This part deals with two separate engineering applications to highlight the utility of the provided estimating approaches and the applicability of the proposed estimators in real situations.
6.1. Electrical Appliances
In this subsection, we analyze the first dataset which consists of the number (in thousands) of cycles to failure for 60 electrical appliances in a life test as presented in
Table 2. The considered dataset is taken from Lawless [
33] and recently analyzed by Dey and Elshahhat [
34]. To show the flexibility of the APE distribution, based on the complete electrical appliances dataset, we compare the fit of the APE distribution with three well-known distributions namely: Weibull (W), gamma (G), and log-normal (LN) distributions. For this purpose, different goodness-of-fit measures are employed, such as negative log-likelihood (NL), Akaike (A), Bayesian (B), consistent Akaike (CA), Hannan–Quinn (HQ), Anderson–Darling (A*), and Cramér von Mises (W*) information criteria. Further, for all considered distributions, the Kolmogorov–Smirnov (KS) statistic with its
p-value is also computed. The MLEs of the model parameters with their standard errors (SEs), as well as the different model selection criteria, are calculated and reported in
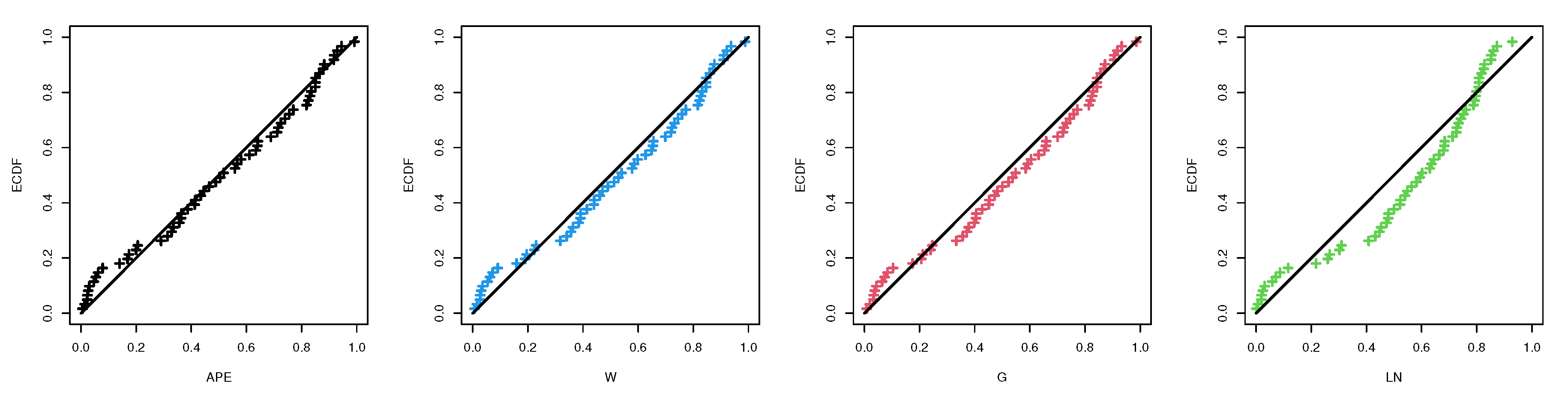
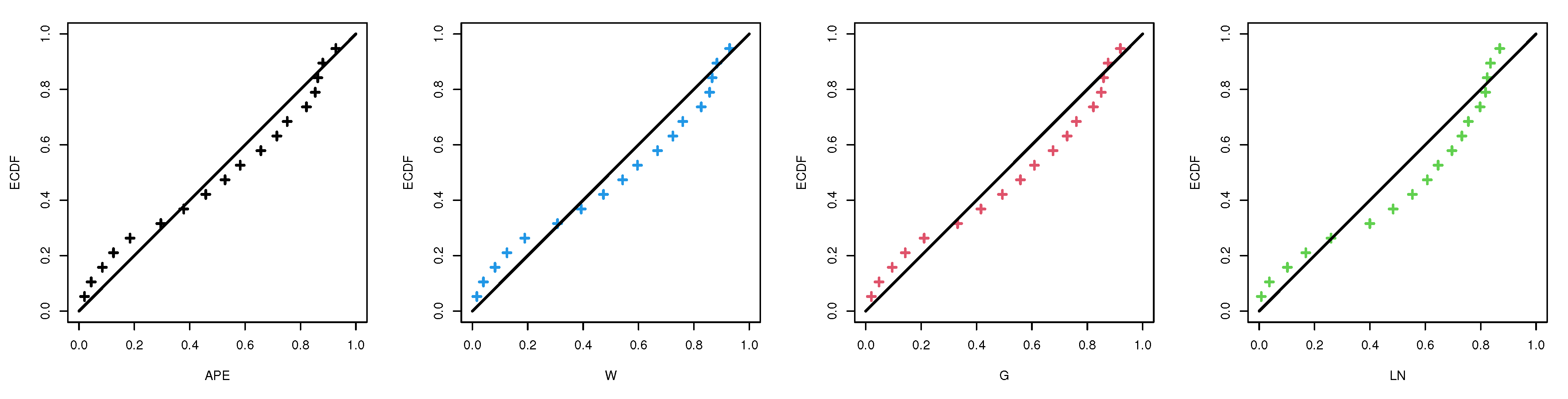
Table 3. The results indicate that the APE distribution provides a better fit than the other distributions because it has the lowest values of all given model selection measures. We also draw quantile–quantile plots of the APE, W, G and LN distributions which are shown in
Figure 5. It also supports the same findings.
