
Dynamic Evolution Method and Symmetric Consistency Analysis for Big Data-Oriented Software Architecture Based on Extended Bigraph


Abstract
1. Introduction
2. Related Work
2.1. Evolution Rule Design and Formal Description
2.2. Formal Modeling Methods for Software Architecture Evolution
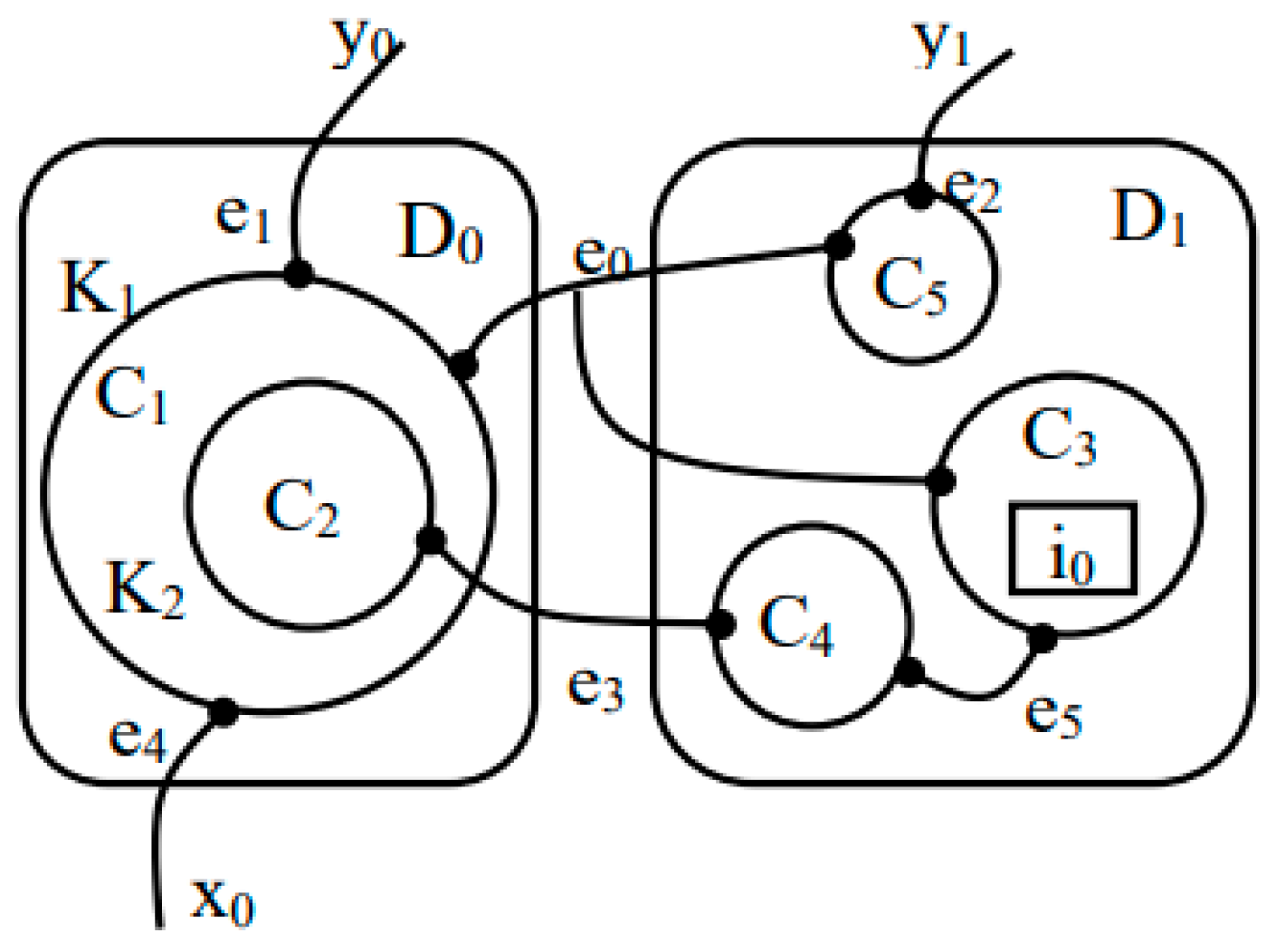
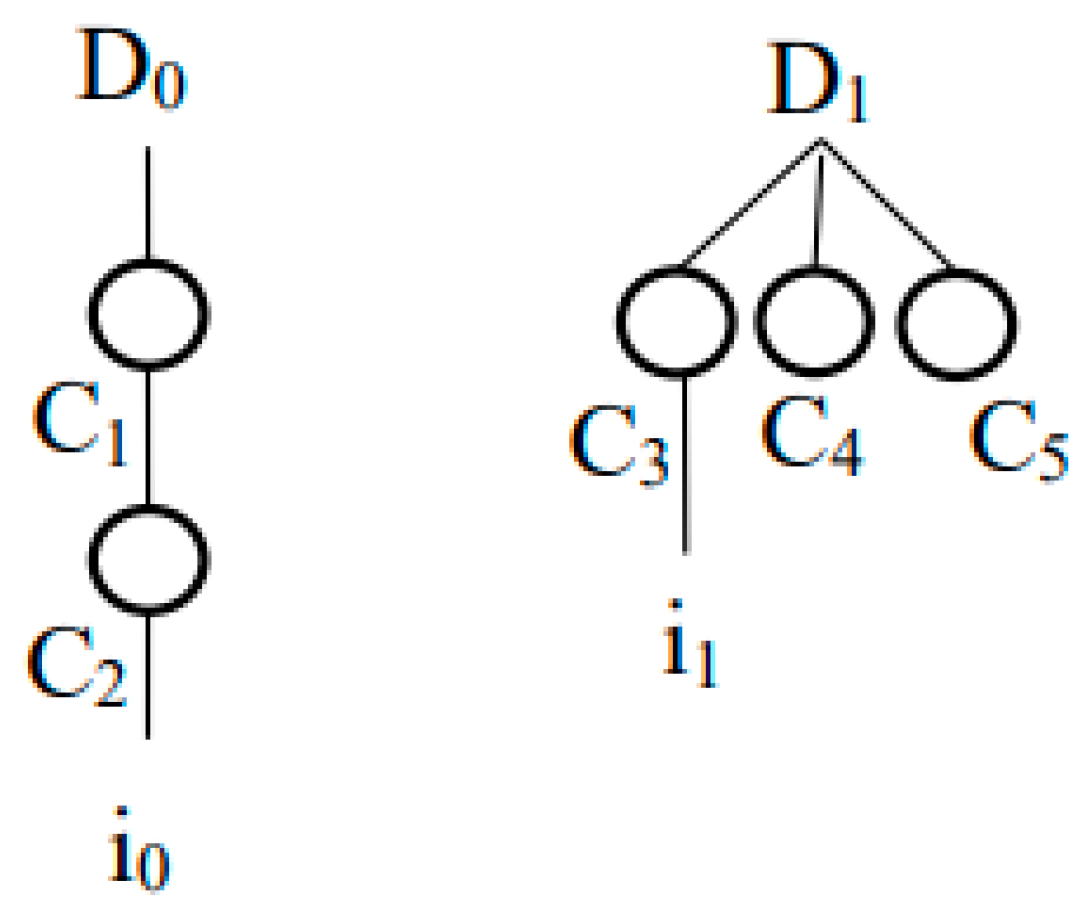
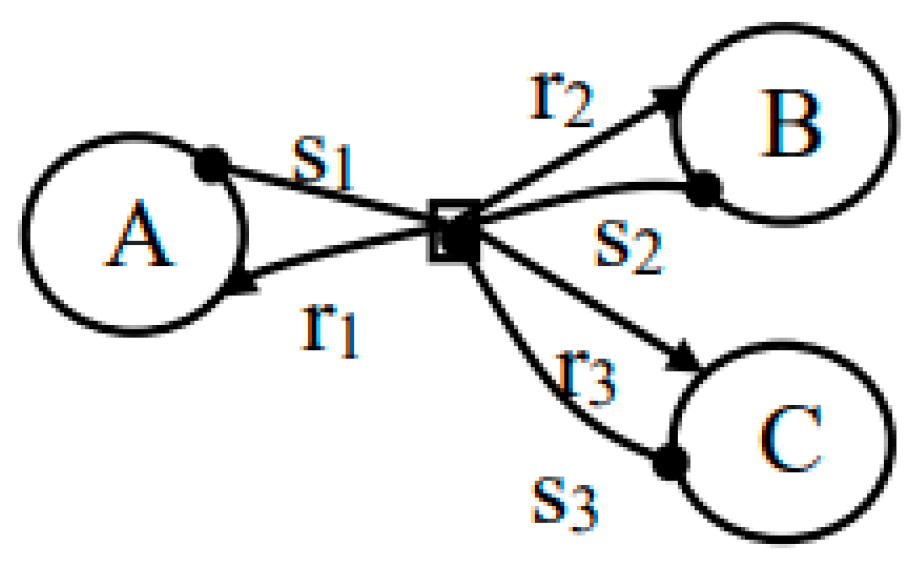
3. The Notion of Bigraph and Extended Bigraph
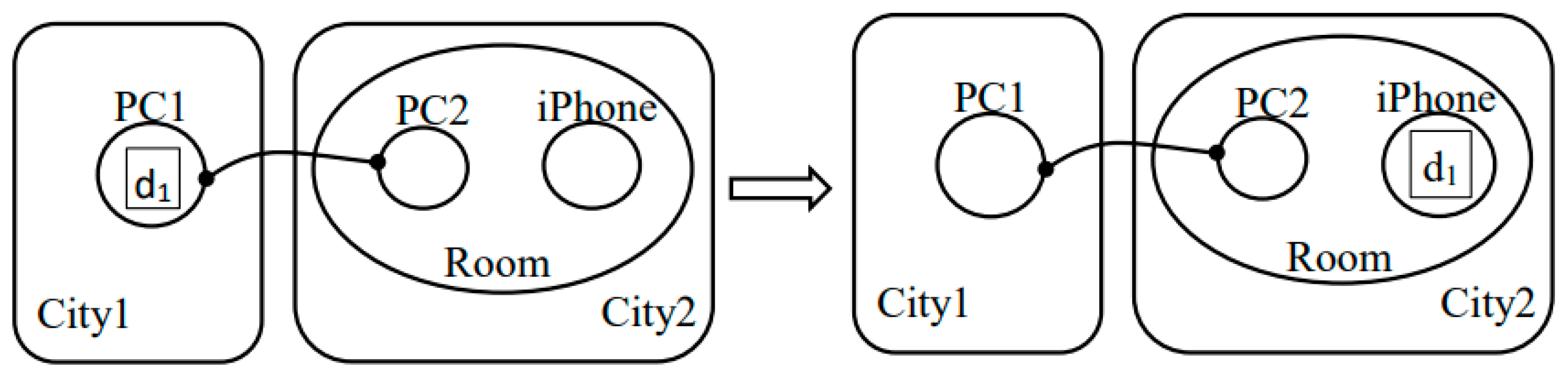
3.1. Static Structure and Dynamic Behavior with Bigraph
3.2. Extend Bigraph
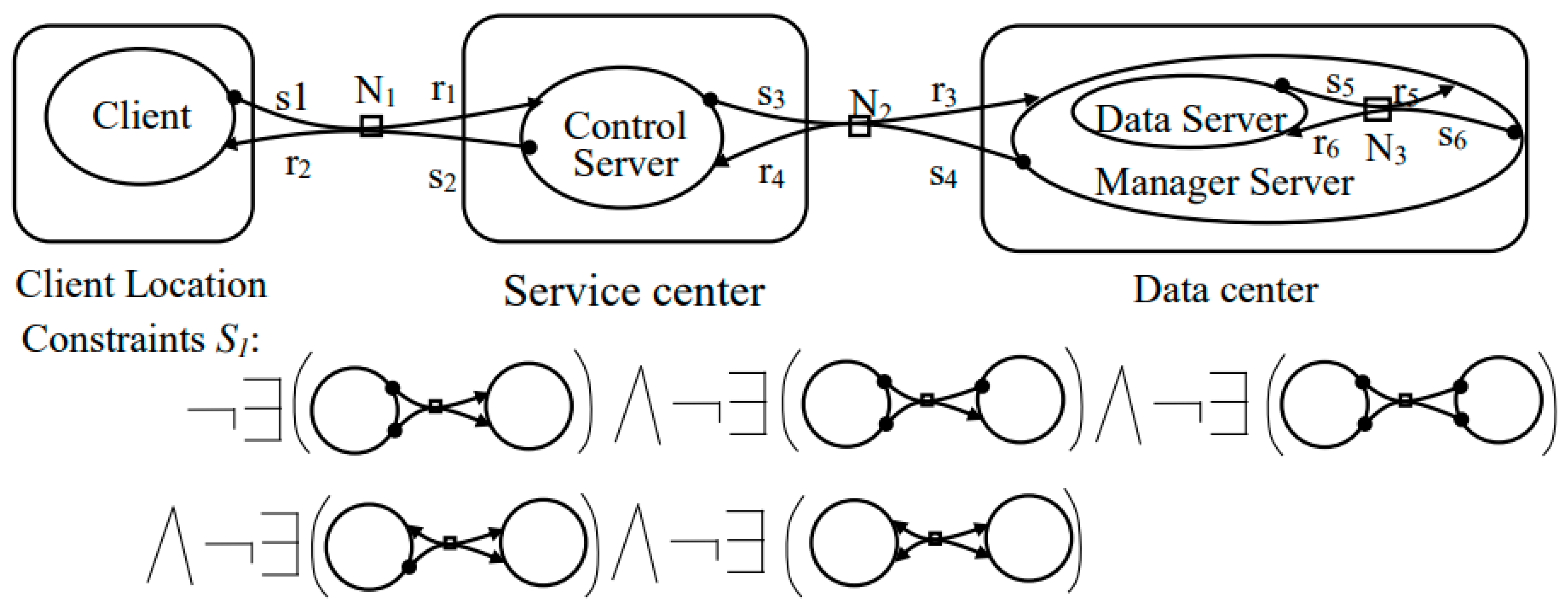
4. Modeling Big Data-Oriented Software Architecture Based on Extend Bigraph
5. The Dynamic Evolution of BDOSA
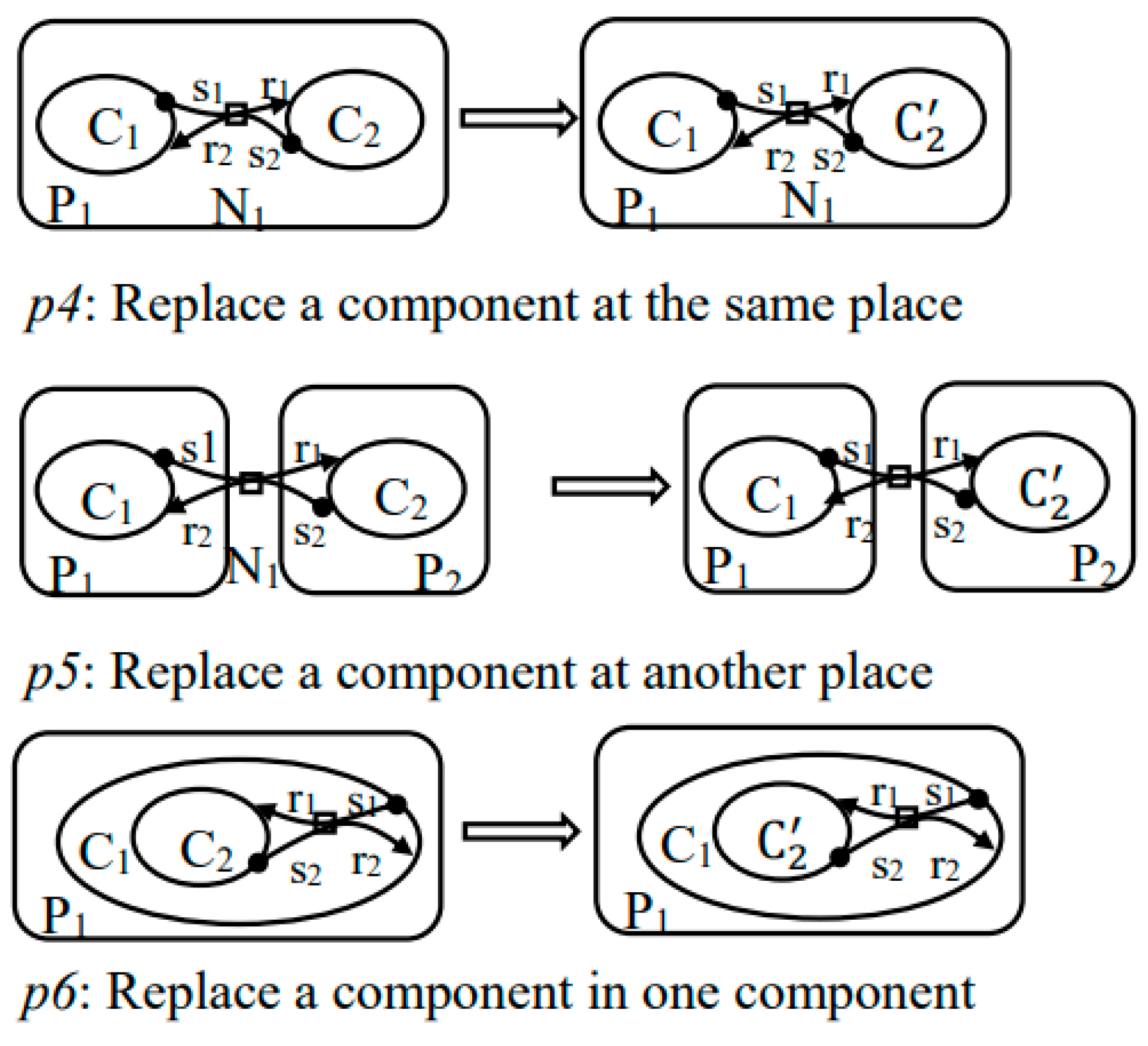
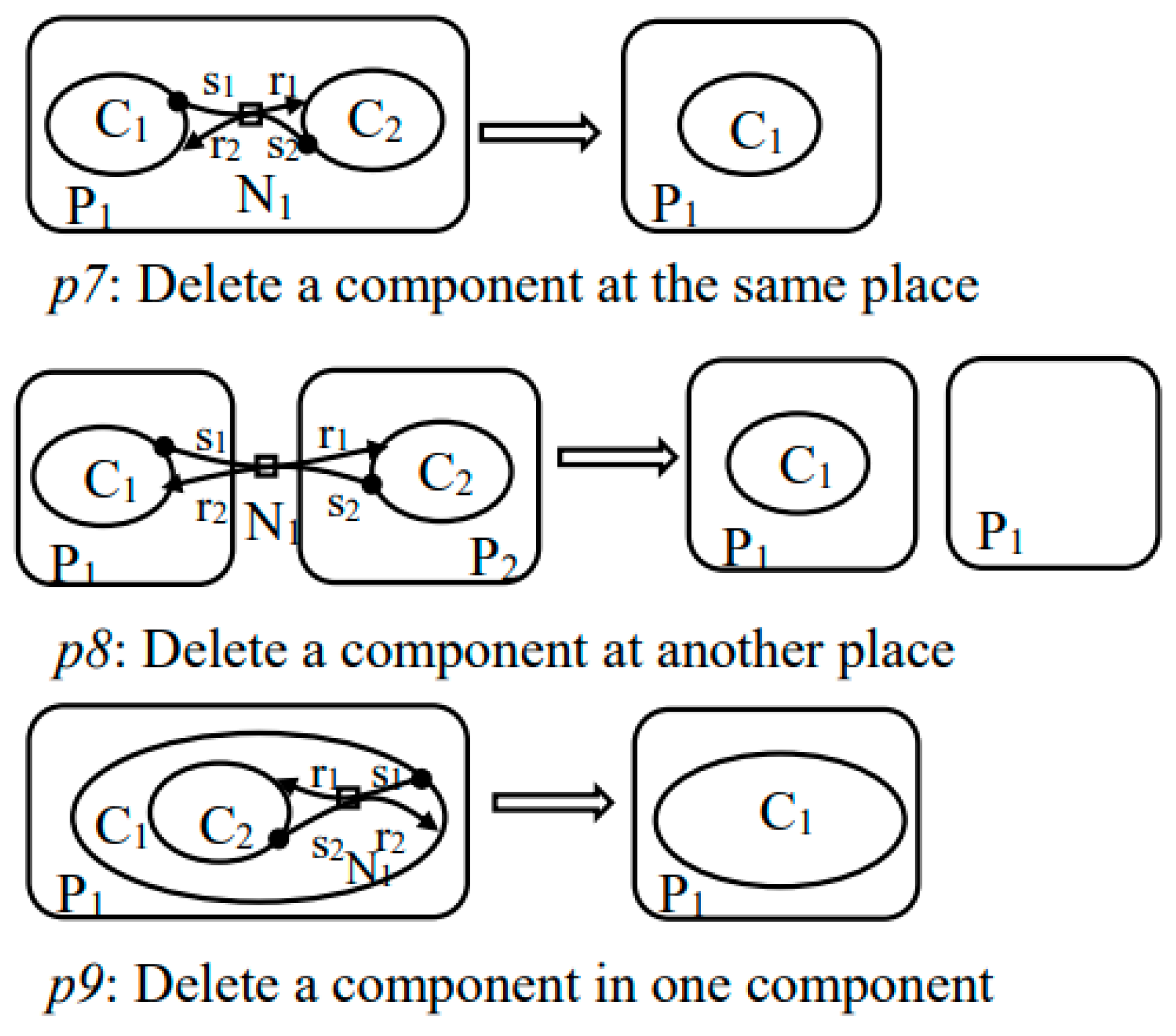
5.1. Dynamic Evolution Rules of BDOSA
5.2. Dynamic Evolution of BDOSA Based on Evolution Rules
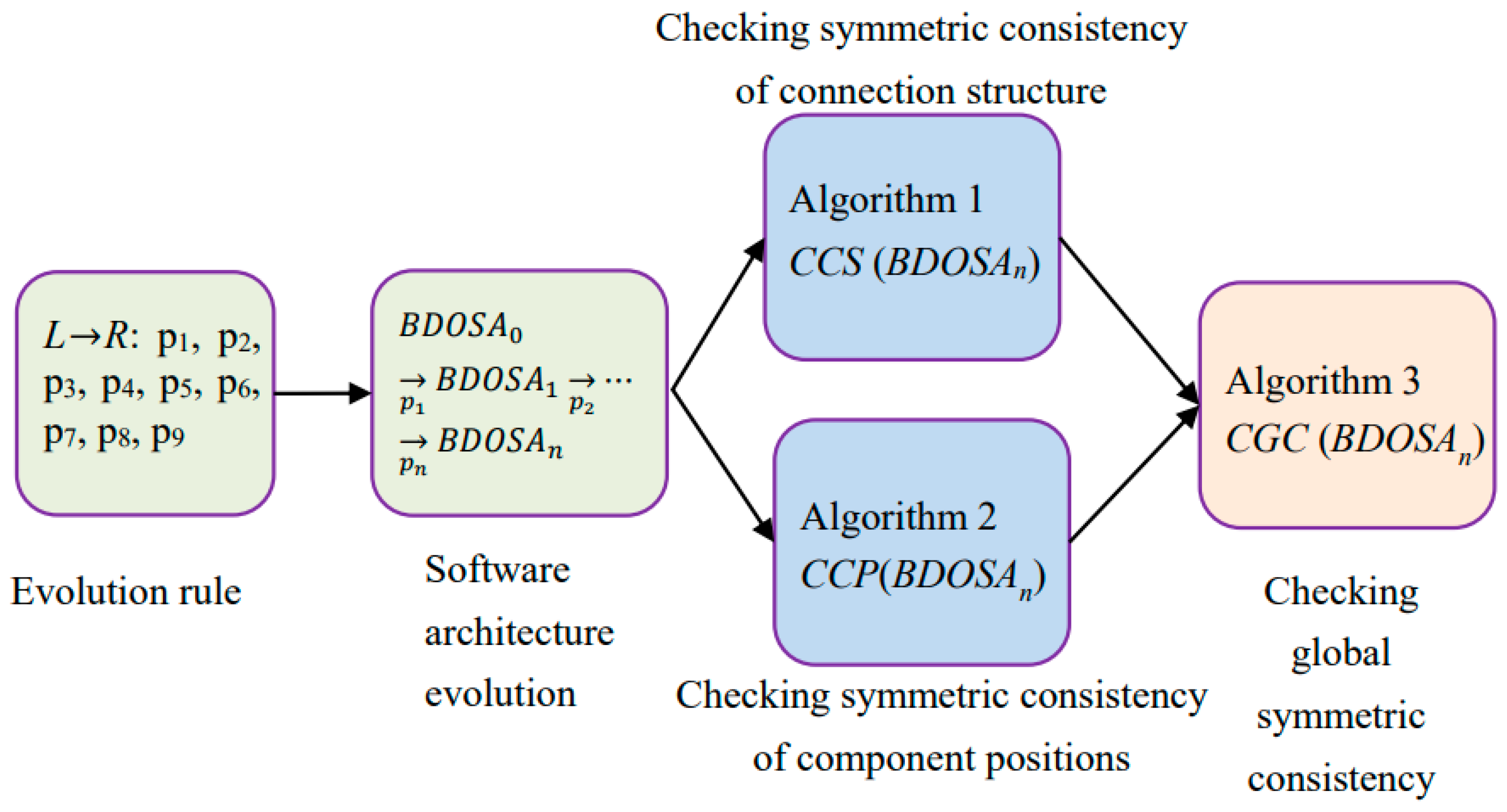
6. Symmetric Consistency Analysis of Software Architecture Evolution
| Algorithm 1: Checking Symmetric Consistency of Connection Structure, CCS |
| Input: Software architecture BDOSA = (C, N*, S, P, Ctrl, Prnt, Link*) |
| Output: Consistent_Structure of No_Consistent_Structure |
| ci C // Traverse each node |
| CN* |
| C–ci |
| 4: else |
| 5: return No_Consistent_Structure |
