
Estimations of Modified Lindley Parameters Using Progressive Type-II Censoring with Applications



Abstract
:1. Introduction
2. Classical Estimation
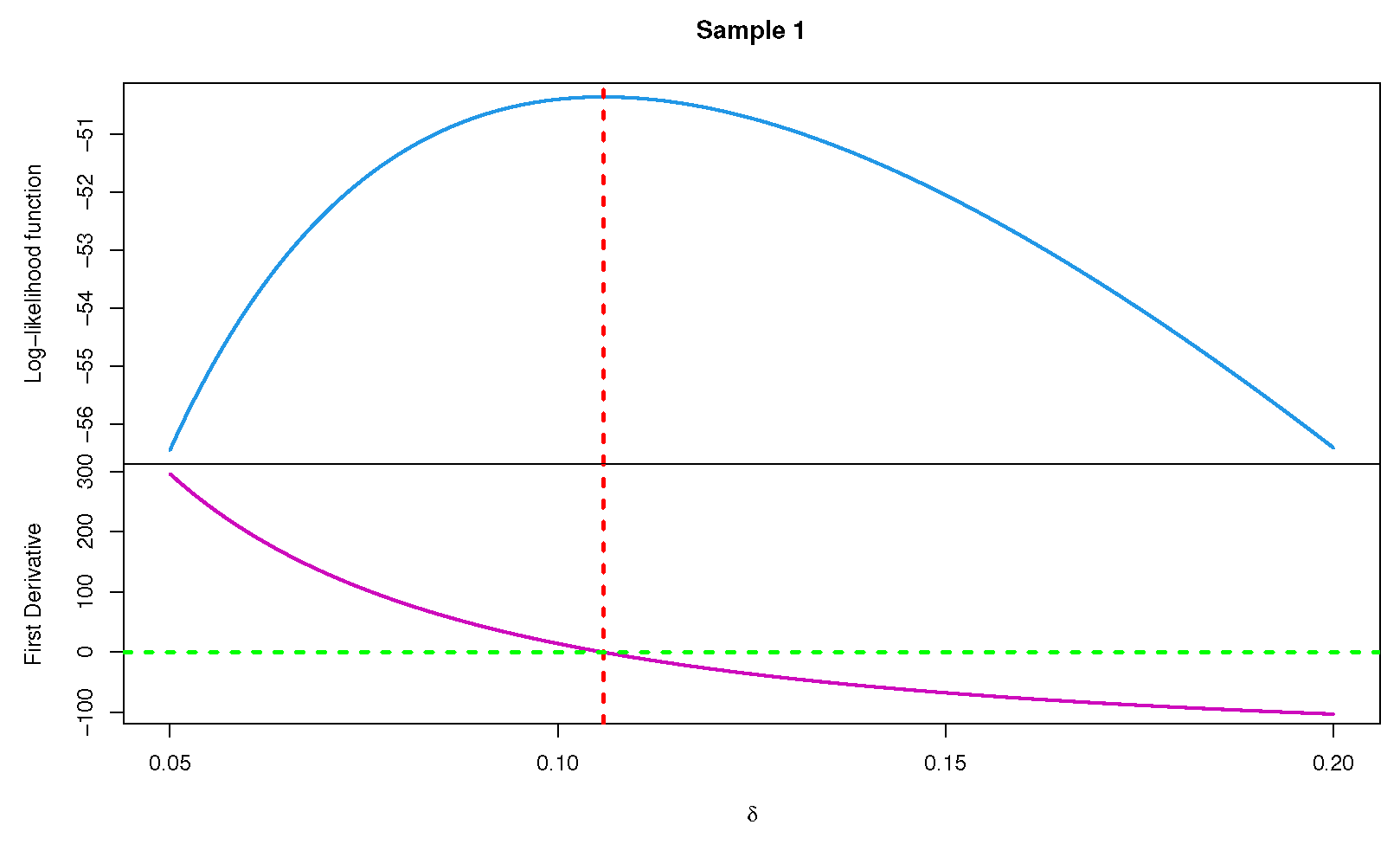
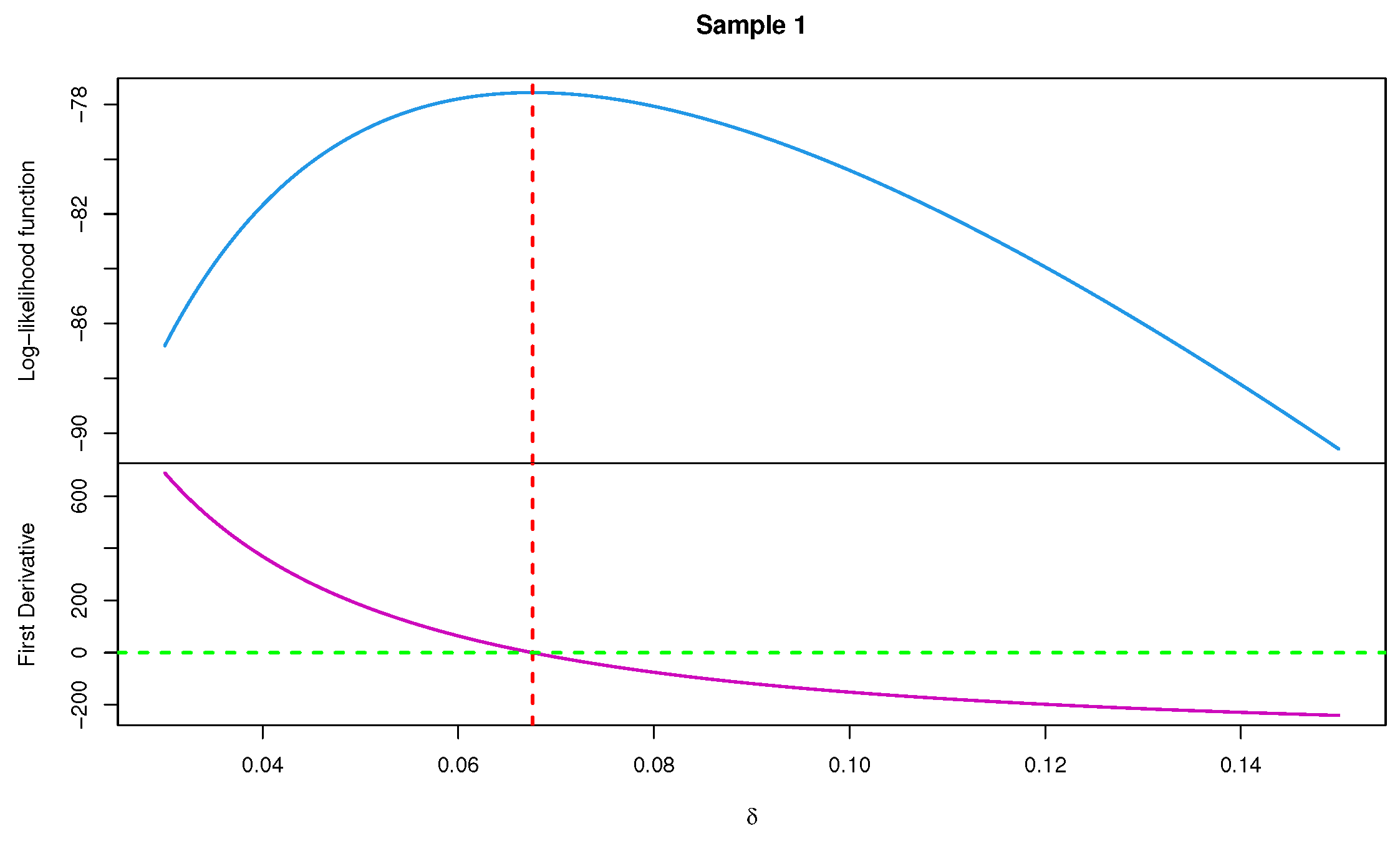
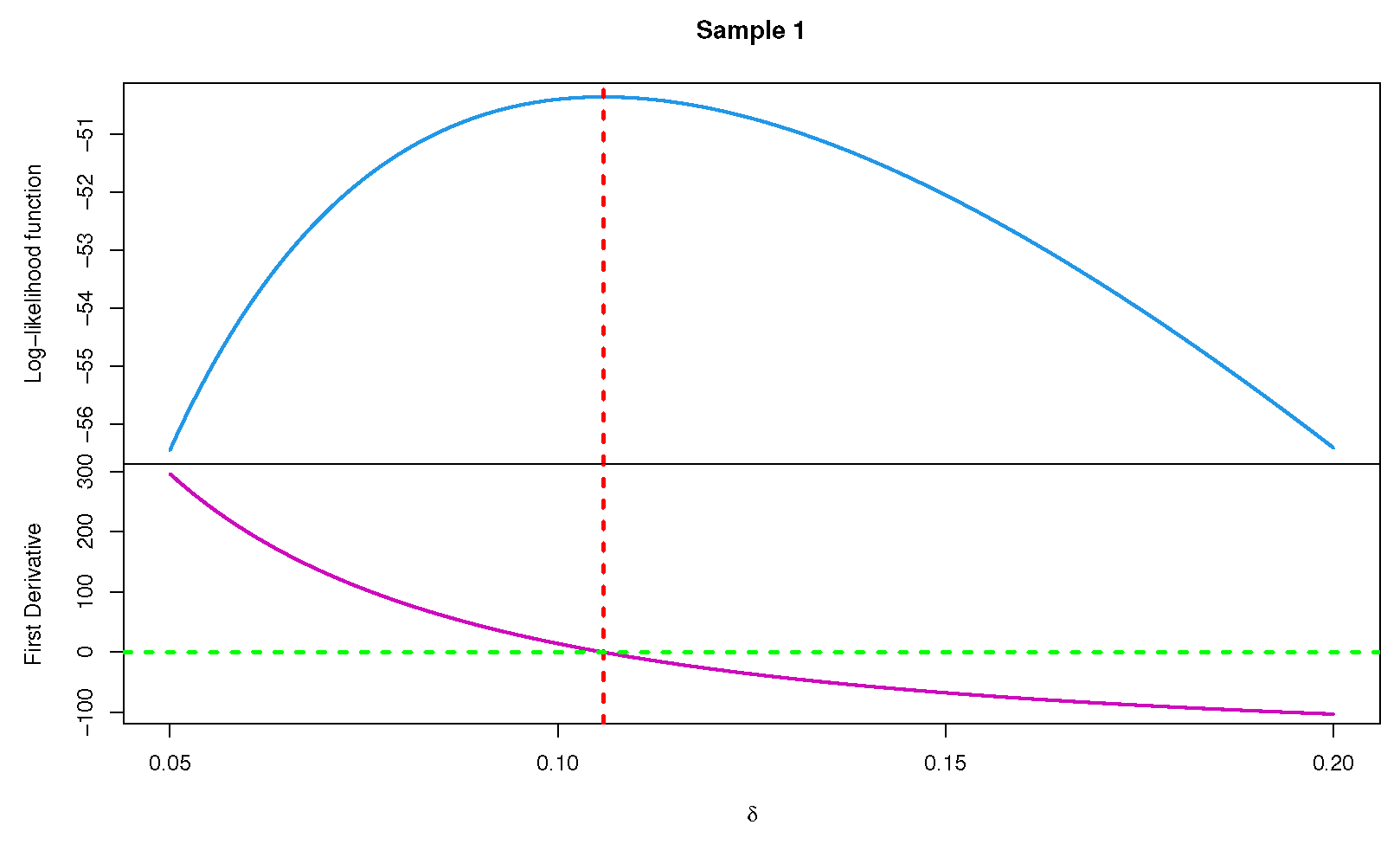
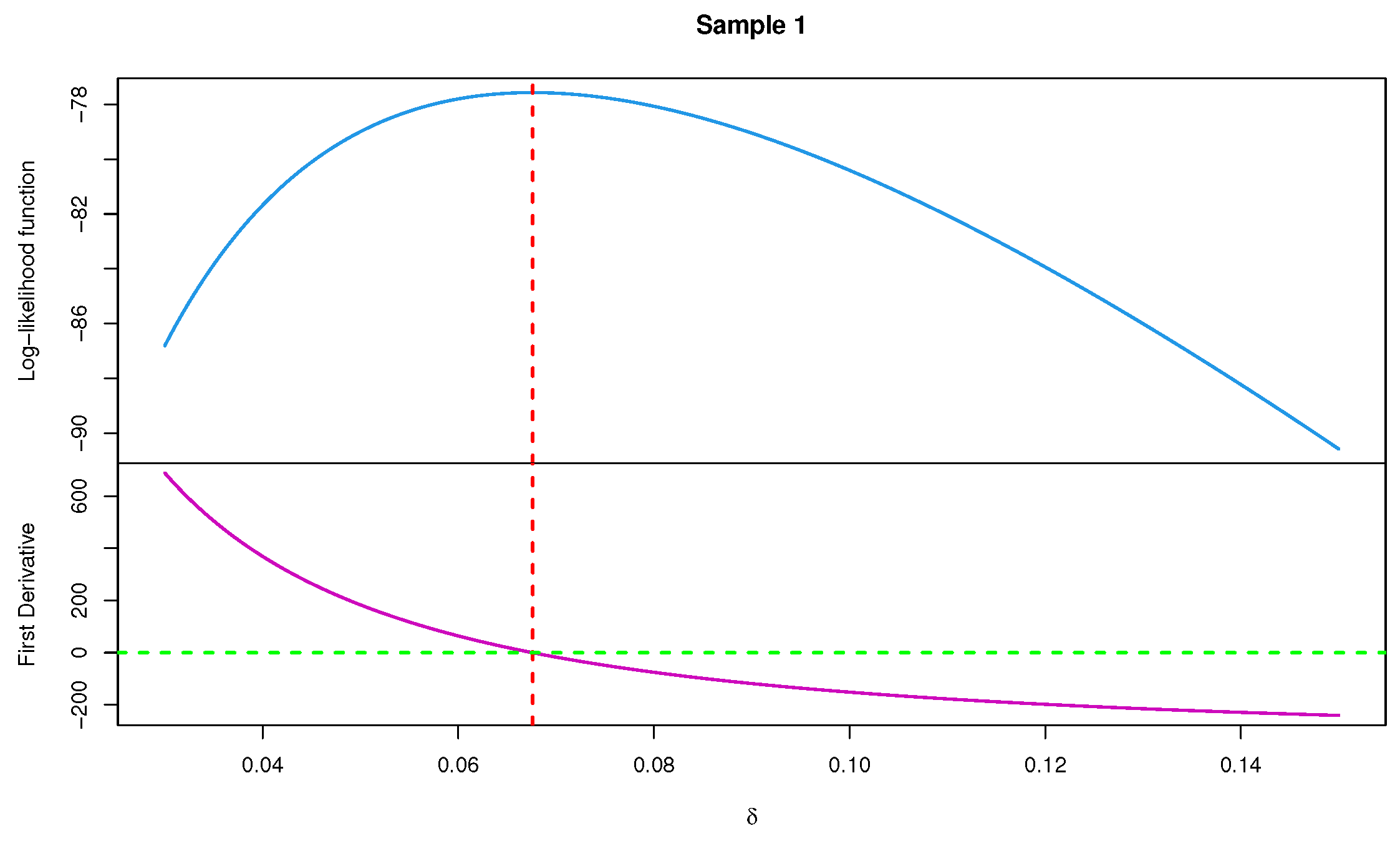
2.1. Maximum Lilekihood Estimation
2.2. Maximum Product of Spacing Estimation
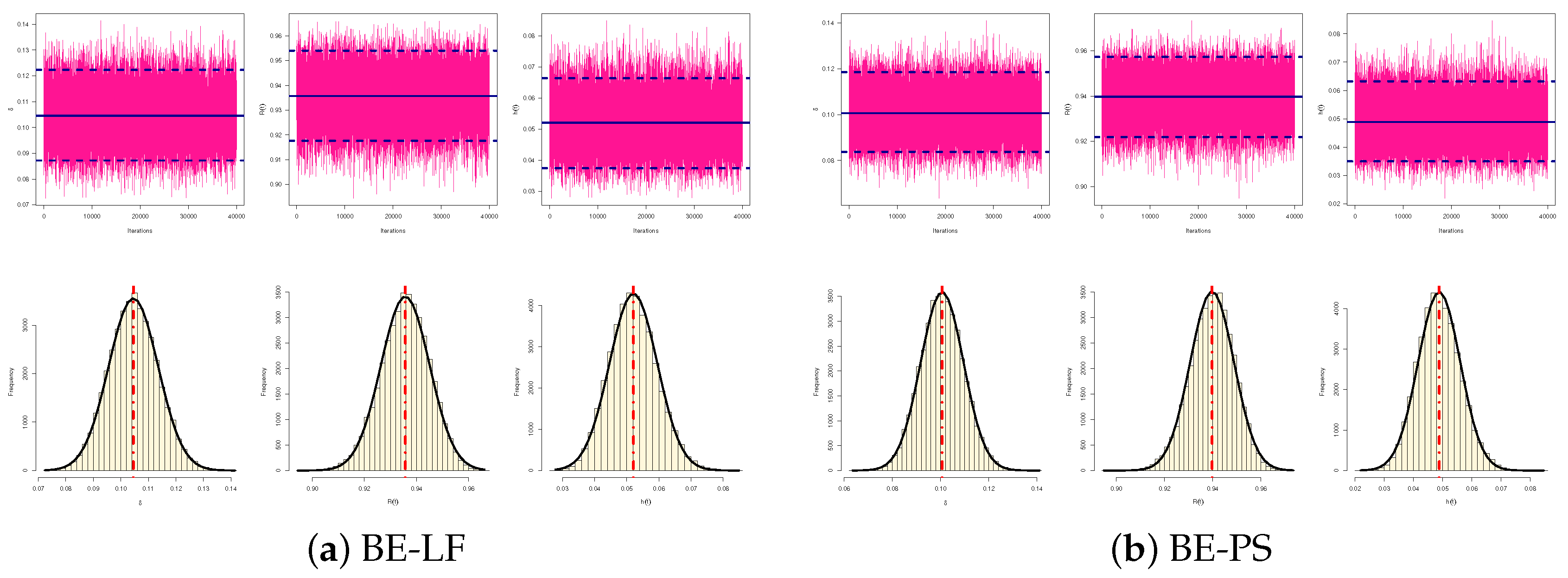
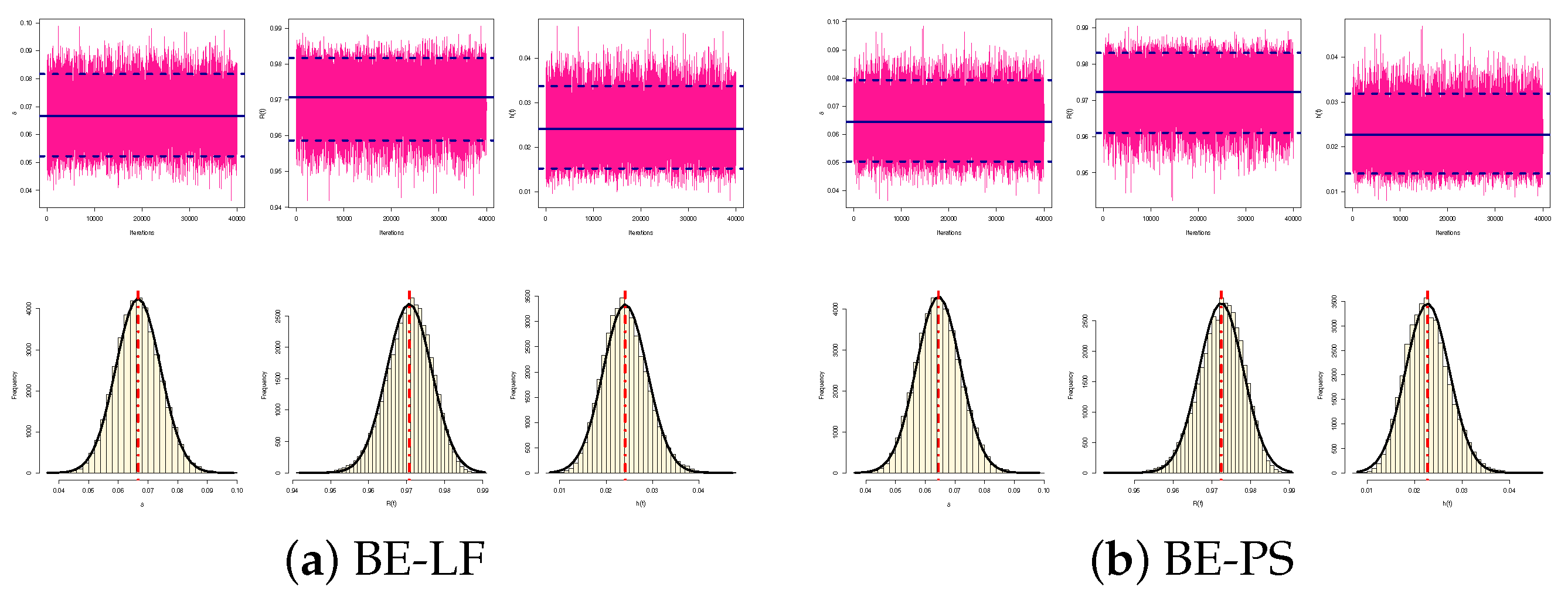
3. Bayesian Estimation
