

Symmetry-Guided Dual-Branch Network with Adaptive Feature Fusion and Edge-Aware Attention for Image Tampering Localization

Abstract
1. Introduction
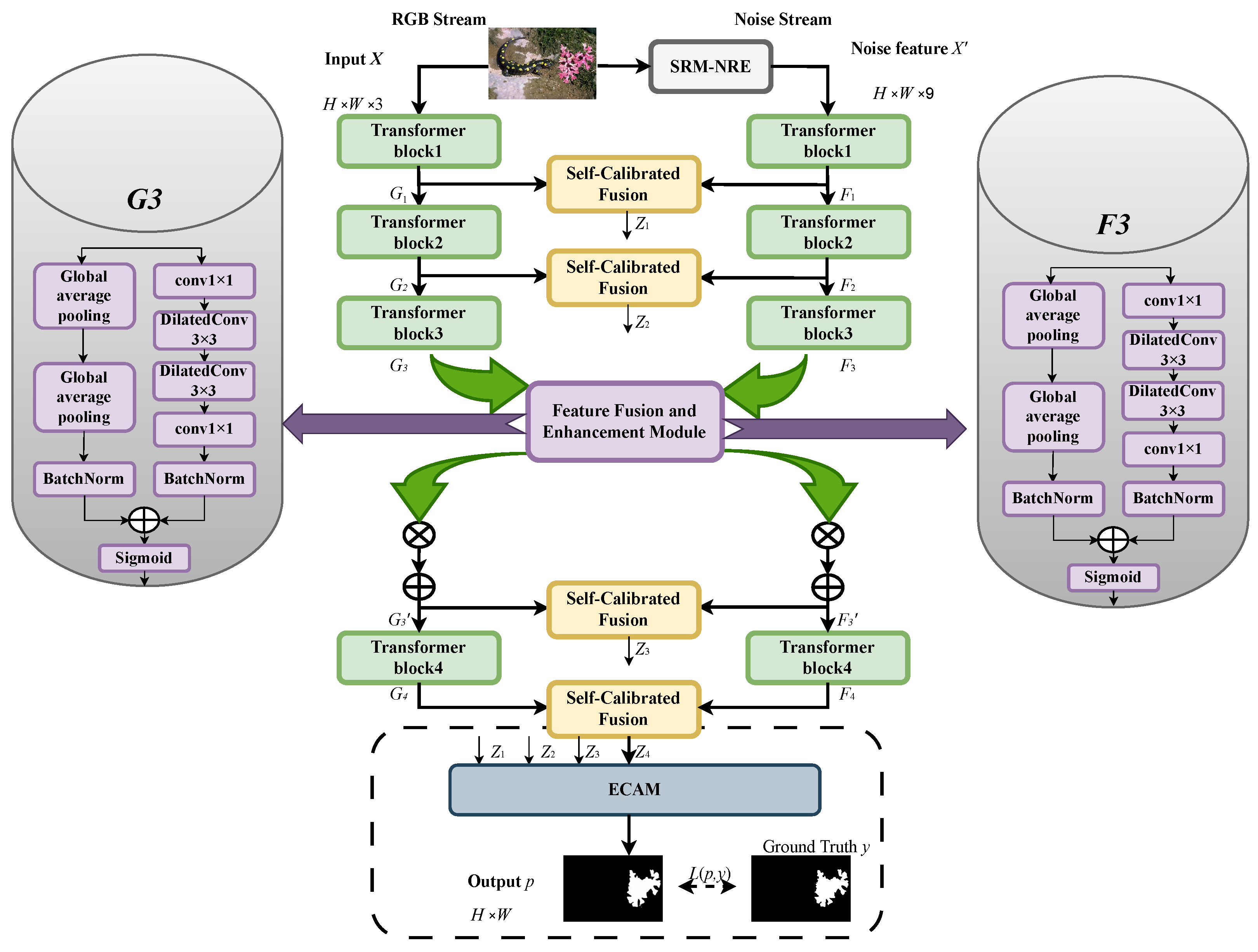
- Symmetrical Dual-Branch Architecture: We designed a dual-branch network featuring a symmetrical structure and complementary functions. The RGB branch extracts semantic features and content-level inconsistencies, while the SRM noise branch focuses on statistical anomalies and tampering artifacts. This architecture enables the model to analyze tampered regions in both the visual and noise domains, significantly enhancing its detection accuracy and robustness against various types of tampering.
