
The Performance of Topic Evolution Based on a Feature Maximization Measurement for the Linguistics Domain

Abstract
:1. Introduction
2. The Related Work
2.1. Feature Maximization Combined with the Contrast Ratio for the Selected Feature
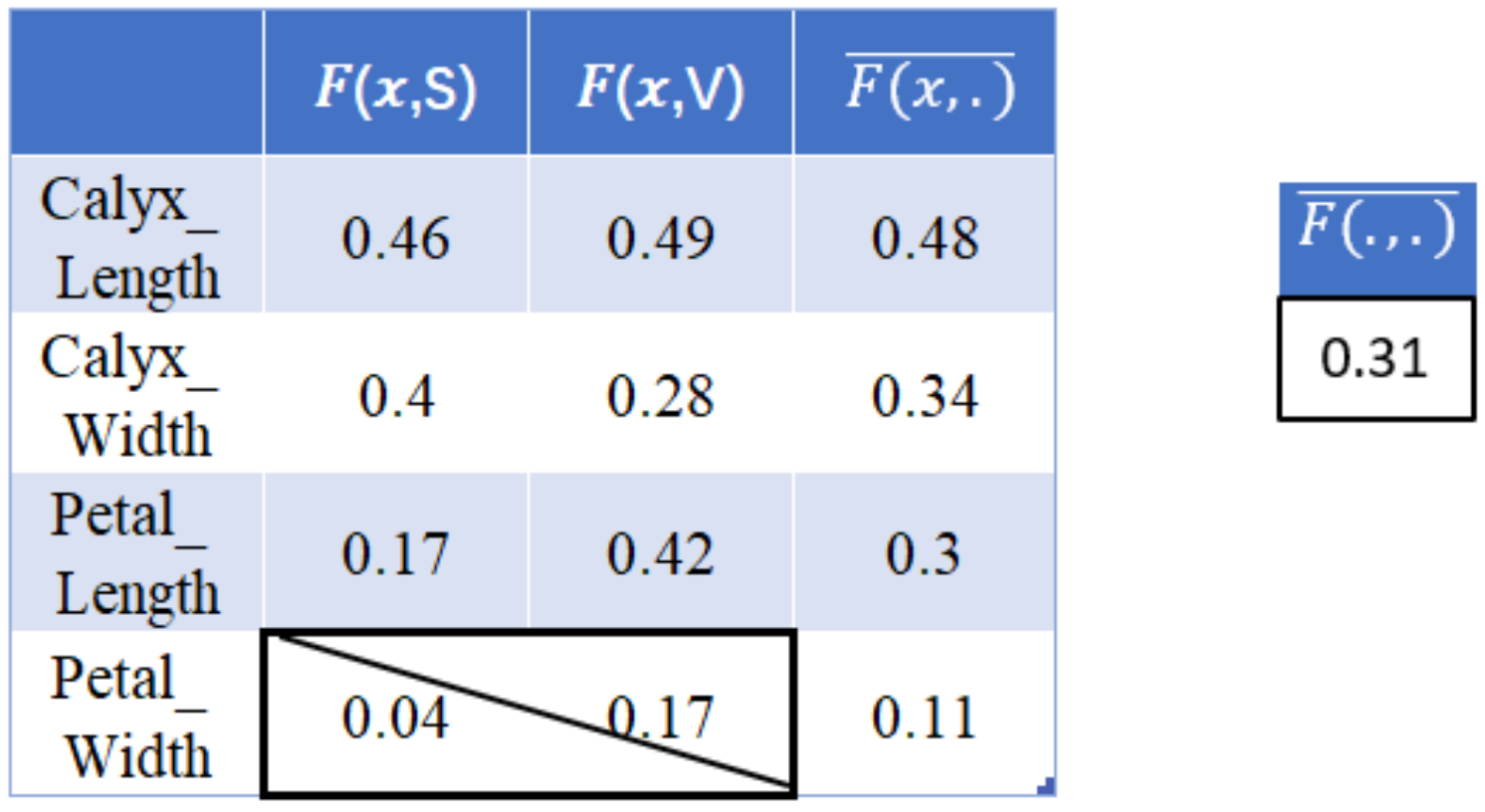
- (1)
- Calyx_Length and Calyx_width are active in Iris-Sentosa’s class (S);
- (2)
- Calyx_Length and Petal_Length are active in Iris-Versicolor’s class (V).
