRef]
- Venkata, R.M.; Gajendra, K.A. Class-based storage-location assignment to minimise pick travel distance. Int. J. Logist. Res. Appl. 2008, 11, 247–265. [Google Scholar] [CrossRef]
- van Gils, T.; Ramaekers, K.; Caris, A.; de Koster, R.B.M. Designing efficient order picking systems by combining planning problems: State-of-the-art classification and review. Eur. J. Oper. Res. 2018, 267, 1–15. [Google Scholar] [CrossRef]
- Van Gils, T.; Ramaekers, K.; Braekers, K.; Depaire, B.; Caris, A. Increasing order picking efficiency by integrating storage, batching, zone picking, and routing policy decisions. Int. J. Prod. Econ. 2018, 197, 243–261. [Google Scholar] [CrossRef]
- Silva, A.; Coelho, L.C.; Darvish, M.; Renaud, R. Integrating storage location and order picking problems in warehouse planning. Transp. Res. Part E Logist. Transp. Rev. 2020, 140, 102003. [Google Scholar] [CrossRef]
- Salhi, S.; Nagy, G. Consistency and robustness in location-routing. In Studies in Locational Analysis; University of Kentucky: Lexington, KY, USA, 1999; pp. 3–19. [Google Scholar]
- Winkelhaus, S.; Grosse, E.H.; Morana, S. Towards a conceptualisation of Order Picking 4.0. Comput. Ind. Eng. 2021, 159, 107511. [Google Scholar] [CrossRef]
- Dekker, R.; de Koster, R.B.M.; Roodbergen, K.J.; Van, K.H. Improving Order Picking Response Time at Ankor’s Warehouse. Interfaces 2004, 34, 303–313. [Google Scholar] [CrossRef]
- Žulj, I.; Glock, C.H.; Grosse, E.H.; Schneider, M. Picker routing and storage-assignment strategies for precedence-constrained order picking. Comput. Ind. Eng. 2018, 123, 338–347. [Google Scholar] [CrossRef]
- Chabot, T.; Lahyani, R.; Coelho, L.C.; Renaud, J. Order picking problems under weight, fragility and category constraints. Int. J. Prod. Res. 2017, 55, 6361–6379. [Google Scholar] [CrossRef]
- Zunic, E.; Besirevic, A.; Skrobo, R.; Hasic, H.; Hodzic, K.; Djedovic, A. Design of optimization system for warehouse order picking in real environment. In Proceedings of the 2017 XXVI International Conference on Information, Communication and Automation Technologies (ICAT), Sarajevo, Bosnia and Herzegovina, 26–28 October 2017; IEEE: Toulouse, France, 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Bolaños-Zuñiga, J.; Saucedo-Martínez, J.A.; Salais-Fierro, T.E.; Marmolejo-Saucedo, J.A. Optimization of the storage location assignment and the picker-routing problem by using mathematical programming. Appl. Sci. 2020, 10, 534. [Google Scholar] [CrossRef]
- Gavish, B.; Graves, S. The Traveling Salesman Problem and Related Problems; Working Paper GR-078-78; Massachusetts Institute of Technology, Operations Research Center: Cambridge, MA, USA, 1978. [Google Scholar]
- Caron, F.; Marchet, G.; Perego, A. Routing policies and COI-based storage policies in picker-to-part systems. Int. J. Prod. Res. 1998, 36, 713–732. [Google Scholar] [CrossRef]
- Dijkstra, A.S.; Roodbergen, K.J. Exact route-length formulas and a storage location assignment heuristic for picker-to-parts warehouses. Transp. Res. Part Logist. Transp. Rev. 2017, 102, 38–59. [Google Scholar] [CrossRef]
