Abstract
Existing artifact-based tampering detection methods face limitations when dealing with secondarily edited images. To address this, this paper proposes a novel semantic-based approach for detecting tampering in bilingual scene text images. Unlike existing artifact-based detection methods, this technique leverages the semantic consistency of bilingual text pairs. By translating both texts into a common language and calculating their semantic similarity, the image is identified as tampered with when the similarity falls below a threshold. Additionally, this paper introduces the Bilingual Scene Text Image Tampering Detection (BSTID) dataset. Experimental results demonstrate that the proposed method excels in detecting secondarily edited tampered images, achieving an average accuracy of 90.03% and an F1 score of 88.5%.
1. Introduction
Information technology has advanced rapidly, transitioning society into a digital multimedia-dominated era. Image tampering technology has evolved, making it easier for images to be manipulated. This technology has shown great potential in sectors such as film and television production, game development, and creative design. However, it also poses new challenges to information security, judicial impartiality, and social stability. Therefore, research on the detection of image tampering has become significantly important.
In the realm of image tampering detection, artifact-based detection is predominantly employed. Tampering traces are identified by capturing abnormal artifacts within images. These artifacts include texture discrepancies, alterations in spatial information, and anomalous frequency characteristics [1]. Although this method generally performs well, its effectiveness is constrained when dealing with secondary-edited tampered images. This is because the artifact features are often removed during the editing process.
In order to solve the above problems, a bilingual image tampering detection method based on semantic conflicts was proposed in our work [2,3]. The method compares the semantics of Chinese and Tibetan text pairs. It is used to confirm the presence of semantic conflicts in scene images containing Chinese and Tibetan languages, which in turn determines whether the image has been tampered with or not. The work presented in this paper is a further extension of the previous work. A large number of comparative analyses and experiments were conducted to improve the performance of the model as well as to expand the scope of tampering detection beyond Chinese and Tibetan languages. This method is no longer confined to specific language pairs but is applicable to any combination of two commonly used languages, significantly enhancing its universality and practical value.
New ideas and methodologies for image tampering detection research from the perspective of semantics were explored in this paper. In the study, it was found that the semantic-based image tampering detection method was effective in detecting tampering in bilingual scene images with textual content. A bilingual scene image with textual content is an image in which texts in two languages are present simultaneously, and these texts are semantically symmetrical, such as billboards, road signs, directional signs, and publicity posters. Attackers often tampered with bilingual scene images with textual content for only one language, so the semantics of the tampered bilingual text in the image appeared inconsistent, resulting in semantic conflicts.
The main contributions of this paper were threefold:
- A framework for image tampering detection based on semantic conflicts was developed. The idea of the framework was to utilize the common sense that the semantics within an image should be logical in order to detect the semantics of the image. If there was a situation contrary to common sense, it was considered that there was a semantic conflict, leading to the determination that the image had been tampered with.
- The bilingual scene image tampering detection model with textual content was built. A model was constructed based on the framework idea mentioned in point 1 for the purpose of detecting semantic conflicts, specifically to ascertain whether the semantics of bilingual texts in bilingual scene images with textual content were consistent. It encompassed several modules, including scene text localization, text recognition, text translation, and semantic similarity comparison.
- A dataset BSTID specialized for bilingual scene image tampering detection with textual content was established, which comprised 1700 bilingual images, encompassing the original image, the tampered image, and the tampered image after secondary editing.
The remainder of this paper is organized as follows: Section 2 reviews related work on image tampering detection. Section 3 outlines the overall research framework and methodology. Section 4 introduces the dataset. Section 5 presents the experimental results and comparative analyses. Finally, Section 6 concludes the paper, summarizing the key findings and discussing potential future research directions.
In this paper, a novel semantic-based approach for detecting image tampering in bilingual scene images is proposed. Unlike artifact-based methods, this technique leverages semantic conflicts between languages to enhance detection accuracy, particularly for secondarily edited tampered images. By translating bilingual text pairs into a common language and evaluating their semantic consistency, the method effectively identifies tampering when semantic conflicts arise. Experimental results demonstrate that the proposed approach outperforms existing methods in detecting secondarily edited images.
2. Related Work
For the detection of tampered images, the mainstream method that was utilized was artifacts-based detection. However, the existing artifact-based detection techniques were found to have obvious limitations in dealing with secondarily edited images. This paper attempted to utilize semantics to address such problems. In recent years, semantics has come to be applied in the field of image tampering detection, having shown its unique advantages in practice. Furthermore, some web architectures have introduced semantics into their experiments in order to achieve better results, exploring this field from various perspectives.
2.1. Artifact-Based Image Tampering Detection Methods
In the field of image tampering detection, methods that utilized artifacts were still dominant. Typical techniques, such as multi-stage feature extraction combined with contextual information, fine-grained detection aimed at specific artifacts, and deep learning methods grounded on different domain feature analyses, were employed.
Recognizing traces of image tampering necessitated consideration of contextual information, and multi-stage feature extraction, which captured different levels of features in an image, aided in extracting rich feature information from it. Examples encompassed the U-shaped detection network proposed by Zhuzhu Wang [4] and the cascaded convolutional neural network introduced by Xiuli Bi et al. [5].
To refine the detection of specific artifacts, attention was focused on the unique traces left in the image generation process, particularly those stemming from the intrinsic mechanism of the generation algorithm. For instance, Yu et al. [6] discovered that the unique “fingerprints” borne by GAN-generated images were attributed to training discrepancies, and Liu et al. [7] devised the Gram-Net architecture, alongside AutoGAN, proposed by Zhang et al. [8].
Image tampering detection approaches, based on differing domain characterizations by integrating image features across various representation domains, such as pixel and frequency, were developed. For example, Frank et al. [9] posited that GAN-generated images exhibited notable anomalies in the frequency domain. Rao et al. [10] introduced Convolutional Neural Networks (CNN) to autonomously learn hierarchical representations of images. Jing Wang et al. [11] proposed a method based on an approximate nearest-neighbor search.
Liu and Pun [12] proposed a deep fusion network-based method for image splicing forgery localization. The approach involves training multiple base networks (Base-Nets) to extract different types of tampering features, such as noise discrepancies and JPEG compression inconsistencies. These features are then integrated through a fusion network (Fusion-Net) to achieve precise localization of tampered regions. Experiments demonstrate that this method outperforms existing forgery detection techniques on multiple benchmark datasets, particularly showing strong robustness in complex tampering scenarios. The innovation of this method lies in its fusion of multiple tampering features, which enhances detection accuracy and generalization capability.
Vakkalanka et al. [13] proposed a video classification method based on multi-classifier fusion, which significantly improved classification accuracy by combining the results of Hidden Markov Models (HMMs) and Support Vector Machines (SVMs). The method extracts five types of spatiotemporal features from videos and employs a weighted Bayesian decision rule to fuse the outputs of multiple classifiers. Experimental results demonstrate that the method achieved a classification accuracy of 93.12% for six types of TV programs (cartoon, commercial, news, cricket, football, and tennis), with particularly outstanding performance in sports videos (97.14%). The innovation of this research lies in the weighted fusion of outputs from different classifiers, overcoming the limitations of single classifiers and enhancing the robustness and accuracy of the classification system.
