1.1. The Tortuous History of Artificial Neural Networks
Artificial neural networks originated from the simulation of biological nerve cells. In early studies, people could only observe the simplest activation behavior of neurons. As the research deepened, people realized that the signals in nerve cells were transmitted through changes in potential and established corresponding differential equations [
1]. Since then, differential equations have become the core of describing the dynamics of nerve cells. In the early 20th century, people had been trying to realize artificial neural networks by simulating the signal transmission of differential equations, but they had not been successful due to the complexity of the equations.
To overcome the complexity of biophysical models and explore computational feasibility, researchers turned to more abstract and manageable discrete models, starting with the simplest models, as early studies of biological nerve cells did. This shift directly led to the birth of the perceptron in the late 1950s [
2]. The perceptron explicitly introduced the concept of learning: its weights could be automatically adjusted from labeled data through an iterative, error-correction-based rule (the perceptron learning rule). The perceptron, a single-layer neural network (containing only input and output layers), was capable of solving linear separable problems, and demonstrated potential in simple image recognition tasks, sparking the first wave of neural network research.
However, the fundamental limitations of the perceptron were sharply revealed in 1969 by Marvin Minsky and Seymour Papert in their book
Perceptrons [
3]. They rigorously proved that single-layer perceptrons could not solve linearly inseparable problems—the classic example being the XOR (exclusive OR) logic function. This critical flaw, compounded by the limited computing power of the time and the absence of effective training methods for multilayer networks, led to a withdrawal of research funding and a steep decline in academic interest. Neural network research consequently entered a prolonged “AI Winter” that lasted more than a decade.
A turning point arrived in the 1980s, when several key breakthroughs collectively revived interest in neural networks. In 1982, physicist John Hopfield proposed the Hopfield network—a fully connected, recurrent neural network [
4]. He introduced the novel concept of an “energy function” and proved that the network evolves toward a state of lower energy, eventually stabilizing at a local minimum (called an attractor or fixed point). The Hopfield network demonstrates that complex problems can be effectively simulated by building a system containing attractors, and that the network can be effectively trained by adjusting the attractors of the system.
Nevertheless, the true catalyst for modern neural networks was the (re)discovery and widespread adoption of the backpropagation algorithm (BP). Although the core idea of the algorithm appeared earlier, it was not until 1986 that a paper published in
Nature magazine—which made the algorithm widely recognized and applied—proved its ability to train multilayer neural networks (MLPs) to solve nonlinear problems [
5]. The BP algorithm uses the chain rule to compute the gradient of the loss function with respect to all network weights, then propagates this gradient information backward from the output layer to the input layer, guiding the adjustment of weights to minimize prediction error. It elegantly solved the challenge of training MLPs, enabling them to learn complex nonlinear mappings. The emergence of the BP algorithm, coupled with gradually increasing computational power, made it feasible to train networks with one or more hidden layers, ushering neural network research into a new phase of rapid development.
In the 21st century—especially after the 2010s—neural network development has experienced an unprecedented boom and has fundamentally reshaped the landscape of artificial intelligence. Today, artificial neural networks have long transcended academic research and achieved large-scale, full-spectrum industrial application. They have become deeply integrated into nearly every corner of modern society, including computer vision [
6], natural language processing [
7], recommendation systems [
8], scientific research [
9,
10,
11], and beyond.
Although artificial neural networks have experienced a long period of twists and turns and will be prosperous in the foreseeable future, we should not forget that the training of artificial neural networks has always been closely related to the architecture of neural networks. In the previous paper, we proposed a new neural network framework, so it is natural to provide the corresponding neural network training method.
1.2. Biological Neural Networks and Biological Interpretability
While artificial neural networks based on digital computing are developing rapidly, researchers have not given up on biological neural network models based on differential equations. This is mainly because such models are directly derived from the simulation of biological neuron behavior, which is the origin of artificial neural networks. Therefore, biological neural networks have higher biological rationality in terms of structure and dynamic characteristics.
On the other hand, biological neural systems show extremely high energy utilization efficiency and can complete complex perception and computing tasks with much less energy than current artificial neural networks. Although modern GPU clusters can achieve large-scale deep learning training, their energy efficiency is still far less than that of the human brain. This gap has also prompted researchers to continue to pay attention to biologically inspired neural models with higher energy efficiency.
Since the 1980s, cellular neural networks, chaotic neural networks, and spiking neural networks have been proposed one after another [
12,
13,
14]. Their core goal is to simulate the behavioral mechanism of biological neurons from the perspective of dynamic systems and strive to strike a balance between computational efficiency and biological rationality.
