


A Unified Learning Approach for Malicious Domain Name Detection

 , , ,
, , ,  , and
, and 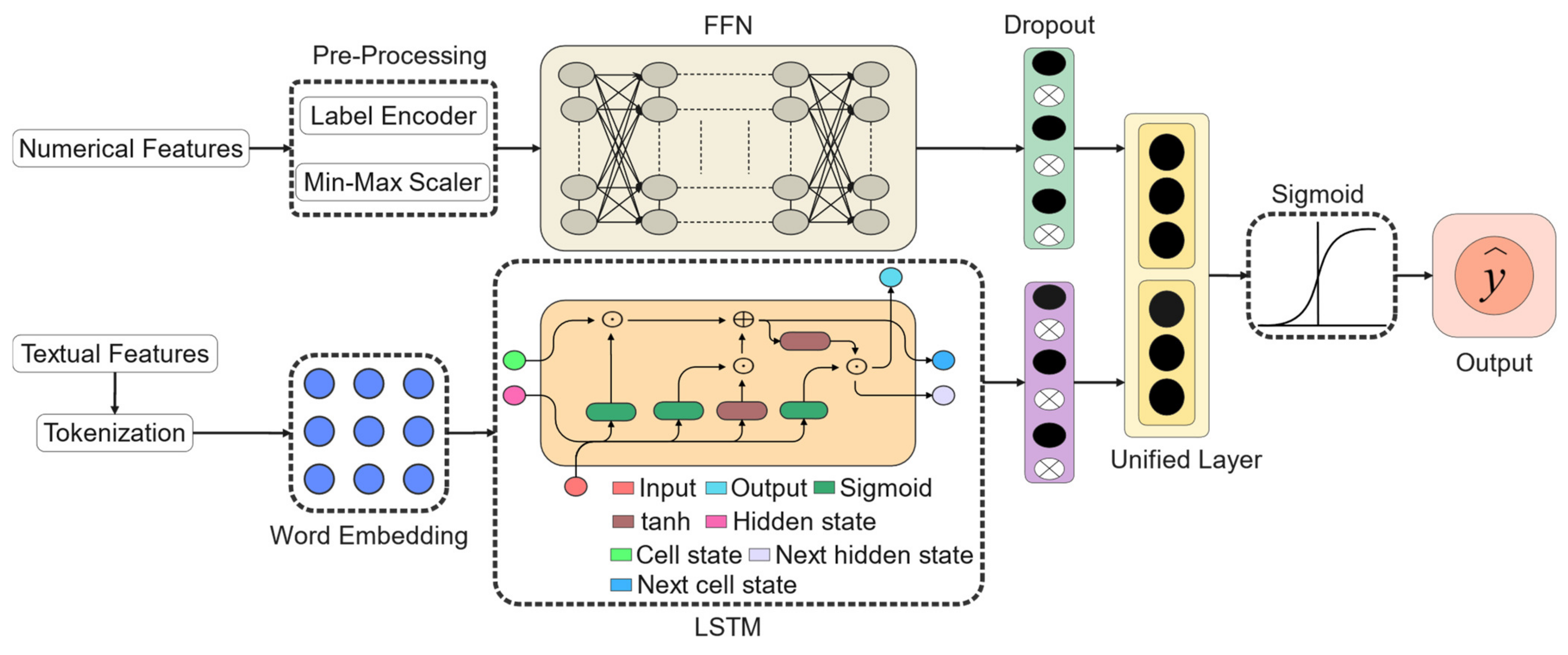{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- (1)
- We consider the domain name textual and numerical features unified representation learning issue in the context of malicious domain name detection tasks.
- (2)
- A new deep learning model is proposed for malicious domain name detection.
- (3)
- Experimental results for the detection of the malicious domain name demonstrate the high performance of the proposed method in comparison with state-of-the-art methods on the malicious domain name dataset.
