Abstract
Recognizing Manchu words can be challenging due to their complex character variations, subtle differences between similar characters, and homographic polysemy. Most studies rely on character segmentation techniques for character recognition or use convolutional neural networks (CNNs) to encode word images for word recognition. However, these methods can lead to segmentation errors or a loss of semantic information, which reduces the accuracy of word recognition. To address the limitations in the long-range dependency modeling of CNNs and enhance semantic coherence, we propose a hybrid architecture to fuse the spatial features of original images and spectral features. Specifically, we first leverage the Short-Time Fourier Transform (STFT) to preprocess the raw input images and thereby obtain their multi-view spectral features. Then, we leverage a primary CNN block and a pair of symmetric CNN blocks to construct a symmetric spectral enhancement module, which is used to encode the raw input features and the multi-view spectral features. Subsequently, we design a feature fusion module via Swin Transformer to fuse multi-view spectral embedding and thereby concat it with the raw input embedding. Finally, we leverage a Transformer decoder to obtain the target output. We conducted extensive experiments on Manchu words benchmark datasets to evaluate the effectiveness of our proposed framework. The experimental results demonstrated that our framework performs robustly in word recognition tasks and exhibits excellent generalization capabilities. Additionally, our model outperformed other baseline methods in multiple writing-style font-recognition tasks.
1. Introduction
Manchu, once an official language of China, has left an abundance of historical archives in both central and local institutions. The First Historical Archives of China alone preserves more than 200,000 Manchu documents. However, due to the critically endangered status of Manchu (UNESCO, 2009), few individuals remain proficient in the language. Consequently, the development and utilization of these archives lag significantly behind other historical records [1]. Therefore, the development of Manchu recognition systems is crucial for the exploitation of Manchu historical documents and the preservation of the Manchu cultural heritage.
The Manchu writing system shares similarities with Mongolian in its vertical writing style and ligature-based structure. Unlike the Latin and Cyrillic alphabets, where characters maintain consistent forms regardless of their position within a word, Manchu characters change based on their position and context. Some characters have different appearances depending on whether they appear at a word’s beginning, middle, or end, as shown in Figure 1. This position-dependent variation complicates the Manchu writing system. Additionally, the presence of polysemy and mandatory ligature further increases the difficulty of detecting and recognizing Manchu characters.
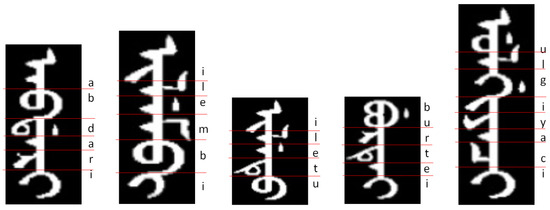
Figure 1.
Manchu words and characters: (1) nominal character (e.g., “a”, “e”, “i”, “r”, “u”). (2) Presentation character (e.g., “i” in “ilembi”, “u” in “iletu” and “ulgiyaci”). (3) Mandatory ligature (e.g., “bu”). (4) Context-sensitive variation (e.g., “e” in “burtei” and “a” in “ulgiyaci”, “b” in “abdari” and “u” in “iletu”).
Manchu character recognition methods [2,3] can work effectively with smaller datasets. Most Manchu words feature a central trunk flanked by left and right strokes. Segmentation-based methods, such as the projection method and the important contour method [4], first identify the vertical axis of the trunk. They then perform horizontal segmentation. These approaches rely on carefully designed feature extraction, image processing, and pattern recognition. However, segmentation-based methods often struggle with accuracy and robustness. Challenges include stroke adhesion, character diversity, and polysemy. Manchu characters are much more complicated than English characters. There are a total of 236 nominal characters, presentation characters, and mandatory ligature [5], so it is difficult to include all the Manchu character usage rules in a data set consisting of only a few hundred words.
The fundamental premise of the Manchu word recognition method is to regard the Manchu word as a cohesive entity. These methods employ neural networks for feature extraction, significantly reducing the reliance on manual design. Convolutional neural networks (CNNs) are widely used for image classification, and some studies have approached the Manchu recognition problem as an image classification task. ResNet and CNNs with Spatial Pyramid Pooling have been employed for Manchu recognition, yielding higher recognition accuracy than segmentation-based methods [6,7]. Recognizing Manchu through image classification requires a large-scale dataset, and the training and validation sets must comprehensively cover the usage rules of Manchu characters to ensure robust generalization. Given that Manchu is a pinyin script, it is nearly impossible for the dataset to encompass all Manchu words. Additionally, while CNNs are effective in extracting local image features, such as strokes, shapes, and details, through convolutional processing, their localized convolutional kernels limit their ability to capture long-range contexts and global dependencies.
In contrast, the self-attention mechanism used in Transformers and the recursive architecture of Long Short-Term Memory Networks (LSTMs) excel at modeling long-range dependencies, demonstrating strong performance in managing long sequences and capturing semantic relationships. Researchers have successfully applied LSTMs and Transformer modules to text recognition tasks. For instance, the Transformer-based model TrOCR (Transformer-based Optical Character Recognition) has shown robust performance on the IC3 benchmark dataset, achieving state-of-the-art capabilities in text recognition [8]. However, the features extracted by the Transformer encoder can be influenced by high-frequency signals, which may reduce recognition accuracy for noisy images. Furthermore, the encoder may struggle to produce distinctive encodings for highly similar Manchu characters, limiting its ability to identify subtle differences.
