Abstract
Various distributed optimization methods have been developed for consensus optimization problems in multi-agent networks. Most of these methods only use gradient or subgradient information of the objective functions, which suffer from slow convergence rate. Recently, a distributed Newton method whose appeal stems from the use of second-order information and its fast convergence rate has been devised for the network utility maximization (NUM) problem. This paper contributes to this method by adjusting it to a special kind of consensus optimization problem in two different multi-agent networks. For networks with Hamilton path, the distributed Newton method is modified by exploiting a novel matrix splitting techniques. For general connected multi-agent networks, the algorithm is trimmed by combining the matrix splitting technique and the spanning tree for this consensus optimization problems. The convergence analyses show that both modified distributed Newton methods enable the nodes across the network to achieve a global optimal solution in a distributed manner. Finally, the distributed Newton method is applied to solve a problem which is motivated by the Kuramoto model of coupled nonlinear oscillators and the numerical results illustrate the performance of the proposed algorithm.
1. Introduction
A number of problems that arise in the context of wired and wireless networks can be posed as the minimization of a sum of functions, when each component function is available only to a specific agent [1]. Decentralized consensus optimization problems are an important class of these problems [2]. To solve these problems, distributed methods—which only require the agents to locally exchange information between each other—gain a growing interest with every passing day. Nedic and Ozdaglar [3,4] proposed distributed subgradient methods and provided convergence results and convergence rate estimates for this method. Some extensions [5,6] of this method were subsequently proposed. Ram et al. [5] adjusted a distributed subgradient method to address the problem of vertically and horizontally distributed regression in large peer-to-peer systems. Lobel and Ozdaglar [6] studied the consensus optimization problem over a time-varying network topolopy and proposed a distributed subgradient method that uses averaging algorithms for locally sharing information among the agents. Moreover, Ram et al. [1] proposed a distributed stochastic subgradient projection algorithm and explored the effects of stochastic subgradient errors on the convergence of the algorithm. These methods only used gradient or subgradient information of the objective functions, which suffered from slow convergence rate. Apart from these gradient or subgradient methods, Mota et al. [7] combined the centering alternating direction method of multiplier (ADMM) [8] and node-coloring technique and proposed a distributed ADMM (D-ADMM) algorithm for the consensus optimization problem. This method makes some improvements in convergence rate over distributed subgradient methods. Compared with conventional centralized methods, the distributed methods have faster computing efficiency and have been widely used in many fields, such as image processing [9,10], computer vision [11], intelligent power grids [12,13], machine learning [14,15], unrelated parallel machine scheduling problems [16], model predictive control (MPC) problems [17], and resource allocation problems in multi-agent communication networks [18,19].
These distributed algorithms mentioned above are all first-order methods, since they only use gradient or subgradient information of the objective function. To substitute for the distributed gradient method for solving the unconstrained minimization problem mentioned by Nedic and Ozdaglar [3], Mokhtari et al. [20] proposed a network Newton (NN)-K method based on the second-order information, where K is the number of Taylor series terms of the Newton step. NN-K can be implemented through the aggregation of information in K-hop neighborhoods in every iteration. Consequently, the communication between the adjacent nodes will increase exponentially with the augment of the number of iterations. To ensure the iterative results closer to the optimal value, a larger K should be selected and it is time-consuming—especially for large-scale networks.
Another second-order method—the distributed Newton method—was proposed by Wei et al. [21] to solve the network utility maximization (NUM) problem in a distributed manner. NUM can be formulated as a convex optimization problem with equality constraints by introducing some slack variables and the coefficient matrix of the equality constraints having full row rank. This distributed Newton-type second-order algorithm achieves superlinear convergence rate in terms of primal iterations, but it cannot solve consensus optimization problems in multi-agent networks. Tracing its root, the coefficient matrix of the constraint does not have full row rank, and predetermined routes cannot be given in the general optimization problem.
The distributed Newton method addressed in this study aims to solve the problem of minimizing a sum of strictly convex objective functions where the components of the objective are available at different nodes of a network. This paper adds to the growing body of knowledge regarding distributed second order methods. The contributions made by this paper are three-fold.
- Adjusting the distributed Newton algorithm for the NUM problem to a special kind of consensus optimization problem in multi-agent networks with a Hamilton path. To overcome the obstacle, computation of the dual step involves the global information of the Hessian matrix, and an iterative scheme based on a novel matrix splitting technique is devised. Further, the convergence of the distributed Newton algorithm is proved theoretically.
- A modified distributed Newton algorithm is proposed for consensus optimization problems in connected multi-agent networks. The coefficient matrix has full row rank by constructing a spanning tree of the connected network. Combined with the matrix splitting technique for NUM, the distributed Newton method for multi-agent convex optimization is proposed and a theory is presented to show the global convergence of the method.
- The effectiveness of the modified distributed Newton methods is demonstrated by a numerical experiment. The experiment is based on the Kuramoto model of coupled nonlinear oscillators. The proposed distributed Newton method can be applied to solve this model more efficiently compared with two first-order methods
The rest of the paper is organized as follows: Section 2 provides some necessary preliminaries. Section 3 formulates the general multi-agent strictly convex consensus optimization problem in connected networks. Section 4 presents a distributed inexact Newton method in networks with a Hamilton path. A solution algorithm to solve the problem in general connected networks is proposed in Section 5. Section 6 presents the simulation results to demonstrate convergence properties of the algorithms. Finally, conclusions and recommendations for future work are provided in Section 7.
2. Preliminaries
Consider a connected network with P nodes and E edges modeled by a undirected graph , where is the set of nodes and is the set of edges.
Referring to Wei et al. [21], the NUM problem can be written as follows:
where is a strictly convex function, matrix A has full row rank, and c is a constant vector. This problem can be solved by an exact Newton method,
where is the Newton direction given as the solution of the following system of linear equations
where is the primal vector, is the dual vector, is the gradient vector, and is the Hessian matrix. Moreover, is abbreviated as for notational convenience.
Solving and in the preceding system yields
Since is a separable, strictly convex function, its Hessian matrix is a positive definite diagonal matrix, and hence Equation (4) can be easily computed by a distributed iterative scheme. Wei et al. [21] proposed a distributed Newton method for the NUM problem (1) by using a matrix splitting scheme to compute the dual vector in Equation (5) in a distributed manner. Let be a diagonal matrix, with diagonal entries
Matrix is given by
Let matrix be a diagonal matrix with diagonal entries
By splitting the matrix as the sum of and , the following theorem [21] can be obtained.
Theorem 1.
Note that the predetermined routes and full row rank coefficient matrix are necessary when running the distributed Newton method for the NUM problem according to Reference [21]. Unfortunately, this property is usually not met in the general multi-agents consensus optimization problems.
