
Predicting Industrial Copper Hydrometallurgy Output with Deep Learning Approach Using Data Augmentation

 ,
,  ,
,
Abstract
1. Introduction
2. Hydrometallurgical Copper Extraction Process
3. Materials and Methods
3.1. Study Overview and Experimental Design
3.2. Data Collection and Preparation
3.3. Data Preprocessing and Feature Engineering
3.3.1. Data Augmentation
3.3.2. Feature Selection and Scaling
3.3.3. Time Series Preparation and Dataset Splitting
3.4. Model Development and Evaluation
3.4.1. Model Architectures
- Vanilla LSTM—A standard Long Short-Term Memory network with a single LSTM layer and a hidden state dimension of 50.
- Stacked LSTM—An LSTM network with multiple stacked LSTM layers (num_layers = 3) and a hidden dimension of 50.
- Bidirectional LSTM (Bi-LSTM)—An LSTM network utilizing a single bidirectional layer, processing the input sequence in both forward and backward directions. The hidden dimension was 50 (resulting in 100 features before the final layer).
- GRU (Gated Recurrent Unit)—A network using a GRU layer instead of LSTM, with a hidden dimension of 50.
- CNN-LSTM—A hybrid model combining a 1D Convolutional Neural Network (CNN) layer for feature extraction across the input features at each time step, followed by an LSTM layer. The CNN layer had 32 filters and a kernel size of 3. The subsequent LSTM layer had a hidden dimension of 50.
- Attention LSTM—An LSTM network augmented with a simple attention mechanism. Attention weights were computed over the LSTM output sequence, allowing the model to weigh the importance of different time steps dynamically before producing the final prediction. It used a single LSTM layer with a hidden dimension of 50.
3.4.2. Training Procedure
3.4.3. Evaluation Metrics
- Mean Absolute Error (MAE): The MAE provides a straightforward interpretation of the average magnitude of errors in the same unit as the target variable. It is robust to outliers and offers an intuitive measure of model accuracy in terms of absolute deviation from true values [38].
