1. Introduction
Automated essay scoring (AES) aims to automatically assess an essay based on a provided prompt that presents the writer with the topic and often includes specific guidelines or instructions. The AES system has the potential to generate objective and equitable results swiftly and efficiently, addressing the issue of resource consumption and strong subjectivity in manual evaluation [
1,
2,
3]. Initial studies in AES focused on providing a holistic evaluation by assigning an overall score to the essay [
4,
5,
6,
7,
8] and gradually shifted to trait scoring from different perspectives [
9,
10] as the functionality expanded and achieved the objective of delivering multidimensional analysis to improve reliability. Currently, the research focus has changed from prompt-specific [
6] to more challenging cross-prompt scenarios [
11,
12,
13,
14,
15,
16], as depicted in
Figure 1.
Cross-prompt AES involves the evaluation of previously unseen target prompts using a training model from the source prompt. In this paper, we focus on the cross-prompt essay trait scoring (CPETS) where both the overall score and detailed trait scores in the target domain are provided, as illustrated in
Figure 1b. Existing CPETS methods improve effectiveness by improving shared representation or facilitating the transfer of common knowledge between source and target prompts through content-related features [
17,
18] or external knowledge [
1,
19]. Ridley et al. [
17] proposed a model for CPETS, which utilizes part-of-speech (POS) embeddings as input for a neural AES model and concatenates features such as readability over essay representation. Sun et al. [
18] fused syntactic embedding with POS embedding to extend the essay representation, leveraging common linguistic knowledge to enhance the essay representation of the target domain. Do et al. [
19] enhanced essay representation through incorporating prompt information and alleviated data insufficiency through extracted topic coherence features. They also endeavored to improve the model by quantifying relations between traits. While the studies above improved essay-shared representation by integrating various features, they devoted less attention to knowledge beyond the essay content, such as genre features and the intrinsic meanings of traits. Moreover, they did not focus on quantifying knowledge transfer across prompts. Knowledge transfer provides methodological support for cross-domain research, and knowledge flows across domains through techniques such as transfer learning and domain adaptation [
20]. Chen and Li [
1] concentrated on the challenge of knowledge transfer across distinct prompts, arguing that similar prompts can gain more shared knowledge.
As shown in
Table 1, Prompt 1 and Prompt 2 were both argumentative essays written to require a discussion of a situation related to the academics of the students, and Prompt 3 was a narrative essay. As can be seen in the essays for Prompt 1 and Prompt 2, both essays are organized as question-and-answer writing with a high degree of vocabulary similarity. However, there were fewer commonalities between Prompt 3 and Prompts 1 and 2 at the organizational level of the essays, as well as greater differences in vocabulary use and language expression. It can be seen that essays with similar prompts or similar genres are more likely to contain similar information, even though the different essays come from different writers. Overall, the rational use of external information can enhance the ability of the model to extract shared features between source and target prompts and significantly improve the effectiveness of the model in scoring cross-prompt essays, further illustrating the effectiveness of solving the problem from the perspective of external information. Despite the study’s success, its focus was limited to the dissimilarities between prompts. The researchers did not explore the transferability of other dimensions of external knowledge between the source and target prompts. In addition, the effective measurement of the degree of commonality between knowledge and the efficient transfer of knowledge are crucial.
To resolve the aforementioned problems, we present cross-prompt trait scoring based on extra-essay knowledge transfer (ExtCTS). For the first problem, inadequate attention to knowledge beyond the content of the essay, we introduce extra-essay knowledge representation. This enhancement augments the understanding in the model of both the prompt under evaluation and the intrinsic meaning of the assessed trait by integrating the essay prompt and the trait description. Description refers to the explanation of a specific essay trait in a natural language text. For instance, a trait description may illustrate the evaluation of the trait “narrativity”, defined as “a measure of the coherence and cohesion of the response to the prompt”. Genre description, prompt description, and trait description details are provided in [
21]. To tackle the problem of insufficient sources for knowledge transfer and the complexity of assessing commonality, we propose extra-essay similarity transfer, which involves evaluating the similarity of different external knowledge in source and target domains, setting similarity factors to determine transferability, and applying it to essay representation. The main contributions of our work are summarized as follows:
We propose extra-essay knowledge representation, which consists of an essay prompt encoder and a trait description encoder to integrate knowledge beyond the content of the essay.
We introduce extra-essay similarity transfer, which quantifies the similarity between various prompts by considering knowledge similarity factors beyond essay content, thereby enhancing essay representation.
Experimental results demonstrate that our approach achieved state-of-the-art performance, validating the effectiveness of the proposed methodology.
The paper is organized as follows. In
Section 2, we first present the literature review. We describe our method and experiments in
Section 3 and
Section 4. Finally, in
Section 5, we provide a conclusion, future work, and the limitations of the paper.
2. Related Work
In this section, we briefly review relevant studies concerning cross-prompt holistic scoring and cross-prompt essay trait scoring.
