5.5.1. Comparison of Loegised with SOTA Methods HSFLA and Gurobi Solver
To verify the correctness and effectiveness of the model, comparison experiments between Loegised and the Gurobi solver were conducted on test cases of different sizes. Following the experimental setup in [
14], test cases containing 6 to 17 customer points were generated based on FP11, denoted as FP11_06 to FP11_17, with FP12 and FP01 selected as additional test cases. FP11_06 to FP11_17 contain the first 4 to 15 customer points from FP11, including the super close and ultra far points. Let
,
, and the termination time for Gurobi is set to 1800 s. In
Table 2, the best result for each test case is marked in bold, ‘*’ indicates that Gurobi did not find the optimal solution for the case, and ‘-’ indicates that Gurobi could not find a feasible solution within the termination time, with
t representing the time.
The experimental results show that the method proposed in this paper has a significant advantage in solving the vehicle–multi-drone cooperative delivery problem with transportation constraints. By comparing with Gurobi, it can be observed that our algorithm performs excellently in terms of solution quality, computational efficiency, and scalability to large test cases. As a mathematical optimization solver, Gurobi typically finds the theoretical optimal solution for small-scale problems. However, as the problem size increases, Gurobi’s solution time increases dramatically, and it even fails to complete the optimization within the specified time. For example, in the case with 10 customers (FP11_10), Gurobi’s running time has already reached 1800 s, while our method completes the solution in only 9.50 s, with the best solution quality almost equal to that of Gurobi (8.46 and 8.47, respectively). In larger test cases (such as FP01), Gurobi fails to find a solution, while Loegised is still able to provide a high-quality solution (BST of 13.03). These results indicate that our method not only effectively handles complex problems but also demonstrates exceptional computational efficiency in large-scale scenarios.
Variance and Robustness Analysis
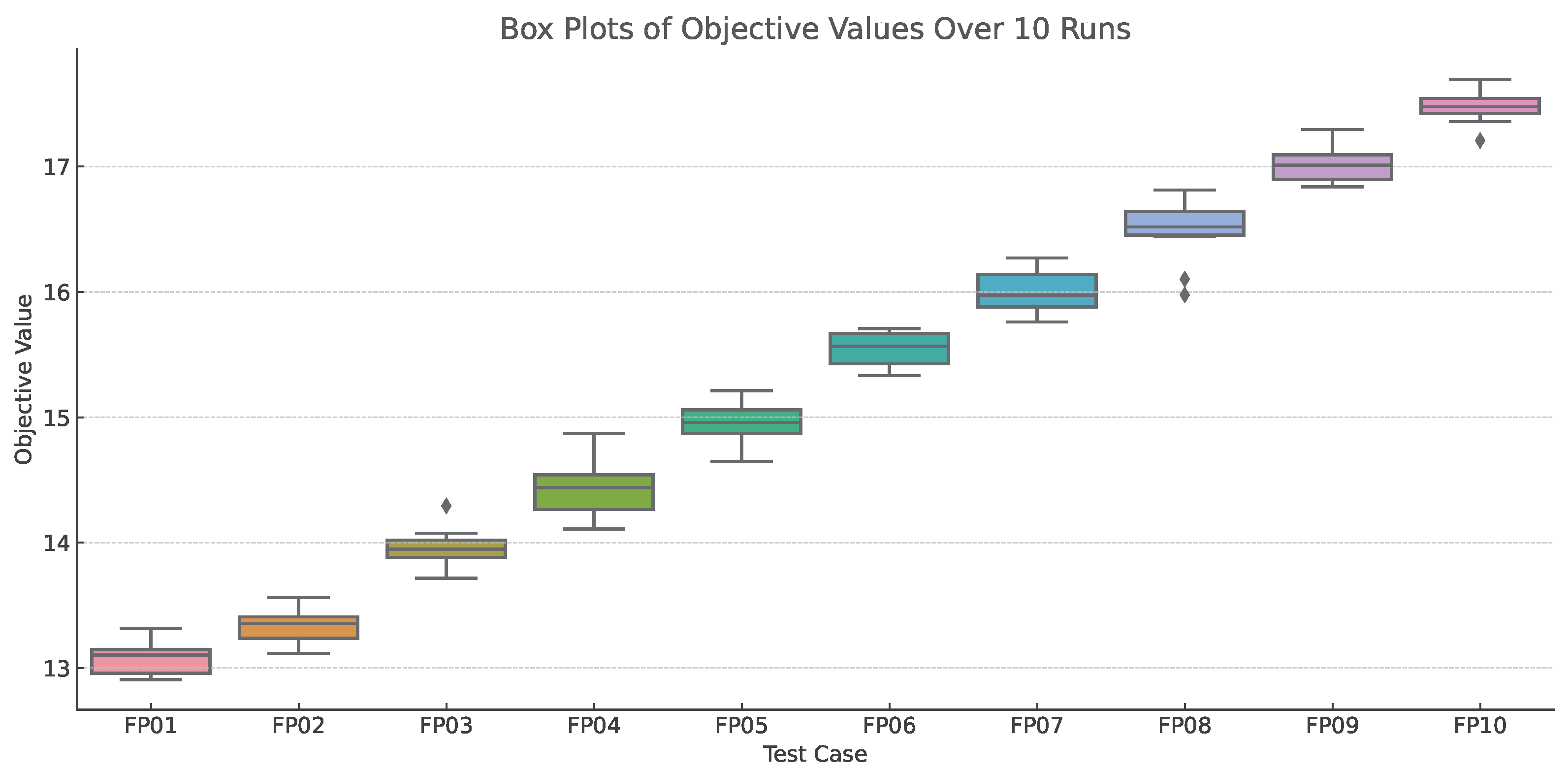
To enhance the robustness evaluation of our approach, we supplemented the comparative experiments with additional metrics—specifically, the worst-case results and the standard deviation (variance) across 10 independent runs. This enables a more comprehensive assessment of the consistency and stability of the Loegised algorithm relative to other baseline methods. Results from cases such as FP06 and FP09 show that Loegised not only achieves the best average performance but also exhibits low variance (e.g., standard deviation below 0.15), indicating stable convergence behavior. In contrast, methods like IPGA and ALNS show higher fluctuation, with standard deviations often exceeding 0.5 in large-scale scenarios.