Yang et al. [14] proposed an image manipulation detection model named Constrained R-CNN, which addresses the reliance of traditional methods on handcrafted features by learning a unified feature representation directly from data. The model adopts a coarse-to-fine two-stage architecture: in the first stage, an attention region proposal network (RPN-A) is used for manipulation classification and coarse localization; in the second stage, a skip structure is employed to fuse multi-level information, further refining local features and achieving pixel-level segmentation of tampered regions. Experiments demonstrate that the model achieves significant performance improvements on datasets such as NIST16, COVERAGE, and Columbia, with F1 scores increasing by 28.4%, 73.2%, and 13.3%, respectively. The innovation of this research lies in its end-to-end learning mechanism, which simultaneously accomplishes both manipulation classification and localization tasks, enhancing the model’s generalizability and robustness.
Wu et al. [15] proposed an end-to-end deep neural network named ManTra-Net for image forgery detection and localization. The network learns robust manipulation trace features from 385 types of image manipulations through a self-supervised learning task and formulates the forgery localization problem as a local anomaly detection problem, designing a Z-score feature to capture local anomalies. ManTra-Net is capable of handling both known and unknown manipulation types without requiring additional preprocessing or postprocessing. Experimental results demonstrate that the network exhibits excellent generalizability and robustness across various manipulation types and their complex combinations, significantly improving the accuracy of forgery detection and localization.
To address the issue of multiple manipulation detection in real-world scenarios, Zhu et al. [16] proposed the HRDA-Net algorithm. This algorithm constructs a multiple manipulation dataset (MM Dataset) containing splicing and removal operations, employs a top-down dilated convolutional attention mechanism (TDDCA) to fuse RGB and SRM features, and utilizes mixed dilated convolution (MDC) to separately extract splicing and removal features, achieving end-to-end multiple manipulation detection and localization. Experimental results demonstrate that this method outperforms semantic segmentation approaches on the MM Dataset and achieves superior F1 and AUC metrics on the CASIA and NIST datasets compared to existing manipulation localization methods. This research provides a novel solution for multiple manipulation detection in complex scenarios.
2.2. Combined Artifacts and Semantics for Image Tampering Detection
In the field of image tampering detection, semantics have been introduced in the network, being combined with artifacts for image tampering detection in a more integrated manner.
For example, a method called Hybrid Feature and Semantic Reinforcement Network (HFSRNet) was proposed by Chen et al. [17], which was capable of capturing manipulation traces from multiple perspectives, while semantic enhancement ensured consistency of the features across different layers. This approach improved the accuracy of detection through learned semantic information. Zhao et al. [18] investigated the application of semantic image segmentation networks in image tampering detection, utilizing the DeepLab V3+ neural network to focus on semantic tampering traces in images. This method was able to localize the tampered region and also identify the type of tampering. Chunfang Yu et al. [19] further deepened the application of semantic segmentation in networks by proposing a multi-supervised encoder-decoder model (MSED) and a contour-aware comparative learning network model (CaCL-Net). The MSED model enhanced the capture of high-dimensional semantic information, while the multi-supervised module optimized the network features. The CaCL-Net strengthened the model’s understanding of tampered pixels versus real pixel differences, and the auxiliary classifier improved the classification accuracy of edge pixels, ensuring clear localization of tampered boundaries. These approaches demonstrated the centrality of semantics in image tampering detection. On the other hand, the study by Jun Zhou [20] emphasized the importance of fusing traditional features in deep neural networks, especially in Deepfake face tampering. The tampered face region had noise in the edge information, and by combining features such as JPEG compression rate, BAG features, noise features, etc., the detection accuracy of the deep learning model had significantly improved, especially when dealing with the boundary information, and this approach made up for the possible shortcomings of relying solely on the deep learning model.
2.3. Semantic-Based Image Tampering Detection
There were also research efforts that directly built network architectures for image authenticity detection based on semantics. Ke et al. [21] introduced a three-part semantic-based detection framework: image recognition, a semantic logical reasoning engine, and semantic rule generation. This framework was aimed at detecting image tampering starting from image content and semantic information. Unlike traditional methods, it emphasized advanced image understanding and detected image combinations that defied common sense through logical reasoning, pioneering a new research direction in image tampering detection. Although still in the experimental prototype stage, this framework demonstrated the potential of leveraging semantic logical reasoning for image tampering detection. Future research may focus on improving semantic inference rules, enhancing image recognition accuracy, and exploring automated construction of a common sense knowledge base.
Ye et al. [22] proposed a framework with three components: an image understanding module, a Normal Rule Bank (NR), and an Abnormal Rule Bank (AR). Similar to the work of Ke et al. [21], this framework offered significant advantages. It integrated dense image captioning models to automate the process without human intervention automatically generated a large number of semantic rules and was not limited to anomaly detection. Instead, it introduced the concept of recognition problems through AR. This research broadened the scope of image forensics from low-level visual features to high-level semantic content, offering new perspectives for image security and authenticity verification.
Currently, public research on image tampering detection based on semantics has been limited, despite its robustness and ability to detect various types of tampered images even after secondary editing. This paper focuses on text image tampering detection in bilingual scene images with textual content, leveraging semantic conflict detection.
3. Methodology of This Paper
3.1. Semantic Conflict-Based Tampering Detection Framework for Bilingual Scene Text Images
In this paper, a semantic conflict-based image tampering detection framework was proposed as shown in Figure 1.
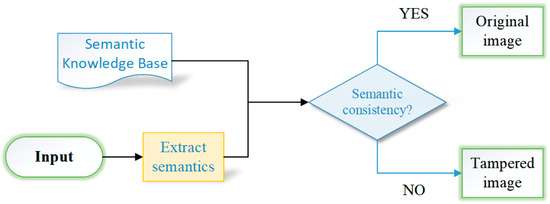
Figure 1.
Bilingual scene text image tampering detection framework.
- A semantic knowledge base was established to store common knowledge pertaining to image semantics.
- Semantic content related to the semantic knowledge base was extracted from the image.
- Semantic conflict detection was conducted by comparing the extracted semantic content with the common knowledge stored in the knowledge base. If significant contradictions were identified, such as common sense errors, logical discrepancies, or unusual combinations, the image was deemed to have a semantic conflict, suggesting potential tampering.
This is a knowledge-driven method which is leveraged by the common sense in a knowledge base to assess the logical consistency of image content, specifically by detecting semantic conflicts that are within the content. This approach, which is known as semantic-based image tampering detection, identifies the authenticity of an image based on its content that is being assessed. The research primarily focuses on bilingual scene images with textual content.
A bilingual scene image with textual content refers to a scene image where the textual content contains two languages, which typically maintain semantic consistency. As illustrated in Figure 2, the semantic meanings of the bilingual text in the image are consistent between the two languages. It should be noted that the definition of "bilingual" in this paper has broader applicability, referring to scene images containing any two common languages, rather than being limited to the combination of Chinese and English. This characteristic enables the method to adapt to a wider range of practical application scenarios.
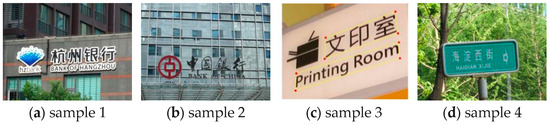
Figure 2.
