
Properties of Various Entropies of Gaussian Distribution and Comparison of Entropies of Fractional Processes
 , , and
, , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
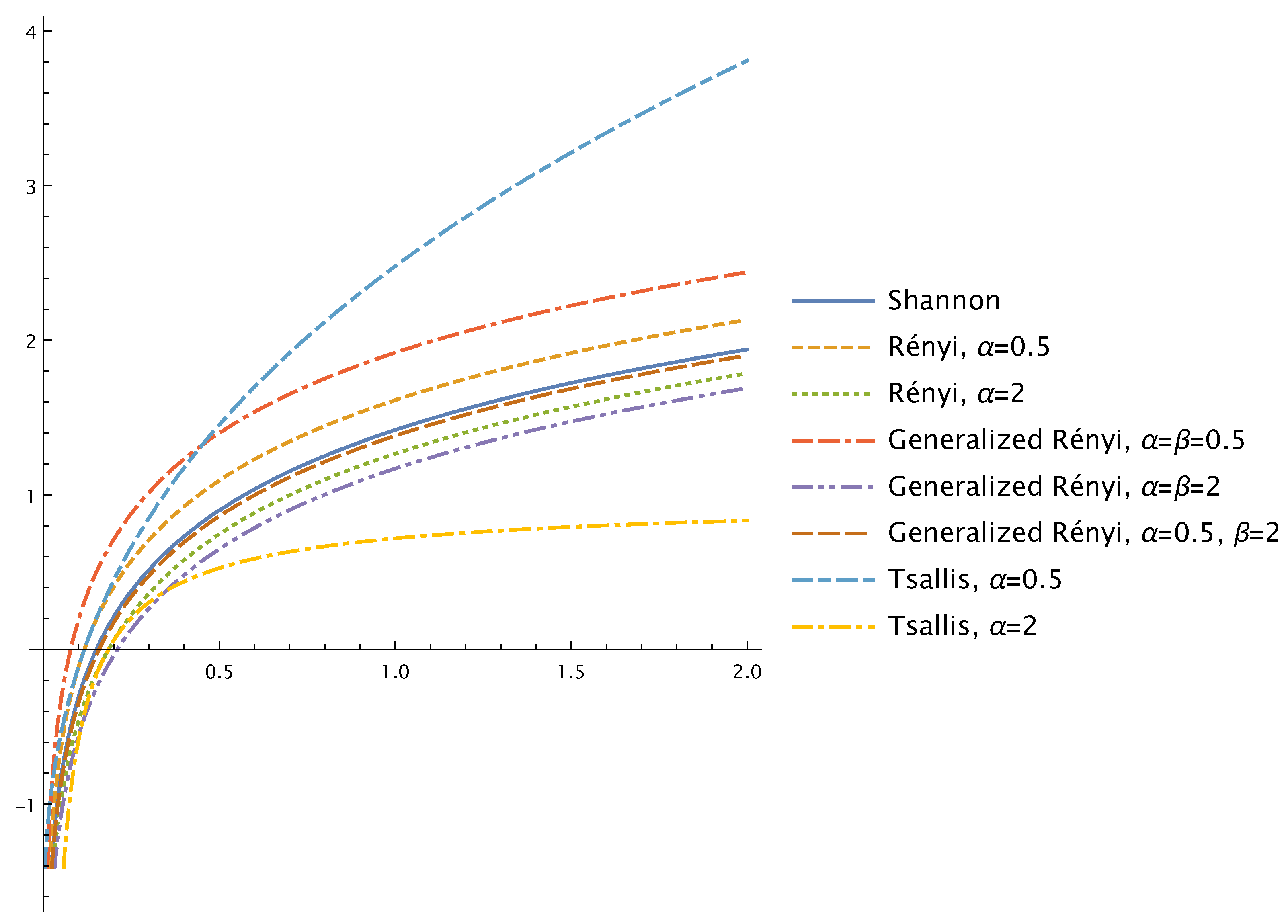
2. Shannon, Rényi, Generalized Rényi, Tsallis and Sharma–Mittal Entropies for Normal Distribution: Properties of Entropies as Functions of Their Parameters
- 1.
- The Shannon entropy is given by
- 2.
- The Rényi entropy with index is given by
- 3.
- The generalized Rényi entropy in the case is given byThe generalized Rényi entropy (in the case ) is given by
- 4.