Moreover, the worst-case performance of Loegised remains close to its average, demonstrating its ability to avoid poor solutions across different runs. For example, in FP08, the worst delivery cost using Loegised is only 0.35 higher than its best, compared to variances exceeding 1.0 for IPGA. These findings confirm that Loegised provides both effective and reliable optimization, which is essential for practical logistics applications where stability is critical.
5.5.2. Ablation Study Results
Table 3 shows the results of the ablation study for different test cases, aiming to assess the contribution of the three optimization modules proposed in this paper—population initialization optimization, dynamic operator parameter adjustment, and local optimum escape mechanism—on the overall algorithm performance. By gradually ablating these modules, we can better observe their impact on the algorithm’s performance. As can be seen from the table, as the complexity of the test cases increases, the role of each module becomes more significant.
For test cases with smaller customer sizes (e.g., FP01, FP02, FP11, and FP12), the performance difference between Loegised and the algorithm with one module ablated is not significant. These test cases are characterized by relatively small problem sizes and a limited search space, which allows the genetic algorithm to quickly find approximate optimal solutions even without the optimization modules. Therefore, for these simpler test cases, the effect of the three optimization modules on the solution quality is not prominent. Among these simple test cases, the impact of the population initialization optimization module is relatively small, and is especially notable for its minor effect. Given the small problem size, the initial solution does not significantly influence the final result. However, with module ablation, there is a slight decrease in performance. For example, in the FP01 test case, the difference between Loegised-1 (removing the population initialization optimization module) and Loegised-2 (removing the dynamic operator parameter adjustment module) is small. This indicates that for simpler problems, the initial search capability of the genetic algorithm is strong, and the role of optimization modules in performance improvement is relatively limited.
