
Orthogonal-Constrained Graph Non-Negative Matrix Factorization for Clustering


Abstract
1. Introduction
2. Preliminaries
2.1. NMF
2.2. NMFOS
2.3. GNMF
3. A New Model
3.1. GNMFOS
| Algorithm 1 GNMFOS |
|
3.2. GNMFOSv2
3.3. Complexity of Algorithms
| Algorithm 2 GNMFOSv2 |
|
4. Experimental Results and Analysis
4.1. Evaluation Indicators and Data Sets
4.2. Comparison Algorithms
- K -means [37]: This algorithm directly performs clustering operations on the original matrices without extracting or analyzing them.
- NMF [29]: This algorithm only directly obtains the factorization of two non-negative matrices without adding any other conditions or constraints.
- ONMF [25]: Building upon NMF, an orthogonal constraint is introduced to the basis matrix or coefficient matrix.
- NMFSC [38]: The algorithm adds sparse representation on NMF, representing the data as a linear combination of a small number of basis vectors.
- GNMF [15]: By integrating graph theory and manifold assumptions with the original NMF, the algorithm extracts the intrinsic geometric structure of the data.
- NMFOS [30]: Building on ONMF, this algorithm incorporates an orthogonal constraint on the coefficient matrix as a penalty term in the objective function.
- NMFOSv2 [36]: This algorithm, based on NMFOS, introduces a small term into the denominator of the update rule formula.
- GNMFOS: Building upon NMFOS, this algorithm incorporates the graph Laplacian term into the objective function.
- GNMFOSv2: Building upon GNMFOS, this algorithm introduces a small term into the denominator of the update rule formula.
4.3. Parameter Settings
4.4. Clustering Results for Image Datasets
4.4.1. Comparison Display on Image Datasets
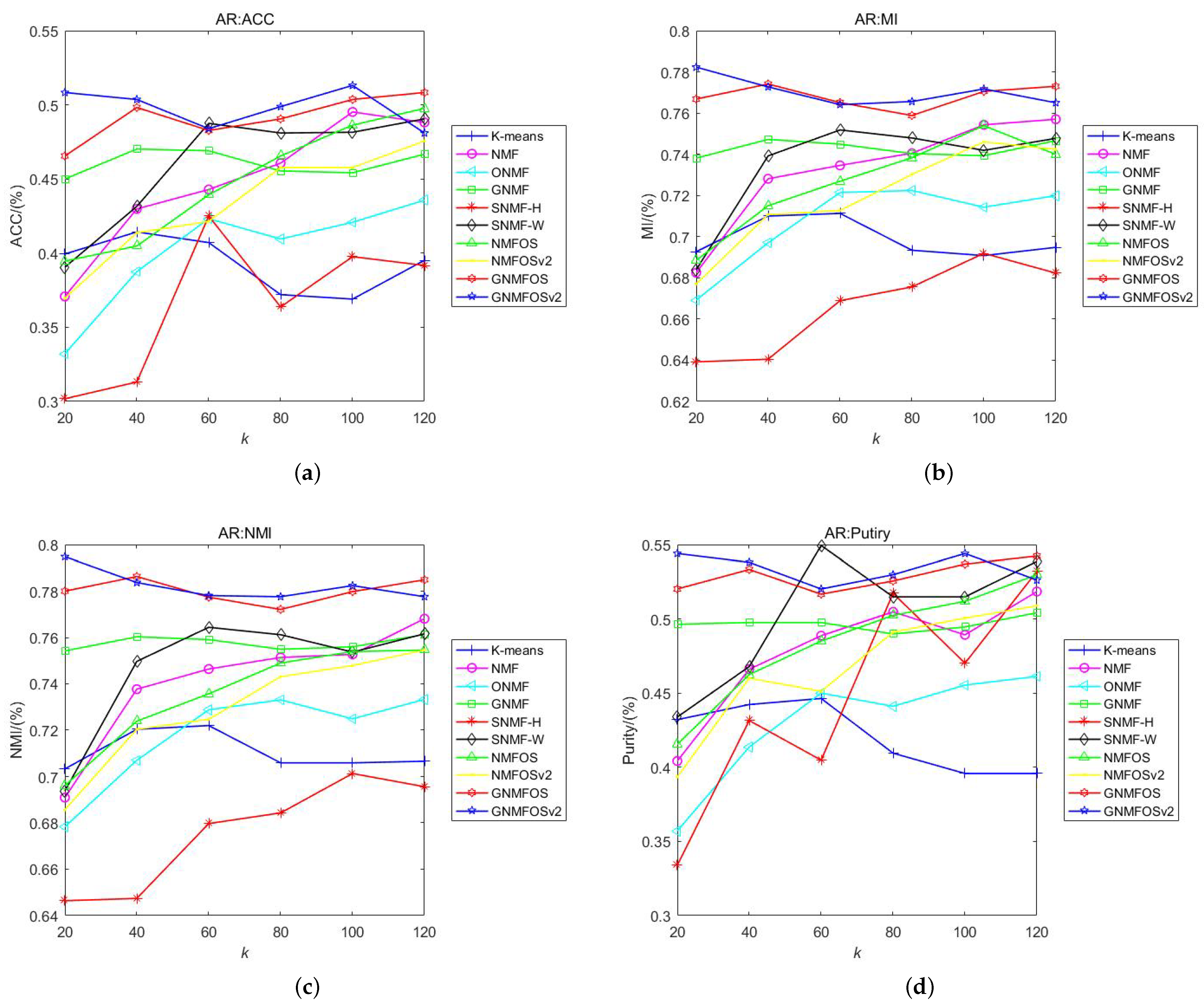
- For indicators of ACC, MI, NMI, and Purity, GNMFOS achieves the highest values at the same clusters’ number in AR dataset, while GNMFOSv2 outperforms GONMF at other cluster numbers. Overall, GNMFOSv2 has the highest clustering indicator values.
- The differences in ACC, MI, NMI, and Purity, as well as their average values, for GNMFOS and GNMFOSv2 are not significant across different cluster numbers K. In contrast, most of other algorithms show larger fluctuations in clustering indicator values at different K. This shows that GNMFOS and GNMFOSv2 exhibit better stability across different cluster numbers, making them more suitable for applications.
- Among the orthogonal-based algorithms, ONMF, NMFOS, NMFOSv2, GNMFOS, and GNMFOSv2, the clustering performance of the proposed GNMFOS and GNMFOSv2 algorithms is the best. This indicates that our algorithms enhance the clustering performance and improve the sparse representation capability based on NMF methods.
- Among the graph Laplacian-based algorithms, GNMFOSv2 and GNMFOS consistently rank among the top two (followed by GNMF). This indicates that our models effectively utilize the hidden geometric structure information in data space.
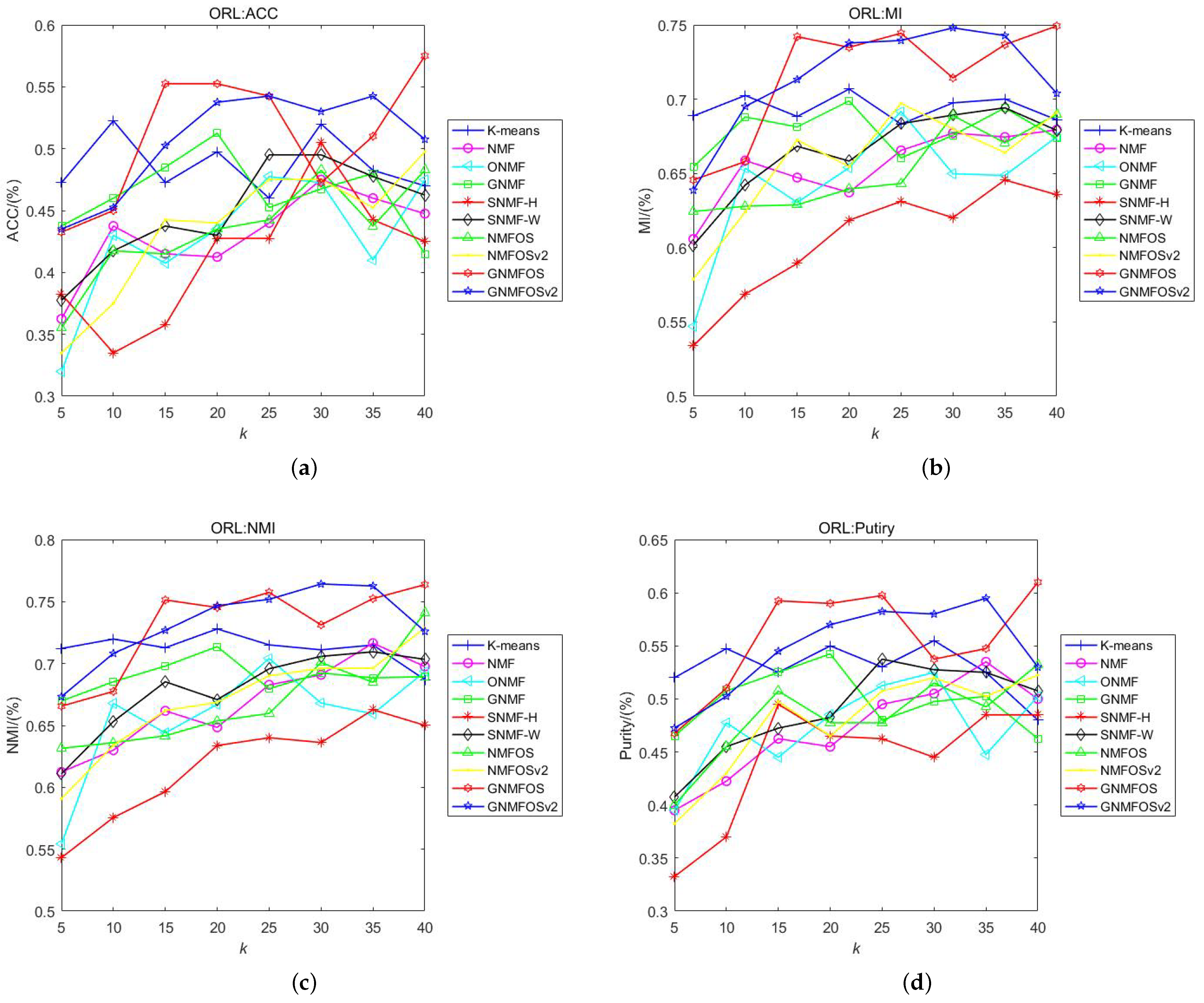
- When K is small (≤10), K-means achieves the highest values in ACC, MI, NMI, and Purity. When K is larger, the GNMFOS and GNMFOSv2 algorithms consistently rank among the top two in terms of the four clustering indicators. This shows that our algorithms are more suitable for larger numbers of clusters in the ORL dataset.