- The Tsallis entropy with index , is given by
- 5.
- The Sharma–Mittal entropy with positive indices and is defined as
- (1)
- The Shannon entropy equals
- (2)
- The Rényi entropy (, ) equals
- (3)
- The generalized Rényi entropy in the case equalswhere .
- (4)
- The generalized Rényi entropy in the case equals
- (5)
- The Tsallis entropy (, ) equalswhere .
- (6)
- The Sharma–Mittal entropy for equals
- (1)
- As , the Rényi entropy converges to the Shannon entropy, and at the point , the Rényi entropy can be extended by the Shannon entropy to be continuous.
- (2)
- The Rényi entropy is a decreasing and convex function of α.
- (1)
- In the case , the generalized Rényi entropy is a decreasing and convex function of α.
- (2)
- In the case , the generalized Rényi entropy converges to the generalized Rényi entropy as , and so at the point , considered as the function of β for fixed α, can be extended by to be continuous.
- (3)
- The generalized Rényi entropy, , considered as the function of β for fixed α, is a decreasing and convex function. The behavior in α with β fixed is symmetric.
- (1)
- As , the Tsallis entropy converges to the Shannon entropy, and at the point , the Tsallis entropy can be extended by the Shannon entropy to obtain a continuous function.
- (2)
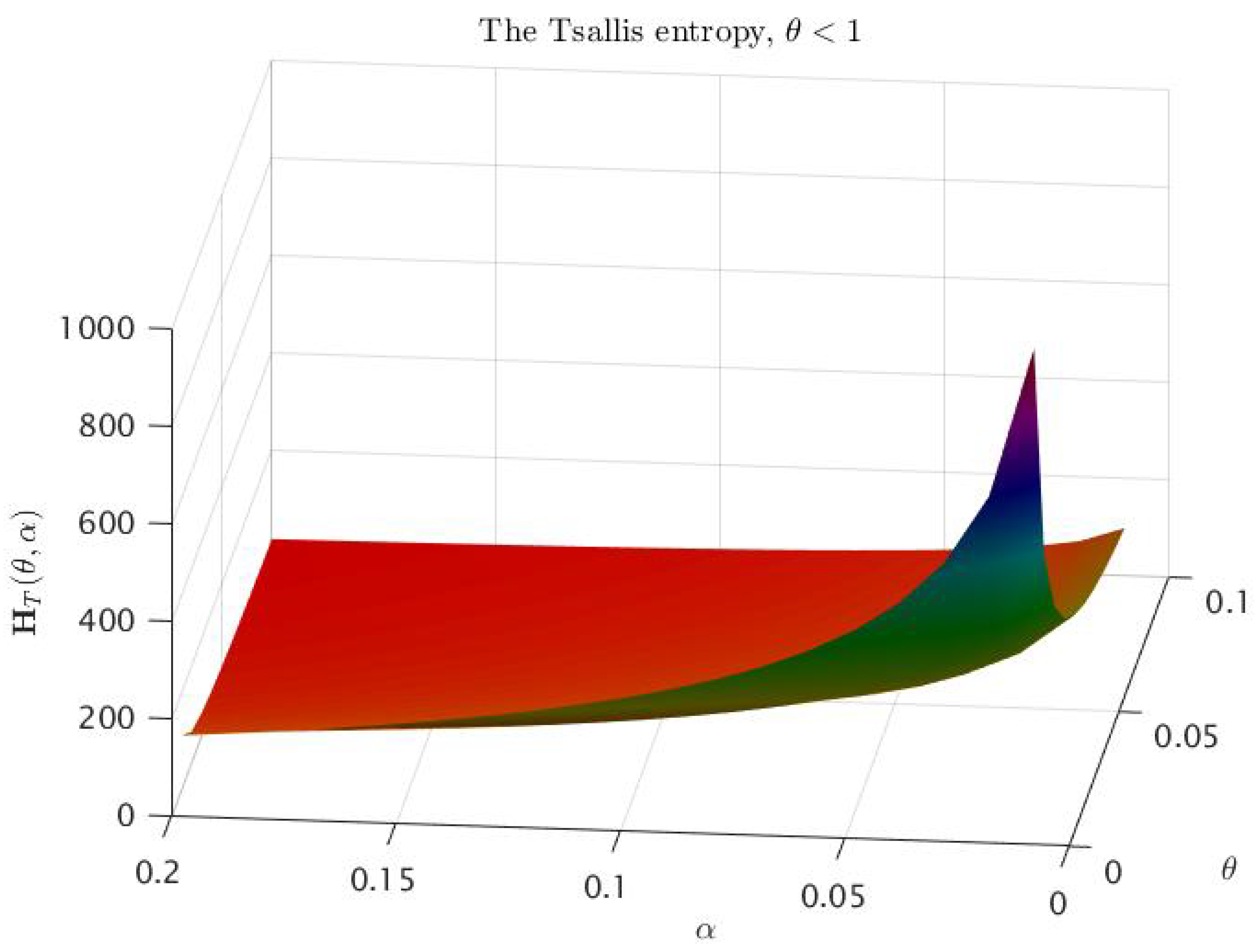
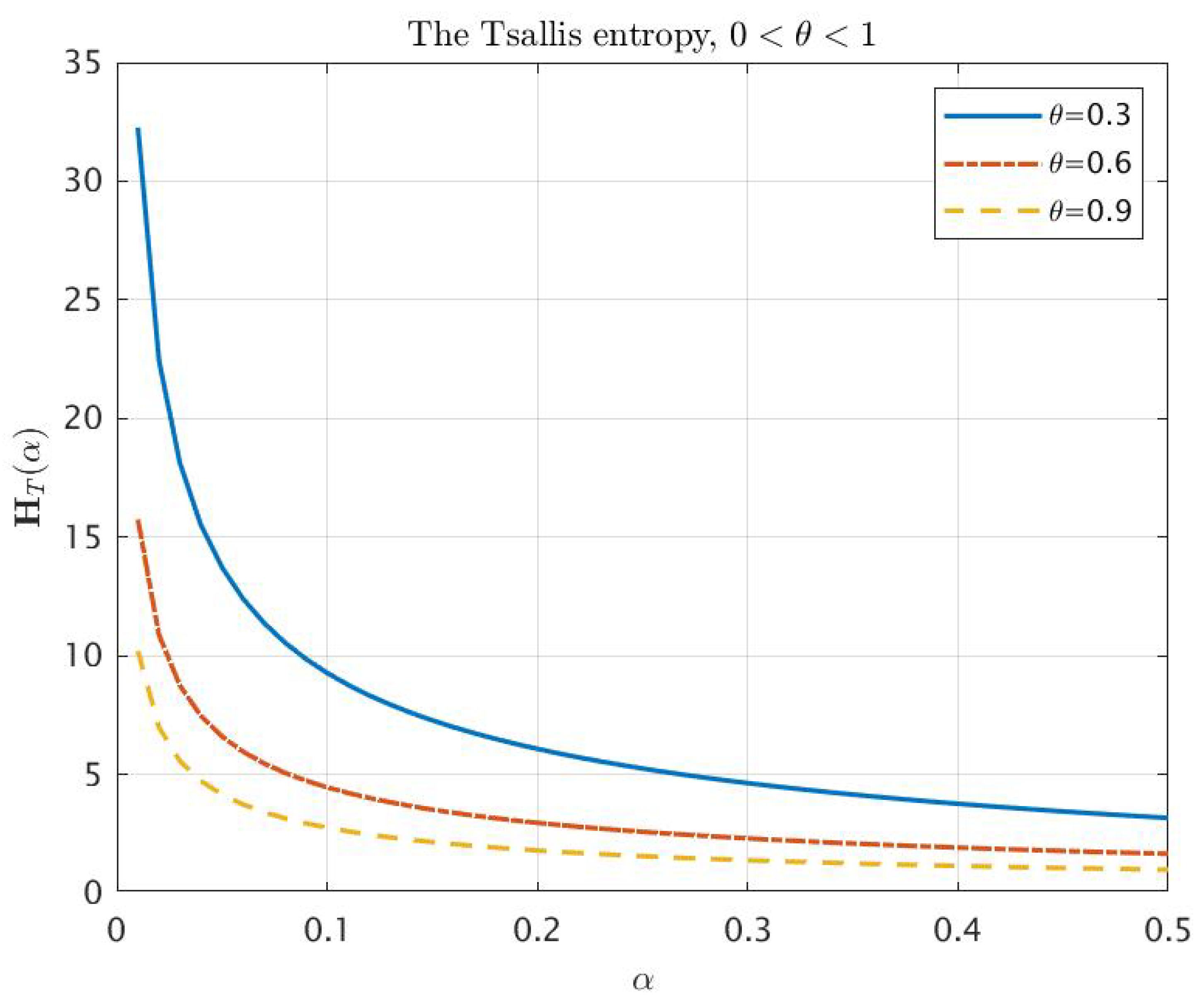
- The Tsallis entropy decreases from to when α increases from 0 to .