- Root Mean Squared Error (RMSE): The RMSE penalizes larger errors more heavily than MAE due to the squaring operation. This makes it especially useful when larger deviations are more critical to the application, providing a more sensitive error measurement for high-impact mispredictions [38].
- Coefficient of Determination (R2): R2 indicates the proportion of variance in the target variable that is predictable from the input features. It offers a normalized metric to assess how well the model explains the data, facilitating comparisons across models regardless of the scale of the target variable [38].
- Mean Absolute Percentage Error (MAPE): The MAPE expresses errors as a percentage of actual values, which is useful for interpretability when comparing performance across datasets or time periods. Since MAPE can become unstable when true values approach zero, care was taken to ensure zero values were appropriately handled or excluded from its calculation [41].
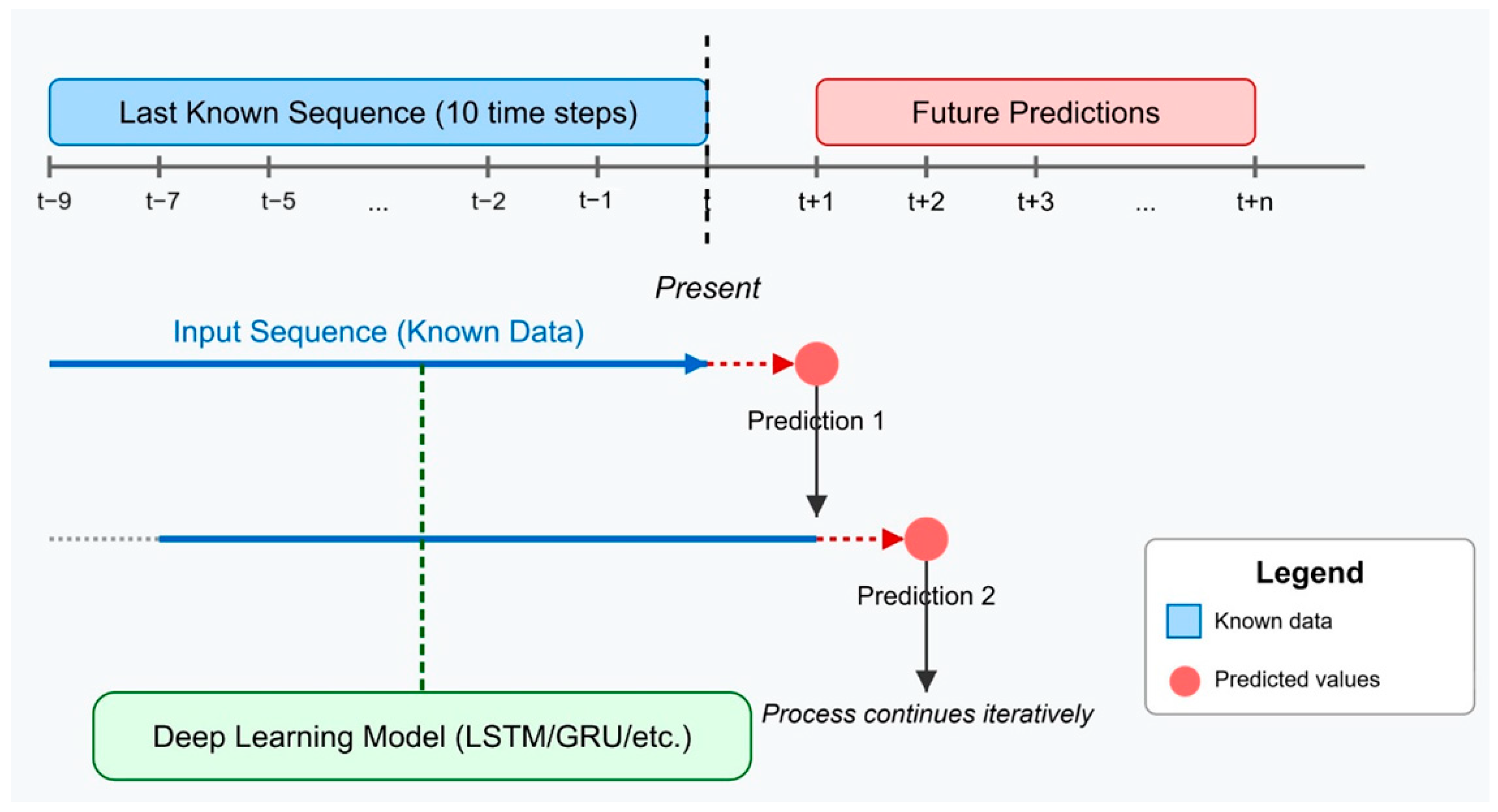
3.4.4. Forecasting Methodology
3.5. Implementation Details
4. Results and Discussion
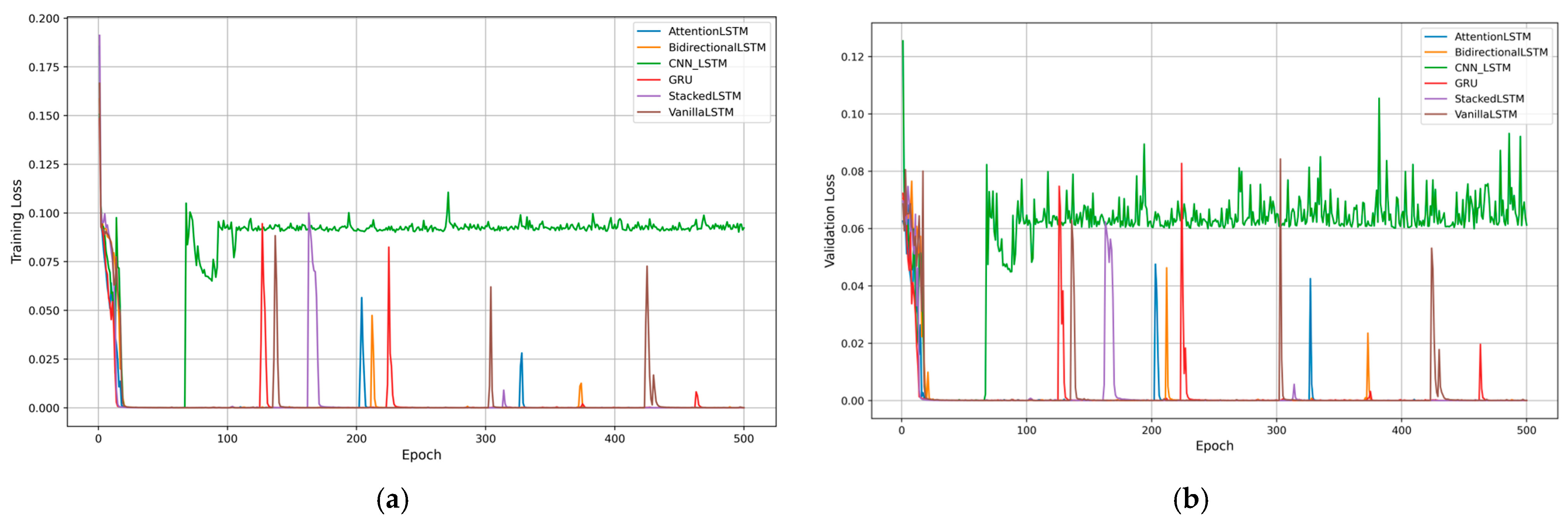
4.1. Training Dynamics
4.2. Model Performance Evaluation
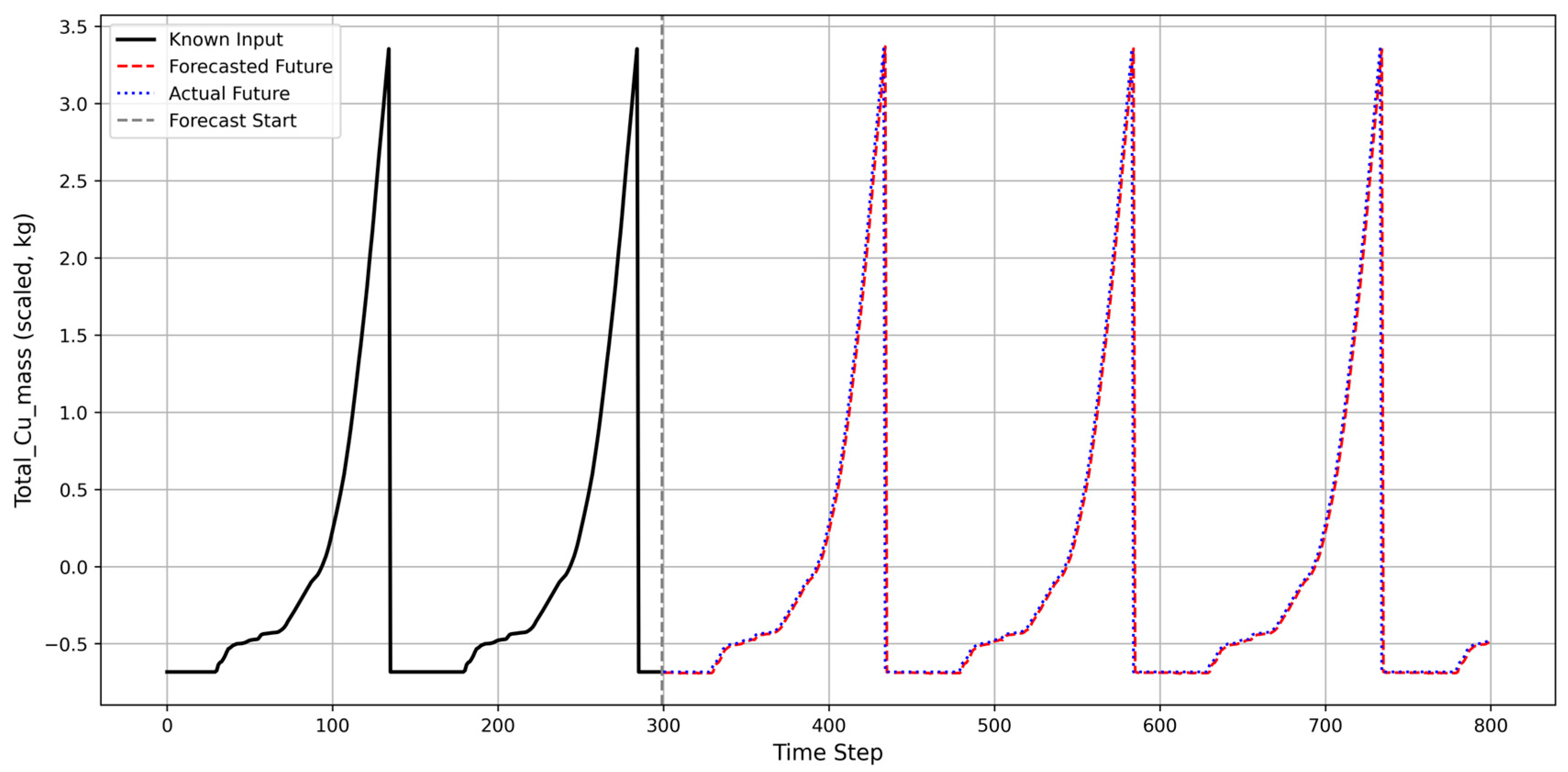
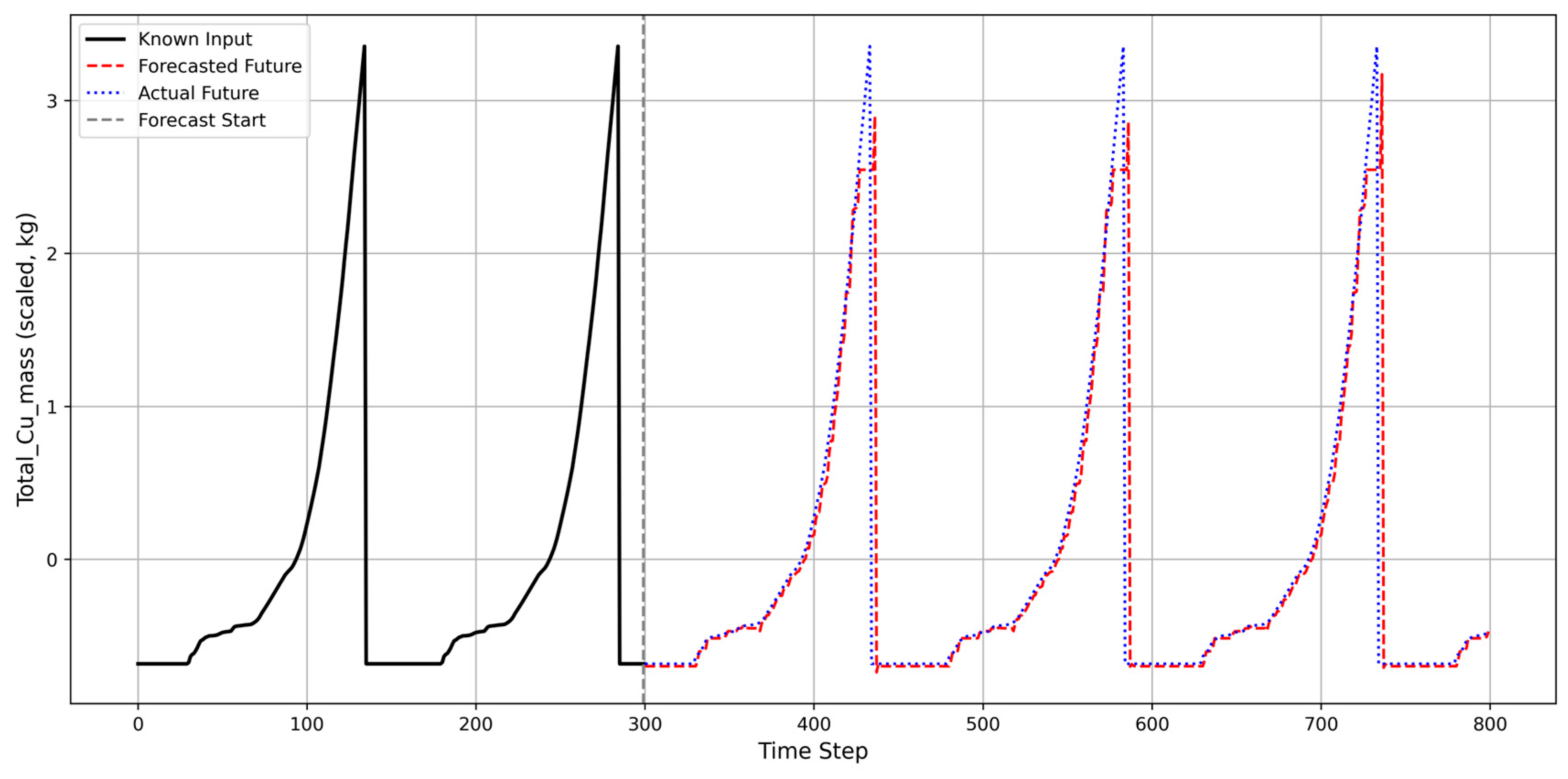
4.3. Forecasting Capability
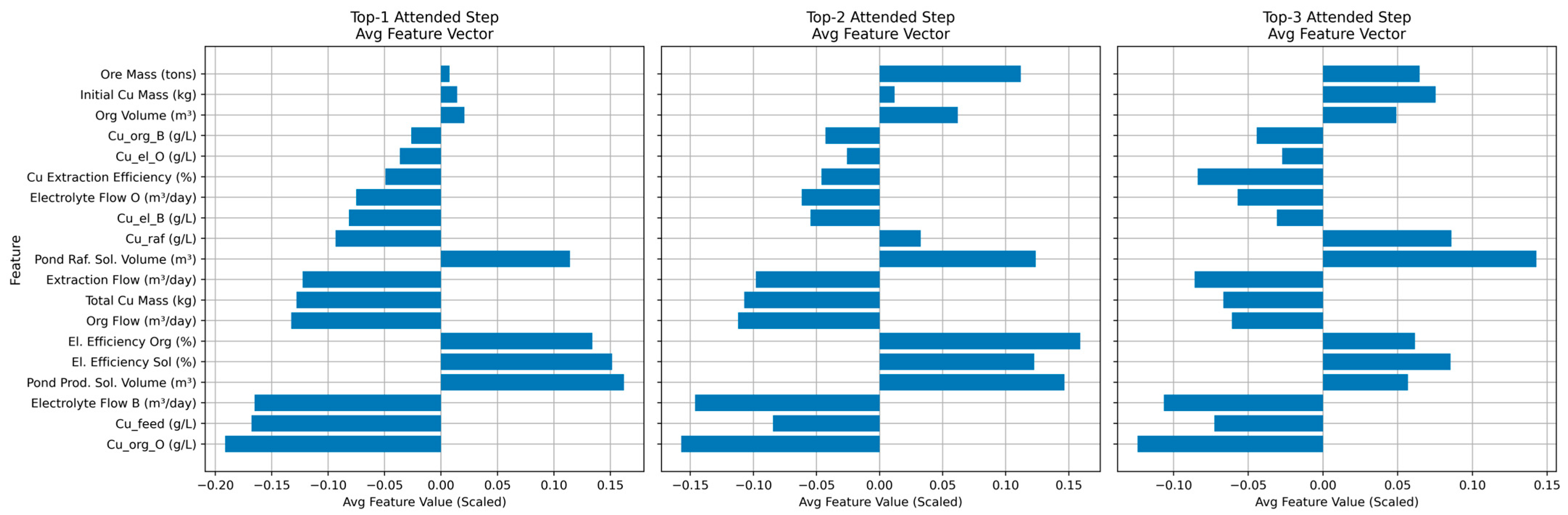
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Kenzhaliyev, B.; Imankulov, T.; Mukhanbet, A.; Kvyatkovskiy, S.; Dyussebekova, M.; Tasmurzayev, N. Intelligent System for Reducing Waste and Enhancing Efficiency in Copper Production Using Machine Learning. Metals 2025, 15, 186. [Google Scholar] [CrossRef]
- Vives Pons, J.; Comerma, A.; Escobet, T.; Dorado, A.D.; Tarrés-Puertas, M.I. Optimizing Bioleaching for Printed Circuit Board Copper Recovery: An AI-Driven RGB-Based Approach. Appl. Sci. 2024, 15, 129. [Google Scholar] [CrossRef]
- Koizhanova, A.K.; Kenzhaliyev, B.K.; Magomedov, D.R.; Erdenova, M.B.; Bakrayeva, A.N.; Abdyldaev, N.N. Hydrometallurgical Studies on the Leaching of Copper from Man-Made Mineral Formations. Complex Use Miner. Resour. 2024, 330, 32–42. [Google Scholar] [CrossRef]
