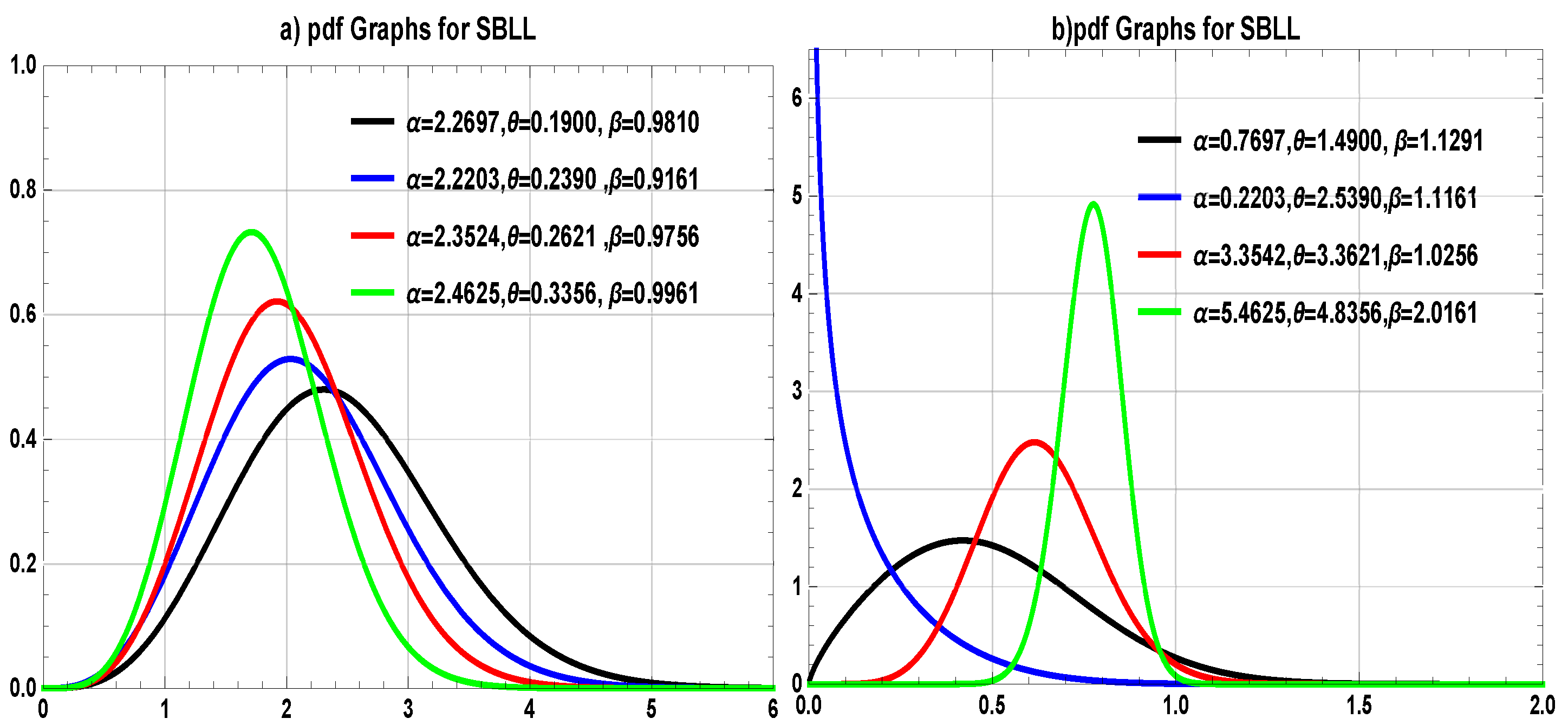
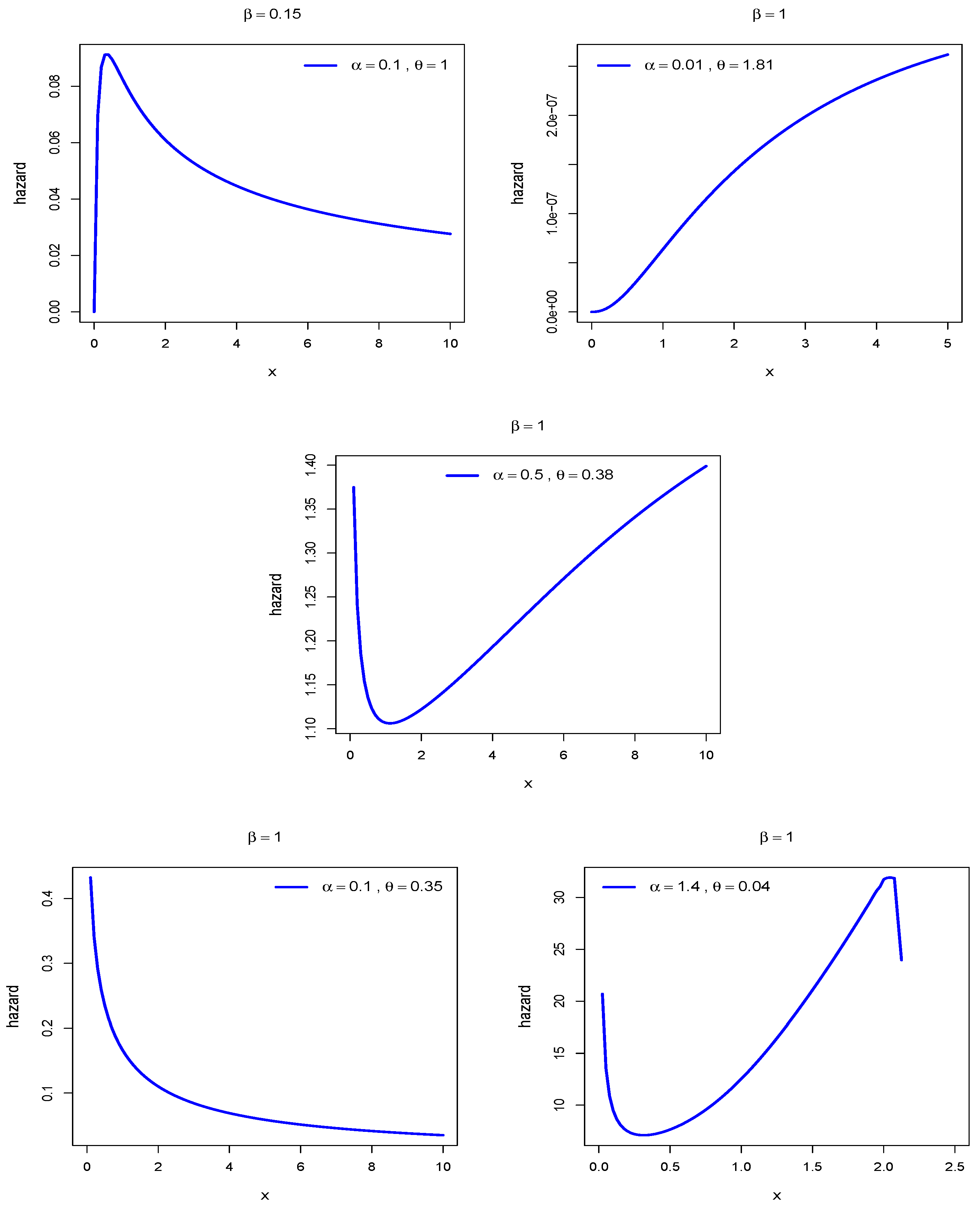
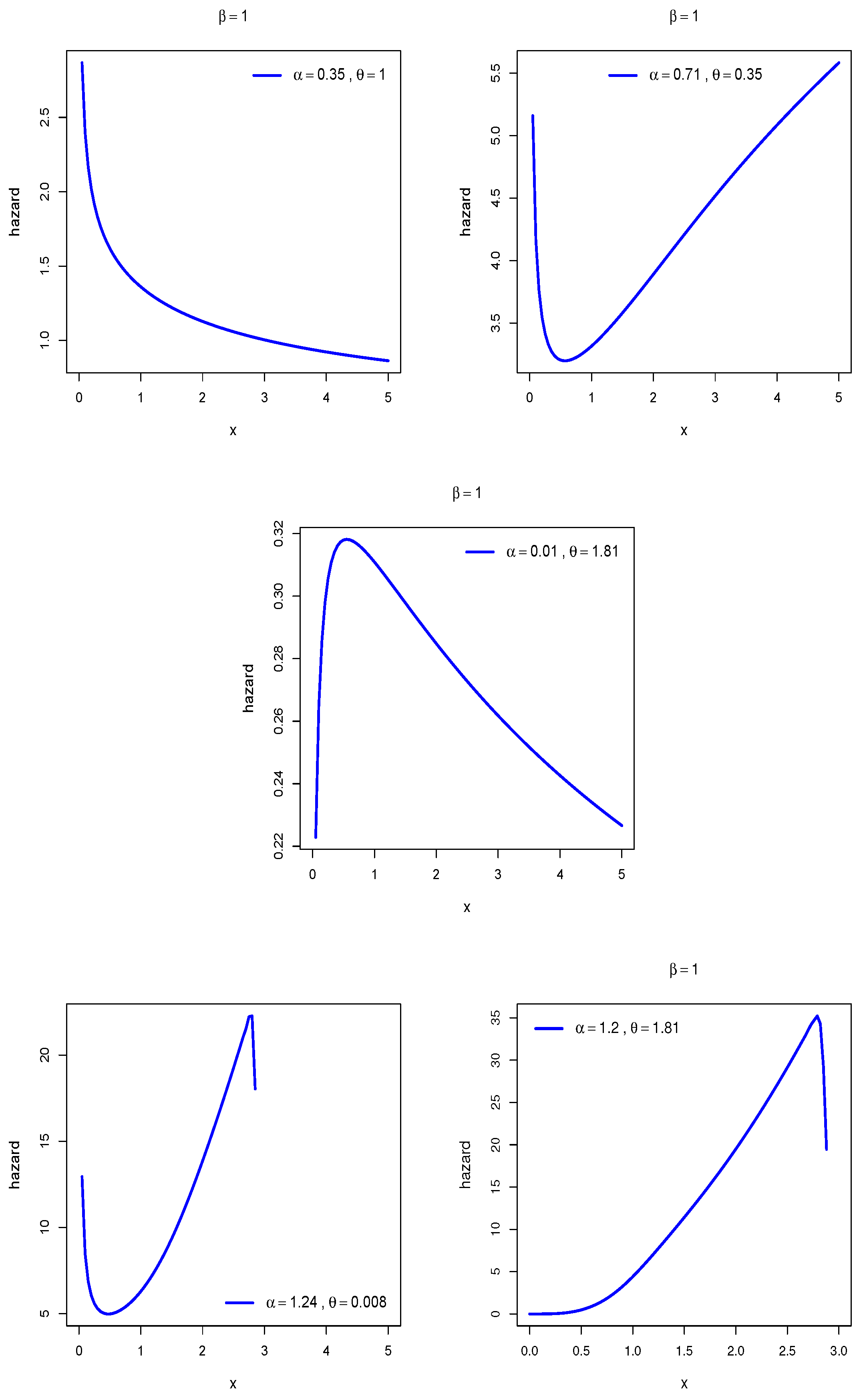
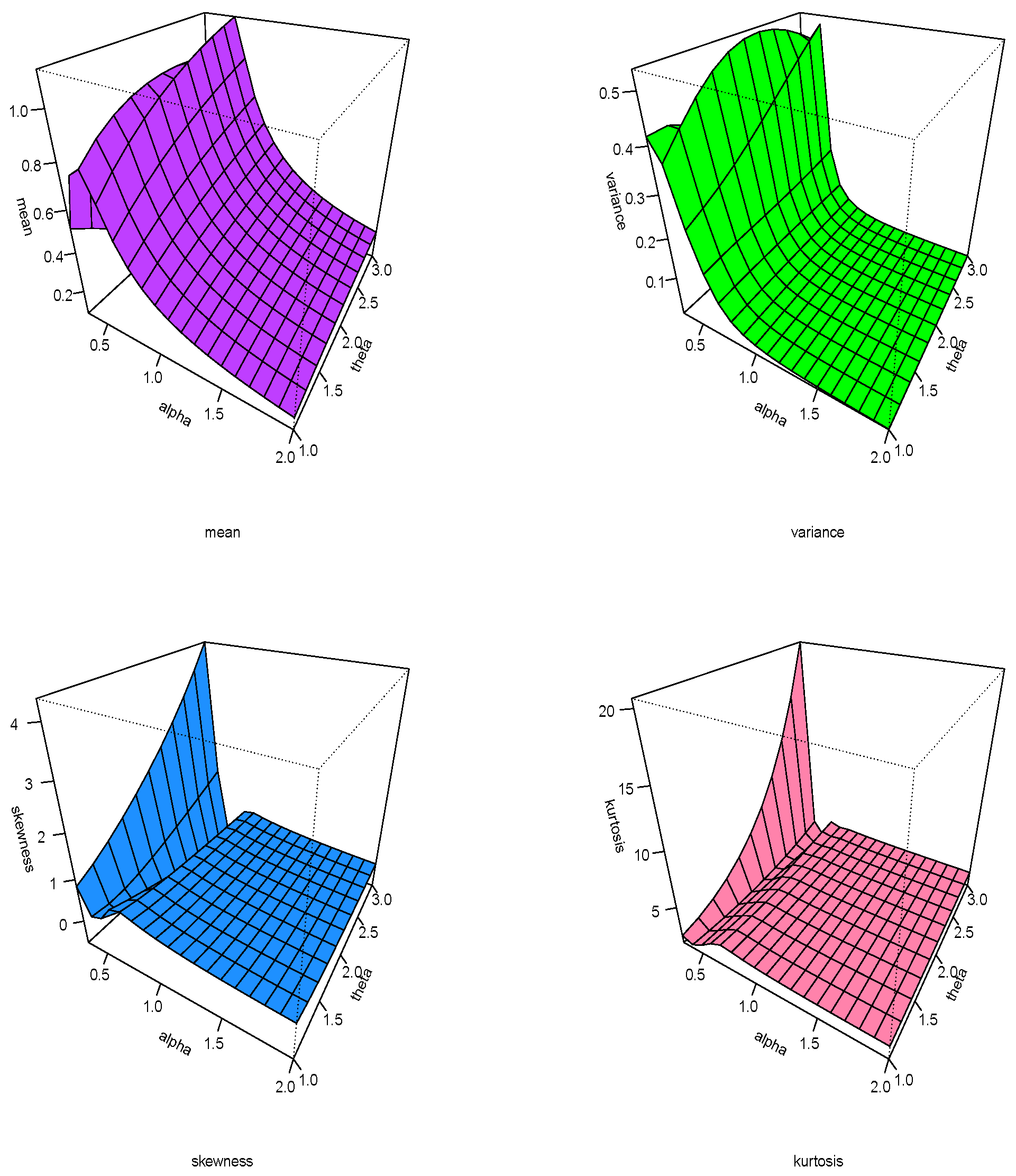
6.3. Examples
Here, we have focused our attention on three types of applications that are frequently desired by different applied researchers, so our target becomes more focused on the environmental, failure time of components and biomedical data of the study. In
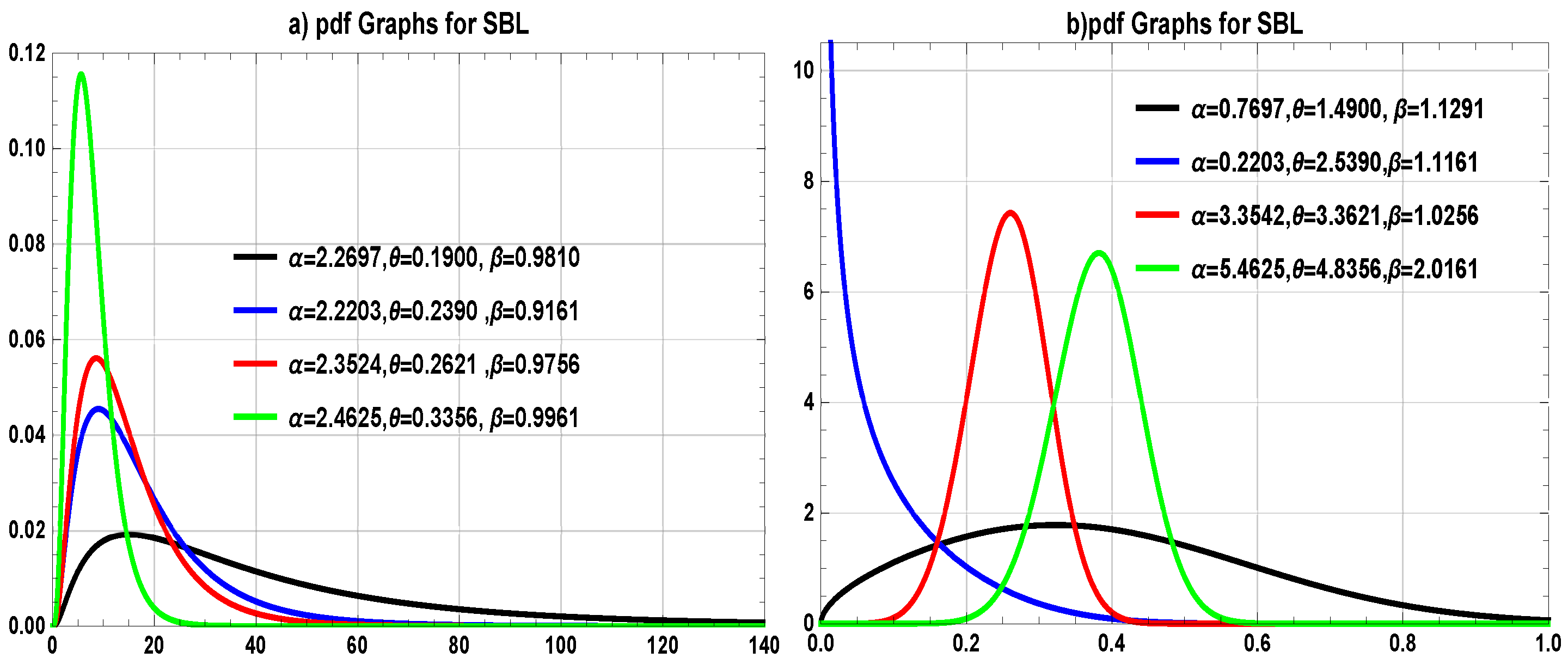
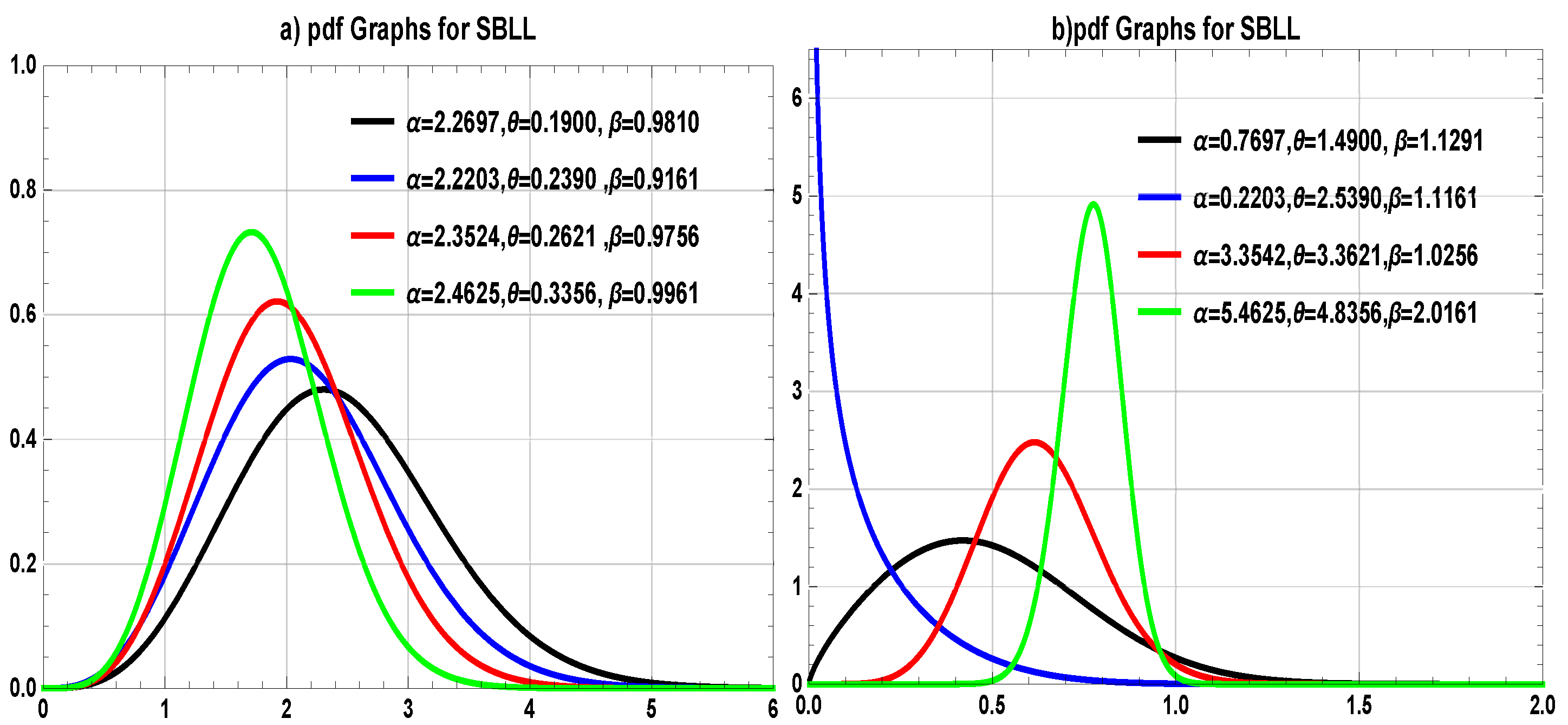
Table 4, we define two proposed distributions, SBXL and SBXLL, by their cdfs as follows.
In order to pursue these targets, we compared our models with the most competing models of that are, i.e., we have compared our proposed models as follows: SBXL is fitted on environmental data sets (Data-I and Data-II), SBXLL is fitted on the failure time of data sets (Data-III and Data-IV), and for biomedical data, (Data-V) both SBXL and SBXLL are fitted, respectively.
Case-I: Environmental Data Sets
Any occurrence, activity, or state that has a harmful effect on the environment is considered an environmental hazard. Physical or chemical pollution in the air, water, and soil is a reflection of environmental risks. Environmental risks have the ability to damage both people and the environment severely. There is a growing global effort to enhance environmental-related decision-making.