2. Related Work
2.1. Non-Machine Learning Approaches
2.2. Machine Learning Approaches
3. Methodology
3.1. Overview
3.2. Numerical Learner
3.3. Text Learner
3.4. Unified Learning
3.5. Training
4. Experiment Setup
4.1. Dataset
4.2. Performance Evaluation
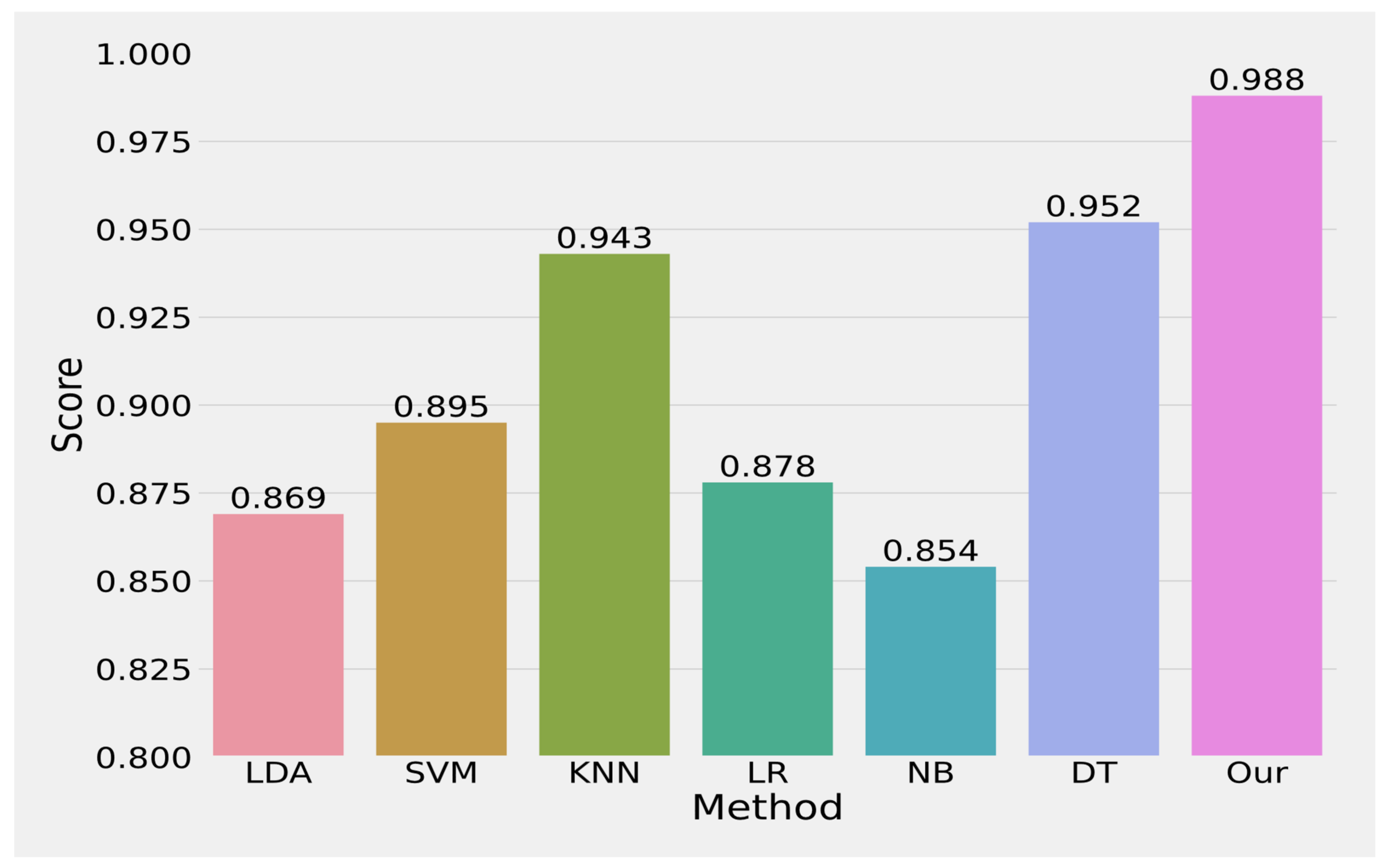
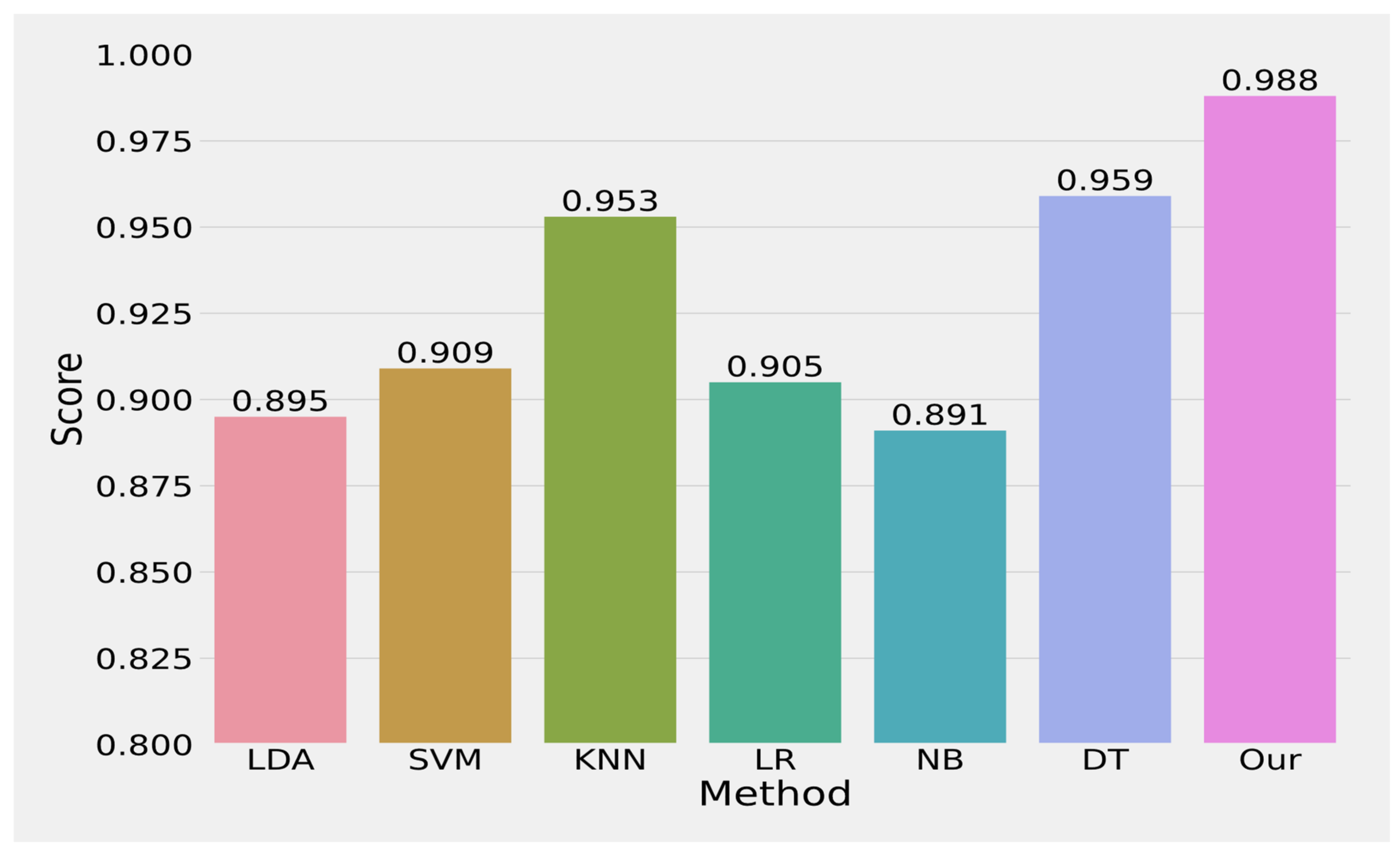
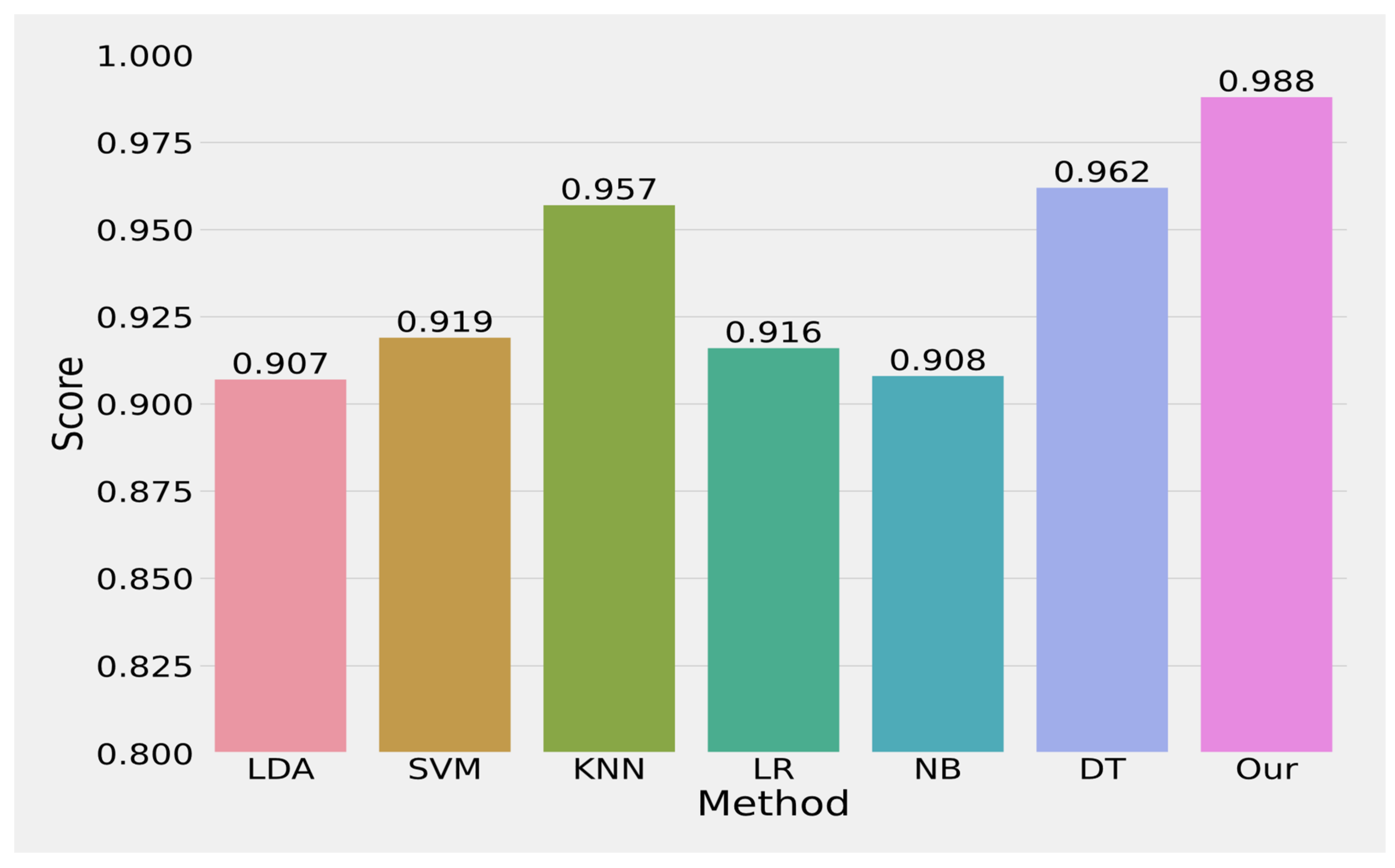
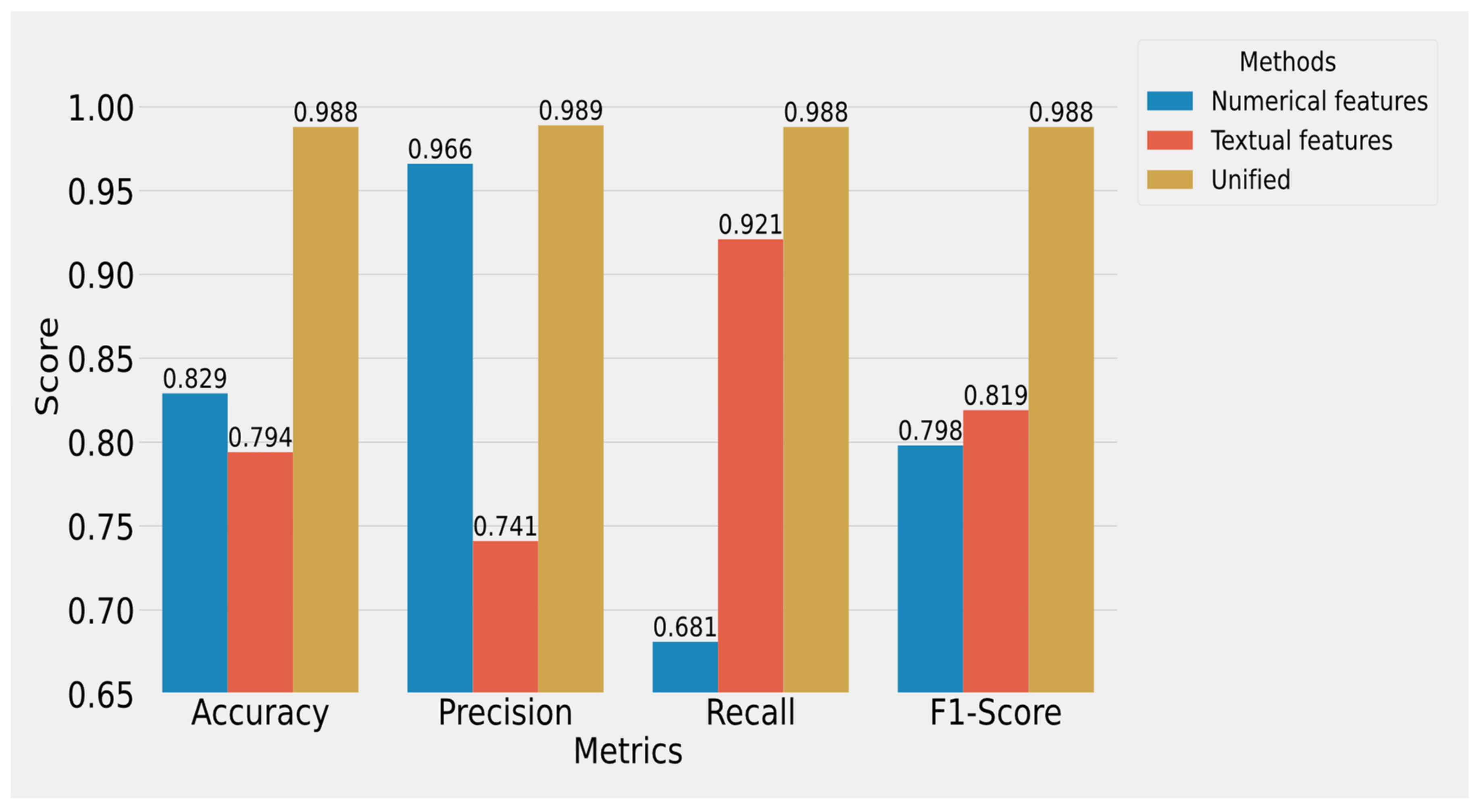
5. Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, A.X. Firewall Design and Analysis; World Scientific: Singapore, 2010. [Google Scholar] [CrossRef]
- Marques, C.; Malta, S.; Magalhães, J. DNS Firewall Based on Machine Learning. Future Internet 2021, 13, 309. [Google Scholar] [CrossRef]