- Çelk, M.; Süral, H. Order picking under random and turnover-based storage policies in fishbone aisle warehouses. IIE Trans. 2014, 46, 283–300. [Google Scholar] [CrossRef]
- Wan, Y.; Liu, Y. Integrating Optimized Fishbone Warehouse Layout, Storage Location Assignment and Picker Routing. IAENG Int. J. Comput. Sci. 2022, 49, 957–974. [Google Scholar]
- Zhou, L.; Zhao, J.; Liu, H.; Wang, F.; Jianglong, Y.; Wang, S. Stochastic models of routing strategies under the class-based storage policy in fishbone layout warehouses. Sci. Rep. 2022, 12, 17. [Google Scholar] [CrossRef]
- Glock, C.H.; Grosse, E.H.; Abedinnia, H.; Emde, S. An integrated model to improve ergonomic and economic performance in order picking by rotating pallets. Eur. J. Oper. Res. 2019, 273, 516–534. [Google Scholar] [CrossRef]
- Castier, M.; Martínez-Toro, E. Planning and picking in small warehouses under industry-relevant constraints. Prod. Eng. 2023, 17, 575–590. [Google Scholar] [CrossRef]
- Cai, J.; Xiaokang, L.; Yue, L.; Ouyang, S. Collaborative Optimization of Storage Location Assignment and Path Planning in Robotic Mobile Fulfillment Systems. Sustainability 2021, 13, 5644. [Google Scholar] [CrossRef]
- Keung, K.; Lee, C.; Ji, P. Industrial internet of things-driven storage location assignment and order picking in a resource synchronization and sharing-based robotic mobile fulfillment system. Adv. Eng. Informatics 2022, 52, 101540. [Google Scholar] [CrossRef]
- Sarkar, B.; Takeyeva, D.; Guchhait, R.; Sarkar, M. Optimized radio-frequency identification system for different warehouse shapes. Knowl.-Based Syst. 2022, 258, 109811. [Google Scholar] [CrossRef]
- Scholz, A.; Henn, S.; Stuhlmann, M.; Wäscher, G. A new mathematical programming formulation for the Single-Picker Routing Problem. Eur. J. Oper. Res. 2016, 253, 68–84. [Google Scholar] [CrossRef]
- Theys, C.; Bráysy, O.; Dullaert, W.; Raa, B. Using a TSP heuristic for routing order pickers in warehouses. Eur. J. Oper. Res. 2010, 200, 755–763. [Google Scholar] [CrossRef]
- Lin, C.C.; Kang, J.R.; Hou, C.C.; Cheng, C.Y. Joint order batching and picker Manhattan routing problem. Comput. Ind. Eng. 2016, 95, 164–174. [Google Scholar] [CrossRef]
- Ratliff, H.D.; Rosenthal, A.S. Order-Picking in a Rectangular Warehouse: A Solvable Case of the Traveling Salesman Problem. Oper. Res. 1983, 31, 507–521. [Google Scholar] [CrossRef]
- Scholz, A.; Wäscher, G. Order Batching and Picker Routing in manual order picking systems: The benefits of integrated routing. Cent. Eur. J. Oper. Res. 2017, 25, 491–520. [Google Scholar] [CrossRef]
- Xu, X.; Ren, C. A novel storage location assignment in multi-pickers picker-to-parts systems integrating scattered storage, demand correlation, and routing adjustment. Comput. Ind. Eng. 2022, 172, 108618. [Google Scholar] [CrossRef]
- Bottani, E.; Cecconi, M.; Vignali, G.; Montanari, R. Optimisation of storage allocation in order picking operations through a genetic algorithm. Int. J. Logist. Res. Appl. 2012, 15, 127–146. [Google Scholar] [CrossRef]