At the same time, although the backpropagation algorithm has made great contributions to the development of deep learning, its biological interpretability has also been increasingly questioned. In the early days, the algorithm faced mathematical challenges such as gradient vanishing and gradient exploding in its applications [
15]. Although these problems have been significantly alleviated with the improvement of network structure and activation function, for some of its basic assumptions—such as the availability of global error signals, the precise symmetry of forward and backward propagation weights, and the synchronous update mechanism—it is difficult to find corresponding biological bases in real neural systems [
16,
17,
18].
As early as 1989, Crick expressed caution toward the craze for neural networks, pointing out that backpropagation lacked consistency with biological neural mechanisms [
19]. In the same year, Stork pointed out more clearly that “backpropagation is biologically irrational” [
20].
In recent years, discussions on this issue have continued [
17]. In a systematic review in 2020, it was pointed out that although there is no conclusive evidence that biological neurons can directly implement backpropagation, under certain conditions, the nervous system may achieve functionally similar learning effects through simplified or alternative mechanisms [
21]. This has further promoted the exploration of learning mechanisms with stronger biological plausibility, such as forward-forward, feedback alignment, equilibrium propagation, and other methods [
16,
22,
23]. These methods do not fundamentally change the structure of the neural network but try to make partial corrections to the training mechanism to alleviate the biological irrationality of backpropagation. Based on this understanding, even Hinton has publicly called for abandoning the current neural network architecture and finding a new neural network framework with better biological interpretability.
1.3. Neural Network Framework and Training Methods
In this paper, our main contribution is to propose an effective training method for the Wuxing neural network. A review of the development of artificial neural networks reveals that each significant breakthrough in training methodology has substantially advanced the field. This observation suggests that network architecture and training algorithms are deeply intertwined, with their alternating progress jointly driving the success of modern neural networks.
Although differential equations are widely regarded as the fundamental tool for modeling biological neurons, neural networks based on such equations have developed slowly. The primary reason lies in the lack of efficient training methods. Moreover, the difficulty in designing effective training strategies is often rooted in the network architecture itself—when the structure is inherently ill-suited for learning, it becomes exceedingly difficult to devise suitable training algorithms.
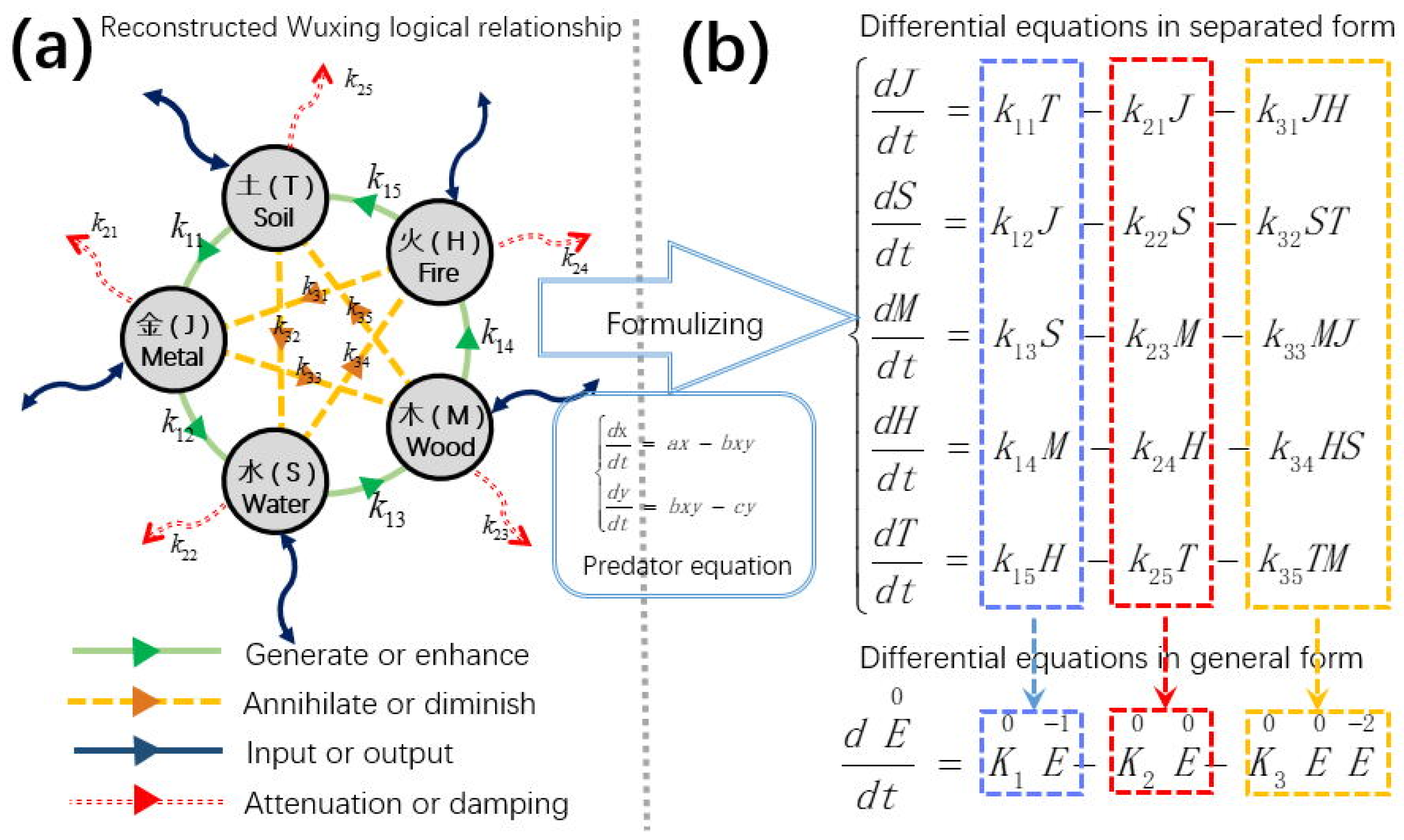
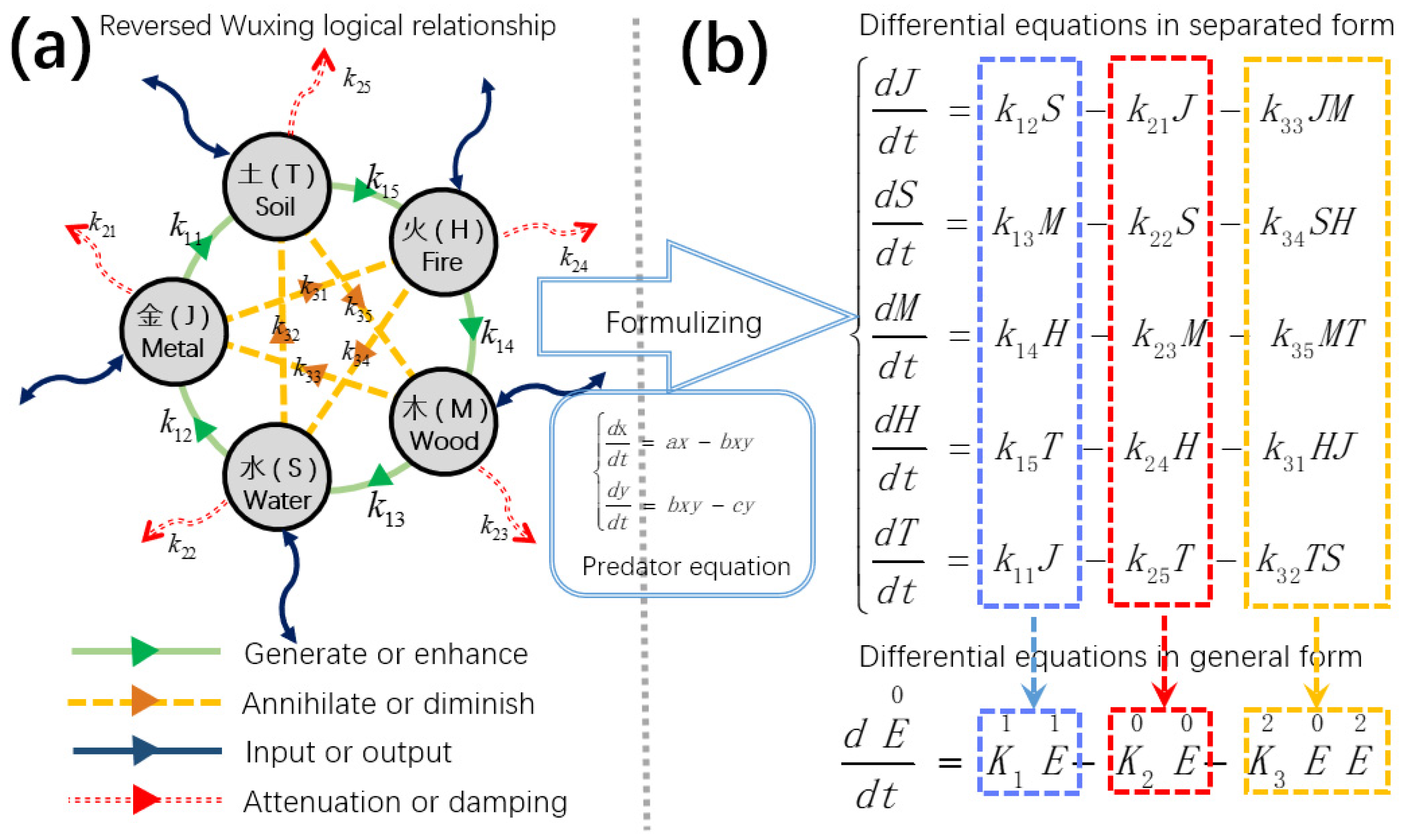
In the previous article, we proposed a neural network framework based on symmetric differential equations [
24]. Compared with other biological neural network frameworks, the new framework starts from group theory and constructs symmetric differential equations based on the five-element logic and predator–prey equations. Because the equation has good symmetry, the reversibility of the system becomes a natural property, without the need for additional methods to find a reversible system [
25].
