1. Introduction
Through the deep integration of data centers, cloud computing, and big data, the “East Data West Computing” project has built a new computing power network architecture, effectively promoted the integration of data processing, and optimized the supply and demand balance of resource equipment. It promotes the efficient interconnection of the Internet and reduces carbon emissions to a large extent. For example, with the support of the architecture of “counting in the East and counting in the West”, remarkable achievements have been made in task unloading [
1], resource integration [
2], and data integration [
3]. However, with the exponential growth of data volume [
4], the problem of unbalanced resource load has gradually become prominent, which can be attributed to the lack of symmetry in task allocation and resource utilization. To solve this problem effectively, it is urgent to scientifically and reasonably allocate the tasks with data to the corresponding computing resources, requiring algorithms to maintain symmetry between exploration and exploitation. At present, common task scheduling methods include the first-come-first-served (FCFS) [
5], which treats all tasks as undifferentiated and only takes the arrival time of tasks as a scheduling standard. Although its implementation is simple, it does not consider the task’s performance and specific requirements, which may lead to an unbalanced computer load, resulting in long task blocking and other problems. In round robin (RR) [
6], each time slice is assigned to a task and switches to the next task when the time slice of a task is used up, ensuring that each task has an equal opportunity to execute. However, because this method does not consider the priority of tasks, it cannot effectively solve the task method problem with correlation. The highest response ratio next (HRRN) [
7] scheduling algorithm determines the execution order of tasks by comprehensively considering the time spent waiting and execution time of tasks, and fully considers the time proportion of tasks, but does not consider the assignment of tasks from the perspective of load, which may cause tasks to be concentrated on a certain computing resource, which affects the system performance. The shortest process first (SPF) [
8] algorithm reduces the average system response time by selecting the task with the shortest waiting time. However, tasks of a large scale and high priority cannot be processed for a long time, resulting in task hunger.
Compared with the classical method, intelligent optimization algorithms show an excellent ability in solving optimization problems and make great efforts in various fields, for instance, working on images [
9], feature selection problems [
10], path planning [
11], and natural language processing [
12]. In this paper, we categorized intelligent optimization algorithms into four groups: intelligent optimization algorithms based on mathematical theory; intelligent optimization algorithms based on physics; intelligent optimization algorithms based on biology; and intelligent optimization algorithms based on human behavior. Among them, mathematical intelligent optimization algorithms include particle swarm optimization (PSO) [
13], arithmetic optimization algorithm (AOA) [
14], sine cosine algorithm (SCA) [
15], subtraction-average-based optimizer (SABO) [
16], and the exponential distribution optimizer (EDO) [
17]. In the field of intelligent physics-based optimization algorithms, the gravitational search algorithm (GSA) [
18], light spectrum optimizer (LSO) [
19], energy valley optimizer (EVO) [
20], Kepler optimization algorithm (KOA) [
21], transient search optimization (TSO) [
22], atom search optimization (ASO) [
23], and other algorithms are representative. In biology-based intelligent optimization algorithms, the puma optimizer (PO) [
24], ant colony optimization (ACO) [
25], grey wolf optimizer (GWO) [
26], whale optimization algorithm (WOA) [
27], glowworm swarm optimization (GSO) [
28], and Harris hawks optimizer (HHO) [
29] perform well. Finally, in terms of intelligent optimization algorithms based on human behavior, the football team training algorithm (FTTA) [
30], teaching-learning-based optimization (TLBO) [
31], student psychology-based optimization (SPBO) [
32], group teaching optimization algorithm (GTOA) [
33], human memory optimization algorithm (HMO) [
34], human evolutionary optimization algorithm (HEOA) [
35], and other algorithms show a unique optimization ability.
In the field of agriculture, Chenbo Ding et al. introduced blockchain technology into the agricultural machinery resource scheduling system [
36], which not only improved the utilization rate of agricultural machinery resources, but also reduced the production costs. However, this method has not been introduced into the field of heterogeneous type systems so far, and therefore has certain limitations. Yiyuan Pang et al. combined the frequency optimization of traditional motors and established multiple scheduling schemes to improve the energy-saving rate of the system [
37]. Yiyuan Pang et al. proposed a new irrigation scheduling scheme [
38] that balanced the relationship between system energy conservation and the working frequency of pumps. In the field of task scheduling, Poria Pirozmand et al. proposed multi-adaptive learning for particle swarm optimization (MALPSO) [
39]. By introducing adaptive learning strategies, this method effectively reduces the response time of the system and improves the efficiency of task scheduling. However, this method does not fully consider the cost factors in actual task scheduling, which may lead to high costs in practical applications. Zhou Zhou et al. introduced the greedy strategy into the genetic algorithm and proposed a modified genetic algorithm combined with the greedy strategy (MGGS) [
40]. MGGS can obtain the optimal solution with fewer iterations, thus shortening the optimization time of task scheduling. However, MGGS does not consider the task load balancing problem. In practical applications, a large number of tasks may be concentrated on resources with strong computing power, resulting in device load imbalance. Ali Al-maamari et al. improved the PSO algorithm by introducing an adaptive strategy and formed a dynamic adaptive particle swarm optimization algorithm (DAPSO) [
41]. The algorithm optimizes the task scheduling process by reducing the period of the task and improving resource utilization. However, DAPSO has its limitations when dealing with large-scale task scheduling, which may not solve the load balancing problem effectively, resulting in unequal resource allocation in large-scale task scheduling scenarios. As “no free lunch (NFL)” expresses [
42], although the structure of the whale migrating algorithm (WMA) is simple and efficient [
43], there are still many problems in the application of task scheduling such as an unbalanced computing resource load, a long system response time, and high computing cost. Fortunately, this paper presents an algorithm that can effectively solve the above problems. The main contributions of this paper are as follows:
- (1)
A mixed disturbance strategy was introduced into WMA. Compared with the traditional random initialization method, the mixed disturbance strategy interferes with the position of individuals in the initial community accurately and effectively by the obvious advantages of chaotic function and Cauchy mutation, that is, its high randomness and aperiodicity. This interference mechanism can make individuals evenly distributed in a larger space, significantly improving the diversity.
- (2)
A balanced learning strategy was introduced into WMA to reduce the time for the WMA to break free from the local optimum to enhance the accuracy of the final solution. Specifically, individuals make up for their shortcomings by comprehensively learning from intermediate individuals and nearby optimal individuals, thus optimizing individual positions. In addition, through the dynamic change of mutation parameters, the population can still maintain sufficient diversity in the late iterations, which further improves the global search capability.