- Sarkar, A.; Guchhait, R.; Sarkar, B. Application of the Artificial Neural Network with Multithreading Within an Inventory Model Under Uncertainty and Inflation. Int. J. Fuzzy Syst. 2022, 24, 2318–2332. [Google Scholar] [CrossRef]
- Singh-Padiyar, S.V.; Vandana, V.; Bhagat, N.; Singh, S.R.; Sarkar, B. Joint replenishment strategy for deteriorating multi-item through multi-echelon supply chain model with imperfect production under imprecise and inflationary environment. RAIRO-Oper. Res. 2022, 56, 3071–3096. [Google Scholar] [CrossRef]
- Lee, H.T. Travel distance estimation of relation-based storage assignment policies in picker-to-part warehouses. J. Bus. Adm. 2022, 47, 17. [Google Scholar] [CrossRef]
- Alqahtani, A. Improving order-picking response time at retail warehouse: A case of sugar company. SN Appl. Sci. 2023, 5, 8. [Google Scholar] [CrossRef]
- Cortés, P.; Gómez-Montoya, R.A.; Muñuzuri, J.; Correa-Espinal, A. A tabu search approach to solving the picking routing problem for large- and medium-size distribution centres considering the availability of inventory and K heterogeneous material handling equipment. Appl. Soft Comput. 2017, 53, 61–73. [Google Scholar] [CrossRef]
- Wang, W.; Gao, J.; Gao, T.; Zhao, H. Optimization of Automated Warehouse Location Based on Genetic Algorithm. In Proceedings of the 2017 2nd International Conference on Control, Automation and Artificial Intelligence (CAAI 2017), Sanya, China, 25–26 June 2017; Atlantis Press: Paris, France, 2017. [Google Scholar] [CrossRef]
- Eydi, A.; Mohagheghi, H.; Ghaseminezhad, S. Routing order pickers in warehouses considering congestion and aisle width. Sci. Iran. 2020, 29, 3455–3469. [Google Scholar] [CrossRef]
- Boudia, M.; Louly, M.; Prins, C. A reactive GRASP and path relinking for a combined production–distribution problem. Comput. Oper. Res. 2007, 34, 3402–3419. [Google Scholar] [CrossRef]
- Cantu-Funes, R.; Salazar-Aguilar, M.A.; Boyer, V. Multi-depot periodic vehicle routing problem with due dates and time windows. J. Oper. Res. Soc. 2018, 69, 296–306. [Google Scholar] [CrossRef]
- Edis, E.; Uzun Araz, O.; Eski, O.; Edis, R. Storage location assignment of steel coils in a manufacturing company: An integer linear programming model and a greedy randomized adaptive search procedure. TOP 2023, 31, 67–109. [Google Scholar] [CrossRef]
- Feo, T.A.; Resende, M.G.C. Greedy randomized adaptive search procedures. J. Glob. Optim. 1995, 6, 109–133. [Google Scholar] [CrossRef]
- Prais, M.; Ribeiro, C.C. Reactive grasp: An application to a matrix decomposition problem in TDMA traffic assignment. INFORMS J. Comput. 2000, 12, 164–176. [Google Scholar] [CrossRef]
- Hota, S.K.; Ghosh, S.K.; Sarkar, B. A solution to the transportation hazard problem in a supply chain with an unreliable manufacturer. AIMS Environ. Sci. 2022, 9, 354–380. [Google Scholar] [CrossRef]