We propose a multi-branch fusion framework based on the Swin Transformer to address the limitations of existing methods. The STFT is employed to convert Manchu word images into spectral features, facilitating the extraction of diverse information patterns. The overall architecture employs a three-branch parallel structure: two symmetric CNN blocks process horizontal and vertical spectral features, respectively, while a third CNN branch is dedicated to processing the original image. Subsequently, the outputs from the two spectral features branches are fused by a Swin Transformer, and the resulting features are then concatenated with those from the main CNN branch. This combined feature representation is finally fed into a Transformer decoder to achieve global feature integration and learn high-quality embeddings.
Our principal contributions can be summarized as follows.
- We propose a novel multi-path architecture based on the CNN and Transformer framework for Manchu recognition. The primary branch processes the raw image to extract spatial features, while two additional branches perform directional spectral analysis through horizontal and vertical STFT decomposition.
- We propose a cross-fusion module that integrates features from the three branches. This module effectively combines information across different domains.
- We created a dataset of single-font and multi-font Manchu words for use by other researchers (https://github.com/zy691/Manchu-Recognition (accessed on 24 August 2025)).
2. Related Work
2.1. Segmentation-Based Recognition Methods
Most Manchu characters resemble Mongolian characters, and their recognition methods are highly similar. Early research on Manchu recognition primarily relied on segmentation-based algorithms. The process involves splitting Manchu words into individual characters, recognizing those characters, and then reconstructing the full words from the sequences.
Traditional Manchu recognition techniques used handcrafted feature extraction, classical image processing, and pattern recognition. These methods included stroke classification by statistical patterns or segmentation-based recognition using image processing. Examples include the improved projection method [3,9], the multi-feature integration approach [10] (combining projection, chain code, endpoints, and intersections), and deep learning-based methods [11,12].
The segmentation-based recognition method relies heavily on precise segmentation, as any errors in this process can directly result in recognition failure. Furthermore, these methods identify characters by isolating them from Manchu words, which causes a loss of semantic information associated with the characters within the context of the words. Although these methods have achieved some success, their accuracy and robustness are more susceptible to the complexities of Manchu characters, including issues like stroke stacking, font variation, and semantic nuances.
2.2. Segmentation-Free Recognition Methods
To overcome the limitations of segmentation-based recognition methods, researchers are increasingly turning to neural networks to recognize entire words directly. The main idea behind these approaches is to treat each Manchu word as a single, inseparable entity, which redefines the text recognition challenge as a large-scale image classification problem [4]. For thousands of Manchu-word pure images, traditional CNN models, such as VGG, ResNet, and GoogleNet, can achieve classification results with an accuracy rate of over 99% [7]. However, their effectiveness significantly decreases when dealing with degraded images, multi-font images, or images that were not included in their training data. Due to the unique challenges associated with Manchu recognition, researchers have proposed several improved models to enhance performance. Li et al. implemented a spatial pyramid pooling layer in place of the last max-pooling layer in a CNN to recognize the arbitrary size of Manchu words and improve the recognition accuracy to 97.68% [6]. Zhang et al. employed CNN to recognize an image covered by a sliding window to identify Manchu words, with the recognition accuracy reaching 98.84% on the test set of 671 Manchu words [13]. Zheng et al. implemented a nine-layer CNN to recognize multi-font Manchu words, achieving accuracy rates of 88% to 95% across different fonts [14].
The Manchu language is written in a pinyin script [15], which makes it challenging for traditional word recognition methods based on classification to accommodate all Manchu words. Consequently, recent studies have shifted their focus toward developing word recognition methods that utilize sequence models and attention mechanisms [16]. Ren et al. proposed an EGA model that incorporates ECA-Net, a BiGRU encoder with an attention mechanism, and a BiLSTM decoder. By utilizing data augmentation techniques during training, EGA achieved a handwriting recognition accuracy of 89.33% for Mongolian [17]. Cui et al. proposed a TAMN model, which utilizes a spatial transformation network to correct deformation, employs gated recursive convolutional layers combined with triplet attention to extract features, and utilizes MoGrafter LSTM with attention decoding for sequence prediction, achieving a recognition accuracy of 90.30% for Mongolian deformed images [18]. Zhang et al. proposed a segmentation-free method that treats Mongolian word recognition as a sequence-to-sequence mapping problem, utilizing an attention-based LSTM model to directly convert images into text letters, with an average recognition accuracy of 89.3% across four different printed fonts in Mongolian [19]. Sun et al. introduced a method that processes word images using a CNN feature extractor and feeds the features to a Transformer for prediction, achieving an average recognition accuracy of 94.57% for four different printed Mongolian fonts [20]. Recognizing handwritten, deformed, or multi-font words presents challenges. In these cases, sequence-based LSTMs or Transformers provide superior contextual understanding and flexibility.