- Fan, X.; Wu, N.; Sun, L.; Jiang, Y.; He, S.; Huang, M.; Yang, K.; Cao, Y. New Separation Technology for Lead and Mercury from Acid Sludge of Copper Smelting Using a Total Hydrometallurgical Process. Min. Metall. Explor. 2024, 41, 1597–1604. [Google Scholar] [CrossRef]
- Dias, J.; De Holanda, J.N.F.; Pinho, S.C.; De Miranda Júnior, G.M.; Da Silva, A.G.P. Systematic LCA-AHP Approach to Compare Hydrometallurgical Routes for Copper Recovery from Printed Circuit Boards: Environmental Analysis. Sustainability 2024, 16, 8002. [Google Scholar] [CrossRef]
- Cheje Machaca, D.M.; Botelho, A.B.; De Carvalho, T.C.; Tenório, J.A.S.; Espinosa, D.C.R. Hydrometallurgical Processing of Chalcopyrite: A Review of Leaching Techniques. Int. J. Miner. Metall. Mater. 2024, 31, 2537–2555. [Google Scholar] [CrossRef]
- Koizhanova, A.; Kenzhaliyev, B.; Magomedov, D.; Kamalov, E.; Yerdenova, M.; Bakrayeva, A.; Abdyldayev, N. Study of Factors Affecting the Copper Ore Leaching Process. ChemEngineering 2023, 7, 54. [Google Scholar] [CrossRef]
- Martín, M.I.; García-Díaz, I.; López, F.A. Properties and Perspective of Using Deep Eutectic Solvents for Hydrometallurgy Metal Recovery. Miner. Eng. 2023, 203, 108306. [Google Scholar] [CrossRef]
- Gómez, M.; Grimes, S.; Fowler, G. Novel Hydrometallurgical Process for the Recovery of Copper from End-of-Life Mobile Phone Printed Circuit Boards Using Ionic Liquids. J. Clean. Prod. 2023, 420, 138379. [Google Scholar] [CrossRef]
- Godirilwe, L.L.; Haga, K.; Altansukh, B.; Jeon, S.; Danha, G.; Shibayama, A. Establishment of a Hydrometallurgical Scheme for the Recovery of Copper, Nickel, and Cobalt from Smelter Slag and Its Economic Evaluation. Sustainability 2023, 15, 10496. [Google Scholar] [CrossRef]
- Kenzhaliyev, B.; Amangeldy, B.; Mukhanbet, A.; Azatbekuly, N.; Koizhanova, A.; Magomedov, D. Development of Software for Hydrometallurgical Calculation of Metal Extraction. Complex Use Miner. Resour. 2024, 335, 78–88. [Google Scholar] [CrossRef]
- Şayan, E.; Çalışkan, B. The Use of Ultrasound in Hydrometallurgical Studies: A Review on the Comparison of Ultrasound-Assisted and Conventional Leaching. J. Sustain. Metall. 2024, 10, 1933–1958. [Google Scholar] [CrossRef]