3. Problem Formulation
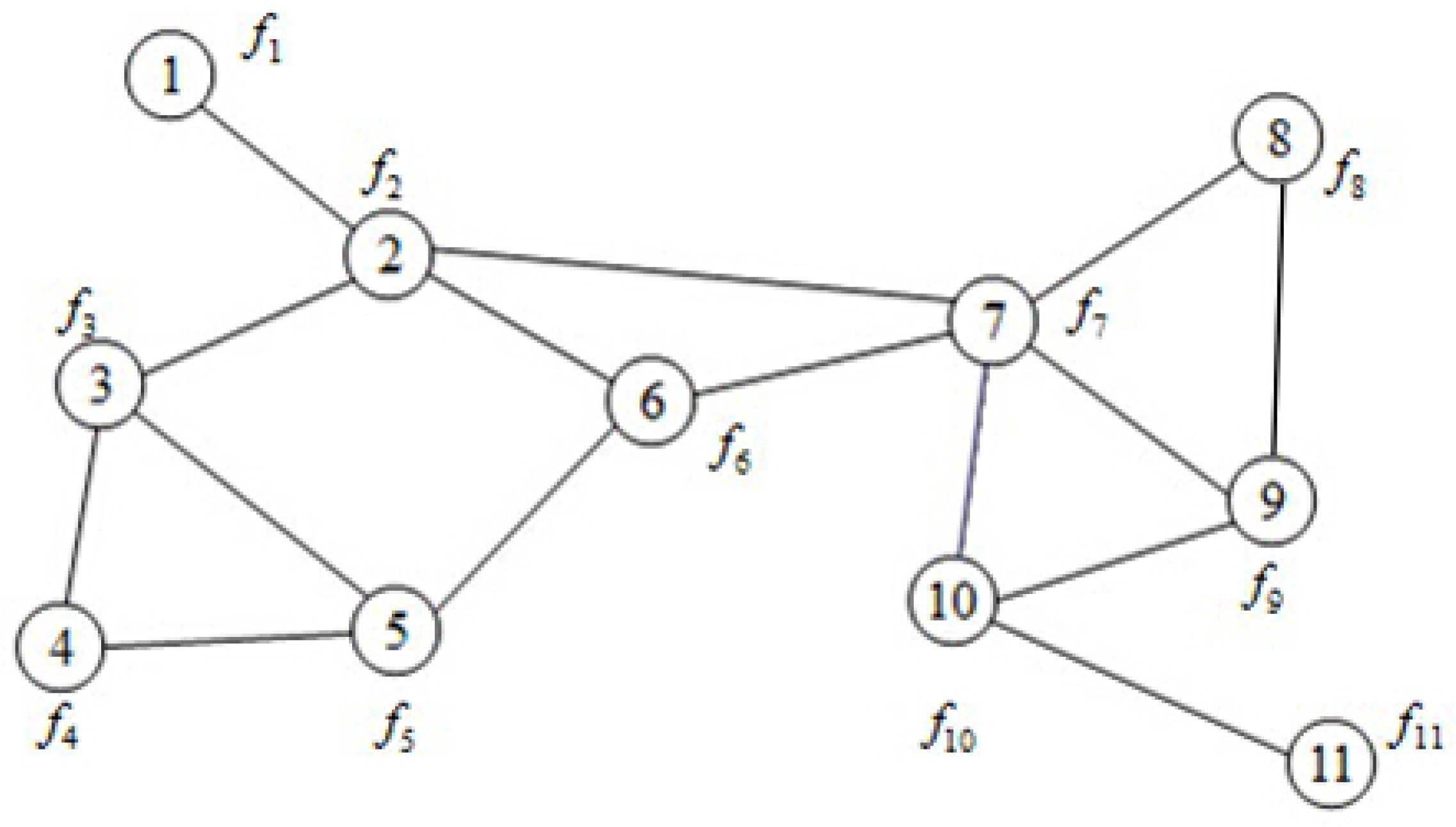
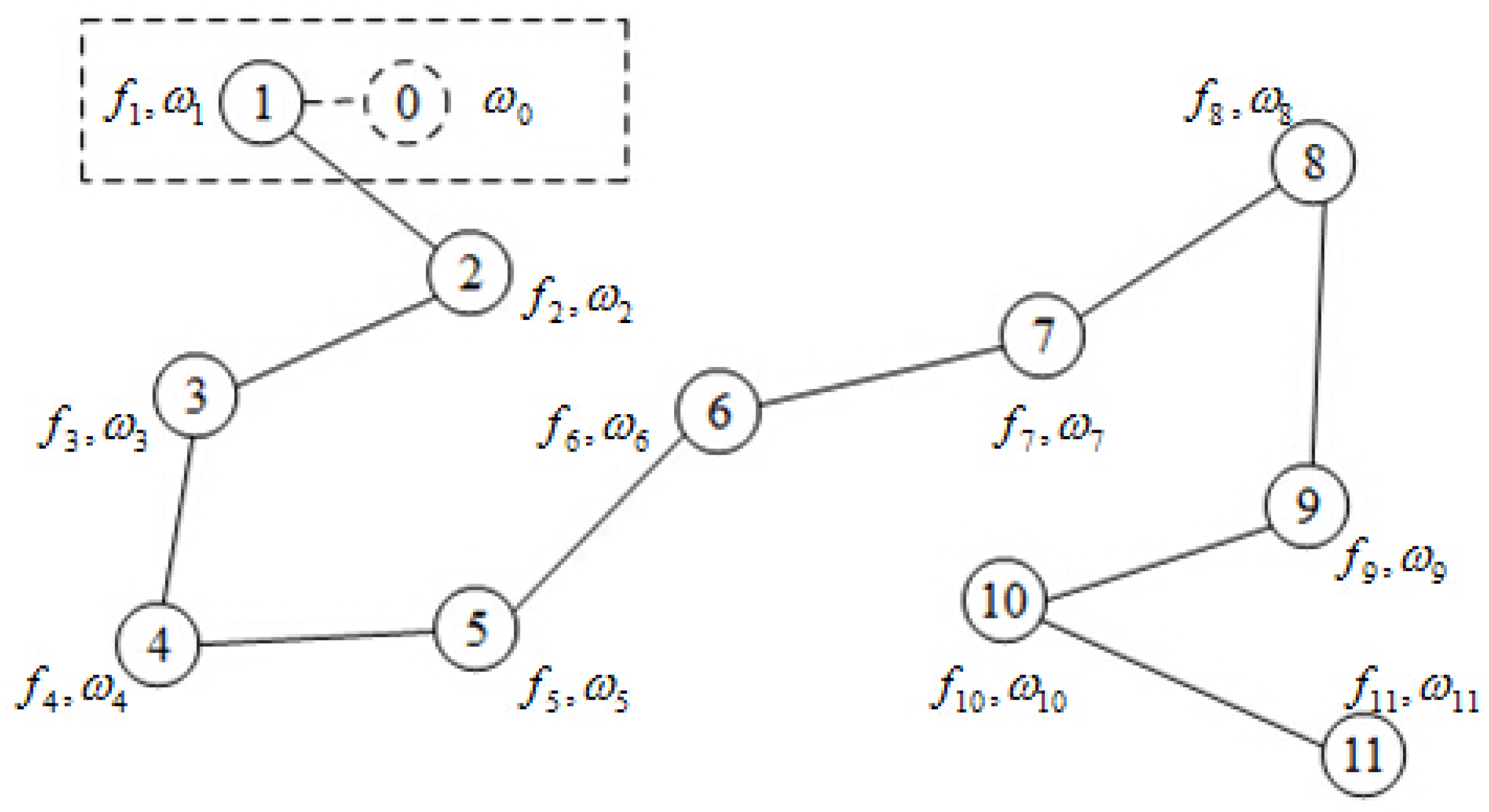
For the multi-agents consensus optimization problems proposed in this paper, only agent p has access to its private cost function and can communicate with its neighbors using the network infrastructure. This situation can be illustrated in Figure 1; i.e., node 2 can communicate with its adjacent nodes 1, 3, 6, and 7. Node i has its own objective function , and all nodes cooperate in minimizing the aggregate cost function
where is the global optimization variable. This problem is also known as the consensus optimization problem and its optimal solution is donated as .