- (3)
An oppositional learning strategy was introduced in the iterative process to enhance the diversity in the iterative process. Individuals explore the direction opposite to their current position by learning their relative knowledge in reverse, thus expanding their position to unknown areas. This strategy can effectively expand the search scope in the iterative process and further promote the WMA’s capability for global exploration.
- (4)
By coordinating the above strategies, the improved whale migrating algorithm (IWMA) was obtained and applied to the CEC2017 test problem and cloud computing task scheduling problem.
The rest of this paper is structured as follows.
Section 2 describes the related works,
Section 3 describes the standard WMA,
Section 4 presents the motivation and principle of IWMA,
Section 5 completes the experimental analysis, and
Section 6 presents the conclusions and outlook.
3. Original Whale Migrating Algorithm
By simulating whale migration behavior to the tropics, the WMA guides the information of each member to the optimal member. By dynamically merging the location information of the leaders and followers, the algorithm cleverly balances the relationship between exploration and development, thus significantly improving its convergence performance.
3.1. Algorithmic Process
Initially, the original community of WMA is obtained based on the scale of solving the problem. Under the characteristics of a random function, each individual is arbitrarily dispersed in the solution space, and the specific generation mode is obtained in Equation (1).
In Equation (1), stands for the whale in the initial population, is the minimum vector for solving the question, is a random value function, is a stochastic value that randomly lies between , and is the maximum for solving the question.
In whale migration, each group of whales has an experienced leader who can guide the other whales toward their destination with their vast experience. In the WMA, other whales are guided toward their destination by the average leader. The position of the average leader is calculated from Equation (2).
where
indicates the location of the average leader and
symbolizes the count of leader whales.
Then, depending on the whale’s characteristics, its position or the leader’s position is updated. Less experienced whales will be guided toward their destination by experienced leaders, the leader, on the other hand, is primarily responsible for identifying and choosing the best path to the destination, which is expressed by Equation (3):
where
represents the individual after the iteration of individual
, and
is randomly situated between 0 and 1.
represents the
whale,
is the destination (the best position at present), and
represents the individual’s serial number.
represents random numbers that are different from
and have values between 0 and 1, and
represents random numbers that are different from
and
and have values between 0 and 1.
Individual
and
are selected, which is expressed in Equation (4).
where
expresses the fitness of
, and
is the fitness of individual
.
Then, the optimal individual in the current population is updated, which is specifically expressed as Equation (5).
where
represents the fitness of
.
3.2. Concrete Implementation Operation of WMA
The pseudo-code of WMA is expressed in Algorithm 1, and the procedure of WMA is described below.
Step 1: Initialization arguments: population magnitude , dimension of solving question , and the lower bound and upper bound of solving problems .
Step 2: Using Equation (1) and the arguments initialized in Step 1, the initial population is generated, and represents a matrix of .
Step 3: Entering the cycle, the average leader in is obtained by Equation (2).
Step 4: The individual is obtained according to Equation (3).
Step 5: Select individual and individual through Equation (4) in the population .
Step 6: Select individual and individual through Equation (4) in the population .
Step 7: If the iteration is complete, the optimal
is returned, otherwise, proceed to Step 3.
| Algorithm 1: Pseudo-code of WMA |
Input: Objective function: , Solve the upper and lower bounds of the problem: , Population size: , Problem dimension: , Maximum iterations: , and set the iteration number: .
Output: Globally optimal individual: |
| 1: Input: . |
| 2: The population is initialized by Equation (1). |
| 3: while do |
| 4: The position of the average leader is calculated by Equation (2). |
| 5: The individual was obtained by updating the individual by Equation (3). |
| 6: if |
| 7: . |
| 8: end if |
| 9: if |
| 10: . |
| 11: end if |
| 12: end while |
| 13: Output: . |
4. An Improved Whale Migrating Algorithm
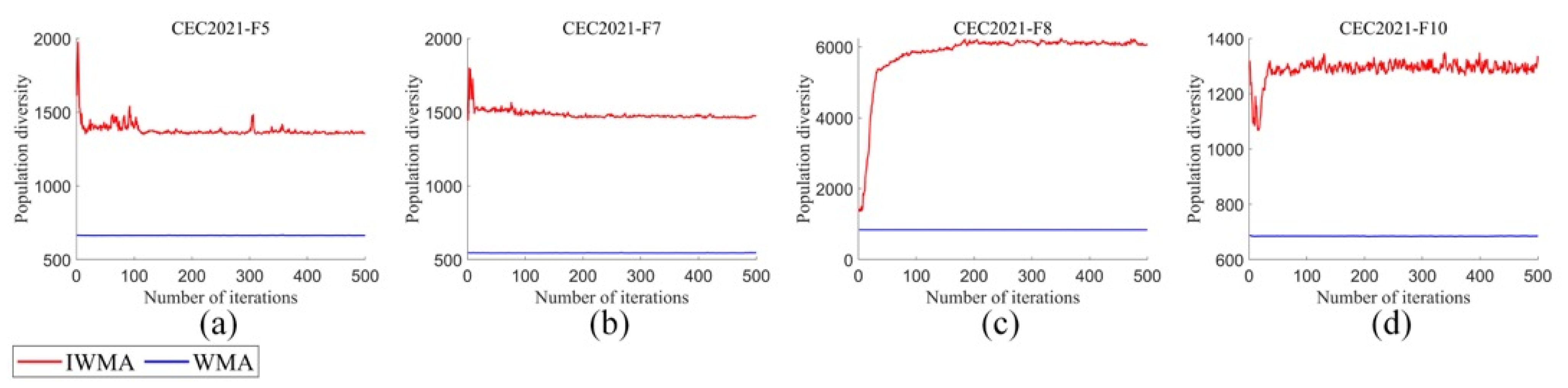
When applying the WMA to task scheduling problems, some limitations are exposed. For example, after the completion of iteration, WMA often only receives the current suboptimal scheduling policy, and the performance of time cost optimization in the optimization process is not ideal. The main reason is that in the process of iteration, the WMA finally obtains a non-optimal solution, which may be due to the poor quality of the initial population or the gradual approach of individuals to the destination, as the iteration progresses, thus reducing the population diversity. Therefore, this paper introduces a mixed disturbance initialization strategy, a balanced learning strategy, and an oppositional learning strategy into the WMA to form the IWMA.