- ECAM: An attention module is proposed that combines coordinate attention with edge-awareness. Position-sensitive features are captured through independent pooling operations along horizontal and vertical directions. Additionally, the Sobel operator is employed to extract edge information, effectively enhancing the model’s perception of tampered boundaries and significantly improving feature representation and localization accuracy along edges. This design effectively addresses common issues of blurred and discontinuous boundaries in existing methods.
- SCF: A content-aware dynamic weighting strategy is designed to adaptively fuse RGB semantic features with SRM noise residual features. This approach effectively suppresses redundant information and enhances the model’s robustness and discriminative power in complex tampering scenarios.
- Channel Attention Enhancement Module: A channel attention mechanism based on global context modeling is introduced, integrating dilated convolution and global average pooling to jointly capture features from both the RGB and SRM branches. This mechanism emphasizes informative channels while suppressing irrelevant ones, thereby enhancing the localization accuracy and discriminative capability of features in tampered regions.
2. Related Work
2.1. Traditional Methods and Feature-Driven Strategies
2.2. Image Tampering Localization Method Based on Deep Learning
- Over-reliance on RGB semantic features leads to weakened localization capabilities in texture-consistent, semantically coherent tampering scenarios.
- Lack of boundary perception modeling mechanisms makes it difficult to accurately locate mask edges.
- Insufficient robustness to post-processing operations such as JPEG compression and Gaussian blurring in real complex images.
2.3. Transformer Architecture and Global Modeling Methods
- Lack of a specialized modeling mechanism for image edge structures, resulting in weak response to high-frequency boundary disturbances.
- Highly sensitive to training data scale and computing resources, making it difficult to train adequately on small to medium-sized annotated datasets and prone to overfitting.
2.4. Boundary Modeling and Robustness Study
- Lack of modeling mechanisms specifically targeting tampered boundary areas, resulting in blurred and discontinuous edge localization.
- Insufficient robustness against different types of tampering in complex degraded scenarios, limiting the model’s application in real-world scenarios.
3. Experimental Methods
3.1. Model Overview
3.2. Symmetric Guided Dual-Branch Feature Extraction
3.3. Self-Calibrating Fusion Module
- Achieving dynamic adjustment of the importance of features and effectively reducing the redundancy of information.
- Adaptive fusion based on content, significantly improving the discriminative performance of the model.
- Optimizing the gradient flow process for efficient learning in multi-branch networks.
3.4. Edge-Aware Coordinate Attention Module
- Explicit modeling of spatial positional information rather than focusing solely on inter-channel relationships.
- Introduction of edge structures as prior knowledge to guide the network in strengthening tampered boundary features.
- Adaptive adjustment of feature importance, enabling dynamic focus on key regions based on the input content.
3.5. Loss Function
4. Experimentation and Analysis
4.1. Experimental Setup
- CASIA-v1 [30]: This dataset includes two typical tampering types: copy-move and splicing. The images are of moderate resolution and do not involve post-processing operations such as compression or blurring, making them suitable for evaluating a model’s ability to detect basic tampering operations.
- Columbia [7]: This dataset primarily consists of uncompressed spliced images, where tampering is performed by combining two source images along boundary regions. With high-quality images and minimal artifacts, it serves as a benchmark for assessing baseline detection performance under ideal conditions.
- NIST16 [32]: Released by the National Institute of Standards and Technology (NIST), this dataset simulates real-world, professional-grade tampering scenarios. It includes a variety of complex manipulations—such as compositing, occlusion, and affine transformations—and offers high-resolution images with pixel-level annotations, making it a critical benchmark for evaluating practical performance.