As the complexity of the test cases increases, such as with the medium-sized cases FP03, FP06, and FP07, the performance differences from ablation modules begin to emerge. In these test cases, the ablation of the optimization modules leads to performance degradation, particularly in terms of BST and AVG results, with the ablation magnitude gradually increasing. These test cases are characterized by an expanding search space, and the impact of ablating optimization modules on the algorithm’s performance becomes more apparent. In these medium-complexity cases, the roles of the dynamic operator parameter adjustment module and the local optimum escape mechanism module begin to stand out. In particular, the ability to dynamically adjust the crossover and mutation rates provides greater flexibility in adjusting the search strategy. In FP06, Loegised-1 (removing the population initialization optimization module) performs worse than Loegised-2 (removing the dynamic operator adjustment module), where the latter shows a more significant performance decline, indicating the importance of dynamic operator parameter adjustment for stability and convergence. Furthermore, the local optimum escape mechanism helps improve solution quality by preventing the algorithm from becoming stuck in local optima. This is particularly evident in FP07, where Loegised-3 performs better than the version without this mechanism.
For high-complexity test cases (e.g., FP08, FP09, and FP10), the performance differences due to module ablation become more significant. These test cases typically involve larger customer sizes and more complex delivery paths, making the algorithm more reliant on the optimization modules to search the solution space. In these complex test cases, the role of optimization modules becomes indispensable, and the ablation of any module results in a noticeable performance drop. This effect is especially pronounced when two modules are simultaneously ablated. In these high-complexity test cases, the contributions of all three optimization modules become particularly important, with the population initialization optimization module playing an especially crucial role. In the FP09 test case, Loegised achieved a BST of 18.73 and AVG of 19.87, whereas Loegised-1 (removing the population initialization optimization module) resulted in a BST of 20.50 and AVG of 21.00, highlighting the critical role of this module in improving search efficiency. As the customer size increases, the contributions of the dynamic operator parameter adjustment module and the local optimum escape mechanism module become more prominent in avoiding local optima and adjusting search strategies. In FP10, the performance drops sharply when these two modules are removed, indicating their importance in optimizing the search process for large-scale problems.
5.5.3. Comparison Results of Loegised with Baseline Methods
The parameters of the baseline algorithms are listed in
Table 4. Specifically, the table includes the following parameters:
(population size),
(runtime),
(initial temperature),
(reaction parameter),
q (cooling factor), and
L (chain length). Since the MDVCP-DR problem involves various complex constraints, existing strategies are unable to ensure solution feasibility. Therefore, the initial solution generation and encoding–decoding process for all baseline algorithms are implemented using the method proposed in this paper. In the SA algorithm, the initial temperature is set to
, but due to the optimization objective in [
29] being different from that considered in this paper, the original parameters are no longer applicable. To adapt to the objective in this paper, the cooling factor has been adjusted to 0.01 as per [
30]. Additionally, since the encoding method in this paper does not include the information about whether the customer is served by a drone or a vehicle, the neighborhood structure in ALNS does not explicitly specify whether the path is a drone path or a vehicle path. For IPGA, based on the study by Zhou et al. [
31], it uses a sequence breakpoint-encoding method, whereas this paper uses only sequence encoding, so only the adjustments related to the sequence are applied in IPGA. Other parameters and settings remain consistent with the source literature. In the specific experiment, the vehicle and drone payloads are set to
and the time limit is set to
.
Table 5 shows the comparison of the Loegised method with six baseline methods (BB, CPM, SA, ALNS, IPGA, and HSFLA) on multiple test cases. The results from the comparison between the BB, CPM, IPGA, SA, ALNS, and HSFLA algorithms on FP01–FP12 are used for further analysis.
Table 5 presents the experimental results comparing the Loegised method with the other six baseline methods (BB, CPM, SA, ALNS, IPGA, and HSFLA) across multiple test cases. The comparison clearly shows that the Loegised method consistently outperforms all other methods, especially in test cases with larger customer sizes and higher problem complexities, where the method demonstrates outstanding global search capability, fast convergence, and high solution quality. For test cases with smaller customer sizes, such as FP01 (33 customers), FP02 (46 customers), and FP11 (17 customers), the advantages of the Loegised method are still evident. Despite the relatively small search space in these cases, the performance differences across all algorithms are minimal, but the BST and AVG values for Loegised remain lower than those for other baseline methods. For example, in the FP01 test case, Loegised achieved a BST of 12.90 and an AVG of 13.32, outperforming SA (13.38, 13.57) and ALNS (13.33, 13.75) with superior performance. Similarly, in test cases like FP02 and FP11, Loegised consistently maintained lower solution values, reflecting its strong solution quality and stability. Notably, BB and CPM also performed well in small-scale cases, particularly in FP01 and FP02, where their BST and AVG values were better than most heuristic algorithms. In FP01, BB’s BST was 13.20 and AVG was 13.60, while CPM’s BST was 13.30 and AVG was 13.65, outperforming SA (13.38, 13.57) and ALNS (13.33, 13.75), showing the clear advantage of exact algorithms for small-scale problems. The same trend was observed in FP02, where BB and CPM produced significantly lower solution values compared to heuristic algorithms, further proving the superiority of exact algorithms for small-scale problems.
