1. Introduction
Resource modeling is a crucial component of the mining value chain, as it outlines the quantity, quality, and location of mineral resources within a specified area. However, resource models are typically based on limited exploration data collected over a large area, often failing to accurately represent reality. As these models are the foundation for future planning, predictions, and optimizations, their accuracy directly impacts production outcomes. To address potential discrepancies, it is essential to evaluate risks by quantifying the uncertainty associated with the orebody using advanced geostatistical simulation algorithms [
1]. Another benefit of geostatistical simulation is its capability to reproduce spatial variability, enabling a more realistic representation of the heterogeneity of mining deposits [
2]. Additionally, collecting more direct measurements during operations can enhance the accuracy and precision of these models.
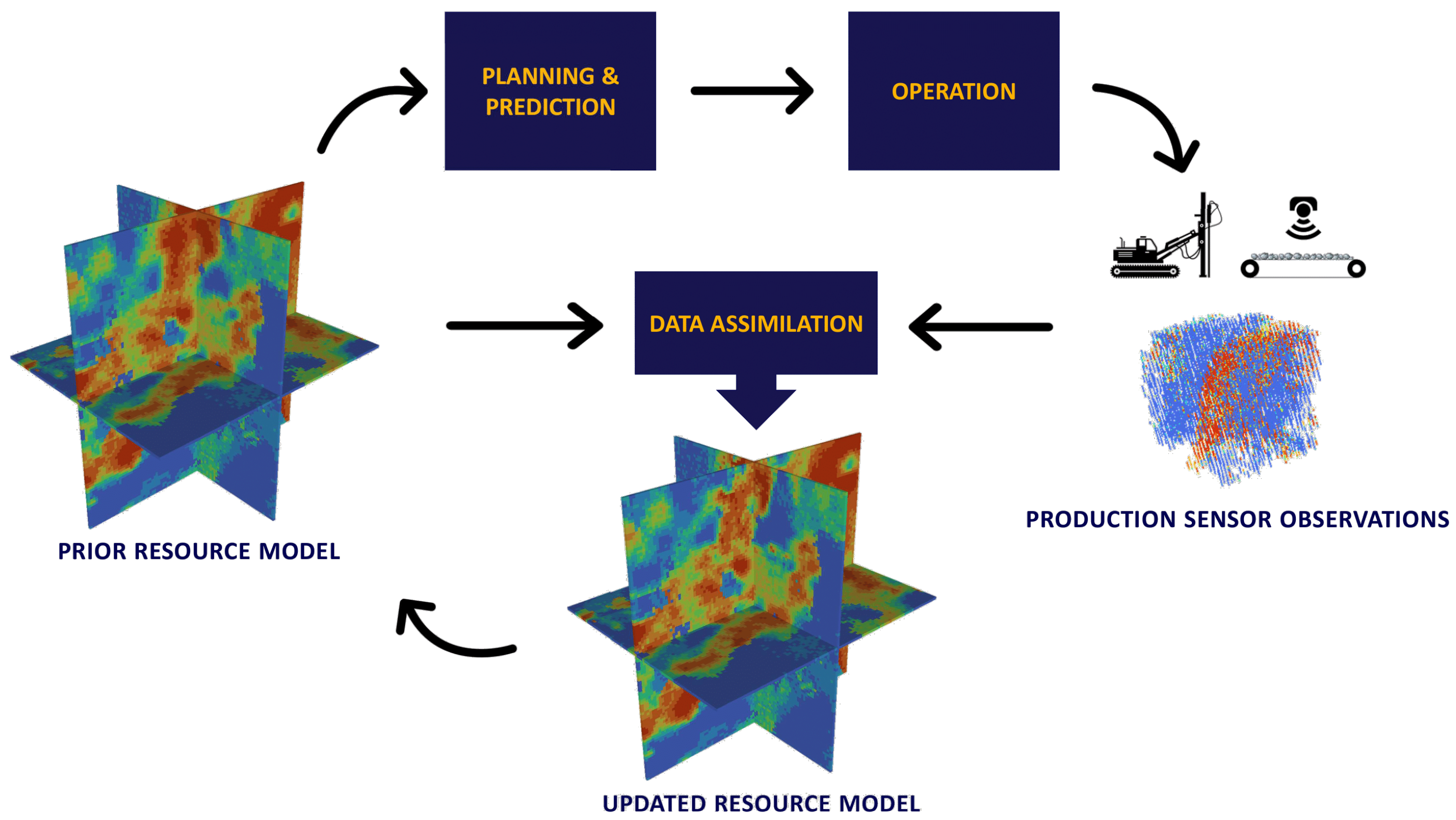
Real-time production data from various sensors can quickly update resource knowledge and inform short-term mine planning decisions. Incorporating these observations into geostatistical models can enhance the accuracy and precision of forecasts. Buxton and Benndorf [
3] suggest that integrating sensor data could reduce uncertainty and deviations from production targets, potentially resulting in an average economic benefit of
$5 million per year for the studied deposit. To effectively integrate sensor observations, tools such as the Kalman filter (KF) [
4] and the ensemble Kalman filter (EnKF) [
5] are recommended for the rapid updating of resource and grade control models [
6,
7]. In addition, Benndorf and Buxton [
8] introduced a real-time mining concept that transforms discontinuous process monitoring into a near-continuous framework through data assimilation (see
Figure 1). In this closed-loop framework, short-term planning decisions can take from minutes for dispatching to up to an hour for block classification tasks [
9].
Data assimilation applications extend beyond mineral grade estimates and can also be used to update coal quality parameters [
10], geometallurgical models [
11], and compositional data [
12]. However, current data assimilation methods for quickly updating resource models still have limitations. For instance, the EnKF updates one variable at a time and does not consider multivariate relationships. Furthermore, single data assimilation is often insufficient to fully utilize the information obtained from observations.
One practical approach for performing multivariate rapid updating is to transform co-regionalized variables into independent factors before data assimilation. This transformation helps preserve multivariate relationships by back-transforming realizations after updates. Techniques such as the minimum-maximum autocorrelation factors (MAF) [
13] and flow transformation (FA) [
14] have been used alongside the EnKF to decorrelate multivariate data before rapid updating [
12,
15]. However, MAF is not well-suited for handling complex multivariate relationships, and FA tends to be too slow for adequate rapid updating. In a comparison of various multivariate transformations, Abulkhair et al. [
16] found that the projection pursuit multivariate transform (PPMT) [
17] and rotation-based iterative Gaussianization (RBIG) [
18] are considerably faster and more appropriate for rapid updating than FA. However, it should be noted that only FA can successfully minimize artifacts in the presence of extreme values, making it an optimal multi-Gaussian transform, provided that runtime is not important [
19].
RBIG is similar in its methodology to PPMT, but instead of iteratively searching for interesting projections, it applies orthonormal rotations. As it needs fewer iterations to achieve convergence and each iteration is faster, RBIG is, on average, 90% faster than PPMT when applied to five variables with the number of samples between 10,000 and 50,000 [
19]. Similar to PPMT and FA, RBIG can be paired with other transforms, such as MAF [
16,
20], log-ratio transforms [
12,
14], and non-logarithmic ratio transforms [
21,
22].
In addition to the EnKF, several other methods have been employed for the rapid updating of resource models, including conditional simulation of successive residuals [
23], direct sequential simulation using point distributions [
24], a variation of the KF for downscaling resource models [
25], and deep reinforcement learning [
26]. Most of these methods perform single data assimilation, which can lead to some deviations between predicted and observed values, especially when observations are highly uncertain. To improve data assimilation in highly non-linear situations, iterative forms of EnKF have been widely explored in petroleum engineering and hydrogeology. For instance, ensemble randomized maximum likelihood, also known as iterative EnKF [
27,
28], yields better-matching results than standard EnKF, although it requires more computational resources. Alternatively, EnKF with multiple data assimilations (EnKF-MDA) [
29,
30] performs multiple data assimilations with an inflated measurement error to significantly outperform single data assimilation methods. While both iterative EnKF and EnKF-MDA are more computationally intensive than standard EnKF, the EnKF-MDA approach typically requires fewer iterations. The effectiveness of EnKF-MDA has been demonstrated in hydrogeology [
31], petroleum engineering [
29,
30], and geophysics [
32]. However, to our knowledge, EnKF-MDA has yet to be applied to the rapid resource model updating problem in mining.
Validating the performance of data assimilation algorithms through real case studies is crucial, especially in the mining industry, where data often show significant variability in terms of spacing between data points, measurement volumes, and associated uncertainties. Several studies of rapid resource model updating have demonstrated the effectiveness of various proposed approaches when applied to real data [
11,
12,
15,
33,
34]. However, some of these studies sample observations from a ground truth model generated from real data [
12,
33]. This makes it difficult to account for preferential sampling and incoming new observations from previously under-sampled locations. Both of these problems complicate multivariate transformations since using the same transformation function for model realizations and new observations may become unreliable.