- IMD [33]: Manually constructed, this dataset covers various tampering types, including splicing, copy-move, and inpainting. It is well-suited for assessing the model’s generalization ability and robustness across heterogeneous forgery scenarios.
- DSO [34]: This dataset focuses on small, blurry, and low-contrast tampered regions that are challenging to detect. It simulates difficult visual conditions, such as weak obfuscation and compression artifacts, serving as a valuable supplement for evaluating boundary sensitivity and fine-grained localization capabilities.
- Input format compatibility: A unified input pipeline was constructed to support mainstream image formats (JPG, PNG, TIF), improving the model’s generalizability and deployment flexibility.
- Spatial resolution normalization: All images were resized to a fixed resolution of 512 × 512. For high-resolution inputs, a sliding-window cropping strategy was employed to preserve spatial details while maintaining computational efficiency.
- Pixel normalization and standardization: A two-stage normalization was applied—first linearly scaling pixel values to [0, 1], followed by standardization using ImageNet statistics (μ = [123.675, 116.28, 103.53], σ = [58.395, 57.12, 57.375]) to promote convergence and numerical stability.
- Label binarization: Tampering masks were strictly binarized ({0,1}), and a threshold-based decision was applied to boundary pixels to ensure label accuracy and consistency.
- Geometric transformations: Including random multi-scale resizing (scaling factor in [0.5, 2.0]), random cropping (512 × 512), horizontal flipping (probability 0.5), vertical flipping (probability 0.3), and random rotation within ±15° (probability 0.3), enhancing spatial invariance.
- Quality degradation simulation: Additive Gaussian noise (), Gaussian blur (5 × 5 kernel, probability 0.15), JPEG compression (quality factor in [70, 100], probability 0.5), and brightness/contrast variation (±10/±20%, probability 0.5) were applied to simulate realistic distortions.
4.2. Experimental Parameters
- A fixed-weight design was employed for the SRM filter, reducing the number of trainable parameters by approximately 9%.
- A self-calibrating feature fusion mechanism was introduced to dynamically adjust feature importance, thereby improving resource utilization efficiency.
- For large-sized images, we implemented a 512 × 512 sliding window processing strategy, where weighted fusion is used to effectively eliminate window boundary effects, allowing the model to handle inputs of arbitrary size within limited GPU memory.
4.3. Comparison Experiment
4.4. Ablation Experiment
4.5. Robustness Assessment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guo, K.; Zhu, H.; Cao, G. Effective image tampering localization via enhanced transformer and co-attention fusion. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: New York, NY, USA, 2024; pp. 4895–4899. [Google Scholar]
- Ma, X.; Du, B.; Jiang, Z.; Hammadi, A.Y.A.; Zhou, J. IML-ViT: Benchmarking Image Manipulation Localization by Vision Transformer. arXiv 2023, arXiv:2307.14863. [Google Scholar]
- Chen, X.; Dong, C.; Ji, J.; Cao, J.; Li, X. Image manipulation detection by multi-view multi-scale supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 14185–14193. [Google Scholar]