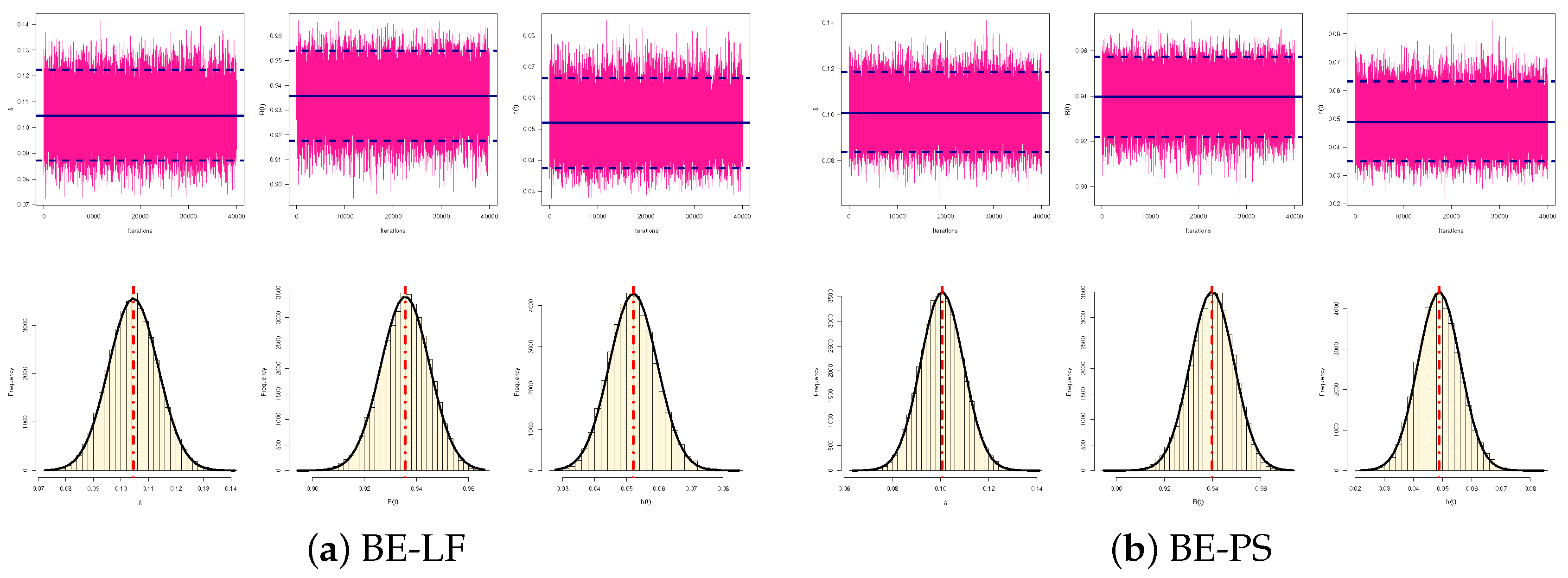
3.1. Bayesian Estimation Using LF
- Step 1.
- Specify the initial value for , say .
- Step 2.
- Set .
- Step 3.
- Generate from (19) with normal proposal distribution using the MH steps.
- Step 4.
- Taking a specific value for t, determine and asand
- Step 5.
- Set .
- Step 6.
- Replicate Steps 3 through 5, M times to obtain
- Step 7.
- Compute the Bayes estimates, after removing samples as a burn-in period, as follows
- Step 8.
