1. Introduction
The distributed state estimation (DSE) problem has drawn more and more attention in the network domain because the large-scale sensor network is universally employed in various areas, for example target tracking [
1,
2,
3], power systems [
4], wireless camera networks [
5], and unmanned aerial vehicles [
6]. The study of distributed state estimation in various sensor networks has gained wide popularity due to its various advantages over most centralized estimation techniques, such as robustness to individual sensor failures, a low communication burden, expandability to sensor topology variation, and adaptability to modular subsystem adjustments [
7]. Dissimilar to the centralized estimation, the distributed approaches do not require the fusion center, where data is interchanged only with the adjacent sensors rather than all the sensors.
Consensus-based methods are one of the most popular DSE algorithms, which are divided into three types [
8,
9,
10,
11]. The first type is consensus on estimates (CE) where the consensus average is applied to the predictions or state estimations [
12]. The drawback of CE is that it overlooks the information that effectively contains the error covariance, which may result in an underestimation of the uncertainty in the estimation. The second type is consensus on measurements (CM) where the consensus average is employed based on the innovation pairs [
13,
14]. However, innovation pairs need to be calculated and exchanged in the CM type, which may make the calculation process complex. The third type is consensus on information (CI), which runs a consensus average on the information matrices and information vectors [
15]. The consensus on the information matrix and information vector fully utilizes all the information from the state estimation; therefore, the CI type is a bit better compared to the other two types. All of these distributed consensus algorithms are devised on the centralized Kalman filter (CKF) or nonlinear Kalman filter family, which are based on the assumption of the Gaussian noise and employ the minimum mean square error (MMSE) criterion. However, non-Gaussian noise environments, such as heavy-tailed or impulsive noise, are commonly encountered in practical engineering applications, especially for low-cost sensor networks.
Based on the MMSE criterion, several distributed filter algorithms have been employed to deal with the non-Gaussian noise problem; the typical filter methods are the distributed particle filter [
16,
17,
18] and the distributed Gaussian sum filter (GSF) [
19]. In distributed particle filtering, each sensor performs local particle filtering and communicates with neighboring sensors to approximate a global estimate, which typically requires a large number of particles. Similarly, in the distributed Gaussian sum filter (GSF), each sensor implements the GSF to generate local estimates. These local estimates, represented by Gaussian components, are merged into a single Gaussian distribution using a moment-matching approach. The resulting merged estimates are then exchanged between neighboring sensors and fused using a weighted Kullback–Leibler divergence. However, a significant limitation of these filters is their high computational cost, which makes them impractical in sensor networks with constrained computational resources.
The performance of distributed state estimation methods can be significantly improved by employing a maximum correntropy criterion (MCC) instead of the aforementioned MMSE criterion, particularly in the presence of non-Gaussian noise disturbances [
20,
21,
22,
23]. B. Chen and X. Liu et al. [
20] studied a maximum correntropy Kalman filter, which adopts MCC as the optimality criterion instead of using the MMSE to deal with the heavy-tailed impulsive noises. C. Lu and Z. Ren et al. [
21] designed a robust recursive filter and smoother based on the cost function induced by the maximum mixture correntropy criterion for nonlinear dynamic models. J. Shao and W. Chen et al. [
22] researched an adaptive multi-kernel sized-based maximum correntropy cubature Kalman filter to overcome the excessive convergence problems against non-Gaussian noise. In contrast to the analytical solution of KF or the KF family algorithms, the MCC-based filtering algorithms cannot yield the desired filter gain directly, so an iterative scheme with the Banach fixed-point theory (also named the contraction mapping theory) is proposed to realize the engineering applications. Generally, the Gaussian kernel function is usually employed to build the cost function in the aforesaid MCC-based filter algorithms, whereas the MCC-based filters based the Gaussian kernel function do not always achieve high performance and high robustness due to the difficulty in choosing the optimal kernel function or the appearance of singular matrices, which cause the algorithms to collapse prematurely [
24,
25]. Therefore, it is crucial to explore alternative types of kernel functions to address the inherent limitations of the Gaussian kernel function during the correntropy applications. The rational quadratic (RQ) kernel function can be regarded as an infinite sum of multiple Gaussian kernels with different characteristic length scales [
26,
27]. Consequently, the RQ kernel function owns the characters that the underlying function exhibits smooth variations across a range of length scales compared to the Gaussian kernel function [
28]. Therefore, it is capable of capturing more intricate and unstable fluctuations in data trends compared to the Gaussian kernel. A challenging attempt has been made by utilizing the rational quadratic kernel function in place of the Gaussian kernel to overcome the shortage of singular matrices [
24]. The work in [
24] only concentrates on state estimation in a single sensor, and the DSE problem based on the rational quadratic kernel-based correntropy also plays a significant role in large-scale sensor networks. Therefore, the distributed maximum correntropy method based on a rational quadratic kernel function is of great research value and deserves taking time to study it.
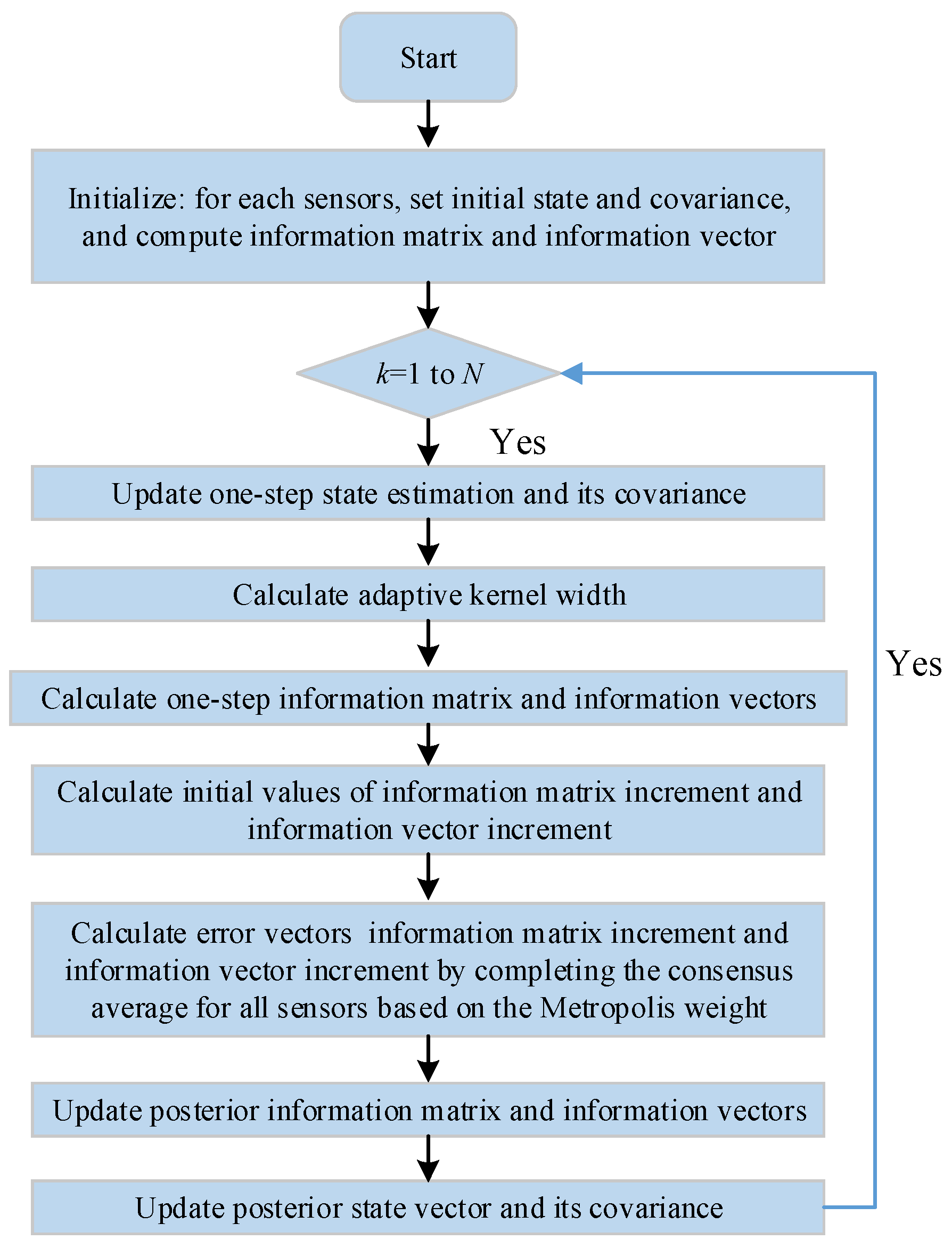
In this paper, to further resolve the problem of the appearance of singular matrices and the kernel selection under the heavy-tailed and outliers of non-Gaussian noise in the sensor network system, the adaptive distributed maximum correntropy filter algorithm and its correlated algorithms, which employ the rational quadratic kernel function, are proposed to deal with the DSE problems. The major contributions of this paper are listed as follows:
The centralized rational quadratic maximum correntropy KF (CRQMCKF) is derived by adopting the correntropy cost function based on the rational quadratic kernel against the non-Gaussian noise for sensor networks.
