Abstract
In this article, a new two-parameter model called the truncated Cauchy power-inverted Topp–Leone (TCP-ITL) is constructed by merging the truncated Cauchy power -G (TCP-G) family with the inverted Topp–Leone (ITL) distribution. Some structural properties of the newly suggested model are obtained. Different types of entropies are proposed under the TCP-ITL distribution. Under the complete and hybrid censored data, the maximum likelihood (ML), maximum product of spacing (MPSP), and Bayesian estimate approaches are explored. A simulation study is developed to test the proposed distribution’s restricted sample attributes. In the majority of cases, the numerical data revealed that the Bayesian estimates provided more accurate outcomes than the equivalent alternative estimates. The adaptability of the proposed approach is proven using examples from dependability, medicine, and engineering. A real-world data set is utilized to demonstrate the potential of the TCP-ITL distribution in comparison to other well-known distributions. The results of the model selection revealed that the proposed distribution is the best choice for the data sets under consideration.
Keywords:
Bayesian estimation; truncated Cauchy power family; inverted Topp–Leone; hybrid censored scheme; maximum likelihood; maximum product spacing; MCMC; COVID-19 MSC:
62P10; 62E20; 62P30; 62E10; 62F15; 62B99
1. Introduction
In the current statistical literature, various univariate continuous distributions may be employed in a variety of data modeling applications. Furthermore, it appears that the number of accessible distributions is insufficient to handle the different data found in domains such as medicine, biology, demography, engineering sciences, actuarial science, finance, economics, and dependability [1]. Researchers in statistics and applied mathematics are interested in developing new extended continuous distributions that are more effective for data modeling. Methods for expanding well-known distributions include adding parameters, compounding, generating, transforming, and composing. Several statisticians were drawn to develop novel models in recent decades by the emergence of new families of continuous distributions. Our specific interest is in the TCP-G family, which was presented by [2]. The TCP-G family’s cumulative distribution function (CDF) and probability density function (PDF) are defined below:
and
where and are the CDF and PDF, respectively, for any baseline distribution, with the set of parameters and being a shape parameter of the TCP-G family.
On the basis of the TCP-G family, relevant studies were supplied, for example, the TCP Weibull-G family [3], TCP inverse exponential distribution [4], TCP odd Frchet-G family [5], and TCP Lomax distribution [6].
Because of their application, inverted or inverse distributions are essential in many domains, including biological sciences, chemical data, life test issues, medical sciences, etc. In terms of the density and hazard rate function (HRF), inverted conformation distributions differ from non-inverted conformation distributions. Many authors studied these inverted models, such as the inverse power Lindley distribution [7], inverted Kumumaraswamy distribution [8], inverted length-biased exponential distribution [9], inverted log-logistic distribution [10], inverted Gompertz distribution [11], inverted Lindley distribution [12], inverted generalized linear exponential distribution [13], inverted Nakagami-m distribution [14], inverted Nadarajah–Haghigh distribution [15], inverse power Maxwell distribution [16], inverse power Lomax distribution [17], discrete inverse Burr distribution [18], discrete inverse Rayleigh distribution [19], inverse Weibull distribution [20], inverse Sushila distribution [21], and inverse log-gamma distribution [22].
The CDF and PDF of the ITL model with a shape parameter a in [23] is provided with:
and
Some academics investigated and created novel extensions and generalizations of the ITL distribution, including the power ITL distribution investigated by [24], Kumaraswamy ITL distribution discussed by [25], alpha power ITL distribution proposed by [26], half-logistic ITL distribution suggested by [27], the odd log-logistic Topp–Leone G family by [28], and the Burr III-Topp–Leone-G family by [29].
The primary purpose of this article is to present and examine the statistical properties of a novel two-parameter model known as the truncated Cauchy power-inverted Topp–Leone (TCP-ITL) distribution. The following considerations persuaded us to investigate the suggested model. It is specified as follows:
- It is fascinating to see the suggested model’s adaptability with the various graphical forms of the PDF and HRF. As a result, the numerical and graphical analyses of the related PDF and HRF revealed unexpected features, demonstrating the previously unknown fitting capability of the TCP-ITL.
- Some different statistical features of the TCP-ITL model, such as the QF, moments and incomplete moments, moment-generating function, and four different types of entropy, such as the Rnyi entropy (RE), Havrda and Charvat entropy (HaChE), Tsallis entropy (TSE), and Arimoto entropy (ArE).
- The statistical inference of the model parameters under complete and hybrid censored data by using the maximum likelihood (ML), maximum product of spacing (MPSP), and Bayesian estimation approaches are explored.
- The potential of the TCP-ITL distribution is demonstrated using four real data sets in contrast to the ITL, the Kumaraswamy (K), Marshall–Olkin–Kumaraswamy (MOK), beta, alpha power Kumaraswamy (APK), and exponentiated Kumaraswamy (EK) distributions. According to the results of the criterion measurements, the recommended distribution is the best option for the data sets under consideration.
Structure of the Paper
This paper has the following structure. Section 2 describes the construction of the TCP-ITL model. The CDF, PDF, reliability function (RF), and HRF, as well as the asymptotes and graphical forms for the PDF and HRF, are all provided in Section 2. Section 3 establishes clear representations of several fundamental aspects of the proposed TCP-ITL, such as the QF, linear representation of the PDF, rth ordinary, and sth incomplete moments and moment-generating function. Various forms of an entropy measure are proposed in Section 4. In Section 5, we carry out the estimation using three approaches, the ML approach, MPSP approach, and Bayesian approach, to estimate the unknown parameters of the TCP-ITL model. In Section 6, a Monte Carlo simulation examination is conducted to determine the efficiency of the three recommended estimation methodologies. In Section 7, we apply the TCP-ITL using three genuine data sets. Furthermore, the suggested model is compared to many well-known comparison models, including the ITL, K, MOK, beta, APK, and EK models. Eventually, in Section 8, we offer some final thoughts on our results from all aspects of this research.
2. The Construction of the TCP-ITL Distribution
A random variable Z is said to have the TCP-ITL distribution when we substitute the CDF (3) and PDF (4) in the CDF (1) and PDF (2). The CDF and PDF of a random variable Z have the TCP-ITL distribution with parameters a and and is defined by:
and
The reliability function, HRF, reversed HRF, and cumulative HRF of Z are provided via:
and
Figure 1 shows how the TCP-ITL distribution’s PDF can be decreasing, unimodal, and skewed to the right. Figure 2 shows that the TCP-ITL distribution’s HRF encompasses J-shaped, upside-down, and decreasing forms.
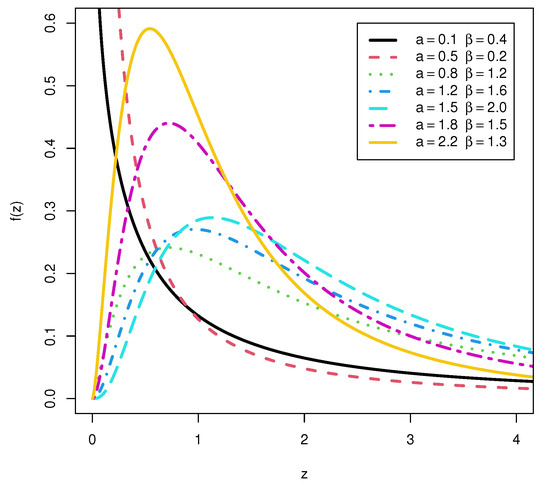
Figure 1.