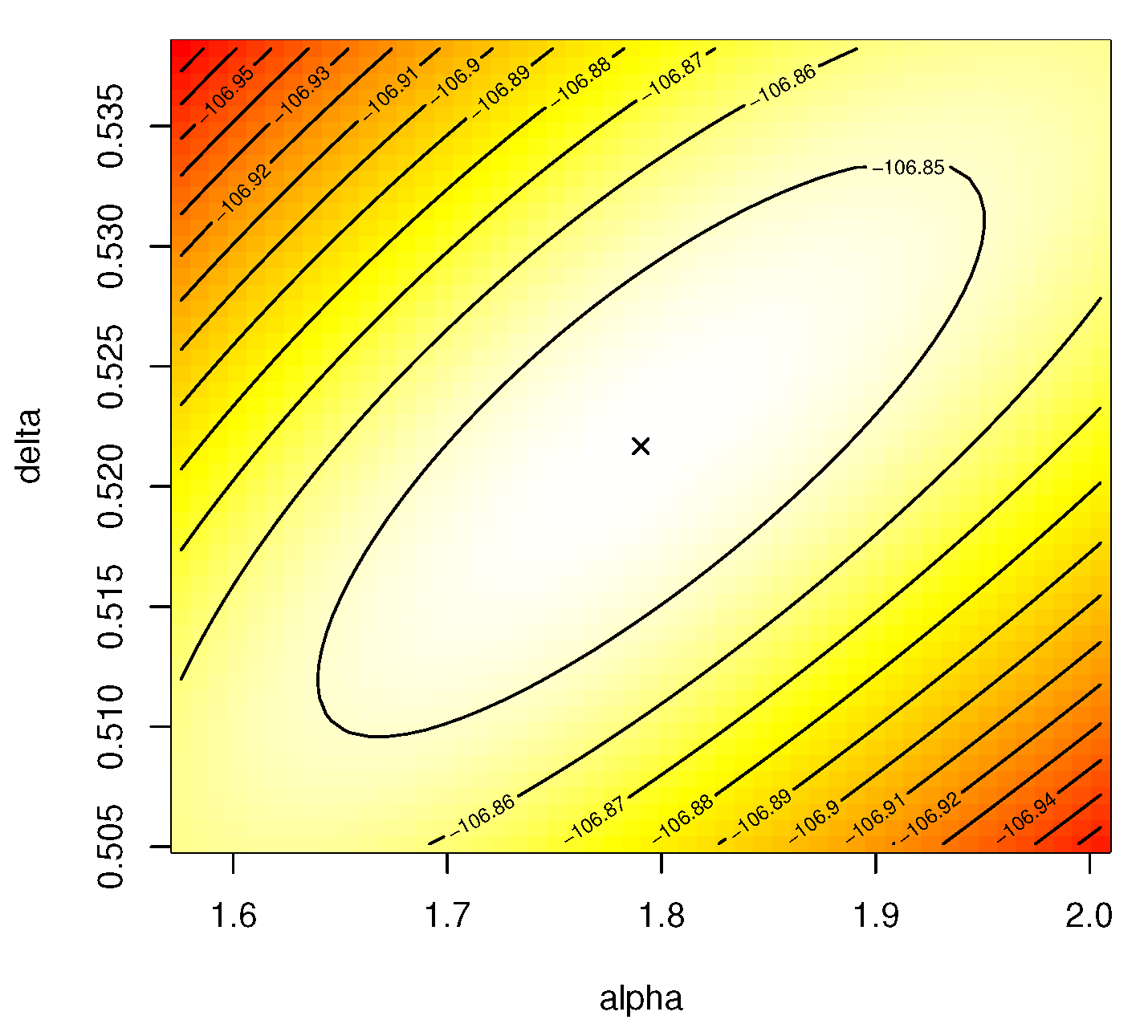
Figure 6 provides the contour plot of the log-likelihood function for
and
by using the complete electrical appliances dataset. It shows that the best starting values of
and
are close to 1.7904 and 0.5217, respectively, as well as the fact that it indicates that their MLEs exist and are unique.
Using the complete electrical appliances failure times, we generate a first-failure censored sample after randomly grouping this dataset into 20 groups with
items within each group and report it in