| 6: end for |
| ni N // Traverse each connector |
| nici C |
| N*–ni |
| 10: else |
| 11: return No_Consistent_Structure |
| 12: end for |
| 13: return Consistent_Structure |
| Algorithm 2: Checking Symmetric Consistency of Component Positions, CCP |
| Input: Software architecture BDOSA = (C, N*, S, P, Ctrl, Prnt, Link*) |
| Output: Consistent_Location of No_Consistent_Location |
| // Component classification variable |
| // Component classification set |
| ci C // Classification |
| ki |
| Cki ci |
| Ck Cki |
| 7: end if |
| 8: end for |
| Cki Ck // Discriminant location |
| ci Cki P |
| 11: return Consistent_Location |
| 12: else |
| 13: return No_Consistent_Location |
| 14: end for |
| Algorithm 3: Checking Global Symmetric Consistency of Software Architecture, CGC |
| Input: Software architecture BDOSAn = (C, N*, S, P, Ctrl, Prnt, Link*) |
| Output: Consistent_Global of No_Consistent_Global |
| // Temporary variable |
| // Temporary variable |
| 3: if CCS(BDOSAn) = true |
| Consistent_Structure |
| 5: else |
| 6: return No_Consistent_Global |
| 7: if CCP(BDOSAn) = true |
| Consistent_Structure |
| 9: else |
| 10: return No_Consistent_Global |
| CL |
| 12: return Consistent_Global |
| 13: else |
| 14: return No_Consistent_Global |
7. Case Studies