2.1. Cross-Prompt Holistic Scoring
Presently, AES is mostly performed as supervised learning, demanding substantial amounts of labeled data. However, the process of labeling data is time-consuming and labor-intensive, resulting in a shortage of training data for identical prompts. Phandi et al. [
11] initiated research on cross-prompt holistic scoring to address the challenges. Phandi et al. [
11] and Dong and Zhang [
22] test the impacts of traditional AES and neural AES in cross-prompt settings on the ASAP [available online:
https://www.kaggle.com/c/asap-aes (accessed on 1 May 2025)] dataset, respectively, establishing the foundational framework for subsequent research.
Subsequent research has focused on refining frameworks [
23,
24,
25] and improving methods of cross-prompt knowledge transfer [
26,
27,
28], utilizing multi-task learning [
29], or transfer learning [
30,
31] in natural language processing. To tackle the challenge of extracting highly transferable scoring knowledge from multiple prompt sources, Li et al. [
28] integrated prompt information and extracted diverse knowledge essential to the target domain through the fusion of data from all source prompts. Cao et al. [
26] proposed a domain-adaptive framework to address the issue of neglecting domain differences in prior studies, optimize the utilization of data under various prompts, and enhance the domain-adaptive capabilities of models. Jiang et al. [
27] developed disentangled representation learning to tackle the challenge of cross-domain generalization in essay representation. They further devised a prompt-aware neural AES model to extract the combined representation of prompt-invariant and prompt-specific features. These studies have enhanced the representation and transfer of knowledge across prompts. However, they have not explored knowledge transfer across traits.
2.2. Cross-Prompt Essay Trait Scoring
Cross-prompt essay trait scoring that evaluates not only the essay as a whole but also the individual trait was first proposed by Ridley et al. [
12]. They proposed a CTS model that evaluates multiple attributes using a multi-task learning framework. The model utilizes POS embeddings as input and concatenates features like readability in essay representation. Furthermore, they improved representation by incorporating inter-trait relationships. Sun et al. [
18] fused syntactic features and contrastive learning to enhance model performance by augmenting trait representation and improving model stability. Although both studies introduced linguistic knowledge, such as lexicon and syntax, at the input layer, they fell short in enhancing the utilization of external knowledge of essay across prompts. Do et al. [
19] employed prompt information and topic coherence features to enhance essay comprehension of evaluation topics. They also established a loss function for trait relations by utilizing the correlation between different traits to improve the representation of the essay. However, they did not focus on quantifying knowledge transfer across prompts. Chen and Li [
1] concentrated on the challenge of knowledge transfer across distinct prompts, arguing that the similarity in essay representations reflects the extent of transferable features. Consequently, they proposed that prompt-mapping captures the consistent representation of the target and source prompts. Zhang et al. [
16] proposed a PDA framework, which effectively aligns the features of source and target prompts by using two alignment strategies, such as prompt-level alignment and category-level alignment, and further improves the performance of the model through classifier consistency constraint. Nevertheless, they only focus on the transfer of shared features within essay representation, neglecting the transfer of external knowledge. We believe that evaluating the degree of commonality of different dimensions of knowledge between source and target prompt samples and quantifying transferable knowledge are crucial directions for addressing cross-prompt trait essay scoring.
3. Methodology
In this paper, we focus on cross-prompt essay trait scoring. When given a dataset of n essay prompts, one is selected from the dataset as the target prompt and the remaining prompts are used as the source prompt set ; the goal of cross-prompt traits scoring is to train a model using the source prompt and test it on the target prompt . The ith prompt contains examples of essays with annotations , where contains the text of the jth essay and the external information of the jth essay , is the set of scores to different traits for the jth essay, and K is the number of traits to be scored. The external information consists of the prompt text for the ith prompt, the genre text for the ith prompt, the trait to be evaluated for the ith prompt, and its corresponding trait description , etc.
Existing cross-prompt essay trait scoring studies have focused on improving shared representations or facilitating the transfer of common knowledge between source and target prompts to improve the effectiveness of AES in cross-prompt scenarios. In this paper, we introduce the transfer of external essay knowledge similarity to assess sample commonality, which to some extent reflects symmetry considerations because when external knowledge has higher similarity, the shared representation of essays is also better, which implies that there is a potential symmetrical correlation between essays with different prompts in terms of external knowledge dimensions, reflecting the dynamic balancing mechanism in the process of knowledge transfer, and through which the grasp of essay commonality can be enhanced. Meanwhile, previous studies have paid insufficient attention to the intrinsic meanings of the assessed features and their varying impacts on the model. In contrast, this paper introduces additional essay knowledge representation, which enables the model to have a more in-depth understanding of the essays to be assessed and the task objectives. This approach also helps to achieve a more balanced and comprehension of the features across essays with different prompts, thereby establishing a kind of symmetry in feature understanding.