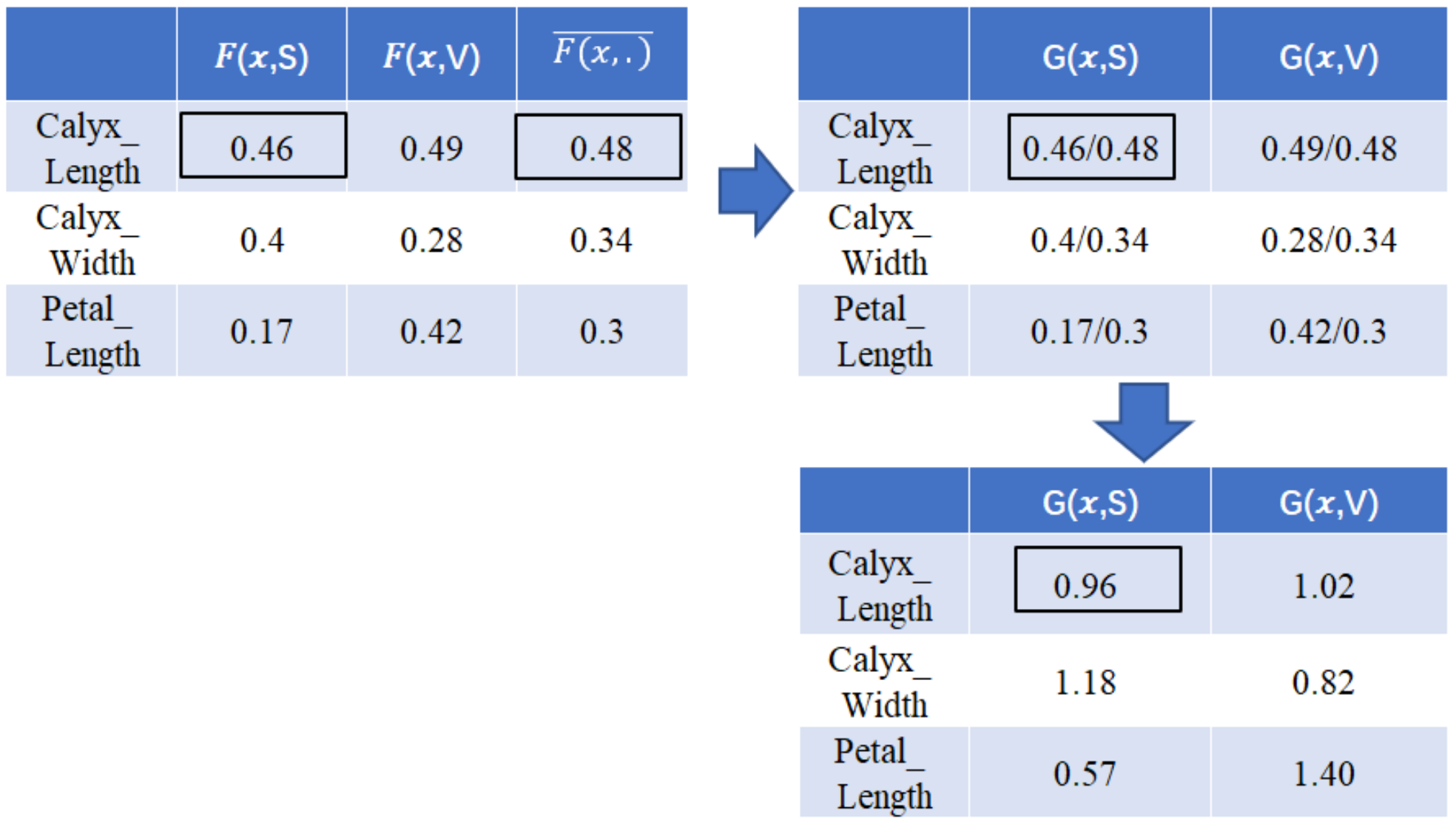
- (1)
- A virtual increase in the width of Iris-Sentosa’s calyx;
- (2)
- An increase in the length of Iris-Versicolor’s calyx and petals;
- (3)
- Conversely, a decrease in the length of Iris-Sentosa’s calyx and petals;
- (4)
- A decrease in the width of Iris-Versicolor’s calyx.
2.2. Deep Embedded Clustering (DEC) Combined with a Keyword-Based Text Representation Matrix (KTRM)
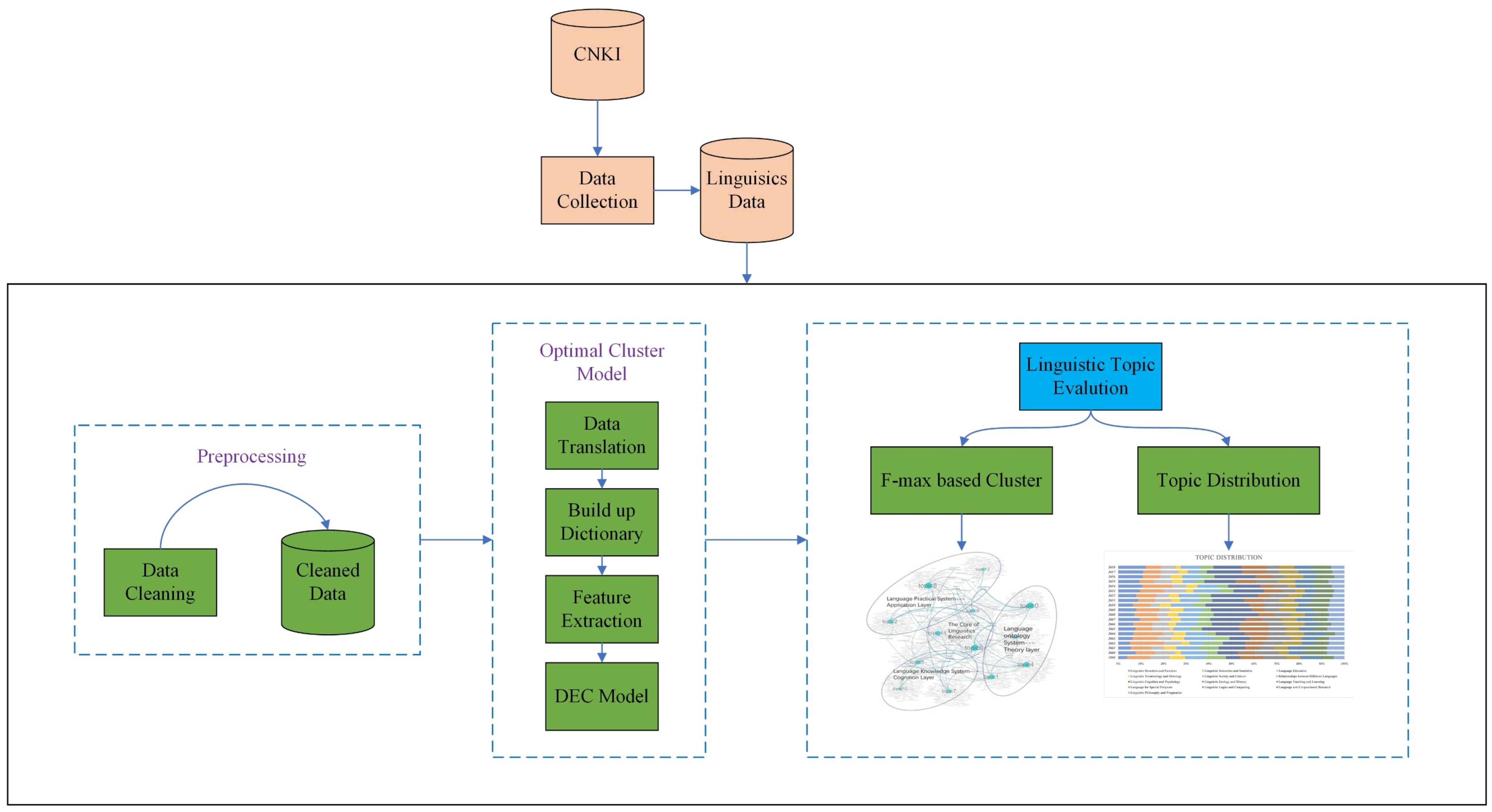
3. Data Collection and Data Preprocessing
4. Research Design and Feature Maximization for Feature Selection
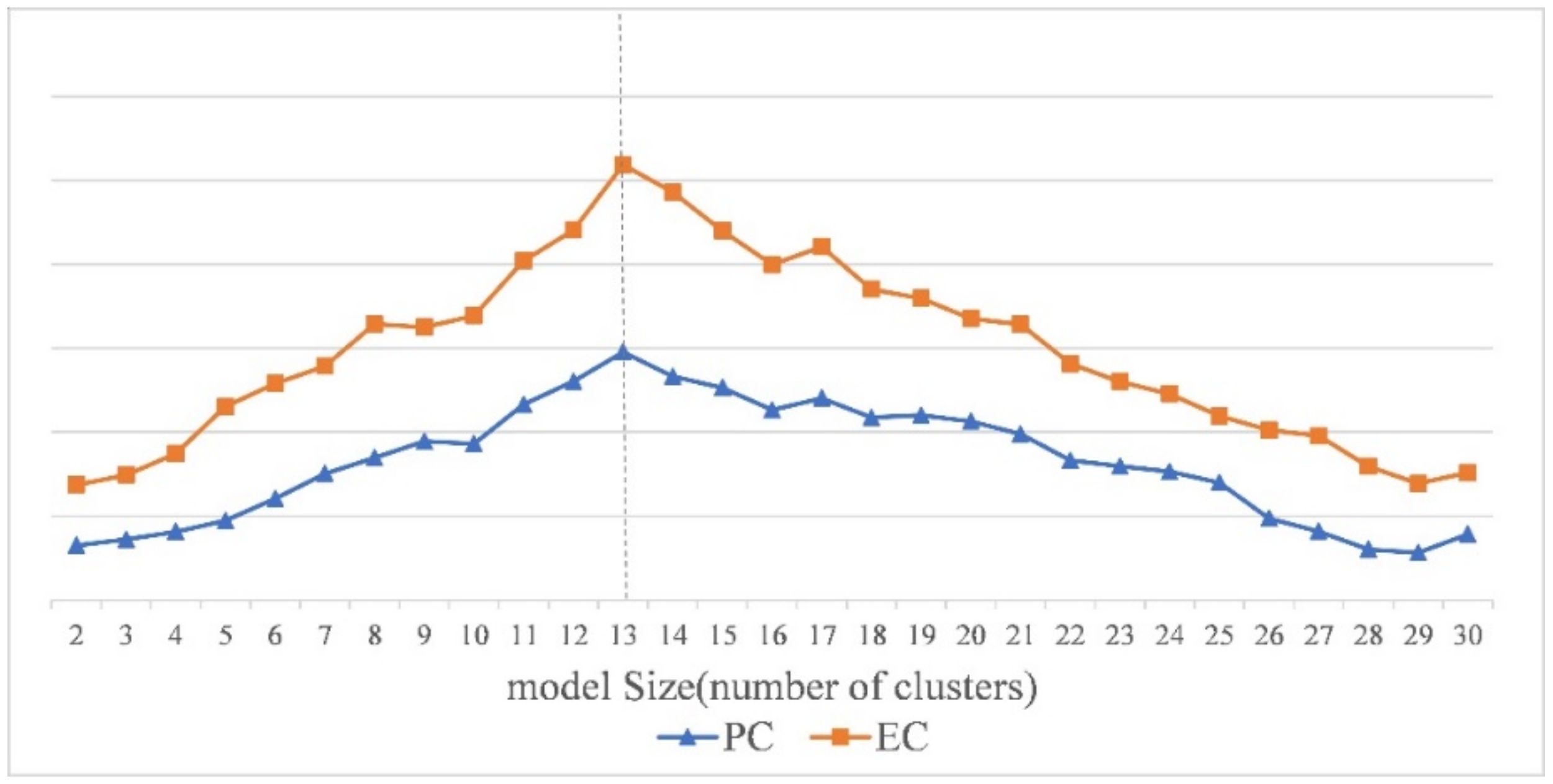
4.1. Clustering and Optimization Model Detection
4.2. Contrast Graph and Its Representation
5. Results and Discussion
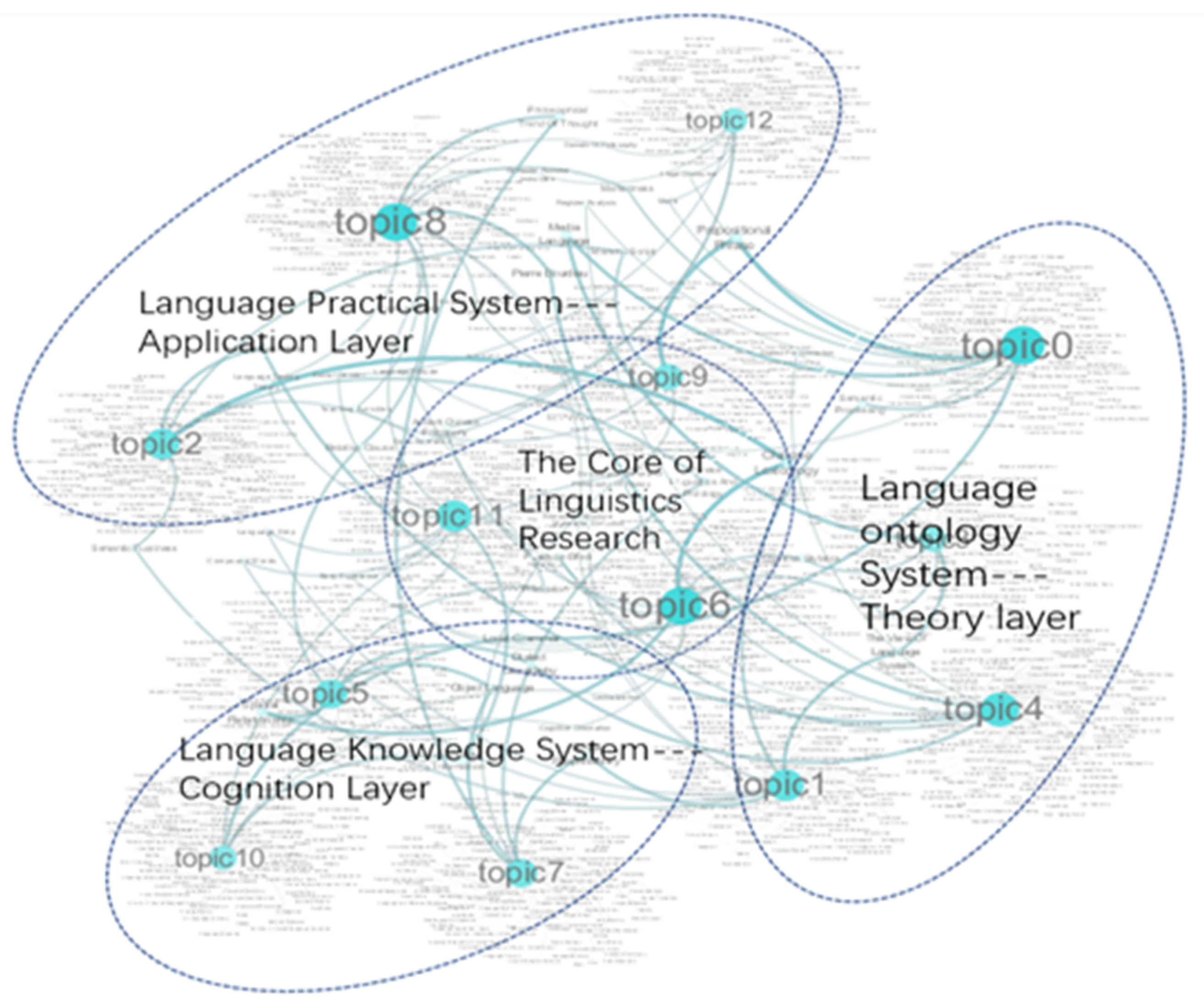
5.1. Topic Clustering for the Linguistics Domain
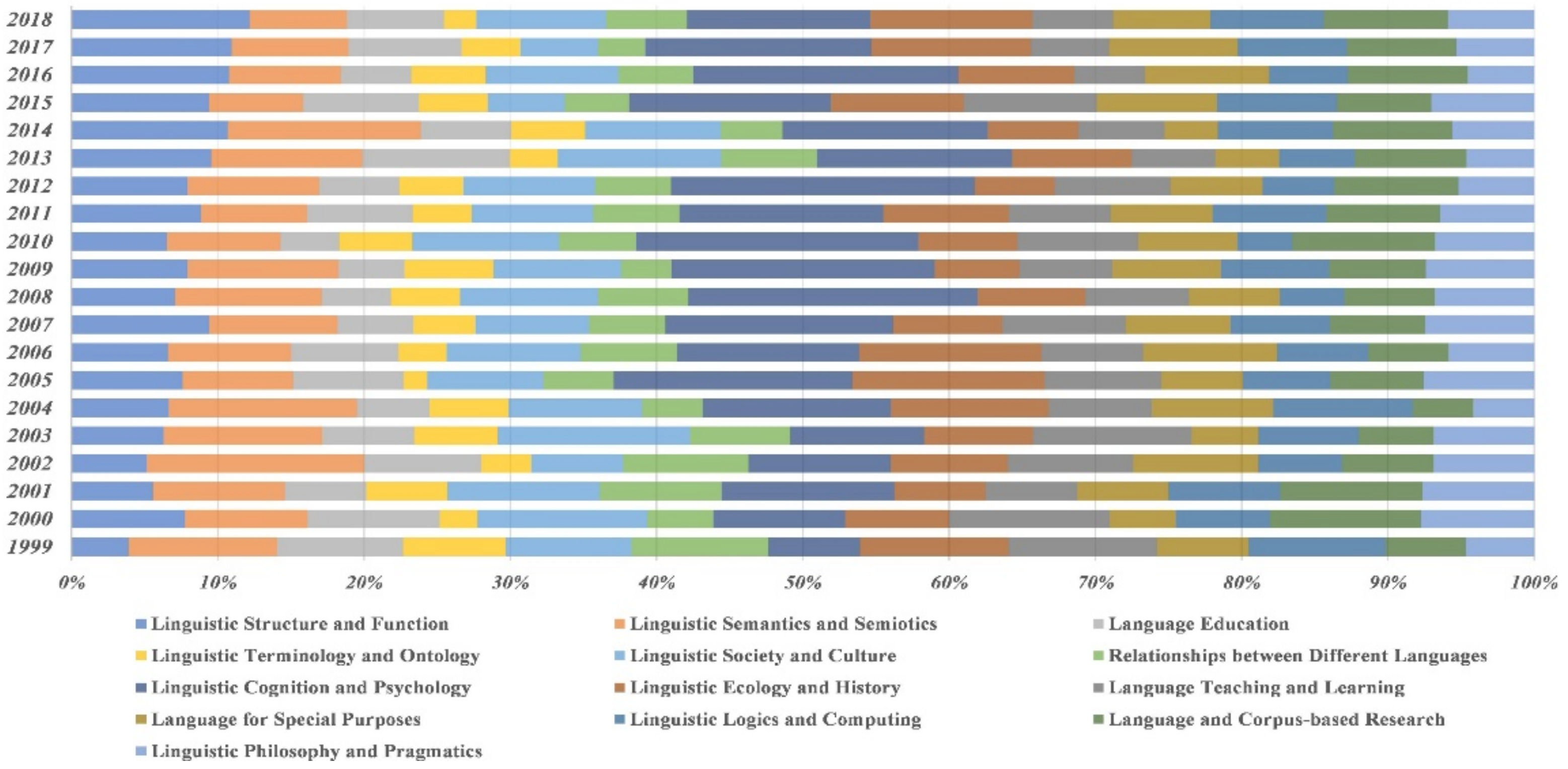
5.2. The Evolution of Linguistics Research Topics
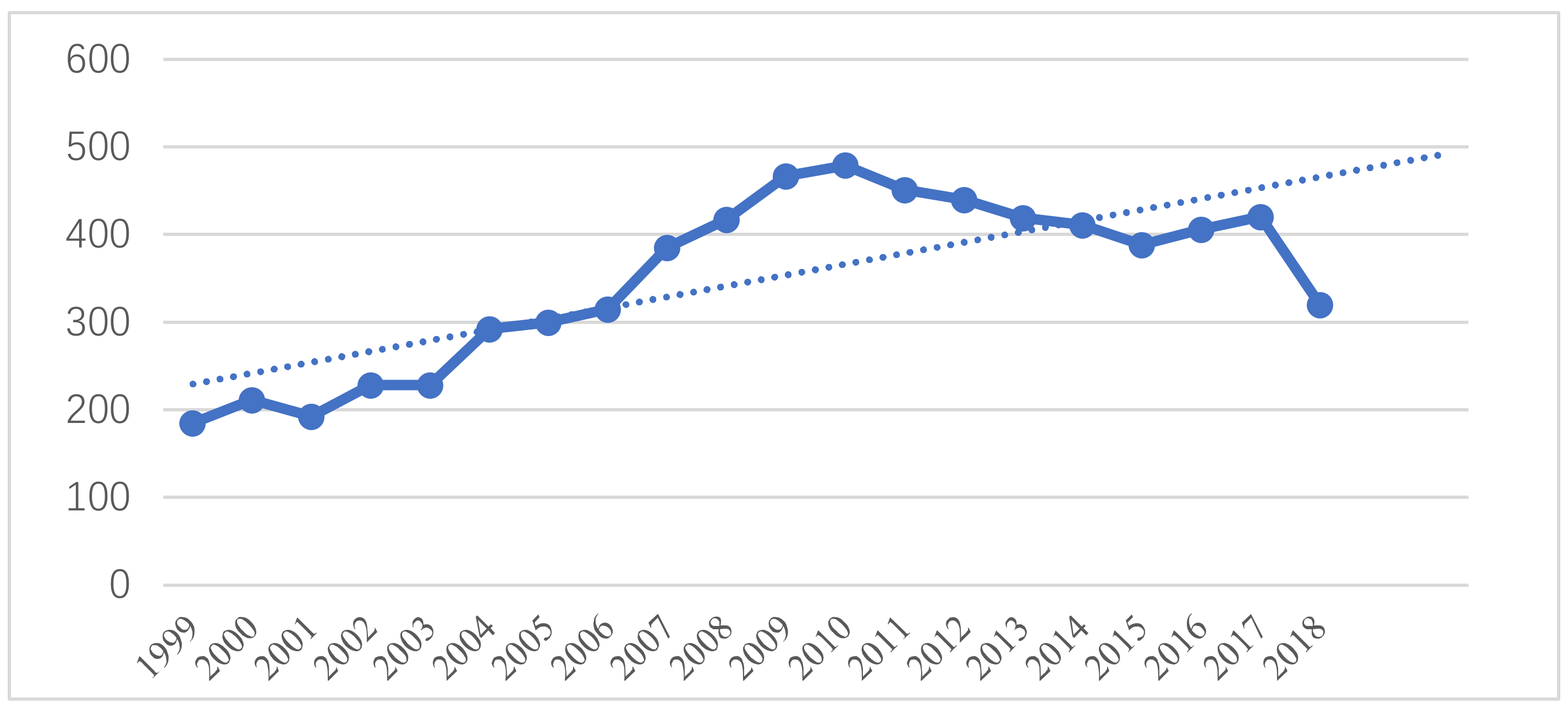
5.3. Predicting the Trend of Hotspots in Linguistics Research
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Li, F.; Li, M.; Guan, P.; Ma, S.; Cui, L. Mapping Publication Trends and Identifying Hot Spots of Research on Internet Health Information Seekinsg Behavior: A Quantitative and Co-Word Biclustering Analysis. J. Med. Internet Res. 2015, 17, e81. [Google Scholar] [CrossRef] [PubMed]
- Lamirel, J.-C. A new approach for automatizing the analysis of research topics dynamics: Application to optoelectronics research. Scientometrics 2012, 93, 151–166. [Google Scholar] [CrossRef]
- Neshati, M.; Fallahnejad, Z.; Beigy, H. On dynamicity of expert finding in community question answering. Inf. Process. Manag. 2017, 53, 1026–1042. [Google Scholar] [CrossRef]
- Hu, K.; Luo, Q.; Qi, K.; Yang, S.; Mao, J.; Fu, X.; Zheng, J.; Wu, H.; Guo, Y.; Zhu, Q. Understanding the topic evolution of scientific literatures like an evolving city: Using Google Word2Vec model and spatial autocorrelation analysis. Inf. Process. Manag. 2019, 56, 1185–1203. [Google Scholar] [CrossRef]
- Zhang, X. A bibliometric analysis of second language acquisition between 1997 and 2018. Stud. Second Lang. Acquis. 2019, 42, 199–222. [Google Scholar] [CrossRef]