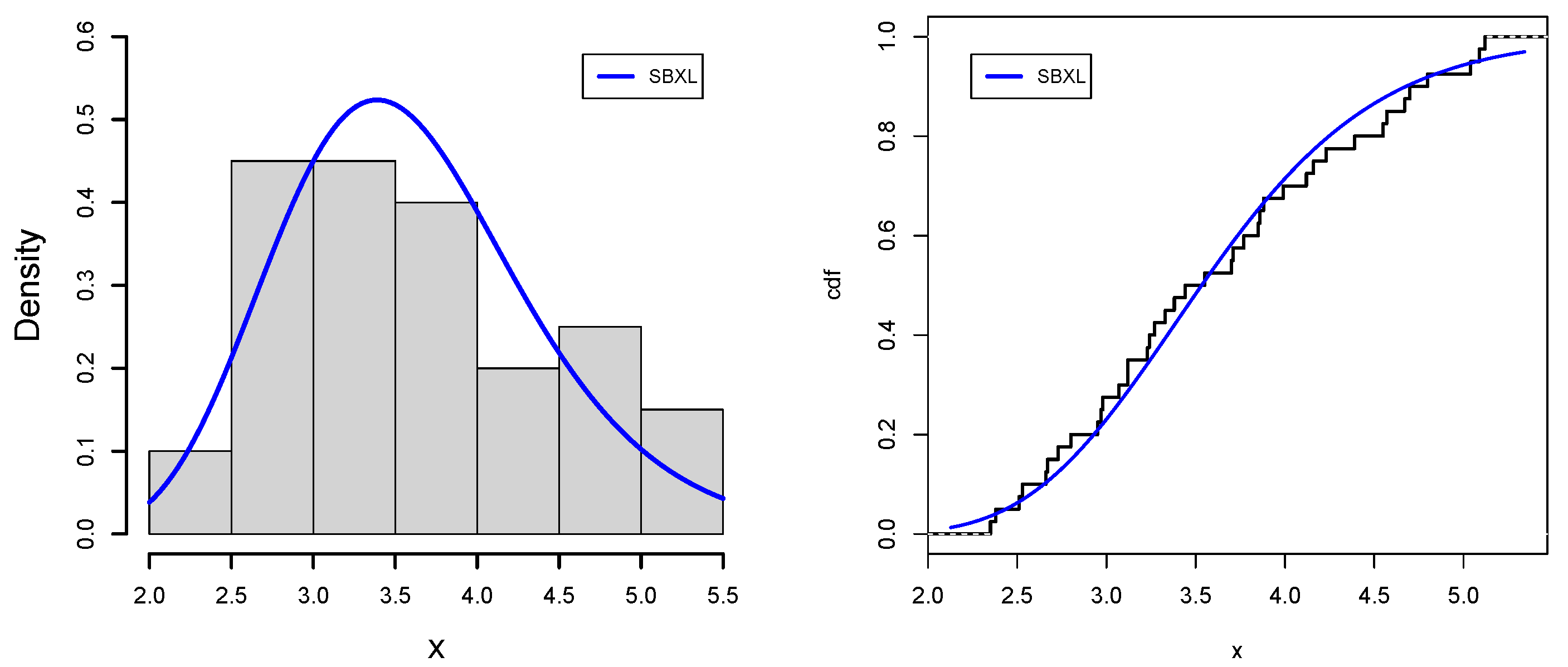
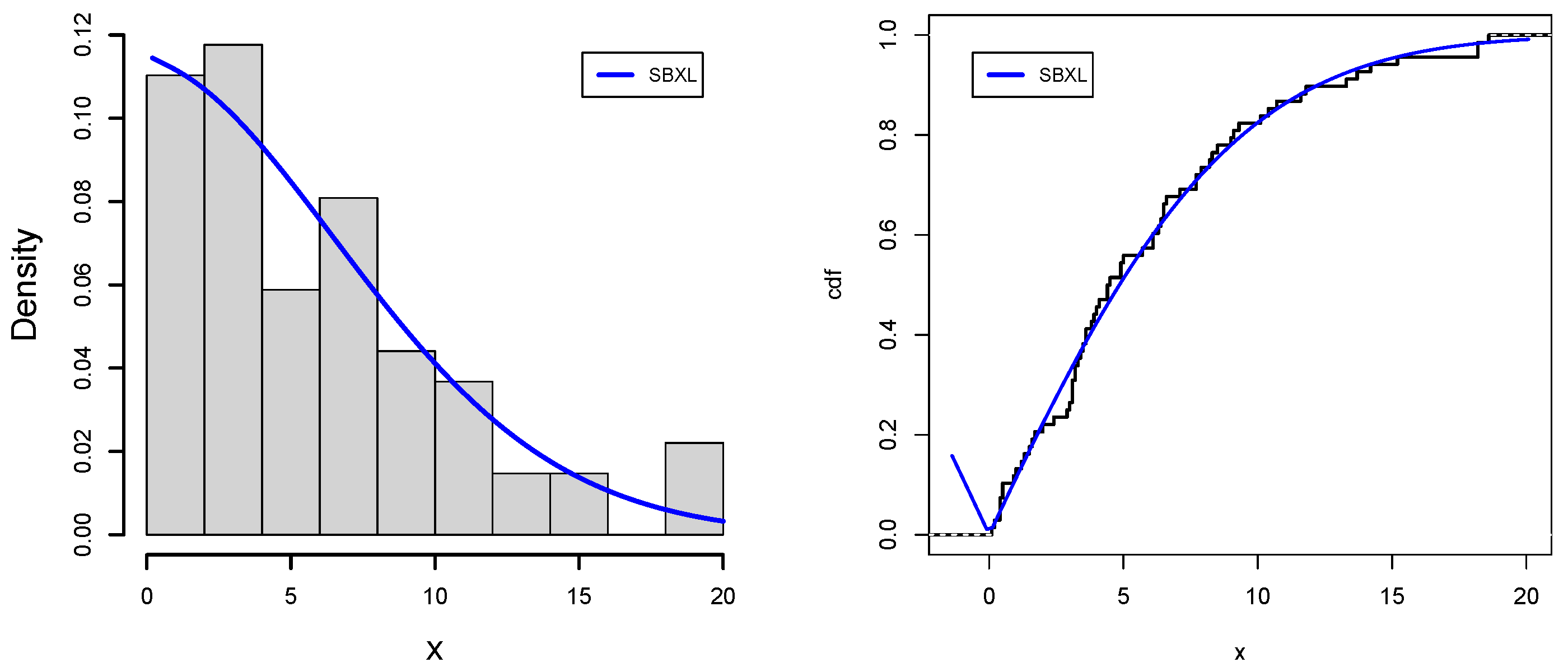
Data-I. Because of the large concentrations of nitric and sulfuric acids in the atmosphere that are washed down to the earth, acid rain is a common environmental phenomenon that has a trickle-down effect on a number of ecological variables, such as numbers of species, abundances of worms, change in the sizes of crabs, measures of quality of water or physiological condition of individual animals, etc. The production of acidic pollutants in the atmosphere results from the oxidation of sulpher and nitrogen in coal and other fossil fuels. In many industrialized nations, acid rain has significantly harmed forests. Acid rain can be avoided by using low-sulfur fuel and coal. Environmental catastrophes are covered in this part of the study. Acidity level is measured on a pH scale, which varies from one (highly acidic) to seven (neutral). Acid rain is considered to have a pH of less than 5.7. The first data measures the acidity of rainfalls for forty days in the state of Minnesota. This data set was reported by [