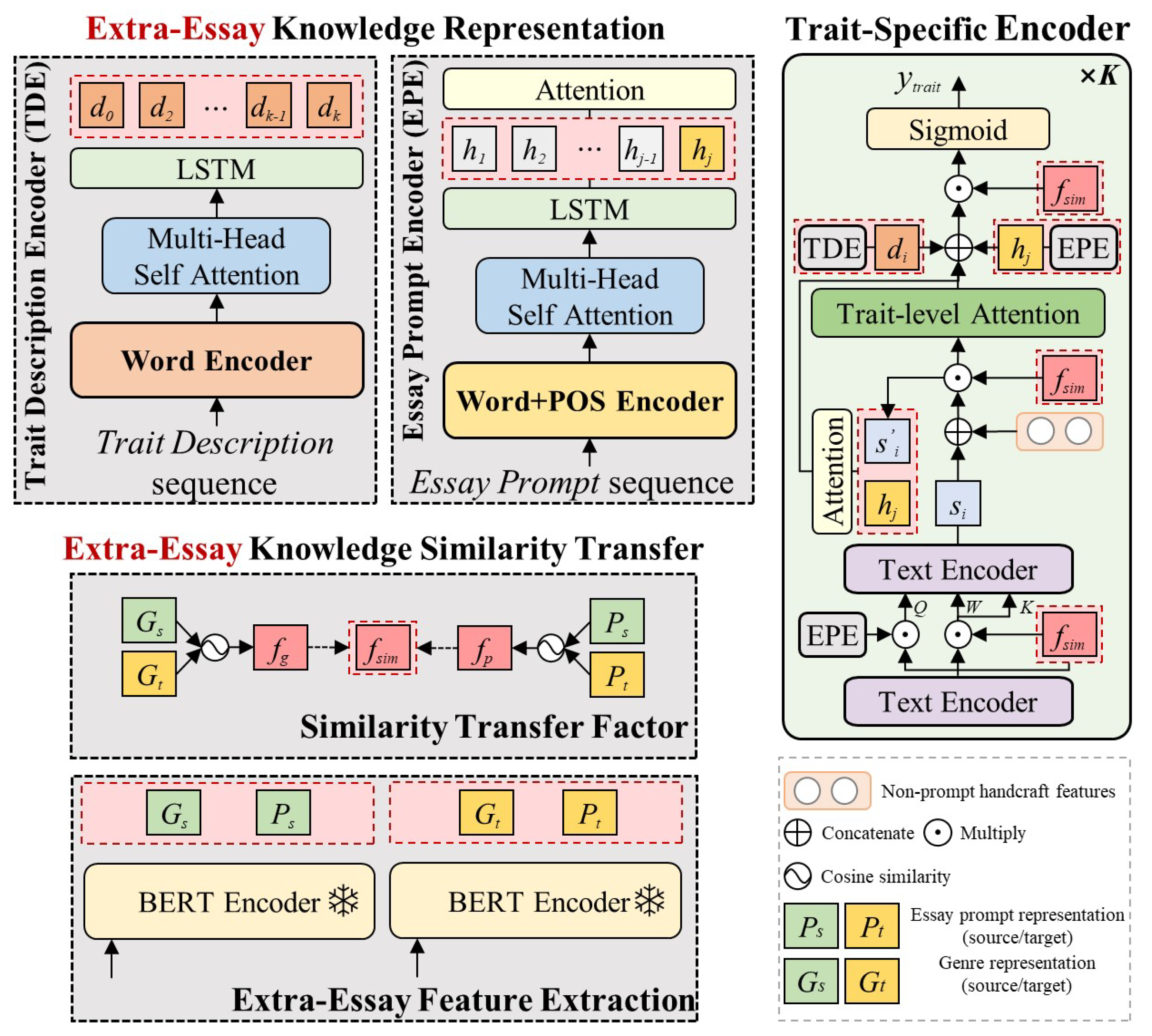
The proposed ExtCTS model is shown in
Figure 2.
Figure 3 is the sub-module of ExtCTS. It contains three components: extra-essay knowledge representation (EKR), multilevel extra-essay knowledge similarity transfer (EST), and a trait-specific encoder. EKR represents external knowledge to enhance the model to understand the prompt under evaluation and the trait being assessed. EST quantifies the degree of commonality among various external knowledge between the source and target domains. The factor from EST is then applied to the trait-specific encoder, enhancing the ability of the model to transfer knowledge from diverse prompts to obtain superior essay representation.
3.1. Extra-Essay Knowledge Representation
In order to enhance the ability of the model to extract shared features of the target prompts through external information, this section incorporates the trait description information under the framework of multi-trait scoring with fused prompt information. The following describes the EKR used in this paper to extract the external information representation, including the trait description encoder (TDE) and the essay prompt encoder (EPE).
