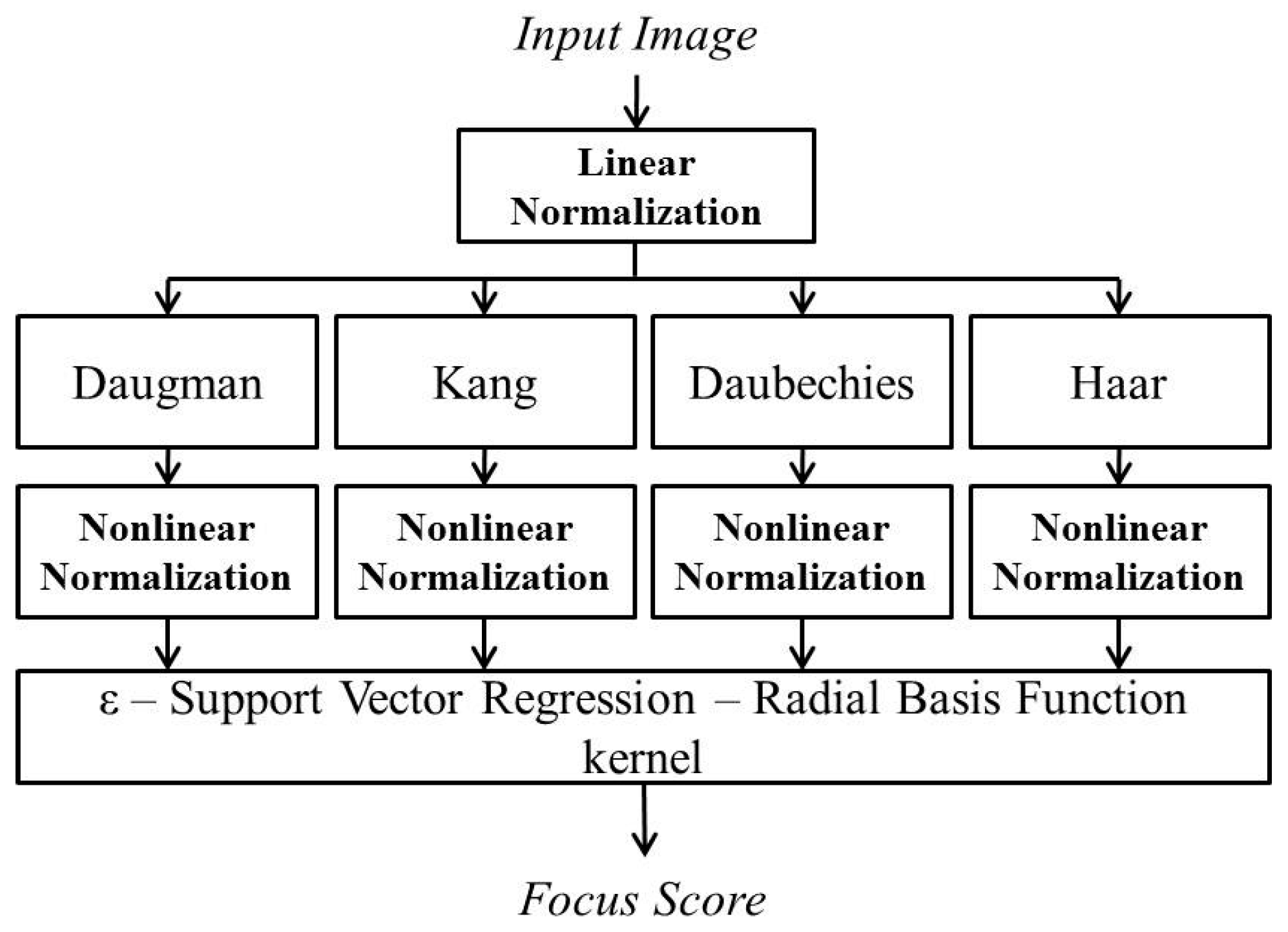
2.2. Linear Normalization of Image Brightness Based on Mathematical Analyses
In spatial domain methods, the masks work as filters to collect the high frequency energy components of the images. The convolution value increases with an increase in the image brightness. Consequently, the calculated focus score can be high when the brightness is high, even if the actual focus level is very low. Thus, the focus score graph of dark images is usually lower than that of bright images. In wavelet domain methods, the phase and amplitude of the wavelet cannot be separated in the transform process [
20]. The amplitude is related to the image brightness. For example, if the image becomes too dark, the high frequency components of the image decrease, whereas the low frequency components increase, resulting in a low response of the focus measure. These phenomena, caused by image brightness variation in the spatial and wavelet domains, are shown in
Figure 3 and
Figure 4, respectively.
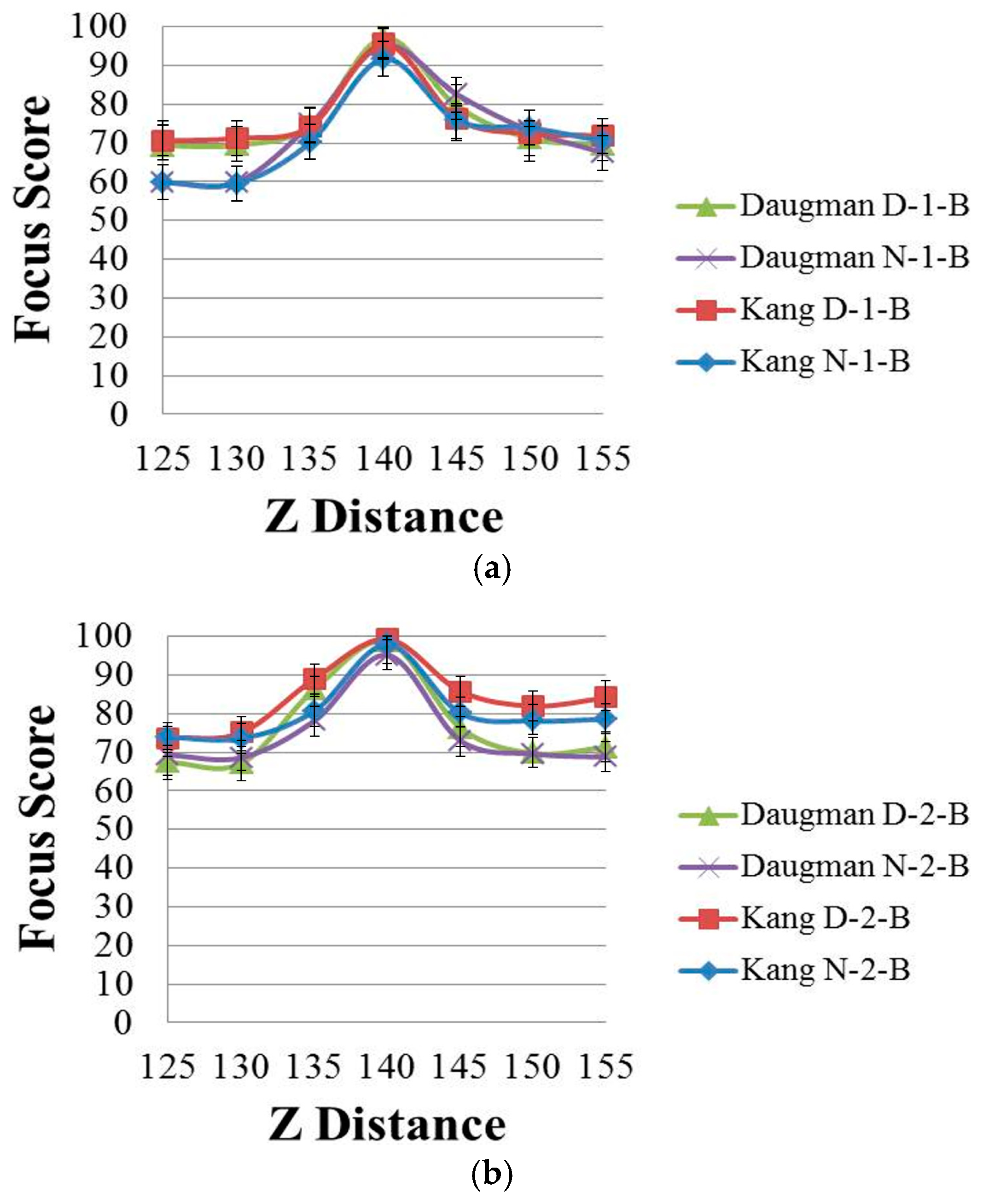
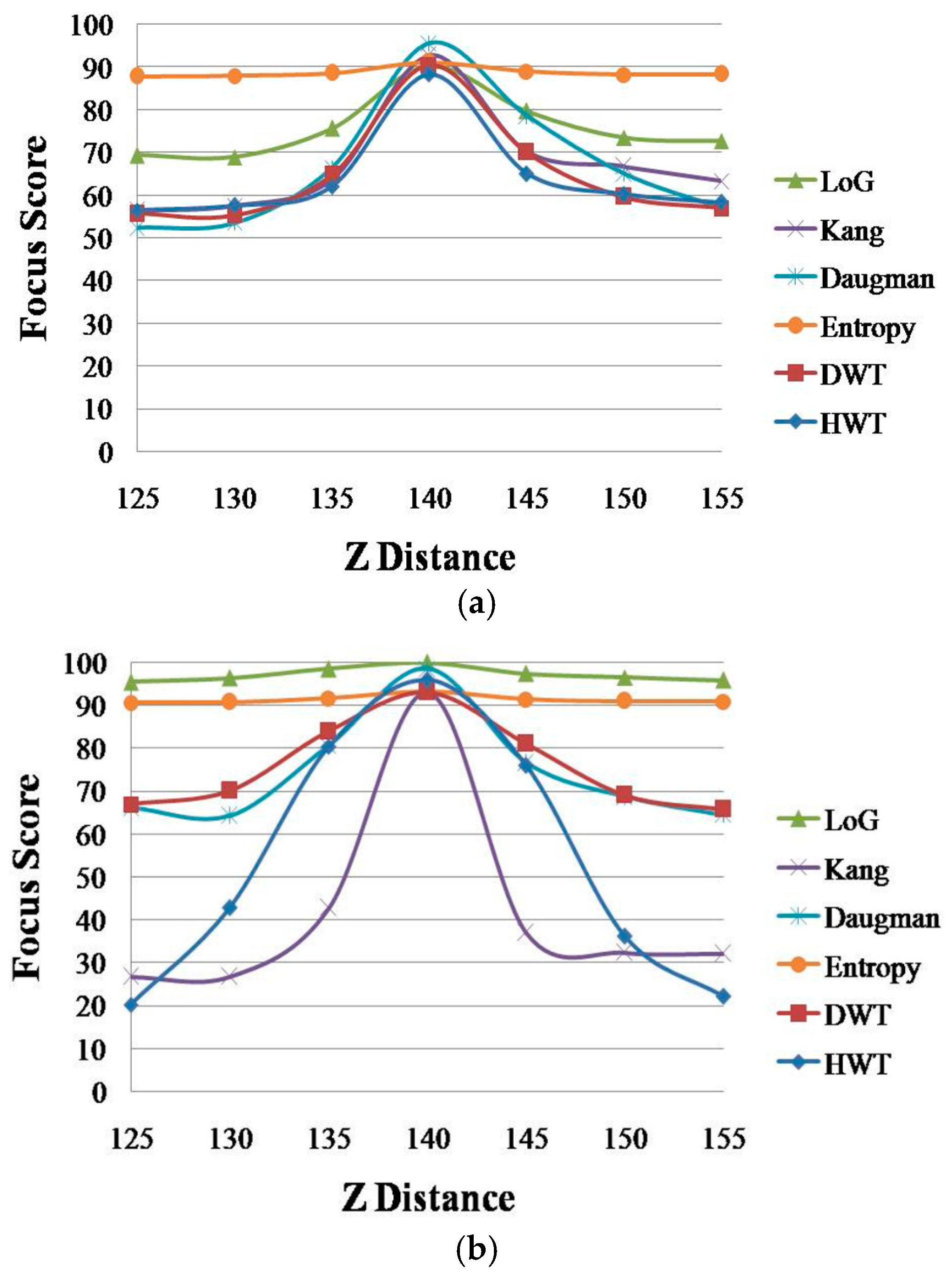
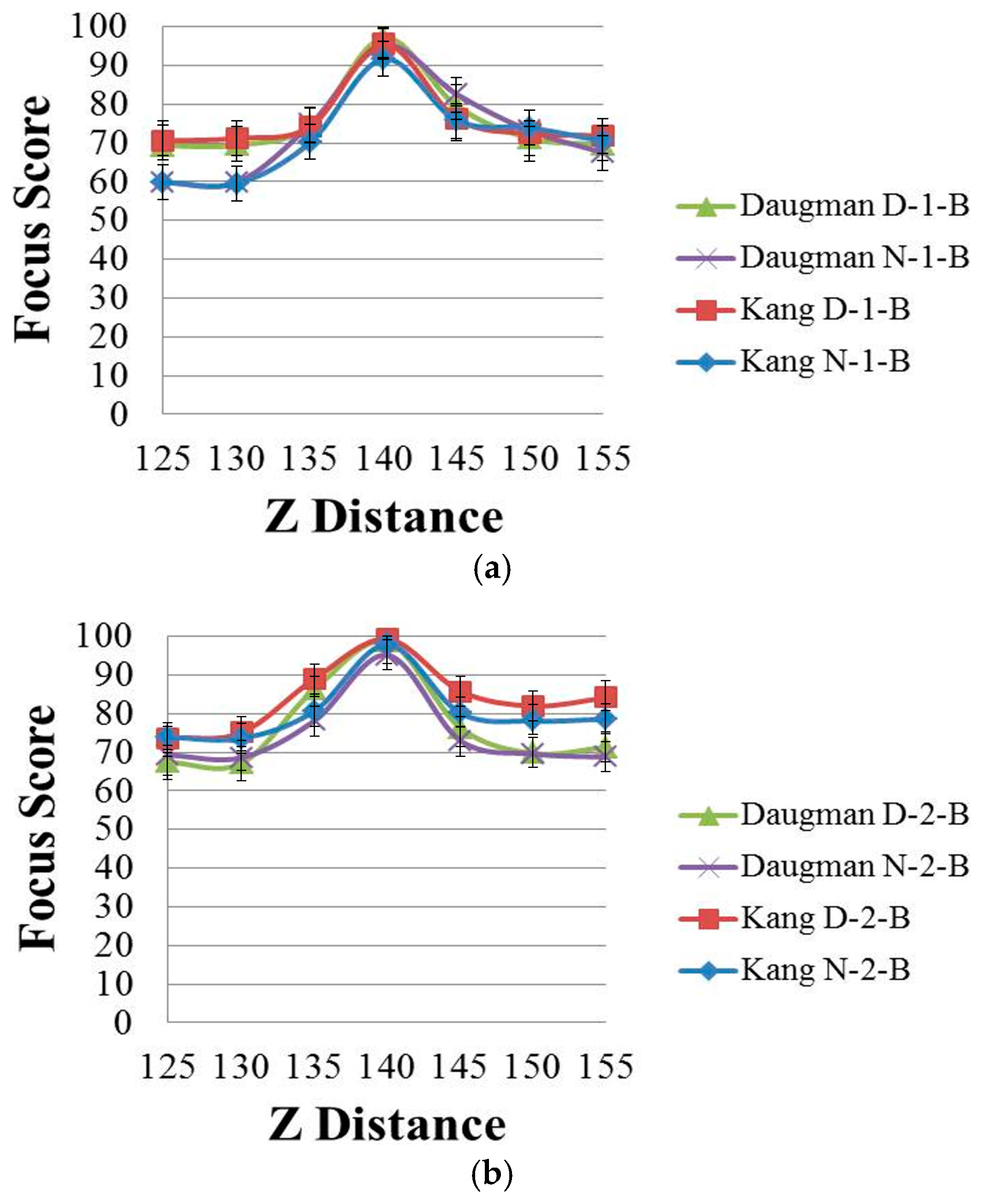
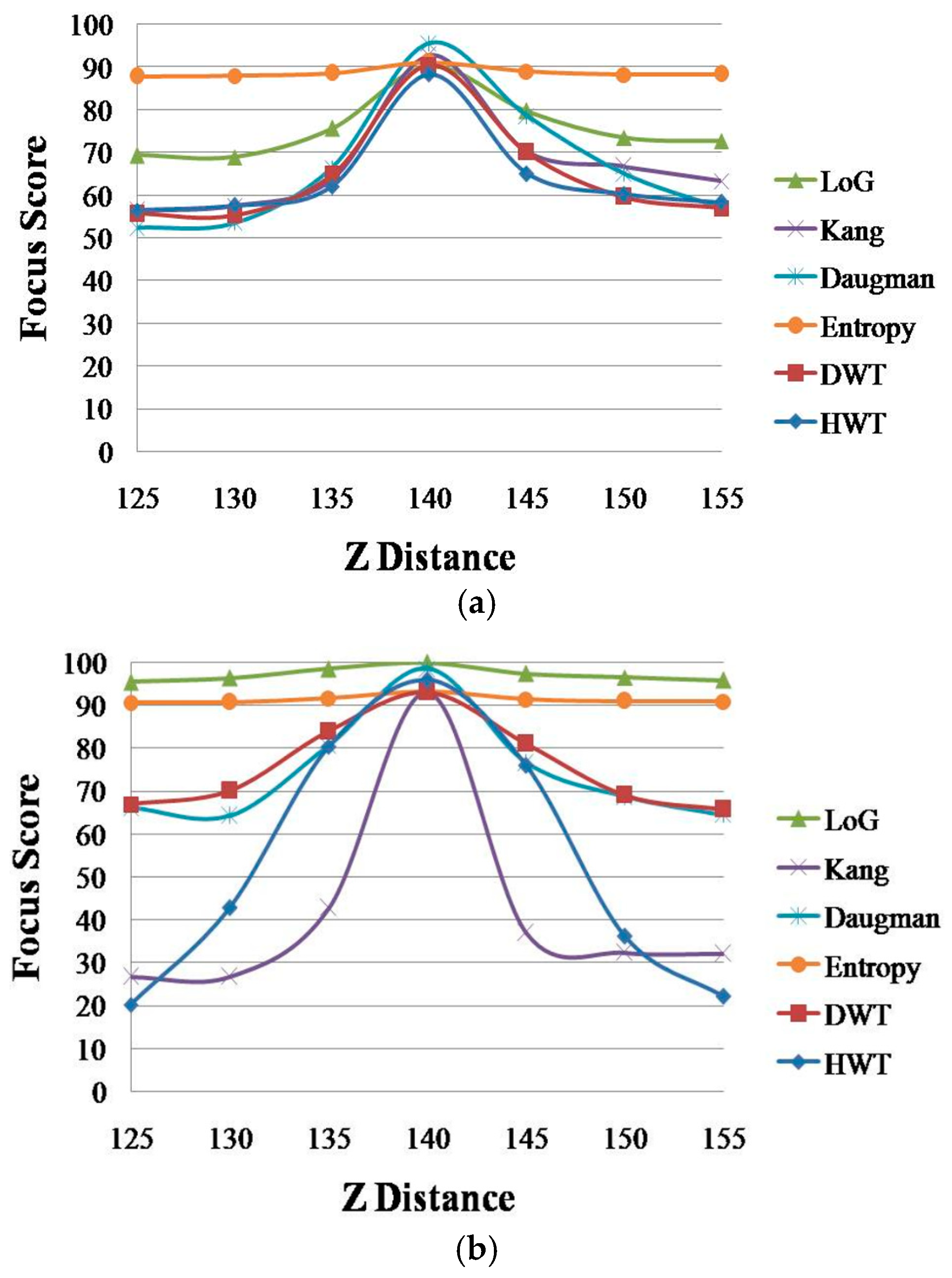
Figure 3 shows the focus score graphs of the same object of the eye region according to the Z distance, and it represents the performances of spatial domain methods before using linear normalization. In
Figure 3 the most focused image can be obtained at a position of 140. The “Daugman D-1-B” graph is the result achieved by Daugman’s mask [