- Garcia, K.; Berton, L. Topic detection and sentiment analysis in Twitter content related to COVID-19 from Brazil and the USA. Appl. Soft Comput. 2021, 101, 107057. [Google Scholar] [CrossRef]
- Chen, W.; Chen, W. The identification and evolution of research frontiers from comparison of science and technology. J. Intell. 2022, 41, 67–73, 163. [Google Scholar]
- Chen, X.; Wang, S.; Tang, Y.; Hao, T. A bibliometric analysis of event detection in social media. Online Inf. Rev. 2019, 43, 29–52. [Google Scholar] [CrossRef]
- He, Q.; Chang, K.; Lim, E.P. Analyzing feature trajectories for event detection. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 207–214. [Google Scholar]
- Ding, Y. Community detection: Topological vs. topical. J. Inf. 2011, 5, 498–514. [Google Scholar] [CrossRef]
- Li, S.; Li, M. A new paradigm of interdisciplinary research on linguistics: A review of PANS research from 2000 to 2016. Lang. Teach. Linguist. Stud. 2019, 1, 102–112. [Google Scholar]
- Duan, L.; Ma, S.; Aggarwal, C.; Sathe, S. Improving spectral clustering with deep embedding, cluster estimation and metric learning. Knowl. Inf. Syst. 2021, 63, 675–694. [Google Scholar] [CrossRef]
- Kim, J.; Yoon, J.; Park, E.; Choi, S. Patent document clustering with deep embeddings. Scientometrics 2020, 123, 563–577. [Google Scholar] [CrossRef]
- Kassab, R.; Lamirel., J.C. Feature Based Cluster Validation for High Dimensional Data. In Proceedings of the International Conference on Artificial Intelligence and Application, Innsbruck, Austria, 2 June 2008; pp. 97–103. [Google Scholar]
- Dayeen, F.R.; Sharma, A.S.; Derrible, S. A text mining analysis of the climate change literature in industrial ecology. J. Ind. Ecol. 2020, 24, 276–284. [Google Scholar] [CrossRef]
- Shen, S.; Li, Q.Y.; Ye, Y.; Sun, H.; Ye, W.H. Topic Mining and Evolution Analysis of Medical Sci-Tech Reports with TWE Model. Data Anal. Knowl. Discov. 2021, 5, 35–44. [Google Scholar]
- Mustak, M.; Salminen, J.; Plé, L.; Wirtz, J. Artificial intelligence in marketing: Topic modeling, scientometric analysis, and research agenda. J. Bus. Res. 2021, 124, 389–404. [Google Scholar] [CrossRef]