- To compute the HPD credible intervals, order and . Then, one can follow the method proposed by Chen and Shao [20] to obtain the required interval for the parameter , as followswhere is chosen such thatThe largest integer less than or equal to x is denoted by . The same process can be applied to obtain the HPD credible intervals of and .
3.2. Bayesian Estimation Using PS Function
- Step 1.
- Determine the initial value of by setting .
- Step 2.
- Put .
- Step 3.
- Use MH steps to obtain from (22) with normal proposal distribution.
- Step 4.
- At a mission time t, obtain and .
- Step 5.
- Put .
- Step 6.
- Repeat Steps 3–5, M times to obtain and .
- Step 7.
- Calculate the Bayes estimates as
- Step 8.
- The same method mentioned in the previous part can be used to determine the HPD credible intervals.
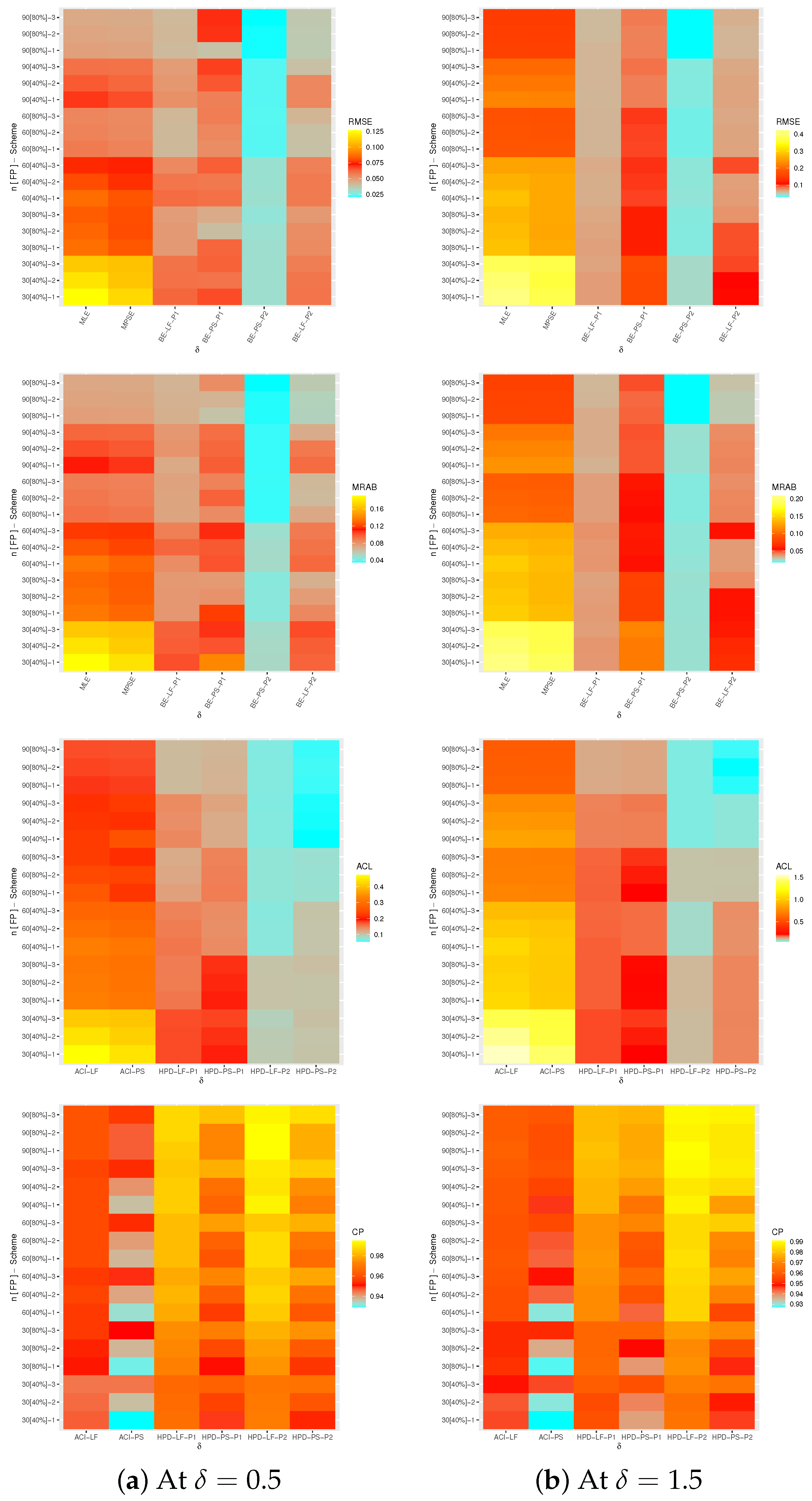
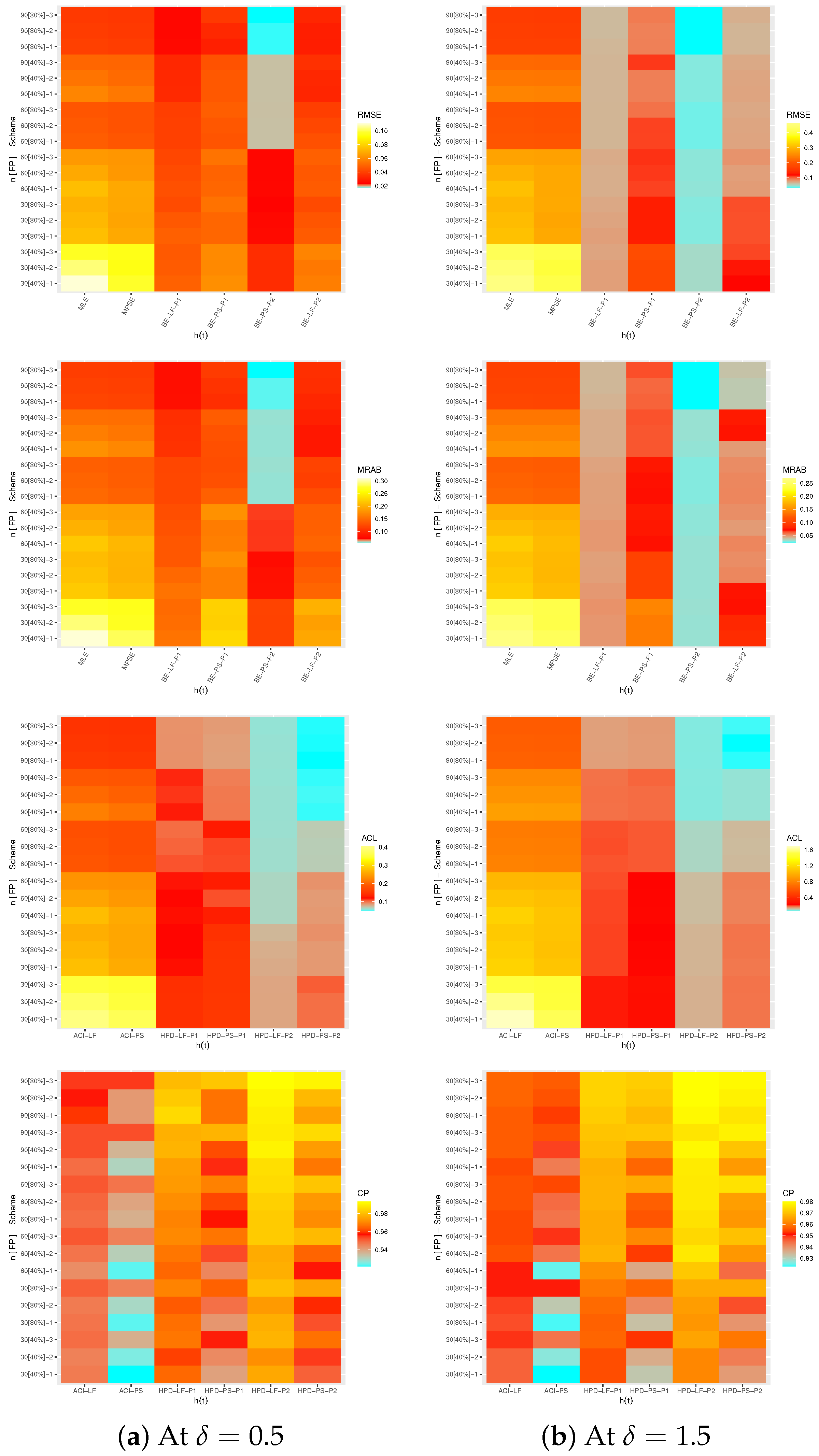
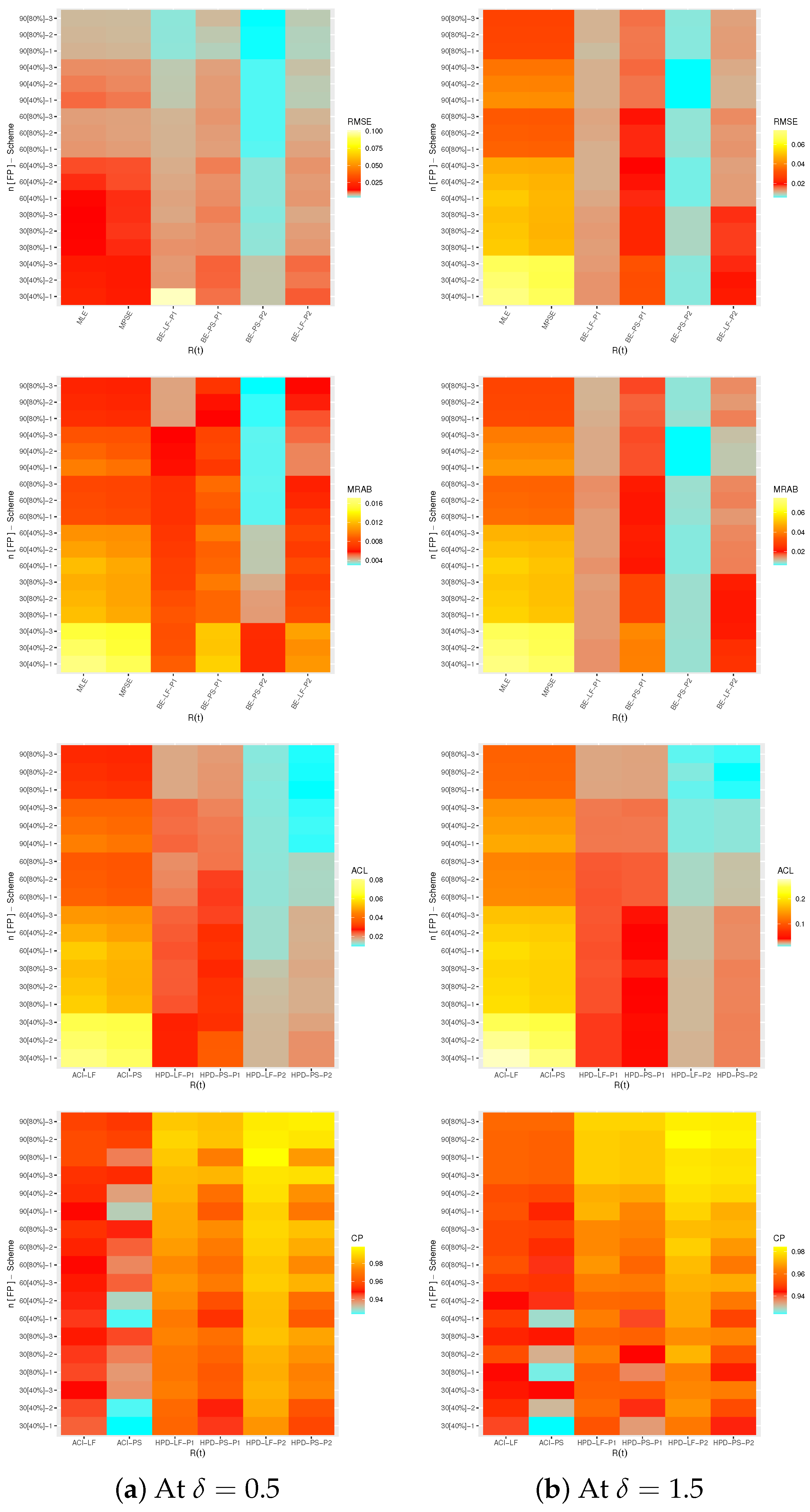
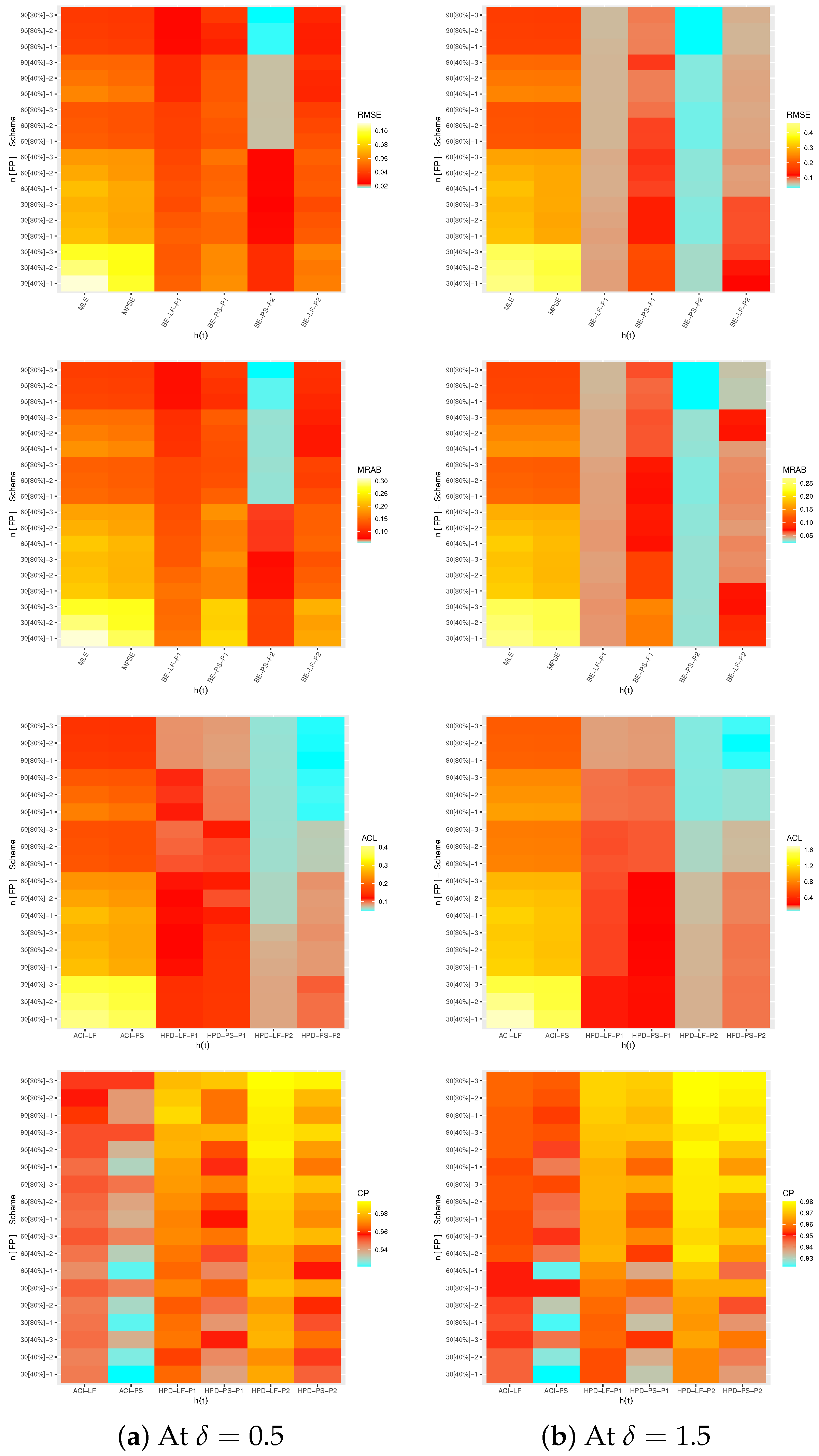
4. Monte Carlo Simulations
- All proposed estimates of , or behave well; this is the general comment.