- (3)
- Let, as in Proposition 1, , and let be the unique root of the equation
- (a)
- Let . Then, is a convex function on the whole interval .
- (b)
- Let . Then, is a convex function on the interval
- (c)
- Let . Then, is a concave function on the interval
- (d)
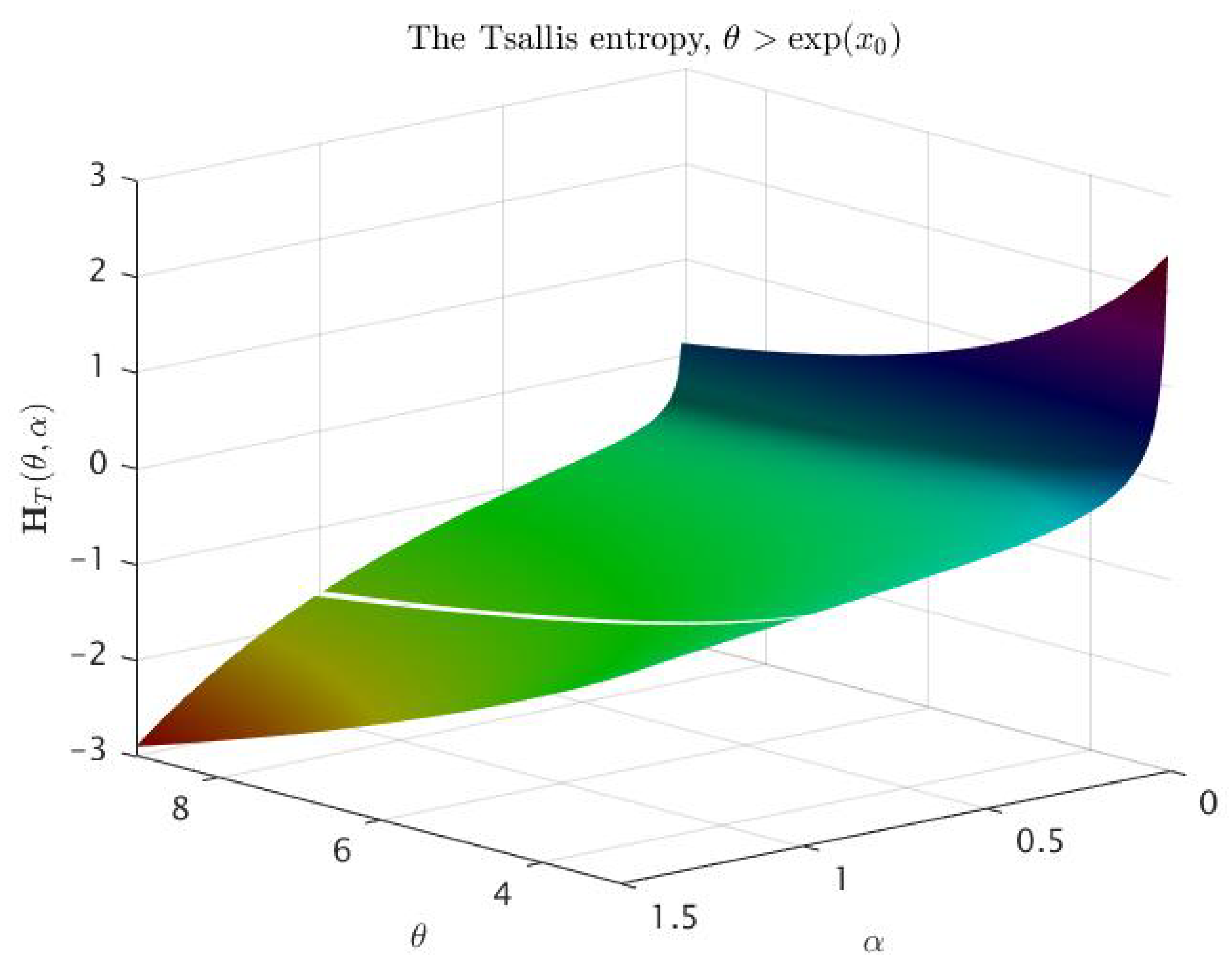
- For any (consequently, for any ), there exist numbers such that is a convex function on the interval , and it is a concave function on the interval .