3.1.1. Trait Description Encoder
Trait description is a piece of natural language that details and describes an evaluation trait. The TDE enhances the understanding of evaluation traits by fusing trait description information. For the traits
included in the training set,
K is the number of traits,
is the
ith target trait, and the trait descriptions are
. The
ith trait description
has the word sequence
,
n is the number of words, and obtains the corresponding word embedding vector as
. All trait descriptions are sequentially input to the word encoder (WE), and the model structure is shown in
Figure 3a. The word encoder captures sentence-level representations of the input sequence using a CNN that incorporates an attention mechanism. Then the sentence-level trait description representation
is obtained by computing the Equations (
1)–(
4), and the formulas are shown below:
where
and
are the CNN trainable weight matrix and bias, respectively,
is the window size of the CNN,
is used to capture the features of all the possible consecutive
words in the sentence,
is the nonlinear activation function, and
,
, and
are weight matrices, trainable weight vectors, and bias for the attention mechanism. The sentence-level trait description representation
is computed from the contextual features
of the CNN output. Attention vectors
and attention weights
are computed by Equation (2) and Equation (3), respectively.
Next, the inter-trait relations are further captured through the multi-head self-attention layer and LSTM with an attention mechanism, thus obtaining the final trait description representation. The sentence-level trait description representation
is input to the multi-head self-attention layer and the formulas are shown below:
where
,
,
are the parameter matrices of the
ith head
, Attention is the scaled dot product attention, ⊕ is concatenation,
is the
ith head used in the multi-head self-attention layer,
is the number of heads in the multi-head self-attention layer, and
is the parameter matrix of the multi-head self-attention layer. Then, an LSTM is used to obtain the trait description representation
, which is computed as shown in Equation (
7):
where
is the output of the multi-head self-attention layer and
denotes the hidden state vector at the
uth time.
3.1.2. Essay Prompt Encoder
In order to enhance the understanding of the model on the evaluation prompt and obtain more consistent evaluation results with the prompt information, this section uses a Word+POS Encoder that fuses word sequences and POS sequences to represent the essay prompt information, and the model structure is shown in
Figure 3b. For the training set containing essay prompt texts
,
J is the total number of prompts, the
ith essay prompt text
has the word sequences
, and obtains the corresponding word embeddings
and the POS embeddings
. First, the word embeddings and POS embeddings are summarized
. Second, the summed embedding vectors are sequentially input to the CNN with attention mechanism to capture the sentence-level prompt features using the Equations (
1)–(4). Then, the sentence-level prompt features are input to the multi-head self-attention layer and LSTM computed using Equations (
5)–(
7) to obtain the essay prompt representation
. Finally, the attention mechanism is computed for the essay prompt representation using Equations (
8)–(10) to obtain the essay prompt contextual representation
:
where
,
and
are the weight matrices, trainable weight vectors, and bias of the attention mechanism. The essay prompt contextual representation
is computed from the LSTM output of the essay prompt representation
. The attention vector
and the attention weight
are computed by Equation (
8) and Equation (9), respectively.
3.2. Multi-Level Extra-Essay Knowledge Similarity Transfer
Essays with a high degree of external knowledge similarity are more likely to help the model learn better-quality shared features. Based on this motivation, we design multilevel similarity transfer to measure the degree of similarity between external information of the source prompts and the target prompt. First, the features of external knowledge are extracted using a pre-trained language model. Given a dataset of
prompts, there is the set of external knowledge
, where
is the set of
genre descriptions,
is the set of
essay prompts,
is the set of
trait descriptions. Given a source prompt training data
with external knowledge
,
, and a target prompt with external knowledge
,
, the representation of the external knowledge of the essay is extracted using BERT with the following formula:
where
c is the input of BERT, ⊕ is concatenation operation. Then the cosine similarity of the external knowledge between the source prompt
and the target prompt
is calculated to obtain the similarity transfer factor; the formula is as follows:
In this paper, we consider two similarity factors,
, where
is the similarity factor for essay prompt and
is the similarity factor for genre description. Finally, the features at different levels of trait-specific encoder are weighted using the
as shown in
Figure 2, so as to enable the source prompt features extracted by the neural network to transfer directionally towards the target prompt and to enhance the ability of the model to generalize to the target prompt.
3.3. Trait-Specific Encoder
We employ a hierarchical structure [
4] and basic framework from [
19]. The model uses POS encoder to obtain sentence-level representation as shown in
Figure 3c and trait-specific encoder for each trait to obtain document-level representation as illustrated in
Figure 2. For a sentence containing
n words
, the POS embedding
is first obtained, and then an attention layer is used to obtain the sentence-level representation
. The formulas are as follows:
where
is the kernel size of CNN.
Then, sentence-level essay representation is extracted using a text encoder as depicted in
Figure 3d and further incorporate prompt representation. In addition, to enhance awareness of the target prompt, we calculate the document-level essay representation. The final representation of the model is
, which is weighted by
, and the score is obtained using the following equation:
where
is the linear layer of sigmoid activation,
and
are the trainable weight matrices and bias terms, and
is the score predicted for the
ith trait;
contains the output of trait-specific encoder and all external knowledge representations obtained from TDE and EPE.