- Overall, GNMFOS has higher average values in ACC, MI, and Purity compared to GNMFOSv2 (NMI is slightly lower than GNMFOSv2), but the differences between GNMFOS and GNMFOSv2 are not significant. This indicates that, for the ORL dataset, GNMFOS is slightly more applicable.
- In terms of ACC, MI, NMI, and Purity, GNMFOS achieves the overall highest values at the same number of clusters . This indirectly indicates that the GNMFOS algorithm is suitable for clustering the dataset into the original classes.
- Among the orthogonal-based algorithms (including ONMF, NMFOS, and NMFOSv2), GNMFOS and GNMFOSv2 exhibit the best clustering performance. This also indicates that our algorithms enhance the clustering performance and improve the sparse representation capability of NMF-based methods.
- Among the graph Laplacian-based algorithms including GNMF, GNMFOS and GNMFOSv2 exhibit the best clustering performance. This also indicates that our models effectively utilize the hidden geometric structure information in data space.
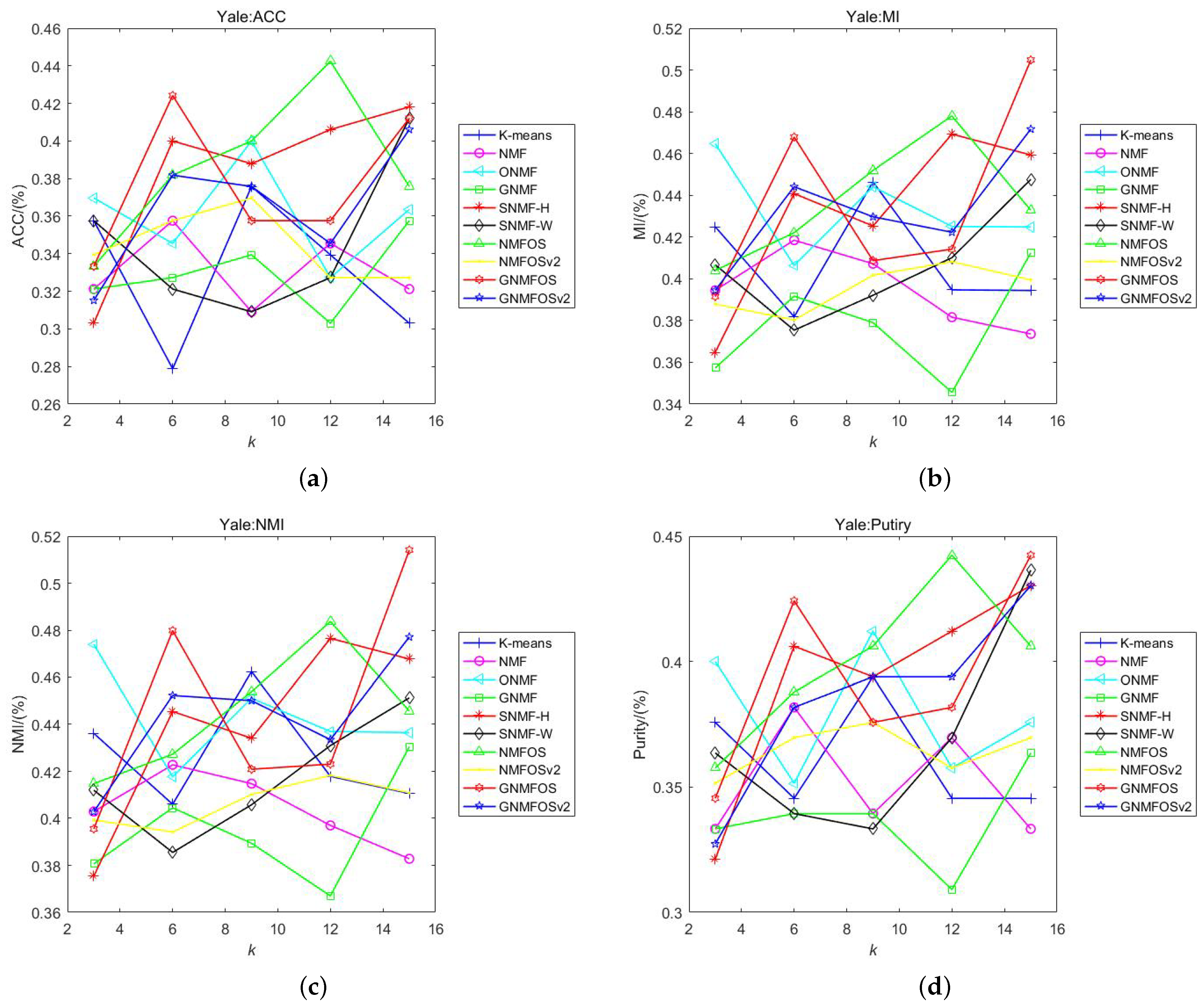
- On the Yale dataset, no algorithm consistently leads in all four clustering indicators, so they need to be discussed separately. For ACC, NMFOS has the highest value (e.g., 0.4424 when ). However, it is worth noting that GNMFOS and GNMFOSv2 do not significantly lag behind NMFOS. Specifically, at , GNMFOS achieves the second-highest rank. For MI, NMFOS also achieves the highest value, but GNMFOS lags behind it by only 0.04%, and GNMFOS attains the overall highest value at , indicating strong competitiveness in MI. For NMI, GNMFOS has the highest value and achieves the overall highest value at . For Purity, NMFOS has the highest value, but GNMFOS attains the overall highest values at and , indicating that GNMFOS is also highly competitive.
- Although in some indicators, the values of NMFOS are slightly higher than those of GNMFOS and GNMFOSv2, these differences are moderate. The results indicate that both the GNMFOS and NMFOS algorithms are viable choices for the Yale dataset.
- For all four clustering indicators at , ONMF has the highest values, indicating that the ONMF algorithm maybe more suitable for smaller K.
- When K increases, the values of ACC, MI, NMI, and Purity for NMFOS do not consistently increase or decrease monotonically. But for GNMFOS, the values of MI and NMI significantly increase. This indicates that our algorithms are more suitable for clustering experiments with larger numbers of clusters on the Yale dataset.
- The orthogonal-based algorithms (ONMF, NMFOS, NMFOSv2, GNMFOS, and GNMFOSv2) exhibit the overall best performance, indicating that algorithms with orthogonality are more suitable for the Yale dataset.
4.4.2. Summary of Analysis on Image Datasets
- In orthogonal-based algorithms, such as ONMF, NMFOS, NMFOSv2, GNMFOS, and GNMFOSv2, they outperform NMF, GNMF, SNMF-H, and SNMF-W algorithms on the Yale dataset. Moreover, on the AR and ORL datasets, GNMFOS and GNMFOSv2 exhibit the best clustering performance among them. In graph Laplacian-based algorithms, such as GNMF, GNMFOS, and GNMFOSv2, their clustering performance is almost superior to other algorithms. This is because graph-based algorithms consider local geometric structures, preserving locality in low-dimensional data space. The GNMFOS and GNMFOSv2 algorithms combine the advantages of orthogonality and graph, enhancing clustering performance and improving the sparse representation capability of NMF based models.
- Due to the various backgrounds in each dataset (e.g., lighting conditions, poses, etc.), the performances of GNMFOS and GNFOSv2 are different. For different feature dimensions, the values of ACC, MI, NMI, and Purity also show slight variations, but the overall performance of GNMFOS and GNFOSv2 remains stable.
- For the Yale dataset, GNMFOS and GNMFOSv2 do not significantly outperform, indicating that orthogonal penalty constraints and graph Laplacian constraints may not necessarily enhance clustering performance in certain situations. Therefore, further research is needed to develop more effective algorithms in the future.
- Considering the results for different clustering numbers K across the three image datasets, the clustering indicators (ACC, MI, NMI, and Purity) of the GNMFOS and GNMFOSv2 algorithms exhibit some fluctuations. However, overall, they outperform algorithms that only have orthogonal or manifold structure constraints, sparse constraints, or no constraints.
4.5. Clustering Results for Document Datasets
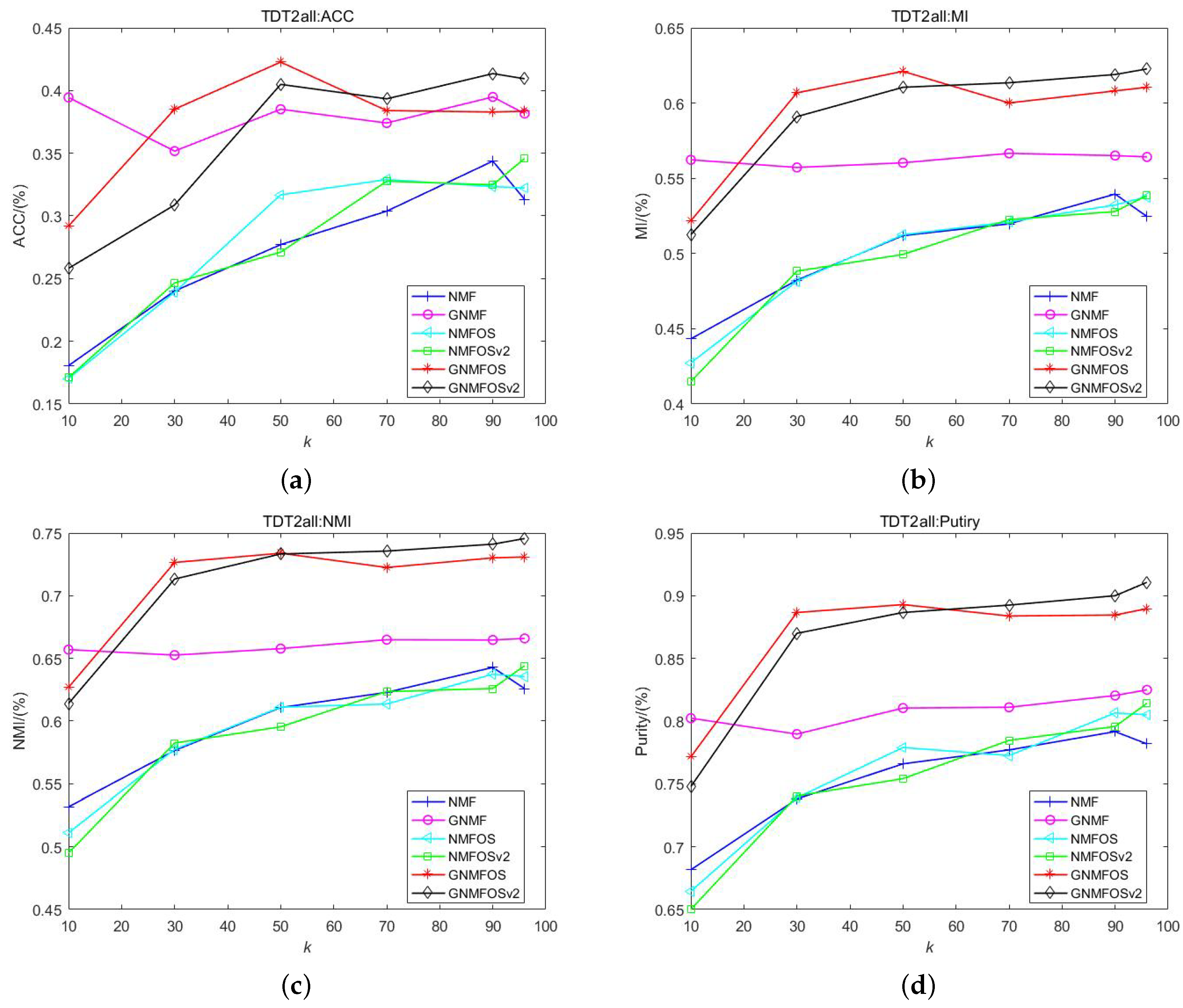
- For the TDT2all dataset, when , GNMFOSv2 achieves the maximum values in ACC, NMI, MI, and Purity; when , GNMFOS achieves the maximum values in ACC, NMI, MI, and Purity; when , GNMF achieves the maximum values in ACC, NMI, MI, and Purity. Although GNMF has the best average performance in the ACC metric, GNMFOS, proposed in this paper, achieves the highest ACC value at , reaching 42.27%. This suggests that GNMFOSv2 is more suitable when the number of clusters is close to the size of the document dataset itself; GNMFOS is more suitable when the number of clusters is moderate; and GNMF is more suitable when the number of clusters is very small. Additionally, GNMFOS ranks first in the average Purity indicator, while GNMFOSv2 ranks first in the average NMI and MI indicators.