As the problem size increases, especially in medium-sized cases such as FP03 (56 customers), FP06 (52 customers), and FP07 (77 customers), the advantages of Loegised begin to emerge more clearly. In FP03, Loegised achieved a BST of 13.76 and an AVG of 14.08, which were significantly better than ALNS (13.98, 15.29) and IPGA (18.85, 20.43). Moreover, although BB and CPM still performed relatively well, their BST and AVG values gradually increased as the problem size grew. In FP03, BB’s BST was 14.20 and AVG was 14.40, while CPM’s BST was 14.10 and AVG was 14.50, showing a noticeable gap in solution quality compared to Loegised, especially in medium-complexity problems. In FP06 and FP07, Loegised continued to excel, with particularly impressive performance in FP07 (77 customers), where Loegised achieved a BST of 14.02 and an AVG of 14.45, outperforming BB (16.50, 17.85) and CPM (16.80, 17.50). This further validates the advantage of Loegised in medium-sized problems, particularly in the presence of complex constraints and a large solution space, where heuristic algorithms can converge more quickly and obtain high-quality solutions.
In high-complexity test cases (such as FP08, FP09, and FP10), the advantages of Loegised become even more evident. These test cases involve larger customer sizes and broader solution spaces, where traditional algorithms often perform poorly in terms of convergence speed and solution quality. In the FP09 (152 customers) and FP10 (201 customers) test cases, Loegised achieved a BST of 18.73 and an AVG of 19.87, and a BST of 21.51 and an AVG of 22.63, respectively, while SA and ALNS showed significant performance drops. For example, in FP09, SA’s BST was 22.85 and AVG was 23.71, while ALNS’s BST was 21.46 and AVG was 22.76, all falling behind Loegised’s performance. In large-scale test cases, BB and CPM’s computational complexity limited their performance, with BB’s BST in FP09 being 28.50 and AVG being 30.90, and CPM’s BST being 29.20 and AVG being 30.40, all significantly lagging behind Loegised.
The comparison shows that while BB and CPM demonstrate strong performance in small-scale problems, heuristic algorithms like Loegised become more advantageous as the problem size increases, especially in medium- and large-scale problems. Overall, the Loegised method consistently performs well across all test cases, especially in high-complexity problems, where its fast convergence and high solution quality significantly outperform exact algorithms.
To further validate the significance of performance differences, we conducted statistical significance tests on the average results across all test cases. As shown in
Table 6, we performed a Wilcoxon signed-rank test on the average delivery time (AVG) over FP01–FP12. As shown in
Table 6, Loegised significantly outperforms all six baselines, with
p-values well below 0.01. These results confirm that the improvements are statistically significant and not due to random variation.
To ensure a fair comparison, all baseline methods were adapted to use the same solution encoding and decoding mechanisms as Loegised, aligning with the problem’s unique constraints. This standardization avoids performance discrepancies caused by inconsistent representations. Nonetheless, we recognize that some newer metaheuristics, such as RFO or COA, were not included in the current study. Integrating such state-of-the-art optimizers is a promising direction for future work to further validate the competitiveness of Loegised.
5.5.4. Sensitivity Analysis
To explore the sensitivity of the Loegised algorithm under different drone parameters, this experiment tests the algorithm’s performance with various combinations of drone endurance and payload capacity limits. We selected the large-scale test case FP08, which contains 102 customers, and conducted 10 independent runs for each combination of
and
. The average result (AVG) for each experiment was recorded.