Table 4. Thus, the first-failure censored sample (in order) is: 0.014, 0.034, 0.059, 0.061, 0.069, 0.080, 0.123, 0.142, 0.210, 0.381, 0.464, 0.479, 0.556, 0.574, 0.839, 0.991, 1.088, 1.275, 1.355, and 1.397.
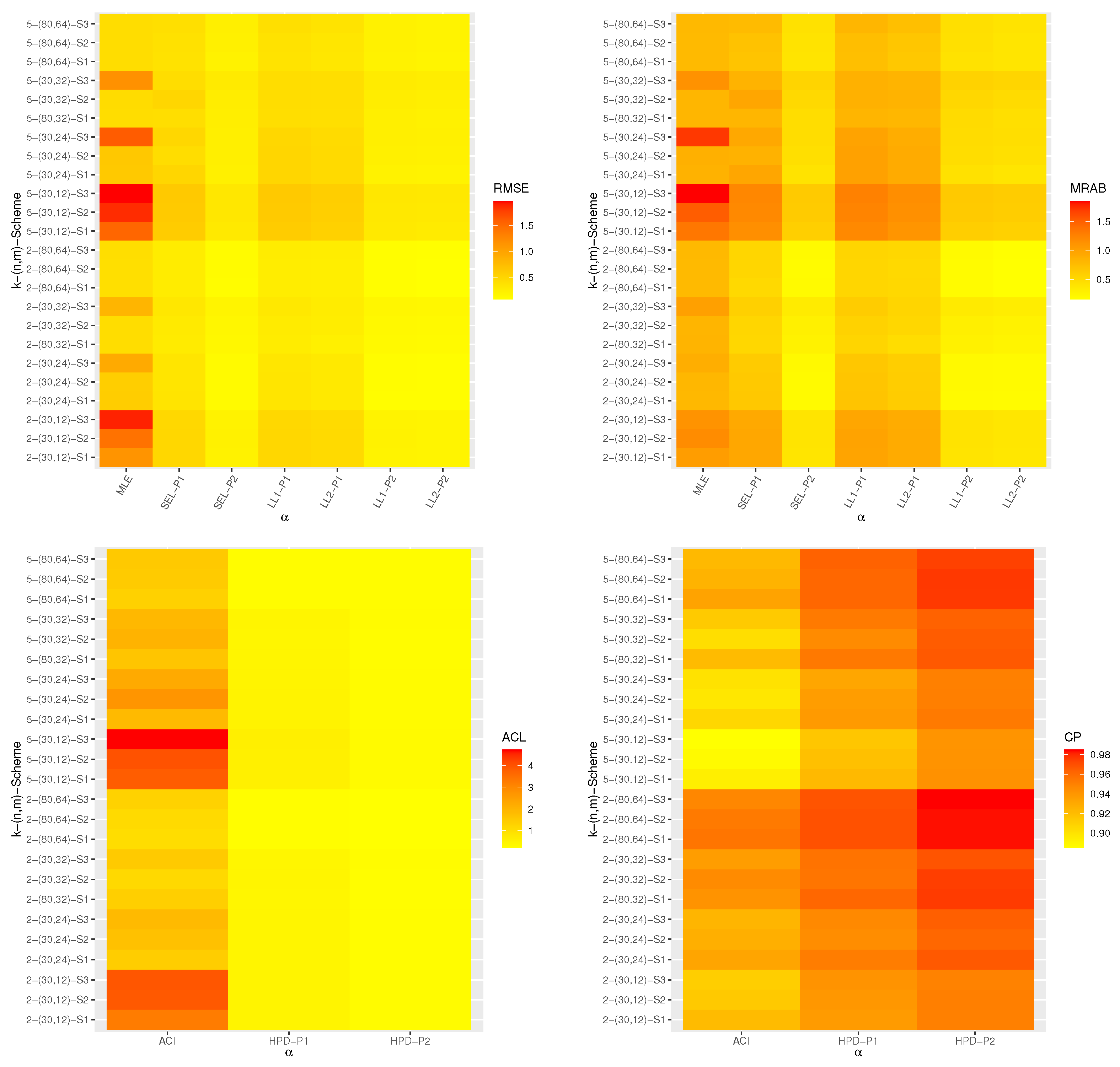
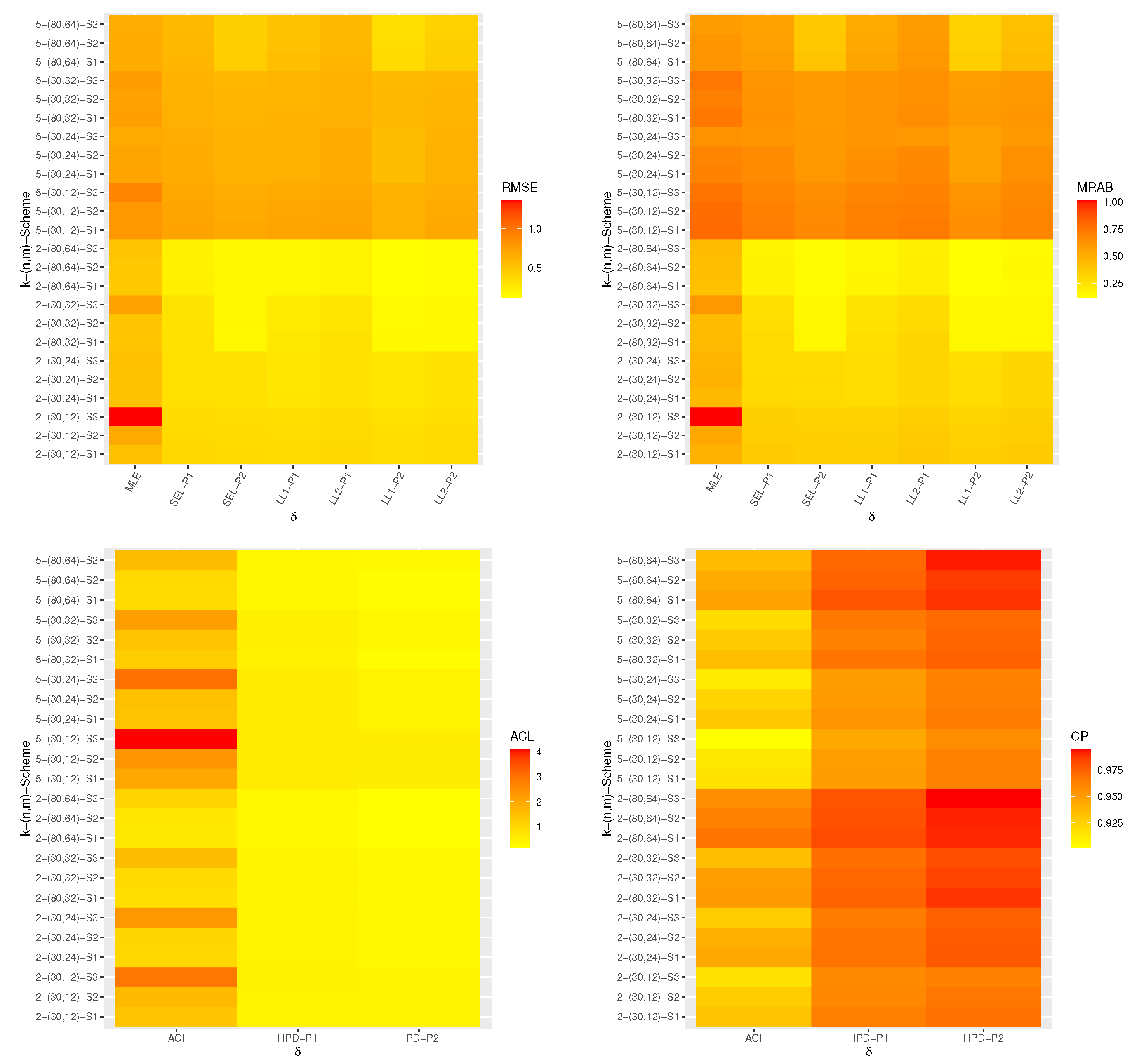
Using this first-failure censored data, three different progressive first-failure censored samples using three different censoring schemes with
are generated and reported in
Table 5. For brevity, the censoring scheme
is denoted by
. For each generated PFFC sample presented in
Table 5, we calculating the MLEs with their SEs of
,
,
and
(at time
).