PDF for the TCP-ITL distribution.
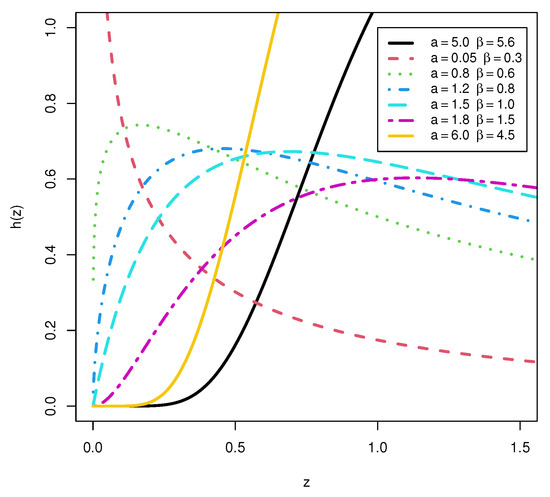
Figure 2.
HRF for the TCP-ITL distribution.
3. Properties
This section describes the structural features of the TCPIL as specified in Equation (6), comprising explicit formulas for the QF, the linear representation of the PDF, the rth ordinary and sth incomplete moment, and the moment-generating function. There are also several graphical and numerical representations of these properties.
3.1. Quantile Function
The QF is necessary for generating random variates. For , the QF of the TCP-ITL is given by Equation (7). Assume Z∼ TCP-ITL (, then its QF is given by Equation (7)
By replacing in Equation (7), the median of the TCP-ITL is readily available. Furthermore, setting and in (7), the 25th and 75th percentiles are computed. The MacGillivrays skewness () function [30] is computed from the next formula
Figure 3 and Figure 4 represent the plots of for some numerous values of the parameters. We may observe that the quantity of rises as and a rise.
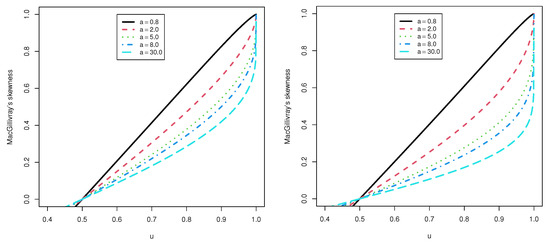
Figure 3.
Plots of the MSK for the TCP-ITL distribution at = 0.5 and 1.5.
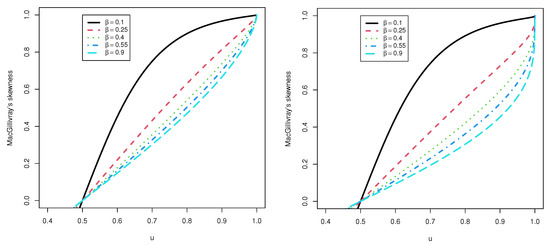
Figure 4.
Plots of the MSK for the TCP-ITL distribution at a = 1.5 and 5.0.
3.2. Important Representation
We demonstrated a beneficial increase in the TCP-ITL density that may be utilized to drive various critical TCP-ITL features. According to [2], the PDF given by Equation (6) may be represented as
using the next binomial expansion in Equation (8), we obtain
again using the next binomial expansion in Equation (9), we obtain
where .
3.3. The rth Moment
The rth ordinary is an essential statistic for determining the distribution dispersion. To derive the central or actual moments, utilize the following relationship: the first moment about the mean is always equal to zero, and the second moment around the mean is equal to variance as , and . The moment-based measurement of skewness and kurtosis is calculated utilizing and , respectively.
Assume that Z∼ TCP-ITL () for and , then its rth ordinary by utilizing Equation (6) and beta prime function is provided via
For r = 1, the mean of TCP-ITL is yielded as and .
Figure 5 depicts the three-dimensional plots of the mean, variance, coefficient of skewness (CS), coefficient of kurtosis (CK), and coefficient of variation (CV) for the TCP-ITL model at . Moreover, some numerical values are provided in Table 1. We can notice from Table 1 that when a is fixed and is increasing, then the measures of , , , , var are increasing, but the measures of SK, KU, and CV are decreasing. Moreover, when is fixed and a is increasing, then the measures of , , , , var, SK, KU, and CV are decreasing.
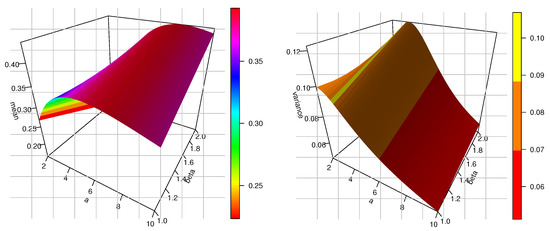
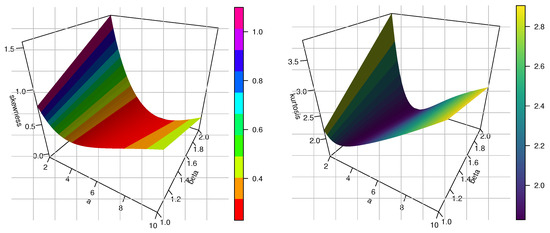
Figure 5.
Three-dimensional plots of mean, variance, CS, and CK for the TCP-ITL model at .

Table 1.
Some numerical values of moments.
3.4. The sth Incomplete Moment
The sth incomplete moment is a significant metric with several uses, including calculating the mean waiting time, conditional moments, and income inequality measures.
Assume that Z∼ TCP-ITL () for and , then its sth incomplete moments by utilizing (6) and incomplete beta function are provided via
Theoretically, Equation (12) is beneficial by utilizing the relationship between incomplete beta and Gauss hypergeometric functions as . The readers are referred to [31] for a more extensive examination of the numerous beta functions and their relationships.
3.5. Moment-Generating Function
According to the definition, the moment-generating function , can be yielded. Assume that Z∼ TCP-ITL () for and , then its moment-generating function may be computed by utilizing (6) and replacing and is provided via
where .
4. Entropy Measures
Entropies are a measurement of the variation, instability, or unpredictability of a system.
4.1. The Rnyi Entropy
The Rnyi entropy (RE) [32] is used in ecology and statistics as a measure of diversity. It is identified by the expression for and .
We employ the same series expansions and mathematical manipulation that we used to calculate Equation (6) to achieve
where
.
4.2. Havrda and Charvat Entropy
The Havrda and Charvat entropy (HCE) [33] measure is provided via
For the TCP-ITL distribution, the Havrda and Charvat entropy is obtained as
4.3. Tsallis Entropy
The Tsallis entropy (TE) [34] measure is provided via
For the TCP-ITL distribution, the Tsallis entropy is obtained as
4.4. Arimoto Entropy
The Arimoto entropy (AE) [35] measure is provided via
For the TCP-ITL distribution, the Arimoto entropy is obtained as
Some numerical values of entropy are provided in Table 2 and Table 3. We can notice from Table 2 and Table 3 the following comments:
- When a and are fixed and is increasing, then the measures of RE, HCE, TE, and AE are decreasing.