52], and its values are given as 3.71, 4.23, 4.16, 2.98, 3.23, 4.67, 3.99, 5.04, 4.55, 3.24, 2.80, 3.44, 3.27, 2.66, 2.95, 4.70, 5.12, 3.77, 3.12, 2.38, 4.57, 3.88, 2.97, 3.70, 2.53, 2.67, 4.12, 4.80, 3.55, 3.86, 2.51, 3.33, 3.85, 2.35, 3.12, 4.39, 5.09, 3.38, 2.73, 3.07. In addition, for drawing a valid conclusion, grouping of the data is made via the R computational package. Possible groups, [0.03, 2.54], [2.54, 6.22], [6.22, 11.8], [11.8, 21.7], [21.7, 38.7], [38.7, 60.6], possess the frequencies 9, 8, 8, 8, 8, 9, respectively.
Table 5 and
Table 6 show that there is a close association between theoretical and descriptive statistics of data. It also implies that the proposed model has an ability to work in platykurtic and positively skewed data much more effectively as compared to the competing distributions.
Furthermore,
Table 7 and
Table 8 exhibit the environment, which supports the proposed model in every aspect. These tables not only display that SBXL has the least values of goodness of fit statistics but also the minimum loss of information principle.
Data-II (
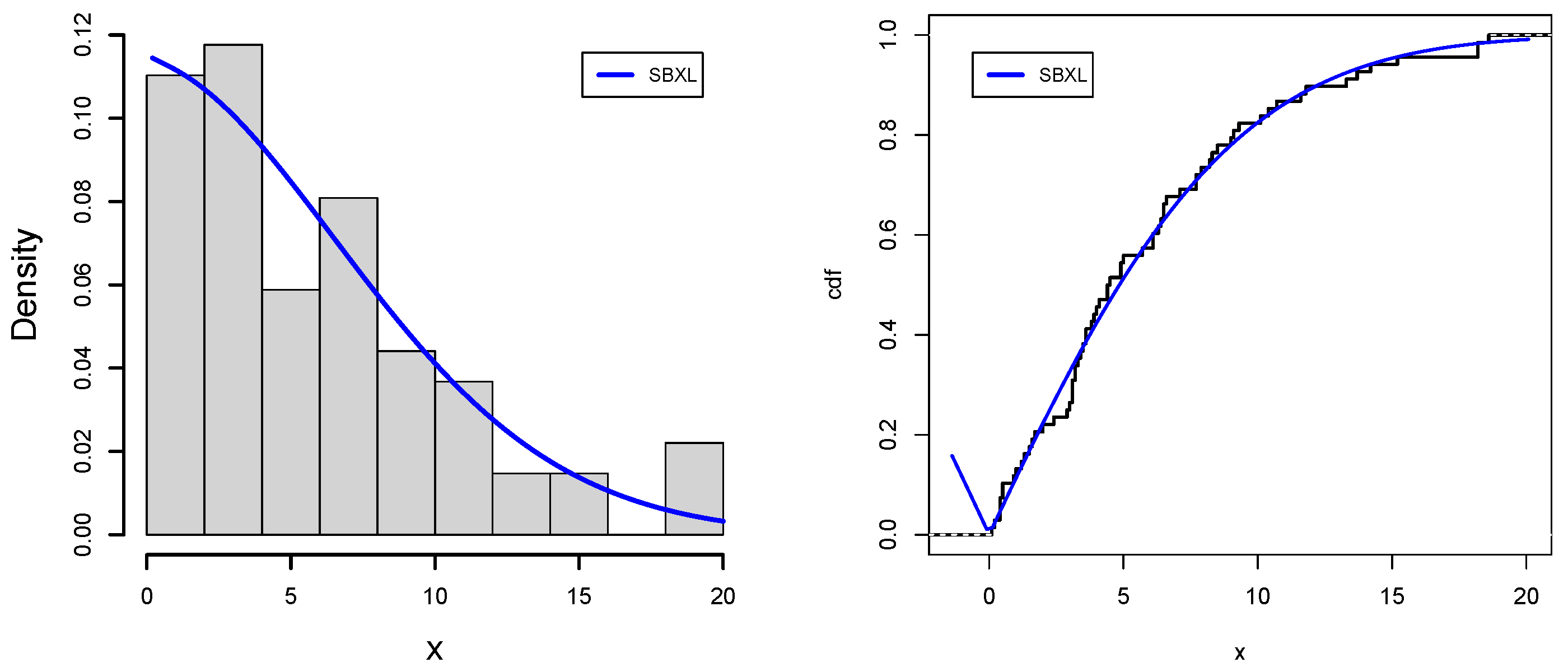