- From Figure 4, it can be observed that, for the TDT2all dataset, the clustering performance is relatively optimal when the number of clusters K is set to 50. This suggests that the optimal number of clusters for the TDT2all dataset is 50. Additionally, the GNMF, GNMFOS, and GNMFOSv2 algorithms outperform the NMF, NMGOS, and NMFOSv2 algorithms significantly across all four indicators. This indicates that graph Laplacian-based algorithms can enhance clustering performance for the TDT2all document dataset.
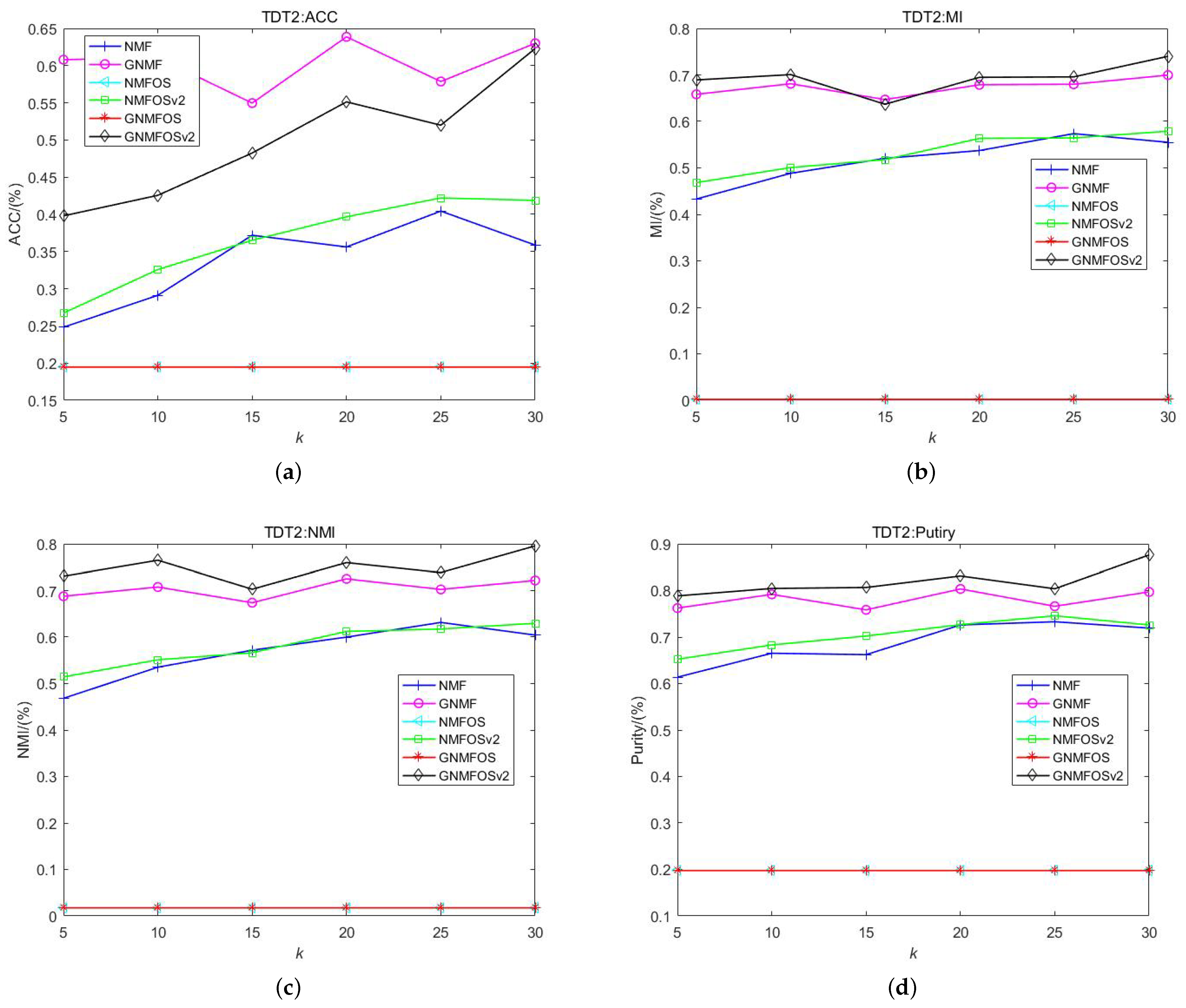
- For the TDT2 dataset, the GNMFOSv2 algorithm achieves the best performance in terms of MI, NMI, and Purity across different numbers of clusters K and their average values. The GNMF algorithm performs better in terms of ACC; however, the ACC values of GNMFOSv2 increase as the number of clusters K increases. Particularly at , the ACC value of GNMFOSv2 is only 0.7% lower than that of the GNMF algorithm. This indicates that when the number of clusters is close to the class structure of the document dataset itself, the GNMFOSv2 algorithm has significant potential in terms of ACC. Combining MI, NMI, and Purity, it can be concluded that the GNMFOSv2 algorithm is more suitable for the TDT2 document dataset when the number of clusters is relatively large.
- Additionally, it is worth nothing that the NMFOS and GNMGOS algorithms exhibit extremely low values in terms of ACC, NMI, MI, and Purity for the TDT2 dataset, and these values do not change with varying numbers of clusters K. This could be due to the zero-locking phenomenon mentioned earlier. In contrast, the NMFOSv2 and GNMFOSv2 algorithms incorporate into their iteration processes, preventing the zero-locking phenomenon. This suggests that the proposed GNMFOSv2 algorithm is practically significant, addressing issues observed in other algorithms.
- However, it is worth noting that no single algorithm consistently outperforms others across all four clustering indicators on the Yale dataset. This reflects the inherent trade-offs among different clustering evaluation metrics and highlights the limitations of current algorithms in achieving uniformly best performance. Such a phenomenon is common in clustering tasks where different metrics emphasize distinct aspects of clustering quality. Future work could focus on developing methods that balance multiple criteria more effectively.
- Considering the results of the two document datasets at different clustering numbers K, it can be concluded that the clustering indicators ACC, MI, NMI, and Purity of the GNMFOS and GNMFOSv2 algorithms exhibit some fluctuations, but overall, these algorithms outperform the other. Therefore, the proposed GNMFOS and GNMFOSv2 algorithms can effectively learn the parts-based representation of the dataset, making them effective for document clustering.