From a biological perspective, it is generally believed that individual neurons cannot access global information. Therefore, a training method is considered biologically plausible if neurons can be trained using only local information. Hebbian learning is a classic example of such a local rule; however, its expressive capacity is limited, and it cannot scale to large networks effectively.
In summary, the choice of neural network architecture is closely linked to the design of feasible training methods. In the context of the Wuxing neural network, conventional training approaches prove to be either ineffective or inefficient. Consequently, it is necessary to develop a novel training strategy tailored to this new architecture.
To develop an effective alternative to the backpropagation algorithm, it is essential to first understand the fundamental strengths of backpropagation. In our view, the key advantage of the backpropagation method lies in its point-to-point, precise adjustment capability, which contributes to both training efficiency and robustness. By using backpropagation, we can quantitatively assess the impact of each parameter on the final outcome, enabling targeted adjustments—a feature that many alternative algorithms fail to provide. Therefore, despite criticisms regarding its biological plausibility, the backpropagation algorithm remains indispensable and cannot easily be replaced by other methods.
In our effort to propose an efficient alternative, we have approached the problem from both mathematical and biological perspectives.
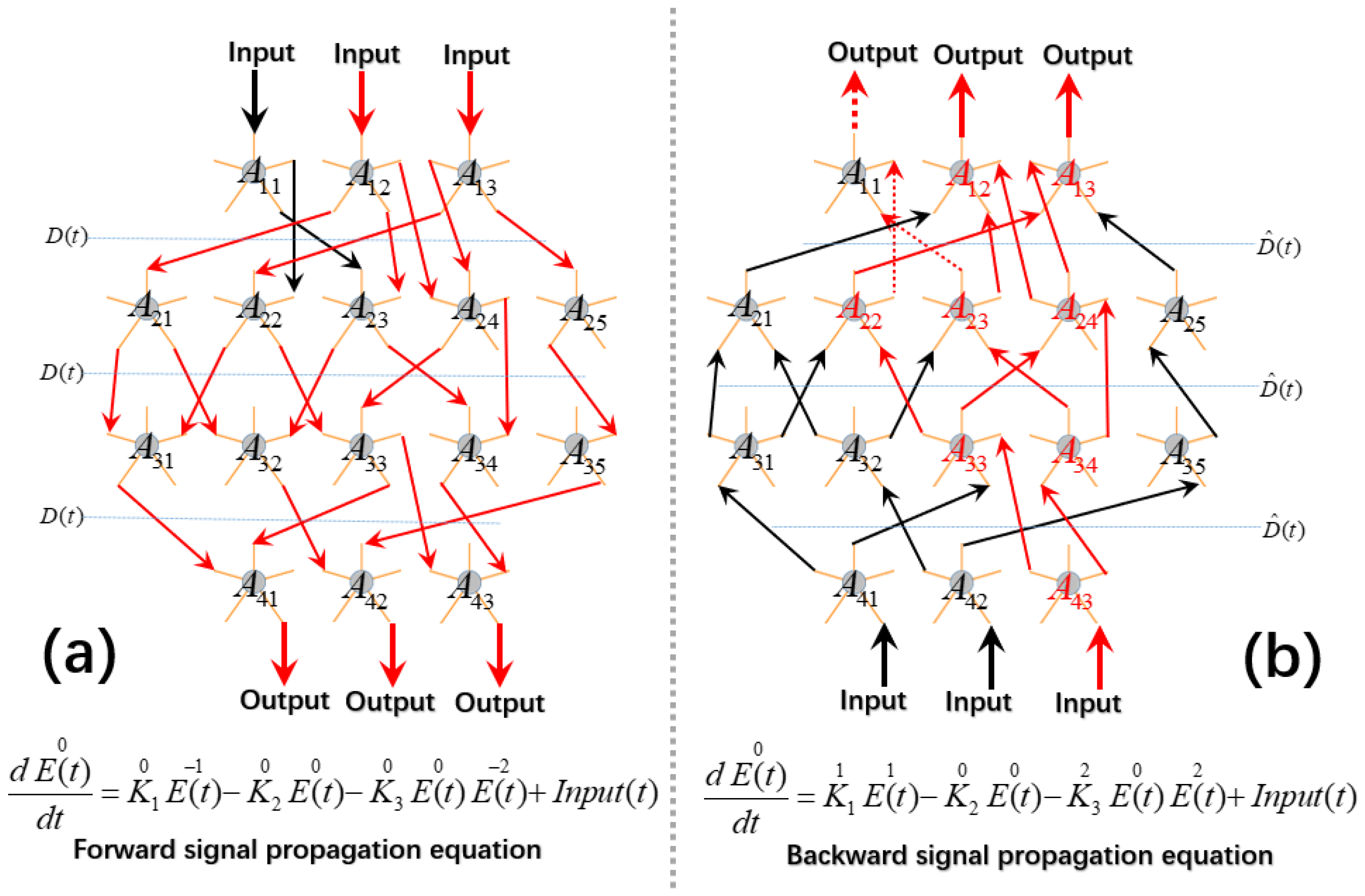
From a mathematical perspective, we propose using signal propagation in differential equations as a replacement for chain rule derivation, a method we refer to as differential equation propagation. This approach maintains a one-to-one correspondence, ensuring high efficiency. The key prerequisite for this method is that the system must be reversible. As established in our earlier design, the system exhibits complete symmetry, which makes reversibility straightforward to achieve. Reversibility implies that we can trace the causal relationships within the system in reverse, analogous to the point-to-point mechanism in the backpropagation algorithm.
From a biological standpoint, we introduce the concept of instinctive design. In this design, each neuron operates autonomously and retains full functionality, meaning that individual neurons can independently execute signal propagation and feedback training without the need for global information. Neurons interact with the external environment through synapses, without requiring any specialized structural design. This approach