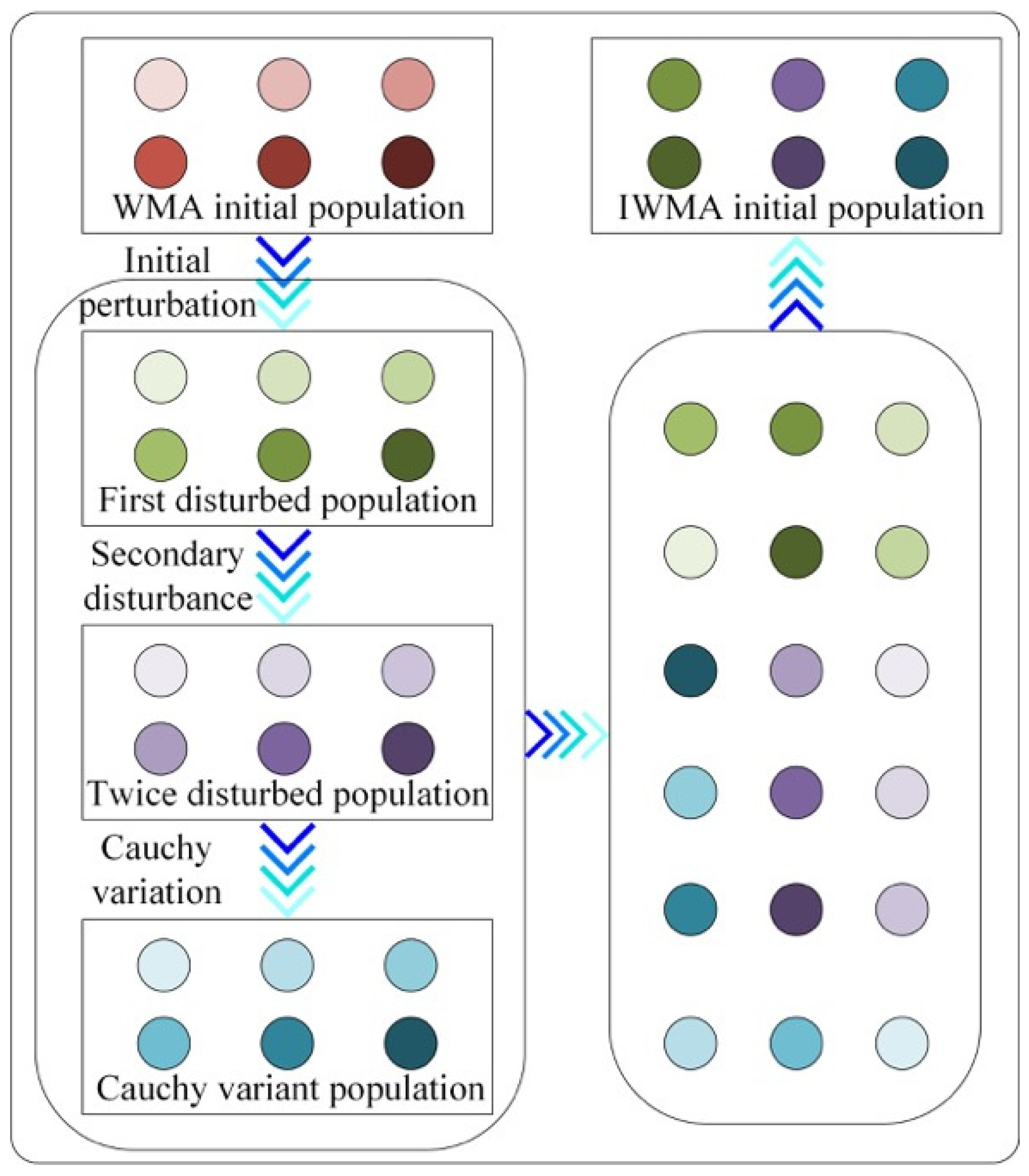
4.1. Mixed Disturbance Initialization Strategy
The more dispersed the individual location distribution, the higher the diversity, and the variety directly determines the final convergence accuracy of the WMA. Reference [
54] pointed out that in the optimization algorithm, the chaos strategy can greatly enhance the quality of the initial population. Therefore, two-dimensional chaotic mapping was introduced into WMA in this paper. However, perturbation of the initial population using only two-dimensional chaotic mapping can only make the initial population individuals change slightly near the original location. Given this, this paper proposed the introduction of the Cauchy variation strategy based on two-dimensional chaotic mapping to further perturb individual positions to enhance diversity. The resulting initial population of the IWMA is described below, and the methodology is presented in
Figure 1.
The initial population
obtained from Equation (1) is initially disturbed by Equation (6) to obtain a one-dimensional chaotic population
.
where
represents the
individual in the population
after one-dimensional chaos mapping and
represents the modular division function.
and
represent the one-dimensional chaos parameters and specifies
,
, and
represents the sinusoidal value function.
After the initial disturbance of one-dimensional chaotic function, the obtained population
is further subjected to two-dimensional chaotic disturbance to obtain a two-dimensional chaotic disturbance population
. The specific disturbance process is calculated by Equation (7).
where
represents the
entity in
,
represents the cosine value function, and
represents the two-dimensional chaos parameter and specifies
.
After the completion of two-dimensional chaotic perturbation, the obtained population
is further disturbed by Cauchy variation, thus the
is obtained. The specific perturbation process is shown in Equation (8).
where
represents the Cauchy variation parameter and specifies
.
is a random value that follows a normal distribution, and
is an absolute value function.
After the three populations (, , and ) are obtained, they are combined. Then, following the individual fitness, the merged population was sorted in ascending order. Finally, individuals with the top fitness values were selected from the sorted populations to form the initial population of the IWMA.