The centralized rational quadratic maximum correntropy information filter (CRQMCIF) is derived to address the non-Gaussian noise disturbance, which is the corresponding information style of CRQMCKF.
The distributed rational quadratic maximum correntropy information filter (DRQMCIF) and the adaptive distributed rational quadratic maximum correntropy information filter (ADRQMCIF) algorithms, by adapting the consensus-weighted average based on the information matrices and information vectors, are acquired to handle the distributed state estimation problem in sensor networks.
The remaining parts of this paper are organized as follows. The relative background knowledge, including correntropy and weighted consensus average, is minutely introduced in
Section 2. The CRQMCKF is designed based on the correntropy cost function by exploiting the rational quadratic kernel function, and then, the corresponding CRQMCIF algorithm is obtained through the information matrices; additionally, the DRQMCIF and ADRQMCIF algorithms are acquired by combining the weighted consensus average based on information matrices and information vectors in
Section 3. The simulation results are shown in
Section 4, which illustrates the robustness and estimation performance of the proposed algorithms. The conclusions are presented in
Section 6.
To increase the readability and comprehensibility of the thesis, the nomenclature table in this paper is given.
3. Main Results
In this section, the centralized rational quadratic maximum correntropy Kalman filter is derived for a linear sensor network system at first. Subsequently, the centralized rational quadratic maximum correntropy information filter algorithm is obtained. Then, the distributed rational quadratic information maximum correntropy information filter and the adaptive distributed rational quadratic information maximum correntropy information filter are deduced, which are realized through the weighted average consensus of the information pairs within the information filter.
3.1. Centralized Rational Quadratic Maximum Correntropy Kalman Filter
Consider a linear dynamic system and measurement model with
S sensors depicted by
where
is the state vector at the
k-th time step and
is the measurement vector in the
s-th sensor at the
k-th time step; the state transition matrix
and measurement matrix
are pre-known;
and
are the mutually independent non-Gaussian process and measurement noise vectors, which have the nominal process noise covariance matrix
and nominal measurement noise covariance matrix
for the Kalman family filter algorithm to proceed; and
S is the total number of sensors. In the case of
, the sensors are placed in a distributed way.
Firstly, the CRQMCKF filter algorithm is devised as follows. Under the Kalman-family framework, the CRQMCKF algorithm is comprised of prediction and update. In the prediction, the prior mean vector
and the covariance matrix
are given by
The Cholesky decomposition of
and
are written as
To deal with non-Gaussian interference, the cost function is adopted by correntropy based on the rational-quadratic kernel as
where
is rational quadratic function described by Equation (4). Additionally,
and
are the
i-th and the
j-th element of the vectors
and
The state solution
is to maximize the above cost function utilizing all sensors’ measurements based on the maximum correntropy criterion (MCC)
The optimal state estimate can be acquired by
Equation (18) can be further shown by
where
and
are the
i-th and the
j-th row of the matrixes
and
, respectively.
The matrix form of Equation (19) is expressed as
in which
According to the symbolism (23), Equation (20) can be expressed as
Adding and subtracting
on the right side of the Equation (24)
Multiplying
on both sides of Equation (25), then the state estimation
can be obtained as the following (See
Appendix A):
where
is stacked measurement vector and defined as
is a stacked measurement matrix of all sensors and expressed as
is the gain matrix, which is given as
in which
is also rewritten as
The detailed derivation of Equation (31) can be seen in
Appendix B.
The state error covariance matrix
can be calculated by
The CRQMCKF algorithm is outlined in Algorithm 1.
| Algorithm 1 Centralized rational quadratic maximum correntropy Kalman filter (CRQMCKF) |
;
For k = 1, 2, 3, …, do
based on Equations (11) and (12);
; |
Remark 2. Compared to the conventional centralized Kalman filter (CKF), the proposed CRQMCKF algorithm introduces
and
for the s-th sensor to modify the estimation performance, which is changed according to deformation ( in Equation (15) and
in Equation (16)) of the one-step predict errors and every sensor’s innovation by the kernel width b. When the model is disturbed by large errors,
and
would reduce and decay according to an inverse proportional function in Equation (4) (the rational quadratic function in Equation (4) can be identically deformed to
, which is a translation of the inverse proportional function and has the same graph trend as the inverse proportional function). Mathematically, the rational quadratic function decays much slower than the exponential function, so
and are not easily equal to zero when the large outlier or pulse noise arises. This character can avoid the singular matrices under the computer precision requirements for multi-dimensional variables. Peculiarly, when , then
and
, the proposed algorithm ends early, which illustrates that this algorithm can voluntarily avoid the bad influence of abnormal errors, which are produced by system or measurement outliers.
Remark 3. The kernel width b has a significant impact on the algorithm estimation effect. When the kernel width b is too small, the estimation performance of the algorithm does not improve and sometimes even decreases, because the rational quadratic function values tend to zero and do not act as a regulator, whereas a large kernel width b makes the CRQMCKF algorithm converge to the centralized Kalman filter. Specially,
and when the kernel width , which means that CRQMCKF tends to CKF.
3.2. Centralized Rational Quadratic Maximum Correntropy Information Filter
To acquire the information form of the above CRQMCKF algorithm, like the standard centralized information filter (CIF), some approximation method in the derivations is adopted.
The step of prediction is the same as the above CRQMCKF algorithm. To obtain the information form of the state update, consider the information matrix
as the following
where the one-prediction information matrix
and the information matrix increment
are denoted as
Let
is the estimation information vector. Multiplying
on both ends of Equation (26),
where the one-prediction information vector
and the information vector increment
are given as
The detailed deducing process can be seen in
Appendix C.
The CRQMCIF algorithm is summarized in Algorithm 2.
| Algorithm 2 Centralized rational quadratic maximum correntropy information filter (CRQMCIF) |
;
For k = 1, 2, 3, …, do
by Equations (34) and (37);
based on Equations (33) and (36);
;
End. |
Remark 4. From (21) and (22), when the kernel width b → ∞,, the estimation of CRQMCIF is similar to that of the standard CIF algorithm, for which the effects are equivalent to the CKF and CRQMCKF; when the
, , the estimation of CRQMCIF is only time prediction, which is the same as CRQMCKF. In general, as shown in the simulation outcome in Section 4.4, the estimation performance of CRQMCIF and CRQMCKF is similar. 3.3. Distributed Rational Quadratic Maximum Correntropy Information Filter
To effectively obtain the DRQMCIF, the weighted consensus average is introduced to calculate the weighted sum of the information matrix increment Equation (35) and the information vector increment Equation (38), respectively. Particularly, each sensor is given the same initial value
and
, and thus
and
for all the sensors
s (
s = 1, 2,…,
S) in the distributed algorithm. The initial value of the information matrix increment
and information vector increment initialization
selects the information increment form of CRQMCIF in Equations (35) and (38), which indicates the information increment items of the
s-th sensor at the
k-th time after the
l-th consensus iteration. Applying the method in Equation (7) to perform the weighted consensus average, thus, the iterative information matrix increment
and information vector increment
is acquired as
where
is the number of consensus iterations,
is the consensus weight value, and
. In this paper, the weighted consensus matrix is built based on the Metropolis weights, which are given as
in which
represents the degree of the
s-th sensor in the sensor network communication topology diagram.
From Equation (40), the Metropolis weight matrix
is row stochastic and primitive, then
and
would respectively converge to the mean value of
and
when the total consensus iterative number
L→∞, i.e.,
which implies that the weight consensus average method could circuitously transmit localized information throughout the overall network.