Sample text image of a bilingual scene.
However, upon observation, it was noted that when bilingual scene images with textual content were tampered with by attackers, typically only one of the languages was targeted. Consequently, the corresponding bilingual text pairs exhibited semantic discrepancies. The detection of these discrepancies could serve as an indicator of image tampering.
3.2. Model Architecture and Knowledge Introduction of Each Module
A tampering detection model for bilingual scene images with textual content was developed, based on the framework outlined in Section 3.1 and taking into account the unique characteristics of such images. The model was comprised of two main components: semantic recognition and semantic conflict detection, as illustrated in Figure 3.
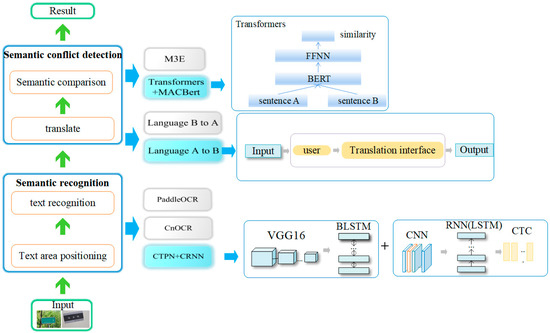
Figure 3.
The structure of a semantic-based text image tampering detection model for bilingual scene images with textual content was proposed.
Firstly, the text region within the image was localized by the model to ascertain its position. Subsequently, using the localized information, the content of the text region was recognized by the model. Based on these recognition results, a text pair was formed. The text segment in language A of this pair was translated into language B to ensure both texts were in the same linguistic context. Following this, the semantic similarity between the two texts in language B was compared by the model and it was assessed whether their semantics were consistent based on the degree of similarity. If the semantic similarity fell below a predetermined threshold, the model concluded that the image had been tampered with.
3.2.1. Semantic Recognition
In the section dealing with image text region localization and text recognition, the algorithm that combined CTPN and CRNN was employed.
CTPN [23] (Connectionist Text Proposal Network) was utilized for precisely locating the specific regions of bilingual scene images with textual content within an image. It adopted a sliding window strategy and character-level connectivity components to generate text candidate regions. The primary innovation was in its flexible adaptability to text shapes, thereby enhancing the accuracy of text detection. Given that text in images was of variable length, CTPN performed a binary classification task on potential text regions in the image using a series of small windows with fixed width but variable height. The goal was to determine whether these regions contained text. Each small window had a consistent width but a variable height. The windows that identified text regions were combined to form the text region of the image. CTPN utilized multiple small windows for text regions, with each window’s bounding box obtained through a formula that calculated the center y-coordinate and height, as detailed in Equations (1) and (2).
where V = {} is represented as the predicted coordinate, denotes the center y-coordinate of the predicted small window that was predicted, represents the height value of the small window that was predicted. = {, } signifies the true coordinate, while and are represented as the center y-coordinate and height of the small window candidate box, respectively, that were considered.
CTPN comprises three loss functions: the classification loss Ls, the border regression loss Lv, and the border left-right regression offset loss Lo. The formula for the total loss function that was presented is shown in Equation (3).
The classification loss function was , using softmax loss to distinguish the presence of text, while the regression functions were and , computed using the L1 function. The normalization parameters were Ns and Nv. The balancing parameter for multitasking was λ1, with λ1 set to 1.0. Additionally, λ2 was set to 2.0.
CRNN [24] (Convolutional Recurrent Neural Network) was employed for recognizing the detected text regions. It was represented as a convolutional recurrent neural network structure, consisting of three primary components: a convolutional layer, a recurrent layer, and a transcription layer. The convolutional layer leveraged the local feature extraction capability of Convolutional Neural Networks (CNNs) to derive high-level features from the input image. The recurrent layer, utilizing the sequence modeling capability of Recurrent Neural Networks (RNNs), predicted the distribution of labels (ground truth values) for the feature sequences obtained from the convolutional layer. The transcription layer applied the CTC (Connectionist Temporal Classification) algorithm to have the RNN’s output sequences converted into readable text sequences, ensuring high recognition accuracy even in cases where the input images were noisy or blurred. This experiment utilized CRNN to recognize the content within the text regions of images, having the text content converted into clear, readable text strings and saving the recognition results in textual format. The loss function of the CRNN algorithm was shown in Equation (4).
It was used where represented the training set, denoted the training image, stood for the real label sequence, and represented the label sequence outputted from the recurrent layer. This function was employed for calculating the loss value between the input image and the real label sequence.
3.2.2. Semantic Conflict Detection
As depicted in Figure 3, once the text within the designated text area had been recognized, the subsequent step involved translating the bilingual scene images with textual content. Specifically, the text in language a from the image-text pair was translated into language b, and the resultant translations were meticulously stored for future experimental use.
Currently, the market has offered a variety of translation models. One example that had been provided was the Long Short-Term Memory (LSTM) network-based model, which excelled in processing long sentences and intricate semantic information during translation tasks. Additionally, models incorporating a multi-head attention mechanism have been made available. This mechanism enabled the model to attend to various sections of the input sentence while each translated word was being generated, thereby enhancing the preservation of original information [25].
After the bilingual scene images with textual content had been translated into a unified language environment, the model proceeded to the semantic similarity comparison stage. During the experiment, the semantic similarity comparison module employed Hugging Face’s Transformers library [26] for text data processing and categorization, utilizing the MacBERT model [27] within the Transformers library as a pre-trained model for tasks such as semantic similarity comparison. MacBERT encompassed a vast majority of commonly used Chinese characters, providing a solid foundation for the model to handle complex and diverse Chinese texts. Regarding its network architecture, MacBERT adopted a 12-layer Transformer encoder structure. This adjustment, compared to the baseline model, deepened the network, facilitating a more thorough capture of the unique complex grammatical features and semantic nuances of Chinese, thereby enhancing the model’s granular understanding of Chinese semantics. By leveraging these technical approaches, MacBERT accurately captured contextual relationships within texts, exhibiting remarkable competitiveness.
By comparing the semantic similarity of the bilingual scene images with textual content, it could be determined whether there was a semantic conflict between the bilingual text in the image. If the semantic similarity fell below the set threshold, it was considered that a semantic conflict had been detected, indicating that the image had been tampered with. Otherwise, the image was deemed to be original. To further validate the effectiveness of the proposed method, we constructed a dedicated Bilingual Scene Text Image Tampering Detection Dataset (BSTID) and conducted experimental evaluations on this dataset.
4. Bilingual Scene Text Image Tampering Detection Dataset
The BSTID (Bilingual Scene Text Image Dataset) that was utilized in this experiment was constructed based on three datasets: BiTCSD [28], Total-Text [29], and MSRA-TD500 [30]. Suitable bilingual scene images with textual content, featuring billboards, street signs, and other elements in Chinese, English, Japanese, Korean, and other languages, were meticulously selected from these datasets. A total of 1700 images were gathered, which comprised original images, tampered images, and tampered images that had undergone secondary editing. After having undergone a series of preprocessing steps, these images were formed into the BSTID that was used in this experiment. Below is an introduction to the three key datasets.