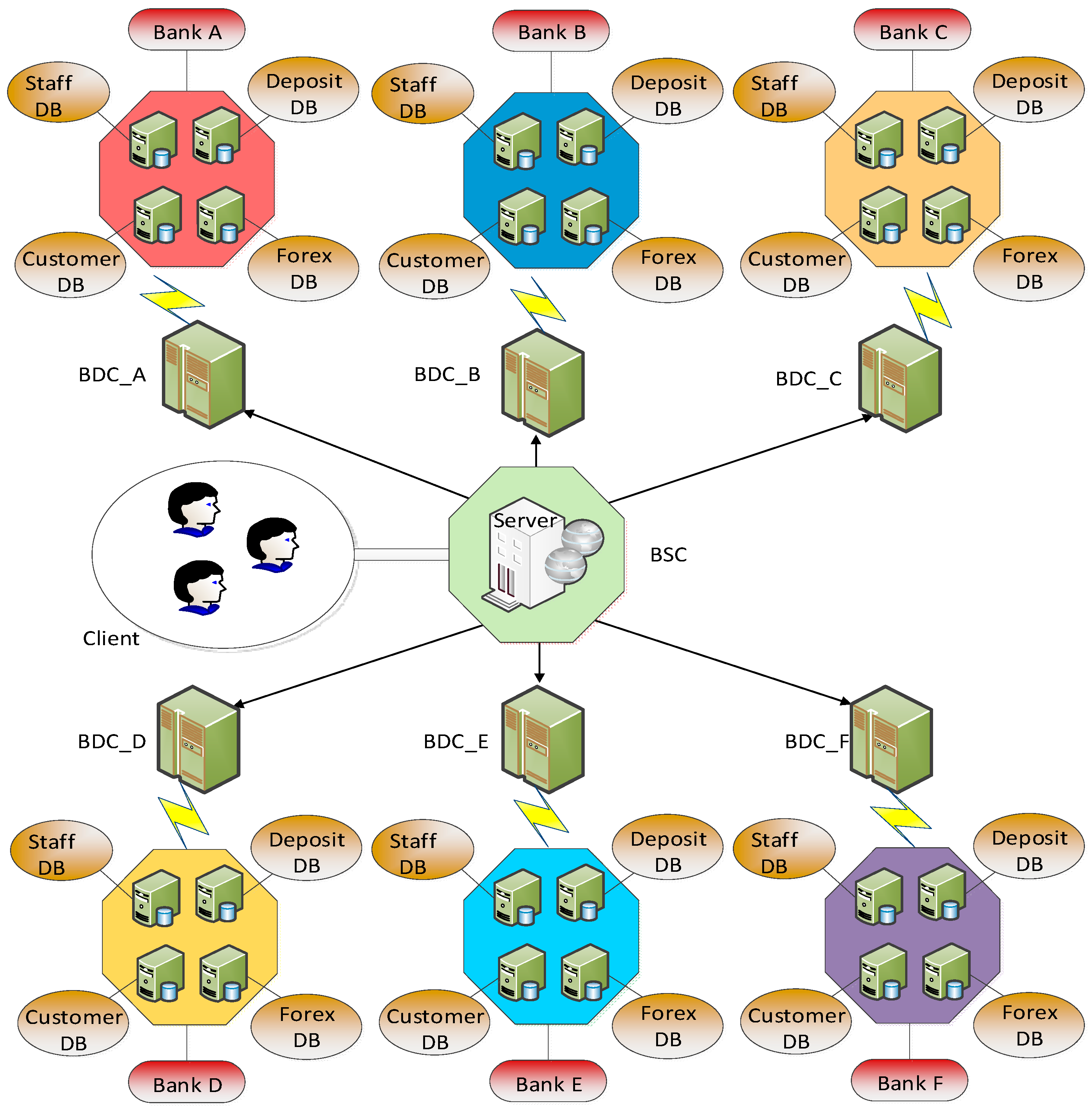
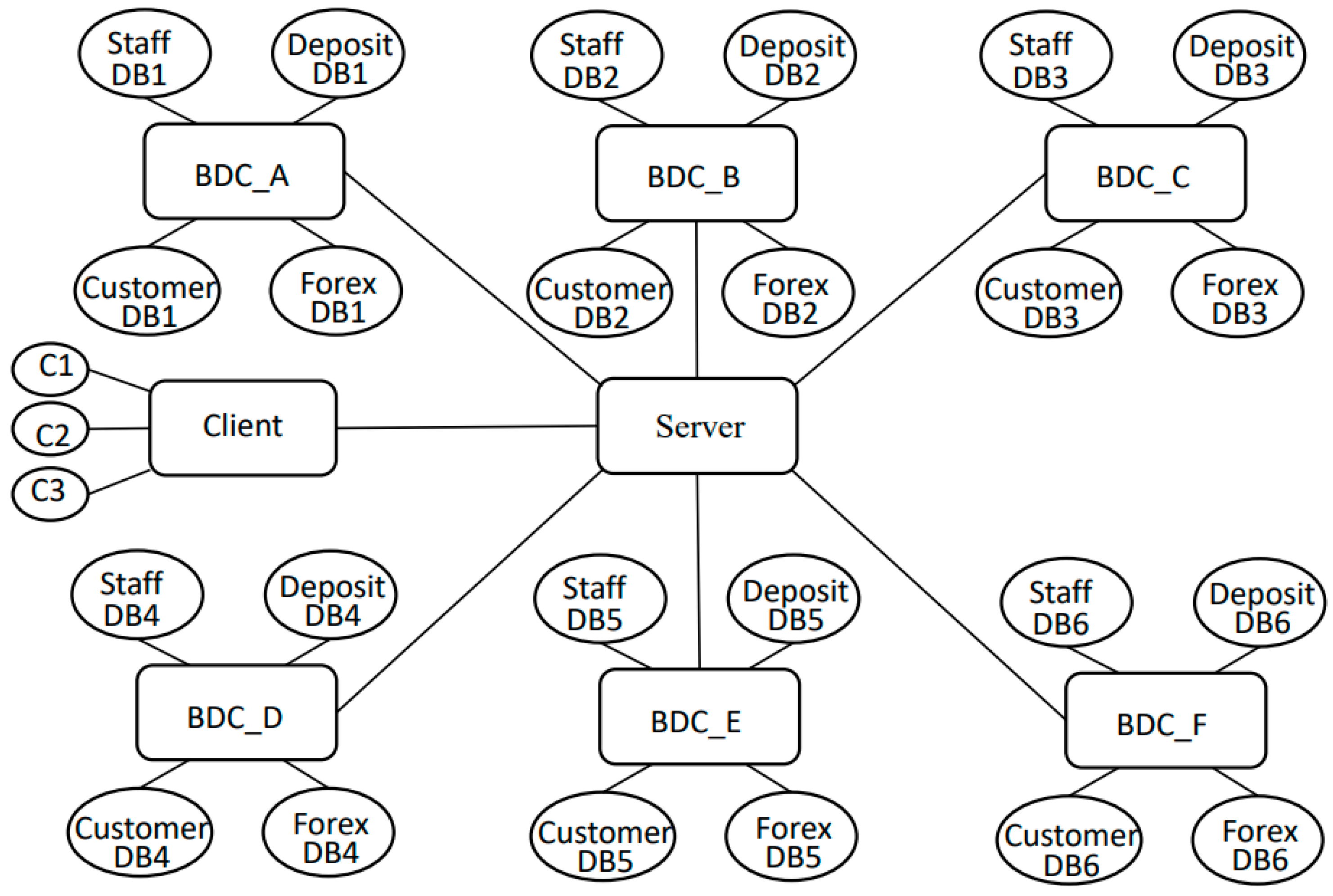
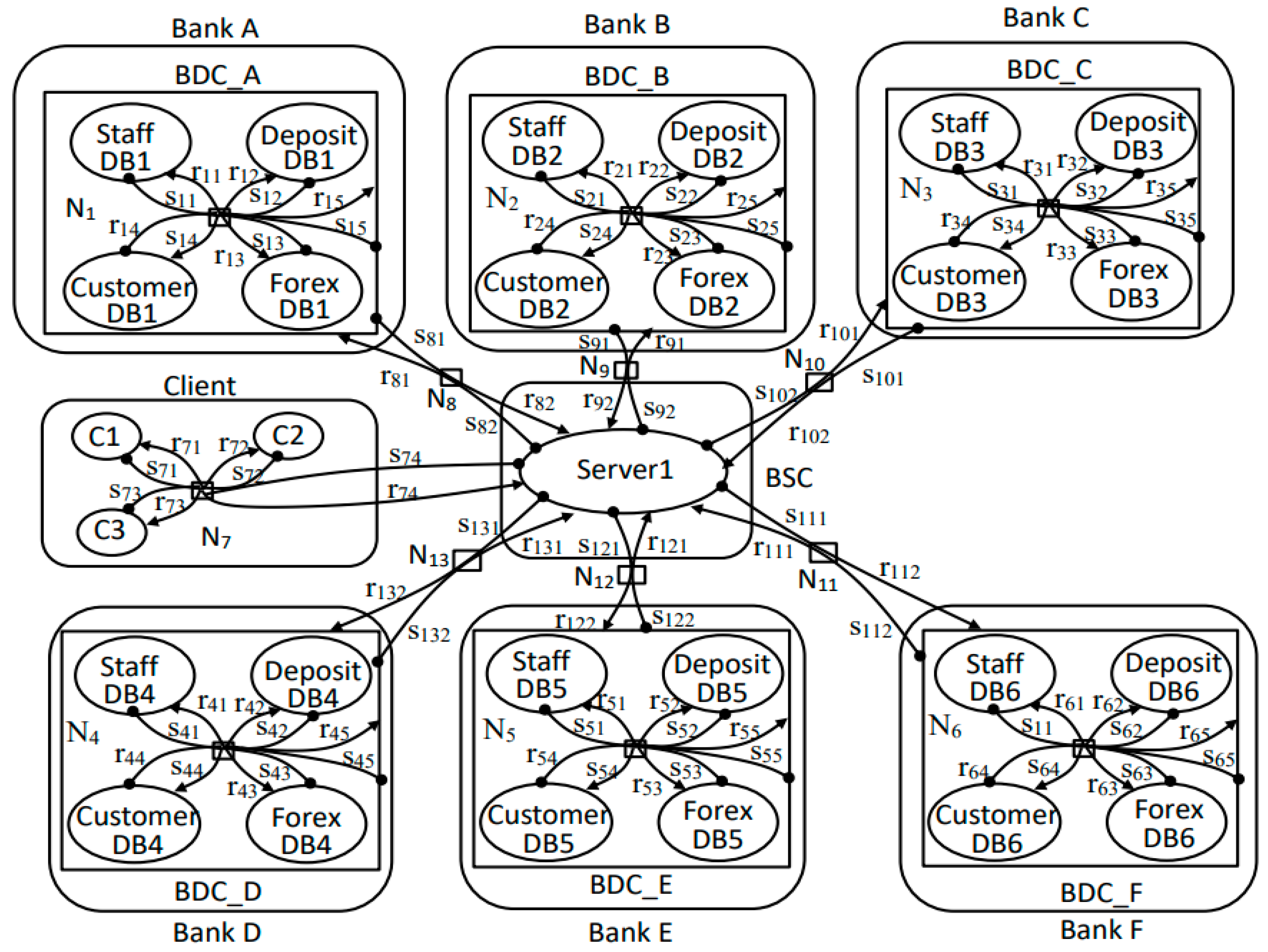
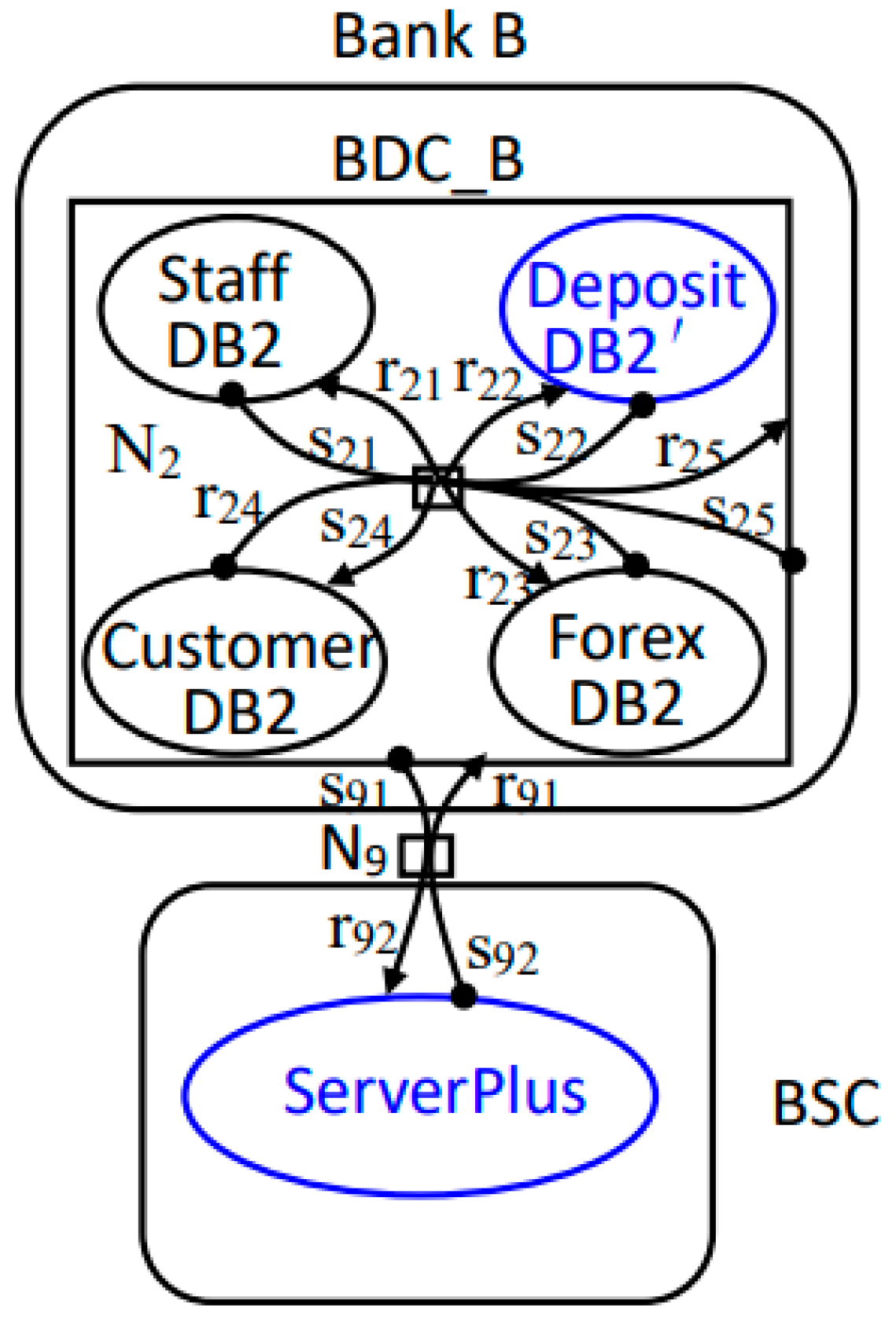
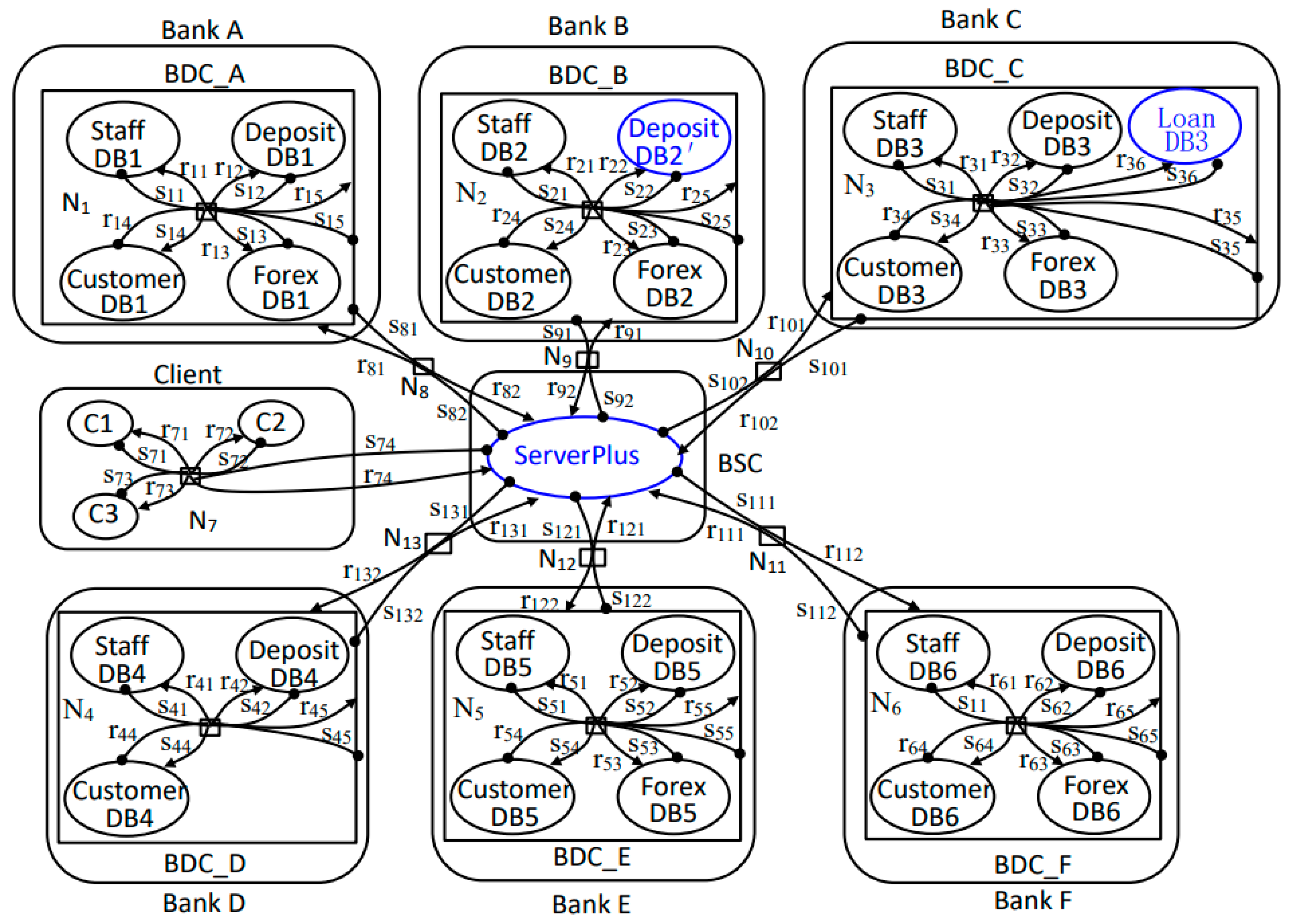
7.1. Bigraph Model of Bank Data Service System
7.2. System Evolution
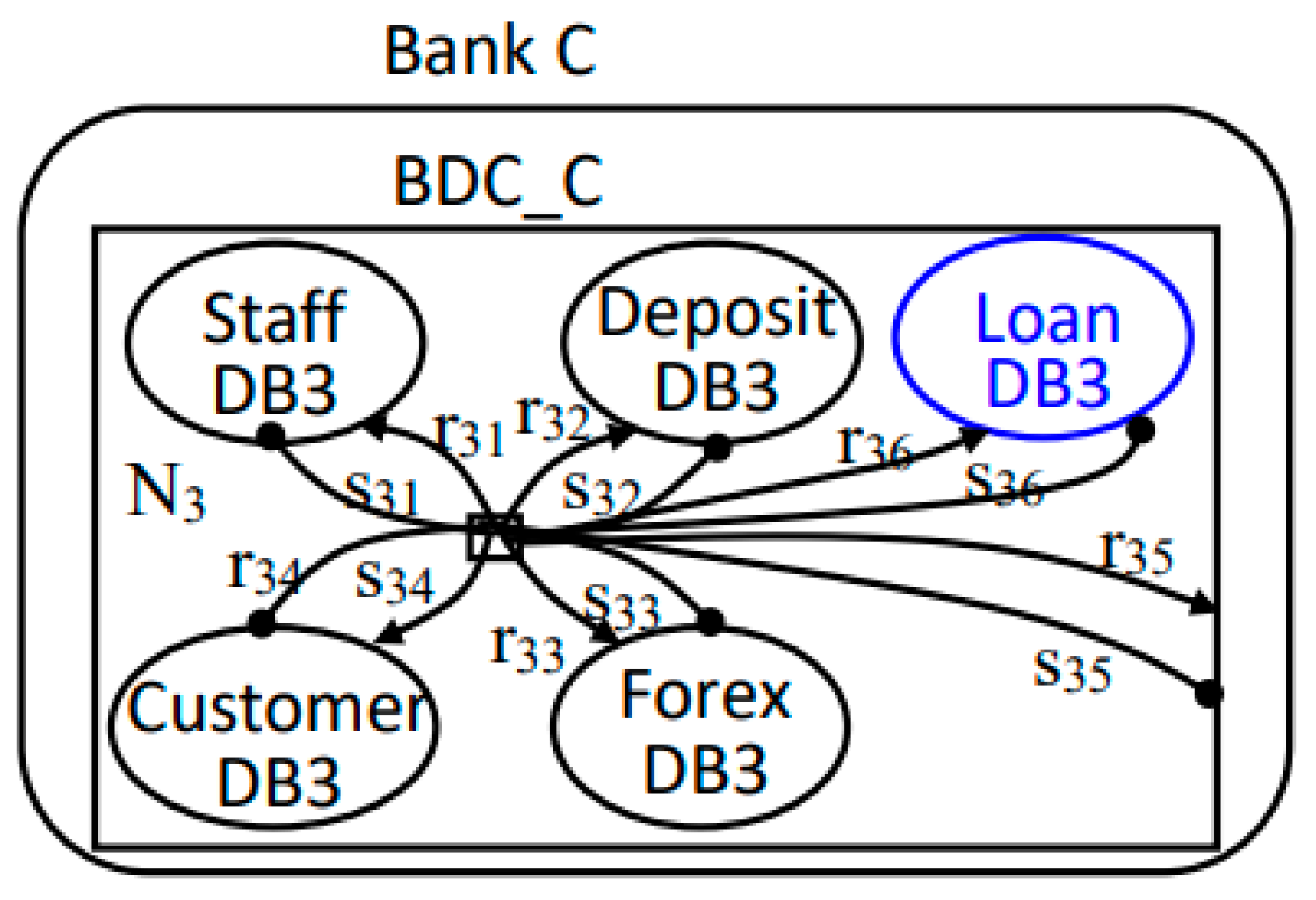
7.2.1. Add Evolution Rules
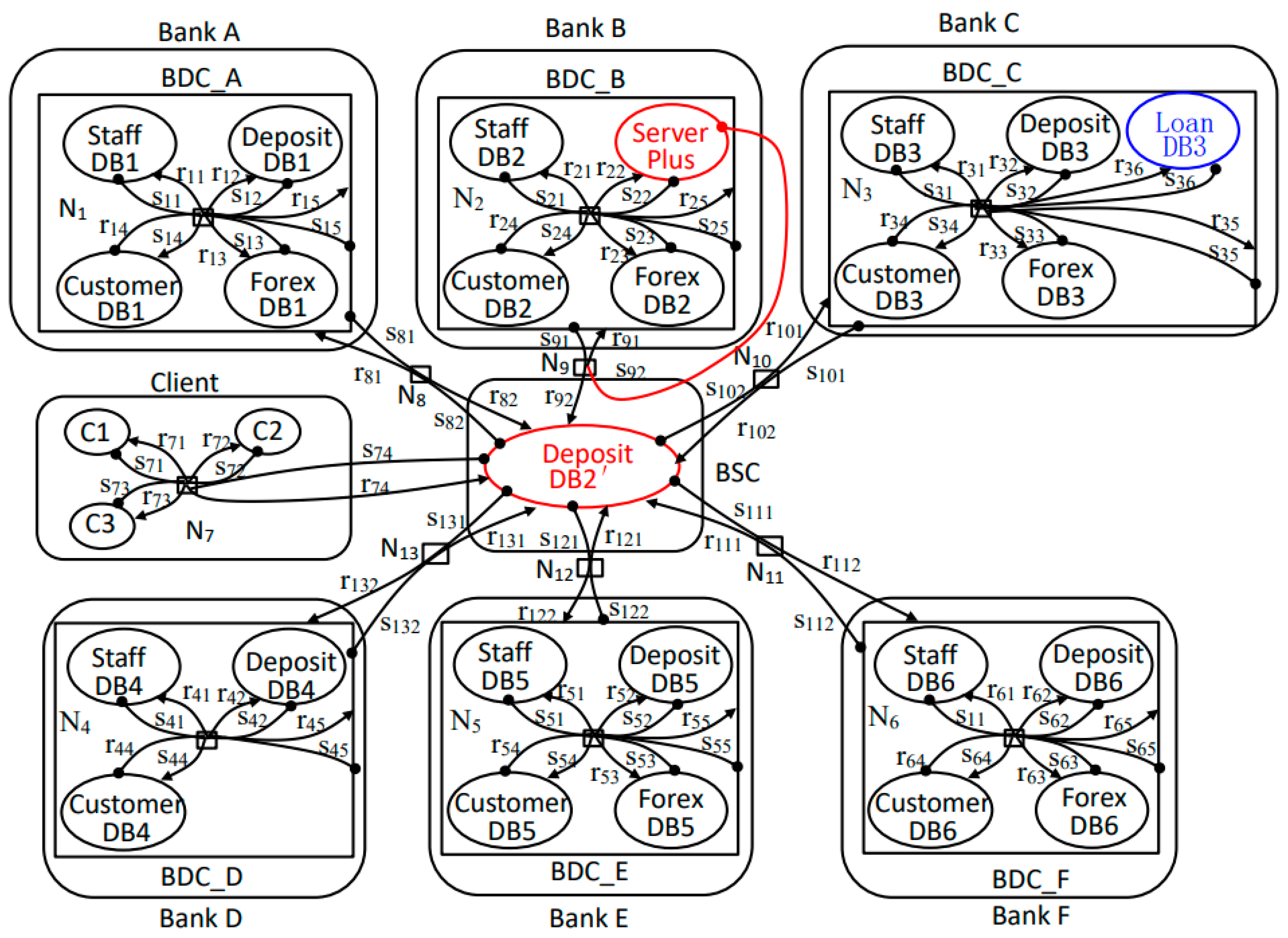
7.2.2. Replace Evolution Rules
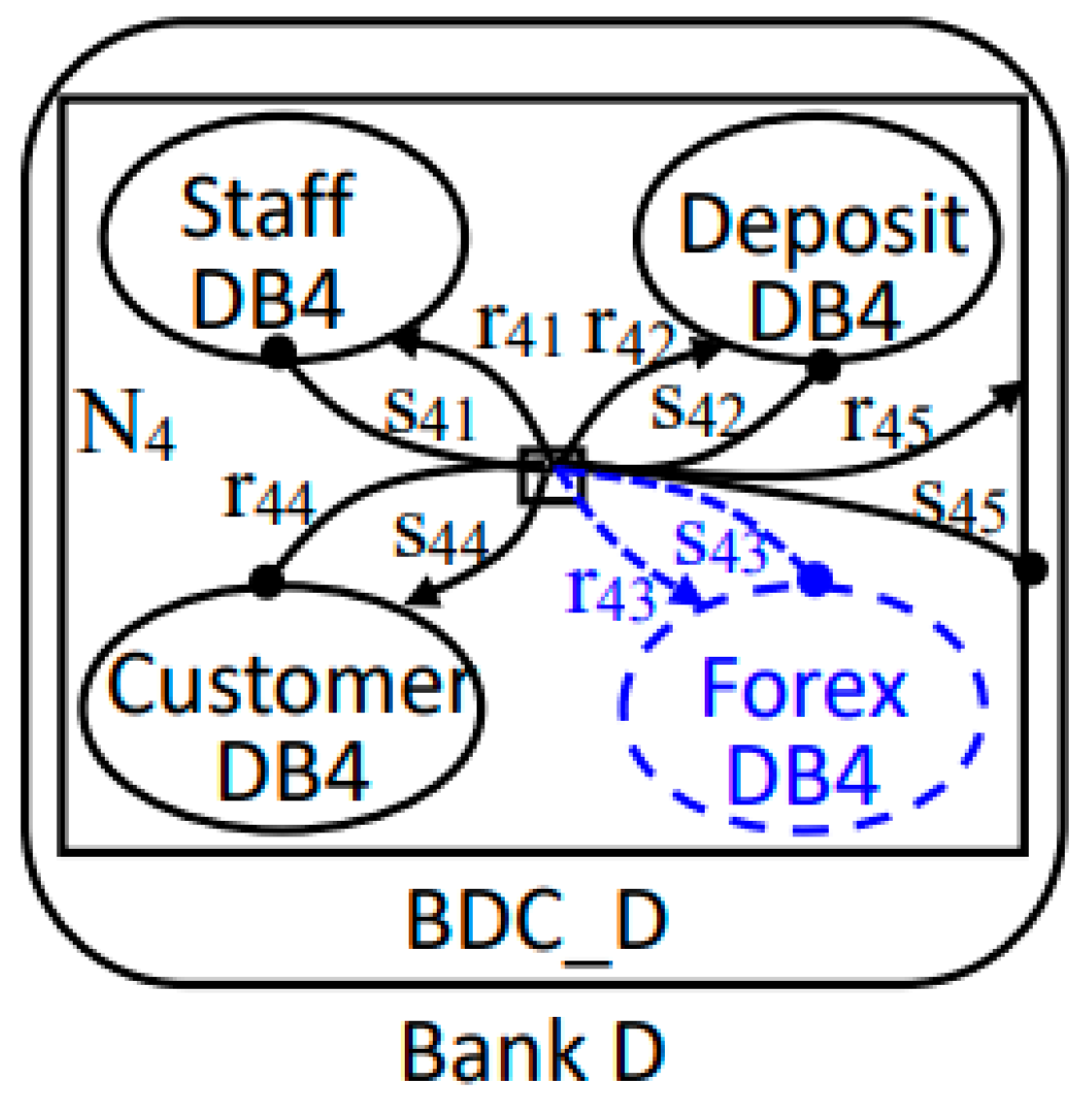
7.2.3. Delete Evolution Rules
7.3. Symmetric Consistency Analysis of System Evolution
7.3.1. Symmetric Consistency Analysis of Connection Structure and Component Positions
7.3.2. Asymmetric Consistency Analysis of Connection Structure and Component Positions
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cerezo, F.; Vela, B. Experience of the Architectural Evolution of a Big Data System. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2024; Volume 14590, pp. 426–437. [Google Scholar]
- Pompeo, D.D.; Tucci, M. Harnessing Genetic Improvement for Sustainable Software Architectures. In Proceedings of the IEEE 21st International Conference on Software Architecture Companion (ICSA-C), Hyderabad, India, 4–8 June 2024. [Google Scholar]
- Zhong, C.; Li, S.; Zhang, H.; Huang, H.; Yang, L.; Cai, Y. Refactoring Microservices to Microservices in Support of Evolutionary Design. IEEE Trans. Soft. Eng. 2025, 51, 484–502. [Google Scholar] [CrossRef]