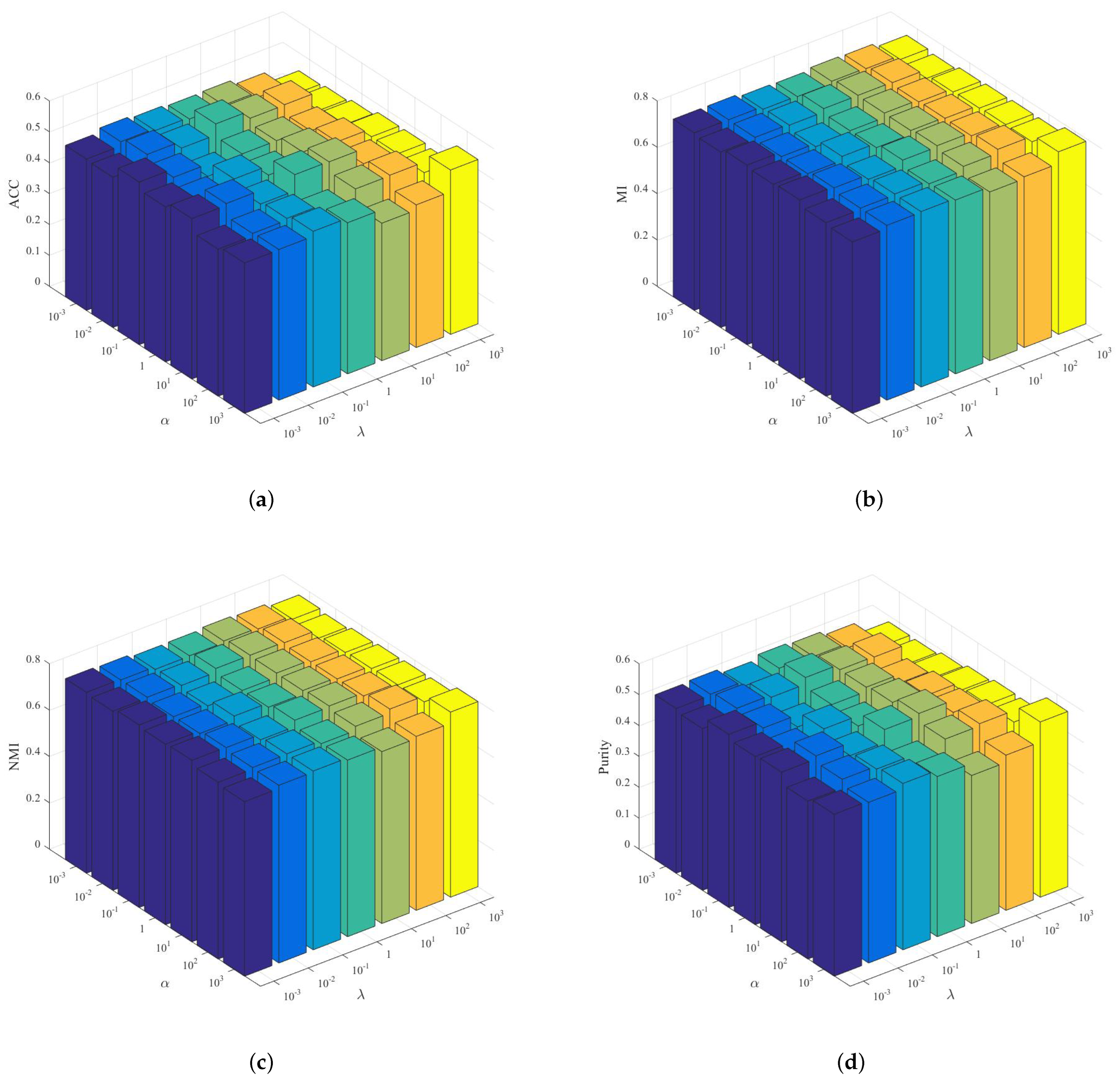
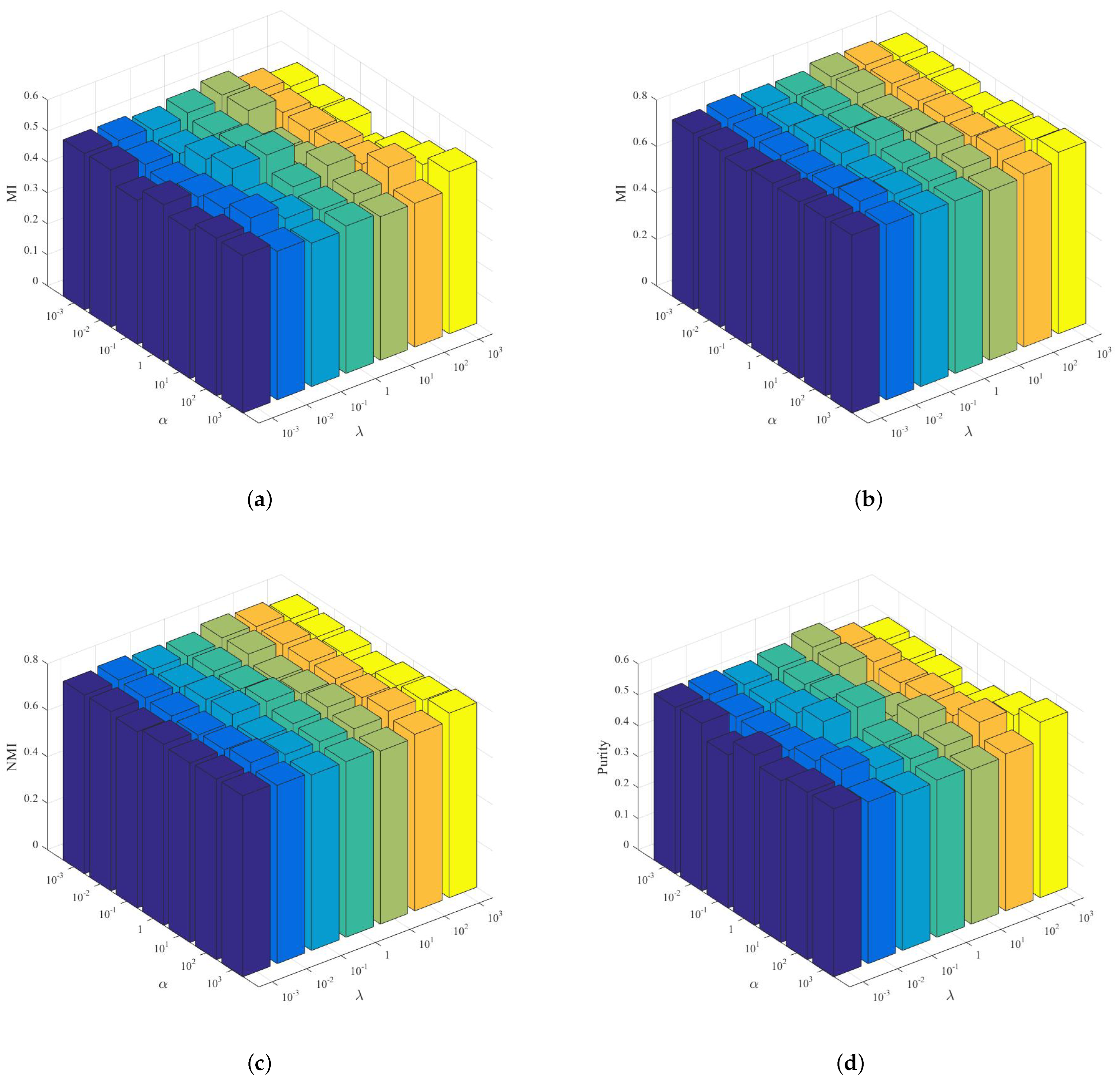
4.6. Parameter Sensitivity
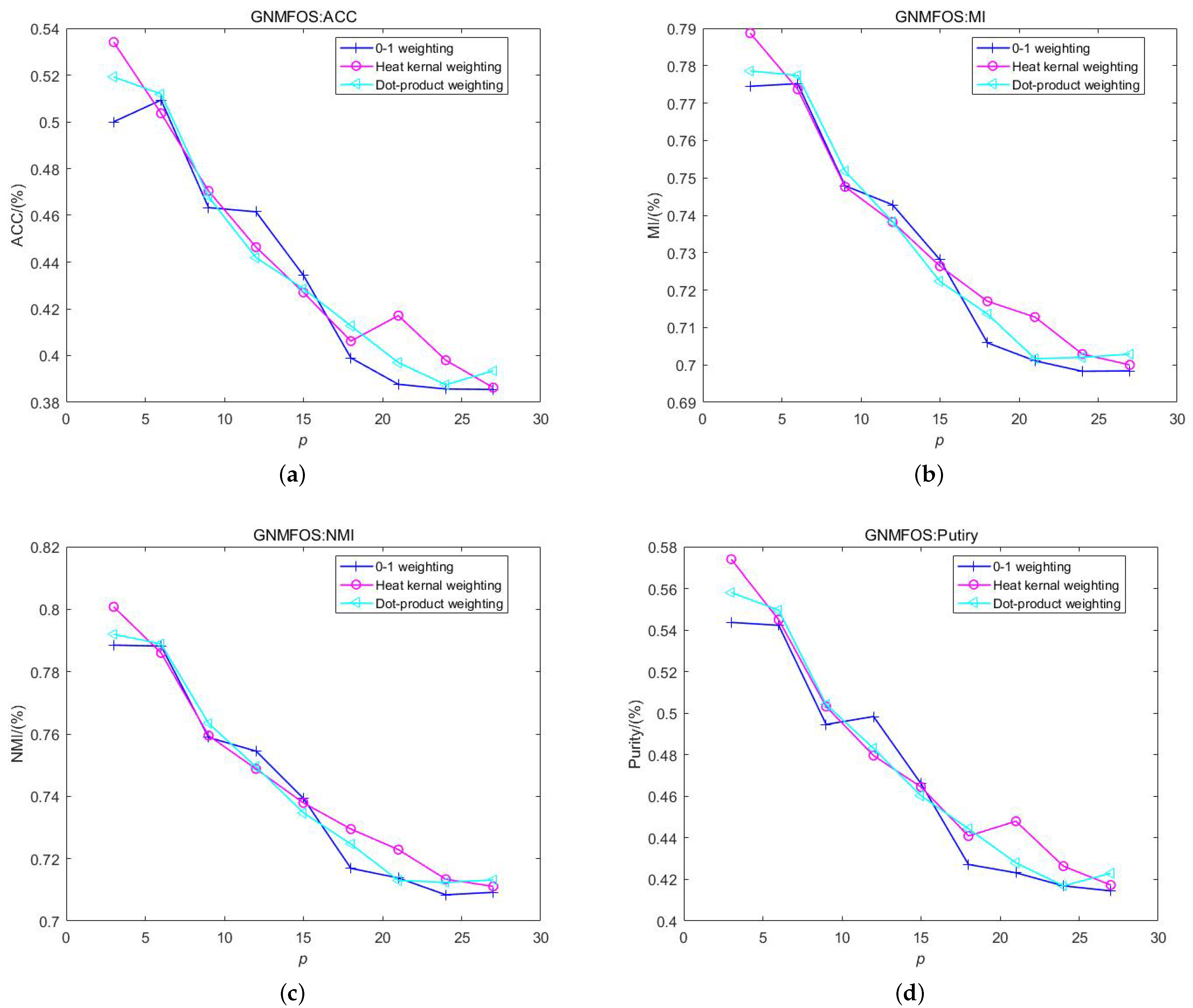
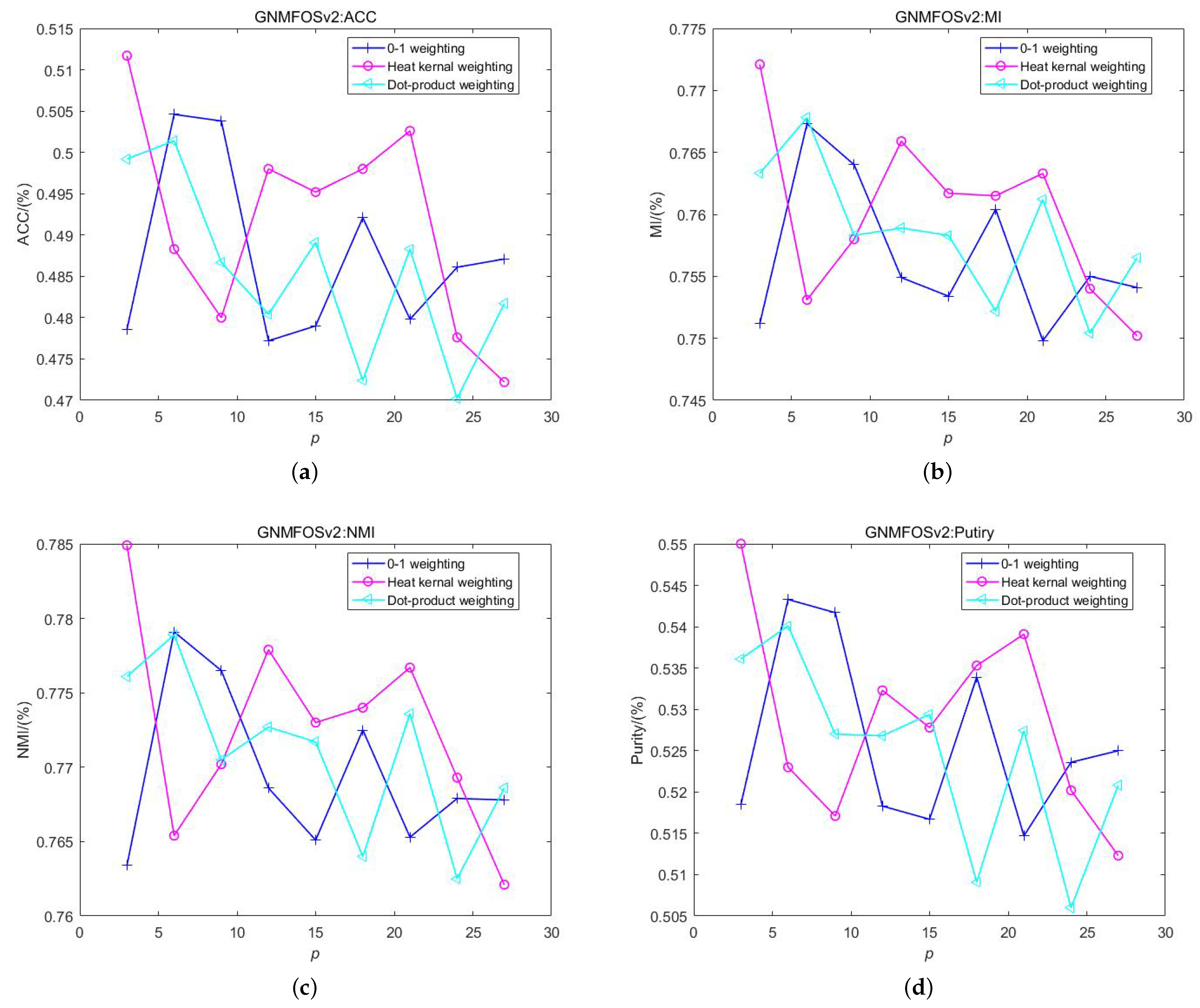
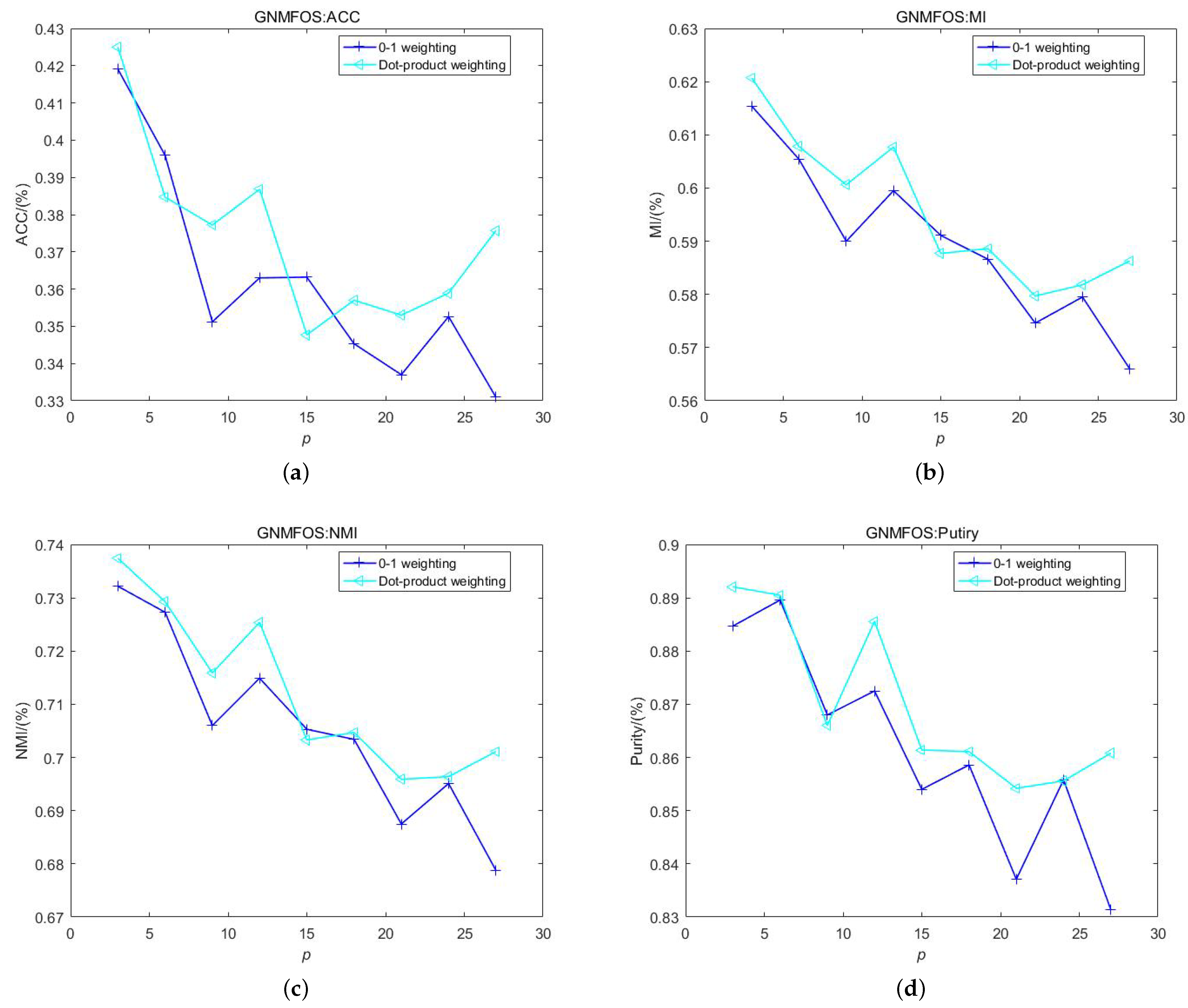
4.7. Weighting Scheme Selection
5. Conclusions
- GNMFOS integrates the strengths of both NMFOS and GNMF by incorporating orthogonality constraints and a graph Laplacian term into the objective function. This enhances the model’s capability in sparse representation, reduces computational complexity, and improves clustering accuracy by leveraging the underlying geometric structure of both data and feature spaces.
- The model supports flexible control over orthogonality and regularization through parameters and , respectively. This makes GNMFOS adaptable to various real-world scenarios.
- Extensive experiments on three image datasets and two document datasets demonstrate the superior clustering performance of GNMFOS and its variant GNMFOSv2. The image experiments show better parts-based feature learning and higher discriminative power, while the document experiments suggest improved semantic structure representation.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Convergence Proof of the Algorithm 1
References
- Devarajan, K. Nonnegative matrix factorization: An analytical and interpretive tool in computational biology. PLoS Comput. Biol. 2008, 4, e1000029. [Google Scholar] [CrossRef] [PubMed]
- Gao, Z.; Wang, Y.T.; Wu, Q.W.; Ni, J.C.; Zheng, C.H. Graph regularized l2, 1-nonnegative matrix factorization for mirna-disease association prediction. BMC Bioinform. 2020, 21, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Liu, Z.; Pu, J.; Song, B. Adaptive graph regularized nonnegative matrix factorization for data representation. Appl. Intell. 2020, 50, 438–447. [Google Scholar] [CrossRef]
- Gillis, N.; Glineur, F. A multilevel approach for nonnegative matrix factorization. J. Comput. Appl. Math. 2012, 236, 1708–1723. [Google Scholar] [CrossRef]
- Hoyer, P.O. Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 2002, 5, 457–469. [Google Scholar]
- Wang, D.; Lu, H. On-line learning parts-based representation via incremental orthogonal projective non-negative matrix factorization. Signal Process. 2013, 93, 1608–1623. [Google Scholar] [CrossRef]
- Berry, M.W.; Browne, M.; Langville, A.N.; Pauca, V.P.; Plemmons, R.J. Algorithms and applications for approximate nonnegative matrix factorization. Comput. Stat. Data Anal. 2007, 52, 155–173. [Google Scholar] [CrossRef]
- Pauca, V.P.; Piper, J.; Plemmons, R.J. Nonnegative matrix factorization for spectral data analysis. Linear Algebra Its Appl. 2006, 416, 29–47. [Google Scholar] [CrossRef]
- Bertin, N.; Badeau, R.; Vincent, E. Enforcing harmonicity and smoothness in bayesian non-negative matrix factorization applied to polyphonic music transcription. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 538–549. [Google Scholar] [CrossRef]
- Zhou, G.; Yang, Z.; Xie, S.; Yang, J.M. Online blind source separation using incremental nonnegative matrix factorization with volume constraint. IEEE Trans. Neural Netw. 2023, 22, 550–560. [Google Scholar] [CrossRef] [PubMed]
- Fan, F.; Jing, P.; Nie, L.; Gu, H.; Su, Y. SADCMF: Self-Attentive Deep Consistent Matrix Factorization for Micro-Video Multi-Label Classification. IEEE Trans. Multimed. 2024, 26, 10331–10341. [Google Scholar] [CrossRef]
- Chen, D.; Li, S.X. An augmented GSNMF model for complete deconvolution of bulk RNA-seq data. Math. Biosci. Eng. 2025, 22, 988. [Google Scholar] [CrossRef] [PubMed]
- Xi, L.; Li, R.; Li, M.; Miao, D.; Wang, R.; Haas, Z. NMFAD: Neighbor-aware mask-filling attributed network anomaly detection. IEEE Trans. Inf. Forensics Secur. 2024, 20, 364–374. [Google Scholar] [CrossRef]
- Chen, X.; Wang, J.; Huang, Q. Dynamic Spectrum Cartography: Reconstructing Spatial-Spectral-Temporal Radio Frequency Map via Tensor Completion. IEEE Trans. Signal Process. 2025, 73, 1184–1199. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Han, J.; Huang, T.S. Graph regularized nonnegative matrix factorization for data representation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1548–1560. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.; Choi, K.S.; Wang, P.; Jiang, Y.; Wang, S. Convex nonnegative matrix factorization with manifold regularization. Neural Netw. 2015, 63, 94–103. [Google Scholar] [CrossRef] [PubMed]
- Meng, Y.; Shang, R.; Jiao, L.; Zhang, W.; Yuan, Y.; Yang, S. Feature selection based dual-graph sparse non-negative matrix factorization for local discriminative clustering. Neurocomputing 2018, 290, 87–99. [Google Scholar] [CrossRef]
