
Transformer–GCN Fusion Framework for Mineral Prospectivity Mapping: A Geospatial Deep Learning Approach

 ,
,  ,
,
Abstract
1. Introduction
2. Geological Background and Dataset
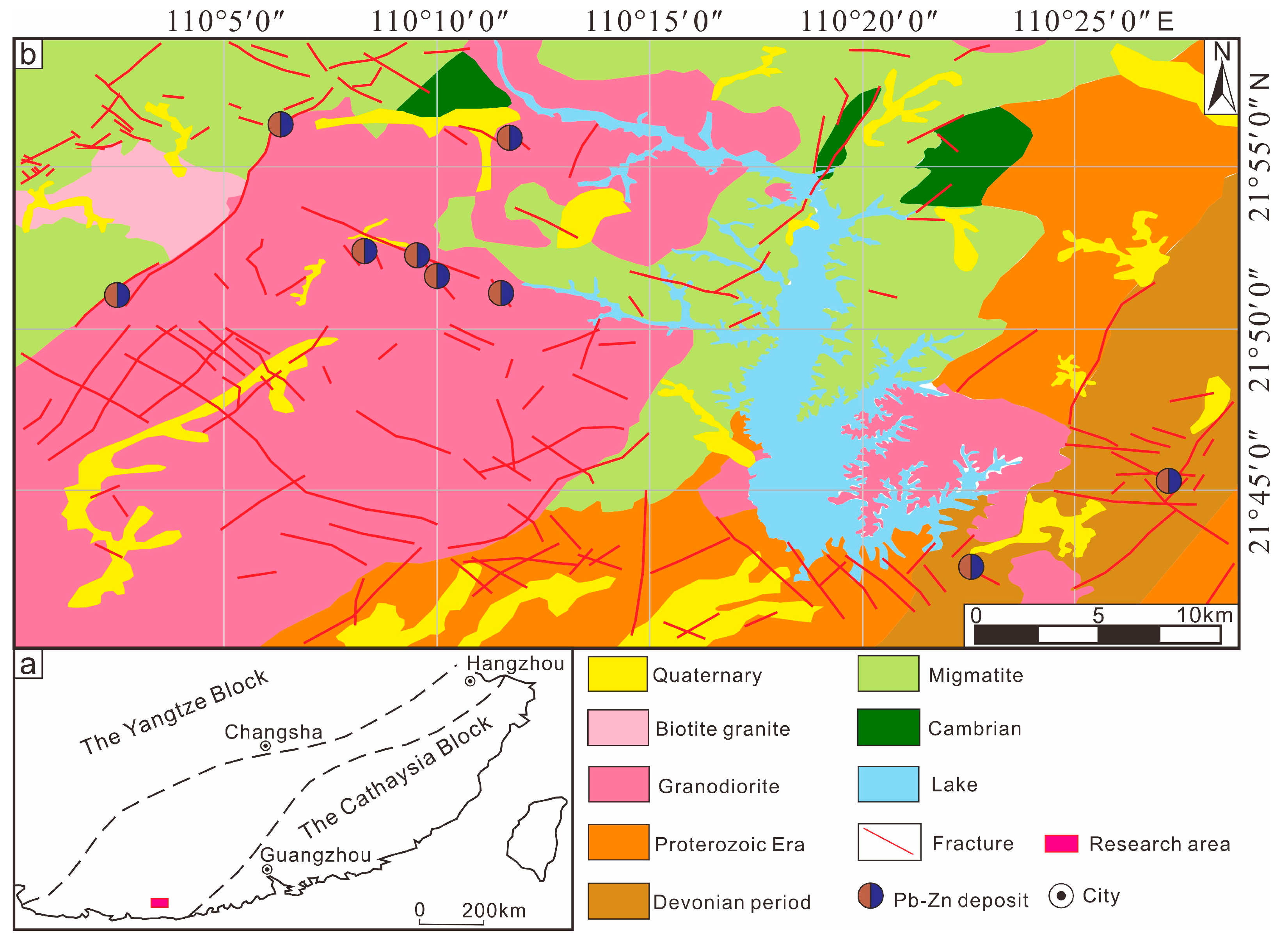
2.1. Geological Background
2.2. Dataset
2.3. Data Characteristic Analysis
3. Methods
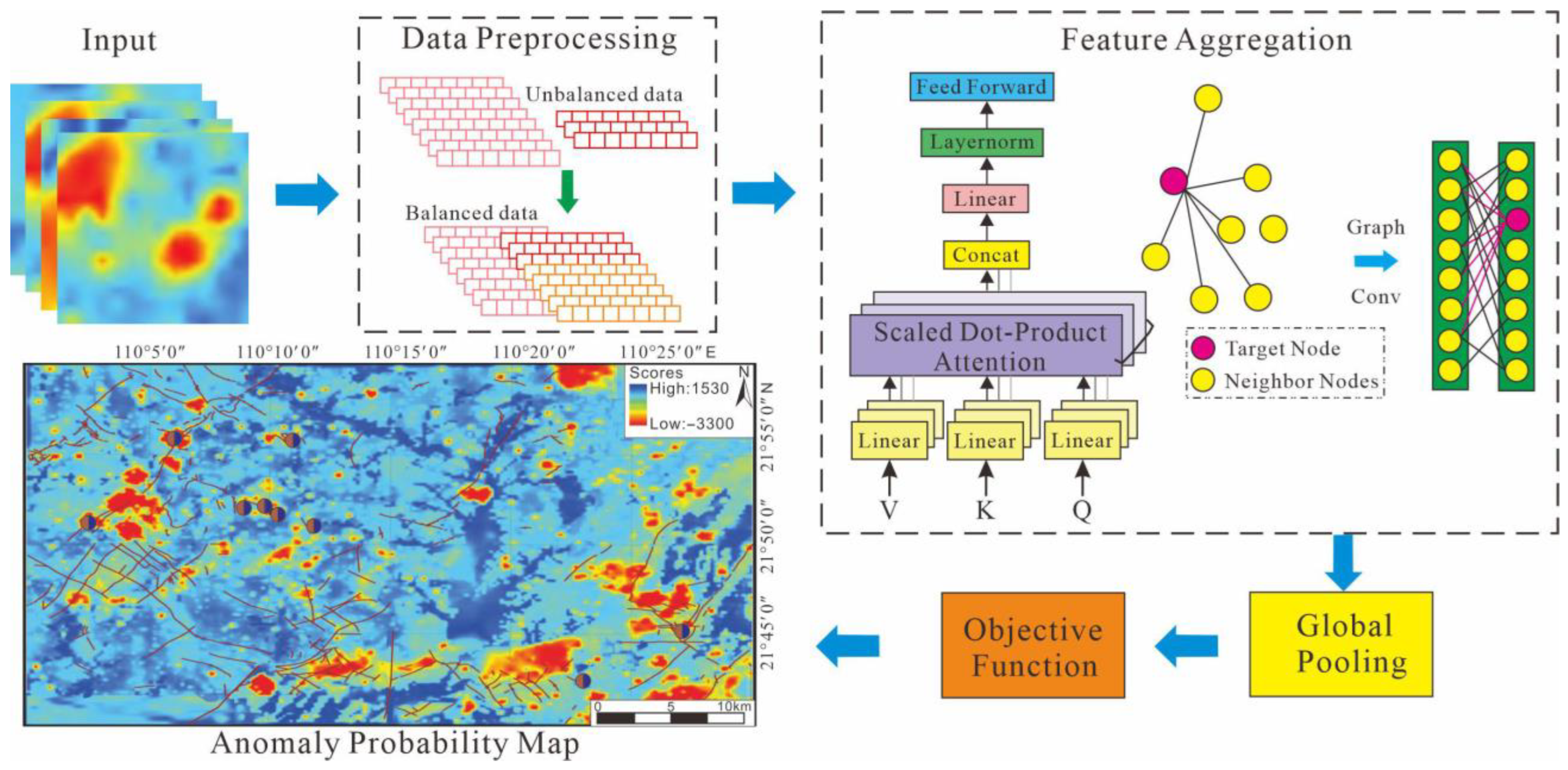
3.1. Data Preprocessing
3.1.1. Data Transformation
3.1.2. Generative Adversarial Network (GAN)
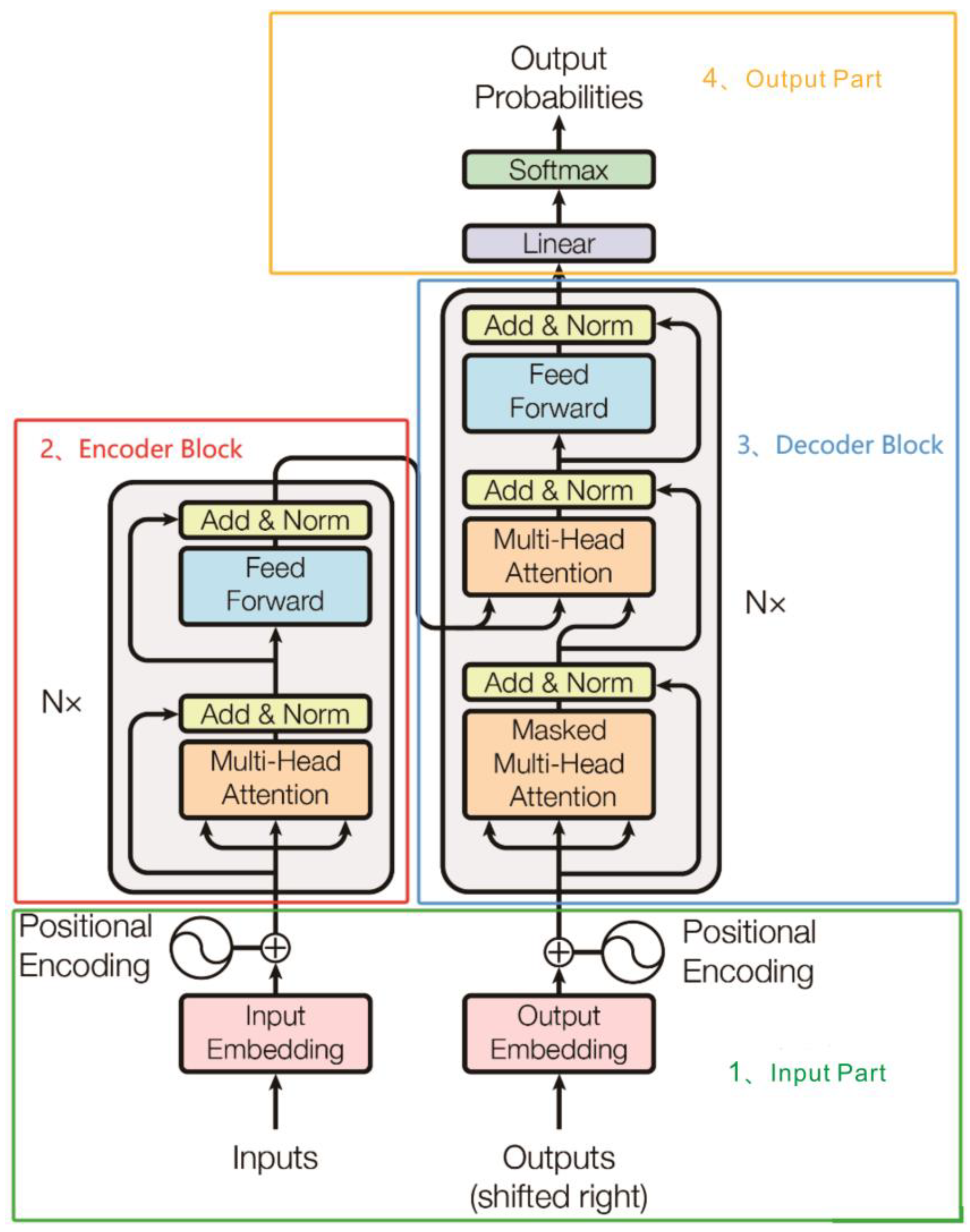
3.2. Transformer Module
3.2.1. Input Part
- (1)
- Source Text Embedding Layer: Converts the numerical representations of words in the source text into vector representations, capturing semantic associations and contextual relationships between words.
- (2)
- Positional Encoding Layer: Generates a unique positional vector for each position in the input sequence, enabling the model to perceive positional relationship information within the sequence.
- (3)
- Target Text Embedding Layer (Decoder-only): Performs the same vectorization operation as the source text on the target text, converting numerical word representations into vector representations containing semantic information to provide the basic input for the decoding process.