3. Methodology
Figure 2 shows the overall architecture of our proposed framework. The preprocessing module begins by applying a STFT to the original Manchu image to extract its spectral features along the horizontal and vertical axes. These features are then fed into a symmetric spectral encoding enhancement module, which processes them through two separate spectral feature encoders. Concurrently, a main encoder processes the original Manchu image as the third branch. The features output from the two spectral feature encoders are subsequently fused using a Swin Transformer block. Finally, this fused result is concatenated with the features from the main encoder to generate a decoding vector, which is then processed by a Transformer decoder to output the final character position encoding.
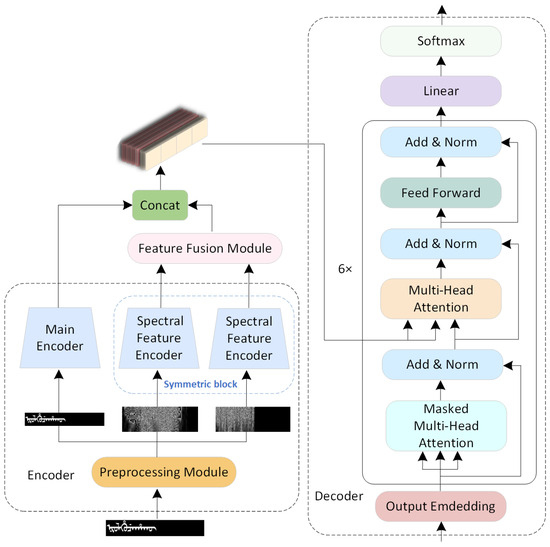
Figure 2.
The overall architecture of our proposed framework.
3.1. Preprocessing Module
A Manchu word image, denoted as I, is a matrix of size , . For the non-standard raw image of a Manchu word, it is first resized to the same width and then filled to a uniform height.
Resize: scales (expands/reduces) and fills the input image to the desired dimensions.
The cursive nature of the Manchu script, characterized by heavily interconnected strokes, poses a significant challenge for character segmentation. To address this, we propose the use of the Short-Time Fourier Transform (STFT). STFT is adept at extracting localized spectral features from continuous signals, which can effectively represent the subtle variations and transitions within the Manchu strokes, thereby providing a robust basis for their differentiation and recognition.
To perform the Short-Time Fourier Transform on Manchu word images, the images are initially converted into one-dimensional sequences, either in rows or columns, as shown in Figure 3. Let be a real-symmetric preprocessing window function. represents the Short-Time Fourier Transform coefficient of a one-dimensional sequence at the time frame , with multiple analyzed frequencies, where the total number of frequencies is L.
where are the starting positions of each sliding window, M is the maximum number of sliding windows, and f is a multiple of .
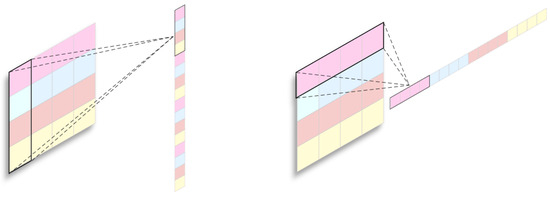
Figure 3.
One-dimensional sequences of images rearranged in two ways: vertically or horizontally.
The Short-Time Fourier Transform of a word image, denoted as , is defined as the modulus of the complex number.
is a matrix of size , . The two spectral features are denote as and , respectively.
3.2. Symmetric Spectral Encoding Enhancement Module
The performance of image classification can be enhanced by employing various subnetworks to extract spatial and spectral features, which are then fused together [21,22,23,24]. Inspired by this approach, this paper utilizes multiple subnetworks to encode image and spectral features separately. Given that some Manchu characters are symmetrical either vertically or horizontally, the spectral features in these directions alone cannot effectively distinguish between the symmetrical characters. Therefore, this paper improves feature discrimination capability by integrating spectral features from two directions using a symmetric spectral encoding enhancement module.
Figure 4 shows a framework that uses CNNs as encoders. The inputs for the three encoders are I, , and , respectively. The outputs from the main encoder and the symmetric spectral encoding enhancement module, which are O, , and , respectively, are all sequences. Specifically, , , , where N is the sequence length; C, , and are the channel numbers of each respective sequence.
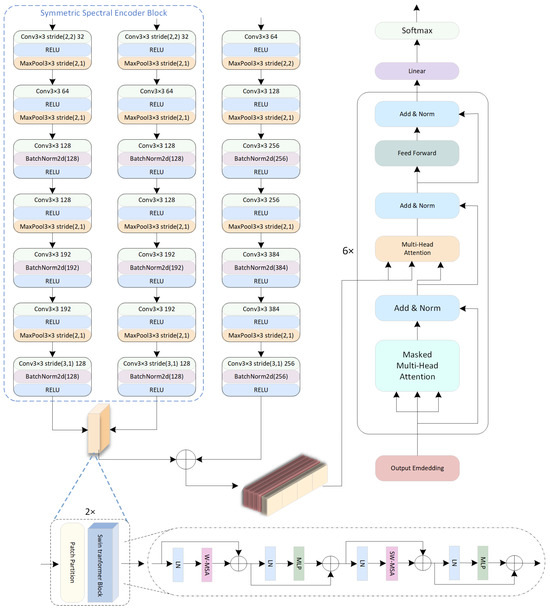
Figure 4.
Multi-path CNN encoder.
