1. Introduction
The quality of an axiom rests on it being both convincing for the application(s) in mind, and compelling in that its denial would be intolerable.
We present elementary symmetries as convincing and compelling axioms, initially for measure, subsequently for probability, and finally for information and entropy. Our aim is to provide a simple and widely comprehensible foundation for the standard quantification of inference. We make minimal assumptions—not just for aesthetic economy of hypotheses, but because simpler foundations have wider scope.
It is a remarkable fact that algebraic symmetries can imply a unique calculus of quantification.
Section 2 gives the background and outlines the procedure and major results.
Section 3 lists the symmetries that are actually needed to derive the results, and the following
Section 4 writes each required symmetry as an axiom of quantification. In
Section 5, we derive the sum rule for valuation from the associative symmetry of ordered combination. This sum rule is the basis of measure theory. It is usually taken as axiomatic, but in fact it is derived from compelling symmetry, which explains its wide utility. There is also a direct-product rule for independent measures, again derived from associativity.
Section 6 derives from the direct-product rule a unique quantitative divergence from source measure to destination.
In
Section 7 we derive the chain product rule for probability from the associativity of chained order (in inference, implication). Probability calculus is then complete. Finally,
Section 8 derives the Shannon entropy and information (
a.k.a. Kullback–Leibler) as special cases of divergence of measures. All these formulas are uniquely defined by elementary symmetries alone.
Our approach is constructivist, and we avoid unnecessary formality that might unduly confine our readership. Sets and quantities are deliberately finite since it is methodologically proper to axiomatize finite systems before any optional passage towards infinity. R.T. Cox [
1] showed the way by deriving the unique laws of probability from logical systems having a mere three elementary “atomic” propositions. By extension, those same laws applied to Boolean systems with arbitrarily many atoms and ultimately, where appropriate, to well-defined infinite limits. However, Cox needed to assume continuity and differentiability to define the calculus to infinite precision. Instead, we use arbitrarily many atoms to define the calculus to arbitrarily fine precision. Avoiding infinity in this way yields results that cover all practical applications, while avoiding unobservable subtleties.
Our approach unites and significantly extends the set-based approach of Kolmogorov [
2] and the logic-based approach of Cox [
1], to form a foundation for inference that yields not just probability calculus, but also the unique quantification of divergence and information.
2. Setting the Scene
We model the world (or some interesting aspect of it) as being in a particular
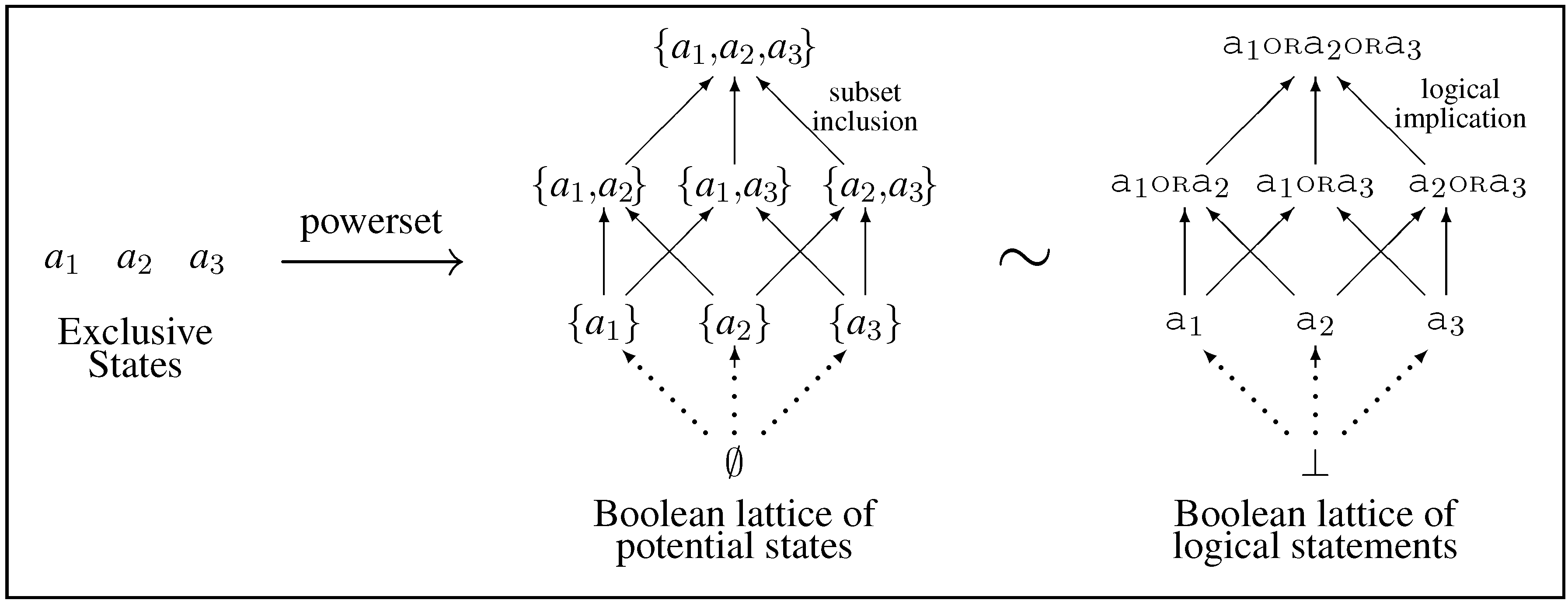
state out of a finite set of mutually exclusive states (as in
Figure 1, left). Since we and our tools are finite, a finite set of states, albeit possibly very large in number, suffices for all practical modeling.
As applied to inference, each state of the world is associated, via isomorphism, with a statement about the world. This results in a set of mutually exclusive statements, which we call
atoms. Atoms are combined through logical
OR to form compound statements comprising the
elements of a
Boolean lattice (
Figure 1, right), which is isomorphic to a Boolean lattice of sets (
Figure 1, center). Although carrying different interpretations, the mathematical structures are identical. Set inclusion “⊂” is equivalent to logical implication “⇒”, which we abstract to lattice order “<”. It is a matter of choice whether to include the null set ∅, equivalent to the logical absurdity ⊥. The set-based view is ontological in character and associated with Kolmogorov, while the logic-based view is epistemological in character and associated with Cox.
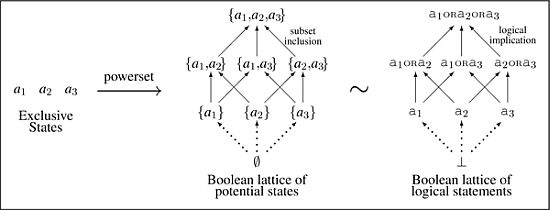
Figure 1.