- Long, X.; Lu, H.; Peng, Y.; Li, W. Graph regularized discriminative non-negative matrix factorization for face recognition. Multimed. Tools Appl. 2014, 72, 2679–2699. [Google Scholar] [CrossRef]
- Shang, F.; Jiao, L.; Wang, F. Graph dual regularization non-negative matrix factorization for co-clustering. Pattern Recognit. 2012, 45, 2237–2250. [Google Scholar] [CrossRef]
- Che, H.; Li, C.; Leung, M.; Ouyang, D.; Dai, X.; Wen, S. Robust hypergraph regularized deep non-negative matrix factorization for multi-view clustering. IEEE Trans. Emerg. Top. Comput. Intell. 2025, 9, 1817–1829. [Google Scholar] [CrossRef]
- Yang, X.; Che, H.; Leung, M.; Liu, C.; Wen, S. Auto-weighted multi-view deep non-negative matrix factorization with multi-kernel learning. IEEE Trans. Signal Inf. Pract. 2025, 11, 23–34. [Google Scholar] [CrossRef]
- Liu, C.; Li, R.; Che, H.; Leung, M.F.; Wu, S.; Yu, Z.; Wong, H.S. Beyond euclidean structures: Collaborative topological graph learning for multiview clustering. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 10606–10618. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Zhang, X.; Zheng, S.; Li, D. Semi-supervised convex nonnegative matrix factorizations with graph regularized for image representation. Neurocomputing 2017, 237, 1–11. [Google Scholar] [CrossRef]
- Li, S.Z.; Hou, X.W.; Zhang, H.J.; Cheng, Q.S. Learning spatially localized, parts-based representation. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Ding, C.; Li, T.; Peng, W.; Park, H. Orthogonal nonnegative matrix t-factorizations for clustering. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 126–135. [Google Scholar]
- Li, S.; Li, W.; Hu, J.; Li, Y. Semi-supervised bi-orthogonal constraints dual-graph regularized nmf for subspace clustering. Appl. Intell. 2022, 52, 227–3248. [Google Scholar] [CrossRef]
- Liang, N.; Yang, Z.; Li, Z.; Han, W. Incomplete multi-view clustering with incomplete graph-regularized orthogonal non-negative matrix factorization. Appl. Intell. 2022, 52, 14607–14623. [Google Scholar] [CrossRef]
- Zhang, X.; Xiu, X.; Zhang, C. Structured joint sparse orthogonal nonnegative matrix factorization for fault detection. IEEE Trans. Instrum. Meas. 2023, 72, 1–15. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Wu, X.; Peng, H. Nonnegative matrix factorization on orthogonal subspace. Pattern Recognit. Lett. 2010, 31, 905–911. [Google Scholar] [CrossRef]
- Peng, S.; Ser, W.; Chen, B.; Sun, L.; Lin, Z. Robust nonnegative matrix factorization with local coordinate constraint for image clustering. Eng. Appl. Artif. Intell. 2020, 88, 103354. [Google Scholar] [CrossRef]
- Tosyali, A.; Kim, J.; Choi, J.; Jeong, M.K. Regularized asymmetric nonnegative matrix factorization for clustering in directed networks. Pattern Recognit. Lett. 2019, 125, 750–757. [Google Scholar] [CrossRef]
- Guo, J.; Wan, Z. A modified spectral prp conjugate gradient projection method for solving large-scale monotone equations and its application in compressed sensing. Math. Probl. Eng. 2019, 2019, 5261830. [Google Scholar] [CrossRef]
- Li, T.; Wan, Z. New adaptive barzilai–borwein step size and its application in solving large-scale optimization problems. ANZIAM J. 2019, 61, 76–98. [Google Scholar]
- Lv, J.; Deng, S.; Wan, Z. An efficient single-parameter scaling memoryless broyden-fletcher-goldfarb-shanno algorithm for solving large scale unconstrained optimization problems. IEEE Access 2020, 8, 85664–85674. [Google Scholar] [CrossRef]
- Mirzal, A. A convergent algorithm for orthogonal nonnegative matrix factorization. J. Comput. Appl. Math. 2014, 260, 149–166. [Google Scholar] [CrossRef]
- Wang, J.; Wang, J.; Ke, Q.; Zeng, G.; Li, S. Fast approximate k-means via cluster closures. In Multimedia Data Mining and Analytics: Disruptive Innovation; Springer: Berlin/Heidelberg, Germany, 2015; pp. 373–395. [Google Scholar]
- Hoyer, P.O. Non-negative sparse coding. In Proceedings of the 12th IEEE Workshop on Neural Networks for Signal Processing, Martigny, Switzerland, 6 September 2002; pp. 557–565. [Google Scholar]
- Lee, D.D.; Seung, H.S. Algorithms for non-negative matrix factorization. Adv. Neural Inf. Process. Syst. 2000, 13, 535–541. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Description |
|---|---|
| The set of all natural numbers | |
| The set of all nonnegative matrices with | |
| X | Input nonnegative data matrix |
| W | The basis matrix |
| H | The coefficient matrix |
| M | The number of data features(or denoted as data dimension) |
| N | The number of data instances(or denoted as data points) |
| K | The number of data clusters |
| i | Elements in the sets |
| j | Elements in the sets |
| k | Elements in the sets |
| Frobenius norm | |