- Zhang, J.; Porras, P.; Ullrich, J. Highly predictive blacklisting. In Proceedings of the 17th Conference on Security Symposium, San Jose, CA, USA, 28 July–1 August 2018; USENIX Association: Berkeley, CA, USA, 2008; pp. 107–122. [Google Scholar]
- Prakash, P.; Kumar, M.; Kompella, R.R.; Gupta, M. PhishNet: Predictive Blacklisting to Detect Phishing Attacks. In Proceedings of the 2010 Proceedings IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–5. [Google Scholar] [CrossRef]
- Akiyama, M.; Yagi, T.; Itoh, M. Searching Structural Neighborhood of Malicious URLs to Improve Blacklisting. In Proceedings of the 2011 IEEE/IPSJ International Symposium on Applications and the Internet, Munich, Germany, 18–21 July 2011; pp. 1–10. [Google Scholar] [CrossRef]
- Fukushima, Y.; Hori, Y.; Sakurai, K. Proactive Blacklisting for Malicious Web Sites by Reputation Evaluation Based on Domain and IP Address Registration. In Proceedings of the 2011 IEEE 10th International Conference on Trust, Security and Privacy in Computing and Communications, Changsha, China, 16–18 November 2011; pp. 352–361. [Google Scholar] [CrossRef]
- Sun, B.; Akiyama, M.; Yagi, T.; Hatada, M.; Mori, T. Automating URL Blacklist Generation with Similarity Search Approach. IEICE Trans. Inf. Syst. 2016, E99.D, 873–882. [Google Scholar] [CrossRef]
- Saxe, J.; Berlin, K. eXpose: A Character-Level Convolutional Neural Network with Embeddings For Detecting Malicious URLs, File Paths and Registry Keys. arXiv 2017, arXiv:1702.08568. [Google Scholar]