The Boolean lattice of potential states (center) is constructed by taking the powerset of an antichain of N mutually exclusive atoms (in this case , left). This lattice is isomorphic to the Boolean lattice of logical statements ordered by logical implication (right).
Figure 1.
The Boolean lattice of potential states (center) is constructed by taking the powerset of an antichain of N mutually exclusive atoms (in this case , left). This lattice is isomorphic to the Boolean lattice of logical statements ordered by logical implication (right).
Quantification proceeds by assigning a real number
, called a
valuation, to elements
. (
Typewriter font denotes lattice elements
, whereas their associated valuations (real numbers)
x are shown in
italic.) We require valuations to be faithful to the lattice, in the sense that
so that compound elements carry greater value than any of their components. Clearly, this by itself is only a weak restriction on the behavior of valuation.
Combination of two atoms (or disjoint compounds) into their compound is written as the operator ⊔, for example
. Our first step is to quantify the combination of disjoint elements through an operator ⊕ that combines values (
Table 1 below lists such operators and their eventual identifications).
We find that the symmetries underlying ⊔ place constraints on ⊕ that effectively require it to be addition +. At this stage, we already have the foundation of measure theory, and the generalization of combination (of disjoint elements) to the lattice join (of arbitrary elements) is straightforward. The wide applicability of these underlying symmetries explains the wide utility of measure theory, which might otherwise be mysterious.
Table 1.
Operators and their symbols.
Table 1.
Operators and their symbols.
| Operation | Symbol | Quantification | (Eventual form) |
|---|
| ordering | < | < | |
| combination | ⊔ | ⊕ | (addition) |
| direct product | × | ⊗ | (multiplication) |
| chaining | , | ⊙ | (multiplication) |
We can consider the atoms
and
from separate problems as
composite atoms
in an equivalent composite problem. The
direct-product operator ⊗ quantifies the composition of values:
We find that the symmetries of × place constraints on ⊗ that require it to be multiplication.
It is common in science to acquire numerical assignments by optimizing a variational potential. By requiring consistency with the numerical assignments of ordinary multiplication, we find that there is a unique variational potential , of “” form, known as the (generalized Kullback–Leibler) Bregman divergence of measure from measure .
Inference involves the relationship of one logical statement (predicate
) to another (context
), initially in a situation where
so that the context includes subsidiary predicates. To quantify inference, we assign real numbers
, ultimately recognised as
probability, to predicate–context
intervals . Such intervals can be
chained (concatenated) so that
, with ⊙ representing the chaining of values.
We find that the symmetries of chaining require ⊙ to be multiplication, yielding the
product rule of probability calculus. When applied to probabilities, the divergence formula reduces to the
information, also known as the Kullback–Leibler formula, with
entropy being a variant.
2.1. The Order-Theoretic Perspective
The approach we employ can be described in terms of order-preserving (monotonic) maps between order-theoretic structures. Here we present our approach, described above, from this different perspective.
Order-theoretically, a finite set of exclusive states can be represented as an
antichain, illustrated in
Figure 1(left) as three states
,
, and
situated side-by-side. Our state of knowledge about the world (more precisely, of our model of it—we make no ontological claim) is often incomplete so that we can at best say that the world is in one of a set of potential
states, which is a subset of the set of all possible states. In the case of total ignorance, the set of potential states includes all possible states. In contrast, perfect knowledge about our model is represented by singleton sets consisting of a single state. We refer to the singleton sets as
atoms, and note that they are exclusive in the sense that no two can be true.
The space of all possible sets of potential states is given by the partially-ordered set obtained from the powerset of the set of states ordered by set inclusion. For an antichain of mutually exclusive states, the powerset is a
Boolean lattice (
Figure 1, center), with the bottom element optional. By conceiving of a
statement about our model of the world in terms of a set of potential states, we have an order-isomorphism from the Boolean lattice of potential states ordered by set inclusion to the Boolean lattice of statements ordered by logical implication (
Figure 1, right). This isomorphism maps each set of potential states to a statement, while mapping the algebraic operations of set union ∪ and set intersection ∩ to the logical
OR and
AND, respectively.
The perspective provided by order theory enables us to focus abstractly on the structure of a Boolean lattice with its generic algebraic operations
join ∨ and
meet∧. This immediately broadens the scope from Boolean to more general
distributive lattices — the first fruit of our minimalist approach. For additional details on partially ordered sets and lattices in particular, we refer the interested reader to the classic text by Birkhoff [
3] or the more recent text by Davey & Priestley [
4].
Quantification proceeds by assigning valuations to elements , to form a real-valued representation. For this to be faithful, we require an order-preserving (monotonic) map between the partial order of a distributive lattice and the total order of the chains that are to be found within. Thus is to imply that , a relationship that we call fidelity. The converse is not true: the total order imposed by quantification must be consistent with but can extend the partial order of the lattice structure.
We write the combination of two atoms into a compound element (and more generally any two disjoint compounds into a compound element) as ⊔, for example
. Derivation of the calculus of quantification starts with this disjoint combination operator, where we find that its symmetries place constraints on its representation ⊕ that allow us the convention of ordinary addition “
”. This basic result generalizes to the standard
join lattice operator ∨ for elements that (possibly having atoms in common) need not be disjoint, for which the sum rule generalizes to its standard inclusion/exclusion form [
5], which involves the meet ∧ for any atoms in common.
There are two mathematical conventions concerning the handling the nothing-is-true null element ⊥ at the bottom of the lattice known as the absurdity. Some mathematicians opt to include the bottom element on aesthetic grounds, whereas others opt to exclude it because of its paradoxical interpretation [
4]. If it is included, its quantification is zero. Either way, fidelity ensures that other elements are quantified by positive values that are positive (or, by elementary generalization, zero). At this stage, we already have the foundation of
measure theory.
Logical deduction is traditionally based on a Boolean lattice and proceeds “upwards” along a chain (as in the arrows sketched in
Figure 1). Given some statement
, one can deduce that
implies
since
includes
. Similarly,
implies
since
includes
. The ordering relationships among the elements of the lattice are encoded by the zeta function of the lattice [
6]
Deduction is definitive.
Inference, or logical induction, is the inverse of deduction and proceeds “downwards” along a chain, losing logical certainty as knowledge fragments. Our aim is to quantify this loss of certainty, in the expectation of deriving probability calculus. This requires generalization of the binary zeta function to some real-valued function which will turn out to be the standard probability of x GIVEN y. However, a firm foundation for inference must be devoid of a choice of arbitrary generalizations. By viewing quantification in terms of an order-preserving map between the partial order (Boolean lattice) and a total order (chain) subject to compelling symmetries alone, we obtain a firm foundation for inference, devoid of further assumptions of questionable merit.