- Coppens, F.; Wuyts, N.; Inzé, D.; Dhondt, S. Unlocking the potential of plant phenotyping data through integration and data-driven approaches. Curr. Opin. Syst. Biol. 2017, 4, 58–63. [Google Scholar] [CrossRef]
- Chen, M.; Flowerdew, J. Introducing data-driven learning to PhD students for research writing purposes: A territory-wide project in Hong Kong. Engl. Specif. Purp. 2018, 50, 97–112. [Google Scholar] [CrossRef]
- Liu, H.; Lin, Y. Methodology and Trends of Linguistic Research in the Era of Big Data. J. Xinjiang Norm. Univ. (Philos. Soc. Sci.) 2018, 1, 72–83. [Google Scholar]
- Liu, Y. Information Visualization Analysis on the Research Hot Spots and Frontiers of International Corpus Linguistics. Knowl. Manag. Forum 2018, 3, 208–224. [Google Scholar]
- Li, Z.; Xu, J. The evolution of research article titles: The case of Journal of Pragmatics 1978–2018. Scientometrics 2019, 121, 1619–1634. [Google Scholar] [CrossRef]
- Lamirel, J.C.; Dugué, N.; Cuxac, P. New efficient clustering quality indexes. In Proceedings of the International Joint Conference on Neural Networks IEEE (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3649–3657. [Google Scholar]
- Chen, Y.; Lamirel, J.-C.; Liu, Z. An overview on 40 years science of science research topic evolution in China: A novel approach based on clustering and feature maximization. Sci. Sci. Manag. Sci. Technol. 2018, 39, 28–45. [Google Scholar]
- Xie, J.; Girshick, R.B.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 24 May 2016; Volume 48. [Google Scholar]
- Pan, Y.; Wang, M.; Wang, J. Clustering of agricultural trade friction news text based on improved text representation and its application prospect. Agric. Outlook 2020, 16, 80–88. [Google Scholar]
- Chen, B.; Tsutsui, S.; Ding, Y.; Ma, F. Understanding the topic evolution in a scientific domain: An exploratory study for the field of information retrieval. J. Inf. 2017, 11, 1175–1189. [Google Scholar] [CrossRef]
- Hui, L.; Jixia, H.; Zhiying, T. Subject topic mining and evolution analysis for multi-source data. Data Anal. Knowl. Discov. 2022, 31, 1–16. [Google Scholar]
- Mane, K.K.; Börner, K. Mapping topics and topic bursts in PNAS. Proc. Natl. Acad. Sci. USA 2004, 101, 5287–5290. [Google Scholar] [CrossRef] [PubMed]