- Ordaz-Oliver, M.; Jiménez-Muñoz, E.; Gutiérrez-Moreno, E.; Borja-Soto, C.E.; Ordaz, P.; Montiel-Hernández, J.F. Application of Artificial Neural Networks for Recovery of Cu from Electronic Waste by Dynamic Acid Leaching: A Sustainable Approach. Waste Biomass Valor 2024, 15, 7057–7076. [Google Scholar] [CrossRef]
- Oráč, D.; Klimko, J.; Klein, D.; Pirošková, J.; Liptai, P.; Vindt, T.; Miškufová, A. Hydrometallurgical Recycling of Copper Anode Furnace Dust for a Complete Recovery of Metal Values. Metals 2021, 12, 36. [Google Scholar] [CrossRef]
- Nizamoğlu, H.; Turan, M.D. Using of Leaching Reactant Obtained from Mill Scale in Hydrometallurgical Copper Extraction. Environ. Sci. Pollut. Res. 2021, 28, 54811–54825. [Google Scholar] [CrossRef]
- Binnemans, K.; Jones, P.T. The Twelve Principles of Circular Hydrometallurgy. J. Sustain. Metall. 2023, 9, 1–25. [Google Scholar] [CrossRef]
- Astudillo, Á.; Garcia, M.; Quezada, V.; Valásquez, L. The Use of Seawater in Copper Hydrometallurgical Processing in Chile: A Review. J. S. Afr. Inst. Min. Metall. 2023, 123, 357–364. [Google Scholar] [CrossRef]
- Amankwaa-Kyeremeh, B.; McCamley, C.; Zanin, M.; Greet, C.; Ehrig, K.; Asamoah, R.K. Prediction and Optimisation of Copper Recovery in the Rougher Flotation Circuit. Minerals 2023, 14, 36. [Google Scholar] [CrossRef]
- Amankwaa-Kyeremeh, B.; Ehrig, K.; Greet, C.; Asamoah, R. Pulp Chemistry Variables for Gaussian Process Prediction of Rougher Copper Recovery. Minerals 2023, 13, 731. [Google Scholar] [CrossRef]
- Zou, G.; Zhou, J.; Li, K.; Zhao, H. An HGA-LSTM-Based Intelligent Model for Ore Pulp Density in the Hydrometallurgical Process. Materials 2022, 15, 7586. [Google Scholar] [CrossRef]
- Murali, A.; Plummer, M.J.; Shine, A.E.; Free, M.L.; Sarswat, P.K. Optimized Bioengineered Copper Recovery from Electronic Wastes to Increase Recycling and Reduce Environmental Impact. J. Hazard. Mater. Adv. 2022, 5, 100031. [Google Scholar] [CrossRef]
- Ji, G.; Liao, Y.; Wu, Y.; Xi, J.; Liu, Q. A Review on the Research of Hydrometallurgical Leaching of Low-Grade Complex Chalcopyrite. J. Sustain. Metall. 2022, 8, 964–977. [Google Scholar] [CrossRef]