To ensure a fair evaluation of the proposed method, the dataset was divided into training, validation, and test sets with a ratio of 7:2:1. Specifically, the training set contains 1190 images, the validation set contains 340 images, and the test set contains 170 images. The division was performed randomly while maintaining a balanced distribution of image types (original, tampered, and secondarily edited) across all subsets. This partitioning strategy ensures that the model is trained on a diverse set of images while being evaluated on an independent and representative subset, thereby providing a robust assessment of its generalization capability.
The BiTCSD dataset contained 87,680 synthetically created images and 5550 labeled images. The background elements of these synthetic images were derived from the Internet and text images of natural scenes that were captured in daily life, exhibiting a wide range of visual diversity.
The Total-text dataset was a multilingual scene text detection dataset, consisting of 1255 images for training and 300 for testing. In addition, each image in the dataset came with detailed annotation information and was fully labeled.
The MSRA-TD500 dataset comprised 500 images that were captured from diverse scenarios, encompassing indoor settings (such as offices and shopping malls) and outdoor environments (like streets). The dataset was partitioned into training and testing subsets, containing 300 and 200 images, respectively, all of which were annotated.
Figure 4 presents a typical example from the BSTID dataset, with columns depicting the original image, the tampered image, and the mask map, respectively. The mask map, in a binary format, explicitly highlights the tampered regions, where white areas signify tampering. Through the mask map, the tampered areas in the image can be readily discerned. For instance, in the first example in Figure 4, the Chinese text “Haidong West Street” in the original image had been altered to “Zhongshan East Street”.

Figure 4.
Sample BSTID dataset.
During the construction of the dataset, the tampered images underwent secondary editing operations such as screenshots and cutouts, and the images in Figure 4 were also subjected to similar secondary processing. These secondary editing operations made the tampered images more complex, increasing the difficulty of detection while also making them more reflective of real-world tampering scenarios.
5. Experimental Analysis
5.1. Evaluation Indicators
This paper employed recall, precision, and F1-score as the evaluation metrics for the experiment, with the following descriptions of each metric being provided.
The three key performance metrics of this experiment, recall, precision, and F1-score, were used to comprehensively evaluate the effectiveness of the text image tampering detection model for bilingual scenes. These metrics assessed the model’s performance from various angles. Recall evaluated the model’s ability to correctly identify all true tampering events, reflecting the number of true positives it could detect. Precision quantified the proportion of true positives among the predicted positives, directly indicating the accuracy of the model’s judgments. The F1-score was the harmonic mean of Precision and Recall, providing a balanced measure to comprehensively assess the model’s overall performance.
The formulas for recall, precision, and F1-score were shown by Equations (5), (6), and (7), respectively.
Then, the experiment introduced Semantic Similarity, which was used to assess the degree of semantic similarity between two texts in a bilingual scene image with textual content, serving as a basis for determining whether there was a semantic conflict.
In subsequent comparative experiments, Accuracy was adopted as an evaluation metric. Accuracy represented the proportion of samples correctly classified by the classifier to the total number of samples. Specifically, TP stood for True Positives, FN for False Negatives (the number of instances where the model predicted negative but was actually positive), and FP for False Positives. In image tampering detection experiments, Accuracy refers to the proportion of samples correctly classified by the model to the total, with higher Accuracy indicating better model performance.
The formulas for semantic similarity and its correlation with Accuracy were presented in Equations (8) and (9).
5.2. Experiments and Analysis of Semantic-Based Bilingual Scene Image Tampering Detection in This Paper
This section is roughly divided into three parts. Firstly, Section 5.2.1 presents the experiments and analysis of the proposed semantic-based bilingual scene images with a textual content tampering detection method. This part aims to demonstrate the effectiveness and accuracy of the method in detecting image tampering.
Secondly, Section 5.2.2 and Section 5.2.3 focus on the experiments and analysis based on artifact methods. Among them, Section 5.2.2 selects existing artifact-based detection models for experimentation. While Section 5.2.3 adopts mature image tampering detection platforms available in the market. The experimental objectives of these two subsections are to verify, through comparative experiments, that the proposed semantic-based method has significant advantages when facing tampered images that have undergone secondary editing.
Finally, multiple comparative experiments were conducted to optimize the proposed model. These experiments cover various components of the model. The purpose is to select the best configuration for each module through comparative experiments, in order to achieve excellent results for the final model.
5.2.1. Experimentation and Analysis of Semantic-Based Tamper Detection Models
The artifact-based method has limitations in detecting tampering in secondarily edited images. To address this, a semantic-based tampering detection approach is introduced in this paper. In bilingual scene images with textual content, this method identifies tampering by detecting semantic conflicts within the image text.
In this experiment, a semantic-based tampering detection model for bilingual scene images with textual content is established. The model detects semantic conflicts between text pairs within these images. If a semantic conflict is detected, the image is deemed tampered.
The experimental procedure follows these standardized steps:
- Image Preprocessing: Implements filtering, tamper trace detection, and pixel normalization.
- Text Region Localization: Employs the CTPN algorithm to accurately detect bounding boxes of text regions in images.
- Bilingual Text Recognition: Based on localization results, utilizes the CRNN model to perform end-to-end extraction and preservation of bilingual text content.
- Language Standardization: Translates identified bilingual texts into a unified language system to eliminate language discrepancy interference.
- Semantic Consistency Verification: Inputs standardized texts into a semantic similarity detection module built upon the MacBERT model from the Hugging Face Transformers library. By calculating the cosine similarity between text pairs, images are flagged as tampered when similarity falls below the predefined 70% threshold, indicating semantic inconsistency.
The model architecture adopts a modular design:
- Text Detection Module: CTPN network enables high-precision text localization.
- Text Recognition Module: CRNN model accomplishes sequential text recognition.
- Semantic Analysis Module: MacBERT model generates deep semantic representations.
- Similarity Calculation Module: Cosine similarity algorithm executes threshold-based decisions.
- The experiment employs Gaussian blur for basic tampering, with kernel sizes randomly selected between 3 × 3 and 9 × 9 pixels, and blur intensity coefficients randomly generated within the range of 1.0 to 3.0. A specialized bilingual tampering method is designed by directly modifying text content in one language within images, followed by screenshot capture, to simulate real-world tampering scenarios.
The evaluation metric system includes:
- Classification Accuracy: Proportion of correctly classified samples in the test set.
- Mean Loss Value: Measures the discrepancy between model predictions and ground truth values.
- F1 Score: Harmonic mean of precision and recall, providing a comprehensive assessment of model performance.

Table 1.
Experimental Effect of Semantic-Based Bilingual Scene Images with Textual Content Detection Model.
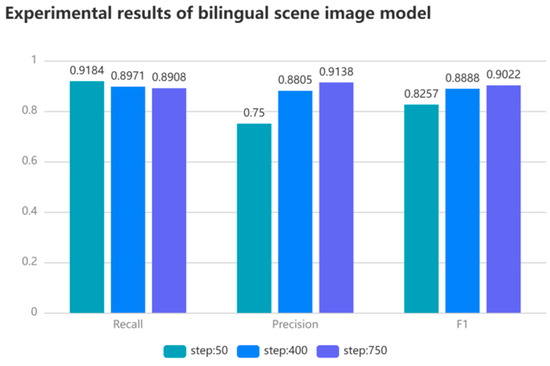
Figure 5.