- Blei, D.M.; Lafferty, J.D. Dynamic topic models. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 113–120. [Google Scholar]
- Lounsbury, J.W.; Roisum, K.G.; Pokorny, L.; Sills, A.; Meissen, G.J. An analysis of topic areas and topic trends in the Community Mental Health Journal from 1965 through 1977. Community Ment. Health J. 1979, 15, 267–276. [Google Scholar] [CrossRef]
- Lamirel, J.-C.; Francois, C.; Al Shehabi, S.; Hoffmann, M. New classification quality estimators for analysis of documentary information: Application to patent analysis and web mapping. Scientometrics 2004, 60, 445–562. [Google Scholar] [CrossRef]
- Lamirel, J.C.; Mall, R.; Cuxac, P.; Safi, G. Variations to incremental growing neutral gas algorithm based on label maximization. In Proceedings of the 2011 International Joint Conference on Neural Networks (IJCNN), San Jose, CA, USA, 3 October 2011; pp. 956–965. [Google Scholar]
- Lamirel, J.-C.; Cuxac, P.; Chivukula, A.S.; Hajlaoui, K. Optimizing text classification through efficient feature selection based on quality metric. J. Intell. Inf. Syst. 2015, 45, 379–396. [Google Scholar] [CrossRef]
- Dempster, A.P. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. 1977, 39, 1–38. [Google Scholar]
- Cuxac, P.; Lamirel, J.C. Analysis of evolutions and interactions between science fields: The cooperation between feature selection and graph representation. In Proceedings of the 14th COLLNET Meeting, Tartu, Estonia, 14 August 2013; pp. 780–788. [Google Scholar]
- Futrell, R.; Mahowald, K.; Gibson, E. Large-scale evidence of dependency length minimization in 37 languages. Proc. Natl. Acad. Sci. USA 2015, 112, 10336–10341. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; El-Diraby, T.E. Social semantic approach to support communication in AEC. J. Comput. Civ. Eng. 2012, 26, 90–104. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, H.; Lu, J.; Zhang, G. Detecting and predicting the topic change of Knowledge-based Systems: A topic-based bibliometric analysis from 1991 to 2016. Knowl.-Based Syst. 2017, 133, 255–268. [Google Scholar] [CrossRef]