- Mohanty, U.; Rintala, L.; Halli, P.; Taskinen, P.; Lundström, M. Hydrometallurgical Approach for Leaching of Metals from Copper Rich Side Stream Originating from Base Metal Production. Metals 2018, 8, 40. [Google Scholar] [CrossRef]
- Panda, S.; Mishra, G.; Sarangi, C.K.; Sanjay, K.; Subbaiah, T.; Das, S.K.; Sarangi, K.; Ghosh, M.K.; Pradhan, N.; Mishra, B.K. Reactor and Column Leaching Studies for Extraction of Copper from Two Low Grade Resources: A Comparative Study. Hydrometallurgy 2016, 165, 111–117. [Google Scholar] [CrossRef]
- Xiao, Y.; Yang, Y.; Van Den Berg, J.; Sietsma, J.; Agterhuis, H.; Visser, G.; Bol, D. Hydrometallurgical Recovery of Copper from Complex Mixtures of End-of-Life Shredded ICT Products. Hydrometallurgy 2013, 140, 128–134. [Google Scholar] [CrossRef]
- Bergh, L.G.; Jämsä-Jounela, S.-L.; Hodouin, D. State of the Art in Copper Hydrometallurgic Processes Control. Control Eng. Pract. 2001, 9, 1007–1012. [Google Scholar] [CrossRef]
- Ashiq, A.; Kulkarni, J.; Vithanage, M. Hydrometallurgical Recovery of Metals From E-Waste. In Electronic Waste Management and Treatment Technology; Elsevier: Amsterdam, The Netherlands, 2019; pp. 225–246. ISBN 978-0-12-816190-6. [Google Scholar]
- Saldaña, M.; Neira, P.; Gallegos, S.; Salinas-Rodríguez, E.; Pérez-Rey, I.; Toro, N. Mineral Leaching Modeling Through Machine Learning Algorithms—A Review. Front. Earth Sci. 2022, 10, 816751. [Google Scholar] [CrossRef]
- Saldaña, M.; Neira, P.; Flores, V.; Robles, P.; Moraga, C. A Decision Support System for Changes in Operation Modes of the Copper Heap Leaching Process. Metals 2021, 11, 1025. [Google Scholar] [CrossRef]
- Flores, V.; Leiva, C. A Comparative Study on Supervised Machine Learning Algorithms for Copper Recovery Quality Prediction in a Leaching Process. Sensors 2021, 21, 2119. [Google Scholar] [CrossRef]
- Correa, P.P.; Cipriano, A.; Nuñez, F.; Salas, J.C.; Lobel, H. Forecasting Copper Electrorefining Cathode Rejection by Means of Recurrent Neural Networks With Attention Mechanism. IEEE Access 2021, 9, 79080–79088. [Google Scholar] [CrossRef]
- Caplan, M.; Trouba, J.; Anderson, C.; Wang, S. Hydrometallurgical Leaching of Copper Flash Furnace Electrostatic Precipitator Dust for the Separation of Copper from Bismuth and Arsenic. Metals 2021, 11, 371. [Google Scholar] [CrossRef]