By considering atoms (singleton sets, which are the join-irreducible elements of the Boolean lattice) as precise statements about exclusive states, and composite lattice elements (sets of several exclusive states) as less precise statements involving a degree of ignorance, the two perspectives of logic and sets, on which the Cox and Kolmogorov foundations are based, become united within the order-theoretic framework.
In summary, the powerset comprises the hypothesis space of all possible statements that one can make about a particular model of the world. Quantification of join using + is the sum rule of probability calculus, and is required by adherence to the symmetries we list. It fixes the valuations assigned to composite elements in terms of valuations assigned to the atoms. Those latter valuations assigned to the atoms remain free, unconstrained by the calculus. That freedom allows the calculus to apply to inference in general, with the mathematically-arbitrary atom valuations being guided by insight into a particular application.
2.2. Commentary
Our results—the sum rule and divergence for measures, and the sum and product rules with information for probabilities—are standard and well known (their uniqueness perhaps less so). The matter we address here is which assumptions are necessary and which are not. A Boolean lattice, after all, is a special structure with special properties. Insofar as fewer properties are needed, we gain generality. Wider applicability may be of little value to those who focus solely on inference. Yet, by showing that the basic foundations of inference have wider scope, we can thereby offer extra—and simpler—guidance to the scientific community at large.
Even within inference, distributive problems may have relationships between their atoms such that not all combinations of states are allowed. Rather than extend a distributive lattice to Boolean by padding it with zeros, the tighter framework immediately empowers us to work with the original problem in its own right. Scientific problems (say, the propagation of particles, or the generation of proteins) are often heavily conditional, and it could well be inappropriate or confusing to go to a full Boolean lattice when a sparser structure is a more natural model.
We also confirm that commutativity is not a necessary assumption. Rather, commutativity of measure is imposed by the associativity and order required of a scalar representation. Conversely, systems that are not commutative (matrices under multiplication, for example) cannot be both associative and ordered.
3. Symmetries
Here, we list the relevant symmetries on which our axioms are based. All are properties of distributive lattices, and our descriptions are styled that way so that a reader wary of further generality does not need to move beyond this particular, and important, example. However, one may note that not all the properties of a distributive lattice (such as commutativity of the join) are listed, which implies that these results are applicable to a broader class of algebraic structures that includes distributive lattices.
Valuation assignments rank statements via an order-preserving map which we call
fidelity .
It is a matter of convention that we choose to order the valuations in the same sense as the lattice order (“more is bigger”). Reverse order would be admissible and logically equivalent, though less convenient.
In the specific case of Boolean lattices of logical statements, the binary ordering relation, represented generically by <, is equivalent to logical implication (⇒) between
different statements, or equivalently, proper subset inclusion (⊂) in the powerset representation. Combination preserves order from the right and from the left
for any
(a property that can be viewed as distributivity of ⊔ over <) on the grounds that ordering needs to be robust if it is to be useful. Combination is also taken to be associative
Independent systems can be considered together (
Figure 2).
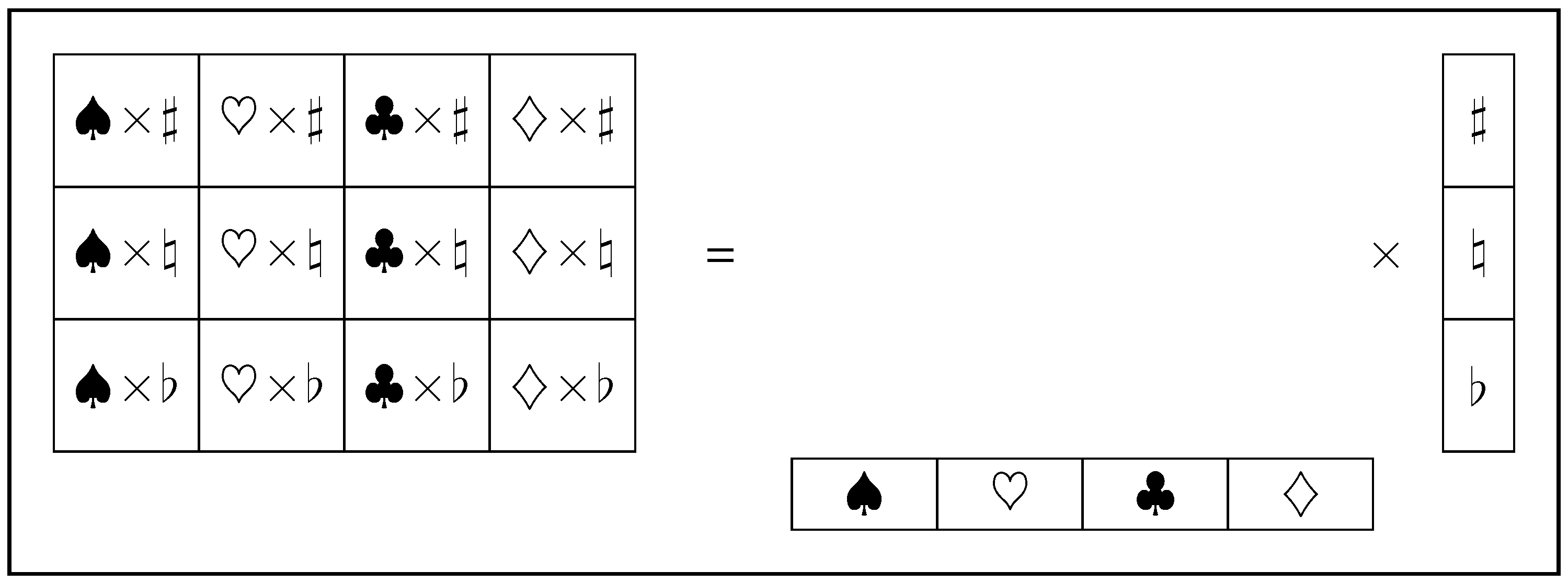
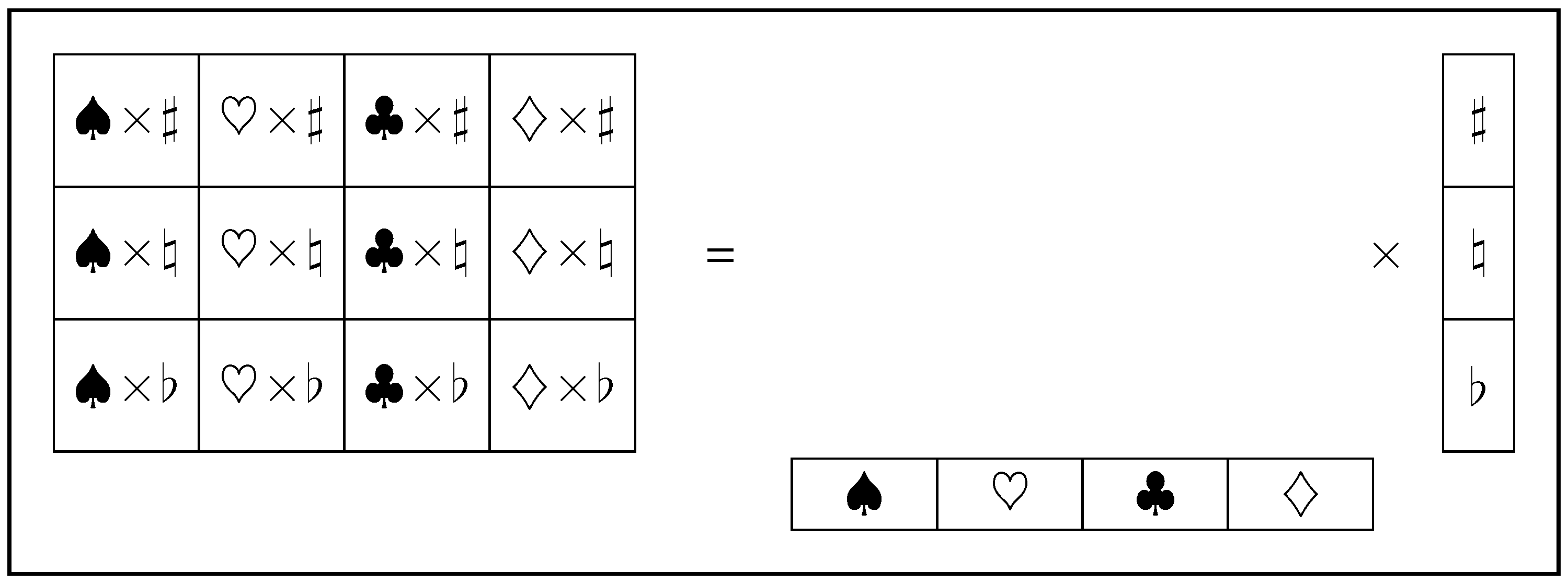
Figure 2.