- When a and are fixed and is increasing, then the measures of RE, HCE, TE, and AE are increasing.
- When and are fixed and a is increasing, then the measures of RE, HCE, TE, and AE are decreasing.
Table 2.
Some numerical values of entropy at .
Table 2.
Some numerical values of entropy at .
| a | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Rnyi | Havrda and Charvat | Tsallis | Arimoto | Rnyi | Havrda and Charvat | Tsallis | Arimoto | ||
| 5.0 | 0.5 | 0.098 | 0.311 | 0.233 | 0.231 | −0.087 | −0.360 | −0.208 | −0.211 |
| 0.7 | 0.189 | 0.612 | 0.460 | 0.455 | 0.035 | 0.135 | 0.080 | 0.079 | |
| 0.9 | 0.243 | 0.797 | 0.601 | 0.593 | 0.100 | 0.370 | 0.221 | 0.217 | |
| 1.2 | 0.294 | 0.977 | 0.739 | 0.726 | 0.157 | 0.565 | 0.341 | 0.331 | |
| 1.5 | 0.328 | 1.098 | 0.832 | 0.816 | 0.194 | 0.683 | 0.415 | 0.400 | |
| 2.0 | 0.367 | 1.238 | 0.941 | 0.920 | 0.235 | 0.808 | 0.494 | 0.473 | |
| 2.5 | 0.394 | 1.337 | 1.018 | 0.994 | 0.262 | 0.890 | 0.547 | 0.522 | |
| 3.0 | 0.414 | 1.413 | 1.077 | 1.051 | 0.283 | 0.951 | 0.587 | 0.557 | |
| 6.0 | 0.5 | 0.032 | 0.101 | 0.075 | 0.075 | −0.140 | −0.599 | −0.342 | −0.351 |
| 0.7 | 0.119 | 0.378 | 0.283 | 0.281 | −0.024 | −0.095 | −0.055 | −0.056 | |
| 0.9 | 0.169 | 0.545 | 0.409 | 0.405 | 0.036 | 0.140 | 0.082 | 0.082 | |
| 1.2 | 0.216 | 0.703 | 0.529 | 0.523 | 0.089 | 0.331 | 0.197 | 0.194 | |
| 1.5 | 0.246 | 0.808 | 0.609 | 0.600 | 0.121 | 0.445 | 0.267 | 0.261 | |
| 2.0 | 0.280 | 0.926 | 0.700 | 0.688 | 0.157 | 0.564 | 0.340 | 0.330 | |
| 2.5 | 0.303 | 1.007 | 0.762 | 0.749 | 0.181 | 0.641 | 0.389 | 0.376 | |
| 3.0 | 0.320 | 1.069 | 0.810 | 0.795 | 0.199 | 0.698 | 0.424 | 0.409 | |
| 7.0 | 0.5 | −0.021 | −0.065 | −0.048 | −0.048 | −0.185 | −0.809 | −0.457 | −0.474 |
| 0.7 | 0.062 | 0.195 | 0.145 | 0.145 | −0.072 | −0.297 | −0.171 | −0.174 | |
| 0.9 | 0.110 | 0.348 | 0.260 | 0.259 | −0.016 | −0.062 | −0.036 | −0.036 | |
| 1.2 | 0.153 | 0.490 | 0.368 | 0.365 | 0.033 | 0.127 | 0.075 | 0.074 | |
| 1.5 | 0.181 | 0.583 | 0.438 | 0.433 | 0.063 | 0.237 | 0.141 | 0.139 | |
| 2.0 | 0.211 | 0.685 | 0.516 | 0.509 | 0.094 | 0.350 | 0.209 | 0.205 | |
| 2.5 | 0.231 | 0.754 | 0.569 | 0.561 | 0.115 | 0.423 | 0.253 | 0.248 | |
| 3.0 | 0.246 | 0.806 | 0.608 | 0.600 | 0.130 | 0.475 | 0.285 | 0.278 | |
Table 3.
Some numerical values of entropy at .
Table 3.
Some numerical values of entropy at .
| a | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Rnyi | Havrda and Charvat | Tsallis | Arimoto | Rnyi | Havrda and Charvat | Tsallis | Arimoto | ||
| 5.0 | 0.5 | −0.150 | −0.826 | −0.377 | −0.413 | −0.192 | −1.452 | −0.654 | −0.626 |
| 0.7 | −0.015 | −0.069 | −0.034 | −0.034 | −0.047 | −0.270 | −0.140 | −0.116 | |
| 0.9 | 0.053 | 0.231 | 0.119 | 0.116 | 0.024 | 0.121 | 0.066 | 0.052 | |
| 1.2 | 0.113 | 0.457 | 0.243 | 0.229 | 0.084 | 0.389 | 0.225 | 0.168 | |
| 1.5 | 0.150 | 0.585 | 0.318 | 0.292 | 0.122 | 0.531 | 0.316 | 0.229 | |
| 2.0 | 0.191 | 0.713 | 0.396 | 0.356 | 0.163 | 0.667 | 0.410 | 0.287 | |
| 2.5 | 0.220 | 0.794 | 0.447 | 0.397 | 0.192 | 0.749 | 0.470 | 0.323 | |
| 3.0 | 0.241 | 0.851 | 0.484 | 0.426 | 0.213 | 0.805 | 0.513 | 0.347 | |
| 6.0 | 0.5 | −0.200 | −1.171 | −0.518 | −0.586 | −0.240 | −1.994 | −0.855 | −0.860 |
| 0.7 | −0.071 | −0.354 | −0.170 | −0.177 | −0.101 | −0.646 | −0.318 | −0.278 | |
| 0.9 | −0.007 | −0.034 | −0.017 | −0.017 | −0.036 | −0.203 | −0.106 | −0.088 | |
| 1.2 | 0.047 | 0.204 | 0.105 | 0.102 | 0.019 | 0.099 | 0.054 | 0.043 | |
| 1.5 | 0.080 | 0.336 | 0.176 | 0.168 | 0.053 | 0.258 | 0.145 | 0.111 | |
| 2.0 | 0.116 | 0.468 | 0.250 | 0.234 | 0.089 | 0.409 | 0.237 | 0.176 | |
| 2.5 | 0.140 | 0.551 | 0.298 | 0.275 | 0.113 | 0.500 | 0.296 | 0.216 | |
| 3.0 | 0.158 | 0.609 | 0.332 | 0.305 | 0.131 | 0.563 | 0.338 | 0.243 | |
| 7.0 | 0.5 | −0.242 | −1.491 | −0.642 | −0.745 | −0.280 | −2.523 | −1.037 | −1.087 |
| 0.7 | −0.117 | −0.619 | −0.289 | −0.309 | −0.146 | −1.016 | −0.479 | −0.438 | |
| 0.9 | −0.057 | −0.282 | −0.136 | −0.141 | −0.085 | −0.525 | −0.262 | −0.226 | |
| 1.2 | −0.007 | −0.034 | −0.017 | −0.017 | −0.034 | −0.192 | −0.100 | −0.083 | |
| 1.5 | 0.023 | 0.102 | 0.052 | 0.051 | −0.003 | −0.019 | −0.010 | −0.008 | |
| 2.0 | 0.055 | 0.236 | 0.122 | 0.118 | 0.029 | 0.145 | 0.080 | 0.063 | |
| 2.5 | 0.076 | 0.319 | 0.167 | 0.160 | 0.050 | 0.244 | 0.137 | 0.105 | |
| 3.0 | 0.091 | 0.378 | 0.199 | 0.189 | 0.065 | 0.311 | 0.177 | 0.134 | |
5. Model Inference and Estimation Method
Hybrid censoring is discussed briefly in this section. Assume that n test units are uniformly distributed with the PDF and that is a vector of unknown parameters. Let represent the ordered s of these test units. Remember that a life test experiment is ended under hybrid censoring when either a pre-specified time T or a pre-determined r number of units fail. In this scenario, an experiment is to be stopped at a random time point , where . As a result, the observed lifespan under this censorship could fall into one of three categories:
- Category I:
- , if and (type-I censored).