- Zhai, Y.; Luan, T.; Doermann, D.; Yuan, J. Towards generic image manipulation detection with weakly supervised self-consistency learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 22390–22400. [Google Scholar]
- Pan, X.; Zhang, X.; Lyu, S. Exposing image forgery with blind noise estimation. In Proceedings of the Thirteenth ACM Multimedia Workshop on Multimedia and Security, Buffalo, NY, USA, 29–30 September 2011; pp. 15–20. [Google Scholar]
- Kwon, M.J.; Nam, S.H.; Yu, I.J.; Lee, H.K.; Kim, C. Learning jpeg compression artifacts for image manipulation detection and localization. Int. J. Comput. Vis. 2022, 130, 1875–1895. [Google Scholar] [CrossRef]
- Hsu, Y.F.; Chang, S.F. Detecting image splicing using geometry invariants and camera characteristics consistency. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; IEEE: New York, NY, USA, 2006; pp. 549–552. [Google Scholar]
- Wu, Y.; AbdAlmageed, W.; Natarajan, P. Mantra-net: Manipulation tracing network for detection and localization of image forgeries with anomalous features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9543–9552. [Google Scholar]
- Liu, X.; Liu, Y.; Chen, J.; Liu, X. PSCC-Net: Progressive spatio-channel correlation network for image manipulation detection and localization. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7505–7517. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, Z.; Jiang, Z.; Chaudhuri, S.; Yang, Z.; Nevatia, R. SPAN: Spatial pyramid attention network for image manipulation localization. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 312–328. [Google Scholar]
- Zhu, H.; Cao, G.; Huang, X. Progressive feedback-enhanced transformer for image forgery localization. arXiv 2023, arXiv:2311.08910. [Google Scholar]
- Fridrich, J.; Kodovsky, J. Rich models for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- Popescu, A.C.; Farid, H. Exposing digital forgeries by detecting traces of resampling. IEEE Trans. Signal Process. 2005, 53, 758–767. [Google Scholar] [CrossRef]
- Mahdian, B.; Saic, S. Using noise inconsistencies for blind image forensics. Image Vis. Comput. 2009, 27, 1497–1503. [Google Scholar] [CrossRef]
- Bappy, J.H.; Simons, C.; Nataraj, L.; Manjunath, B.; Roy-Chowdhury, A.K. Hybrid lstm and encoder–decoder architecture for detection of image forgeries. IEEE Trans. Image Process. 2019, 28, 3286–3300. [Google Scholar] [CrossRef]
- Chen, T.; Li, B.; Zeng, J. Learning traces by yourself: Blind image forgery localization via anomaly detection with ViT-VAE. IEEE Signal Process. Lett. 2023, 30, 150–154. [Google Scholar] [CrossRef]
- Zheng, A.; Huang, T.; Huang, W.; Huang, L.; Ye, F.; Luo, H. DSSE-net: Dual stream skip edge-enhanced network with forgery loss for image forgery localization. Int. J. Mach. Learn. Cybern. 2024, 15, 2323–2335. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Zhuo, L.; Tan, S.; Li, B.; Huang, J. Self-adversarial training incorporating forgery attention for image forgery localization. IEEE Trans. Inf. Forensics Secur. 2022, 17, 819–834. [Google Scholar] [CrossRef]
