
Spatiotemporal Analysis of the Background Seismicity Identified by Different Declustering Methods in Northern Algeria and Its Vicinity


Abstract
1. Introduction
2. Seismicity Declustering Methods
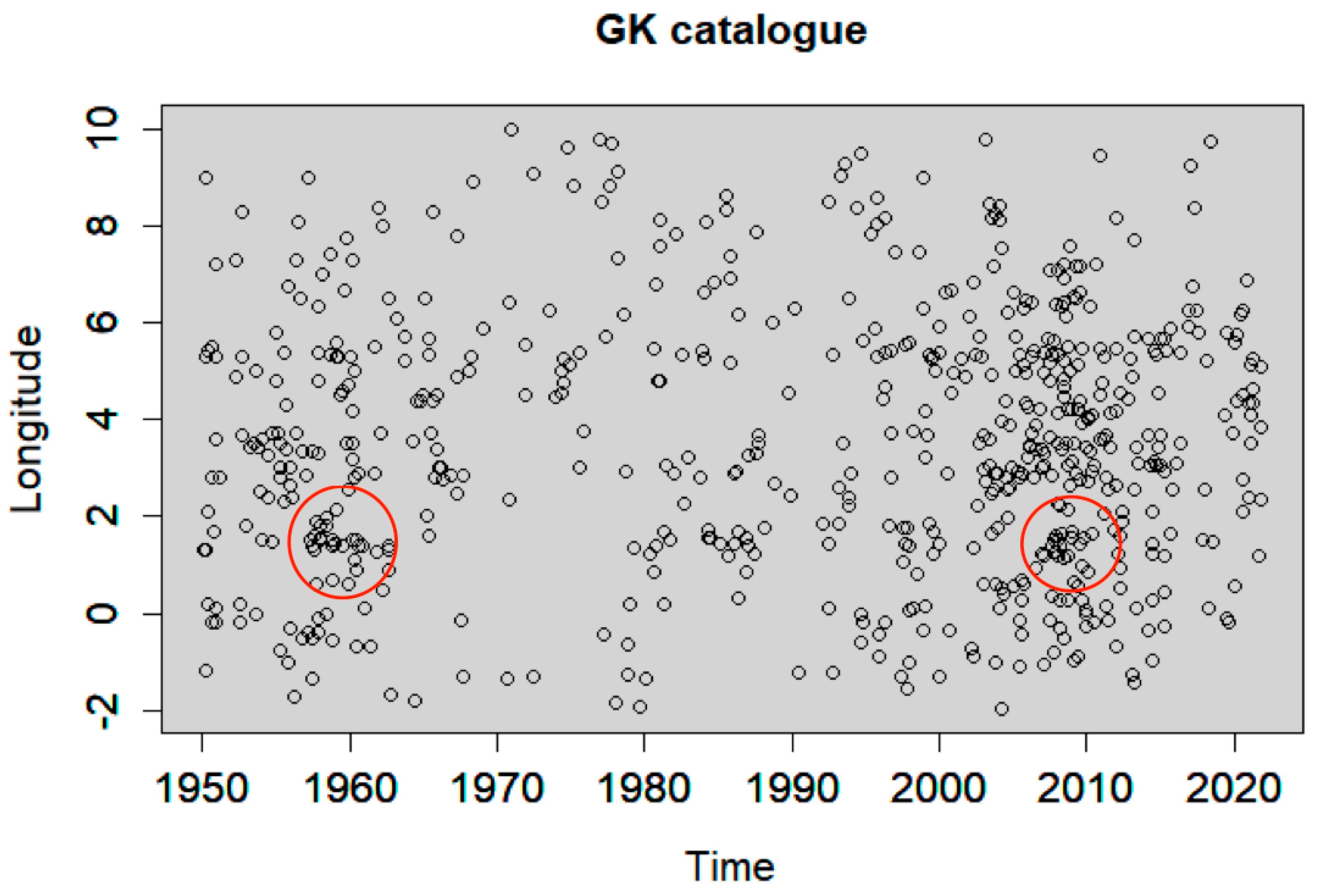
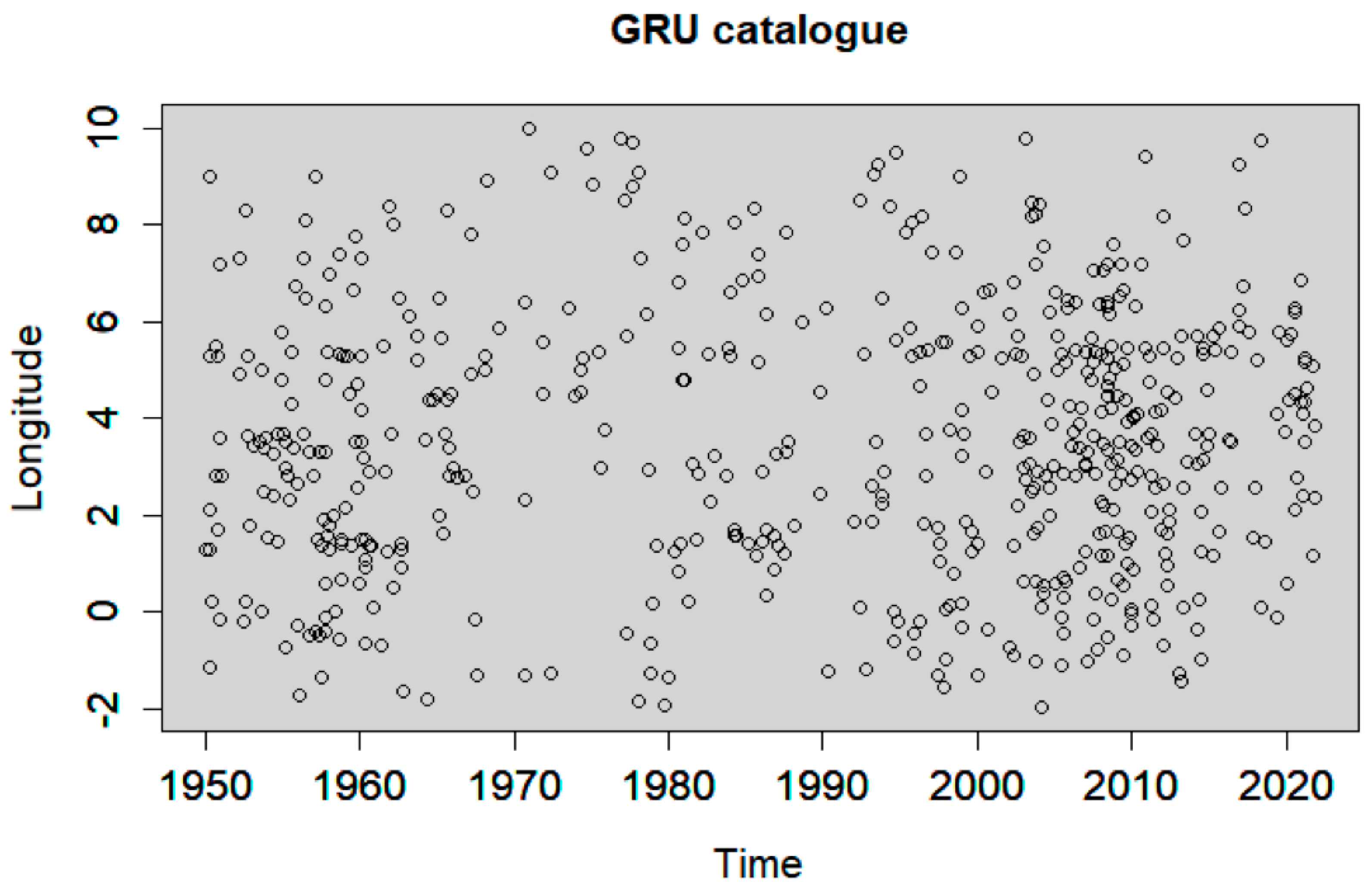
2.1. Window-Based Methods
2.2. Cluster-Based Method
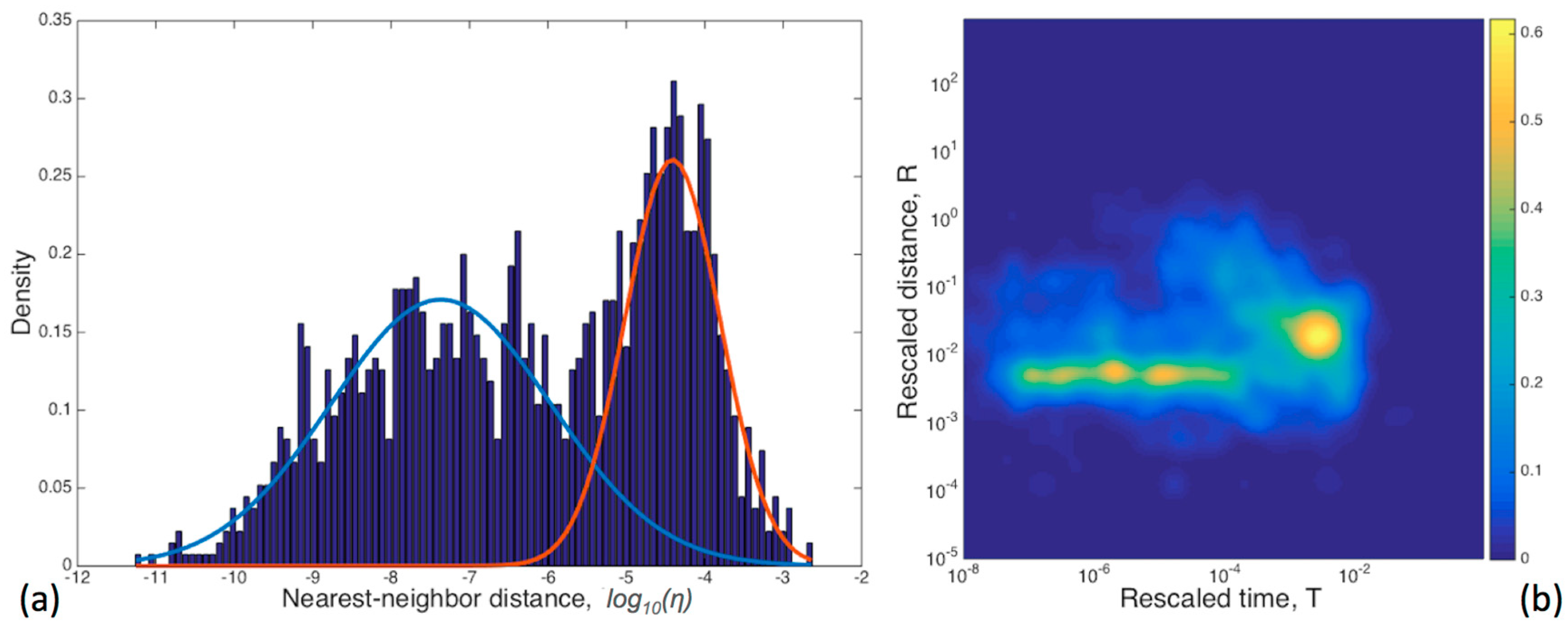
2.3. Nearest Neighbour Declustering Method
2.4. Stochastic Declustering Method
3. Statistical Measures for Spatiotemporal Analysis of Background Earthquakes
3.1. Coefficient of Variation
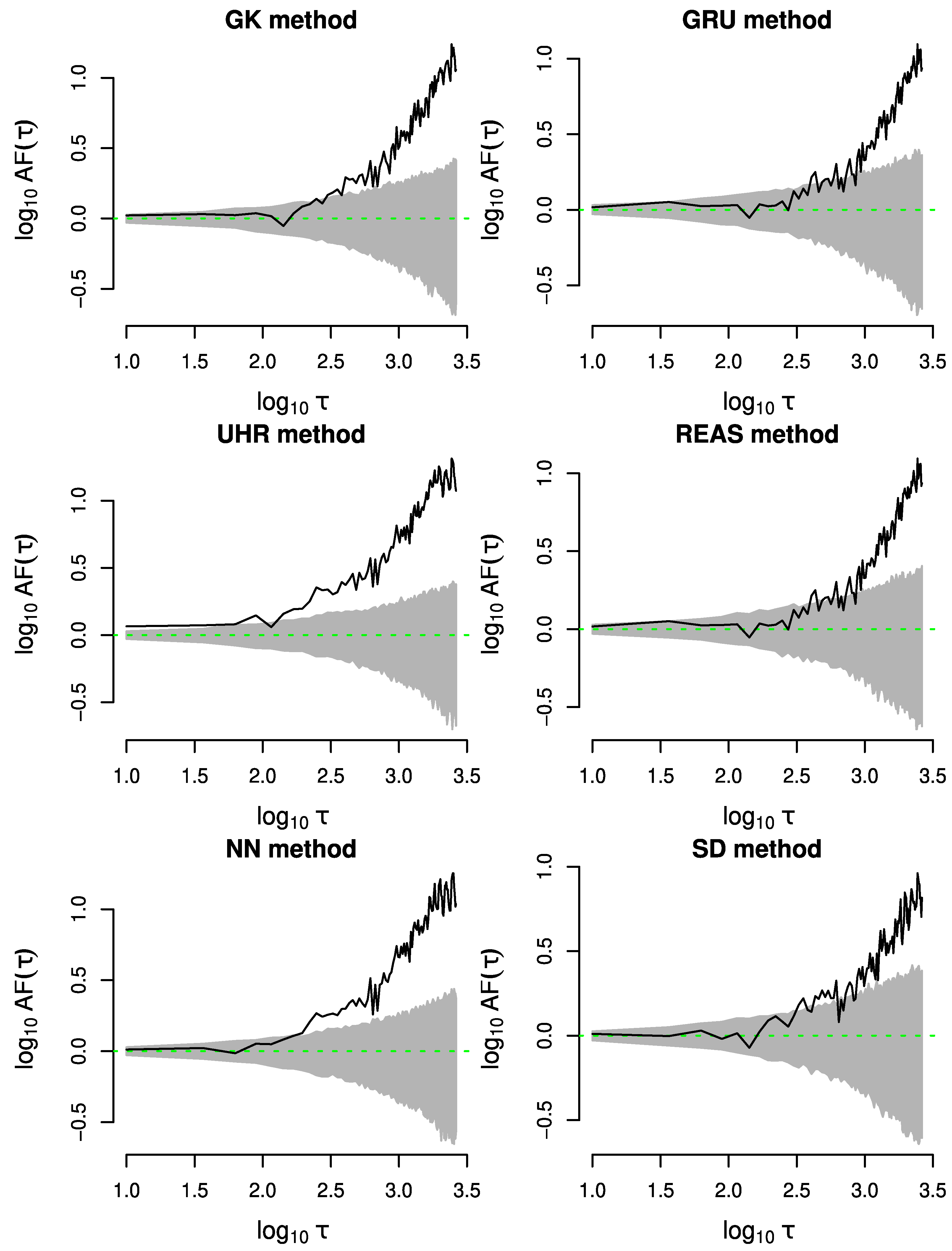
3.2. Allan Factor
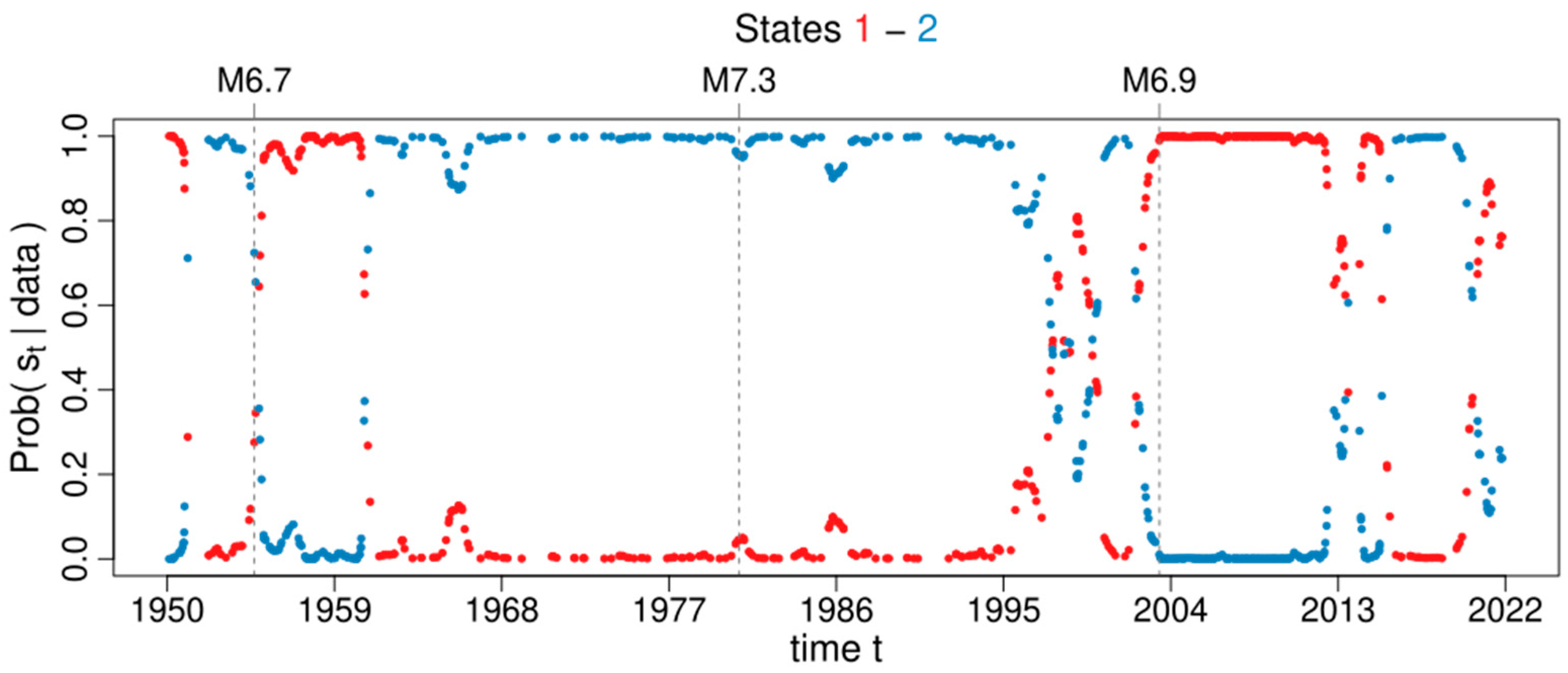
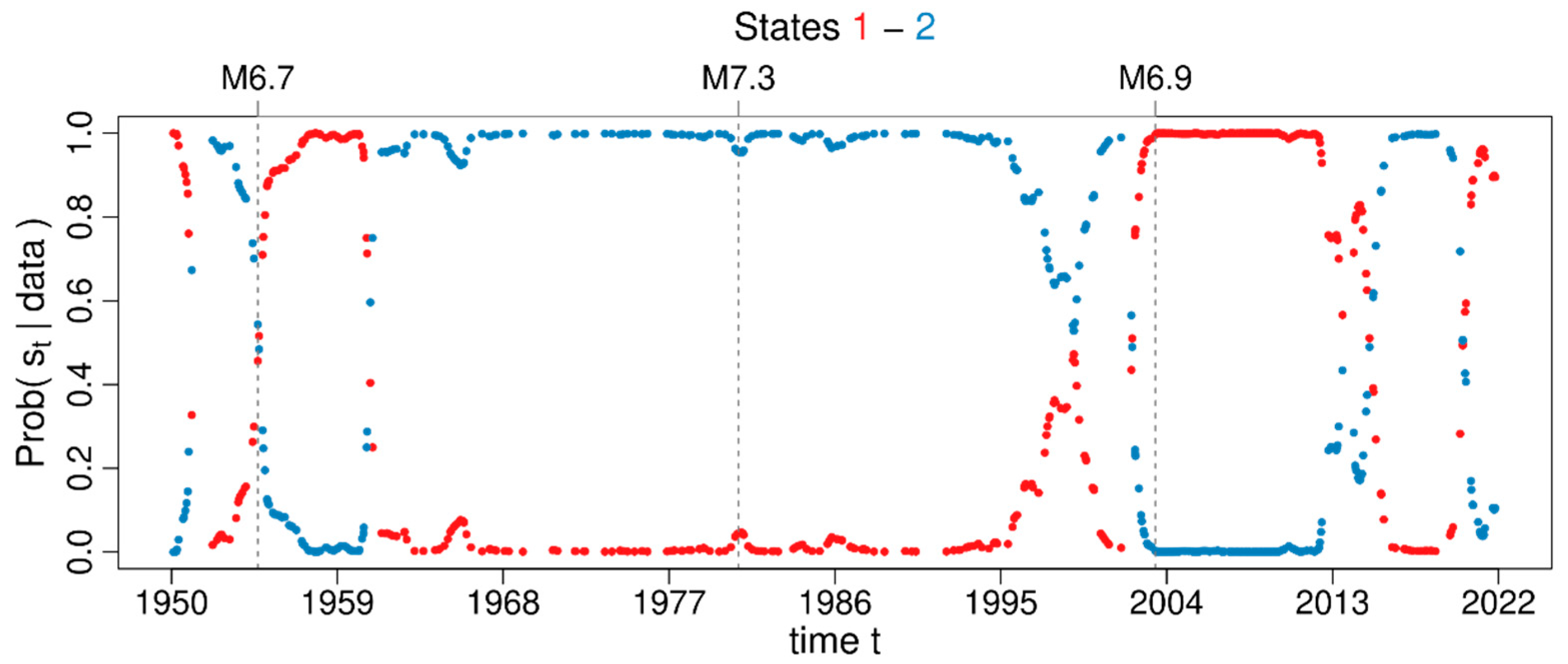
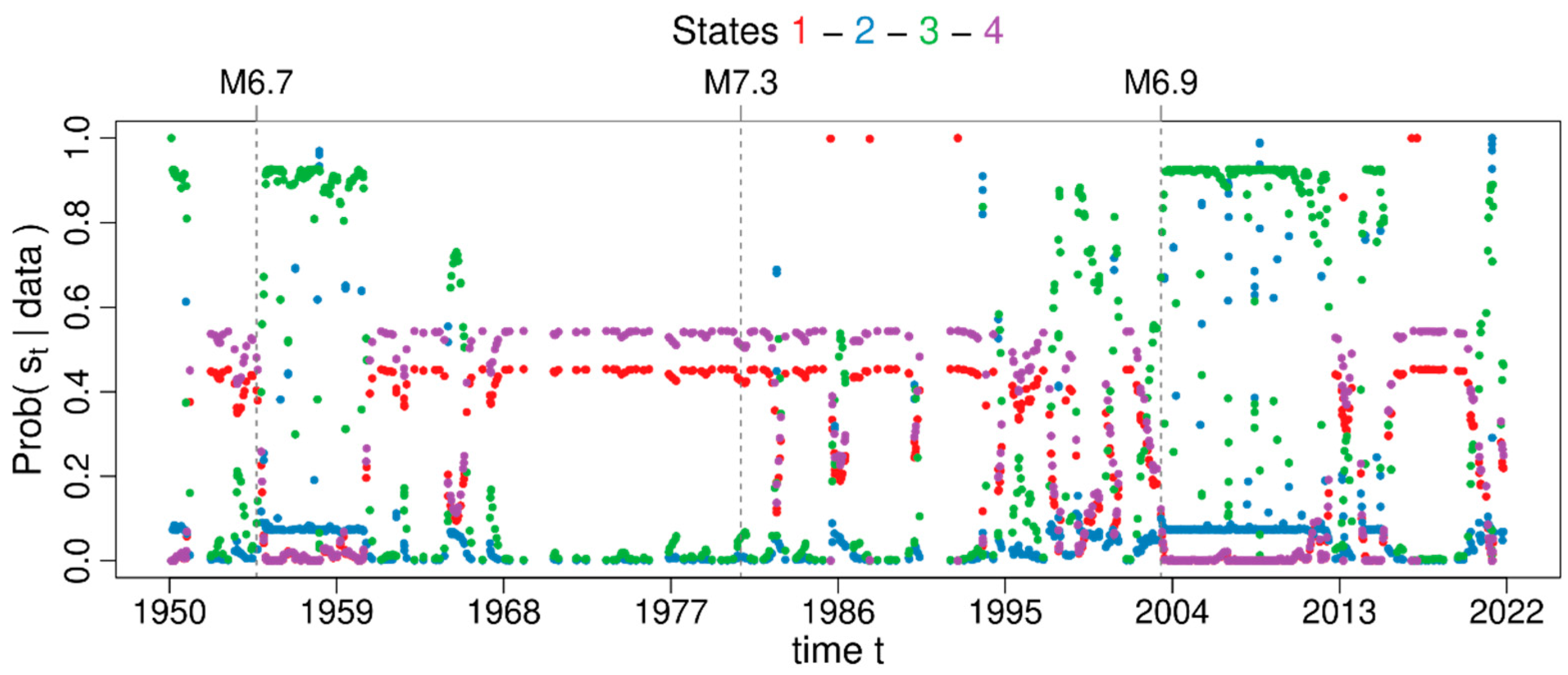
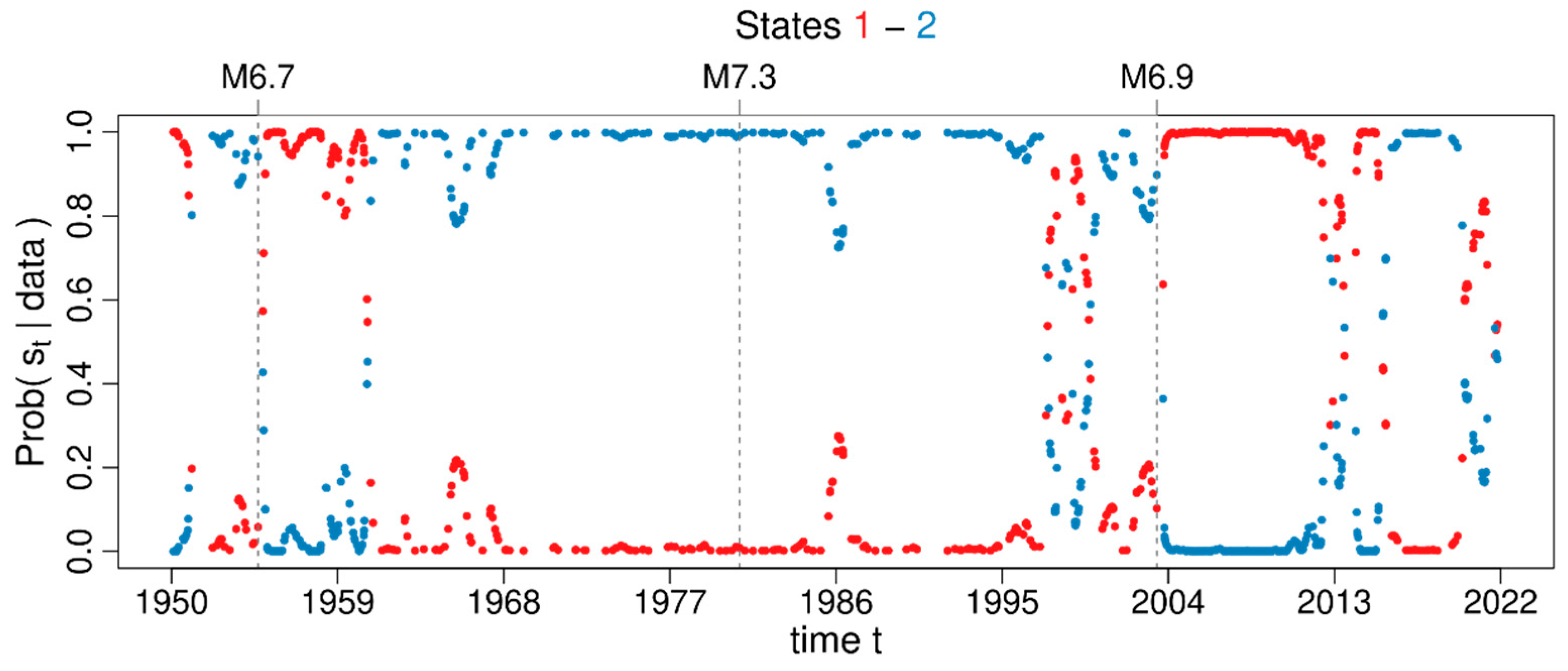
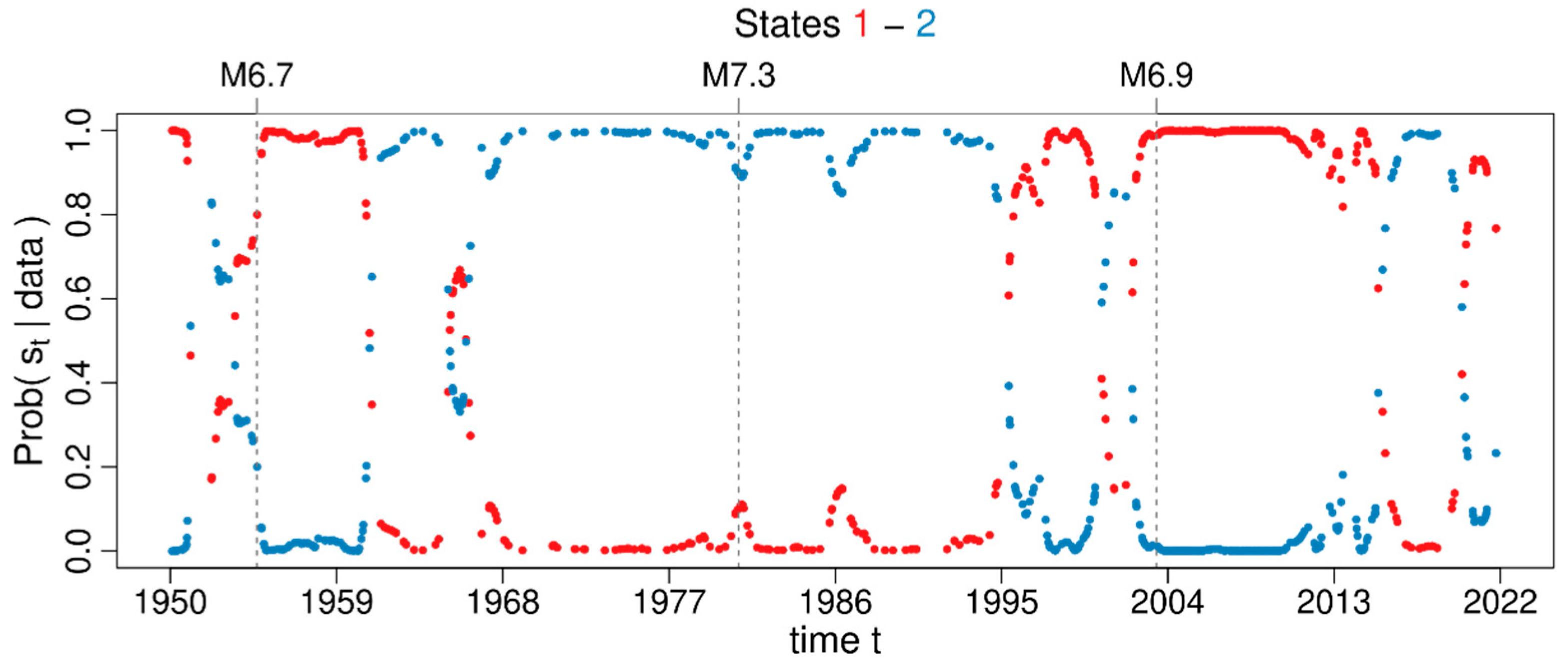
3.3. Markov Modulated Poisson Process
3.4. Morisita Index
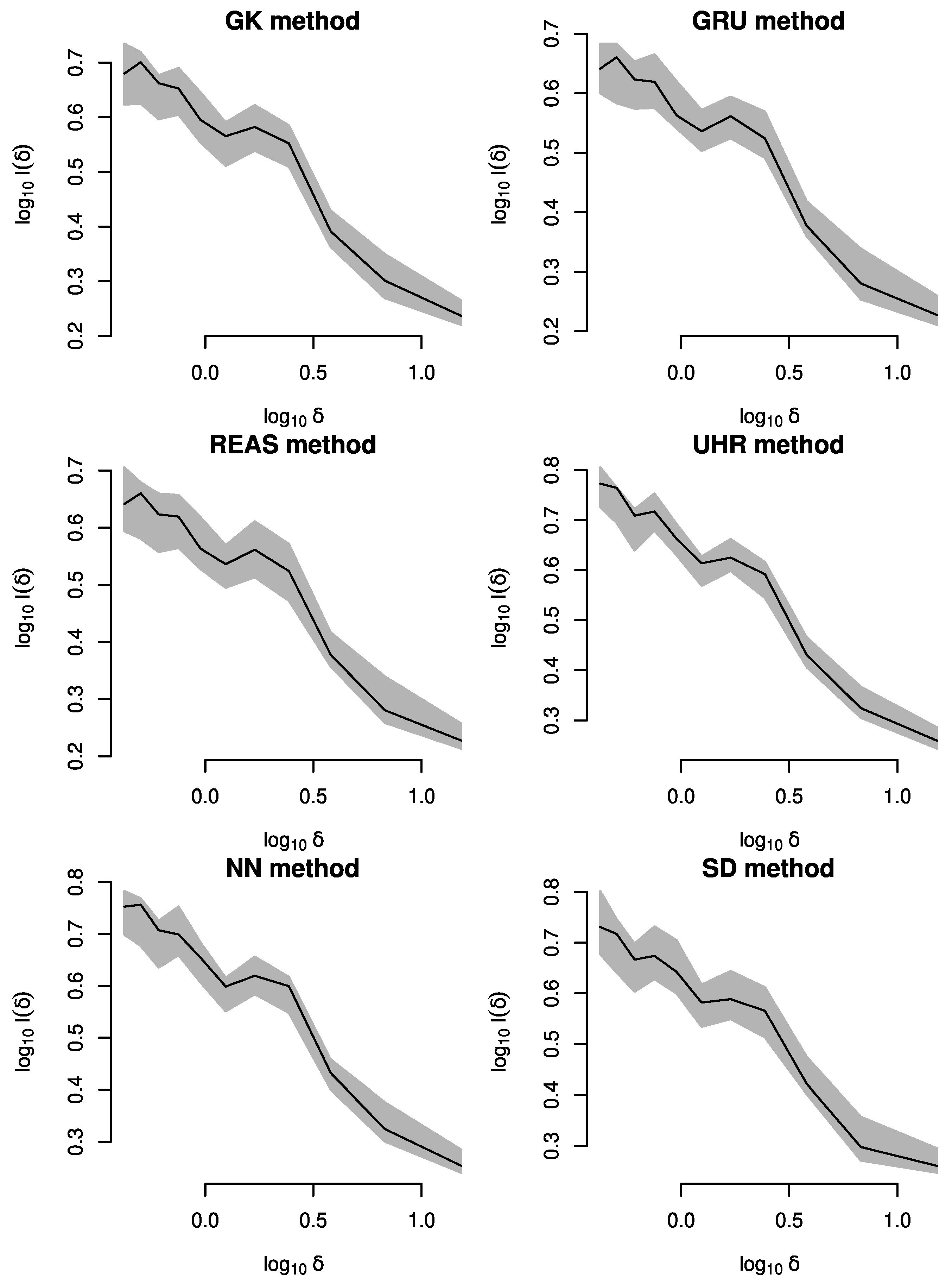
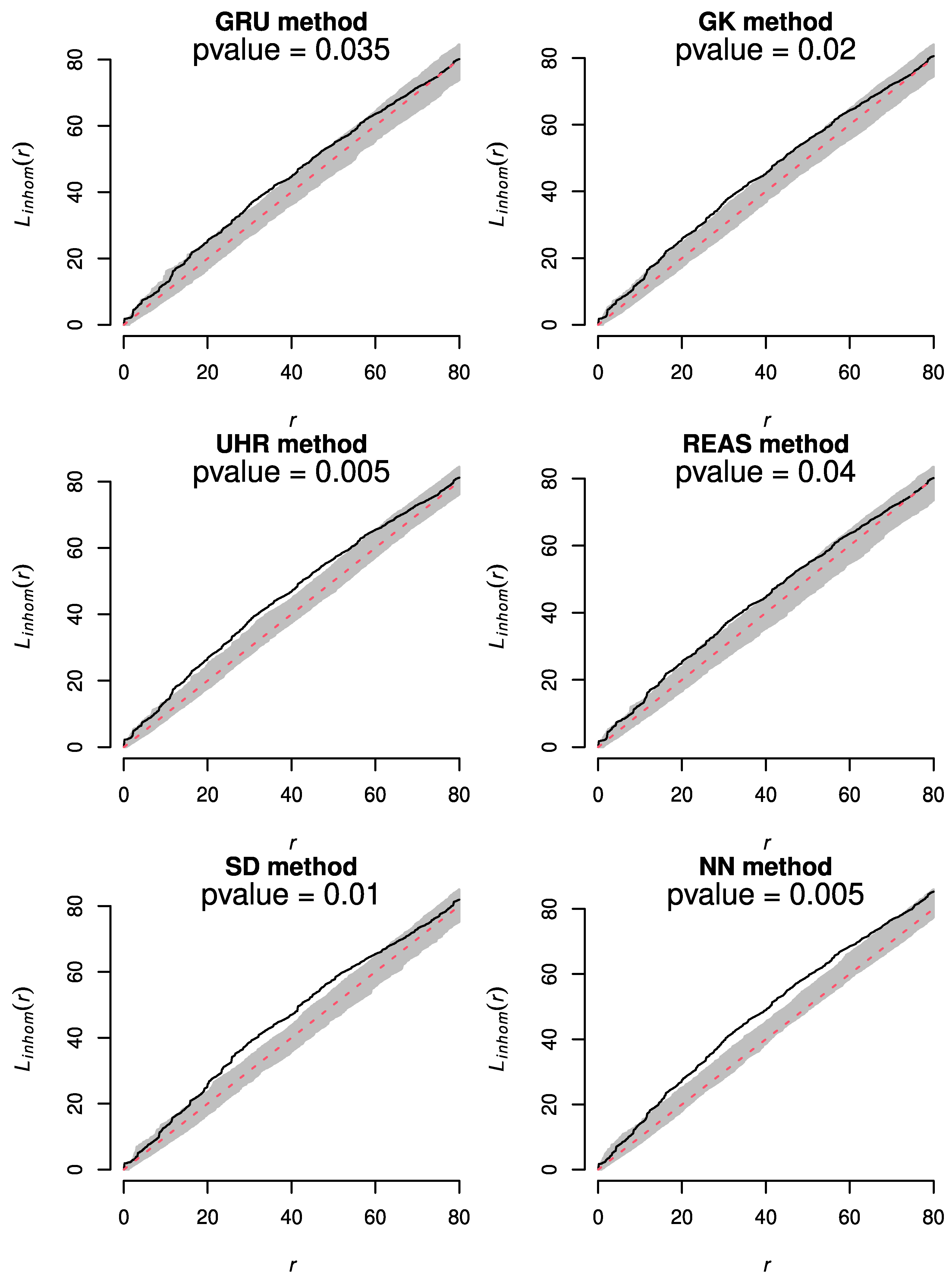
3.5. Inhomogeneous Version of L-Function
4. Statistical Analysis of the Declustered Catalogues
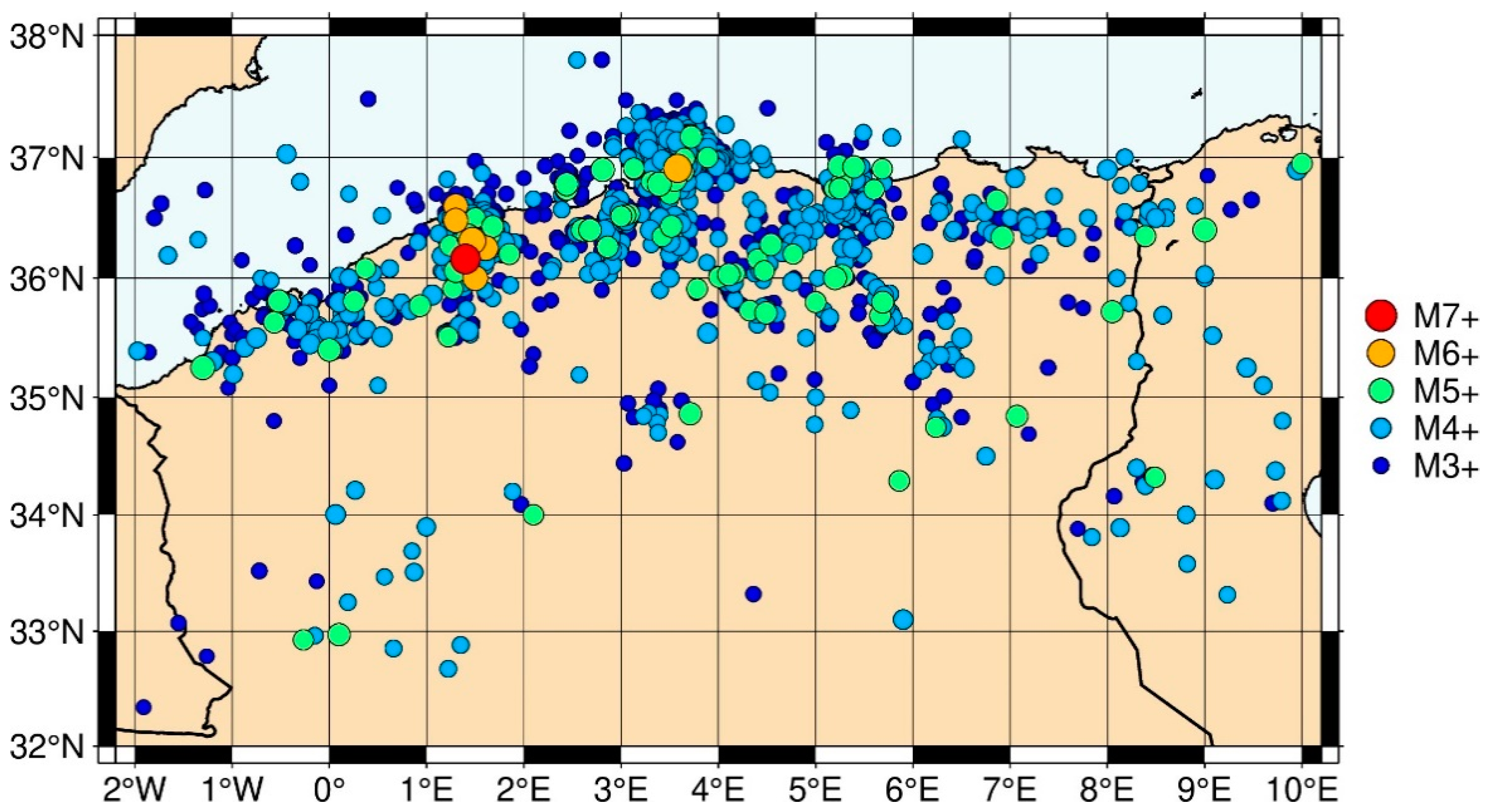
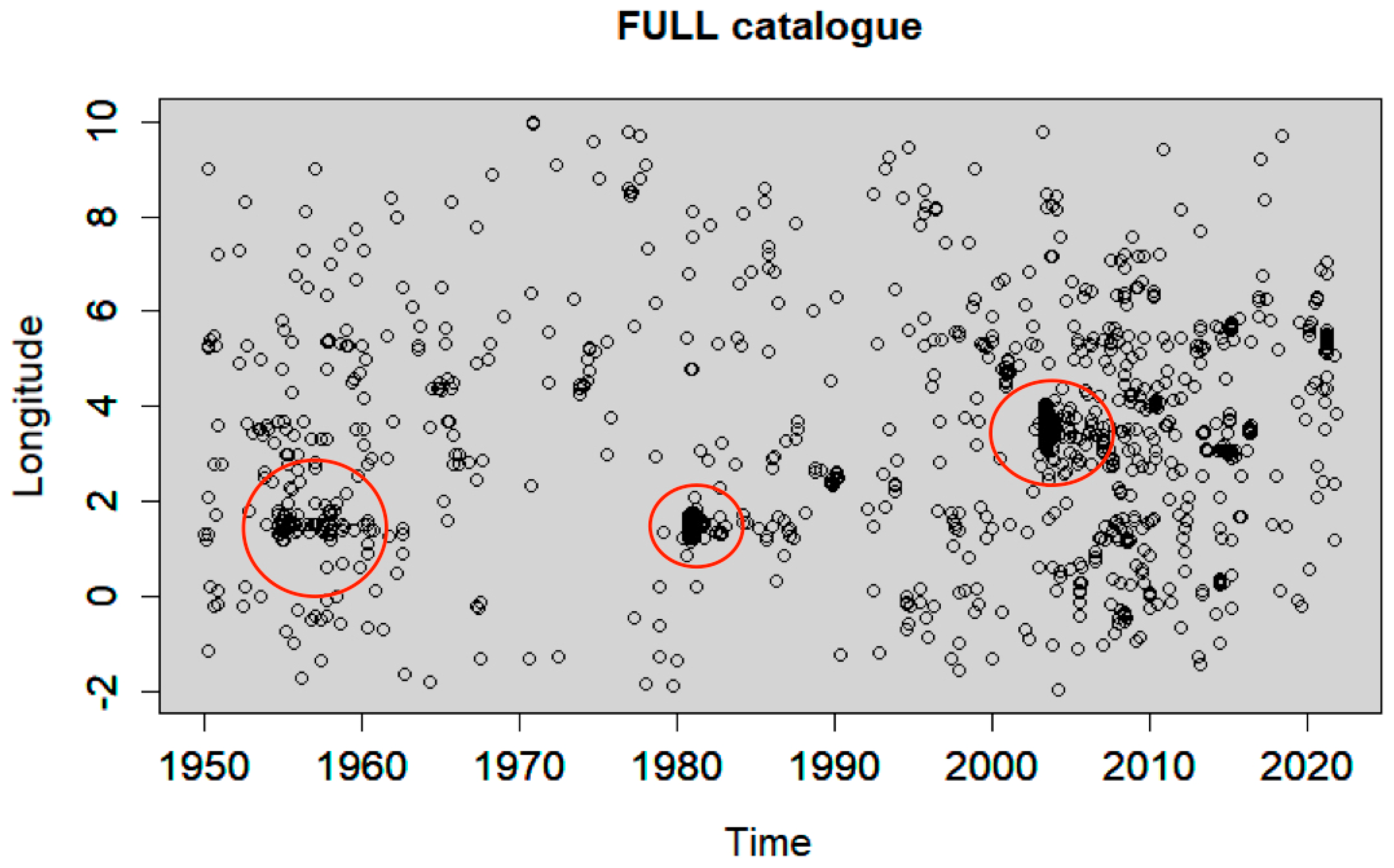
4.1. Earthquake Catalogue of Northern Algeria and Its Vicinity
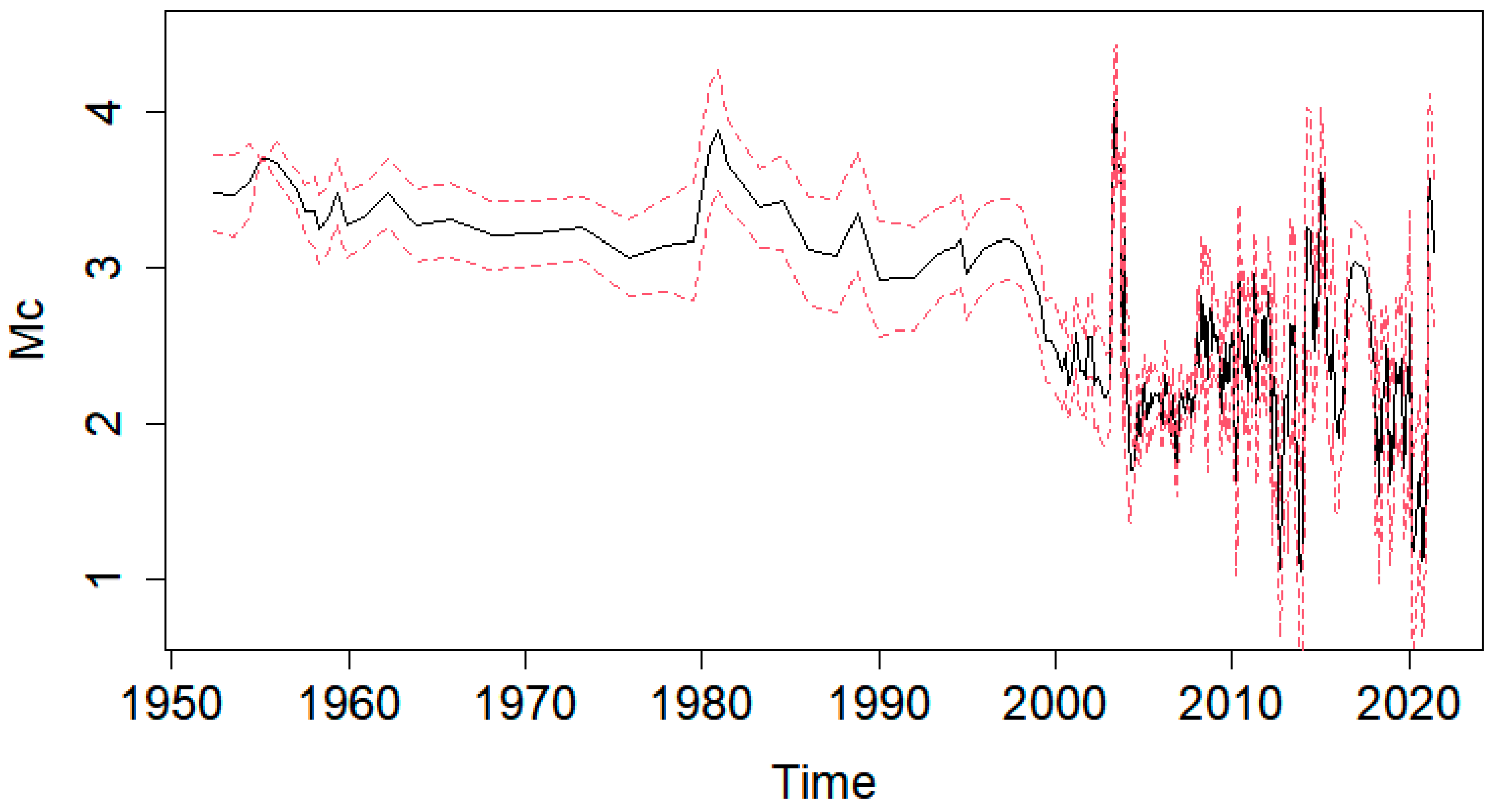
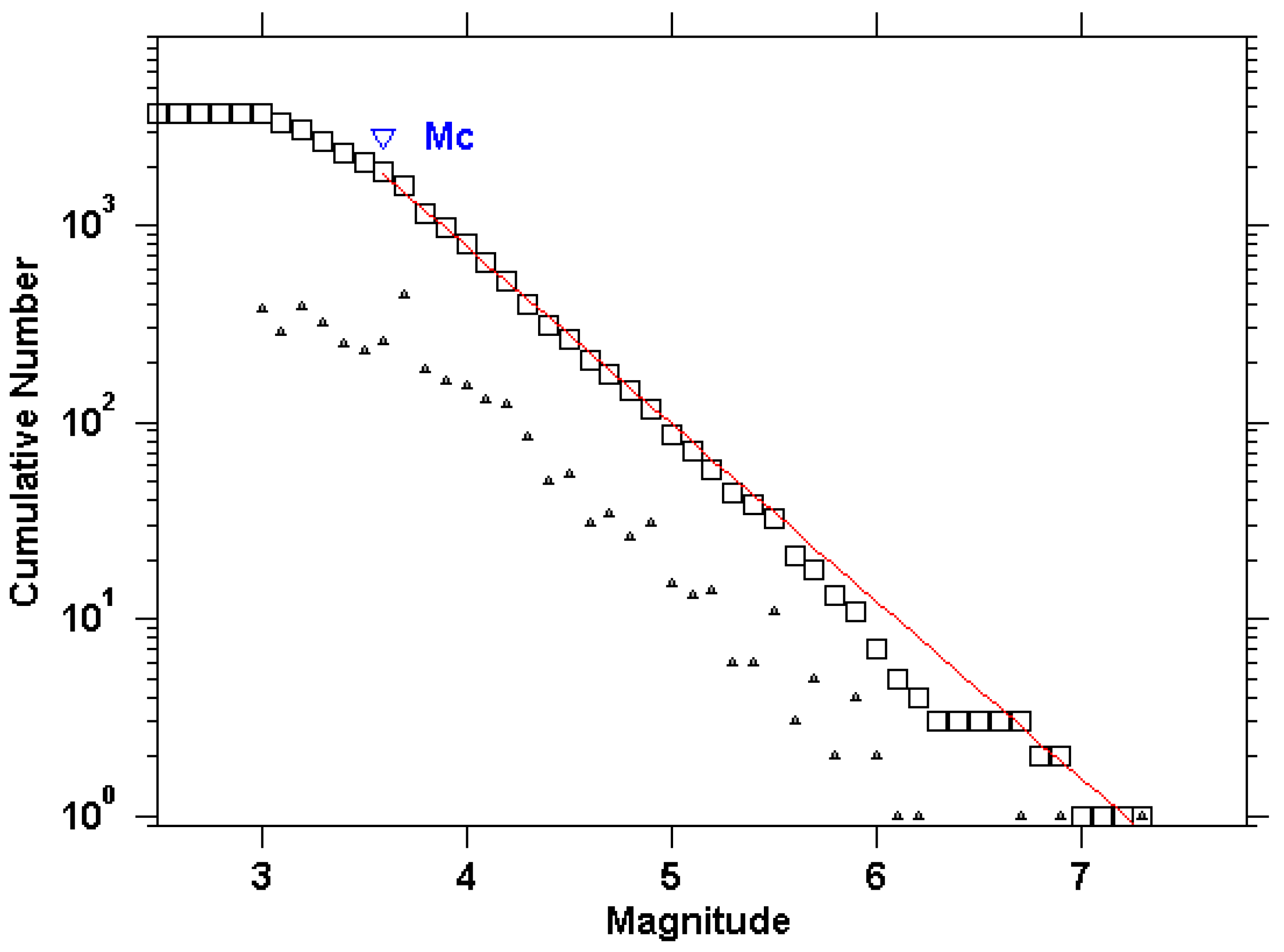
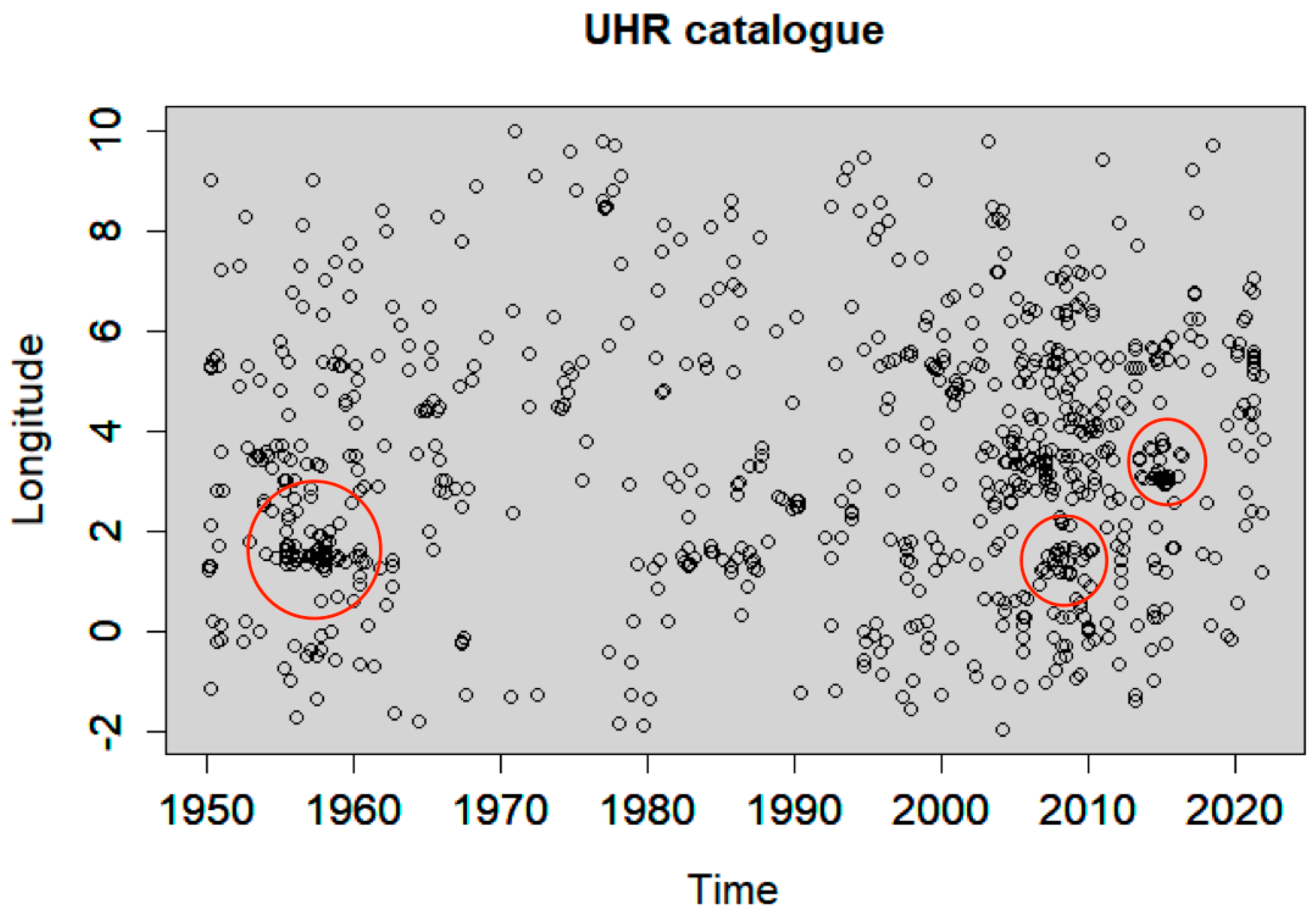
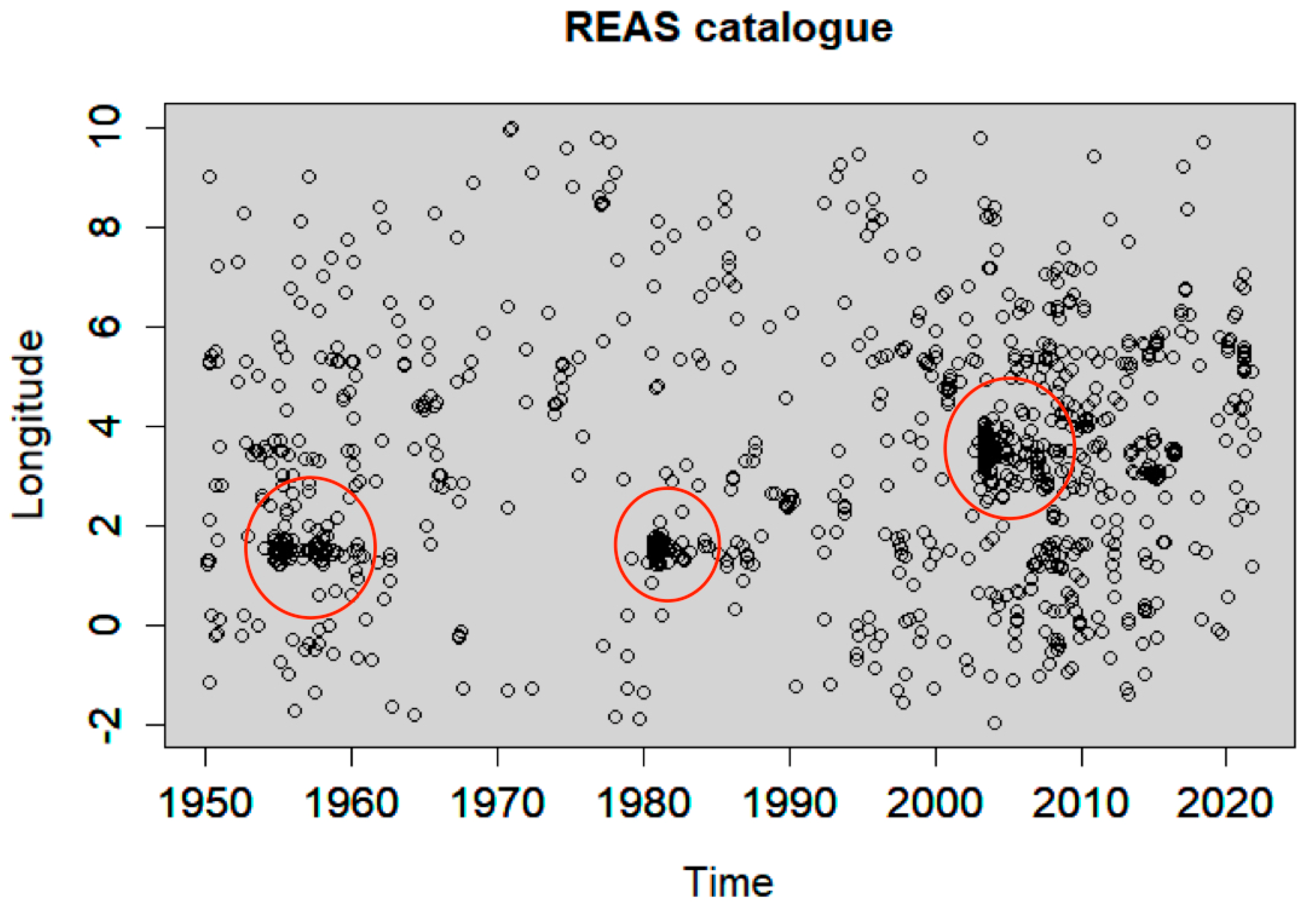
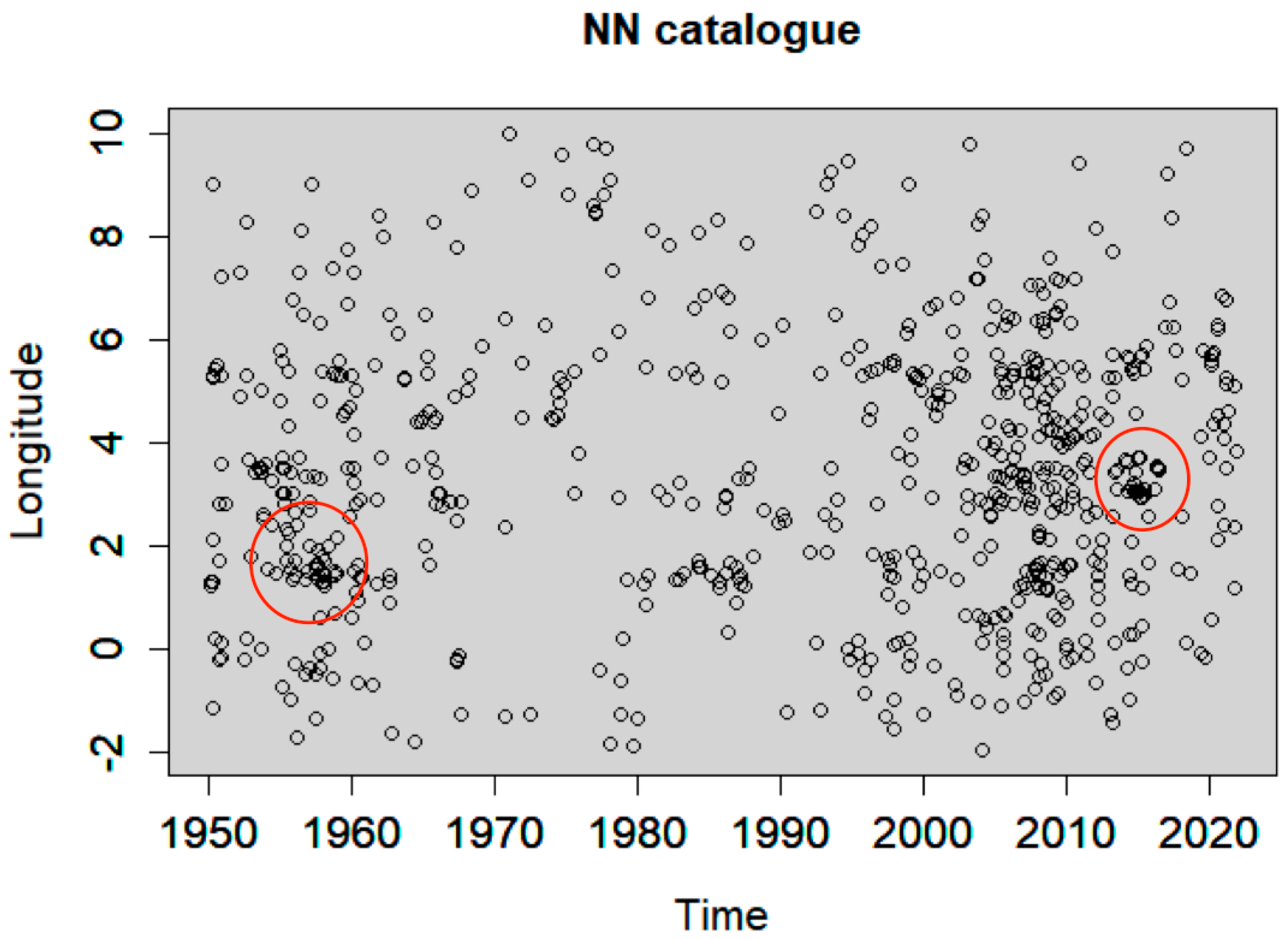
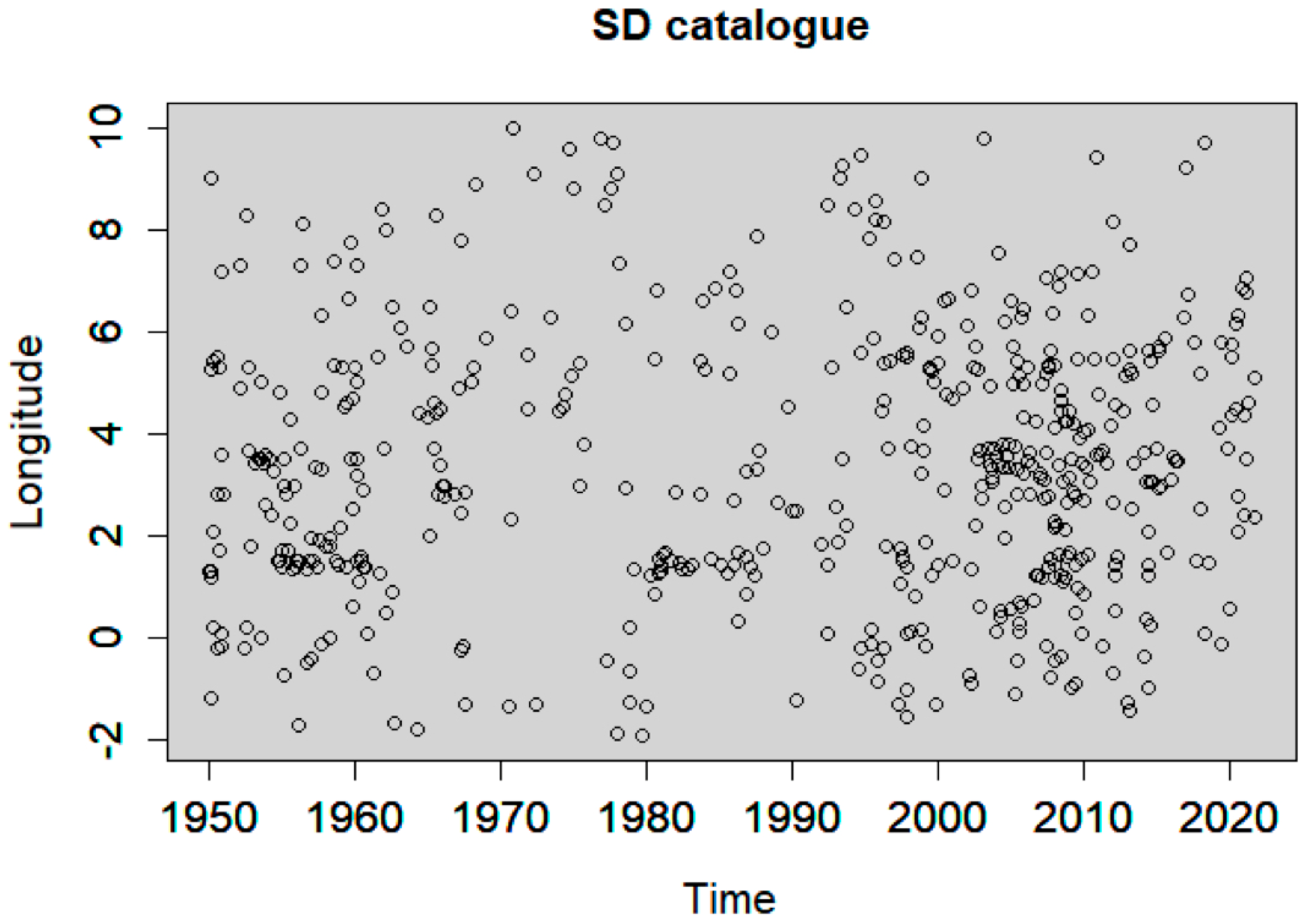
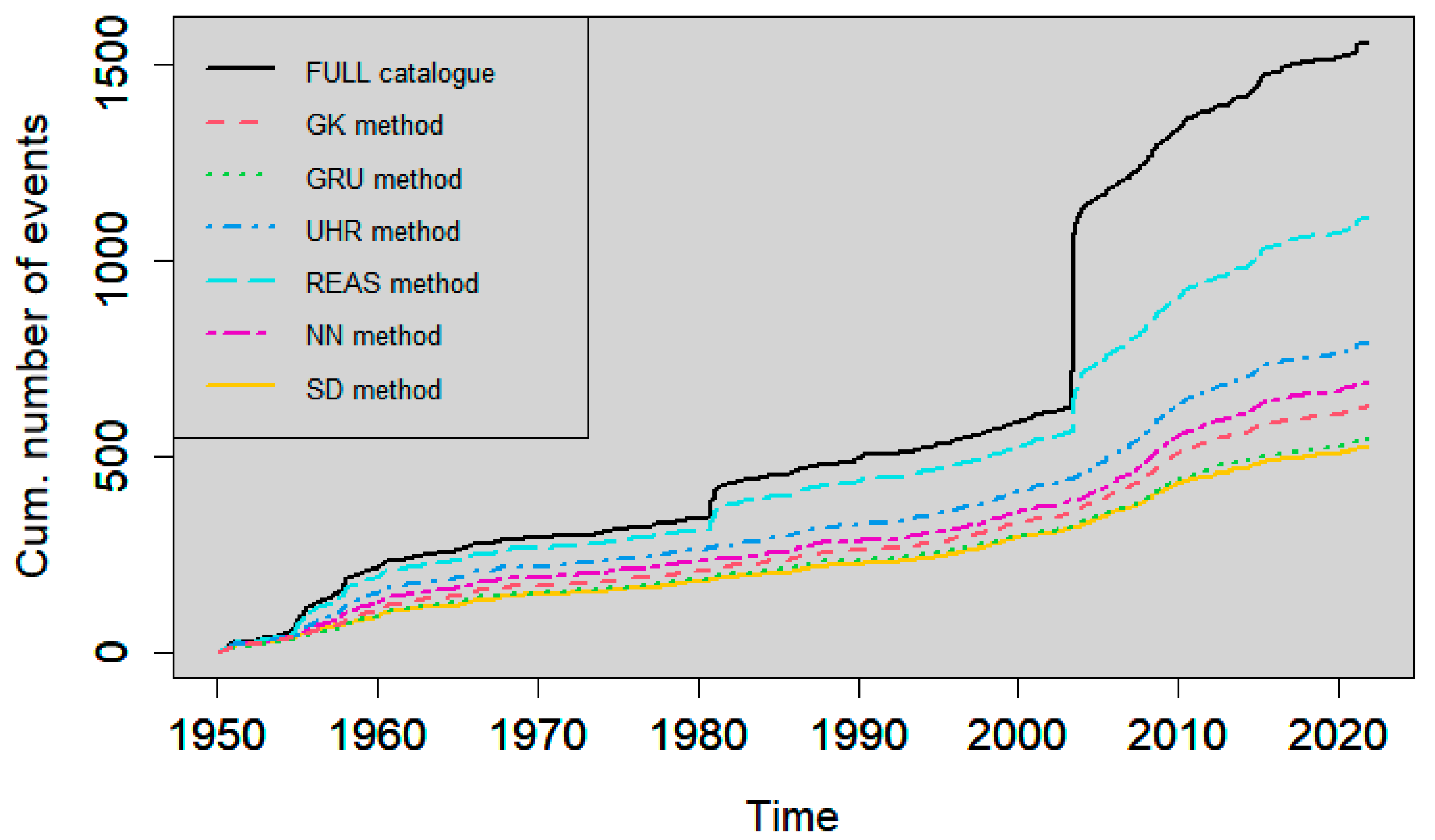
4.2. Declustering Application
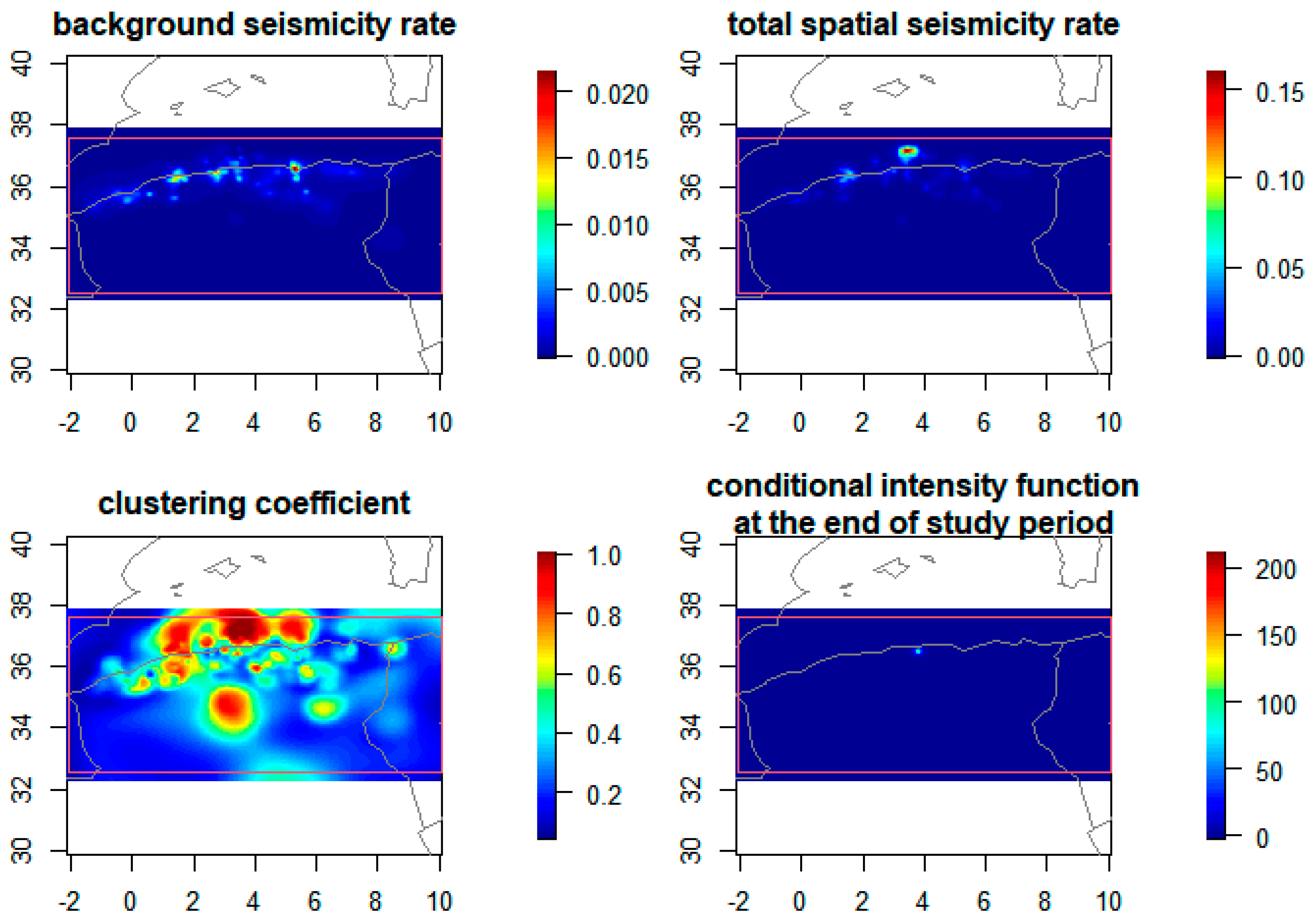
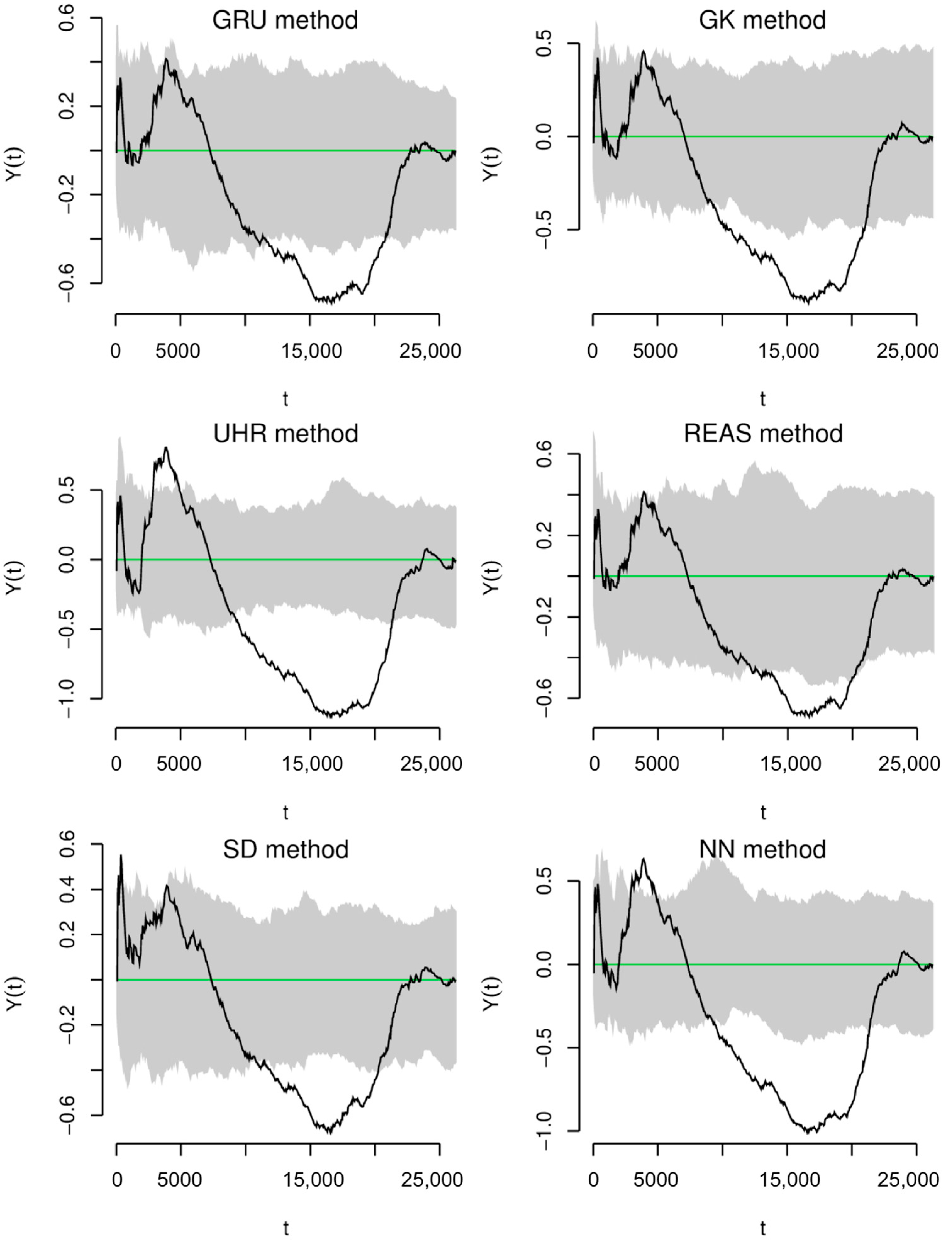
4.3. Spatiotemporal Analysis of the Declustered Catalogues
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aki, K. Some Problems in Statistical Seismology. Zisin 1956, 8, 205–228. [Google Scholar] [CrossRef] [PubMed]
- Kagan, Y.; Jackson, D. Long–term earthquake clustering. Geophys. J. Int. 1991, 104, 117–133. [Google Scholar] [CrossRef]
- Ogata, Y. Statistical models for earthquake occurrences and residual analysis for point processes. J. Am. Stat. Assoc. 1988, 83, 9–27. [Google Scholar] [CrossRef]