- (a)
- Let . Then, , and for all ; consequently, , and for all This means that in the case , is a convex function on the whole interval .
- (b)
- Let Then, and Consequently, and . Similarly, let . Then, and Consequently, and . This means that in the case , is a convex function on the interval
- (c)
- Let Then, ; therefore, , and consequently, , whence . Let Then, and whence . Therefore, in the case , is a concave function on the interval
- (d)
- Analyzing the asymptotics of , and at 0 and at , respectively, we obtain that forFurthermore, for and for , it is sufficient to analyze the sign of the valueThis means that is convex on some interval and concave on some interval , where the first statement is true for any , while the second is true only for .
- (1)
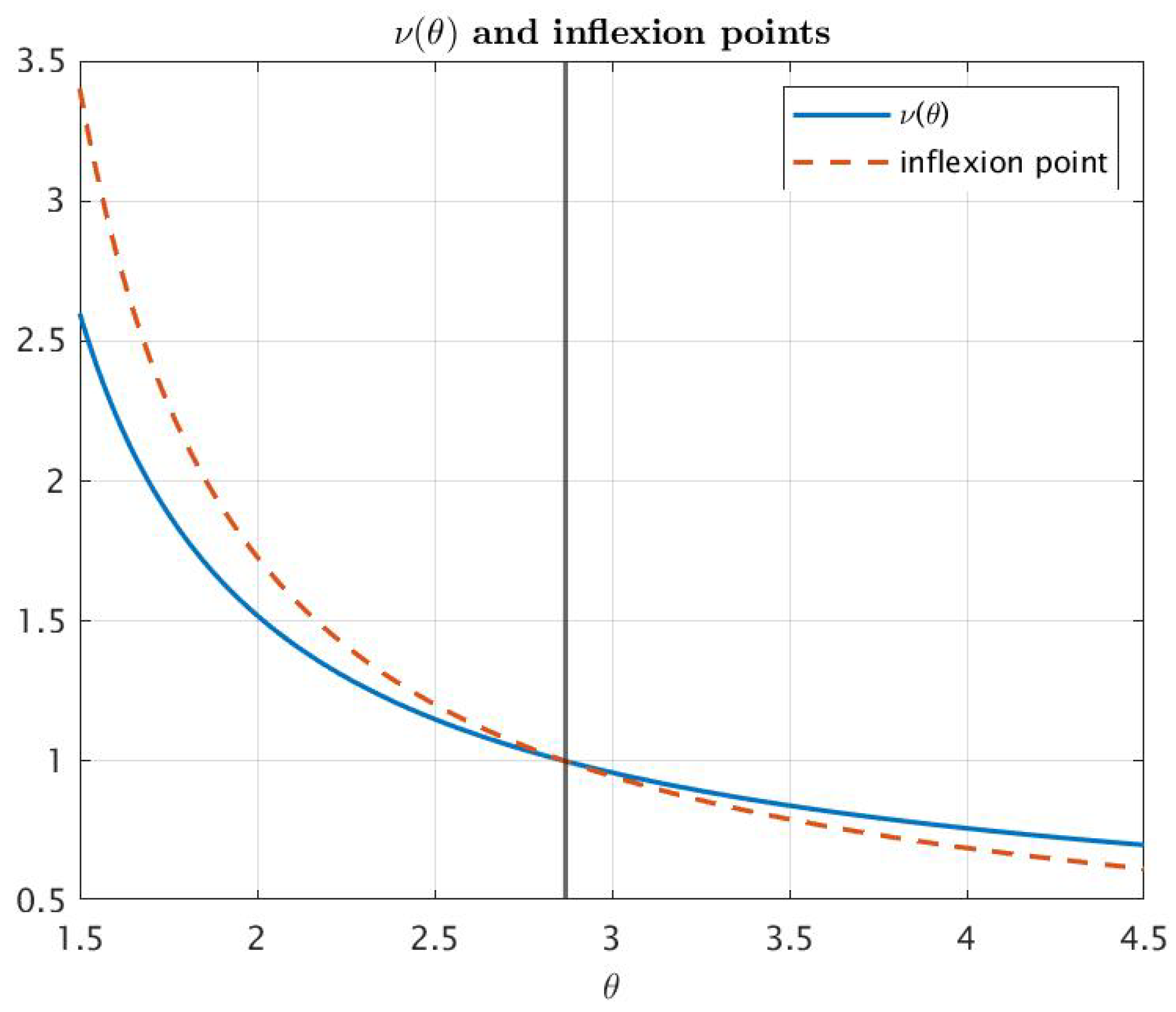
- Let us denoteFor any fixed , , decreases in , namely as follows:
- (i)
- If , then .