After the weighted consensus averaging step, each sensor independently updates its information matrix and information vector through data transmitted from the neighboring sensor. Specifically, the information matrix and information vector are updated as follows:
Update of the Information Matrix: The information matrix
for each sensor
s at the
k-th time step is computed by adding the weighted average increment of the information matrix
obtained after
L rounds of consensus iterations to the information matrix at the previous time step
. This updating process encapsulates the integration of information exchanged between sensors and reflects the consensus gradually achieved during the iterative process.
in which
for
; when
L = 1, let
, which implies that each sensor simply accomplishes one local CRQMCIF employing the information transmitted by its linked sensors.
Update of the Information Vector: Similarly, the information vector
for the
s-th sensor at the
k-th time step is updated by adding the corresponding consensus averaged information vector increment
to the estimate at the previous time step
. This ensures that the state estimation vector incorporates a collective understanding of the observed data after the consensus process.
is expressed by
where
is the same as described above.
The DRQMCIF algorithm is outlined in Algorithm 3.
| Algorithm 3 Distributed rational quadratic maximum correntropy information filter (DRQMCIF) |
;
For k = 1, 2, 3, …, n
by Equations (35) and (38);
based on the Metropolis weight Equation (40);
based on Equations (42) and (43);
;
End. |
In distributed Algorithm 3, each sensor simply communicates with the neighbor sensors, which is ideal for low-cost sensors with finite communication capabilities. For every time interval k, each sensor s completes L consensus iterations. In the practice application, the estimation effect of DRQMCIF approaches that of CRQMCIF. For L→∞, there is the following conclusion.
Theorem 1. For the undirected linked sensor network, the weights consensus matrix is a right random matrix, i.e., , for . And is primitive; that is, there exists a positive integer k, satisfying . When the iterative number L→∞, the DRQMCIF can attain the same estimation effect as the CRQMCIF.
3.4. Adaptive Distributed Rational Quadratic Maximum Correntropy Information Filter
The kernel width of the rational quadratic kernel function plays a magnificent role in the convergence speed of the MCC-family algorithm. When other parameters are changeless, an extremely small kernel width affects the convergence and stability, and even the steady-state error may become larger. However, a particularly large kernel width reduces the rate of convergence and estimation performance. There is no way to obtain the theoretical optimal kernel width in the current research works. Thus, an adaptive adjustable kernel width is one of the popular manners to be selected to resolve this problem.
An online recursion design is enforced to update the kernel width in the MCC-family algorithm. Herein, the kernel width is designed as follows to enable the measurement-specific treatment of outliers
where
is the adaptive coefficient in the
j-th element of measurement at the
k-th step for the
s-th sensor;
is the presetting kernel width. The innovation vector at the
s-th sensor is defined by
To detect the measurement outliers, the innovation vector covariance matrix is acquired by
and
is chosen as the following
where
is the
j-th diagonal element of
,
is the
j-th element of
, and
is the confidence level factor, which is set based on the chi-square distribution with a single degree of freedom.
The adaptive coefficient
is devised by
where
is bounded and positive. The adaptive kernel width is obtained by substituting Equation (48) into Equation (44).
The ADRMCIF algorithm is listed in Algorithm 4.
Remark 5. When the measurement noise is Gaussian noise,
would be smaller than , is large. Under this circumstance, the adaptive coefficient becomes larger from Equation (48), which indicates that the kernel width is restructured to keep it large to ensure higher estimation precision. Meanwhile, conversely, when the measurement noise encounters the outliers, would be prominently larger than , will be smaller. In this case, the adaptive coefficient becomes smaller, which forces the correntropy value to reduce to zero to eliminate the influence of outliers.
| Algorithm 4 Adaptive distributed rational quadratic maximum correntropy information filter (ADRQMCIF) |
;
For k = 1, 2, 3, …, n
based on Equations (11) and (12);
by Equations (44)–(48);
by Equations (34) and (37);
by Equations (35) and (38);
based on the Metropolis weight Equation (40);
based on Equations (42) and (43);
by
End. |
The flowchart of Algorithm 4 is showed in
Appendix E.