Table 9). In order to simulate detectability, distances of observed targets from transect lines are frequently utilized in line-transect distance sampling to estimate population densities. The present crisis is associated with large populations of wild animals in a particular environment. This method’s fundamental premise is that all creatures are found where they first appear. Thus, animal migration that is not controlled by the transect and observer might seriously disrupt the natural food chain in a community. This data set, obtained from [
53], represents the distances from the transect line for the 68 stakes detected in walking L = 1000 m and searching w = 20 m on each side of the line. The measurements are: 2.0, 0.5, 10.4, 3.6, 0.9, 1.0, 3.4, 2.9, 8.2, 6.5, 5.7, 3.0, 4.0, 0.1, 11.8, 14.2, 2.4, 1.6, 13.3, 6.5, 8.3, 4.9, 1.5, 18.6, 0.4, 0.4, 0.2, 11.6, 3.2, 7.1, 10.7, 3.9, 6.1, 6.4, 3.8, 15.2, 3.5, 3.1, 7.9, 18.2, 10.1, 4.4, 1.3, 13.7, 6.3, 3.6, 9.0, 7.7, 4.9, 9.1, 3.3, 8.5, 6.1, 0.4, 9.3, 0.5, 1.2, 1.7, 4.5, 3.1, 3.1, 6.6, 4.4, 5.0, 3.2, 7.7, 18.2, 4.1. For converting into groups, the bins code of the R computational package is used, and possible groups with respective frequencies are displayed as [0.1, 1.52], [1.52, 3.23], [3.23, 4.45], [4.45, 6.57], [6.57, 9.97], [9.97, 18.6], and the frequencies are 12, 11, 11, 11, 11 and 12, respectively.