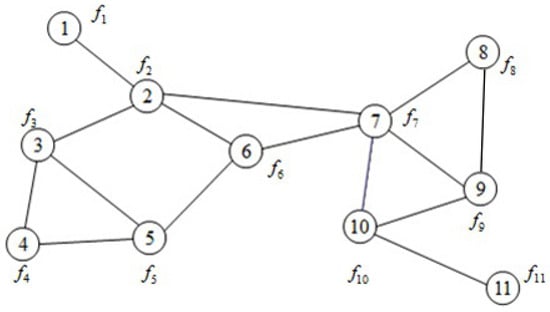
Figure 1.
Network with nodes.
A common technique to decouple problem (10) is to assign copies of the global variable x to each node and then constrain all copies to be equal. Denoting the copy held by node p with , problem (10) is written equivalently as
Problem (11) is no longer coupled by the common variable in all , but instead by the new equations , for all pairs of edges in the network . These equations enforce all copies to be equal while the network is connected. Note that they can be written more compactly as , where is the node arc-incidence matrix of the graph, is the identity matrix in , and ⨂ is the Kronecker product, is the optimization variable. Each column of B is associated with an edge and has 1 and -1 in the ith and jth entry, respectively; the remaining entries are zeros. Problem (11) can be rewritten as
where A is the coefficient matrix taking values . In this paper we assume that the local costs are twice differentiable and strongly convex.
4. Distributed Newton Method For Multi-Agent Consensus Optimization Problems in Networks with a Hamilton Path
For some networks with particular topology structures (e.g., a Hamilton path), we can use special techniques to solve the proposed consensus optimization problem. In this section, a novel matrix splitting technique is devised for multi-agent consensus optimization problems in networks with a Hamilton path, which travels every node in the network just once. For simplicity, we renumber these nodes from 1 to along this path as depicted in Figure 2. We know that every dual variable corresponds to one link, so () can be used to denote the dual variable , which is stored in node i. In Figure 2, node 0 is the copy of node 1 and it is actually non-existent. We add the definition of and for the sake of analysis.
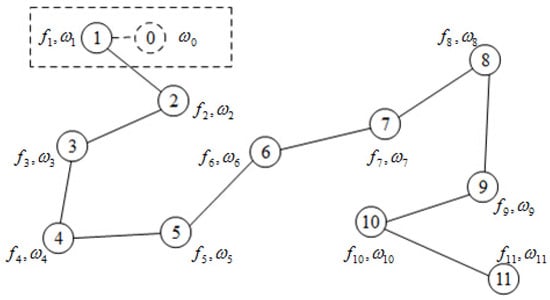
Figure 2.
A Hamilton path of network with nodes.
From Figure 2, the coefficient matrix A in problem (12) is a dual-diagonal matrix given by
where I is an identity matrix of dimension n.
Let be a diagonal matrix with diagonal entries
where is the diagonal block of the Hessian matrix. Matrix is given by
By splitting matrix as the sum of and , a Jacobian iteration can be used to compute the dual vector in (5) in a distributed manner.
Theorem 2.
Proof of Theorem 2.
The proof is described in Appendix A. ☐
There are many ways to split the matrix , Jacobian iteration is selected in our method due to two reasons. Firstly, considering the special structure of the matrices A and , the spectral radius of Jacobian matrix can be guaranteed strictly bounded above by 1 and thus the sequence converges as . Secondly, the matrix is diagonal, which guarantees that the dual variable is updated without global information.
Next, a distributed computation procedure to calculate the dual vector will be developed by rewriting the iteration (16).
Theorem 3.
Proof of Theorem 3.
The proof is described in Appendix B. ☐
From this theorem, each link variable is updated using its private result, , and the information from its neighbors; i.e., , . The adjacent nodes’ information is obtained directly through the information exchange. Therefore, the dual variable can be obtained in a distributed manner.
Once the dual variables are computed, the primal Newton direction can be obtained according to (4) as:
From this equation system, the primal Newton direction is computed only using the local information , and ; hence, the calculation of Newton direction is decentralized.
For the consensus optimization problem (10), we convert it to a separable optimization problem with equality constraints (11) and introduce Equations (4) and (5) to solve it. However, the computation of the dual variable at a given primal solution cannot be implemented in a distributed manner, since the evaluation of the matrix inverse requires global information. We provide a decentralized computation of using Jacobian iteration. Then, the primal Newton direction is expressed in (18). Now we present the details of the algorithm.
Algorithm 1 is distributed and local. Node i receives from its neighbors and computes the values of . Step 2 and Step 3 are dual iterations. Node i generates by using and from its neighbors and sends the estimates to them. We find that the values of are not changed at a given primal solution . Hence, they are calculated only once before the iteration of dual variable. Lastly, Algorithm 1 computes the Newton direction and updates the primal variable based on the previous result and sends them to their neighbors. If some stopping criterion is met, the algorithm stops and produces the result within the desired accuracy.
Algorithm 1 is proposed based on networks with a Hamilton path. In the next section, a distributed inexact Newton algorithm is proposed for multi-agent consensus optimization problems in any connected network.
| Algorithm 1. Distributed Inexact Newton Method in Networks with a Hamilton Path |
| Step 0: Initialization: Initialize primal variables and dual variables , set the number of iterations . |
| Step 1: For each node i, |
| If , calculate and ; |
| If , continue. |
| End for. |
| Step 2: Set . |
| For each node i, |
| If , continue; Otherwise, calculate |
| Send to . |
| End for. |
| Step 3: If some stopping criterion is met for , continue; otherwise, set and go back to Step 2. |
| Step 4: For each node i |
| Calculate Newton direction |
| Update the primal variable and send it to . |
| End for. |
| Step 5: If some stopping criterion is met, stop; otherwise, set and go back to Step 1. |
5. Distributed Newton Method for Multi-agent Problems in General Connected Networks
This distributed Newton method is proposed for multi-agent consensus optimization problems in general connected networks. Before giving this method, a theorem is firstly introduced.
Theorem 4.
In reference [22], each connected graph has at least one spanning tree.