Performance Evaluation of the Semantic-Based Bilingual Scene Text Image Tampering Detection Model.
As illustrated in Table 1 and Figure 5, the model’s performance was progressively enhanced with increasing training steps. Specifically, at the 50th iteration, the model showed a high recall rate but a relatively low precision. This indicated that it could effectively identify all tampered images but also generated some false positives. By the 400th iteration, both precision and recall had improved, and the F1 score increased, suggesting an enhanced balanced performance of the model. At the 750th iteration, the precision and recall rates converged further, with the F1 score peaking at 0.9022, signifying optimal performance balance. The entire training process lasted 708.1361 s, demonstrating the model’s high efficiency. It was important to avoid excessive training rounds to prevent overfitting.
The model’s performance on the validation set was also evaluated. Despite the recall rate being slightly lower than the optimal value achieved on the training set, the precision rate remained high. The F1 score averaged at 0.8849, indicating that the model maintained good detection performance on unseen data. This demonstrated the model’s generalization capability and stability.
In numerous experiments, the model exhibited excellent performance in detecting tampered images that had undergone secondary editing, such as screenshots. Specifically, in Figure 6a, the semantic conflict between the Chinese text “请勿吸烟” and the English text “SMOKING” was promptly flagged as tampering by the model. Similarly, in Figure 6b, the conflict between the English text “Chrysanthemum” and the Chinese text “花” was correctly identified as tampering.

Figure 6.
Examples of test samples.
The experimental results have demonstrated the effectiveness and reliability of the model in detecting tampering in bilingual scene images with textual content. The limitations of artifact-based detection methods were effectively addressed by this model.
5.2.2. Artifact-Driven Convolutional Neural Network for Image Tampering Detection
This section aims to systematically verify the limitation of artifact-based methods in detecting secondary-edited image tampering through comparative experiments. A Convolutional Neural Network (CNN) model based on artifact features is constructed to learn and extract subtle features from images, especially the blurring features, thereby detecting whether an image has been tampered with. Experiments are conducted separately on tampered images and tampered images that have undergone secondary editing, aiming to reveal the differences in detection effects between the two through comparative analysis, providing strong support for the research on semantic-based image tampering detection presented in this paper.
The model used in the comparative experiments is independently built and trained based on the concept of artifact methods. There are two reasons why mainstream models available on the market were not used for training. Firstly, the purpose of the comparative experiments is to demonstrate the limitation of artifact models in detecting secondary-edited tampered images. The failure of the independently trained artifact model to effectively detect such tampered images already sufficiently demonstrates the correctness of this research approach. Even mainstream artifact models that perform well are only superior on tampered images that have not undergone secondary editing. Therefore, there is no need to build a model with even better performance. Secondly, Section 5.2.3 will use a mature commercial tampering detection platform available on the market as a comparison. As a representative mainstream model of artifact detection methods, its performance also reveals significant limitations when facing secondary-edited tampered images.
To ensure the validity of the experiment, the following protocols were established:
- Two comparative experiments were conducted: one aimed at detecting tampered images, and another focused on detecting secondarily edited tampered images.
- Dataset: The BSTID dataset was utilized for both comparative experiments.
- Tampering Method: Image tampering was done using Gaussian blur, with the blur kernel size randomly selected from 3, 5, 7, or 9. The blurring intensity was controlled by a function that generated random numbers between 1.0 and 3.0.
- Model Architecture: The network structure, which was integrated with VGG, consisted of six convolutional layers. The Adam optimizer was employed. The initial learning rate was set to 1 × 10−4 and was adjusted to 1 × 10−5 after the fifth epoch. At the end of each epoch, the model was evaluated on a test set to compute accuracy.
The information and data related to the comparative experiments are shown in Figure 7.
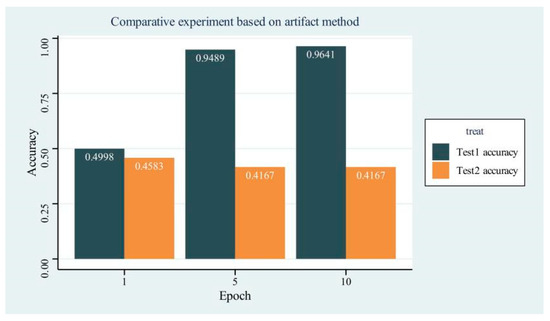
Figure 7.
Performance Comparison of Artifact-Based Methods on Tampered and Secondarily Edited Images.
As illustrated in Figure 7, the accuracy of the dataset containing tampered images was represented by Test1 Accuracy, while Test2 Accuracy pertained to the dataset after the tampered images had undergone secondary editing. Notably, Test1 Accuracy experienced a substantial increase, rising from 0.4998 at the first epoch to 0.9489 at the fifth epoch, and ultimately reaching 0.9641 at the tenth epoch. This marked improvement highlighted the exceptional performance of the model in detecting image tampering, effectively extracting features from input data for accurate predictions. Conversely, Test2 Accuracy exhibited a more muted improvement, remaining approximately 0.4167, which underscored the limitations of artifact-based tamper detection models when dealing with secondary-edited tampered images.
Furthermore, experiments had confirmed that the images correctly identified in the tests were predominantly the original ones. For the second experiment of the model, which focused on the detection of secondary-edited tampered images, the histogram of the sampled test results was depicted in Figure 8.
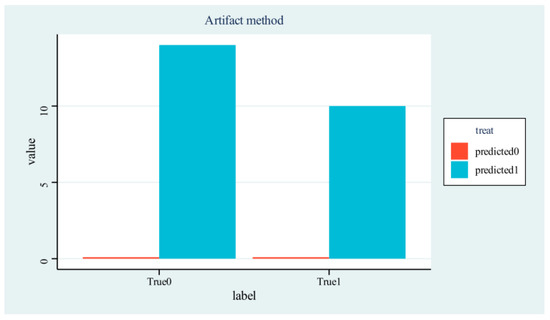
Figure 8.
Detection Performance on Secondarily Edited Tampered Images.
Figure 8 Experimental Label Definitions:
- True0: Authentic tampered images subjected to secondary editing
- True1: Original pristine images without any processing
- Predicted0: Model’s predicted label for secondary-edited tampered images
- Predicted1: Model’s predicted label for original images
In the experiments, artifact-based detection models exhibited systematic misclassification across all test samples, categorizing both True0 and True1 instances as original images (Predicted1). This uniform prediction bias reveals a fundamental defect in the model’s core discriminative ability when confronting secondary-edited tampering artifacts.
The secondary editing process significantly degrades the detectability of tampering evidence. Specifically, Gaussian blurring operations applied in the experiments effectively smoothed high-frequency artifact features from the initial tampering. These once-identifiable traces become indistinguishable from natural image characteristics after secondary editing, causing systematic model failure.
The results expose a critical vulnerability in conventional artifact-detection paradigms: their lack of robustness against post-processing operations that obscure tampering evidence. This underscores the need for more resilient detection frameworks capable of:
- Identifying persistent tampering imprints resistant to secondary editing.
- Incorporating contextual analysis beyond localized artifact features.
- Implementing adaptive learning mechanisms to counter feature degradation patterns.