9] using the daytime images in Database 1, whereas the “Daugman N-1-B” graph is the result achieved by Daugman’s mask using the nighttime images in Database 1. The “Kang D-1-B” graph is the result achieved by Kang’s mask [
10] using the daytime images in Database 1, whereas the “Kang N-1-B” graph is the result achieved by Kang’s mask using the nighttime images in Database 1. Following the same notation, “Daugman D-2-B”, “Daugman N-2-B”, “Kang D-2-B” and “Kang N-2-B” represent the results obtained using Database 2. “D” denotes a daytime image and “N” denotes a nighttime image. “B” indicates that the results are obtained before using linear normalization. The numbers “1” or “2” represent the results obtained using Database 1 and Database 2, respectively.
Databases 1 and 2 were captured using the gaze-tracking system shown in
Figure 1. All of the images were captured in both daytime and nighttime, and our databases involve a variety in brightness. Database 1 contains 84 gray images from 12 people, which were captured by the gaze-tracking camera with the
f-number of 4. In addition, Database 2 contains 140 images from 20 people captured using a camera with the
f-number of 10 in order to increase the DOF. However, when we captured Database 2, we increased the power of the NIR illuminators twice by increasing the number of NIR LEDs, which causes the images in Database 2 to be brighter than those in Database 1, although the
f-number in Database 2 is larger. The captured image is 1600 × 1200 pixels with a gray image of 8 bits. Detailed explanations of Databases 1 and 2 are included in
Section 3.1.