One system might, for example, be playing-card suits , while another independent system might be music keys . The direct-product combines the spaces of and to form the joint space of with atoms like .
Figure 2.
One system might, for example, be playing-card suits , while another independent system might be music keys . The direct-product combines the spaces of and to form the joint space of with atoms like .
The direct-product operator × is taken to be (right-)distributive over ⊔
so that relationships in one set, such as perhaps
, remain intact whether or not an independent element from the other, such as perhaps ♮, is appended. Left distributivity may well hold but is not needed. The direct product of independent lattices is also taken to be associative (
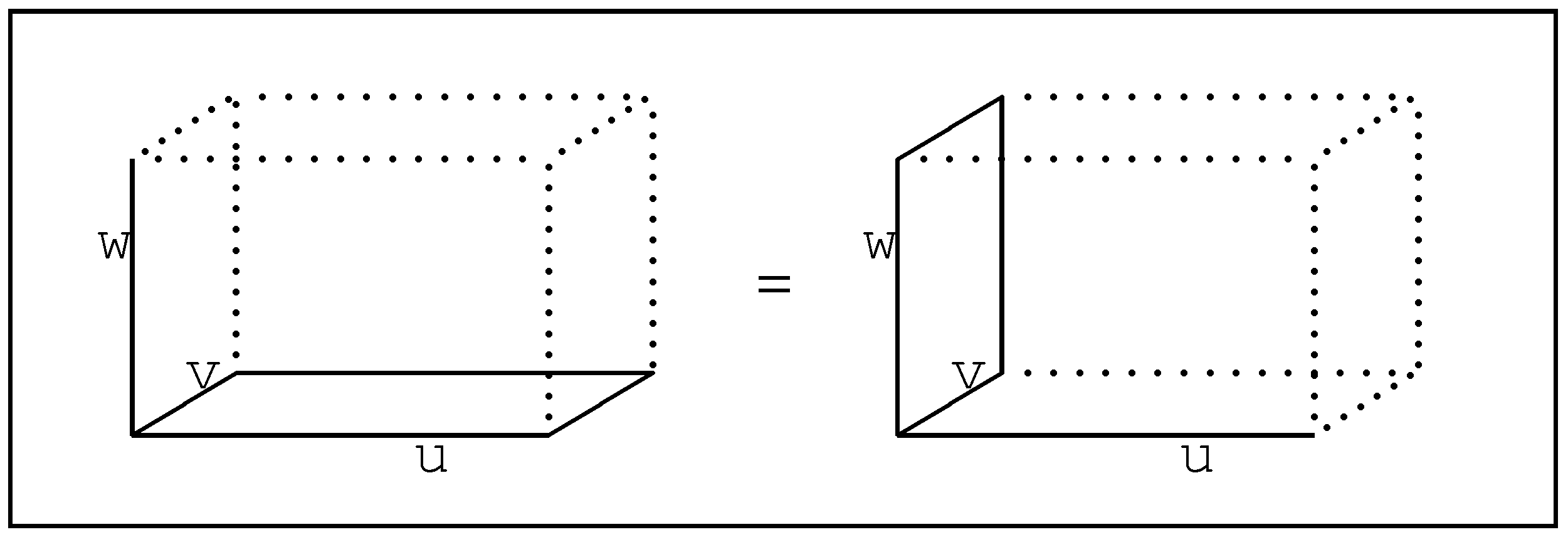
Figure 3).