- Marimekala, S.K.; Lamb, J.; Epstein, R.; Bhupathi, V. Using AI and Big Data in the HealthCare Sector to Help Build a Smarter and more Intelligent HealthCare System. In Proceedings of the IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, 29–31 May 2024. [Google Scholar]
- Lee, J.Y. An Exploratory Study on Issues Related to chatGPT and Generative AI through News Big Data Analysis. Int. J. Adv. Cult. Technol. 2023, 11, 378–384. [Google Scholar]
- Chen, H.; Yu, J.; Hang, C.; Zang, B.; Yew, P. Dynamic software updating using a relaxed consistency model. IEEE Trans. Soft. Eng. 2011, 37, 679–694. [Google Scholar] [CrossRef]
- Chouikh, A.; Khalfaoui, K.; Kerkouche, E.; Chaoui, A. An approach for UML sequence diagram models/metamodels co-evolution using transformation rules. In Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2025; Volume 1267, pp. 69–84. [Google Scholar]
- Zhang, T.; Zhu, J.; Wang, Y. A Design Method of Service-Oriented Software Architecture Description Language Supporting Performance Modeling. In Proceedings of the IEEE International Conference on Image Processing and Computer Applications, Changchun, China, 11–13 August 2023. [Google Scholar]
- Huang, G.; Huang, L.; Chen, X.; Sun, L. Rationality of Service Composition of Workflow Net in a Service Oriented Architecture. In Proceedings of the International Conference on Informatics and Semiotics in Organisations, Hangzhou, China, 6 October 2014. [Google Scholar]
- Zeng, J.; Sun, H.L.; Liu, X.D.; Dent, T.; Huai, J.P. Dynamic Evolution Mechanism for Trustworthy Software Based on Service Composition. J. Soft. 2010, 21, 89–104. [Google Scholar] [CrossRef]
- Xu, H.Z.; Zeng, G.S. Modeling and Verifying Composite Dynamic Evolution of Software Architectures Using Hypergraph Grammars. Int. J. Soft. Eng. Knowl. Eng. 2013, 23, 775–799. [Google Scholar] [CrossRef]
- Zhao, H.Q.; Sun, J. An Algebraic Model of Internetware Software Architecture. Sci. China Inf. Sci. 2013, 43, 161–177. [Google Scholar]
- Spanoudakis, G.; Zisman, A. Discovering Services During Service-based System Design Using UML. IEEE Trans. Soft. Eng. 2010, 36, 371–389. [Google Scholar] [CrossRef]
- Mokni, A.; Urtado, C.; Vauttier, S.; Huchard, M.; Zhang, Y. A Formal Approach for Managing Component-based Architecture Evolution. Sci. Comput. Program. 2016, 127, 24–49. [Google Scholar] [CrossRef]
- Taoufik, S.R.; Tahar, B.M.; Mourad, K. Behavioral Verification of UML2.0 Software Architecture. In Proceedings of the International Conference on Semantics, Beijing, China, 13–14 August 2017. [Google Scholar]