Additionally, the adaptive kernel width is undiscerning to the value of . If the maximum value is preset as larger, because of the inadequate restraint of outliers, the innovation item would become larger, which will result in a decrease in the adaptive coefficient . Therefore, the kernel width will not increase with the increment of but will keep becoming smaller to resist the outliers. Consequently, the proposed method of the adaptive kernel width is more convenient and stable in choosing the maximum kernel width. The adaptive distributed rational quadratic maximum correntropy information filter (ADRQMCIF) is listed in Algorithm 4.
3.5. Computational Complexity Analysis
In this subsection, the computational complexity is analyzed according to the floating-point operations. According to the ADRQMCIF algorithm, the computational complexities for some equations are presented in
Table 1, where
L represents consensus iterative numbers and
d denotes the average numbers of each sensor’s neighbors.
Remark 6. O notation is utilized to depict the computational burden and O stands for the same order; and .
Assume that the average of fixed-pointed iterative number of every sensor is
T. The center rational quadratic maximum correntropy information filter algorithm involves Equations (11) and (12), (33) and (34), and (36) and (37). According to
Table 1, the total computational complexity of CRQMCIF is
The computational complexity of the ADRQMCIF is
From Equations (50) and (51), the computation consumption of CRQMCIF is generated by the central node, while that of the ADRQMCIF is dispersed by all sensors. The main difference between CRQMCIF and ADRQMCIF is the distributed consensus iteration and adaptive factor. The computational complexity of the consensus iteration step in ADRQMCIF depends on the numbers d and L of neighbors and the consensus iteration, i.e., (2n3 + 2n2 + n)TLd + dnT + O(n3). For large-scale networks (S d), the distributed algorithm can significantly reduce the computational consumption for every sensor compared to the centralized algorithm.
4. Simulation Result
In this section, the influence of the kernel width and the impact of the consensus iteration are discussed for the DRQMCIF algorithm, separately. Then the performances of the proposed CRQMCKF, CRQMCIF, DRQMCIF, and ADRQMCIF algorithms are contrasted with the conventional CKF, CMCKF ( = 2), and DMCKF ( = 2) algorithms through simulations.
4.1. Simulation Model and Evaluation Benchmark
Consider the widely representative 2-D nearly-constant-velocity target tracking problem within a sensor network, which is commonly utilized in the literature [
37] of distributed filtering, where the target’s positions are measured amidst clutter. The system model is described as
where
,
and
are respectively the position and velocity of tracking targe in
x and
y directions. The sampling period is selected as
t = 1
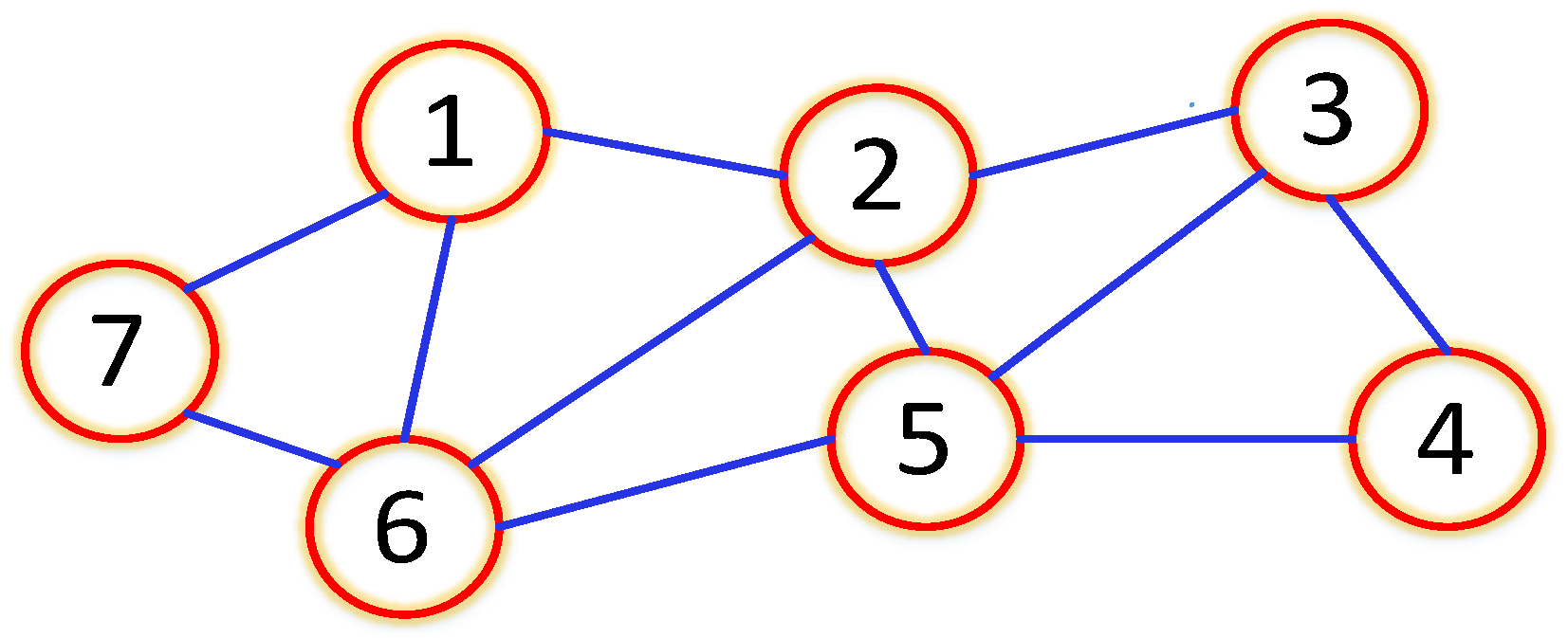
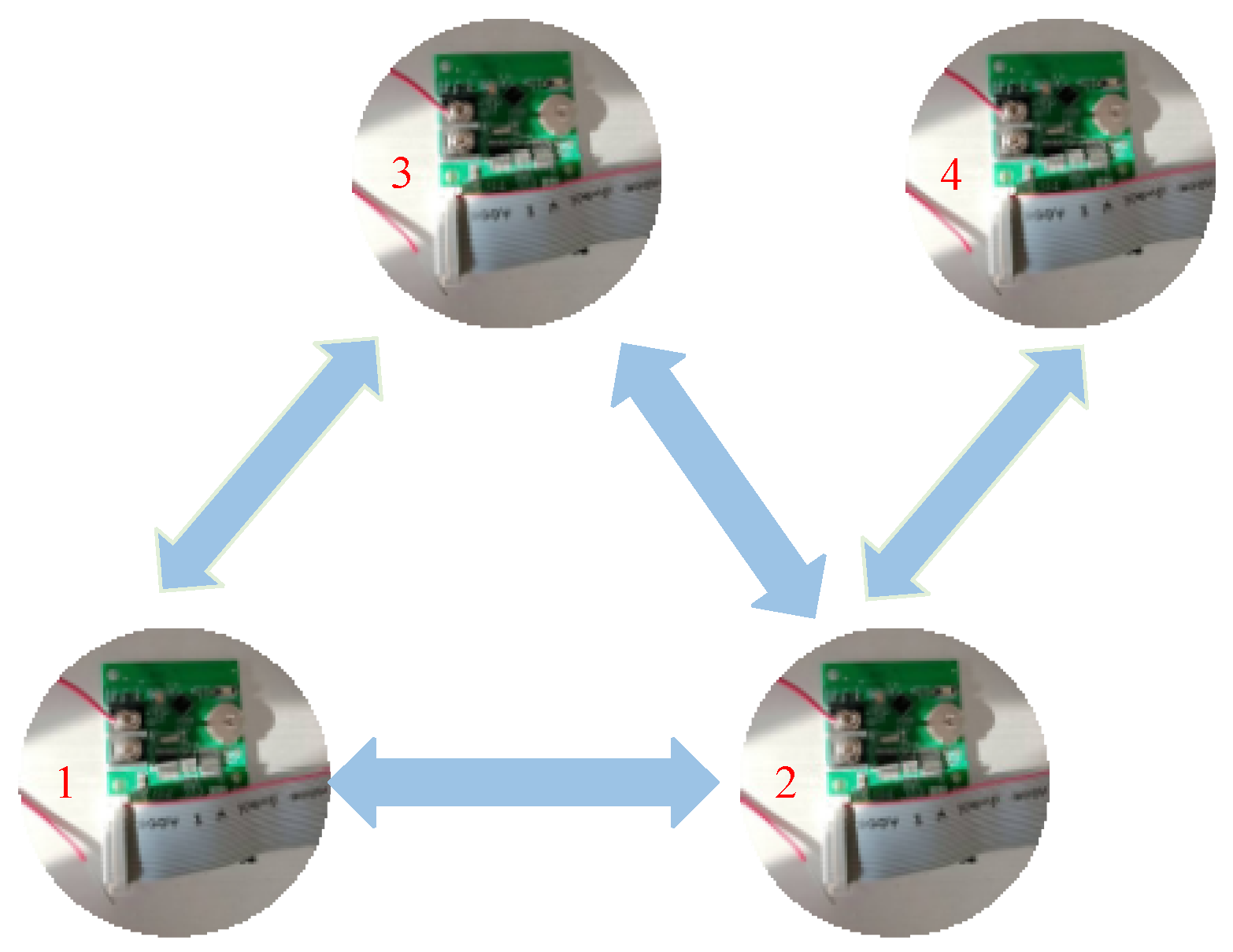
s. There are seven sensors to observe the target, and the communication topology graph among sensors is shown in
Figure 1.
In the linear model, the measurements are the positions of the target, and the corresponding measurement model is given by
The initial value of the target is with covariance . To guarantee the convergence of fixed-point iteration, the fixed-point iterative threshold and the maximum number of fixed-point iterations are preset as and .
The root-mean-square error (RMSE) and the average (RMSE) are adopted as the performance evaluation benchmarks. The RMSE and ARMSE of the position are calculated as
where
M is the count of Monte Carlo runs,
K is the total simulation period, and
is the estimation of the true position
at the
s-th sensor for the
r-th Monte Carlo experiment. The RMSE and ARMSE of velocity are calculated to those for the above position. The total time steps
K are chosen as
K = 200
s and the total Monte Carlo runs are
M, selected as
M = 100. All the simulations are conducted in MATLAB 2016b and run on an Intel Core i7-7700HQ, 2.80 GHz, 8 GB PC.
4.2. The Influence of Kernel Width
Firstly, the selection of the kernel width in the kernel function application can greatly influence the algorithm’s estimation precision and robustness. Therefore, the different kernel widths under the proposed DRQMCIF algorithm are discussed in this section.
This is considering that the process noise is Gaussian but the measurement noises are Gaussian mixture noise as follows
where 0.9 and 0.1 are the probabilities in Gaussian mixture noises separately,
and
. The Gaussian mixture noise is one of the representatives of non-Gaussian noise. The consensus iterative number
L is set as
L = 10. Let the kernel width
c = 1, 20, 25, 35, 50, 80, 180, respectively. The confidence level factor is chosen by
, and the maximum kernel width is preset as
bmax = 90 in the proposed adaptive kernel width. The measurement noises in Equation (56) are one of the typical heavy-tailed non-Gaussian noises with a mixed-Gaussian distribution, which is often employed in the non-Gaussian filtering literature [
20,
37].