Table 10 and
Table 11 also advocate that SBXL explains the data situation in a better manner. However, the tune of working the SBXL is encouraging in that it not only works in positively skewed data but also has the strength to manage the lepto kurtic curves in a better fashion as compared with the competing distributions.
Moreover,
Table 12 and
Table 13 represent that the SBXL model and the data conditions are very well by showing the minimum values of
and the highest
p-value of KS statistics alongside the least values of
and
.
Overall Analysis of Data set-I and II via Goodness of Fit:
Table 7 and
Table 8 indicate that the proposed model exhibits much better goodness of fit statistics values compared with the competing distribution. However, some silent features are worth mentioning, such as chi-square
, A
, and W
, and KS values are the least among the competing models along with the highest
p-value; thus, the mentioned tables totally support the suitability of the proposed model. Further,
Table 9 further consolidates our claim of the suitability of a larger Vuong test statistics value. In addition, the proposed model also openly displays its suitability for data set II in which
Table 12 and
Table 13 exhibit the minimum values of chi-square
and A
. Additionally,
Table 14 suggests that the proposed model is the only model with reliable Vuong statistics. Overall,
Table 8 and
Table 13 suggest that the proposed model also possesses the minimum values of log-likelihood (
) and all the other information criteria, especially when compared to its competing four-parameter and three-parameter distributions asserting the acclaimed supremacy.
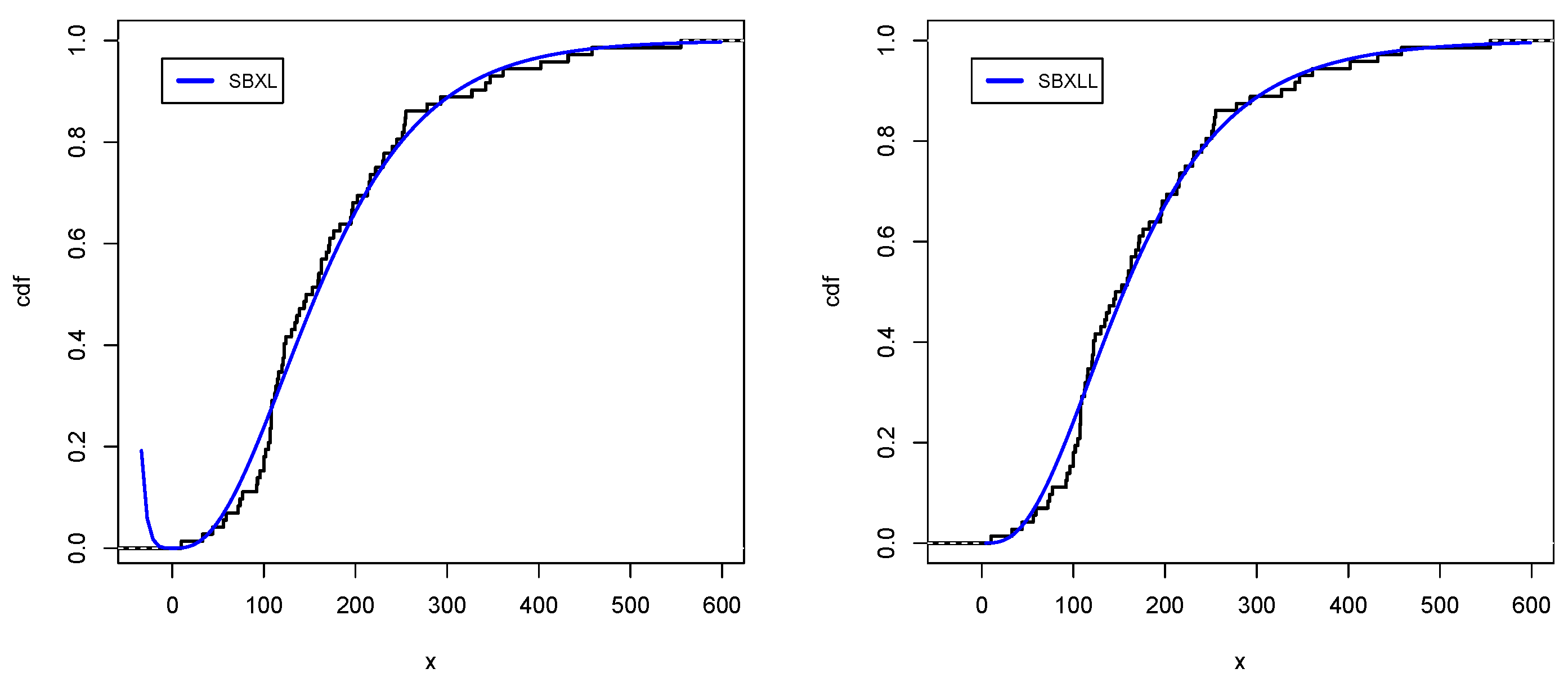
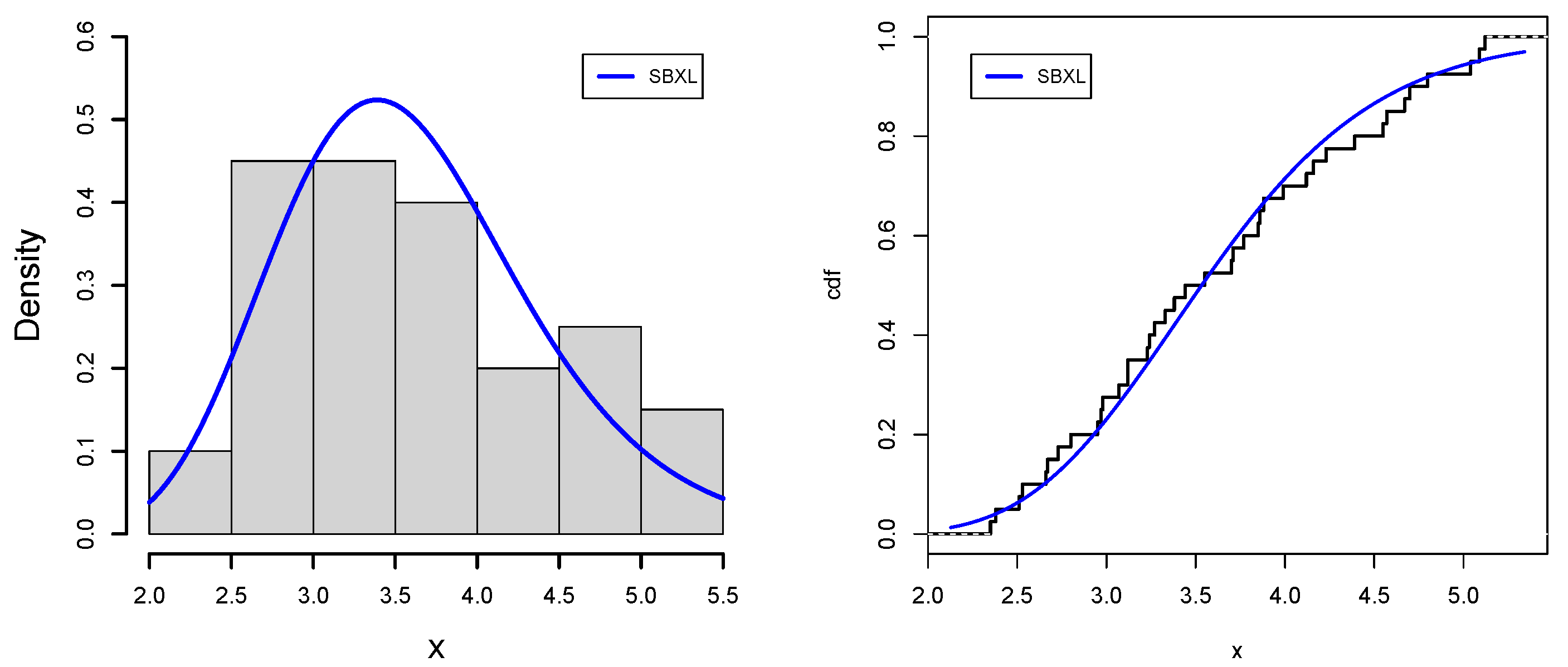
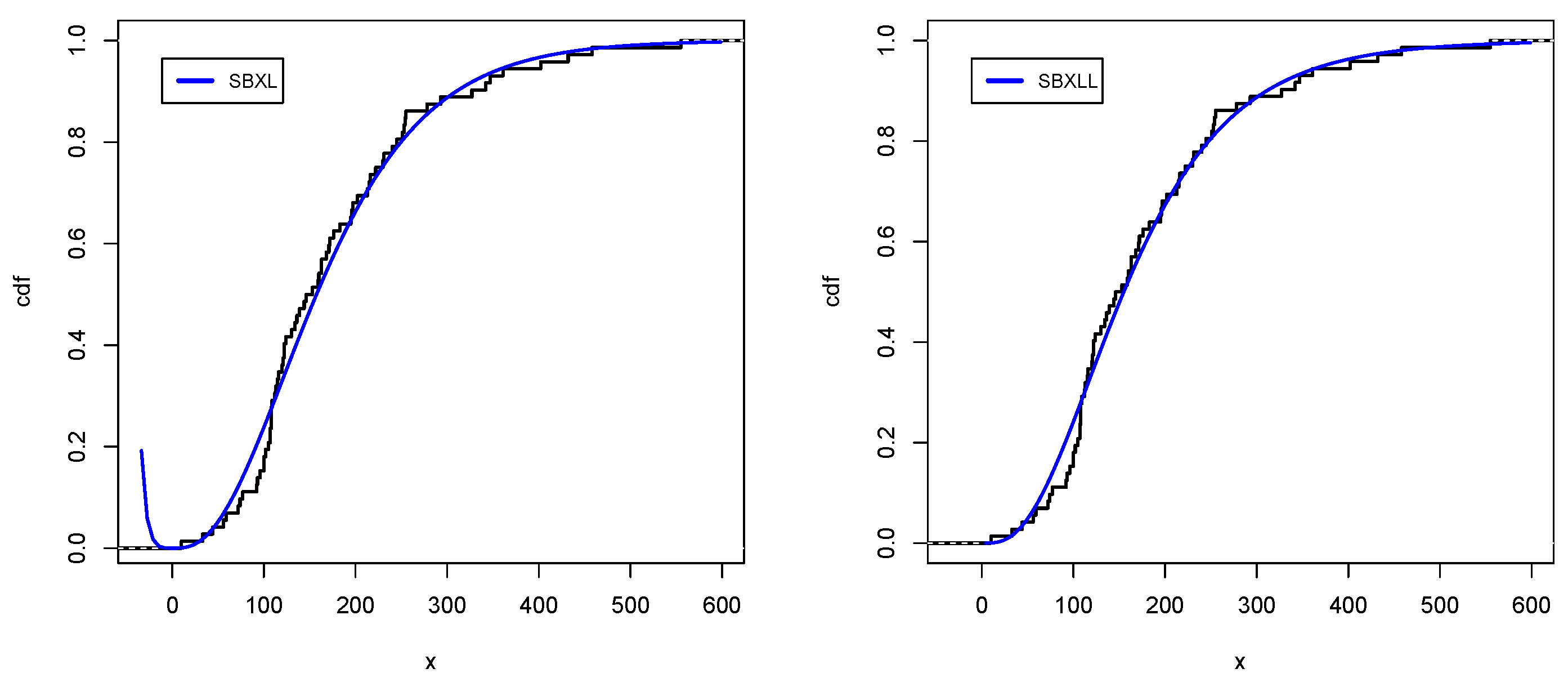
Figure 7,
Figure 8,
Figure 9 and