- Yang, C.; Wang, Z.; Shen, H.; Li, H.; Jiang, B. Multi-modality image manipulation detection. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; IEEE: New York, NY, USA, 2021; pp. 1–6. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Luo, X.; Ai, Z.; Liang, Q.; Xie, Y.; Shi, Z.; Fan, J.; Qu, Y. EdgeFormer: Edge-aware Efficient Transformer for Image Super-resolution. IEEE Trans. Instrum. Meas. 2024, 73, 5029312. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wei, Q.; Li, X.; Yu, W.; Zhang, X.; Zhang, Y.; Hu, B.; Mo, B.; Gong, D.; Chen, N.; Ding, D.; et al. Learn to segment retinal lesions and beyond. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: New York, NY, USA, 2021; pp. 7403–7410. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhu, H.; Cao, G.; Zhao, M.; Tian, H.; Lin, W. Effective image tampering localization with multi-scale convnext feature fusion. J. Vis. Commun. Image Represent. 2024, 98, 103981. [Google Scholar] [CrossRef]
- Bappy, J.H.; Roy-Chowdhury, A.K.; Bunk, J.; Nataraj, L.; Manjunath, B. Exploiting spatial structure for localizing manipulated image regions. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4970–4979. [Google Scholar]
- Dong, J.; Wang, W.; Tan, T. Casia image tampering detection evaluation database. In Proceedings of the 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 6–10 July 2013; IEEE: New York, NY, USA, 2013; pp. 422–426. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Guan, H.; Kozak, M.; Robertson, E.; Lee, Y.; Yates, A.N.; Delgado, A.; Zhou, D.; Kheyrkhah, T.; Smith, J.; Fiscus, J. MFC datasets: Large-scale benchmark datasets for media forensic challenge evaluation. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; IEEE: New York, NY, USA, 2019; pp. 63–72. [Google Scholar]
- De Carvalho, T.J.; Riess, C.; Angelopoulou, E.; Pedrini, H.; de Rezende Rocha, A. Exposing digital image forgeries by illumination color classification. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1182–1194. [Google Scholar] [CrossRef]
- Novozamsky, A.; Mahdian, B.; Saic, S. IMD2020: A large-scale annotated dataset tailored for detecting manipulated images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops, Snowmass, CO, USA, 1–5 March 2020; pp. 71–80. [Google Scholar]
- Zhuang, P.; Li, H.; Tan, S.; Li, B.; Huang, J. Image tampering localization using a dense fully convolutional network. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2986–2999. [Google Scholar] [CrossRef]
- Dong, C.; Chen, X.; Hu, R.; Cao, J.; Li, X. Mvss-net: Multi-view multi-scale supervised networks for image manipulation detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3539–3553. [Google Scholar] [CrossRef]
- Wu, H.; Zhou, J.; Tian, J.; Liu, J.; Qiao, Y. Robust image forgery detection against transmission over online social networks. IEEE Trans. Inf. Forensics Secur. 2022, 17, 443–456. [Google Scholar] [CrossRef]
- Cozzolino, D.; Verdoliva, L. Noiseprint: A CNN-based camera model fingerprint. IEEE Trans. Inf. Forensics Secur. 2019, 15, 144–159. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Columbia | CASIAv1 | DSO | NIST | IMD |
|---|---|---|---|---|---|
| Image Count | 160 | 920 | 100 | 564 | 2010 |
| Parameters | Notation | Value |
|---|---|---|
| Batch Size | b | 8 |
| Max Epoch | E | 100 |
| Encoder Learning Rate | 1 × 10−4 for first 5 epochs | |
| Decoder Learning Rate | 1 × 10−6 | |
| Weight Decay | 5 × 10−2 | |
| Momentum Coefficient | 0.9 | |
| Focal Gamma | 2.0 | |
| Focal Alpha | 0.25 |
| Methods | Columbia | CASIAv1 | DSO | NIST | IMD | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | |
| Mantra-Net [8] | 0.357 | 0.258 | 0.130 | 0.086 | 0.332 | 0.243 | 0.088 | 0.054 | 0.183 | 0.124 | 0.228 | 0.159 |
| Noiseprint [38] | 0.364 | 0.262 | - | - | 0.339 | 0.253 | 0.122 | 0.081 | 0.179 | 0.120 | 0.230 | 0.161 |