Each encoder contains seven consecutive CNN modules with specialized operations: For the spatial branch :
For the spectral branches :
The architecture displays three key distinctions between branches: (1) The spatial branch maintains full resolution, while the spectral branches utilize stride(2,2) downsampling in their initial layer. (2) All branches alternate between BatchNorm-after-Conv and Conv-after-BatchNorm patterns for odd/even modules. (3) The second module universally incorporates MaxPool2x1 with stride(2,1) for dimension reduction while preserving the horizontal structure critical for Manchu’s vertical writing system. This design simultaneously captures spatial textures and multi-view spectral features via specialized pathway configurations.
3.3. Feature Fusion Module
The Swin Transformer [25] has demonstrated remarkable success in various computer vision tasks [26,27], particularly in handling high-resolution images and multi-scale features [28,29]. Inspired by its effectiveness, this study employs the Swin Transformer for feature fusion. This choice is motivated by the unique characteristics of the Manchu script, where the shape of a single letter is heavily influenced by its adjacent letters, introducing significant long-range dependencies. Conventional adaptive feature fusion methods, with their limited receptive fields, often struggle to capture such complex contextual relationships and are susceptible to interference when integrating spatial and spectral features. The self-attention mechanism within the Swin Transformer, however, is specifically designed to model these long-range dependencies, making it an ideal solution to overcome the aforementioned limitations.
The core component of the feature fusion module is a Swin Transformer block. The Swin Transformer block consists of two key modules: the Window Multi-head Self-Attention Mechanism (W-MSA) and the Shifted Window Multi-head Self-Attention Mechanism (SW-MSA). The input to this block is a fused feature, denoted as , which is generated by fusing and from the symmetric spectral encoding module.
Denote the result of the patch embedding of as , . is divided into non-overlapping windows, with each window processed by windowed multi-head self-attention:
where the window attention mechanism is computed as follows:
The multi-head attention operation combines h attention heads through
With each attention head calculated as follows:
where , , and project queries, keys, values for head i, maintains constant compute across heads, and combines head outputs.
Alternating layers apply a half-window shift ( pixels vertically) to capture cross-window dependencies:
Processed by shifted window attention:
Each Swin Transformer block sequentially applies
The output of the Swin Transformer block is a sequence, . This output () is then concatenated with the main encoder’s output to form the final production, , , which serves as the input for the decoder.
3.4. Transformer Decoder Module
The Transformer decoder has powerful sequence modeling capabilities [30,31]. The fused features from the Swin Transformer module are processed through a 6-layer Transformer decoder architecture. We made a critical modification to the standard decoder by removing the positional encoding entirely. This design choice is motivated by the unique characteristics of the Manchu script. The script lacks positional invariance—identical characters exhibit different morphological forms depending on their position within a word (initial, medial, or final positions). Conventional positional encoding may increase recognition error rates for Manchu text. The decoder processes the Transformer’s fused features through
where each of these layers contains multi-head self-attention (MHA), a feed-forward network (FFN), and layer normalization (LayerNorm).
4. Experiment
4.1. Manchu Datasets
This study used two datasets for model evaluation.
Dataset 1: A single-font dataset containing 130,917 words in the Abkai font [32].
Dataset 2: A multi-font dataset comprising 1570 words from 11 different fonts. We used the KaikKi Manchu Dictionary, which includes 2395 Manchu words and phrases [7], and removed the phrases to generate the second dataset from the remaining words using a Python2.0 program. The twelve fonts used in both datasets are displayed in Figure 5.

Figure 5.
The Manchu word “niyalma” in twelve fonts.
Our dataset is composed of Dataset 1 and Dataset 2, which together contain a total of 12 fonts and 148,187 Manchu images.
We randomly selected 90,000 Manchu words from the single-font dataset and divided them into a training set of 50,000 words, including all words with a character length of less than 4, and a test set of 40,000 words. Both sets contain the same collection of Manchu characters as described in [5]. Manchu characters are written in three different formats: initial, medial, and final, depending on their position in the word. The distribution of nominal characters and mandatory ligatures at the beginning, middle, and end of the word is illustrated in Figure 6.
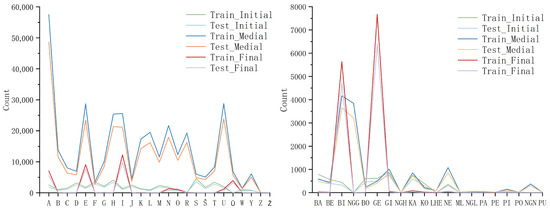
Figure 6.
Distribution statistics of nominal characters (left) and mandatory ligature (right) in different positions across test and training sets.
Despite the differences between the test and training sets, Figure 6 illustrates that the character distribution is similar. This suggests that both datasets adhere to the same character usage rules. Furthermore, the 130,917-word dataset reflects character usage rules that align with the training and test sets.
From the multi-font dataset comprising 17,270 images, we randomly selected approximately 14,000 images (around 80%) as the training set, with the remainder used as the test set.
4.2. Data Enhancements
To improve model resilience to document deformations and quality variations, we implemented two augmentation techniques:
Random Rotation enhances robustness to skewed text by applying a randomly selected angle constrained to to each pixel in Manchu images, thereby ensuring characters remain intact and simulating real-world applications.
where are original coordinates and are transformed coordinates. Bilinear interpolation computes the rotated pixel value using four neighboring points:
where , , , and are the values of the four neighbors of the target point . We calculate the value of the target point.