Table 6 lists the AVG values for each set of experiments, with the best result in each experiment highlighted in bold.
From
Table 7, it can be seen that the Loegised algorithm consistently exhibits optimal performance across all drone parameter configurations. For example, in Experiment 1 (
), Loegised achieved an AVG of 15.76, significantly outperforming HSFLA (16.09), SA (17.09), ALNS (16.78), and IPGA (21.18). This optimized performance demonstrates the strong sensitivity advantage of the Loegised method to different drone parameter configurations. Particularly, when handling different combinations of endurance and payload capacity, Loegised consistently generates optimal task scheduling solutions, improving delivery efficiency and reducing total delivery time.
Further analysis shows that even under extreme conditions, such as higher payload and endurance times, Loegised maintains higher stability and adaptability. For instance, in Experiment 25 (), Loegised achieved an AVG of 14.13, showing a noticeable improvement compared to other methods (such as HSFLA’s 14.67, SA’s 14.98, ALNS’s 14.87, and IPGA’s 17.41), further validating the advantage of Loegised when facing complex constraint conditions.
To further validate the reliability and convergence behavior of our proposed Loegised method, we present the visualization in
Figure 7. Box plots of objective values over 10 independent runs for selected test cases are provided to assess solution stability and variation. The visual results demonstrate both the consistency and efficiency of Loegised across different problem scales.
Ethical and Operational Considerations: The integration of generative AI models such as LLMs into logistics systems introduces critical ethical and operational concerns. Reliability must be ensured, especially under high-stakes delivery scenarios. Additionally, the use of external APIs or cloud-based inference raises data privacy concerns regarding customer locations and delivery schedules. Failure recovery strategies should also be incorporated to address potential LLM misbehavior or service interruptions. These aspects are essential for translating research into real-world, safe logistics deployment and are important directions for the future refinement of Loegised.