5.2.3. TextIn Platform-Based Artifact-Driven Image Tampering Detection
In this section, the TextIn intelligent document processing platform from Hehe Information was utilized to conduct tampering detection experiments. This platform employs mainstream models based on artifact methods, providing more compelling evidence for the limitations of artifact-based models when facing tampered images that have undergone secondary editing.
During the experiment, tampered images and tampered images that had undergone secondary editing were both input into the TextIn platform for tampering detection. The detection results of the two were then compared.
Experimental Scheme:
- The text within the original image was altered.
- The tampered image was submitted to the TextIn platform for tamper detection, and the results were retained.
- Secondary editing was conducted on the tampered image (by taking a screenshot).
- The secondarily edited tampered image was submitted to the TextIn platform for tamper detection, and the results were retained.
For instance, Figure 9 presents two sets of images. From left to right, they are the original image, the tampered image, the heatmap of the tampered area, the detection result of the tampered image, and the detection result of the tampered image after secondary editing. In both cases, the tampered image underwent detection on the TextIn platform. The platform correctly identified the tampering and highlighted the tampered part in green. However, when the screenshot of the tampered image was detected, it incorrectly indicated no tampering.

Figure 9.
Example of TextIn image tampering detection.
Detection conducted on the TextIn platform further underscores the limitations of artifact-based tamper detection approaches when confronted with secondary-edited images. Initially, we conducted a semantic-based tampering detection experiment for bilingual scene text images, as presented in this paper. Subsequently, two artifact-based tampering detection experiments were performed. Upon comparison, it is evident that artifact-based methods exhibit limitations when dealing with secondarily edited images. In contrast, semantic-based tamper detection methods remain unaffected by secondary editing and can still accurately identify whether an image has been tampered with. Therefore, research into semantic-based tamper detection is highly warranted.
5.3. Optimal Module Selection and Parameter Tuning: A Comparative Study for Model Optimization
5.3.1. Comparison of Text Area Localization and Recognition Methods
This paper has employed the CTPN and CRNN algorithms for semantic recognition, specifically for locating text regions in images and recognizing text content. Subsequent comparative experiments were conducted using the open-source text recognition models, PaddleOCR [31] and CnOCR [32].
The PaddleOCR model was provided through the PaddleHub platform in an easy-to-use, ultra-lightweight version, supporting text recognition tasks. On the contrary, the CnOCR model was specialized in recognizing a diverse range of text and common characters, featuring multiple built-in pre-trained models.
Pre-training of the models utilized a subset of the classification recall dataset within the SimCLUE dataset [33], which aggregates multiple open-source datasets for semantic similarity and natural language inference.
This experiment was designed to compare the performance of three methods: the combination of CTPN and CRNN, the PaddleOCR model, and the CnOCR model, in tasks related to image text region localization and text content recognition. The experimental protocol was outlined as follows:
- Both methods utilized SimCLUE as their pre-training dataset.
- The test datasets exclusively consisted of BSTID.
- Testing was conducted in an identical hardware and software environment to mitigate the impact of external factors on the experimental outcomes.
- Average accuracy was used as the evaluation metric for the test samples.
The results of the comparison experiment for text region localization and recognition methods are illustrated in
Figure 10.
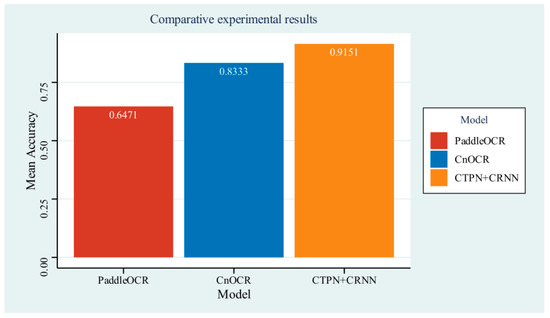
Figure 10.
Performance Comparison of Text Region Localization and Recognition Methods.
As illustrated in Figure 10, the performance of PaddleOCR in the experiment was moderate, achieving an average accuracy of 0.6471. CnOCR was demonstrated to have good performance in detection, with an average accuracy of 0.8333. However, the combination of the CTPN and CRNN algorithms was found to outperform both, achieving an average accuracy of 0.9151. Additionally, the accuracies of both the PaddleOCR and CnOCR models fluctuated during the experiment, whereas the combination of CTPN and CRNN algorithms demonstrated greater stability. Notably, in test samples containing numerous text and punctuation, PaddleOCR performed exceptionally well, with an average accuracy of 0.9474, whereas the CnOCR model only achieved 0.1810 in the same samples.
Through continuous testing, special results in the experiment were observed for different samples extracted from the dataset. After numerous experimental comparisons, it was discovered that the PaddleOCR model only performed well in recognizing regular fonts and symbols. Specifically, the PaddleOCR model struggled with recognizing special symbols, especially bold fonts, which often led to misrecognition. Consequently, the overall recognition performance in the tests was poor. However, in test samples where the text area consisted entirely of neatly arranged regular fonts and symbols, the PaddleOCR model exhibited good recognition performance. Although the accuracy rate fluctuated across different samples, the overall accuracy rate remained above 80%. This indicated that factors such as the type of characters in the text area within the image and the image quality had a significant impact on the accuracy of the PaddleOCR model.
The CnOCR model, on the other hand, exhibited poor performance in recognizing certain symbols and may have resulted in the loss of spaces in specific scenarios, thereby compromising its recognition accuracy.
In comparing the three models for the tasks of image text region localization and recognition, this paper selects the more stable and highly accurate combination of the CTPN and CRNN algorithms. In experimental tests, the CTPN and CRNN algorithms were demonstrated to have high accuracy in locating and recognizing images, and they were unaffected by special fonts, special symbols, and other pertinent factors.
5.3.2. Text-to-Translation Module Comparison Experiments
After completing the bilingual text content recognition, the texts acquired were in mixed languages like Chinese and English. To improve semantic similarity comparisons and avoid biases due to language differences, methods for creating a uniform text-language environment were explored. Considering the dataset mainly contained text images from Chinese and English scenes, the translation directions were set as Chinese to English and English to Chinese. The experiment followed these steps:
- Used the same models and dataset for consistency.
- Compared bilingual environments by translating from English to Chinese and then back.
Figure 11 shows the results of how Chinese and English environments affected semantic similarity.
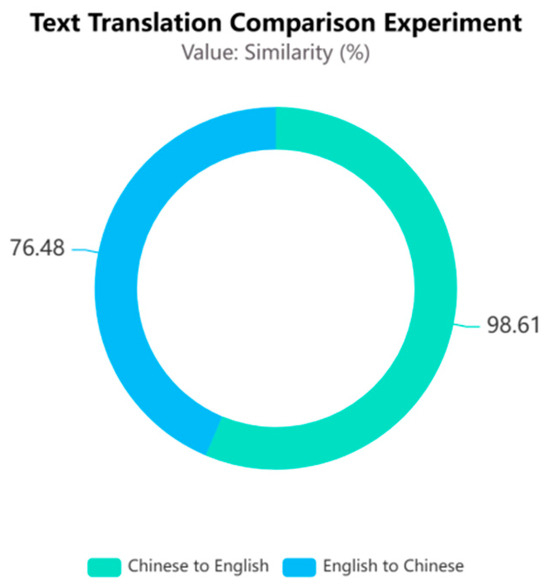
Figure 11.