In this paper, we apply a combination of EnKF-MDA and RBIG to a real case study from an iron ore mine in Western Australia. Because of its iterative nature, EnKF-MDA achieves a better match between observations and model-based predictions than EnKF. Additionally, RBIG enables EnKF-MDA to account for multivariate relationships between cross-correlated variables. Because the real data were fused to track historical data to the resource model locations, it makes it easier to validate the proposed approach.
The following section offers a detailed methodology for the proposed multivariate rapid updating algorithm. Next, real fused data are used to sequentially update the resource model over 25 time periods, the results of which are thoroughly analyzed. The paper then concludes with a discussion of key results, limitations of the proposed algorithm, and future research directions.
3. Results
3.1. Overview of a Case Study
In this case study, the proposed approach is applied to real anonymized mining data. The dataset was fused to track the historical data points back to their respective resource blocks. Readers are referred to the paper [
35] for more details about the data fusion and orebody learning involved in creating this dataset.
Table 1 shows the statistics of the fused dataset, including the mean, standard deviation, skewness, and kurtosis. The data are from an iron ore deposit in Western Australia and include the nine cross-correlated assay variables Fe, S, SiO
2, CaO, MgO, P, Al
2O
3, TiO
2 and K
2O. Please note that the assay variables are not listed in the same order as the variable names in the table. Due to confidentiality reasons, we cannot disclose the name of the deposit, the variable names, or the coordinates.
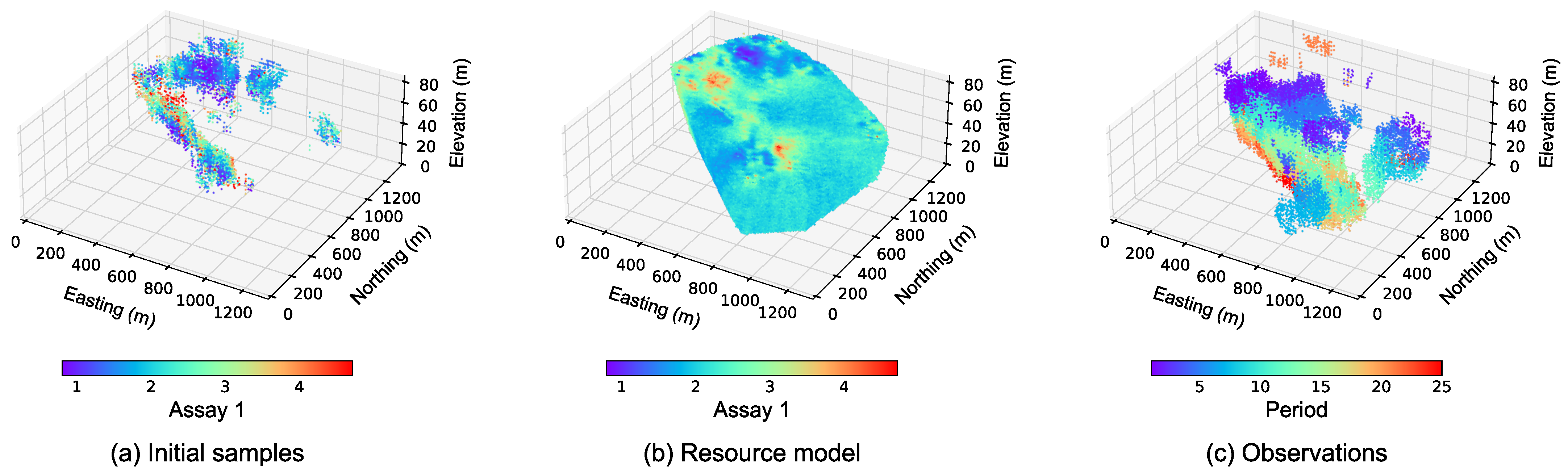
The original data points are categorized into 31 periods based on the months in which they were collected. A total of 5327 data points from the first six months were used to simulate the prior resource model. Turning bands simulation was used to model the multi-Gaussian factors of the original assay variables (the variogram models are shown in
Table 2). The remaining 25 periods serve as observations to sequentially update the resource model.