Figure 10 support the numerical values results of the application for data sets I and II, respectively, which strengthen our claim regarding the dominance of the SBXL model over its respective competitive models.
Case-II: Failure time data sets
Failure is the occurrence, or unsuitable state, in which any object or component of an item does not or would not operate as previously defined. Failure analysis is the logical, systematic investigation of a product, its design, use, and documentation after a failure in order to pinpoint the failure mode, pinpoint the failure mechanism, and pinpoint the failure’s fundamental cause. As systems are becoming more diverse, failure time analysis is a discipline whose significance continues to expand. In the subsection under study, we explore two data sets that are related to this field.
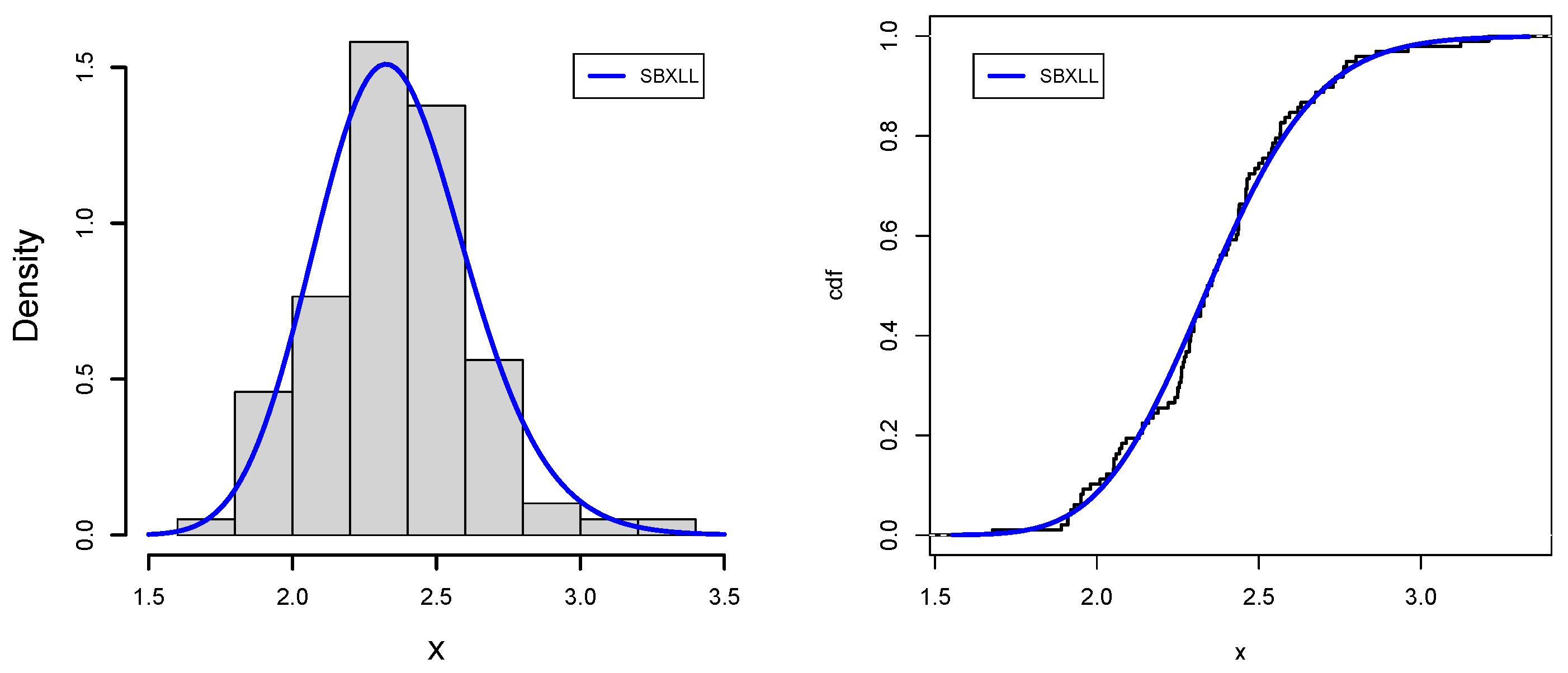
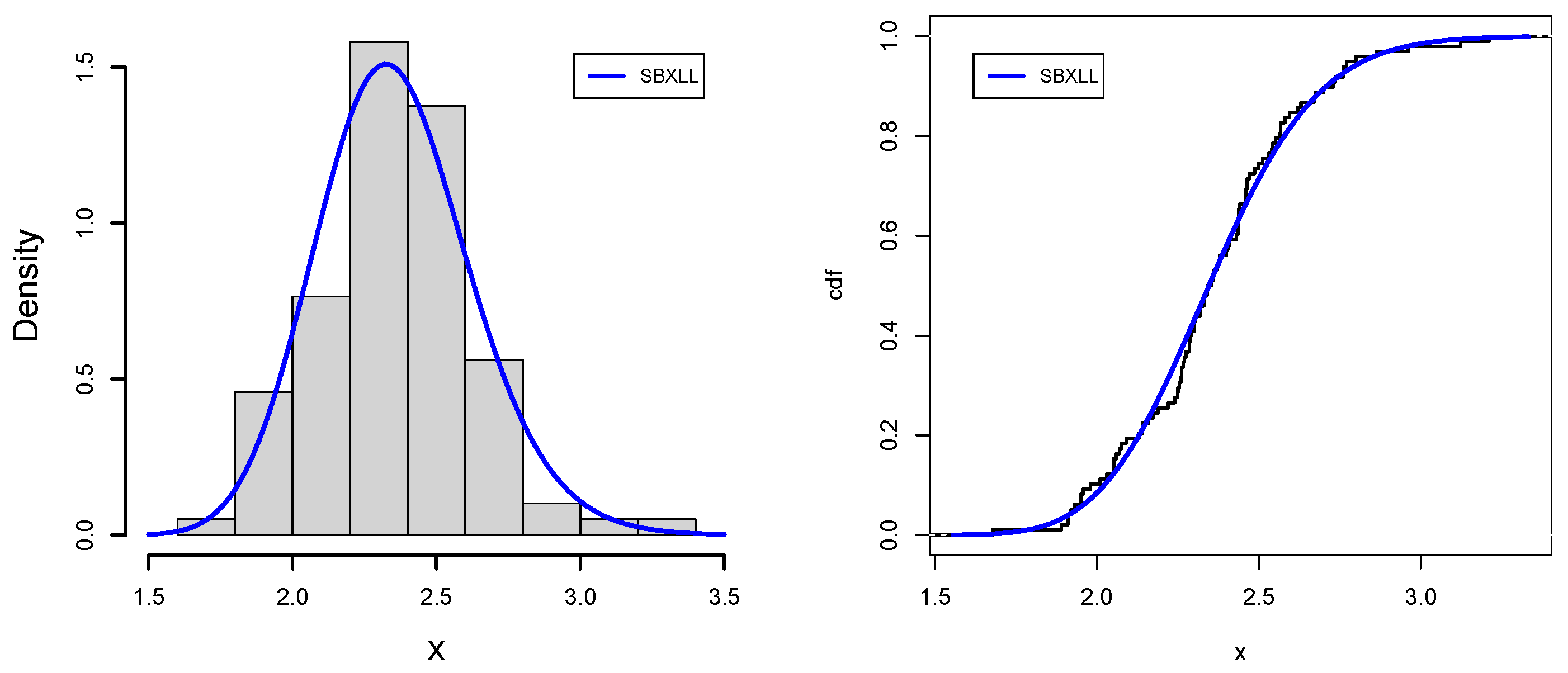
Data-III: The braking system on a vehicle defines the safety of the vehicle. The brake pads and disk setup make up the braking system, where the brake pads are critical safety components see [
27]. In this regard, a manufacturer decided to select a sample of vehicles sold over the preceding 12 months at a specific group of dealers. After that period, only the cars that still had the initial pads were reselected. For each car, the brake pad failure time measurement
could have been observed. In this regard, the following data represent the failure time of automobile brake pads for 98 cars, where the number of miles or kilometers are driven is known to be related to the pads failure time; see [
50]. However, the current data only present the failure time
(in km) data, which is left truncated; see [
47]. In addition, for drawing a valid conclusion, we have created different classes, such as [18.6, 44], [44, 53.9], [53.9, 65], [65, 77.6], [77.6, 91], [91, 166], having a number of observations against each class, which are 15, 15, 14, 15, 14, 15, respectively.
