
Federated Learning Incentive Mechanism Design via Shapley Value and Pareto Optimality

 , , , , , and
, , , , , and
Abstract
1. Introduction
- (1)
- Discussing the conditions satisfied by the fines paid to the regulator by the limited-liability federated agent if Pareto optimality is achieved;
- (2)
- Demonstrating that the federated players’ inputs constitute the mechanism’s Nash equilibrium when Pareto optimality is satisfied;
- (3)
- Numerical examples are performed to verify the rationality of designing the mechanism for the both equal and unequal statuses of the federated players.
2. Related Work
3. Preliminaries
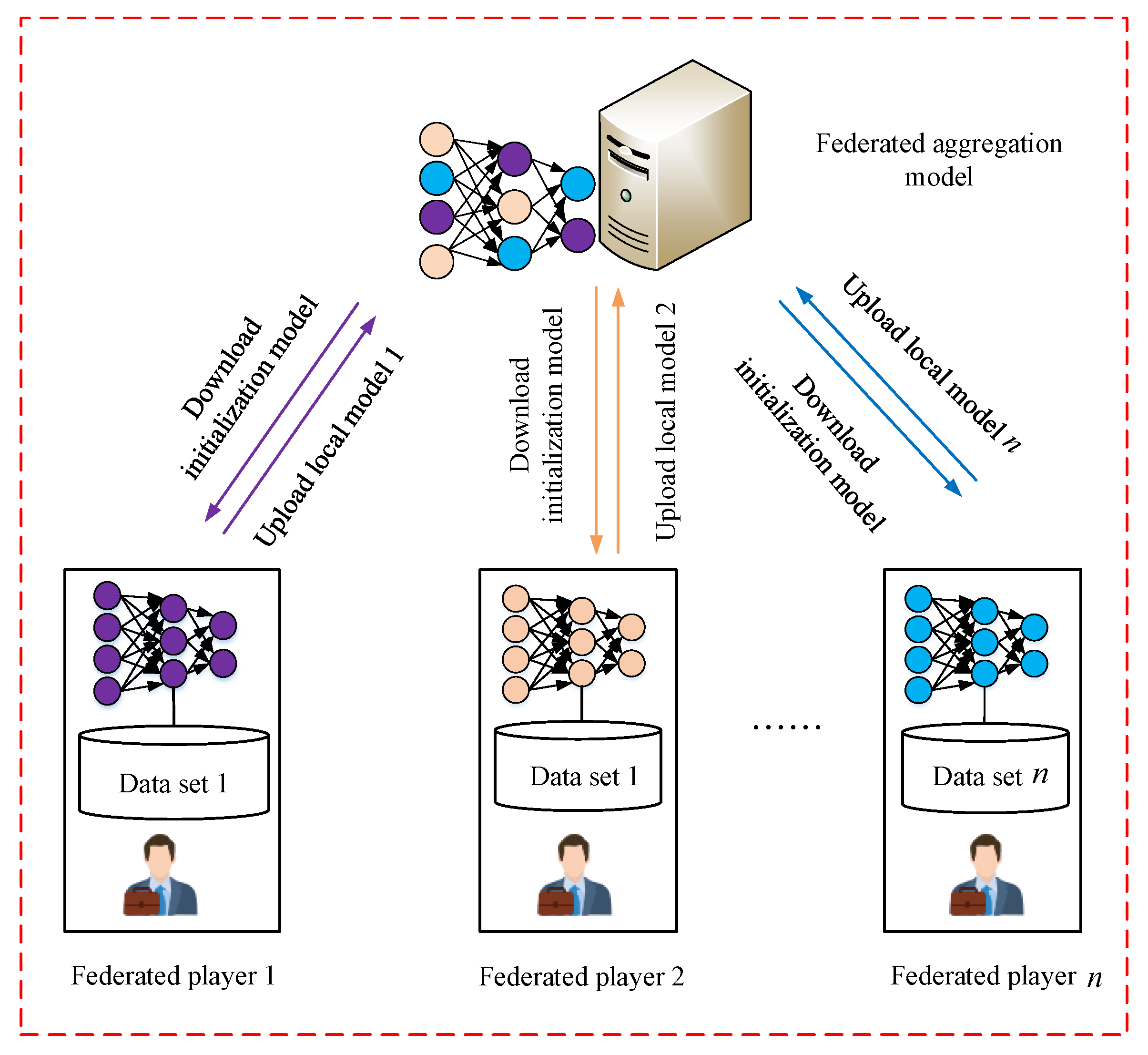
3.1. Federated Learning Framework
3.2. Cooperative Games
3.3. Shapley Value
3.4. Pareto Optimality
- (1)
- If , then weakly dominates and is marked by ;
- (2)
- If and , then dominates and is marked by .