The weights and are calculated based on the horizontal and vertical distances between and its neighbors. This two-stage interpolation first processes horizontal then vertical axes:
Gaussian Blur addresses quality degradation from lighting and document wear. The Gaussian kernel with standard deviation is
Convolution with a kernel implements the blur:
where are kernel weights and are neighboring pixel values. This preserves stroke boundaries while reducing noise, which is particularly beneficial for historical documents.
4.3. Implementation Details
In our experiment, a Manchu word is represented by , where denotes the ith character. When X is input to the Transformer decoder, we encode it as
where denotes the start token vector, denotes the 32-float one-hot vector of , denotes the end token vector, denotes the th zero vector, and N denotes the maximum word length.
The output from the Transformer decoder is encoded as follows:
The list of characters used in the experiment is shown in Table 1.

Table 1.
Character index.
The Manchu words in the experimental dataset varied in length from 1 to 22 characters, with an average length of 10.19 characters. Additionally, 95% of the words fell between 5 and 15 characters. Given that the longest word in the dataset is 22 characters, we set the maximum length, N, to 24. The predicted output is a 24 × 32 matrix that is computed by the Softmax function.
where is a vector of the predicted probability for the pth character, and is the element in row p, column i of . The denominator is the sum of the exponentiations of all elements in the pth row of , ensuring that the total sum of the probability is 1.
To align with our model’s architectural design, which inherently integrates a Softmax layer into the Transformer decoder’s output, and to prevent redundant computation, we adopt the Negative Log-Likelihood Loss (NLLLoss) as the optimization objective. The loss function is formulated as follows:
where is the predicted probability of the pth character on the target category.
In our experiment, we adjusted the size of the Manchu word images to 64 × 384 and set the window size to 256, the hop size to 64 in STFT, C to 256, to 128, and to 128. We implemented our model using PyTorch2.0 and trained the network with the Adam optimizer. The training parameters are as follows: the batch size is 8, the learning rate is , the learning rate decay factor is 0.9, and the step size is 5. We trained the model for 60 epochs when using CNNs as the encoder and for 100 epochs when using Swin Transformers as the encoder.
4.4. Evaluation Index
The primary evaluation metric is recognition accuracy, which measures the proportion of correctly identified Manchu words relative to the total number of tested words. TP refers to the count of Manchu words that were accurately recognized. FP represents the count of Manchu words that were incorrectly identified as matches. The recognition accuracy is calculated using the following formula:
The computational efficiency of the proposed model was assessed using two primary metrics: the average inference time per Manchu word () and the average inference time per Manchu character (). These metrics are formally defined by the following equations:
where N is the total number of words, is the processing time for the i-th word, and is the total number of characters of the i-th word.
4.5. Ablation Study
We performed various ablation studies to show the effectiveness of the encoder and decoder in the model. Each alternative network was trained using the same parameters, and the results are shown in Figure 7.
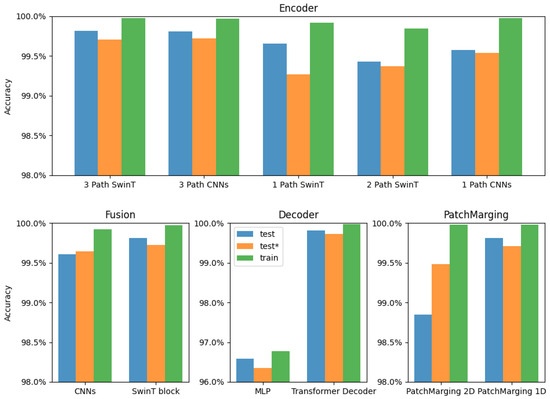
Figure 7.
Ablation study results (* denotes degraded image).
Encoder: We compared the performance of the 3-path Swin Transformer with that of the 3-path CNNs used as encoders. Both methods first converted the three data types into one-dimensional sequences of 192 and then utilized the Swin Transformer block for data fusion. There is only a slight difference in recognition accuracy between the two approaches on both the test and training datasets. When the data is serialized into one-dimensional formats, the Swin Transformer and CNNs can produce similar results.
Path number: We compared the performance of the 3-path Swin Transformer with the standard Swin Transformer, the 2-path Swin Transformer, the 1-path CNNs, and the 3-path CNNs as encoders. The 3-path encoders achieved a higher recognition accuracy on the test dataset. This advantage was particularly pronounced when the test dataset consisted of degraded images. This improvement can be attributed to the richer feature data extracted from the original images, combined with the STFT data processed in both directions.
Fusion: We compared convolutional blocks and Swin Transformer blocks for data fusion in three-path CNNs. The Swin Transformer blocks exhibited notably higher recognition accuracy, particularly with degraded images, due to their effectiveness in modeling long-range dependencies.
Sequences generation methods: We tested two methods for generating sequences in Swin Transformer. The one-dimensional PatchMerging operation is more robust to degraded images than the two-dimensional PatchMerging operation.
Decoder: We compared the performance of the two decoders. The Transformer decoder outperformed the MLP in terms of recognition accuracy and overall convergence.