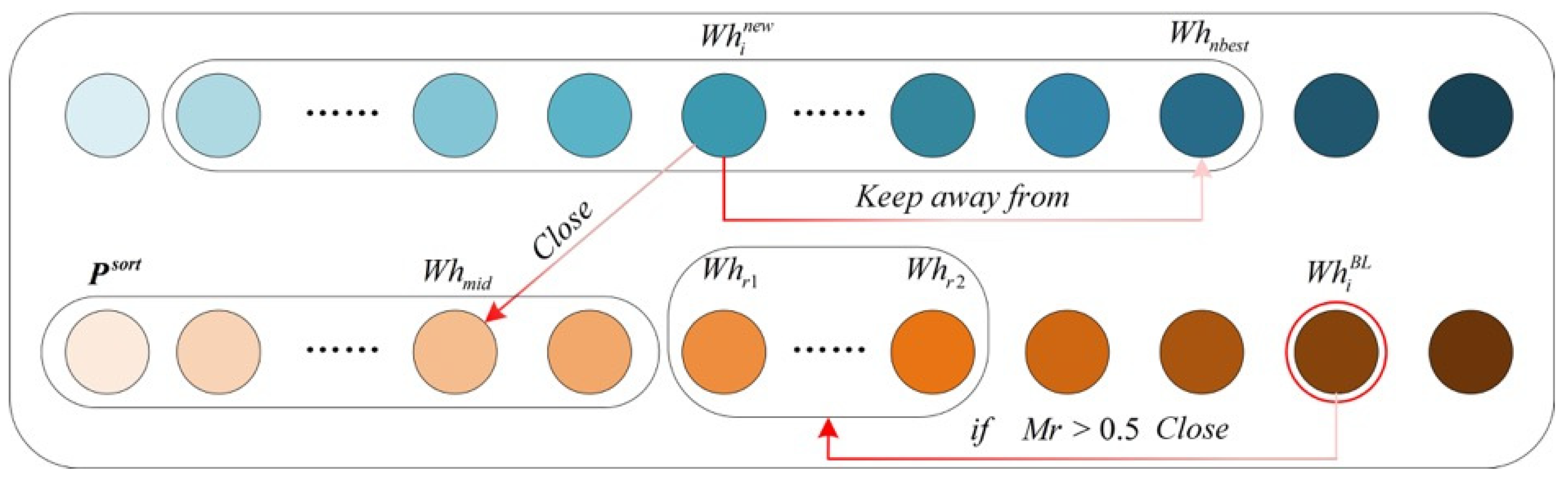
4.2. Balanced Learning Strategy
In the iterative process, WMA tends to fall into local optimization, which leads to load imbalance and cost optimization problems in task scheduling. The cause is that the operation process of the WMA only takes the individual with the best performance as the reference base, and through its guiding role, other individuals gradually approach the local optimal solution and eventually converge to the local optimality. To this end, the IWMA introduces a balanced learning strategy to assist individuals in updating their positions by learning from intermediate individuals and neighborhood optimal individuals. Meanwhile, to maintain the diversity in the iterative process, variation factors are introduced to participate in individual renewal. The process is expressed in
Figure 2, and the individual updating process is listed below.
The intermediate individual
is calculated by Equation (9).
where
represents the population after the
in order of fitness values arranged in increasing order, and
is calculated by Equation (10).
where
means the sequence number of an individual in population
, and
is a real number randomly generated in the range of 0 to 1.
Then, the first 5 and last 5 individuals of the individual are selected to form the neighborhood population, and the optimal individual is selected.
Then, the value of the variation parameter
is calculated by Equation (11).
In Equation (11),
represents the exponential function with
as the base. Finally, the individual
is updated according to the value of the variation parameter, and the specific updating is Equation (12).
where
represents the individual updated by the balanced learning strategy,
and
are two distinct positive integers that are not equal to
and have values ranging from
to
,
is said population
in the first
individuals, and
is said population
in the first
individuals.
Finally, individual
and individual
are selected by the greedy strategy, and the specific expression is shown in Equation (13).
In Equation (13), is the fitness of the individual .
4.3. Oppositional Learning Strategy
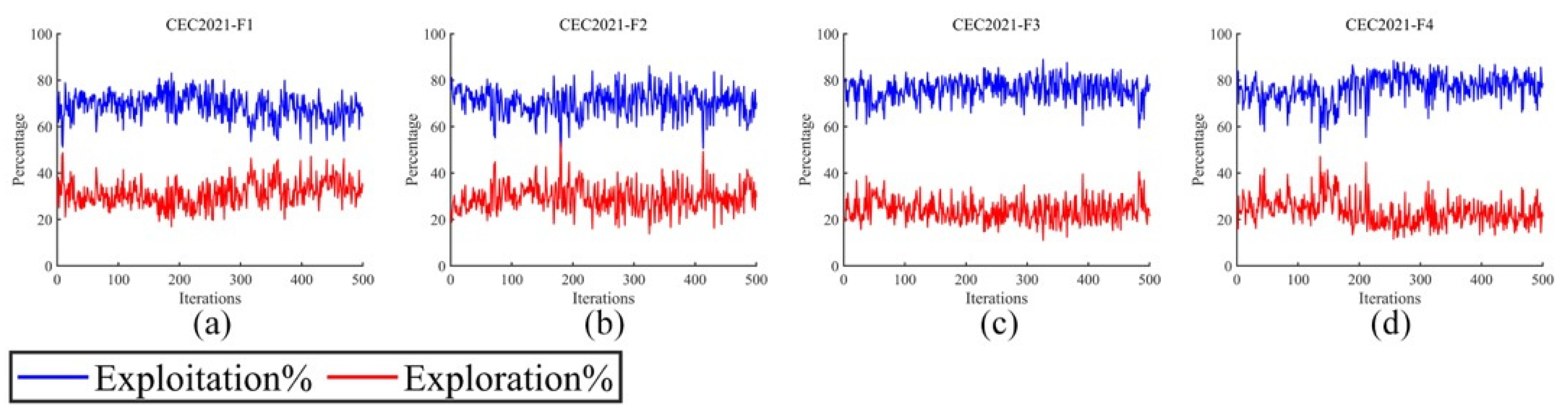
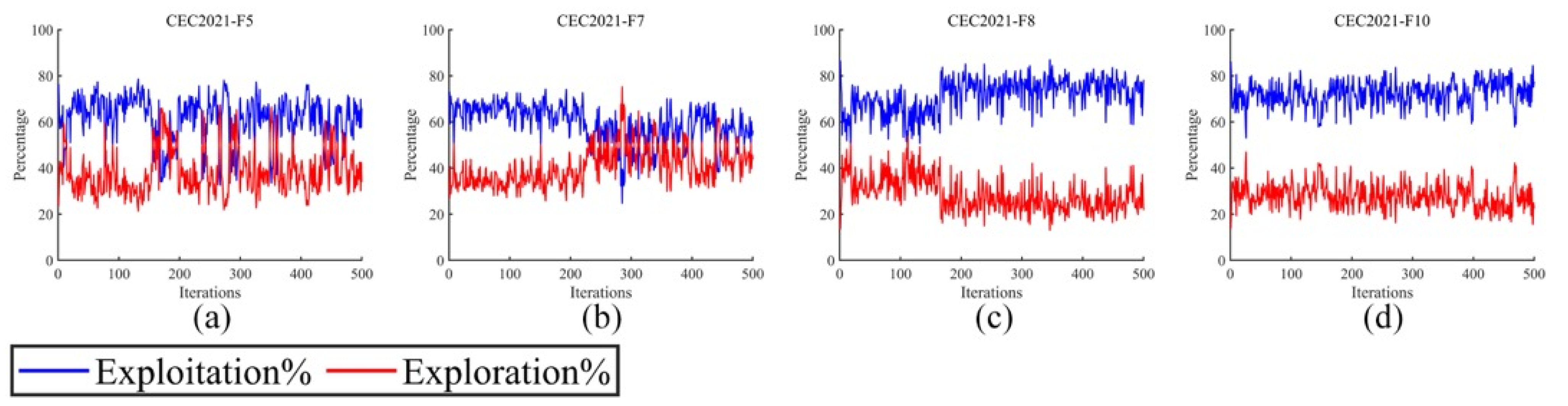
In the WMA, the main purpose of the development stage is to prevent it from finally obtaining a non-optimal solution. However, when the WMA is solving multi-task scheduling, the computer’s response time is too long, which may cause task blocking, which in turn affects the service life of the computer. Therefore, an oppositional learning way is cooperated in the IWMA to improve the development process in the iterative process.