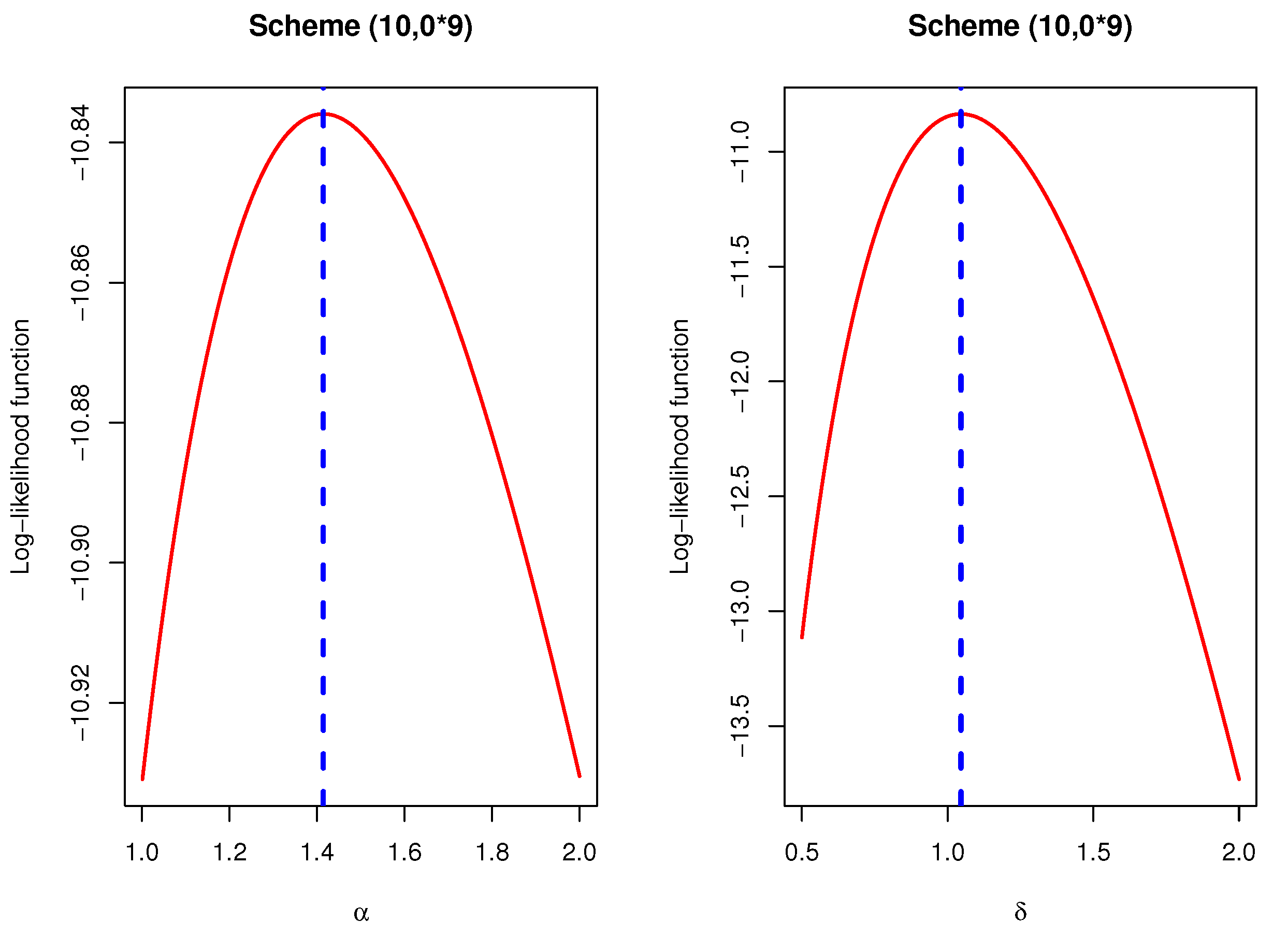
Figure 7 shows the plots of the log-likelihood functions of
and
for scheme
as an example which shows that the MLEs of
and
exist and unique.
Via the M-H algorithm sampler, from 30,000 MCMC samples with 5000 burn-in, the Bayes estimates with their SEs of
,
,
, and
(at time
) are developed under SEL and LL (for
) functions using non-informative prior. Additionally, the lower and upper bounds of the 95% ACI/HPD credible interval estimates with their interval lengths are also calculated. The MLEs of
and
are chosen as the initial guesses to apply the M-H algorithm. All point and interval estimates of
,
,
, and
are reported in
Table 6 and
Table 7, respectively. It is clear, from
Table 6 and
Table 7, that the point estimates of
,
,
, and
obtained by both likelihood and Bayesian estimation methods are quite close to each other. A similar pattern is also observed in the case of interval estimation using ACIs and HPD credible intervals.
Using the data in
Table 5, the proposed optimum criteria are also computed and provided in
Table 8. It shows that the progressive censoring scheme
is the optimal scheme over others for criteria 1, 2, and 3, while the progressive censoring scheme
is the optimal scheme than others for criterion 4.