- Oquendo, F. Formally Describing the Architectural Behavior of Software-intensive Systems-of-Systems with SosADL. In Proceedings of the IEEE International Conference on Engineering of Complex Computer Systems, Dubai, United Arab Emirates, 6–8 November 2016. [Google Scholar]
- Rufiange, S.; Melançon, G. AniMatrix: A Matrix-Based Visualization of Software Evolution. In Proceedings of the Second IEEE Working Conference on Software Visualization, Victoria, BC, Canada, 29–30 September 2014. [Google Scholar]
- He, J.; Li, T.; Zhang, D.H. A Cumulative SaaS Service Evolution Model Based on Expanded Pi Calculus. In Proceedings of the 19th International Conference on Industrial Engineering and Engineering Management, Changsha, China, 27–29 October 2013. [Google Scholar]
- Song, W.; Ma, X.; Jacobsen, H.A. Instance migration validity for dynamic evolution of data-aware processes. IEEE Trans. Soft. Eng. 2019, 45, 782–801. [Google Scholar] [CrossRef]
- Xu, H.Z.; Song, W.; Liu, Z. A Specification and Detection Approach for Parallel Evolution Conflicts of Software Architectures. Int. J. Softw. Eng. Knowl. Eng. 2017, 27, 373–398. [Google Scholar] [CrossRef]
- Wang, L.; Rong, M.; Zhang, G.Q.; Wang, S. Research on Bigraph-based Aspect-oriented Dynamic Software Architecture Evolution. Comput. Sci. 2010, 37, 137–140. [Google Scholar]