Opposites are learned from individuals
using Equation (14) to generate opposites
.
where
is the value of the
of the
entity in the
dimension,
represents the maximum value in all dimensions of the
entity,
is the smallest information of the
individual in all dimensions, and
is the value of the
entity in the
dimension.
Then, the individual
and individual
are selected according to the greedy strategy, and the specific expression is shown in Equation (15).
where
represents the fitness of the entity
.
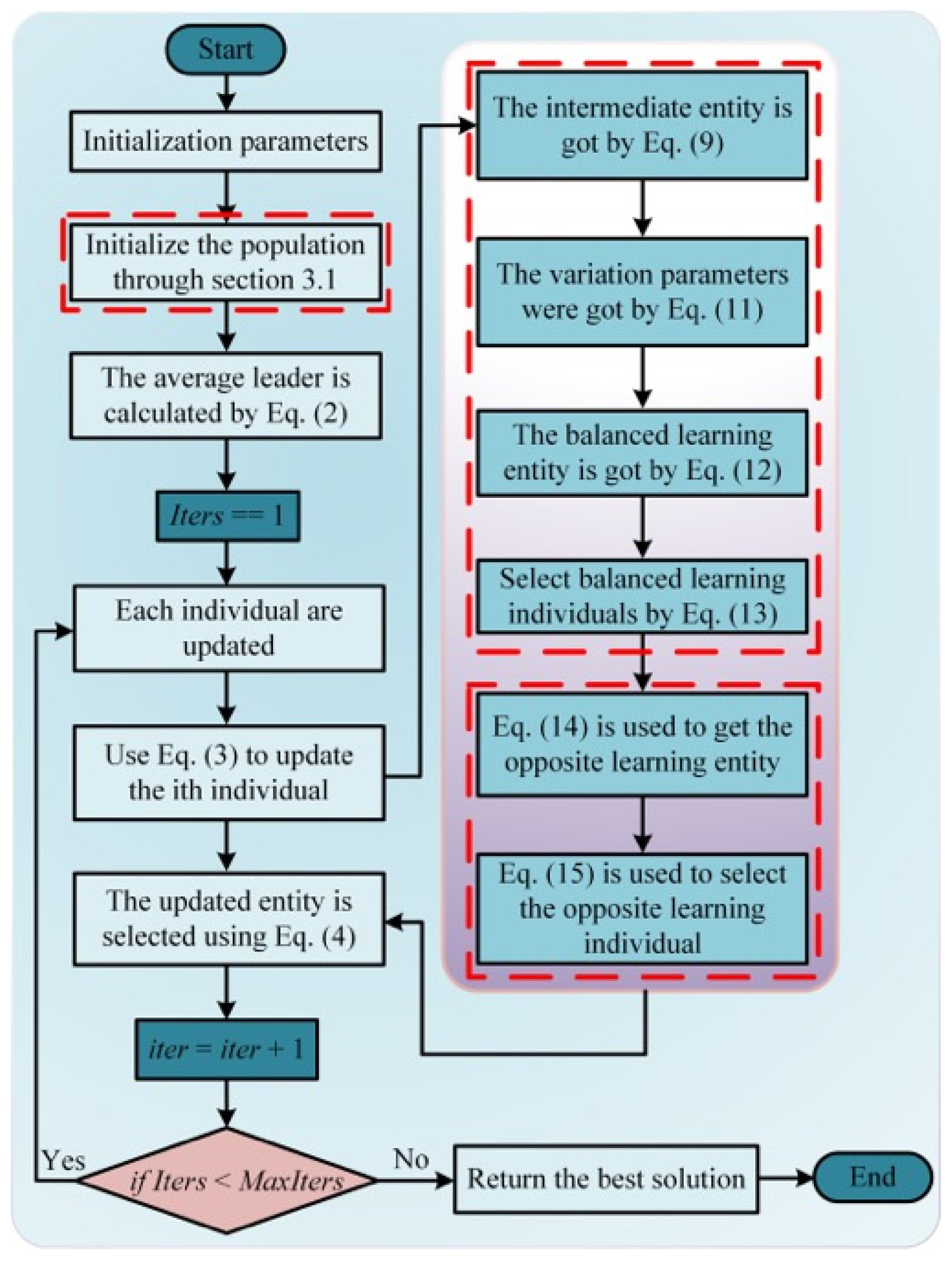
4.4. The Concrete Implementation Process of IWMA
The pseudo-code of the IWMA is shown in Algorithm 2, and its specific flow is shown in
Figure 3. The following is a detailed description of the IWMA implementation details.
Step 1: Set parameters: Initial population number , dimension of solving problem , lower bound and upper bound of the solved problem , chaotic parameter , , and .
Step 2: Initialize population
by
Section 3.1,
represents a matrix of
.
Step 3: Entering the cycle, the position of the average leader in the population is calculated by Equation (2).
Step 4: The individual is obtained according to Equation (3).
Step 5: Individual is calculated by Equation (12).
Step 6: The individual is updated by Equation (13).
Step 7: The opposite individual is calculated by Equation (14).
Step 8: The individual is updated by Equation (15).
Step 9: Individuals in the population are selected by Equation (4).
Step 10: The current optimal individual is updated by Equation (5).
Step 11: If the iteration is complete, the optimal entity
is returned, otherwise, go to Step 3 to continue the execution.
| Algorithm 2: Pseudo-code of the IWMA |
Input: Objective function: , the upper and lower bounds of the solve problem: , Initial population size: , Problem dimension: , Maximum iterations: , chaotic parameter and . And set the current iteration number: .