- Category II:
- , if (type-II censored).
- Category III:
- , if and (complete sample).
Notice that Category I, Category II, and Category III, respectively, correspond to the type-I, type-II censoring, and complete sample. Then, is a censored hybrid sample with the PDF and the CDF describing its distribution. The corresponding likelihood function can then be expressed as
For more information on the hybrid censoring sample, see Balakrishnan and Kundu [36]. For more information examples, see [37]’s obtained Bayesian estimation and prediction for a hybrid censored lognormal distribution.
To evaluate the estimation problem of the TCP-ITL distribution based on hybrid censoring samples, this part uses three estimate methods: the maximum likelihood, maximum product of spacing, and Bayesian.
5.1. Maximum Likelihood Estimation
The maximum likelihood estimators (MLEs) of the TCP-ITL distribution were investigated. It was worked as the case when both are unknown. Suppose that be a random sample from the TCP-ITL distribution and assume that be the parameter vector. The likelihood function of the TCP-ITL distribution under the hybrid censored samples takes the form
The log-likelihood function is defined as follows:
The components of score vector are given below
and
To produce the MLE, two nonlinear systems of equations that are differentiating (20) and (21) with respect to and and equating each solution to zero must be solved concurrently. By using the ’maxLik’ package, which uses the Newton–Rabson (NR) method of maximization in the maximum likelihood computations, one can utilize the R statistical programming language software to calculate the desired MLEs and for any given data set.
5.2. Maximum Product of Spacing Method
If is a random sample of the size n, you can describe the uniform spacing as:
where denotes the uniform spacings, , , and . This is the general form of MPS with hybrid censored samples.
The maximum product of spacing (MPS) estimators (MPSE) of the TCP-ITL distribution parameters based on hybrid censored samples can be obtained by maximizing
with respect to a and . Further, the MPSE of the TCP-ITL distribution can also be obtained by solving the nonlinear equation of derivatives of with respect to and .
5.3. Bayesian Estimation
In this subsection, the Bayesian estimation of the parameter of the model is obtained when data are observed based on the squared error loss function (SELF), which is defined by
where is an estimator of . Denote the prior and posterior distributions of by and , respectively. Under the SELF, the Bayesian estimation of any function of is given by
Prior distribution is important for the development of Bayes estimators.
Under the assumption of gamma prior distributions, we investigate this estimate problem. Therefore, it is assumed here that a and follow independent gamma distributions with , and , with probability densities given by, respectively,
Using the informative prior (26) and the likelihood function (18), the joint posterior density can be derived as follows:
The marginal posterior densities of the parameters a and can be derived as
Because the marginal posterior densities in (28) are not well-known distributions, we will utilize the Metropolis–Hastings sampler to produce values for a and using the normal proposal distribution in (28).
Furthermore, Chen and Shao’s [38] approach was widely used to create the highest posterior density (HPD) intervals for the Bayesian estimation with uncertain benefit distribution parameters. For example, using two endpoints from the MCMC sample outputs, and percentiles, a HPD interval can be produced. The Bayes trustworthy intervals for the , and parameters are calculated as follows:
- Sorted parameters as , and , and N is the length of MCMC generated.
- The symmetric credible intervals of and become and .
6. Simulation
In this section, we conduct a simulation study to compare the performance of the proposed methods. We first simulate the hybrid censored data from the TCP-ITL distribution for different choices of n and r for all cases as:
If , , and 50. While , , and 100.
The time of the hybrid censored sample was changed for each case as follows:
In Table 4: If , and 9999 when . If , and 999 when . If , and 99 when .
Table 4.
MSE and length of CI for MLE, MPS, and Bayesian estimation for parameter of the TCP-ITL based on hybrid censored samples: when .
In Table 5: If , and 9999 when . If , and 99 when . If , and 99 when .
Table 5.
MSE and length of CI for MLE, MPS, and Bayesian estimation for parameter of the TCP-ITL based on hybrid censored samples: when .
In Table 6: If , and 99,999,999 when . If , and 99 when . If , and 99 when .
Table 6.
MSE and length of CI for MLE, MPS, and Bayesian estimation for parameter of the TCP-ITL based on hybrid censored samples: when .
In the simulation study, the comparison between the MLE, MPS, and Bayesian estimation methods were discussed, although we know it is impossible to compare Bayesian methods to a classical estimation method, but by using information of the MLE to generate the Bayesian estimate, we can compare between the MLE and Bayesian estimation methods. Many recent papers discussed the comparison between the MLE and Bayesian and also different estimation methods. The mathematical difference between the MLE and Bayesian is the parameters have prior distribution (random variables). We used gamma as the prior distribution with shapes and scale parameters (hyper-parameters). Now, how to select the hyper-parameters? We select the hyper-parameters by using the information of the MLE and gamma information. This method is denoted as the elicitation of hyper-parameters, see Dey et al. [39].
By equating and with the mean and variance of gamma priors distribution, we may determine their respective means and variances. We obtain
where N is a total iteration of simulation. Now, on solving the above two equations, the estimated hyper-parameters can be written as
We then compute the MLE and MPS of a and using the NR algorithm and Bayesian estimates using the Metropolis–Hastings (MH) algorithm based on 10000 Monte Carlo simulations. We would like to point out that we used the R programming language to generate estimators for the shake computation. We recommend utilizing the ’maxLik’ package, which solves classical estimates using the NR algorithm of maximizing in numerical calculations, see [40], and the ’CODA’ package, which simulates MCMC varieties to generate Bayesian estimates, see [41]. It is seen that the performance of the MLE, MPS, and Bayesian estimates were obtained using the mean square error (MSE) and the length of the confidence intervals values. In the confidence interval, the asymptotic confidence interval for the MLE and MPS were determined where the length of these terms is L.ACI, see [42,43]. While in the Bayesian estimation, the credible confidence interval (L.CCI) was obtained. To determine the best method, the smallest terms of the MSE and the length of the confidence interval values were selected.