- Ogata, Y. Space–time point process models for earthquake occurrences. Ann. Inst. Stat. Math. 1998, 50, 379–402. [Google Scholar] [CrossRef]
- Zhuang, J.; Ogata, Y.; Vere–Jones, D. Stochastic declustering of space–time earthquake occurrences. J. Am. Stat. Assoc. 2002, 97, 369–380. [Google Scholar] [CrossRef]
- Zhuang, J.; Ogata, Y.; Vere–Jones, D. Analyzing earthquake clustering features by using stochastic reconstruction. J. Geophys. Res. 2004, 109, B05301. [Google Scholar] [CrossRef]
- Zhuang, J.; Murru, M.; Falcone, G.; Guo, Y. An extensive study of clustering features of seismicity in Italy from 2005 to 2016. Geophys. J. Int. 2019, 216, 302–318. [Google Scholar] [CrossRef]
- Zaliapin, I.; Ben–Zion, Y. Earthquake clusters in southern California I: Identification and stability. J. Geophys. Res. Solid Earth 2013, 118, 2847–2864. [Google Scholar] [CrossRef]
- Zaliapin, I.; Ben–Zion, Y. A global classification and characterization of earthquake clusters. Geophys. J. Int. 2016, 207, 608–634. [Google Scholar] [CrossRef]
- Zaliapin, I.; Ben–Zion, Y. Earthquake declustering using the nearest–neighbor approach in space–time–magnitude domain. J. Geophys. Res. Solid Earth 2020, 125, e2018JB017120. [Google Scholar] [CrossRef]
- Benali, A.; Peresan, A.; Varini, E.; Talbi, A. Modelling background seismicity components identified by nearest neighbour and stochastic declustering approaches: The case of Northeastern Italy. Stoch. Environ. Res. Risk Assess. 2020, 34, 775–791. [Google Scholar] [CrossRef]
- Benali, A.; Zhuang, J.; Talbi, A. An updated version of the ETAS model based on multiple change points detection. Acta Geophys. 2022, 70, 2013–2031. [Google Scholar] [CrossRef]
- Varotsos, P.A.; Sarlis, N.V.; Skordas, E.S.; Uyeda, S.; Kamogawa, M. Natural-time analysis of critical phenomena: The case of seismicity. Europhys. Lett. 2010, 92, 29002. [Google Scholar] [CrossRef]
- Sarlis, N.V.; Skordas, E.S.; Varotsos, P.A.; Nagao, T.; Kamogawa, M.; Uyeda, S. Spatiotemporal variations of seismicity before major earthquakes in the Japanese area and their relation with the epicentral locations. Proc. Natl. Acad. Sci. USA 2015, 112, 986–989. [Google Scholar] [CrossRef]