Output: Globally optimal individual: |
| 1: Input: . |
| 2: The population is initialized by the Section 3.1. |
| 3: while do |
| 4: The position of the average leader is calculated by Equation (2). |
| 5: The individual was obtained in population according to Equation (3). |
| 6: The balanced learning entity is obtained by Equation (12). |
| 7: Individual is updated by Equation (13). |
| 8: if . |
| 9: The opposite learning entity is obtained by Equation (14). |
| 10: Individual is updated by Equation (15). |
| 11: if . |
| 12: end while. |
| 13: Output: . |
4.5. Complexity Assessment
In this section, we focus on discussing the time complexity and the complexity of function evaluation times of the proposed IWMA. To present its performance characteristics more clearly, we first reviewed the time complexity characteristics of the standard WMA. In the standard WMA, the time complexity of the initialization stage is , where represents the population size and indicates the dimension of the problem to be optimized. During the iterative process, each individual in the population updates its position under the guidance of the leader whale. Therefore, the time complexity of the WMA throughout the entire iteration process is , where is the number of iterations. Compared with the WMA, the IWMA introduces a mixed perturbation strategy in the initialization stage, aiming to enhance the diversity of the population. In the update stage, the IWMA incorporates balanced learning strategies and adversarial learning strategies to enhance the global search ability and convergence speed of the