- Brest, K.K.; Monga, K.J.J.; Henock, M.M. Implementation of Artificial Neural Network into the Copper and Cobalt Leaching Process. In Proceedings of the 2021 Southern African Universities Power Engineering Conference/Robotics and Mechatronics/Pattern Recognition Association of South Africa (SAUPEC/RobMech/PRASA), Potchefstroom, South Africa, 27–29 January 2021; pp. 1–5. [Google Scholar]
- Aleksandrova, T.N.; Orlova, A.V.; Taranov, V.A. Current Status of Copper-Ore Processing: A Review. Russ. J. Non-Ferrous Met. 2021, 62, 375–381. [Google Scholar] [CrossRef]
- Jia, L.; Huang, J.; Ma, Z.; Liu, X.; Chen, X.; Li, J.; He, L.; Zhao, Z. Research and Development Trends of Hydrometallurgy: An Overview Based on Hydrometallurgy Literature from 1975 to 2019. Trans. Nonferrous Met. Soc. China 2020, 30, 3147–3160. [Google Scholar] [CrossRef]
- Flores, V.; Keith, B.; Leiva, C. Using Artificial Intelligence Techniques to Improve the Prediction of Copper Recovery by Leaching. J. Sens. 2020, 2020, 1–12. [Google Scholar] [CrossRef]
- Saldaña, M.; González, J.; Jeldres, R.I.; Villegas, Á.; Castillo, J.; Quezada, G.; Toro, N. A Stochastic Model Approach for Copper Heap Leaching through Bayesian Networks. Metals 2019, 9, 1198. [Google Scholar] [CrossRef]
- Dildabek, A.; Abdiakhmetova, Z. Using Synthetic Data to Improve Data Processing Algorithms in Business Intelligence. J. Probl. Comput. Sci. Inf. Technol. 2024, 2, 44–49. [Google Scholar] [CrossRef]
- Daribayev, B.; Azatbekuly, N.; Mukhanbet, A. Optimization of Neural Networks for Predicting Oil Recovery Factor Using Quantization Techniques. J. Probl. Comput. Sci. Inf. Technol. 2024, 2, 25–33. [Google Scholar] [CrossRef]
- Amangeldy, B.; Tasmurzayev, N.; Shinassylov, S.; Mukhanbet, A.; Nurakhov, Y. Integrating Machine Learning with Intelligent Control Systems for Flow Rate Forecasting in Oil Well Operations. Automation 2024, 5, 343–359. [Google Scholar] [CrossRef]
- Glavackij, A.; David, D.P.; Mermoud, A.; Romanou, A.; Aberer, K. Beyond S-Curves: Recurrent Neural Networks for Technology Forecasting. arXiv 2022, arXiv:2211.15334. [Google Scholar] [CrossRef]