3.4. Loss Function
Loss function includes score loss
and inter-trait similarity loss based on trait description
, where
uses the same strategy as [
12].
where
is a manual hyperparameter;
N is the number of essays, and
K is the number of traits; cos is the cosine similarity,
is the similarity threshold, and
C is the number of times the similarity of the trait description is greater than the threshold;
is the prediction of the
ith trait of
N training data;
is the trait description for the
ith trait.
4. Experiments
4.1. Datasets and Settings
We conducted experiments on the ASAP++ dataset [
21], initially introduced by Ridley et al. [
17] for CPETS, which was labeled with fine-grained trait scores on the ASAP [available online:
https://www.kaggle.com/c/asap-aes (accessed on 1 May 2025)] dataset. The statistical results are presented in
Table 2. Compared with overall scoring, trait scoring mainly evaluates the quality of essays in terms of language quality (vocabulary, syntax, etc.), content quality (strength of argument), and thinking level (organization). Evaluating the quality of essays from multiple dimensions can reflect writing level more comprehensively and promote the comprehensive improvement of the writing ability of students.
Additionally, other resources like genre descriptions, prompt descriptions, and trait descriptions derived from expert annotations are detailed in [
21]. Prompt descriptions are shown in the
Table 3. Genre descriptions are shown in the
Table 4. For evaluation, we employed quadratic weighted kappa (QWK) [available online:
https://www.kaggle.com/c/asap-aes#evaluation. (accessed on 1 May 2025)], a widely used metric in existing AES research [
2]. QWK assesses the consistency between the AES system results and the golden score and assigns a value between
. QWK can be calculated by Equations (
20) and (
21):
where
denotes the number of essays that receive a rating
i by the human rater and a rating
j by the AES system. The expected rating matrix
is histogram vectors of the golden rating and AES system rating and normalized so that the sum of its elements equals the sum of its elements in
;
N is the range of score for each essay.
We use the same data settings as Ridley et al. [
12], who first proposed the CPETS task, with the data in the target domain coming from a prompt that does not appear in the training set and the other prompts serving as the source domain. We use the same data settings as Ridley et al. [
12]. We employ the handcrafted features proposed by Do et al. [
19], encompassing length-based, readability, text complexity, text variation, sentiment, and topic coherence features. We employ the handcrafted features proposed by Do et al. [
19]. We utilize word 50-dimension embedding as input from [
32]. We build POS 50-dimension embedding and train all models for 50 epochs with a batch size of 32. The output size of the CNN layer and the LSTM layer are both configured at 100. The window size for the CNN layer is set to 5, and we employ two heads for the multi-head self-attention. Each model is executed five times with the seeds
, following Ridley et al. [
12], and the average QWK is reported. We utilize the RMSProp optimizer, setting the initial learning rate to 0.001 and the dropout rate to 0.5.
is set to 0.7 and
is set to 0.7. Our experiments are conducted using an NVIDIA GeForce GTX 1080 Ti GPU.
4.2. Comparisons
We compare our method with the existing CPETS models:
Hi att [
4]: This model was first applied to CPETS by Ridley et al. [
12]. The model utilizes a hierarchical structure that uses a convolutional neural network with attention and a recurrent neural network with attention to model word-level and sentence-level representation.
AES aug [
33]: The model builds on [
6] by simultaneously evaluating multiple traits through multi-task learning.
PAES [
17]: This model employs POS embedding as input, employing a hierarchical structure with distinct models dedicated to each trait.
CTS-w/o att [
12]: This model removes the trait-level attention layer compared to CTS.
CTS [
12]: This model is based on [
17], which designs shared encoder modeling word-level representation, builds submodules for each trait, and enhances the representation by exploiting the relationships between different traits via trait-level attention.
FEATS [
34]: This model is based on the handcrafted features produced by Ridley et al. [
17] and Uto et al. [
35], with the addition of POS bigram, prompt adherence features, top-N words features, and pronoun features.
PMAES [
1]: This model improves representation by facilitating knowledge transfer through prompt-mapping, thus acquiring more shared knowledge from similar prompts.
RDCTS [
18]: This model integrates POS embedding and syntactic embedding as inputs, leveraging contrastive learning to address data insufficiency.
PLAES [
36]: This model captures shared knowledge between different source prompts through meta-learning and utilizes level-aware learning to improve the ability of model to distinguish between different levels of essay.
ProTACT [
19]: This model utilizes prompt information and prompt coherence features to enhance the understanding of essays within the evaluation prompt.