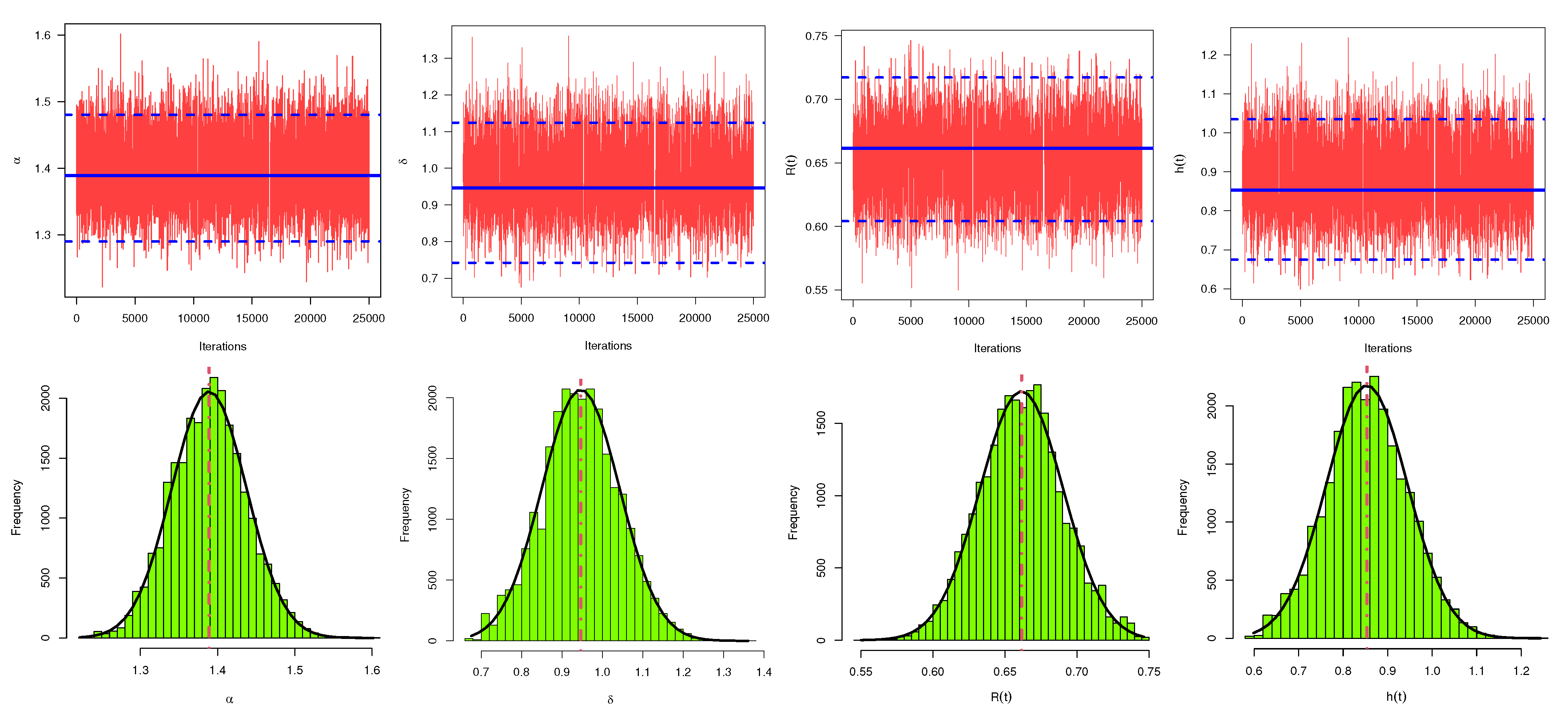
To assess the convergence of MCMC outputs, using the generated sample by censoring scheme
(as an example), trace plots of MCMC simulated variates with their sample mean (horizontal soled line (—)) and two bounds of 95% HPD credible intervals (horizontal dashed lines (- - -)) of
,
,
and
are displayed in
Figure 8. Additionally, using a Gaussian kernel for the same sample, the histograms of the simulated MCMC estimates with their sample mean (vertical dotted line (:)) of
,
,
, and
are also displayed in
Figure 8. It shows that the MCMC technique converges very well and it also shows that discarding the first 5000 samples is appropriate size to ignore the effect of the initial values. It can be also seen, from
Figure 8, that the simulated MCMC variates of
and
are fairly symmetrical while the generated posteriors of the
and
are negative and positive quite skewed, respectively.
6.2. Electronic Devices
The second dataset contains the failure times of 18 electronic devices which are: 5, 11, 21, 31, 46, 75, 98, 122, 145, 165, 196, 224, 245, 293, 321, 330, 350, and 420. This dataset was originally reported by Wang [
35], and recently analyzed by Elshahhat and Abu El Azm [
36] and Alotaibi et al. [
15]. From the complete electronic devices data, the MLEs (along with their SEs) and the model selection criteria (NL, A, B, CA, HQ, A*, W*, and KS) of APE distribution and the other competitive lifetime (W, G, and LN) models are calculated and displayed in
Table 9. It shows that the APE distribution fits the electrical appliances data quite well, compared to others. Moreover, the corresponding quantile–quantile plots of the APE distribution and its competing models are displayed in
Figure 9. It is evident that the APE distribution is the best choice among all the competing models based on fitting electronic devices data.
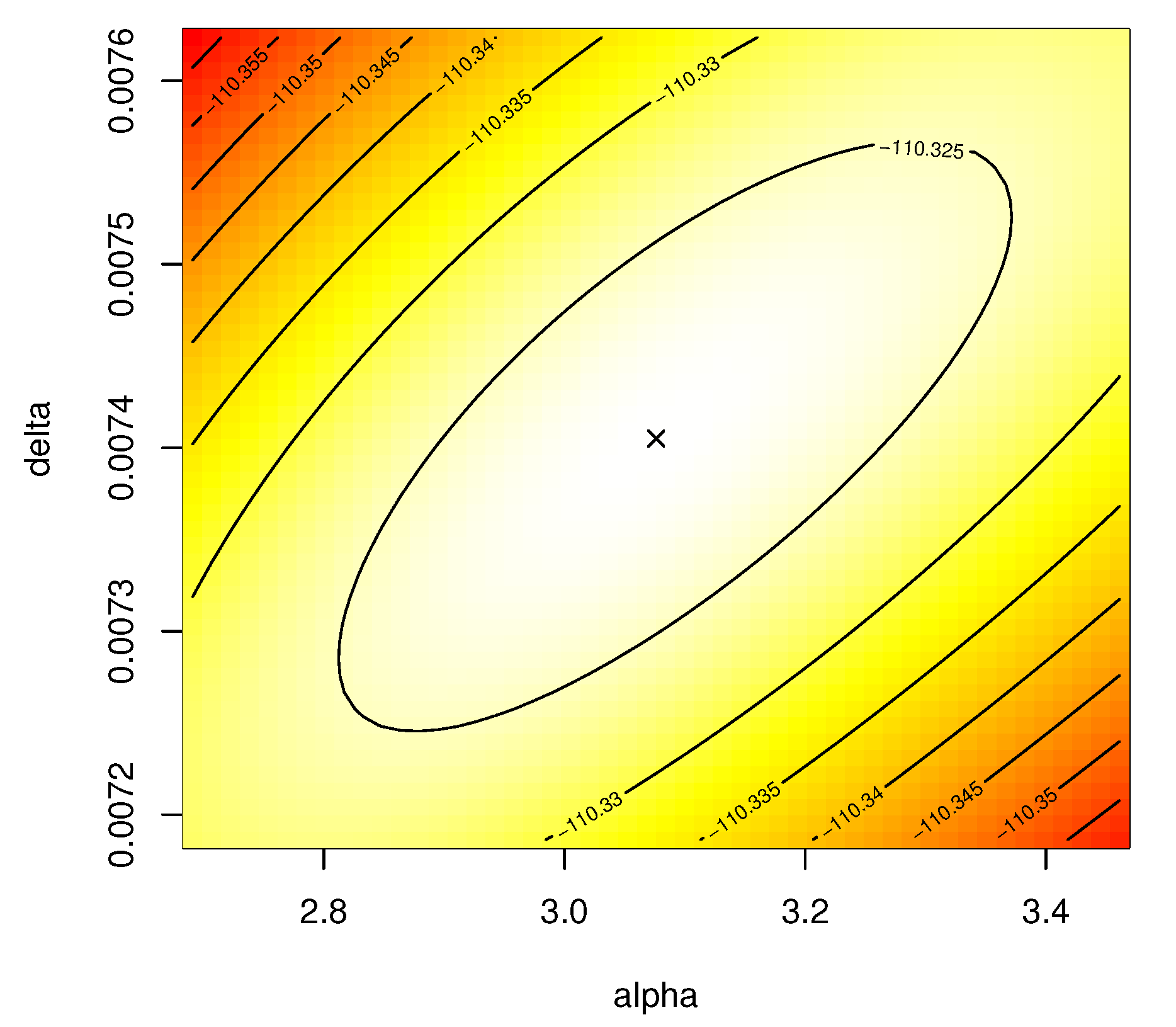
Figure 10 shows that the best initial values of
and
are close to 3.0761 and 0.0074, respectively, as well as it also indicates that their MLEs exist and are also unique.