- (ii)
- If , then decreases from to .
- (iii)
- If , then decreases from to 0.
- (b)
- For any fixed , , the function is concave in β if , and it is convex if .
- (b)
- For a fixed , is a decreasing and convex function in α.
- If , then and (iii) holds.
- If , then (iii) holds too.
- If , then let be a number such thatIf , then and (iii) holds. If , then and (ii) holds. If , then and (i) holds.
3. Examples of Gaussian Fractional Processes with Their Variances: Entropies of Fractional Gaussian Processes
3.1. Fractional, Subfractional and Bifractional Brownian Motions
- (1)
- The Shannon entropy equals
- (2)
- The Rényi entropy (, ) equalsFor , we extend the Rényi entropy by the Shannon entropy continuously.
- (3)
- The generalized Rényi entropy in the case equalsand for , we extend the generalized Rényi entropy by the Shannon entropy (and Rényi entropy with ) continuously.
- (4)
- The generalized Rényi entropy in the case equalsand for , it can be extended by the generalized Rényi entropy in the case continuously.
- (5)
- The Tsallis entropy (, ) equalsand for , it can be extended by the Shannon entropy continuously.
- (6)
- The Sharma–Mittal entropy for equalsand for , it can be extended by the Rényi entropy continuously.
- (7)
- The same statements hold for with instead of H. This means that any entropy of bifractional Brownian motion with parameters H and K equals to the corresponding entropy of fBm with Hurst index In turn, this means that if we fix the same H in fBm and bifractional Brownian motion and take , thenand opposite inequality holds for . For , the situation is more involved: if or , thenand for or , the opposite inequality holds.
3.2. Multifractional Brownian Motion
- (1)
- The Shannon entropy equals
- (2)
- The Rényi entropy (, ) equals
- (3)
- The generalized Rényi entropy in the case equals
- (4)
- The generalized Rényi entropy in the case equals
- (5)
- The Tsallis entropy (, ) equals
- (6)
- The Sharma–Mittal entropy for equals
- (1)
- For all , .
- (2)
- Let . Then
3.3. Tempered Fractional Brownian Motion
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Computation of Entropies for Centered Normal Distribution
Appendix A.1. Shannon Entropy
Appendix A.2. Rényi Entropy
Appendix A.3. Generalized Rényi Entropy
Appendix A.4. Tsallis Entropy
Appendix A.5. Sharma–Mittal Entropy
Appendix B. Auxiliary Lemma
Appendix C. Special Functions Kν and 2F3
References
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Pathria, R.K. Statistical Mechanics; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Schneier, B. Applied Cryptography: Protocols, Algorithms, and Source Code in C; Wiley: Hoboken, NJ, USA, 1996. [Google Scholar]
- Nei, M.; Tajima, F. DNA polymorphism detectable by restriction endonucleases. Genetics 1981, 97, 145–163. [Google Scholar] [CrossRef]
- Brock, W.; Lakonishok, J.; LeBaron, B. Simple technical trading rules and the stochastic properties of stock returns. J. Financ. 1992, 47, 1731–1764. [Google Scholar] [CrossRef]
- Lorenz, E.N. Deterministic nonperiodic flow. J. Atmos. Sci. 1963, 20, 130–141. [Google Scholar] [CrossRef]
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Mullet, E.; Karakus, M. A cross-cultural investigation of the triarchic model of well-being in Turkey and the United States. J. Cross-Cult. Psychol. 2006, 37, 141–149. [Google Scholar]
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Rahman, A.U.; Haddadi, S.; Javed, M.; Kenfack, L.T.; Ullah, A. Entanglement witness and linear entropy in an open system influenced by FG noise. Quantum Inf. Process. 2022, 21, 368. [Google Scholar] [CrossRef]