- Lei, L.; Liao, S. Publications in Linguistics Journals from Mainland China, Hong Kong, Taiwan, and Macau (2003–2012): A Bibliometric Analysis. J. Quant. Linguist. 2017, 24, 54–64. [Google Scholar] [CrossRef]
- Jin, Y. Development of Word Cloud Generator Software Based on Python. Procedia Eng. 2017, 174, 788–792. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Procedure | Merge Equivalent Words | Delete Fuzzy Words | Control Word Frequency (>5) |
|---|---|---|---|
| Initial Data Size | 9183 | 8845 | 8426 |
| Disposed Words | —— | 419 | 6315 |
| Merged Words | 338 | —— | —— |
| Final Data Size | 8845 | 8426 | 2111 |
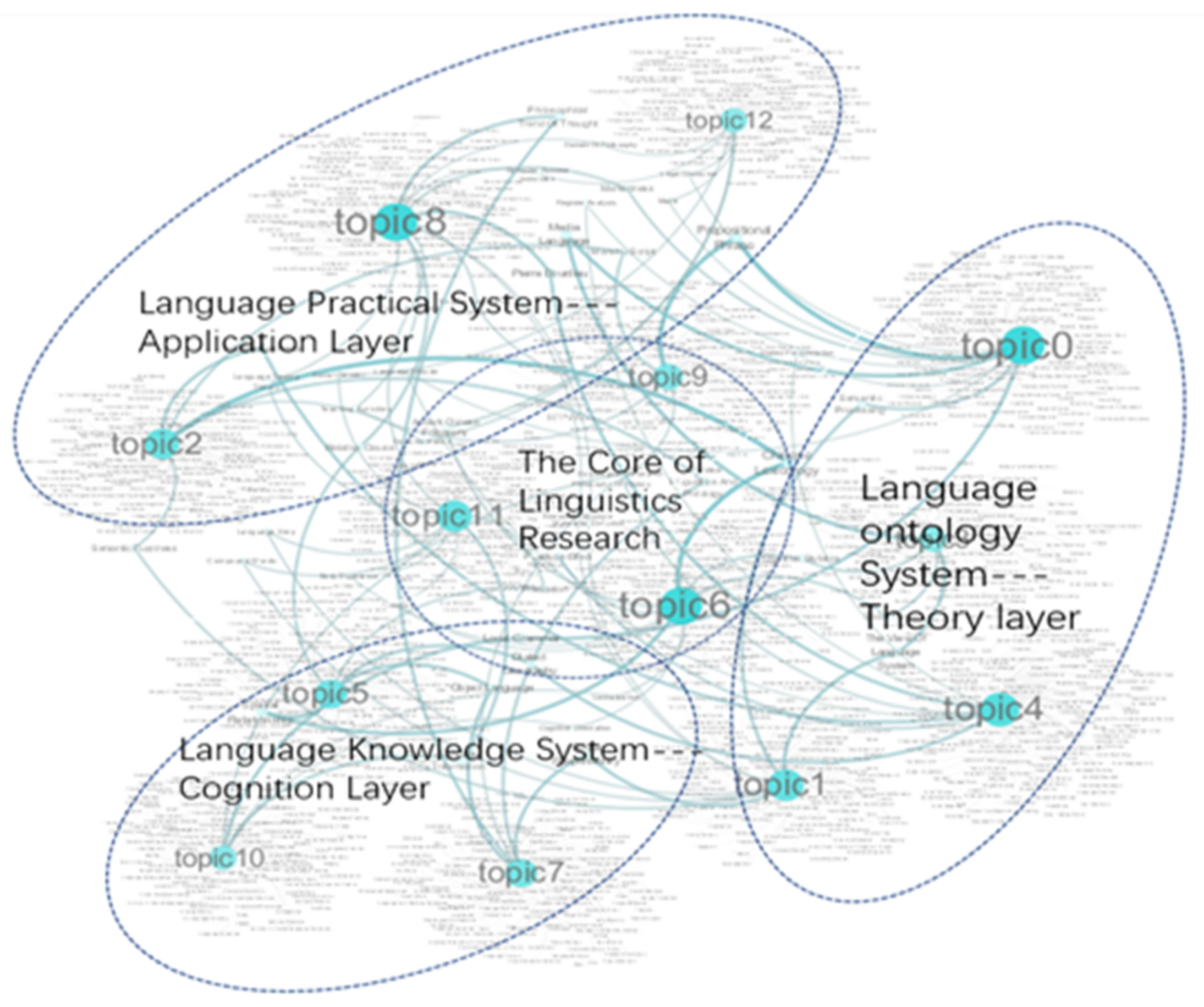
| Clustering | Label Name | Content (Active Feature Words) |
|---|---|---|
| Topic 0 | Linguistic Structure and Function | System Function, Functional Structure, Systemic Functional Linguistics Theory, Interpersonal Function, Functional Discourse Analysis, Thematic Structure, Leonard Bloomfield, Textual Function, American Structuralism, Systemic Functional Grammar, Construction Grammar Theory, Functional Theory, Grammatical Unit, Functional Grammar Theory, Grammatical Pattern |
| Topic 1 | Linguistic Semantics and Semiotics | Russian Semiotics, Symbolic Value System, Symbolic Arbitrariness, Linguistic Semiotics, Genre Study, Utterance Meaning, Signifier, Signified, Semantic Fuzziness, Semantic Processing, Textual Meaning, Sound and Meaning, Text Interpretation, Later Wittgenstein, Cultural Semiotics |
| Topic 2 | Language Education | Teaching of Language and Literature, Grammar Teaching, Linguistic Teaching, Natural Language Understanding, Teacher Education, Language Environment, Discourse Teaching, English Reading Teaching, Bilingual Education, Chinese Language Studies, English Writing Teaching, Cooperative Principle, Educational Research, Curriculum Setting, Construction Theory, Chinese Education |
| Topic 3 | Linguistic Terminology and Ontology | Ontology of Knowledge, Linguistic Terminology, Case-Auxiliary Word, Sense of Meaning, Theory of Meaning, Word Meaning, Social Turn, Meaning Potential, Terminology Translation, Taboo Words, Brand Naming, Interpreting Studies, Translated Names, Kinship Terminology, Dictionary Definition |