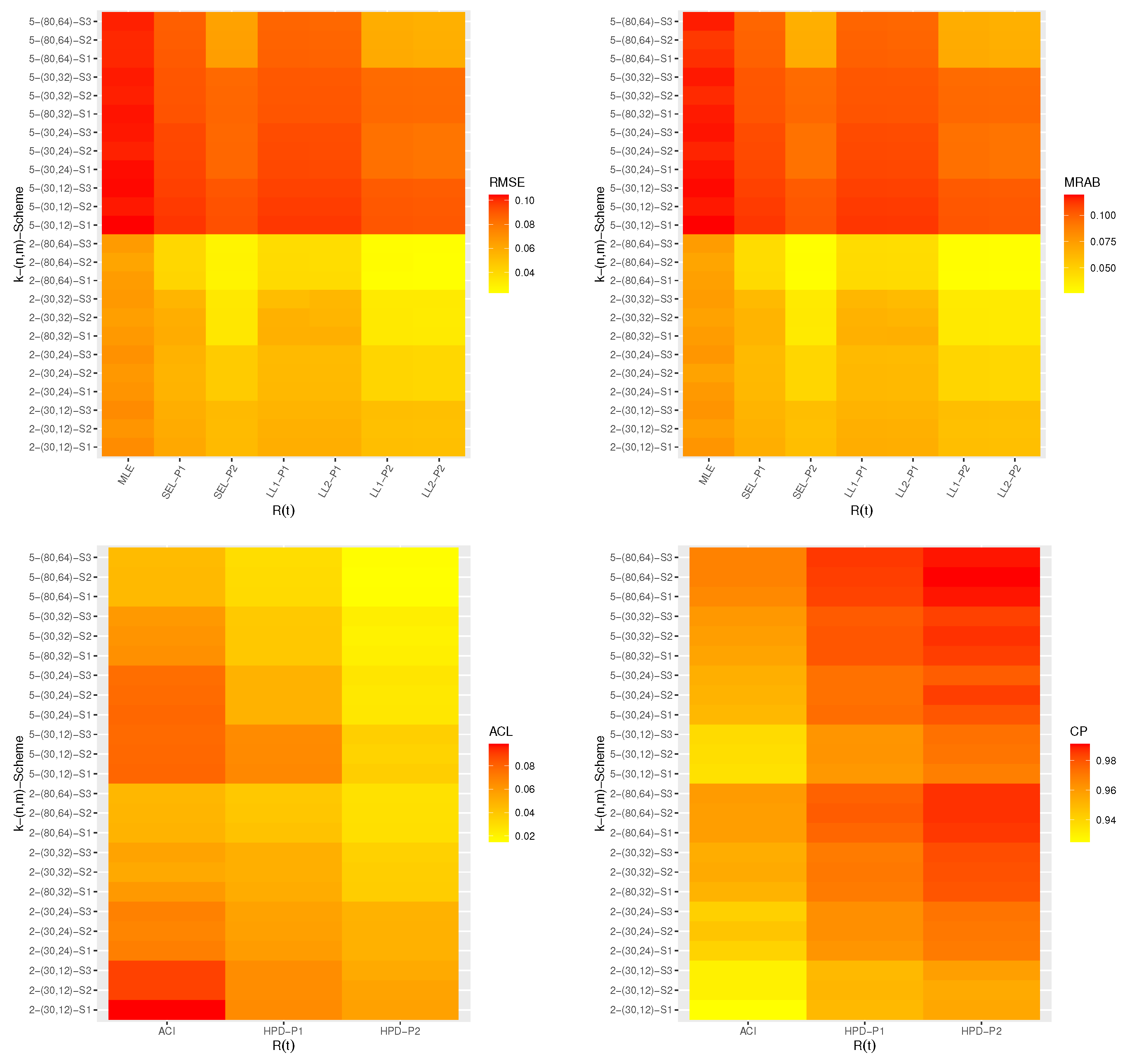
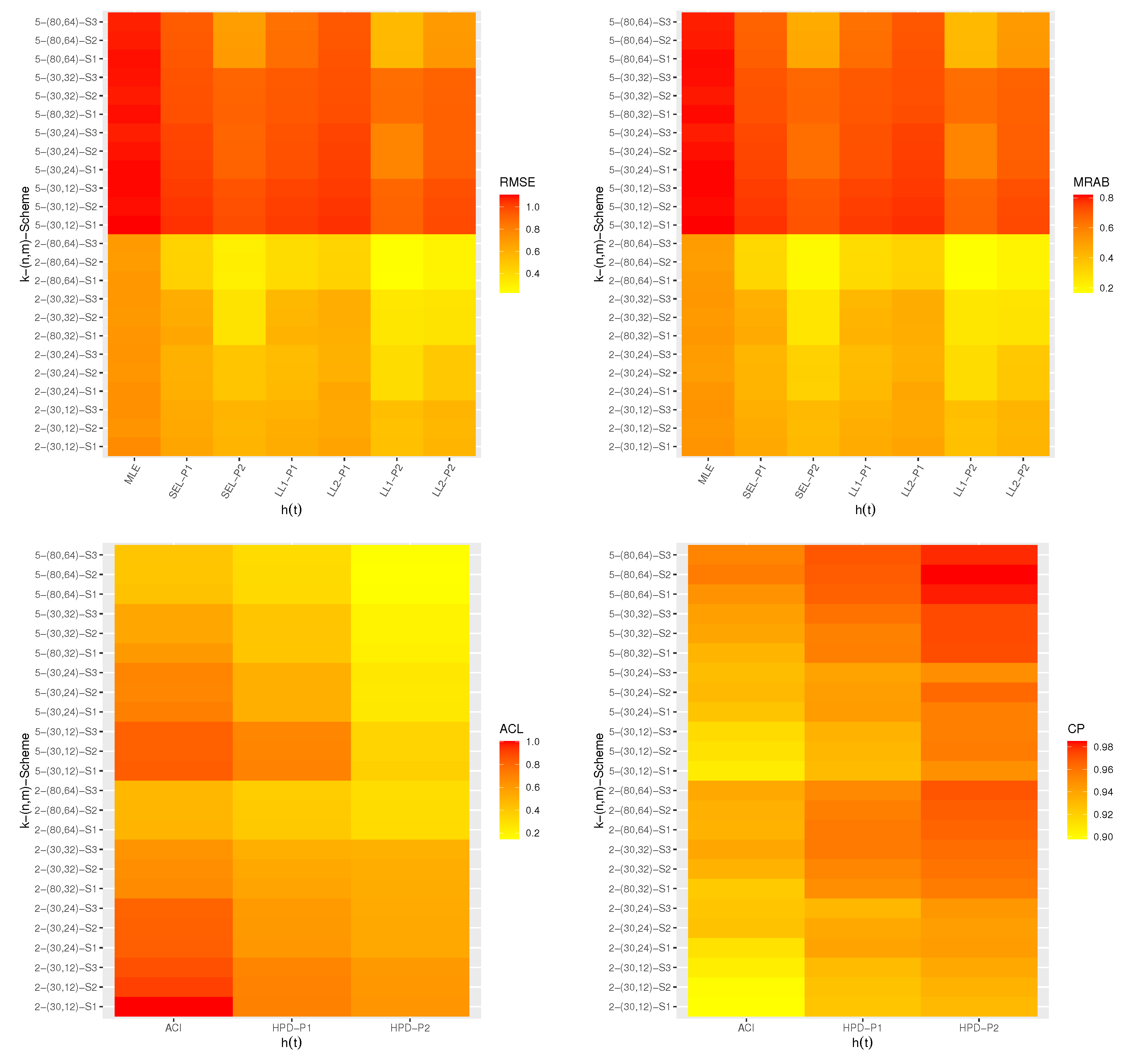
Using the complete electronic devices data, one first-failure censored sample is generated by randomly grouping this dataset into 9 groups with
items within each group, see
Table 10. As a result, the first-failure censored sample (in order) is: 5, 11, 21, 31, 46, 75, 98, 165, and 245. Now, three different progressive first-failure censored samples based on three different censoring schemes with