- Rundle, J.B.; Turcotte, D.L.; Donnellan, A.; Grant Ludwig, L.; Luginbuhl, M.; Gong, G. Nowcasting earthquakes. Earth Space Sci. 2016, 3, 480–486. [Google Scholar] [CrossRef]
- Varotsos, P.K.; Perez-Oregon, J.; Skordas, E.S.; Sarlis, N.V. Estimating the Epicenter of an Impending Strong Earthquake by Combining the Seismicity Order Parameter Variability Analysis with Earthquake Networks and Nowcasting: Application in the Eastern Mediterranean. Appl. Sci. 2021, 11, 10093. [Google Scholar] [CrossRef]
- Perez-Oregon, J.; Varotsos, P.K.; Skordas, E.S.; Sarlis, N.V. Estimating the epicenter of a Future Strong Earthquake in Southern California, Mexico and Central America by means of Natural Time Analysis and earthquake Nowcasting. Entropy 2021, 23, 1658. [Google Scholar] [CrossRef]
- van Stiphout, T.; Zhuang, J.; Marsan, D. Seismicity Declustering. Community Online Resource for Statistical Seismicity Analysis. 2012, pp. 1–25. Available online: http://www.corssa.org (accessed on 1 September 2022). [CrossRef]
- Nas, M.; Jalilian, A.; Bayrak, Y. Spatiotemporal comparison of declustered catalogs of earthquakes in Turkey. Pure Appl. Geophys. 2019, 176, 2215–2233. [Google Scholar] [CrossRef]
- Talbi, A.; Nanjo, K.; Satake, K.; Zhuang, J.; Hamdache, M. Comparison of seismicity declustering methods using a probabilistic measure of clustering. J. Seismol. 2013, 17, 1041–1061. [Google Scholar] [CrossRef]
- Telesca, L.; Lovallo, M.; Golay, J.; Kanevski, M. Comparing seismicity declustering techniques by means of the joint use of Allan Factor and Morisita index. Stoch. Environ. Res. Risk Assess. 2015, 30, 77–90. [Google Scholar] [CrossRef]
- Touati, S.; Naylor, M.; Main, I. Detection of change points in underlying earthquake rates, with application to global mega earthquakes. Geophys. J. Int. 2016, 204, 753–767. [Google Scholar] [CrossRef]
- Gardner, J.K.; Knopoff, L. Is the sequence of earthquakes in Southern California, with aftershocks removed, Poissonian? Bull. Seismol. Soc. Am. 1974, 64, 1363–1367. [Google Scholar] [CrossRef]