3.2.2. Encoder Part
- (1)
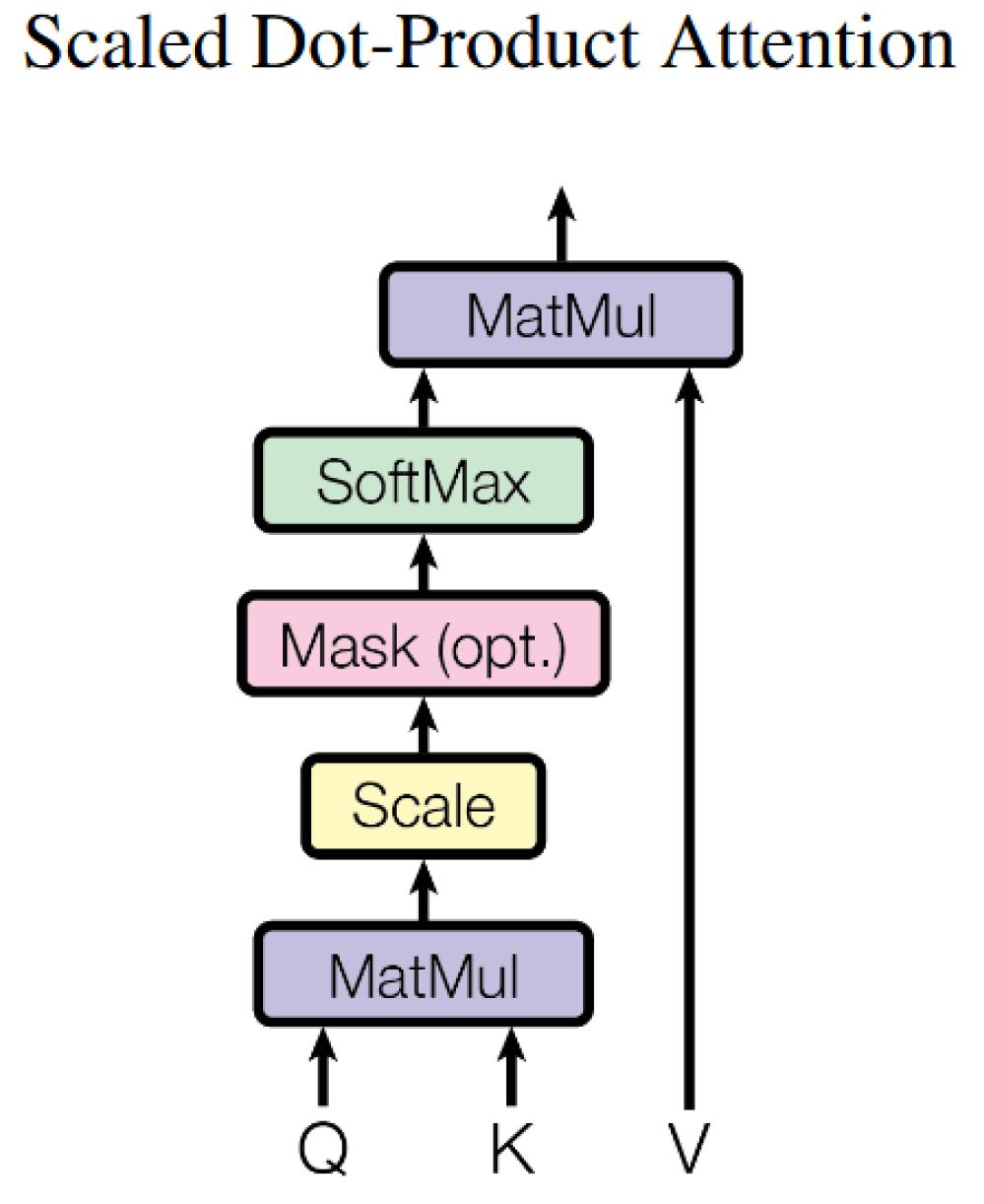
- Self-Attention Mechanism: The core of the Transformer architecture enables the model to dynamically focus on the semantic associations of other tokens when processing a specific token. This enhances the ability to capture long-range dependencies and models global semantic relationships. Its structure is shown in Figure 8.
- (2)
- The multi-head attention mechanism is an extension of the self-attention mechanism. By parallelly setting multiple attention heads, the model can learn differentiated attention weights from different semantic subspaces, thereby capturing multi-dimensional semantic associations and feature patterns. Its structure is shown in Figure 9. The specific implementation process is as follows:
- (3)
- The FFN consists of two fully connected layers (linear) and a non-linear activation function (ReLU). Its function is to perform non-linear transformations on the features output by the attention mechanism to enhance the model’s ability to express complex semantic patterns. The specific calculation formula is as shown in Formula (11):