By comparing the four graphs of
Figure 3a, even in the case of the same Z distance, the focus score with the daytime image is different from that with the nighttime image even by the same focus assessment method. For example, in
Figure 3a, considering the Z-distance range of 125–140 cm, the focus score by Kang’s method with the daytime image (Kang D-1-B) is about 71 at the Z distance of 130 cm, whereas that with the nighttime image (Kang N-1-B) is about 60 at the Z distance of 130 cm. This means that the focus score has a standard deviation at each Z distance according to daytime and nighttime images, although all of the other conditions, such as the object (to be captured), camera, Z distance, focus measurement method, etc., are the same.
As shown in
Figure 3a, with the nighttime image (Kang N-1-B), the Z distance becomes 135 cm (instead of 130 cm) in the case of the focus score of 71. This means that even with the same focus score (by the same focus measurement method), the calculated Z distance can be different, from 130 cm with the daytime image to 135 cm with the nighttime image, which make it difficult to estimate the accurate Z distance for auto-focusing based on the focus score. The same cases occur in the methods of
Figure 3b and
Figure 4a,b. Therefore, we propose a new focus measure (by combining four focus measurement methods based on ε-SVR, as shown in
Figure 2), which is less affected by the variations of image brightness.
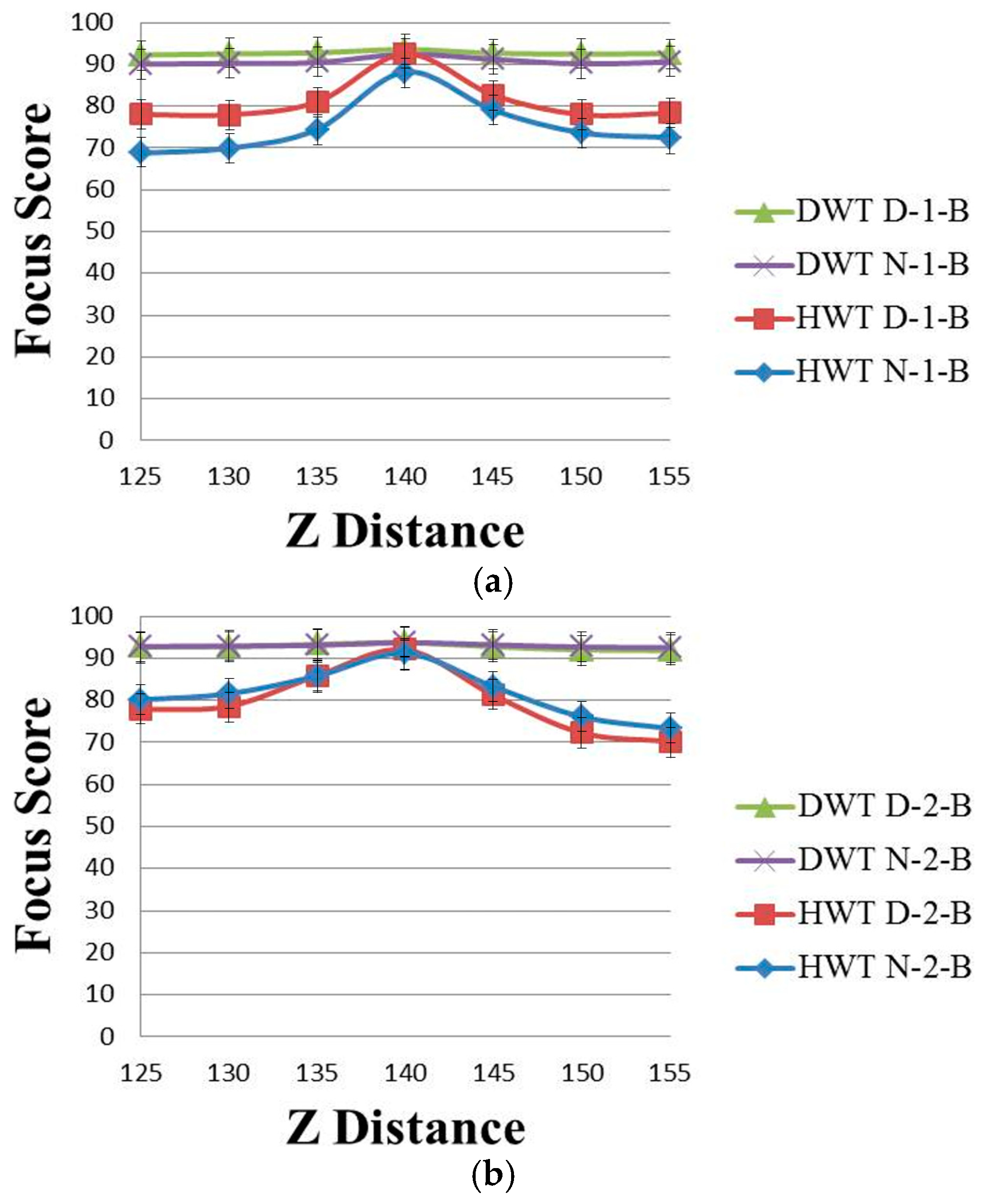
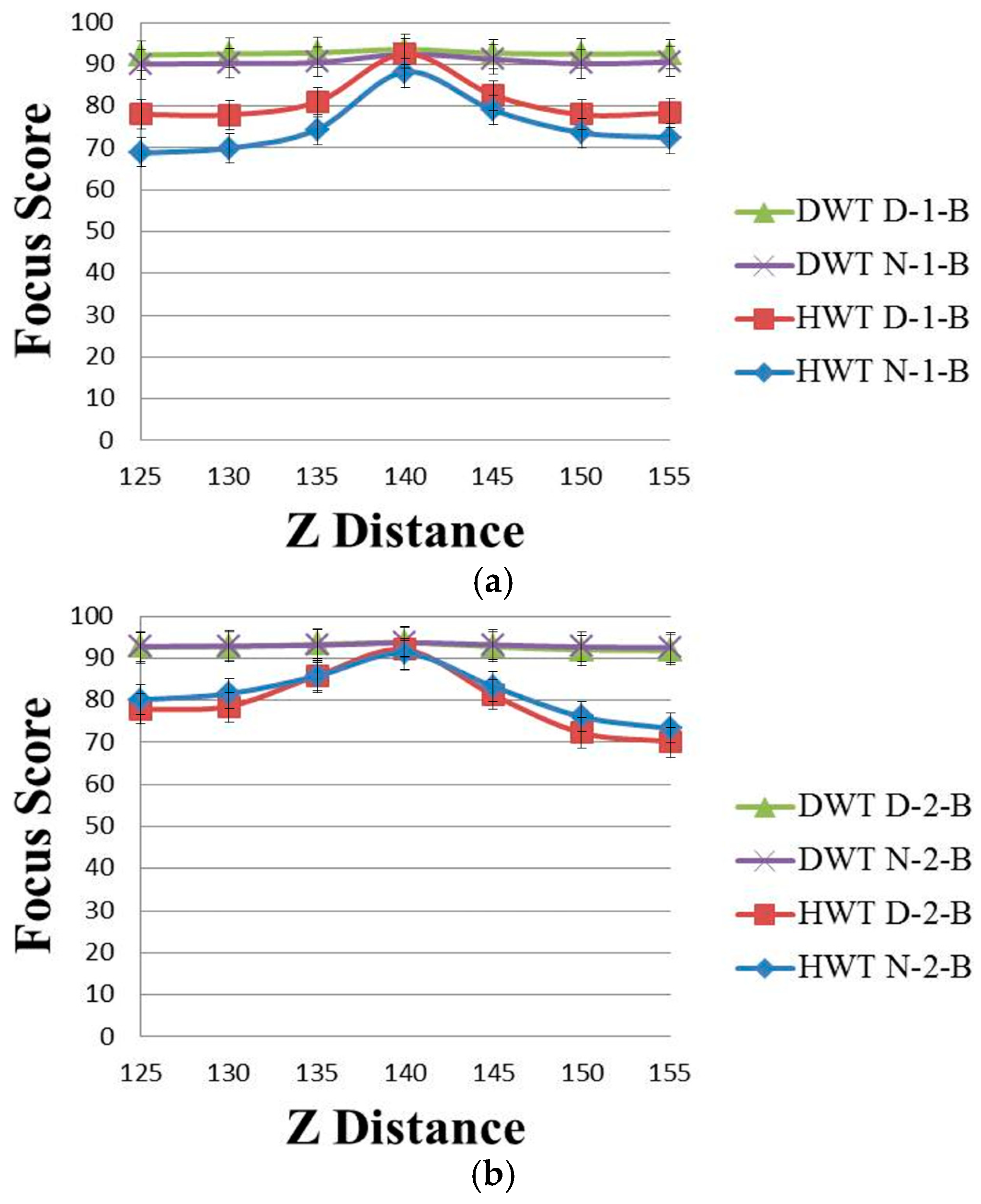
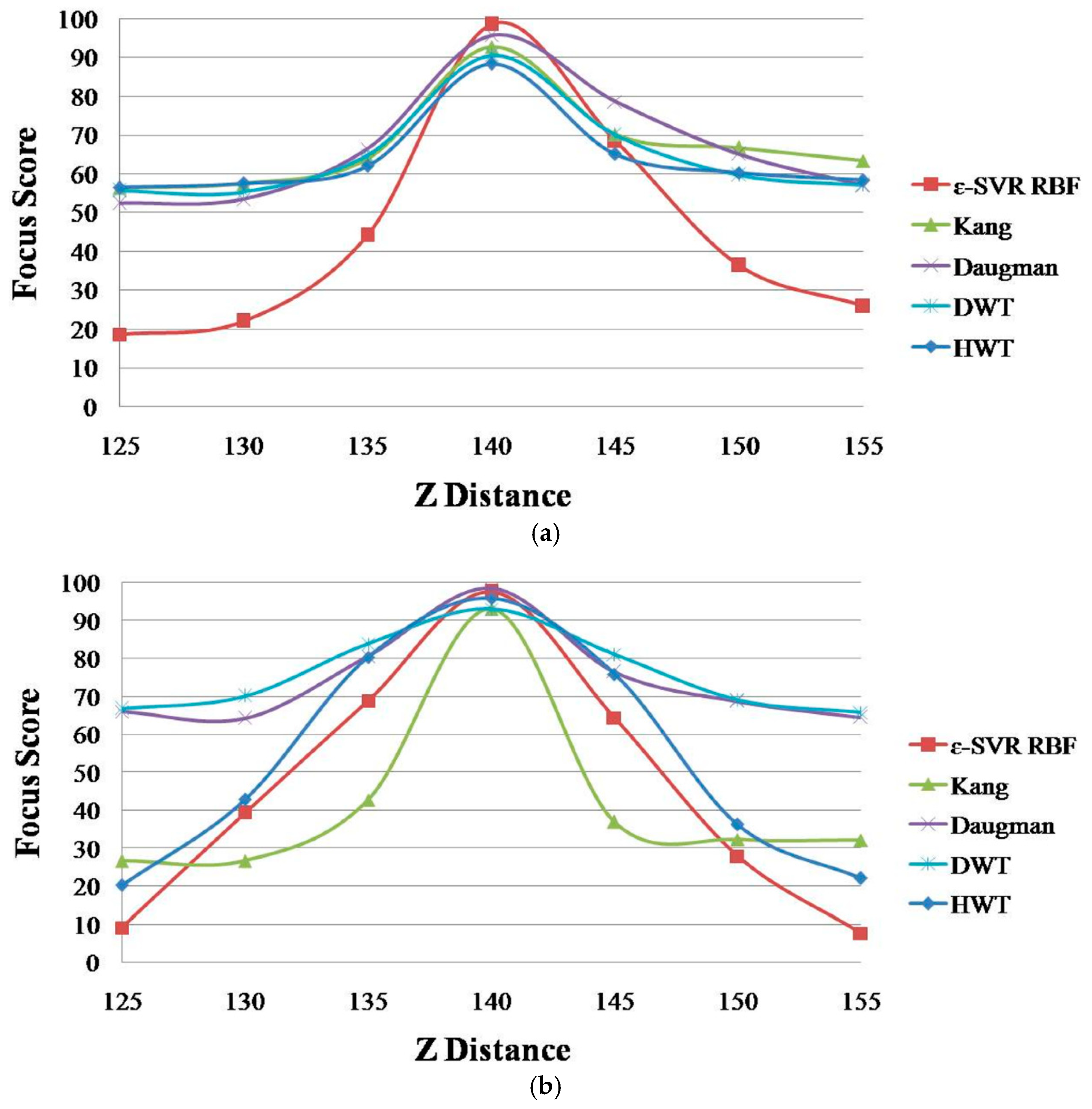
Figure 4 shows the focus score graphs of the same object of the eye region according to the
Z distance of the wavelet domain methods before using linear normalization. Furthermore, in
Figure 4a,b, the most focused image can be obtained at a position of 140. “DWT” and “HWT” indicate Daubechies wavelet transform and Haar wavelet transform, respectively. “D” denotes a daytime image, and “N” denotes a nighttime image. “B” indicates that the results are obtained before using linear normalization. The numbers “1” or “2” represent the results obtained using Database 1 and Database 2, respectively. In
Figure 3 and
Figure 4, we presented standard deviation values, as well. In all of the cases of
Figure 3 and
Figure 4, the standard deviation values are similar, 2.74 (minimum value)–2.92 (maximum value).