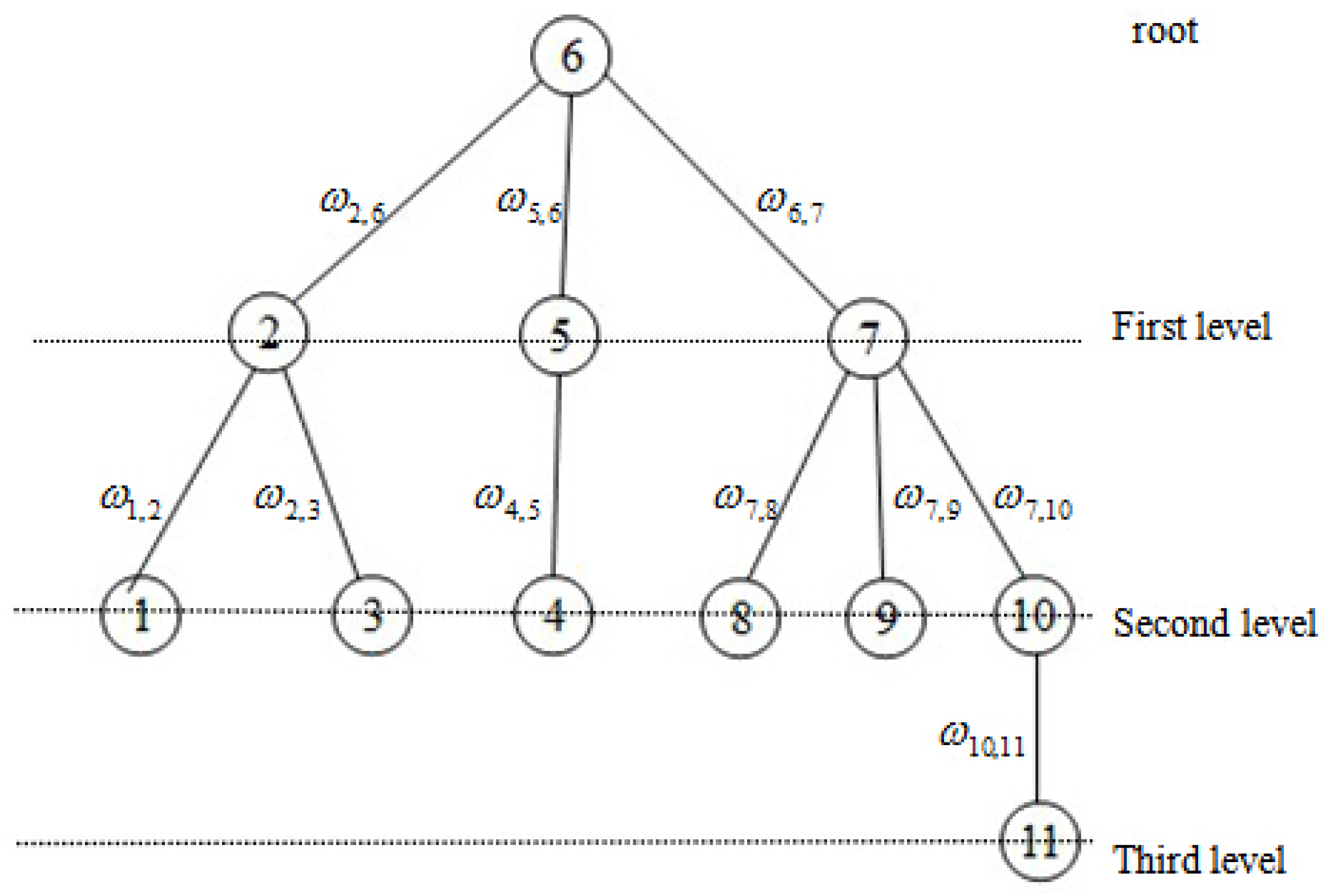
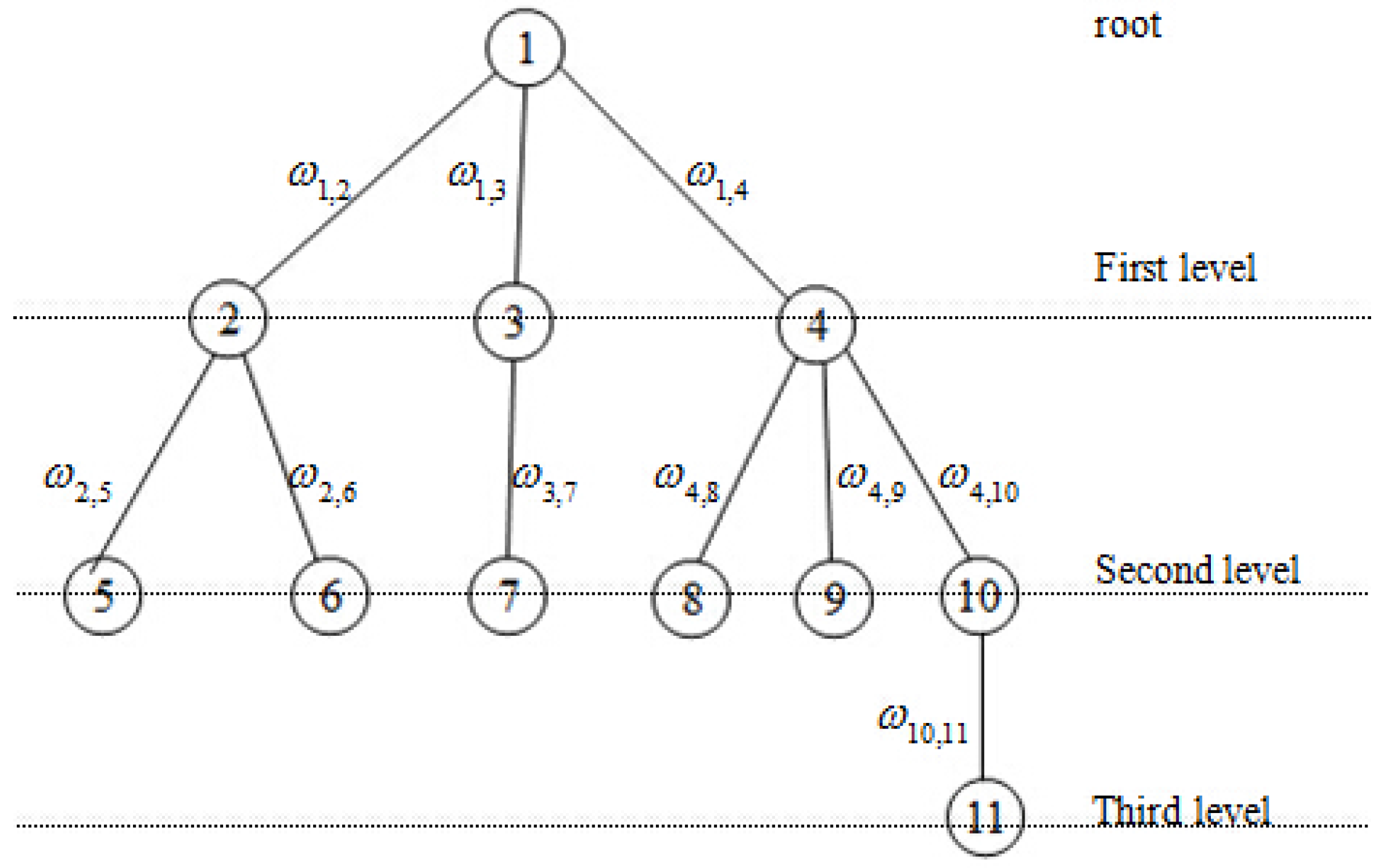
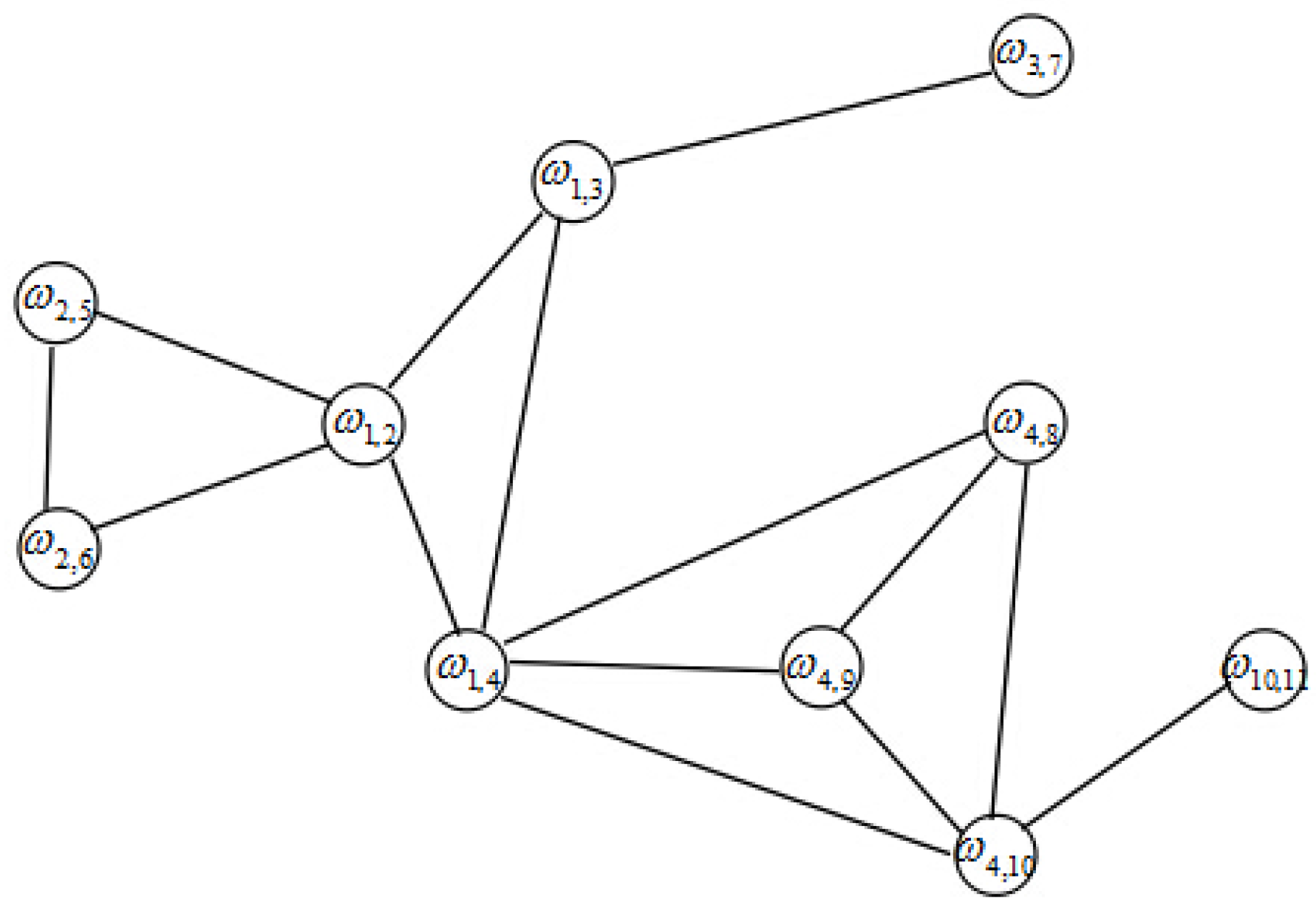
Thus, we can find at least one spanning tree in a connected graph. Now we select an arbitrary node as the root of the tree. We call the nodes connecting to root the first-level nodes, and the nodes which connected to -level nodes is called -level nodes. All nodes are renumbered according to these levels. The dual variable corresponds to a link between node i and node j. In order to ensure that the coefficient matrix A has full row rank, we eliminate the links between nodes belonging to the same level. Without loss of generality, we choose node 6 to be the root of the tree, as shown in Figure 3. In order to facilitate the analysis, all nodes in Figure 3 are renumbered according to the rule