- (4)
- Residual connection and layer normalization are applied after the multi-head attention module and the feed-forward neural network module, respectively. Their core roles are to mitigate the gradient vanishing problem in deep networks, accelerate the training process, and prevent excessive modification of feature representations by preserving original input information. The specific calculations are shown in Formulas (12) and (13):
3.2.3. Decoder Part
3.2.4. Output Part
3.3. GCN Module
3.4. Global Pooling
3.5. Objective Function
4. Results and Discussion
4.1. Experimental Setup
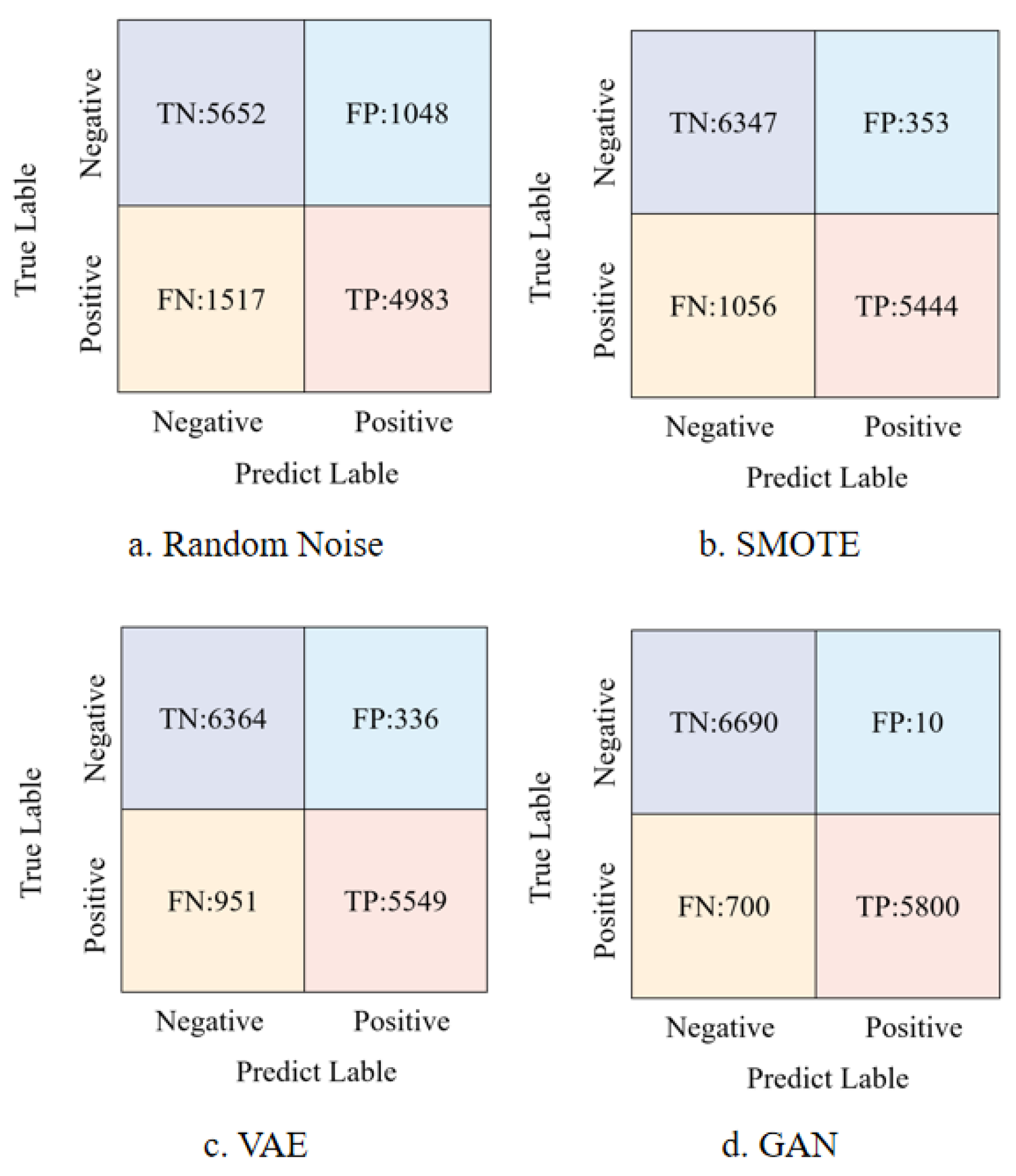
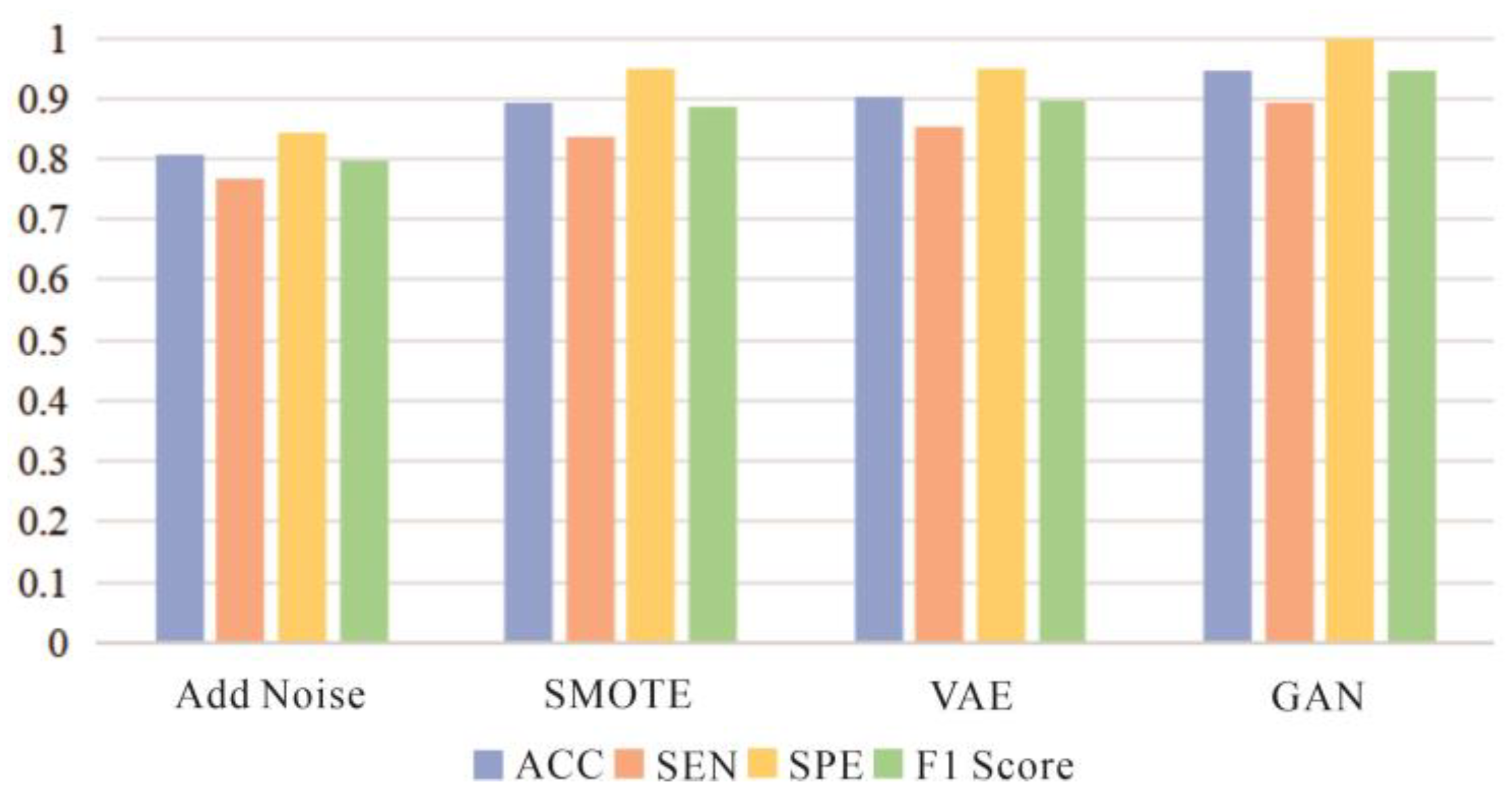
4.2. Comparison of Data Augmentation Methods
- (1)
- Direct Noise Addition: Although simple to implement, experimental results show that while this method could identify some mineral deposit samples, it significantly increased the misclassification risk of non-deposit samples, leading to a high number of false positives (FPs) and interfering with the model’s classification ability.