- Azadnia, A.H.; Taheri, S.; Ghadimi, P.; Mat, S.; Muhamad, Z.; Wong, K.Y. Order batching in warehouses by minimizing total tardiness: A hybrid approach of weighted association rule mining and genetic algorithms. Sci. World J. 2013, 2013, 246578. [Google Scholar] [CrossRef]
- Miller, C.E.; Tucker, A.; Zemlin, R. Integer Programming Formulation of Traveling Salesman Problems. J. Assoc. Comput. Mach. 1960, 7, 326–329. [Google Scholar] [CrossRef]
- Palomo-Martínez, P.; Salazar-Aguilar, M.; Albornoz, V. Formulations for the orienteering problem with additional constraints. Ann. Oper. Res. 2017, 258, 503–545. [Google Scholar] [CrossRef]
- Chaovalitwongse, W.; Kim, D.; Pardalos, P.M. Grasp with a new local search scheme for vehicle routing problems with time window. J. Comb. Optim. 2003, 7, 179–207. [Google Scholar] [CrossRef]
- Villegas, J.G.; Prins, C.; Prodhon, C.; Medaglia, A.; Velasco, N. A GRASP with evolutionary path relinking for the truck and trailer routing problem. Comput. Oper. Res. 2011, 38, 1319–1334. [Google Scholar] [CrossRef]
- Haddadene, S.R.A.; Labadie, N.; Prodhon, C. A GRASP × ILS for the vehicle routing problem with time windows, synchronization and precedence constraints. Expert Syst. Appl. 2016, 66, 274–294. [Google Scholar] [CrossRef]
- Festa, P.; Resende, M.G.C. GRASP: Basic components and enhancements. Telecommun. Syst. 2010, 46, 253–271. [Google Scholar] [CrossRef]



| Index Sets | |
|---|---|
| I | Store locations including the depot |
| K | Available products in the warehouse |
| P | Requested orders |
| Products to assign | |
| Parameters | |
| Demand of product in order | |
| Physical capacity of location to store product | |
| Time matrix between locations | |
| Weight of product | |
| min {, } | |
| M | |
| Decision variables | |
| Number of boxes of product for picking in order at location . | |
| Auxiliary variable for subtour elimination constraints, it keeps the position in which location is visited while picking order | |
| Instance Size | Storage Location | Requested Products | Products to Assign | Orders to Pick | Number of Instances |
|---|---|---|---|---|---|
| Small | 10–16 | 4 | 1–16 | 2–4 | 90 |
| Medium type_1 | 32 | 8–16 | 5–32 | 1–5 | 144 |
| Medium type_2 | 61 | 15–30 | 12–61 | 1–5 | 75 |
| Large | 121–185 | 30 | 25–104 | 1–6 | 25 |
| Size Instance | Scenarios | SLAUPR | SLAUPR_V2 | SLAUPR_V3 | |||
|---|---|---|---|---|---|---|---|
| F/O | Average Optimality Gap (%) | F/O | Average Optimality Gap (%) | F/O | Average Optimality Gap (%) | ||
| Small | 1 | 24/24 | 0.00 | 24/24 | 0.00 | 24/24 | 0.00 |
| 2 | 24/24 | 0.00 | 24/24 | 0.00 | 24/24 | 0.00 | |
| 3 | 18/6 | 33.47 | 18/12 | 19.24 | 18/12 | 3.83 | |
| 4 | 24/6 | 35.92 | 24/12 | 23.27 | 24/12 | 8.48 | |
| Totals | 90/60 | 90/72 | 90/72 | ||||
| Medium type_1 | 1 | 30/3 | 32.11 | 31/23 | 7.68 | 34/25 | 6.15 |
| 2 | 30/16 | 22.62 | 33/24 | 13.13 | 36/24 | 15.63 | |
| 3 | 17/12 | 14.21 | 17/12 | 15.20 | 27/12 | 23.54 | |
| 4 | 6/0 | 63.49 | 14/0 | 74.43 | 19/0 | 54.98 | |
| Totals | 83/32 | 95/59 | 116/61 | ||||