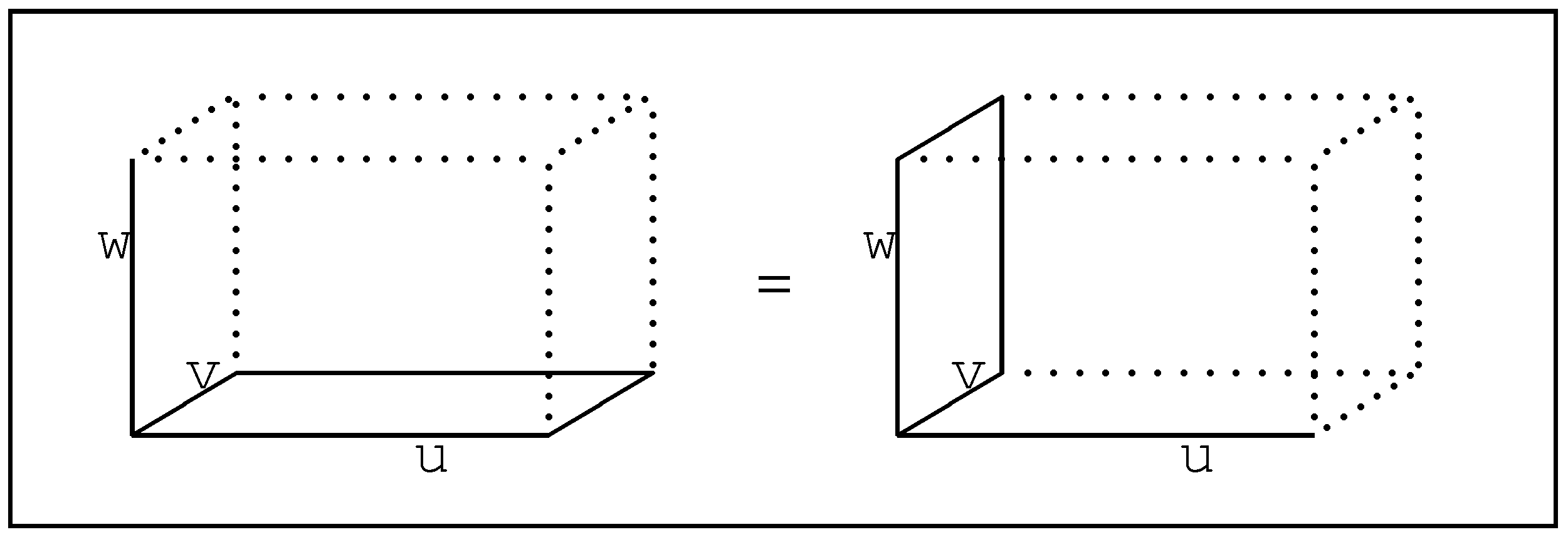
Figure 3.
Associativity of direct product can be viewed geometrically.
Figure 3.
Associativity of direct product can be viewed geometrically.
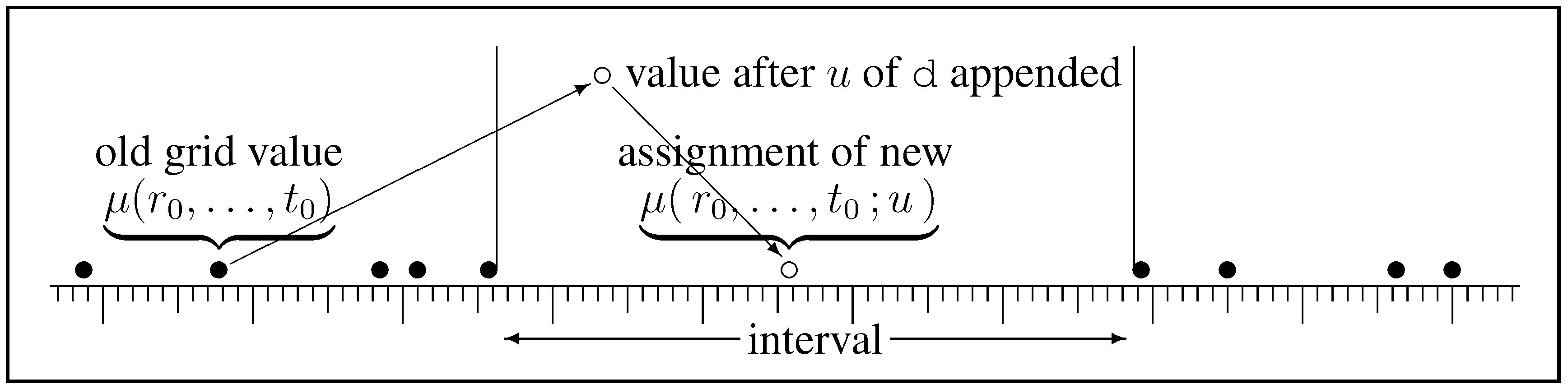
Finally, we consider a totally ordered set of logical statements that form a chain
. We focus on an interval on the chain, which is defined by an ordered pair of logical statements
. Adjacent intervals can be chained, as in
, and chaining is associative
Using Greek symbols to represent an interval,
,
,
, we have
These and these alone are the symmetries we need for the axioms of quantification. They are presented as a cartoon in the “Conclusions” section below.
4. Axioms
We now introduce a layer of quantification. Our axioms arise from the requirement that any quantification must be consistent with the symmetries indicated above. Therefore, each symmetry gives rise to an axiom. We seek scalar valuations to be assigned to elements of a lattice, while conforming to the above symmetries (#0—#5)for disjoint elements.
Fidelity (symmetry #0) requires us to choose an increasing measure so that, without loss of generality, we may set
and thereafter
To conform to the ordering symmetry #1, we require ⊕ as set up in Equation 2 to obey
To conform to the associative symmetry #2, we also require ⊕ to obey
These equations are to hold for arbitrary values
x,
y,
z assigned to the disjoint
,
,
.
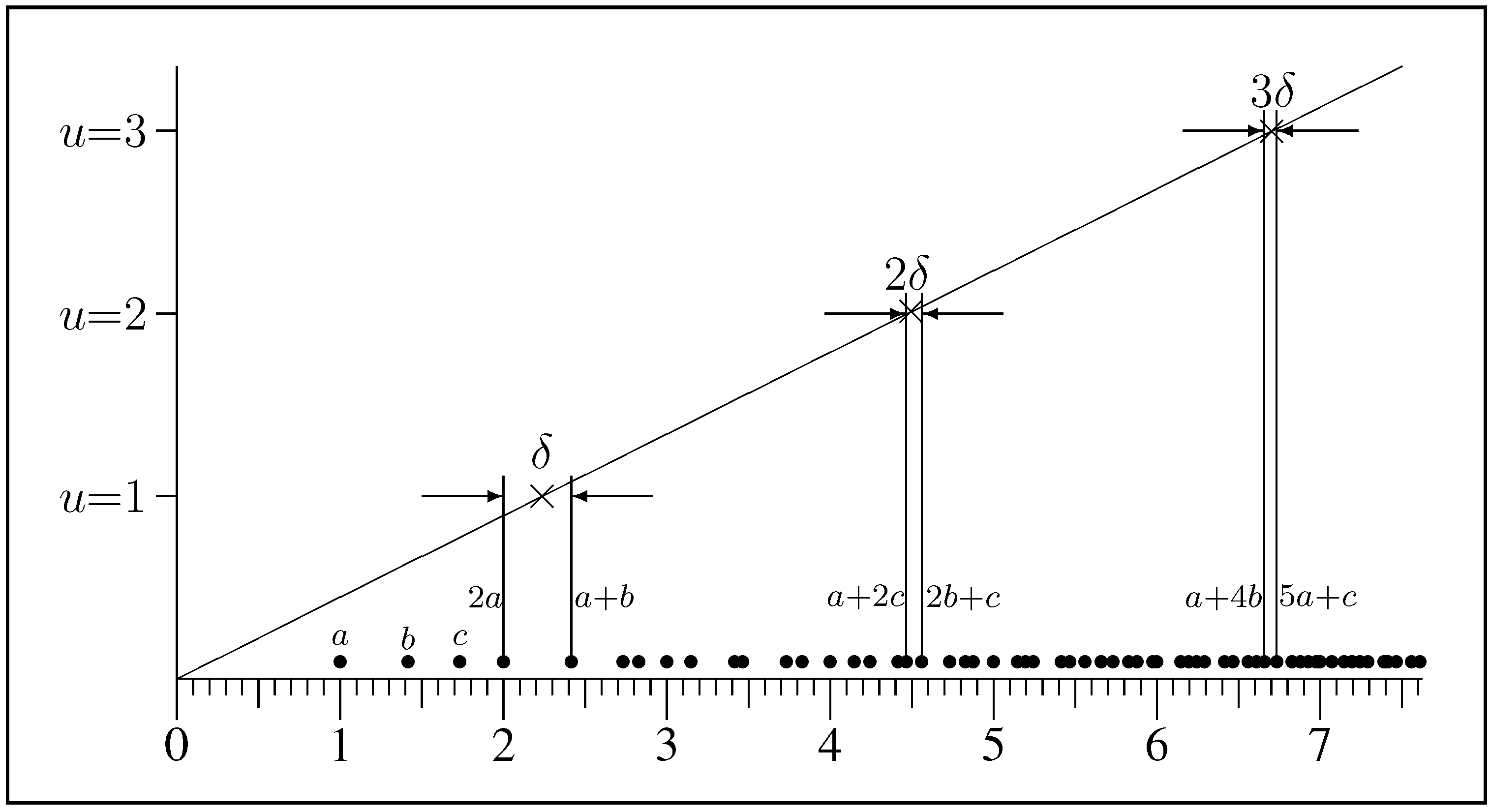
Appendix A will show that these order and associativity axioms are necessary and sufficient to determine the additive calculus of measure.