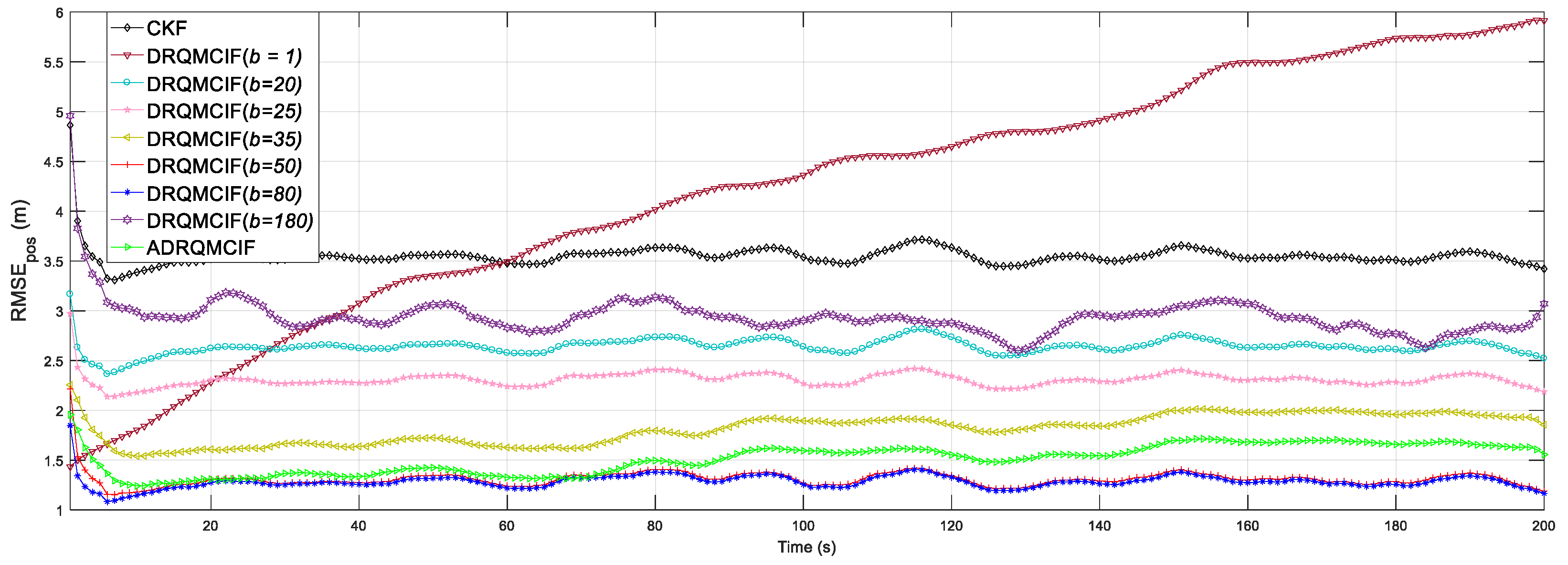
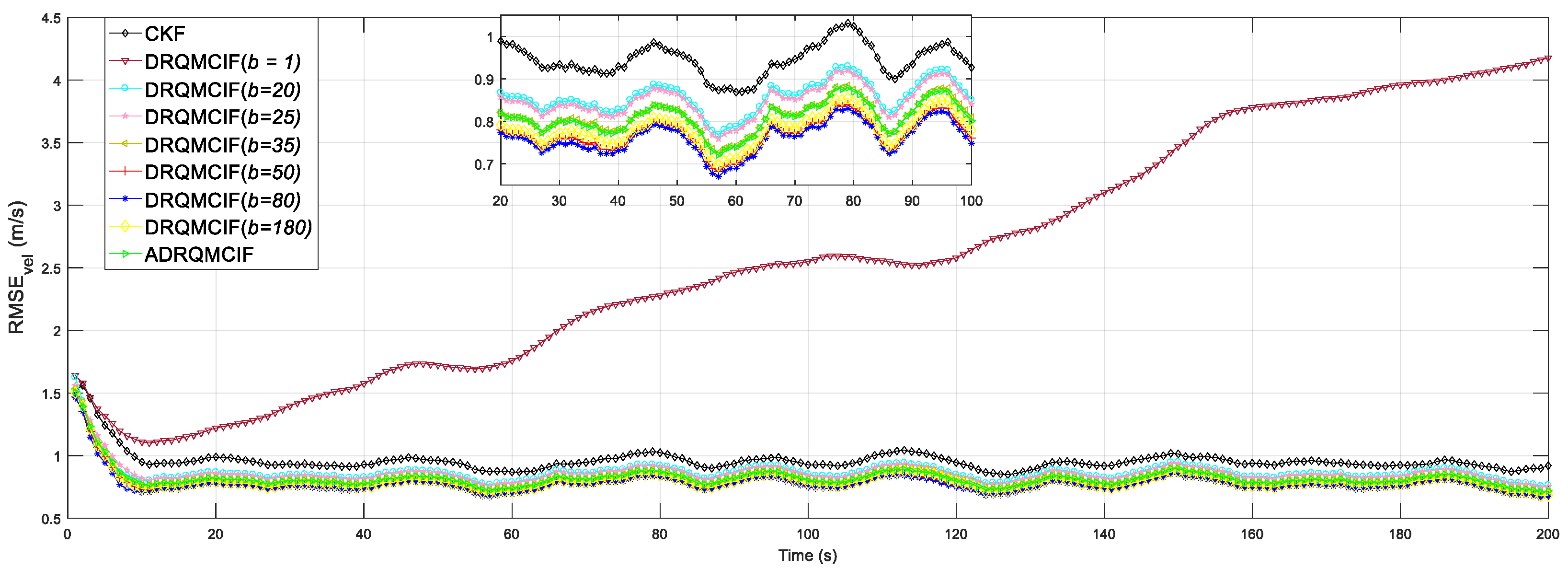
From
Figure 2 and
Figure 3, a too-small kernel width may decrease the estimation accuracy and robustness performance of the proposed DRQMCIF algorithm; for example, the DRQMCIF algorithm is even divergent when the kernel width
b = 1. As the kernel width grows, the ARMSEs under the DRQMCIF algorithm get smaller and smaller, which means that the estimation accuracy is getting higher and higher. However, a too-large kernel width would make the DRQMCIF estimation performance decrease severely. It can easily be seen that the DRQMCIF estimation accuracy with the kernel width
b = 180 is lower than
b = 80. With the increase in the kernel width, the effect of the DRQMCIF algorithm effect reduces to the CKF. Thus, the estimation performance is influenced magnificently by the selection of the kernel width. It is concluded that the optimal kernel width is
b = 80 from
Figure 2 and
Figure 3. According to the simulation results, the kernel width amid [50, 80] can acquire better estimation precision for the proposed DRQMCKF algorithm. The DRQMCIF algorithm result under the adaptive kernel width cannot reach that under the suitable kernel width
b ∈ [50, 80]. Therefore, when the optimal kernel width selects
b = 80, the proposed DRQMCKF algorithm can acquire better estimation precision and robustness performance than that under other kernel widths and adaptive kernel widths.
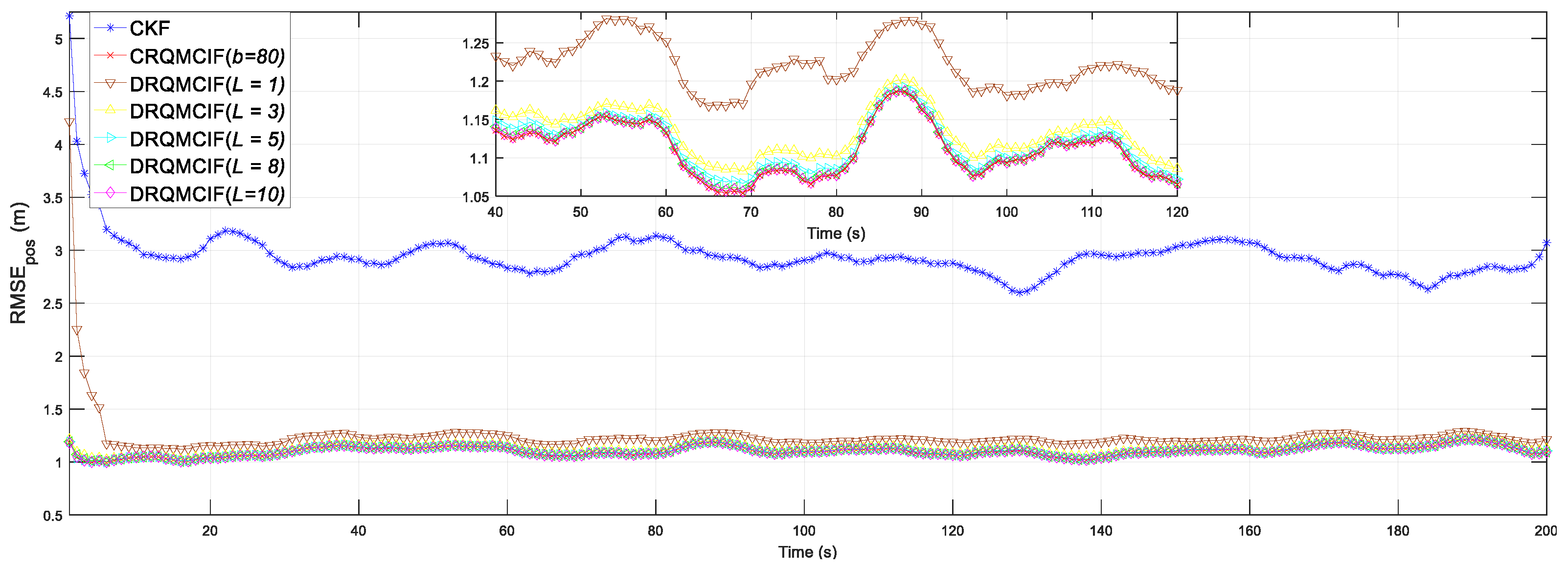
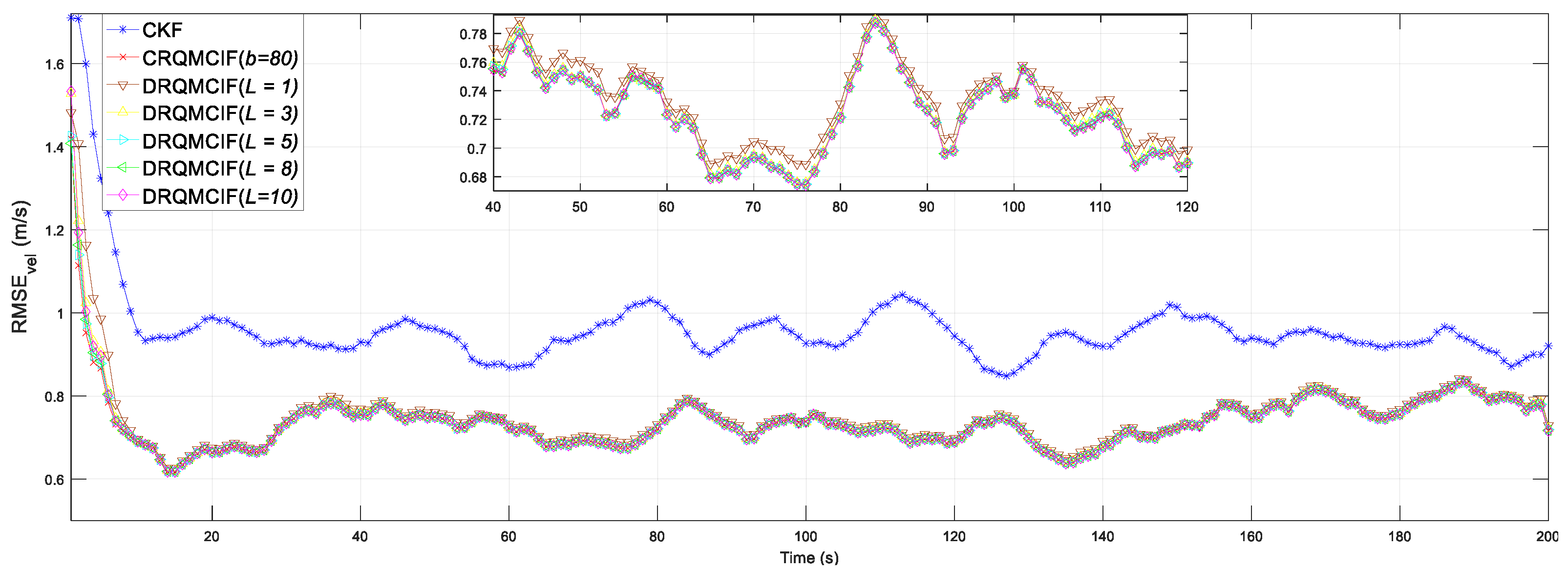
4.3. The Impact of Consensus Iterations
To assess the impact of consensus iterations, the devised DRQMCKF algorithm is simulated for the consensus iteration
L = 1, 3, 5, 8, 10 under the same noise interference (in Equations (55) and (56)) as
Section 4.2. The kernel width is selected as
b = 80 from the conclusion in
Section 4.2. The CRQMCIF and CKF algorithms are employed as the performance counterparts. Both CRQMCIF and DRQMCIF algorithms choose the optimal kernel width
b = 80 obtained in
Section 4.2.
The simulation outcomes are shown in
Figure 4 and