- Uhrhammer, R. Characteristics of northern and central California seismicity. Earthq. Notes 1986, 57, 21. [Google Scholar]
- Luen, B.; Stark, P.B. Poisson tests of declustered catalogues. Geophys. J. Int. 2012, 189, 691–700. [Google Scholar] [CrossRef]
- Kolev, A.A.; Ross, G.J. Inference for etas models with non–poissonian mainshock arrival times. Stat. Comput. 2019, 29, 915–931. [Google Scholar] [CrossRef]
- Li, C.; Song, Z.; Wang, W. Space–time inhomogeneous background intensity estimators for semi parametric space–time self–exciting point process models. Ann. Inst. Stat. Math. 2019, 72, 945–967. [Google Scholar] [CrossRef]
- Baiesi, M.; Paczuski, M. Scale-free networks of earthquakes and aftershocks. Phys. Rev. E 2004, 69, 066106. [Google Scholar] [CrossRef]
- Bountzis, P.; Kostoglou, A.; Papadimitriou, E.; Karakostas, V. Identification of spatiotemporal seismicity clusters in central Ionian Islands (Greece). Phys. Earth Planet. Inter. 2021, 312, 106675. [Google Scholar] [CrossRef]
- Reasenberg, P. Second-order moment of central California seismicity, 1969–1982. J. Geophys. Res. 1985, 90, 5479–5495. [Google Scholar] [CrossRef]
- Zhuang, J. Second-order residual analysis of spatiotemporal point processes and applications in model evaluation. J. R. Stat. Soc. Ser. B 2006, 68, 635–653. [Google Scholar] [CrossRef]
- Teng, G.; Baker, J.W. Seismicity Declustering and Hazard Analysis of the Oklahoma-Kansas Region. Bull. Seismol. Soc. Am. 2019, 109, 2356–2366. [Google Scholar] [CrossRef]
- Allan, D.W. Statistics of atomic frequency standards. Proc. IEEE 1966, 54, 221–230. [Google Scholar] [CrossRef]
- Morisita, M. Measuring of the dispersion of individuals and analysis of the distributional patterns. Mem. Fac. Sci. Kyushu Univ. Ser. E 1959, 2, 215–235. [Google Scholar]
- Telesca, L.; Cuomo, V.; Lapenna, V.; Macchiato, M. On the methods to identify clustering properties in sequences of seismic time-occurrences. J. Seismol. 2002, 6, 125–134. [Google Scholar] [CrossRef]