To conform to the distributive symmetry #3, we require ⊗ as set up in Equation 3 to obey
for disjoint
and
combined with any
from the second lattice. Presence of
may change the measures, but does not change their underlying additivity. To conform to the associative symmetry #4, we also require ⊗ to obey
These axioms determine the multiplicative form of ⊗ and also lead to a unique divergence between measures.
To conform to the associative symmetry #5, we require ⊙ as set up in Equation 4 to obey
where
,
,
are individual steps concatenated along the chain
, which is
. This final axiom will let us pass from measure to probability and Bayes’ theorem, and from divergence to information and entropy. For each operator (
Table 1), the eventual form satisfies all relevant axioms, which assures existence. Uniqueness remains to be demonstrated.
6. Variation
Variational principles are common in science—minimum energy for equilibrium, Hamilton’s principle for dynamics, maximum entropy for thermodynamics, and so on—and we seek one for measures. The aim is to discover a variational potential whose constrained minimum allows the valuations of N atoms to be assigned subject to appropriate constraints of the form . (The vectors which appear in this section are shown in bold-face font.)
The variational potential is required to be general, applying to arbitrary constraints. Just like values themselves, constraints on individual atom values can be combined into compound constraints that influence several values: indeed the constraints could simply be imposition of definitive values. Such combination allows a Boolean lattice, entirely analogous to
Figure 1, to be developed from individual atomic constraints. The variational potential
H is to be a valuation on the measures resulting from these constraints, combination being represented by some operator
so that
for constraints acting on disjoint atoms or compounds.
Adding extra constraints always increases
H, otherwise the variational requirement would be broken, so
H must be faithful to chaining in the lattice.
We also have order
because if
y is a “harder” constraint than
x (meaning
), that ranking should not be affected by some other constraint on something else. Associativity
is likewise required and expresses the combination of three constraints. It would also be natural to assume commutativity,
, but that is not necessary because we already recognize Equations 30–32 as our axioms 0, 1, 2. Hence, using
Appendix A again, there exists a “
= +” grade on which
H is additive.
We have now justified additivity, thus filling a gap in traditional accounts of the calculus of variations.
Under perturbation, the minimization requirement is
The standard “
” form of the sum rule happens to be continuous and differentiable, so is applicable to valuation of systems that differ arbitrarily little. We adopt it, and can then justifiably require the variational potential to be valid for arbitrarily small perturbations:
This limit Equation 35 is weaker than the original Equation 34 not only because of the restricted context, but also because the nature of the extremum (maximum or minimum or saddle) is lost in the discarded second-order effects. However, it still needs to be satisfied. It also shows that any variational potential must by its nature be differentiable at least once.
One now invents supposedly constant “Lagrange multiplier” coefficients
and considers what appears at first to be the different problem of solving
for
. Clearly, Equation 36 is equivalent to Equation 35 for perturbations that happen to hold the
f’s constant (
). However, the values those
f’s take may well be wrong. The trick is to choose the
λ’s so that the
f’s take their correct constraint values. That being done, Equation 36 solves the variational problem Equation 35.
Let the application be two-dimensional,
x-by-
y, in the sense of applying to values
of elements on a direct-product lattice. Suppose we have
x-dependent constraints that yield
on one factor (say the card suits in
Figure 2 above), and similar
y-dependent constraints that yield
on the other factor (say music keys in
Figure 2). Both factors being thus controlled, their direct-product is implicitly controlled by the those same constraints. Here, we already know the target value
from the direct-product rule Equation 28. Hence the variational assignment for the particular value
derives from
(where′ indicates derivative). The variational theorem (
Appendix C) gives the solution of this functional equation as
for the individual valuation being considered, where
are constants. Combining all the atoms yields
The coefficient represents the intrinsic importance of atom in the summation, but usually the atoms are a priori equivalent so that the C’s take a common value. The scaling of a variational potential is arbitrary (and is absorbed in the Lagrange multipliers), so we may set , ensuring that H has a minimum rather than a maximum. Alternatively, would ensure a maximum. However, the settings of A and B depend on the application.
6.1. Divergence and Distance
One use of
H is as a quantifier of the divergence of destination values
from source values
that existed before the constraints that led to
were applied. For this, we set
to get a minimum,
to place the unconstrained minimizing
at
, and
to make the minimum value zero. This form is
This formula is unique: none other has the properties Equations 33,37 that elementary applications require. Equivalently, any different formula would give unjustifiable answers in those applications. Plausibly,
H is non-negative,
with equality if and only if
, so that it usefully quantifies the separation of destination from source.
In general, H obeys neither commutativity nor the triangle inequality, and . Hence it cannot be a geometrical “distance”, which is required to have both those properties. In fact, there is no definition of geometrical measure-to-measure distance that obeys the basic symmetries, because H is the only candidate, and it fails.
Here again we see our methodology yielding clear insight. “From–to” can be usefully quantified, but “between” cannot. A space of measures may have connectedness, continuity, even differentiability, but it cannot become a metric space and remain consistent with its foundation.