of top-to-bottom and left-to-right as depicted in Figure 4. Figure 5 is the dual graph of the spanning tree. From this figure, we have the observation that the dual graph is no longer a tree and there are many circuits.
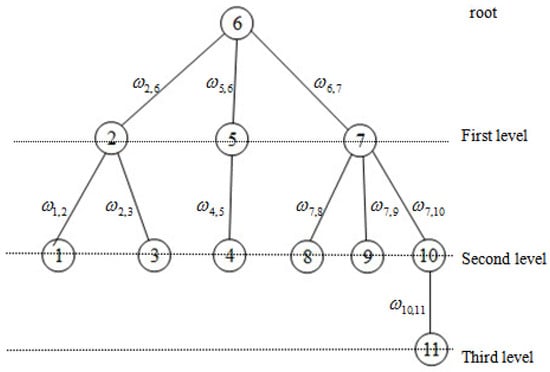
Figure 3.
Spanning tree of network with 11 nodes in Figure 1.
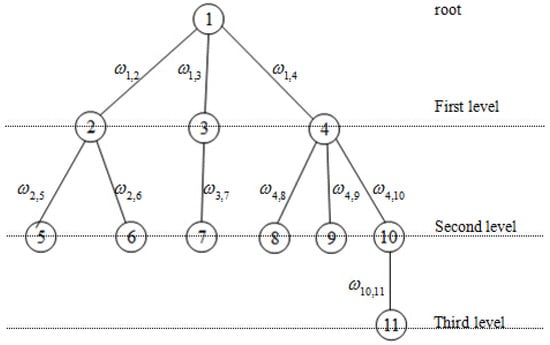
Figure 4.
Spanning tree after renumbering.
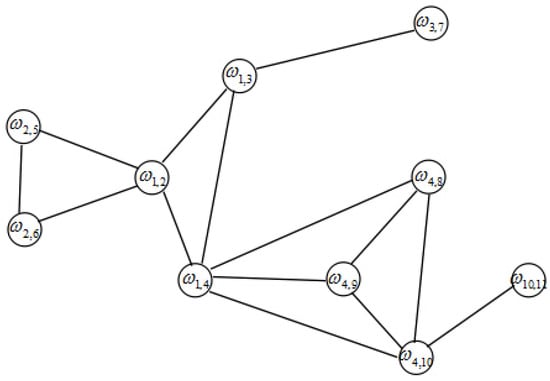
Figure 5.
Dual graph for the network in Figure 3.
Iteration Equation (9) in Theorem 1 can be used to compute the dual sequence , since the matrix A has full row rank and the objective function is strictly convex. The matrix A in this problem has different forms with it in NUM, and therefore predetermined routes are not needed when we rewrite Equation (9).
Theorem 5.