Figure 5. From these two figures, it can be seen that the estimation precision and performance would enhance when the consensus iteration number increases. The proposed DRQMCIF algorithm approximates the performance of the CRQMCIF algorithm when the number of consensus iterations
L = 10, which illustrates that the consensus result of the distributed filtering algorithm will be closer to the global optimum (i.e., the central filtering algorithm) and can improve the accuracy of distributed filtering as the number of consensus iterations increases. When the number of consensus iteration
L = 10, the performance of the proposed DRQMCIF algorithm is approximately equal to that of the CRQMCIF algorithm, which verifies the conclusion just mentioned. On the other side, the distributed algorithm could still acquire relatively better estimation performance under the consensus iteration number
L = 5 and
L = 8, which is of practical application for real sensor networks with limited communication resources. Each consensus iteration requires the exchange of information between nodes. If there are too many iterations, the communication requirements increase significantly, especially in large-scale networks, which may lead to bandwidth exhaustion or increased latency. Therefore, a smaller number of consensus iterations can be chosen in practical applications to avoid possible bandwidth exhaustion or delay increases, for instance, the number of consensus iterations can select
L = 5, which may reach a better estimation performance in the practical engineering application.
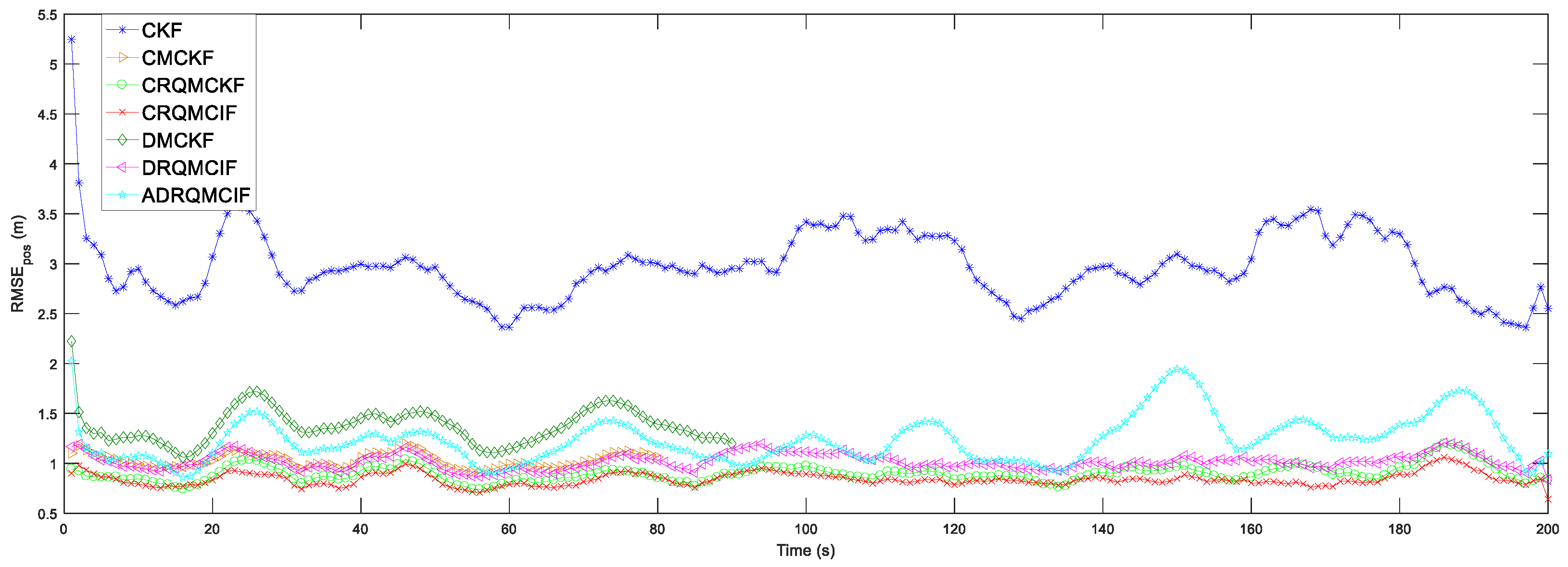
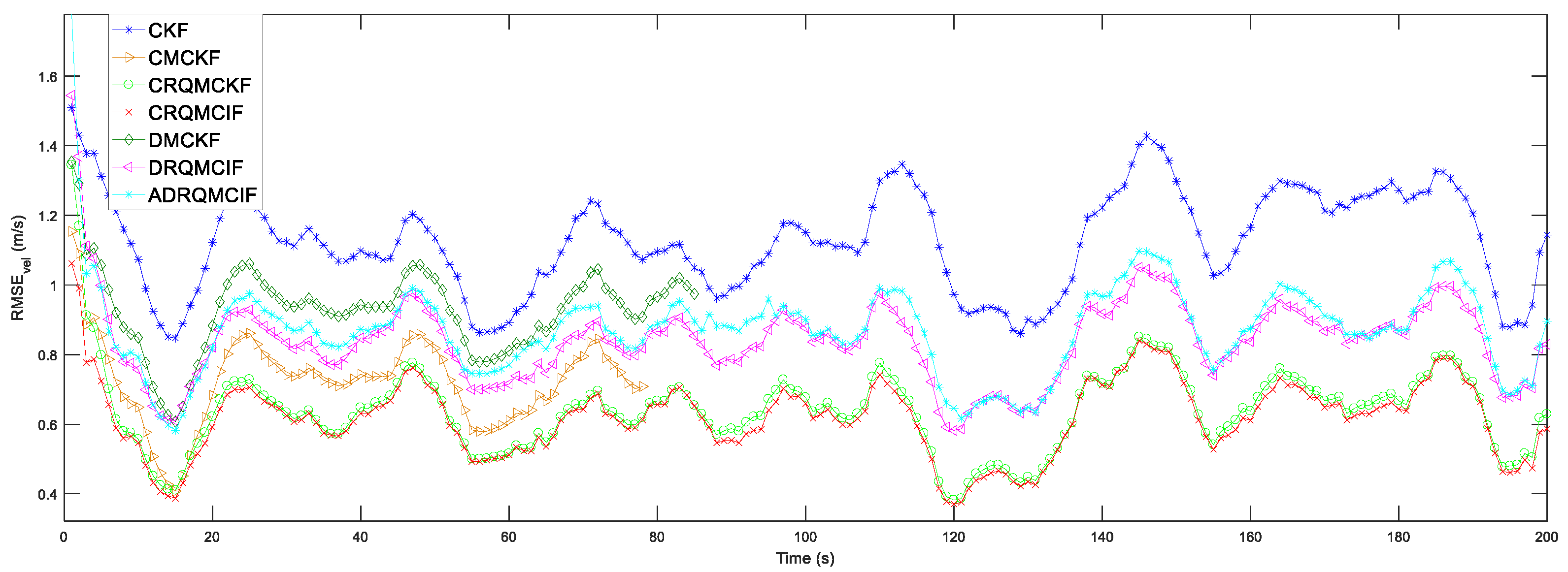
4.4. Comparisons with the Relevant Algorithms
In this subsection, the performance of the proposed algorithms is contrasted with other related filter algorithms under the non-Gaussian noise. The following several algorithms are evaluated: the CRQMCKF (Algorithm 1), the CRQMCIF (Algorithm 2), the DRQMCIF (Algorithm 3), the (ADRQMCIF) (Algorithm 4), the CKF, the centralized maximum correntropy Kalman filter (CMCKF) [
20] and the distributed maximum correntropy Kalman filter (DMCKF) [
37]. The three performance indexes are adopted in the following discussion, which are RMSEs and ARMSEs of the position and velocity defined in
Section 4.1, and the single-step run time (SSRT), separately.