We can draw the following conclusions from Table 4, Table 5 and Table 6. As expected, the proposed estimates of a and perform better as n increases in terms of their MSE and length of CI. The findings showed that the MSE and length of CI decrease with the sample size. These results unequivocally show the accuracy and consistency of the estimators. As a result, the three estimation approaches do a good job of the TCP-ITL distribution parameters. We show the Bayesian method of estimation is better than the other methods. It is also observed that the L.CCI are smaller as compared to the length of the CI. Figure 6 discusses the heat map of the MSE for Table 4, Table 5 and Table 6, including the following:
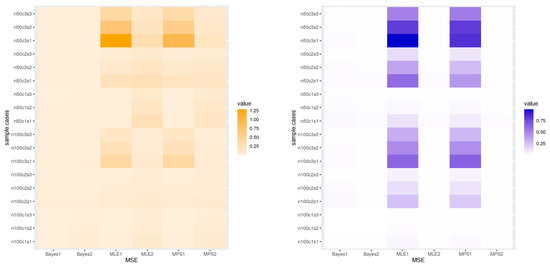
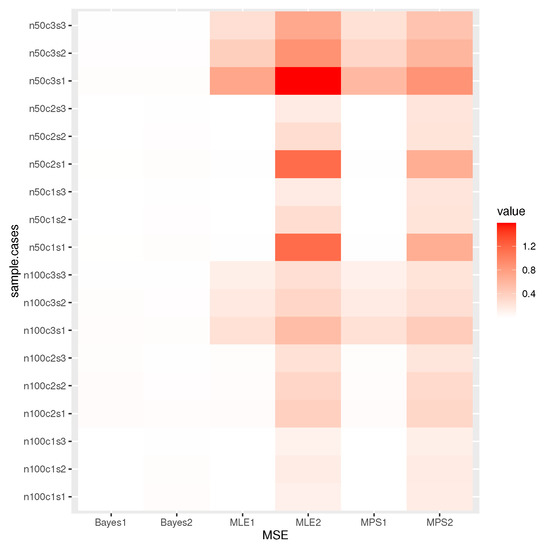
Figure 6.
Heat maps of MSE results.
X-label: Bayes1 is the MSE of a for the Bayesian, Bayes2 is the MSE of for the Bayesian, MPS1 is the MSE of a for the MPS, MPS2 is the MSE of for the MPS, MLE1 is the MSE of a for the MLE, and MLE2 is the MSE of for the MLE.
Y-label: n50c1s1 is the MSE when , , , and the first T value; n50c1s2 is the MSE when , , and the second T value; n50c1s3 is the MSE when , , , and the third T value; n50c2s1 is the MSE when , , , and the first T value; n50c2s2 is the MSE when , , , and the second T value; n50c2s3 is the MSE when , , , and the third T value; n50c3s1 is the MSE when , , , and the first T value; n50c3s2 is the MSE when , , , and the second T value; n50c3s3 is the MSE when , , , and the third T value; n100c1s1 is the MSE when , , , and the first T value; n100c1s2 is the MSE when , , , and the second T value; n100c1s3 is the MSE when , , , and the third T value; n100c2s1 is the MSE when , , , and the first T value; n100c2s2 is the MSE when , , , and the second T value; n100c2s3 is the MSE when , , , and the third T value; n100c3s1 is the MSE when , , , and the first T value; n100c3s2 is the MSE when , , , and the second T value; n100c3s3 is the MSE when , , , and the third T value. The dark color indicates that the MSE value is large, while the light color indicates that the MSE value is small.
7. Application of Real Data
In this section, three actual data sets are used to demonstrate the TCP-ITL distribution’s potential. The TCP-ITL distribution is contrasted with many rival models, including the odd log-logistic modified Weibull (OLLMW) distribution by Saboor et al. [44], Kumaraswamy Weibull (KW) distribution by Cordeiro et al. [45], extended odd Weibull Lomax (EOWL) distribution by Alsuhabi et al. [46], Weibull–Lomax (WL) distribution by Tahir et al. [47], extended Weibull (EW) distribution by Peng et al. [48], modified Kies inverted Topp–Leone (MKITL) distribution by Almetwally et al. [49], inverse Weibull (IW) distribution and X-gamma Lomax (XGL) distribution by Almetwally et al. [50], generalized inverse Weibull (GIW) distribution by De Gusmao et al. [51], and gamma distribution.
For Global Reserves Natural data set I in Table 7, we obtained different comparison models in Table 8 and results of estimation methods. Table 9, Table 10 and Table 11 provide values for the Cramer–von Mises (CVM), Anderson–Darling (AD), and Kolmogorov–Smirnov (KSD) statistics, along with their P-values (PVKS), for all the models fitted based on the three real data sets. These statistics include the Akaike information criterion (AIC), correct Akaike information criterion (CAIC), Bayesian information criterion (BIC), and Hannan–Quinn. The MLE and standard errors (SE) of the parameters for the models under consideration are also included in these tables. The SE values were obtained by the square root of the diagonal of the inverse of a Hessian matrix, where we obtained the Hessian matrix by using the ’maxLik’ package. When compared to all the other models applied to each real data set in Table 9, Table 10 and Table 11, the TCP-ITL distribution has the highest P-value and the lowest KS, CvM, AD, AIC, BIC, HQIC, and CAIC values.
Table 7.
The percent Global Reserves Natural Gas of the Countries (2020).
Table 8.
MLE and Bayesian estimation for TCP-ITL based on hybrid censored samples: Data I.
Table 9.
MLE and different measures for each model of Data set I Global Reserves Natural.
Table 10.
MLE and different measures for each model of Senegal COVID-19 data II.
Table 11.
MLE and different measures for each model of the flood level data III.
Figure 7, Figure 8 and Figure 9 show the fit empirical, histogram, QQ-plot, and PP-plot for the TCP-ITL distribution for the COVID-19 data of the United Kingdom and Canada.
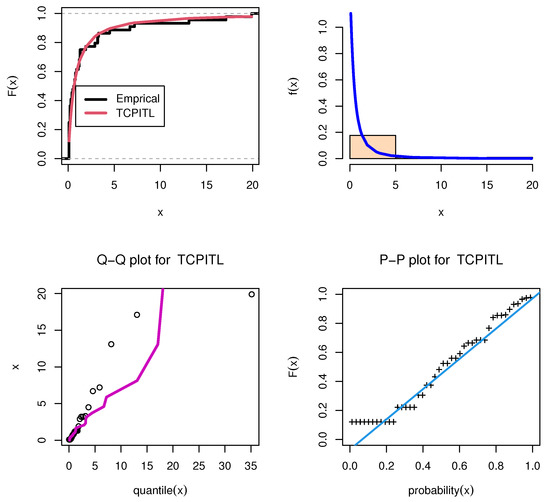
Figure 7.
Fitted PDF for Global Reserves Natural data set I.
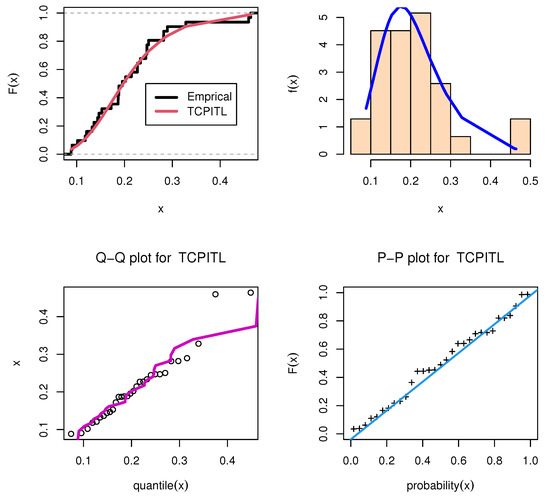
Figure 8.