| The trace operator | |
| L | The graph Laplacian operators of the data manifold |
| S | The weighted matrix |
| D | The diagonal matrices with |
| p | The size of nearestneighbors |
| I | The identity matrix |
| The penalty parameter for controlling orthogonality | |
| The regularization parameter | |
| Lagrange multiplier |
| K | K-Means | NMF | ONMF | GNMF | SNMF-H | SNMF-W | NMFOS | NMFOSv2 | GNMFOS | GNMFOSv2 |
|---|---|---|---|---|---|---|---|---|---|---|
| ACC | ||||||||||
| 20 | 0.3994 | 0.3708 | 0.3321 | 0.4500 | 0.3018 | 0.3905 | 0.3946 | 0.3696 | 0.4655 | 0.5083 |
| 40 | 0.4143 | 0.4298 | 0.3875 | 0.4702 | 0.3131 | 0.4315 | 0.4048 | 0.4137 | 0.4982 | 0.5036 |
| 60 | 0.4071 | 0.4429 | 0.4232 | 0.4690 | 0.4250 | 0.4875 | 0.4393 | 0.4214 | 0.4827 | 0.4839 |
| 80 | 0.3720 | 0.4607 | 0.4095 | 0.4554 | 0.3637 | 0.4810 | 0.4655 | 0.4577 | 0.4905 | 0.4988 |
| 100 | 0.3690 | 0.4952 | 0.4208 | 0.4542 | 0.3976 | 0.4815 | 0.4863 | 0.4577 | 0.5036 | 0.5131 |
| 120 | 0.3952 | 0.4881 | 0.4357 | 0.4667 | 0.3917 | 0.4905 | 0.4976 | 0.4756 | 0.5083 | 0.4810 |
| Avg. | 0.3929 | 0.4479 | 0.4015 | 0.4609 | 0.3655 | 0.4604 | 0.4480 | 0.4326 | 0.4915 | 0.4981 |
| MI | ||||||||||
| 20 | 0.6927 | 0.6825 | 0.6692 | 0.7381 | 0.6392 | 0.6839 | 0.6885 | 0.6770 | 0.7668 | 0.7823 |
| 40 | 0.7100 | 0.7281 | 0.6970 | 0.7472 | 0.6405 | 0.7392 | 0.7150 | 0.7107 | 0.7741 | 0.7727 |
| 60 | 0.7113 | 0.7346 | 0.7214 | 0.7449 | 0.6689 | 0.7518 | 0.7269 | 0.7127 | 0.7651 | 0.7641 |
| 80 | 0.6934 | 0.7405 | 0.7224 | 0.7403 | 0.6756 | 0.7479 | 0.7383 | 0.7302 | 0.7588 | 0.7656 |
| 100 | 0.6908 | 0.7543 | 0.7143 | 0.7393 | 0.6919 | 0.7419 | 0.7539 | 0.7460 | 0.7705 | 0.7717 |
| 120 | 0.6948 | 0.7570 | 0.7199 | 0.7466 | 0.6823 | 0.7477 | 0.7399 | 0.7424 | 0.7730 | 0.7650 |
| Avg. | 0.6988 | 0.7328 | 0.7074 | 0.7428 | 0.6664 | 0.7354 | 0.7271 | 0.7198 | 0.7681 | 0.7702 |
| NMI | ||||||||||
| 20 | 0.7033 | 0.6909 | 0.6783 | 0.7542 | 0.6464 | 0.6938 | 0.6961 | 0.6857 | 0.7800 | 0.7948 |
| 40 | 0.7204 | 0.7377 | 0.7070 | 0.7603 | 0.6474 | 0.7497 | 0.7239 | 0.7204 | 0.7863 | 0.7837 |
| 60 | 0.7220 | 0.7464 | 0.7288 | 0.7591 | 0.6797 | 0.7644 | 0.7357 | 0.7247 | 0.7774 | 0.7781 |
| 80 | 0.7059 | 0.7514 | 0.7331 | 0.7549 | 0.6843 | 0.7612 | 0.7490 | 0.7431 | 0.7721 | 0.7776 |
| 100 | 0.7059 | 0.7527 | 0.7249 | 0.7560 | 0.7013 | 0.7537 | 0.7539 | 0.7479 | 0.7798 | 0.7824 |
| 120 | 0.7066 | 0.7681 | 0.7333 | 0.7613 | 0.6956 | 0.7616 | 0.7546 | 0.7546 | 0.7849 | 0.7776 |
| Avg. | 0.7107 | 0.7412 | 0.7176 | 0.7576 | 0.6758 | 0.7474 | 0.7355 | 0.7294 | 0.7801 | 0.7824 |
| Purity | ||||||||||
| 20 | 0.4321 | 0.4042 | 0.3571 | 0.4964 | 0.3339 | 0.4339 | 0.4155 | 0.3935 | 0.5202 | 0.5440 |
| 40 | 0.4423 | 0.4661 | 0.4137 | 0.4976 | 0.4315 | 0.4679 | 0.4625 | 0.4601 | 0.5333 | 0.5381 |
| 60 | 0.4464 | 0.4887 | 0.4500 | 0.4976 | 0.4048 | 0.5494 | 0.4851 | 0.4512 | 0.5167 | 0.5202 |
| 80 | 0.4095 | 0.5048 | 0.4411 | 0.4899 | 0.5173 | 0.5149 | 0.5024 | 0.4911 | 0.5256 | 0.5298 |
| 100 | 0.3958 | 0.4893 | 0.4554 | 0.4946 | 0.4702 | 0.5149 | 0.5119 | 0.5006 | 0.5369 | 0.5440 |
| 120 | 0.3958 | 0.5185 | 0.4613 | 0.5042 | 0.5321 | 0.5387 | 0.5298 | 0.5089 | 0.5423 | 0.5262 |
| Avg. | 0.4203 | 0.4786 | 0.4298 | 0.4967 | 0.4483 | 0.5033 | 0.4845 | 0.4676 | 0.5292 | 0.5337 |
| Clusters K | K-Means | NMF | ONMF | GNMF | SNMF-H | SNMF-W | NMFOS | NMFOSv2 | GNMFOS | GNMFOSv2 |
|---|---|---|---|---|---|---|---|---|---|---|
| ACC | ||||||||||
| 5 | 0.4725 | 0.3625 | 0.3200 | 0.4375 | 0.3825 | 0.3775 | 0.3550 | 0.3350 | 0.4325 | 0.4350 |
| 10 | 0.5225 | 0.4375 | 0.4300 | 0.4600 | 0.3350 | 0.4175 | 0.4175 | 0.3750 | 0.4500 | 0.4525 |
| 15 | 0.4725 | 0.4150 | 0.4075 | 0.4850 | 0.3575 | 0.4375 | 0.4150 | 0.4425 | 0.5525 | 0.5025 |
| 20 | 0.4975 | 0.4125 | 0.4350 | 0.5125 | 0.4275 | 0.4300 | 0.4350 | 0.4400 | 0.5525 | 0.5375 |
| 25 | 0.4600 | 0.4400 | 0.4775 | 0.4525 | 0.4275 | 0.4950 | 0.4425 | 0.4750 | 0.5425 | 0.5425 |
| 30 | 0.5200 | 0.4750 | 0.4725 | 0.4675 | 0.5050 | 0.4950 | 0.4825 | 0.4750 | 0.4725 | 0.5300 |
| 35 | 0.4825 | 0.4600 | 0.4100 | 0.4800 | 0.4425 | 0.4775 | 0.4375 | 0.4525 | 0.5100 | 0.5425 |
| 40 | 0.4700 | 0.4475 | 0.4750 | 0.4150 | 0.4250 | 0.4625 | 0.4825 | 0.4975 | 0.5750 | 0.5075 |
| Avg. | 0.4872 | 0.4313 | 0.4284 | 0.4638 | 0.4128 | 0.4491 | 0.4334 | 0.4366 | 0.5109 | 0.5063 |
| MI | ||||||||||
| 5 | 0.6887 | 0.6058 | 0.5470 | 0.6543 | 0.5339 | 0.6016 | 0.6243 | 0.5788 | 0.6456 | 0.6387 |
| 10 | 0.7025 | 0.6587 | 0.6535 | 0.6880 | 0.5688 | 0.6422 | 0.6279 | 0.6241 | 0.6580 | 0.6951 |
| 15 | 0.6883 | 0.6472 | 0.6305 | 0.6813 | 0.5894 | 0.6683 | 0.6289 | 0.6725 | 0.7421 | 0.7132 |
| 20 | 0.7068 | 0.6372 | 0.6538 | 0.6988 | 0.6185 | 0.6583 | 0.6395 | 0.6545 | 0.7349 | 0.7378 |