4.3. Main Results
This section describes the overall effectiveness of the model proposed in this paper on a cross-prompt multi-trait task. The experimental results are summarized in terms of prompts and traits, and the average results for each prompt are shown in
Table 5, while the results for each trait are shown in
Table 6. The table contains two scenarios proposed in this paper, ExtCTS using BERT(base) and ExtCTS using BERT(large) to extract external information for calculating the similarity transfer factor. From
Table 5 and
Table 6, it can be seen that the ExtCTS model obtains the best results in terms of average QWK values for all prompts and traits. In particular, the ExtCTS model using BERT(base) to extract external information has average QWK values of
and
for all prompts and traits, respectively, which are 1% and 1.2% higher compared to the best baseline model. The ExtCTS model using BERT (large) to extract external information has average QWK values of
and
for all prompts and traits, respectively, which are 0.9% and 1.2% higher than the best baseline model.The above results show that ExtCTS is effective.
Comparing the results for each prompt, the two ExtCTS models were only slightly lower than the ProTACT model for Prompt 7, and the other results were superior to all baseline models. Compared with the best baseline model, ProTACT, the two ExtCTS gain about 2% improvement on prompts 1, 3, 4, and 6. Comparing the two different external information extraction schemes, ExtCTS using BERT(base) works better on Prompts 4, 5, 6, and 8, and ExtCTS using BERT(large) works better on Prompts 1 to 3. The above results show that the proposed method can enhance the effectiveness of each prompt set, and both external information feature extraction using BERT(base) and BERT(large) are effective.
Comparing the results for each trait, the best results for ExtCTS outperform the baselines on all traits, with only ExtCTS using BERT(large) being slightly lower than the best baseline on Organization. The two pre-trained models have similar results in the attribute dimension. Comparing ExtCTS with the best baseline, ExtCTS gains 2.5%, 2%, 1.6%, and 1.6% in Sentence Fluency, Word Choice, Content, and Prompt Adherence, respectively. The above results show that our method is able to obtain great enhancement in each trait. ExtCTS has more improvement in the traits of Sentence Fluency and Word Choice which are related to language expression, indicating that our method is able to better obtain the shared features from the source prompt that are related to language expression. ExtCTS has more enhancement in the trait of Content, and Prompt Adherence also gained good improvement, indicating the effectiveness of the fusion of external knowledge. However, the two traits of Organization and Conventions are not very sensitive to external knowledge. Organization focuses on internal text structure, such as paragraphing and levels of argumentation, which can be assessed directly through the analysis of contextual relationships in the model. Conventions relies on grammatical rules and standardized writing conventions and is less influenced by subject matter or domain knowledge.
4.4. Ablation Studies
In order to further validate the effectiveness of our method, ablation studies are conducted in this section, and the experimental results are shown in
Table 7. The average QWK values for the ExtCTS model using BERT(base) over all prompts are given, the results with different external information removed are given in rows 1–5, and the results with different levels of transfer removed are given in rows 6–11. First, the effect of different external information on the model is verified. Comparing lines 1 to 4 of
Table 7, removing
,
, and
, the model performances all decrease, with
decreasing the most. It shows that using external knowledge can effectively enhance the model performance. Comparing lines 2 to 5 of
Table 7, the models using the above three representations are all able to enhance, further demonstrating the effectiveness of fusing external knowledge.
Then, the effect of different layers of similarity transfer on the model is verified. Comparison of
Table 7, lines 1 and 6 to 8 shows that the results of removing the shallow level feature transfer have been improved, and removing the middle and deep level feature transfer have been decreased. The above results indicate that the factor used at the shallow level is less effective; most likely, the model mainly contains sentence-level features at the shallow level, which are more semantically different from the deep-level features that are directly used for scoring, and thus it is more difficult to transfer features from the shallow level. In addition, migrating at a shallow level of the model may further affect the training of the overall representation of the model, thus degrading the model performance. Comparison of rows 1 and 9 to 11 of
Table 7 shows that the results of using only similarity feature transfer at the deeper level of the model decreased less, and the results of using only shallow transfer decreased more and were lower than the results of the best baseline model, further suggesting that transfer at a shallow level of the model affects the model results. In contrast, similarity feature transfer at the deeper level of the model is more effective, indicating that our method is more suitable for feature transfer at the deeper level of the model.