In the limit of many small values,
H admits a continuum limit
The constraints that force a measure away from the original source may admit several destinations, but minimizing
H is the unique rule that defines a defensibly optimal choice. This is the rationale behind maximum entropy data analysis [
8].
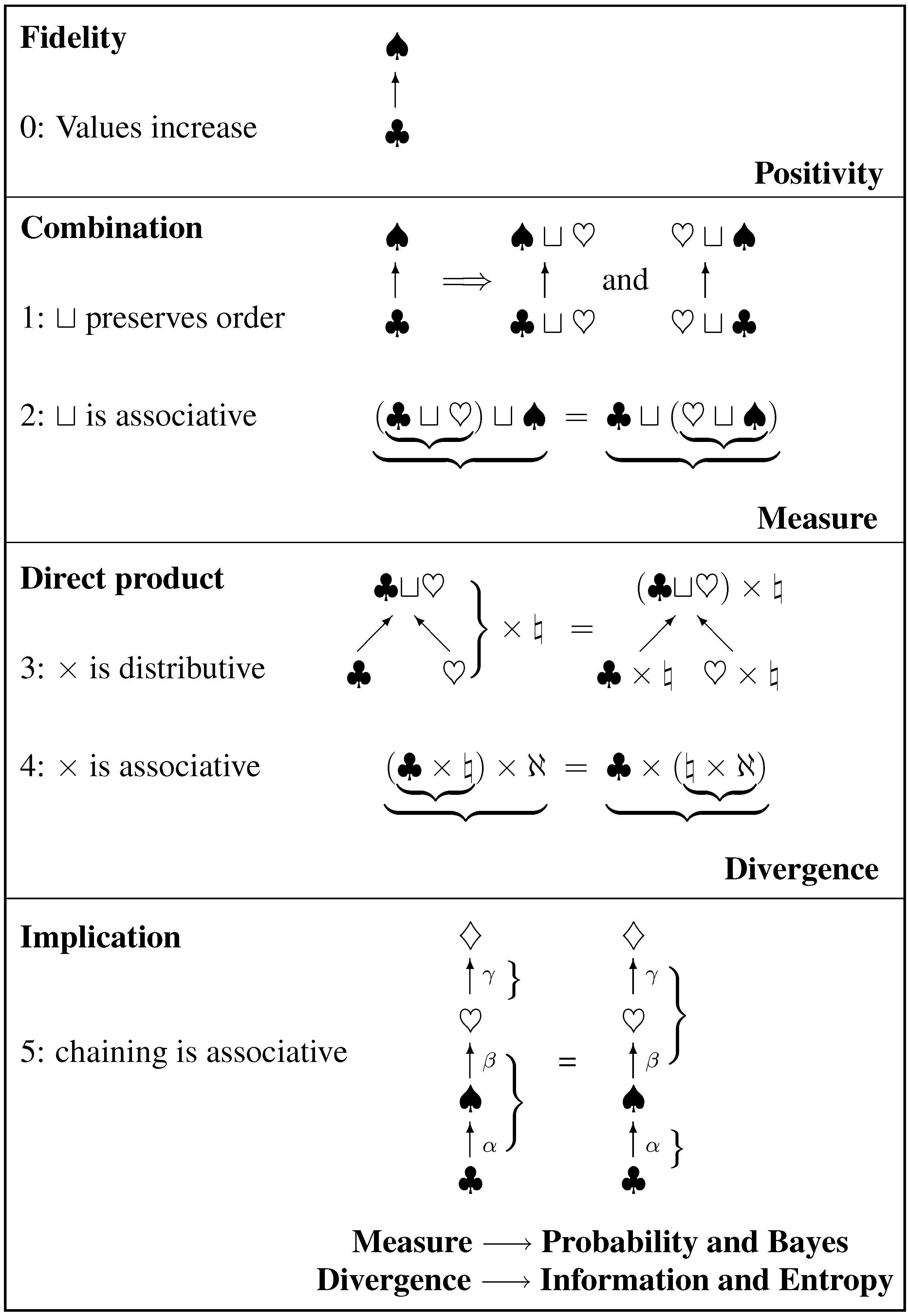
9. Conclusions
9.1. Summary
We start with a set
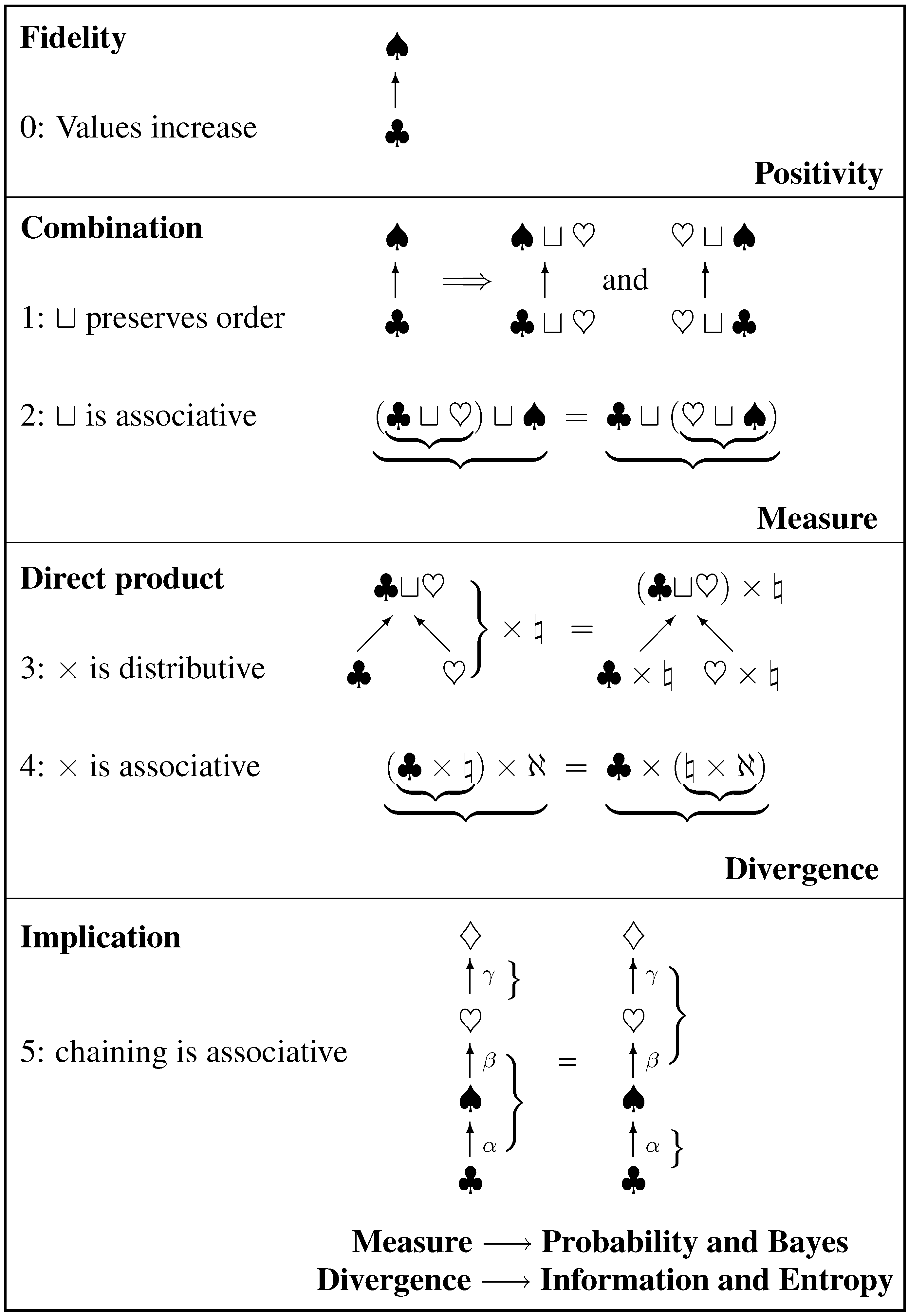
of “atomic” elements which in inference represent the most fundamental exclusive statements we can make about the states (of our model) of the world. Atoms combine to form a Boolean lattice which in inference is called the hypothesis space of statements. This structure has rich symmetry, but other applications may have less and we have selected only what we needed, so that our results apply more widely and to distributive lattices in particular. The minimal assumptions are so simple that they can be drawn as the cartoon below (
Figure 4).