- (2)
- SMOTE: As a classic technique for handling imbalanced datasets, SMOTE effectively reduced the number of false positives in this experiment, demonstrating its advantage in minimizing non-deposit sample misclassifications. However, the relatively high number of false negatives (FNs) indicates that some actual mineral deposit samples were incorrectly classified as non-deposits, affecting the overall classification performance.
- (3)
- VAE: The deep learning-based data augmentation method exhibited superior performance by reducing both false positives and false negatives, with significant improvements across all evaluation metrics.
- (4)
- GAN: The GAN method achieved the best performance across key metrics such as accuracy, sensitivity, specificity, and F1-score. By generating new samples that closely mimic the original data distribution, GAN effectively expanded the dataset size and enhanced the model’s generalization ability, enabling more precise classification of mineral deposits and non-deposits.
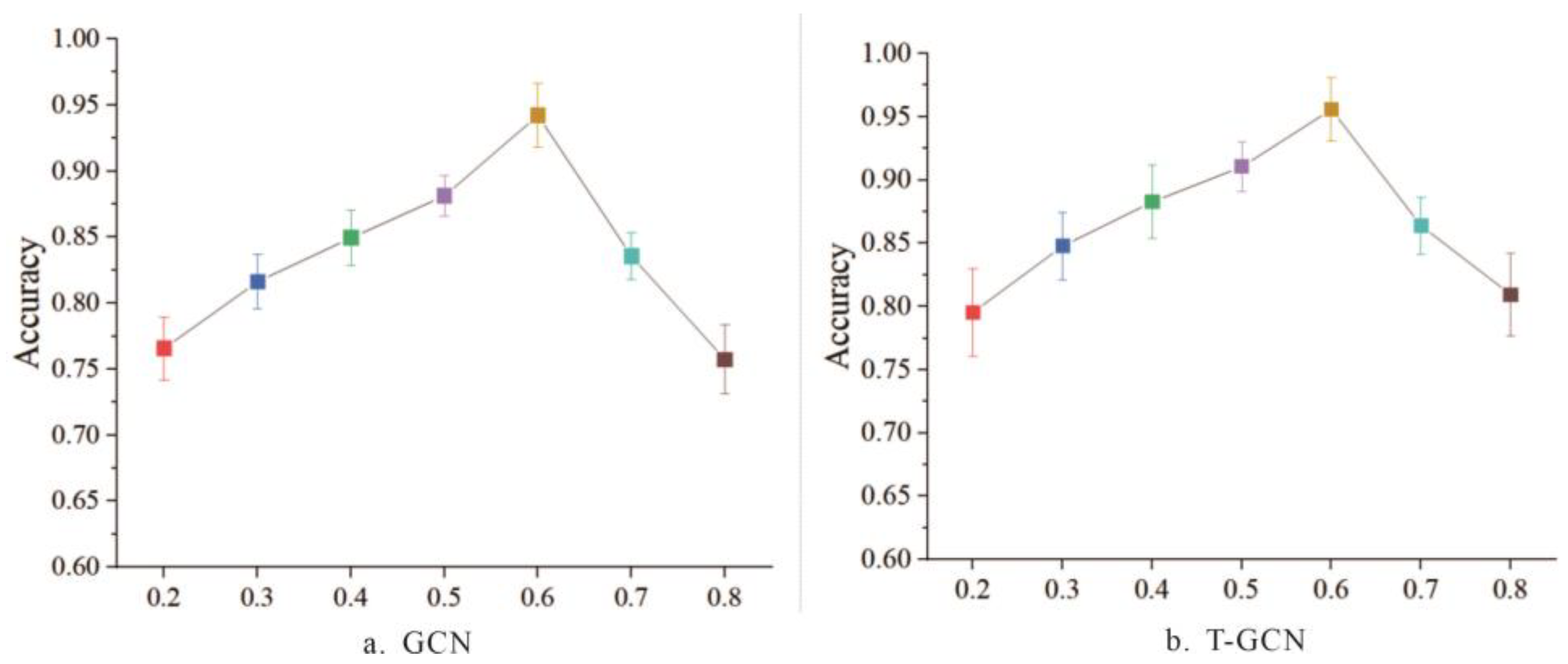
4.3. Influence of Hyperparameter α on Classification Performance
4.4. Comparative Experiment with GCNs and Transformer
- (1)
- Overall Classification Task Performance
- (2)
- Sen
- (3)
- Spe
- (4)
- F1 Score
4.5. Comparative Experiments of Different Models
4.6. Visualization Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singer, D.A. Comparison of expert estimates of number of undiscovered mineral deposits with mineral deposit densities. Ore Geol. Rev. 2018, 99, 235–243. [Google Scholar] [CrossRef]
- Lederer, G.W.; Solano, F.; Coyan, J.A.; Denton, K.M.; Watts, K.E.; Mercer, C.N.; Bickerstaff, D.P.; Granitto, M. Tungsten skarn mineral resource assessment of the great basin region of western Nevada and eastern California. J. Geochem. Explor. 2021, 223, 106712. [Google Scholar] [CrossRef]
- Jo, J.; Lee, B.H.; Heo, C.H. Geochemical approaches to mineral resources exploration. Econ. Environ. Geol. 2024, 57, 593–608. [Google Scholar] [CrossRef]
- Coyan, J.; Solano, F.; Taylor, C.; Finn, C.; Smith, S.; Holm-Denoma, C.; Pianowski, L.; Crocker, K.; Mirkamalov, R.; Divaev, F. Tungsten skarn quantitative mineral resource assessment and gold, rare earth elements, graphite, and uranium qualitative assessments of the kuldjuktau and auminzatau ranges, in the central kyzylkum region, Uzbekistan. Minerals 2024, 14, 1240. [Google Scholar] [CrossRef]
- Partington, G.A.; Peters, K.J.; Czertowicz, T.A.; Greville, P.A.; Blevin, P.L.; Bahiru, E.A. Ranking mineral exploration targets in support of commercial decision making: A key component for inclusion in an exploration information system. Appl. Geochem. 2024, 168, 106010. [Google Scholar] [CrossRef]
- Ding, M.; Vatsalan, D.; Gonzalez-Alvarez, I.; Mrabet, S.; Tyler, P.; Klump, J. Trusted data sharing for mineral exploration and mining tenements. J. Geochem. Explor. 2024, 267, 107580. [Google Scholar] [CrossRef]
- Liu, F.M. Enabling data conversion between Micromine and Surpac- enhancing efficiency in geological exploration. Cogent Educ. 2024, 11, 2438591. [Google Scholar] [CrossRef]
- Huang, J.; Fang, Y.; Wang, C.; Li, Y. Research on 3D geological and numerical unified model of in mining slope based on multi-source data. Water 2024, 16, 2421. [Google Scholar] [CrossRef]
- Jin, X.; Wang, G.W.; Tang, P.; Zhang, S.K. 3D geological modelling and uncertainty analysis for 3D targeting in Shanggong gold deposit (China). J. Geochem. Explor. 2020, 210, 106442. [Google Scholar] [CrossRef]
- Cai, H.H.; Chen, S.Q.; Xu, Y.Y.; Li, Z.X.; Ran, X.J.; Wen, X.P. Intelligent recognition of ore-forming anomalies based on multisource data fusion: A case study of the Daqiao mining area, Gansu province, China. Earth Space Sci. 2021, 8, e2021EA001927. [Google Scholar] [CrossRef]
- Zuo, R.G.; Yang, F.F.; Cheng, Q.M.; Kreuzer, O.P. A novel data-knowledge dual-driven model coupling artificial intelligence with a mineral systems approach for mineral prospectivity mapping. Geology 2025, 53, 284–288. [Google Scholar] [CrossRef]
- He, L.H.; Zhou, Y.Z.; Zhang, C. Application of target detection based on deep learning in intelligent mineral identification. Minerals 2024, 14, 873. [Google Scholar] [CrossRef]