- Besio, G.; Briganti, R.; Romano, A.; Mentaschi, L.; De Girolamo, P. Time clustering of wave storms in the Mediterranean Sea. Nat. Hazards Earth Syst. Sci. 2017, 17, 505–514. [Google Scholar] [CrossRef]
- Telesca, L.; Kanevski, M.; Tonini, M.; Pezzatti, G.B.; Conedera, M. Temporal patterns of fire sequences observed in Canton of Ticino (southern Switzerland). Nat. Hazards Earth Syst. Sci. 2010, 10, 723–728. [Google Scholar] [CrossRef]
- Yip, C.F.; Ng, W.L.; Yau, C.Y. A hidden Markov model for earthquake prediction. Stoch. Environ. Res. Risk Assess. 2018, 32, 1415–1434. [Google Scholar] [CrossRef]
- Lu, S. A Bayesian multiple changepoint model for marked Poisson processes with applications to deep earthquakes. Stoch. Environ. Res. Risk Assess. 2019, 33, 59–72. [Google Scholar] [CrossRef]
- Peresan, A.; Gentili, S. Identification and characterization of earthquake clusters: A comparative analysis for selected sequences in Italy and adjacent regions. Boll. Di Geofis. Teor. E Appl. 2020, 61, 57–80. [Google Scholar] [CrossRef]
- Wiemer, S.; Wyss, M. Minimum magnitude of completeness in earthquake catalogs: Examples from Alaska, the western United States, and Japan. Bull. Seismol. Soc. Am. 2000, 90, 859–869. [Google Scholar] [CrossRef]
- Wiemer, S. A software package to analyze seismicity: ZMAP. Seismol. Res. Lett. 2001, 72, 373–382. [Google Scholar] [CrossRef]
- Omori, F. Investigation of aftershocks. Rep. Earthq. Inv. Comm. 1894, 2, 103–139. [Google Scholar]
- Zaliapin, I.; Gabrielov, A.; Wong, H.; Keilis-Borok, V.I. Clustering analysis of seismicity and aftershock identification. Phys. Rev. Lett. 2008, 101, 018501. [Google Scholar] [CrossRef]
- Papadopoulou, K.A.; Skordas, E.S.; Sarlis, N.V. A tentative model for the explanation of Båth law using the order parameter of seismicity in natural time. Earthq. Sci. 2016, 29, 311–319. [Google Scholar] [CrossRef]
- Gutenberg, B.; Richter, C.F. Frequency of earthquakes in California. Bull. Seismol. Soc. Am. 1944, 34, 185–188. [Google Scholar] [CrossRef]