Axiom 1 represents the order property that is required of the combination operator ⊔. Axiom 2 says that valuation must conform to the associativity of ⊔. These axioms are compelling in inference. By the associativity theorem (
Appendix A — see the latter part for a proof of minimality) they require the valuation to be a measure
, with ⊔ represented by addition (the
sum rule). Any 1:1 regrading is allowed, but such change alters no content so that the standard linearity can be adopted by convention. This is the rationale behind measure theory.
The direct product operator × that represents independence is distributive (axiom 3) and associative (axiom 4), and consequently independent measures multiply (the direct-product rule). There is then a unique form of variational potential for assigning measures under constraints, yielding a unique divergence of one measure from another.
Probability is to be a bivaluation, automatically a measure over predicate within any specified context . Axiom 5 expresses associativity of ordering relations (in inference, implications) and leads to the chain-product rule which completes probability calculus. The variational potential defines the information (Kullback–Leibler) carried by a destination probability relative to its source, and also yields the Shannon entropy of a partitioned probability distribution.
9.2. Commentary
We have presented a foundation for inference that unites and significantly extends the approaches of Kolmogorov [
2] and Cox [
1], yielding not just probability calculus, but also the unique quantification of divergence and information. Our approach is based on quantifying finite lattices of logical statements in such a way that quantification satisfies minimal required symmetries. This generalizes algebraic implication, or equivalently subset inclusion, to a calculus of degrees of implication. It is remarkable that the calculus is unique.
Our derivations have relied on a set of explicit axioms based on simple symmetries. In particular, we have made no use of negation (
NOT), which in applications other than inference may well not be present. Neither have we assumed any additive or multiplicative behavior (as did Kolmogorov [
2], de Finetti [
12], and Dupré & Tipler [
13]). On the contrary, we find that sum and product rules follow from elementary symmetry alone.
Figure 4.
Cartoon graphic of the symmetries invoked, and where they lead. Ordering is drawn as upward arrows.
Figure 4.
Cartoon graphic of the symmetries invoked, and where they lead. Ordering is drawn as upward arrows.
We find that associativity and order provide minimal assumptions that are convincing and compelling for scalar additivity in all its applications. Associativity alone does not force additivity, but associativity with order does. Positivity was not assumed, though it holds for all applications in this paper.
Commutativity was not assumed either, though commutativity of the resulting measure follows as a property of additivity. Associativity and commutativity do not quite force additivity because they allow degenerate solutions such as
. To eliminate these, strict order is required in some form, and if order is assumed then commutativity does not need to be. Hence scalar additivity rests on ordered sequences rather than the disordered sets for which commutativity would be axiomatic.
Aczél [
14] assumes order in the form of reducibility, and he too derives commutativity. However, his analysis assumes the continuum limit already attained, which requires him to assume continuity.
Our constructivist approach uses a finite environment in which continuity does not apply, and proceeds directly to additivity. Here, continuity and differentiability are merely emergent properties of + as the continuum limit is approached by allowing arbitrarily many atoms of different type.
Yet there can be no requirement of continuity, which is merely a convenient convention. For example, re-grading could take the binary representations of standard arguments ( representing ) and interpret them in base-3 ternary (with representing ), so that . Valuation becomes discontinuous everywhere, but the sum rule still works, albeit less conveniently. Indeed, no finite system can ever demonstrate the infinitesimal discrimination that defines continuity, so continuity cannot possibly be a requirement of practical inference.
At the cost of lengthening the proofs in the appendices, we have avoided assuming continuity or differentiability. Yet we remark that such infinitesimal properties ought not influence the calculus of inference. If they did, those infinitesimal properties would thereby have observable effects. But detecting whether or not a system is continuous at the infinitesimal scale would require infinite information, which is never available. So assuming continuity and differentiability, had that been demanded by the technicalities of mathematical proof (or by our own professional inadequacy), would in our view have been harmless. As it happens, each appendix touches on continuity, but the arguments are appropriately constructed to avoid the assumption, so any potential controversy over infinite sets and the rôle of the continuum disappears.
Other than reversible regrading, any deviation from the standard formulas must inevitably contradict the elementary symmetries that underlie them, so that popular but weaker justifications (e.g., de Finetti [
12]) in terms of decisions, loss functions, or monetary exchange can be discarded as unnecessary. In fact, the logic is the other way round: such applications must be cast in terms of the unique calculus of measure and probability if they are to be quantified rationally. Indeed, we hold generally that it is a tactical error to buttress a strong argument (like symmetry) with a weak argument (like betting, say). Doing that merely encourages a skeptic to sow confusion by negating the weak argument, thereby casting doubt on the main thesis through an illogical impression that the strong argument might have been circumvented too.
Finally, the approach from basic symmetry is productive. Goyal and ourselves [
15] have used just that approach to show why
quantum theory is forced to use complex arithmetic. Long a deep mystery, the sum and product rules of complex arithmetic are now seen as inevitably necessary to describe the basic interactions of physics. Elementary symmetry thus brings measure, probability, information and fundamental physics together in a remarkably unified synergy.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}