- Yang, L.; Liu, M.; Liu, N.; Guo, J.Y.; Lin, L.A.; Zhang, Y.Y.; Du, X.; Wang, Y.K. Recovering bathymetry from satellite altimetry-derived gravity by fully connected deep neural network. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1502805. [Google Scholar] [CrossRef]
- Zhang, Z.H.; Wang, Y.B.; Wang, P. On a deep learning method of estimating reservoir porosity. Math. Probl. Eng. 2021, 2021, 6641678. [Google Scholar] [CrossRef]
- Saremi, M.; Bagheri, M.; Mirzabozorg, S.; Hassan, N.E.; Hoseinzade, Z.; Maghsoudi, A.; Rezania, S.; Pour, A.B. Evaluation of deep isolation forest(DIF) algorithm for mineral prospectivity mapping of polymetallic deposits. Minerals 2024, 14, 1015. [Google Scholar] [CrossRef]
- Chen, M.M.; Xiao, F. Projection pursuit random forest for mineral prospectivity mapping. Math. Geosci. 2023, 55, 963–987. [Google Scholar] [CrossRef]
- Gao, L.; Zhang, W.T.; Liu, Q.Y.; Zhang, X. Machine learning based on the graph convolutional self-organizing map method increases the accuracy of pollution source identification: A case study of trace metal(loid)s in soils of Jiangmen City, south China. Ecotoxicol. Environ. Saf. 2023, 250, 114467. [Google Scholar] [CrossRef]
- Zuo, R.G.; Carranza, E.J.M. Support vector machine: A tool for mapping mineral prospectivity. Comput. Geosci. 2011, 37, 1967–1975. [Google Scholar] [CrossRef]
- Maepa, F.; Smith, R.S.; Tessema, A. Support vector machine and artificial neural network modelling of orogenic gold prospectivity mapping in the Swayze greenstone belt, Ontario, Canada. Ore Geol. Rev. 2021, 130, 103968. [Google Scholar] [CrossRef]
- Behnia, P.; Harris, J.; Sherlock, R.; Naghizadeh, M.; Vayavur, R. Mineral prospectivity mapping for orogenic gold mineralization in the rainy river area, Wabigoon subprovince. Minerals 2023, 13, 1267. [Google Scholar] [CrossRef]
- Cao, C.J.; Wang, X.L.; Yang, F.; Xie, M.; Liu, B.; Zhou, Z.L. Attention-driven graph convolutional neural networks for mineral prospectivity mapping. Ore Geol. Rev. 2025, 180, 106554. [Google Scholar] [CrossRef]
- Cao, M.X.; Yin, D.M.; Zhong, Y.; Lv, Y. Detection of geochemical anomalies related to mineralization using the random forest model optimized by the competitive mechanism and beetle antennae search. J. Geochem. Explor. 2023, 249, 107195. [Google Scholar] [CrossRef]
- Lachaud, A.; Adam, M.; Miskovic, I. Comparative study of random forest and support vector machine algorithms in mineral prospectivity mapping with limited training data. Minerals 2023, 13, 1073. [Google Scholar] [CrossRef]
- Ghezelbash, R.; Maghsoudi, A.; Shamekhi, M. Genetic algorithm to optimize the SVM and K-means algorithms for mapping of mineral prospectivity. Neural Comput. Appl. 2023, 35, 719–733. [Google Scholar] [CrossRef]
- Shaw, K.O.; Goita, K.; Germain, M. Prospectivity mapping of heavy mineral ore deposits based upon machine-learning algorithms: Columbite-tantalite deposits in west-central cote d’lvoire. Minerals 2022, 12, 1453. [Google Scholar] [CrossRef]
- Xiao, F.; Chen, W.L.; Erten, Q. A hybrid logistic regression: Gene expression programming model and its application to mineral prospectivity mapping. Nat. Resour. Res. 2022, 31, 2041–2064. [Google Scholar] [CrossRef]
- Li, H.; Li, X.h.; Yuan, F.; Jowitt, S.M.; Wu, B.C. Convolutional neural network and transfer learning based mineral prospectivity modeling for geochemical exploration of Au mineralization within the Guandian-Zhangbaling area, Anhui Province, China. Appl. Geochem. 2020, 122, 104747. [Google Scholar] [CrossRef]
- Gao, L.; Huang, Y.J.; Zhang, X.; Liu, Q.Y.; Chen, Z.Q. Prediction of prospecting target based on resnet convolutional neural network. Appl. Sci. 2022, 12, 11433. [Google Scholar] [CrossRef]
- Huang, Y.; Feng, Q.; Zhang, W.; Zhang, X.; Gao, L. Prediction of prospecting target based on selective transfer network. Minerals 2022, 12, 1112. [Google Scholar] [CrossRef]
- Xiao, F.; Wang, Y.; Zhou, Y.Z. Determining thresholds of arsenic and mercury in stream sediment for mapping natural toxic element anomaly using data-driven models: A comparative study on probability plots and fractal methods. Arab. J. Geosci. 2020, 13, 9155. [Google Scholar] [CrossRef]