4.6. Hyperparameter Analysis
We tested the impact of key hyperparameters:
STFT Window Size: Table 2 indicates that n_fft = 2 × W and hop_length = W can achieve a higher recognition accuracy, which is less computationally expensive than n_fft = 4 × W, and the model uses n_fft = 2 × W and hop_length = W to compute STFT.
Table 2.
Hyperparameter study results of the proposed model on Dataset 2 (* denotes degraded image).
Decoder Feature Length: We tested two different decoder feature lengths, and there was only a slight difference in the accuracy of the Transformer decoder for Manchu word recognition at the decoder feature length of 384 and 512.
4.7. Results Analysis
The experimental results are compared with existing Manchu word recognition methods, as shown in Table 3. We trained the model using both single-font and multi-font training datasets. The recognition accuracy on the single-font test dataset was 99.81%, while the accuracy for the test dataset composed of degraded images was 99.71%. When the test dataset was expanded to include 130,917-word samples, the recognition accuracy for degraded images slightly improved to 99.72%. On the multi-font test dataset, the recognition accuracy was 99.75%, with the recognition accuracy for degraded images being 99.69%. These experimental results demonstrate that the model has strong generalization capabilities. However, our model’s inference time is relatively long, with being 0.1753 s and being 0.0306 s.
Table 3.
Comparison of the proposed model with other methods (* denotes degraded image).
The word recognition accuracy of the proposed model is 2.37 percentage points higher than that of the attention-based CRNN method, which has an accuracy of 97.44%, and 0.95 percentage points higher than that of Deep CNN, with an accuracy of 98.87% (using only 671 words). For multi-font recognition, the word recognition accuracy of the proposed model is 4.0 percentage points higher than that of the CNN Transformers model. This demonstrates the robustness of our model in recognizing Manchu words, particularly its stable recognition ability when faced with degraded images and varying writing styles.
The superior performance of our model is attributed to the effective integration of Swin Transformer’s contextual modeling and STFT-based frequency analysis within our multi-branch design. This approach has proven particularly effective in addressing challenges such as positional allomerism and ligature formation, which often hinder traditional recognition systems. Overall, our advancements establish this method as a state-of-the-art solution for archival document processing and real-world Manchu text recognition applications.
5. Discussion
This study shows that the Transformer decoder is suitable for Manchu recognition in extracting semantic features. After training with tens of thousands of words, the architecture combining the encoder and the Transformer decoder yields impressive recognition results. There is only a minor recognition accuracy difference when using CNNs, Swin Transformer, or multi-path Swin Transformer as encoders for clean Manchu word images. For degraded images, the multi-path Swin Transformer or CNN encoder achieves better results. Previous studies have used small datasets or clean images for training, while this study utilized a large-scale collection of degraded images. The experimental results demonstrate that the proposed model achieves outstanding word recognition accuracy for degraded images and multi-font Manchu words.
Table 4 presents the cross-domain recognition results for various fonts. In our multi-font dataset, we selected 10 fonts of Manchu word images for training to recognize Manchu words that were not included in the training. As shown in the table, the model achieved a higher cross-domain recognition accuracy with Manchu text fonts that have a typographic style. In contrast, the accuracy for handwriting-style fonts remained relatively low. This indicates that the model, which was trained using a general training method, has limited capabilities for causal inference.
Table 4.
Cross domain accuracy of the proposed model.
A comparison of recognition errors between CNN and three-path CNN encoders on the single-font test dataset is shown in Figure 8. This paper categorizes the types of errors into five distinct categories:
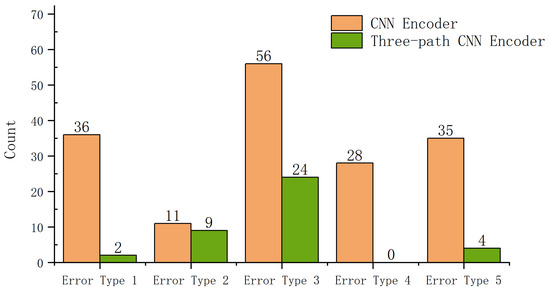
Figure 8.
Comparison of the count of recognition errors between CNN encoders and 3-path CNN encoders.
1. Error Type 1: Duplicate Structural Errors. These errors occur when duplicate characters are incorrectly merged or omitted.
2. Error Type 2: Single-Character Recognition Errors. These refer to mistakes in accurately recognizing individual characters.
3. Error Type 3: Semantic Errors. These errors occur when the recognized word is reasonable in some contexts but incorrect in the specific context; for example, “NA” may be recognized as “A”.
4. Error Type 4: Translation Invariance Errors. These errors arise from the translation invariance characteristic of CNNs.
5. Error Type 5: Other Errors. This category includes errors not covered by the previous types.
The results indicate that the three-path CNN encoder effectively reduces errors associated with translational invariance, addressing the inherent challenges posed by this issue in CNNs. Additionally, the model significantly minimizes recognition errors caused by repetitive structures, demonstrating an enhanced ability to handle the unique repetitive pattern structures in Manchu. However, semantic errors continue to present a major challenge. This suggests that while improvements have been made in structural processing, contextual constraints still lead to semantic errors.
The preservation of historical Manchu documents is challenged by time-induced damage, such as image degradation, creasing, and curling. These physical defects, compounded by the cursive nature of Manchu script, significantly hinder character recognition. While our current model demonstrates a baseline capability, its accuracy on these “extreme” cases needs substantial improvement. Future work will therefore focus on enhancing the model’s generalization to achieve higher recognition rates for damaged documents.