3.5. Nash Equilibrium
4. Federated Learning Incentive Mechanism
4.1. The FL Incentive Model
- (1)
- All players can pay for FL, and in the payoff distribution process, they adopt the best payoff distribution scheme.
- (2)
- All players are satisfied with the final distribution of payoffs, as all players were willing to join the coalition.
- (3)
- All players are entirely trustworthy and have no cheating in the FL.
- (4)
- To ensure the smooth implementation of the strategy, the FL should adopt a multi-party agreement to accept the payoff distribution plan.
4.2. The Conflict between Fairness and Pareto Optimality
4.3. FL Incentive Mechanism via Introducing Supervisory Organization
4.3.1. The Establishment of Supervisory Organization Mechanism
4.3.2. Penalty Conditions
- (1)
- If the independent input of the player i is less than the Pareto optimality federated input , i.e., e.g., , and is monotonically increasing, i.e., , then the player i is fined, and the payoff remaining after the fine is , and finally the profit of the player i is
- (2)
- If the independent input of the player i is equal to the Pareto optimality federated input , i.e.,, then , and the payoff remaining after the penalty is , and finally the profit of player i iswhere represents the Pareto optimality federated input vector composed of players.
5. Numerical Examples and Simulation Experiments
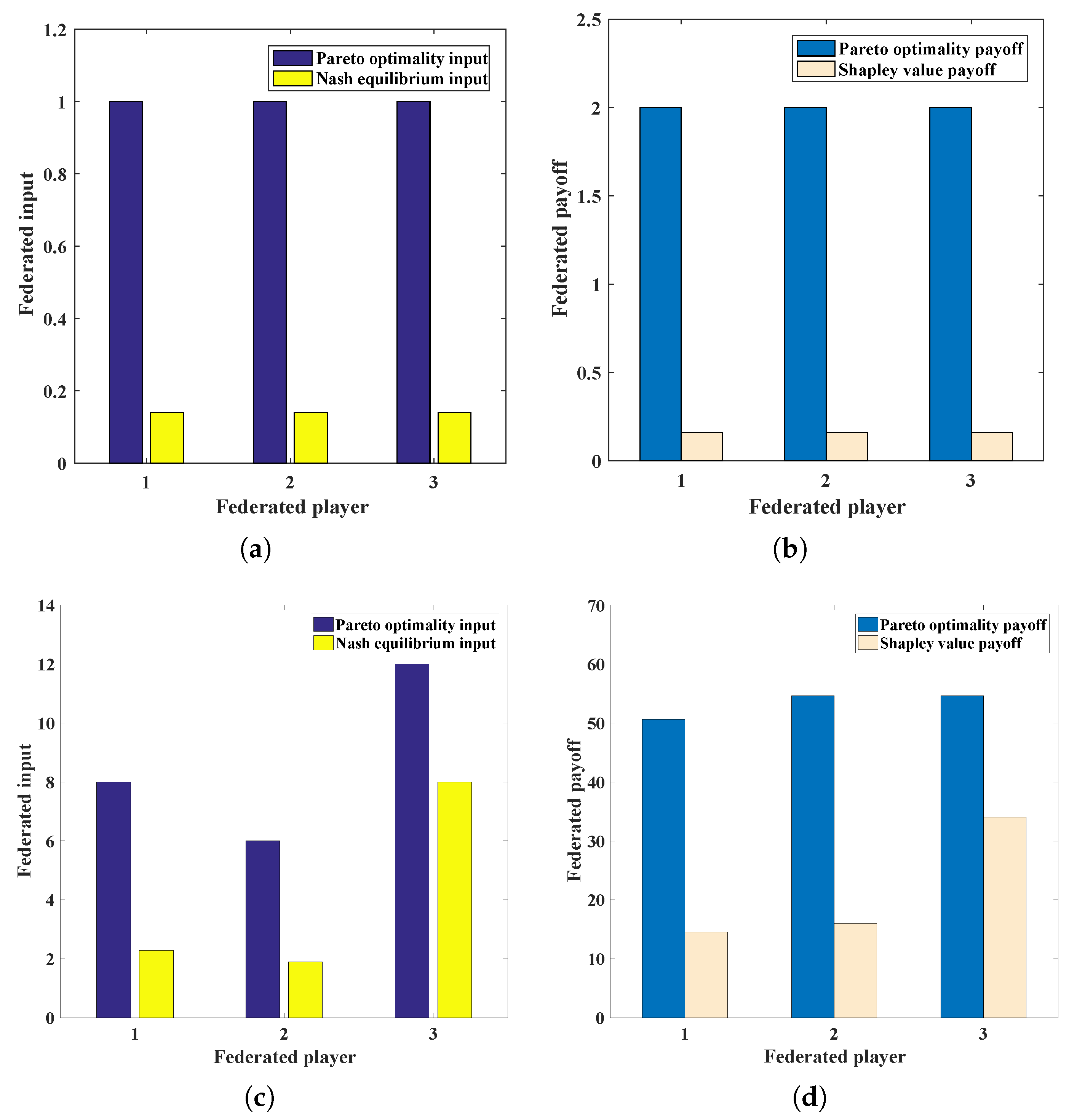
5.1. Numerical Example 1: Equal Status of Federated Players
5.2. Numerical Example 2: Unequal Status of Federated Players
5.3. Numerical Simulation Experiments
6. Conclusions and Future Work
7. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| N | The set of n players |
| D | The set of players’ local dataset |
| M | The model trained jointly by all players |
| The FL sharing model | |
| The traditional machine learning model | |
| The model accuracy of | |
| The model accuracy of | |
| S | The alliance subset of different players, |
| A characteristic function | |
| The player’s payoff through the alliance S | |
| The overall federated payoff | |
| The payoff allocated to player i | |
| The number of players in subset S | |
| The sorted total number when players i participates in coalition S | |
| The sorted total number of remaining players | |
| The alliance after removing player i from alliance S | |
| The marginal contribution of i to coalition S | |
| The weight coefficient | |
| x | A feasible action space |
| The federated player’s payoff function | |
| The coalition cost input of player | |
| The penalty condition for the supervisor to achieve Pareto optimality | |
| The supervisor obtained fines | |
| R | The federated player’s profit |
Appendix A
Appendix A.1. Proof of Theorem 1
Appendix A.2. Proof of Theorem 2
References
- Konečnỳ, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; y Arcas, B.A. Federated learning of deep networks using model averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Sarikaya, Y.; Ercetin, O. Motivating workers in federated learning: A stackelberg game perspective. IEEE Netw. Lett. 2019, 2, 23–27. [Google Scholar] [CrossRef]