Figure 2 provides a 3D view of the study area, specifically highlighting the initial six months of samples, the prior resource model, and the observations that are used to update the model. It should be noted that some areas in the block model lack the initial conditional data, especially in the central regions. For simplicity, the measurement error is assumed to be a constant value of 10%.
The resource model consists of 100 realizations with blocks of size 10 m × 10 m × 4 m.
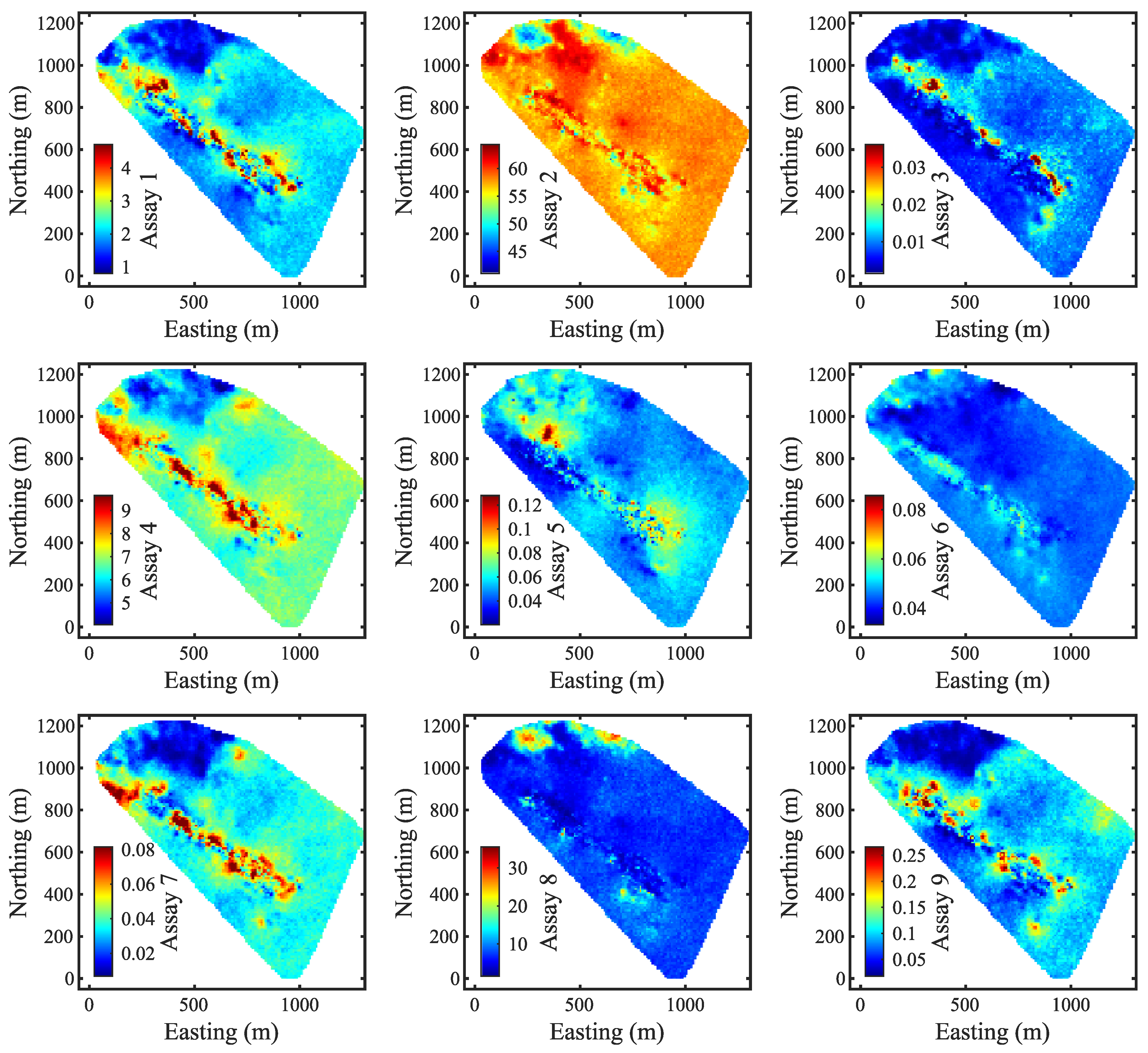
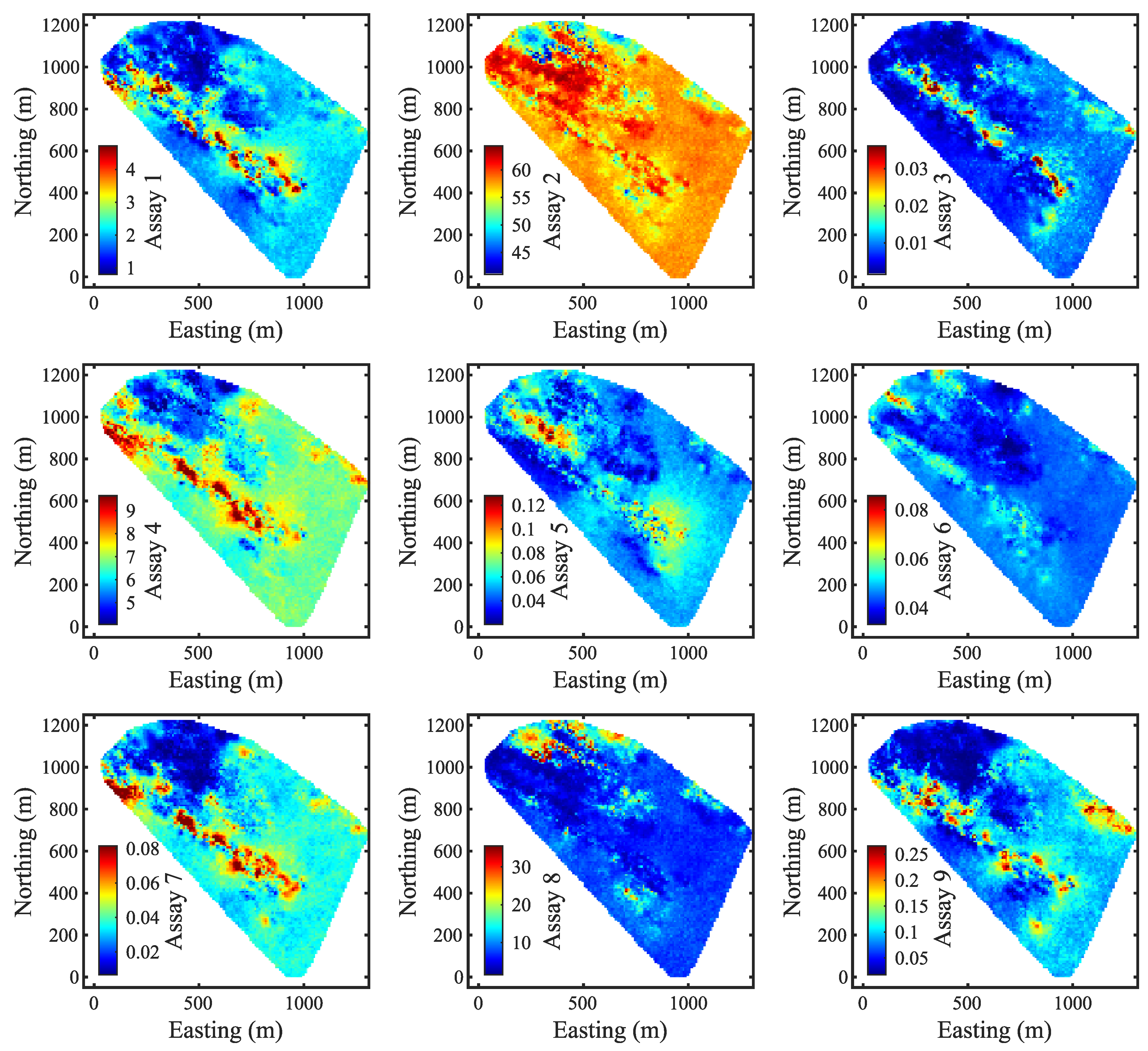
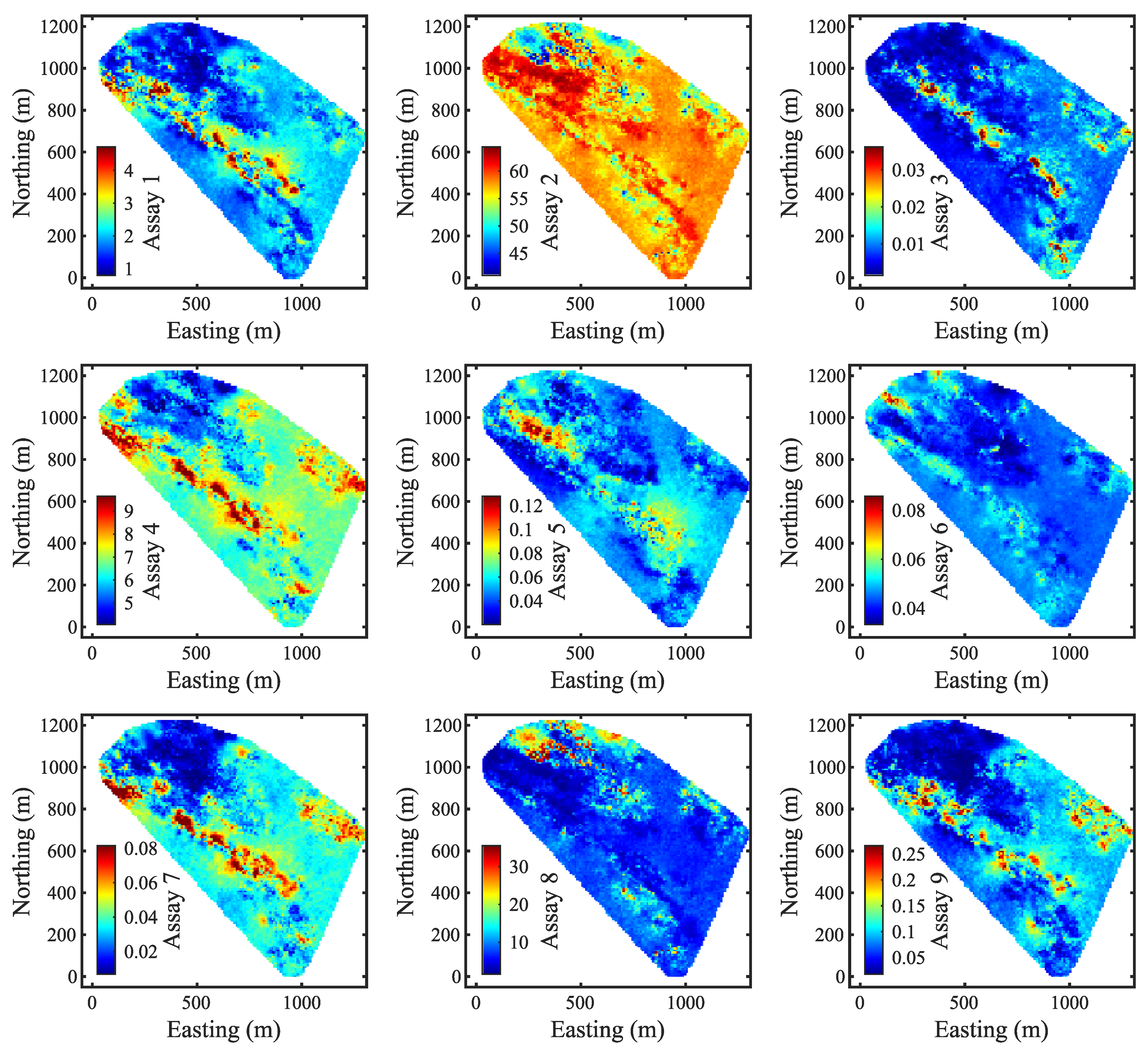
Figure 3 provides a 2D view of the e-type models for each assay variable at an elevation of 44 m. As the observations were tracked back to their corresponding blocks, the spacing between the data points aligned with the dimensions of the blocks.
3.2. An Illustrative Example of Rapid Updating for Period 1
As outlined in the methodology of the proposed updating algorithm, observations are not used to update the entire block model. For one reason, updating blocks that are far from the observations would unnecessarily reduce the uncertainty of those blocks. More importantly, calculating covariance matrices for the entire model is both time-consuming and inefficient in terms of memory usage. Therefore, the first step of the updating algorithm is to select the neighborhood around the observations. In this study, the neighborhood is defined as being within three blocks away from observation points. For example, for period 1, with 868 observations, the neighborhood consists of 15,561 blocks.
The next step involves transforming neighborhood realizations and observations into multi-Gaussian factors. If the prior model were created using RBIG, one possible strategy would be to use stored RBIG functions and matrices from the prior model. However, this could make the proposed algorithm inflexible and overly dependent on the original exploration data. The transformation step of the proposed algorithm must be capable of transforming any prior model realizations, not just those created using RBIG. Additionally, new observations should be taken into account during the transformation, as they may exhibit slightly different distributions.