4.5. Effect of Loss Function
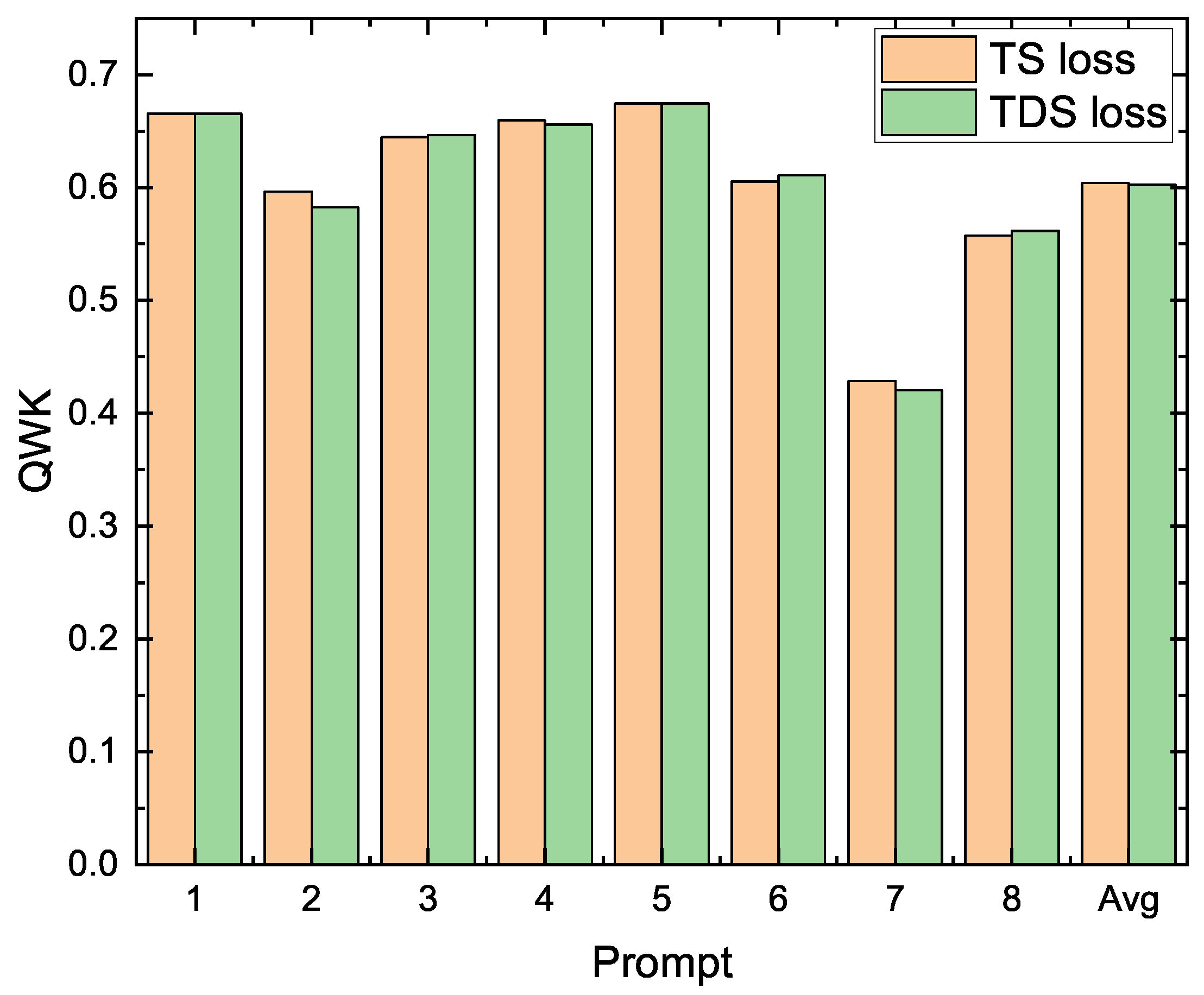
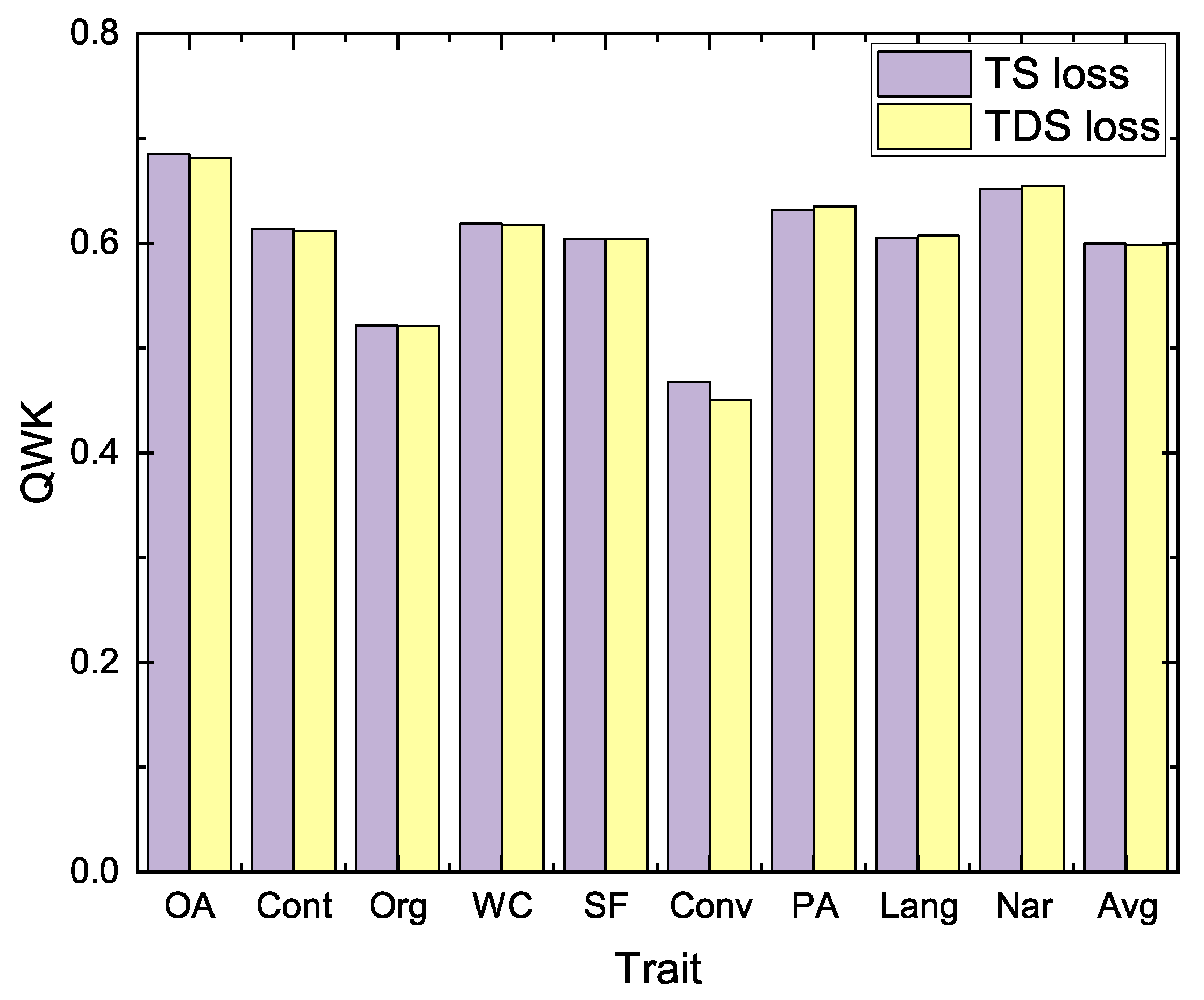
This section analyzes the impact of the similarity loss function between traits proposed in this paper (TDS), and the experimental results are shown in
Table 8. When
takes the value of 1, the training objective of the model contains only the scoring loss, and it can be seen that the effect of the model using only the scoring loss is slightly degraded; the results are slightly better only in Prompt 5, which proves the validity of the inter-trait similarity loss function.
Next, the trait similarity (TS) loss function proposed by the baseline [
19] is compared. The difference between the two lies in the calculation of the similarity threshold, and our method proposes to utilize the cosine similarity between different trait descriptions instead of the Pearson correlation coefficient. The experimental results are shown in
Figure 4 and
Figure 5. The TDS loss proposed in this paper is closer to the results of the baseline modeling method, which proves that the proposed method is competitive.
4.6. Effect of Transfer Factors
This section verifies the effect of the two trait similarity factors of
and
, and the results are shown in
Table 9, which shows that the effect of using the essay prompt similarity factor is better. The genre similarity factor has a negative effect on the model, which may be due to the fact that essays of similar genres have similar essay organization, language expression, etc., but there is no explicit distinction between the different information in the representation of ExtCTS, and the similarity factor will transfer all the information of the essays to the target prompt and thus have a negative effect. Compared to genre information, the prompt unifies the entire essay and the overall representation of the essay is influenced by the prompt information; therefore, using the essay prompt for transfer is effective.
5. Conclusions