are generated from the first-failure censored data and are listed in
Table 11. For each generated PFFC sample, the maximum likelihood and Bayes M-H estimates with their SEs of
,
,
and
(at time
) are computed and provided in
Table 12.
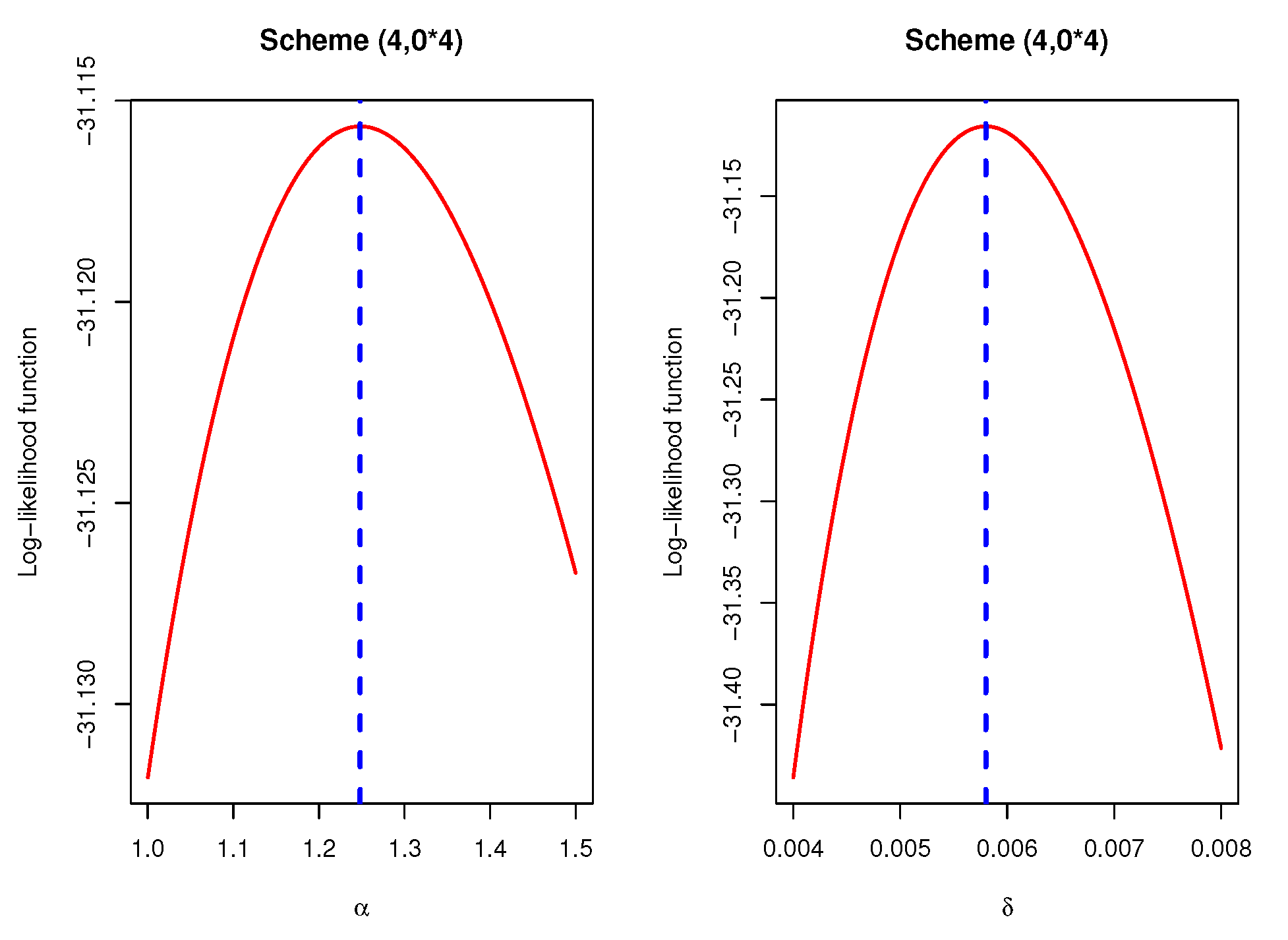
Figure 11 presents the plots of the log-likelihood functions of
and
for scheme
as an example which shows that the MLEs of
and
exist and unique.