To address this issue, the proposed algorithm simultaneously applies RBIG to both the prior neighborhood realizations and the observations (see Equation (
1)). A potential drawback, however, is that it will take more time to transform a vector combining observations and blocks from all realizations. Nevertheless, previous studies of the application of RBIG in geostatistics indicated that it is much faster than other methods, such as PPMT [
16,
19]. In this case, it took 70 s to transform a 9-dimensional vector combining 100 realizations of 15,561 blocks and 868 observations, giving a total of 1,556,968 rows.
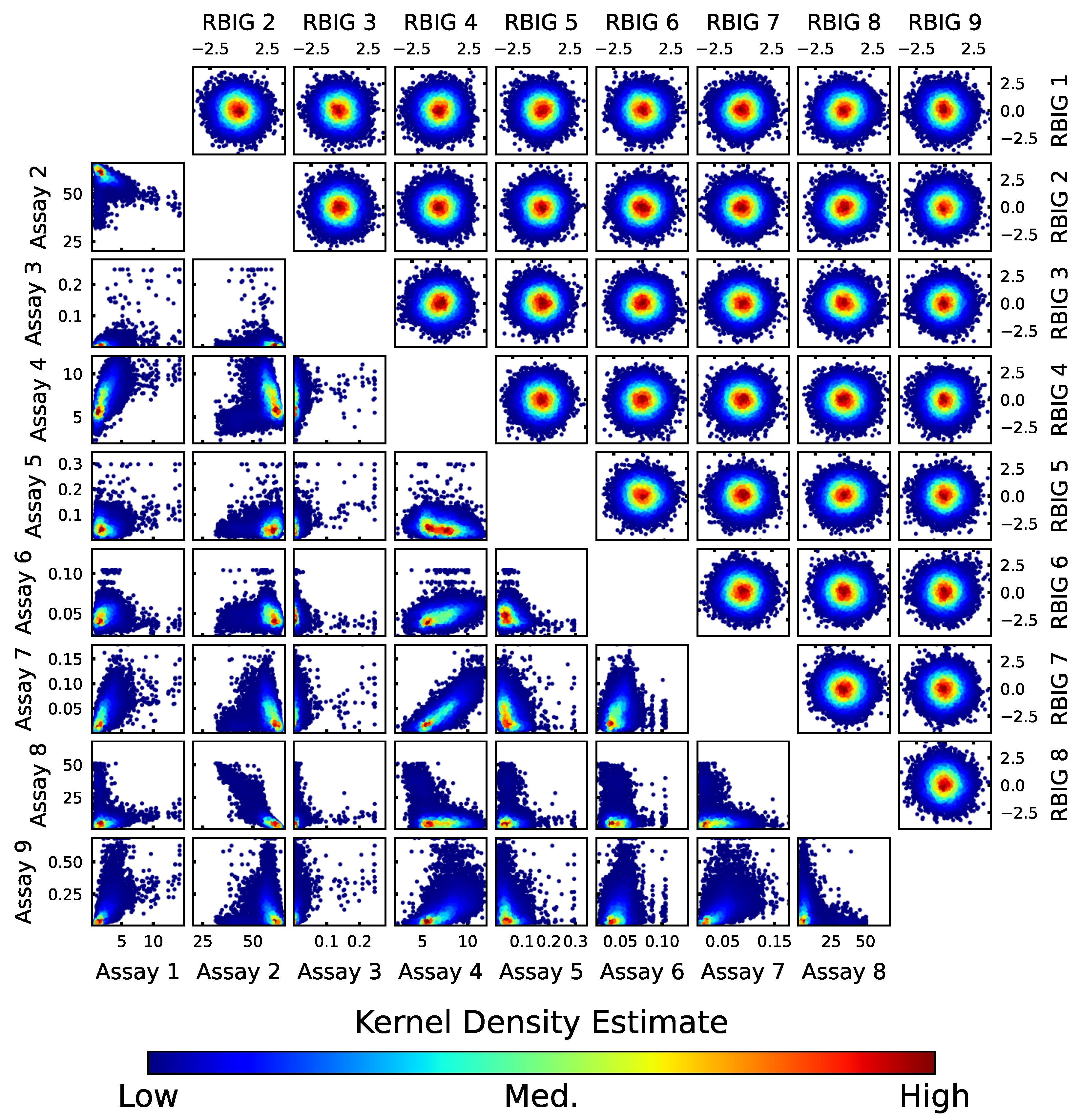
Cross-plots of original and transformed variables are shown in
Figure 4. The multivariate relationships in this dataset are complex, with non-linearities in some bivariate distributions. There is also a noticeable skewness in some variables, particularly Assay 3. The cross-plots of both prior realization and observations are visually similar in terms of kernel density and ranges. Ultimately, RBIG successfully generated multi-Gaussian factors that satisfy the Gaussian assumption of EnKF-MDA.
Multi-Gaussian realizations and observations are used as inputs for EnKF-MDA to perform rapid updating. The critical decision at this stage is to choose the number of data assimilations, as this choice impacts both performance and computation time. Typically, the run time of EnKF-MDA is equal to the run time of EnKF multiplied by the number of data assimilations. However, it is important to note that while accuracy improves with each data assimilation, the rate of improvement decreases with each subsequent assimilation.
Table 3 shows the mean squared error (MSE) reduction results for all variables updated with a number of data assimilations ranging from 1 to 10. MSE reduction is defined as
where
is an error between prior predictions and observations and
is an error between updated predictions and observations.
A standard EnKF helps reduce MSE by 61%–77% across nine assay variables. With five data assimilations, the error reduction improves to 84%–91%, which provides a good balance between accuracy and computation time. Finally, after ten data assimilations, all nine variables achieved an MSE reduction of over 90%. Each data assimilation, which involved 100 realizations with 15,561 blocks and 868 observations, took 1.7 s to complete. This means that ten data assimilations took just 153 s in total. Given the relatively fast computation speed, we have set the number of data assimilations in this case to ten. Additionally, the covariance localization radius was chosen to be 30 m.
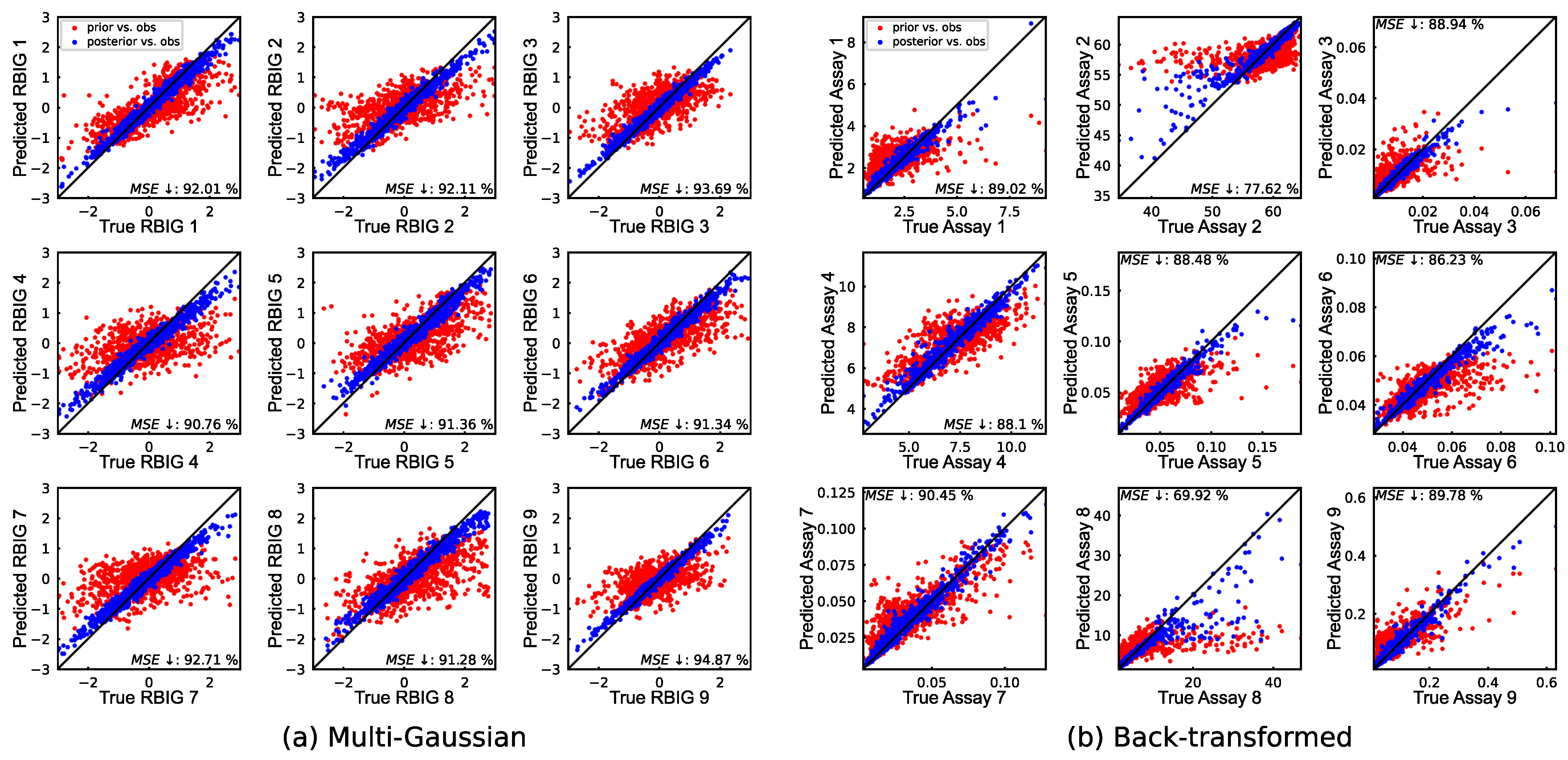
Predictions versus observations plots indicate that the updated multi-Gaussian results closely align with the diagonal line (
Figure 5). After back-transformation, all variables, except for Assay 2 and Assay 8, maintained an error reduction close to 90%. The lower error reductions for these two variables can be attributed to the combination of different factors. As shown in
Table 1 and
Figure 5, these two have larger values compared to other variables, are skewed, and were predicted less accurately in the prior model. Although Assay 1 also has relatively larger values than others, its distribution is not skewed. On the other hand, despite it being significantly more skewed, Assay 3 has an excellent error reduction of 89% due to a much closer prior prediction. The long tails of the predicted values for Assay 2 and Assay 8 contain numerous highly inaccurate predictions, ultimately impacting the final updated results. Notably, removing Assay 2 and Assay 8 does not significantly affect other variables, with only a 1.24% average difference compared to the results in
Figure 5.