- When n(or m) grows, all estimates of , , and perform satisfactorily. When decreases, the same outcome is observed.
- Due to the gamma prior, the MCMC estimates of , , and (from LF or PS) outperform the other estimates as expected. When comparing the HPD credible intervals to the ACIs, the same conclusion is reached.
- It is obvious that the Bayes findings based on Prior 2 perform better than others for all unknown parameters, since the associated variance of Prior 2 is smaller than the associated variance of Prior 1.
- All proposed estimates of , , and behave better utilizing scheme 3 than others when comparing the proposed censoring plans 1, 2 and 3.
- Using the frequentist perspective, it can be observed that the proposed point estimates of , , and using the PS technique become even better than those derived from the LF approach in terms of the least RMSEs, MRABs, and ACLs. The ACI-PS interval estimates of , , and perform better than others in terms of ACLs criteria whereas the ACI-LF interval estimates of , , and perform better than others in terms of CPs criteria.
- From the Bayesian perspective, it is clear that the proposed point estimates of , , and produced using the BE-LF approach are superior to those obtained using the BE-PS approach. It is also noted that the HPD-LF interval estimates , and perform better than others.
- As increases, in most cases, the RMSEs, MRABs, and ACLs of , and increase while their CPs decrease.
- To sum up, in order to estimate the unknown parameters of life , , and of the ML model using the PT-IIC data, we recommend using the PS approach (as a frequentist technique) and BE-LF (as a Bayesian method).
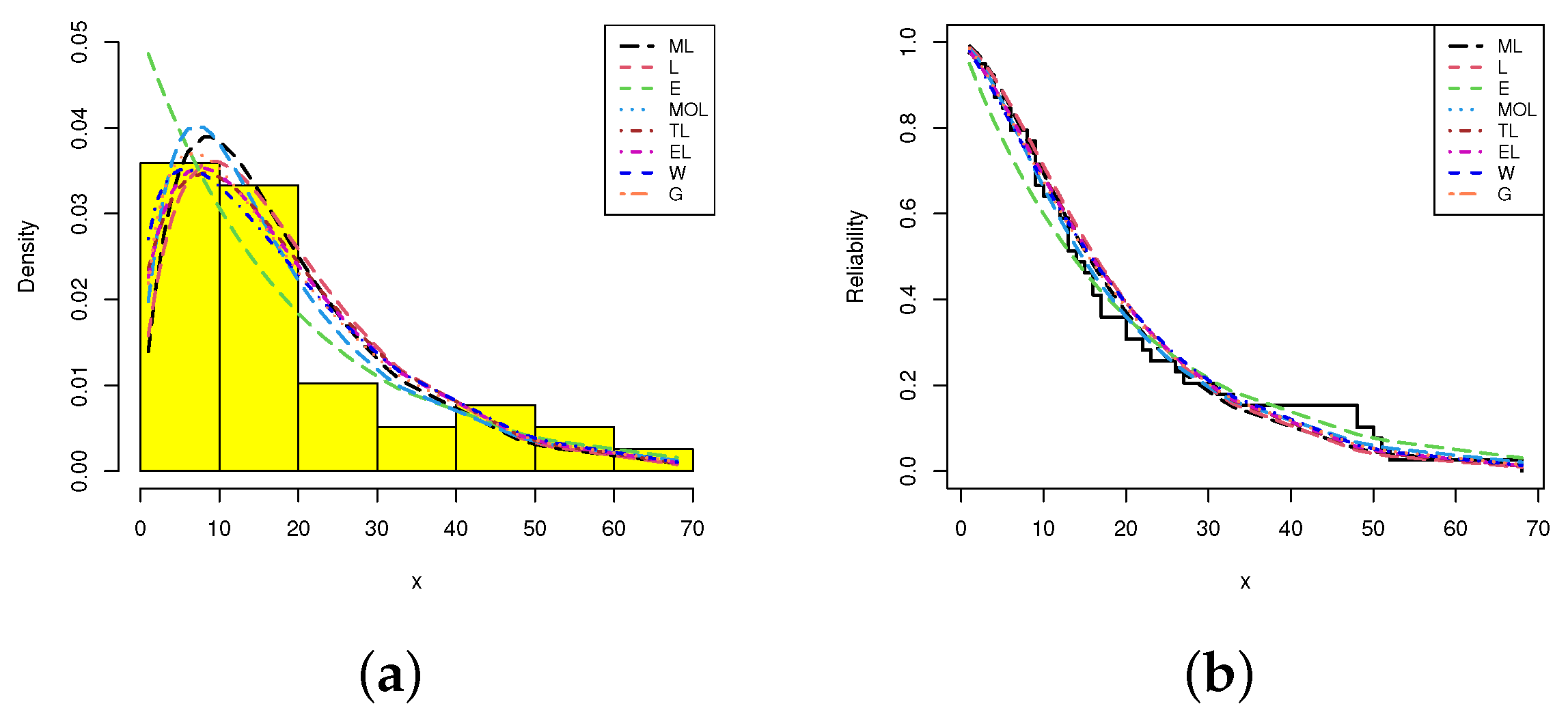
5. Real-Life Applications
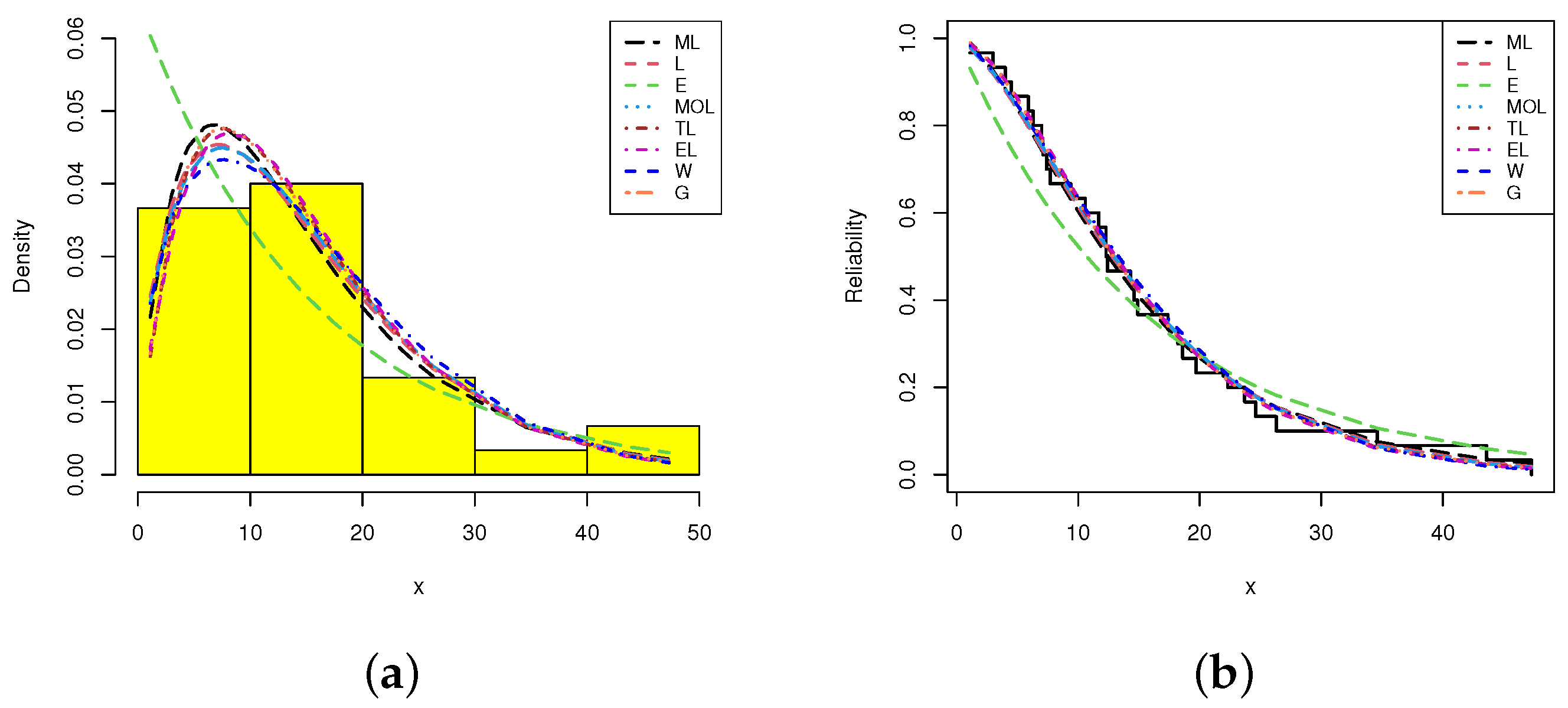
5.1. Mechanical Equipment
5.2. Motor Vehicle Deaths
6. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chesneau, C.; Tomy, L.; Gillariose, J. A new modified Lindley distribution with properties and applications. J. Stat. Manag. Syst. 2021, 24, 1383–1403. [Google Scholar] [CrossRef]
- Veena, G.; Lishamol, T. A comparative study of various estimation methods for modified Lindley distribution. Biom. Biostat. Int. J. 2022, 11, 79–81. [Google Scholar]
- Balakrishnan, N. Progressive Censoring Methodology: An Appraisal (with Discussion). TEST 2007, 16, 211–259. [Google Scholar] [CrossRef]
- EL-Sagheer, R.M. Estimation of parameters of Weibull–Gamma distribution based on progressively censored data. Stat. Pap. 2018, 59, 725–757. [Google Scholar] [CrossRef]
- El-Sagheer, R.M. Estimating the parameters of Kumaraswamy distribution using progressively censored data. J. Test. Eval. 2019, 47, 905–926. [Google Scholar] [CrossRef]
- Dey, S.; Nassar, M.; Maurya, R.K.; Tripathi, Y.M. Estimation and prediction of Marshall–Olkin extended exponential distribution under progressively type-II censored data. J. Stat. Comput. Simul. 2018, 88, 2287–2308. [Google Scholar] [CrossRef]
- Chacko, M.; Mohan, R. Statistical inference for Gompertz distribution based on progressive type-II censored data with binomial removals. Statistica 2018, 78, 251–272. [Google Scholar]
- Nik, A.S.; Asgharzadeh, A.; Raqab, M.Z. Estimation and prediction for a new Pareto-type distribution under progressive type-II censoring. Math. Comput. Simul. 2021, 190, 508–530. [Google Scholar]
- Alotaibi, R.; Nassar, M.; Rezk, H.; Elshahhat, A. Inferences and Engineering Applications of Alpha Power Weibull Distribution Using Progressive Type-II Censoring. Mathematics 2022, 10, 2901. [Google Scholar] [CrossRef]
- Maiti, K.; Kayal, S. Statistical Inferences to the Parameter and Reliability Characteristics of Gamma-mixed Rayleigh Distribution under Progressively Censored Data with Application. REVSTAT-Stat. J. 2022. Available online: https://revstat.ine.pt/index.php/REVSTAT/article/view/453. (accessed on 10 December 2022).