Table 15 and
Table 16 also reinforce that SBXLL explains the data situation in a nice way. However, the theoretical values of mean, median, standard deviation, skewness and kurtosis are in accordance with its observed facts. Further, the tune of working the SBXLL is encouraging in that it not only works in positively skewed data but also has the strength to manage the lepto kurtic curves in a better fashion compared with its competing distributions (
Table 17 and
Table 18).
Furthermore, the VT statistics, as displayed in
Table 19, are also in close association with the above results. Thus, our proposed model seems to be a natural choice for such data sets.
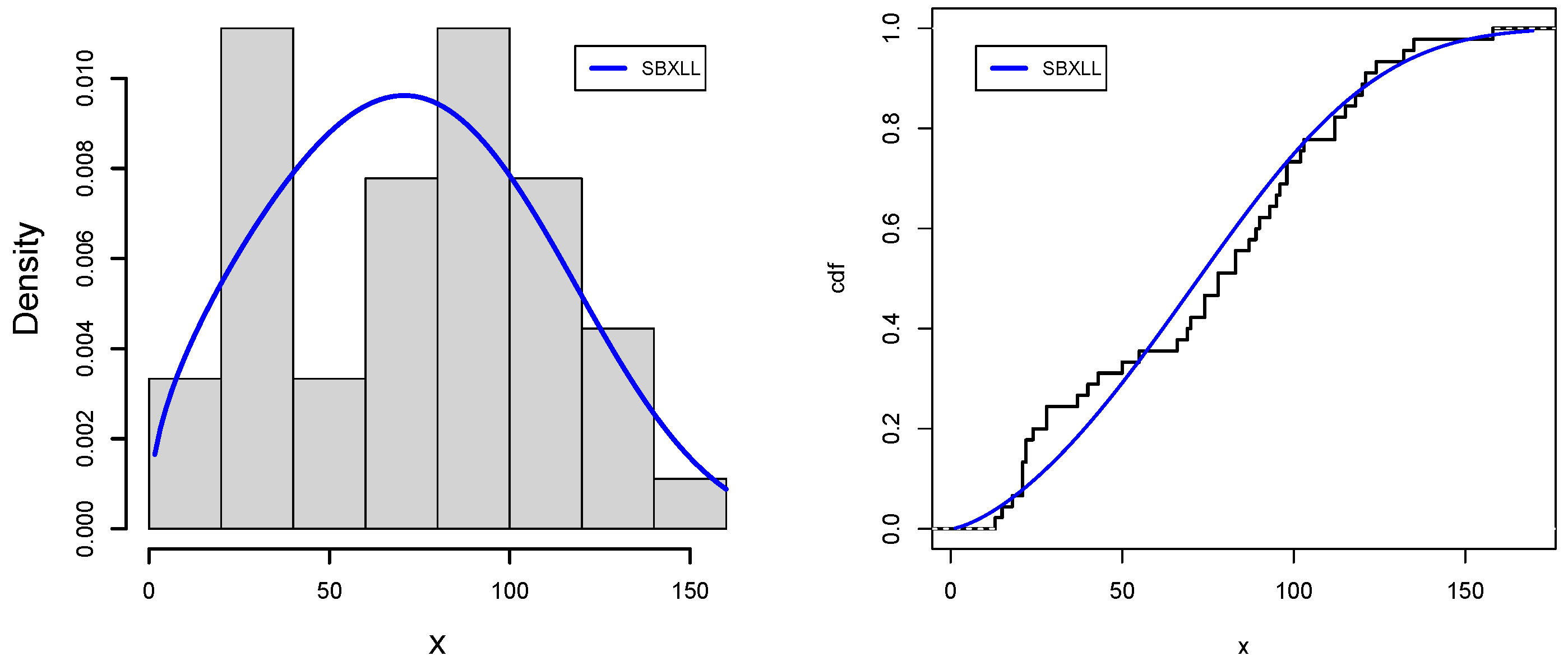
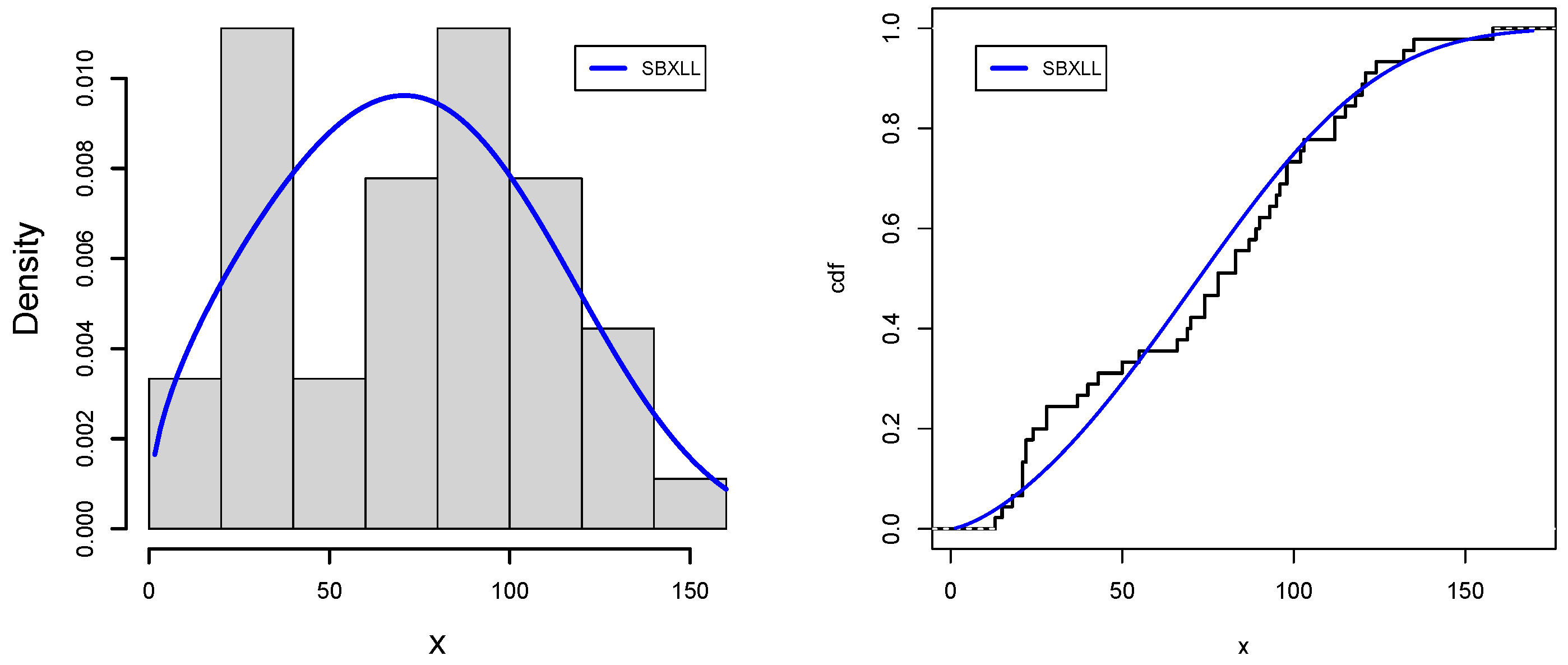
Data IV: A power failure is a period of time during which the electricity supply to a specific structure or area is interrupted, typically as a result of a natural weather event, such as damage to the cables caused by strong winds, lightning, freezing rain, ice buildup on the lines, snow, etc. Power outages can also be triggered by wildlife and tree branches hitting power cables. This data set is obtained from [
29] the power failures’ lengths measured in minutes: 22, 18, 135, 15, 90, 78, 69, 98, 102, 83, 55, 28, 121, 120, 13, 22, 124, 112, 70, 66, 74, 89, 103, 24, 21, 112, 21, 40, 98, 87, 132, 115, 21, 28, 43, 37, 50, 96, 118, 158, 74, 78, 83, 93, 95. We have also grouped the data with the help of the bins code of the R computational package, where possible classes with respective frequencies are enlisted as [13, 22.7], [22.7, 53.3], [53.3, 78], [78, 95.3], [95.3, 114], [114, 158] and frequencies are 8,7,8, 7,7 and 8, respectively (
Table 20 and
Table 21).