Comparison of Translation Performance in Bilingual Text-to-Translation Module.
Under the same experimental conditions illustrated in Figure 11, the translation of English text into Chinese resulted in a semantic similarity score of only 76.48% for the text pairs, indicating poor performance in terms of semantic similarity in the Chinese context. In contrast, when Chinese text was translated into English, the semantic similarity of the same set of test samples significantly increased to 98.61% when constructing English text pairs. This outcome suggests that different language environments indeed impact the assessment of linguistic similarity. The semantic richness of Chinese may have contributed to increased difficulty during the translation process, leading to a decrease in semantic similarity. Conversely, the more direct expression of English facilitated the maintenance of semantic consistency across translations, thereby significantly enhancing semantic similarity.
5.3.3. Semantic Similarity Comparison Experiments
The experiment was broadly categorized into two primary components: semantic recognition and semantic conflict detection. Semantic recognition encompassed the localization of text regions and the recognition of text content. Semantic conflict detection encompassed text translation, the comparison of semantic similarity, and the determination of tampering. Notably, the module for comparing semantic similarity served as the cornerstone of semantic conflict detection, making the comparison experiment for this module particularly crucial. For comparison purposes, two pre-trained models, the MACBert model and the M3E (Moka Massive Mixed Embedding) model, were employed in the experiments to evaluate their performance in the task of bilingual semantic similarity comparison.
The M3E is a pre-trained multimodal text embedding model, which is a variant of the BERT architecture. It was designed to process both text and image data simultaneously and perform cross-modal retrieval tasks. To ensure the fairness and validity of the comparative experiments, consistency was maintained in the dataset, experimental hardware, software, parameters, and other conditions. The results of the comparative experiments conducted for the semantic similarity module are presented in Figure 12.
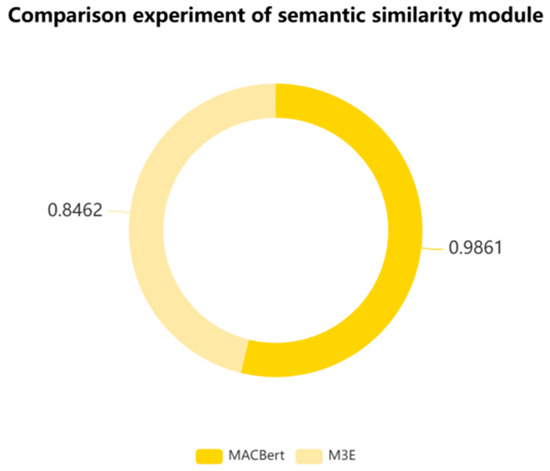
Figure 12.
Comparative Performance of Semantic Similarity Models in Bilingual Text Tampering Detection.
The results shown in Figure 12 indicated that MACBert achieved a similarity score of 0.9861 with the same test samples used. This score demonstrated MACBert’s superiority in detecting semantic similarity between text pairs. In contrast, M3E was given a score of 0.8462, which was acceptable but significantly inferior to MACBert’s. The experiment confirmed the superiority of MACBert in the task of semantic similarity comparison. Furthermore, it enhanced the overall model performance.
5.3.4. Setting of Thresholds
By obtaining the semantic similarity of text pairs within an image, it was determined whether the image had been tampered with. Specifically, if the semantic similarity exceeded the set threshold, the image was deemed original; otherwise, it was considered tampered.
The thresholds were set based on the following considerations:
To avoid misjudgment, it was crucial to delineate the boundary between natural variations and tampering behaviors. The threshold needed to be set in such a way that natural variations (such as translation style and minor semantic shifts) would not be misclassified as tampering. The similarity between bilingual text pairs within an image was calculated, and statistically analyzed, and a reasonable range of threshold values was determined. The thresholds were set above the range of similarity decrease that may result from typical natural variations, yet not excessively high to overlook actual tampering.
Consideration of specificity: In bilingual scene images with textual content, only a few keywords may be modified for tampering purposes. Setting lower thresholds might result in a significant number of false positives. The effectiveness of thresholds in detecting actual tampering behaviors was evaluated to ensure that the detection capability of key tampering behaviors was not compromised while reducing the false positive rate.
To determine the optimal threshold for semantic similarity, a series of experiments were conducted to balance detection accuracy and false positive rates. The threshold selection process involved testing multiple values (60%, 70%, and 80%) on a validation set to evaluate their performance in distinguishing between tampered and original images. The results revealed that a threshold of 70% achieved the best balance, with an error rate of only 8%, significantly lower than the 42% and 21% observed for thresholds of 60% and 80%, respectively. This value was chosen to minimize misjudgments caused by natural variations, such as translation style differences, while ensuring the detection of actual tampering behaviors. By iteratively refining the threshold, the model achieved robust performance in identifying tampered images without compromising specificity or sensitivity.
This section initially conducted comparative experiments on text region localization and recognition to identify the optimal solution, thereby minimizing interference arising from recognition issues and establishing a solid foundation for subsequent experiments. Subsequently, comparative experiments were conducted on the translation component to select the best translation module, which translates bilingual content into a unified language environment, thereby reducing errors attributed to linguistic differences. Following this, comparative experiments were performed on the semantic similarity component to select the optimal experimental model, a crucial step in determining the authenticity of images. Finally, the rules for setting thresholds were explained. Through experimental comparisons, the optimal module was chosen for each part of the model, ensuring overall model optimization.
6. Summary
With the widespread adoption of social media and the Internet, the prevalence of image tampering has been escalating, posing a grave threat to the authenticity and credibility of information dissemination. The image tampering detection framework, which was presented in this paper and is based on semantic conflicts, has offered a potent tool to counter false information dissemination and uphold a healthy cyberspace ecology. This framework has found applications across diverse domains, including news, forensic investigations in law, and copyright protection, thus possessing significant social and practical importance.
Currently, in the realm of text image tampering detection for bilingual scenarios, artifact-based methods have dominated the field. However, these methods have exhibited notable limitations when detecting tampered images that had undergone secondary editing. The widespread use of secondary image editing techniques, such as re-photography, screenshot capture, and compression, had often rendered artifact features difficult to detect or completely obsolete, thereby constraining the effectiveness of tampering detection. In response to this challenge, our paper introduces a semantic conflict-based image tampering detection framework, offering a fresh perspective within the domain of image tampering detection.
Based on the framework concept, this paper proposed a semantic-based detection model for tampering in bilingual scene images with textual content. The core of this model was to detect semantic inconsistencies within bilingual scene images with textual content, specifically verifying the consistency of semantics between bilingual text pairs. This methodology addressed the limitations of existing mainstream techniques and introduced novel perspectives into image tampering detection.
The research presented in this paper, despite achieving preliminary results, necessitates further exploration and refinement. Future endeavors could incorporate more sophisticated semantic understanding models to augment the recognition capabilities for intricate semantics. Furthermore, customized detection tools and solutions could be devised to address the specific requirements of image tampering detection in specialized fields, such as medicine and law.