Due to the characteristics of Daubechies wavelet transform of using the longer supports of wavelets and scaling signals than Haar wavelet transform [
19,
21], the focus score by Daubechies wavelet transform is less affected by the illumination change in the daytime and nighttime images than that by the Haar wavelet transform. Therefore, the difference in “DWT D-2-B” and “DWT N-2-B” in
Figure 4 is much smaller than that in “HWT D-2-B” and “HWT N-2-B”, and even the value of “DWT D-2-B” is the same as that of “DWT N-2-B”.
Nevertheless, in
Figure 3 and
Figure 4, the two main differences still observed in the focus score are the difference between daytime images and nighttime images, as well as the difference between the two databases. The difference between daytime and nighttime images is shown in
Table 2, which indicates that linear normalization can reduce the difference between daytime and nighttime images. Therefore, linear normalization can decrease the effect of brightness variation on focus measurements. These differences are explained by the camera optics theory in the following discussions.
The first explanation for the difference between daytime and nighttime images is provided by the solar spectrum theory. The Sun emits electromagnetic radiation across most of the electromagnetic spectrum [
22,
23,
24]. In our experiment, the NIR illuminators emit light of a wavelength of 850 nm, and a filter is used in the camera to prevent environmental light of other wavelengths from being incident on the camera sensor. Therefore, the light energy incident on the sensor consists of the NIR light of illuminators and a part of the NIR spectrum of solar radiation. Accordingly, we can analyze the energy incident on the camera sensor in the case that the image is focused, as shown in
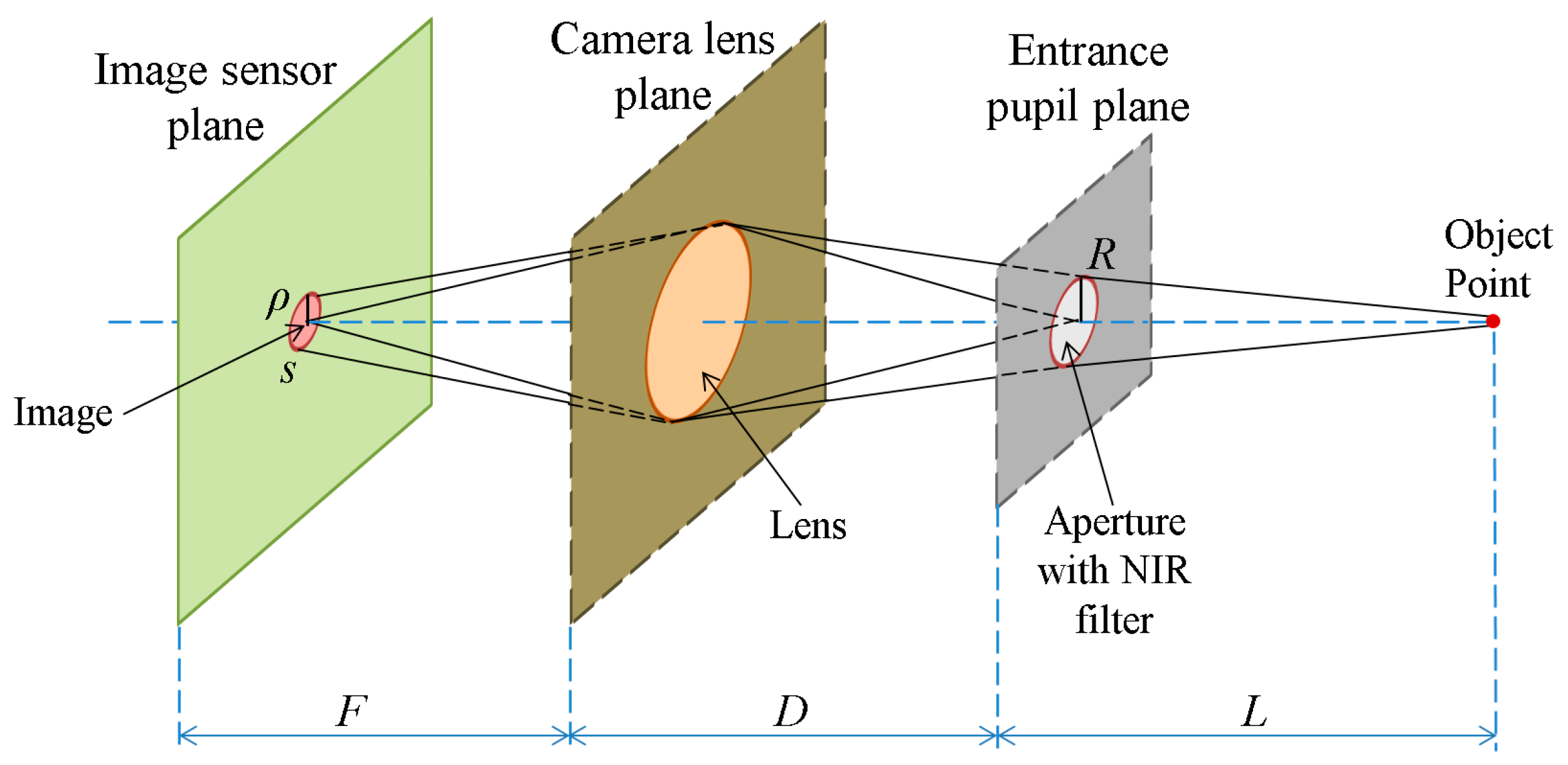
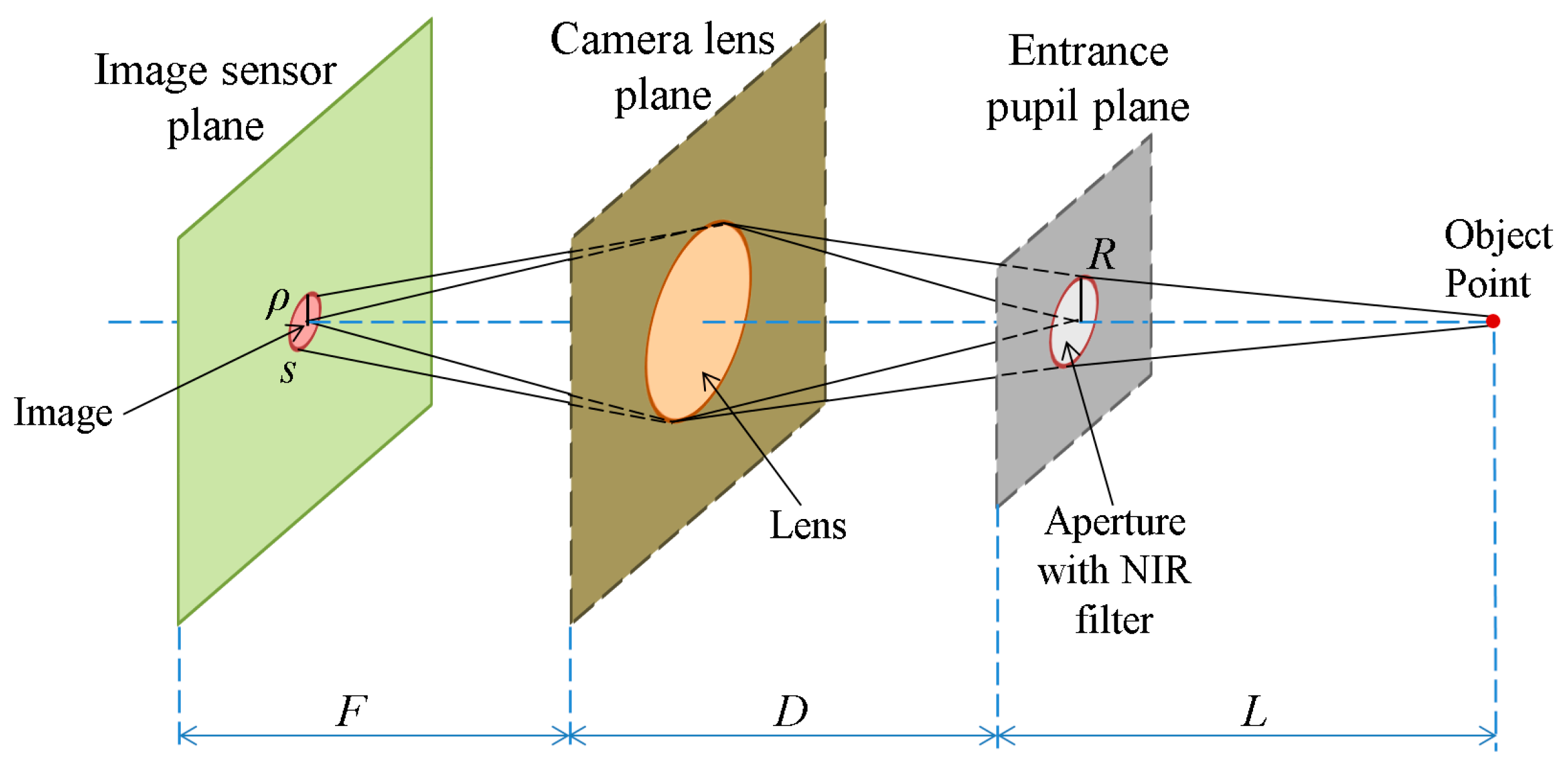
Figure 5.