Fitted PDF for Senegal COVID-19 data set II.
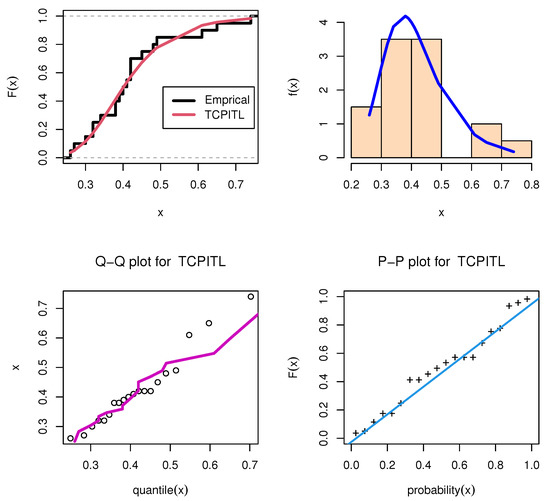
Figure 9.
Fitted PDF for flood level data set III.
Table 8, Table 12, and Table 13 discuss the different estimation methods for the parameters of the TCP-ITL distribution based on the hybrid censored samples. By these results, we note the time T increases and the size r increases, and the SE decreased. The Bayesian estimation method has the smallest SE for the parameters of the TCP-ITL distribution based on the hybrid censored samples comparing the MLE. The MPS is not applicable in data I and III because we note the data sets have the same observation.
Table 12.
MLE, MPS, and Bayesian estimation for parameters of TCP-ITL based on hybrid censored samples: Data II.
Table 13.
MLE and Bayesian estimation for TCP-ITL based on hybrid censored samples with different cases: Data set III.
For the Bayesian estimation, we discussed Figure 10, Figure 11 and Figure 12 of the MCMC results to check the convergences, and we conclude the MCMC results have convergence.
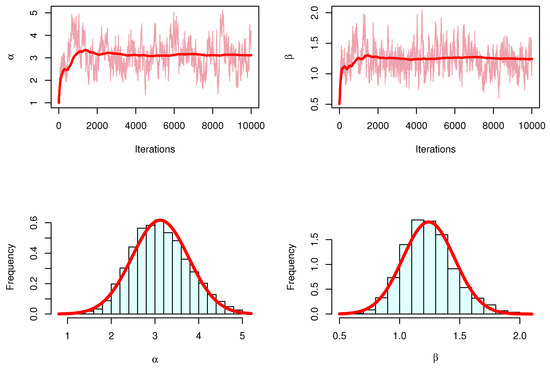
Figure 10.
Trace and posterior density with normal curve for MCMC results for data I.
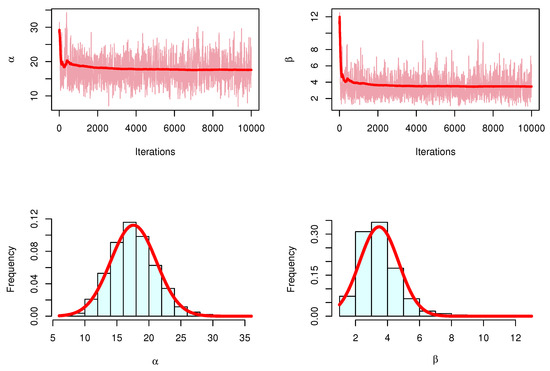
Figure 11.
Trace and posterior density with normal curve for MCMC results: Data II.
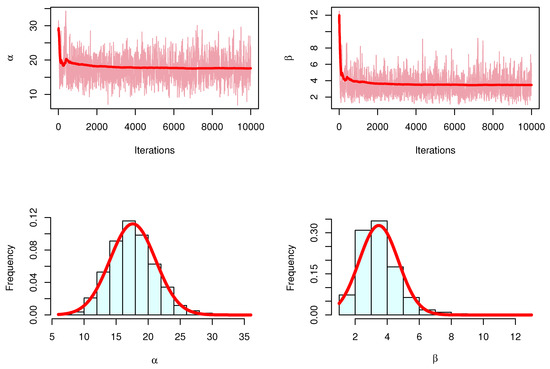
Figure 12.
Trace and posterior density with normal curve for MCMC results: Data III.
7.1. Data Set I
The first data set represents the percent of the Global Reserves of Natural Gas of the Countries (2020). The data set was obtained from the following electronic address: https://worldpopulationreview.com/country-rankings/natural-gas-by-country. The data set is reported in Table 7.
7.2. Data Set II
The second data set was obtained from the WHO [52], with the set of data belonging to Senegal for 31 days from 18 July 2021 to 17 August 2021 where the mortality rate received for COVID-19 is 0.1017, 0.1179, 0.1361, 0.1720, 0.1885, 0.1867, 0.1465, 0.0904, 0.2144, 0.0883, 0.2447, 0.1207, 0.1869, 0.2504, 0.3282, 0.2271, 0.2897, 0.1437, 0.4596, 0.2817, 0.2469, 0.1528, 0.2269, 0.1954, 0.4639, 0.2820, 0.1323, 0.2334, 0.2470, 0.1882, and 0.2022. The mortality rate equation is
Throughout this subsection, we apply the TCP-ITL model to a real-world data set to assess its adaptability. To compare the TCP-ITL model to the other six fitted distributions, one, two, and three parameters are employed. We compare the TCP-ITL distribution with the ITL [23], beta, Kumaraswamy (K), Marshall–Olkin–Kumaraswamy (MOK) [53], alpha power Kumaraswamy (MOK) [54], and exponentiated Kumaraswamy (EK) [55].
The parameter estimates of the MLE with the standard error (SE) and the numerical value are presented in Table 9 and Table 10. Moreover, the numerical values of the KSD and its PVKS, AIC, BIC, HQIC, and CAIC statistics for the data sets are presented in Table 9 and Table 10. From Table 9 and Table 10, the values of the KSD, AIC, BIC, HQIC, and CAIC are minimum for the TCP-ITL distribution. Thus, the TCP-ITL distribution is a better model for the data sets as compared with the other six models. Figure 7, Figure 8 and Figure 9 display the fitted PDF plots of each data set.
7.3. Data Set III
The third data set, given in Dumonceaux and Antle, includes 20 observations of the maximum flood level (in millions of cubic feet per second) for the Susquehanna River near Harrisburg, Pennsylvania [56], and Mazucheli et al. [57]. The data are as follows: 0.26, 0.27, 0.30, 0.32, 0.32, 0.34, 0.38, 0.38, 0.39, 0.40, 0.41, 0.42, 0.42, 0.42, 0.45, 0.48, 0.49, 0.61, 0.65, 0.74.