- Yang, W.; Zuo, W.; Cui, B. Detecting Malicious URLs via a Keyword-Based Convolutional Gated-Recurrent-Unit Neural Network. IEEE Access 2019, 7, 29891–29900. [Google Scholar] [CrossRef]
- Luo, C.; Su, S.; Sun, Y.; Tan, Q.; Han, M.; Tian, Z. A Convolution-Based System for Malicious URLs Detection. Comput. Mater. Contin. 2020, 62, 399–411. [Google Scholar] [CrossRef]
- Mondal, D.K.; Singh, B.C.; Hu, H.; Biswas, S.; Alom, Z.; Azim, M.A. SeizeMaliciousURL: A novel learning approach to detect malicious URLs. J. Inf. Secur. Appl. 2021, 62, 102967. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- sklearn.preprocessing.LabelEncoder. Scikit-Learn. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html (accessed on 16 December 2022).
- sklearn.preprocessing.MinMaxScaler. Scikit-Learn. Available online: https://scikit-learn/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html (accessed on 26 February 2022).
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; Omnipress: Madison, WI, USA, 2010; pp. 807–814. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Bengio, Y., LeCun, Y., Eds.; 2015. Available online: http://arxiv.org/abs/1412.6980 (accessed on 20 November 2022).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Marques, C.; Malta, S.; Magalhães, J.P. DNS dataset for malicious domains detection. Data Brief 2021, 38, 107342. [Google Scholar] [CrossRef] [PubMed]
- Wayback Machine. 2022. Available online: https://web.archive.org/web/20220615132544/http://datajobstest.com/data-science-repo/LDA-Primer-[Balakrishnama-and-Ganapathiraju].pdf (accessed on 27 March 2023).