The proposed approach not only accurately updated most of the variables but also preserved the multivariate relationships. In
Figure 6, cross-plots of RBIG factors and back-transformed assay variables for the updated realization show distributions identical to those in
Figure 4. Additionally, the back-transformation of all updated neighborhood realizations was completed in just 55 s. This is a major advantage of combining EnKF-MDA with RBIG, as many traditional methods struggle to maintain these complex relationships or lack computational efficiency.
All data assimilation and multi-Gaussian transformations were carried out on a Mac Mini (Apple M4 chip with four performance cores, six efficiency cores, and 16 GB of RAM). The data assimilation was implemented in Python 3.8, with covariances calculated using Cython. The multi-Gaussian transformation and back-transformation were performed in MATLAB R2024b. Overall, updating the model in period 1 took 278 s: 70 s for the RBIG transformation, 153 s for the EnKF-MDA, and 55 s for the back-transformation. This efficiency makes the proposed algorithm suitable for near real-time applications in mining, where accurate and up-to-date resource models are essential for rapid decision-making.
3.3. Sequential Rapid Updating for the Remaining Periods
To evaluate the effectiveness of the proposed rapid updating algorithm over time, the resource model realizations were updated sequentially using observations from 25 time periods. However, unlike the rapid updating in period 1, the subsequent periods have one key difference. The neighborhood around the observations in these periods may contain blocks that were accurately updated in earlier periods. One way to mitigate the issue of potentially overwriting the previously updated blocks is to incorporate observations from prior periods. Therefore, after selecting the neighborhood around new observations, the proposed algorithm also includes previous observations that are located in the same neighborhood.
Table 4 shows the MSE reduction results after updating the first five periods, comparing the scenarios with and without the inclusion of previous observations. Across all nine variables, the error reductions show consistent improvement. Additionally, since updates are performed within local neighborhoods around new observations, including previous observations does not significantly slow down the process.
The following figures illustrate how the model is progressively refined as more observations become available. Instead of presenting the updates for each individual period, the updates are grouped into approximately equal batches of observations, focusing on a 2D section of the model at an elevation of 44 m.
The prior models, shown in
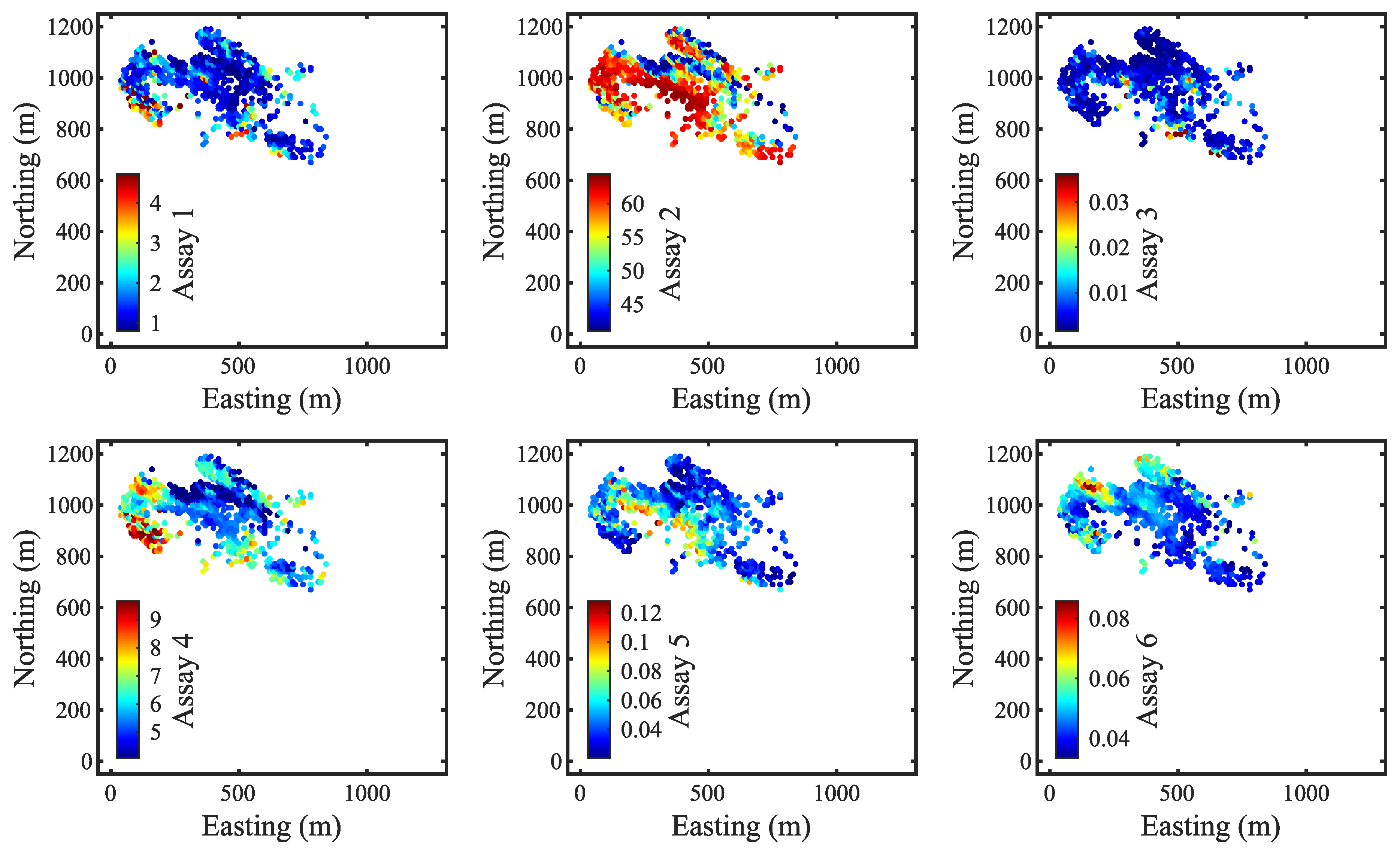
Figure 3, exhibit a smoothing effect that is common in geostatistical modeling.