- Zhan, Y.; Li, P.; Qu, Z.; Zeng, D.; Guo, S. A learning-based incentive mechanism for federated learning. IEEE Internet Things J. 2020, 7, 6360–6368. [Google Scholar] [CrossRef]
- Kang, J.; Xiong, Z.; Niyato, D.; Xie, S.; Zhang, J. Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory. IEEE Internet Things J. 2019, 6, 10700–10714. [Google Scholar] [CrossRef]
- Tran, N.H.; Bao, W.; Zomaya, A.; Nguyen, M.N.; Hong, C.S. Federated learning over wireless networks: Optimization model design and analysis. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1387–1395. [Google Scholar]
- Yu, H.; Liu, Z.; Liu, Y.; Chen, T.; Cong, M.; Weng, X.; Niyato, D.; Yang, Q. A fairness-aware incentive scheme for federated learning. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–8 February 2020; Volume 2020, pp. 393–399. [Google Scholar]
- Li, T.; Sanjabi, M.; Beirami, A.; Smith, V. Fair resource allocation in federated learning. arXiv 2019, arXiv:1905.10497. [Google Scholar]
- Holmstrom, B. Moral hazard in teams. Bell J. Econ. 1982, 13, 324–340. [Google Scholar] [CrossRef]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.L. Blockchained on-device federated learning. IEEE Commun. Lett. 2019, 24, 1279–1283. [Google Scholar] [CrossRef]
- Feng, S.; Niyato, D.; Wang, P.; Kim, D.I.; Liang, Y.C. Joint service pricing and cooperative relay communication for federated learning. In Proceedings of the 2019 International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Atlanta, GA, USA, 14–17 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 815–820. [Google Scholar]
- Yang, X. An exterior point method for computing points that satisfy second-order necessary conditions for a C1, 1 optimization problem. J. Math. Anal. Appl. 1994, 187, 118–133. [Google Scholar] [CrossRef]
- Wang, Z.; Hu, Q.; Li, R.; Xu, M.; Xiong, Z. Incentive mechanism design for joint resource allocation in blockchain-based federated learning. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 1536–1547. [Google Scholar] [CrossRef]
- Song, T.; Tong, Y.; Wei, S. Profit allocation for federated learning. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2577–2586. [Google Scholar]
- Wang, T.; Rausch, J.; Zhang, C.; Jia, R.; Song, D. A principled approach to data valuation for federated learning. In Federated Learning: Privacy and Incentive; Springer: Cham, Switzerland, 2020; pp. 153–167. [Google Scholar]
- Wang, G.; Dang, C.X.; Zhou, Z. Measure contribution of participants in federated learning. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2597–2604. [Google Scholar]
- Liu, Y.; Ai, Z.; Sun, S.; Zhang, S.; Liu, Z.; Yu, H. Fedcoin: A peer-to-peer payment system for federated learning. In Federated Learning: Privacy and Incentive; Springer: Berlin/Heidelberg, Germany, 2020; pp. 125–138. [Google Scholar]
- Zeng, R.; Zeng, C.; Wang, X.; Li, B.; Chu, X. A comprehensive survey of incentive mechanism for federated learning. arXiv 2021, arXiv:2106.15406. [Google Scholar]
- Liu, Z.; Chen, Y.; Yu, H.; Liu, Y.; Cui, L. Gtg-shapley: Efficient and accurate participant contribution evaluation in federated learning. ACM Trans. Intell. Syst. Technol. (TIST) 2022, 13, 1–21. [Google Scholar] [CrossRef]