- Lu, J.; Plataniotis, K.N.; Venetsanopoulos, A.N. Face recognition using LDA-based algorithms. IEEE Trans. Neural Netw. 2003, 14, 195–200. [Google Scholar] [CrossRef] [PubMed]
- Fu, R.; Tian, Y.; Shi, P.; Bao, T. Automatic Detection of Epileptic Seizures in EEG Using Sparse CSP and Fisher Linear Discrimination Analysis Algorithm. J. Med. Syst. 2020, 44, 43. [Google Scholar] [CrossRef] [PubMed]
- Elnasir, S.; Shamsuddin, S.M. Palm vein recognition based on 2D-discrete wavelet transform and linear discrimination analysis. Int. J. Adv. Soft Comput. Appl. 2014, 6, 43–59. [Google Scholar]
- 1.4. Support Vector Machines. Scikit-Learn. Available online: https://scikit-learn/stable/modules/svm.html (accessed on 26 February 2022).
- kNN Definition|DeepAI. 2022. Available online: https://web.archive.org/web/20220701054511/https://deepai.org/machine-learning-glossary-and-terms/kNN (accessed on 27 March 2023).
- Hassanat, A.B.; Abbadi, M.A.; Altarawneh, G.A.; Alhasanat, A.A. Solving the problem of the K parameter in the KNN classifier using an ensemble learning approach. arXiv 2014, arXiv:1409.0919014. [Google Scholar]
- Sklearn.Neighbors.KNeighborsClassifier—Scikit-Learn 1.2.2 Documentation. 2023. Available online: https://web.archive.org/web/20230315064604/https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html (accessed on 27 March 2023).
- Advantages and Disadvantages of Linear Regression. 2023. Available online: https://web.archive.org/web/20230111220233/https://iq.opengenus.org/advantages-and-disadvantages-of-linear-regression/ (accessed on 27 March 2023).
- 1.9. Naive Bayes—Scikit-Learn 1.2.1 Documentation. 2023. Available online: https://web.archive.org/web/20230307185232/https://scikit-learn.org/stable/modules/naive_bayes.html (accessed on 27 March 2023).
- 1.10. Decision Trees—Scikit-Learn 1.2.2 Documentation. 2023. Available online: https://web.archive.org/web/20230320174546/https://scikit-learn.org/stable/modules/tree.html (accessed on 27 March 2023).
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wagan, A.A.; Li, Q.; Zaland, Z.; Marjan, S.; Bozdar, D.K.; Hussain, A.; Mirza, A.M.; Baryalai, M. A Unified Learning Approach for Malicious Domain Name Detection. Axioms 2023, 12, 458. https://doi.org/10.3390/axioms12050458
Wagan AA, Li Q, Zaland Z, Marjan S, Bozdar DK, Hussain A, Mirza AM, Baryalai M. A Unified Learning Approach for Malicious Domain Name Detection. Axioms. 2023; 12(5):458. https://doi.org/10.3390/axioms12050458
Chicago/Turabian StyleWagan, Atif Ali, Qianmu Li, Zubair Zaland, Shah Marjan, Dadan Khan Bozdar, Aamir Hussain, Aamir Mehmood Mirza, and Mehmood Baryalai. 2023. "A Unified Learning Approach for Malicious Domain Name Detection" Axioms 12, no. 5: 458. https://doi.org/10.3390/axioms12050458
APA StyleWagan, A. A., Li, Q., Zaland, Z., Marjan, S., Bozdar, D. K., Hussain, A., Mirza, A. M., & Baryalai, M. (2023). A Unified Learning Approach for Malicious Domain Name Detection. Axioms, 12(5), 458. https://doi.org/10.3390/axioms12050458