- Li, K.; Zhou, W.; Yu, S.; Dai, B. Effective DDoS Attacks Detection Using Generalized Entropy Metric. In Proceedings of the Algorithms and Architectures for Parallel Processing; 9th International Conference, ICA3PP 2009, Taipei, Taiwan, 8–11 June 2009; Hua, A., Chang, S.L., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 266–280. [Google Scholar]
- Morabito, F.C.; Labate, D.; Foresta, F.L.; Bramanti, A.; Morabito, G.; Palamara, I. Multivariate multi-scale permutation entropy for complexity analysis of Alzheimer’s disease EEG. Entropy 2012, 14, 1186–1202. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, P.; Luo, X.; Wu, M.; Liao, L.; Yang, S.; Rangayyan, R.M. Measuring signal fluctuations in gait rhythm time series of patients with Parkinson’s disease using entropy parameters. Biomed. Signal Process. Control 2017, 31, 265–271. [Google Scholar] [CrossRef]
- Rényi, A. On measures of entropy and information. In Proceedings of the 4th Berkeley Symposium on Mathematical Statistics and Probability, Vol. I, Berkeley, CA, USA, 20 June–30 July 1960; University California Press: Berkeley, CA, USA; Los Angeles, CA, USA, 1960; pp. 547–561. [Google Scholar]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Tsallis, C. The nonadditive entropy Sq and its applications in physics and elsewhere: Some remarks. Entropy 2011, 13, 1765–1804. [Google Scholar] [CrossRef]
- Sharma, B.D.; Taneja, I.J. Entropy of type (α, β) and other generalized measures in information theory. Metrika 1975, 22, 205–215. [Google Scholar] [CrossRef]
- Sharma, B.D.; Mittal, D.P. New non-additive measures of relative information. J. Combin. Inform. Syst. Sci. 1977, 2, 122–132. [Google Scholar]
- Nielsen, F.; Nock, R. A closed-form expression for the Sharma–Mittal entropy of exponential families. J. Phys. A 2012, 45, 032003. [Google Scholar] [CrossRef]
- Buryak, F.; Mishura, Y. Convexity and robustness of the Rényi entropy. Mod. Stoch. Theory Appl. 2021, 8, 387–412. [Google Scholar] [CrossRef]
- Stratonovich, R.L. Theory of Information and Its Value; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Malyarenko, A.; Mishura, Y.; Ralchenko, K.; Shklyar, S. Entropy and alternative entropy functionals of fractional Gaussian noise as the functions of Hurst index. Fract. Calc. Appl. Anal. 2023, 26, 1052–1081. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. Wienersche Spiralen und einige andere interessante Kurven im Hilbertschen Raum. Dokl. Acad. Sci. USSR 1940, 26, 115–118. [Google Scholar]
- Bojdecki, T.; Gorostiza, L.G.; Talarczyk, A. Sub-fractional Brownian motion and its relation to occupation times. Statist. Probab. Lett. 2004, 69, 405–419. [Google Scholar] [CrossRef]
- Mishura, Y.; Zili, M. Stochastic Analysis of Mixed Fractional Gaussian Processes; ISTE Press: London, UK; Elsevier Ltd.: Oxford, UK, 2018. [Google Scholar]
- Russo, F.; Tudor, C.A. On bifractional Brownian motion. Stoch. Process. Appl. 2006, 116, 830–856. [Google Scholar] [CrossRef]
- Norros, I.; Valkeila, E.; Virtamo, J. An elementary approach to a Girsanov formula and other analytical results on fractional Brownian motions. Bernoulli 1999, 5, 571–587. [Google Scholar] [CrossRef]
- Cheridito, P.; Kawaguchi, H.; Maejima, M. Fractional Ornstein–Uhlenbeck processes. Electron. J. Probab. 2003, 8, 1–14. [Google Scholar] [CrossRef]
- Cherstvy, A.G.; Wang, W.; Metzler, R.; Sokolov, I.M. Inertia triggers nonergodicity of fractional Brownian motion. Phys. Rev. E 2021, 104, 024115. [Google Scholar] [CrossRef]