- Lundberg, S.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. arXiv 2017, arXiv:arXiv.1705.07874. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Physical Measurement (Units) | Description |
|---|---|---|
| Cu_feed | Copper concentration (g/L) | Concentration of copper in the feed solution entering the extraction process |
| Cu_raf | Copper concentration (g/L) | Concentration of copper in the raffinate solution (the aqueous phase after extraction) |
| Extraction_flow | Flow rate (m3/day) | Volume flow rate of solution during the extraction stage |
| Cu_extr_eff | Efficiency (%) | Percentage of copper successfully extracted from feed solution |
| Pond_prod_sol_vol | Volume (m3) | Total volume of productive solution stored in the leaching pond |
| Pond_raf_sol_vol | Volume (m3) | Total volume of raffinate solution stored in the pond |
| Cu_org_B | Copper concentration (g/L) | Concentration of copper in the organic phase before loading (entering re-extraction) |
| Cu_org_O | Copper concentration (g/L) | Concentration of copper in the organic phase after loading (leaving extraction) |
| Org_flow | Flow rate (m3/day) | Volume flow rate of the organic extractant through the system |
| Cu_el_B | Copper concentration (g/L) | Concentration of copper in the electrolyte before electrolysis |
| El_flow_B | Flow rate (m3/day) | Volume flow rate of the electrolyte before electrolysis |
| Cu_el_eff_org | Efficiency (%) | Percentage efficiency of copper transfer from organic phase to electrolyte |
| Cu_el_eff_sol | Efficiency (%) | Percentage efficiency of copper electrodeposition from solution to cathodes |
| Cu_el_O | Copper concentration (g/L) | Concentration of copper in the electrolyte after electrolysis |
| El_flow_O | Flow rate (m3/day) | Volume flow rate of the electrolyte after electrolysis |
| Cu_cat_growth | Mass growth rate (kg/day) | Rate of copper deposition on cathodes during electrolysis |
| Total_Cu_mass | Mass (kg) | Total cumulative mass of copper produced (target variable) |
| Ore_to_metal_extr | Ratio (kg ore/kg Cu) | Mass ratio of ore processed to metal extracted |