- Cheng, R.C.H.; Amin, N.A.K. Estimating parameters in continuous univariate distributions with a shifted origin. J. R. Stat. Soc. Ser. B Methodol. 1983, 45, 394–403. [Google Scholar] [CrossRef]
- Ranneby, B. The maximum spacing method. An estimation method related to the maximum likelihood method. Scand. J. Stat. 1984, 11, 93–112. [Google Scholar]
- Anatolyev, S.; Kosenok, G. An alternative to maximum likelihood based on spacings. Econom. Theory 2005, 21, 472–476. [Google Scholar] [CrossRef]
- Ng, H.K.T.; Luo, L.; Hu, Y.; Duan, F. Parameter estimation of three-parameter Weibull distribution based on progressively Type-II censored samples. J. Stat. Comput. Simul. 2012, 82, 1661–1678. [Google Scholar] [CrossRef]
- Mazucheli, J.; Ghitany, M.E.; Louzada, F. Comparisons of ten estimation methods for the parameters of Marshall–Olkin extended exponential distribution. Commun.-Stat.-Simul. Comput. 2017, 46, 5627–5645. [Google Scholar] [CrossRef]
- Rodrigues, G.C.; Louzada, F.; Ramos, P.L. Poisson–exponential distribution: Different methods of estimation. J. Appl. Stat. 2018, 45, 128–144. [Google Scholar] [CrossRef]
- Almarashi, A.M.; Algarni, A.; Nassar, M. On estimation procedures of stress-strength reliability for Weibull distribution with application. PLoS ONE 2020, 15, e0237997. [Google Scholar] [CrossRef]
- Nassar, M.; Dey, S.; Wang, L.; Elshahhat, A. Estimation of Lindley constant-stress model via product of spacing with Type-II censored accelerated life data. Commun.-Stat.-Simul. Comput. 2021. [Google Scholar] [CrossRef]
- Cheng, R.C.H.; Traylor, L. Non-regular maximum likelihood problems. J. R. Stat. Soc. Ser. B Methodol. 1995, 57, 3–24. [Google Scholar] [CrossRef]
- Chen, M.H.; Shao, Q.M. Monte Carlo estimation of Bayesian credible and HPD intervals. J. Comput. Graph. Stat. 1999, 8, 69–92. [Google Scholar]
- Henningsen, A.; Toomet, O. maxLik: A package for maximum likelihood estimation in R. Comput. Stat. 2011, 26, 443–458. [Google Scholar] [CrossRef]
- Plummer, M.; Best, N.; Cowles, K.; Vines, K. CODA: Convergence diagnosis and output analysis for MCMC. R News 2006, 6, 7–11. [Google Scholar]
- Murthy, D.N.P.; Xie, M.; Jiang, R. Weibull Models; Wiley Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 2004. [Google Scholar]
- Elshahhat, A.; Aljohani, H.M.; Afify, A.Z. Bayesian and Classical Inference under Type-II Censored Samples of the Extended Inverse Gompertz Distribution with Engineering Applications. Entropy 2021, 23, 1578. [Google Scholar] [CrossRef] [PubMed]
- Shanker, R.; Mishra, A. A two-parameter Lindley distribution. Stat. Transit. New Ser. 2013, 14, 45–56. [Google Scholar] [CrossRef]
- Nadarajah, S.; Bakouch, H.S.; Tahmasbi, R. A generalized Lindley distribution. Sankhya B 2011, 73, 331–359. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Al-Mutairi, D.K.; Al-Awadhi, F.A.; Al-Burais, M.M. Marshall-Olkin extended Lindley distribution and its application. Int. J. Appl. Math. 2012, 25, 709–721. [Google Scholar]
- Eghwerido, J.T.; Ogbo, J.O.; Omotoye, A.E. The Marshall-Olkin Gompertz Distribution: Properties and Applications. Statistica 2021, 81, 183–215. [Google Scholar]


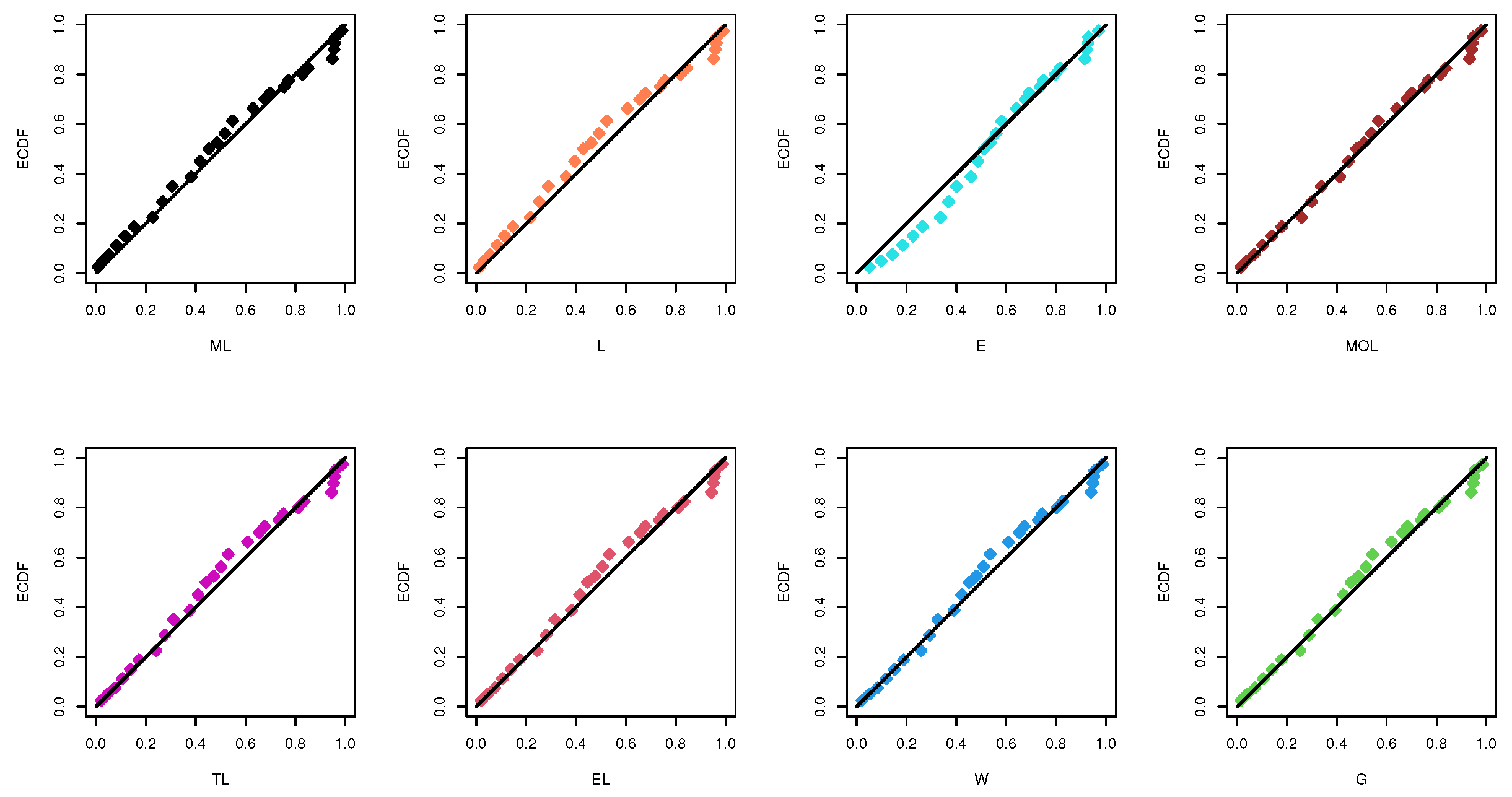


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1.1 | 3.0 | 4.0 | 4.5 | 5.9 | 6.3 | 7.0 | 7.1 | 7.4 | 7.7 |
| 9.4 | 10.6 | 11.7 | 12.3 | 12.3 | 12.4 | 14.3 | 14.6 | 14.9 | 17.4 |
| 18.2 | 18.6 | 19.7 | 22.3 | 23.7 | 24.6 | 26.3 | 34.6 | 43.6 | 47.3 |
| Model | MLE (St.E) | NL | A | CA | B | HQ | KS (p-Value) | |
|---|---|---|---|---|---|---|---|---|
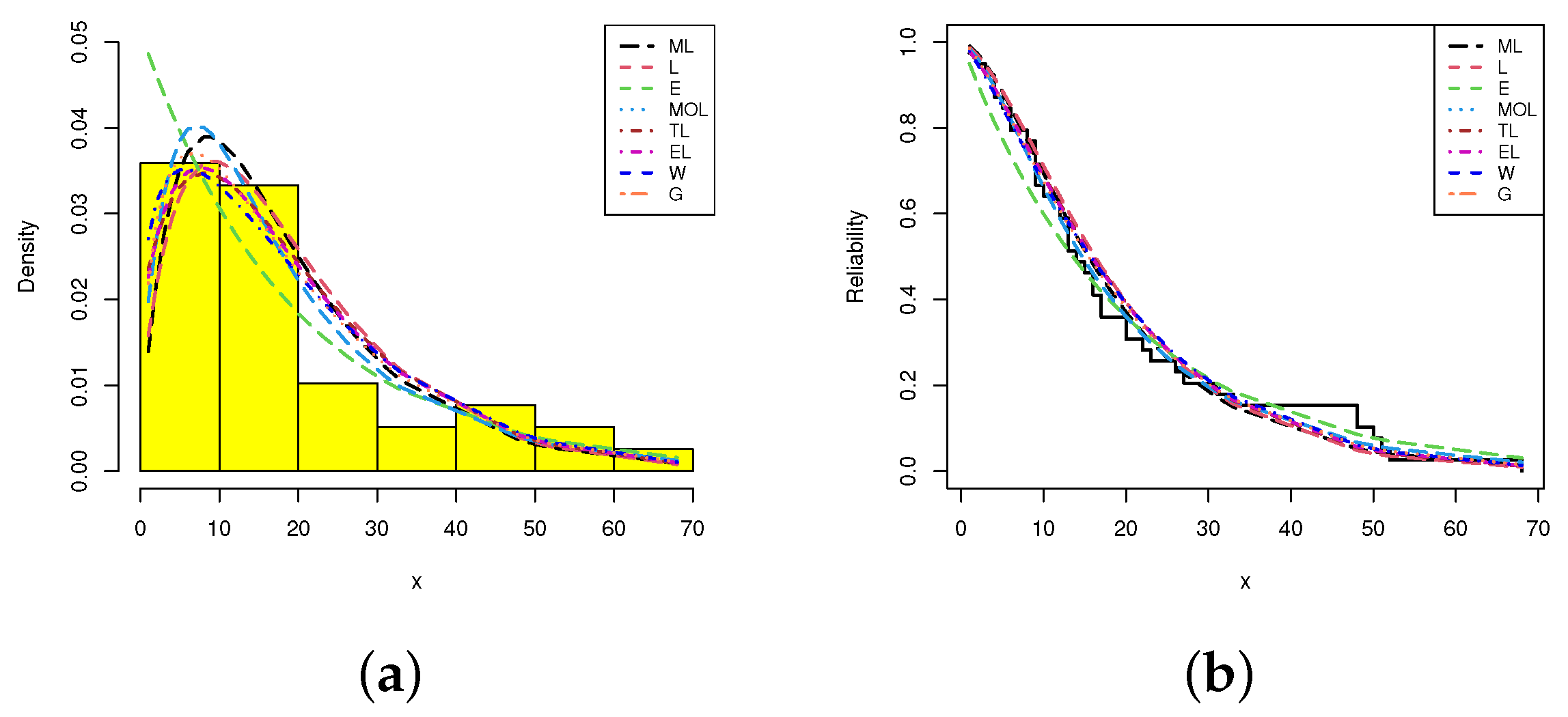
| ML | - | 0.0792 (0.0111) | 108.707 | 219.770 | 219.913 | 221.171 | 220.219 | 0.0630 (0.999) |
| L | - | 0.1225 (0.0159) | 108.942 | 219.884 | 220.027 | 221.285 | 220.332 | 0.0688 (0.999) |
| E | - | 0.0648 (0.0118) | 112.083 | 226.166 | 226.309 | 227.567 | 226.614 | 0.1844 (0.259) |
| G | 1.9732 (0.4712) | 7.8105 (2.1200) | 108.711 | 221.414 | 221.859 | 224.217 | 222.311 | 0.0669 (0.999) |
| W | 1.4633 (0.2029) | 17.099 (2.2539) | 108.988 | 221.976 | 222.420 | 224.778 | 222.872 | 0.0749 (0.996) |
| TL | 0.0242 (1.4529) | 0.1294 (0.0206) | 108.771 | 221.422 | 221.867 | 224.225 | 222.319 | 0.0692 (0.999) |
| EL | 1.1767 (0.3244) | 0.1330 (0.0243) | 108.885 | 221.542 | 221.986 | 224.344 | 222.438 | 0.0751 (0.996) |
| MOL | 1.1345 (0.8926) | 0.1286 (0.0412) | 108.929 | 221.859 | 222.303 | 224.661 | 222.755 | 0.0697 (0.999) |
| Sample | Scheme | Censored Data |
|---|---|---|
| 1 | (15, 014) | 1.1, 3.0, 4.0, 4.5, 5.9, 7.0, 7.1, 7.7, 9.4, 12.3, 14.3, 17.4, 22.3, 24.6, 26.3 |
| 2 | 1.1, 3.0, 4.0, 4.5, 5.9, 6.3, 7.0, 7.4, 9.4, 10.6, 12.4, 14.6, 18.2, 22.3, 24.6 | |