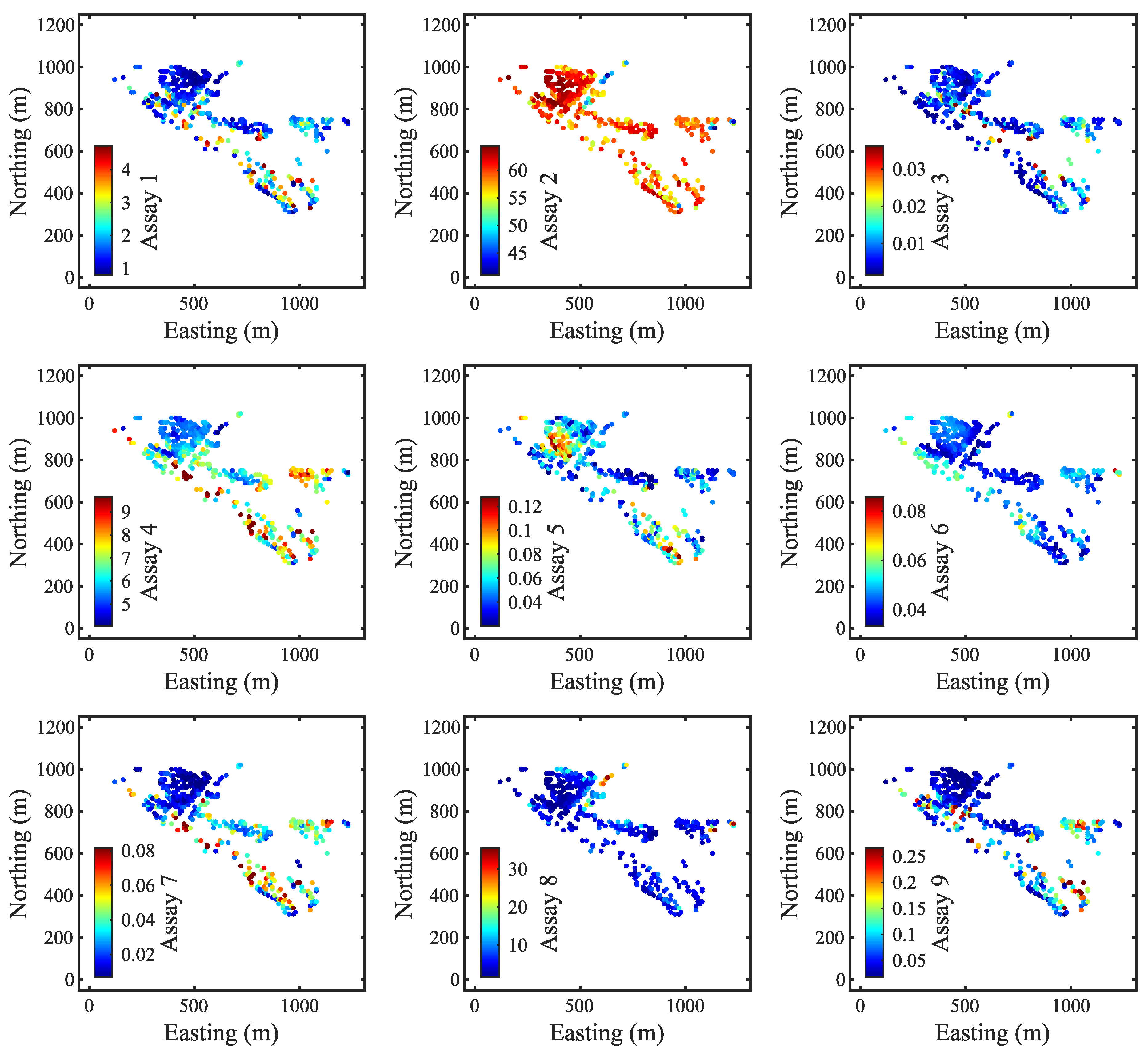
Figure 7 shows the observations from periods 1 to 5 at an elevation of 44 m. In contrast to prior maps, these observations are evidently different at the exact locations and exhibit greater spatial variability. This emphasizes why rapid updating is important, as resource models often struggle to capture small-scale variability due to the limited resolution of exploration data. Although sensor observations come with a degree of uncertainty, they offer a vast amount of real-time data that can be integrated into the model.
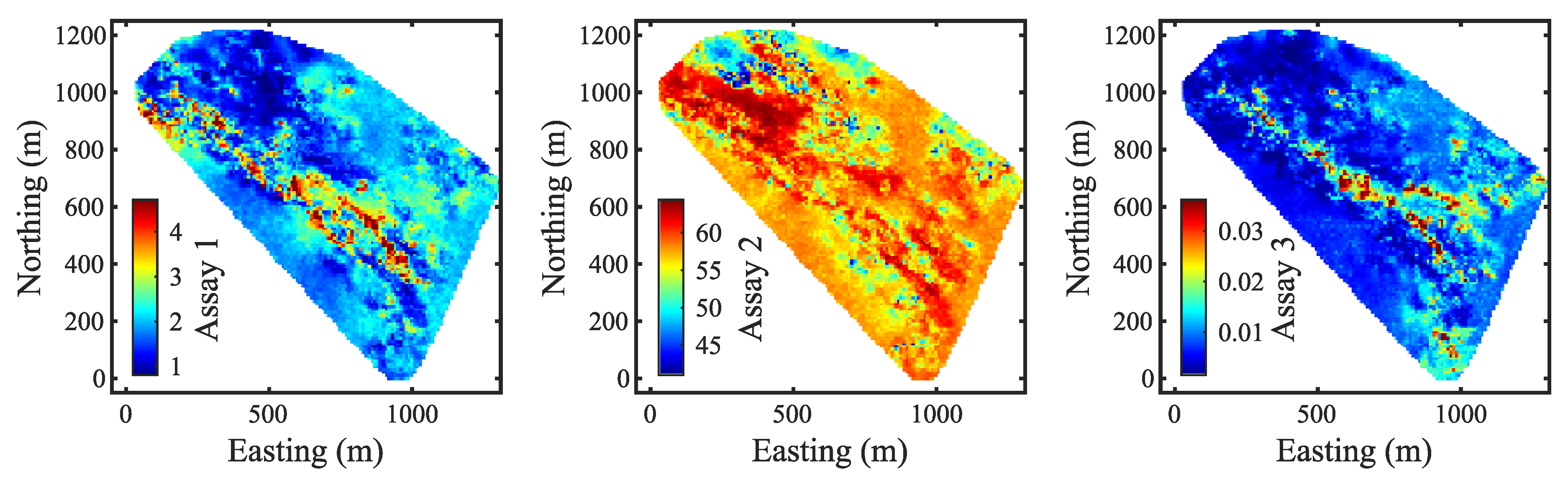
After updating the model sequentially over the first five periods, the updated e-type models are shown in
Figure 8. First, the updated models align more closely with the observations and demonstrate greater variability in that part of the deposit. The rapid updating also increased the spatial variability and reduced the over-smoothing in the area surrounding the observations. However, there is a region between 600–800 m northing and 1100–1300 m easting that differs significantly from the prior models despite lacking observations there. This is likely the result of neighboring observations at adjacent elevations affecting this area.