provides both strong biological interpretability and efficient training capabilities. Within this training framework, each neuron adjusts system parameters by comparing forward and reverse signals passing through it, thereby facilitating neural network training without the need for global coordination.
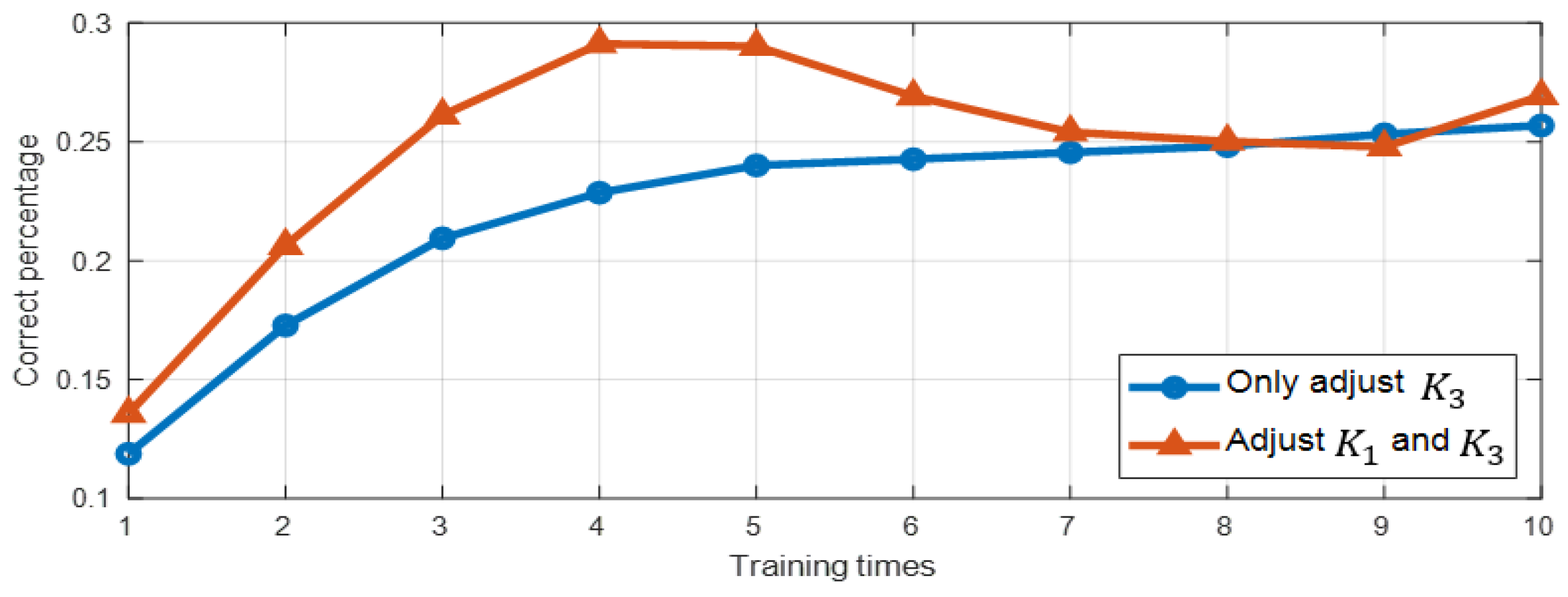
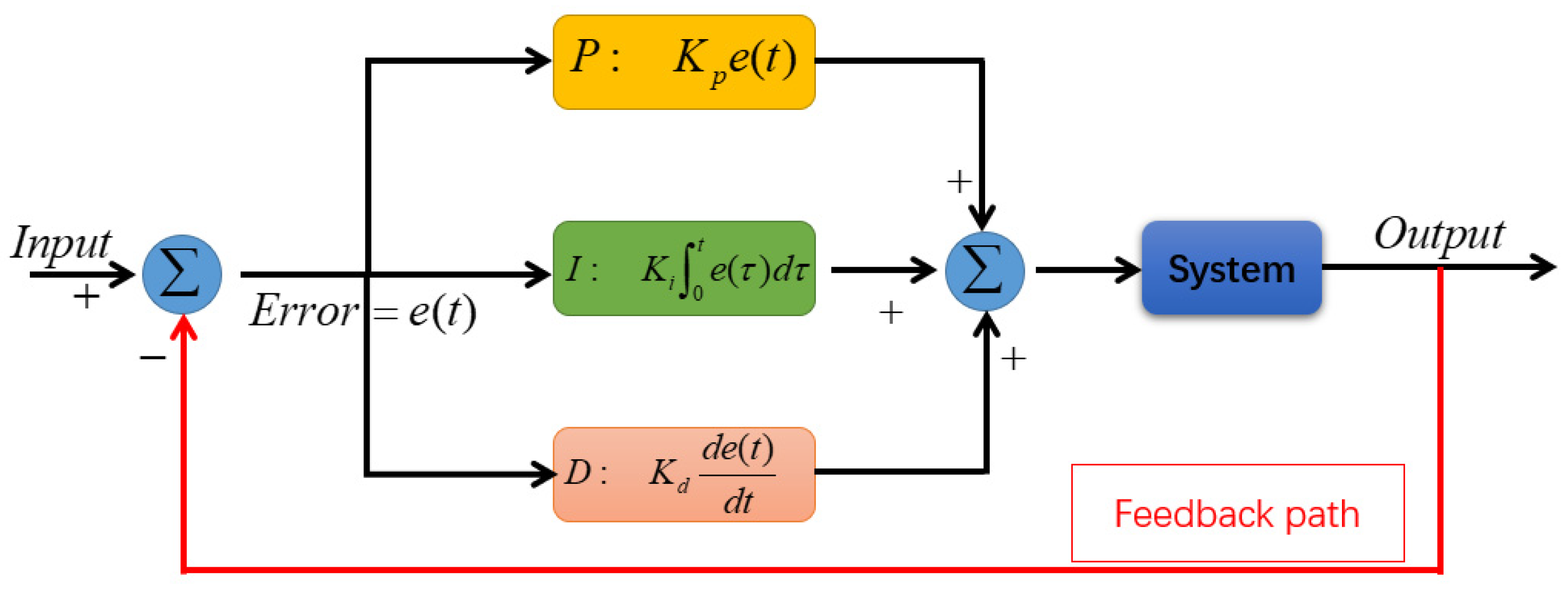
However, adopting this strategy alone is insufficient. The system composed of differential equations contains three distinct sets of parameters. If the same adjustment strategy were applied to all three parameter sets during training, it would be ineffective in enhancing neural network performance. To address this issue, we introduce a distributed Proportional–Integral–Derivative (PID) control method. PID control holds a dominant position in traditional control systems, whether in academic teachings or industrial applications, and remains a critical tool [
26]. However, our approach deviates from the conventional PID method. In alignment with the principle of instinctive design, we focus on implementing the PID control logic within a single closed system. Building on the fundamental concepts of PID control, we have developed a novel control method that not only adheres to the instincts of design but also effectively incorporates PID functionality.