- Yu, X.T.; Yu, P.; Wang, K.Y.; Cao, W.; Zhou, Y.Z. Data-driven mineral prospectivity mapping based on known deposits using association rules. Nat. Resour. Res. 2024, 33, 1025–1048. [Google Scholar] [CrossRef]
- Zhou, Y.Z.; Zhang, Q.L.; Huang, Y.J.; Yang, W.; Xiao, F.; Shen, W.J. Constructing knowledge graph for the porphyry copper deposit in the Qinzhou-Hangzhou bay area: Insight into knowledge graph based mineral resource prediction and evaluation. Earth Sci. Front. 2021, 28, 67–75. [Google Scholar] [CrossRef]
- He, J.X.; Zhang, Q.L.; Xu, Y.; Liu, Y.; Zhou, Y.Z. Research progress ofQinzhou-Hangzhou metallogenic belt- analysed from citespace community discovery. Geol. Rev. 2023, 69, 1919–1927. [Google Scholar] [CrossRef]
- Salomao, G.N.; Dall’Agnol, R.; Angelica, R.S.; Sahoo, P.K. Geochemical mapping in stream sediments of the Carajás Mineral Province, part 2: Multi-element geochemical signatures using Compositional Data Analysis(CoDA). J. S. Am. Earth Sci. 2021, 110, 103361. [Google Scholar] [CrossRef]
- Yerke, A.; Brumit, D.F.; Fodor, A.A. Proportion-based normalizations outperform compositional data transformations in machine learning applications. Microbiome 2024, 12, 45. [Google Scholar] [CrossRef] [PubMed]
- Graffelman, J.; Pawlowsky-Glahn, V.; Egozcue, J.J.; Buccianti, A. Exploration of geochemical data with compositional canonical biplots. J. Geochem. Explor. 2018, 194, 120–133. [Google Scholar] [CrossRef]
- Cheng, J.R.; Yang, Y.; Tang, X.Y.; Xiong, N.X.; Zhang, Y.; Lei, F.F. Generative adversarial networks: A literature review. KSII Trans. Internet Inf. Syst. 2020, 14, 4625–4647. [Google Scholar] [CrossRef]
- Nayak, G.H.H.; Alam, M.W.; Avinash, G.; Kumar, R.R.; Ray, M. Transformer-based deep learning architecture for time series forecasting. Softw. Impacts 2024, 22, 100716. [Google Scholar] [CrossRef]
- Zhou, Y.; Zheng, H.X.; Huang, X.; Hao, S.F.; Li, D.; Zhao, J.M. Graph neural networks: Taxonomy, advances, and trends. ACM Trans. Intell. Syst. Technol. 2022, 13, 15. [Google Scholar] [CrossRef]
- De Carvalho, A.M.; Prati, R.C. DTO-SMOTE: Delaunay tessellation oversampling for imbalanced data sets. Information 2020, 11, 557. [Google Scholar] [CrossRef]
- Jagadish, D.N.; Chauhan, A.; Mahto, L.; Chakraborty, T. Autonomous vehicle path prediction using conditional variational autoencoder networks. Adv. Knowl. Discov. Data Min. 2021, 12712, 129–139. [Google Scholar] [CrossRef]
- Kivela, M.; Porter, M.A. Isomorphisms in multilayer networks. IEEE Trans. Netw. Sci. Eng. 2018, 5, 198–211. [Google Scholar] [CrossRef]
- Liu, C.; Zhan, Y.B.; Yu, B.S.; Liu, L.; Liu, T.L. Onexploring node-feature and graph-structure diversities for node drop graph pooling. Neural Netw. 2023, 167, 559–571. [Google Scholar] [CrossRef] [PubMed]
- Pham, H.V.; Thanh, D.H.; Moore, P. Hierarchical pooling in graph neural networks to enhance classification performance in large datasets. Sensors 2021, 21, 6070. [Google Scholar] [CrossRef]
- Zhang, T.; Shan, H.R.; Little, M.A. Causal graphSAGE: A robust graph method for classification based on causal sampling. Pattern Recognit. 2022, 128, 108696. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| X | Y | Ag | Au | B | Sn | Cu | Ba | Mn | Pb | Zn | As | Sb | Hg | Mo | W | Bi | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 421.63 | 2416.85 | 0.078 | 0.54 | 4 | 2.56 | 7 | 88 | 209 | 12 | 23 | 0.9 | 0.29 | 0.04 | 0.82 | 1.16 | 0.42 | 204 |
| 420.93 | 2416.80 | 0.06 | 0.81 | 3 | 3.74 | 5 | 885 | 305 | 33 | 22 | 0.58 | 0.36 | 0.04 | 0.82 | 1.11 | 1.41 | 222 |
| 420.95 | 2416.35 | 0.086 | 0.94 | 4 | 2.41 | 5 | 797 | 267 | 53 | 35 | 1.15 | 0.34 | 0.09 | 0.51 | 1.16 | 0.42 | 212 |
| 421.21 | 2415.85 | 0.043 | 0.81 | 3 | 1.52 | 5 | 1111 | 423 | 42 | 14 | 0.51 | 0.35 | 0.07 | 0.59 | 0.38 | 0.23 | 222 |
| 420.30 | 2416.35 | 0.046 | 0.37 | 2 | 1.65 | 6 | 941 | 498 | 38 | 17 | 0.53 | 0.31 | 0.02 | 0.57 | 0.33 | 0.61 | 222 |
| 419.86 | 2416.15 | 0.033 | 1.09 | 4 | 1.53 | 8 | 427 | 338 | 37 | 29 | 0.74 | 0.28 | 0.07 | 1.68 | 0.73 | 0.47 | 204 |
| Element (mg/kg−1) | Maximum Value | Minimum Value | Mean Value | Standard Deviation | Coefficient of Variation |
|---|---|---|---|---|---|
| Au | 1.145 | 0.2 × 10−3 | 2.06 × 10−3 | 0.019 | 9.5 |
| B | 950 | 1 | 38.92 | 50.82 | 1.39 |
| Sn | 280 | 0.85 | 4.99 | 6.92 | 1.4 |
| Cu | 440 | 1 | 12.01 | 16.82 | 1.31 |