For each primal iteration k, the dual iteration (9) can be written as
where is defined as the set of nodes connected to node i, excluding node j; sign if belongs to the same level and sign ; otherwise, , and .
Proof of Theorem 5.
The proof is described in Appendix C. ☐
From this theorem, each dual component is updated using its private result and the adjacent nodes’ information; i.e., , , . Therefore, the dual variable can be computed in a distributed manner. Next, we obtain the primal Newton direction in a distributed way.
Recall the definition of matrix A; i.e., and if , and otherwise. Therefore, we have
Thus, the Newton direction can be given by
From this equation, the primal Newton direction is computed using only the local information and the dual information which is connected with node l. Hence, the calculation of Newton direction is decentralized.
For the consensus optimization problem (10), we have proposed a distributed inexact Newton method in the previous subsection. In order to get rid of the dependence on the network topology, we propose the following distributed Newton algorithm using a novel matrix splitting technique (Algorithm 2).
| Algorithm 2. Distributed Inexact Newton Method for Arbitrary Connected Network |
| Step 0: Initialization: Initialize primal variables and dual variables , set the number of iterations . |
| Step 1: For each link , |
| Calculate , and . |
| End for. |
| Step 2: For each link , |
| Calculate by Equation (20) and send the result to nodes i and j. |
| End for. |
| Step 3: If some stopping criterion is met for , continue; otherwise, set and go back to Step 2. |
| Step 4: For each node i, |
| Calculate Newton direction by Equation (22); |
| Update the primal variable . |
| Send to . |
| End for. |
| Step 5: If some stopping criterion is met, stop; otherwise, set , and go back to Step 1. |
Algorithm 2 is also distributed and local. Step 2 and 3 are dual iterations. An immediate consequence of Theorem 6 is that the dual iteration is distributed. We find that the values of are not changed at a given primal solution . Hence, they are calculated only once before the dual iteration. Lastly, Algorithm 2 computes the Newton direction and updates the primal variable based only on the previous result and the dual components of the nodes connected node i.
Algorithm 1 and Algorithm 2 are distributed, and they are second-order methods. We will demonstrate the effectiveness of the proposed distributed inexact Newton methods by applying them to the convex programming.
6. Numerical Experiments
In this section, we demonstrate the effectiveness of the proposed distributed Newton methods by applying them to solve a problem which is motivated by the Kuramoto model of coupled nonlinear oscillators [23]. This problem is selected in numerical experiments for two reasons. On one hand, the objective function of this problem is strict convex and separable, which are consistent with the requirement of the special consensus optimization problem. On the other hand, compared with least square problem, the Kuramoto model is more universal and representative. Our simulations were based on random network topology. The codes were written in MATLAB. All numerical experiments were run in MATLAB 7.10.0 on a laptop with Pentium(R) Dual-Core E5500 2.80GHz CPU and 2GB of RAM.