6. Conclusions
This paper presents a novel multi-path hyperarchitecture for recognizing Manchu script, which effectively combines spatial and spectral features. The proposed model employs three parallel paths: one path analyzes spatial features from the original image, while the other two paths process spectral features through dimensionally-specific STFT analysis. This innovative design allows for complementary feature extraction, where the spatial branch captures local structural patterns and the spectral branches model global textural characteristics. By integrating CNN and the Transformer architecture, the model gains significant advantages in modeling long-range dependencies inherent in Manchu’s vertically connected script. This approach effectively addresses challenges related to positional allography and ligature formations. Comprehensive evaluation across multiple dataset scales demonstrates the model’s robust performance, achieving state-of-the-art recognition accuracy while maintaining strong generalization capabilities. The parallel processing framework enhances feature representation for Manchu recognition, establishing a versatile approach that can be adapted to other complex writing systems with similar structural characteristics.
Author Contributions
Conceptualization, Y.Z., M.L., H.Y., J.Y., M.S. and D.W.; methodology, Y.Z., M.L. and J.Y.; software, Y.Z., M.L., H.Y., J.Y. and D.W.; validation, Y.Z., M.L., J.Y., H.Y. and D.W.; formal analysis, Y.Z., M.L. and J.Y.; investigation, Y.Z. and D.W.; resources, Y.Z.; data curation, Y.Z.; writing—original draft preparation, Y.Z. and M.S.; writing—review and editing, Y.Z., J.Y., M.S. and D.W.; visualization, Y.Z. and M.L.; supervision, Y.Z. and D.W.; project administration, D.W.; funding acquisition, D.W. All authors have read and agreed to the published version of the manuscript.
Funding
Scientific Research Project of Education Department of Jilin Province: JJKH20240573KJ.
Data Availability Statement
The data presented in this study is publicly available on GitHub at the following URL: https://github.com/zy691/Manchu-Recognition (accessed on 24 August 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wang, W.; Hu, J.; Wei, H.; Ubul, K.; Fan, W.; Bi, X.; He, J.; Li, Z.; Ding, K.; Jin, L.; et al. Survey on text analysis and recognition for multiethnic scripts. J. Image Graph. 2024, 29, 1685–1713. [Google Scholar] [CrossRef]
- Zhang, G.-y.; Li, J.; Wang, A. A New Recognition Method for the Handwritten Manchu Character Unit. In Proceedings of the 2006 International Conference on Machine Learning and Cybernetics, Dalian, China, 13–16 August 2006; Volume 8, pp. 3339–3344. [Google Scholar] [CrossRef]
- Zheng, R.; Liu, M.; Xu, S.; Huang, Y.; Wang, B. A New Method for Baseline Extraction of Manchu Word. J. Discret. Math. Sci. Cryptogr. 2016, 19, 523–534. [Google Scholar] [CrossRef]
- Huang, D.; Li, M.; Zheng, R.R.; Xu, S.; Bi, J.J. Synthetic data and DAG-SVM classifier for segmentation-free Manchu word recognition. In Proceedings of the 2017 International Conference on Computing Intelligence and Information System (CIIS), Nanjing, China, 21–23 April 2017; Volume 4, pp. 46–50. [Google Scholar] [CrossRef]
- Sile, H.; Jabu, Q.J.; Tao, X. Information Technology Manchu Nominal Characters, Presentation Characters, and Use Rules of Controlling Characters. Available online: https://openstd.samr.gov.cn/bzgk/gb/newGbInfo?hcno=67DA394E47B970F80BBABE5511B9AAE2 (accessed on 24 August 2025).
- Li, M.; Zheng, R.; Xu, S.; Feng, Y.; Hou, D. Manchu Word Recognition Based on Convolutional Neural Network with Spatial Pyramid Pooling. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Cheng, C. Hafumbukū: A Text Recognition Model for the Manchu Script. Bachelor’s Thesis, Harvard College, Cambridge, MA, USA, 2023. Available online: https://dash.harvard.edu/server/api/core/bitstreams/074e5d47-1251-4d40-babf-15d76a357a75/content (accessed on 12 September 2024).