Moreover,
Table 22 and
Table 23 offer that the SBXLL models and the data conditions are very well by showing the minimum values of
and highest
p-value of KS statistics along with the lowest values of
, as well as the lowest loss of information behavior.
Furthermore, the VT statistics, as displayed in
Table 24, are in close association with the above results. Thus, our proposed model seems to be a natural choice for such data sets.
General discussion about data set-III and IV:
Table 15 and
Table 16 show that data set-III is positively skewed; however,
Table 20 and
Table 21 related to data set-IV exhibit a negatively skewed behavior of platykurtic nature. In addition, both data sets are in a non-normal phenomenon, which is tested by the Shapiro–Wilk test and found to be non-normal with the Shapiro–Wilk test statistics 0.9603 and 0.9455 with
p-values 0.0087 and 0.0342, respectively. Furthermore, for outlier detection, Grubbsťest is used, which indicates that data set-III shows some evidence of outlier presence with critical values of
, whereas data set-IV does not produce any sign of outliers with
at the 5% level of significance.
Analysis of Data set-III and IV via Goodness of Fit: From
Table 17,
Table 18,
Table 22 and
Table 23, it is quite evident that the proposed model yielded much better goodness of fit statistics as compared to its competing distributions. These statistics completely outfit the competing models in all respects. Further, minimum
outweighs the VT statistic value in
Table 19 and
Table 24, which paves the path of suitability of the proposed model.
Figure 11 and
Figure 12 support the numerical value results of applications for data sets III and IV, respectively, which further solidifies the superiority of SBXLL models over the competitive models.
Case-III: Biomedical Data Set
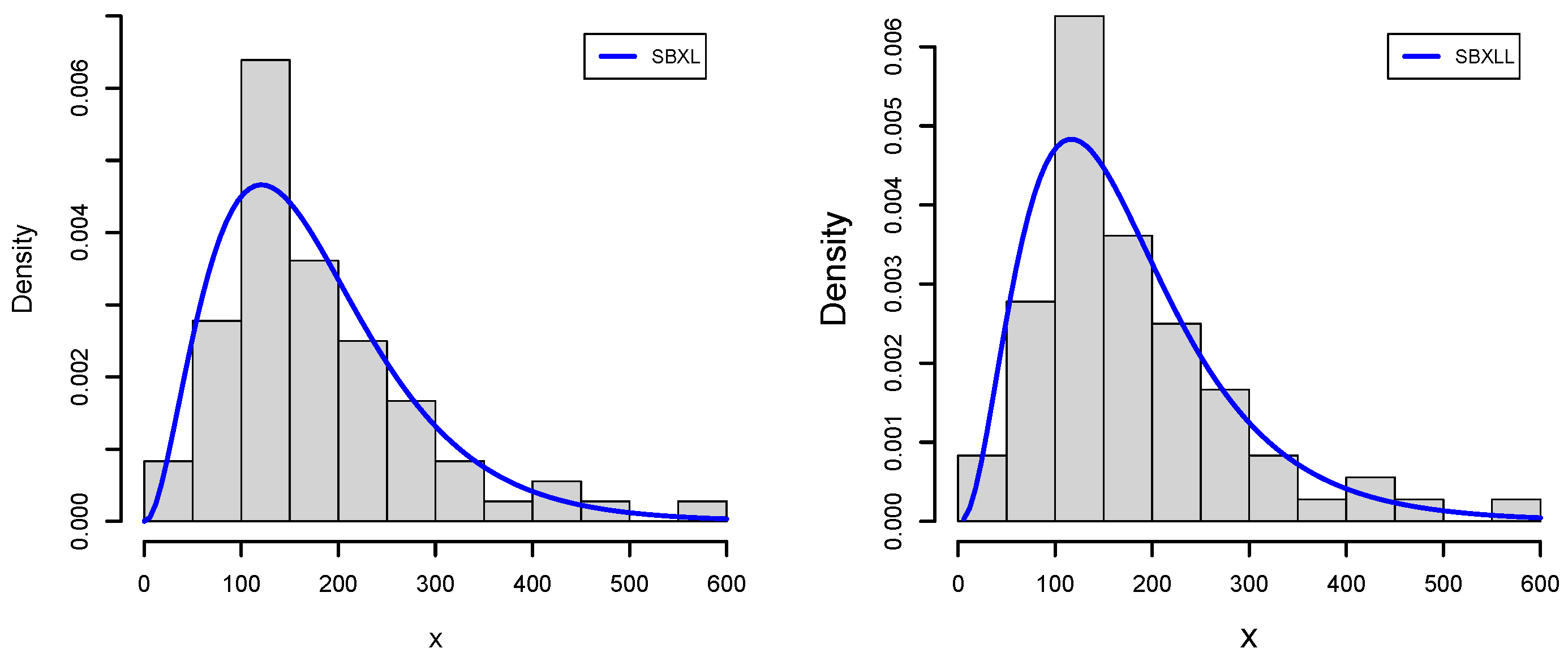
Data-V One of the most serious bacterial diseases in the world is mycobacterial tuberculosis (MBT). MBT infection affects two billion people, according to estimates. Since MTB is easily transmitted and long-course chemotherapy treatments are challenging to deliver, controlling the disease is a daunting task. Developing short-term antibiotic regimens to reduce the emergence of drug resistance, developing novel medications to treat TB patients, and developing new vaccines with more efficacy than traditional vaccines, such as BCG, are all critically needed new methods for the control of TB. Organs and tissues from guinea pigs are typically utilized in scientific research. Guinea pig blood transfusions and isolated organ preparations, including lung and intestine from the species, are extensively used in studies to develop novel drugs. The fifth data set corresponds to the survival time of the guinea pigs after receiving an injection of a specific amount of MBT in a medical experiment, as recently studied by [
54] in the context of comparative parameter estimation techniques. some descriptive measures of the data are reported in
Table 25.
The descriptive statistics reveal that data-V has a right-tailed distribution. A higher
signifies more varied results when MBT is infused into the bloodstream of guinea pigs. This variability is evident from the kurtosis result of platykurtic characteristics. The result in
Table 26 shows that both special models, SBXL and SBXLL, have similar properties to fit data of this nature.
Moreover,
Table 27 and
Table 28 represent that for SBXL and SBXLL models, the data are displayed very well by showing minimum values of
, the highest
p-value of KS statistics, and the lowest values of AD
and CVM
, as well as the lowest loss of information behavior.
Furthermore, the VT statistics as displayed in
Table 29 are closely related to the above results. These results suggest that the proposed model (SBXL) seems to be more appropriate for such data set.
The comparison of VT statistics, presented in
Table 30, reasserts the superior behaviour of the proposed SBXLL for the data set.
Analysis of Data set-V via Goodness of Fit: The empirical findings in
Table 27 and
Table 28 are quite revealing of the fact that the proposed models, SBXL and SBXLL, yield far better goodness of fit statistics than its parallel models. Moreover, the minimum
is significant to the VT statistic value in
Table 29 and
Table 30, which further strengthens the suitability of the proposed model.
Figure 11 and
Figure 12 support the evaluated results of application for data set V, which further solidifies the superiority of SBXL and SBXLL models over well-established competing models.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}