In
Figure 5, we describe an object point in the NIR light environment. The image is a circular shape in the image sensor plane according to the size of the aperture of the camera. Assuming that the photon density,
I, is constant,
s is the image sensor area that the point is projected on, given the aperture of size
R, and
ρ is the radius of the circle in the image, we obtain the equation
E (image brightness) =
s ×
I ×
h ×
ν =
πρ2Ihν based on [
25]. As evident in
Figure 5, we obtain the equations,
ρ/
R =
F/
D, and
ρ =
R(
F/
D), where
R is the radius of aperture,
F is the focal length of the lens and
D is the distance from the lens plane to the entrance pupil plane. Therefore,
E =
πR2(
F2/
D2)
Ihν =
R2I × (
πF2hν/
D2). In the case that the image is focused,
D is fixed, and
F is a constant. If the constant
M denotes
π F2hν/
D2, we can obtain the following equation:
Based on the principle that the focus level is the energy of the high frequency component in the image domain, we can divide the energy
E into two parts,
E =
A +
a, where
A is the energy of the high frequency component, which defines the focus level, and
a is the energy of the low frequency component, which is the so-called “blur amount”. In the case that the image is focused, the ideal image of the object point can be shown as a point. However, since the aperture is not a pinhole, a blurred region appears around the exact image point. Accordingly, we can consider that the blur amount (
a) is the energy incident on the region of the image excluding the exact image point. Assume that the energy
E spreads homogeneously on the image area; we can calculate
A as shown in Equation (2):
where
sp is the area of one pixel of image sensor. If the image is an ideally-focused one,
s becomes the area of one pixel of the image sensor, and
s is the same as
sp. If the image is a blurred one,
s becomes the area of multiple pixels of the image sensor, which is larger than
sp and symmetrical based on
s. Considering our previous discussion on the difference of daytime and nighttime images, we denote
Ed and
En as the energies incident on the sensor in the case of a daytime image and a nighttime image, respectively. Furthermore, we denote
Ad and
An as the focus levels of the daytime image and nighttime image, respectively. Using the same
f-number to capture these images, we obtain the same radius of aperture,
R. By referring to Equation (1), we obtain
Ed =
R2IdM, and
En =
R2InM. Therefore, by referring to Equations (1) and (2), we obtain
Ad =
R2IdM(
sp/
s), and
An =
R2InM(
sp/
s). As explained previously, since the energy originates from a part of the NIR spectrum of solar radiation and the NIR light of illuminators, we can rewrite these equations as
Ad =
R2(
IdS +
IdI)
M(
sp/
s) and
An =
R2(
InS +
InI)
M(
sp/
s), where
IdS and
InS denote the NIR light intensity of solar radiation during day and night, respectively;
IdI and
InI denote the NIR light intensity of illuminators during day and night, respectively. Since we have used the same NIR illuminators in the daytime and nighttime cases,
IdI =
InI =
II, we obtain the following equation:
where Δ
IS =
IdS −
InS is the difference between the light intensities of daytime and nighttime, and Δ
IS is a large positive value. Therefore,
Ad/
An is larger than 1, and consequently,
Ad is larger than
An. Since
A is defined as the energy of the high frequency component, which defines the focus level, we determine that the energy (
Ad) of the daytime of the high-frequency component, which defines the focus level, is larger than (
An) of the nighttime of the high-frequency component, which also defines the focus level. Therefore, the focus scores of daytime images are usually higher than those of nighttime images, as shown in
Figure 3 and
Figure 4.
In addition, in Equation (3), if
II is much larger than
InS, Δ
IS/(
InS +
II) is almost 0, and
Ad/
An is close to 1, which indicates that the focus scores of the daytime images can be similar to those of nighttime images. Since we used a brighter NIR illuminator while collecting Database 2 compared to Database 1 (see
Section 3.1),
II of Database 2 is larger than
II of Database 1, and the consequent difference between the focus scores of daytime images and nighttime images is smaller in Database 2 compared to that in Database 1, as shown in
Figure 3 and
Figure 4.
The second explanation is regarding the difference between the two databases. Ignoring the difference between daytime and nighttime images, we consider the focus amounts
A1 and
A2 of Databases 1 and 2, respectively. Based on Equations (1) and (2), we obtain
A1 =
R12I1M(
sp/
s1), and
A2 =
R22I2M(
sp/
s2). In our experiments, Database 1 is captured using a camera of
f-number 4, whereas Database 2 is acquired using a camera of
f-number 10. Further, the
f-number is usually proportional to the ratio of the focal length of the lens to the diameter of aperture. As shown in
Figure 5,
R is the radius of aperture, and
F is the focal length of the lens. Therefore,
F/
R1 = 4 in the case of Database 1, and
F/
R2 = 10 in the case of Database 2, which implies
R1 = (10/4)
R2 = 2.5
R2. As shown in
Figure 5,
ρ is proportional to
R. Therefore,
ρ1 =
2.5ρ2, which results in
s1 = 2.5
2s2 because
s =
πρ2, as shown in
Figure 5. In our experiments, the power of illuminators in Database 2 is twice that in Database 1, which implies,
II1 = 0.5
II2. Assuming that the NIR energy of solar light is constant:
Accordingly, we obtain the following equation:
The relationship between
A1 and
A2 is shown as follows:
Based on Equations (5) and (6), we can conclude that the high frequency components of Database 2 (A2) are larger than those of Database 1 (A1). The difference between these two high frequency components is ΔA = 0.5II2hνsp, which depends on the power of illuminators (II2).
Based on these two explanations, the difference between daytime and nighttime images or the brightness difference of illuminators can cause a variation of the focus score. The brightness of the illuminator can be fixed and remains unchanged if the hardware of the gaze-tracking system with an NIR illuminator is determined. Therefore, we can only consider the difference between daytime and nighttime images, and the right side of Equation (3) should be equated to 1. Accordingly, we have two options: decreasing Δ
IS (=
IdS −
InS) or increasing
II. In order to decrease Δ
IS, we apply linear normalization by compensating the brightness of the entire pixels of the daytime and nighttime images to adjust the average grey-level to be the same value. The result of decreasing Δ
IS can be seen in
Table 2 by comparing the results of “before linear normalization” and “after linear normalization”. On the other hand, in order to increase
II, we increase the power of illuminators in the gaze-tracking system. The result of this work is Database 2, in which we set the power of the illuminator to be two-times larger than that of the illuminator in Database 1.
Figure 3 and
Figure 4 show that the difference between daytime and nighttime images in Database 2 is smaller than that in Database 1. This result can be also observed in
Table 2. The last right column (“Database 2” and “after linear normalization”) of
Table 2 describes the result of decreasing Δ
IS and increasing
II, simultaneously.
In these derivations, we attempt to confirm that the high frequency components (A2) of daytime images are theoretically larger than those (A1) of nighttime images if not considering other factors. To prove this, all of the mentioned factors of object distance, image distance, point spread function, etc., are actually set to be the same in both daytime and nighttime images of our experiments. Through this simplified derivation, in the case that all of the mentioned factors are the same, we found that the variation of high frequency components in the captured images even at the same position of Z distance can be reduced by decreasing the brightness change of captured images (ΔIS of Equation (3)), and it can be done by our linear normalization method. Considering that all of these factors for this theoretical derivation are so complicated, and we would do this derivation considering all of these factors in future work.
2.3. Four Focus Measurements
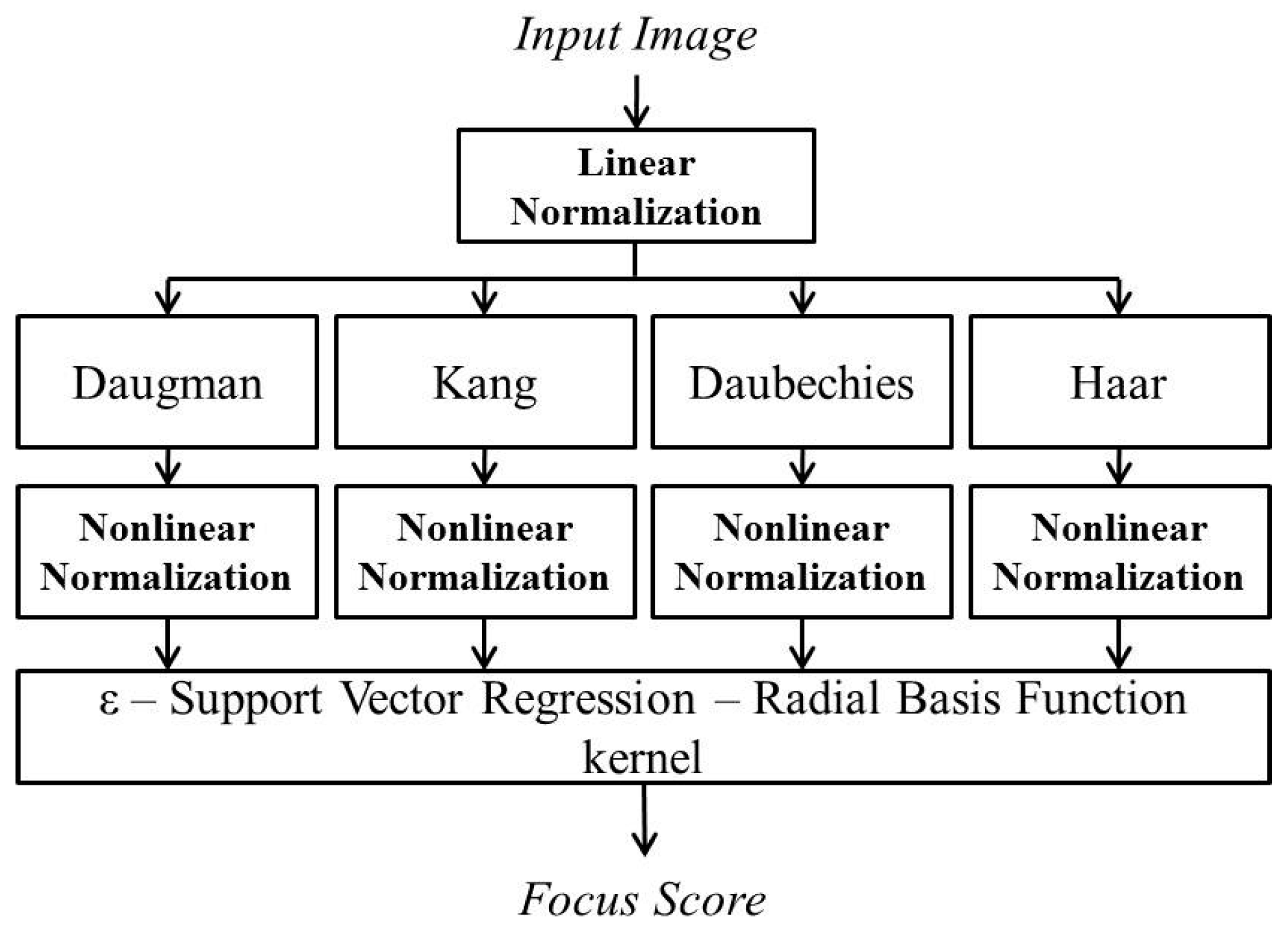
As explained in
Section 2.1 with
Figure 2, four separate focus scores are used as the inputs to ε-SVR in our method. In order to calculate the focus scores, we use two spatial domain-based methods: Daugman’s symmetrical convolution kernel [
9] and Kang’s symmetrical convolution kernel [
10]. In addition, two wavelet domain-based methods are used: the ratio of high-pass and low-pass bands of DWT [
11] and that of HWT.