The problem can be reformulated on the form
The problem instances of this problem were generated in the following manner. The number of nodes was 100. We terminated all algorithms whenever reaching an absolute error or the iteration number exceeded . In addition to the decentralized incremental algorithm, we also compared the proposed distributed Newton method with the distributed subgradient algorithm.
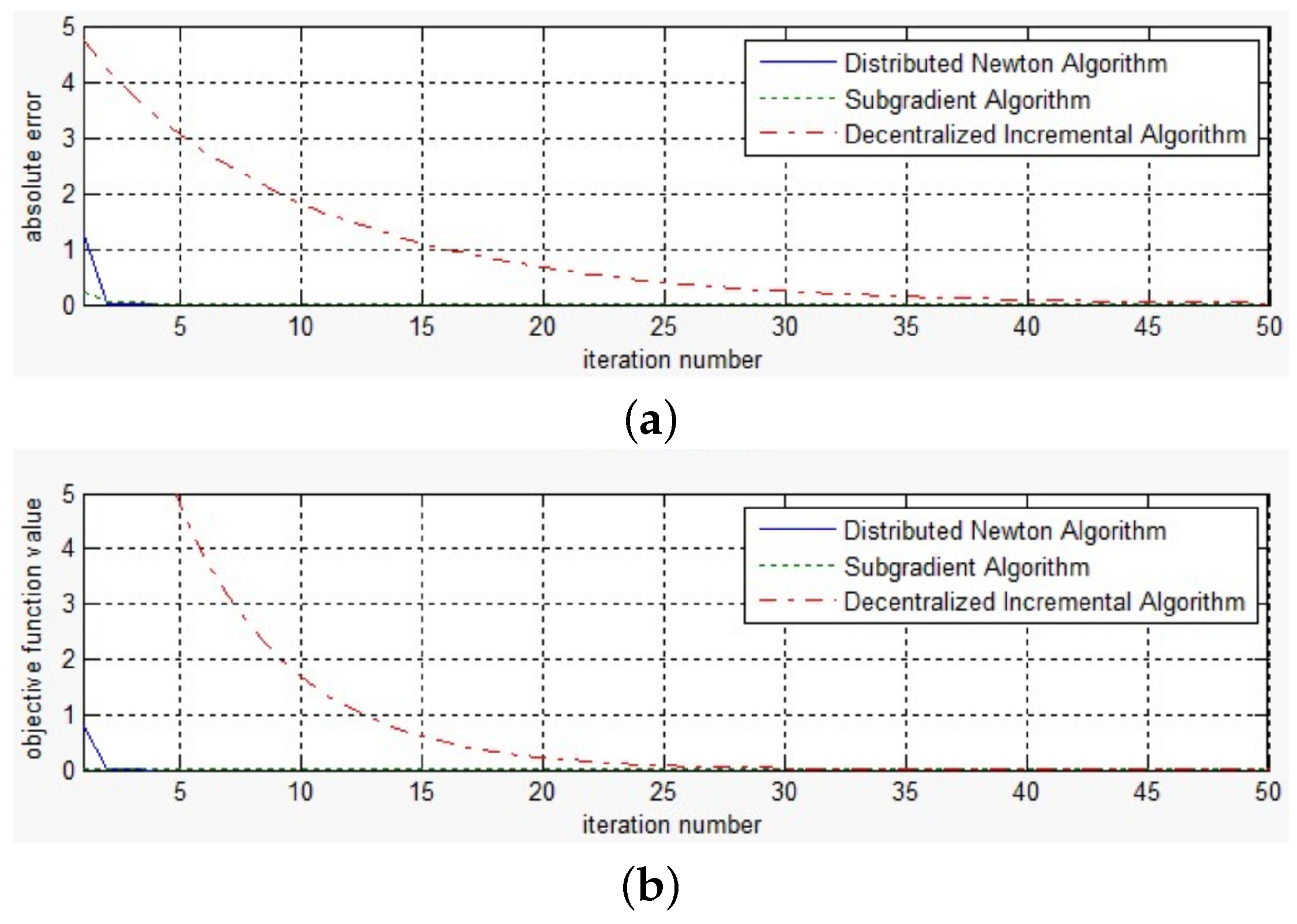
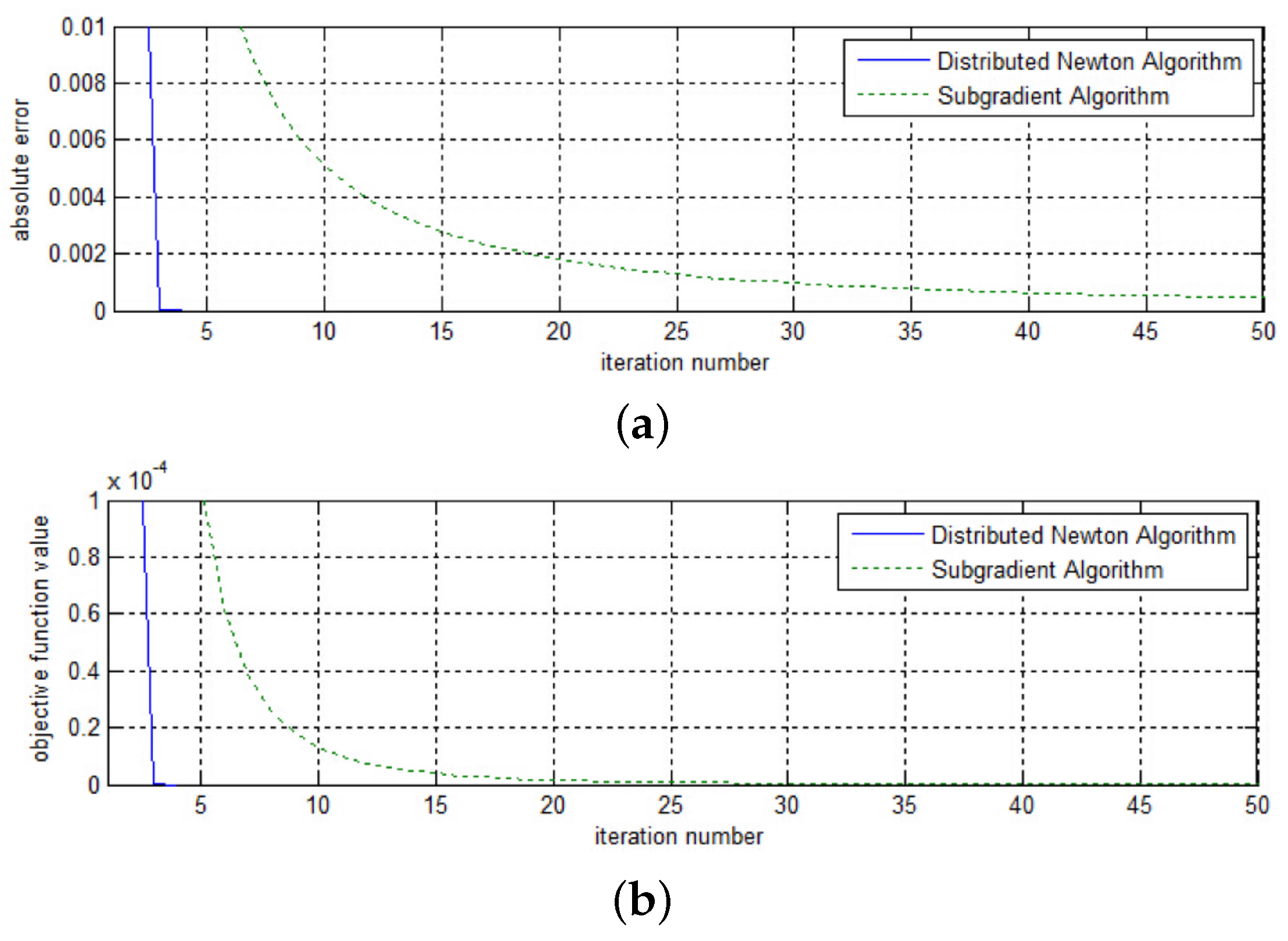
Figure 6 and Figure 7 show the convergence curves of the three methods under test with . The curves shown in these figures are the corresponding absolute error and objective function value of the running average iterates of the three methods. The step size of the decentralized incremental algorithm is set to , and that of the distributed subgradient method is . From Figure 6, we observe that the proposed distributed Newton method and the distributed subgradient method exhibit comparable convergence behavior; both methods converge to a reasonable value within 10 iterations and outperform the decentralized incremental algorithm. For the decentralized incremental method, the convergence speed slows down when the iteration number becomes large. From Figure 7, we decrease the absolute value and see that the proposed Newton method performs better than the distributed subgradient algorithm. One should note that the distributed subgradient method is more computationally expensive than the proposed distributed Newton method, since in each iteration the former requires the computation of the projection of the iteration value.
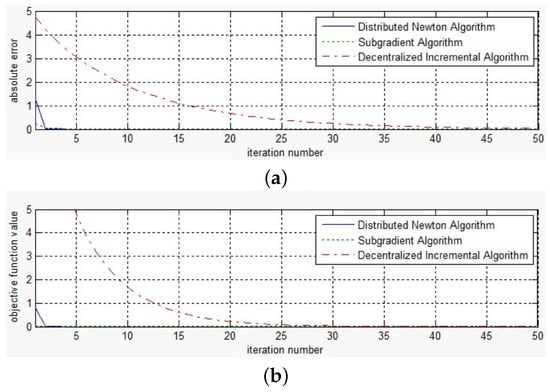
Figure 6.
Absolute error along iterations for network with 100 nodes (1). (a) Absolute error; (b) Objective function value.
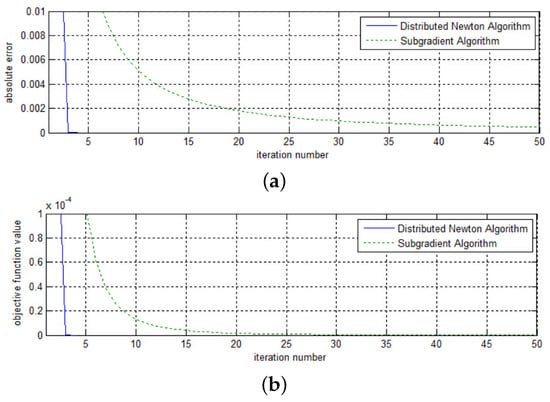
Figure 7.
Absolute error along iterations for network with 100 nodes (2). (1). (a) Absolute error; (b) Objective function value.
7. Conclusions
This paper adjusted the distributed Newton methods for the NUM problem to solve the consensus optimization problem in different multi-agent networks. Firstly, a distributed inexact Newton method for consensus optimization problem in networks with a Hamilton path was devised. This method achieves the decomposition of a Hessian matrix by exploiting matrix splitting techniques. The convergence analysis of this method followed. Secondly, a distributed Newton algorithm for consensus optimization problems in general multi-agent networks was proposed by combining the matrix splitting technique for NUM and the spanning tree of the network. Meanwhile, the convergence analysis showed that the proposed algorithms enable the nodes across the network to achieve a global optimal solution in a distributed manner. Lastly, the proposed distributed inexact Newton method was applied to solving a problem which is motivated by the Kuramoto model of coupled nonlinear oscillators. The numerical experiment showed that the proposed algorithm converged with less iterations compared with the distributed projected subgradient method and the decentralized incremental approach. Moreover, the number of iterations of the proposed algorithm has a small change with the increase of the nodes’ number.