| 3 | 1.1, 3.0, 4.0, 4.5, 5.9, 6.3, 7.0, 7.1, 7.4, 7.7, 9.4, 10.6, 11.7, 12.3, 12.3 |
| Sample | Par. | MLE | BE-LF | ACI-LF | HPD-LF | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Est. | St.E | Est. | St.E | Lower | Upper | Length | Lower | Upper | Length | ||
| 1 | 0.1059 | 0.0209 | 0.1046 | 0.0091 | 0.0649 | 0.1468 | 0.0819 | 0.0872 | 0.1223 | 0.0351 | |
| 0.9346 | 0.0219 | 0.9357 | 0.0094 | 0.8916 | 0.9775 | 0.0859 | 0.9176 | 0.9540 | 0.0364 | ||
| 0.0530 | 0.0174 | 0.0521 | 0.0075 | 0.0188 | 0.0871 | 0.0683 | 0.0375 | 0.0664 | 0.0290 | ||
| 2 | 0.0808 | 0.0145 | 0.0797 | 0.0082 | 0.0524 | 0.1092 | 0.0568 | 0.0640 | 0.0959 | 0.0319 | |
| 0.9590 | 0.0130 | 0.9598 | 0.0073 | 0.9336 | 0.9845 | 0.0509 | 0.9456 | 0.9737 | 0.0281 | ||
| 0.0335 | 0.0104 | 0.0329 | 0.0058 | 0.0131 | 0.0538 | 0.0407 | 0.0217 | 0.0442 | 0.0225 | ||
| 3 | 0.0772 | 0.0135 | 0.0761 | 0.0081 | 0.0508 | 0.1036 | 0.0527 | 0.0608 | 0.0922 | 0.0314 | |
| 0.9622 | 0.0117 | 0.9629 | 0.0069 | 0.9393 | 0.9851 | 0.0458 | 0.9494 | 0.9763 | 0.0269 | ||
| 0.0309 | 0.0094 | 0.0304 | 0.0056 | 0.0126 | 0.0493 | 0.0367 | 0.0196 | 0.0411 | 0.0215 | ||
| MPSE | BE-PS | ACI-PS | HPD-PS | ||||||||
| 1 | 0.1020 | 0.0199 | 0.1007 | 0.0090 | 0.0629 | 0.1410 | 0.0781 | 0.0838 | 0.1186 | 0.0348 | |
| 0.9386 | 0.0205 | 0.9397 | 0.0092 | 0.8985 | 0.9787 | 0.0802 | 0.9219 | 0.9573 | 0.0354 | ||
| 0.0498 | 0.0163 | 0.0489 | 0.0073 | 0.0178 | 0.0817 | 0.0639 | 0.0350 | 0.0632 | 0.0282 | ||
| 2 | 0.0792 | 0.0141 | 0.0781 | 0.0082 | 0.0515 | 0.1069 | 0.0554 | 0.0621 | 0.0941 | 0.0320 | |
| 0.9605 | 0.0125 | 0.9612 | 0.0072 | 0.9360 | 0.9849 | 0.0489 | 0.9467 | 0.9746 | 0.0279 | ||
| 0.0323 | 0.0100 | 0.0317 | 0.0058 | 0.0127 | 0.0519 | 0.0392 | 0.0211 | 0.0434 | 0.0223 | ||
| 3 | 0.0768 | 0.0133 | 0.0757 | 0.0080 | 0.0507 | 0.1029 | 0.0522 | 0.0603 | 0.0911 | 0.0307 | |
| 0.9626 | 0.0115 | 0.9632 | 0.0068 | 0.9400 | 0.9852 | 0.0452 | 0.9496 | 0.9759 | 0.0263 | ||
| 0.0306 | 0.0092 | 0.0301 | 0.0055 | 0.0125 | 0.0488 | 0.0362 | 0.0199 | 0.0410 | 0.0211 | ||
| Sample | Par. | Mean | Mode | St.D | Skewness | |||
|---|---|---|---|---|---|---|---|---|
| BE-LF | ||||||||
| 1 | 0.10456 | 0.09494 | 0.09847 | 0.10451 | 0.11058 | 0.00897 | 0.05709 | |
| 0.93570 | 0.93287 | 0.92955 | 0.93597 | 0.94216 | 0.00934 | −0.19348 | ||
| 0.05208 | 0.04413 | 0.04694 | 0.05186 | 0.05697 | 0.00744 | 0.19173 | ||
| 2 | 0.07970 | 0.07904 | 0.07409 | 0.07965 | 0.08510 | 0.00814 | 0.06236 | |
| 0.95975 | 0.96057 | 0.95509 | 0.96003 | 0.96485 | 0.00722 | −0.25378 | ||
| 0.03289 | 0.03224 | 0.02881 | 0.03267 | 0.03662 | 0.00578 | 0.24463 | ||
| 3 | 0.07610 | 0.07467 | 0.07068 | 0.07595 | 0.08148 | 0.00800 | 0.07658 | |
| 0.96290 | 0.96186 | 0.95840 | 0.96327 | 0.96769 | 0.00690 | −0.28396 | ||
| 0.03036 | 0.02920 | 0.02653 | 0.03008 | 0.03398 | 0.00553 | 0.27351 | ||
| BE-PS | ||||||||
| 1 | 0.10065 | 0.10150 | 0.09462 | 0.10055 | 0.10659 | 0.00890 | 0.06119 | |
| 0.93972 | 0.93907 | 0.93378 | 0.94004 | 0.94599 | 0.00908 | −0.20777 | ||
| 0.04887 | 0.04939 | 0.04388 | 0.04862 | 0.05360 | 0.00723 | 0.20478 | ||
| 2 | 0.07806 | 0.07300 | 0.07245 | 0.07786 | 0.08358 | 0.00817 | 0.09572 | |
| 0.96119 | 0.95890 | 0.95649 | 0.96161 | 0.96622 | 0.00717 | −0.29196 | ||
| 0.03173 | 0.02808 | 0.02771 | 0.03141 | 0.03551 | 0.00574 | 0.28236 | ||
| 3 | 0.07571 | 0.07240 | 0.07029 | 0.07563 | 0.08102 | 0.00791 | 0.07238 | |
| 0.96323 | 0.96627 | 0.95881 | 0.96354 | 0.96801 | 0.00679 | −0.27788 | ||
| 0.03010 | 0.02767 | 0.02627 | 0.02986 | 0.03365 | 0.00544 | 0.26747 | ||
| 22 | 26 | 17 | 4 | 48 | 9 | 9 | 31 | 27 | 20 |
| 12 | 6 | 5 | 14 | 9 | 16 | 3 | 33 | 9 | 20 |
| 68 | 13 | 51 | 13 | 2 | 4 | 17 | 16 | 6 | 52 |
| 50 | 48 | 23 | 12 | 13 | 10 | 15 | 8 | 1 |
| Model | MLE (St.E) | NL | A | CA | B | HQ | KS (p-Value) | |
|---|---|---|---|---|---|---|---|---|
| ML | - | 0.0641(0.0080) | 152.968 | 308.786 | 308.894 | 310.450 | 309.383 | 0.1016(0.8157) |
| L | - | 0.0978(0.0111) | 153.745 | 309.489 | 309.598 | 311.153 | 310.086 | 0.1180(0.6492) |
| E | - | 0.0512(0.0082) | 154.923 | 311.846 | 311.954 | 313.510 | 312.443 | 0.1384(0.4440) |
| G | 1.5081(0.3114) | 12.961(3.1672) | 153.393 | 310.297 | 310.630 | 313.624 | 311.491 | 0.0974(0.8532) |
| W | 1.2502(0.1532) | 21.055(2.8507) | 153.439 | 310.878 | 311.211 | 314.205 | 312.071 | 0.1062(0.7711) |
| TL | 2.8681(4.7327) | 0.0917(0.0165) | 153.600 | 311.200 | 311.533 | 314.527 | 312.393 | 0.1109(0.7232) |
| EL | 0.8519(0.1945) | 0.0898(0.0155) | 153.493 | 310.985 | 311.319 | 314.313 | 312.179 | 0.1076(0.7577) |
| MOL | 0.4195(0.3400) | 0.0695(0.0264) | 153.148 | 309.935 | 310.268 | 313.262 | 311.129 | 0.0867(0.9310) |