- Wang, W.; Seno, F.; Sokolov, I.M.; Chechkin, A.V.; Metzler, R. Unexpected crossovers in correlated random-diffusivity processes. New J. Phys. 2020, 22, 083041. [Google Scholar] [CrossRef]
- Mandelbrot, B.B.; Van Ness, J.W. Fractional Brownian motions, fractional noises and applications. SIAM Rev. 1968, 10, 422–437. [Google Scholar] [CrossRef]
- Samorodnitsky, G.; Taqqu, M.S. Stable Non-Gaussian Random Processes; Chapman & Hall: New York, NY, USA, 1994. [Google Scholar]
- Mishura, Y.S. Stochastic Calculus for Fractional Brownian Motion and Related Processes; Lecture Notes in Mathematics; Springer-Verlag: Berlin, Germany, 2008; Volume 1929. [Google Scholar]
- Peltier, R.F.; Lévy Véhel, J. Multifractional Brownian Motion: Definition and Preliminary Results; [Research Report] RR-2645; INRIA: Le Chesnay, France, 1995. [Google Scholar]
- Boufoussi, B.; Dozzi, M.; Marty, R. Local time and Tanaka formula for a Volterra-type multifractional Gaussian process. Bernoulli 2010, 16, 1294–1311. [Google Scholar] [CrossRef]
- Ralchenko, K.; Shevchenko, G. Properties of the paths of a multifractal Brownian motion. Theory Probab. Math. Statist. 2010, 80, 119–130. [Google Scholar] [CrossRef]
- Benassi, A.; Jaffard, S.; Roux, D. Elliptic Gaussian random processes. Rev. Mat. Iberoam. 1997, 13, 19–90. [Google Scholar] [CrossRef]
- Stoev, S.A.; Taqqu, M.S. How rich is the class of multifractional Brownian motions? Stoch. Process. Appl. 2006, 116, 200–221. [Google Scholar] [CrossRef]
- Ayache, A.; Cohen, S.; Lévy Véhel, J. The covariance structure of multifractional Brownian motion, with application to long range dependence. In Proceedings of the 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No. 00CH37100), Istanbul, Turkey, 5–9 June 2000; Volume 6, pp. 3810–3813. [Google Scholar]
- Meerschaert, M.M.; Sabzikar, F. Tempered fractional Brownian motion. Statist. Probab. Lett. 2013, 83, 2269–2275. [Google Scholar] [CrossRef]
- Sabzikar, F.; Surgailis, D. Tempered fractional Brownian and stable motions of second kind. Statist. Probab. Lett. 2018, 132, 17–27. [Google Scholar] [CrossRef]
- Zeng, C.; Yang, Q.; Chen, Y. Bifurcation dynamics of the tempered fractional Langevin equation. Chaos 2016, 26, 084310. [Google Scholar] [CrossRef]
- Azmoodeh, E.; Mishura, Y.; Sabzikar, F. How does tempering affect the local and global properties of fractional Brownian motion? J. Theoret. Probab. 2022, 35, 484–527. [Google Scholar] [CrossRef]
- Gradshteyn, I.S.; Ryzhik, I.M. Table of Integrals, Series, and Products; Academic Press: New York, NY, USA, 2020. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malyarenko, A.; Mishura, Y.; Ralchenko, K.; Rudyk, Y.A. Properties of Various Entropies of Gaussian Distribution and Comparison of Entropies of Fractional Processes. Axioms 2023, 12, 1026. https://doi.org/10.3390/axioms12111026
Malyarenko A, Mishura Y, Ralchenko K, Rudyk YA. Properties of Various Entropies of Gaussian Distribution and Comparison of Entropies of Fractional Processes. Axioms. 2023; 12(11):1026. https://doi.org/10.3390/axioms12111026
Chicago/Turabian StyleMalyarenko, Anatoliy, Yuliya Mishura, Kostiantyn Ralchenko, and Yevheniia Anastasiia Rudyk. 2023. "Properties of Various Entropies of Gaussian Distribution and Comparison of Entropies of Fractional Processes" Axioms 12, no. 11: 1026. https://doi.org/10.3390/axioms12111026
APA StyleMalyarenko, A., Mishura, Y., Ralchenko, K., & Rudyk, Y. A. (2023). Properties of Various Entropies of Gaussian Distribution and Comparison of Entropies of Fractional Processes. Axioms, 12(11), 1026. https://doi.org/10.3390/axioms12111026