| DFCN [35] | 0.419 | 0.280 | 0.181 | 0.119 | 0.320 | 0.217 | 0.082 | 0.055 | 0.233 | 0.161 | 0.250 | 0.165 |
| MVSS-Net [36] | 0.684 | 0.596 | 0.451 | 0.397 | 0.271 | 0.188 | 0.294 | 0.240 | 0.200 | 0.401 | 0.401 | 0.333 |
| OSN [37] | 0.707 | 0.608 | 0.509 | 0.465 | 0.436 | 0.308 | 0.332 | 0.255 | 0.456 | 0.367 | 0.456 | 0.367 |
| ConvNeXt [28] | 0.885 | 0.857 | 0.581 | 0.548 | 0.270 | 0.228 | 0.370 | 0.318 | 0.500 | 0.432 | 0.521 | 0.477 |
| FENet | 0.858 | 0.803 | 0.585 | 0.543 | 0.451 | 0.335 | 0.355 | 0.281 | 0.514 | 0.431 | 0.553 | 0.479 |
| Methods | Columbia | CASIAv1 | DSO | NIST | IMD | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | |
| Baseline | 0.787 | 0.736 | 0.505 | 0.466 | 0.317 | 0.221 | 0.286 | 0.223 | 0.455 | 0.365 | 0.470 | 0.402 |
| Baseline + SCF | 0.839 | 0.777 | 0.541 | 0.491 | 0.366 | 0.256 | 0.316 | 0.249 | 0.498 | 0.403 | 0.512 | 0.435 |
| Baseline + SCF + ECAM | 0.858 | 0.803 | 0.585 | 0.543 | 0.451 | 0.335 | 0.355 | 0.281 | 0.514 | 0.431 | 0.553 | 0.479 |
| OSN | Methods | Columbia | CASIAv1 | DSO | NIST | Average | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | ||
| DFCN | 0.315 | 0.214 | 0.161 | 0.102 | 0.049 | 0.030 | 0.116 | 0.077 | 0.160 | 0.106 | |
| MVSS-Net | 0.691 | 0.603 | 0.387 | 0.334 | 0.277 | 0.193 | 0.264 | 0.213 | 0.405 | 0.336 | |
| OSN | 0.724 | 0.611 | 0.462 | 0.417 | 0.447 | 0.320 | 0.329 | 0.253 | 0.488 | 0.400 | |
| ConvNeXt | 0.873 | 0.841 | 0.534 | 0.496 | 0.260 | 0.216 | 0.362 | 0.311 | 0.507 | 0.466 | |
| FENet | 0.809 | 0.757 | 0.536 | 0.489 | 0.417 | 0.308 | 0.375 | 0.310 | 0.534 | 0.466 | |
| DFCN | 0.172 | 0.107 | 0.159 | 0.101 | 0.056 | 0.032 | 0.075 | 0.050 | 0.115 | 0.072 | |
| MVSS-Net | 0.689 | 0.601 | 0.403 | 0.353 | 0.258 | 0.183 | 0.251 | 0.200 | 0.400 | 0.334 | |
| OSN | 0.724 | 0.626 | 0.466 | 0.421 | 0.370 | 0.253 | 0.294 | 0.219 | 0.463 | 0.380 | |
| ConvNeXt | 0.882 | 0.853 | 0.529 | 0.497 | 0.262 | 0.216 | 0.357 | 0.308 | 0.507 | 0.468 | |
| FENet | 0.827 | 0.778 | 0.506 | 0.469 | 0.481 | 0.362 | 0.333 | 0.269 | 0.537 | 0.470 | |
| DFCN | 0.404 | 0.278 | 0.196 | 0.126 | 0.167 | 0.104 | 0.050 | 0.032 | 0.204 | 0.135 | |
| MVSS-Net | 0.690 | 0.603 | 0.248 | 0.209 | 0.214 | 0.150 | 0.212 | 0.165 | 0.341 | 0.282 | |
| OSN | 0.727 | 0.631 | 0.405 | 0.358 | 0.366 | 0.252 | 0.286 | 0.214 | 0.446 | 0.364 | |
| ConvNeXt | 0.882 | 0.854 | 0.358 | 0.324 | 0.230 | 0.187 | 0.349 | 0.298 | 0.455 | 0.416 | |
| FENet | 0.824 | 0.772 | 0.408 | 0.361 | 0.449 | 0.332 | 0.361 | 0.283 | 0.511 | 0.437 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Li, L.; Wang, H. Symmetry-Guided Dual-Branch Network with Adaptive Feature Fusion and Edge-Aware Attention for Image Tampering Localization. Symmetry 2025, 17, 1150. https://doi.org/10.3390/sym17071150
He Z, Li L, Wang H. Symmetry-Guided Dual-Branch Network with Adaptive Feature Fusion and Edge-Aware Attention for Image Tampering Localization. Symmetry. 2025; 17(7):1150. https://doi.org/10.3390/sym17071150
Chicago/Turabian StyleHe, Zhenxiang, Le Li, and Hanbin Wang. 2025. "Symmetry-Guided Dual-Branch Network with Adaptive Feature Fusion and Edge-Aware Attention for Image Tampering Localization" Symmetry 17, no. 7: 1150. https://doi.org/10.3390/sym17071150
APA StyleHe, Z., Li, L., & Wang, H. (2025). Symmetry-Guided Dual-Branch Network with Adaptive Feature Fusion and Edge-Aware Attention for Image Tampering Localization. Symmetry, 17(7), 1150. https://doi.org/10.3390/sym17071150