| Sample | Scheme | Censored Data |
|---|---|---|
| 1 | (19, 019) | 1, 2, 4, 5, 6, 9, 10, 12, 13, 14, 15, 17, 20, 22, 23, 26, 31, 33, 48, 50 |
| 2 | 1, 2, 3, 4, 4, 5, 6, 6, 8, 10, 12, 14, 15, 17, 20, 23, 26, 27, 31, 48 | |
| 3 | 1, 2, 3, 4, 4, 5, 6, 6, 8, 9, 9, 9, 9, 10, 12, 12, 13, 13, 13, 14 |
| Sample | Par. | MLE | BE-LF | ACI-LF | HPD-LF | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Est. | St.E | Est. | St.E | Lower | Upper | Length | Lower | Upper | Length | ||
| 1 | 0.0676 | 0.0116 | 0.0667 | 0.0076 | 0.0448 | 0.0904 | 0.0456 | 0.0522 | 0.0817 | 0.0294 | |
| 0.9702 | 0.0092 | 0.9707 | 0.0060 | 0.9521 | 0.9883 | 0.0362 | 0.9587 | 0.9817 | 0.0230 | ||
| 0.0245 | 0.0074 | 0.0241 | 0.0048 | 0.0099 | 0.0391 | 0.0292 | 0.0152 | 0.0338 | 0.0186 | ||
| 2 | 0.0602 | 0.0094 | 0.0631 | 0.0083 | 0.0417 | 0.0787 | 0.0370 | 0.0497 | 0.0771 | 0.0274 | |
| 0.9758 | 0.0069 | 0.9734 | 0.0063 | 0.9623 | 0.9894 | 0.0271 | 0.9631 | 0.9837 | 0.0206 | ||
| 0.0200 | 0.0056 | 0.0219 | 0.0051 | 0.0090 | 0.0309 | 0.0219 | 0.0136 | 0.0302 | 0.0166 | ||
| 3 | 0.0706 | 0.0107 | 0.0697 | 0.0073 | 0.0497 | 0.0916 | 0.0419 | 0.0558 | 0.0839 | 0.0281 | |
| 0.9677 | 0.0088 | 0.9683 | 0.0059 | 0.9506 | 0.9849 | 0.0343 | 0.9562 | 0.9790 | 0.0227 | ||
| 0.0265 | 0.0070 | 0.0260 | 0.0048 | 0.0127 | 0.0403 | 0.0276 | 0.0174 | 0.0357 | 0.0183 | ||
| MPSE | BE-PS | ACI-PS | HPD-PS | ||||||||
| 1 | 0.0653 | 0.0111 | 0.0645 | 0.0075 | 0.0434 | 0.0871 | 0.0437 | 0.0504 | 0.0793 | 0.0289 | |
| 0.9720 | 0.0086 | 0.9724 | 0.0057 | 0.9551 | 0.9889 | 0.0339 | 0.9610 | 0.9831 | 0.0221 | ||
| 0.0231 | 0.0070 | 0.0227 | 0.0046 | 0.0094 | 0.0367 | 0.0273 | 0.0141 | 0.0319 | 0.0178 | ||
| 2 | 0.0588 | 0.0092 | 0.0580 | 0.0068 | 0.0408 | 0.0768 | 0.0360 | 0.0449 | 0.0713 | 0.0264 | |
| 0.9769 | 0.0066 | 0.9772 | 0.0048 | 0.9639 | 0.9898 | 0.0259 | 0.9677 | 0.9863 | 0.0186 | ||
| 0.0191 | 0.0054 | 0.0188 | 0.0039 | 0.0087 | 0.0296 | 0.0210 | 0.0114 | 0.0265 | 0.0151 | ||
| 3 | 0.0702 | 0.0106 | 0.0694 | 0.0073 | 0.0495 | 0.0910 | 0.0415 | 0.0553 | 0.0838 | 0.0285 | |
| 0.9680 | 0.0086 | 0.9685 | 0.0059 | 0.9511 | 0.9850 | 0.0339 | 0.9568 | 0.9796 | 0.0229 | ||
| 0.0262 | 0.0070 | 0.0259 | 0.0048 | 0.0126 | 0.0399 | 0.0273 | 0.0169 | 0.0353 | 0.0184 | ||
| Sample | Par. | Mean | Mode | St.D | Skewness | |||
|---|---|---|---|---|---|---|---|---|
| BE-LF | ||||||||
| 1 | 0.06668 | 0.05799 | 0.06153 | 0.06653 | 0.07168 | 0.00752 | 0.11872 | |
| 0.97067 | 0.96880 | 0.96687 | 0.97102 | 0.97485 | 0.00593 | −0.35553 | ||
| 0.02412 | 0.01868 | 0.02076 | 0.02385 | 0.02719 | 0.00478 | 0.34243 | ||
| 2 | 0.06312 | 0.06001 | 0.05826 | 0.06294 | 0.06784 | 0.00706 | 0.10234 | |
| 0.97344 | 0.97596 | 0.96999 | 0.97379 | 0.97723 | 0.00536 | −0.33419 | ||
| 0.02189 | 0.01986 | 0.01884 | 0.02162 | 0.02468 | 0.00432 | 0.32112 | ||
| 3 | 0.06965 | 0.06600 | 0.06458 | 0.06954 | 0.07459 | 0.00725 | 0.08971 | |
| 0.96832 | 0.96864 | 0.96442 | 0.96862 | 0.97254 | 0.00590 | −0.29753 | ||
| 0.02602 | 0.02351 | 0.02263 | 0.02579 | 0.02915 | 0.00474 | 0.28626 | ||
| BE-PS | ||||||||
| 1 | 0.06447 | 0.06257 | 0.05934 | 0.06432 | 0.06938 | 0.00742 | 0.12590 | |
| 0.97239 | 0.96984 | 0.96875 | 0.97274 | 0.97645 | 0.00572 | −0.36481 | ||
| 0.02273 | 0.02139 | 0.01947 | 0.02247 | 0.02568 | 0.00462 | 0.35142 | ||
| 2 | 0.05799 | 0.05607 | 0.05338 | 0.05784 | 0.06241 | 0.00671 | 0.13964 | |
| 0.97722 | 0.97877 | 0.97419 | 0.97753 | 0.98060 | 0.00480 | −0.39356 | ||
| 0.01883 | 0.01759 | 0.01610 | 0.01859 | 0.02130 | 0.00388 | 0.37901 | ||
| 3 | 0.06945 | 0.06207 | 0.06445 | 0.06928 | 0.07436 | 0.00728 | 0.09881 | |
| 0.96848 | 0.97094 | 0.96462 | 0.96883 | 0.97264 | 0.00591 | −0.30656 | ||
| 0.02589 | 0.02109 | 0.02255 | 0.02561 | 0.02899 | 0.00475 | 0.29525 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alotaibi, R.; Nassar, M.; Elshahhat, A. Estimations of Modified Lindley Parameters Using Progressive Type-II Censoring with Applications. Axioms 2023, 12, 171. https://doi.org/10.3390/axioms12020171
Alotaibi R, Nassar M, Elshahhat A. Estimations of Modified Lindley Parameters Using Progressive Type-II Censoring with Applications. Axioms. 2023; 12(2):171. https://doi.org/10.3390/axioms12020171
Chicago/Turabian StyleAlotaibi, Refah, Mazen Nassar, and Ahmed Elshahhat. 2023. "Estimations of Modified Lindley Parameters Using Progressive Type-II Censoring with Applications" Axioms 12, no. 2: 171. https://doi.org/10.3390/axioms12020171
APA StyleAlotaibi, R., Nassar, M., & Elshahhat, A. (2023). Estimations of Modified Lindley Parameters Using Progressive Type-II Censoring with Applications. Axioms, 12(2), 171. https://doi.org/10.3390/axioms12020171