8. Concluding Remarks
In this article, the truncated Cauchy power family is combined with the inverted Topp–Leone distribution to create a new two-parameter model called the truncated Cauchy power-inverted Topp–Leone distribution. Some statistical and mathematical features of the TCP-ITL distribution are implemented, including the quantile function, moments and incomplete moments, the moment-generating function, and various types of entropy, such as the Rnyi entropy, Havrda and Charvat entropy, Tsallis entropy, and Arimoto entropy (ArE). The maximum likelihood (ML), maximum product of spacing (MPSP), and Bayesian estimate approaches are investigated for complete and hybrid censored data. To test the proposed distribution’s restricted sample attributes, a simulation study is created. The majority of the time, the numerical data revealed that the Bayesian estimates were more accurate than the comparable alternative estimates. Examples from dependability, medicine, and engineering demonstrate the adaptability of the proposed approach. The potential of the TCP-ITL distribution is demonstrated in comparison with some known distributions using three real-world data sets. According to the results of the criteria measurements, the proposed distribution is the best option for the data sets under consideration.
Author Contributions
Conceptualization, R.A.H.M., E.M.A., T.R. and M.E.; methodology, R.A.H.M., M.H.A., E.M.A., T.R. and M.E.; software, E.M.A. and M.E.; validation, R.A.H.M., M.H.A., E.M.A., M.E. and M.H.A.; formal analysis, R.A.H.M., T.R. and M.H.A.; investigation, R.A.H.M., M.E., T.R. and M.H.A.; resources, R.A.H.M., M.E., M.H.A. and E.M.A.; data curation, R.A.H.M., E.M.A., M.E. and M.H.A.; writing—original draft preparation, E.M.A., M.E., T.R. and M.H.A.; writing—review and editing, R.A.H.M., E.M.A. and M.E.; visualization, All authors. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The three real data sets are available in the application section of the paper.
Acknowledgments
The authors are thankful to the Editor-in-Chief and the anonymous referees for their meticulous and thorough reading, which significantly enhanced the readability of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Taketomi, N.; Yamamoto, K.; Chesneau, C.; Emura, T. Parametric Distributions for Survival and Reliability Analyses, a Review and Historical Sketch. Mathematics 2022, 10, 3907. [Google Scholar] [CrossRef]
- Aldahlan, M.A.; Jamal, F.; Chesneau, C.; Elgarhy, M.; Elbatal, I. The Truncated Cauchy power family of distributions with inference and applications. Entropy 2020, 22, 346. [Google Scholar] [CrossRef]
- Alotaibi, N.; Elbatal, I.; Almetwally, E.M.; Alyami, S.A.; Al-Moisheer, A.S.; Elgarhy, M. Truncated Cauchy Power Weibull-G Class of Distributions: Bayesian and Non-Bayesian Inference Modelling for COVID-19 and Carbon Fiber Data. Mathematics 2022, 10, 1565. [Google Scholar] [CrossRef]
- Chaudhary, A.K.; Sapkota, L.P.; Kumar, V. Truncated Cauchy Powera Inverse Exponential Distribution: Theory and Applications. IOSR J. Math. 2020, 16, 12–23. [Google Scholar]
- Shrahili, M.; Elbatal, I. Truncated Cauchy power odd Fréchet family of distributions: Theory and applications. Complexity 2021, 2021, 4256945. [Google Scholar] [CrossRef]
- Almarashi, A.M. Truncated Cauchy power Lomax model and its application to biomedical data. Nanosci. Nanotechnol. Lett. 2020, 12, 16–24. [Google Scholar] [CrossRef]
- Barco, K.V.P.; Mazucheli, J.; Janeiro, V. The inverse power Lindley distribution. Commun. Stat.-Simul. Comput. 2017, 46, 6308–6323. [Google Scholar] [CrossRef]
- Abd AL-Fattah, A.M.; El-Helbawy, A.A.; Al-Dayian, G.R. Inverted Kumumaraswamy distribution: Properties and estimation. Pak. J. Stat. 2017, 33, 37–61. [Google Scholar]
- Almutiry, W. Inverted Length-Biased Exponential Model: Statistical Inference and Modelling. J. Math. 2021, 2021, 1980480. [Google Scholar] [CrossRef]
- Chiodo1, E.; Falco, P.D.; Noia, L.P.D.; Mottola, F. Inverse Log-logistic distribution for extreme wind speed modeling: Genesis, identification and Bayes estimation. AIMS Energy 2018, 6, 926–948. [Google Scholar] [CrossRef]
- Eliwa, M.S.; El-Morshedy, M.; Ibrahim, M. Inverse Gompertz distribution: Properties and different estimation methods with application to complete and censored data. Ann. Data Sci. 2019, 6, 321–339. [Google Scholar] [CrossRef]
- Sharma, V.K.; Singh, S.K.; Singh, U.; Agiwal, V. The inverse Lindley distribution: A stress-strength reliability model with application to head and neck cancer data. J. Ind. Prod. Eng. 2015, 32, 162–173. [Google Scholar] [CrossRef]
- Mahmoud, M.A.W.; Ghazal, M.G.M.; Radwan, H.M.M. Inverted generalized linear exponential distribution as a lifetime model. Appl. Math. Inf. Sci. 2017, 11, 1747–1765. [Google Scholar] [CrossRef]
- Louzada, F.; Ramos, P.L.; Nascimento, D. The Inverse Nakagami-m Distribution: A Novel Approach in Reliability. IEEE Trans. Reliab. 2018, 67, 1030–1042. [Google Scholar] [CrossRef]
- Tahir, M.H.; Cordeiro, G.M.; Ali, S.; Dey, S.; Manzoor, A. The inverted Nadarajah-Haghighi distribution: Estimation methods and applications. J. Stat. Comput. Simul. 2018, 88, 2775–2798. [Google Scholar] [CrossRef]
- Al-Kzzaz, H.S.; El-Monsef, M.M.E.A. Inverse power Maxwell distribution: Statistical properties, estimation and application. J. Appl. Stat. 2022, 49, 2287–2306. [Google Scholar] [CrossRef] [PubMed]
- Hassan, A.S.; Abd-Allah, M. On the inverse power Lomax distribution. Ann. Data Sci. 2018, 6, 259–278. [Google Scholar] [CrossRef]
- Chesneau, C.; Yousof, H.; Hamedani, G.; Ibrahim, M. The Discrete Inverse Burr Distribution with Characterizations, Properties, Applications, Bayesian and Non-Bayesian Estimations. Stat. Optim. Inf. Comput. 2022, 10, 352–371. [Google Scholar] [CrossRef]
- Hussain, T.; Ahmad, M. Discrete inverse Rayleigh distribution. Pak. J. Stat. 2014, 30, 203–222. [Google Scholar]
- Jazi, A.M.; Lai, D.C.; Alamatsaz, H.M. Inverse Weibull distribution and estimation of its parameters. Stat. Methodol. 2010, 7, 121–132. [Google Scholar] [CrossRef]
- Adetunji, A.A.; Ademuyiwa, J.A.; Adejumo, O.A. The Inverse Sushila Distribution: Properties and Application. Asian Res. J. Math. 2020, 16, 28–39. [Google Scholar] [CrossRef]