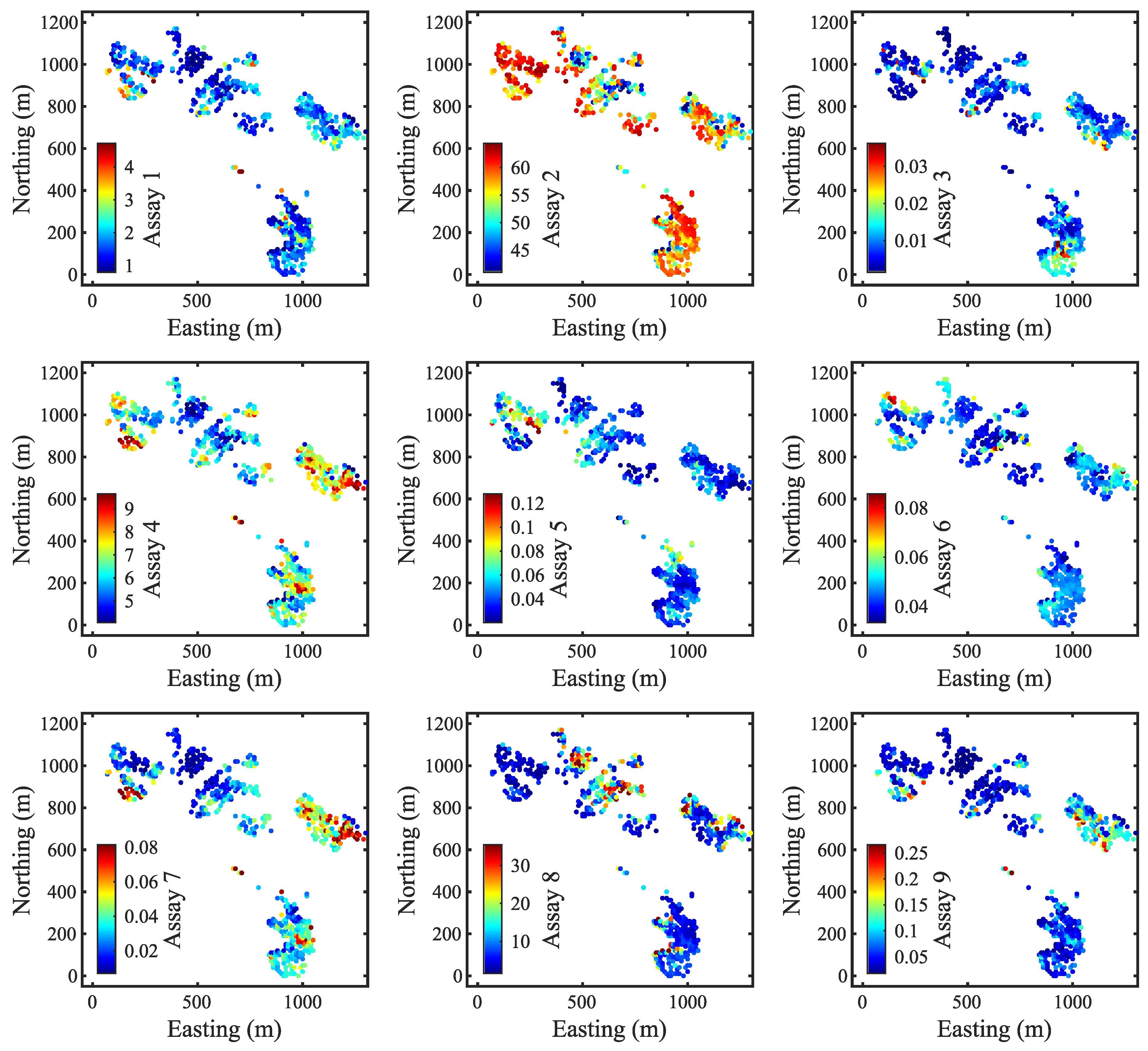
Figure 9 illustrates four more sets of observations from periods 6 to 9. The first thing to notice here is that the area between 600–800 m northing and 1100–1300 m easting, which was unexpectedly updated in
Figure 8, aligns closely with actual observations at those locations. This indicates that nearby data can contribute to refining the model predictions. However, the biggest discrepancies between new observations and previous models are found in the lower sections of the maps. Updated models after period 9 now provide a more accurate representation of that lower part of the map (
Figure 10). Furthermore, previously underestimated high-grade zones have also become more distinct for variables such as Assay 4 and Assay 7.
Finally, the observations from the remaining periods are presented in
Figure 11. The reason for displaying such a large set of periods is that most observations from this batch are not present at an elevation of 44 m. The final updated models demonstrate greater spatial variability and a higher level of detail compared to the prior models, particularly in areas with dense observation coverage (
Figure 12). Visually, there is a clear and gradual improvement throughout the updates, as seen in
Figure 8 and
Figure 10.
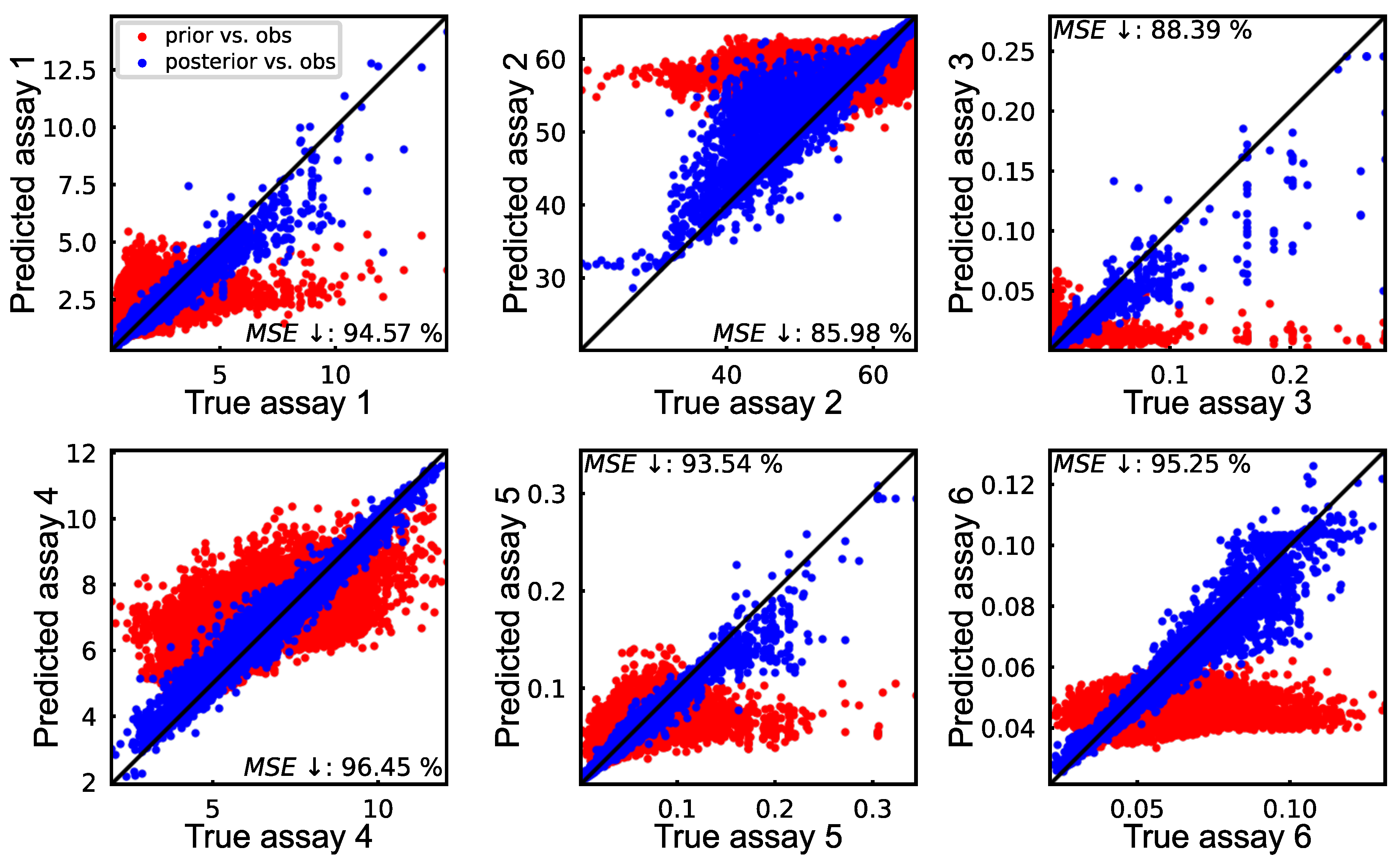
A more detailed analysis of the final updated models is presented in
Figure 13, where predictions are plotted against the observed values. The updated results closely align with the diagonal line, and most variables achieve an error reduction between 86% and 9%. However, Assay 8 only reduced its MSE by 76.73%, which is significantly lower compared to the other variables. This discrepancy is particularly evident in the plot, with many points positioned far from the diagonal line.
A similar trend was noted in
Figure 5, where, for period 1, Assay 8 achieved an error reduction of less than 70%. As mentioned earlier, this issue can be partly attributed to the skewness of the distribution, which makes it challenging to accurately back-transform the tail end. Other factors are the relatively high number of significantly inaccurate prior predictions and the larger value range.
Interestingly, Assay 2 showed an improvement in error reduction compared to period 1, but there are still points that deviate from the diagonal line. Assay 3 demonstrates even better accuracy despite having a more skewed distribution. The difference between Assay 8 and Assay 3 is that the latter has fewer observations at the tail end of its distribution. However, RBIG still struggled to back-transform the tails in both cases, raising concerns about its reliability for highly skewed distributions. Overall, the proposed algorithm effectively reduced the MSE by 94%–98% across six out of nine variables.