In the following simulation comparisons, the kernel width under the DRQMCIF algorithm is selected as
b = 80 according to the discussion in
Section 4.2 and the consensus iterations are chosen as
L = 10 according to the discussion in
Section 4.3. To ensure a fair evaluation, the kernel width of the existing CMCKF is set as
σ = 2 because this configuration provides better estimation performance compared to
σ = 80 under these specified simulation conditions according to the results in the reference article [
20]. For the ADRQMCIF algorithm, the pre-setting maximum kernel width selects
bmax = 90 according to the conclusion in
Section 4.2, and the confidence level factor is chosen as
= 3.5. The two scenarios where the process and measurement noises are set as Gaussian-mixture and t non-Gaussian noise, respectively.
4.4.1. Scenario 1
In scenario 1, the process and measurement noises are assumed as the Gaussian-mixture noises, which is one of the representatives of common non-Gaussian noise,
where
and
are the same as in
Section 4.2.
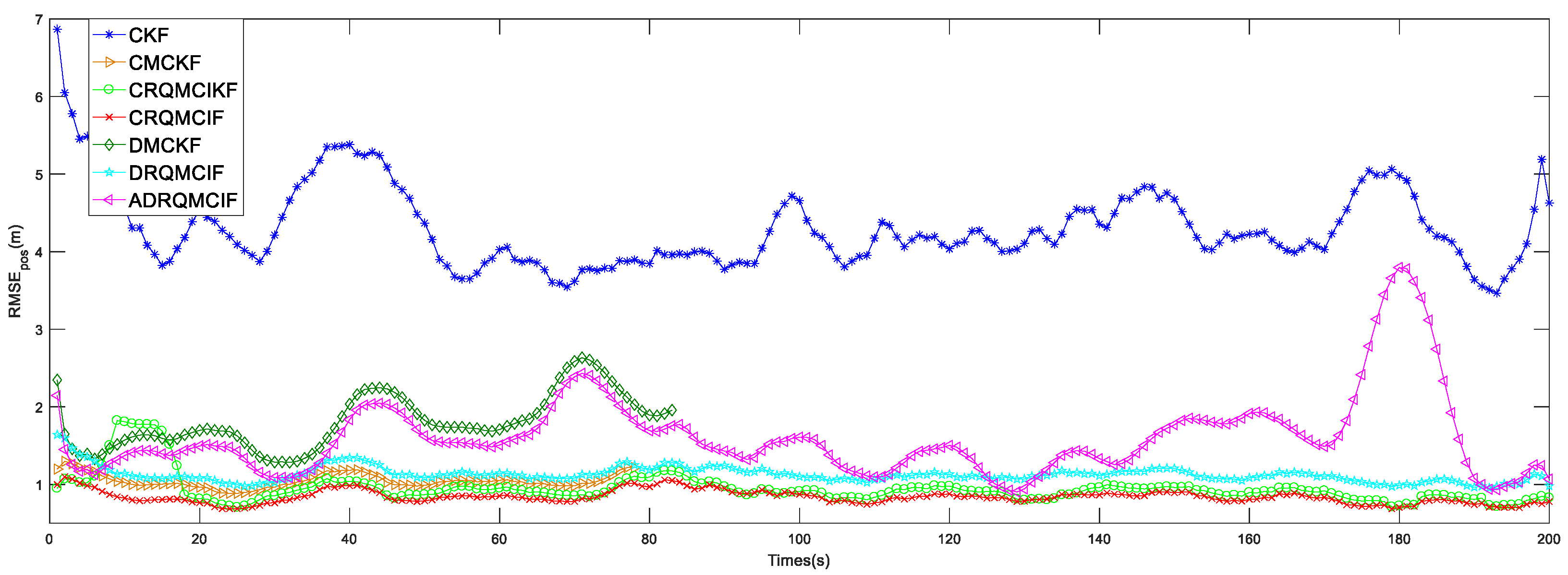
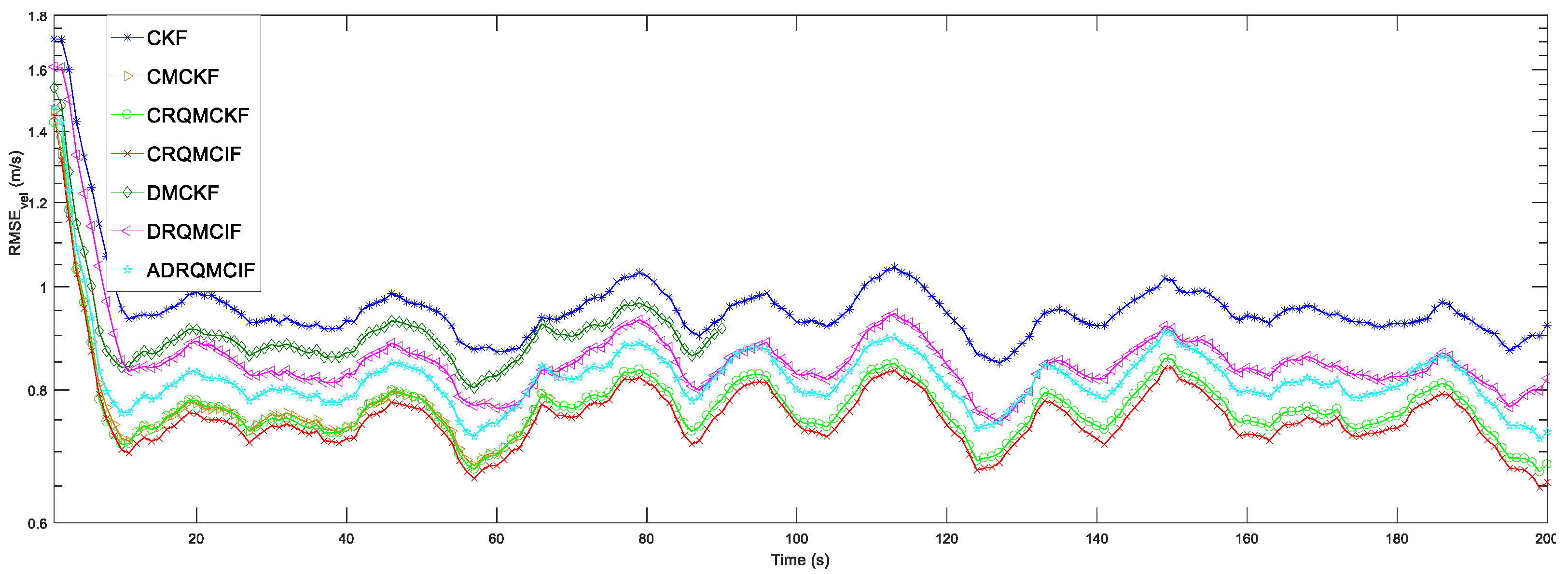
The simulation outcomes under Gaussian-mixture noise are displayed in
Figure 6 and
Figure 7 and
Table 2. The estimation capability of the CKF algorithm is the worst among all algorithms due to the breakdown of the Gaussian noise assumption since the CKF algorithm is suitable to be employed in Gaussian noise problems. The RMSEs and ARMSEs of the position and velocity in these CMCKF, CRQMCKF, CRQMCIF, DRQMCIF, and ADRQMCIF algorithms are less than that of the CKF algorithm for all these algorithms and are based on MCC, which is specialized in handling the non-Gaussian noise problems. From
Table 2, compared with the CMCKF algorithm, the proposed CRQMCIF algorithm improves the ARMS
pos by 13.18%, the ARMSE
vel by 4.75%, and the single-step run time (SSRT) by 13.89%; the proposed CRQMCKF algorithm improves the ARMS
pos by 13.18%, the ARMSE
vel by 4.75%, and the single-step run time (SSRT) by 17.12%. These outcomes illustrate that the estimation precision of the CRQMCIF algorithm is equivalent to that of the CRQMCKF algorithm and the single-step run time of the CRQMCIF is higher than that of the CRQMCKF algorithm since the information matrices increase the computational burden. Compared to the DMCKF algorithm, the proposed DRQMCIF in this paper improves the ARMS
pos by 1.93‰, the ARMSE
vel by 2.51%, and the single-step run time (SSRT) by 28.33%. However, the ARMS
pos, the ARMSE
vel, and the single-step run time (SSRT) of the ADRQMCIF algorithm are degraded because adaptive filtering recalculates the kernel width at each step based on error, which does not achieve the performance of the DRQMCIF under the optimal kernel width and leads to an increase in the computation time.