In this paper, we propose extra-essay knowledge representation and similarity transfer to enhance shared representation learning in cross-prompt essay trait scoring. Our framework addresses two critical limitations of existing methods: (a) the oversight of external knowledge in measuring inter-prompt commonality, and (b) insufficient alignment between task traits. By explicitly incorporating external knowledge representation to enrich task-specific understanding and quantifying sample similarity through knowledge transfer, we effectively bridge the gap between source and target prompts. Experiments on the ASAP++ dataset show significant improvements over baselines, validating the effectiveness of the proposed method.
In the future, we will further refine the trait descriptions and explore effective combinations of large language models (LLMs), which can give fine-grained evaluations and timely feedback to enhance cross-prompt essay trait scoring. Integrating LLMs into essay scoring systems presents both challenges and opportunities. LLMs might prioritize shallow features (e.g., word choice) over critical thinking, stifling creativity. LLMs also complicate transparent scoring rationales, raising issues of credibility and fairness.
Cross-prompt scoring aims to generalize the evaluation of essays across different prompts or writing tasks, and our model suffers from the following limitations. First, the model is susceptible to prompt bias, and the training data are mostly focused on common prompts, which decreases the accuracy of the evaluation effect for prompts with large domain spans. Second, it is difficult to generalize the scoring criteria, as the core requirements of different writing tasks vary greatly and the scoring scales are different, making it difficult for a single model to accurately adapt to diverse scoring dimensions. Finally, data sparsity limits the robustness of the model, and insufficient samples for some topics may lead to overfitting or underfitting of the scoring rules.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}