| Total_extraction_eff | Efficiency (%) | Overall percentage efficiency of the entire extraction process |
| Ore_mass | Mass (tons) | Total mass of ore processed in the extraction operation |
| Initial_Cu_mass | Mass (kg) | Initial mass of copper in the ore before processing begins |
| Org_volume | Volume (m3) | Total volume of organic extractant in the system |
| Model | MAE | RMSE | R2 | MAPE |
|---|---|---|---|---|
| VanillaLSTM | 0.004 | 0.008 | 1 | 1.456 |
| Figure | 0.003 | 0.006 | 1 | 0.682 |
| BidirectionalLSTM | 0.002 | 0.003 | 1 | 0.928 |
| GRU | 0.004 | 0.005 | 1 | 1.361 |
| CNN_LSTM | 0.057 | 0.266 | 0.926 | 9.706 |
| AttentionLSTM | 0.002 | 0.004 | 1 | 0.731 |
| Model | h = 10 | h = 50 | h = 100 | h = 500 |
|---|---|---|---|---|
| Bidirectional LSTM | 0.0480/6.84% | 0.0509/7.09% | 0.0510/6.68% | 0.0515/7.07% |
| Attention LSTM | 0.0475/6.31% | 0.0507/6.57% | 0.0508/6.24% | 0.0511/6.76% |
| CNN-LSTM | 0.1238/11.67% | 0.1333/12.28% | 0.1334/11.84% | 0.1336/12.35% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kenzhaliyev, B.; Azatbekuly, N.; Aibagarov, S.; Amangeldy, B.; Koizhanova, A.; Magomedov, D. Predicting Industrial Copper Hydrometallurgy Output with Deep Learning Approach Using Data Augmentation. Minerals 2025, 15, 702. https://doi.org/10.3390/min15070702
Kenzhaliyev B, Azatbekuly N, Aibagarov S, Amangeldy B, Koizhanova A, Magomedov D. Predicting Industrial Copper Hydrometallurgy Output with Deep Learning Approach Using Data Augmentation. Minerals. 2025; 15(7):702. https://doi.org/10.3390/min15070702
Chicago/Turabian StyleKenzhaliyev, Bagdaulet, Nurtugan Azatbekuly, Serik Aibagarov, Bibars Amangeldy, Aigul Koizhanova, and David Magomedov. 2025. "Predicting Industrial Copper Hydrometallurgy Output with Deep Learning Approach Using Data Augmentation" Minerals 15, no. 7: 702. https://doi.org/10.3390/min15070702
APA StyleKenzhaliyev, B., Azatbekuly, N., Aibagarov, S., Amangeldy, B., Koizhanova, A., & Magomedov, D. (2025). Predicting Industrial Copper Hydrometallurgy Output with Deep Learning Approach Using Data Augmentation. Minerals, 15(7), 702. https://doi.org/10.3390/min15070702