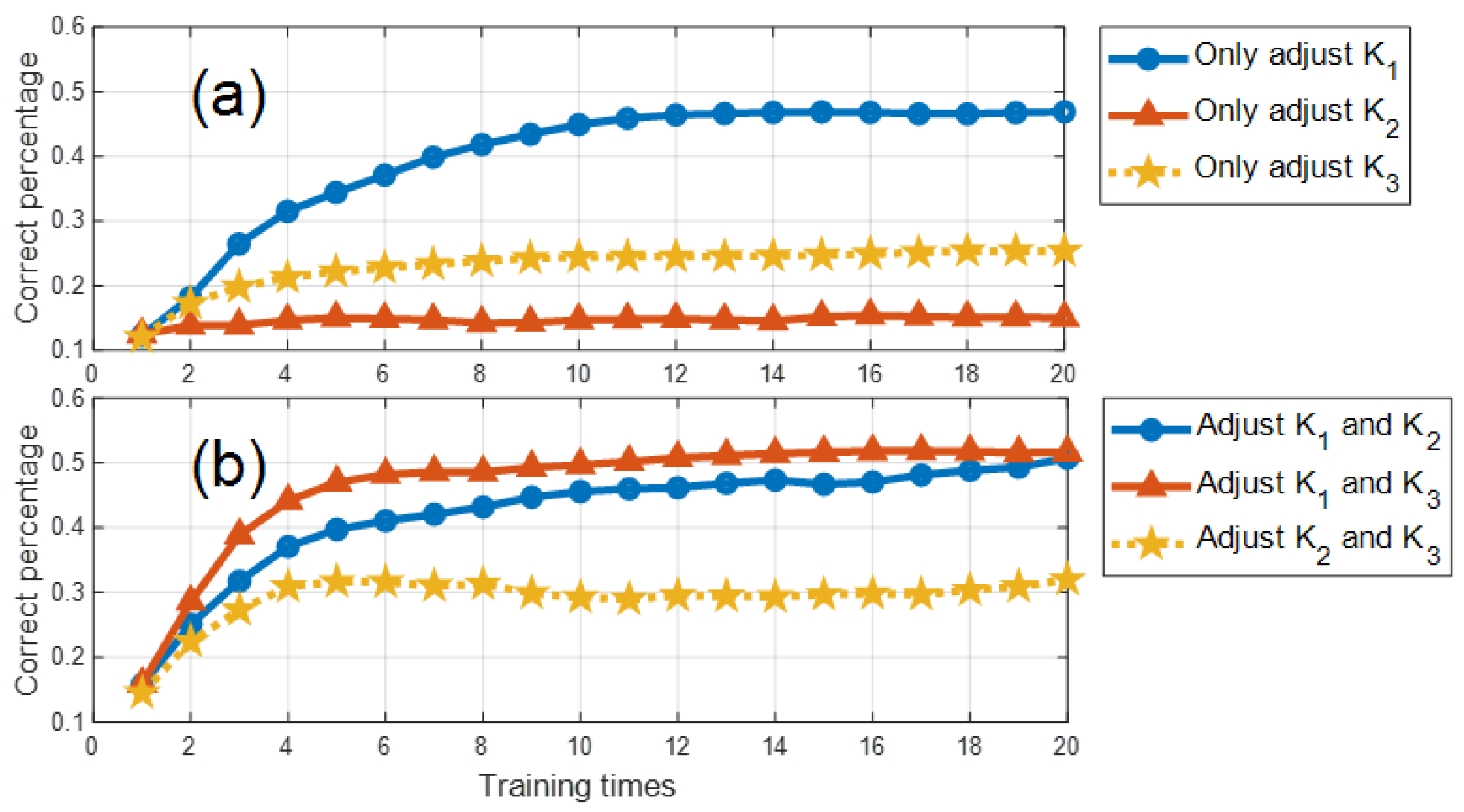
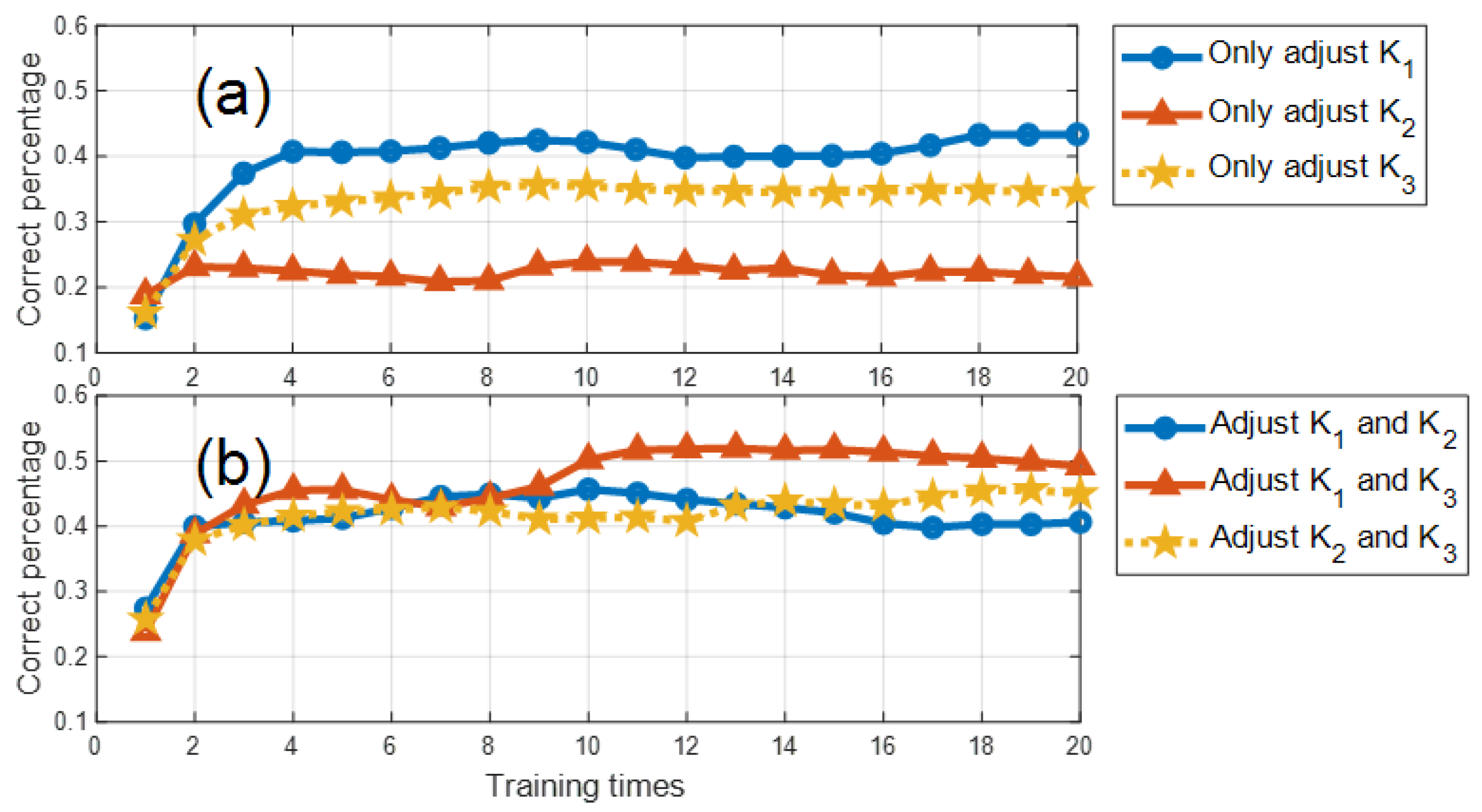
To validate our approach, we conducted experiments on the MNIST (Modified National Institute of Standards and Technology database) and Fashion-MNIST. The results demonstrate that the distributed PID control method effectively enhances the system’s accuracy and training speed.
The remainder of this article is organized as follows:
Section 2 provides a brief introduction to the Wuxing neural network, offering a foundational understanding of its core concepts.
Section 3 details the training methodology for the Wuxing neural network, emphasizing the use of differential equation signal propagation as a replacement for chain rule derivation.
Section 4 explores PID control theory and its application to neural network training, with a particular focus on implementing distributed PID methods in closed systems.
Section 5 concludes with a summary of our work and prospects for future research.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}