Author Contributions
Conceptualization, Z.L.; Methodology, Z.L. and J.S.; Software, J.S.; Validation, J.S.; Formal analysis, J.S. and S.W.; Investigation, J.S.; Resources, Z.L.; Data curation, J.S.; Writing—original draft, J.S.; Writing—review & editing, Z.L. and J.S.; Visualization, J.S.; Supervision, Z.L. and S.W.; Project administration, Z.L. and J.S.; Funding acquisition, Z.L. All authors have read and agreed to the published version of the manuscript.
Funding
The research was funded by the National Natural Science Foundation of China, grant number 62166036. Innovation Foundation of Gansu Provincial Department of Education, grant number 2022B-152. Gansu Province Talent Project 2025QNGR13.
Data Availability Statement
The data that support the findings of this study are available within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhang, Z.P. Research on Image Tampering Detection Based on Generative Adversarial Network; Chongqing University of Posts and Telecommunications: Chongqing, China, 2022; p. 001049. [Google Scholar]
- Li, Z.; Sun, J. Image tampering detection in bilingual scenes based on semantic. In Proceedings of the 2024 International Conference on Data Science and Network Security (ICDSNS), Tiptur, India, 26–27 July 2024; pp. 1–5. [Google Scholar]
- De Carvalho, T.J.; Riess, C.; Angelopoulou, E.; Pedrini, H.; de Rezende Rocha, A. Exposing digital image forgeries by illumination color classification. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1182–1194. [Google Scholar] [CrossRef]
- Wang, Z. Image tampering detection algorithm based on U-shaped detection network. J. Commun. 2019, 40, 171–178. [Google Scholar]
- BI, X.; Wei, Y.; Xiao, B.; Li, W.; Ma, J. Image tampering detection algorithm based on cascaded convolutional neural network. J. Electron. Inf. Technol. 2019, 41, 2987–2994. [Google Scholar]
- Yu, N.; Davis, L.S.; Fritz, M. Attributing fake images to GANs: Learning and analyzing GAN fingerprints. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7556–7566. [Google Scholar]
- Liu, Z.; Qi, X.; Torr, P.H.S. Global texture enhancement for fake face detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8060–8069. [Google Scholar]
- Zhang, X.; Karaman, S.; Chang, S.-F. Detecting and simulating artifacts in gan fake images. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Delft, The Netherlands, 9–12 December 2019; pp. 1–6. [Google Scholar]
- Frank, J.; Eisenhofer, T.; Schönherr, L.; Fischer, A.; Kolossa, D.; Holz, T. Leveraging frequency analysis for deep fake image recognition. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020. [Google Scholar]
- Rao, Y.; Ni, J. A deep learning approach to detection of splicing and copy-move forgeries in images. In Proceedings of the 2016 IEEE International Workshop on Information Forensics and Security (WIFS), Abu Dhabi, United Arab Emirates, 4–7 December 2016; pp. 1–6. [Google Scholar]
- Wang, J.; Zhang, Y.; Huo, Z.; Jia, L. Image tampering detection method based on approximate nearest neighbor search. J. Adv. Lasers Optoelectron. 2020, 57, 244–251. [Google Scholar]
- Liu, B.; Pun, C.M. Deep fusion network for splicing forgery localization. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Vakkalanka, S.; Mohan, C.K.; Kumaraswamy, R.; Yegnanarayana, B. Combining multiple evidence for video classification. In Proceedings of the 2005 International Conference on Intelligent Sensing and Information Processing, Bangalore, India, 14–17 December 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 187–192. [Google Scholar]
- Yang, C.; Li, H.; Lin, F.; Jiang, B.; Zhao, H. Constrained R-CNN: A general image manipulation detection model. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Wu, Y.; AbdAlmageed, W.; Natarajan, P. Mantra-net: Manipulation tracing network for detection and localization of image forgeries with anomalous features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9543–9552. [Google Scholar]
- Zhu, Y.; Yu, Y.; Guo, Y. HRDA-Net: Image multiple manipulation detection and location algorithm in real scene. J. Commun. Tongxin Xuebao 2022, 43, 217. [Google Scholar]
- Chen, H.; Chang, C.; Shi, Z.; Lyu, Y. Hybrid features and semantic reinforcement network for image forgery detection. Multimed. Syst. 2022, 28, 363–374. [Google Scholar] [CrossRef]
- Zhao, Q.; Cao, G.; Zhou, A.; Huang, X.; Yang, L. Image tampering detection via semantic segmentation network. In Proceedings of the 2020 15th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 6–9 December 2020; Volume 1, pp. 165–169. [Google Scholar]
- Yu, C. Research on Image Tampering Detection Based on Semantic Segmentation Network; East China Normal University: Shanghai, China, 2022; p. 001635. [Google Scholar]
- Zhou, J. Research on Face Tampering Detection Based on Semantic Segmentation; University of Electronic Science and Technology: Chengdu, China, 2020; p. 000266. [Google Scholar]
- Ke, Y.; Min, W.; Qin, F.; Shang, J. Image forgery detection based on semantics. Int. J. Hybrid Inf. Technol. 2014, 7, 109–124. [Google Scholar] [CrossRef][Green Version]
- Ye, K.; Dong, J.; Wang, W.; Xu, J.; Tan, T. Image forgery detection based on semantic image understanding. In Proceedings of the Computer Vision: Second CCF Chinese Conference, CCCV 2017, Tianjin, China, 11–14 October 2017; Proceedings, Part I. Springer: Singapore, 2017; pp. 472–481. [Google Scholar]
- Zhi, T.; Huang, W.; He, T.; He, P.; Qiao, Y. Detecting text in natural image with connectionist text proposal network. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Volume 14, pp. 56–72. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [PubMed]
- Yanfi, Y.; Soeparno, H.; Setiawan, R.; Budiharto, W. Multi-head Attention Based Bidirectional LSTM for Spelling Error Detection in the Indonesian Language. IEEE Access 2024, 12, 188560–188571. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Nshish, G.A.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Cornell University: Ithaca, NY, USA, 2017. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Wang, S.; Hu, G. Revisiting pre-trained models for Chinese natural language processing. arXiv 2020, arXiv:2004.13922. [Google Scholar]
- Hao, Y.S.; Wang, W.L. A Method for Bilingual Tibetan-Chinese Scene Image Dataset Synthesis and Text Detection. J. Comput.-Aided Des. Comput. Graph. 2022, 34, 592–604. [Google Scholar]
- Ch’ng, C.K.; Chan, C.S. Total-text: A comprehensive dataset for scene text detection and recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; p. 1. [Google Scholar]
- Yao, C.; Bai, X.; Liu, W.; Ma, Y.; Tu, Z. Detecting texts of arbitrary orientations in natural images. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; Volume 16–21, pp. 1083–1090. [Google Scholar]
- Baidu Open Source OCR Introduction [EB/OL]. Available online: https://gitee.com/computer-vision/PaddleOCR#/ (accessed on 21 December 2021).
- CnOCR. Available online: https://github.com/breezedeus/cnocr (accessed on 30 November 2024).
- Xu, L.; Hu, H.; Zhang, X.; Li, L.; Cao, C.; Li, Y.; Xu, Y.; Sun, K.; Yu, D.; Yu, C.; et al. CLUE: A Chinese language understanding evaluation benchmark. arXiv 2004, arXiv:2004.05986. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).