| 25 | 0.6832 | 0.6655 | 0.6917 | 0.6604 | 0.6312 | 0.6835 | 0.6433 | 0.6972 | 0.7444 | 0.7395 |
| 30 | 0.6975 | 0.6772 | 0.6498 | 0.6757 | 0.6202 | 0.6893 | 0.6890 | 0.6800 | 0.7143 | 0.7480 |
| 35 | 0.7001 | 0.6745 | 0.6486 | 0.6941 | 0.6456 | 0.6942 | 0.6706 | 0.6640 | 0.7367 | 0.7428 |
| 40 | 0.6860 | 0.6794 | 0.6747 | 0.6738 | 0.6356 | 0.6790 | 0.6898 | 0.6911 | 0.7493 | 0.7039 |
| Avg. | 0.6941 | 0.6557 | 0.6437 | 0.6783 | 0.6054 | 0.6645 | 0.6517 | 0.6578 | 0.7157 | 0.7149 |
| NMI | ||||||||||
| 5 | 0.7122 | 0.6124 | 0.5543 | 0.6698 | 0.5432 | 0.6109 | 0.6315 | 0.5909 | 0.6656 | 0.6733 |
| 10 | 0.7198 | 0.6300 | 0.6679 | 0.6853 | 0.5756 | 0.6532 | 0.6361 | 0.6339 | 0.6775 | 0.7082 |
| 15 | 0.7128 | 0.6618 | 0.6439 | 0.6980 | 0.5965 | 0.6853 | 0.6417 | 0.6620 | 0.7514 | 0.7269 |
| 20 | 0.7280 | 0.6485 | 0.6671 | 0.7137 | 0.6338 | 0.6709 | 0.6537 | 0.6687 | 0.7453 | 0.7468 |
| 25 | 0.7151 | 0.6828 | 0.7041 | 0.6797 | 0.6401 | 0.6958 | 0.6597 | 0.6902 | 0.7575 | 0.7519 |
| 30 | 0.7111 | 0.6909 | 0.6681 | 0.6924 | 0.6362 | 0.7058 | 0.7008 | 0.6960 | 0.7313 | 0.7643 |
| 35 | 0.7150 | 0.7165 | 0.6593 | 0.6884 | 0.6627 | 0.7095 | 0.6849 | 0.6963 | 0.7525 | 0.7627 |
| 40 | 0.6870 | 0.6976 | 0.6935 | 0.6894 | 0.6501 | 0.7034 | 0.7413 | 0.7288 | 0.7638 | 0.7260 |
| Avg. | 0.7126 | 0.6676 | 0.6573 | 0.6896 | 0.6173 | 0.6794 | 0.6687 | 0.6708 | 0.7306 | 0.7325 |
| Purity | ||||||||||
| 5 | 0.5200 | 0.3950 | 0.3950 | 0.4650 | 0.3325 | 0.4075 | 0.4000 | 0.3825 | 0.4675 | 0.4725 |
| 10 | 0.5475 | 0.4225 | 0.4775 | 0.5075 | 0.3700 | 0.4550 | 0.4550 | 0.4300 | 0.5100 | 0.5025 |
| 15 | 0.5250 | 0.4625 | 0.4450 | 0.5250 | 0.4950 | 0.4725 | 0.5075 | 0.4975 | 0.5925 | 0.5450 |
| 20 | 0.5500 | 0.4550 | 0.4850 | 0.5425 | 0.4650 | 0.4825 | 0.4775 | 0.4650 | 0.5900 | 0.5700 |
| 25 | 0.5300 | 0.4950 | 0.5125 | 0.4800 | 0.4625 | 0.5375 | 0.4775 | 0.5075 | 0.5975 | 0.5825 |
| 30 | 0.5550 | 0.5050 | 0.5250 | 0.4975 | 0.4450 | 0.5275 | 0.5150 | 0.5200 | 0.5375 | 0.5800 |
| 35 | 0.5250 | 0.5350 | 0.4475 | 0.5025 | 0.4850 | 0.5250 | 0.4925 | 0.5025 | 0.5475 | 0.5950 |
| 40 | 0.4800 | 0.5000 | 0.5025 | 0.4625 | 0.4850 | 0.5075 | 0.5325 | 0.5225 | 0.6100 | 0.5300 |
| Avg. | 0.5291 | 0.4713 | 0.4738 | 0.4978 | 0.4425 | 0.4894 | 0.4822 | 0.4784 | 0.5566 | 0.5472 |
| Clusters K | K-Means | NMF | ONMF | GNMF | SNMF-H | SNMF-W | NMFOS | NMFOSv2 | GNMFOS | GNMFOSv2 |
|---|---|---|---|---|---|---|---|---|---|---|
| ACC | ||||||||||
| 3 | 0.3576 | 0.3212 | 0.3697 | 0.3212 | 0.3030 | 0.3576 | 0.3333 | 0.3394 | 0.3333 | 0.3152 |
| 6 | 0.2788 | 0.3576 | 0.3455 | 0.3273 | 0.4000 | 0.3212 | 0.3818 | 0.3576 | 0.4242 | 0.3818 |
| 9 | 0.3758 | 0.3091 | 0.4000 | 0.3394 | 0.3879 | 0.3091 | 0.4000 | 0.3697 | 0.3576 | 0.3758 |
| 12 | 0.3394 | 0.3455 | 0.3273 | 0.3030 | 0.4061 | 0.3273 | 0.4424 | 0.3273 | 0.3576 | 0.3455 |
| 15 | 0.3030 | 0.3212 | 0.3636 | 0.3576 | 0.4182 | 0.4121 | 0.3758 | 0.3273 | 0.4121 | 0.4061 |
| Avg. | 0.3309 | 0.3309 | 0.3612 | 0.3297 | 0.3830 | 0.3455 | 0.3867 | 0.3442 | 0.3770 | 0.3648 |
| MI | ||||||||||
| 3 | 0.4249 | 0.3945 | 0.4647 | 0.3573 | 0.3648 | 0.4067 | 0.4040 | 0.3879 | 0.3915 | 0.3945 |
| 6 | 0.3818 | 0.4185 | 0.4064 | 0.3917 | 0.4408 | 0.3754 | 0.4221 | 0.3803 | 0.4679 | 0.4441 |
| 9 | 0.4464 | 0.4072 | 0.4441 | 0.3790 | 0.4253 | 0.3921 | 0.4519 | 0.4017 | 0.4087 | 0.4297 |
| 12 | 0.3947 | 0.3816 | 0.4251 | 0.3456 | 0.4693 | 0.4101 | 0.4780 | 0.4082 | 0.4142 | 0.4223 |
| 15 | 0.3944 | 0.3736 | 0.4248 | 0.4124 | 0.4593 | 0.4476 | 0.4328 | 0.3995 | 0.5048 | 0.4717 |
| Avg. | 0.4085 | 0.3951 | 0.4330 | 0.3772 | 0.4319 | 0.4064 | 0.4378 | 0.3955 | 0.4374 | 0.4325 |
| NMI | ||||||||||
| 3 | 0.4362 | 0.4029 | 0.4740 | 0.3806 | 0.3754 | 0.4120 | 0.4148 | 0.3993 | 0.3955 | 0.4028 |
| 6 | 0.4060 | 0.4228 | 0.4177 | 0.4045 | 0.4455 | 0.3855 | 0.4273 | 0.3942 | 0.4798 | 0.4523 |
| 9 | 0.4624 | 0.4148 | 0.4511 | 0.3894 | 0.4341 | 0.4058 | 0.4539 | 0.4102 | 0.4209 | 0.4501 |
| 12 | 0.4179 | 0.3970 | 0.4370 | 0.3670 | 0.4765 | 0.4310 | 0.4837 | 0.4183 | 0.4231 | 0.4335 |
| 15 | 0.4106 | 0.3828 | 0.4365 | 0.4305 | 0.4677 | 0.4513 | 0.4457 | 0.4109 | 0.5141 | 0.4771 |
| Avg. | 0.4266 | 0.4040 | 0.4433 | 0.3944 | 0.4399 | 0.4171 | 0.4451 | 0.4066 | 0.4467 | 0.4432 |
| Purity | ||||||||||
| 3 | 0.3758 | 0.3333 | 0.4000 | 0.3333 | 0.3212 | 0.3636 | 0.3576 | 0.3515 | 0.3455 | 0.3273 |
| 6 | 0.3455 | 0.3818 | 0.3515 | 0.3394 | 0.4061 | 0.3394 | 0.3879 | 0.3697 | 0.4242 | 0.3818 |
| 9 | 0.3939 | 0.3394 | 0.4121 | 0.3394 | 0.3939 | 0.3333 | 0.4061 | 0.3758 | 0.3758 | 0.3939 |
| 12 | 0.3455 | 0.3697 | 0.3576 | 0.3091 | 0.4121 | 0.3697 | 0.4424 | 0.3576 | 0.3818 | 0.3939 |