- Jordanova, P.K.; Petkova, M.P.; Stehlík, M. Inverse Log-Gamma-G processes. AIP Conf. Proc. 2017, 1895, 030003. [Google Scholar]
- Hassan, A.S.; Elgarhy, M.; Ragab, R. Statistical properties and estimation of inverted Topp-Leone distribution. J. Stat. Appl. Probab. 2020, 9, 319–331. [Google Scholar]
- Abushal, T.A.; Hassan, A.S.; El-Saeed, A.R.; Nassr, S.G. Power inverted Topp- Leone distribution in acceptance sampling plans. Comput. Mater. Contin. 2021, 67, 991–1011. [Google Scholar] [CrossRef]
- Hassan, A.S.; Almetwally, E.M.; Ibrahim, G.M. Kumaraswamy inverted Topp-Leone distribution with applications to COVID-19data. Comput. Mater. Contin. 2021, 68, 337–356. [Google Scholar]
- Ibrahim, G.M.; Hassan, A.S.; Almetwally, E.M.; Almongy, H.M. Parameter estimation of alpha power inverted Topp-Leone distribution with applications. Intell. Autom. Soft Comput. 2021, 29, 353–371. [Google Scholar] [CrossRef]
- Bantan, R.; Elsehetry, M.; Hassan, A.S.; Elgarhy, M.; Sharma, D.; Chesneau, C.; Jamal, F. A Two-Parameter Model: Properties and Estimation under Ranked Sampling. Mathematics 2021, 9, 1214. [Google Scholar] [CrossRef]
- Alizadeh, M.; Lak, F.; Rasekhi, M.; Ramires, T.G.; Yousof, H.M.; Altun, E. The odd log-logistic Topp-Leone G family of distributions: Heteroscedastic regression modelsand applications. Comput. Stat. 2018, 33, 1217–1244. [Google Scholar] [CrossRef]
- Chipepa, F.; Oluyede, B.; Peter, O.P. The Burr III-Topp-Leone-G family of distributions with applications. Heliyon 2021, 7, e06534. [Google Scholar] [CrossRef]
- MacGillivray, H.L. Skewness and asymmetry: Measures and orderings. Ann. Stat. 1986, 14, 994–1011. [Google Scholar] [CrossRef]
- Nadarajah, S.; Kotz, S. Some beta distributions. Bull. Braz. Math. Soc. 2006, 37, 103–125. [Google Scholar] [CrossRef]
- Rényi, A. On measures of entropy and information. Berkeley Symp. Math. Stat. Probab. 1961, 1961, 547–561. [Google Scholar]
- Havrda, J.; Charvat, F. Quantification method of classification processes, Concept of Structural -Entropy. Kybernetika 1967, 3, 30–35. [Google Scholar]
- Tsallis, C. The role of constraints within generalized nonextensive statistics. Physica 1998, 261, 547–561. [Google Scholar] [CrossRef]
- Arimoto, S. Information-theoretical considerations on estimation problems. Inf. Control 1971, 19, 181–194. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Kundu, D. Hybrid censoring: Models, inferential results and applications. Comput. Stat. Data Anal. 2013, 57, 166–209. [Google Scholar] [CrossRef]
- Singh, S.; Tripathi, Y.M. Bayesian estimation and prediction for a hybrid censored lognormal distribution. IEEE Trans. Reliab. 2015, 65, 782–795. [Google Scholar] [CrossRef]
- Chen, M.H.; Shao, Q.M. Monte Carlo estimation of Bayesian credible and HPD intervals. J. Comput. Graph. Stat. 1999, 8, 69–92. [Google Scholar]
- Dey, S.; Singh, S.; Tripathi, Y.M.; Asgharzadeh, A. Estimation and prediction for a progressively censored generalized inverted exponential distribution. Stat. Methodol. 2016, 32, 185–202. [Google Scholar] [CrossRef]
- Henningsen, A.; Toomet, O. maxLik: A package for maximum likelihood estimation in R. Comput. Stat. 2011, 26, 443–458. [Google Scholar] [CrossRef]
- Plummer, M.; Best, N.; Cowles, K.; Vines, K. Package ‘Coda’. Available online: http://cran.r-project.org/web/packages/coda/coda.pdf (accessed on 25 January 2015).
- El-Sherpieny, E.S.A.; Almetwally, E.M.; Muhammed, H.Z. Progressive Type-II hybrid censored schemes based on maximum product spacing with application to Power Lomax distribution. Phys. A Stat. Mech. Its Appl. 2020, 553, 124251. [Google Scholar] [CrossRef]
- Singh, U.; Singh, S.K.; Singh, R.K. Product spacings as an alternative to likelihood for Bayesian inferences. J. Stat. Appl. Probab. 2014, 3, 179–188. [Google Scholar] [CrossRef]
- Saboor, A.; Alizadeh, M.; Khan, M.N.; Ghosh, I.; Cordeiro, G.M. Odd log-logistic modified Weibull distribution. Mediterr. J. Math. 2017, 14, 1–19. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Ortega, E.M.; Nadarajah, S. The Kumaraswamy Weibull distribution with application to failure data. J. Frankl. Inst. 2010, 347, 1399–1429. [Google Scholar] [CrossRef]
- Alsuhabi, H.; Alkhairy, I.; Almetwally, E.M.; Almongy, H.M.; Gemeay, A.M.; Hafez, E.H.; Sabry, M. A superior extension for the Lomax distribution with application to Covid-19 infections real data. Alex. Eng. J. 2022, 61, 11077–11090. [Google Scholar] [CrossRef]
- Tahir, M.H.; Cordeiro, G.M.; Mansoor, M.; ZUBAÄ°R, M. The Weibull-Lomax distribution: Properties and applications. Hacet. J. Math. Stat. 2015, 44, 455–474. [Google Scholar] [CrossRef]
- Peng, X.; Yan, Z. Estimation and application for a new extended Weibull distribution. Reliab. Eng. Syst. Saf. 2014, 121, 34–42. [Google Scholar] [CrossRef]
- Almetwally, E.M.; Alharbi, R.; Alnagar, D.; Hafez, E.H. A New Inverted Topp-Leone Distribution: Applications to the COVID-19 Mortality Rate in Two Different Countries. Axioms 2021, 10, 25. [Google Scholar] [CrossRef]
- Almetwally, E.M.; Kilai, M.; Aldallal, R. X-Gamma Lomax Distribution with Different Applications. J. Bus. Environ. Sci. 2022, 1, 129–140. [Google Scholar] [CrossRef]
- De Gusmao, F.R.; Ortega, E.M.; Cordeiro, G.M. The generalized inverse Weibull distribution. Stat. Pap. 2011, 52, 591–619. [Google Scholar] [CrossRef]
- WHO World Health Organization. Responding to Community Spread of COVID-19. 2020. Available online: https://www.who.int/ (accessed on 28 January 2023).
- Chakraborty, S.; Handique, L. The generalized Marshall-Olkin-Kumaraswamy-G family of distributions. J. Data Sci. 2017, 15, 391–422. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.A. On the alpha power Kumaraswamy distribution: Properties, simulation and application. Rev. Colomb. Estad. 2020, 43, 285–313. [Google Scholar] [CrossRef]
- Lemonte, A.J.; Barreto-Souza, W.; Cordeiro, G.M. The exponentiated Kumaraswamy distribution and its log-transform. Braz. J. Probab. Stat. 2013, 27, 31–53. [Google Scholar] [CrossRef]
- Dumonceaux, R.; Antle, C.E. Discrimination between the log-normal and the Weibull distributions. Technometrics 1973, 15, 923–926. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.; Dey, S. Unit-Gompertz distribution with applications. Statistica 2019, 79, 25–43. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).