- Nekrasova, A.; Kossobokov, V.; Peresan, A.; Aoudia, A.; Panza, G.F. A multiscale application of the unified scaling law for earthquakes in the central Mediterranean area and alpine region. Pure Appl. Geophys. 2011, 168, 297–327. [Google Scholar] [CrossRef]
- Bottiglieri, M.; Lippiello, E.; Godano, C.; de Arcangelis, L. Identification and spatiotemporal organization of aftershocks. J. Geophys. Res. 2009, 114, B03303. [Google Scholar] [CrossRef]
- Telesca, L.; Cuomo, V.; Lapenna, V.; Macchiato, M. Analysis of the time-scaling behaviour in the sequence of the aftershocks of the Bovec (Slovenia) April 12, 1998 earthquake. Phys. Earth Planet Int. 2000, 120, 315–326. [Google Scholar] [CrossRef]
- Cox, D.R.; Isham, V. Point Processes; Chapman and Hall: London, UK, 1980. [Google Scholar]
- Telesca, L.; Lovallo, M.; Amin Mohamed, A.E.E.; ElGabry, M.; El-hady, S.; Abou Elenean, K.M.; ElShafey Fat ElBary, R. Investigating the time-scaling behavior of the 2004–2010 seismicity of Aswan area (Egypt) by means of the Allan factor statistics and the detrended fluctuation analysis. Nat. Hazards Earth Syst. Sci. 2012, 12, 1267–1276. [Google Scholar] [CrossRef]
- Telesca, L.; Bernardi, M.; Rovelli, C. Time-scaling analysis of lightning in Italy. Commun. Nonlinear Anal. Numer. Simul. 2008, 13, 1384–1396. [Google Scholar] [CrossRef]
- Rydén, T. Parameter estimation for Markov modulated Poisson processes. Commun. Stat. Stoch. Model. 1994, 10, 795–829. [Google Scholar] [CrossRef]
- Rydén, T. An EM algorithm for estimation in Markov-modulated Poisson processes. Comput. Stat. Data Anal. 1996, 21, 431–447. [Google Scholar] [CrossRef]
- Harte, D. HiddenMarkov: Hidden Markov Models R Package Version 1.8-11; Statistics Research Associates: Wellington, New Zealand, 2017; Available online: http://www.statsresearch.co.nz/dsh/sslib/ (accessed on 11 July 2022).
- Kass, R.E.; Raftery, A.E. Bayes factors. J. Am. Stat. Assoc. 1995, 90, 773–795. [Google Scholar] [CrossRef]
- Hayes, J.J.; Castillo, O. A new approach for interpreting the Morisita index of aggregation through quadrat size. ISPRS Int. J. Geo-Inf. 2017, 6, 296. [Google Scholar] [CrossRef]
- Morisita, M. Iδ-index, a measure of dispersion of individuals. Res. Popul. Ecol. 1962, 4, 1–7. [Google Scholar] [CrossRef]