- Li, M.; Lv, T.; Chen, J.; Cui, L.; Lu, Y.; Florencio, D.; Zhang, C.; Li, Z.; Wei, F. TrOCR: Transformer-based optical character recognition with pre-trained models. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 13094–13102. [Google Scholar] [CrossRef]
- Xu, S.; Li, M.; Zheng, R.; Shulman, M. Manchu Character Segmentation and Recognition Method. J. Discret. Math. Sci. Cryptogr. 2016, 20, 43–53. [Google Scholar] [CrossRef]
- Wei, W.; Guo, C. Off-line Manchu character recognition based on multi-classifier ensemble with combination features. Comput. Eng. Des. 2012, 33, 2347–2352. [Google Scholar] [CrossRef]
- Peng, L.; Liu, C.; Ding, X.; Jin, J.; Wu, Y.; Wang, H.; Bao, Y. Multi-font printed Mongolian document recognition system. Int. J. Doc. Anal. Recognit. 2010, 13, 93–106. [Google Scholar] [CrossRef]
- Xu, S.; Qi, G.; Li, M.; Zheng, R.; John, C. An improved Manchu character recognition method. J. Mech. Eng. Res. Dev. 2016, 39, 536–543. [Google Scholar]
- Zhang, D.; Li, Y.; Wang, Z.; Wang, D. OCR with the deep CNN model for ligature script-based languages like Manchu. Sci. Program. 2021, 2021, 5520338. [Google Scholar] [CrossRef]
- Zheng, R.; Liu, M.; Hao, J.; Bao, J.; Wang, B. Segmentation-Free Multi-Font Printed Manchu Word Recognition Using Deep Convolutional Features and Data Augmentation. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Snowberger, A.D.; Lee, C.H. Manchu Script Letters Dataset Creation and Labeling. J. Inf. Commun. Converg. Eng. 2024, 22, 80–87. [Google Scholar] [CrossRef]
- Shi, B.; Bai, X.; Yao, C. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- Ren, Q.-D.-E.-J.; Wang, L.; Ma, Z.; Barintag, S. Offline Mongolian handwriting recognition based on data augmentation and improved ECA-Net. Electronics 2024, 13, 835. [Google Scholar] [CrossRef]
- Cui, S.; Su, Y.; Ji, R.; Ji, Y. An end-to-end network for irregular printed Mongolian recognition. Int. J. Doc. Anal. Recognit. 2022, 25, 41–50. [Google Scholar] [CrossRef]
- Zhang, H.; Wei, H.; Bao, F.; Gao, G. Segmentation-free printed traditional Mongolian OCR using sequence to sequence with attention model. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 11, pp. 585–590. [Google Scholar] [CrossRef]
- Sun, S.; Wang, H.; Wang, Y. A Hybrid Approach Using Convolution and Transformer for Mongolian Ancient Documents Recognition. In Proceedings of the Neural Information Processing: 30th International Conference, ICONIP 2023, Proceedings, Part XIII, Changsha, China, 20–23 November 2023; Volume 1967, pp. 165–176. [Google Scholar] [CrossRef]
- Ren, S.; Zhou, D.; He, S.; Feng, J.; Wang, X. Shunted self-attention via multi-scale token aggregation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; Volume 6, pp. 10843–10852. [Google Scholar] [CrossRef]
- Gu, X.; Wang, L.; Dai, Z.; Chen, Y.; Han, X.; Zhang, Y. AdaFuse: Adaptive Medical Image Fusion Based on Spatial-Frequential Cross Attention. arXiv 2023. [Google Scholar] [CrossRef]
- Li, K.; Li, Y. Lightweight Single-Image Super-Resolution Network Based on Dual Paths. arXiv 2024, arXiv:2409.06590. [Google Scholar] [CrossRef]
- Tan, G.; Wang, R.; Li, F.; Gao, X.; Zhang, L.; Gao, X. Dual-View Spectral and Global Spatial Feature Fusion Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5512913. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z. Swin Transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; Volume 10, pp. 9992–10002. [Google Scholar] [CrossRef]
- Zeng, C.; Sun, C. Swin Transformer with Feature Pyramid Networks for Scene Text Detection of the Secondary Circuit Cabinet Wiring. In Proceedings of the 2022 IEEE 4th International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 29–31 July 2022; pp. 255–258. [Google Scholar] [CrossRef]
- Zhang, B.; Chen, J.; Wen, Q. Single Image Super-Resolution Using Lightweight Networks Based on Swin Transformer. arXiv 2022, arXiv:2210.11019. [Google Scholar] [CrossRef]
- Chen, C.-F.R.; Fan, Q.; Panda, R. CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 347–356. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, Y.; Wang, C.; Xu, H.; Shi, B.; Wang, H. Image Super-Resolution Reconstruction Network Based on Enhanced Swin Transformer via Alternating Aggregation of Local–Global Features. arXiv 2024, arXiv:2401.00241. [Google Scholar] [CrossRef]
- Jing, T.; Liu, C.; Chen, Y. A Lightweight Single-Image Super-Resolution Method Based on the Parallel Connection of Convolution and Swin Transformer Blocks. Appl. Sci. 2025, 15, 1806. [Google Scholar] [CrossRef]
- Li, W.; Liu, Y.; Li, W.; Yang, Y.; Li, J. An Attention-Based Multiscale Transformer Network for Remote Sensing Image Change Detection. ISPRS J. Photogramm. Remote Sens. 2023, 202, 599–609. [Google Scholar] [CrossRef]
- Manchu Dataset. Available online: https://deepwiki.com/tyotakuki/ManchuOCR (accessed on 11 June 2025).
- Wang, Z.; Liu, S.; Wang, M.; Wang, X.; Qu, Y. AMRE: An Attention-Based CRNN for Manchu Word Recognition on a Woodblock-Printed Dataset. In Proceedings of the Neural Information Processing: 29th International Conference, ICONIP 2022, Proceedings, Part II, Virtual, 22–26 November 2022; pp. 267–278. [Google Scholar] [CrossRef]
- Bi, X.; Tao, W.; Chen, Z.; Sun, H. SSC3: A novel structure-connected cognition cube network for Manchu word recognition. Expert Syst. Appl. 2025, 297, 129374. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).