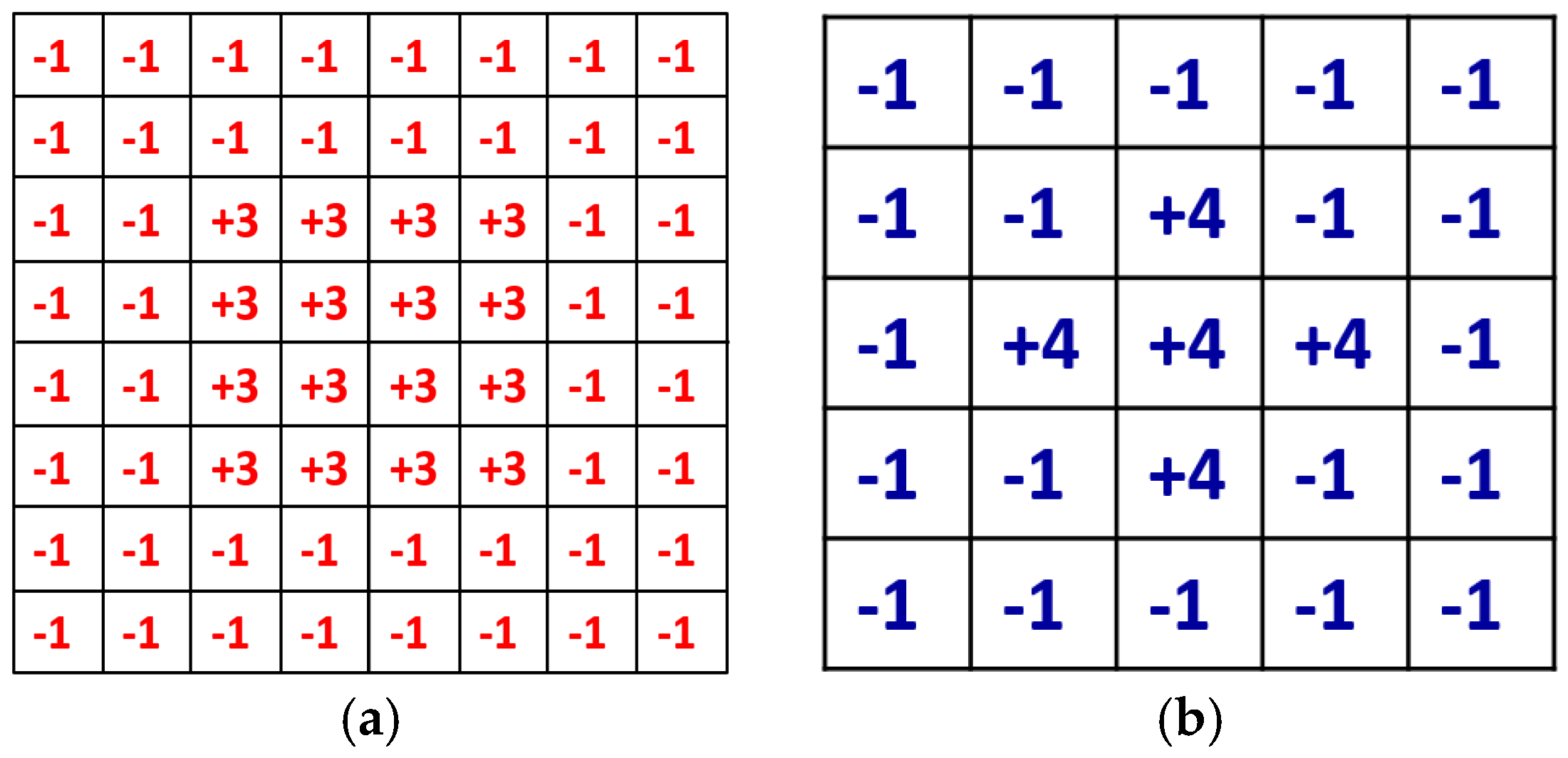
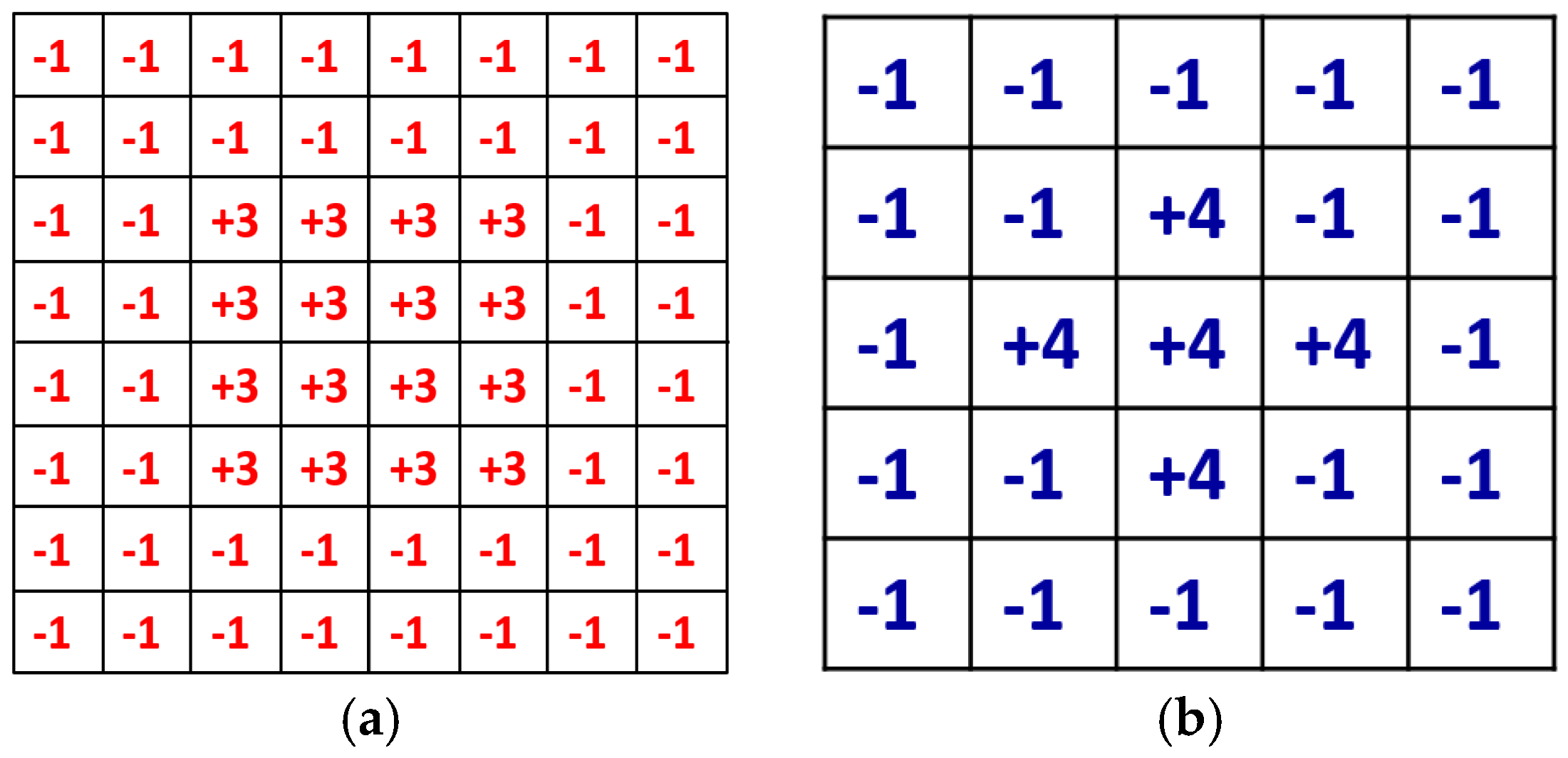
A defocused image can be usually described as a convolution of a focused image by a 2D point-spread function (PSF) defined by a Gaussian function, whose sigma value is proportional to the defocus level. Daugman considered the PSF as an isotropic (symmetrical) Gaussian function, and in the 2D Fourier domain, a defocused image is the product of a focused image and the Gaussian function of defocusing. Daugman’s convolution kernel is an 8 × 8 pixel mask, shown in
Figure 6a, and it is a band-pass filter that accumulates the high frequency components of the image. The summated 2D spectral power measured by the convolution kernel was passed through a compressive nonlinearity equation in order to generate a normalized focus score in the range of 0–100 [
9]. In our method, the focus score is scaled into the range of 0–1 for the input of ε-SVR.
Kang’s convolution kernel improves the performance of Daugman’s method [
10]. The size of Kang’s mask is 5 × 5 pixels, as shown in
Figure 6b, which achieves a smaller processing time than Daugman’s mask. Similar to Daugman’s mask, Kang’s mask has the symmetrical shape. It collects the total high frequency energy of the input image, which is passed through a nonlinear normalization. Thus, the focus score is represented in the range of 0–100, and we re-scale the score into the range of 0–1 for the input of ε-SVR.