| 15 | 0.3455 | 0.3333 | 0.3758 | 0.3636 | 0.4303 | 0.4364 | 0.4061 | 0.3697 | 0.4424 | 0.4303 |
| Avg. | 0.3612 | 0.3515 | 0.3794 | 0.3370 | 0.3927 | 0.3685 | 0.4000 | 0.3648 | 0.3939 | 0.3855 |
| Clusters K | NMF | GNMF | NMFOS | NMFOSv2 | GNMFOS | GNMFOSv2 |
|---|---|---|---|---|---|---|
| ACC | ||||||
| 10 | 0.1806 | 0.3945 | 0.1703 | 0.1711 | 0.2919 | 0.2582 |
| 30 | 0.2401 | 0.3517 | 0.2391 | 0.2465 | 0.3851 | 0.3087 |
| 50 | 0.2771 | 0.3851 | 0.3168 | 0.2711 | 0.4227 | 0.4049 |
| 70 | 0.3038 | 0.3741 | 0.3290 | 0.3277 | 0.3840 | 0.3934 |
| 90 | 0.3437 | 0.3949 | 0.3234 | 0.3248 | 0.3829 | 0.4135 |
| 96 | 0.3131 | 0.3816 | 0.3223 | 0.3458 | 0.3835 | 0.4094 |
| Avg. | 0.2764 | 0.3803 | 0.2835 | 0.2811 | 0.3750 | 0.3647 |
| MI | ||||||
| 10 | 0.4433 | 0.5623 | 0.4273 | 0.4149 | 0.5217 | 0.5125 |
| 30 | 0.4823 | 0.5572 | 0.4816 | 0.4883 | 0.6068 | 0.5910 |
| 50 | 0.5119 | 0.5603 | 0.5125 | 0.4994 | 0.6211 | 0.6105 |
| 70 | 0.5197 | 0.5666 | 0.5210 | 0.5226 | 0.6001 | 0.6135 |
| 90 | 0.5395 | 0.5651 | 0.5323 | 0.5279 | 0.6081 | 0.6190 |
| 96 | 0.5246 | 0.5642 | 0.5377 | 0.5385 | 0.6105 | 0.6227 |
| Avg. | 0.5036 | 0.5626 | 0.5021 | 0.4986 | 0.5947 | 0.5949 |
| NMI | ||||||
| 10 | 0.5318 | 0.6570 | 0.5111 | 0.4950 | 0.6269 | 0.6140 |
| 30 | 0.5765 | 0.6526 | 0.5774 | 0.5825 | 0.7265 | 0.7133 |
| 50 | 0.6108 | 0.6578 | 0.6111 | 0.5954 | 0.7339 | 0.7333 |
| 70 | 0.6229 | 0.6649 | 0.6136 | 0.6235 | 0.7225 | 0.7356 |
| 90 | 0.6428 | 0.6647 | 0.6374 | 0.6260 | 0.7302 | 0.7411 |
| 96 | 0.6259 | 0.6659 | 0.6355 | 0.6442 | 0.7309 | 0.7456 |
| Avg. | 0.6018 | 0.6605 | 0.5977 | 0.5944 | 0.7118 | 0.7138 |
| Purity | ||||||
| 10 | 0.6817 | 0.8023 | 0.6645 | 0.6501 | 0.7714 | 0.7477 |
| 30 | 0.7380 | 0.7896 | 0.7389 | 0.7404 | 0.8866 | 0.8700 |
| 50 | 0.7659 | 0.8104 | 0.7789 | 0.7541 | 0.8929 | 0.8866 |
| 70 | 0.7770 | 0.8110 | 0.7725 | 0.7846 | 0.8838 | 0.8925 |
| 90 | 0.7916 | 0.8204 | 0.8065 | 0.7957 | 0.8846 | 0.9000 |
| 96 | 0.7818 | 0.8249 | 0.8050 | 0.8142 | 0.8897 | 0.9107 |
| Avg. | 0.7560 | 0.8098 | 0.7611 | 0.7565 | 0.8682 | 0.8679 |
| Clusters K | NMF | GNMF | NMFOS | NMFOSv2 | GNMFOS | GNMFOSv2 |
|---|---|---|---|---|---|---|
| ACC | ||||||
| 5 | 0.2482 | 0.6080 | 0.1947 | 0.2673 | 0.1947 | 0.3980 |
| 10 | 0.2912 | 0.6108 | 0.1947 | 0.3258 | 0.1947 | 0.4256 |
| 15 | 0.3719 | 0.5496 | 0.1947 | 0.3652 | 0.1947 | 0.4825 |
| 20 | 0.3562 | 0.6387 | 0.1947 | 0.3967 | 0.1947 | 0.5513 |
| 25 | 0.4044 | 0.5786 | 0.1947 | 0.4221 | 0.1947 | 0.5199 |
| 30 | 0.3587 | 0.6300 | 0.1947 | 0.4188 | 0.1947 | 0.6230 |
| Avg. | 0.3385 | 0.6026 | 0.1947 | 0.3660 | 0.1947 | 0.5001 |
| MI | ||||||
| 5 | 0.4330 | 0.6583 | 0.0019 | 0.4683 | 0.0019 | 0.6892 |
| 10 | 0.4884 | 0.6810 | 0.0019 | 0.5007 | 0.0019 | 0.7007 |
| 15 | 0.5204 | 0.6469 | 0.0019 | 0.5178 | 0.0019 | 0.6369 |
| 20 | 0.5373 | 0.6788 | 0.0019 | 0.5633 | 0.0019 | 0.6948 |
| 25 | 0.5737 | 0.6799 | 0.0019 | 0.5644 | 0.0019 | 0.6958 |
| 30 | 0.5550 | 0.6996 | 0.0019 | 0.5789 | 0.0019 | 0.7400 |
| Avg. | 0.5180 | 0.6741 | 0.0019 | 0.5322 | 0.0019 | 0.6929 |
| NMI | ||||||
| 5 | 0.4682 | 0.6878 | 0.0174 | 0.5143 | 0.0174 | 0.7309 |
| 10 | 0.5352 | 0.7077 | 0.0174 | 0.5511 | 0.0174 | 0.7648 |
| 15 | 0.5718 | 0.6739 | 0.0174 | 0.5663 | 0.0174 | 0.7029 |
| 20 | 0.5999 | 0.7251 | 0.0174 | 0.6121 | 0.0174 | 0.7597 |
| 25 | 0.6315 | 0.7025 | 0.0174 | 0.6173 | 0.0174 | 0.7384 |
| 30 | 0.6043 | 0.7217 | 0.0174 | 0.6297 | 0.0174 | 0.7956 |
| Avg. | 0.5685 | 0.7031 | 0.0174 | 0.5818 | 0.0174 | 0.7487 |
| Purity | ||||||
| 5 | 0.6137 | 0.7623 | 0.1977 | 0.6523 | 0.1977 | 0.7886 |
| 10 | 0.6652 | 0.7919 | 0.1977 | 0.6831 | 0.1977 | 0.8046 |
| 15 | 0.6622 | 0.7586 | 0.1977 | 0.7022 | 0.1977 | 0.8067 |
| 20 | 0.7261 | 0.8035 | 0.1977 | 0.7267 | 0.1977 | 0.8313 |
| 25 | 0.7330 | 0.7663 | 0.1977 | 0.7459 | 0.1977 | 0.8039 |
| 30 | 0.7193 | 0.7971 | 0.1977 | 0.7260 | 0.1977 | 0.8761 |
| Avg. | 0.6866 | 0.7799 | 0.1977 | 0.7060 | 0.1977 | 0.8185 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Zhao, J.; Chen, Y. Orthogonal-Constrained Graph Non-Negative Matrix Factorization for Clustering. Symmetry 2025, 17, 1154. https://doi.org/10.3390/sym17071154
Li W, Zhao J, Chen Y. Orthogonal-Constrained Graph Non-Negative Matrix Factorization for Clustering. Symmetry. 2025; 17(7):1154. https://doi.org/10.3390/sym17071154
Chicago/Turabian StyleLi, Wen, Junjian Zhao, and Yasong Chen. 2025. "Orthogonal-Constrained Graph Non-Negative Matrix Factorization for Clustering" Symmetry 17, no. 7: 1154. https://doi.org/10.3390/sym17071154
APA StyleLi, W., Zhao, J., & Chen, Y. (2025). Orthogonal-Constrained Graph Non-Negative Matrix Factorization for Clustering. Symmetry, 17(7), 1154. https://doi.org/10.3390/sym17071154