When constructing the spanning tree of an arbitrary connected network, the links between nodes belonging to the same level are eliminated in order to ensure that the coefficient matrix A has full row rank. In other words, a large number of network resources have not been effectively utilized. Consequently, the efficiency of the distributed inexact Newton algorithm can be further improved. In addition, the number of primal iterations is only considered in numerical experiments and compared with other two algorithms. We will take the number of dual iterations into consideration in future work.
Acknowledgments
The work was supported by the National Natural Science Foundation of China (71371026 & 71771019), Science Fund for Creative Research Groups of the National Natural Science Foundation of China (71621001).
Author Contributions
The authors contributed equally to this work.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Proof of Theorem 2.
Since each is a strictly convex function, both the Hessian matrix and its inverse are positive definite and block-diagonal for all k. In addition, the matrix A has full row rank as shown in (13). Therefore, the product is real and symmetric.
We now prove that matrix is a positive definite matrix. Let matrix be given by , and
For any nonzero vector , it can be obtained that
Since the matrices , their inverse and , are all positive definite, we have combining the nonnegativity of the vector v. Thus, the matrix is positive definite. Evidenced by the same token, the matrix is also a positive definite matrix.
Appendix B
Proof of Theorem 3.
Appendix C
Proof of Theorem 5.
Without loss of generality, we assume that is the lth component of the dual vector ; i.e., . Recalling the definition of coefficient matrices A and , we can obtain that: if is connected to node i. In addition, node s and node j belong to the same level; if is connected to node i and node s and node j belong to different levels. Then, we have
Using the definition of coefficient matrix A one more time, we have this fact: there are matrix and matrix in the lth row of the matrix . Combining the definition of in (8), we obtain
From the preceding relation and the definition of matrix in (6), we have
Finally, we obtain the desired distributed iteration (20) when substituting Equations (A4)–(A6) into (9). ☐
References
- Ram, S.S.; Nedić, A.; Veeravalli, V.V. Distributed stochastic subgradient projection algorithms for convex optimization. J. Optim. Theory Appl. 2010, 147, 516–545. [Google Scholar]
- Shi, W.; Ling, Q.; Yuan, K.; Wu, G.; Yin, W. On the Linear Convergence of the ADMM in Decentralized Consensus Optimization. IEEE Trans. Signal Process. 2014, 62, 1750–1761. [Google Scholar] [CrossRef]
- Nedić, A.; Ozdaglar, A. Distributed subgradient methods for multi-agent optimization. Autom. Control IEEE Trans. 2009, 54, 48–61. [Google Scholar] [CrossRef]
- Nedić, A.; Ozdaglar, A. On the rate of convergence of distributed subgradient methods for multi-agent optimization. In Proceedings of the IEEE CDC, New Orleans, LA, USA, 12–14 December 2007; pp. 4711–4716. [Google Scholar]
- Sundhar Ram, S.; Nedić, A.; Veeravalli, V.V. A new class of distributed optimization algorithms: Application to regression of distributed data. Optim. Methods Softw. 2012, 27, 71–88. [Google Scholar] [CrossRef]
- Lobel, I.; Ozdaglar, A. Distributed subgradient methods for convex optimization over random networks. Autom. Control IEEE Trans. 2011, 56, 1291–1306. [Google Scholar] [CrossRef]
- Mota, J.F.; Xavier, J.M.; Aguiar, P.M.; Puschel, M. D-ADMM: A communication-efficient distributed algorithm for separable optimization. Signal Process. IEEE Trans. 2013, 61, 2718–2723. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Xu, F.; Han, J.; Wang, Y.; Chen, M.; Chen, Y.; He, G.; Hu, Y. Dynamic Magnetic Resonance Imaging via Nonconvex Low-Rank Matrix Approximation. IEEE Access 2017, 5, 1958–1966. [Google Scholar] [CrossRef]
- Chen, Y.; Guo, Y.; Wang, Y.; Wang, D.; Peng, C.; He, G. Denoising of Hyperspectral Images Using Nonconvex Low Rank Matrix Approximation. IEEE Trans. Geosci. Remote Sens. 2017. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Y.; Li, M.; He, G. Augmented Lagrangian alternating direction method for low-rank minimization via non-convex approximation. Signal Image Video Process. 2017. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, X.J.; Qu, B. Distributed Model Predictive Load Frequency Control of Multi-area Power System with DFIGs. IEEE/CAA J. Autom. Sin. 2017, 4, 125. [Google Scholar]
- Ram, S.S.; Veeravalli, V.V.; Nedić, A. Distributed non-autonomous power control through distributed convex optimization. In Proceedings of the IEEE INFOCOM 2009, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 3001–3005. [Google Scholar]
- Cavalcante, R.L.; Yamada, I.; Mulgrew, B. An adaptive projected subgradient approach to learning in diffusion networks. Signal Process. IEEE Trans. 2009, 57, 2762–2774. [Google Scholar] [CrossRef]
- Elad, M.; Figueiredo, M.A.; Ma, Y. On the role of sparse and redundant representations in image processing. Proc. IEEE 2010, 98, 972–982. [Google Scholar] [CrossRef]
- Wang, L.; Wang, S.Y.; Zheng, X.L. A Hybrid Estimation of Distribution Algorithm for Unrelated Parallel Machine Scheduling with Sequence-Dependent Setup Times. IEEE/CAA J. Autom. Sin. 2016, 3, 235. [Google Scholar]
- Song, Y.; Lou, H.F.; Liu, S. Distributed Model Predictive Control with Actuator Saturation for Markovian Jump Linear System. IEEE/CAA J. Autom. Sin. 2015, 2, 374. [Google Scholar]
- Chiang M, Hande P, L.T.e.a. Power control in wireless cellular networks. Found. Trends Netw. 2008, 2, 381–533. [Google Scholar]
- Shen, C.; Chang, T.H.; Wang, K.Y.; Qiu, Z.; Chi, C.Y. Distributed robust multicell coordinated beamforming with imperfect CSI: An ADMM approach. Signal Process. IEEE Trans. 2012, 60, 2988–3003. [Google Scholar] [CrossRef]
- Mokhtari, A.; Ling, Q.; Ribeiro, A. Network newton-part i: Algorithm and convergence. Available online: https://arxiv.org/abs/1504.06017 (accessed on 5 August 2017).
- Wei, E.; Ozdaglar, A.; Jadbabaie, A. A distributed newton method for network utility maximization. In Proceedings of the 49th IEEE Conference on Decision and Control (CDC) IEEE, Atlanta, GA, USA, 15–17 December 2010; pp. 1816–1821. [Google Scholar]
- West, D.B. Introduction to Graph Theory; Prentice Hall: Upper Saddle River, NJ, USA, 2001. [Google Scholar]
- Jadbabaie, A.; Motee, N.; Barahona, M. On the stability of the Kuramoto model of coupled nonlinear oscillators. In Proceedings of the 2004 IEEE American Control Conference, Boston, MA, USA, 30 June–2 July 2004; Volume 5, pp. 4296–4301. [Google Scholar]
- Mangasarian, O.L. Convergence of iterates of an inexact matrix splitting algorithm for the symmetric monotone linear complementarity problem. SIAM J. Optim. 1991, 1, 114–122. [Google Scholar] [CrossRef]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).