algorithm. Although the IWMA introduces these improvement strategies, its core computing logic has not changed. Therefore, the time complexity of the IWMA remains . This result indicates that the IWMA significantly improves the performance of the algorithm through strategy optimization while maintaining the same time complexity as the WMA. In terms of function evaluation, the proposed IWMA evaluates three populations in the initialization stage. Therefore, in the initialization stage, the number of function evaluations of the IWMA is three times that of the WMA. In the iterative process, IWMA introduces two learning strategies, and each learning strategy has a function evaluation. Therefore, in an iterative process, the IWMA’s function evaluation times are three times that of the WMA.
6. Conclusions and Prospects
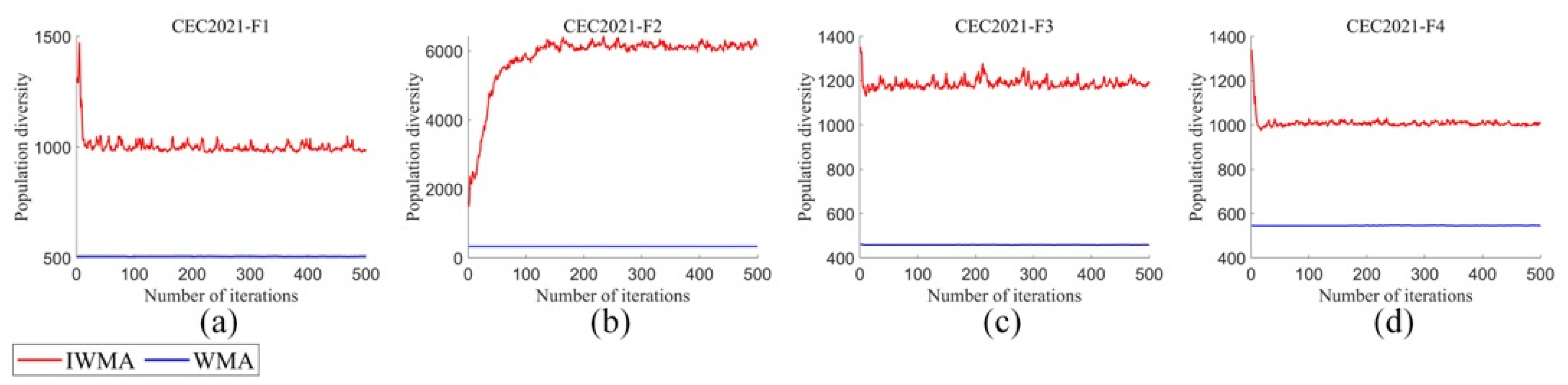
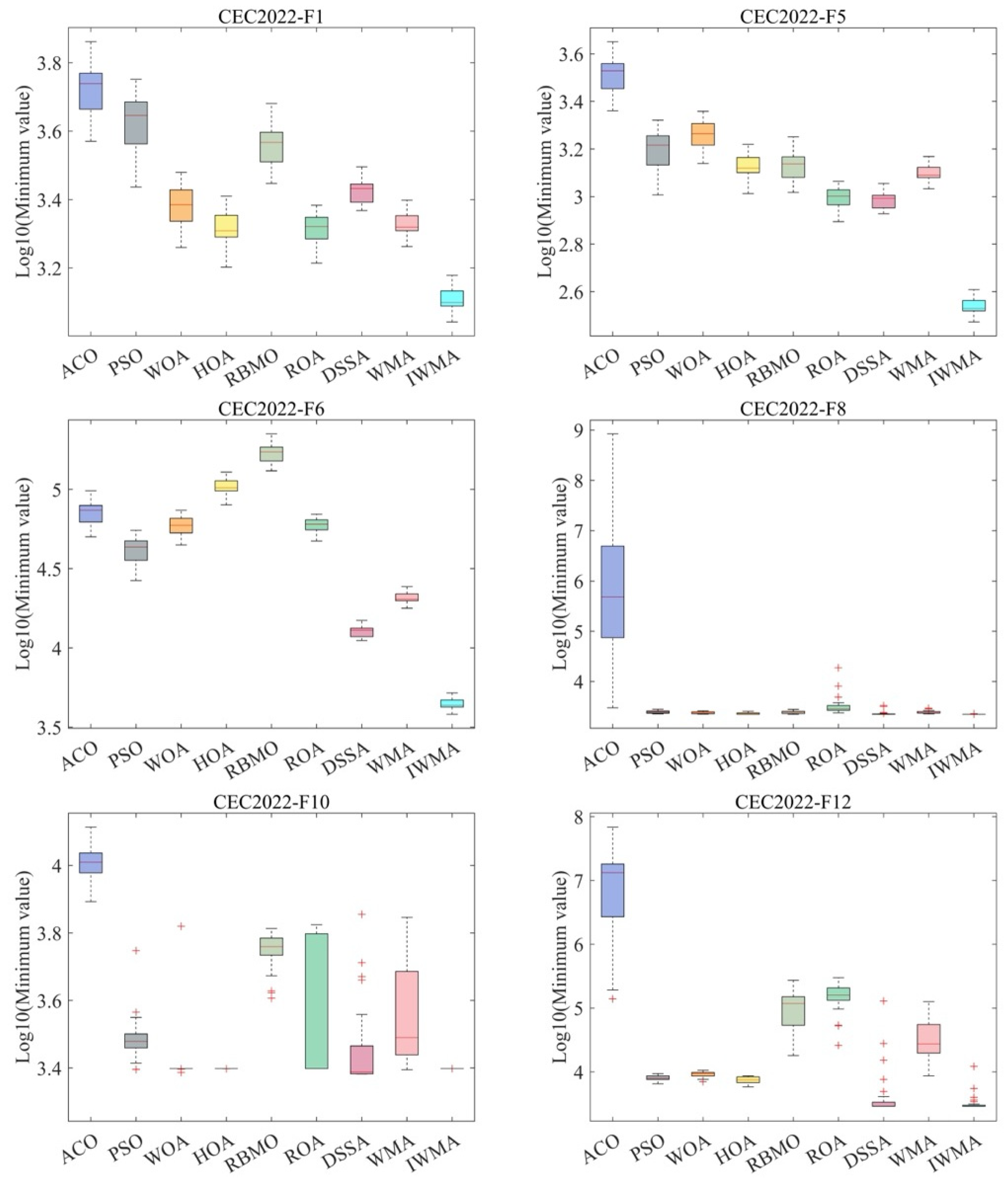
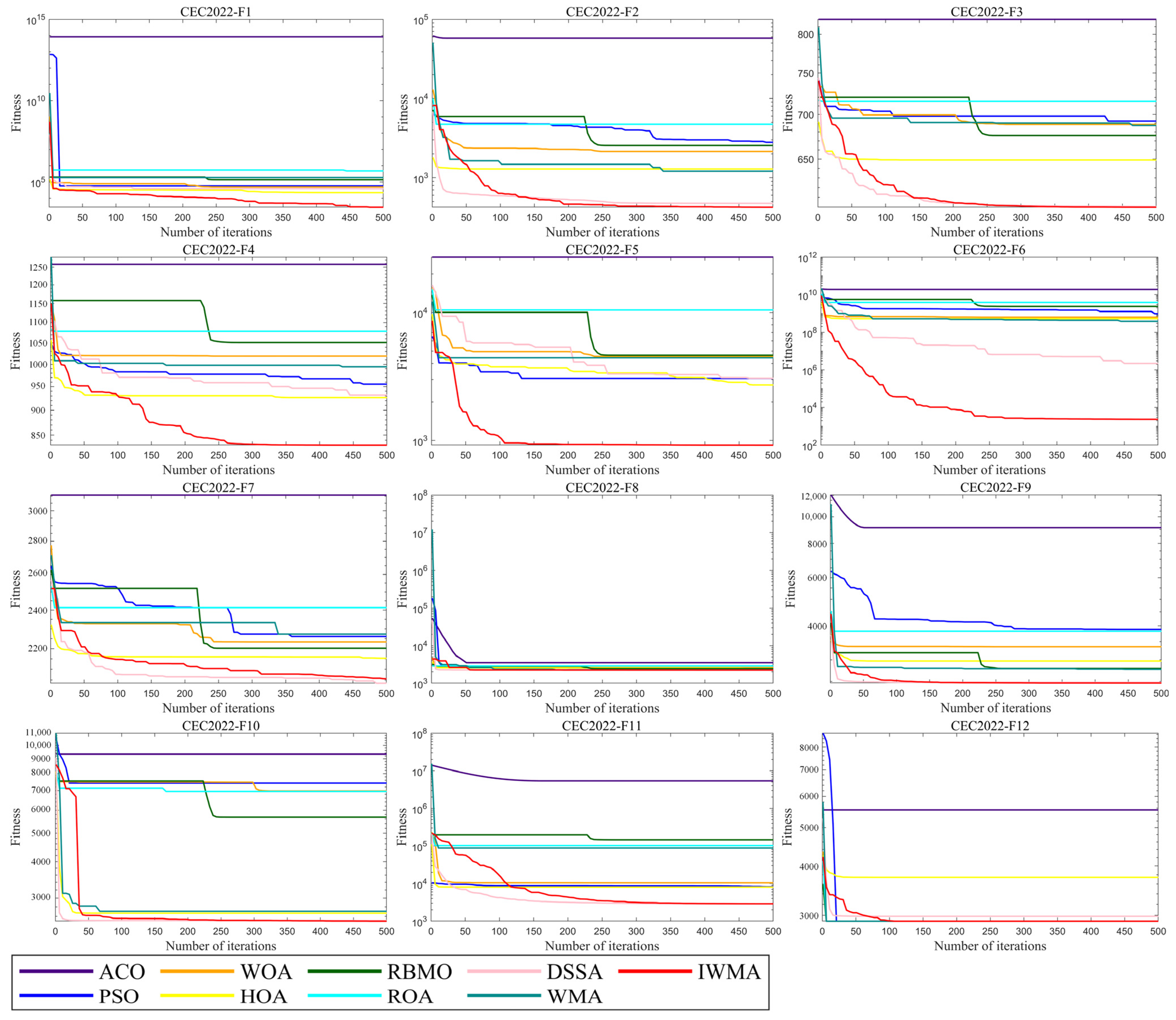
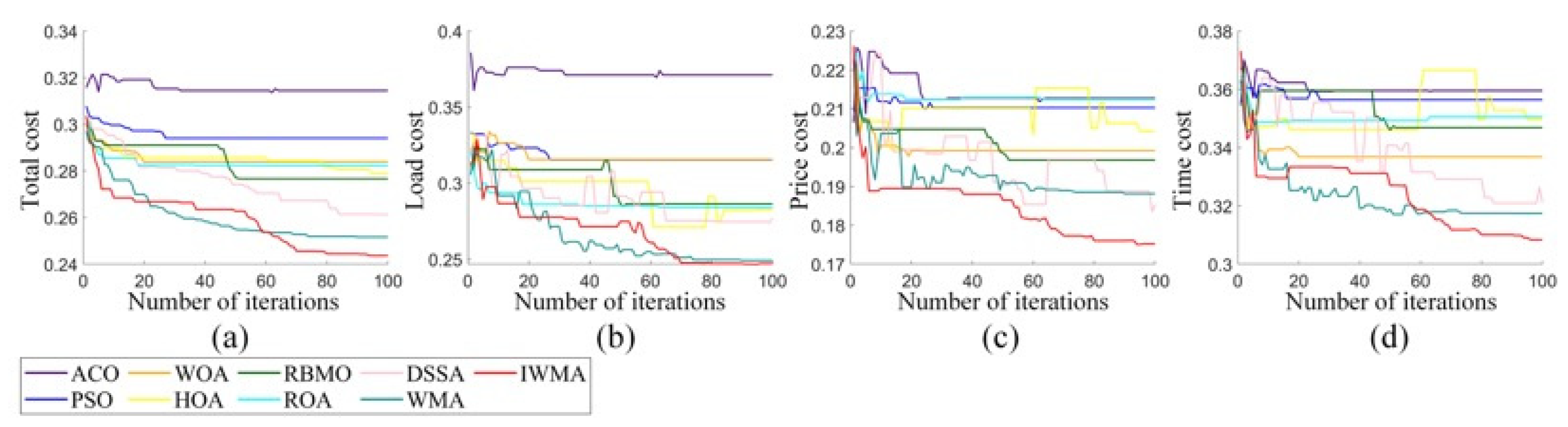
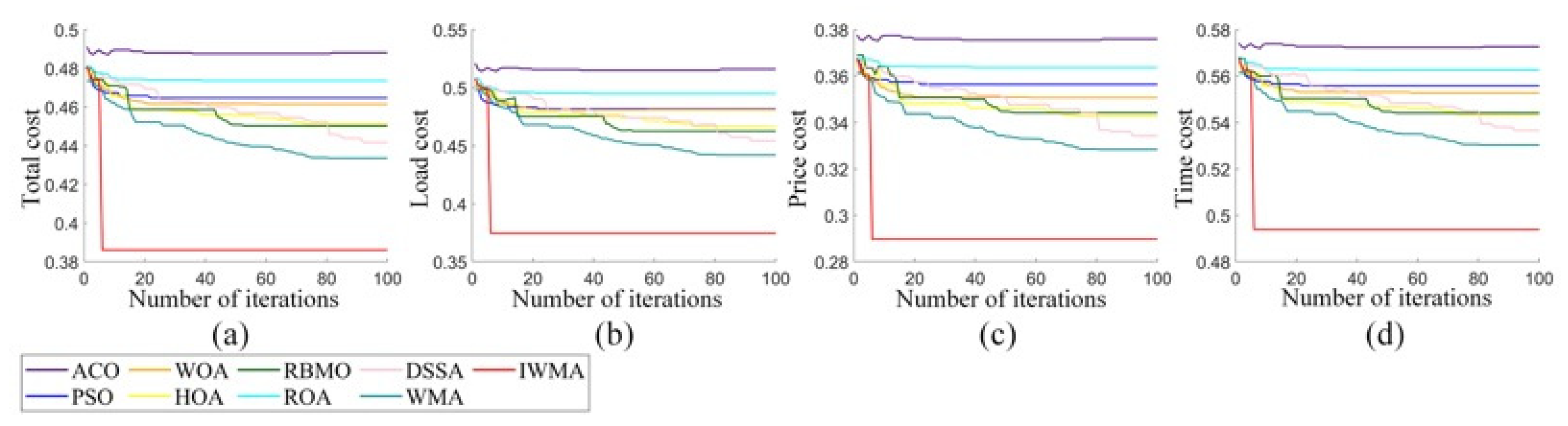
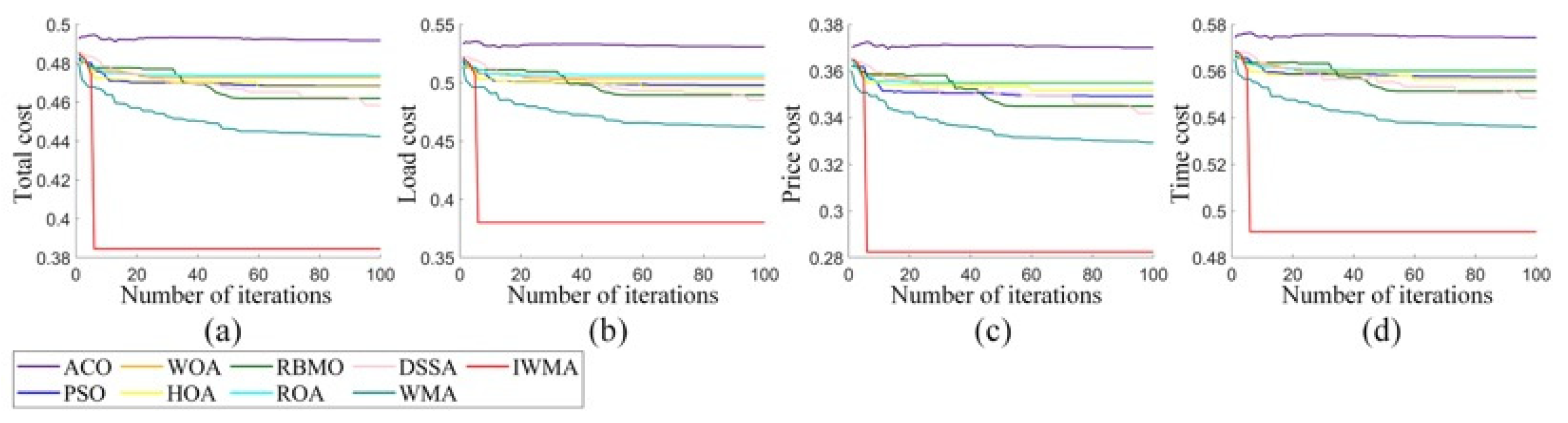
Aiming at the shortcomings of solving global optimization and scheduling problems, this paper proposed the IWMA. Firstly, by introducing the mixed disturbance initialization strategy, the diversity of the initial population as improved, thus improving the accuracy of the final optimal solution. Secondly, the balanced learning method and the opposition learning strategy were combined into the WMA, which effectively improved the development ability in the iterative process and further improved the population diversity in later iterations. The IWMA could effectively avoid falling into the global optimization trap. Through the verification of the CEC2021 test function, it was proven that these strategies significantly improved the diversity and development ability of IWMA. To comprehensively evaluate the global optimization ability of the IWMA, this paper applied it to the CEC2022 test problem together with several classical algorithms, new algorithms, and mutation algorithms. The results showed that the IWMA has an excellent optimization performance and strong global optimization ability. In addition, the IWMA was applied to the task scheduling problem of cloud computing to further verify the performance of the IWMA in dealing with complex scheduling problems. The results showed that the IWMA is an efficient and robust algorithm.
In future research work, we are committed to constructing solutions to complex scheduling problems that are more suitable for practical applications. On the one hand, given that the IWMA is currently mainly applied to single-objective task scheduling problems, future work will focus on the improvement and expansion of the IWMA to enable it to handle multi-objective problems more effectively. On the other hand, considering that when the IWMA is applied to cloud task scheduling, as the number of tasks increases, the optimization time of IWMA also increases. Therefore, future research will also focus on improving the running time of the IWMA to enhance its efficiency and applicability in large-scale task scheduling.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}