| Ag | 40.7 | 0.04 | 0.63 | 0.59 | 0.94 |
| Ba | 1872 | 6 | 200.72 | 188.7 | 7 |
| Mn | 3183 | 49 | 345.33 | 199.68 | 0.578 |
| Pb | 5504 | 1 | 34.57 | 74.3 | 2.57 |
| Zn | 2955 | 3 | 36.11 | 50 | 5.35 |
| As | 1520 | 0.1 | 6.11 | 22.85 | 2.72 |
| Sb | 2610 | 0.14 | 0.89 | 30.69 | 0.62 |
| Bi | 250 | 0.01 | 0.98 | 3.97 | 2.15 |
| Hg | 14.5 | 0.03 | 0.07 | 0.19 | 1.39 |
| Mo | 407.59 | 0.12 | 1.69 | 9.01 | 3.74 |
| W | 511 | 0.14 | 3.18 | 8.64 | 34.43 |
| F | 3930 | 33 | 300.95 | 185.12 | 4.06 |
| Model | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GCNs | Acc | 94.78 | 94.90 | 94.99 | 93.38 | 93.52 | 94.72 | 94.15 | 94.26 | 94.32 | 95.49 | 94.45 |
| Sen | 87.93 | 87.81 | 88.51 | 84.55 | 85.07 | 88.06 | 86.40 | 86.85 | 87.38 | 89.39 | 87.2 | |
| Spe | 99.91 | 99.91 | 99.91 | 99.93 | 99.91 | 99.86 | 99.93 | 99.82 | 99.88 | 99.89 | 99.9 | |
| F1 | 93.52 | 93.45 | 93.84 | 91.58 | 91.87 | 93.55 | 92.66 | 92.88 | 93.18 | 94.59 | 93.11 | |
| Transformer | Acc | 95.06 | 94.68 | 95.18 | 95.25 | 94.61 | 95.19 | 95.46 | 94.85 | 95.27 | 95.06 | 95.03 |
| Sen | 90.67 | 89.54 | 91.84 | 90.94 | 89.63 | 91.32 | 91.01 | 90.86 | 91.57 | 90.67 | 90.69 | |
| Spe | 98.99 | 99.83 | 97.79 | 99.19 | 98.89 | 99.58 | 98.91 | 98.27 | 97.98 | 98.99 | 98.76 | |
| F1 | 94.33 | 93.41 | 94.43 | 93.92 | 94.23 | 94.91 | 94.42 | 94.75 | 94.71 | 94.33 | 94.32 | |
| T-GCN | Acc | 97.50 | 97.04 | 96.44 | 97.09 | 97.53 | 98.04 | 97.85 | 96.94 | 97.44 | 97.50 | 97.27 |
| Sen | 92.41 | 91.93 | 91.21 | 92.14 | 92.38 | 92.72 | 92.62 | 91.78 | 92.29 | 92.41 | 92.15 | |
| Spe | 99.93 | 99.89 | 99.87 | 99.91 | 99.94 | 99.89 | 99.95 | 99.90 | 99.94 | 99.93 | 99.9 | |
| F1 | 95.91 | 95.33 | 94.87 | 95.64 | 95.96 | 96.23 | 96.07 | 94.95 | 95.89 | 95.91 | 95.65 |
| Model | NCII | MUTAG | IMB-BINARY | PangXD |
|---|---|---|---|---|
| SVM [23] | 73.61 | 71.26 | 70.25 | 74.2 |
| Random forest [22] | 72.55 | 71.55 | 69.92 | 73.26 |
| K-means [24] | 74.56 | 76.22 | 75.45 | 78.03 |
| KNN [22] | 73.20 | 75.10 | 76.12 | 77.32 |
| GIN [42] | 76.52 | 82.67 | 84.22 | 91.61 |
| SAGPool [43] | 73.82 | 81.49 | 80.72 | 93.38 |
| DiffPool [44] | 75.74 | 80.99 | 87.26 | 92.25 |
| GraphSAGE [45] | 72.98 | 84.63 | 86.34 | 93.51 |
| T-GCN | 80.41 | 82.98 | 89.63 | 97.27 |
| Target Number | Fault Structure Characteristics | Element Anomaly and Deposit Distribution |
|---|---|---|
| I | Development of deep NE-trending faults with densely distributed secondary faults | Element anomalies distributed in strips along the faults, hosting known large ore deposits |
| II | Low fault density | Sparsely distributed high-value element anomalies, containing five known ore deposits |
| III | Conjugate intersection of NE-trending and NW-trending faults with extremely high fault density | Significant element anomaly intensity; no proven ore deposits discovered yet |
| IV | Densely distributed NW-trending secondary faults | High element anomaly values distributed in a planar manner, with known ore deposits |
| V | Development of major NE-trending faults with densely developed associated secondary faults | Element anomalies continuously distributed along the fault zone, with known ore deposits |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, L.; Gopalakrishnan, G.; Nasri, A.; Li, Y.; Zhang, Y.; Ou, X.; Xia, K. Transformer–GCN Fusion Framework for Mineral Prospectivity Mapping: A Geospatial Deep Learning Approach. Minerals 2025, 15, 711. https://doi.org/10.3390/min15070711
Gao L, Gopalakrishnan G, Nasri A, Li Y, Zhang Y, Ou X, Xia K. Transformer–GCN Fusion Framework for Mineral Prospectivity Mapping: A Geospatial Deep Learning Approach. Minerals. 2025; 15(7):711. https://doi.org/10.3390/min15070711
Chicago/Turabian StyleGao, Le, Gnanachandrasamy Gopalakrishnan, Adel Nasri, Youhong Li, Yuying Zhang, Xiaoying Ou, and Kele Xia. 2025. "Transformer–GCN Fusion Framework for Mineral Prospectivity Mapping: A Geospatial Deep Learning Approach" Minerals 15, no. 7: 711. https://doi.org/10.3390/min15070711
APA StyleGao, L., Gopalakrishnan, G., Nasri, A., Li, Y., Zhang, Y., Ou, X., & Xia, K. (2025). Transformer–GCN Fusion Framework for Mineral Prospectivity Mapping: A Geospatial Deep Learning Approach. Minerals, 15(7), 711. https://doi.org/10.3390/min15070711