From
Figure 6 and
Figure 7, it can be seen that the proposed CRQMCKF, CRQMCIF, DRQMCIF, and ADRQMCIF algorithms based the rational quadratic kernel function can run to the specified step length and end prematurely compared to the CMCKF and DMCKF algorithms based the Gaussian kernel function. The CMCKF and DMCKF algorithms are unable to reach the required step and end the algorithm prematurely because the Gaussian kernel function induces a singular matrix. Compared with the Gaussian kernel function, the rational quadratic kernel function offers several advantages: it is robust to outliers and non-Gaussian noise; it can avoid the appearance of the singular matrices; it has lower computational complexity for that rational quadratic kernel function and avoids the exponential operation and thus reduces a large amount computational burden. These several benefits make the rational quadratic kernel function more suitable for data characterized by non-Gaussian heavy-tailed noise or large outliers. In contrast, the Gaussian kernel function is more sensitive to outliers and has a higher computational expense. However, the estimation performance of the ADRQMCIF algorithm cannot reach that of the DRQMCIF algorithm with the optimal kernel width. When the optimal kernel width cannot be determined in the practical engineering application, the ADRQMCIF algorithm can be an alternative algorithm to deal with the distributed state estimation problem under non-Gaussian noise interference.
4.4.2. Scenario 2
In scenario 2, the process and measurement noises are assumed to obey
t distribution with the degree of freedom 1,
t distribution is one of the probability distributions that is similar to the normal distribution with its bell shape but has heavier tails and is one of the non-Gaussian noises. The probability distribution function of the
d1-dimension
t distribution is
where
,
is the mean vector,
denotes the covariance matrix or scale matrix satisfying
,
is the freedom,
is gamma function, and
.
The simulation results under
t noise (which is another non-Gaussian noise) are exhibited in
Table 3 and
Figure 8 and
Figure 9. Since
t noise destroys the assumption of Gaussian noise, which is a prerequisite for the good estimation performance of the CKF algorithm, the estimation performance of the CKF algorithm is significantly worse than the other algorithms. From
Table 3, compared to the CMCKF algorithm, which is based on the Gaussian kernel function, the proposed CRQMCKF increases the ARMS
pos by 10.91%, the ARMSE
vel by 5.45%, and the single-step run time (SSRT) by 14.08%; the proposed CRQMCIF algorithm improves the ARMS
pos by 12.59%, the ARMSE
vel by 4.16%, and the single-step run time (SSRT) by 8.88%. These results show that the estimation accuracy of the CRQMCKF algorithm approximates that of the CRQMCIF algorithm and the single-step run time of the CRQMCIF is larger than that of CRQMCKF algorithm because the information matrix enhanced the computation burden of the CRQMCIF algorithm. Compared to the DMCKF algorithm, the proposed DRQMCIF in this paper improves the ARMS
pos by 1.67‰, the ARMSE
vel by 2.51%, and the single-step run time (SSRT) by 26.57%, whereas the ARMS
pos, the ARMSE
vel, and the single-step run time (SSRT) of the ADRQMCIF algorithm are higher than that of the DMCKF algorithm since adaptive filtering needs to repeatedly calculate the corresponding kernel width according to the different error values at each step, which cannot reach the estimation performance of the DRQMCIF with the optimal kernel width and meanwhile results in an increase in the SSRT computation time.
From
Figure 8 and
Figure 9, it can easily be concluded that the presented CRQMCKF, CRQMCIF, DRQMCIF, and ADRQMCIF algorithms can arrive at the assigned step length; however, the CMCKF and DMCKF algorithms based on Gaussian kernel function were forced to end early. When the Gaussian function encounters a large outlier, its function rapidly becomes smaller or even tends to 0. When its function value exceeds the calculation accuracy of the computer, a singular matrix will appear and the algorithm will be forced to end early. The rational quadratic kernel function can easily avoid this situation. Simultaneously, the rational quadratic kernel function is only operated by addition, subtraction, multiplication, and division, so the exponential operation is avoided, and the computational complexity of the related algorithms will be reduced. Finally, the estimation accuracy of the ADRQMCIF algorithm cannot acquire that of the DRQMCIF algorithm with the optimal kernel width. When the optimal kernel width cannot be obtained in the engineering application, the ADRQMCIF algorithm can be chosen to resolve the distributed state estimation problems interfered with by the large outlier non-Gaussian noise.
In sum, from the discussion of two different non-Gaussian noises, Scenario 1 and Scenario 2, it can be seen that the distributed maximum correntropy linear algorithms based on rational quadratic kernel function are superior to the corresponding algorithms based on the Gaussian kernel function.
6. Conclusions
In this paper, some centralized and distributed maximum correntropy linear filters based on a rational quadratic kernel function are devised for state estimation over the sensor network system under the non-Gaussian noise, where each sensor transmits solely to its neighboring sensors without the need for a fusion center. A classical target tracking numerical simulation over the sensor network displays the performance and robustness of the proposed filter algorithms based on the appearance of the non-Gaussian noise interference. The proposed distributed algorithms can achieve a balance between the estimation precision and exchange burden when the optimal kernel width b = 80 is obtained. Although the optimal consensus performance is achieved when the number of iterations is selected to L = 10, the case of L = 5 still provides satisfactory estimation results in practical scenarios. Importantly, reducing the number of iterations to L = 5 leads to a notable decrease in the computational load. As such, adopting L = 5 represents a practical compromise that maintains acceptable estimation accuracy while significantly improving the computational efficiency. Further, when the optimal kernel width cannot be predetermined, the adaptive kernel distributed filter is a kind of substitute algorithm that can approximate the estimation performance in the practical application. However, several problems need to be further researched in future work as follows: the distributed maximum correntropy algorithms based on a rational quadratic kernel function can be extended to a nonlinear sensor network system operation under non-Gaussian noise interference. The authors are required to learn more methods that can also be against non-Gaussian noise interference to be used as comparison algorithms. Additionally, to improve the practical engineering application value, it should address more cost-effective sensor network-evoked scenarios, for example, packet loss, data delay, and a time-varying topology network (i.e., dynamic sensor network).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}