- Besag, J.E. Contribution to the discussion on Dr. Ripley’s Paper. J. R. Stat. Soc. Ser. B 1977, 39, 193–195. [Google Scholar]
- Bezzeghoud, M.; Ayadi, A.; Caldeira, B.; Fontiela, J.; Borges, J.F. The largest earthquakes in Algeria in the modern period: The El Asnam and Zemmouri Boumerdès faults. Física De La Tierra 2017, 29, 183–202. [Google Scholar] [CrossRef]
- Meghraoui, M. Géologie des Zones Sismiques du Nord de l’Algérie, Paléosismologie, Tectonique Active et Synthèse Sismotectonique. Ph.D. Thesis, Université Paris, Paris, France, 1988; p. 356. [Google Scholar]
- Yelles–Chaouche, A.; Kherroubi, A.; Beldjoudi, H. The large Algerian earthquakes (267 A.D.–2017). Física De La Tierra 2017, 29, 159–182. [Google Scholar] [CrossRef]
- Benouar, D. An earthquake catalogue for the Maghreb region 20°–38° N, 10° W–12° E for the period 1900–1990. Ann. Geofis. 1994, 37, 511–528. [Google Scholar]
- Harbi, A.; Peresan, A.; Panza, G.F. Seismicity of Eastern Algeria: A revised and extended earthquake Catalogue. Nat. Hazards 2010, 54, 725–747. [Google Scholar] [CrossRef]
- Ayadi, A.; Bezzeghoud, M. Seismicity of Algeria from 1365 to 2013: Maximum observed intensity map (MOI2014). Seismol. Res. Lett. 2015, 86, 236–244. [Google Scholar] [CrossRef]
- Ogata, Y.; Katsura, K. Analysis of temporal and spatial heterogeneity of magnitude frequency distribution inferred from earthquake catalogues. Geophys. J. Int. 1993, 113, 727–738. [Google Scholar] [CrossRef]
- Woessner, J.; Wiemer, S. Assessing the quality of earthquake catalogues: Estimating the magnitude of completeness and its uncertainty. Bull. Seismol. Soc. Am. 2005, 95, 684–698. [Google Scholar] [CrossRef]
- Cao, A.M.; Gao, S.S. Temporal variations of seismic b-values beneath northeastern Japan island arc. Geophys. Res. Lett. 2002, 29, 1334. [Google Scholar] [CrossRef]
- Idrissou, S.; (Département de Génie Civil, Faculté de Technologie, Université Abderrahmane Mira, Béjaia, Algeria). Personal communication, 2023.