In the wavelet domain-based method, the more focused the image, the larger the focus score [
16]. Since the wavelet transform requires a square-sized image, a change of image width or height is needed. In our work, the size of the captured images is 1600 × 1200 pixels, and their size is changed into 1024 × 1024 pixels for DWT and HWT by bi-linear interpolation, whereas the original image can be used for the spatial domain-based method of focus measurement. Consequently, the focus measure in DWT and HWT can be more erroneous owing to the change in size compared to that of the spatial domain-based method.
The procedures used for DWT and HWT in our method are the same. When an input image
with the dimensions of
is decomposed by the wavelet transforms with a level of
n and a multiplicity of
m, we can obtain high-pass sub-bands
and low-pass sub-bands
with the dimensions of
. In the proposed method, we collect the ratios of the average values per pixel in the high-pass (
) and low-pass sub-bands (
) of the four levels of the transformed image, as shown in Equation (7).
where
F denotes the focus score of the image and
wi represents the weight at the
i-th level index.
HHi and
LLi are the high frequency (in both horizontal and vertical directions) sub-band and low frequency (in both horizontal and vertical directions) sub-band, respectively, at the
i-th level index. The weight is required because the values of high-high (HH) components are very small and decrease according to the level of transformation. The focus score is passed through nonlinear normalization to obtain a focus score in the range of 0–1.
2.4. ε-Support Vector Regression with a Symmetrical Gaussian Radial Basis Function Kernel for Combining Four Focus Scores
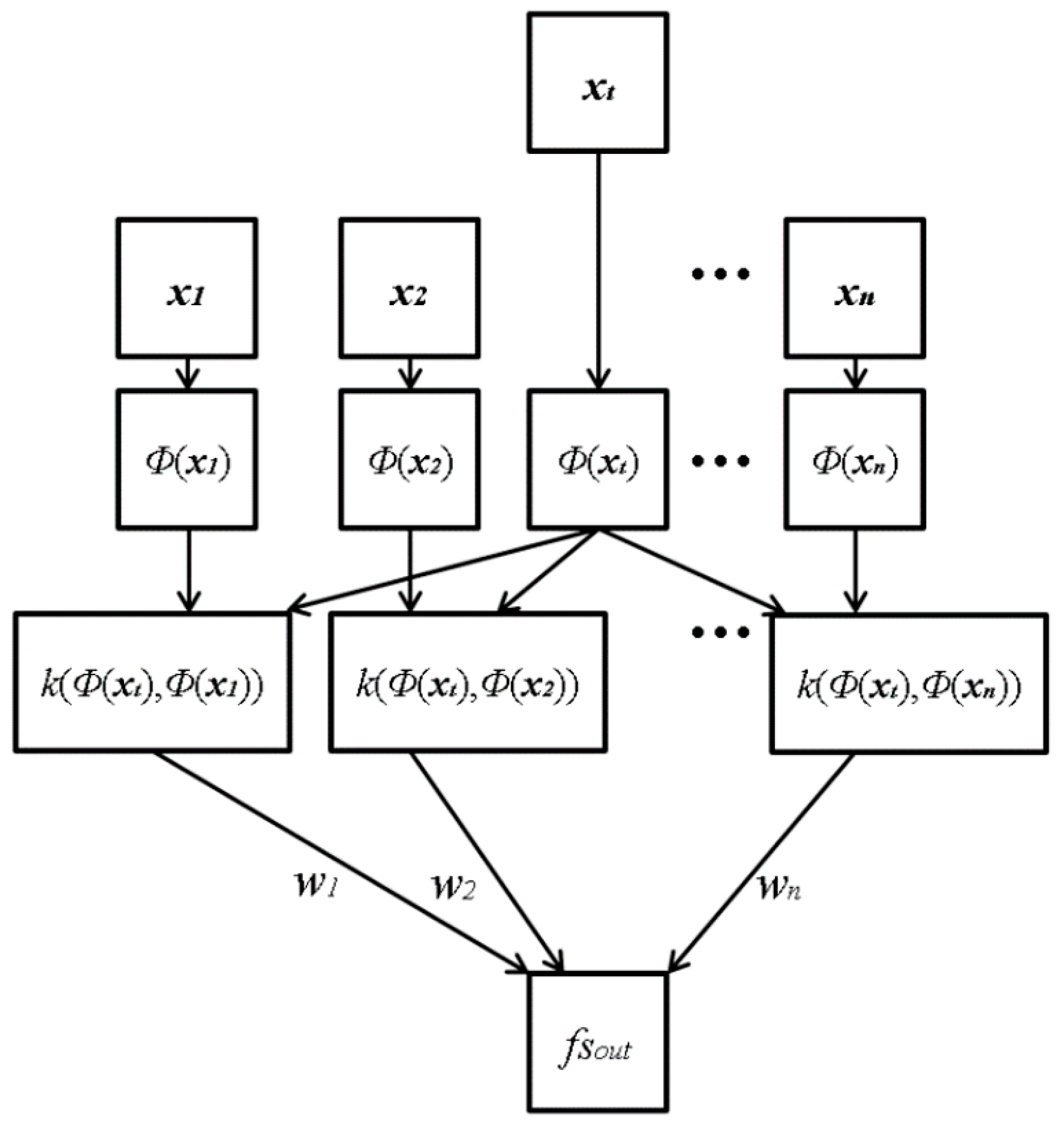
Using four individual methods of focus measurement, we propose a method to use ε-SVR with a symmetrical Gaussian RBF kernel to combine the information from both spatial and wavelet domain-based methods, as shown in
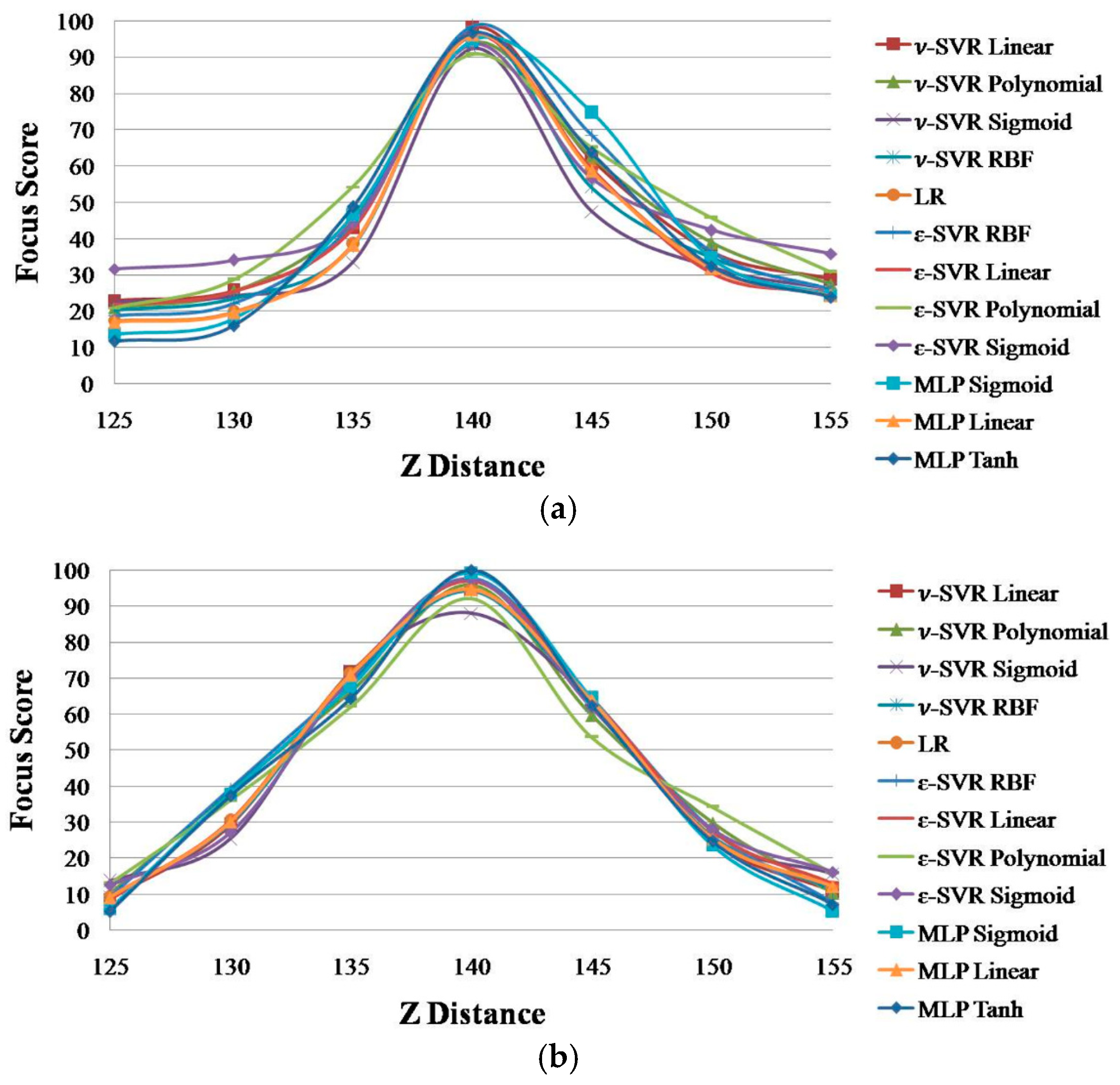
Figure 2. The output of our architecture is the combination of the four input focus scores obtained from the four individual methods. Consequently, the accuracy of the focus assessment can be increased. In the four individual focus measurements, the focus score graphs vary according to the users. The variation of the focus score graph leads to an error in auto-focusing. However, the reasons for an error in one method may be different from those of other methods, and they do not affect each other. Therefore, we utilize the advantages of one of these four methods to overcome the errors in the other methods by using a suitable combiner.