| Topic 4 | Linguistic Society and Culture | Speech Community Theory, Discourse Style, Chinese Sociolinguistics, Language Variation, Identity Construction, Sociolinguists, Social Varieties, Language Contact, Politeness Principle, Socio-Cultural Factors, Cultural Difference, Cross-Cultural Communication, Register Analysis, Language and Society, Conversational Implicature |
| Topic 5 | Relationships between Different Languages | Language Renaissance, Sino-Tibetan Languages, Tibetan, Burmese, Endangered Language, Language Comparison, Geographical Linguistics, Word Families in Chinese, Modern Chinese Dialect, Minority Language, Indo-European Languages, Language Family, Language World View, Ethnolinguistics, Language Evolution |
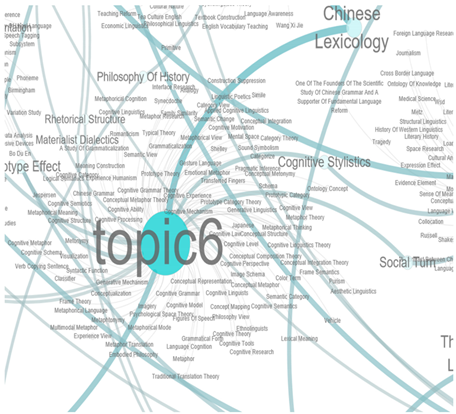
| Topic 6 | Linguistic Cognition and Psychology | Concept Mapping, Conceptual Metaphor Theory, Mental Space, Metaphorical Meaning, Metaphorical Language, Multimodal Metaphor, Cognitive Linguists, Cognitive Metaphor, Cognitive Category, Conceptualization, Conceptual Integration Theory, Cognitive Schema, Cognitive Grammar Theory, Conceptual Representation, Cognitive Processing |
| Topic 7 | Linguistic Ecology and History | Linguistic Ecology, Eco-Discourse Analysis, Language Ecosystem, Eco-linguistics, Historiography, Language Ecological Environment, Historical Narration, Immanence Theory, Language Diversity, Deep Structure, Surface Structure, Historical Research, Metalanguage, Philosophy of History, History of Rhetoric |
| Topic 8 | Language Teaching and Learning | Linguistic Competence, Individual Difference, Learning Motivation, College English Teaching Model, Foreign Language Teaching, Teaching Method, Language Testing Theory, Second Language Acquisition Process, Teaching Strategies, Computer Assisted Instruction, College English Teaching Reform, Teaching Effectiveness, Foreign Language Learning, Applied Linguistics Theory, Autonomous Learning |
| Topic 9 | Language for Special Purposes | Explanatory Turn, Legal Linguistic Psychology, Task-Based Language Learning, Economics of Language, Slogan, Business English, Tea Culture, Linguistic Nationality Studies, Tourism English, Language Taboo, Artistic Language, Culture Teaching, Manchu Script, Categorization Theory, the Use of Language, Target Language, Wittgenstein, Cultural Connotations |