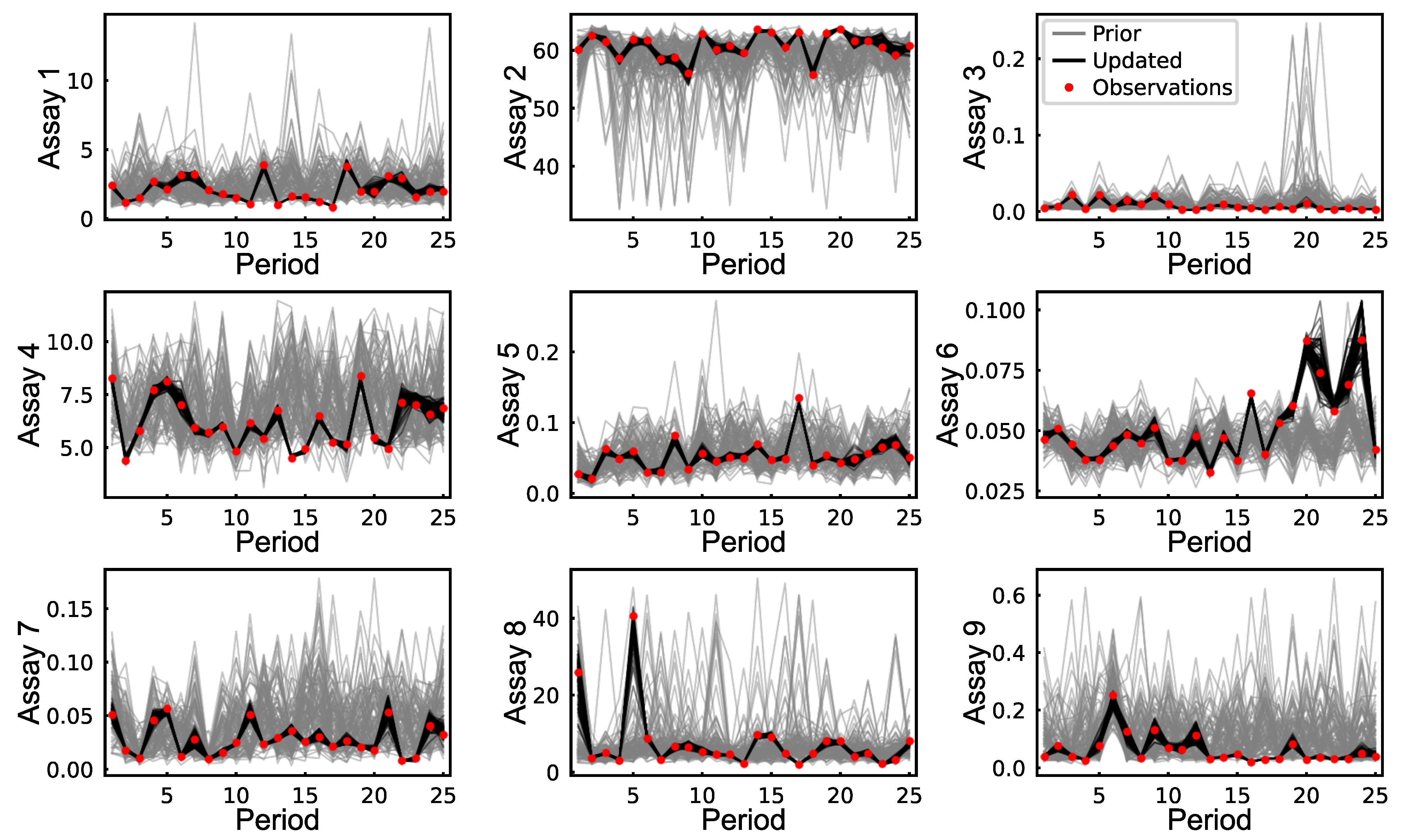
All the previous figures primarily analyze the average results from all realizations. To focus on how rapid updating affects individual realizations, we calculated the errors between the updated results and the observations. In each period, we selected a block with an error close to the median of all the errors. We chose the median because it ensures that 50% of the blocks exhibit better predictions while the other 50% show worse predictions.
Figure 14 displays the prior and updated realizations for the blocks that have errors near the median in each period. The updated results closely match the observations for each variable. Furthermore, rapid updating has minimized uncertainty, as demonstrated by the reduced spread of realizations before and after the updates. However, uncertainty is slightly higher for larger values due to the skewness of the distributions. This is particularly evident in Assay 6, where values in later periods are significantly higher and have a broader spread of realizations. Interestingly, Assay 8, despite showing relatively low error reduction, shows very accurate results in this figure.
The proposed approach, as shown in the predictions versus observations plots in
Figure 13, produces some outliers that are far from the diagonal line. This issue is particularly evident in Assays 2 and 8, which demonstrate lower error reductions than the other variables. To illustrate this,
Figure 15 shows the realizations before and after rapid updating for the blocks with the highest errors during each period. Variables that had good error reductions remain close to the observed values. For instance, in Assay 4, the slight deviation from the observations is primarily due to overestimation in prior models. In contrast, Assay 6 shows that prior models have both overestimation and underestimation in different periods, leading to deviations from observations in the updated models. For Assays 2 and 8, however, the gap between realizations and observations is more significant, primarily due to back-transformation issues.
4. Discussion
The application of the proposed combination of EnKF-MDA and RBIG in a real case study demonstrated its effectiveness in rapidly and accurately updating multivariate resource models. Across all nine variables, the proposed approach achieved an error reduction ranging from 77% to 98%, reducing errors by more than 94% for five of those variables. The results indicate that the updated models provide a more realistic representation of spatial variability and align closely with observations while also maintaining multivariate relationships. Moreover, transforming realizations and observations together helps to account for potential new observations coming from previously under-sampled locations.
In addition to the accuracy, the proposed algorithm operates with impressive speed, even on low-cost hardware. For example, it can update 100 block model realizations with 878 observations in under five minutes. The process could be further enhanced through parallelization across multiple virtual machines, which is easily achievable in an industrial setting. Notably, the rapid updating requires no human intervention and can be automated to run either at specified time intervals or immediately when new information becomes available. As a result, mining operations can make near real-time decisions based on updated models, leading to improved short-term mine planning and optimization.
Achieving such computational efficiency and flexibility comes with some drawbacks and limitations. Despite its advantages, the Kalman filter (KF) is less effective than kriging or cokriging estimates. Li et al. [
25] compared the updates from KF to estimates produced by ordinary kriging, which unsurprisingly showed better performance for kriging. Incorporating kriging to update resource model realizations can be done using residuals between observations and prior realizations [
23,
36]. However, such kriging updates are still computationally demanding and inflexible to be used in the real-time mining framework presented in
Figure 1. On the other hand, data assimilation methods are faster, especially when dealing with large resource models. The use of EnKF-MDA helps to further minimize the deviation between model predictions and observations by updating the same data multiple times.
Another drawback noted in this paper is the less accurate updating of extreme values in highly skewed distributions. This limitation is characteristic of RBIG and similar transforms, which can produce artifacts in the presence of extreme values. On the contrary, FA has previously been used for rapid updating [
12] and can minimize artifacts after back-transformation. However, it is also significantly more computationally intensive, and using it for time-sensitive tasks such as rapid updating is not recommended [
16,
19]. Additionally, multi-Gaussian transforms require the multivariate dataset to be homotopic, making the proposed approach impractical for datasets where some variables are under-sampled. In such cases, a data imputation technique such as Gibbs sampling can be used to generate additional observations [
37,
38].
Finally, the real data used in the case study has already undergone data fusion and ore tracking. For confidentiality reasons, measurement errors and ore tracking uncertainty were not disclosed. For simplicity, a measurement error of 10% is assumed in this paper. However, the uncertainty associated with sensor observations extends beyond measurement errors typically identified in laboratory settings. The way sensors are used on an actual mine site can differ from how they are intended to be used. Not to mention the difference between harsh mining conditions and a laboratory environment in which measurement errors are evaluated. Furthermore, although more practical, downstream sensors, such as those on conveyor belts, are hard to link back to resource models. This challenge is particularly relevant in underground mining, where ore tracking remains a significant issue. Thus, the uncertainty introduced by ore tracking must be considered during real rapid updating.
5. Conclusions
This paper presents a rapid updating algorithm designed explicitly for multivariate resource models. The algorithm combines EnKF-MDA and RBIG, where the former offers more accurate updates compared to the traditional EnKF, while RBIG transforms multivariate data into independent multi-Gaussian factors that are suitable for updating. This approach is applicable to any mining deposit that has multiple cross-correlated quantitative variables. The effectiveness of the proposed algorithm was demonstrated through a real case study of an iron ore mine in Western Australia.
Quantitative grade variables are not the only critical components of resource models. Qualitative (e.g., lithology, alterations, and various domain types) and non-additive geometallurgical variables (e.g., operating work index, ore recovery, Axb, etc.) are also essential for resource modeling, optimization, and mine planning. The primary challenge with these types of variables is that ensemble-based data assimilation mainly operates on Gaussian values. However, EnKF has been applied to update geological domains using discrete wavelet transforms [
39]. Additionally, EnKF has been effective in updating the Bond Ball Mill Work index and improving its future forecasts by 26% [
11].
Future research will focus on expanding the rapid updating algorithm to enable the updating of qualitative variables and geometallurgical properties. The limitations of the current approach will be investigated further, especially the updating of extreme values in highly skewed distributions. Finally, it is important to test how data assimilation performs in a real underground mining scenario and its applicability in enhancing short-term mine planning.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}