- Lu, C.Z.; Zeng, G.S. Toward an Analysis Method of Software Evolution Triggered by Place Change in Mobile Computing. IEEE Trans. Reliab. 2023, 72, 527–541. [Google Scholar] [CrossRef]
- Wachholder, D.; Stary, C. Enabling Emergent Behavior in Systems-of-Systems Through Bigraph-based Modeling. In Proceedings of the IEEE System of Systems Engineering Conference, San Antonio, TX, USA, 17–20 May 2015. [Google Scholar]
- Li, C.; Huang, L.; Chen, L. Breeze Graph Grammar: A Graph Grammar Approach for Modeling the Software Architecture of Big Data-oriented Software Systems. Softw. Pract. Exp. 2015, 45, 1023–1050. [Google Scholar] [CrossRef]
- Milner, R. The Space and Motion of Communicating Agents; Cambridge University Press: Cambridge, UK, 2009; pp. 1–96. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning |
|---|---|
| Domain split parallel operator | |
| Node parallel operator | |
| Node composition operator | |
| Domain juxtaposition extended operator | |
| ( ) | Domain or component nesting operator |
| / | Link operator |
| BDOSA | Extend Bigraph |
|---|---|
| Component | Node |
| Connector | Super edge |
| Port | The tentacle of super edge |
| Component type | Control |
| Constraints | Control |
| Place | Domain and site |