Various methods can be considered as the combiner, including SVR [
26,
27,
28,
29], linear regression (LR) [
30] and multi-layered perception (MLP) [
31,
32,
33,
34,
35,
36]. SVR represents the decision boundary in terms of a typically small subset of all training examples [
28]. This algorithm seeks estimation functions based on independent and identically distributed data. This type of SVR is called ε-SVR because it uses an ε-insensitive loss function proposed by Vapnik [
26]. The parameter ε is related to a specific level of accuracy. This detail makes ε-SVR different from the subsequent proposed method of ν-SVR in [
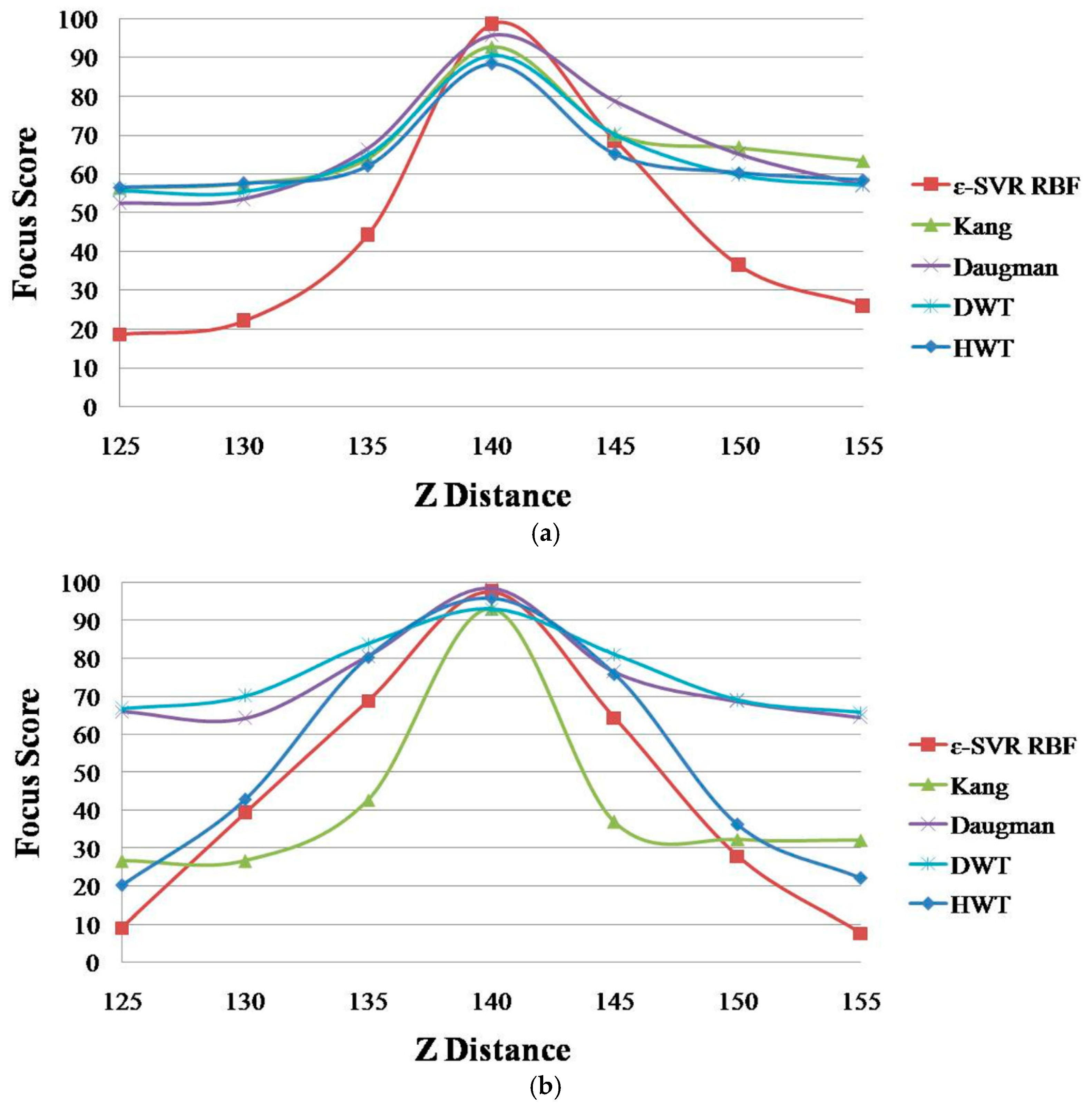
28]. In the proposed method, we use focus values of four individual measurements as the input for ε-SVR to obtain the final focus score. The experimental result using our two experimental databases shows that ε-SVR performs better than ν-SVR, LR, and MLP (see
Section 3).
Contrary to SVM, which deals with the output of {±1}, SVR is a regression estimate concerned with real-valued estimating functions [
27]. Vapnik proposed ε-SVR, including ε-insensitive loss functions;
L(
y,
f(
xi,
α)) =
L(|
y −
f(
xi,
α)|
ε), where
y is the output,
xi is the input pattern,
α is a dual variable and
f(
xi,
α) is the estimation function. |
y −
f(
xi,
α)|
ε is zero if |
y −
f(
xi,
α)| ≤ ε, and the value of (|
y −
f(
xi,
α)| − ε) is obtained otherwise [
26]. In order to estimate the regression function using SVR, we adjust two parameters: the value of ε-insensitivity and the regularization parameter
C with the kernel type [
27]. There are many types of kernel functions used in ε-SVR, such as linear, polynomial, sigmoid, RBF kernels, etc. In our research, we compared the accuracies of various kernels (see
Section 3), and we used the RBF kernel in ε-SVR. The RBF kernel is described as a symmetrical Gaussian function,
. With training data, the parameter
γ is optimized to the value of 0.025. By changing the value of ε, we can control the sparseness of the SVR solution [
27]. In our research, we set ε to be the optimal value of 0.001 with training data, and the regularization parameter
C is set to 10,000.
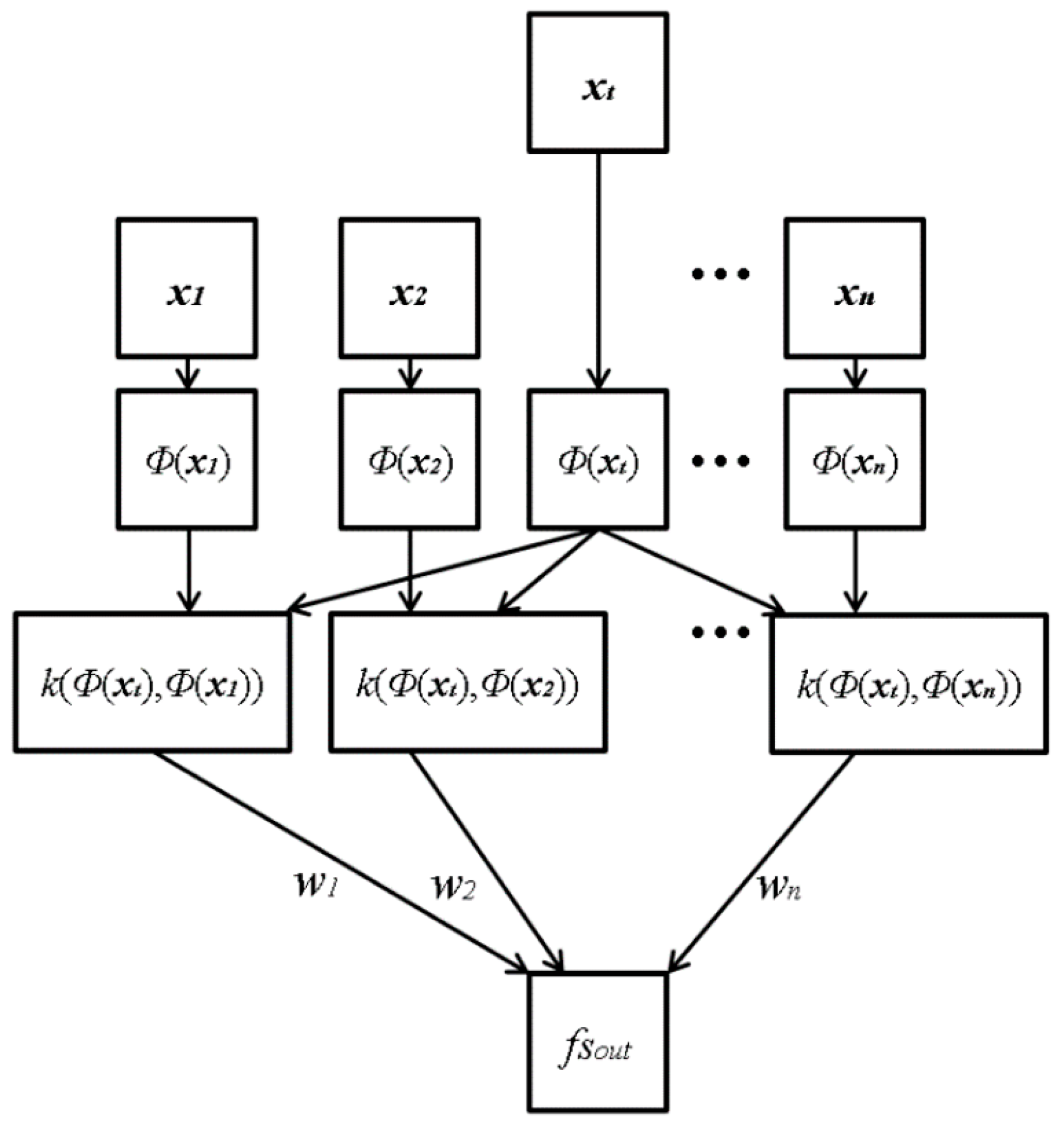
Figure 7 shows the proposed architecture of ε-SVR with RBF. The input vectors,
xt, consist of four elements, which are the focus scores obtained by four individual methods: Daugman’s kernel, Kang’s kernel, DWT and HWT. The input vectors (
xi) are mapped through mapping function
Φ(
xi) onto the feature space, where the kernel function RBF can be computed.
Φ(
xi) is used for mapping the input vector (
xt) in low dimension into the vector in high dimension. For example, the input vector in 2 dimensions is transformed into that in 3 dimensions by
Φ(
xi). That is because the possibility of separating the vectors in higher dimensions is greater than those in lower dimensions [
26,
27,
28,
29]. The function of
Φ(
xi) is not determined as one type, such as the sigmoid function, and any kinds of non-linear function can be used. The mapped vectors are sent to the symmetrical Gaussian RBF kernel:
k(
xi,
x) = RBF(
Φ(
xi),
Φ(
x)). Subsequently, the kernel function values are weighted with
wi to calculate the output focus score (
fsout). In the last step, the weighted kernel function values are summed into the value
P (=Σ
i(
wi k(
xi,
x))), and subsequently,
P is passed to the linear combination for the regression estimation
fsout = σ(
P) =
P +
b, where
b is a scalar real value.
The ideal graph of the focus score according to the Z distance should be a linearly-increased one from 125 cm to 140 cm, whereas it should be a linearly-decreased one from 140 cm to 155 cm of
Figure 3 and
Figure 4. Based on this, we determine the desired output for the training of ε-SVR. For example, with the image captured at the position of the Z distance of 125 cm, the desired output is determined as 10, whereas with that of 140 cm, the desired output is determined as 100. In addition, with the image at the position of the Z distance of 155 cm, the desired output is determined as 10. In the ranges from 125 cm to 140 cm and from 140 cm to 155 cm, the desired output is determined based on two linear equations, respectively.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}