Using gamma improper priors, based on 30,000 MCMC samples with 5000 burn-in, the MCMC estimates with their SEs of
,
,
and
(at time
) are developed under SEL and LL (for
). Moreover, the two-sided 95% ACI/HPD credible interval estimates with their interval lengths for
,
,
, and
are also calculated and reported in
Table 13. The calculated values of
and
are chosen as the initial values to run the M-H algorithm. It is noted, from
Table 12 and
Table 13, that the statistical inferences of
,
,
, and
derived from the Bayesian M-H approach perform better than the maximum likelihood approach in terms of smallest SEs, and the HPD credible interval estimates perform better than asymptotic interval estimates in terms of shortest interval lengths. Furthermore, for each PFFC sample, the proposed optimum criteria are presented in
Table 14. It shows that the progressive censoring scheme
is the optimal scheme compared to others for criteria 1, 2, and 3, while the censoring scheme
is the optimal scheme compared to others for criterion 4.
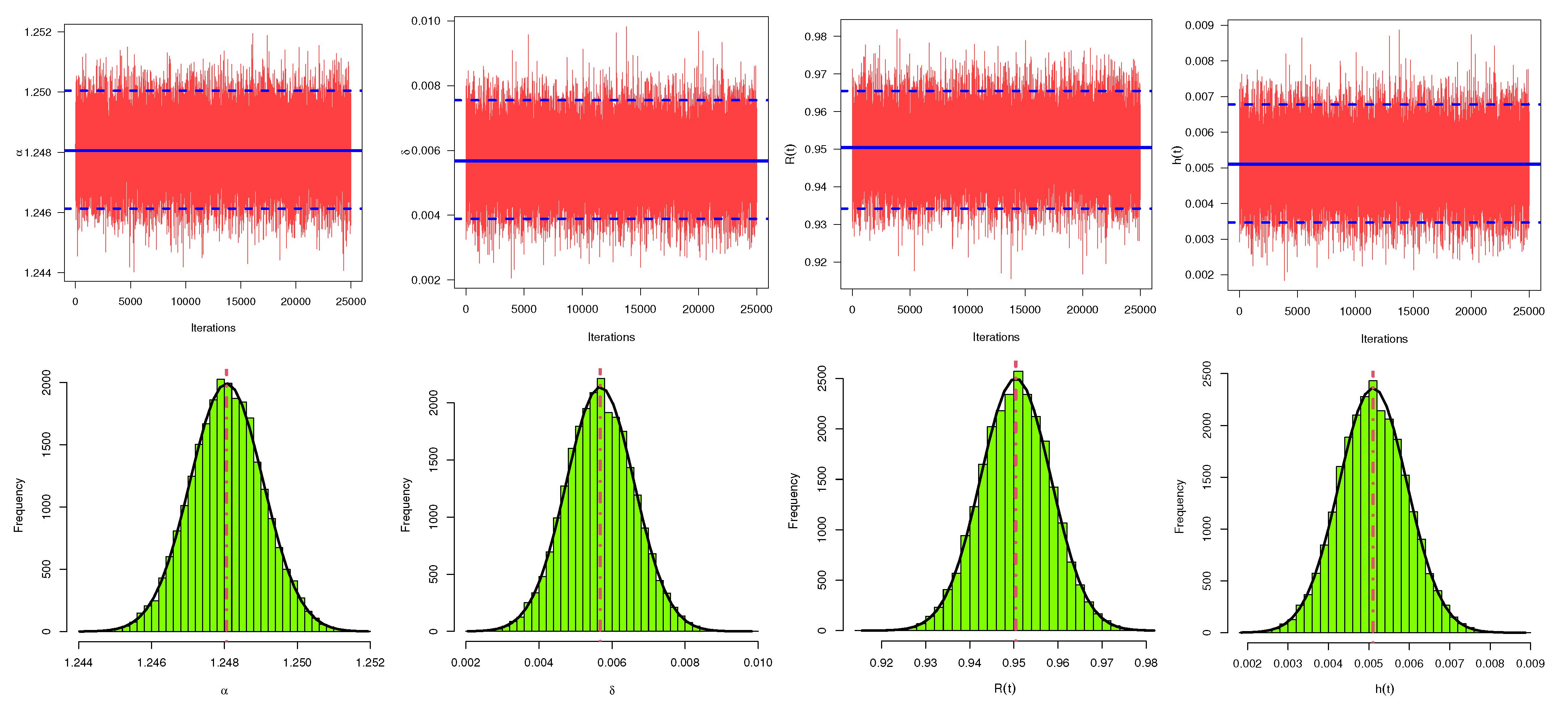
As an example, using the generated sample by censoring scheme
, trace and histogram plots of the MCMC simulated variates of
,
,
, and
are provided in
Figure 12. It shows that the MCMC mechanism converges well and that the simulated MCMC variates of all unknown parameters are fairly symmetrical. Finally, both numerical results of the proposed methodologies under the complete failure times dataset of electrical appliances and electronic devices provide a good explanation to the proposed model.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}