| Evolution Rules | Evolutionary Components | Consistent State (Yes/No) | Evolved System Functional Status |
|---|---|---|---|
| p1 | LoanDB3 | Yes | Loan services available |
| p4 | DepositDB2, DepositDB2’ | No | Deposit service failed |
| p5 | Server1, ServerPlus | No | All services failed |
| p7 | ForexDB4 | Yes | Suspension of foreign exchange services |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, C.; Zou, Q. Dynamic Evolution Method and Symmetric Consistency Analysis for Big Data-Oriented Software Architecture Based on Extended Bigraph. Symmetry 2025, 17, 626. https://doi.org/10.3390/sym17040626
Lu C, Zou Q. Dynamic Evolution Method and Symmetric Consistency Analysis for Big Data-Oriented Software Architecture Based on Extended Bigraph. Symmetry. 2025; 17(4):626. https://doi.org/10.3390/sym17040626
Chicago/Turabian StyleLu, Chaoze, and Qifeng Zou. 2025. "Dynamic Evolution Method and Symmetric Consistency Analysis for Big Data-Oriented Software Architecture Based on Extended Bigraph" Symmetry 17, no. 4: 626. https://doi.org/10.3390/sym17040626
APA StyleLu, C., & Zou, Q. (2025). Dynamic Evolution Method and Symmetric Consistency Analysis for Big Data-Oriented Software Architecture Based on Extended Bigraph. Symmetry, 17(4), 626. https://doi.org/10.3390/sym17040626