- Jalilian, A. ETAS: An R package for fitting the space-time ETAS model to earthquake data. J. Stat. Softw. 2019, 88, 1–39. [Google Scholar] [CrossRef]
- Yelles-Chaouche, A.; Allili, T.; Alili, A.; Messemen, W.; Beldjoudi, H.; Semmane, F.; Kherroubi, A.; Djellit, H.; Larbes, Y.; Haned, S.; et al. The new Algerian Digital Seismic Network (ADSN): Towards an earthquake early-warning system. Adv. Geosci. 2013, 36, 31–38. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Space Window Size [Km] | Time Window Size [Day] |
|---|---|---|
| GK | ||
| GRU | ||
| UHR |
| Method | GK | GRU | UHR | REAS | NN | SD |
| CV | 1.50 | 1.40 | 1.68 | 2.06 | 1.57 | 1.35 |
| Declustering Method | K-MMPP Model | Poisson Rate | Maximum Log–Likelihood | BIC |
|---|---|---|---|---|
| GK | 2-MMPP | |||
| GRU | 2-MMPP | |||
| UHR | 4-MMPP | |||
| REAS | 5-MMPP | |||
| NN | 2-MMPP | |||
| SD | 2-MMPP |
| Declustering Method | Full Catalogue | GK | GRU | UHR | REAS | NN | SD |
| 0.49 | 0.31 | 0.29 | 0.34 | 0.37 | 0.33 | 0.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benali, A.; Jalilian, A.; Peresan, A.; Varini, E.; Idrissou, S. Spatiotemporal Analysis of the Background Seismicity Identified by Different Declustering Methods in Northern Algeria and Its Vicinity. Axioms 2023, 12, 237. https://doi.org/10.3390/axioms12030237
Benali A, Jalilian A, Peresan A, Varini E, Idrissou S. Spatiotemporal Analysis of the Background Seismicity Identified by Different Declustering Methods in Northern Algeria and Its Vicinity. Axioms. 2023; 12(3):237. https://doi.org/10.3390/axioms12030237
Chicago/Turabian StyleBenali, Amel, Abdollah Jalilian, Antonella Peresan, Elisa Varini, and Sara Idrissou. 2023. "Spatiotemporal Analysis of the Background Seismicity Identified by Different Declustering Methods in Northern Algeria and Its Vicinity" Axioms 12, no. 3: 237. https://doi.org/10.3390/axioms12030237
APA StyleBenali, A., Jalilian, A., Peresan, A., Varini, E., & Idrissou, S. (2023). Spatiotemporal Analysis of the Background Seismicity Identified by Different Declustering Methods in Northern Algeria and Its Vicinity. Axioms, 12(3), 237. https://doi.org/10.3390/axioms12030237