LLM Dependency and Interpretability: While Loegised benefits from LLM-guided initialization and dynamic operator adjustment, such dependence may introduce risks due to the opaque nature of LLMs. Over-reliance could reduce interpretability and make the behavior of the system harder to validate. To mitigate this, future work will explore hybrid frameworks, combining LLM reasoning with rule-based validation to enhance transparency and reliability.




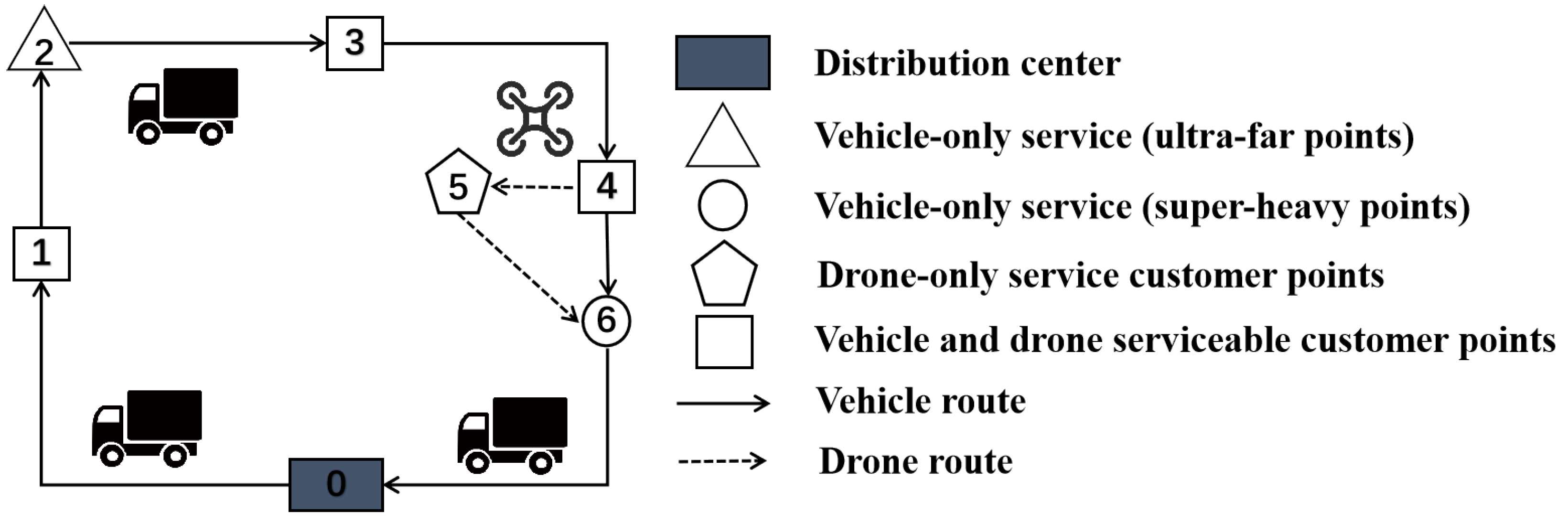


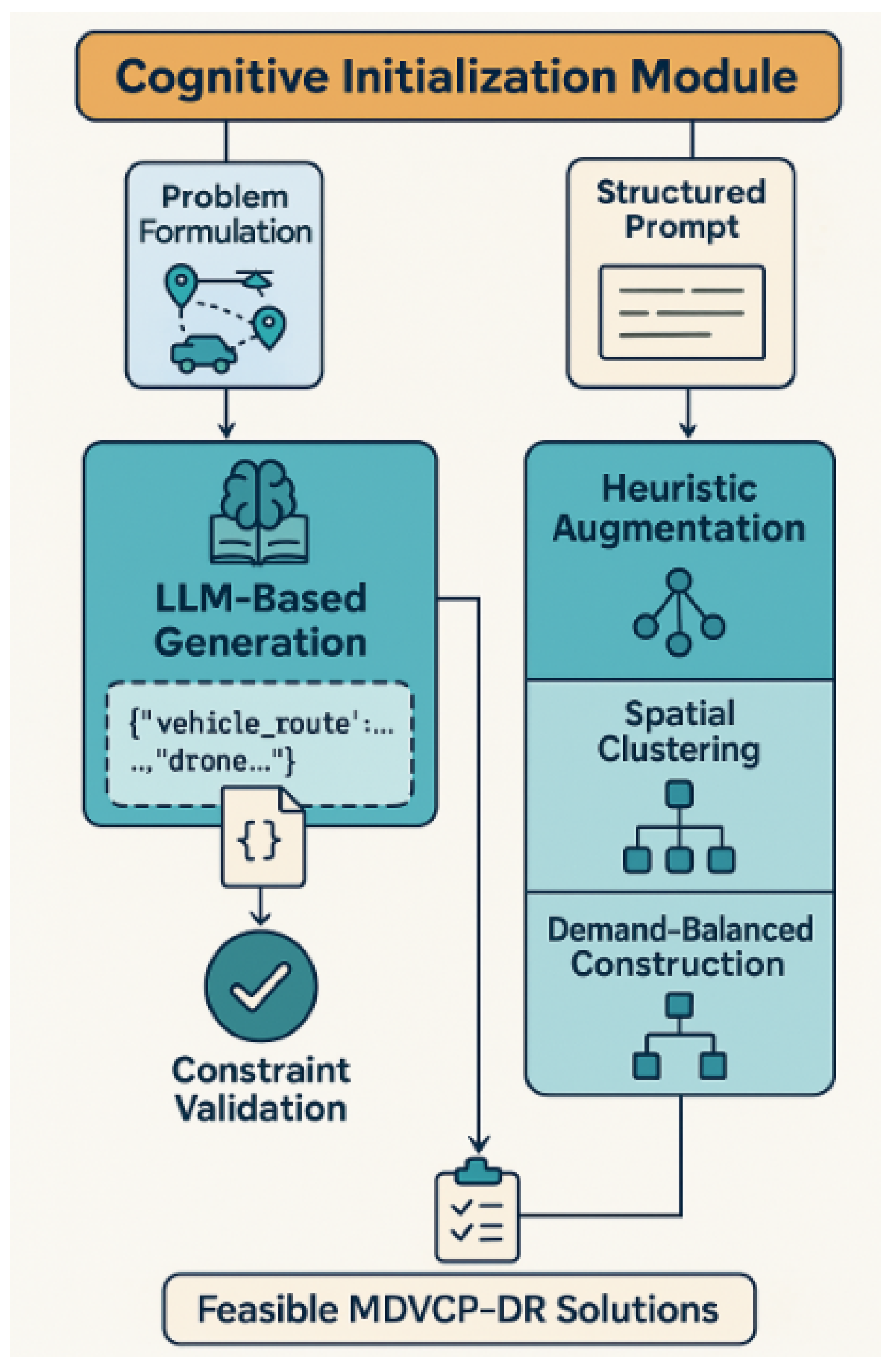
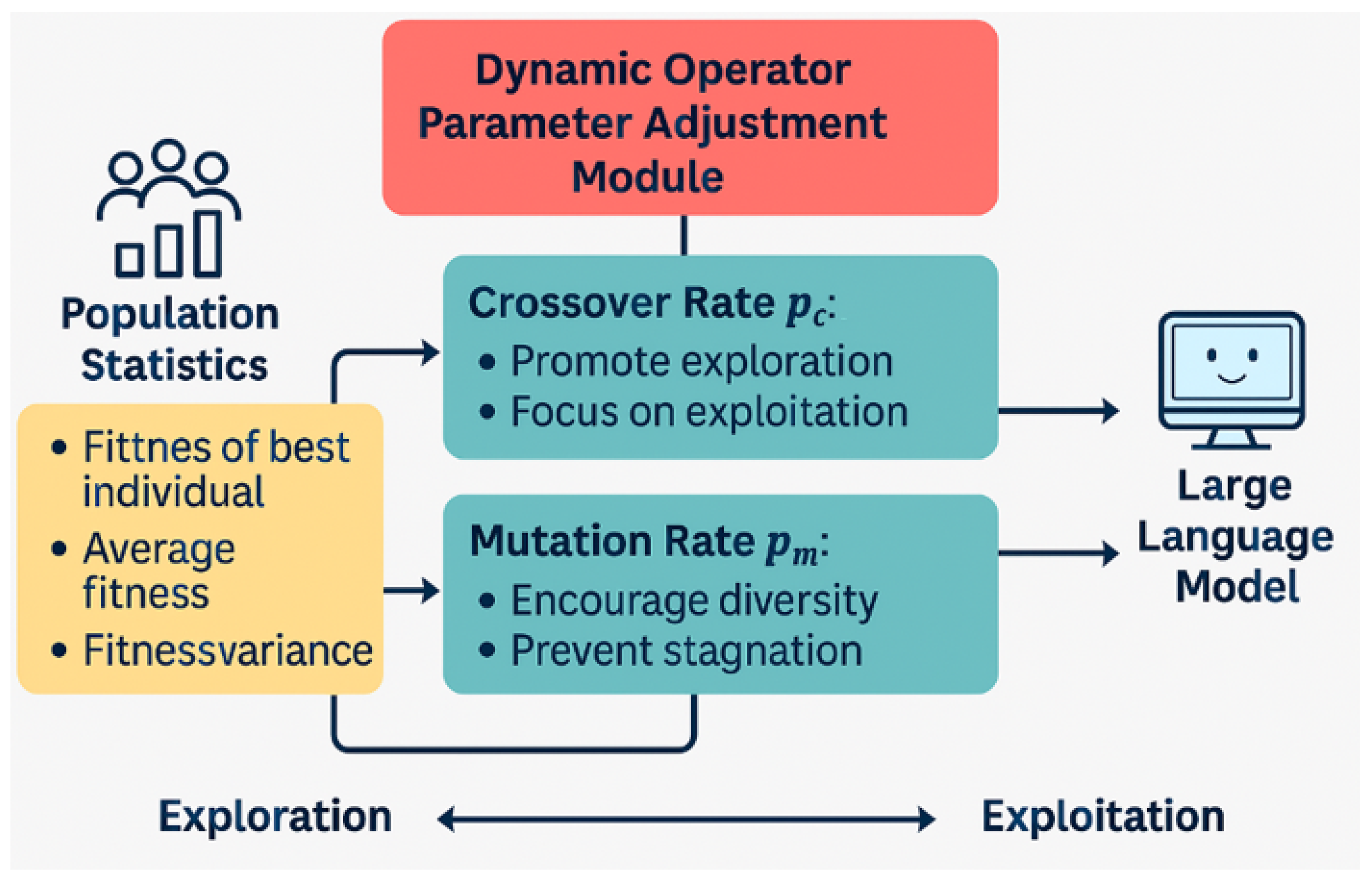
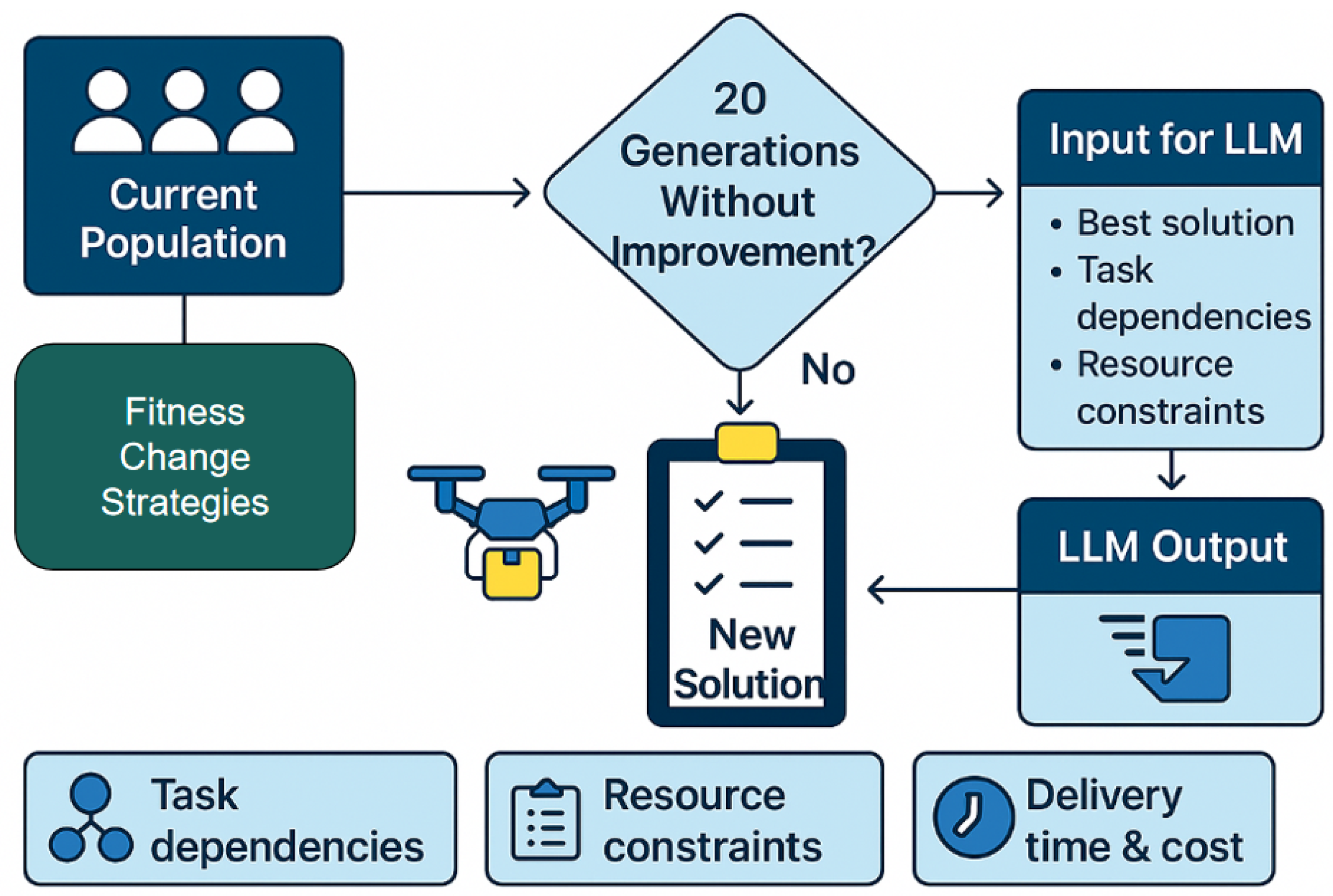

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}