| Topic 10 | Linguistic Logics and Computing | Cognitive Logic, Complex Theory, Structural Law, Montague Grammar, Dependency Tree, Logic Language, Computational Simulation, Computational Linguistics, Vague Language, Decode, Language and Thinking, Mathematical Logic, Cognitive Neuroscience, Natural Language Processing, Machine Learning |
| Topic 11 | Language and Corpus-Based Research | Chinese Corpora, Multimodal Corpus, Political Text, Sign Language Studies, Corpus-Based Translation Studies, Corpus Stylistics, Complex Network, Corpus Linguistics, Word Frequency, Data Mining, Discourse Coherence, Advertising Language, Pragmatic Features, Corpus Approach, Chinese Information Processing |
| Topic 12 | Linguistic Philosophy and Pragmatics | Discourse View, Dialogue Theory, Discourse Theory, Communication Strategy, Discourse Markers, Pragmatic Turn, Philosophical Thought of Language, Linguistic Philosophy, Conversational Implicature, Legal Discourse, Philosophical Thinking, Discourse System, Pragmatics Research, Cognitive Pragmatics, Pragmatic Inference |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, J.; Miao, J.; Tang, Y.; Li, Y.; Feng, J. The Performance of Topic Evolution Based on a Feature Maximization Measurement for the Linguistics Domain. Axioms 2022, 11, 412. https://doi.org/10.3390/axioms11080412
Feng J, Miao J, Tang Y, Li Y, Feng J. The Performance of Topic Evolution Based on a Feature Maximization Measurement for the Linguistics Domain. Axioms. 2022; 11(8):412. https://doi.org/10.3390/axioms11080412
Chicago/Turabian StyleFeng, Junchao, Jianjun Miao, Yue Tang, Yuechen Li, and Jundong Feng. 2022. "The Performance of Topic Evolution Based on a Feature Maximization Measurement for the Linguistics Domain" Axioms 11, no. 8: 412. https://doi.org/10.3390/axioms11080412
APA StyleFeng, J., Miao, J., Tang, Y., Li, Y., & Feng, J. (2022). The Performance of Topic Evolution Based on a Feature Maximization Measurement for the Linguistics Domain. Axioms, 11(8), 412. https://doi.org/10.3390/axioms11080412