| Medium type_2 | 1 | 18/0 | 81.81 | 17/0 | 57.15 | 25/0 | 34.94 |
| 2 | 24/0 | 88.51 | 26/0 | 73.17 | 25/0 | 57.53 | |
| 3 | 7/1 | 53.41 | 7/4 | 22.44 | 8/3 | 37.78 | |
| 4 | 0/0 | - | 0/0 | 1/0 | 81.04 | ||
| Totals | 49/1 | 50/4 | 59/3 | ||||
| Large | 1 | 0/0 | - | 0/0 | - | 0/0 | - |
| 2 | 3/0 | 94.68 | 6/0 | 99.29 | 0/0 | - | |
| 3 | 2/0 | 83.16 | 1/0 | 98.23 | 4/0 | 87.55 | |
| Totals | 5/0 | 7/0 | 4/0 | ||||
| Totals | 227/87 | 242/135 | 269/136 | ||||
| Size Instance | Scenarios | Best-Known | AMH | Average (%) | ||
|---|---|---|---|---|---|---|
| F/O | Average Time (s) | F/O | Average Time (s) | |||
| Small | 1 | 24/24 | 0 | 24/24 | 8 | 0 |
| 2 | 24/24 | 0 | 24/24 | 4 | 0 | |
| 3 | 18/12 | 1209 | 18/12 | 12 | −2.46 | |
| 4 | 24/12 | 1833 | 24/12 | 16 | 0.16 | |
| Totals | 90/72 | 731 | 90/72 | 10 | ||
| Medium type_1 | 1 | 36/25 | 1145 | 36/24 | 19 | −3.12 |
| 2 | 36/24 | 1211 | 36/23 | 13 | 3.15 | |
| 3 | 27/12 | 2047 | 36/6 | 53 | −5.57 | |
| 4 | 25/0 | 3600 | 36/0 | 78 | 27.42 | |
| Totals | 124/61 | 1855 | 144/53 | 41 | ||
| Medium type_2 | 1 | 26/0 | 7200 | 28/0 | 47 | 5.47 |
| 2 | 28/0 | 7054 | 28/0 | 37 | 27.89 | |
| 3 | 9/5 | 5882 | 11/0 | 202 | −7.91 | |
| 4 | 1/0 | 7200 | 8/0 | 496 | 59.87 | |
| Totals | 64/5 | 6951 | 75/0 | 114 | ||
| Large | 1 | 0/0 | 4/0 | 107 | ||
| 2 | 6/0 | 11,040 | 15/0 | 121 | 78.72 | |
| 3 | 5/0 | 10,800 | 6/0 | 114 | 66.92 | |
| Totals | 11/0 | 10,800 | 25/0 | 117 | ||
| Totals | 289/138 | 334/125 | ||||
| Size Instance | Scenarios | Average Improvement (%) | ||
|---|---|---|---|---|
| SLAUPR | SLAUPR_V2 | SLAUPR_V3 | ||
| Small | 1 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | |
| 3 | 5.84 | 0.50 | 0.28 | |
| 4 | 2.72 | 1.67 | 0.80 | |
| Medium type_1 | 1 | 8.8 | 0.41 | 1.98 |
| 2 | 12.52 | 3.67 | 8.12 | |
| 3 | 1.42 | 2.83 | 10.75 | |
| 4 | 30.11 | 35.03 | 26.08 | |
| Medium type_2 | 1 | 59.01 | 16.03 | 15.9 |
| 2 | 74.1 | 35.87 | 35.95 | |
| 3 | 47.52 | 15.41 | 31.46 | |
| 4 | - | - | 59.87 | |
| Large | 2 | 75.97 | 82.29 | - |
| 3 | 60.13 | 72.01 | 73.69 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bolaños-Zuñiga, J.; Salazar-Aguilar, M.A.; Saucedo-Martínez, J.A. Solving Location Assignment and Order Picker-Routing Problems in Warehouse Management. Axioms 2023, 12, 711. https://doi.org/10.3390/axioms12070711
Bolaños-Zuñiga J, Salazar-Aguilar MA, Saucedo-Martínez JA. Solving Location Assignment and Order Picker-Routing Problems in Warehouse Management. Axioms. 2023; 12(7):711. https://doi.org/10.3390/axioms12070711
Chicago/Turabian StyleBolaños-Zuñiga, Johanna, M. Angélica Salazar-Aguilar, and Jania Astrid Saucedo-Martínez. 2023. "Solving Location Assignment and Order Picker-Routing Problems in Warehouse Management" Axioms 12, no. 7: 711. https://doi.org/10.3390/axioms12070711
APA StyleBolaños-Zuñiga, J., Salazar-Aguilar, M. A., & Saucedo-Martínez, J. A. (2023). Solving Location Assignment and Order Picker-Routing Problems in Warehouse Management. Axioms, 12(7), 711. https://doi.org/10.3390/axioms12070711