- Nagalapatti, L.; Narayanam, R. Game of gradients: Mitigating irrelevant clients in federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 9046–9054. [Google Scholar]
- Fan, Z.; Fang, H.; Zhou, Z.; Pei, J.; Friedlander, M.P.; Liu, C.; Zhang, Y. Improving fairness for data valuation in horizontal federated learning. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2440–2453. [Google Scholar]
- Fan, Z.; Fang, H.; Zhou, Z.; Pei, J.; Friedlander, M.P.; Zhang, Y. Fair and efficient contribution valuation for vertical federated learning. arXiv 2022, arXiv:2201.02658. [Google Scholar]
- Yang, X.; Tan, W.; Peng, C.; Xiang, S.; Niu, K. Federated Learning Incentive Mechanism Design via Enhanced Shapley Value Method. Wirel. Commun. Mob. Comput. 2022, 2022, 9690657. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Shapley, L.S. A value for n-person games. Contrib. Theory Games 1953, 2, 307–317. [Google Scholar]
- Zhou, Z.H.; Yu, Y.; Qian, C. Evolutionary Learning: Advances in Theories and Algorithms; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Pardalos, P.M.; Migdalas, A.; Pitsoulis, L. Pareto Optimality, Game Theory and Equilibria; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008; Volume 17. [Google Scholar]
- Nas, J. Non-cooperative games. Ann. Math. 1951, 54, 286–295. [Google Scholar] [CrossRef]
- Ye, M.; Hu, G. Distributed Nash Equilibrium Seeking by a Consensus Based Approach. IEEE Trans. Autom. Control 2017, 62, 4811–4818. [Google Scholar] [CrossRef]
- Alchian, A.A.; Demsetz, H. Production, information costs, and economic organization. Am. Econ. Rev. 1972, 62, 777–795. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Input and Profit Comparison | Input | Input | Input | Federated Profit | Maximum Profit |
|---|---|---|---|---|---|
| Pareto optimality | 1 | 1 | 1 | 6 | 1.5 |
| Nash equilibrium | 0.14 | 0.14 | 0.14 | 0.49 | 0.4 |
| Input and Profit Comparison | Input | Input | Input | Federated Profit | Maximum Profit |
|---|---|---|---|---|---|
| Pareto optimality | 8 | 6 | 12 | 160 | 56 |
| Nash equilibrium | 2.19 | 1.90 | 8 | 64.53 | 42.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Xiang, S.; Peng, C.; Tan, W.; Li, Z.; Wu, N.; Zhou, Y. Federated Learning Incentive Mechanism Design via Shapley Value and Pareto Optimality. Axioms 2023, 12, 636. https://doi.org/10.3390/axioms12070636
Yang X, Xiang S, Peng C, Tan W, Li Z, Wu N, Zhou Y. Federated Learning Incentive Mechanism Design via Shapley Value and Pareto Optimality. Axioms. 2023; 12(7):636. https://doi.org/10.3390/axioms12070636
Chicago/Turabian StyleYang, Xun, Shuwen Xiang, Changgen Peng, Weijie Tan, Zhen Li, Ningbo Wu, and Yan Zhou. 2023. "Federated Learning Incentive Mechanism Design via Shapley Value and Pareto Optimality" Axioms 12, no. 7: 636. https://doi.org/10.3390/axioms12070636
APA StyleYang, X., Xiang, S., Peng, C., Tan, W., Li, Z., Wu, N., & Zhou, Y. (2023). Federated Learning Incentive Mechanism Design via Shapley Value and Pareto Optimality. Axioms, 12(7), 636. https://doi.org/10.3390/axioms12070636